Zeroth-order optimisation on subsets of symmetric matrices with application to MPC tuning
Abstract
This paper provides a zeroth-order optimisation framework for non-smooth and possibly non-convex cost functions with matrix parameters that are real and symmetric. We provide complexity bounds on the number of iterations required to ensure a given accuracy level for both the convex and non-convex case. The derived complexity bounds for the convex case are less conservative than available bounds in the literature since we exploit the symmetric structure of the underlying matrix space. Moreover, the non-convex complexity bounds are novel for the class of optimisation problems we consider. The utility of the framework is evident in the suite of applications that use symmetric matrices as tuning parameters. Of primary interest here is the challenge of tuning the gain matrices in model predictive controllers, as this is a challenge known to be inhibiting industrial implementation of these architectures. To demonstrate the framework we consider the problem of MIMO diesel air-path control, and consider implementing the framework iteratively “in-the-loop” to reduce tracking error on the output channels. Both simulations and experimental results are included to illustrate the effectiveness of the proposed framework over different engine drive cycles.
1 Introduction
Optimisation with matrix-valued decision variables is a problem that appears in a wide variety of applications. Particularly, this approach can be found in non-negative matrix factorization [19], low-rank matrix optimisation [45, 44], signal processing with independent component analysis [3], energy efficient wireless systems [26], graph weight allocation [33, 6], and controller tuning such as model predictive controllers [8], linear quadratic regulators [23], and PIDs for MIMO systems [9]. In most of the aforementioned applications, either explicit expressions of the cost function are not available, or derivatives are difficult or infeasible to obtain. Consequently, we restrict our attention to this class of problems in which the cost function is treated as a black-box. In this case, the cost function directional derivatives can still be approximated by means of cost function values using finite-differences for instance. Of main interest in this paper is the challenge of tuning the gain matrices in model predictive controllers (MPC), which have the property of being symmetric and positive (semi) definite. Efficient calibration of MPCs is often a difficult task given the large number of tuning parameters and their non-intuitive correlation with the output response.
Existing literature regarding MPC tuning can be broadly divided in heuristic guidelines [12], analytical studies [36, 34, 5], and meta-heuristic algorithms [32, 43, 18, 38, 40, 8, 16, 30]. Both heuristic guidelines and analytical studies hold for specific scenarios and MPC formulations, thus trial-and-error approaches are unavoidably adopted in practice. Regarding meta-heuristic methods, the works [32, 38, 40, 16, 30] focus on set-point tuning based on step response characteristics (e.g. overshoot, settling and rise times, and steady-state errors). The authors in [43] deal with trajectory tuning of MPC in which the trajectories are generated by first-order transfer function models. General trajectory tuning is considered in [18] and [8] via particle swarm optimisation (PSO) and gradient-based algorithms, respectively. The number of particles in PSO algorithms depends on the specific problem and it usually oscillates around 20 to 50 particles. This translates into running 20 to 50 closed-loop experiments per iteration, which is not practical for applications where the plant is in the loop. Gradient-based methods [8] and Bayesian optimisation (BO) methods [22, 37] can also be used as an alternative with less experiments per iteration, but existent results are presented only for vectors of parameters (i.e. diagonal tuning matrices). Lastly, inverse optimal control techniques such as [25] could be used for MPC tuning, see e.g. [28]. However, [28] does not provide any theoretical guarantees and it relies on a good choice of initial weighting matrices and heuristic guidelines. We note there is currently a lack of a general framework with convergence guarantees that can directly deal with, not only diagonal matrices, but also general subsets of symmetric matrices in which the algorithm preserves the structure of the tuning matrix at every iteration.
In response to the above discussion, we propose a zeroth-order optimisation framework for non-smooth and possibly non-convex cost functions with matrix parameters that are real and symmetric. We adopt iterates that use zeroth-order matrix oracles to approximate the directional derivative in a randomly chosen direction. This random direction is taken from the Gaussian orthogonal ensemble (GOE), which is the set of matrices with independent normally distributed entries, see e.g. [11, 2, 39]. The algorithm we use is the natural extension of the zeroth-order random search algorithm from [27] but tailored to deal with cost functions with matrix parameters. For this optimisation framework, we provide convergence guarantees in terms of complexity bounds for both convex and non-convex cost functions. In [27], the counterpart of our optimisation problem is studied, in which functions with vector parameters are used, and the zeroth-order oracle samples from the normal distribution. The authors in [27] present complexity bounds for both convex and non-convex functions. The bounds for the convex case can be applied to our matrix setup if one vectorises both the parameter and random direction matrices. However, this does not carry the matrix structure and, in fact, these bounds are significantly more conservative than the ones we propose. Moreover, the non-convex bounds proposed in [27] are only applicable to unconstrained problems and thus cannot be used in our constrained setting. Consequently, we develop novel bounds for the non-convex case, in which the optimisation parameters are constrained to subsets of symmetric matrices. The optimisation framework presented in this paper, when applied to the context of MPC tuning, offers a more general approach with respect to available literature, and it also comes with convergence guarantees. Particularly, it can deal with MPC tuning over trajectories in a general setting as opposed to [32, 38, 40, 16, 43], and it provides MPC weighting matrices that satisfy the required constraints of being symmetric and positive (semi) definite, and thus provide more degrees of freedom than the usual diagonal choices in [8, 18, 22, 37].
The applicability of the proposed approach is illustrated via both simulations and experiments in the problem of diesel air-path control. The MPC parameters are iteratively tuned within the closed-loop setting with the goal of improving the overall tracking performance over an engine drive cycle. For the simulation study, we compare the performance of our proposed framework with other gradient-free algorithms available in the literature such as dividing rectangles (DIRECT), PSO, and BO. In the experimental testing, we tune MPC controllers in a diesel engine test bench over two segments of the new European driving cycle (NEDC), and one segment of the worldwide harmonised light duty test cycle (WLTC).
A summary of our main contributions can be found below.
-
1.
