Zero-Shot Knowledge Distillation from a Decision-Based Black-Box Model
Abstract
Knowledge distillation (KD) is a successful approach for deep neural network acceleration, with which a compact network (student) is trained by mimicking the softmax output of a pre-trained high-capacity network (teacher). In tradition, KD usually relies on access to the training samples and the parameters of the white-box teacher to acquire the transferred knowledge. However, these prerequisites are not always realistic due to storage costs or privacy issues in real-world applications. Here we propose the concept of decision-based black-box (DB3) knowledge distillation, with which the student is trained by distilling the knowledge from a black-box teacher (parameters are not accessible) that only returns classes rather than softmax outputs. We start with the scenario when the training set is accessible. We represent a sample’s robustness against other classes by computing its distances to the teacher’s decision boundaries and use it to construct the soft label for each training sample. After that, the student can be trained via standard KD. We then extend this approach to a more challenging scenario in which even accessing the training data is not feasible. We propose to generate pseudo samples distinguished by the teacher’s decision boundaries to the largest extent and construct soft labels for them, which are used as the transfer set. We evaluate our approaches on various benchmark networks and datasets and experiment results demonstrate their effectiveness. Codes are available at: https://github.com/zwang84/zsdb3kd.
1 Introduction
Training compact deep neural networks (DNNs) (Howard et al., 2017) efficiently has become an appealing topic because of the increasing demand for deploying DNNs on resource-limited devices such as mobile phones and drones (Moskalenko et al., 2018). Recently, a large number of approaches have been proposed for training lightweight DNNs with the help of a cumbersome, over-parameterized model, such as network pruning (Li et al., 2016; He et al., 2019; Wang et al., 2021), quantization (Han et al., 2015), factorization (Jaderberg et al., 2014), and knowledge distillation (KD) (Hinton et al., 2015; Phuong & Lampert, 2019; Jin et al., 2020; Yun et al., 2020; Passalis et al., 2020; Wang, 2021). Among all these approaches, knowledge distillation is a popular scheme with which a compact student network is trained by mimicking the softmax output (class probabilities) of a pre-trained deeper and wider teacher model (Hinton et al., 2015). By doing so, the rich information learned by the powerful teacher can be imitated by the student, which often exhibits better performance than solely training the student with a cross-entropy loss. Many variants have been developed to improve the vanilla KD approach by not only mimicking the softmax output but also matching extra elements in the teacher.
The success of KD relies on three factors: (1) access to the teacher’s training dataset, (2) the white-box teacher model, i.e., access to the teacher’s parameters, and (3) the score-based outputs, i.e., class probabilities of the training samples outputted by the teacher. In real-world applications, however, these prerequisites are usually unrealistic. Due to storage costs of large training datasets (such as ImageNet (Deng et al., 2009)) or privacy issues (such as sensitive patient data or personal photos), accessing the training samples are sometimes not feasible. With this concern, the concept of zero-shot knowledge distillation (ZSKD) (Nayak et al., 2019; Chen et al., 2019; Yin et al., 2020; Wang, 2021) is proposed. ZSKD generates pseudo training samples via backpropagation with access to the parameters of the white-box teacher, which are then used as the transfer set for training the student model via KD. However, we argue that this scenario is still not realistic under certain circumstances.
In some cases, training samples are publicly available, but pre-trained models are not. For example, YouTube’s recommendation system (Covington et al., 2016) is trained with tons of videos that can be accessed by any user. However, the trained model is a core competitiveness of the company and its parameters are not released. One can argue that a surrogate teacher can be trained locally with the accessible training set, but due to the limitations such as computing resources, its performance is usually not satisfactory compared to the provided powerful model with much more parameters and complicated architectures.
Moreover, a much more challenging scenario is that, in many real-world applications, none of the three factors mentioned above is available. A pre-trained model stored on the remote server may only provide APIs for inference, neither the model parameters nor the training samples are accessible to the users. Worse than that, these APIs usually return a category index for each sample (i.e., hard-label), rather than the class probabilities over all classes. For example, speech recognition systems like Siri and Cortana are trained with internal datasets and only return the results to users (López et al., 2017). Cloud-based object classification systems like Clarifai (Clarifai, 2020) just give the top-1 classes of the identified objects in the images uploaded by users.
With these concerns, we propose the concept of decision-based black-box knowledge distillation (DB3KD), i.e., training a student model by transferring the knowledge from a black-box teacher that only returns hard-labels rather than probability distributions. We start with the scenario when the training data is available. Our key idea is to extract the class probabilities of the training samples from the DB3 teacher. We claim that the decision boundary of a well-trained model distinguishes the training samples of different classes to the largest extent. Therefore, the distance from a sample to the targeted decision boundary (the boundary to the samples of a certain class) can be used as a representation of a sample’s robustness, which determines how much confidence of a specific class is assigned to the sample. Based on this, the soft label of each training sample can be constructed with the value of sample robustness and used for training the student via KD.
We further extend DB3KD to the scenario when training data are not accessible. As the decision boundary makes every effort to differentiate the training samples of all classes, samples used for training the teacher tend to be with longer distances to the boundary than others. We propose to optimize randomly generated noises away from the boundary to obtain robust pseudo samples that simulate the distribution of the training samples. This is achieved by iteratively estimating the gradient direction on the boundary and pushing the samples away from the boundary in that direction. After that, pseudo samples are used for training the student via DB3KD. To our best knowledge, this is the first study of KD from a DB3 teacher, both with and without access to the training set.
The contribution of this study is summarized as follows. (1) We propose the concept of decision-based black-box knowledge distillation for the first time, with which a student is trained by transferring knowledge from a black-box teacher that only returns hard-labels. (2) We propose to use sample robustness, i.e., the distance from a training sample to the decision boundaries of a DB3 teacher, to construct soft labels for DB3KD when training data is available. (3) We extend the DB3KD approach to a more challenging scenario when accessing training data is not feasible and name it zero-shot decision-based black-box knowledge distillation (ZSDB3KD). (4) Extensive experiments validate that the proposed approaches achieve competitive performance compared to existing KD methods in more relaxed scenarios.
2 Related Work
Knowledge distillation. Knowledge distillation is first introduced in (Buciluǎ et al., 2006) and generalized in (Ba & Caruana, 2014; Hinton et al., 2015), which is a popular network compression scheme to train a compact student network by mimicking the softmax output predicted by a high-capacity teacher or ensemble of models. Besides transferring the knowledge of class probabilities, many variants have been proposed to add extra regulations or alignments between the teacher and the student to improve the performance (Romero et al., 2014; Yim et al., 2017; Kim et al., 2018; Heo et al., 2019). For example, FitNet (Romero et al., 2014) introduces an extra loss term that matches the values of the intermediate hidden layers of the teacher and the student, which allows fast training of deeper student models. (Zagoruyko & Komodakis, 2016) defines the attention of DNNs and uses it as the additional transferred knowledge.
Knowledge distillation with limited data. To mitigate the storage and transmission costs of large training datasets, several studies propose the concept of few-shot KD, which generates pseudo samples with the help of a small number of the original training samples (Kimura et al., 2018; Wang et al., 2020; Li et al., 2020). Another study suggests that instead of the raw data, some surrogates with much smaller sizes (also known as metadata) can be used to distill the knowledge from the teacher. (Lopes et al., 2017) leverages the statistical features of the activations of the teacher to train a compact student without access to the original data. However, releasing this kind of metadata along with the pre-trained teacher is usually not a common scenario.
