Which Strategies Matter for Noisy Label Classification? Insight into Loss and Uncertainty
Abstract
Label noise is a critical factor that degrades the generalization performance of deep neural networks, thus leading to severe issues in real-world problems. Existing studies have employed strategies based on either loss or uncertainty to address noisy labels, and ironically some strategies contradict each other: emphasizing or discarding uncertain samples or concentrating on high or low loss samples. To elucidate how opposing strategies can enhance model performance and offer insights into training with noisy labels, we present analytical results on how loss and uncertainty values of samples change throughout the training process. From the in-depth analysis, we design a new robust training method that emphasizes clean and informative samples, while minimizing the influence of noise using both loss and uncertainty. We demonstrate the effectiveness of our method with extensive experiments on synthetic and real-world datasets for various deep learning models. The results show that our method significantly outperforms other state-of-the-art methods and can be used generally regardless of neural network architectures.
1 Introduction
Recent advances in deep learning have significantly improved performance in numerous tasks due to large quantities of human-annotated data. While standard large-scale benchmark datasets used for deep learning research such as ImageNet [1] are generally clean and error-free, most real-world data contain noisy labels, which refer to observed labels that are incorrect [2]. Because obtaining reliably labeled data is expensive, labor-intensive and time-consuming, label noise is common and inevitable in most real-world datasets.
The ubiquity of noise is all the more a critical issue for it is known that learning with noisy labels severely degrades model performance. As reported by Zhang et al. [3], deep neural networks are capable of fitting random noisy labels. If even a small portion of noisy labels exists within the training data, deep learning models can eventually memorize the wrongly given labels, thus deteriorating performance. It is, therefore, necessary to design methods that are robust to label noise such that negative consequences are minimized.
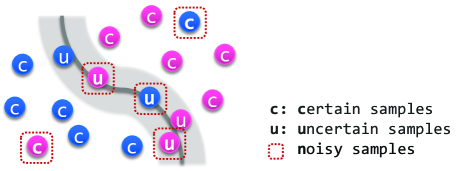
One approach for dealing with noisy labels is to focus on samples according to their uncertainty during the training phase (see Figure 1). Some methods emphasize uncertain samples, the predictions of which are inconsistent during training [4, 5]. As reported in previous studies on active learning, these uncertain samples are informative and require more training than other samples [6, 7], while samples that are well-trained and have consistent predictions have less information in improving the model. Performance can consequently be boosted by preferring uncertain samples which are near the class decision boundary. On the other hand, some methods reduce the importance or exclude uncertain samples so that only highly certain samples remain in the training data [8]. Although the impact of informative samples is minimized, it can produce a coherent model and be a safer way of training.
Another way to address noisy labels is by managing samples depending on their loss. Loss can signify the difficulty and the confidence of predictions, so giving precedence to samples with low loss or samples with high loss can work well depending on the amount of noise in the data or the complexity of the problem [9, 10]. Difficult samples are known to accelerate training, especially for datasets with a small amount of noise [11]. For this reason, there have been studies that increase the weights of high loss samples so that the network focuses on difficult samples [12]. More recently, however, researchers have somewhat ironically taken the opposite approach by emphasizing easy samples [13, 14, 15]. Because easy samples are likely to be clean, favoring low loss samples has been proven to enhance performance, especially when solving a difficult task such as training with severe label noise [4].
| Dataset | Train # | Test # | Class # | Image size |
| CIFAR-10 | 50K | 10K | 10 | 32x32 |
| CIFAR-100 | 50K | 10K | 100 | 32x32 |
| Tiny ImageNet∗ | 100K | 10K | 200 | 64x64 |
| Clothing1M | 1M noisy | 10K | 14 | 256x256 |
| ∗a subset of ImageNet [1] | ||||
In the literature, it is shown that contrasting strategies effectively diminish the effect of noisy samples, leading to improved performance over the baseline. Motivated to understand how all approaches can enhance accuracy, we analyze the changing loss and uncertainty of samples in the course of training for CIFAR-10, CIFAR-100, and Tiny ImageNet with different noise types. Data show that symmetric noise is easy to identify using either loss or uncertainty, whereas asymmetric noise is challenging to distinguish from clean samples, indicating the need for an efficient alternative method.