We present theoretical guarantees for a general class of optimisation problems with matrix-valued decision variables on subsets of real and symmetric matrices. The adopted iterates are tailored to this setting in the sense that they produce matrices that belong to the adequate space through projection. When the cost function is convex, the derived complexity bounds are demonstrably less conservative than the ones in [27] (vector-valued decision variables), since we exploit the symmetric structure of the underlying matrix space. In the non-convex case, we derive new complexity bounds that were not available in the literature for this context.
- 2.
-
3.
We highlight the efficacy of the approach by a simulation study in which we compare it to other available gradient-free algorithms in the literature (DIRECT, PSO, and BO).
-
4.
We provide various experimental evaluations in a diesel engine test bench showing significant improvement of MPC tracking performance with only a few iterations of the proposed optimisation approach.
Organisation: Section 2 introduces optimisation framework. The complexity bounds are derived in Section 3. In Section 4, the proposed optimisation framework is applied to MPC tuning in the context of air-path control. In Section 5, we compare different gradient-free algorithms available in the literature to our framework. Experimental testing is presented in Section 6 for different engine drive cycles. Lastly, conclusions are drawn in Section 7.
Notation: Denote by the set of real matrices of dimension , and the set of real symmetric matrices of dimension . Let and . Given a matrix , denotes its transpose. We use to denote the standard block diagonal matrix. The identity and zero matrices of dimension are denoted by and , respectively. denotes the matrix gradient for a scalar function with matrix parameter , see e.g. [4, 10]. For matrices and , the Frobenius inner product is defined as , which induces the norm . For a random variable , we write to say that is normally distributed with zero mean and variance .
2 Optimisation framework
We consider the following class of optimisation problems
| (1) |
where is an matrix parameter, is a closed convex set of admissible parameters, and is a non-smooth and possibly non-convex cost function. We build upon the random search ideas of [27], but tailored to the matrix space . That is, we are interested in solving (1) using iterates of the form
| (2) |
where denotes the Euclidean projection onto the closed convex set , is a positive scalar known as the step size, and denotes the so-called zeroth-order random oracle which is defined as
| (3) |
where denotes the oracle’s precision, and is a random symmetric matrix that belongs to the Gaussian orthogonal ensemble (GOE) as per Definition 1 below.
Definition 1
The overall method to solve (1) is represented by the pseudo-code above, which we name zeroth-order random matrix search (ZO-RMS) algorithm, where denotes the number of iterations. Note that the oracle, per iteration, only requires the cost function value at two points instead of first-order or second-order derivative information, and it computes an estimate of the directional derivative in a randomly chosen direction.
-
1:
Choose , and .
-
2:
for , do
-
3:
Generate
-
4:
-
5:
-
6:
end for
-
7:
Return .
We emphasise that the ZO-RMS algorithm is the natural extension of the random vector search algorithm proposed in [27] but tailored to matrix decision variables. This extension is essential to our setting since there is currently an absence of a general framework for the constrained class of problems (1), i.e. adequate algorithm and convergence guarantees. In [27], the authors provide gradient-free algorithms to solve the optimisation problem for both convex and non-convex cost functions, which is the counterpart of (1) for vector optimisation variables. A zeroth-order random oracle with a multivariate normally distributed direction is used. In this paper, we extend the setting in [27] to optimisation problems over a matrix space using random search matrices from the GOE, which are the natural counterpart to the normally distributed vector . Note that the complexity bounds provided in [27] for the convex case are applicable to our setting if we consider and . However, the matrix structure of and is immediately lost. Consequently, the first theoretical goal of this work is to obtain less conservative complexity bounds for the ZO-RMS algorithm when in (1) is convex, by exploiting the structure of the underlying matrix space. With respect to the non-convex case, we note that the complexity bounds available in [27] are not applicable to our case since they consider an unconstrained non-convex problem in as opposed to a constrained one such as (1). Therefore, our second theoretical goal is to develop new complexity bounds for the ZO-RMS algorithm when solving constrained non-convex optimisation problems in a matrix space, i.e. problem (1) with non-convex.
As mentioned in the introduction, the proposed optimisation framework presented here is general and fits many applications. Therefore, the theoretical results presented in the following section will hold for any family of problems that fit the framework. Particularly, in this paper we will illustrate how to apply this framework to tune MPC controllers, since it is an important application for which we can provide interesting contributions validated by simulations and experiments.
3 Complexity bounds
In this section, we study the performance of the ZO-RMS algorithm in terms of complexity bounds that guarantees a given level of accuracy for the algorithm. We provide complexity bounds for both the convex and non-convex case.
Let us first introduce some important definitions. Definition 1 implies that the probability distribution in the GOE is , where is the Lebesgue measure on , i.e. , and is the normalising constant defined as . Therefore, we can define the expectation of a function as , and the following moments of interest in , , for . We state the following lemma for some moments of interest.
Lemma 1
For every , we have that , , and .
Proof: Define , and note that this function is convex in . Let us write (i.e. ). For we have . Therefore, since is convex, we have that . Particularly, , and , then , and thus . Particularly, . On the other hand, from [14] we get that and , which concludes the proof.
Our analysis relies in the following assumption.
Assumption 1
-
(a)
The set of admissible parameters is a subset of the set of real symmetric matrices of dimension , i.e. .
-
(b)
The function is Lipschitz continuous, i.e. s.t. holds for all .
3.1 Convex case
Let be a stationary point of (1), and . In addition, define , a random matrix composed by i.i.d. variables associated with each iteration of the scheme.
We are now in a position to state the main result.
Theorem 1
Proof: See Appendix B.
A corollary from Theorem 1 can be obtained which provides expressions for , , and that ensure a given level of accuracy for the ZO-RMS algorithm.
Corollary 1
Let be given. If and are chosen such that
| (5a) | ||||
| (5b) | ||||
for , then, is guaranteed by the ZO-RMS algorithm in
| (6) |
iterations, where is such that .
