X-ReID: Cross-Instance Transformer for Identity-Level Person Re-Identification
Abstract
Currently, most existing person re-identification methods use Instance-Level features, which are extracted only from a single image. However, these Instance-Level features can easily ignore the discriminative information due to the appearance of each identity varies greatly in different images. Thus, it is necessary to exploit Identity-Level features, which can be shared across different images of each identity. In this paper, we propose to promote Instance-Level features to Identity-Level features by employing cross-attention to incorporate information from one image to another of the same identity, thus more unified and discriminative pedestrian information can be obtained. We propose a novel training framework named X-ReID. Specifically, a Cross Intra-Identity Instances module (IntraX) fuses different intra-identity instances to transfer Identity-Level knowledge and make Instance-Level features more compact. A Cross Inter-Identity Instances module (InterX) involves hard positive and hard negative instances to improve the attention response to the same identity instead of different identity, which minimizes intra-identity variation and maximizes inter-identity variation. Extensive experiments on benchmark datasets show the superiority of our method over existing works. Particularly, on the challenging MSMT17, our proposed method gains 1.1 mAP improvements when compared to the second place.
1 Introduction
Person Re-Identification (ReID) aims to retrieve a person of interest across multiple non-overlapping cameras. Given a single image of an identity, the goal of the ReID model is to learn the pedestrian characteristics, so that the distance of intra-identity features is smaller than that of inter-identity. However, the task of ReID is very challenging, since various complex conditions, such as human pose variations, different backgrounds, or varying illuminations, usually appear on different images of the same identity.

Several previous studies(Ye et al. 2021; Luo et al. 2019b; Chen et al. 2019; Sun et al. 2018; Zhu et al. 2020; He et al. 2021) present promising results on supervised ReID. Since these works extract features from only a single image, rather than from a combination of multiple images of the same identity, we refer to them as Instance-Level methods. According to the different processing methods for individual images, Instance-Level methods can be roughly classified into the following categories. (1) Global-Level methods(Luo et al. 2019b; Chen et al. 2020, 2019; Zhang et al. 2020; Fang et al. 2019; Si et al. 2018; Zheng et al. 2019; Chen et al. 2018; Luo et al. 2019a), which directly learn the global representation by optimizing Instance-Level features of each single complete image, as shown in Figure 1.b. (2) Part-Level methods(Sun et al. 2018; Wang et al. 2018; Li et al. 2021b; Zhu et al. 2020; He and Liu 2020; Zhang et al. 2019; Jin et al. 2020; Zhu et al. 2021, 2022), as shown in Figure 1.c, which learn local aggregated features from different parts. (3) Patch-Level methods such as TransReID(He et al. 2021), which rearranges and re-groups the patch embeddings of each single image (see Figure 1.d). Each group forms an incomplete global representation.
Due to various factors such as human pose and camera variations, the appearance of the same identity varies greatly in different images. Instance-Level methods focus on features only from a single image, so the features of different images of the same identity are prone to large differences. For example, Figure 1.a shows the front and back of the same identity captured by different cameras. As the backpack in the back image is more salient than that in the front image, features independently learned by Instance-Level methods will vary greatly. Consequently, it may lead to intra-identity variation being larger than inter-identity variation, which further limits the performance in inference.
We argue the reason is that Instance-Level methods are unable to learn discriminative features shared across different images of the same identity. To resolve this problem, we propose a novel Identity-Level method to fuse different Instance-Level features of the same identity, as shown in Figure 1.e. In this way, more unified and robust pedestrian information can be learned. With our method, for the discriminative information of the “backpack” in the back image, the front can gain knowledge from the back to strengthen its representation, thereby reducing intra-identity variation, enlarging inter-identity variation and obtaining a more robust features.
Our proposed method is based on the pure Transformer structure(Dosovitskiy et al. 2020). The Multi-Head Attention module can exploit long-range dependencies between patches divided from the input image, which can get fine-grained features with rich structural patterns. However, previous works(He et al. 2021; Zhu et al. 2021) only use the Instance-Level Transformer and thus can not jointly encode multiple images to extract Identity-Level features. In this paper, we introduce cross-attention to the encoder, which has not been fully explored in vision task, especially in ReID. Cross-attention can incorporate information from different instances, which mitigates the impact of the variable appearance of the same identity.
