WINNet: Wavelet-inspired Invertible Network for Image Denoising
Abstract
Image denoising aims to restore a clean image from an observed noisy image. The model-based image denoising approaches can achieve good generalization ability over different noise levels and are with high interpretability. Learning-based approaches are able to achieve better results, but usually with weaker generalization ability and interpretability. In this paper, we propose a wavelet-inspired invertible network (WINNet) to combine the merits of the wavelet-based approaches and learning-based approaches. The proposed WINNet consists of -scale of lifting inspired invertible neural networks (LINNs) and sparsity-driven denoising networks together with a noise estimation network. The network architecture of LINNs is inspired by the lifting scheme in wavelets. LINNs are used to learn a non-linear redundant transform with perfect reconstruction property to facilitate noise removal. The denoising network implements a sparse coding process for denoising. The noise estimation network estimates the noise level from the input image which will be used to adaptively adjust the soft-thresholds in LINNs. The forward transform of LINNs produce a redundant multi-scale representation for denoising. The denoised image is reconstructed using the inverse transform of LINNs with the denoised detail channels and the original coarse channel. The simulation results show that the proposed WINNet method is highly interpretable and has strong generalization ability to unseen noise levels. It also achieves competitive results in the non-blind/blind image denoising and in image deblurring.
Index Terms:
Image denoising, Wavelet transform, Invertible neural networks.I Introduction
Image denoising is a classical and fundamental inverse problem in image processing and computer vision. Image denoising algorithms aim to restore a noiseless image from noisy observations obtained by digital cameras. Given that the observations are inevitably noisy due to the random nature of the photon emission and sensing process, and the imperfection of the signal conversion process [1, 2]; image denoising is an essential step for further image processing and computer vision applications. With the plug-and-play and the unfolding technique [3, 4, 5, 6, 7], image denoising algorithms have become even more important as they can also be used to solve other image restoration problems by acting as a powerful prior. In this paper, we assume the noise is additive, white and Gaussian. The observed noisy image is expressed as:
| (1) |
where is the clean image and represents the measurement noise with variance .
Image denoising has a rich literature. Depending on how priors have been exploited, image denoising algorithms can be generally classified into model-based methods e.g., [8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18] and learning-based methods e.g., [19, 20, 21, 22, 23]. Currently, the learning-based methods achieve state-of-the-art performances, but the model-based methods are still highly competitive.
The model-based methods [8, 9, 10, 11, 14, 15, 12, 13, 16, 17, 18] use optimization strategies based on well-defined image priors or noise statistics which lead to algorithms with good interpretability and strong generalization ability. The typical priors used for image denoising include for instance image-domain smoothness, transform-domain sparsity [8, 9, 10, 11, 12, 13], patch-domain non-local self-similarity [16, 15] and low-rank [17, 18].
The wavelet transform has been very effective in many imaging applications due to its ability to provide sparse representation of images. It provides a versatile multi-resolution analysis with perfect reconstruction property and time-frequency localization property. Due to its properties, the wavelet transform has been applied for a wide range of image restoration problems, including image denoising [8, 10, 11], image deconvolution [24, 25] and image inpainting [26, 27]. The wavelet transform is a fixed transform and, in some cases, learning a transformation better adapted to the data at hand may lead to more effective solutions. Dictionary learning tries to achieve that by learning a (redundant) sparsifying transform from training data. Elad and Aharon [12] proposed to perform image denoising with learned redundant dictionaries. Compared to fixed transforms, the combination of learned dictionaries and sparse coding leads to significantly improved denoising performance. However, both the analytical transforms and the learned dictionaries are linear transformations. A suitable non-linear transform with perfect reconstruction property has the potential to achieve better performances.
Besides the nice properties of the wavelet transform, the noise adaptive non-linear operator also contributes to the effectiveness of wavelet-based methods. Donoho and Johnstone [8] proposed soft-thresholding operator and applied it with the optimal “universal threshold” (where is the number of samples) to the wavelet-domain coefficients to remove noise. Chang et al. [10] proposed a BayesShrink threshold (where and are the estimated standard deviation of noise and signal, respectively) for soft-thresholding with a Bayesian framework for wavelet-domain image denoising. Both the “universal threshold” and BayesShrink threshold are adaptively adjusted for different noise levels.
The learning-based methods [19, 20, 21, 22, 23] construct a denoising model by learning from noisy-clean image pairs. The availability of training data and the flexibility of network structure simplifies and enriches the algorithm design and boosts the performance, while the learned models have more restricted generalization ability compared to the model-based methods and are usually treated as black-box systems with poor interpretability. Therefore, learning-based methods mainly aim to explore more efficient and effective architecture as well as strategies to improve the generalization ability of the learned denoising model. The denoising convolutional neural networks (DnCNN) method [21] learns a deep CNN model with batch normalization layers and a skip connection. By learning from training samples with different noise levels, DnCNN can perform blind image denoising when the noise level of the testing image is within the range of the training noise levels. The fast and flexible denoising network (FFDNet) [22] takes the noise level map and the noisy image as input to the model, and therefore can handle spatially varying noises. The convolutional blind denoising network (CBDNet) [23] consists of two convolution subnetworks: a noise estimation subnetwork and a non-blind denoising subnetwork. The noise estimation subnetwork learns to infer a noise level map from the noisy image, and the non-blind denoising subnetwork which has a U-Net like structure takes both the noise level map and input noisy image as input and estimates the clean image.
Here we propose to learn a (redundant) invertible sparsifying transform by leveraging the invertible neural network framework. In our design we want our non-linear transform to inherit some of the properties of the wavelet transform, including its sparsifying ability as well as its multi-scale property where wavelets at larger scales are more global that the wavelets at finer scales which are instead very local. We aim to combine the merits of the model-based and learning-based image denoising approaches. Specifically by following a strategy similar to wavelet domain thresholding, we aim to enhance the generalization ability and interpretability of the learning-based image denoising method.
We propose a novel wavelet-inspired invertible network (WINNet) for image denoising. The architecture is shown in Fig. 2 and is described in detail in Section III and IV. Rather than learning features with unconstrained CNNs, we propose to learn a non-linear wavelet-like transform with perfect reconstruction property using invertible neural networks with a structure inspired by the lifting scheme [28, 29]. We call these lifting inspired networks LINNs. With PR property, the learned LINNs can serve as a versatile transform. For denoising, a sparsity-driven denoising network is applied to the transform coefficients to remove the noise. The restored image can then be reconstructed using the inverse transform of the learned LINNs.