Zero-shot knowledge distillation. To deal with the scenario when training data is not accessible, (Nayak et al., 2019) proposes zero-shot knowledge distillation (ZSKD). The authors model the softmax output space of the teacher with a Dirichlet distribution and samples soft labels as the targets. Randomly generated noise inputs are optimized towards these targets via backpropagation and are used as the transfer set. (Wang, 2021) replaces the Dirichlet distribution with a multivariate normal distribution to model the softmax output space of the generated samples. Therefore, pseudo samples of different classes can be generated simultaneously rather than one after another as in (Nayak et al., 2019). Generative adversarial networks (GANs) (Goodfellow et al., 2014) are leveraged in (Chen et al., 2019; Micaelli & Storkey, 2019) to solve this task so that pseudo sample synthesis and student network training can be conducted simultaneously. Another study (Yin et al., 2020) proposes to use the features in the batch normalization layers to generate pseudo samples. However, these methods still need access to the parameters of the teacher for backpropagation, which is unrealistic in many cases.
Black-box knowledge distillation. Although the vanilla KD is built with a black-box teacher (Hinton et al., 2015), the whole training dataset is used for training. (Wang et al., 2020) investigates the possibility that a student is trained with limited samples and a black-box teacher. Other than zero-shot KD methods that generate pseudo inputs, (Orekondy et al., 2019) proposes to sample from a large pool (such as ImageNet) to get the transfer set to train the student. Therefore, there is no need to access the teacher’s parameters. Although the prerequisites in these methods are relaxed, weak assumptions on the training samples and a score-based teacher that outputs class probabilities are still needed. Different from these studies, we consider a much more challenging case in which knowledge is transferred from a black-box teacher that only returns top-1 classes.
Decision-based adversarial attack. Our approach leverages the distance from a sample to the decision boundary for soft label construction, which is related to the research of decision-based black-box adversarial attack (Brendel et al., 2017; Cheng et al., 2018, 2019; Liu et al., 2019). These methods aim to add some imperceptible perturbations to the inputs to create adversarial samples that fool a well-trained DNN with high confidence. This is achieved by identifying the points on the decision boundary with minimal distance to the original inputs. Inspired by these studies, we use the distance from a sample to the targeted decision boundaries as a representation of a sample’s robustness against other categories, which can be converted to a probability distribution of all classes with proper operations.

3 Methodology
We first formulate KD in its standard form and present our approach that creates soft labels of the training samples with a DB3 teacher. Finally, we extend our approach to the scenario in which the training set is not accessible.
3.1 Knowledge Distillation
KD is used for training a compact student by matching the softmax outputs of a pre-trained, cumbersome teacher (Hinton et al., 2015) (Fig. 1(left)). For an object classification task, denote and the teacher and the student DNNs, respectively, which take an image as the input, and output a vector , i.e., , , where is the number of classes and is the pre-softmax activation. In a KD procedure, a temperature is usually introduced to soften the softmax output, i.e., , which is proved to be efficient to boost the training process. The student is trained by minimizing the loss function in Eq. (1).
| (1) |
where is the ground truth label, and are the cross-entropy loss and the distillation loss. A scaling factor is used for balancing the importance of the two losses.

3.2 Decision-Based Black-Box Knowledge Distillation
As mentioned, in many real-world applications, users are prohibited from querying any internal configuration of the teacher except for the final decision (top-1 label). Denote the DB3 teacher, then . In this case, cannot be obtained and the student cannot be trained with Eq. (1). We claim that a sample’s robustness against a specific class can be used as a representation of how much confidence should be assigned to this class, with proper post-operations. Therefore, we extract the sample’s robustness against each class from the DB3 teacher and convert it to a class distribution as an estimate of (Fig. 1(bottom)). In the following, we propose three metrics to measure sample robustness and present how to construct class distributions with the sample robustness measurements. Intuitively, if a sample is closer to some points in the region of a specific class, it is more vulnerable to this class and thus should be assigned higher confidence.
3.2.1 Sample Robustness
Sample Distance (SD). The most straightforward way to quantify the sample robustness is to compute the minimal -norm distance from a sample to those of other classes (Fig. 2(left)). Denote a sample of the -th class, a batch of samples from the -th class, where , are the number of channels, width and height of the sample, respectively. The robustness of against class is computed with Eq. (2).
| (2) |
The advantage of using SD is it can be implemented without querying from the teacher. However, SD is a rough estimate of sample robustness since it does not mine any information from the teacher. Therefore, we introduce two advanced strategies to measure sample robustness.
Boundary Distance (BD). To obtain better representation of sample robustness, we propose to leverage the distances from a sample to the targeted decision boundaries of the teacher (Fig. 2(middle)). For each , we implement a binary search in the direction and find the corresponding point on the decision boundary (Eq. (3)).
| (3) | ||||
We then compute the sample robustness with Eq. (2) in which is replaced by .
Minimal Boundary Distance (MBD). Inspired by recent studies of decision-based black-box adversarial attack (Brendel et al., 2017; Cheng et al., 2018; Liu et al., 2019; Cheng et al., 2019), we further optimize by moving it along the decision boundary to the point where is minimized (Fig. 2(right)). Starting from , we first estimate the gradient of the boundary via zeroth order optimization (Wang et al., 2018), which is achieved by sampling Gaussian random vectors and averaging them (Fig. 3, Eq. (4)).
| (4) |
where is a very small scalar, and is a sign function, i.e,
| (5) |

Once the gradient is determined, we get a new sample outside the decision boundary with a step size . Then we conduct the same binary search procedure (Eq. (3)) in the direction and obtain an updated . Since the search is within a very small region, the decision boundary in such a region is smooth. Therefore, the new has a smaller distance to (Fig. 3). We repeat the procedure above to get the optimal solution until cannot be further minimized or the query limit is reached. Finally, we compute the sample robustness with Eq. (2) in which is replaced by .
3.2.2 Soft Label Construction
After obtaining all the samples’ robustness on all classes, we construct the soft labels for them with proper manipulations. We start with the pre-softmax activations for better illustration. Suppose the pre-softmax activation of a sample is . Then the pre-softmax activation and the sample robustness should be in correlation with the following conditions. (1) . It is obvious that should be the largest number to ensure that the sample is assigned to the correct class. (2) If , then . This is because bigger sample robustness indicates longer distance to the targeted decision boundary, which means that the sample is more robust against the certain class and should be assigned a lower confidence. (3) If , then . This is because when the sum of a sample’s distances to its targeted decision boundaries is larger, the probability mass of this sample is more concentrated in its top-1 class. Otherwise, the mass is more dispersed among all elements.
3.2.3 Training of Student Model
Once the soft labels of all the training samples are constructed with the above approach, we can train the student with standard KD, using the objective function in Eq. (1).
3.3 Zero-shot Decision-Based Black-Box Knowledge Distillation
In zero-shot KD, pseudo samples are usually generated by optimizing some noise inputs via backpropagation towards some soft labels sampled from a prior distribution, which are then used as the transfer set. However, with a DB3 teacher, backpropagation cannot be implemented and the prior distribution cannot be obtained, which makes ZSDB3KD a much more challenging task. Since the teacher is trained to largely distinguish the training samples, the distance between a training sample to the teacher’s decision boundary is usually much larger than the distance between a randomly generated noise image to the boundary. With this claim, we propose to iteratively push random noise inputs towards the region that is away from the boundary to simulate the distribution of the original training data (Fig. 1(right)).
