22email: [email protected]
YotoR-You Only Transform One Representation
Abstract
This paper introduces YotoR (You Only Transform One Representation), a novel deep learning model for object detection that combines Swin Transformers and YoloR architectures. Transformers, a revolutionary technology in natural language processing, have also significantly impacted computer vision, offering the potential to enhance accuracy and computational efficiency. YotoR combines the robust Swin Transformer backbone with the YoloR neck and head. In our experiments, YotoR models TP5 and BP4 consistently outperform YoloR P6 and Swin Transformers in various evaluations, delivering improved object detection performance and faster inference speeds than Swin Transformer models. These results highlight the potential for further model combinations and improvements in real-time object detection with Transformers. The paper concludes by emphasizing the broader implications of YotoR, including its potential to enhance transformer-based models for image-related tasks.
Keywords:
Object Detection Transformers Yolo1 Introduction
Convolutional neural networks have revolutionized computer vision applications in the last decade, enabling task-solving like object detection, image segmentation, and instance segmentation, among others. Despite the improvement of the convolutional network backbones in recent years, even surpassing human performance for several tasks, the use of Transformers [22] in computer vision tasks remained elusive for several years.
The first application of transformers for computer vision tasks was proposed in 2020 [8]. However, because of the high resolution of images, the use of Transformers was limited to low-resolution applications like image classification. High-resolution tasks like object detection required the development of more specialized Transformers architectures like the Swin Transformer [16], which circumvent the computing limitations of Transformers by dynamically changing the attention window and allowing them to be used as a general purpose backbone for multiple vision tasks. Also, object detector heads based on transformers like DETR [3] have become state-of-the-art in tasks previously dominated by convolutional neural networks.
On the other hand, real-time object detectors, exemplified by the Yolo / YoloR family [19] [25], remain indispensable for tasks dependent on high frame rates, such as autonomous driving, or on platforms constrained by limited hardware resources. Despite recent advancements in Transformers for computer vision, real-time object detection predominantly relies on convolutional neural networks. Their established reliability and computational efficiency in feature extraction have been a challenge for Transformers to overcome. Then, combining transformers with Yolo-like object detectors could deliver novel architectures able to achieve both high frame rates and high detection accuracies.
This paper introduces YotoR (You Only Transform One Representation), a novel deep learning model for object detection that combines Swin Transformers and YoloR architectures. YotoR combines the robust Swin Transformer backbone with the YoloR neck and head. In our experiments, YotoR models TP5 and BP4 consistently outperform YoloR P6 and Swin Transformers in various evaluations, delivering improved object detection performance and faster inference speeds than Swin Transformer models. These results highlight the potential for further model combinations and improvements in real-time object detection with Transformers.
The contributions of this paper are:
1) A new family of object detection architectures named YotoR, which is composed of backbones based on Swin Transformers and heads based on YoloR.
2) An exhaustive evaluation of different YotoR variants, which shows that YotoR models TP5 and BP4 consistently outperform YoloR P6 and Swin Transformers in various evaluations that consider both object detection performance and inference speed.
The code will be released upon acceptance of the paper.
2 Related work
2.1 Real-time CNN-based object detection
CNN-based object detectors, which started with Faster R-CNN [20], have become a widely used approach to solving object detection tasks. In some applications, in which real-time processing is needed or there are hardware limitations, lightweight object detectors are needed.
The most widely used real-time object detectors are based on FCOS [21] or the YOLO family of detectors [19] [23]. Progress in this area has been made by improving the backbones, the necks, the detection heads, the loss functions, and the training procedures used. The backbone is the section of the network whose task is to obtain embeddings that encode the input images. In the case of the backbones, the improvements have been led by the use of building blocks inspired by RepVGG [7], CSP [24], ELAN [4], and VoVNet [13]. The task of the neck is to further process the embeddings to make them useful for generating the detections. In the case of the necks, the most successful approaches are inspired by RepVGG [7] and PAN [18]. Finally, the detection heads generate the output detections of the network. In the case of the YOLO family of detectors, there are several heads, each one dedicated to detecting objects of different sizes. Then, a good design of the backbones, necks, and detection heads is critical for obtaining architectures capable of performing real-time detection without sacrificing performance.
2.2 Multi-task-oriented real-time CNN architectures
The use of multi-task architectures is promising, as they can integrate several information modalities for improving performance on all of the tasks. However, designing architectures able to perform multiple tasks in real time is challenging because using ensembles of per-task networks negatively affects the runtime of the system.