Inspired by the finding that only a minority of samples with low loss and high uncertainty have noisy labels, we propose FOCI (Focus On Clean and Informative samples), a novel robust training method. Our key idea is to emphasize the samples that are likely to be clean and informative. FOCI prioritizes samples with low loss and high uncertainty and minimizes the impact of samples of high loss since they are very likely to be noisy. To validate our method, we conducted extensive experiments on CIFAR-10, CIFAR-100, and Tiny ImageNet with diverse noise types from 40% to 70% of noise levels, as well as on a real-world dataset Clothing1M. Moreover, we observed the performance of training with various deep learning models to check generalizability. Our empirical analysis demonstrates the enhanced robustness of FOCI on noisy datasets, and its generalizability to any network architecture, making FOCI a useful addition to real-world deep learning pipelines.
The contribution of this paper is three-fold. (1) We identify insights on how loss and uncertainty affect noisy label classification via an in-depth analysis. (2) Inspired by these insights, we design a novel lightweight method that robustly learns by focusing on clean and informative samples from data with various conditions and types of noisy labels without any additional clean data. (3) With thorough experiments, we demonstrate our FOCI’s robustness to label noise that substantially outperforms state-of-the-art methods on a real-world dataset and three benchmark datasets injected with diverse synthetic noise.


2 Loss and Uncertainty in Noisy Datasets
We explore how loss and uncertainty differ for various label noise by training DenseNet (L=25, k=12, momentum optimizer) on three benchmark datasets, listed in Table 1: CIFAR-10, CIFAR-100, and Tiny ImageNet. These datasets are commonly used to evaluate noisy labels [16, 17]. We artificially corrupted the data by following typical protocols [13, 18]. In accordance with prior studies, for classes, noise is given by swapping true labels for other class labels with some constant probability, namely, noise rate [13]. In this experiment, we set . While labels are swapped between two classes for asymmetric noise, labels are swapped to classes other than the true class label with probability of for symmetric noise [19, 20]. Each noise type is described in Appendix A.
To analyze uncertainty in noisy datasets, we explore various representations of uncertainty. Uncertainty can be quantified by the variance of loss or predicted probabilities for a given class in a -sized history [4]. Another definition is by the variance of the predicted probabilities over all the classes at one step [21, 22]. The normalized distributions of each definition where are displayed in Figure 2. The difference of distributions between noisy and clean samples is more pronounced for variance based on the history of predicted probabilities, so we use this definition for uncertainty.
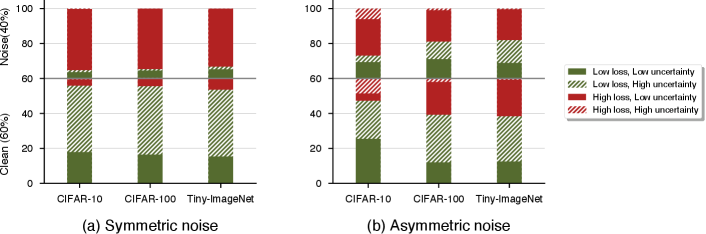
As can be seen from Figure 3, we check samples based on their loss and uncertainty (prediction variance) by dividing them into four groups. Samples are split into low loss and high loss with a ratio of as suggested by Han et al. [13]. The same applies for uncertainty in which the ratio of low uncertainty and high uncertainty samples is . The proportions concerning loss and uncertainty did not change much during training, so we only display the results at epoch 50 due to lack of space. The detailed results can be found in Appendix B.
2 .1 Analysis of symmetric noise
As shown in Figures 2a and 3a, clean and noisy samples have distinct characteristics for symmetric noise, seemingly due to the easiness of symmetric noise and deep neural networks’ capability of generalizing on data with symmetric noise [23]. The majority of clean samples have lower loss and relatively higher uncertainty than noisy samples, providing evidence for enhanced accuracy of approaches which emphasize high uncertainty. In contrast to clean samples, most noisy samples have higher loss and lower uncertainty. The loss of noisy samples tends to be higher than those of clean samples because predictions are different from the given labels, and the uncertainty of noisy samples is close to 0 because the predicted probabilities for the given noisy labels maintain a very small value. Approaches that emphasize easy samples (low loss) or uncertain samples can thus benefit from this fact. These findings not only support our idea of emphasizing low loss and high uncertainty samples, but also confirm that symmetric noise is an easy problem to be solved and less practical as stated in prior works [13, 24].
