Zero-shot Generation of Coherent Storybook from Plain Text Story using Diffusion Models
Abstract
Recent advancements in large scale text-to-image models have opened new possibilities for guiding the creation of images through human-devised natural language. However, while prior literature has primarily focused on the generation of individual images, it is essential to consider the capability of these models to ensure coherency within a sequence of images to fulfill the demands of real-world applications such as storytelling. To address this, here we present a novel neural pipeline for generating a coherent storybook from the plain text of a story. Specifically, we leverage a combination of a pre-trained Large Language Model and a text-guided Latent Diffusion Model to generate coherent images. While previous story synthesis frameworks typically require a large-scale text-to-image model trained on expensive image-caption pairs to maintain the coherency, we employ simple textual inversion techniques along with detector-based semantic image editing which allows zero-shot generation of the coherent storybook. Experimental results show that our proposed method outperforms state-of-the-art image editing baselines.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/794c5d06-6d5f-4011-935b-a10fa6ad9cb1/figure1.jpeg)
1 Introduction
The progress in image synthesis using large-scale text-to-image models has garnered significant attention due to their unprecedented synthetic capacity. Text-guided image synthesis methods such as VQGAN-CLIP [7] and CLIP-guided Diffusion [6], utilize the superior performance of text-to-image alignment in the CLIP [35] latent spaces.
Parti [54], Make-a-scene [12], and DALL-E 1 [39] have employed large auto-regressive architectures, while Imagen [43], DALL-E 2 [38], and Stable Diffusion [42] have utilized diffusion-based architectures. MUSE [5] employs a masked transformer architecture and learns to predict masked tokens using the embeddings projected from Large Language Models (LLM) and image tokens. The overwhelming performance of these models has sparked ongoing research efforts to harness their power for image editing.
While prior frameworks have mainly focused on the generation of individual, high-quality images, real-world applications place an equal emphasis on coherency within a series of generated images. For example, in the context of an AI-generated storybook, it is crucial for the main character to maintain a consistent appearance throughout the book. Therefore, we address the challenge of not only locally editing an image, but also applying these techniques to a practical real-world application: the generation of a training-free storybook that maintains the coherency of the main character.
One prior attempt at this is Long Stable Diffusion [58], which generates a book (both plot and corresponding illustrations) using a combination of LLM and text-image models. However, their use of a LLM is limited to generating illustration ideas, which can lead to irrelevant images if directly used as text conditioning or require significant manual modification of prompts. Another pioneering work in the field of story synthesis is StoryGAN [24], a conditional GAN [29] trained to generate visual sequences corresponding to text descriptions of a story. Subsequently, StoryDALL-E [28] proposed the adaptation of pre-trained text-to-image transformers to generate visual sequences that continue a given text-based story, introducing a new task of story continuation. More recently, Pan et al. [32] proposed history-aware Auto-Regressive Latent Diffusion Models that leverage diffusion models for story synthesis, utilizing a history-aware conditioning network to encode past caption-image pairs. While previous works have made important strides in story synthesis by utilizing datasets of specific domains [55] for training, generalizing their methods to other domains or stories often requires expensive image-caption pairs and additional training.
To address these issues, here we introduce a neural pipeline for the zero-shot generation of coherent storybooks without additional training data. Specifically, our method starts with a simple, yet powerful prompt generation pipeline that takes as input the plain text of existing stories. Furthermore, we ensure that the main character maintains a consistent appearance throughout the book by utilizing our proposed semantic image editing method that injects the desired identity into the facial regions, which play a crucial role in distinguishing a character’s identity. Our experimental results demonstrate the effectiveness of our approach in comparison to state-of-the-art semantic image editing baselines.
In summary, the contributions of our work are as follows:
-
•
We propose a novel prompt generation pipeline, in which LLMs understand the context and generate prompt inputs for text-to-image models, replacing the need for human-devised natural language prompts.
-
•
We propose our semantic image editing method and demonstrate its effectiveness against other baselines in terms of smooth editing, coherency maintenance across independent images, and preservation of background regions.
-
•
Our method allows for fine-grained control over the degree of semantic change by adjusting the number of cycles.
2 Related Works
Large Language Models and Prompt Engineering. Large Language Models (LLMs) [10, 37, 36, 4] have gained significant attention in recent years due to their capability to create human-like text and accomplish a wide range of natural language processing (NLP) tasks accurately. Recent works demonstrated that LLMs can perform both few-shot [4] and zero-shot [22] reasoning tasks with high accuracy, generalizing well to both common and rare examples. This is achieved by conditioning the models on a few examples or task instructions, a method commonly referred to as ”prompting” [25]. While most of the research in prompt engineering has focused on text generation in NLP [45, 41, 60], relatively little exploration has been conducted on prompting text generation frameworks in visual tasks, e.g. text-to-image generation. Various guidelines [26, 31, 51] for designing prompts have been suggested through empirical analysis of the relationship between prompt components and the resulting visual effects. The studies employed extensive experimentation, utilizing a variety of prompt modifiers on the generation model to gain a deeper understanding of the factors that influence the generated images.