The proposed WINNet is made of several LINNs, one per scale. Moreover, to achieve good generalization ability, all the soft-thresholds in WINNet are set to be noise adaptive and can be adjusted according to the estimated noise level. In this way, the proposed denoising network achieves good generalization ability even to unseen noise. The noise level is estimated using a model-inspired noise estimation network which exploits low-rank patches on the input noisy image and estimates noise levels as the minimum singular value of the weighted patches.
The contribution of this paper is three-fold:
-
•
We propose an invertible thresholding network for image denoising. It is designed based on the principles of wavelet-based methods, therefore leads to a model with high interpretability. The LINNs at various scales produce a non-linear redundant transform with perfect reconstruction property, and the denoising network implements a basis pursuit denoising process.
-
•
The proposed method is able to achieve blind image denoising. The noise estimation network estimates noise from the input image. To adapt the learned WINNet to the test noise level, the soft-thresholds in network are adaptively adjusted with respect to the estimated noise level.
-
•
The proposed WINNet is with high interpretability and strong generalization ability. It achieves performances comparable to those of state-of-the-art algorithms on non-blind/blind image denoising and image deblurring.
The rest of the paper is organized as follows: Section II discusses related works in image denoising and invertible neural networks. Section III provides an overview of WINNet. Section IV describes the architecture of LINNs which are the building blocks of WINNet, whereas Section V focuses on the denoising network, the noise estimation strategy and the training strategy. Section VI shows the numerical results, compares the proposed method with other image denoising methods and demonstrates the application of WINNet on image deblurring. Finally Section VII concludes the paper.
II Related Work
II-A Learning Universal Image Denoising
Blind image denoising can be achieved by learning from training samples with varying noise levels [21, 22, 23], however, the learned deep models still have poor generalization ability on images with noise levels beyond the training levels. Hence, one may wish to learn a universal denoising model with good performances on arbitrary noise levels.
Mohan et al. [30] found that the bias term in a denoising CNN will lead to a model bias to the training noise levels. Hence, they propose to remove all the bias terms in both ReLU activation functions and the batch normalization layers. The resultant bias-free CNN (BF-CNN) has a scale homogeneity property, i.e., where denotes a bias-free CNN and , and shows consistently better generalization ability than its counterpart with bias terms. Helou and Süsstrunk [31] proposed a blind universal image fusion denoiser (BUIFD) whose structure is derived from a Bayesian framework and consists of a noise level CNN, a prior CNN and a fusion network. The information of noisy image and image prior are fused based on signal-to-noise ratio (SNR). By explicitly incorporating the noise level, BUIFD shows stronger generalization ability than that of conventional denoising CNNs.


II-B Lifting Scheme and Invertible Neural Networks
The lifting scheme introduced in [28, 29] proposes to construct a wavelet transform by first splitting the signal into an even and an odd part. A predictor is used to predict the odd signal from the even part, therefore leading to a sparse residual signal. The update step is used to adjust the even signal based on the prediction error of the odd part to make it a better coarse version of the original signal. There can be multiple pairs of predictor and updater. The lifting scheme can represent a transform with perfect reconstruction condition and any intermediate representation can be used to infer the input signal and the final representation.

Inspired by this scheme, the invertible neural networks (INNs) [32, 33, 34, 35] was proposed for memory-efficient backpropagation model and used for constructing flow-based generative models. INNs are bijective function approximators and the intermediate feature representation of INNs can be used to perfectly reconstruct the input signal. Different invertible architectures have been proposed, including coupling layer [32], affine coupling layer [33], reversible residual network [34] and i-RevNet architecture [35]. INNs have been applied for low-level computer vision tasks, including image rescaling [36], image segmentation [37], image colorization [38, 39], image compression [40, 41, 42], and image denoising [43, 44].
III Overview
Our goal is to design an invertible neural network (INN) where the design choices are made to induce an invertible transform with properties similar to the wavelet transform. In Fig. 1(a), we show one level of a 1-D discrete wavelet transform which is obtained using a filter bank. Here is a “smooth” version of and contains high-frequency information of and is sparse. We know that this decomposition can be achieved using the lifting scheme shown in Fig. 1(b).
The split operation divides the sequence into the even and odd components, “P” predicts the even using the odd leading to a sparse error sequence and “U” updates the odd sequence to make it smoother. The process is then repeated until and are obtained. “P” and “U” are fixed and depend on the filters and . A two-level wavelet decomposition can also be implemented with the lifting scheme by applying it again on . We note that the equivalent low-pass filter in the two-scale case is and is less local than . It is therefore more adapted at catching more global proprieties of . The transforms discussed so far are non-redundant but the undecimated wavelet transform can be easily obtained by shifting-out the downsampler in Fig. 1(a) and by upsampling the filter coefficients by , with and is the number of decomposition levels. The upsampling is essential to keep the multi-resolution property of the wavelet transform.
The architecture of our INN is inspired by the lifting scheme in the wavelet transform and the multi-resolution property of the wavelet transform. A WINNet with -level lifting inspired neural network (LINN) is shown in Fig. 2, where we iterate the decomposition only on the coarse version of the image and replace the standard “P” and “U” operations with two convolutional neural networks. Through the use of a denoising strategy we enforce “P” to act as a “Predictor” and “U” as an “Update”. Moreover, at larger scales, we upsample the filters in the convolutional layers to mimic the algorithm à trous [45] used in wavelets theory to implement the wavelet transform. Finally we replace the split operator with a redundant invertible linear operator which leads to a redundant decomposition.
We achieve sparsity by applying a non-invertible denoising operation on the detail coefficients. The denoising operation forces the network to sparsify the detail coefficients so that only noise is removed. The network we use for denoising is also a sparsity-driven network. WINNet is then trained using noisy images as input and ground-truth noiseless images as output. By training the network with paired noisy and clean images, we force the network to sparsify the detail coefficients whilst preserving essential information in the coarse part. Besides leading to an effective and versatile non-linear invertible transform, this approach also leads to a very effective denoising algorithm. To make it more universal we also include a network to estimate the noise variance which in turn changes the soft-thresholds in WINNet. In this way, our system adapts automatically to different unknown levels of noise. We also note that our scheme is highly interpretable as we know what each part of the network is doing. In what follows we describe in more detail each element of our network.
IV Lifting Inspired Invertible Neural Networks
The lifting inspired invertible neural network (LINN) is used to replace one level of the wavelet transform (see Fig. 2 and Fig. 3). Compared to wavelet transforms and learned dictionaries, LINN can represent more complex features. Similar to the lifting scheme which splits the input signal and then alternates prediction and update [28, 29], LINN consists of splitting/merging operators and learnable predict and update networks.
