ZipGait: Bridging Skeleton and Silhouette with Diffusion Model
for Advancing Gait Recognition
Abstract
Current gait recognition research predominantly focuses on extracting appearance features effectively, but the performance is severely compromised by the vulnerability of silhouettes under unconstrained scenes. Consequently, numerous studies have explored how to harness information from various models, particularly by sufficiently utilizing the intrinsic information of skeleton sequences. While these model-based methods have achieved significant performance, there is still a huge gap compared to appearance-based methods, which implies the potential value of bridging silhouettes and skeletons. In this work, we make the first attempt to reconstruct dense body shapes from discrete skeleton distributions via the diffusion model, demonstrating a new approach that connects cross-modal features rather than focusing solely on intrinsic features to improve model-based methods. To realize this idea, we propose a novel gait diffusion model named DiffGait, which has been designed with four specific adaptations suitable for gait recognition. Furthermore, to effectively utilize the reconstructed silhouettes and skeletons, we introduce Perception Gait Integration (PGI) to integrate different gait features through a two-stage process. Incorporating those modifications leads to an efficient model-based gait recognition framework called ZipGait. Through extensive experiments on four public benchmarks, ZipGait demonstrates superior performance, outperforming the state-of-the-art methods by a large margin under both cross-domain and intra-domain settings, while achieving significant plug-and-play performance improvements.
1 Introduction
Gait recognition, as a biometric technology, facilitates remote identification in uncontrolled settings without necessitating subject participation, discerning individuals based on their gait patterns (Wu et al. 2016; Wang et al. 2003). Current research focuses on utilizing shape information of silhouettes for recognition, known as appearance-based methods (Dou et al. 2024, 2023; Wang et al. 2023a; Lin, Zhang, and Yu 2021; Zheng et al. 2022a). However, these methods are vulnerable to complex backgrounds, severe occlusion, arbitrary viewpoints, and diverse clothing changes. This gives rise to a surging interest in model-based methods that extract gait features through various models, including 2D/3D Skeleton, SMPL model, and Point cloud (Loper et al. 2023; Yam, Nixon, and Carter 2004; Shen et al. 2023).

Among them, 2D skeleton is particularly attractive since it achieves higher pose estimation accuracy due to low spatial complexity which demonstrates simplicity and effectiveness (Liao et al. 2020; Li et al. 2020; Teepe et al. 2021). Most existing model-based works, using the skeleton as input, focus on extracting intrinsic information from skeleton sequences to provide sufficient features, broadly categorized as follows: utilization of skeleton structural features (i.e. position, angle, length, local-global (Liao et al. 2020)); computation of physical information from skeleton sequences (i.e. motion velocity, gait periodicity (Frank, Mannor, and Precup 2010; Liu et al. 2022)); generation of complementary skeleton information (i.e. multi-view, frame-level correlations (Gao et al. 2022; Wang, Chen, and Liu 2022)).
Although existing model-based methods have shown progressive improvements in performance, they continue to lag behind appearance-based approaches, suggesting that shape features can offer more gait imformation, as indicated in Fig 1. This observation prompts us to consider whether merely utilizing intrinsic information of skeletons could bridge this huge gap between these two types of methods. We propose a novel concept: establishing a natural correlation between silhouettes and skeletons to reconstruct dense body shapes from sparse skeleton structures, inspired by the progress of diffusion models (Ho, Jain, and Abbeel 2020; Song, Meng, and Ermon 2020). As shown in Fig. 2, instead of solely leveraging information from intra-modality gait features, we shift towards connecting cross-modality gait features for a more effective gait representation, thereby enhancing the performance of model-based methods.

To realize the aforementioned idea, we introduce a novel Gait Diffusion Model named DiffGait, which denoises the skeleton features mixed with standard Gaussian noise using a diffusion model to retrieve matching silhouettes. Intuitively, several limitations hinder the diffusion model’s direct application in gait recognition, which DiffGait addresses with four aspects: 1) Given that silhouettes and skeletons represent two unalignable modalities that inherently resist direct transformation via the diffusion process, we employ Heat-skeleton Alignment to transform 2D skeleton joints into a unified mesh grid, bridging skeletons and silhouettes across spatial-temporal dimensions; 2) To address the cumbersome algorithms of the standard diffusion process for gait recognition, the DiffGait Forward Process has been developed to convert the diffusion object from the silhouette to the Hybrid Gait Volume (HGV), streamlining the condition and noise encoding stages; 3) Recognizing that existing diffusion models neglect the intrinsic correspondence between modalities during the denoising process, we implement the DiffGait Reverse Process to produce multi-level silhouettes, which improves the distinction in denoising outcomes; 4) Mainstream diffusion models, predominantly based on U-Net (Ronneberger, Fischer, and Brox 2015), are unsuitable for gait recognition due to their large scale. In response, our DiffGait Architecture adopts a decoder-only configuration to achieve a surprisingly efficient model with just 1.9M parameters and a rapid inference speed of 3628 FPS.
Furthermore, to efficiently leverage appearance and structure features, we propose a gait feature fusion module termed Perceptual Gait Integration (PGI), which operates through a two-stage process that refines silhouettes and extracts hybrid gait features respectively. By incorporating these two designs into our baseline, we create a simple-but-effective model-based gait recognition architecture, named ZipGait, which seamlessly bridges skeleton and silhouette like a zipper. Fig. 2 summarizes the distinctions between our proposed method and existing gait recognition approaches, which are further discussed in detail in the Appendix. C. Extensive experiments on four dominant datasets demonstrate that our method outperforms state-of-the-art approaches in both cross-domain and intra-domain settings while achieving significant plug-and-play performance improvements.

2 Related Work
Model-based Gait Recognition. These methods utilize the underlying structure of the human body as input. In particular, skeleton representation is enhanced by extracting intrinsic information from skeletal sequences. GaitGraph2 (Teepe et al. 2022) pre-computes skeletons to obtain joint positions, motion velocities, and length of bones as gait features. GPGait (Fu et al. 2023) transforms the arbitrary human pose into a unified representation and allows efficient partitions of the human graph. (Fan et al. 2024; Min et al. 2024) represents the coordinates of human joints as a heatmap to provide explicit structural features. (Li and Zhao 2022; Choi et al. 2019) utilize gait periodicity priors and frame-level discriminative power, respectively. (Huang et al. 2023) dynamically adapts to the specific attributes of each skeleton sequence and the corresponding view angle. (Pan et al. 2023) generate multi-view pose sequences for each single-view sample to reduce the cross-view variance. Existing studies have significantly improved the extraction of efficient gait features from skeletons. However, none has explored the connection between structure and appearance to improve the performance of model-based methods.