Based on the attention mechanism, we introduce a novel training framework, CrossReID termed as X-ReID, which performs attention across different instances of the same identity to extract Identity-Level features. Firstly, we propose a Cross Intra-Identity Instances module (IntraX). Cross-attention is applied among different intra-identity instances to get more unified features. Then, we transfer Identity-Level knowledge to Instance-Level features, which makes features more compact. Second, We further propose a Cross Inter-Identity Instances module (InterX). Hard positive and negative instances are utilized in cross-attention. The fused features, which contain hard negative instance, are less discriminative. The fused features are optimized by our proposed X-Triplet loss to improve the attention response to the same identity rather than different identity, so that intra-identity variation is minimized and inter-identity variation is maximized. Our modules consider both Intra- and Inter-Identity instances to improve the Identity-Level ability of Instance-Level features. Only the improved Instance-Level features are used for inference, which brings no additional cost compared with Transformer-based state-of-the-art methods.
Our major contributions can be summarized as follows:
-
•
We propose to exploit Identity-Level features shared across different images of each identity to build a more unified, discriminative and robust representation.
-
•
We introduce a novel training framework, termed as X-ReID, which contains IntraX for Intra-Identity instances and InterX for Inter-Identity instances to improve the Identity-Level ability of Instance-Level features.
- •
2 Related Work
2.1 Supervised ReID
Existing works extract instance representations from a single image, so we refer to them as Instance-Level methods, which can be roughly categorized into three classes: (1) Global-Level methods(Zheng et al. 2017; Luo et al. 2019b), which learn the global representation of each single complete image. The misalignment problem is handled in attention-based methods(Chen et al. 2020, 2019; Zhang et al. 2020; Fang et al. 2019; Si et al. 2018; Zheng et al. 2019; Chen et al. 2018; Luo et al. 2019a). (2) Part-Level methods(Sun et al. 2018; Wang et al. 2018; Li et al. 2021b; Zhu et al. 2020; He and Liu 2020; Zhang et al. 2019; Jin et al. 2020; Zhu et al. 2021), which learn local aggregated features from different parts. (3) Patch-Level methods such as TransReID(He et al. 2021), which shuffles patches into several incomplete representations.
There are a few CNN-based works that leverage the cross-image information. These works mine the relationships between multiple Instance-Level feature maps. DuATM(Si et al. 2018) performs dually attentive comparison for pair-wise feature alignment and refinement. CASN(Zheng et al. 2019) designs a Siamese network with attention consistency. Group similarity is proposed in GCSL(Chen et al. 2018) for learning robust multi-scale local similarities. SFT(Luo et al. 2019a) optimizes group-wise similarities to capture potential relational structure.

2.2 Transformer in Vision
Inspired by the success of Transformers(Vaswani et al. 2017) in natural language tasks, many studies(Khan et al. 2021; Han et al. 2020; Gao et al. 2021; Carion et al. 2020; Xie et al. 2021; Zhao et al. 2021; Chen et al. 2021) have shown the superiority of Transformer in vision tasks. ViT(Dosovitskiy et al. 2020) first introduces a pure Transformer to image classification.
In the field of ReID, PAT(Li et al. 2021b) utilizes Transformer to improve CNN backbone(He et al. 2016). NFormer(Wang et al. 2022) proposes a parametric post-processing method by modeling the relations among all the input images. TransReID(He et al. 2021) investigates a pure Transformer encoder framework, and AAformer(Zhu et al. 2021) integrates the part alignment into the self-attention. DCAL(Zhu et al. 2022) introduces cross-attention mechanisms to learn subtle feature embeddings. Instead, we exploit cross-attention to fuse Instance-Level features.
As for image classification, cross-attention in Cross-ViT(Chen, Fan, and Panda 2021) is used to learn multi-scale features. In Trear(Li et al. 2021a), features from different modalities are fused to obtain the conjoint cross-modal representation. Unlike these approaches, our proposed cross-attention extracts Identity-Level features for more unified and discriminative pedestrian information.
3 Method
Our method is built on top of pure Transformer architecture, so we first present a brief overview of Instance-Level Transformer in Sec 3.1. Then, we introduce the proposed Identity-Level framework (X-ReID) in Sec 3.2, which contains a Cross Intra-Identity Instances module (IntraX) and a Cross Inter-Identity Instances (InterX).