An architecture named YoloR [25] was proposed to solve real-time multitask problems. The system is based on using a single unified architecture for solving several tasks. YoloR is based on modeling two sources of knowledge: explicit knowledge and implicit knowledge. Traditionally, explicit knowledge is strongly tied to the inputs of the network, and it is represented by the first layers of the network, while the dependence of the implicit knowledge on the inputs is lower, and it is encoded by the deeper layers. For achieving multi-task capabilities with a unified architecture, it is proposed that instead the explicit knowledge is modeled by weights shared by all of the input modalities, while the implicit knowledge is modeled as input-independent parameters in deep layers of the network. The weights related to the implicit knowledge can modify the internal network embeddings by applying operations like concatenation, addition, and multiplication. By using this approach, a single network architecture can benefit from being trained for multiple tasks, as the network weights related to the explicit knowledge can condense the information from all of the input modalities at the same time.
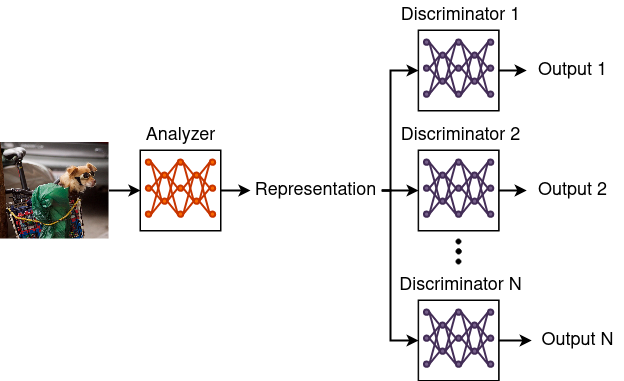

2.3 Transformer-based object detection
While transformers have been used successfully in natural language processing [22], their use in computer vision has been delayed because the amount of computing processing needed squares quadratically with the number of tokens (patches) in the image. The first work which used plain ViT (visual transformers) for classification [8] used patches of size 16x16 as tokens, and the transformer architecture consisted of a sequence of encoders. Despite the ViTs being able to process all of the tokens at the same time, they have no inductive biases like translation invariance, which are intrinsic to the CNNs architectures. Then, the largest ViT model proposed in that work needed over 300M images to achieve a better performance than state-of-the-art CNN models like ResNets trained with BiT [12]. Also, the problems of the quadratic increase in computational computing power by the number of tokens, the large size of the patches, and the lack of multiscale processing cause the plain ViT architecture to be unable to be used for tasks like object detection or image segmentation.
An efficient visual-transformer-based backbone able to replace CNN-based ones, named Swin Transformer, was proposed in [16]. Swin transformers work by using small patches with size as tokens and dividing the image into windows. Then, an encoder is applied to all of the tokens contained on each of the windows independently. This strategy enables the computing power requirement to remain low. As the windows are processed independently, their information must be combined in subsequent layers of the network. Then, after the application of encoders on the windows of a layer, the windows of the following layer are shifted. In other words, each window in a layer can integrate information from four windows in the previous layer. Also, after the application of a nonshifted and a shifted window layer, the tokens are merged, which increases the embedding dimension while decreasing the number of tokens. Also, the patch merging strategy enables the architecture to generate feature pyramids which are useful for tasks involving multiscale processing. Then, Swin transformers can be used instead of CNN-based backbones for tasks like object detection, object instance segmentation, and semantic segmentation.
In recent years, there has been a surge in proposals suggesting innovative combinations of architectures featuring Transformers for object detection. Notably, the authors of [27] present a distinctive fusion involving the anchor-free implementation of YOLO, namely YOLOX [10], and the Swin Transformer. An increase of 6.1% in the mAP performance in their private dataset was observed for the detection of obstacles for autonomous driving, setting a good precedent for the combination of the Swin Transformer backbone with the Yolo family of detectors. Our proposal differs from the YOLOX-S models by keeping the YoloV3 anchors on the detection heads and implementing the improvements added by YoloV4 and YoloR like the new BoG and BoS techniques and the implicit knowledge modeling. Also, the proposed method was trained on the MSCOCO dataset to directly compare with the rest of the state-of-the-art.
Another strong contender has been the DETR [3] family of transformer-based object detection architectures, with some variants like the Co-DETR [28] achieving state-of-the-art performance. The DETR works by using an encoder-decoder Transformer over features extracted by a backbone. This allows the model to achieve better accuracy and the ability to handle complex relations between the objects while keeping a simple structure for the architecture.
3 YotoR
In this work, a family of network architectures is introduced that merges the Swin Transformer backbone with the YoloR head. Inspired by Yolo’s nomenclature, these architectures are named YotoR, short for "You Only Transform One Representation". This reflects the use of a single unified representation generated by Transformer blocks, versatile and suitable for multiple tasks. The idea behind this proposal is to use the powerful Swin Transformers feature extraction to improve detection accuracy, while also having the ability to solve multiple tasks with fast inference times by using the YoloR heads.