2 .2 Analysis of asymmetric noise
Inspection of Figure 3b indicates that noisy samples can have high or low loss and uncertainty, thus justifying the enhanced performance of strategies that contradicted each other. However, according to Figure 2b, it is not effective to distinguish clean and noisy samples solely based on loss or uncertainty; the loss of clean and noisy samples are alike, and the difference between the uncertainty of clean and noisy samples is very subtle. Taking both loss and uncertainty into consideration seems more effective and plausible when training data with asymmetric noise, which is problematic and similar to real-world noise [24, 25].
Input: mini-batch from dataset
3 Method
3 .1 Overview
To validate findings from our analysis, we design a novel lightweight method FOCI that aims at focusing on clean and informative samples. The overall procedure of our method is summarized in Algorithm 1.
Let the training set be of size , and the dataset for a mini-batch be of size . When training a network parameter in the warm-up phase with learning rate (Lines 2-3), updating parameters can be formulated as:
| (1) |
The algorithm starts by updating the network in the conventional way stated above. This is because deep neural networks can learn simple and common patterns, even with the presence of noisy labels during the early warm-up phase [19, 26]. However, since real-world datasets are bound to have noise, our method pursues robust training after the warm-up phase (Lines 4-6) by reweighting samples so clean and informative samples are emphasized and the impact of noisy samples are minimized:
| (2) |
where is the reweighting function.
[ caption = Classification accuracy (%) on benchmark datasets with noise. Asymmetric and symmetric noise are denoted by A and S respectively. , label = tab:all, doinside = , pos=t ]cl|ccccc
Default Active Bias Coteaching SELFIE FOCI
Asymmetric noise CIFAR-10 71.81.5 78.01.5 83.71.4 84.90.1 86.20.4
CIFAR-100 45.31.4 50.30.6 47.31.4 52.80.5 59.50.9
Tiny ImageNet 30.80.1 33.20.9 30.30.5 36.10.3 37.60.9
Mixed noise
(A-, S-)
CIFAR-10 79.60.8 84.90.5 80.61.7 84.90.9 85.70.4
CIFAR-100 49.90.7 56.20.5 50.90.8 58.50.3 61.50.5
Tiny ImageNet 35.00.8 36.20.4 34.00.6 39.00.6 39.70.7
Mixed noise
(A-, S-)
CIFAR-10 81.20.8 84.80.3 82.10.3 84.80.4 86.10.9
CIFAR-100 53.00.4 58.21.1 54.21.0 59.10.5 60.60.5
Tiny ImageNet 36.80.9 37.60.6 37.11.5 37.90.2 37.90.2
Nearest noise CIFAR-100 45.80.8 54.80.7 55.90.8 57.80.3 57.90.5
3 .2 Sample weighting
Our aim is to ensure that clean and informative samples contribute more to training, so we place more importance on samples with low loss and high uncertainty. Because the loss value and the predicted softmax probability are inversely proportional to each other, emphasizing samples with a high predicted probability of the given label would more or less be identical to focusing on samples with low loss. As a result, to favor clean samples, we compute using , the predicted probability of the given label, and , the variance of predicted probabilities in the history queue for epochs from to .
| (3) |
The weights are subsequently standardized (i.e., mean is 0 and standard deviation is 1), and bounded with the sigmoid function to give a clipping effect, and are further divided by a normalizing factor to have unit mean. These normalized sample weights are multiplied to the loss function, allowing cleaner samples to contribute more when updating the network (Line 6).
We also reduce the impact of samples that are likely to be noisy using methods partially based on SELFIE. We screen samples with inconsistent predictions and high loss or samples with consistent predictions but the predicted label disagrees from the given label, and set their weights to zero.
Inconsistency is represented by a normalized information entropy of label frequency i.e., , where denotes the frequency proportion of label in the sized prediction history, and denotes each predicted class label of classes. Samples that have inconsistency values higher than a certain threshold are considered noisy because their predicted classes have changed constantly during training. To identify high loss samples, we adopt the widely used loss-based separation method. Loss values ranked in the top within the minibatch are classified as high loss. The noise rate can be estimated through cross-validation if unknown [27, 28].
4 Experiments
Datasets and label corruption schemes. To validate the effectiveness of our method, we perform an image classification task on three benchmark datasets: CIFAR-10111https://www.cs.toronto.edu/~kriz/cifar.html, CIFAR-100††footnotemark: , and Tiny ImageNet222https://www.kaggle.com/c/tiny-imagenet and a real-world dataset Clothing1M [29] (see Table 1). For the benchmark datasets, we use four label corruption schemes: symmetric noise, asymmetric noise, mixed noise, and nearest label transfer. In this work, we are concerned with scenarios of abundant data with very poor but realistic label quality. Because labelers make mistakes within very few and similar classes [13, 24, 25], asymmetric noise is injected to these datasets with varying noise rates , and symmetric noise is mixed with asymmetric noise. To simulate confusions between visually similar classes, we also employ nearest label transfer [30], in which labels are swapped according to a confusion matrix of a pretrained network. All the noise types are detailed in Appendix A.