Denote and a random noise input of the -th class and a batch of random noises with any other class, respectively. Similar but slightly different from Eq. (3), for each , we first identity its corresponding points on the boundary with Eq. (8).
| (8) | ||||
Similarly, the MBDs of , i.e., , can be iteratively estimated with Eq. (4) and (5). Let be the one of such that attains its minimal value, i.e., . We then estimate the gradient at the boundary with Eq. (4) and update as with the step size . The new is usually with longer distance to the boundary. We repeat the above process until cannot be further maximized or the query limit is reached. Finally, we used the generated pseudo samples with the DB3KD approach to train the student as described in Section 3.2.
4 Experiments
In this section, we first demonstrate the performance of DB3KD when training samples are accessible. Then we show the results of ZSDB3KD under the circumstance that training data is not accessible.
| Algorithm | MNIST | Fashion-MNIST | CIFAR10 | FLOWERS102 | |||
| LeNet5 | LeNet5 | LeNet5 | LeNet5 | AlexNet | AlexNet | ResNet-18 | |
| -half | -1/5 | -half | -1/5 | -half | -quarter | ||
| Teacher CE | 99.33% | 99.33% | 91.63% | 91.63% | 79.30% | 79.30% | 95.07% |
| Student CE | 99.11% | 98.77% | 90.21% | 88.75% | 77.28% | 72.21% | 92.18% |
| Standard KD | 99.33% | 99.12% | 90.82% | 89.09% | 77.81% | 73.14% | 94.05% |
| Surrogate KD | 99.13% | 98.85% | 90.27% | 88.72% | 77.49% | 72.49% | 92.93% |
| Noise logits | 99.01% | 98.72% | 89.81% | 88.20% | 77.04% | 72.06% | 91.99% |
| DB3KD-SD | 99.15% | 98.98% | 90.86% | 89.31% | 77.66% | 72.78% | 93.18% |
| DB3KD-BD | 99.51% | 99.19% | 90.68% | 89.47% | 77.92% | 72.94% | 93.30% |
| DB3KD-MBD | 99.52% | 99.22% | 91.45% | 89.80% | 78.30% | 73.78% | 93.77% |
4.1 Experiment Setup of DB3KD
We demonstrate the effectiveness of DB3KD with several widely used DNNs and datasets as follows. (1) A LeNet-5 (LeCun et al., 1998) with two convolutional layers is pre-trained on MNIST (LeCun et al., 1998) as the teacher, following the configurations in (Lopes et al., 2017; Chen et al., 2019). A LeNet-5-Half and a LeNet-5-1/5 are designed as the student networks, which contains half and 1/5 number of convolutional filters in each layer compared to LeNet-5, respectively. (2) The same teacher and student networks as in (1) are used but are trained and evaluated on the Fashion-MNIST dataset. (3) An AlexNet (Krizhevsky et al., 2012) pre-trained on CIFAR-10 (Krizhevsky et al., 2009) is used as the teacher. An AlexNet-Half and an AlexNet-Quarter with half and 25% filters are used as student networks. (4) A ResNet-34 (He et al., 2016) pre-trained on the high-resolution, fine-grained dataset FLOWERS102 (Nilsback & Zisserman, 2008) is used as the teacher, and the student is a ResNet-18.
We evaluate our approach with the three strategies for sample robustness calculation as described in Section 3.2.1, represented as DB3KD-SD, DB3KD-BD, and DB3KD-MBD, respectively. For DB3KD-SD, we use 100 samples from each class to compute the sample robustness for MNIST, Fashion-MNIST, and CIFAR-10. Since there are only 20 samples in each class of FLOWERS102, we use all of them. Starting with these samples, is set to as the stop condition of the binary search in DB3KD-BD. In DB3KD-MBD, we use 200 Gaussian random vectors to estimate the gradient and try different numbers of queries from 1000 to 20000 with to optimize the MBD and report the best test accuracies. The sample robustness are calculated in parallel with a batch size of 20 with FLOWERS102, and 200 with the other datasets.
With the constructed soft labels, we train the student networks for 100 epochs, using an Adam optimizer (learning rate ), for all the datasets except for FLOWERS102, which is trained for 200 epochs. The scaling factor is set to 1 for simplicity. Since Eq. (7) has the similar functionality with the temperature , is not need to be as large as in previous studies (Hinton et al., 2015).With a hyperparameter search, we find that smaller s between and leads to good performance. We use in our experiments. All experiments are evaluated for 5 runs with random seeds.
| Approach | Teacher | Student | Accuracy |
| Cross-entropy | ResNet-34 | - | 78.63% |
| Cross-entropy | ResNet-18 | - | 75.91% |
| Standard KD | ResNet-34 | ResNet-18 | 77.18% |
| Surrogate KD | 76.52% | ||
| BAN∗ | 76.84% | ||
| TF-KD | 77.23% | ||
| SSKD | 76.20% | ||
| DB3KD | 77.31% | ||
| DB3KD | ResNet-50 | ResNet-18 | 78.65% |




4.2 Performance Evaluation of DB3KD
The performance of DB3KD is presented in Table 1. To understand the proposed approach better, we also present the performance of the following training strategies. (1) The teacher and the student networks trained solely with the cross-entropy loss. (2) The standard KD with Eq. (1) (Hinton et al., 2015). (3) Training the student network via KD with a surrogate white-box teacher (Surrogate KD in Table 1), which is used for simulating the scenario in which one can train a smaller but affordable surrogate model with full access to its parameters compared to the powerful DB3 teacher. Here the surrogate has the same architecture with the student. The performance of surrogate KD is considered as the lower bound of DB3KD. (4) Training with the soft labels constructed with randomly generated sample robustness (Noise logits in Table 1), which is used for verifying the effectiveness of DB3KD for soft label construction.
We observe from the results that DB3KD works surprisingly well. With the most straightforward strategy SD, our approach still achieve competitive performance on all experiments compared to standard KD and outperform surrogate KD. When using MBD to compute sample robustness, DB3KD-MBD outperforms standard KD on all the experiments except for FLOWERS102. On FLOWERS102, the performance of DB3KD is slightly worse due to the complexity of the pre-trained teacher model. However, DB3KD still outperforms the surrogate KD with a clear margin. These results validate the effectiveness of DB3KD and indicates that sample robustness with proper post-operation provides an informative representation of a sample’s probabilities over all classes and can be used as an alternative to the softmax output when only a DB3 teacher is provided.
We also observe the following phenomena in the experiments. (1) Training with noise logits via KD does not work, but even results in worse performance than training with cross-entropy. It indicates noise logits cannot capture the distribution of class probabilities, but are even harmful due to the wrong information introduced. (2) Training a student with a surrogate teacher not only results in unsatisfactory performance, but is also a difficult task due to the low capacity of the surrogate model. Also, the performance is sensitive to hyperparameter selection (, , learning rate, etc.). Therefore, training an extra affordable surrogate teacher is not an optimal solution compared to DB3KD.
We notice that in some experiments, surprisingly, DB3KD even works better than standard KD, though the models are trained with a more challenging setting. A reasonable hypothesis is that, for some problems, the distance between a training sample to the decision boundary may provide more information than the softmax output. These results provide future research directions that the dark knowledge behind the teacher’s decision boundary is more instructive compared to the teacher’s logits in certain cases.