Since LINN satisfies PR conditions, the obtained transform coefficients contain the same amount of information as the input image. Though noise is not removed in the transform coefficients, the non-linear transform will learn to separate signal and noise into the coarse and detail parts through the denoising operation applied on the detail part. The PR property of LINN also makes it a versatile transform for image denoising with different noise levels and for other image restoration problems.
IV-A Splitting/Merging Operator
The splitting operator is used to separate the input image into two parts, and the merging operator performs the inverse of the splitting operator. The splitting/merging operator in current methods [32, 33, 34, 35, 46, 38, 40, 36, 37] keep the same number of input and output coefficients.
In this paper, we propose to learn LINNs with redundant representations in analogy with the redundant wavelet transform which provides better performance compared to the decimated wavelet transform in image restoration tasks [47, 11]. Therefore, the splitting operator will lead to a redundant representation, and merging operator recovers the input image from the redundant representation.
For an input image at the -th scale, the splitting operator is parameterized by a convolutional kernel where denotes the number of channels and denotes the spatial filter size. A convolution is performed to obtain multi-channel features :
| (2) |
where denotes the convolution operator.
The split operation then divides the first channels of into coarse part , and the remaining channels into detail part . In this paper, we set the number of coarse channels to , and we denote the splitting operator as:
| (3) |
The merging operator represents the inverse of the splitting operator, and is parameterized by a convolutional kernel . It first concatenates and and this results in . A convolution is performed to recover :
| (4) |
The merging operator can then be denoted as:
| (5) |
To achieve invertibility, we can pick so that it can be reshaped to a tight frame with . The merging convolutional kernel then simply corresponds to the transpose of the splitting convolutional kernel. This will ensure the splitting and merging operators are invertible. We can use orthogonal transforms of size such as orthogonal wavelet transforms, Discrete Cosine Transforms (DCT) and other analytical transforms as the splitting and merging operators. The tight frame is then obtained by picking columns of the original orthogonal matrix.
Besides the analytical transforms, it is also possible to learn an orthogonal matrix with proper parameterization methods, for example, the Cayley transform [48] of a skew-symmetric matrix is an orthogonal matrix:
| (6) |
where is the identity matrix. The corresponding tight frame can therefore be a sub-matrix (i.e., extracting columns) of the learned orthogonal matrix parameterized by learnable parameters .





IV-B Network Architecture of LINN
At each scale, the Predict/Update networks are shared among the forward and inverse transform of LINN, but are connected with different signs and direction.
Fig. 3(a) and Fig. 3(b) shows the schematics of the forward transform and the inverse transform of the -th scale LINN, respectively. In the forward transform, will be non-linearly transformed to a representation which is more suitable for denoising. After denoising, the denoised detail part and the original coarse part will be transformed back to the original domain using the inverse transform of LINN.
In the forward transform (shown in Fig. 3(a)), a Predict network conditioned on the coarse part aims to predict the detail part to make the resultant residual of the detail part sparse. The Update network conditioned on the detail part is used to adjust the coarse part to make it a smoother version of the input image. The Predict and Update networks are applied alternatively to update the coarse and detail parts. Let us denote . The -th pair () of update and predict operation can be expressed as:
| (7) | ||||
| (8) |
where and denotes the updated detail part and coarse part using the -th Predict network and Update network , respectively.
In the inverse transform of the -th scale LINN (shown in Fig. 3(b)), for can be estimated based on and and as follows:
| (9) | ||||
| (10) |
When no lossy operation is applied on , the inverse transform of LINN can, by construction, perfectly recover the inputs of the forward transform with any Predict and Update networks. In this paper, we enforce LINN to learn a sparsifying transformation through denoising.
IV-C Predict/Update Networks
The Predict and Update networks can be any functions and their properties will not affect the invertibility of LINN. In this paper, we use the same structure for each Predict/Update networks which we therefore denote with PUNets. To achieve a better complexity and performance trade-off, we construct PUNets with depth-wise separable convolution (SepConv) layers [49] and soft-thresholding non-linearity [8]. As shown in Fig. 4(c), a PUNet consists of an input convolutional layer with a soft-thresholding, residual blocks with SepConv layers, and an output convolutional layer .
Separable Convolution: A depth-wise separable convolution layer [49] consists of a depth-wise convolution layer and a convolution layer (shown in Fig. 4(a)). It can reduce the number of parameters, especially when the channel number and the spatial filter size are large. Compared to the standard convolution of size , the SepConv layer only requires parameters.
Soft-thresholding: The soft-thresholding operator is used as the non-linearity in PUNets. The soft-thresholding operator has a tight connection with sparse coding. It can also be considered as a two-sided ReLU non-linearity and can be more effective than ReLU for some image processing applications. The soft-thresholding operator can be expressed as:
| (11) |
To ensure are non-negative, a Softplus function111. is applied on each learned thresholds.
Multi-scale Property: Multi-resolution signal decomposition is an essential property of the wavelet transform. For an input image, the wavelet transform provides a multi-scale analysis which captures the information at different scales. In order to mimic the wavelet transform, we iterate the LINN-based decomposition on the coarse part. Moreover, we apply à trous convolution with dilation rate for the -th scale LINN even though the redundancy factor in our setting is not two. As a result, the larger scale LINN will have a bigger receptive field. Fig. 5 shows the exemplars of dilated filter at two different levels.


V Blind Image Denoising
The denoising network aims to denoise the detail part by removing the noise features while retaining the image content. The denoising networks are the only non-invertible components in WINNet, and the noisy information can only be removed there. The denoising networks also force LINNs to be a sparsifying transformation which is desirable for many image processing tasks.
V-A Sparsity-Driven Denoising Network
Any existing image denoiser can be applied here, however, as our objective is to achieve an image denoising algorithm with high interpretability, we propose to use a sparsity-driven denoising architecture.
Let us assume that the learned forward transform by LINN is a sparsifying transform and the small number of large coefficients correspond to the image contents. (The forward transformed images by LINN will be shown in Section VI Simulation Results to validate this assumption). The denoising process can then be modeled as a basis pursuit denoising problem. To enrich the representation ability of the sparsity-driven denoising network, we over-parameterize with a convolutional dictionary as:
| (12) |
where are the sparse features, is the over-parameterized convolutional dictionary, and are the regularization parameters.

The above -norm minimization problem can be solved using Iterative Shrinkage-Thresholding Algorithm (ISTA) [50]:
| (13) |
where is the step size.