Diffusion Models. Diffusion models [46] are trained to learn the underlying data distribution by gradually denoising a variable sampled from Gaussian distribution. In particular, this is equivalent to learning the reverse process of the Markov Chain of fixed length . In a forward diffusion process , noised sampled from Gaussian distribution is added to a ground truth image at every time step :
| (1) | |||
where decides the step size which gradually increases. Let and . Then we can sample in a single step:
| (2) |
where is a noise sampled from . DDPM [18] learns to predict the noise component of and generate a marginally denoised from by maximizing the variational lower bound to minimize the negative log-likelihood of . A function is parameterized by a UNet-shaped model to reverse the forward step and mean is learned in the reverse process:
| (3) | |||
The training objective of the diffusion model is then:
| (4) |
Denoising Diffusion Implicit Models (DDIM) [47] proposed a method for accelerating the sampling process of diffusion models by replacing the Markov forward process used in DDPM with a non-Markovian process. DDIM formulates a Markov chain that reverses a non-Markovian perturbation process. This chain is fully deterministic when the variance of the reverse noise is set to zero. DDIM method is formulated using the following Markov chain:
| (5) | |||
where
| (6) |
Text-to-Image Generation and Semantic Image Editing. The field of text-guided synthesis has seen a significant amount of progress in recent years, with various methods proposed to address the challenge of generating images from natural language descriptions. Early works [29, 40, 52, 56, 57] in this field were based on Generative Adversarial Networks (GAN) [15].
A widely adopted approach is the use of auxiliary models such as CLIP [35] to guide the optimization of pre-trained generators towards the objective of minimizing text-to-image similarity scores [7, 6]. Additionally, other works have exploited the use of CLIP in conjunction with generative models for various tasks such as image manipulation [33, 20], domain adaptation [14], style transfer [23], and even object segmentation [27, 50]. Recently, large-scale text-to-image models demonstrated impressive image generation performance [54, 12, 39, 38, 43, 42, 5]. These models have sparked research efforts using diffusion models [46] for text-driven image generation and editing. In regard to image editing, previous works such as Blended Diffusion [3], Blended Latent Diffusion [2], and Paint by Example [53] have addressed the issue of background preservation through user-provided masks. Another approach demonstrated the ability to edit synthesized images using text prompts as editing guidance [17]. DALL-E 2 [38] also proved its impressive capability in text-guided image editing, commonly referred to as ‘inpainting’. However, when generating images from these models, the identity of a subject is not sustained among images. This is because the diffusion-based generators only use text as a guidance and changing the context in the prompt also alters the appearance.
3 Method
In this section, we detail our neural pipeline for generating a training-free storybook that maintains the coherence of the main character. Specifically, for a given plain text of a story, our algorithm automatically generates matched images and storybook that maintains the coherence of the main character. The overall process of our method can be summarized as follows:
-
1.
Generate prompts by providing instruction to LLM along with the text of a story.
-
2.
Utilize a Diffusion-based Text-to-Image model to generate initial images from the set of prepared prompts.
-
3.
Apply Face Restoration on the initial images.
-
4.
Find the textual embedding of a specific identity by Textual Inversion learning.
-
5.
Use the obtained textual embedding to perform Iterative Coherent Identity Injection on enhanced images.