Appearance-based Gait Recognition. These methods attempt to learn gait features directly from silhouette sequences, which has a big performance gap compared with model-based methods. GaitSet (Chao et al. 2019) innovatively regarded the gait sequence as a set and compressed frame-level spatial features. GaitPart (Fan et al. 2020) carefully explored the local details of the input silhouette and modeled the temporal dependencies. GaitBase (Fan et al. 2023) is an efficient baseline model that demonstrates applicability across various frameworks and gait modalities. MTSGait (Zheng et al. 2022a) learns spatial features and multi-scale temporal features simultaneously. This demonstrates the feasibility of bridging the gap between skeletons and silhouettes to improve the model-based methods.
Additionally, recent works aim to effectively integrate gait modalities to enhance recognition performance (Peng et al. 2024; Cui and Kang 2023; Dong et al. 2024; Zheng et al. 2022b), and some research is devoted to obtaining richer gait representations (Guo et al. 2023; Pinyoanuntapong et al. 2023; Han and Bhanu 2005; Wang et al. 2023b; Zheng et al. 2023b; Zou et al. 2024; Wang et al. 2024). Our proposed ZipGait diverges from these multimodal methods that use both silhouettes and skeletons as inputs, we only use skeletons. For a detailed comparison, see the Appendix. C.
Diffusion Model. Diffusion models, also widely known as DDPM, are a series of models generated through Markov chains trained via variational inference (Ho, Jain, and Abbeel 2020). (Song, Meng, and Ermon 2020) replaced the Markovian forward process used in earlier studies with a non-Markovian process, introducing the well-known DDIM. LDM (Rombach et al. 2022) has achieved image generation guided by textual inputs, advancing research in cross-modal generation using diffusion models. Diffusion-based methods have achieved impressive results in generation and segmentation tasks (Chen et al. 2023; Feng et al. 2023; Holmquist and Wandt 2023; Gong et al. 2023). Inspired by these studies, we have introduced diffusion models to generate dense body shapes from sparse skeleton distributions, thereby establishing a direct relational model between gait modalities for the first time.
3 Method
3.1 Problem Formulation
Denote a human skeleton sequence with total frames as , where refers to the -th frame, previous methods identify individuals based on skeleton structure features within the video sequence . Our work is the first attempt to establish the natural correlation between appearance and structure features to eliminate discrepancies between silhouette and skeleton, which can easily reconstruct silhouette appearance features from and achieve excellent performance.
3.2 ZipGait Workflow
Inspired by (Min et al. 2024; Duan et al. 2022; Fan et al. 2024), our work employs heatmaps to represent skeletons, termed ’Heat-skeleton’. Leveraging the OpenGait (Fan et al. 2023) framework, we have optimized its structure for enhanced fine-grained gait fusion, as shown in Fig. 3.
Given a skeleton frame , it is first transformed into Heat-skeletons . Subsequently, is input into DiffGait to reconstruct the corresponding silhouettes. DiffGait Reverse Process could generate multi-level silhouettes under different sampling steps. This process undergoes M rounds of sampling to predict , which we regard as Diffusion Silhouette Reconstruction.
, serve as inputs to Perceptual Gait Integration to obtain a comprehensive gait representation. In stage one, are then refined through dynamic weight allocation to yield the final composite silhouette . In stage two, after convolutional initialization, and are blended through gait fusion layer to obtain the hybrid gait feature .
Finally, is processed through GaitBase (He et al. 2016; Fan et al. 2023) to generate the predicted identity as a one-hot vector. During the training phase, the model’s learning process is supervised by calculating both the triplet loss (Hermans, Beyer, and Leibe 2017) and the cross-entropy loss, which can be formulated as:
| (1) |
| (2) |
, are the features of sample i and sample k, is equal to , represents the Euclidean distance, m denotes the margin for the triplet loss.

3.3 DiffGait
We designed a pioneering diffusion model, termed DiffGait, aimed at reconstructing dense body shapes from sparse skeleton structures. However, directly applying diffusion models for this task inevitably encounters limitations due to modality inconsistency, non-specific diffusion process and model scale. To handle these issues, we initially employ Heat-skeleton Alignment to unify the modalities; subsequently, we design the DiffGait Process consisting of two opposite processes: the DiffGait Forward Process and the DiffGait Reverse Process; ultimately, we develop a highly streamlined DiffGait Architecture, as shown in Fig. 4.
Heat-skeleton Alignment. This improvement focuses on two aspects: 1) Heat-skeletons explicitly provide spatial structure features; 2) Heat-skeletons and silhouettes share modality consistency.
According to the method proposed by (Duan et al. 2022), the joint-based heatmap centered on each skeleton point is created using the coordinate triplets :
| (3) |
regulates the variance of the Gaussian maps, while represents the spatial location of the -th joint, and represents the corresponding confidence score. We can also create the limb-based heatmap :
| (4) |
The limb indexed as k connects two joints, and . The function calculates the distance from the point to the segment .
DiffGait Forward Process. To simplify the diffusion process, we convert the diffusion object from silhouettes to Hybrid Gait Volume (HGV). Given a Heat-skeleton sequence with total frames as , where refers to the -th frame.
To obtain , we designate the silhouettes aligned with Heat-skeletons as the diffusion target and define them as the initial state of the diffusion process. We introduce Gaussian noise at various timesteps to facilitate the forward diffusion of the silhouettes,
| (5) |
Subsequently, is extracted by . For dimension matching, we apply Gait Mapping to reduce by a factor of four via a two-layer convolution and increase feature channels to . This approach retains more details compared to the direct bilinear interpolation used in DiffuVolume (Zheng et al. 2023a).
Furthermore, timestep embedding of dimension corresponding to is generated by Timestep Embedding and is added to , then we match the features of and by element-wise multiplication and introduce skip connections to ensure a smooth transition of the features,
| (6) |
where is the element-wise multiplication, means the Hybrid Gait Volume, means the Gait Mapping, is the selected timestep and means Timestep Embedding.