The LISTA [51] algorithm parameterizes the unknown dictionaries in ISTA as learnable parameters. We apply a convolutional LISTA (CLISTA) as our sparsity-driven denoising network. The schematic of the CLISTA denoising network is shown in Fig. 6. There are layers of soft-thresholding operations in CLISTA. The convolutional dictionaries and are shared across layers. For the -th layer, there is a soft-thresholding operator with learnable soft-thresholds:
| (14) |
where is the analysis convolutional dictionary, is the synthesis convolutional dictionary, and is the soft-threshold vector.
For the first layer, is initialized as . At the last layer, the synthesis convolution layer is used to reconstruct the denoised detail channels from the estimated sparse feature , i.e., .
V-B Noise Adaptive Network
To achieve robust image denoising, we propose to adapt the soft-thresholds in PUNets and CLISTA to the noise level in the image. For images with larger noise levels, the soft-thresholds will be larger leading to more effective denoising. This is similar to the model-based image denoising methods in [8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18] where the soft-thresholds scale with the noise levels. For noisy image super-resolution problem, DeepAM [52] also shows that better generalization can be achieved by adjusting soft-thresholds with respect to noise level.
Different from BF-CNN which does not have bias terms and has restricted expressive power, our PUNets and CLISTA denoising network have the dynamically adjusted soft-thresholds with respect to the noise level. This gives us good generalization ability, flexibility as well as improved expressive power.
Spectral Norm Loss: When learning from noisy-clean image pairs of a single noise level , the parameters of PUNets are learned to optimize the performance of this training noise level. When the test noise level , the rescaled soft-thresholds could make the PUNets change from a contractive function to an expansive function. We therefore use a spectral norm loss to regularize the property of the PUNets:
| (15) |
where denotes the spectral norm of a matrix, and and are the effective linear filter of the -th residual block on the -th lifting step at the -th scale when soft-thresholds are set to zeros.
The linear loss is used to regularize the Lipschitz constant of the PUNets when , i.e., assuming that soft-thresholding operators in PUNets are identity functions. It can improve the generalization ability of WINNets to unseen small noise levels and can also stabilize the training of deep/multi-scale models by constraining the expansiveness of the PUNets.
Orthogonal Loss: For CLISTA denoising network, the soft-thresholds will also be adjusted with respect to noise level. We would like to enforce when . That is, the CLISTA denoising network should be close to an identity function when there is no noise. This can be achieve when and are orthogonal. Therefore, an orthogonal loss is imposed between the synthesis and the analysis convolutional dictionary:
| (16) |
where is the Kronecker delta function which takes value 1 at coordinate otherwise 0.
V-C Noise Estimation Network

Since the PUNets are conditioned on the image noise level, we propose a simple model-inspired noise estimation network in order to achieve blind image denoising. The proposed noise estimation network is inspired by [53] here, authors use an iterative algorithm to select low-rank patches from the input noisy image and estimate the noise level as the smallest eigenvalue of the covariance matrix of the selected low-rank patches. Compared to CNNs used to infer noise levels, e.g., [23, 31], this model-based method can provide more interpretable results and robust generalization ability.
We propose a learnable noise estimation network (NENet) which is based on the principles of [53] and uses backpropagation through singular value decomposition (SVD) in PyTorch. The network is shown in Fig. 7. The input image is divided into patches where each column represents a vectorized patch and is the number of patches. Instead of iteratively selecting low-rank patches, we propose to use a selection network (SENet) to estimate a scalar weight for each patch. The SENet performs a soft selection and will learn to assign large weights to low-rank patches and vice versa. Given the estimated weights and the patches, the noise variance is estimated as the minimum singular value of the weighted covariance matrix of the patch matrix:
| (17) |
where denotes the smallest singular value of the weighted covariance matrix with .
The SENet is composed of blocks with 1-D convolution layer and ReLU non-linearity without bias term, followed by a global averaging pooling and a Sigmoid function to map the weight in the range of . The parameters of SENet can be learned using backpropagation. For the noise estimation network, the MSE noise loss is used:
| (18) |
where and denotes the ground-truth noise level and the estimated noise level, respectively.
V-D Training Details
WINNet can learn from noisy-clean image pairs of a single noise level or a range of noise levels as in [21, 22, 23]. The average mean squared error (MSE) between the restored image and the clean image is used as the reconstruction loss:
| (19) |
where and denotes the input clean image and the denoised image, respectively.
The overall training objective of our WINNet is:
| (20) |
where , and are regularization parameters.
VI Experimental Results
In this section, we perform experiments to show the properties and validate the effectiveness of the proposed WINNet. We will first introduce the experimental settings, visualize the learned transform and the sparsity-driven denoising network results, and finally perform comparisons with other methods.
VI-A Implementation Details







We follow the training and evaluation settings in [21] to perform experiments. Before training and testing, the clean images are normalized to . The noisy images are obtained by adding additive white Gaussian noise to the clean image with respect to Eq. (1) with variance .
VI-A1 WINNet Configuration
For default setting, the convolution kernel of the splitting operator are reshaped from a DCT transform matrix (i.e. the -th row of is the reshaped -th filter in ). We set and . The convolution kernel for the merging operator can be constructed in a similar manner. Since by default , there will be 1 coarse channel and 15 detail channels.
The number of update and predict network pairs is set to , and the number of residual blocks in each PUNet is set to . The number of feature channels in PUNet is set to 32 and the spatial filter size in SepConv layers is set to . For CLISTA denoising network, there are layers with 64 channels. The support of the spatial filter for and is set to .
VI-A2 Training and Testing settings
The 400 training images from the Berkeley segmentation dataset (BSD) [54] of size are used for training. The training patch size is , and the number of patches for training is .
For training with a single noise level, three noise levels are considered, i.e., and . For blind image denoising scenario, the training noise level is uniformly drawn from . The regularization parameter for spectral norm loss and orthogonal loss is set to and , respectively. The spectral norm loss is evaluated once every 10 iterations. As discussed in Section V-B, when training blind image denoising models, all the soft-thresholds will be rescaled with respect to the training noise level.
The weights of the convolution layers are initialized using the Kaiming initialization method [55]. The stochastic gradient descent with Adam optimizer [56] is used for training with initial learning rate and . The total number of training epochs is set to 50 and the learning rate decays from to at the 30-th epoch. The batch size is set to 32.
VI-B Visualizing the Intermediate Results
In this section, we will visualize the output produced by components of a WINNet with levels which is trained on data with noise level .