Proof: Note that
Suppose the number of steps is fixed, we can choose and as in (5) and further obtain the following bound
Therefore, in order to satisfy , we need , concluding the proof.
The complexity bound (6) in Corollary 1 corresponds to the number of iterations in which the ZO-RMS algorithm guarantees a given accuracy of , provided the step size and parameter are chosen as per (5). Certainly, the expressions for , and depend on the Lipschitz constant and which may be hard to obtain explicitly depending on the application. However, these can be numerically bounded as we explain further below in Section 6.1. Since the oracle (3) is random, the guarantees of the ZO-RMS algorithm hold in expectation. In essence, Corollary 1 provides sufficient conditions on the oracle’s precision and step size such that we can get sufficiently close to the optimal cost function in iterations, in average.
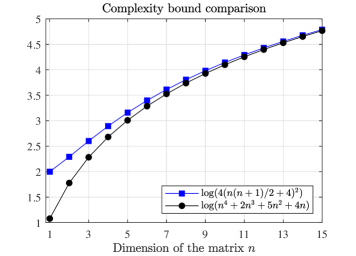
We now compare our complexity bound (6) to the bounds in [27] which are applicable to (1) (for convex ) after grouping the elements of the tuning matrix into a single vector. Particularly, since is symmetric, we group the lower triangular elements into a vector of size (or often called half vectorization), therefore the results in [27] apply and the following complexity bound holds (cf. Theorem 6 in [27])
| (7) |
Fig. 1 depicts (6) and (7) for different values of . We can see that our bound (6) is less conservative than (7) for all , and tends to (7) as . We emphasise that our optimisation framework is directly tailored to matrix parameters, and the reduction in conservatism with respect to a vector approach such as [27] follows from exploiting the special structure of the underlying matrix space, namely the symmetry, and the use of iterates that are tailored to it. The reduction in conservativeness is significant, for instance, for matrices (i.e. ), . This translates in a sufficient condition that guarantees a level of accuracy in twice less iterations.
3.2 Non-convex case
Compared to the convex optimisation problem considered in Section 3.1, the analysis for constrained non-convex problems is more challenging. Particularly, constrained convex problems typically focus on the optimality gap to measure the convergence rate (as we do in Corollary 1). On the other hand, Nesterov in [27] provided complexity bounds for unconstrained non-convex problems using zeroth order iterates, where the optimisation variable is a vector in a subset of . In these unconstrained non-convex problems, the object is the typical measure for stationarity. We emphasise that the bounds for unconstrained non-convex problems in [27] are not applicable to our constrained problem (1), since we need to search over the matrix space and use iterates of the form (2) that project onto . For constrained non-convex problems like ours, a fitting alternative to is to consider the so-called gradient mapping, see e.g. [21, 13], which is defined as follows
where is the random zeroth order oracle in (3), and recall that denotes the Euclidean projection onto the closed convex set . The natural interpretation of is that it represents the projected gradient, which offers a feasible update from the previous point . The main goal in this section is to provide complexity bounds for the ZO-RMS algorithm (2) in terms of bounding when solving the constrained optimisation problem (1) with non-convex.
Before stating our results, we impose an additional assumption.
Assumption 2
, , where is the Gaussian approximation of defined in (16).
Assumption 2 essentially bounds the variance of the random oracle . This assumption is often adopted in non-convex problems, see e.g. [13]. If constructing explicitly is of interest, we can construct it as follows. We note that is an unbiased estimator of (cf. (18)), i.e. , then .
The main result for the non-convex case is stated below. It can be seen as the non-convex counterpart of Theorem 1.
Theorem 2
Proof: See Appendix C.
The next corollary provides a choice of , and that ensure a given level of accuracy for the ZO-RMS algorithm up to an error of order .
Corollary 2
Let and be given, and for all . If and are chosen as
| (9) | ||||
| (10) |
then is guaranteed by the ZO-RMS algorithm in
| (11) |
iterations, where
Proof: Recall that is a smooth approximation of , and the gap in this approximation can be upper bounded by , see Lemma 2-(III) in the appendix. Then, to bound this gap by we need to choose as per (9). For this choice of , which we denote , . For a constant step size, the right-hand size of (8) becomes
Let . Minimising in leads to , which corresponds to (10). For this choice of step size, we get . Note that . Then, we can guarantee that in iterations, which corresponds to (11), completing the proof.
Our analysis shows that ZO-RMS for constrained non-convex problems can suffer an additional error of order which does not appear in the convex case, see Corollary 1. This effect is consistent with the literature on constrained non-convex problems, where this effect has been reported for different algorithms, see e.g. [21, 13, 20].
4 Application to MPC tuning: air-path control in diesel engines
In this section, we illustrate how to apply the proposed optimisation framework to tune MPC controllers in the context of diesel air-path control.
4.1 Diesel engine air-path model
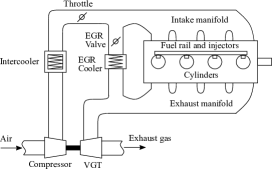
A schematic representation of the diesel air-path is shown in Fig. 2. The dynamics of a diesel engine air-path are highly non-linear, see e.g. [41], and can be captured in the general form
| (12a) | ||||
| (12b) | ||||
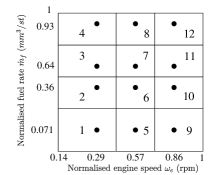
where , and are the state, output, and input of the system respectively, at time instant . The engine operational space is typically parametrised by , where denotes the engine speed, denotes the fuel rate, and is the engine operating space defined as , for some . Given these highly non-linear dynamics, a common approach to control-oriented modelling of the air-path is to generate linear models trimmed at various operating points . Particularly, we follow [30] and use twelve models to approximate the operating space uniformly. That is, the engine operating space is divided into twelve regions as per Fig. 3, with a linear model representing the engine dynamics in each region. For commercial in confidence purposes, we only show normalised axes in every plot. We emphasise that these regions are chosen to provide adequate coverage over the range of operating points encountered along a drive cycle. The control-oriented model state consists in the intake manifold pressure (also known as boost pressure), the exhaust manifold pressure , the compressor flow , and the EGR rate . The input consists of the throttle position , EGR valve position , and VGT valve position . Lastly, the measured output is .