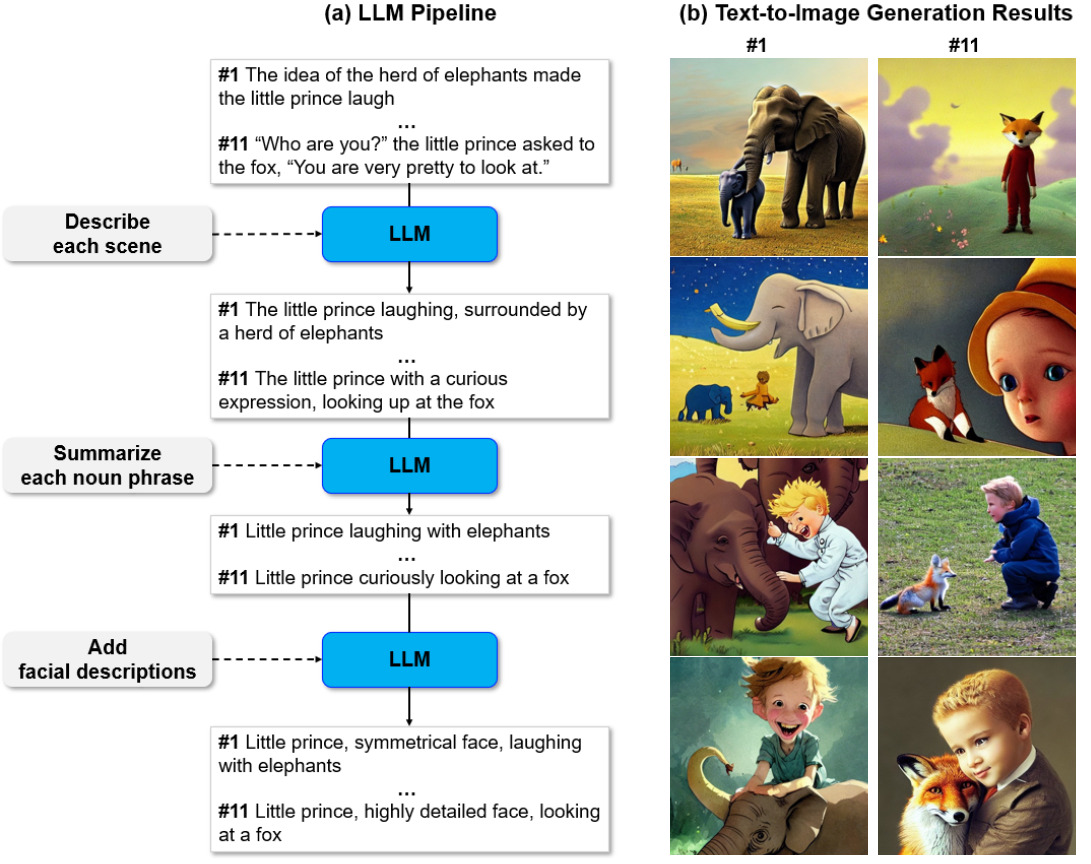

3.1 Prompt Generation
Prior literature has primarily leveraged text-to-image models for generating a wide range of images with human-devised text prompts.
Instead, this article proposes an approach where we utilize prompts generated by a LLM when given the plain text of a story.
Our pipeline, as outlined in Figure 2 (a), is able to generate a series of prompts corresponding to each scene of a story.
Let us utilize ‘The Little Prince’ [8] as a case study for our corresponding prompts generation pipeline.
The process begins by providing the LLM with the instruction to ”Describe each scene” along with the sentences of the story.
One example input-output pair for this step would be ”The idea of the herd of elephants made the little prince laugh” and ”The little prince laughing, surrounded by a herd of elephants”.
The LLM expresses its creativity through this step, with the strength of creativity being controlled by the temperature parameter .
However, text-to-image synthesis models often struggle to effectively handle the complexity of the outputs generated from the ”Describe each scene” instruction.
As demonstrated in Figure 2 (b), the amount of information contained in these outputs exceeds the capacity of text-to-image models.
To address this issue, we employ a summarization step in which we provide the LLM with the ”Summarize each noun phrase” instruction and the outputs obtained from the previous step.
An example of the output generated in this step, given the previous output ”The little prince laughing, surrounded by a herd of elephants,” is ”The little prince laughing with elephants.”
To further enhance the quality of the generated images, we employ additional processing of the prompts by the LLM, through the use of magic words already popular to practitioners. These magic words, such as ‘highly detailed’ and ‘insanely intricate’ are known to be effective in adding detailed properties to images. Additionally, when the main subject of the prompt is a person, we also utilize descriptions of facial features, such as ‘symmetrical face’ and ‘beautiful eyes’ to enhance the realism of the generated images. This is accomplished through the use of simple instructions given to the LLM, specifically, ”If the main subject of the prompt is a person, add facial descriptions such as ‘symmetrical face’ or ‘beautiful eyes’, where the LLM expresses its creativity again.
In order to generate images in a specific style, we employ the use of style modifiers. In this work, we specifically target the style of a storybook. Examples of utilized style modifiers that achieved the storybook aesthetic include: 1. Modifiers that include children’s book illustrators such as ”illustrated by Quentin Blake” 2. Modifiers that indicate a specific type of book such as ”1950s adventure book character illustration” 3. Modifiers that include artists with desired artistic style such as ”watercolor by Carl Larsson” or ”painting by Jean-Baptiste Monge”. This step of incorporating style modifiers allows for increased scalability as it enables the generation of an infinite number of variations of the storybook by simply altering the style modifiers used, according to the demands of users. Visual effects of mentioned modifiers are illustrated in Figure 4.

3.2 Iterative Coherent Identity Injection
Initial Image Generation using Latent Diffusion Models. We utilize a text-conditioned Latent Diffusion model (LDM) [42] to generate initial images from a set of prepared prompts.