| DataSet | Batch Size | Milestones | Total Steps | Train Set | Test Set | Scenario | Modalities | ||
|---|---|---|---|---|---|---|---|---|---|
| #ID | #Seq | #ID | #Seq | ||||||
| CASIA-B | (8, 16) | (20k, 40k, 50k) | 60k | 74 | 8,140 | 50 | 5,500 | Constrained | Sil., RGB |
| OU-MVLP | (32, 8) | (60k, 80k, 100k) | 120k | 5,153 | 144,284 | 5,154 | 144,412 | Constrained | Sil., Ske. |
| Gait3D | (32, 4) | (20k, 40k, 50k) | 60k | 3,000 | 18,940 | 1,000 | 6,369 | Real-world | Sil., Ske., Mesh |
| GREW | (32, 4) | (80k, 120k, 150k) | 180k | 20,000 | 102,887 | 6,000 | 24,000 | Real-world | Sil., Ske. |
| Input | Method | Testing Datasets | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Gait3D | GREW | OU-MVLP | CASIA-B | ||||||||
| NM | BG | CL | Mean | ||||||||
| Rank-1 | Rank-5 | mAP | mINP | Rank-1 | Rank-1 | Rank-1 | |||||
| Silhouette | GaitSet(AAAI19) | 36.7 | 59.3 | 30.0 | 17.3 | 46.3 | 87.1 | 95.0 | 87.2 | 70.4 | 84.2 |
| GaitPart(CVPR20) | 28.2 | 47.6 | 21.6 | 12.4 | 44.0 | 88.5 | 96.2 | 91.5 | 78.7 | 88.8 | |
| MTSGait(ACM MM22) | 48.7 | 67.1 | 37.6 | 22.0 | 55.3 | - | - | - | - | - | |
| GaitBase(CVPR23) | 64.6 | - | - | - | 60.1 | 90.8 | 97.6 | 94.0 | 77.4 | 89.7 | |
| Skeleton | GaitGraph(ICIP21) | 12.6 | 28.7 | 11.0 | 6.5 | 10.2 | 4.2 | 86.3 | 76.5 | 65.2 | 76.0 |
| GaitGraph2(CVPRW22) | 7.2 | 15.9 | 5.2 | 3.0 | 34.8 | 70.7 | 80.3 | 71.4 | 63.8 | 71.8 | |
| GPGait(ICCV23) | 22.4 | - | - | - | 57.0 | 59.1 | 93.6 | 80.2 | 69.3 | 81.0 | |
| SkeletonGait(AAAI24) | 38.1 | 56.7 | 28.9 | 16.1 | 77.4 | 67.4 | - | - | - | - | |
| Ours | 39.5 | 60.1 | 30.4 | 17.1 | 72.5 | 68.2 | 94.1 | 81.3 | 74.9 | 83.4 | |
DiffGait Reverse Process. We have modified the DDIM (Song, Meng, and Ermon 2020) sampling method to generate multi-level silhouettes under different timesteps and reduce Gaussian uncertainty, as shown in Fig. 5.
Standard Gaussian noise serves as the initial input. Then, is calculated based on Equation 6, and is predicted by . We consider as the maximum likelihood of , denoted as . Then we calculate the noise for the current timestep via the following formula:
| (7) |
Furthermore, and are used to recover the . The formulation is expressed as,
| (8) |
where , means sampling coefficient and means the Standard Gaussian Noise. will continue to participate in the reverse process, following the method mentioned above, until the end of the sampling process.
DiffGait Architecture. The inference speed and model parameter size exhibited by existing UNet-based diffusion models render their application to gait recognition entirely impractical. Considering gait modalities are ’clean’, DiffGait employs an extremely streamlined architecture with a surprisingly low model parameter size of 1.9M and an impressive inference speed of 3628 FPS.
Compared with previous models, DiffGait incorporates two key improvements: 1) DiffGait adopts a Decoder-only architecture. 2) DiffGait eliminates unnecessary convolutional layers and attention modules, operating within a low-dimensional feature space. To be specific, a five-layer ResNet-like encoder is designed to extract skeleton structure features . Gait Mapping is adopted for downsampling silhouette-based Gaussian noise . A similarly sized decoder , denoises silhouettes from Hybrid Gait Volume (HGV) integrated by and .
3.4 Perceptual Gait Integration (PGI)
Through the above designs, DiffGait produces multi-level silhouettes , each emphasizing various appearance feature levels. Effective integration of structure and appearance features to construct a comprehensive gait representation significantly influences the overall recognition performance, so we propose Perceptual Gait Integration (PGI) consisting of two stages:
In stage one, our strategy is to allocate varying weights to different timesteps to generate the well-defined silhouette , acknowledging that the reconstruction process progresses from local to global features, with later steps yielding enhanced outcomes. We set the weights as (0, 0, 0.2, 0.3, 0.5) and discuss them in Tab. 9.
In stage two, our goal is to mitigate noise arising from gait modalities fusion and effectively integrate structure and appearance features. The initialized and are concatenated to create a fused feature, which serves as the input for subsequent processing. Following (Min et al. 2024), by employing a perceptual structure centered on ReLU and Sigmoid activations, we assign higher weights to features that are similar across skeletons and silhouettes, eliminate the impact of redundant features, and derive through an attention-like approach (Vaswani et al. 2017).
4 Experiment

4.1 Experimental Settings
Datasets & Metrics. We evaluated our proposed method on four mainstream datasets, including two outdoor datasets: Gait3D (Zheng et al. 2022b) GREW (Zhu et al. 2021), and two indoor datasets: CASIA-B (Yu, Tan, and Tan 2006) OU-MVLP (Takemura et al. 2018). The key statistics of these gait datasets are listed in Tab. 1. We use the following metrics to evaluate model performance quantitatively: rank retrieval (Rank-1, Rank-5), mean Average Precision(mAP) and mean Inverse Negative Penalty (mINP), and Rank-1 accuracy is considered the primary metric.
Implementation details. During the training and inference stages, we use PyTorch as the framework to conduct all experiments on two RTX 3090. For the full four datasets, we used silhouettes with a resolution of , and skeletons are the 2D coordinates of joints that conform to COCO 17 and transformed into Heat-skeletons with a resolution of . Tab. 1 displays the main hyper-parameters of our experiments.
When training DiffGait, we choose Adam as the optimizer, with the initial learning rate set to 0.01 and batch size (16, 4). We set the timestep as 1000. A cosine schedule is adopted to set the noise coefficient , . When training ZipGait, the SGD optimizer with an initial learning rate of 0.1 and weight decay of 0.0005 is utilized.