For a given operating point , , the engine control unit (ECU) applies certain steady-state actuator values. We denote by , and the steady-state values of the input, state, and output respectively at each operating condition . Then, by following the system identification procedure detailed in [35], a linear representation of the non-linear diesel air-path (12) trimmed around the grid point is given by
| (13a) | ||||
| (13b) | ||||
where , is the perturbed state around the corresponding steady-state , is the perturbed input around the corresponding steady-state input , and is the perturbed output around the corresponding steady-state output .
4.2 MPC formulation
For each operating point , , and corresponding model (13) associated to that region, we formulate an MPC with augmented integrator (see e.g. [29, 42]). To this end, define the augmented state , where is the integrator state with dynamics . Define the cost function as
where is the prediction horizon, is the sequence of control values applied over the horizon , and , and are real symmetric matrices containing the tuning weights. Particularly, we further assume that is positive definite, and that and are positive semidefinite.
The corresponding MPC problem is stated below,
where , , , , and are given by the relevant state and input constraints. The solution to the above optimisation problem yields the optimising control sequence . The first element of the sequence is applied to the system and the whole process is repeated as is incremented.
For transient operations between operating points, we use a switching LTI-MPC architecture so that the controllers are switched based on the current operating condition. As in [31], the switching LTI-MPC strategy selects the MPC controller at the nearest operating point to the current operating condition.
Under the above scenario, our goal is to use the ZO-RMS algorithm to tune the MPC weighting matrices in order to achieve a satisfactory tracking performance for a given prediction horizon . Since there are twelve available controllers to tune, we could potentially use the ZO-RMS algorithm to tune all of them. However, since experiments are costly, we will focus on tuning only the controllers that have poor performance given an initial choice of tuning parameters. That is, we utilise an initial calibration denoted by for every controller , which we call baseline controller. The choice of may be based on model dynamics, experience, or using ad-hoc guidelines as per [12]. Then, by looking at a drive cycle response with the baseline controller, we detect the controllers that have poor performance. Let us denote by a controller with unsatisfactory performance and that we attempt to tune with the ZO-RMS algorithm. Therefore, in this context, we want to solve
| (14) |
where is the tracking performance of the MPC defined in (15) below, which depends on a closed-loop response of interest , and and denote the set of symmetric positive semi-definite matrices and the set of symmetric positive definite matrices, respectively.
As mentioned above, we use the tracking error as the measure of performance for the MPC controller, that is,
| (15) |
where is the experiment length, is the vector containing the boost pressure and EGR rate references, respectively, and is the process measured output when the -th controller is using tuning parameters , and the rest of controllers are using the baseline parameters . We emphasise that for the simulations and experiments below we input normalised signals in (15) so that they are weighted equally.
4.3 Implementing the ZO-RMS algorithm
We now show how to implement the ZO-RMS algorithm for the MPC tuning problem (14). First note that (14) fits the general optimisation problem (1) with , , and
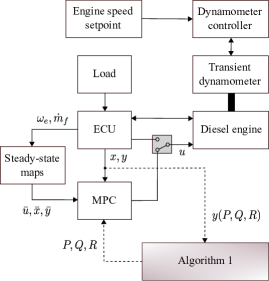
Therefore, we can apply ZO-RMS to solve (14). The overall implementation of ZO-RMS in this context is depicted in Fig. 4. the ZO-RMS algorithm iteratively updates the MPC parameters to minimise , which is calculated from closed-loop response experiments carried out between the MPC and diesel engine.
It remains to show how to compute the oracle and projection in (2). Particularly, the oracle in this context is computed as per (3) with , where and (see Definition 1). We emphasise that, at each iteration step, the oracle is computed once the entire closed-loop response is available. Particularly, two experiments are required to compute the oracle, one with parameters and one with . Once the two closed-loop responses are finished, then ZO-RMS computes the oracle and next update . Two new closed-loop experiments are then performed with these new controller parameters and the process continues iteratively in this fashion.
Since is block diagonal, the projection onto is computed as , where and denote the Euclidean projection onto and , respectively. To compute them, we follow the well known results in [15]. That is, let be the eigenvalue decomposition of a matrix . Then, and , .

5 Simulation study
We now perform numerical simulations to show the advantage of our proposed MPC tuning framework with respect to other available gradient-free algorithms in the literature. Particularly, we compare our approach to the dividing rectangles (DIRECT) algorithm [17], particle swarm optimisation algorithms [18], and Bayesian optimisation algorithms [22, 37]. DIRECT is a sample-based global optimisation method for Lipschitz continuous functions defined over multidimensional domains. It partitions the space into hyperrectangles, each with a sampled point at its centre. The cost function is evaluated at these centrepoints, and then the algorithm keeps sampling and dividing into rectangles until the iteration limit has been reached. PSO algorithms solve the problem by having a population of so-called particles which move along the search space according to the updating rules of their position and velocity. The movement of the particles are guided by their own best known position as well as the entire swarm’s best known position in the search space. At each iteration, the cost function is evaluated for every particle in the swarm. Lastly, BO seeks to identify the optimal tuning parameters by strategically exploring and exploiting the parameter space. Exploration aims to evaluate the objective at points in the decision space with the goal of improving the accuracy of a surrogate model of the objective function, while exploitation aims to use the surrogate model to identify decisions that reduce (or increase) the objective function [22].
Intuition suggests that methods such as DIRECT and PSO would perform many cost function evaluations in order to find the optimal value, since they rely on the number of rectangles/centre points (DIRECT) and particles (PSO). We demonstrate that this is indeed true for the MPC tuning problem described in Section 4.