VI-B1 Elementary Building Blocks Learned by WINNet









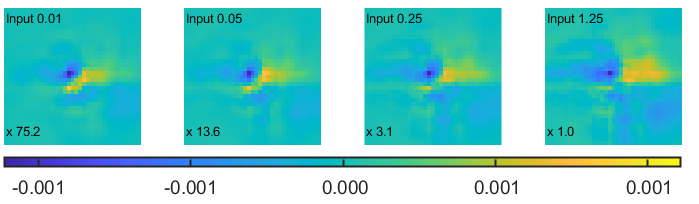
The proposed invertible network is inspired by the lifting scheme [28, 29] in wavelets, therefore, it would be meaningful to visualize the learned elementary atoms.
The basis functions or elementary atoms of the wavelet transform can be visualized by setting to zero all the wavelet coefficients with the exception of one coefficient and then by reconstructing the corresponding signal with the synthesis filter bank. In analogy with the wavelet case, we set all the feature maps in to zero with the exception of the center pixel on one of the feature maps, and then reconstruct the image using the backward pass of LINN. As the PUNets represent highly non-linear functions and may have different responses for signals with varying amplitudes, the elementary atoms is visualized using different non-zero values. Since our transform is highly non-linear, it is incorrect to call the reconstructed functions “basis functions”or elementary atoms, however, to keep the intuition that what we are visualizing is a variation of the basis functions related to linear transforms, with a slight abuse, we keep calling them “elementary atoms”.
Fig. 8 shows the atoms corresponding to different channels at level 1 and level 2 in WINNet. For better visualization, the maximum absolute value in each visualized basis function has been rescaled by a factor shown on the lower left corner of each figure. Fig. 8 (a) - (d) show the elementary atoms of 4 representative channels from level 1 LINN. We can see that the basis functions have compact support. For the coarse channel, the basis function gradually changes to a delta function when the amplitude increases from 0.01 to 1.25. For the detail channels, the shape of the elementary atoms only slightly changes when we increase the amplitude of the input pixel. Fig. 8 (e) - (h) show the atoms of 4 representative channels from level 2 LINN. Different from what we observed at level 1, the basis functions in level 2 have larger support, and the shapes change from concentrated to spread.
Both level 1 and level 2 functions have non-linear responses to the input amplitude, while the atoms of the level 2 have much larger support compared to that of the level 1. The different support size of the functions at level 1 and level 2 is possibly due to their different functionality in WINNet, and is also a consequence of the dilation of the filter support discussed before and depicted in Fig. 5.





| Dataset | Methods | Model Size | |||
|---|---|---|---|---|---|
| BSD68 | BM3D [16] | - | 31.07 | 28.57 | 25.63 |
| WNNM [17] | - | 31.37 | 28.83 | 25.87 | |
| EPLL [57] | - | 31.21 | 28.68 | 25.67 | |
| TNRD [20] | 31.42 | 28.92 | 25.97 | ||
| DnCNN-S [21] | 31.71 | 29.20 | 26.22 | ||
| BF-CNN [30] | 31.58 | 29.08 | 26.12 | ||
| FFDNet [22] | 32.63 | 29.19 | 26.29 | ||
| WINNet (1-scale) | 31.69 | 29.22 | 26.29 | ||
| WINNet (2-scale) | 31.70 | 29.24 | 26.31 | ||
| Set12 | BM3D [16] | - | 32.37 | 29.97 | 26.72 |
| WNNM [17] | - | 32.70 | 30.26 | 27.05 | |
| EPLL [57] | - | 32.14 | 29.69 | 26.47 | |
| TNRD [20] | 32.50 | 30.06 | 26.81 | ||
| DnCNN-S [21] | 32.83 | 30.40 | 27.16 | ||
| BF-CNN [30] | 32.67 | 30.25 | 27.03 | ||
| FFDNet [22] | 32.75 | 30.43 | 27.32 | ||
| WINNet (1-scale) | 32.82 | 30.43 | 27.25 | ||
| WINNet (2-scale) | 32.83 | 30.47 | 27.29 |
VI-B2 Noisy and Denoised Feature Maps
The CLISTA denoising network is the only non-invertible component in WINNet, and is responsible for removing the feature components corresponding to noise. By visualizing the feature maps before and after the denoising network, we can further gain insights into the workings of the proposed WINNet.
In Fig. 9, we show the feature maps of an exemplar Butterfly image from Set12. Each sub-figure shows the feature map of a channel and the corresponding histogram. Fig. 9 (a) (b) (d) show the feature map of 3 exemplar channels output from the level 1 LINN in WINNet. We can see that the coarse channel feature map looks like a natural image but is still with artifacts and the detail channel feature maps before denoising contain both noise and some image contents and the histogram is spread. Fig. 9 (c) - (e) show the corresponding detail channels after denoising. We can see that the noise has been significantly reduced, the edges are sharper and the histograms become more concentrated around the origin. This indicates that noise has been effectively removed by CLISTA denoising network.
In Fig. 9 (f), the coarse channel feature map contains high-frequency enhanced features. For the detail channels, there is no significant differences on the feature maps before and after the CLISTA denoising network since the 1-st level coarse channel feature (shown in Fig. 9(a)) mainly contains minor artifacts. Therefore, we only show the feature maps before denoising in Fig. 9 (g) (i), and also include the difference of the feature maps before and after denoising in Fig. 9 (h) (j). We can observe that the 2-nd level CLISTA makes minor modifications to the feature maps.
VI-B3 Noise Estimation Network
The proposed noise estimation network is based on the idea that the Gaussian noise level can be estimated as the smallest eigenvalue of the low-rank patches. Therefore, NENet would have highly interpretable results and strong generalization ability.
Fig. 10 (a) shows an exemplar clean image, and (b) - (e) shows the region of the selected low-rank patches by the selection network (SENet) for different noise levels, respectively. We can see that SENet tends to select different regions for noise estimation. For low noise level, SENet carefully selects smooth regions, while for high noise level SENet avoids highly textured regions and selects more patches. The results are consistent with that in [53] which uses a heuristic and iterative algorithm to select low-rank patches. Fig. 10 (c) further shows the noise estimation results for images with noise level . We can find that the proposed NENet is able to provide highly accurate noise estimation for images with though the training data is only with noise level .
VI-C Comparison with Other Methods
We compare the proposed WINNet with several state-of-the-art image denoising algorithms including the model-based methods: BM3D [16], WNNM [17], EPLL [57], and the learning-based methods: DnCNN [21], FFDNet [22], BUIFD [31], BF-CNN [30]. The model-based methods can handle images with arbitrary noise levels. DnCNN [21] and BUIFD [31] can perform blind image denoising when the test noise level is within the range of the training noise levels, BF-CNN [30] can handle unseen noise levels, while the FFDNet [22] requires as input a noise map of the test noise level.