4.2 Comparison with State-of-the-art Methods
4.2.1 Quantitative comparison
We initiate our analysis with an Intra-domain comparison, where we systematically evaluate our approach against the current state-of-the-art model-based methods, with comparative results presented in Tab. 2. Our method improves the performance by 10.2% compared to GPGait and 1.8% compared to SkeletonGait in Gait3D. Similarly, our method also holds a significant advantage over other methods in the indoor datasets.
We further perform a Cross-domain comparison to assess our method’s efficacy across different testing scenarios, and detailed results are shown in Fig. 6. We compare two representative skeleton-based methods, GaitGraph2 and GPGait, with the latter demonstrating superior generalization capabilities. We can observe from the experimental results: 1) Skeletons are susceptible to data distribution; 2) Reconstructed appearance features can enhance representation robustness; 3) Training on real datasets leads to improved generalization capabilities.
| Model | Inference speed (FPS) | Params (M) |
|---|---|---|
| DDPM | 345 | 45.09 |
| DDIM | 1754 | 45.09 |
| DiffGait (ours) | 3628 | 1.9 |
4.2.2 Qualitative comparison
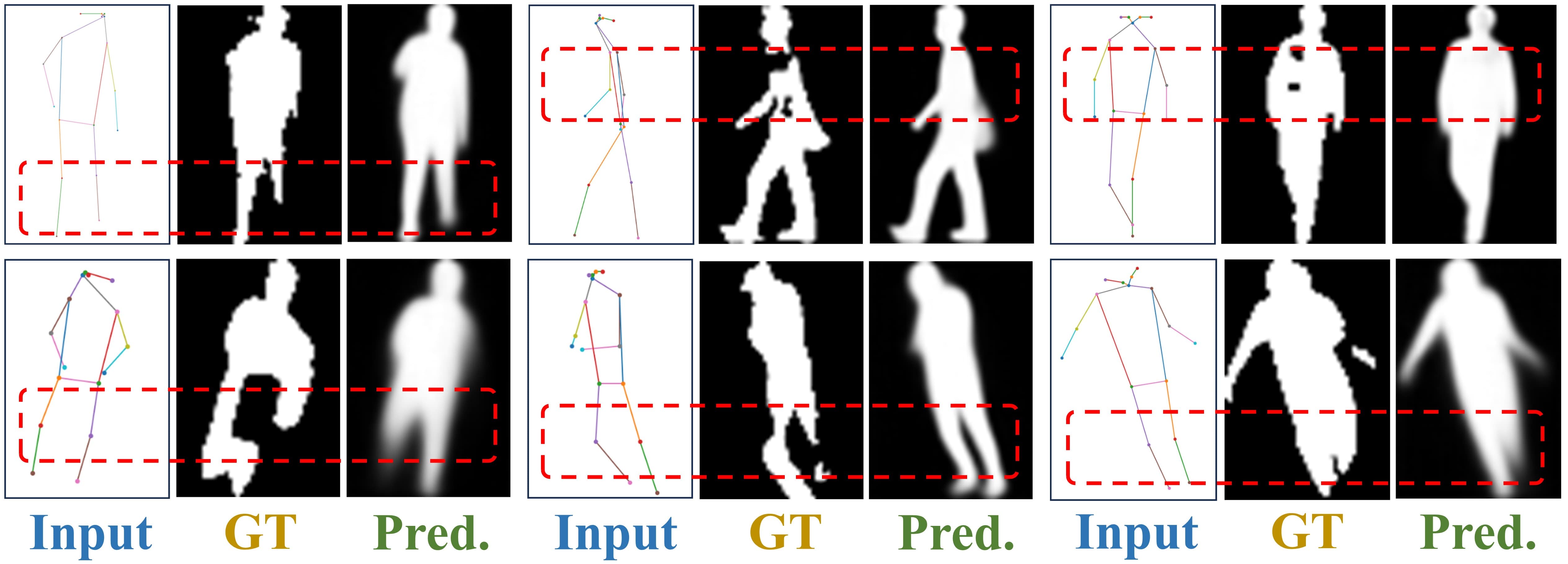
As illustrated in Fig. 7, we randomly selected over a dozen test skeletons from four datasets. DiffGait can efficiently reconstruct occluded body parts by learning the a priori distribution of the human body. It can be observed that, compared to GT, various gait noises, such as occlusions, have been eliminated.
We further examine the ability of our model in dealing with challenging scenarios. We depict in Fig. 8 side-by-side comparisons of (a) our DiffGait against standard (b) DDIM and (c) DDPM, GT stands for ground truth. It is observed that our DiffGait consistently reconstructs silhouettes for various challenging scenes.
4.2.3 Efficiency comparison.
In addition, to demonstrate the efficiency of our proposed method, we compare the number of model parameters and inference speed between our DiffGait and two typical methods DDPM and DDIM in Tab. 3. DiffGait achieves significant performance while only requiring approximately 1.9M model parameters. It outperforms them by achieving a speedup of about 10 times and 2 times faster in terms of Frames Per Second (FPS).

| Rank-1 (%) | mAP (%) | |
|---|---|---|
| GaitGraph(ICIP21) | 12.6 | 11.0 |
| GaitGraph + DiffGait | 23.2 (10.6 ) | 17.1 (6.1 ) |
| GaitTR(ES23) | 7.8 | 6.6 |
| GaitTR + DiffGait | 19.6 (11.8 ) | 15.7 (9.1 ) |
| GaitGraph2(CVPRW22) | 7.2 | 5.2 |
| GaitGraph2 + DiffGait | 18.9 (11.7 ) | 15.9 (10.7 ) |
| GPGait(ICCV23) | 22.3 | 16.5 |
| GPGait + DiffGait | 31.3 (9.0 ) | 22.9 (6.4 ) |
| SkeletonGait(AAAI24) | 38.1 | 28.9 |
| SkeletonGait + DiffGait | 39.2 (1.1 ) | 29.5 (0.6 ) |
4.3 Plug-and-Play Performance Evaluation.
we demonstrate the plug-and-play performance of DiffGait by applying it to state-of-the-art model-based methods (Teepe et al. 2021, 2022; Zhang et al. 2023; Fu et al. 2023; Fan et al. 2024). The experimental outcomes, detailed in Tab. 4, reveal that DiffGait significantly enhances the performance of all existing model-based methods across various metrics. The effectiveness stems from reconstructed silhouettes, which provides richer gait features. Contrasting with ZipGait, we integrate gait features by padding and concatenating before passing them into the head layer.