Experimental settings. We use two different schemes for the learning rate policy and number of epochs depending on the type of noise that is used. For symmetric noise, we follow the experimental settings of Arazo et al. [31] and train PreAct ResNet-18 using SGD with a momentum of 0.9, weight decay of , and a batch size of 128 for 300 epochs. The initial learning rate is 0.1 and reduced by a factor of 10 at epoch 100 and 250. We set , , for CIFAR-10 and for CIFAR-100. Data preprocessing and augmentation is also applied, including mean subtraction, horizontal random flip, 32x32 random crops after padding with 4 pixels on each side, and mixup augmentation [32]. We report the best classification accuracy (i.e., the percentage of correct predictions out of the entire test dataset) across epochs following prior works [30, 31]. For other types of noise, we trained DenseNet (L=25, k=12) for 100 epochs using SGD with a momentum of 0.9 in line with experiments conducted by Huang et al. [33]. The initial learning rate is 0.1 and divided by 5 at epoch 50 and 75. We use batch size of 128, , , and . Each image is scaled to have zero mean and unit variance. We measure performance by the mean of last classification accuracies over three runs for it is common to measure the robustness of noisy labels with the test error at the end of training [5, 8]. We also compute the label precision by the fraction of true clean samples among all the samples selected for training or samples that have non-zero weights. All of the experiments were executed using NAVER Smart Machine Learning (NSML) platform [34, 35].
4 .1 Performance Comparison
Baselines. We compare FOCI with a baseline algorithm (denoted by Default), which trains noisy data without any strategies, an uncertainty-based approach Active Bias, loss-based approach Coteaching, and a hybrid approach SELFIE. Active Bias [4] emphasizes uncertain samples with high prediction variances. Coteaching [13] uses two networks that feed each other low loss samples. SELFIE [8] selects low loss samples and relabels samples with high certainty. It is fair to compare algorithms with the same number of epochs, so we did not restart SELFIE, which caused different results from the paper. FOCI can handle label noise with only a noisy train dataset, so we did not compare methods that require an additional clean dataset [36].
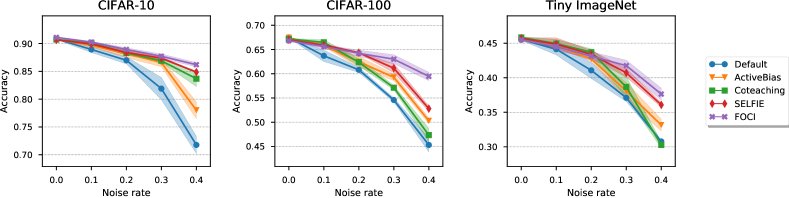
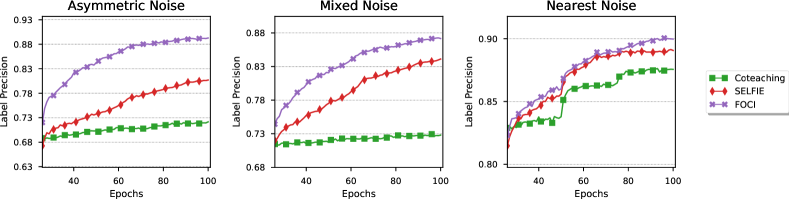
Asymmetric noise. Figure 4 displays the test accuracies of FOCI along with other baseline methods for varying rates of asymmetric noise. It appears that the performance of Default degrades drastically as the noise rate increases. Although other methods achieve higher accuracies than those of Default, our method outperforms all other baselines with significant margins for each dataset and noise rate. Moreover, as can be seen from Table LABEL:tab:all, there is a remarkable improvement in performance for CIFAR-100 where the accuracy differs with the second-best algorithm by 7%. Figure 5 also shows that our method is effective at detecting and filtering out noise even for the difficult scenario of asymmetric noise.