4.3 Comparison with Self-Distillation Approaches
Similar to our proposed scenario, in the absence of a pre-trained teacher, self-knowledge distillation aims to improve the performance of the student by distilling the knowledge within the network itself (Furlanello et al., 2018). Since self-distillation approaches can also deal with our proposed scenario, we compare the performance of DB3KD to recent self-distillation approaches, including born-again neural networks (BAN) (Furlanello et al., 2018), teacher-free knowledge distillation (TF-KD) (Yuan et al., 2020), and self-supervision knowledge distillation (SSKD) (Xu et al., 2020). We use ResNet-34/18 as the teacher and the student on CIFAR-100 for illustration. For further comparison, we also implement DB3KD with a ResNet-50 teacher.
The results are shown in Table 2. It is observed that our approach is still competitive in this case. With the same network configuration, our student achieves a test accuracy of 77.31%, which outperforms other self-distillation approaches, even with a DB3 teacher. It is also worth mentioning that, given a fixed student, the performance of self-distillation has an upper bound because it is teacher-free. One advantage of our approach is that the student can leverage the information from a stronger teacher and its performance can be further improved. As an example, we substitute the DB3 teacher with a ResNet-50 network and keep other other configurations unchanged, the performance of our student network is further increased by 1.34%, which outperforms self-distillation approaches with a clear margin.



4.4 Ablation Studies and Analyses of DB3KD
We conduct several ablation studies and analyses for further understanding of the effectiveness of DB3KD.
Number of queries in label construction. We first investigate whether different numbers of queries used for computing sample robustness has any influence on the performance. For each dataset, we query from the teacher for a variety of times from 1000 to 20000 to compute the sample robustness (Fig. 4). It can be observed that with more queries, the student models perform slightly better, especially for deeper architectures (ResNet) and high-resolution datasets (FLOWERS102). In general, the student models perform well with various numbers of queries. Even using a binary search with around 100 queries (DB3KD-BD), the performance are satisfactory on all student models. This is because the quality of a sample’s soft label is largely related to its robustness against different classes. Moreover, the MBD used for computing sample robustness shows a highly positive correlation with the number of queries (Fig. 5(a)). The ratios of sample robustness against different classes remain stable against the number of queries. Therefore, it is not necessary to optimize the MBD with a large number of queries, which indicates that DB3KD is query efficient. It is also worth noting that the performance is not linearly correlated with the query numbers. This is because for all experiments, we use the same set of hyperparameters for fair comparison, which may not be optimal as the query number increases. However, we’d like to emphasize the performance is not sensitive to query numbers and is satisfactory with a wide range of numbers (from 2k to 20k).
Although the boundary may be complex in the pixel domain and the boundary sample may be fragile, what we actually care about is the minimal boundary distance (MBD). It actually measures how fragile a training sample is against other classes and is a robust measurement. As supplementary evidence, the standard deviations of the MDBs are relatively small (shown with the error bars in Fig. 5(a)), indicating the robustness of the proposed approach.
| Algorithm | Data | Model | MNIST | FMNIST |
|---|---|---|---|---|
| Teacher CE | Yes | White | 99.33% | 91.63% |
| Student CE | Yes | White | 99.11% | 90.21% |
| Standard KD | Yes | Black-S | 99.33% | 90.82% |
| FSKD | Few | White | 86.70% | 72.60% |
| BBKD | Few | Black-S | 98.74% | 80.90% |
| Meta KD | Meta | White | 92.47% | - |
| DAFL | No | White | 98.20% | - |
| ZSKD | No | White | 98.77% | 79.62% |
| DFKD | No | White | 99.08% | - |
| ZSDB3KD | No | Black-D | 96.54% | 72.31% |
Correlation between sample robustness and class probability. To further analyze the effectiveness of DB3KD for constructing soft labels, we visualize the normalized average MBDs of the samples with different classes (Fig. 5(b-d)). It is observed that classes semantically closer with each other are with smaller distances to their decision boundary. For example, in MNIST, the distance between ‘8’ and ‘9’ is smaller than ‘8’ and ‘1’ because ‘8’ looks more like ‘9’ than ‘1’. Therefore, a sample of ‘8’ is assigned higher confidence in class ‘9’ than ‘1’. Similarly, in Fashion-MNIST, ‘T-shirt’ looks more like ‘shirt’ than ‘sneaker’ so that their distance are smaller. In CIFAR-10, samples of the ‘dog’ class are with smaller distances to the boundary with ‘cat’ than ‘truck’ since ‘dog’ and ‘cat’ are semantically closer. These analyses confirm the consistency between sample robustness and class probability distribution.
4.5 Experiment Setup of ZSDB3KD
We evaluate ZSDB3KD with (1) a LeNet-5 and a LeNet-5-Half (on MNIST and Fashion-MNIST), and (2) an AlexNet and an AlexNet-Half (on CIFAR-10) as the teacher and the student. The networks are the same as in Section 4.1.
We optimize the pseudo samples for 40 () and 100 iterations () for the two LeNet-5 and the AlexNet experiments, respectively. The query is limited to 5000 when iteratively searching for the MBD. We generate 8000 samples for each class with a batch size of 200 for all the experiments. We use data augmentation to enrich the transfer set (see Appendix). We use 5000 queries for computing the sample robustness since we have shown the number of queries is trivial. Other parameters are the same as the DB3KD experiments. We compare the performance of ZSDB3KD with several popular KD approaches in more relaxed scenarios, including FSKD (Kimura et al., 2018), BBKD (Wang et al., 2020), Meta KD (Lopes et al., 2017), DAFL (Chen et al., 2019), ZSKD (Nayak et al., 2019) and DFKD (Wang, 2021).
| Algorithm | Data | Model | Accuracy |
|---|---|---|---|
| Teacher CE | Yes | White | 79.30% |
| Student CE | Yes | White | 77.28% |
| Standard KD | Yes | Black-S | 77.81% |
| FSKD | Few | White | 40.58% |
| BBKD | Few | Black-S | 74.60% |
| DAFL | No | White | 66.38% |
| ZSKD | No | White | 69.56% |
| DFKD | No | White | 73.91% |
| Noise input | No | Black-S | 14.79% |
| Noise input | No | Black-D | 13.53% |
| ZSDB3KD | No | Black-D | 59.46% |

4.6 Performance Comparison of ZSDB3KD
The performance of ZSDB3KD on MNIST and Fashion-MNIST, and CIFAR-10 presented in Table 3 and 4 show that ZSDB3KD achieves competitive performance. The accuracies of the student networks are and on MNIST and Fashion-MNIST, which are quite close to other KD approaches with more relaxed scenarios (training data or the teacher’s parameters are accessible). On CIFAR-10, our AlexNet-Half model achieves an accuracy of 59.46% without accessing any training samples and the softmax outputs of the teacher. It is worth noting that using random noise as the input results in very poor performance with a DB3 teacher. These results indicate that the samples generated with our proposed approach indeed capture the distribution of the samples used for training the teachers.
4.7 Ablation Studies and Analyses of ZSDB3KD
In this subsection, we perform several studies to understand the effectiveness of ZSDB3KD, using LeNet-5-Half trained on MNIST as an example.
Iteration of sample generation. We first evaluate the performance of the student with pseudo samples generated with different iterations (Fig. 6(upper right)). As expected, the performance is improved as the samples are optimized away from the decision boundaries with more iterations. As shown in Fig. 6(left), with more steps, more pixels in the pseudo samples are activated, with sharper edges and recognizable digits, which indicates that the samples become more robust as we keep moving them to the opposite of the gradient direction on the decision boundaries.