4.4 Ablation Study
Study on components of ZipGait. We empirically evaluate the effectiveness of each proposed component, and report the results in Tab. 5 (a) is our baseline, using Heat-skeletons as input; (b) solely uses silhouettes predicted by DiffGait; (c) illustrates a simple sum fusion of shape and structure features; (d) demonstrates that our proposed PGI improves performance from 38.7% to 39.5%.
| Structure | Heat. | Silh. | PGI | Rank-1 | mAP |
|---|---|---|---|---|---|
| (a) Baseline | ✓ | ✗ | ✗ | 33.6 | 23.4 |
| (b) | ✗ | ✗ | 24.7 | 18.1 | |
| (c) | ✗ | 38.7 | 27.2 | ||
| (d) ZipGait | 39.5 | 30.4 |
| Structure | Stage 1 | Stage 2 | Rank-1 | mAP |
|---|---|---|---|---|
| (a) | ✗ | 39.0 | 28.9 | |
| (b) | ✗ | 39.2 | 29.5 | |
| (c) Full | 39.5 | 30.4 |
Study on Perceptual Gait Integration. We further explore the influence of two stages within PGI, and tabulate the results in Tab. 6. (a) only utilizes stage 1, refining the predicted multi-level silhouettes through dynamic weight allocation; (b) employs a gait fusion layer to generate mixed gait features, representing stage 2; (c) demonstrates the complete two-stage integration. Each stage independently enhances performance, and their integration results in even greater improvements, thereby proving the efficacy of the modules.
| Method | Rank-1 | Rank-5 | mAP | mINP |
|---|---|---|---|---|
| DDIM Process | 38.4 | 58.1 | 29.2 | 16.5 |
| DiffGait Process | 39.5 | 60.1 | 30.4 | 17.1 |
Study on DiffGait Process. To validate the effect of the DiffGait Process, we consider two alternative ways to train our DiffGait. Fig. 10 visualizes the denoising process in detail, highlighting the distinctions between the two methods. Further experiments under identical conditions demonstrated superior performance of the DiffGait Process, providing a clear validation of its effectiveness, shown in Tab. 7. Model training and inference of DDIM process can be found in Appendix, along with more detailed comparisons.

4.5 Further Analysis
Denoising steps analysis. As shown in Fig. 11, setting the denoising steps to three or more can generate effective silhouettes. To select the most appropriate number of denoising steps, we analyzed several possible values, with performance and efficiency serving as the criteria. The experimental results in Tab. 8 reveal that the best performance is achieved with 5 denoising steps, striking a balance by enhancing performance without significant additional resource demands, with only a slight 0.2s increase per iteration.
| Sampling Steps | Training time | Rank-1 | mAP |
|---|---|---|---|
| No DiffGait | 37.2s | 33.6 | 23.4 |
| 1 sampling steps | 43.8s | 6.8 | 1.7 |
| 3 sampling steps | 53.4s | 37.4 | 27.1 |
| 4 sampling steps | 54.2s | 38.4 | 28.3 |
| 5 sampling steps | 59.6s | 38.7 | 29.2 |
| 10 sampling steps | 76.4s | 37.9 | 28.8 |
Dynamic weight allocation analysis. As shown in Fig. 10, during the denoising process, the quality of predicted silhouettes varies at each step. We established various potential combinations of weights and conducted experimental validations. The results, displayed in Tab. 9, indicate that is the optimal choice for Stage 1 of PGI.
| groups | Rank-1 | mAP | |||||
|---|---|---|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0 | 12.8 | 6.2 | |
| 0 | 0 | 0 | 0 | 1 | 39.0 | 29.4 | |
| 0 | 0 | 0 | 0.5 | 0.5 | 39.2 | 29.8 | |
| 0 | 0 | 0.2 | 0.3 | 0.5 | 39.5 | 30.4 | |
| 0.2 | 0.2 | 0.2 | 0.2 | 0.2 | 38.7 | 29.2 |
5 Conclusion
This paper establishes the connection between skeletons and silhouettes via the diffusion model, providing new insights into utilizing gait modalities. The proposed DiffGait is the first successful method to reconstruct dense body shapes from sparse skeleton structures. Simultaneously, Perceptual Gait Integration is proposed for efficient fusion of gait modality. Ultimately, ZipGait demonstrates superior performance in both cross-domain and intra-domain settings and achieves plug-and-play improvements. This study highlights the potential of gait modality interaction in gait recognition.
References
- Chao et al. (2019) Chao, H.; He, Y.; Zhang, J.; and Feng, J. 2019. Gaitset: Regarding gait as a set for cross-view gait recognition. In Proceedings of the AAAI conference on artificial intelligence, volume 33, 8126–8133.
- Chen et al. (2023) Chen, S.; Sun, P.; Song, Y.; and Luo, P. 2023. Diffusiondet: Diffusion model for object detection. In Proceedings of the IEEE/CVF international conference on computer vision, 19830–19843.
- Choi et al. (2019) Choi, S.; Kim, J.; Kim, W.; and Kim, C. 2019. Skeleton-based gait recognition via robust frame-level matching. IEEE Transactions on information forensics and security, 14(10): 2577–2592.
- Cui and Kang (2023) Cui, Y.; and Kang, Y. 2023. Multi-modal gait recognition via effective spatial-temporal feature fusion. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 17949–17957.
- Dong et al. (2024) Dong, Y.; Yu, C.; Ha, R.; Shi, Y.; Ma, Y.; Xu, L.; Fu, Y.; and Wang, J. 2024. HybridGait: A benchmark for spatial-temporal cloth-changing gait recognition with hybrid explorations. In Proceedings of the AAAI conference on artificial intelligence, volume 38, 1600–1608.
- Dou et al. (2023) Dou, H.; Zhang, P.; Su, W.; Yu, Y.; Lin, Y.; and Li, X. 2023. Gaitgci: Generative counterfactual intervention for gait recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 5578–5588.
- Dou et al. (2024) Dou, H.; Zhang, P.; Zhao, Y.; Jin, L.; and Li, X. 2024. CLASH: Complementary Learning with Neural Architecture Search for Gait Recognition. IEEE Transactions on image processing.
- Duan et al. (2022) Duan, H.; Zhao, Y.; Chen, K.; Lin, D.; and Dai, B. 2022. Revisiting skeleton-based action recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2969–2978.