YotoR models following the YoloR architecture are named using the following convention:
YotoR {Backbone Swin}{Head YoloR}{# Blocks}
For a clearer understanding, consider the following examples:
-
•
YotoR TP5 has a Swin-T backbone, YoloR P6 head and neck, and a 5-block backbone.
-
•
YotoR BP4 has a Swin-B backbone, YoloR P6 head and neck, and a 4-block backbone.
-
•
YotoR LD4 has a Swin-L backbone, YoloR D6 head and neck, and a 4-block backbone.
Similar to the relationship between YoloR and its base model P6, YotoR TP4 is the starting point for YotoR models, representing the most basic combination of components.
Using the unaltered SwinT backbone also comes with a significant advantage, allowing for the application of transfer learning techniques. This is because, by not altering the Swin Transformer’s structure, the publicly provided weights from its creators can be used. This simplifies the transfer of pre-trained Swin Transformer weights onto other datasets, speeding up the training process and improving performance.
3.1 Architecture
3.1.1 Backbone:
In Figure 2, the Swin Transformer’s simplified architecture used for the backbone is presented, particularly the T (tiny) version known as Swin T. The main part of the architecture has four stages; it starts by dividing the image into small patches, which are then transformed into tokens. These tokens go through a linear embedding layer to convert them into tokens with a certain size, referred to as , which are then fed into the first Swin Transformer Block array that constitutes the first stage. The other three are composed of a patch merging block that merges patches by groups, reducing the feature maps width and height resolution by half, which is then passed on to a corresponding array of Swin Transformer Blocks.
Apart from Swin T, there are three more architectures: Swin S, Swin B, and Swin L. They are quite similar but differ in the number of Swin Transformer Blocks and channels. The details for each architecture can be found in Table 1.
For the object detection task in the Swin Transformer article [16], Mask R-CNN [11] and Cascade R-CNN [2] were the main heads used. In models B and L, they also used a framework named HTC++, which includes HTC [5], instaboost [9], and more advanced training methods with higher resolutions. While HTC++ gives better results, it is worth noting that it has not been made publicly available. Therefore, most of our focus will be on models without HTC++, unless we specify otherwise.

|
Swin-T | Swin-S | Swin-B | Swin-L | ||||||||||||||||
| stage 1 | 4x (56x56) |
|
|
|
|
|||||||||||||||
|
x2 |
|
x2 |
|
x2 |
|
x2 | |||||||||||||
| stage 2 | 8x (28x28) |
|
|
|
|
|||||||||||||||
|
x2 |
|
x2 |
|
x2 |
|
x2 | |||||||||||||
| stage 3 | 16x (14x14) |
|
|
|
|
|||||||||||||||
|
x6 |
|
x18 |
|
x18 |
|
x18 | |||||||||||||
| stage 4 | 32x (7x7) |
|
|
|
|
|||||||||||||||
|
x2 |
|
x2 |
|
x2 |
|
x2 | |||||||||||||
3.1.2 Head
To build the YoloR models, the authors decided to base them on the architecture of Scaled YoloV4 [1]. In particular, they started with YoloV4-P6-light as their foundation and sequentially modified it to create different versions of YoloR: P6, W6, E6, and D6. The changes between each of these versions are as follows:
-
•
YoloR-P6: Replaced the Mish activation functions of YoloV4-P6-light with SiLU.
-
•
YoloR-W6: Increased the number of channels in the outputs of the backbone blocks.
-
•
YoloR-E6: Multiplied the number of channels from W6 by 1.25 and replaced the downsampling convolutions with CSP convolutions [24].
-
•
YoloR-D6: Increased the depth of the backbone.
3.1.3 YotoR models
Selecting the YotoR models for implementation involved considering two essential aspects. Firstly, the discrepancy between the feature pyramid dimensions generated by the Swin Transformer backbone and the dimensions required by the YoloR head was analyzed. A significant disparity between these dimensions could create bottlenecks in the network, limiting its performance. Second, to adapt the connections, the Swin Transformer features had to be re-shaped back to images with the attention maps. This is then normalized and passed through a convolution to adjust the number of channels. This is done to give the YoloR head the same feature size as the DarknetCSP backbone [1] and to soften the information bottlenecks between the connections.
Based on these considerations, we selected the YotoR TP4, YotoR TP5, YotoR BP4, and YotoR BB4 models, which are described below:
-
•
YotoR TP4
The smallest model among the proposed combinations, YotoR TP4, uses a Swin Transformer Tiny backbone with the YoloR P6 head and neck. However, this combination poses a challenge because the connections between these parts have drastically different dimensions, potentially leading to information bottlenecks.