Number of samples used for training. We then investigate the effect of the number of pseudo samples used for training on the performance of the student network. The results of training the student network with different numbers of generated samples (from 1k to 8k per class) are presented in Fig. 6(bottom right). Not surprisingly, with more samples, the test accuracy increases. Even with a small number of samples (1k per class), the student network can still achieve a competitive performance of 94% test accuracy. With 8k samples per class, the student’s performance gets saturated and is comparable to the performance of standard KD.
Visualization of generated samples. As mentioned above, we have shown the evolution of individual samples over iterations (Fig. 6(left)), which gradually exhibits clear digits. To have a further visualization of the generated pseudo samples, we further average 1k samples for each class as shown in Fig. 6(middle). Even though generated with a DB3 teacher, the samples are with a satisfactory quality compared with the averaged samples generated with ZSKD and DAFL that use white-box teachers.
5 Conclusion
In this study, we introduced KD from a decision-based black-box teacher for the first time. We proposed DB3KD to deal with this problem, which uses sample robustness to construct the soft labels for the training samples by iteratively querying from the teacher. We also extend DB3KD to a much more challenging scenario in which the training set is not accessible and named it Zero-shot DB3KD (ZSDB3KD). Experiments on various networks and datasets validated the effectiveness of the proposed approaches.
Our study motivated a new line of research on KD, in which the black-box teacher only returns top-1 classes. It is a much more challenging scenario because the class probabilities of the training samples need to be constructed by iteratively querying from the DB3 teacher. With the training set accessible, our DB3KD achieved competitive performance on FLOWERS102, in which samples largely overlap with ImageNet. We believe that DB3KD can work effectively on large-scale datasets. With the training samples not available, like most of the existing works, a large amount of computing resource is required for pseudo sample generation, making zero-shot KD hard to accomplish with large-scale datasets. With a DB3 teacher, even more iterations are needed compared to learning from a white-box model. Although we proposed the first principled solution, we hope it helps to raise attention in this area and promote efficient approaches.
References
- Ba & Caruana (2014) Ba, J. and Caruana, R. Do deep nets really need to be deep? In Advances in neural information processing systems, pp. 2654–2662, 2014.
- Brendel et al. (2017) Brendel, W., Rauber, J., and Bethge, M. Decision-based adversarial attacks: Reliable attacks against black-box machine learning models. arXiv preprint arXiv:1712.04248, 2017.
- Buciluǎ et al. (2006) Buciluǎ, C., Caruana, R., and Niculescu-Mizil, A. Model compression. In Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining, pp. 535–541, 2006.
- Chen et al. (2019) Chen, H., Wang, Y., Xu, C., Yang, Z., Liu, C., Shi, B., Xu, C., Xu, C., and Tian, Q. Data-free learning of student networks. In Proceedings of the IEEE International Conference on Computer Vision, pp. 3514–3522, 2019.
- Cheng et al. (2018) Cheng, M., Le, T., Chen, P.-Y., Yi, J., Zhang, H., and Hsieh, C.-J. Query-efficient hard-label black-box attack: An optimization-based approach. arXiv preprint arXiv:1807.04457, 2018.
- Cheng et al. (2019) Cheng, M., Singh, S., Chen, P., Chen, P.-Y., Liu, S., and Hsieh, C.-J. Sign-opt: A query-efficient hard-label adversarial attack. arXiv preprint arXiv:1909.10773, 2019.
- Clarifai (2020) Clarifai, I. Clarifai: Computer vision and ai enterprise platform. 2020. URL http://www.clarifai.com.
- Covington et al. (2016) Covington, P., Adams, J., and Sargin, E. Deep neural networks for youtube recommendations. In Proceedings of the 10th ACM conference on recommender systems, pp. 191–198, 2016.
- Deng et al. (2009) Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., and Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pp. 248–255. Ieee, 2009.
- Furlanello et al. (2018) Furlanello, T., Lipton, Z., Tschannen, M., Itti, L., and Anandkumar, A. Born again neural networks. In International Conference on Machine Learning, pp. 1607–1616. PMLR, 2018.
- Goodfellow et al. (2014) Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., and Bengio, Y. Generative adversarial nets. In Advances in neural information processing systems, pp. 2672–2680, 2014.
- Han et al. (2015) Han, S., Mao, H., and Dally, W. J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv preprint arXiv:1510.00149, 2015.
- He et al. (2016) He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778, 2016.
- He et al. (2019) He, Y., Liu, P., Wang, Z., Hu, Z., and Yang, Y. Filter pruning via geometric median for deep convolutional neural networks acceleration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4340–4349, 2019.
- Heo et al. (2019) Heo, B., Lee, M., Yun, S., and Choi, J. Y. Knowledge transfer via distillation of activation boundaries formed by hidden neurons. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pp. 3779–3787, 2019.
- Hinton et al. (2015) Hinton, G., Vinyals, O., and Dean, J. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015.
- Howard et al. (2017) Howard, A. G., Zhu, M., Chen, B., Kalenichenko, D., Wang, W., Weyand, T., Andreetto, M., and Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861, 2017.
- Jaderberg et al. (2014) Jaderberg, M., Vedaldi, A., and Zisserman, A. Speeding up convolutional neural networks with low rank expansions. arXiv preprint arXiv:1405.3866, 2014.
- Jin et al. (2020) Jin, X., Lan, C., Zeng, W., and Chen, Z. Uncertainty-aware multi-shot knowledge distillation for image-based object re-identification. arXiv preprint arXiv:2001.05197, 2020.
- Kim et al. (2018) Kim, J., Park, S., and Kwak, N. Paraphrasing complex network: Network compression via factor transfer. In Advances in neural information processing systems, pp. 2760–2769, 2018.
- Kimura et al. (2018) Kimura, A., Ghahramani, Z., Takeuchi, K., Iwata, T., and Ueda, N. Few-shot learning of neural networks from scratch by pseudo example optimization. arXiv preprint arXiv:1802.03039, 2018.
- Krizhevsky et al. (2009) Krizhevsky, A., Hinton, G., et al. Learning multiple layers of features from tiny images. Technical report, Citeseer, 2009.
- Krizhevsky et al. (2012) Krizhevsky, A., Sutskever, I., and Hinton, G. E. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, pp. 1097–1105, 2012.
- LeCun et al. (1998) LeCun, Y., Bottou, L., Bengio, Y., and Haffner, P. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998.
- Li et al. (2016) Li, H., Kadav, A., Durdanovic, I., Samet, H., and Graf, H. P. Pruning filters for efficient convnets. arXiv preprint arXiv:1608.08710, 2016.
- Li et al. (2020) Li, T., Li, J., Liu, Z., and Zhang, C. Few sample knowledge distillation for efficient network compression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14639–14647, 2020.
- Liu et al. (2019) Liu, Y., Moosavi-Dezfooli, S.-M., and Frossard, P. A geometry-inspired decision-based attack. In Proceedings of the IEEE International Conference on Computer Vision, pp. 4890–4898, 2019.
- Lopes et al. (2017) Lopes, R. G., Fenu, S., and Starner, T. Data-free knowledge distillation for deep neural networks. arXiv preprint arXiv:1710.07535, 2017.
- López et al. (2017) López, G., Quesada, L., and Guerrero, L. A. Alexa vs. siri vs. cortana vs. google assistant: a comparison of speech-based natural user interfaces. In International Conference on Applied Human Factors and Ergonomics, pp. 241–250. Springer, 2017.
- Micaelli & Storkey (2019) Micaelli, P. and Storkey, A. J. Zero-shot knowledge transfer via adversarial belief matching. In Advances in Neural Information Processing Systems, pp. 9551–9561, 2019.