- Fan et al. (2023) Fan, C.; Liang, J.; Shen, C.; Hou, S.; Huang, Y.; and Yu, S. 2023. Opengait: Revisiting gait recognition towards better practicality. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 9707–9716.
- Fan et al. (2024) Fan, C.; Ma, J.; Jin, D.; Shen, C.; and Yu, S. 2024. SkeletonGait: Gait Recognition Using Skeleton Maps. In Proceedings of the AAAI conference on artificial intelligence, volume 38, 1662–1669.
- Fan et al. (2020) Fan, C.; Peng, Y.; Cao, C.; Liu, X.; Hou, S.; Chi, J.; Huang, Y.; Li, Q.; and He, Z. 2020. Gaitpart: Temporal part-based model for gait recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 14225–14233.
- Feng et al. (2023) Feng, R.; Gao, Y.; Tse, T. H. E.; Ma, X.; and Chang, H. J. 2023. DiffPose: SpatioTemporal diffusion model for video-based human pose estimation. In Proceedings of the IEEE/CVF international conference on computer vision, 14861–14872.
- Frank, Mannor, and Precup (2010) Frank, J.; Mannor, S.; and Precup, D. 2010. Activity and gait recognition with time-delay embeddings. In Proceedings of the AAAI conference on artificial intelligence, volume 24, 1581–1586.
- Fu et al. (2023) Fu, Y.; Meng, S.; Hou, S.; Hu, X.; and Huang, Y. 2023. Gpgait: Generalized pose-based gait recognition. In Proceedings of the IEEE/CVF international conference on computer vision, 19595–19604.
- Fu et al. (2019) Fu, Y.; Wei, Y.; Zhou, Y.; Shi, H.; Huang, G.; Wang, X.; Yao, Z.; and Huang, T. 2019. Horizontal pyramid matching for person re-identification. In Proceedings of the AAAI conference on artificial intelligence, volume 33, 8295–8302.
- Gao et al. (2022) Gao, S.; Yun, J.; Zhao, Y.; and Liu, L. 2022. Gait-D: skeleton-based gait feature decomposition for gait recognition. IET computer vision, 16(2): 111–125.
- Gong et al. (2023) Gong, J.; Foo, L. G.; Fan, Z.; Ke, Q.; Rahmani, H.; and Liu, J. 2023. Diffpose: Toward more reliable 3d pose estimation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 13041–13051.
- Guo et al. (2023) Guo, Y.; Shah, A.; Liu, J.; Chellappa, R.; and Peng, C. 2023. GaitContour: Efficient Gait Recognition based on a Contour-Pose Representation. arXiv preprint arXiv:2311.16497.
- Han and Bhanu (2005) Han, J.; and Bhanu, B. 2005. Individual recognition using gait energy image. IEEE Transactions on pattern analysis and machine intelligence, 28(2): 316–322.
- He et al. (2016) He, K.; Zhang, X.; Ren, S.; and Sun, J. 2016. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 770–778.
- Hermans, Beyer, and Leibe (2017) Hermans, A.; Beyer, L.; and Leibe, B. 2017. In defense of the triplet loss for person re-identification. arXiv preprint arXiv:1703.07737.
- Ho, Jain, and Abbeel (2020) Ho, J.; Jain, A.; and Abbeel, P. 2020. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33: 6840–6851.
- Holmquist and Wandt (2023) Holmquist, K.; and Wandt, B. 2023. Diffpose: Multi-hypothesis human pose estimation using diffusion models. In Proceedings of the IEEE/CVF international conference on computer vision, 15977–15987.
- Huang et al. (2023) Huang, X.; Wang, X.; Jin, Z.; Yang, B.; He, B.; Feng, B.; and Liu, W. 2023. Condition-adaptive graph convolution learning for skeleton-based gait recognition. IEEE Transactions on image processing.
- Li and Zhao (2022) Li, N.; and Zhao, X. 2022. A strong and robust skeleton-based gait recognition method with gait periodicity priors. IEEE Transactions on multimedia, 25: 3046–3058.
- Li et al. (2020) Li, X.; Makihara, Y.; Xu, C.; Yagi, Y.; Yu, S.; and Ren, M. 2020. End-to-end model-based gait recognition. In Proceedings of the asian conference on computer vision.
- Liao et al. (2020) Liao, R.; Yu, S.; An, W.; and Huang, Y. 2020. A model-based gait recognition method with body pose and human prior knowledge. Pattern recognition, 98: 107069.
- Lin, Zhang, and Yu (2021) Lin, B.; Zhang, S.; and Yu, X. 2021. Gait recognition via effective global-local feature representation and local temporal aggregation. In Proc5eedings of the IEEE/CVF international conference on computer vision, 14648–14656.
- Liu et al. (2022) Liu, X.; You, Z.; He, Y.; Bi, S.; and Wang, J. 2022. Symmetry-Driven hyper feature GCN for skeleton-based gait recognition. Pattern recognition, 125: 108520.
- Loper et al. (2023) Loper, M.; Mahmood, N.; Romero, J.; Pons-Moll, G.; and Black, M. J. 2023. SMPL: A skinned multi-person linear model. In Seminal graphics papers: pushing the boundaries, Volume 2, 851–866.
- Min et al. (2024) Min, F.; Guo, S.; Hao, F.; and Dong, J. 2024. GaitMA: Pose-guided Multi-modal Feature Fusion for Gait Recognition. arXiv preprint arXiv:2407.14812.
- Pan et al. (2023) Pan, H.; Chen, Y.; Xu, T.; He, Y.; and He, Z. 2023. Toward complete-view and high-level pose-based gait recognition. IEEE Transactions on information forensics and security, 18: 2104–2118.
- Peng et al. (2024) Peng, Y.; Ma, K.; Zhang, Y.; and He, Z. 2024. Learning rich features for gait recognition by integrating skeletons and silhouettes. Multimedia tools and applications, 83(3): 7273–7294.
- Pinyoanuntapong et al. (2023) Pinyoanuntapong, E.; Ali, A.; Wang, P.; Lee, M.; and Chen, C. 2023. Gaitmixer: skeleton-based gait representation learning via wide-spectrum multi-axial mixer. In ICASSP 2023-2023 IEEE International conference on acoustics, speech and signal processing (ICASSP), 1–5. IEEE.
- Rombach et al. (2022) Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; and Ommer, B. 2022. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 10684–10695.