We perform simulations using the tuning scheme from Fig. 4 in which the diesel engine block is simulated via a high-fidelity model, see e.g. [30]. This model is physics-based with the form (12), in which the parameters have been obtained from system identification experiments conducted at Toyota’s Higashi-Fuji Technical Centre. The specific equations and parameters are not included due to commercial in confidence purposes. We focus on tuning controller (see Fig. 3), over a segment of the NEDC, which is called the urban drive cycle (UDC). We focus on tuning diagonal matrices with positive elements so that we can compare to vector-valued methods like DIRECT, PSO, and BO. We emphasise another contribution of the proposed optimisation framework is that it allows the direct tuning of the weighting matrices so that they satisfy the required constraints of symmetricity and positive (semi) definiteness. For these simulations, we do not include the augmented integrator states.
The cost function is the tracking error as per (15), and to assess the complexity of each algorithm we will use the total number of cost function evaluations that takes to achieve the optimal cost function value up to a certain tolerance. The initial calibration is and , and the number of tuning parameters is eleven. The ZO-RMS algorithm uses step size and oracle’s precision (). For the PSO algorithm we have picked 40 particles as suggested by the literature [18]. For DIRECT, PSO, and BO, we use the decision variable range .
One realisation run of all four algorithms is summarised in Table 1, where denotes the optimal value of the cost function achieved by each algorithm. Next we show the number of cost function evaluations, followed by the total execution time of each algorithm. We can see that in order to achieve a similar value of (up to a 0.0002 difference), the ZO-RMS algorithm performs 20 function evaluations, compared to 66 for DIRECT, 200 for PSO, and 28 for BO. We emphasise that each function evaluation in this context corresponds to a closed-loop experiment, and thus having to perform many of these is intractable in practice. We can see that BO requires only a few more cost function evaluations than ZO-RMS. It can also be observed that DIRECT, PSO, and BO take longer to execute in comparison to ZO-RMS.
Since PSO, BO, and ZO-RMS are stochastic, we also performed a Monte Carlo simulation of 100 realisations in order to compare the three of them more accurately. These results are listed in Table 2. We can see that all achieve a similar optimal value for in average, but it takes about 199 cost function evaluations in average for PSO to achieve this, and only 22 for BO and 20 for ZO-RMS which makes them more efficient for applications in which the plant is in the loop. Overall, BO exhibits comparable performance with respect to ZO-RMS in terms of cost function evaluations and execution time; however, as mentioned in the introduction, these methods only work for vector decision variables and the PSD matrix structure of the MPC tuning matrices is not preserved by the algorithm. They also lack theoretical guarantees in this context.
| Algorithm | N∘ of cost fcn. evaluations | Execution time | |
|---|---|---|---|
| DIRECT | 0.0478 | 66 | 0.6 hours |
| PSO | 0.0476 | 200 | 1.6 hours |
| BO | 0.0477 | 28 | 0.5 hours |
| ZO-RMS | 0.0476 | 20 | 0.3 hours |
| Algorithm | |||
|---|---|---|---|
| PSO | 0.0472 | 199 | |
| BO | 0.0477 | 22 | |
| ZO-RMS | 0.0496 | 20 |
6 Experiments
The experimental testing of the proposed MPC tuning framework was performed at Toyota’s Higashi-Fuji Technical Center in Susono, Japan. The test bench is equipped with a diesel engine, a transient dynamometer, and a dSPACE DS1006 processor board, which is in turn interfaced to the ECU. The block diagram in Fig. 5 depicts the overall experimental setting. The ECU logs sensor data from the engine and transmits the current state information to the controller. In addition, the ECU directly controls all engine sub-systems, however, the ECU commands for the three actuators (throttle, EGR valve, and VGT) can be overridden by the MPC commands through a virtual switch in the ControlDesk interface. The proposed tuning architecture is implemented iteratively in-the-loop as per Fig. 4, in which the diesel engine block is the real engine described above. Particularly, the switched MPC is implemented in real-time on the dSPACE board to generate the required closed-loop drive cycle responses, and the computations in the ZO-RMS algorithm are performed by Matlab, i.e. oracle, projections, and next set of parameters.
6.1 Choice of algorithm parameters
To run ZO-RMS we need to choose the parameters and . Corollary 1 provides a choice for these parameters so that a given level of accuracy is achieved by the algorithm in iterations as per (6). However, this choice depends on the Lipschitz constant , and the bound . These can be numerically bounded depending on the application. Since we apply the proposed optimisation framework to MPC tuning over a real engine, it is not possible to find an explicit expression for the cost function in terms of . Instead, a common approach is to adopt experimental optimisation methods such as the ones in [7, 1] to ensure that the Lipschitz condition is at least satisfied in the experimental data. Particularly, since the oracle uses values of the cost function at two different points, we can store these values and use a consistency-check algorithm to see if the Lipschitz condition is verified (see e.g. [7, Section 4.3]). This could be done by performing high-fidelity simulations of the closed-loop to compute the oracle at different points, and pick the largest constant that satisfies the Lipschitz condition as a first estimate. Later on in the experiments, we can further adjust this first estimate accordingly, and verify whether the bound is satisfied for the collected experimental measurements. Similarly, can be estimated with the stored data of and from multiple simulations so that holds for the experimental space. In this paper, we initially picked conservative estimates from simulations, and we later refine these heuristically during experimental testing. Online estimation of the Lipschitz constant can improve the aforementioned methods and it is considered as a future direction.
In what follows, we tune three out of the twelve MPC controllers depicted in Fig. 3 over three different drive cycle segments. Particularly, we tune: controller over the middle segment of the UDC (49–117[s]), and we call it UDC2; controller over the first 100 seconds of the WLTC, which call WLTC1; and controller over the last segment of the UDC (117–195[s]), which we call UDC3.
For all the experiments below we consider an initial calibration , , , for all twelve controllers, where and respectively relate to the engine state and integrator state. In addition, all the drive cycle references are generated by the ECU based on a driver model. These models are responsible for converting the drive cycle vehicle speed reference into reference operating points in terms of engine speed and load.