- Moskalenko et al. (2018) Moskalenko, V., Moskalenko, A., Korobov, A., Boiko, O., Martynenko, S., and Borovenskyi, O. Model and training methods of autonomous navigation system for compact drones. In 2018 IEEE Second International Conference on Data Stream Mining & Processing (DSMP), pp. 503–508. IEEE, 2018.
- Nayak et al. (2019) Nayak, G. K., Mopuri, K. R., Shaj, V., Babu, R. V., and Chakraborty, A. Zero-shot knowledge distillation in deep networks. arXiv preprint arXiv:1905.08114, 2019.
- Nilsback & Zisserman (2008) Nilsback, M.-E. and Zisserman, A. Automated flower classification over a large number of classes. In 2008 Sixth Indian Conference on Computer Vision, Graphics & Image Processing, pp. 722–729. IEEE, 2008.
- Orekondy et al. (2019) Orekondy, T., Schiele, B., and Fritz, M. Knockoff nets: Stealing functionality of black-box models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4954–4963, 2019.
- Passalis et al. (2020) Passalis, N., Tzelepi, M., and Tefas, A. Heterogeneous knowledge distillation using information flow modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2339–2348, 2020.
- Phuong & Lampert (2019) Phuong, M. and Lampert, C. Towards understanding knowledge distillation. In International Conference on Machine Learning, pp. 5142–5151. PMLR, 2019.
- Romero et al. (2014) Romero, A., Ballas, N., Kahou, S. E., Chassang, A., Gatta, C., and Bengio, Y. Fitnets: Hints for thin deep nets. arXiv preprint arXiv:1412.6550, 2014.
- Wang et al. (2020) Wang, D., Li, Y., Wang, L., and Gong, B. Neural networks are more productive teachers than human raters: Active mixup for data-efficient knowledge distillation from a blackbox model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 1498–1507, 2020.
- Wang et al. (2018) Wang, Y., Du, S., Balakrishnan, S., and Singh, A. Stochastic zeroth-order optimization in high dimensions. In International Conference on Artificial Intelligence and Statistics, pp. 1356–1365, 2018.
- Wang (2021) Wang, Z. Data-free knowledge distillation with soft targeted transfer set synthesis. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pp. 10245–10253, 2021.
- Wang et al. (2021) Wang, Z., Li, C., and Wang, X. Convolutional neural network pruning with structural redundancy reduction. arXiv preprint arXiv:2104.03438, 2021.
- Xu et al. (2020) Xu, G., Liu, Z., Li, X., and Loy, C. C. Knowledge distillation meets self-supervision. In European Conference on Computer Vision, pp. 588–604. Springer, 2020.
- Yim et al. (2017) Yim, J., Joo, D., Bae, J., and Kim, J. A gift from knowledge distillation: Fast optimization, network minimization and transfer learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4133–4141, 2017.
- Yin et al. (2020) Yin, H., Molchanov, P., Alvarez, J. M., Li, Z., Mallya, A., Hoiem, D., Jha, N. K., and Kautz, J. Dreaming to distill: Data-free knowledge transfer via deepinversion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8715–8724, 2020.
- Yuan et al. (2020) Yuan, L., Tay, F. E., Li, G., Wang, T., and Feng, J. Revisiting knowledge distillation via label smoothing regularization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3903–3911, 2020.
- Yun et al. (2020) Yun, S., Park, J., Lee, K., and Shin, J. Regularizing class-wise predictions via self-knowledge distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13876–13885, 2020.
- Zagoruyko & Komodakis (2016) Zagoruyko, S. and Komodakis, N. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. arXiv preprint arXiv:1612.03928, 2016.
Appendix
A. Architectures Used in DB3KD and ZSDB3KD Experiments
We use several networks to evaluate the performance of DB3KD and ZSDB3KD. LeNet-5 (teacher)/ LeNet-5-Half (student) and AlexNet (teacher)/ AlexNet-Half (student) are used for both DB3KD and ZSDB3KD experiments (Table S1-S4). For the DB3KD experiments, we also design two student networks, i.e., LeNet-5-1/5 and AlexNet-Quarter for further evaluation (Table S5-S6). We also conduct experiments with ResNet-34 (teacher)/ ResNet-18 (student) with DB3KD and the architectures used are the same as the original ResNet architectures.
| Index | Layer | Type | Feature map | Kernel size | Stride | Padding | Activation |
| 0 | Input | Input | 1 | - | - | - | - |
| 1 | conv1 | conv | 20 | 5x5 | 1 | 0 | ReLu |
| 2 | maxpool1 | pooling | - | 2x2 | 2 | 1 | - |
| 3 | conv2 | conv | 50 | 5x5 | 1 | 0 | ReLu |
| 4 | maxpool2 | pooling | - | 2x2 | 2 | 1 | - |
| 5 | fc1 | fc | 200 | - | - | - | ReLu |
| 6 | fc2 | fc | 10 | - | - | - | Softmax |
| Index | Layer | Type | Feature map | Kernel size | Stride | Padding | Activation |
| 0 | Input | Input | 1 | - | - | - | - |
| 1 | conv1 | conv | 10 | 5x5 | 1 | 0 | ReLu |
| 2 | maxpool1 | pooling | - | 2x2 | 2 | 1 | - |
| 3 | conv2 | conv | 25 | 5x5 | 1 | 0 | ReLu |
| 4 | maxpool2 | pooling | - | 2x2 | 2 | 1 | - |
| 5 | fc1 | fc | 100 | - | - | - | ReLu |
| 6 | fc2 | fc | 10 | - | - | - | Softmax |
| Index | Layer | Type | Feature map | Kernel size | Stride | Padding | Activation |
| 0 | Input | Input | 1 | - | - | - | - |
| 1 | conv1 | conv | 64 | 3x3 | 2 | 1 | ReLu |
| 2 | maxpool1 | pooling | - | 3x3 | 2 | 0 | - |
| 3 | bn1 | batch norm | - | - | - | - | - |
| 4 | conv2 | conv | 192 | 3x3 | 1 | 2 | ReLu |
| 5 | maxpool2 | pooling | - | 3x3 | 2 | 0 | - |
| 6 | bn2 | batch norm | - | - | - | - | - |
| 7 | conv3 | conv | 384 | 3x3 | 1 | 1 | ReLu |
| 8 | bn3 | batch norm | - | - | - | - | - |
| 9 | conv4 | conv | 256 | 3x3 | 1 | 1 | ReLu |
| 10 | bn4 | batch norm | - | - | - | - | - |
| 11 | conv5 | conv | 256 | 3x3 | 1 | 1 | ReLu |
| 12 | maxpool3 | pooling | - | 3x3 | 2 | 0 | - |
| 13 | bn5 | batch norm | - | - | - | - | - |
| 14 | fc1 | fc | 4096 | - | - | - | ReLu |
| 15 | bn6 | batch norm | - | - | - | - | - |
| 16 | fc2 | fc | 4096 | - | - | - | ReLu |
| 17 | bn7 | batch norm | - | - | - | - | - |
| 18 | fc3 | fc | 10 | - | - | - | Softmax |
| Index | Layer | Type | Feature map | Kernel size | Stride | Padding | Activation |
| 0 | Input | Input | 1 | - | - | - | - |
| 1 | conv1 | conv | 32 | 3x3 | 2 | 1 | ReLu |
| 2 | maxpool1 | pooling | - | 3x3 | 2 | 0 | - |
| 3 | bn1 | batch norm | - | - | - | - | - |
| 4 | conv2 | conv | 96 | 3x3 | 1 | 2 | ReLu |
| 5 | maxpool2 | pooling | - | 3x3 | 2 | 0 | - |
| 6 | bn2 | batch norm | - | - | - | - | - |
| 7 | conv3 | conv | 192 | 3x3 | 1 | 1 | ReLu |