- Ronneberger, Fischer, and Brox (2015) Ronneberger, O.; Fischer, P.; and Brox, T. 2015. U-net: Convolutional networks for biomedical image segmentation. In Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18, 234–241. Springer.
- Shen et al. (2023) Shen, C.; Fan, C.; Wu, W.; Wang, R.; Huang, G. Q.; and Yu, S. 2023. Lidargait: Benchmarking 3d gait recognition with point clouds. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 1054–1063.
- Song, Meng, and Ermon (2020) Song, J.; Meng, C.; and Ermon, S. 2020. Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502.
- Takemura et al. (2018) Takemura, N.; Makihara, Y.; Muramatsu, D.; Echigo, T.; and Yagi, Y. 2018. Multi-view large population gait dataset and its performance evaluation for cross-view gait recognition. IPSJ Transactions on computer vision and applications, 10: 1–14.
- Teepe et al. (2022) Teepe, T.; Gilg, J.; Herzog, F.; Hörmann, S.; and Rigoll, G. 2022. Towards a deeper understanding of skeleton-based gait recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 1569–1577.
- Teepe et al. (2021) Teepe, T.; Khan, A.; Gilg, J.; Herzog, F.; Hörmann, S.; and Rigoll, G. 2021. Gaitgraph: Graph convolutional network for skeleton-based gait recognition. In 2021 IEEE international conference on image processing (ICIP), 2314–2318. IEEE.
- Vaswani et al. (2017) Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, Ł.; and Polosukhin, I. 2017. Attention is all you need. Advances in neural information processing systems, 30.
- Wang, Chen, and Liu (2022) Wang, L.; Chen, J.; and Liu, Y. 2022. Frame-level refinement networks for skeleton-based gait recognition. Computer cision and image understanding, 222: 103500.
- Wang et al. (2003) Wang, L.; Tan, T.; Ning, H.; and Hu, W. 2003. Silhouette analysis-based gait recognition for human identification. IEEE Transactions on pattern analysis and machine intelligence, 25(12): 1505–1518.
- Wang et al. (2023a) Wang, M.; Guo, X.; Lin, B.; Yang, T.; Zhu, Z.; Li, L.; Zhang, S.; and Yu, X. 2023a. DyGait: Exploiting dynamic representations for high-performance gait recognition. In Proceedings of the IEEE/CVF international conference on computer vision, 13424–13433.
- Wang et al. (2023b) Wang, Z.; Hou, S.; Zhang, M.; Liu, X.; Cao, C.; and Huang, Y. 2023b. GaitParsing: Human semantic parsing for gait recognition. IEEE Transactions on multimedia.
- Wang et al. (2024) Wang, Z.; Hou, S.; Zhang, M.; Liu, X.; Cao, C.; Huang, Y.; Li, P.; and Xu, S. 2024. QAGait: Revisit Gait Recognition from a Quality Perspective. In Proceedings of the AAAI conference on artificial intelligence, volume 38, 5785–5793.
- Wu et al. (2016) Wu, Z.; Huang, Y.; Wang, L.; Wang, X.; and Tan, T. 2016. A comprehensive study on cross-view gait based human identification with deep cnns. IEEE Transactions on pattern analysis and machine intelligence, 39(2): 209–226.
- Yam, Nixon, and Carter (2004) Yam, C.; Nixon, M. S.; and Carter, J. N. 2004. Automated person recognition by walking and running via model-based approaches. Pattern recognition, 37(5): 1057–1072.
- Yu, Tan, and Tan (2006) Yu, S.; Tan, D.; and Tan, T. 2006. A framework for evaluating the effect of view angle, clothing and carrying condition on gait recognition. In 18th International conference on pattern recognition (ICPR’06), volume 4, 441–444. IEEE.
- Zhang et al. (2023) Zhang, C.; Chen, X.-P.; Han, G.-Q.; and Liu, X.-J. 2023. Spatial transformer network on skeleton-based gait recognition. Expert systems, 40(6): e13244.
- Zheng et al. (2023a) Zheng, D.; Wu, X.-M.; Liu, Z.; Meng, J.; and Zheng, W.-s. 2023a. Diffuvolume: Diffusion model for volume based stereo matching. arXiv preprint arXiv:2308.15989.
- Zheng et al. (2022a) Zheng, J.; Liu, X.; Gu, X.; Sun, Y.; Gan, C.; Zhang, J.; Liu, W.; and Yan, C. 2022a. Gait recognition in the wild with multi-hop temporal switch. In Proceedings of the 30th ACM international conference on multimedia, 6136–6145.
- Zheng et al. (2022b) Zheng, J.; Liu, X.; Liu, W.; He, L.; Yan, C.; and Mei, T. 2022b. Gait recognition in the wild with dense 3d representations and a benchmark. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 20228–20237.
- Zheng et al. (2023b) Zheng, J.; Liu, X.; Wang, S.; Wang, L.; Yan, C.; and Liu, W. 2023b. Parsing is all you need for accurate gait recognition in the wild. In Proceedings of the 31st ACM international conference on multimedia, 116–124.
- Zhu et al. (2021) Zhu, Z.; Guo, X.; Yang, T.; Huang, J.; Deng, J.; Huang, G.; Du, D.; Lu, J.; and Zhou, J. 2021. Gait recognition in the wild: A benchmark. In Proceedings of the IEEE/CVF international conference on computer vision, 14789–14799.
- Zou et al. (2024) Zou, S.; Fan, C.; Xiong, J.; Shen, C.; Yu, S.; and Tang, J. 2024. Cross-Covariate Gait Recognition: A Benchmark. In Proceedings of the AAAI conference on artificial intelligence, volume 38, 7855–7863.
Supplementary Material for ZipGait: Bridging Skeleton and Silhouette with Diffusion Model for Advancing Gait Recognition
Written by AAAI Press Staff1With help from the AAAI Publications Committee.
AAAI Style Contributions by Pater Patel Schneider,
Sunil Issar,
J. Scott Penberthy,
George Ferguson,
Hans Guesgen,
Francisco Cruz\equalcontrib,
Marc Pujol-Gonzalez\equalcontrib

In appendix, we provide background on diffusion models, DiffGait training and inference algorithms, comparison with other related gait recognition methods, analysis of the impact on generalization and more visualization details in Section A, Section B, Section C, Section D and Section E.