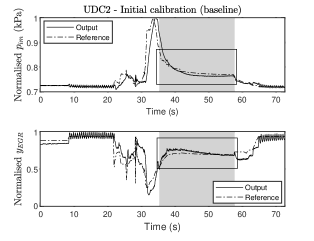
6.2 Controller over UDC2
The engine output response to the UDC2 segment with the baseline controller is given in Fig. 6. The grey area illustrates when controller is active, and we consider its tracking performance as unsatisfactory (we draw the attention to this with the boxed area). We would like to improve the tracking performance for this controller by using ZO-RMS. The parameters used in this experiment are111We note that for this particular experiment we used a very conservative estimate of the Lipschitz constant based on different experimental tests. , . ().
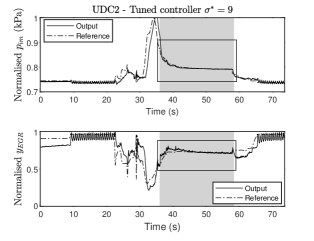
In this experiment, we consider and use ZO-RMS to tune , whilst is constructed by solving the discrete-time algebraic Riccati equation (DARE) [24], at each iteration. We emphasise that the proposed tuning framework provides enough flexibility to either tune a single matrix, or all of the MPC matrices depending on the particular application. For instance, for this drive cycle segment, tuning the integrator state matrix helped significantly in improving tracking performance, but for the experiments further below it was not necessary to tune this matrix and it was thus fixed.
The resulting optimal tuning matrices for iterations are given by
The engine output response over the UDC2 using the above matrices is shown in Fig. 7. The tracking performance has significantly improved in the region where controller nine is acting. Particularly, the tuned matrices provide an improvement of performance222We compute the percentage of improvement with respect to the baseline controller as: . of 16.2% with only eleven iterations.
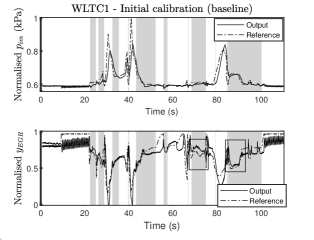
6.3 Controller over WLTC1
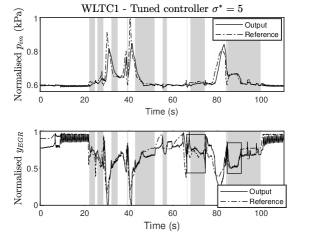
The engine output response to the WLTC1 segment with the baseline controller is given in Fig. 8. The grey area illustrates when controller is active, and we have boxed the areas with unsatisfactory performance that we would like to improve. The parameters used in this experiment are , (). Similar to the previous experiment, the matrix is constructed by solving the corresponding DARE, and we consider , but now the integrator state matrix is not tuned but kept equal to the initial value .
Consequently, the tuning parameters are , and their optimal values for iterations are given by
The engine output response over the WLTC1 using the above matrices is shown in Fig. 9. The tracking performance has improved in the region where controller nine is acting. Particularly, the tuned matrices provide an improvement of performance of 22.67% with only eleven iterations, as illustrated by the boxed regions in Fig. 9. We can observe that the tracking has clearly improved in the boxed areas, but we can see that in the grey area 40-50s in Fig. 8 and 9, the EGR tracking got slightly deteriorated. However, we emphasise that the cost function being minimised is the overall tracking performance considering every grey area where controller is acting. This is considered satisfactory since the overall tracking improvement in this case was 22.67%. Different cost functions or tuning approaches could be potentially used to tackle each region individually.
6.4 Controller over UDC3
The engine output response to the UDC3 segment with the baseline controller is given in Fig. 10. The grey area illustrates when controller is active, and we have boxed the areas with unsatisfactory performance. The parameters used in this experiment are , (). The integrator state matrix was not tuned but kept equal to the initial value . As opposed to the previous two experiments, we do include in the tuning process for this experiment. Specifically, we construct it as and tune .
Consequently, the tuning parameters are {}, and their optimal values for iterations are given by
The engine output response over the UDC3 using the above matrices is shown in Fig. 11. We can see that the tracking performance has improved in the region where controller nine is acting. Particularly, the tuned matrices provide an improvement of performance of 7.73% with only eight iterations.
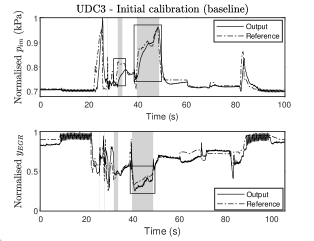
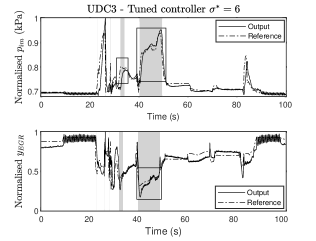
The theoretical results in Section 3 are sufficient conditions on the step size and oracle’s precision that ensure a certain level of accuracy in a fixed number of iterations. We note that the complexity bounds presented in this paper hold for any problem that fits the optimisation framework surrounding (1). Depending on the application, these bounds could become more or less conservative, as we observed in the air-path control case study. In fact, since these are sufficient conditions, we observed that the experimental performance of the algorithm showed tracking error improvement only in a few iterations. Nevertheless, the theoretical results serve as a design tool that guide the choice of algorithm parameters as opposed to a heuristic choice of parameters.
Remark 1
Overall, we observed that the proposed approach successfully provides improved tracking performance over three different drive cycle segments, i.e. different data sets, which sheds some light on the robustness of the method. However, an interesting future work direction is to provide a theoretical study on robustness guarantees.
7 Conclusion
This paper provided an optimisation framework with theoretical guarantees for the minimisation of non-smooth and possibly non-convex cost functions with matrix parameters. We applied the proposed algorithm to tune MPCs in the context of air-path control in diesel engines, which is then validated by experimental testing. The algorithm provides improvement of performance with a few iterations, which is demonstrated in different engine drive cycles. Therefore, it creates potential for the development of efficient tuning tools for advanced controllers (and potentially retuning online), even though the theoretical complexity bounds may be large depending on the application.