-
•
YotoR TP5
To address the bottleneck issue in YotoR TP4, it was decided to retain the B6 block, which matches the last CSPDarknet block in the YoloR backbone. This choice allowed for more coherent connections between both parts, preventing information loss in the transition to the neck. The "5" in its name refers to the inclusion of the additional B6 CSPDarknet block in addition to the four Swin Transformer blocks.
-
•
YotoR BP4
It follows a similar premise and structure as YotoR TP4, but it replaces the Swin Transformer Tiny (T) backbone with a Swin Transformer Basic (B) backbone. The decision to opt directly for the Basic backbone, rather than the Small (S) backbone, is based on the similarity in connection sizes with the YoloR P6 backbone to avoid connection discrepancies, as the case in YotoR TP4.
-
•
YotoR BB4
As the final proposed model, YotoR BB4 takes a different approach to its design. Instead of adapting the connections between the YoloR P6 neck and the Swin B backbone, we decided to completely redesign the P6 head, following the dimensions of the Swin B embeddings. This results in an expansion of dimensions in the deeper parts of the network while reducing them in the shallower layers. In YotoR BB4, all model dimensions are directly in accordance, with no adapting convolutional layers, unlike the previous models.
Figure 3 shows the YotoR BP4 architecture. It introduces the STB (Swin Transformer Block), representing the Swin Transformer blocks used in the different YotoR architectures. Additionally, there is an inclusion of a Linear Embedding block between these components. This Linear Embedding block comes from the Swin Transformer implementation for object detection and is incorporated into the YotoR implementation without alterations.
These four models were chosen because they are composed of the base architectures of YoloR and Swin Transformer, allowing for a valid comparison to assess the proposed model’s validity. While training and evaluating larger models like YotoR BW4 or YotoR BW5 were considered, resource limitations on a V100 GPU made this option unfeasible.

4 Experimental Results
The experiments to test and compare the models were implemented on the MSCOCO dataset. This dataset was chosen because of its common use for benchmarking object detectors.
4.1 Experimental Setup
Both training and evaluation were performed on a V100 GPU with 32 GB and 16 GB respectively. 111All provided speed evaluations of the implemented models were performed on a similar V100 GPU with 16 GB and no TensorRT, and are therefore not directly comparable with those reported by other groups on COCO val2017 The training parameters used are the same as YoloR as shown in Table 2. The YoloR training schedule was followed and trained for 300 epochs first, then fine-tuned using 125 epochs, and finally trained for an extra 25 epochs using a lower mosaic count.
| Parameter | Training | Tuning | End |
|---|---|---|---|
| num epochs | 300 | 125 | 25 |
| initial learning rate | 0.01 | 0.01 | 0.01 |
| final learning rate | 0.2 | 0.2 | 0.2 |
| momentum | 0.937 | 0.937 | 0.937 |
| optimizer weight decay | 0.0005 | 0.0005 | 0.0005 |
| warmup epochs | 3.0 | 3.0 | 3.0 |
| warmup initial momentum | 0.8 | 0.8 | 0.8 |
| warmup initial bias lr | 0.1 | 0.1 | 0.1 |
| box loss gain | 0.05 | 0.05 | 0.05 |
| cls loss gain | 0.5 | 0.5 | 0.5 |
| cls BCELoss positive_weight | 1.0 | 1.0 | 1.0 |
| obj loss gain | 1.0 | 1.0 | 1.0 |
| obj BCELoss positive weight | 1.0 | 1.0 | 1.0 |
| IoU training threshold | 0.2 | 0.2 | 0.2 |
| anchor-multiple threshold | 4.0 | 4.0 | 4.0 |
| focal loss gamma | 0.0 | 0.0 | 0.0 |
| image HSV-Hue augmentation | 0.015 | 0.015 | 0.015 |
| image HSV-Saturation augmentation | 0.7 | 0.7 | 0.7 |
| image HSV-Value augmentation | 0.4 | 0.4 | 0.4 |
| image rotation | 0.0 | 0.0 | 0.0 |
| image translation | 0.5 | 0.5 | 0.5 |
| image scale | 0.5 | 0.8 | 0.8 |
| image shear | 0.0 | 0.0 | 0.0 |
| perspective | 0.0 | 0.0 | 0.0 |
| image flip up-down | 0.0 | 0.0 | 0.0 |
| image flip left-right | 0.5 | 0.5 | 0.5 |
| image mosaic probability | 1.0 | 1.0 | 1.0 |
| image mosaic quantity | 4.0 | 9.0 | 4.0 |
| image mixup | 0.0 | 0.2 | 0.2 |
4.2 Results of Inference Speed
From the results shown in Table 5, it is clear that none of the YotoR models can match the speed of YoloR. However, all the YotoR models have increased inference speeds compared to their respective Swin backbones. In particular, TP5 is notable for its inference frame rate that more than doubles compared to Swin-T, while BP4 and BB4 increase by just over 80% to Swin B.