3.1 Instance-Level Transformer for ReID
Instance-Level Transformer for ReID is a Transformer-based strong baseline and we follow the baseline in TransReID(He et al. 2021). As shown in Figure 3, given a single input image, we reshape it into a sequence of flattened patches , where C is the number of channels. is the resolution of each patch, and is the length of fixed-sized patches according to image size. We flatten the patches and map to vectors with a trainable linear projection. An extra learnable embedding CLS is added to the sequence of embedded patches. Learnable position embeddings are used for retaining spatial information. The output embeddings can be expressed as: , where represents the input fed into backbone, is CLS token and are patch tokens.
The backbone is composed of a stack of identical Transformer layers. Because the input is a single image and the layers encode the Instance-Level information, the Transformer layer is named as Instance-Layer in this paper. And each layer can encode the embeddings: , where is the output of the -th Instance-Layer and is the weight of this layer. After LayerNorm(Ba, Kiros, and Hinton 2016), the last layer’s output of CLS token gets Instance-Level features , to extract global representation, which is used to calculate ID loss(Zheng, Zheng, and Yang 2017) and Triplet loss(Liu et al. 2017) that constitute the ReID Head(Luo et al. 2019b):
| (1) |

3.2 X-ReID
Our proposed Identity-Level framework is illustrated in Figure 2 based on Instance-Level Transformer, which contains IntraX and InterX. For a single image of person , the tokens obtained from Instance-Level Transformer are . On the left side of Figure 2, as for other images of the same person , we get . IntraX are performed among Intra-Identity instances. as Key and as Query are fed to X-Layers to extract Identity-Level features of person . Rather than all positive instances as IntraX does, InterX utilizes both positive instance and negative instance . As shown on the right side of Figure 2, and are used as Key and we get features . Our X-ReID explores both Intra- and Inter-Identity instances to enhance Instance-Level features.

X-Layer.
Instance-Layer, which consists of alternating layers of Multi-Head Attention and FFN blocks, only has Self Attention. The output of MHA is formulated as:
| (2) |
where is the scaling factor. Figure 4 shows the detailed structure of our proposed X-Layer. Cross Attention is added to Instance-Layer to become X-Layer. With Cross Attention, X-Layer can obtain features across multiple inputs:
| (3) |
where is Self Attention and is Cross Attention. It is worth noting that Self Attention and Cross Attention share parameters, so the parameters of X-Layer are the same as those of Instance-Layer.
Cross Intra-Identity Instances.
We propose a Cross Intra-Identity Instances module to transfer Identity-Level knowledge to Instance-Level features. All positive instances of the input are fused in X-Layer to extract Identity-Level features. To enhance the Identity-Level capability, IntraX trains Instance-Level features to predict Identity-Level representation of the same identity by knowledge distillation.
layers of X-Layer in IntraX uses the Exponential Moving Average (EMA) on Instance-Layers, which is proposed to maintain consistency. Specifically, the parameters of -th X-Layer can be calculated as:
| (4) |
where follows a cosine schedule from 0.999 to 1 during training. Knowledge about the different appearances of person is mixed in X-Layer. , and of -th X-Layer in IntraX are:
| (5) |
where are the outputs of the previous X-Layer, except that of the first layer are the same as . We concatenates all features of positive instances of in the mini-batch to get . On account of X-Layer, IntraX incorporates different appearances of the same identity into Identity-Level features . Then, we transfer the knowledge from to :
| (6) |
where are the dimensions of features and is a temperature parameter. The output of a softmax of the dot products of is the probability distribution , which provides information on how the features represent knowledge. Matching distributions of and by minimizing is used to improve Instance-Level features by Identity-Level features. Therefore, Instance-Level features are more compact.
Cross Inter-Identity Instances.
Our proposed Cross Inter-Identity Instances module deals with inter-identity instances of , instead of all positive instances in IntraX. InterX uses both hard positive and hard negative as of X-Layer, where the negative instance has not the same identity as the anchor . X-Layers in InterX may incorrectly notice the negative, whose interfering information affects the final fused features of InterX. We optimize the fused features to suppress the attention response of the anchor to negative instance and improve the attention response to positive instance, so that intra-identity variation is minimized and inter-identity variation is maximized.