Unlike traditional diffusion models that operate in the pixel space, LDM utilizes the latent space, using a pre-trained autoencoder (VAE [21] or VQ-VAE [48, 1]). An encoder maps image to latent representations , while a decoder maps the latents back to images . Our trained perceptual compression models, the autoencoder consisting of and , enable access to low-dimensional latent space where high-frequency, indiscernible details are ignored. A diffusion model is additionally trained to generate representations within this learned latent space, while conditioned on texts, and initial images. Note that the text condition and the initial image are the two important control knobs that will be used for the iterative coherent identity injection described later. Based on image-conditioning pairs, the model tries to precisely eliminate the noise added to a latent representation of an image via:
| (7) |
where is the time step, is the noisy version of initial latent on time , is the sampled noise, is a conditional denoising autoencoder, and is a encoder that projects input to a conditioning vector . and are jointly optimized to minimize the loss.
Iterative Coherent Identity Injection. Given an initial image generated by Latent Diffusion Model (LDM) using the prompt , we employ a face restoration model [49, 59] on to obtain an enhanced image to elevate the quality of the initial images before proceeding to the next step of Iterative Coherent Identity Injection. This is an important step as it addresses the issue of mutated facial features in the generated images, and also helps to reduce the domain gap between the generated images and the target textual embedding which we obtain from Textual Inversion [13] of real-photo domain images. Subsequently, we utilize a Face Detector [9] to extract the bounding box of the facial region in the image. This bounding box is used to generate a binary mask that marks the region of the face in the image.
To incorporate a target identity, we edit the prompt to obtain by replacing the original subject in with a placeholder string of the target identity, for example replacing ”the little prince” in the original prompt with ””. To find a designated placeholder string which represents the desired target identity given a few images (or a single image) of the target identity, the textual inversion technique proposed by Gal et al.[13] is used to find the target embedding vector in the embedding space of text encoder , where . The optimization goal of minimizing the LDM loss is defined as:
| (8) |
where parameters of and are frozen.
The objective is then to generate an altered image , where the facial region is consistent to the identity encoded in , while preserving the background (non-facial) region of the source image. The overall cycles of identity injection process is guided by and , i.e., LDM performs textual embedding guidance denoising in the latent space of a Variational Autoencoder (VAE) consisting of an encoder and a decoder . We denote the facial area as ‘face’ () and to the complementary non-facial area as ‘non-face’ (). The enhanced input first moves to the latent space using the VAE Encoder . As the width and the height of latent representations are downsampled from the input image pixel space, we downsample the facial mask as well. With the downsampled facial mask , we extract ground truth latent representation of non-face region by . As the denoising step progresses, the non-facial region of the intermediate representation will repeatedly be replaced with the extracted .
More specifically, we do the following process for cycles: We noise the initial latent to the noise level . Replace the non-facial region of noised sample with the corresponding region of as . The resulting becomes the input of the denoising process. Then after each denoising step, which is conditioned by the edited prompt , we obtain the less noisy sample . Preserve the facial region of but replace the complementary region with as . The resultant becomes the input of the next denoising step. Once the denoising process terminates, instead of being decoded back to pixel space, the resulting denoised sample becomes the input of the next cycle, which eliminates the inefficiency of going back and forth between latent space and pixel space. After cycles are carried out, we get the output image by decoding it from the latent space to the pixel space. The overall procedure is outlined in Algorithm 1 and illustrated in Figure 3.

4 Experiment
4.1 Implementation Details
We first provide details on the implementation choices of our proposed method. For the story-to-prompts component, we employed the GPT-3 model [4], specifically the ”text-davinci-003” variant, as well as the ChatGPT language model. For the text-to-image synthesis component, we adopted the Stable Diffusion model(v1.5) [42], a publicly available text-to-image latent diffusion model trained on LAION-5B [44] and its default settings. We utilized CodeFormer[59] for face restoration and RetinaFace face detector [9] to accurately detect and align faces in the generated images.
4.2 Experiment Settings
The experiments were conducted on a GPU of Quadro RTX 6000. We employed the DDIM scheduler [47] for sampling the latent space of the Stable Diffusion model [42]. In the initial image generation phase, we used 100 reverse diffusion steps, with scale guidance [19] between 7.5 and 10. A fidelity weight of 0.5 was used during face restoration [59]. For one cycle of coherent identity injection, we used about 50 forward and reverse diffusion steps. The number of coherent identity injection cycles varied between 1 and 8. The generated images had a resolution of 512x512 and the latent representations were of size 4x64x64. Lastly, the story ‘The Lazy John’ presented in Figure 1 is from an article presented in [16], ‘The Boy Who Cried Wolf’ in Figure 5 is from [34], and ‘The Little Prince’ in Figure 12 is from [8].
4.3 Qualitative Results
Figure 1 illustrates examples of our zero-shot generation of the storybook with two different identities, which clearly demonstrates that our method can control and maintain the coherency of the stories that are generated without any training data.