Due to significant variation in time measurements across models, we conducted all timing evaluations on a consistent platform: a 16GB V100 GPU, operating at a resolution of , without non-maximum suppression (NMS) or TensorRT acceleration. Each timing measurement represents the mean of three consecutive runs performed sequentially within a single session. Despite our best efforts, the recorded times were approximately half of those reported in the papers for YoloR and Swin Transformer models. This suggests that there is potential to double the speed results through further optimization.
| model | inference time (ms) | frames per second (fps) |
|---|---|---|
| Swin T | 135.1 | 7.4 |
| Swin B | 196.1 | 5.1 |
| YoloR P6 | 34.7 | 28.8 |
| YotoR TP4 | 51.9 | 19.3 |
| YotoR TP5 | 48.6 | 20.6 |
| YotoR BP4 | 106.2 | 9.4 |
| YotoR BB4 | 103.9 | 9.6 |
4.3 Results on COCO val2017
The mAP (mean Average Precision) of the four YotoR models on val2017 is shown in Table 5. TP5 and BP4 models outperform all the baselines, even YoloR P6, which serves as a reference due to its high mAP performance. The only model that does not surpass it is BB4. However, considering that BB4 is built solely from Swin B without using the YoloR P6 head, this result was expected. However, BB4 manages to outperform Swin B in terms of performance, suggesting the possibility of exploring solutions in larger models such as Swin L, which surpasses the performance of YoloR D6.
The advantages of YotoR models become evident when comparing inference time in milliseconds with mAP, as shown in Figure 4. It allows us to analyze the relationship between inference speed and model performance, which is essential because there is typically a trade-off between both. Speed tends to decrease when aiming for higher accuracy, and vice versa. In this figure, it is clear how all the YotoR models outperform their equivalent Swin detectors in both performance and speed, representing a significant improvement for all these models. Although YoloR P6 still has a considerable advantage in inference time, its performance can be surpassed by YotoR TP5 and YotoR BP4, despite using the same head architecture.

| Swin T | Swin B | YoloR P6 | YotoR TP4 | YotoR TP5 | YotoR BP4 | YotoR BB4 | ||||
| AP | IoU=.5:.95 | area=all | maxDets=100 | 0.505 | 0.519 | 0.525 | 0.234 | 0.529 | 0.533 | 0.523 |
| AP | IoU=.5 | area=all | maxDets=100 | 0.693 | 0.705 | 0.707 | 0.555 | 0.712 | 0.720 | 0.713 |
| AP | IoU=.75 | area=all | maxDets=100 | 0.549 | 0.564 | 0.575 | 0.163 | 0.580 | 0.583 | 0.569 |
| AP | IoU=.5:.95 | area=s | maxDets=100 | - | 0.354 | 0.371 | 0.138 | 0.384 | 0.388 | 0.369 |
| AP | IoU=.5:.95 | area=m | maxDets=100 | - | 0.552 | 0.569 | 0.251 | 0.576 | 0.577 | 0.567 |
| AP | IoU=.5:.95 | area=l | maxDets=100 | - | 0.673 | 0.661 | 0.352 | 0.661 | 0.675 | 0.673 |
| AR | IoU=.5:.95 | area=all | maxDets= 1 | - | 0.638 | 0.392 | 0.196 | 0.391 | 0.390 | 0.388 |
| AR | IoU=.5:.95 | area=all | maxDets= 10 | - | 0.638 | 0.652 | 0.433 | 0.643 | 0.639 | 0.631 |
| AR | IoU=.5:.95 | area=all | maxDets=100 | - | 0.638 | 0.714 | 0.523 | 0.699 | 0.693 | 0.683 |
| AR | IoU=.5:.95 | area=s | maxDets=100 | - | 0.478 | 0.578 | 0.373 | 0.567 | 0.553 | 0.534 |
| AR | IoU=.5:.95 | area=m | maxDets=100 | - | 0.673 | 0.753 | 0.576 | 0.738 | 0.732 | 0.721 |
| AR | IoU=.5:.95 | area=l | maxDets=100 | - | 0.782 | 0.840 | 0.648 | 0.820 | 0.818 | 0.818 |
4.4 Results on COCO testdev
Looking at Table 6, it can be observed that the YotoR models TP5 and BP4 outperform the YoloR P6 model in all mAP metrics. This confirms the significant improvement in the performance of these models. These results are publicly available thanks to the CodaLab team, making it easy to compare them with other participants in the COCO competition.