| Dataset | Methods | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| BSD68 | DnCNN-B [21] | 37.75 | 29.15 | 26.62 | 23.00 | 16.07 | 13.19 | 11.68 | 10.79 |
| BUIFD [31] | 37.41 | 28.76 | 25.61 | 23.07 | 18.81 | 15.98 | 14.45 | 13.52 | |
| BF-CNN [30] | 37.73 | 29.11 | 26.58 | 25.12 | 24.10 | 23.33 | 22.70 | 22.18 | |
| WINNet (1-scale) | 37.82 | 29.13 | 26.66 | 25.23 | 24.23 | 23.46 | 22.81 | 22.23 | |
| Set12 | DnCNN-B [21] | 37.88 | 30.38 | 27.68 | 23.52 | 15.95 | 13.18 | 11.78 | 10.92 |
| BUIFD [31] | 37.34 | 30.18 | 27.01 | 24.27 | 19.41 | 16.28 | 14.66 | 13.73 | |
| BF-CNN [30] | 37.81 | 30.33 | 27.58 | 25.83 | 24.54 | 23.55 | 22.74 | 22.07 | |
| WINNet (1-scale) | 38.22 | 30.33 | 27.72 | 26.03 | 24.77 | 23.76 | 22.94 | 22.24 |


VI-C1 Non-blind Image Denoising
Table I shows the comparison results of different non-blind image denoising methods evaluated on three noise levels (i.e., ). All the learning-based methods learn from training samples with the correct noise level. From the table, we can see that the proposed WINNets achieve better performance than the model-based methods i.e., BM3D [16], WNNM [17], and EPLL [57] by a large margin, and our proposed WINNets also outperforms the deep learning based methods including TNRD [20], DnCNN-S [21], BF-CNN [30] and FFDNet [22]. We also note that the model size of WINNet (1-scale) is only around 30% of the model size of DnCNN, and WINNet (1-scale) achieves comparable or better results than DnCNN-S. With one more level decomposition, WINNet (2-scale) further improves the WINNet (1-scale).
Without the bias terms, BF-CNN [30] has stronger generalization ability to testing images with unseen noise levels than DnCNN-S (we will show this in Fig. 11), while in Table I the performance of BF-CNN is around 0.15 dB lower than that of the DnCNN-S. This suggests that the generalization ability is improved at the cost of reduced expressiveness.
WINNet has strong generalization ability to images with unseen noise levels as well. Although WINNet only sees training image pairs with a fixed noise level , its parameters can be adjusted to adapt to unseen noise levels. When the testing noise level , all the soft-thresholds in PUNets and in CLISTA denoising networks are rescaled by a factor . When , only the soft-thresholds in CLISTA denoising networks are rescaled by a factor .
Fig. 11 shows the performance of the proposed WINNet, BF-CNN and DnCNN-S which are trained on noise level , while are tested on testing noise levels . We can see that the performance of DnCNN remains similar when and quickly deteriorates otherwise. For BF-CNN and WINNet, they can well generalize to testing images with noise levels . When , WINNet achieves improved gain compared to BF-CNN. When , the performance of WINNet is inferior to BF-CNN, but when , WINNet achieves around 0.8 dB higher PSNR than BF-CNN.
VI-C2 Blind Image Denoising
For blind image denoising, the comparison methods include DnCNN-B [21], BUIFD [31], and BF-CNN [30]. The depth of DnCNN-B and BF-CNN are increased form 17 to 20 and their number of parameters is around . For WINNet, we use the 1-scale model for comparison which has around parameters. The number of parameters for NENet is only around . The training data for all methods is BSD400 with AWGN .
Table II shows the testing results of different methods evaluated with images with noise level . We can see that the performance of DnCNN-B [21] is highly competitive when the testing noise level is within the range of the training noise level, while quickly deteriorates otherwise. BUIFD [31] consists of a noise level CNN, a prior CNN and a fusion network which are all based on DnCNN architecture. Its total number of parameters is around . With explicit noise level learning, BUIFD shows stronger generalization ability towards unseen noise levels compared to DnCNN-B. By removing all bias terms in DnCNN, BF-CNN [30] is able to well generalize beyond the training noise levels, however, it is slightly less effective when compared to DnCNN. With the exception of , WINNet consistently outperforms all the other methods.
Fig. 12 further shows the noisy image with different noise levels and the blind image denoising results by the proposed WINNet. We can see that the proposed WINNet is able to achieve robust denoising not only within the training noise level range (marked in green) but also beyond the training noise levels.

| kernel | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
| EPLL [57] | 31.47 | 31.00 | 31.23 | 29.80 | 32.47 | 32.28 | 31.12 | 30.53 |
| IRCNN [6] | 32.26 | 31.65 | 30.87 | 31.76 | 31.82 | 31.99 | 31.10 | 31.07 |
| Proposed | 32.37 | 32.04 | 32.03 | 31.52 | 32.47 | 33.17 | 32.02 | 31.87 |
VI-D Application on Image Deblurring
With the plug-and-play technique, image denoisers can be applied to solve general image restoration problems [19, 20, 21, 22, 23], for example, image deblurring. In this case, the goal is to recover a sharp image from the blurred and noisy observation where is the blurring kernel and represents the measurement noise with variance . The image deblurring task can be formulated as the following optimization problem:
| (21) |
where is a prior term and is the regularization parameter. With half-quadratic splitting [6], the image deblurring problem can be solved by iteratively optimizing two sub-problems:
| (22) | ||||
| (23) |
where is a hyper-parameter and can be interpreted as the noise level if the sub-problem is treated as Gaussian denoising on .
In [6], a CNN-based Gaussian denoiser is used to solve the sub-problem. The hyper-parameter is set to be fixed during iterations, while is set to exponentially decay from a large value to the given noise level with a fixed iteration number. Since the proposed NENet is an effective noise level estimator and WINNet can denoise images with noise beyond training noise levels, we propose to use WINNet for image deblurring. The sub-problem can be solved with closed-form solution with the estimated noise level by NENet. The sub-problem can be solved using the proposed blind WINNet with noise level (perform denoising with a stronger strength to ensure convergence). With the proposed robust NENet and WINNet, we can achieve image deblurring without accessing the noise levels and using the pre-defined regularization parameters; is the only free parameter and is set to 0.23 as in [6]. Algorithm 1 illustrates the plug-and-play image deblurring algorithm with the proposed WINNet.