A. Background on Diffusion Models
Diffusion models typically consist of two basic processes: 1) a forward process that gradually adds Gaussian noise to sample data, and 2) a reverse process that learns to invert the forward diffusion.
Our work extends the framework of Denoising Diffusion Probabilistic Models (DDPMs), a class of deep generative models that approximate the distribution of natural images using the terminal state of a Markov chain that originates from a standard Gaussian distribution. DDPMs are trained to reverse a diffusion process that gradually adds Gaussian noise to the training data over steps until it becomes pure noise at .
To be specific, the forward process may be formalized as sampling from a conditional distribution , denoted as , which mainly involves adding noise to the data without depending on any parameterized distribution,
| (9) |
where is the identity matrix and the rate at which the original data is diffused into noise is controlled by a variance scheduling given by , . . . , . Importantly, the forward process and its schedule may be reparameterized as:
| (10) |
| (11) |
In contrast, the reverse process reconstructs the data distribution from noise, represented as . This reverse conditional distribution is arbitrarily complex, but we might approximate it via a denoising deep neural network,
| (12) |
where is a learned deep neural network that has as input both the noisy data and its step t (usually position encoded); depends on the variance schedule but is not otherwise learned.
The conditional diffusion models, which add an extra term in the denoising process, provide the opportunity for the cross-modal generation tasks:
| (13) |
where the conditioning inputs added to may be derived from the original modality.
B. DiffGait Training and Inference Algorithms
Training. During the training phase, we perform the diffusion process that corrupts ground truth silhouette to noisy silhouette , then is integrated with to . We learn the reverse denoising process by continuously using to recover into , thus optimizing DiffGait to gradually remove the uncertainty of and redefine the source distribution to , which can be formulated as:
| (14) |
We employ MSE to supervise the model training:
| (15) |
Algorithm A provides the overall training procedure.
Inference. Algorithm B summarizes the detailed inference procedure of DiffGait, which can be seen as iteratively generating more complete silhouettes. We have redesigned the sampling method based on DDIM to generate effective silhouettes at each sampling step, observing that later-generated features are more complete yet tend to lack some details. Specifically, for each sampling step, takes the initial or the from the previous step as input and outputs the estimated silhouette for the current step. Then, our new sampling method is used to update the silhouette for the next step.
C. Comparison with Other Related Gait Recognition Methods
In the aforementioned article, we briefly delineate the differences between our ZipGait approach and other common gait recognition methods in terms of input modalities and feature utilization. To concretely highlight the distinctions of our architecture, we have illustrated four pipelines in Fig A, each representing the overall workflow of our method compared to three other approaches in gait recognition.
As shown in Fig A(a), appearance-based methods are currently the mainstream algorithms in the field of gait recognition. This paradigm, followed by most studies, typically exhibits the best performance under general conditions. However, these methods inevitably suffer from the quality of silhouettes; in environments with complex backgrounds or significant occlusions, performance is limited, as low-quality silhouettes do not enable the models to learn robust gait representations, which is a very critical factor.
Fig A(b) illustrates model-based approaches, which primarily extract gait features from human body models. The skeleton is the only model that can be used as a standalone input for gait recognition, often referred to as skeleton-based methods. SMPL models and point clouds are usually employed as supplementary modalities to provide additional information. The main limitation of model-based methods is the accuracy of the models, especially three-dimensional ones, which currently cannot effectively estimate the absolute posture of the human body in three-dimensional space, making gait recognition using these models unreliable.
The basic workflow of multimodal methods is depicted in Fig A(c), which extracts features from different modalities through two branches and then merges them for feature classification. This approach does offer a novel strategy for obtaining more effective gait representations, but it requires inputs from multiple modalities and the processing of features from these modalities, which is particularly demanding in terms of computational and storage resources. Although this can achieve high performance, further efforts are needed to make the structure more lightweight.
Fig A(d) presents our ZipGait method, which borrows the advantages of the three aforementioned approaches while addressing some of their shortcomings. Our method solely uses the skeleton as an input but establishes a relationship with the silhouette through our DiffGait model. In terms of feature fusion, we have refined the dual-branch structure of current multimodal methods by merging features at a lower dimension, effectively simplifying the model structure. Overall, ZipGait employs a highly streamlined structure, using only one modality as input, yet achieving the effects of multi-modality.
It must be noted that our proposed method still lags behind appearance-based and multimodal methods in performance. This is primarily due to the predicted silhouettes not fully restoring all external details, tending instead to reconstruct a more averaged distribution.
D. Analysis of the Impact on Generalization
| Heat. | Silh. | Trained on CASIA-B | Trained on Gait3D | ||
|---|---|---|---|---|---|
| CASIA-B | Gait3D | CASIA-B | Gait3D | ||
| ✗ | 77.2 | 10.2 | 27.4 | 33.6 | |
| ✗ | 67.1 | 9.8 | 34.5 | 24.7 | |
| 83.4 | 12.8 | 44.2 | 39.5 | ||
Our proposed ZipGait outperforms other methods in cross-domain evaluations. To ascertain whether the enhanced generalization ability is due to the use of DiffGait in reconstructing silhouettes, we specifically designed experiments to separately assess the intra-domain and cross-domain evaluation effects of Heat-skeleton and predicted Silhouette. The experiments demonstrate that incorporating DiffGait is a key factor in improving the model’s generalization capability.



E. More Visualization Details.
In this section, we provide more comprehensive visualizations to demonstrate the effectiveness of our proposed DiffGait model. Fig. B displays the denoising results at different denoising steps, showing that visually effective silhouettes can be achieved when the denoising step is set to three or more,. Fig. C compares the performance with other diffusion models, revealing that our model does not significantly differ in denoising quality from the DDIM and DDPM models, and that our DiffGait is far more efficient than these methods. Fig. D visualizes the intermediate modalities used in ZipGait: skeleton, Heat-skeleton, and reconstructed silhouette, along with the ground truth silhouette. Fig. E compares the predicted silhouettes of two long sequences (each with 60 frames) derived from our DiffGait. Fig. F presents visualizations under normal conditions, where there is enough shape information to reconstruct high-quality contours. Fig. G shows visualizations under challenging conditions, where the silhouettes reconstructed by DiffGait provide more effective features, as the robustness displayed by the skeleton allows it to address the impacts of occlusions.
These sufficient visualizations evaluate the quality of the DiffGait reconstructed silhouettes from different aspects and can fully demonstrate the effectiveness of our method.