In addition to the traditional metrics, Table 6 includes measurements of FLOPs (Floating-Point Operations) and the number of parameters for each model, which provide interesting insights. YotoR models have fewer FLOPs than YoloR P6, even though they have longer inference times. This could be explained by the nature of floating-point operations in YotoR, which, although less numerous, might be more computationally intensive or less optimized than those in YoloR. This suggests the potential for optimizing the inference time of YotoR models by improving their operations. On the other hand, the number of parameters in YotoR models falls in between Swin and YoloR models, as expected, since they combine elements from both.
These results are promising, especially when considering that the YotoR models were implemented using the most basic versions of YoloR and the Swin Transformer. This opens the door to exploring new combinations between models from the YOLO family and Swin Transformer, either to create a real-time object detection model with Transformers or to advance the state of the art in performance.
| YotoR Tp5 | YotoR Bp4 | YotoR BB4 | ||||||||||
| mAP.5:.95 | FPS | mAP.5:.95 | FPS | mAP.5:.95 | FPS | |||||||
| 52.9% | 20.6 | 53.6% | 9.4 | 52.3% | 9.6 | |||||||
| Swin T | 50.4% | +2.5% | 7.4 | +178% | 50.4% | +3.2% | 7.4 | +27% | 50.4% | +1.9% | 7.4 | +30% |
| Swin B | 51.9% | +1.0% | 5.1 | +303% | 51.9% | +1.7% | 5.1 | +84% | 51.9% | +0.4% | 5.1 | +88% |
| YoloR P6 | 52.5% | +0.4% | 28.8 | - 28% | 52.5% | +1.1% | 28.8 | - 70% | 52.5% | - 0.3% | 28.8 | - 67% |
| Model | Size | FPS | FLOPs | # parameters | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| YoloR P6 | 1280 | 28.8 | 326G | 37M | 52.6% | 70.6% | 57.6% | 34.7% | 56.6% | 64.2% |
| Swin T | 1280 | 7.4 | 745G | 86M | - | - | - | - | - | - |
| Swin B | 1280 | 5.1 | 982G | 145M | - | - | - | - | - | - |
| YotoR TP5 | 1280 | 20.6 | 107G | 56M | 52.9% | 70.9% | 57.7% | 35.3% | 56.5% | 64.7% |
| YotoR BP4 | 1280 | 9.4 | 296G | 117M | 53.4% | 71.8% | 58.2% | 35.1% | 57.1% | 66.5% |
| YotoR BB4 | 1280 | 9.6 | 281G | 131M | 52.4% | 71.0% | 57.1% | 33.8% | 56.1% | 65.7 |
In Figure 5, we showcase instances of detections executed by the YotoR BP4 model on the val2017 and testdev datasets. These examples demonstrate the model’s proficiency in effectively detecting objects of varying sizes, even when they overlap within a group.

4.5 Comparison with the state of the art
In Table 7, we present a detailed comparison between the YotoR models and various state-of-the-art object detection models, which encompass different sizes and architectures. Our focus specifically centers on models of similar sizes and structures. This table provides insights into the performance of these models in both the COCO val2017 and testdev datasets.
While it is evident that the YotoR models exhibit lower performance compared to some of the latest and larger models, it is important to note that only the smaller versions of YotoR were implemented, featuring the smallest number of channels in the connections. This choice accounts for their comparatively lower performance compared to YoloR-W6, YOLOv7-W6, and their larger variants. Despite this, the YotoR models still outperform its individual components like YoloR-P6 and Swin Transformer B. It is worth mentioning that the performance surpasses that of the Swin Transformer without HTC++, albeit with certain details not publicly disclosed and some adaptations made to the YoloR head for processing images of varying resolutions.
In essence, the YotoR models appear to strike a commendable balance between performance and speed. It’s noteworthy that this equilibrium could potentially be further optimized by incorporating larger models within the YotoR family, such as YotoR LE5 or YotoR LD5. The implementation of these larger variants holds promise for enhancing the competitiveness of the models, opening up intriguing avenues for future exploration.