In Figure 5, we present a qualitative evaluation of our proposed method in comparison to state-of-the-art semantic image editing baselines. To demonstrate the effectiveness of our pipeline, we first show initial images generated by our pipeline, which includes prompt generation, initial text-to-image generation, and face restoration. We then compare our method with a range of baselines, including text-guided methods such as CLIP-guided Diffusion [6] and Stable Diffusion Img2img [42], DALL-E2 Inpainting [38], Blended Latent Diffusion [2] and an image-guided method such as Paint by Example [53]. The ‘Source’ images show that our pipeline successfully synthesizes images corresponding to the plot of the story. The comparison results show that our method outperforms the baselines in terms of coherency preservation and background region preservation. Further comparisons on additional stories are presented in Figure 11 and Figure 12.
4.4 Quantitative Results
We created three questionnaires for a total of four stories, with each questionnaire designed to assess different aspects of the generated images. The first questionnaire, labeled as Correspondence, assessed the level of correspondence between the plot of the text and the generated image pairs. The second questionnaire, labeled as Coherency, assessed the coherency of the main characters across images within a story. Lastly, the third questionnaire, labeled as Smoothness, assessed how smooth and seamless the transition was between the foreground and background in the images. To evaluate detailed opinions, we employed a custom-made opinion scoring system. The results of this study on 76 random people are summarized in Table 1 in the form of mean scores for each of the questionnaires. Overall, our method achieved the highest scores in all aspects, indicating the effectiveness of our proposed pipeline.
Methods CLIP-guided Stable DALL-E2 Blended Paint by Ours Diffusion Diffusion Latent Diffusion Example Correspondence 2.96 2.68 2.75 2.42 2.32 4.06 Coherence 2.16 2.64 2.44 2.36 2.24 3.84 Smoothness 2.55 2.87 2.96 2.71 2.20 4.23
4.5 Ablation Study
To validate the optimality of our approach, we performed ablation studies. First, we compare the generative performance on varying numbers of cycles. The results are presented in Figure 6, which illustrates that as the number of injection cycles increases, the source identity gradually fades away while the target identity becomes more discernible. It demonstrates the ability of the proposed method to provide delicate control over the amount of editing applied to an image. The edited results in the first and the third columns demonstrate that our method is also robust to occlusions. Additionally, a comparison with a method using only Textual Inversion is presented in Figure 7. It shows that our method is more effective in preserving the background, while the transition between foreground and background appears more seamless. Further results are presented in Figure 10.


5 Conclusion
In this paper, we presented a new approach for zero-shot storybook synthesis. Our pipeline utilized Large Language Models to generate text-based conditioning, which can replace human-crafted natural language prompts and guide image synthesis models. We then developed an iterative identity injection step, using a textual embedding and a face detector to guide the generation process of Latent Diffusion Models in terms of semantic changes and background preservation. Our experimental results demonstrated that our proposed framework outperforms both text- and image-guided semantic image editing baselines in terms of coherency preservation and background preservation.
References
- [1] Eirikur Agustsson, Fabian Mentzer, Michael Tschannen, Lukas Cavigelli, Radu Timofte, Luca Benini, and Luc V Gool. Soft-to-hard vector quantization for end-to-end learning compressible representations. Advances in neural information processing systems, 30, 2017.
- [2] Omri Avrahami, Ohad Fried, and Dani Lischinski. Blended latent diffusion. arXiv preprint arXiv:2206.02779, 2022.
- [3] Omri Avrahami, Dani Lischinski, and Ohad Fried. Blended diffusion for text-driven editing of natural images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18208–18218, 2022.
- [4] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- [5] Huiwen Chang, Han Zhang, Jarred Barber, AJ Maschinot, Jose Lezama, Lu Jiang, Ming-Hsuan Yang, Kevin Murphy, William T Freeman, Michael Rubinstein, et al. Muse: Text-to-image generation via masked generative transformers. arXiv preprint arXiv:2301.00704, 2023.
- [6] Katherine Crowson. Clip-guided diffusion. 2022.
- [7] Katherine Crowson, Stella Biderman, Daniel Kornis, Dashiell Stander, Eric Hallahan, Louis Castricato, and Edward Raff. Vqgan-clip: Open domain image generation and editing with natural language guidance. In European Conference on Computer Vision, pages 88–105. Springer, 2022.
- [8] Antoine de Saint-Exupéry. The Little Prince: And Letter to a Hostage. Penguin UK, 2021.
- [9] Jiankang Deng, Jia Guo, Evangelos Ververas, Irene Kotsia, and Stefanos Zafeiriou. Retinaface: Single-shot multi-level face localisation in the wild. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5203–5212, 2020.
- [10] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- [11] Ohad Fried, Jennifer Jacobs, Adam Finkelstein, and Maneesh Agrawala. Editing self-image. Communications of the Acm, 63(3):70–79, 2020.