Particularly, InterX contains layers of X-Layer that are learnable. and are the same as in Equation 5. of -th X-Layer in interX is:
| (7) |
where is the result of concatenating of hard positive and of hard negative . We conduct hard-mining(Hermans, Beyer, and Leibe 2017) in to get hard positive and negative instance. As illustrated in Figure 5.a, in the ReID Head is calculated as follows:
| (8) |
where a, p and n is the anchor, hard positive and hard negative. The anchor may be closer to hard negative compared to hard positive. Therefore in Figure 5.b, the anchor as is difficult to distinguish which one is positive in InterX. The fused features will be heavily influenced by hard negative. Red represents hard negative and green represents hard positive. In the fused features , red occupies most of the space. Then, we propose X-Triplet loss:

| (9) |
Therefore, is pulled into hard positive and pushed away by hard negative. Then, the InterX Head composed of and are shown as follows:
| (10) |
By , the anchor are encouraged to pay more attention to hard positive than hard negative in X-Layer. will be optimized to represent the person of the anchor and hard positive. At this stage, green occupies most of the space. Accordingly, InterX simultaneously reduces the distance of intra-identity and enlarges the distance of inter-identity.
Loss Function.
In the training phase, the overall objective function is:
| (11) |
where and are hyper-parameters to balance the entire loss. Notably, only the boosted Instance-Level features is used for inference. In this way, the final model has the same structure as Instance-Level Transformer whose input is a single image.
4 Experiments
4.1 Evaluation Setting and Metrics
Our proposed method are evaluated on the popular benchmark datasets: MSMT-17(Wei et al. 2018) which contains 126441 person images of 4101 identities, Market1501(Zheng et al. 2015) which contains 32668 person images of 1501 identities. Following the common setting, the cumulative matching characteristics (CMC) at Rank-1 and the mean average precision (mAP) are adopted to evaluate the performance of all methods.
4.2 Implementation Details
We use the ImageNet(Deng et al. 2009)-pretrained model of ViT-Base, which contains Instance-Layers and the patch size is 1616. We build X-Layers in both IntraX and InterX. X-Layers in IntraX use an exponential moving average on Instance-Layer. X-layers are learnable in InterX. In Equation 11, we set and for Market1501 and MSMT17, respectively. The input images are resized to 256128. Following common practices, random horizontal flipping, padding, random cropping and random erasing(Zhong et al. 2020) are used as augmentation for training. We randomly sample instances for each identity in a mini-batch with batch size 64. SGD optimizer with a momentum of 0.9 and the weight decay of 1e-4 is applied with a learning rate of 0.008 with cosine learning rate decay. We train 120 epochs in total. All the experiments are performed with one NVIDIA Geforce RTX 3090.
4.3 Comparisons with State-of-the-art Methods
In Table 1, we compare our proposed X-ReID with state-of-the-art methods on MSMT17 and Market1501. On Market1501, our method achieves comparable performance with the recent Transformer-based methods, especially on mAP. On the challenging MSMT17, Transformer-based methods outperform CNN-based methods significantly. X-ReID reaches state-of-the-art performance, which gains 1.1 mAP improvements when compared to the second place.
Our Baseline follows the setup in (He et al. 2021). The Baselines of X-ReID and TransReID have the same implementation. In order to compare the experiments better, we reproduce Baseline and TransReID, whose performance is slightly different from that in the original paper due to different hardware environments. Our X-ReID is the Baseline with proposed IntraX and InterX. Based on the same Baseline, X-ReID outperforms TransReID by 1.6 mAP on MSMT17 and 0.6 mAP on Market1501.