Future work includes exploring algorithms over other matrix manifolds with practical applications, testing of the proposed algorithms in stochastic drive cycles, robustness guarantees, and online estimation/adaptation of Lipschitz constant .
Appendix A Technical results
Consider a function , and let us define the Gaussian approximation of as
| (16) |
We first introduce the following definition.
Definition 2
Let be a convex function. A matrix is called a subgradient of function at if for any we have . The set of all subgradients of at is called subdifferential and is denoted by .
The following lemma holds for .
Lemma 2
Proof:
-
(I)
We prove this statement as follows.
where the last equality follows from .
-
(II)
Define , and note that by the change of variable formula for multivariate integrals, , where . Consequently,
Then,
where the last equality follows from .
- (III)
- (IV)
For the random oracle in (3), we have the following bound.
Theorem 3
If satisfies Assumption 1, then
| (20) |
Proof: Note that . Then, . The proof thus follows from Lemma 1.
Appendix B Proof of Theorem 1
We first note that the projection in ZO-RMS satisfies
| (21) |
for all .
Now, let point with be generated after iterations of ZO-RMS, and define . Then,
Then, taking expectation
Taking now the expectation in , we obtain
Moreover, note that , thus (19) implies that . Consequently,
| (22) |
Appendix C Proof of Theorem 2
Define . From Lemma 2(IV), we have
From non-expansiveness of projection, i.e. (21), and from the fact that , we have
Define , then . Based on [13, Lemma 1] we have , where if and otherwise. Since and based on (2), we know that for . Therefore,
| (24) |
From [13, Proposition 1], we can write . With this fact, we take expectation in (24) and get
| (25) |
where we also used , Theorem 3 to compute , and Assumption 2 to upper bound . Recall that and that . Then, taking expectation in in (25) and then taking summation, we obtain (8) as required.
Acknowledgment
The authors would like to thank the engineering staff at Toyota Higashi-Fuji Technical Centre, Susono, Japan, for their assistance in running the experiments included in this paper.
References
- [1] Mohamed Osama Ahmed, Sharan Vaswani, and Mark Schmidt. Combining bayesian optimization and lipschitz optimization. Machine Learning, 109(1):79–102, 2020.
- [2] Greg W Anderson, Alice Guionnet, and Ofer Zeitouni. An introduction to random matrices, volume 118. Cambridge university press, 2010.
- [3] Matthew Anderson, Xi-Lin Li, Pedro Rodriguez, and Tülay Adali. An effective decoupling method for matrix optimization and its application to the ICA problem. In 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1885–1888. IEEE, 2012.
- [4] M. Athans and F.C. Schweppe. Gradient matrices and matrix calculations. Technical report, M.I.T. Lincoln Lab., 1965.
- [5] Peyman Bagheri and Ali Khaki-Sedigh. An analytical tuning approach to multivariable model predictive controllers. Journal of Process Control, 24(12):41–54, 2014.
- [6] Alexander Bertrand and Marc Moonen. Topology-aware distributed adaptation of Laplacian weights for in-network averaging. In 21st European Signal Processing Conference (EUSIPCO 2013), pages 1–5. IEEE, 2013.
- [7] Gene A Bunin and Grégory François. Lipschitz constants in experimental optimization. arXiv preprint arXiv:1603.07847, 2016.
- [8] Gene A Bunin, Fernando Fraire Tirado, Grégory François, and Dominique Bonvin. Run-to-run MPC tuning via gradient descent. In Computer Aided Chemical Engineering, volume 30, pages 927–931. Elsevier, 2012.
- [9] MM Chaikovskii and Igor’Borisovich Yadykin. Optimal tuning of PID controllers for MIMO bilinear plants. Automation and Remote Control, 70(1):118–132, 2009.
- [10] Jon Dattorro. Convex optimization & Euclidean distance geometry. Meboo Publishing USA, 2011.
- [11] Peter J Forrester. Log-gases and random matrices (LMS-34). Princeton University Press, 2010.
- [12] Jorge L Garriga and Masoud Soroush. Model predictive control tuning methods: A review. Industrial & Engineering Chemistry Research, 49(8):3505–3515, 2010.
- [13] Saeed Ghadimi, Guanghui Lan, and Hongchao Zhang. Mini-batch stochastic approximation methods for nonconvex stochastic composite optimization. Mathematical Programming, 155(1-2):267–305, 2016.
- [14] T. Hayakawa and Y. Kikuchi. The moments of a function of traces of a matrix with a multivariate symmetric normal distribution. South African Statistical Journal, 13(1):71–82, 1979.
- [15] Nicholas J Higham. Computing a nearest symmetric positive semidefinite matrix. Linear algebra and its applications, 103:103–118, 1988.
- [16] Alex S Ira, Chris Manzie, Iman Shames, Robert Chin, Dragan Nešić, Hayato Nakada, and Takeshi Sano. Tuning of multivariable model predictive controllers through expert bandit feedback. International Journal of Control, pages 1–9, 2020.
- [17] Donald R Jones, Cary D Perttunen, and Bruce E Stuckman. Lipschitzian optimization without the lipschitz constant. Journal of optimization Theory and Applications, 79(1):157–181, 1993.
- [18] Gesner A Nery Júnior, Márcio AF Martins, and Ricardo Kalid. A PSO-based optimal tuning strategy for constrained multivariable predictive controllers with model uncertainty. ISA transactions, 53(2):560–567, 2014.
- [19] Chih-Jen Lin. Projected gradient methods for nonnegative matrix factorization. Neural computation, 19(10):2756–2779, 2007.
- [20] Sijia Liu, Bhavya Kailkhura, Pin-Yu Chen, Paishun Ting, Shiyu Chang, and Lisa Amini. Zeroth-order stochastic variance reduction for nonconvex optimization. Advances in Neural Information Processing Systems, 31:3727–3737, 2018.