| 8 | bn3 | batch norm | - | - | - | - | - |
| 9 | conv4 | conv | 128 | 3x3 | 1 | 1 | ReLu |
| 10 | bn4 | batch norm | - | - | - | - | - |
| 11 | conv5 | conv | 128 | 3x3 | 1 | 1 | ReLu |
| 12 | maxpool3 | pooling | - | 3x3 | 2 | 0 | - |
| 13 | bn5 | batch norm | - | - | - | - | - |
| 14 | fc1 | fc | 2048 | - | - | - | ReLu |
| 15 | bn6 | batch norm | - | - | - | - | - |
| 16 | fc2 | fc | 2048 | - | - | - | ReLu |
| 17 | bn7 | batch norm | - | - | - | - | - |
| 18 | fc3 | fc | 10 | - | - | - | Softmax |
| Index | Layer | Type | Feature map | Kernel size | Stride | Padding | Activation |
| 0 | Input | Input | 1 | - | - | - | - |
| 1 | conv1 | conv | 4 | 5x5 | 1 | 0 | ReLu |
| 2 | maxpool1 | pooling | - | 2x2 | 2 | 1 | - |
| 3 | conv2 | conv | 10 | 5x5 | 1 | 0 | ReLu |
| 4 | maxpool2 | pooling | - | 2x2 | 2 | 1 | - |
| 5 | fc1 | fc | 40 | - | - | - | ReLu |
| 6 | fc2 | fc | 10 | - | - | - | Softmax |
| Index | Layer | Type | Feature map | Kernel size | Stride | Padding | Activation |
| 0 | Input | Input | 1 | - | - | - | - |
| 1 | conv1 | conv | 16 | 3x3 | 2 | 1 | ReLu |
| 2 | maxpool1 | pooling | - | 3x3 | 2 | 0 | - |
| 3 | bn1 | batch norm | - | - | - | - | - |
| 4 | conv2 | conv | 48 | 3x3 | 1 | 2 | ReLu |
| 5 | maxpool2 | pooling | - | 3x3 | 2 | 0 | - |
| 6 | bn2 | batch norm | - | - | - | - | - |
| 7 | conv3 | conv | 96 | 3x3 | 1 | 1 | ReLu |
| 8 | bn3 | batch norm | - | - | - | - | - |
| 9 | conv4 | conv | 64 | 3x3 | 1 | 1 | ReLu |
| 10 | bn4 | batch norm | - | - | - | - | - |
| 11 | conv5 | conv | 64 | 3x3 | 1 | 1 | ReLu |
| 12 | maxpool3 | pooling | - | 3x3 | 2 | 0 | - |
| 13 | bn5 | batch norm | - | - | - | - | - |
| 14 | fc1 | fc | 1024 | - | - | - | ReLu |
| 15 | bn6 | batch norm | - | - | - | - | - |
| 16 | fc2 | fc | 1024 | - | - | - | ReLu |
| 17 | bn7 | batch norm | - | - | - | - | - |
| 18 | fc3 | fc | 10 | - | - | - | Softmax |
B. Experiment details
B.1. Training of the Models with Cross-Entropy
In this subsection, we introduce the details of training the models with cross-entropy loss, for both the pre-trained models used as the DB3 teachers, and the performance of the student models trained solely with the cross-entropy loss reported in Tables 1, 2, 3, and 4.
LeNet-5 on MNIST and Fashion-MNIST For the LeNet-5 architecture on MNIST and Fashion-MNIST, we train the teacher model for 200 epochs, with a batch size of 1024, an Adam optimizer with a learning rate of 0.001. For the student models trained with cross-entropy (reported in Tables 1 and 3), we use the same hyperparameters as above.
AlexNet on CIFAR-10 For the AlexNet architecture on CIFAR-10, we train the teacher model for 300 epochs, with a batch size of 1024 and an SGD optimizer. We set the momentum to 0.9, and weight decay to 0.0001. The learning rate is set to 0.1 at the beginning, and is divided by 10 at epochs 60, 120, and 180. For the student models trained with cross-entropy (reported in Tables 1 and 4), we use the same hyperparameters as above.
ResNet on CIFAR-100 For the ResNet-{50,34} on CIFAR-100, we train the teacher models for 300 epochs, with a batch size of 256 and an SGD optimizer. We set the momentum to 0.9 and weight decay to 0.0001. The learning rate is set to 0.1 at the beginning, and is divided by 10 at epochs 60, 120, and 180. For the student model (ResNet-18) trained with cross-entropy (reported in Table 2), we use the same hyperparameters as above.
ResNet-34 on FLOWERS102 For the ResNet-34 architecture on FLOWERS102, we start with the model pre-trained on ImageNet, which is provided by Pytorch, and fine-tune the pre-trained model for 200 epochs with an SGD optimizer. We set the batch size to 64 and the momentum to 0.9. The learning rate is set to 0.01 at the beginning, and set to 0.005 and 0.001 at epochs 60 and 100, respectively. For the student model (Resnet-18) trained with cross-entropy (reported in Table 1), we use the same hyperparameters as above.
B.2. Standard Knowledge Distillation Training Details
For the standard knowledge distillation results reported in Tables 1, 2, 3, and 4, we train the student models via standard KD with the following hyperparameters. The scaling factor that balances the importance of cross-entropy loss and knowledge distillation loss is set to 1. The Adam optimizer is used for all experiments and the student networks are trained for 200 epochs with a temperature of 20. For the experiments with MNIST, Fashion-MNIST, and CIFAR-10, we set the batch size to 512; for the experiments with CIFAR-100 and FLOWERS102, we set the batch size to 64. The learning rate is set to 0.001 for MNIST and Fashion-MNIST, 0.005 for CIFAR-10/100, and 0.0005 for FLOWERS102.
B.3. Surrogate Knowledge Distillation Training Details
Training the student networks by transferring the knowledge from a surrogate, low-capacity white-box teacher whose parameters can be fully accessed is sensitive to hyperparameter selection. We did an extensive hyperparameter search in our experiments and report the best numbers in Table 1. We use the hyperparameters listed below. The optimizer and batch size used for surrogate KD are the same as in standard KD. We train the student models for 300 epochs for all experiments. For MNIST and Fashion-MNIST, the scaling factor is set to 0.7, the temperature is set to 3, and the learning rate is set to 0.005. For CIFAR-10/100, is set to 0.5, the temperature is set to 5, and the learning rate is set to 0.005. For FLOWERS102, is set to 1, the temperature is set to 10, and the learning rate is set to 0.001.
B.4. Data Augmentation Used in ZSDB3KD Experiments
In ZSDB3KD experiments, we found that data augmentation can improve the performance. Since the number of queries for the soft label construction of the samples is trivial to the performance, as shown in the DB3KD experiments (Fig. 4), we can apply various augmentation strategies to enrich the transfer set with affordable extra computing cost. In our study, we implement the following data augmentation strategies.
-
•
(1) Padding and crop. We first pad two pixels on each side of the generated samples and crop it to the original size, starting from the upper left corner to the bottom right corner, with an interval of 1.
-
•
(2) Horizontal and vertical flip. We flip the generated samples horizontally and vertically to create mirrored samples.