| Backbone | Methods | Ref | MSMT17 | Market1501 | ||
| mAP | Rank-1 | mAP | Rank-1 | |||
| CNN | DuATM(Si et al. 2018) | CVPR2018 | - | - | 76.6 | 91.4 |
| GCSL(Chen et al. 2018) | CVPR2018 | - | - | 81.6 | 93.5 | |
| CASN(Zheng et al. 2019) | CVPR2019 | - | - | 82.8 | 94.4 | |
| SFT(Luo et al. 2019a) | ICCV2019 | 47.6 | 73.6 | 82.7 | 93.4 | |
| PAT(Li et al. 2021b) | CVPR2021 | - | - | 88.0 | 95.4 | |
| ISP(Zhu et al. 2020) | ECCV2020 | - | - | 88.6 | 95.3 | |
| PCB(Sun et al. 2018) | ECCV2018 | 40.4 | 68.2 | 81.6 | 93.8 | |
| SCSN(Chen et al. 2020) | CVPR2020 | 58.5 | 83.8 | 88.5 | 95.7 | |
| ABDNet(Chen et al. 2019) | ICCV2019 | 60.8 | 82.3 | 88.3 | 95.6 | |
| Transformer | (He et al. 2021) | ICCV2021 | 62.3 | 82.2 | 87.1 | 94.6 |
| AAformer(Zhu et al. 2021) | Arxiv2021 | 63.2 | 83.6 | 87.7 | 95.2 | |
| (He et al. 2021) | ICCV2021 | 63.5 | 83.0 | 87.4 | 94.2 | |
| DCAL(Zhu et al. 2022) | CVPR2022 | 64.0 | 83.1 | 87.5 | 94.7 | |
| X-ReID | Ours | 65.1 | 84.0 | 88.0 | 94.9 | |
CNN-based methods in the 1st group leverage the cross-image information, which mine the relations among Instance-Level features. Transformer-based DCAL(Zhu et al. 2022) proposes cross-attention to learn local features better, which is classified as a Part-Level method. However, our proposed Identity-Level method are introduced to extract more unified features among all intra-identity instances and push inter-identity instances far away. X-ReID surpasses the CNN-based cross-image methods by a large margin, at least 5.3 mAP on Market1501. X-ReID outperforms the cross-attention related method DCAL by 1.1 mAP on MSMT17 and 0.5 mAP on Market1501.
4.4 Effectiveness of X-ReID
We propose to improve Instance-Level features with our Identity-Level framework. Compared to Instance-Level features generated from a single image, Identity-Level features, generated across different images of each identity, have more unified pedestrian information. So that in X-ReID, different Instance-Level features of each identity are very compact and features from different identities are easy to distinguish, which facilitates the model to learn more discriminative and unified features.
Compactness Analysis.
We evaluate intra-identity variation as follows:
| (12) |


where denotes the set containing all the feature vectors of the -th person and represents the feature center of the -th person. calculates the average distance from each instance to the center in the -th person. is the number of persons and the overall compactness is the mean compactness of all persons. The lower the value of , the more compact the features of each identity. Figure 6 shows the compactness of different persons in the test set on MSMT17 and Market1501. Although TransReID outperforms Baseline, the compactness is almost the same. With Identity-Level, the compactness is much lower than Baseline and TransReID. Such results prove the Identity-Level knowledge can reduce intra-identity variation.
The Calinski-Harabasz Score Analysis.
The Calinski-Harabasz score (Caliński and Harabasz 1974) is defined as ratio of the sum of between-cluster dispersion and of within-cluster dispersion, which can be used to evaluate intra- and inter-identity variations. CH is higher when identities are both dense and well separated. Fig.7 shows CH metric during the training epochs. We can find that the curves of TransReID and Baseline rise slowly and the curve of X-ReID rises rapidly. The curve of X-ReID is significantly higher than that of TransReID and Baseline. By our proposed method, intra-identity instances are more compact and inter-identity instances are well separated.



Visualization Analysis.
In Figure 8, we further conduct visualization experiments(Chefer, Gur, and Wolf 2021) to show the effectiveness of X-ReID. We compare our method with Baseline and TransReID. Our model focuses on more comprehensive areas, while high attention regions are relatively scattered instead of focusing on a small area, which indicates that our model can obtain more unified pedestrian information. In the second column, the “handbag” is only a small part of the middle image. Our model learns the Identity-Level information from multiple images to improve the discriminative ability to recognize the “handbag”.
4.5 Ablation Studies of X-ReID
The effectiveness of individual components.