- [21] Sijia Liu, Xingguo Li, Pin-Yu Chen, Jarvis Haupt, and Lisa Amini. Zeroth-order stochastic projected gradient descent for nonconvex optimization. In 2018 IEEE Global Conference on Signal and Information Processing (GlobalSIP), pages 1179–1183. IEEE, 2018.
- [22] Qiugang Lu, Ranjeet Kumar, and Victor M Zavala. MPC controller tuning using bayesian optimization techniques. arXiv preprint arXiv:2009.14175, 2020.
- [23] Alonso Marco, Philipp Hennig, Jeannette Bohg, Stefan Schaal, and Sebastian Trimpe. Automatic LQR tuning based on gaussian process global optimization. In 2016 IEEE international conference on robotics and automation (ICRA), pages 270–277. IEEE, 2016.
- [24] D.Q. Mayne, J.B. Rawling, C.V. Rao, and P.O.M. Scokaert. Constrained model predictive control: Stability and optimality. Automatica, 36:789–814, 2000.
- [25] Marcel Menner, Peter Worsnop, and Melanie N Zeilinger. Constrained inverse optimal control with application to a human manipulation task. IEEE Transactions on Control Systems Technology, 2019.
- [26] Panayotis Mertikopoulos, E Veronica Belmega, Romain Negrel, and Luca Sanguinetti. Distributed stochastic optimization via matrix exponential learning. IEEE Transactions on Signal Processing, 65(9):2277–2290, 2017.
- [27] Yurii Nesterov and Vladimir Spokoiny. Random gradient-free minimization of convex functions. Foundations of Computational Mathematics, 17(2):527–566, 2017.
- [28] Ahmed Ramadan, Jongeun Choi, Clark J. Radcliffe, John M. Popovich, and N. Peter Reeves. Inferring control intent during seated balance using inverse model predictive control. IEEE Robotics and Automation Letters, 4(2):224–230, 2019.
- [29] James Blake Rawlings and David Q Mayne. Model predictive control: Theory and design. Nob Hill Pub., 2009.
- [30] Gokul S Sankar, Rohan C Shekhar, Chris Manzie, Takeshi Sano, and Hayato Nakada. Fast calibration of a robust model predictive controller for diesel engine airpath. IEEE Transactions on Control Systems Technology, 2019.
- [31] Gokul S Sankar, Rohan C Shekhar, Chris Manzie, Takeshi Sano, and Hayato Nakada. Fast calibration of a robust model predictive controller for diesel engine airpath. IEEE Transactions on Control Systems Technology, 2019.
- [32] Jose Eduardo W Santos, Jorge Otávio Trierweiler, and Marcelo Farenzena. Robust tuning for classical MPC through the multi-scenarios approach. Industrial & Engineering Chemistry Research, 58(8):3146–3158, 2019.
- [33] S Yusef Shafi, Murat Arcak, and Laurent El Ghaoui. Graph weight allocation to meet Laplacian spectral constraints. IEEE Transactions on Automatic Control, 57(7):1872–1877, 2011.
- [34] Gaurang Shah and Sebastian Engell. Tuning MPC for desired closed-loop performance for mimo systems. In Proceedings of the 2011 American Control Conference, pages 4404–4409. IEEE, 2011.
- [35] Rohan C Shekhar, Gokul S Sankar, Chris Manzie, and Hayato Nakada. Efficient calibration of real-time model-based controllers for diesel engines–Part I: Approach and drive cycle results. In 2017 IEEE 56th Annual Conference on Decision and Control (CDC), pages 843–848. IEEE, 2017.
- [36] Rahul Shridhar and Douglas J Cooper. A tuning strategy for unconstrained multivariable model predictive control. Industrial & engineering chemistry research, 37(10):4003–4016, 1998.
- [37] Farshud Sorourifar, Georgios Makrygirgos, Ali Mesbah, and Joel A Paulson. A data-driven automatic tuning method for mpc under uncertainty using constrained bayesian optimization. arXiv preprint arXiv:2011.11841, 2020.
- [38] Ryohei Suzuki, Fukiko Kawai, Hideyuki Ito, Chikashi Nakazawa, Yoshikazu Fukuyama, and Eitaro Aiyoshi. Automatic tuning of model predictive control using particle swarm optimization. In 2007 IEEE Swarm Intelligence Symposium, pages 221–226. IEEE, 2007.
- [39] C.A. Tracy and H. Widom. On orthogonal and symplectic matrix ensembles. Communications in Mathematical Physics, 177(3):727–754, 1996.
- [40] JH Van der Lee, WY Svrcek, and BR Young. A tuning algorithm for model predictive controllers based on genetic algorithms and fuzzy decision making. ISA transactions, 47(1):53–59, 2008.
- [41] Johan Wahlström and Lars Eriksson. Modelling diesel engines with a variable-geometry turbocharger and exhaust gas recirculation by optimization of model parameters for capturing non-linear system dynamics. Proceedings of the Institution of Mechanical Engineers, Part D: Journal of Automobile Engineering, 225(7):960–986, 2011.
- [42] Liuping Wang. Model predictive control system design and implementation using MATLAB®. Springer Science & Business Media, 2009.
- [43] André Shigueo Yamashita, Paulo Martin Alexandre, Antonio Carlos Zanin, and Darci Odloak. Reference trajectory tuning of model predictive control. Control Engineering Practice, 50:1–11, 2016.
- [44] Tuo Zhao, Zhaoran Wang, and Han Liu. A nonconvex optimization framework for low rank matrix estimation. In Advances in Neural Information Processing Systems, pages 559–567, 2015.
- [45] Zhihui Zhu, Qiuwei Li, Gongguo Tang, and Michael B Wakin. Global optimality in low-rank matrix optimization. IEEE Transactions on Signal Processing, 66(13):3614–3628, 2018.