| model | # parameters | FLOPs | size | |||||
| YOTOR-TP4 | 55M | 111.5G | 1280 | 19.3* | 23.9% | 23.5% | 54.9% | 15.7% |
| YOTOR-TP5 | 56M | 107G | 1280 | 20.6* | 52.9 % | 52.9 % | 70.9 % | 57.7 % |
| YOTOR-BP4 | 117M | 296G | 1280 | 9.4* | 53.6 % | 53.4 % | 71.8 % | 58.2 % |
| YOTOR-BB4 | 131M | 281G | 1280 | 9.6* | 52.3 % | 52.4 % | 71.0 % | 57.1 % |
| YOLOR-P6 | 37M | 326G | 1280 | 76/28.8* | 52.5% | 52.6% | 70.6% | 57.6% |
| YOLOR-P6D | 37M | 326G | 1280 | - | 53.0% | 71.0% | 58.0% | |
| YOLOR-W6 | 80M | 454G | 1280 | 66 | 54.0% | 54.1% | 72.0% | 59.2% |
| YOLOR-E6 | 116M | 684G | 1280 | 45 | 54.6% | 54.8% | 72.7% | 60.0% |
| YOLOR-D6 | 152M | 937G | 1280 | 34 | 55.4% | 55.4% | 73.3% | 60.6% |
| YOLOv7 | 36.9M | 104.7G | 640 | 161 | 51.2% | 51.4% | 69.7% | 55.9% |
| YOLOv7-W6 | 70.4M | 360.0G | 1280 | 84 | 54.6% | 54.9% | 72.6% | 60.1% |
| YOLOv7-E6 | 97.2M | 515.2G | 1280 | 56 | 55.9% | 56.0% | 73.5% | 61.2% |
| YOLOv7-D6 | 154.7M | 806.8G | 1280 | 44 | 56.3% | 56.6% | 74.0% | 61.8% |
| YOLOv4-CSP-P5 [1] | 71M | 328G | 896 | 41 | 51.7% | 51.8% | 70.3% | 56.6% |
| YOLOv4-CSP-P6 [1] | 128M | 718G | 1280 | 30 | 54.4% | 54.5% | 72.6% | 59.8% |
| YOLOv4-CSP-P7 [1] | 287M | 1639G | 1536 | 16 | 55.3% | 55.5% | 73.4% | 60.8% |
| YOLOv6-L6 [14] | 140M | 773.4G | - | 26 | 57.2% | - | - | - |
| PRB-FPN6-E-ELAN [6] | - | - | - | 31 | - | 56.9% | 74.1% | 62.7% |
| Swin T-T (C-M-RCNN) | 86M | 745G | - | 15.3/7.4* | 50.5% | - | - | - |
| Swin T-S (C-M-RCNN) | 107M | 838G | - | 12 | 51.8% | - | - | - |
| Swin T-B (C-M-RCNN) | 145M | 982G | - | 11.6/5.1* | 51.9% | - | - | - |
| Swin T-B (HTC++) | 160M | 1043G | - | 11.6 | 56.4% | - | - | - |
| Swin T-L (HTC++) | 284M | 1470G | - | - | 57.1% | 57.7% | - | - |
| SwinV2-L(HTC++) [15] | 197M | - | 1536 | - | 60.2% | 60.8% | - | - |
| SwinV2-G(HTC++) [15] | 3.0B | - | 1536 | - | 62.5% | 63.1% | - | - |
| DETR [3] | 41M | 86G | <1333 | 42.0% | ||||
| DETR-DC5 [3] | 41M | 187G | <1333 | 43.3% | ||||
| DETR-R101 [3] | 60M | 152G | <1333 | 43.5% | ||||
| DETR-DC5-R101 [3] | 60M | 253G | <1333 | 44.9% | ||||
| Co-DETR [28] | 348M | - | - | 65.9% | 66.0% | - | - | |
| InternImage-H [26] | 2180M | - | - | 65.0% | 65.4% | - | - | |
| RT-DETR-R50 [17] | 42M | 136G | 640 | 108(T4) | 53.1% | |||
| RT-DETR-R101 [17] | 76M | 259G | 640 | 74(T4) | 54.3% | |||
| RT-DETR-L [17] | 32M | 110G | 640 | 114(T4) | 53.0% | |||
| RT-DETR-X [17] | 67M | 234G | 640 | 74(T4) | 54.8% |
5 Conclusions
In this article, we introduced YotoR, a hybrid architecture that combines the Swin Transformer and YoloR models for object detection. YotoR outperforms its constituent models in both accuracy and inference speed. Although this study focused on four specific YotoR configurations, it opens avenues for exploring larger models and adaptations to new architectures beyond YoloR and Swin Transformer.
The fact that Transformer-based backbones can be combined with Yolo-like heads has broader implications, extending to the design of new hybrid models for different kinds of image-related tasks.
Further experiments are necessary to fully understand the impact of Yolo-style heads and implicit knowledge, as well as to address performance challenges in real-time processing.
Future research directions include upgrading YotoR’s backbone, investigating implicit knowledge integration, exploring novel techniques for head enhancements, considering multi-modal networks, and incorporating language tasks into the predictions.