There are two important components in our proposed X-ReID: a Cross Intra-Identity Instances module (IntraX) and a Cross Inter-Identity Instances module (InterX). We evaluate the contribution of each component in Table 2. EMA means the Exponential Moving Average operation in IntraX. The improvement of Baseline+IntraX is more impressive than that of Baseline+EMA, which validates the effectiveness of Identity-Level rather than EMA. Through fusing intra-identity instances, IntraX transfer the Identity-Level knowledge to Instance-Level features to gain promising performance. InterX deals with inter-identity instances to minimize intra-identity variation and maximize inter-identity variation. Compared with Baseline, our full X-ReID significantly boosts the performance by 2.8 mAP and 0.9 mAP on MSMT17 and Market1501, respectively.
| Methods | MSMT17 | Market1501 | ||
|---|---|---|---|---|
| mAP | Rank-1 | mAP | Rank-1 | |
| Baseline | 62.3 | 82.2 | 87.1 | 94.6 |
| Baseline+EMA | 62.4 | 82.3 | 87.1 | 94.7 |
| Baseline+IntraX | 64.7 | 83.4 | 87.8 | 94.7 |
| Baseline+InterX | 63.7 | 83.2 | 87.4 | 94.7 |
| X-ReID | 65.1 | 84.0 | 88.0 | 94.9 |



Hyper-parameters Analysis
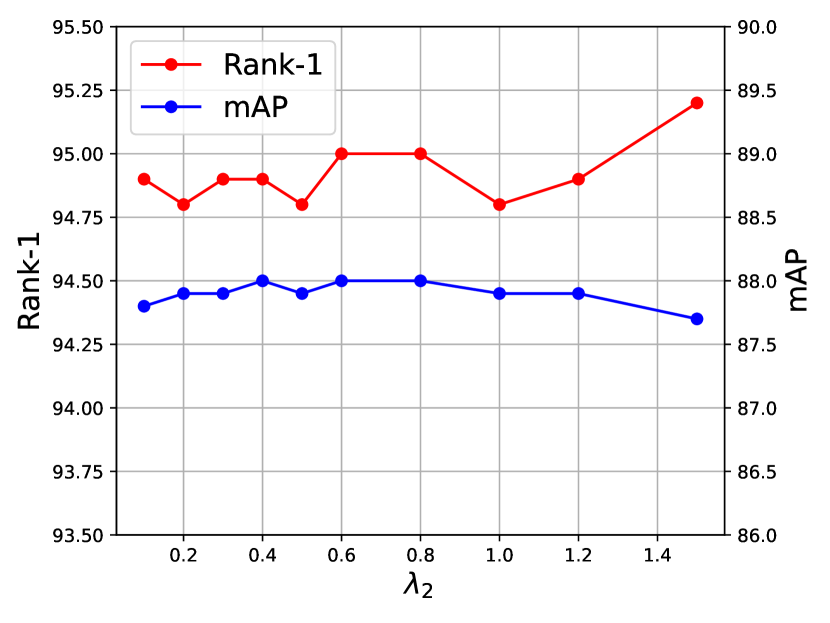
We evaluate the impact of weight and of the entire loss (Equation 11) in Figure 9. balances the weight of IntraX and balances the weight of InterX. The first row shows the impact of when is fixed at 0.4. Although the final selected is not the same on the two datasets, the performance fluctuates very little with the change of and mAP is at least above 64.6 on MSMT17. The second row shows the impact of when is fixed at 20.0 on MSMT17 and 5.0 on Market1501. The performance obtains a further improvement when the value of is around 0.4.
5 Conclusion and Future Work
In this paper, we propose a novel training framework named X-ReID, which contains a Cross Intra-Identity Instances module and a Cross Inter-Identity Instances module. Our proposed methods extract Identity-Level features for more unified and discriminative pedestrian information. Extensive experiments on benchmark datasets show the superiority of our methods over state-of-the-art methods. In the future, more sophisticated solutions for improving the Identity-Level capability can be exploited.
References
- Ba, Kiros, and Hinton (2016) Ba, J. L.; Kiros, J. R.; and Hinton, G. E. 2016. Layer normalization. arXiv preprint arXiv:1607.06450.
- Caliński and Harabasz (1974) Caliński, T.; and Harabasz, J. 1974. A dendrite method for cluster analysis. Communications in Statistics-theory and Methods, 3(1): 1–27.
- Carion et al. (2020) Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; and Zagoruyko, S. 2020. End-to-end object detection with transformers. In European conference on computer vision, 213–229. Springer.
- Chefer, Gur, and Wolf (2021) Chefer, H.; Gur, S.; and Wolf, L. 2021. Transformer interpretability beyond attention visualization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 782–791.