Table III shows the average PSNR (dB) of the EPLL [57], IRCNN [6] and the proposed method evaluated on Set12 with 8 different kernels from [58] and noise level 2.55. We can see that the proposed method is able to achieve highly competitive performance. Fig. 13 shows an exemplar image deblurring process of the proposed method on image Cameraman which is blurred using the first kernel from [58]. We can see that the proposed method converges after 8 iterations and the PSNR of and consistently improves and finally reaches a similar result.
VII Conclusions
In this paper, we have proposed a wavelet-inspired invertible network (WINNet). It consists of levels of lifting inspired invertible neural network (LINN) and sparsity-driven denoising networks. LINNs are designed to mimic the nice properties of wavelet transform and are used as a non-linear redundant transform with perfect reconstruction property. For image denoising task, the sparsity-driven denoising network is used to remove the noise in the detail parts of the transform coefficients and the denoising network can be adjusted to adapt to unseen noise levels. Together with a model-inspired noise estimation network, the proposed blind WINNet can achieve robust blind image denoising results beyond the training noise levels. The flexibility of WINNet has also been demonstrated on the image deblurring task.
References
- [1] T. Brooks, B. Mildenhall, T. Xue, J. Chen, D. Sharlet, and J. T. Barron, “Unprocessing images for learned raw denoising,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 11 036–11 045.
- [2] Y. Wang, H. Huang, Q. Xu, J. Liu, Y. Liu, and J. Wang, “Practical deep raw image denoising on mobile devices,” in European Conference on Computer Vision. Springer, 2020, pp. 1–16.
- [3] S. V. Venkatakrishnan, C. A. Bouman, and B. Wohlberg, “Plug-and-play priors for model based reconstruction,” in 2013 IEEE Global Conference on Signal and Information Processing, 2013, pp. 945–948.
- [4] C. A. Metzler, A. Maleki, and R. G. Baraniuk, “BM3D-AMP: A new image recovery algorithm based on BM3D denoising,” in 2015 IEEE International Conference on Image Processing (ICIP), 2015, pp. 3116–3120.
- [5] Y. Romano, M. Elad, and P. Milanfar, “The little engine that could: Regularization by denoising (RED),” SIAM Journal on Imaging Sciences, vol. 10, no. 4, pp. 1804–1844, 2017.
- [6] K. Zhang, W. Zuo, S. Gu, and L. Zhang, “Learning deep CNN denoiser prior for image restoration,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 3929–3938.
- [7] T. Meinhardt, M. Moller, C. Hazirbas, and D. Cremers, “Learning proximal operators: Using denoising networks for regularizing inverse imaging problems,” in Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 1781–1790.
- [8] D. L. Donoho and J. M. Johnstone, “Ideal spatial adaptation by wavelet shrinkage,” biometrika, vol. 81, no. 3, pp. 425–455, 1994.
- [9] D. L. Donoho and I. M. Johnstone, “Adapting to unknown smoothness via wavelet shrinkage,” Journal of the american statistical association, vol. 90, no. 432, pp. 1200–1224, 1995.
- [10] S. G. Chang, B. Yu, and M. Vetterli, “Adaptive wavelet thresholding for image denoising and compression,” IEEE transactions on image processing, vol. 9, no. 9, pp. 1532–1546, 2000.
- [11] T. Blu and F. Luisier, “The SURE-LET approach to image denoising,” IEEE Transactions on Image Processing, vol. 16, no. 11, pp. 2778–2786, 2007.
- [12] M. Elad and M. Aharon, “Image denoising via sparse and redundant representations over learned dictionaries,” IEEE Transactions on Image processing, vol. 15, no. 12, pp. 3736–3745, 2006.
- [13] W. Dong, X. Li, L. Zhang, and G. Shi, “Sparsity-based image denoising via dictionary learning and structural clustering,” in CVPR 2011. IEEE, 2011, pp. 457–464.
- [14] A. Buades, B. Coll, and J.-M. Morel, “A non-local algorithm for image denoising,” in 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), vol. 2. IEEE, 2005, pp. 60–65.
- [15] M. Mahmoudi and G. Sapiro, “Fast image and video denoising via nonlocal means of similar neighborhoods,” IEEE signal processing letters, vol. 12, no. 12, pp. 839–842, 2005.
- [16] K. Dabov, A. Foi, V. Katkovnik, and K. Egiazarian, “Image denoising by sparse 3-D transform-domain collaborative filtering,” IEEE Transactions on image processing, vol. 16, no. 8, pp. 2080–2095, 2007.
- [17] S. Gu, L. Zhang, W. Zuo, and X. Feng, “Weighted nuclear norm minimization with application to image denoising,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2014, pp. 2862–2869.
- [18] J. Xu, L. Zhang, D. Zhang, and X. Feng, “Multi-channel weighted nuclear norm minimization for real color image denoising,” in 2017 IEEE International Conference on Computer Vision (ICCV), 2017, pp. 1105–1113.
- [19] H. C. Burger, C. J. Schuler, and S. Harmeling, “Image denoising: Can plain neural networks compete with BM3D?” in 2012 IEEE conference on computer vision and pattern recognition. IEEE, 2012, pp. 2392–2399.
- [20] Y. Chen and T. Pock, “Trainable nonlinear reaction diffusion: A flexible framework for fast and effective image restoration,” IEEE transactions on pattern analysis and machine intelligence, vol. 39, no. 6, pp. 1256–1272, 2016.
- [21] K. Zhang, W. Zuo, Y. Chen, D. Meng, and L. Zhang, “Beyond a Gaussian denoiser: Residual learning of deep CNN for image denoising,” IEEE transactions on image processing, vol. 26, no. 7, pp. 3142–3155, 2017.
- [22] K. Zhang, W. Zuo, and L. Zhang, “FFDNet: Toward a fast and flexible solution for CNN-based image denoising,” IEEE Transactions on Image Processing, vol. 27, no. 9, pp. 4608–4622, 2018.
- [23] S. Guo, Z. Yan, K. Zhang, W. Zuo, and L. Zhang, “Toward convolutional blind denoising of real photographs,” 2019.
- [24] D. Donoho and M. Raimondo, “A fast wavelet algorithm for image deblurring,” ANZIAM Journal, vol. 46, pp. C29–C46, 2004.
- [25] N. Pustelnik, A. Benazza-Benhayia, Y. Zheng, and J.-C. Pesquet, “Wavelet-based image deconvolution and reconstruction,” Wiley Encyclopedia of Electrical and Electronics Engineering, pp. 1–34, 1999.