References
- [1] Bochkovskiy, A., Wang, C.Y., Liao, H.Y.M.: Yolov4: Optimal speed and accuracy of object detection (2020)
- [2] Cai, Z., Vasconcelos, N.: Cascade r-cnn: Delving into high quality object detection (2017)
- [3] Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End-to-end object detection with transformers. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M. (eds.) Computer Vision – ECCV 2020. pp. 213–229. Springer International Publishing, Cham (2020)
- [4] Chen, G., Zheng, Y.D., Chen, Z., Wang, J., Lu, T.: Elan: Enhancing temporal action detection with location awareness. pp. 1020–1025 (07 2023). https://doi.org/10.1109/ICME55011.2023.00179
- [5] Chen, K., Pang, J., Wang, J., Xiong, Y., Li, X., Sun, S., Feng, W., Liu, Z., Shi, J., Ouyang, W., Loy, C.C., Lin, D.: Hybrid task cascade for instance segmentation (2019)
- [6] Chen, P.Y., Chang, M.C., Hsieh, J.W., Chen, Y.S.: Parallel residual bi-fusion feature pyramid network for accurate single-shot object detection. IEEE Transactions on Image Processing 30, 9099–9111 (2021)
- [7] Ding, X., Zhang, X., Ma, N., Han, J., Ding, G., Sun, J.: Repvgg: Making vgg-style convnets great again (2021)
- [8] Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth 16x16 words: Transformers for image recognition at scale (2021)
- [9] Fang, H.S., Sun, J., Wang, R., Gou, M., Li, Y.L., Lu, C.: Instaboost: Boosting instance segmentation via probability map guided copy-pasting (2019)
- [10] Ge, Z., Liu, S., Wang, F., Li, Z., Sun, J.: Yolox: Exceeding yolo series in 2021 (2021)
- [11] He, K., Gkioxari, G., Dollár, P., Girshick, R.: Mask r-cnn (2018)
- [12] Kolesnikov, A., Beyer, L., Zhai, X., Puigcerver, J., Yung, J., Gelly, S., Houlsby, N.: Big transfer (bit): General visual representation learning (2020)
- [13] Lee, Y., Park, J.: Centermask : Real-time anchor-free instance segmentation (2020)
- [14] Li, C., Li, L., Geng, Y., Jiang, H., Cheng, M., Zhang, B., Ke, Z., Xu, X., Chu, X.: Yolov6 v3. 0: A full-scale reloading. arXiv preprint arXiv:2301.05586 (2023)
- [15] Liu, Z., Hu, H., Lin, Y., Yao, Z., Xie, Z., Wei, Y., Ning, J., Cao, Y., Zhang, Z., Dong, L., Wei, F., Guo, B.: Swin transformer v2: Scaling up capacity and resolution (2022)
- [16] Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B.: Swin transformer: Hierarchical vision transformer using shifted windows (2021)
- [17] Lv, W., Zhao, Y., Xu, S., Wei, J., Wang, G., Cui, C., Du, Y., Dang, Q., Liu, Y.: Detrs beat yolos on real-time object detection (2023)
- [18] Ma, Z., Li, M., Wang, Y.: Pan: Path integral based convolution for deep graph neural networks (2019)
- [19] Redmon, J., Divvala, S., Girshick, R., Farhadi, A.: You only look once: Unified, real-time object detection (2016)
- [20] Ren, S., He, K., Girshick, R., Sun, J.: Faster r-cnn: Towards real-time object detection with region proposal networks. Advances in neural information processing systems 28 (2015)
- [21] Tian, Z., Shen, C., Chen, H., He, T.: Fcos: A simple and strong anchor-free object detector (2020)
- [22] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., Polosukhin, I.: Attention is all you need. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. p. 6000–6010. NIPS’17, Curran Associates Inc., Red Hook, NY, USA (2017)
- [23] Wang, C.Y., Bochkovskiy, A., Liao, H.Y.M.: Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors (2022)
- [24] Wang, C.Y., Liao, H.Y.M., Yeh, I.H., Wu, Y.H., Chen, P.Y., Hsieh, J.W.: Cspnet: A new backbone that can enhance learning capability of cnn (2019)
- [25] Wang, C.Y., Yeh, I.H., Liao, H.Y.M.: You only learn one representation: Unified network for multiple tasks (2021)
- [26] Wang, W., Dai, J., Chen, Z., Huang, Z., Li, Z., Zhu, X., Hu, X., Lu, T., Lu, L., Li, H., et al.: Internimage: Exploring large-scale vision foundation models with deformable convolutions. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14408–14419 (2023)
- [27] Zhang, H., Lu, C., Chen, E.: Obstacle detection: improved yolox-s based on swin transformer-tiny. Optoelectronics Letters 19, 698 – 704 (2023), https://api.semanticscholar.org/CorpusID:265297393
- [28] Zong, Z., Song, G., Liu, Y.: Detrs with collaborative hybrid assignments training. 2023 IEEE/CVF International Conference on Computer Vision (ICCV) pp. 6725–6735 (2022), https://api.semanticscholar.org/CorpusID:253802116