- Chen, Fan, and Panda (2021) Chen, C.-F. R.; Fan, Q.; and Panda, R. 2021. Crossvit: Cross-attention multi-scale vision transformer for image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 357–366.
- Chen et al. (2018) Chen, D.; Xu, D.; Li, H.; Sebe, N.; and Wang, X. 2018. Group consistent similarity learning via deep crf for person re-identification. In Proceedings of the IEEE conference on computer vision and pattern recognition, 8649–8658.
- Chen et al. (2021) Chen, H.; Wang, Y.; Guo, T.; Xu, C.; Deng, Y.; Liu, Z.; Ma, S.; Xu, C.; Xu, C.; and Gao, W. 2021. Pre-trained image processing transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 12299–12310.
- Chen et al. (2019) Chen, T.; Ding, S.; Xie, J.; Yuan, Y.; Chen, W.; Yang, Y.; Ren, Z.; and Wang, Z. 2019. Abd-net: Attentive but diverse person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 8351–8361.
- Chen et al. (2020) Chen, X.; Fu, C.; Zhao, Y.; Zheng, F.; Song, J.; Ji, R.; and Yang, Y. 2020. Salience-guided cascaded suppression network for person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 3300–3310.
- Deng et al. (2009) Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; and Fei-Fei, L. 2009. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, 248–255. Ieee.
- Dosovitskiy et al. (2020) Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. 2020. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929.
- Fang et al. (2019) Fang, P.; Zhou, J.; Roy, S. K.; Petersson, L.; and Harandi, M. 2019. Bilinear attention networks for person retrieval. In Proceedings of the IEEE/CVF international conference on computer vision, 8030–8039.
- Gao et al. (2021) Gao, W.; Wan, F.; Pan, X.; Peng, Z.; Tian, Q.; Han, Z.; Zhou, B.; and Ye, Q. 2021. TS-CAM: Token Semantic Coupled Attention Map for Weakly Supervised Object Localization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2886–2895.
- Han et al. (2020) Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. 2020. A survey on visual transformer. arXiv e-prints, arXiv–2012.
- He et al. (2016) He, K.; Zhang, X.; Ren, S.; and Sun, J. 2016. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 770–778.
- He and Liu (2020) He, L.; and Liu, W. 2020. Guided saliency feature learning for person re-identification in crowded scenes. In European Conference on Computer Vision, 357–373. Springer.
- He et al. (2021) He, S.; Luo, H.; Wang, P.; Wang, F.; Li, H.; and Jiang, W. 2021. Transreid: Transformer-based object re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 15013–15022.
- Hermans, Beyer, and Leibe (2017) Hermans, A.; Beyer, L.; and Leibe, B. 2017. In defense of the triplet loss for person re-identification. arXiv preprint arXiv:1703.07737.
- Jin et al. (2020) Jin, X.; Lan, C.; Zeng, W.; Wei, G.; and Chen, Z. 2020. Semantics-aligned representation learning for person re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, 11173–11180.
- Khan et al. (2021) Khan, S.; Naseer, M.; Hayat, M.; Zamir, S. W.; Khan, F. S.; and Shah, M. 2021. Transformers in vision: A survey. ACM Computing Surveys (CSUR).
- Li et al. (2021a) Li, X.; Hou, Y.; Wang, P.; Gao, Z.; Xu, M.; and Li, W. 2021a. Trear: Transformer-based rgb-d egocentric action recognition. IEEE Transactions on Cognitive and Developmental Systems.
- Li et al. (2021b) Li, Y.; He, J.; Zhang, T.; Liu, X.; Zhang, Y.; and Wu, F. 2021b. Diverse part discovery: Occluded person re-identification with part-aware transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2898–2907.
- Liu et al. (2017) Liu, H.; Feng, J.; Qi, M.; Jiang, J.; and Yan, S. 2017. End-to-end comparative attention networks for person re-identification. IEEE Transactions on Image Processing, 26(7): 3492–3506.
- Luo et al. (2019a) Luo, C.; Chen, Y.; Wang, N.; and Zhang, Z. 2019a. Spectral feature transformation for person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 4976–4985.
- Luo et al. (2019b) Luo, H.; Gu, Y.; Liao, X.; Lai, S.; and Jiang, W. 2019b. Bag of tricks and a strong baseline for deep person re-identification. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, 0–0.