- [26] B. Dong, H. Ji, J. Li, Z. Shen, and Y. Xu, “Wavelet frame based blind image inpainting,” Applied and Computational Harmonic Analysis, vol. 32, no. 2, pp. 268–279, 2012.
- [27] L. He and Y. Wang, “Iterative support detection-based split bregman method for wavelet frame-based image inpainting,” IEEE Transactions on Image Processing, vol. 23, no. 12, pp. 5470–5485, 2014.
- [28] W. Sweldens, “The lifting scheme: A construction of second generation wavelets,” SIAM journal on mathematical analysis, vol. 29, no. 2, pp. 511–546, 1998.
- [29] I. Daubechies and W. Sweldens, “Factoring wavelet transforms into lifting steps,” Journal of Fourier analysis and applications, vol. 4, no. 3, pp. 247–269, 1998.
- [30] S. Mohan, Z. Kadkhodaie, E. P. Simoncelli, and C. Fernandez-Granda, “Robust and interpretable blind image denoising via bias-free convolutional neural networks,” 2020.
- [31] M. El Helou and S. Süsstrunk, “Blind universal bayesian image denoising with gaussian noise level learning,” IEEE Transactions on Image Processing, vol. 29, pp. 4885–4897, 2020.
- [32] L. Dinh, D. Krueger, and Y. Bengio, “Nice: Non-linear independent components estimation,” arXiv preprint arXiv:1410.8516, 2014.
- [33] L. Dinh, J. Sohl-Dickstein, and S. Bengio, “Density estimation using real NVP,” arXiv preprint arXiv:1605.08803, 2016.
- [34] A. N. Gomez, M. Ren, R. Urtasun, and R. B. Grosse, “The reversible residual network: Backpropagation without storing activations,” arXiv preprint arXiv:1707.04585, 2017.
- [35] J.-H. Jacobsen, A. W. Smeulders, and E. Oyallon, “i-RevNet: Deep invertible networks,” in International Conference on Learning Representations, 2018.
- [36] M. Xiao, S. Zheng, C. Liu, Y. Wang, D. He, G. Ke, J. Bian, Z. Lin, and T.-Y. Liu, “Invertible image rescaling,” in European Conference on Computer Vision. Springer, 2020, pp. 126–144.
- [37] C. Etmann, R. Ke, and C.-B. Schönlieb, “iUNets: Learnable invertible up- and downsampling for large-scale inverse problems,” in 2020 IEEE 30th International Workshop on Machine Learning for Signal Processing (MLSP), 2020, pp. 1–6.
- [38] L. Ardizzone, C. Lüth, J. Kruse, C. Rother, and U. Köthe, “Guided image generation with conditional invertible neural networks,” arXiv preprint arXiv:1907.02392, 2019.
- [39] R. Zhao, T. Liu, J. Xiao, D. P. K. Lun, and K.-M. Lam, “Invertible image decolorization,” IEEE Transactions on Image Processing, vol. 30, pp. 6081–6095, 2021.
- [40] H. Ma, D. Liu, N. Yan, H. Li, and F. Wu, “End-to-end optimized versatile image compression with wavelet-like transform,” IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1–1, 2020.
- [41] H. Ma, D. Liu, R. Xiong, and F. Wu, “iWave: CNN-based wavelet-like transform for image compression,” IEEE Transactions on Multimedia, vol. 22, no. 7, pp. 1667–1679, 2020.
- [42] S. Li, Z. Zheng, W. Dai, J. Zou, and H. Xiong, “REV-AE: A learned frame set for image reconstruction,” in ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020, pp. 1823–1827.
- [43] J.-J. Huang and P. L. Dragotti, “LINN: Lifting inspired invertible neural network for image denoising,” in The 29th European Signal Processing Conference, EUSIPCO 2021, 2020.
- [44] Y. Liu, Z. Qin, S. Anwar, P. Ji, D. Kim, S. Caldwell, and T. Gedeon, “Invertible denoising network: A light solution for real noise removal,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 13 365–13 374.
- [45] M. J. Shensa et al., “The discrete wavelet transform: wedding the a trous and mallat algorithms,” IEEE Transactions on signal processing, vol. 40, no. 10, pp. 2464–2482, 1992.
- [46] M. X. Bastidas Rodriguez, A. Gruson, L. F. Polanía, S. Fujieda, F. P. Ortiz, K. Takayama, and T. Hachisuka, “Deep adaptive wavelet network,” in 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), 2020, pp. 3100–3108.
- [47] J.-L. Starck, J. Fadili, and F. Murtagh, “The undecimated wavelet decomposition and its reconstruction,” IEEE Transactions on Image Processing, vol. 16, no. 2, pp. 297–309, 2007.
- [48] P.-A. Absil, R. Mahony, and R. Sepulchre, Optimization algorithms on matrix manifolds. Princeton University Press, 2009.
- [49] F. Chollet, “Xception: Deep learning with depthwise separable convolutions,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 1251–1258.
- [50] I. Daubechies, M. Defrise, and C. De Mol, “An iterative thresholding algorithm for linear inverse problems with a sparsity constraint,” Communications on Pure and Applied Mathematics: A Journal Issued by the Courant Institute of Mathematical Sciences, vol. 57, no. 11, pp. 1413–1457, 2004.
- [51] K. Gregor and Y. LeCun, “Learning fast approximations of sparse coding,” in Proceedings of the 27th international conference on international conference on machine learning, 2010, pp. 399–406.
- [52] J.-J. Huang and P. L. Dragotti, “Learning deep analysis dictionaries for image super-resolution,” IEEE Transactions on Signal Processing, vol. 68, pp. 6633–6648, 2020.
- [53] X. Liu, M. Tanaka, and M. Okutomi, “Single-image noise level estimation for blind denoising,” IEEE transactions on image processing, vol. 22, no. 12, pp. 5226–5237, 2013.
- [54] S. Roth and M. J. Black, “Fields of experts,” International Journal of Computer Vision, vol. 82, no. 2, p. 205, 2009.
- [55] K. He, X. Zhang, S. Ren, and J. Sun, “Delving deep into rectifiers: Surpassing human-level performance on imagenet classification,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 1026–1034.
- [56] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” CoRR, vol. abs/1412.6, 2014.
- [57] D. Zoran and Y. Weiss, “From learning models of natural image patches to whole image restoration,” in 2011 International Conference on Computer Vision. IEEE, 2011, pp. 479–486.
- [58] A. Levin, Y. Weiss, F. Durand, and W. T. Freeman, “Understanding and evaluating blind deconvolution algorithms,” in 2009 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2009, pp. 1964–1971.