-
•
(3) Rotation. We rotate each generated image starting from to with an interval of to create 6 more rotated samples.
-
•
(4) Flip after padding and crop. We flip the images after (1), horizontally and vertically.
-
•
(5) Rotation after padding and crop. We rotate the images after (1), using the same operation as (3).
For the MNIST and Fashion-MNIST datasets, only the strategies (1) and (2) are used. For the CIFAR-10 dataset, all five strategies are used. For the DB3KD experiment with CIFAR-100, we also use the above five strategies.
It is also worth mentioning that after generating images with the above operations, some of the samples’ top-1 classes change to others. If this happens, we use the approach described in Section 3 to find the sample’s corresponding point on the targeted decision boundary, i.e., , to recover its top-1 class back to the top-1 class of the sample before augmentation.
Table S7 presents the performance comparison with and without data augmentation on each dataset used in the ZSDB3KD experiments. It is observed that training the student networks with more samples augmented with the above strategies can improve the performance.
| Dataset | Acc. without augmentation | Acc. with augmentation |
| MNIST | 94.20% | 96.54% |
| Fashion-MNIST | 67.24% | 72.31% |
| CIFAR-10 | 37.58% | 59.46% |
C. More Experiment Results
C.1. Comparison of the Sample Robustness Computed with DB3KD and the Logits Generated by the Teacher
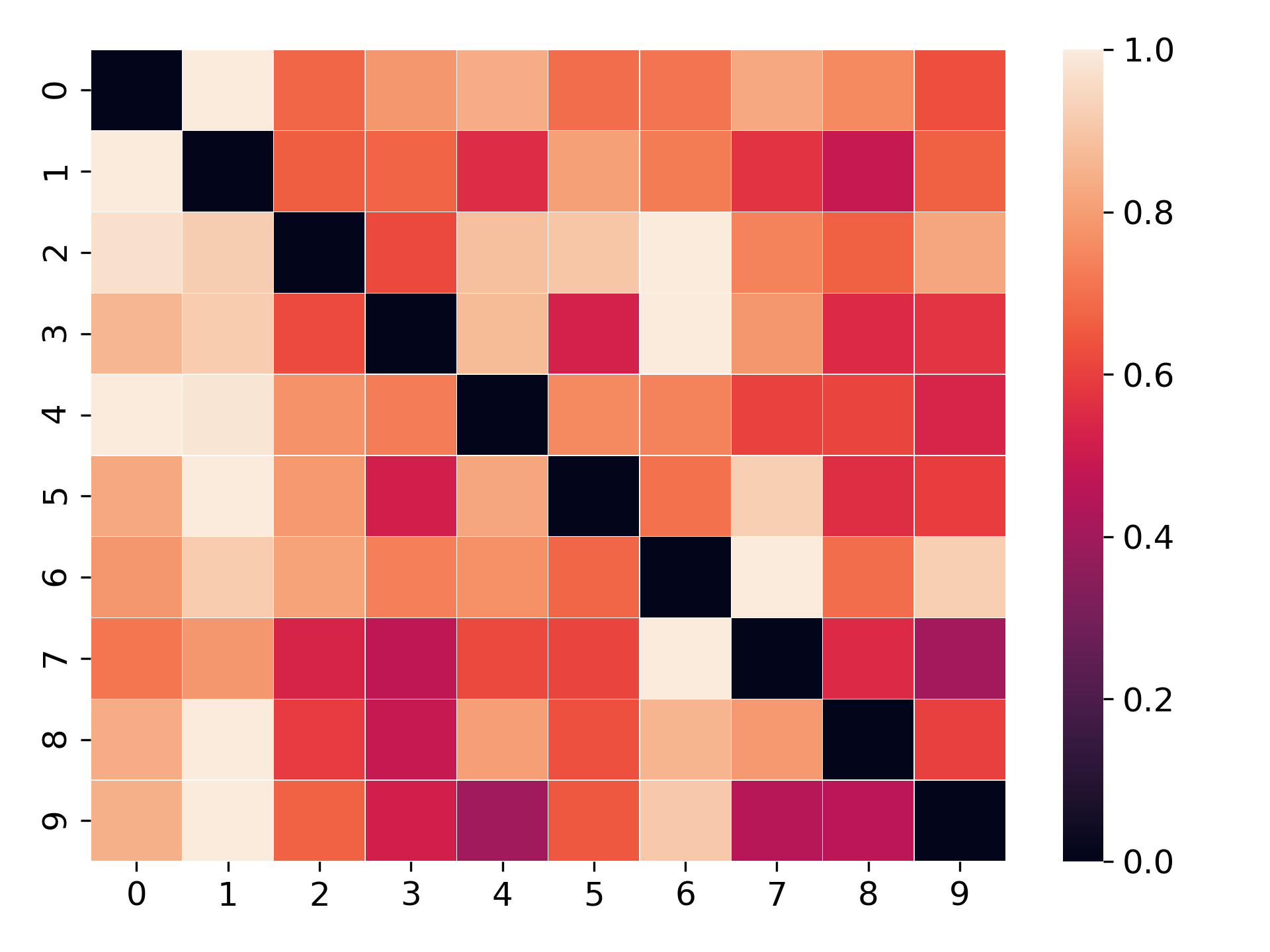
To further understand the effectiveness of the label construction with sample robustness in our DB3KD approach, we visualize the sample distances that are computed with the softmax outputs of the teacher networks, by accessing the teachers’ parameters. We first feed the training samples to the teacher model and get the softmax output. For a training sample, if a bigger probability is assigned to a class, it means the distance between this sample to the specific class is smaller. Therefore, we simply use 1 - class probability to represent the sample distance. The results are presented in Fig. S1. It can be observed that the visualized heatmaps look similar to those visualized with the sample robustness computed with our DB3 approach (Fig. 5(b-d)). For example, both of the MNIST heatmaps indicate that digit ’4’ is close to digit ’9’. For the Fashion-MNIST, Fig. S1(b) shows that class T-shirt is semantically close to class ’Shirt’ and ’Pullover’, which is consistent with the results in Fig. 5(c). These results further validate that our proposed approach to construct soft labels with sample robustness is meaningful.



C.2. Ablation Studies of ZSDB3KD on Fashion-MNIST and CIFAR-10




Similar to the ablation studies of ZSDB3KD on the MNIST dataset, we also investigate the effect of (1) different numbers of iterations for sample generation and (2) different numbers of pseudo samples used for KD training on the performance of the student networks (without using data augmentation). The results are presented in Fig. S2 and Fig. S3, respectively.
Similar to the results of MNIST, it is observed that, with more iterations for the sample optimization, more robust pseudo samples can be generated and the performance of the student networks are increased via DB3KD. For example, when optimizing the randomly generated noises for only 5 iterations, the performance of the student network on the Fashion-MNIST is less than 58% without data augmentation. After 40 iterations, the performance increases by around 7%. The performance of the AlexNet-Half network on CIFAR-10 is only around 15% when using pseudo samples that are optimized for only 10 iterations. On the other hand, the performance increases to 37% after 70 iterations.
The test accuracies of the student networks are also higher when using more pseudo samples as the transfer set. For the Fashion-MNIST dataset, the performance increases from 61.39% to 67.24% as the number of pseudo samples used as the transfer set increases from 1000 to 8000 per category. For the CIFAR-10 dataset, the performance is less than 28% when using only 1000 samples per class. When the number of samples for each class increases to 8000, an accuracy of 37.58% can be achieved.