- Si et al. (2018) Si, J.; Zhang, H.; Li, C.-G.; Kuen, J.; Kong, X.; Kot, A. C.; and Wang, G. 2018. Dual attention matching network for context-aware feature sequence based person re-identification. In Proceedings of the IEEE conference on computer vision and pattern recognition, 5363–5372.
- Sun et al. (2018) Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; and Wang, S. 2018. Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline). In Proceedings of the European conference on computer vision, 480–496.
- Vaswani et al. (2017) Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, Ł.; and Polosukhin, I. 2017. Attention is all you need. Advances in neural information processing systems, 30.
- Wang et al. (2018) Wang, G.; Yuan, Y.; Chen, X.; Li, J.; and Zhou, X. 2018. Learning discriminative features with multiple granularities for person re-identification. In Proceedings of the 26th ACM international conference on Multimedia, 274–282.
- Wang et al. (2022) Wang, H.; Shen, J.; Liu, Y.; Gao, Y.; and Gavves, E. 2022. NFormer: Robust Person Re-identification with Neighbor Transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 7297–7307.
- Wei et al. (2018) Wei, L.; Zhang, S.; Gao, W.; and Tian, Q. 2018. Person transfer gan to bridge domain gap for person re-identification. In Proceedings of the IEEE conference on computer vision and pattern recognition, 79–88.
- Xie et al. (2021) Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J. M.; and Luo, P. 2021. SegFormer: Simple and efficient design for semantic segmentation with transformers. Advances in Neural Information Processing Systems, 34.
- Ye et al. (2021) Ye, M.; Shen, J.; Lin, G.; Xiang, T.; Shao, L.; and Hoi, S. C. 2021. Deep learning for person re-identification: A survey and outlook. IEEE Transactions on Pattern Analysis and Machine Intelligence.
- Zhang et al. (2019) Zhang, Z.; Lan, C.; Zeng, W.; and Chen, Z. 2019. Densely semantically aligned person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 667–676.
- Zhang et al. (2020) Zhang, Z.; Lan, C.; Zeng, W.; Jin, X.; and Chen, Z. 2020. Relation-aware global attention for person re-identification. In Proceedings of the ieee/cvf conference on computer vision and pattern recognition, 3186–3195.
- Zhao et al. (2021) Zhao, H.; Jiang, L.; Jia, J.; Torr, P. H.; and Koltun, V. 2021. Point transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 16259–16268.
- Zheng et al. (2015) Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; and Tian, Q. 2015. Scalable person re-identification: A benchmark. In Proceedings of the IEEE international conference on computer vision, 1116–1124.
- Zheng et al. (2017) Zheng, L.; Zhang, H.; Sun, S.; Chandraker, M.; Yang, Y.; and Tian, Q. 2017. Person re-identification in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1367–1376.
- Zheng et al. (2019) Zheng, M.; Karanam, S.; Wu, Z.; and Radke, R. J. 2019. Re-identification with consistent attentive siamese networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 5735–5744.
- Zheng, Zheng, and Yang (2017) Zheng, Z.; Zheng, L.; and Yang, Y. 2017. A discriminatively learned cnn embedding for person reidentification. ACM transactions on multimedia computing, communications, and applications (TOMM), 14(1): 1–20.
- Zhong et al. (2020) Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; and Yang, Y. 2020. Random erasing data augmentation. In Proceedings of the AAAI conference on artificial intelligence, volume 34, 13001–13008.
- Zhu et al. (2022) Zhu, H.; Ke, W.; Li, D.; Liu, J.; Tian, L.; and Shan, Y. 2022. Dual Cross-Attention Learning for Fine-Grained Visual Categorization and Object Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 4692–4702.
- Zhu et al. (2020) Zhu, K.; Guo, H.; Liu, Z.; Tang, M.; and Wang, J. 2020. Identity-guided human semantic parsing for person re-identification. In European Conference on Computer Vision, 346–363. Springer.
- Zhu et al. (2021) Zhu, K.; Guo, H.; Zhang, S.; Wang, Y.; Huang, G.; Qiao, H.; Liu, J.; Wang, J.; and Tang, M. 2021. AAformer: Auto-aligned transformer for person re-identification. arXiv preprint arXiv:2104.00921.