- [12] Oran Gafni, Adam Polyak, Oron Ashual, Shelly Sheynin, Devi Parikh, and Yaniv Taigman. Make-a-scene: Scene-based text-to-image generation with human priors. arXiv preprint arXiv:2203.13131, 2022.
- [13] Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H Bermano, Gal Chechik, and Daniel Cohen-Or. An image is worth one word: Personalizing text-to-image generation using textual inversion. arXiv preprint arXiv:2208.01618, 2022.
- [14] Rinon Gal, Or Patashnik, Haggai Maron, Amit H Bermano, Gal Chechik, and Daniel Cohen-Or. Stylegan-nada: Clip-guided domain adaptation of image generators. ACM Transactions on Graphics (TOG), 41(4):1–13, 2022.
- [15] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks. Communications of the ACM, 63(11):139–144, 2020.
- [16] Vijay Gupta. 10 lines short stories with moral for kids in english, 2021.
- [17] Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt image editing with cross attention control. arXiv preprint arXiv:2208.01626, 2022.
- [18] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems, 33:6840–6851, 2020.
- [19] Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598, 2022.
- [20] Gwanghyun Kim and Jong Chul Ye. Diffusionclip: Text-guided image manipulation using diffusion models. 2021.
- [21] Diederik P Kingma and Max Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013.
- [22] Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. arXiv preprint arXiv:2205.11916, 2022.
- [23] Gihyun Kwon and Jong Chul Ye. Clipstyler: Image style transfer with a single text condition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18062–18071, 2022.
- [24] Yitong Li, Zhe Gan, Yelong Shen, Jingjing Liu, Yu Cheng, Yuexin Wu, Lawrence Carin, David Carlson, and Jianfeng Gao. Storygan: A sequential conditional gan for story visualization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6329–6338, 2019.
- [25] Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. arXiv preprint arXiv:2107.13586, 2021.
- [26] Vivian Liu and Lydia B Chilton. Design guidelines for prompt engineering text-to-image generative models. In CHI Conference on Human Factors in Computing Systems, pages 1–23, 2022.
- [27] Timo Lüddecke and Alexander Ecker. Image segmentation using text and image prompts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7086–7096, 2022.
- [28] Adyasha Maharana, Darryl Hannan, and Mohit Bansal. Storydall-e: Adapting pretrained text-to-image transformers for story continuation. In European Conference on Computer Vision, pages 70–87. Springer, 2022.
- [29] Mehdi Mirza and Simon Osindero. Conditional generative adversarial nets. arXiv preprint arXiv:1411.1784, 2014.
- [30] P Mishkin, L Ahmad, M Brundage, G Krueger, and G Sastry. Dall· e 2 preview-risks and limitations. Noudettu, 28:2022, 2022.
- [31] Jonas Oppenlaender. A taxonomy of prompt modifiers for text-to-image generation. arXiv preprint arXiv:2204.13988, 2022.
- [32] Xichen Pan, Pengda Qin, Yuhong Li, Hui Xue, and Wenhu Chen. Synthesizing coherent story with auto-regressive latent diffusion models. arXiv preprint arXiv:2211.10950, 2022.
- [33] Or Patashnik, Zongze Wu, Eli Shechtman, Daniel Cohen-Or, and Dani Lischinski. Styleclip: Text-driven manipulation of stylegan imagery. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2085–2094, 2021.
- [34] Judy Ponio. 10 lines short stories with moral lessons for kids, 2021.
- [35] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, pages 8748–8763. PMLR, 2021.
- [36] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- [37] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J Liu, et al. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res., 21(140):1–67, 2020.
- [38] Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 2022.
- [39] Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. In International Conference on Machine Learning, pages 8821–8831. PMLR, 2021.
- [40] Scott Reed, Zeynep Akata, Xinchen Yan, Lajanugen Logeswaran, Bernt Schiele, and Honglak Lee. Generative adversarial text to image synthesis. In International conference on machine learning, pages 1060–1069. PMLR, 2016.
- [41] Laria Reynolds and Kyle McDonell. Prompt programming for large language models: Beyond the few-shot paradigm. In Extended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems, pages 1–7, 2021.
- [42] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022.
- [43] Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S Sara Mahdavi, Rapha Gontijo Lopes, et al. Photorealistic text-to-image diffusion models with deep language understanding. arXiv preprint arXiv:2205.11487, 2022.
- [44] Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. Laion-5b: An open large-scale dataset for training next generation image-text models. arXiv preprint arXiv:2210.08402, 2022.
- [45] Taylor Shin, Yasaman Razeghi, Robert L Logan IV, Eric Wallace, and Sameer Singh. Autoprompt: Eliciting knowledge from language models with automatically generated prompts. arXiv preprint arXiv:2010.15980, 2020.
- [46] Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. In International Conference on Machine Learning, pages 2256–2265. PMLR, 2015.
- [47] Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502, 2020.
- [48] Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning. Advances in neural information processing systems, 30, 2017.
- [49] Xintao Wang, Yu Li, Honglun Zhang, and Ying Shan. Towards real-world blind face restoration with generative facial prior. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9168–9178, 2021.
- [50] Zhaoqing Wang, Yu Lu, Qiang Li, Xunqiang Tao, Yandong Guo, Mingming Gong, and Tongliang Liu. Cris: Clip-driven referring image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11686–11695, 2022.
- [51] Sam Witteveen and Martin Andrews. Investigating prompt engineering in diffusion models. arXiv preprint arXiv:2211.15462, 2022.
- [52] Tao Xu, Pengchuan Zhang, Qiuyuan Huang, Han Zhang, Zhe Gan, Xiaolei Huang, and Xiaodong He. Attngan: Fine-grained text to image generation with attentional generative adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1316–1324, 2018.
- [53] Binxin Yang, Shuyang Gu, Bo Zhang, Ting Zhang, Xuejin Chen, Xiaoyan Sun, Dong Chen, and Fang Wen. Paint by example: Exemplar-based image editing with diffusion models. arXiv preprint arXiv:2211.13227, 2022.
- [54] Jiahui Yu, Yuanzhong Xu, Jing Yu Koh, Thang Luong, Gunjan Baid, Zirui Wang, Vijay Vasudevan, Alexander Ku, Yinfei Yang, Burcu Karagol Ayan, et al. Scaling autoregressive models for content-rich text-to-image generation. arXiv preprint arXiv:2206.10789, 2022.
- [55] Gangyan Zeng, Zhaohui Li, and Yuan Zhang. Pororogan: an improved story visualization model on pororo-sv dataset. In Proceedings of the 2019 3rd International Conference on Computer Science and Artificial Intelligence, pages 155–159, 2019.
- [56] Han Zhang, Tao Xu, Hongsheng Li, Shaoting Zhang, Xiaogang Wang, Xiaolei Huang, and Dimitris N Metaxas. Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks. In Proceedings of the IEEE international conference on computer vision, pages 5907–5915, 2017.
- [57] Han Zhang, Tao Xu, Hongsheng Li, Shaoting Zhang, Xiaogang Wang, Xiaolei Huang, and Dimitris N Metaxas. Stackgan++: Realistic image synthesis with stacked generative adversarial networks. IEEE transactions on pattern analysis and machine intelligence, 41(8):1947–1962, 2018.
- [58] Sharon Zhou. Long stable diffusion. 2022.
- [59] Shangchen Zhou, Kelvin CK Chan, Chongyi Li, and Chen Change Loy. Towards robust blind face restoration with codebook lookup transformer. arXiv preprint arXiv:2206.11253, 2022.
- [60] Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. Large language models are human-level prompt engineers. arXiv preprint arXiv:2211.01910, 2022.
Appendix A Implementation Details
In our proposed method, we utilized a large language model, specifically the GPT-3 model [4] with the ”text-davinci-003” version, in conjunction with the ChatGPT language model, to generate prompts for the text-to-image component. Our experiments revealed that both models produce comparable results. During the story-to-prompts process, the GPT-3 model was configured with a ‘Temperature’ of 0.5 and a ‘Top P’ parameter of 1. An example instruction set used in our implementation was ”Prompts to generate painting that best describes each scene of a story.” followed by ”Summarize each noun phrase.” and lastly, ”If the main subject of the prompt is categorized as a human, add facial descriptions on the subject such as symmetrical face’,emerald eyes’.”
For the initial text-to-image synthesis component, we utilized the official codebase of the Stable Diffusion model 111https://github.com/CompVis/stable-diffusion [42] with its default hyperparameter settings and the according model checkpoints from Hugging Face 222https://huggingface.co/runwayml/stable-diffusion-v1-5. We used Textual Inversion method [13] to find the target textual embedding, referencing both the official codebase 333https://github.com/rinongal/textual_inversion and an unofficial codebase 444https://github.com/nicolai256/Stable-textual-inversion_win by nicolai256. Additionally, we applied the face restoration step on the initially generated images by using the Codeformer Face Restoration model 555https://github.com/sczhou/CodeFormer,https://huggingface.co/spaces/sczhou/CodeFormer [59], where ‘Fidelity’ parameter was set to 0.5. To precisely detect and align facial parts in the generated images, we employed the RetinaFace Face Detector model 666https://github.com/biubug6/Pytorch_Retinaface [9]. Details of the Iterative Coherent Identity Injection method are explained in Section 4.2 of the main paper.
Appendix B Experimental Details of Baselines
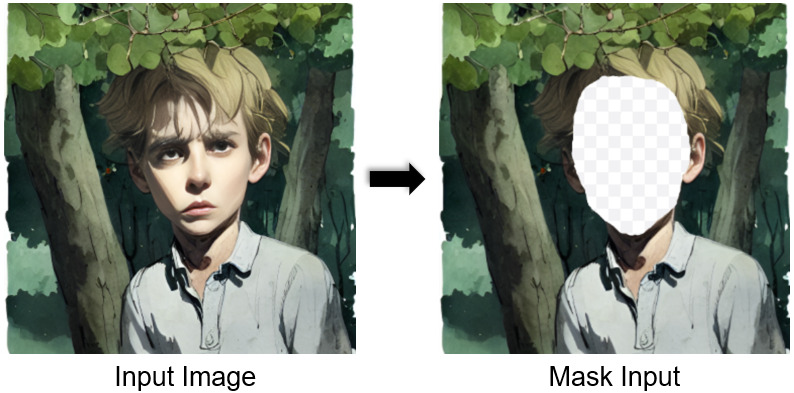
In our experiments, we compared our method to several state-of-the-art baselines, including CLIP-guided Diffusion [6], Stable Diffusion [42], DALL-E 2 [38], Blended Latent Diffusion [2], and Paint by Example [53]. We utilized the official codebase of the works 777https://github.com/afiaka87/clip-guided-diffusion 888https://github.com/omriav/blended-latent-diffusion 999https://github.com/Fantasy-Studio/Paint-by-Example and according demo web sites 101010https://huggingface.co/spaces/EleutherAI/clip-guided-diffusion 111111https://huggingface.co/spaces/Fantasy-Studio/Paint-by-Example if provided. For DALL-E 2, we utilized the paid inpainting demo 121212https://openai.com/dall-e-2/ by OpenAI as we could not access the trained model freely. In particular, for the experiment with the CLIP-guided Diffusion model, we configured the model with the following hyperparameter settings: ‘skip timesteps’:30, ‘clip guidance scale’:1600, ‘tv scale’:150, ‘range scale’:50, ‘initial scale’: 1000. This deviated from the default settings reported in the CLIP Guided Diffusion code repository, as the default settings resulted in poor image quality. Additionally, for the methods that are guided by user-provided masks (DALL-E 2, Blended Latent Diffusion, Paint by Example), we manually generated the masks as illustrated in Figure 8.
Appendix C User Study Details
In order to evaluate the performance of our proposed method, a user study was conducted. A total of 76 participants were recruited, with a diverse age range of the 20s and 30s. The study was conducted using a Google Form, in which participants were asked to provide scores for images generated by our method and several state-of-the-art methods. The evaluation was conducted in a blind manner, in which participants were not informed of which method was used to generate the images. Three questions were asked for each of the four stories, with each story featuring variations of 6 different image editing methods (1 ours + 5 baselines). In total, 72 questions were asked. The first question assessed the Correspondence of the generated story set, with the following instruction used: ”Your task is to evaluate the correspondence between the plot and images, which refers to how well the images depict the corresponding plot.” The second question assessed the Coherency of the generated story set, with the following instruction used: ”Your task is to evaluate the coherency of appearance, which refers to how consistent the appearance of the main character is across the images.” The third question assessed the Smoothness of the generated story set, with the following instruction used: ”Your task is to evaluate the smoothness of the images, which refers to how well the facial regions blend seamlessly with the background regions.” A 5-point Likert scale was used for each aspect, with a minimum score of 1 and a maximum score of 5. The options provided were: 1- Very Bad, 2- Bad, 3- Medium, 4-Good, 5-Very Good.
Appendix D Limitations
In our work, we employed a publicly available text-guided Latent Diffusion Model, Stable Diffusion, as the backbone of our proposed method. However, due to its inherent limitations, not all text conditioning methods generated optimal images, particularly in cases where images of people were involved. For example, images with mutated facial or body features were generated in some instances. To address this limitation, we incorporated the step of ‘Add facial descriptions’ in our prompt generation pipeline, which partially mitigated this issue. However, it is important to note that the imperfect nature of Stable Diffusion may still lead to suboptimal results in some cases.
Appendix E Social Impact
The use of Text-Image models and generative image editing techniques poses several ethical challenges. These models have the potential to be used for malicious purposes, such as creating misleading or fake images, and can have negative societal impacts [11]. Our work is built on such models and is also susceptible to these issues. Additionally, the models were trained on a dataset of images collected from the web [44], which may contain inappropriate content and biases. As a result, the models may inherit these biases [30] and generate inappropriate images. To mitigate these risks, we will release our code under a license that promotes ethical and legal use, similar to the license used for the Stable Diffusion model.
Appendix F Additional Results
F.1 Face Restoration

F.2 Different Number of Cycles

F.3 Additional Story Synthesis Results