[ pos=t, caption = Classification accuracy (%) on CIFAR-100 with high-level noise. Asymmetric and symmetric noise are denoted by A and S respectively., label = tab:largenoise, doinside = ]cc|ccccc
Default Active Bias Coteaching SELFIE FOCI
Mixed noise 50% (A-40, S-10) 38.01.2 41.21.0 37.30.9 42.12.7 48.82.1
Mixed noise 60% (A-30, S-30) 35.90.4 40.81.5 37.00.7 43.80.4 48.51.4
Mixed noise 70% (A-20, S-50) 32.90.7 35.80.5 32.20.2 41.50.9 42.02.2
Nearest noise 60% 36.30.9 43.20.1 44.01.6 46.61.1 47.10.9
[
pos=t,
caption = Classification accuracy (%) of various architectures on CIFAR-100 with asymmetric noise.,
label = tab:modelcomparison,
doinside = ,
]l|ccccc
Default Active Bias Coteaching SELFIE FOCI
DenseNet 45.31.4 50.30.6 47.31.4 52.80.5 59.50.9
VGG-19 35.41.9 31.40.7 35.60.5 39.30.3 43.10.6
ResNet50 29.80.2 28.20.5 32.60.2 32.80.2 35.90.4
MobileNetV2 32.90.6 38.10.6 31.90.8 35.10.2 39.10.2
Mixed noise. According to Table LABEL:tab:all, the performance of FOCI achieves the best performance for mixed noise. As symmetric noise increases under the same noise level, the accuracy of Default increases, presumably resulting from that symmetric noise is easy to distinguish. This result is in good agreement with results from Section 2. We can also observe that the difference between Default and other baselines reduces with more symmetric noise, indicating that symmetric noise does not require developed algorithms and lacks significance. Furthermore, FOCI can identify noise with high precision than other methods as indicated in Figure 5. These results of mixed noise imply our model’s advantages against noisy real-world data, where symmetric and asymmetric noise may coexist.
Nearest noise. We can observe from Table LABEL:tab:all that FOCI yields higher accuracy for nearest noise compared to other methods. The label precision of our method also surpasses other methods and continues to increase as training proceeds, while other methods appear to converge towards the end of training as shown in Figure 5.
High level noise. To validate our method for another challenging problem, we conducted experiments on CIFAR-100 with larger noise rates for mixed noise and nearest noise. As shown in Table LABEL:tab:largenoise, FOCI outperforms other state-of-the-art methods for larger noise rates. These results confirm that our method effectively downplays noisy samples and emphasizes clean and informative samples for all noise types.
Symmetric noise. When adding symmetric noise, the true label can be included or excluded from the candidates of labels to be swapped, so we evaluated our method for both cases. We present the results of both definitions of symmetric noise in Appendix C due to lack of space and show that FOCI achieves comparable or better performance than other state-of-the-art methods for symmetric noise.
Model architectures. We evaluated whether FOCI is generic by comparing the performance of each method using various model architectures trained on CIFAR-100 with 40% asymmetric noise. As shown in Table LABEL:tab:modelcomparison, FOCI obtains the highest accuracy while producing consistent results despite changes in architectures. DenseNet (L=25, k=12) had the smallest architecture, thereby yielding better performance than those of other models such as ResNet50, which suffered severe overfitting. These results suggest that FOCI can be reliably applied to different model architectures.
| Variations | Acc.[%] |
|---|---|
| None (all the same) | 57.11.0 |
| Low loss | 52.41.0 |
| High uncertainty | 55.71.7 |
| \hdashlineLow loss, high uncertainty | 59.50.9 |
4 .2 Empirical Analysis of Algorithm
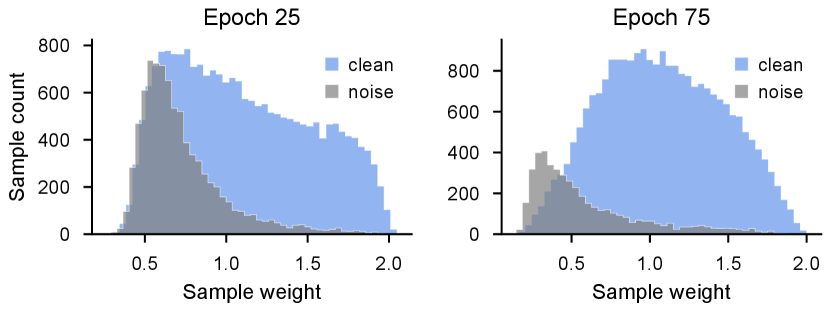
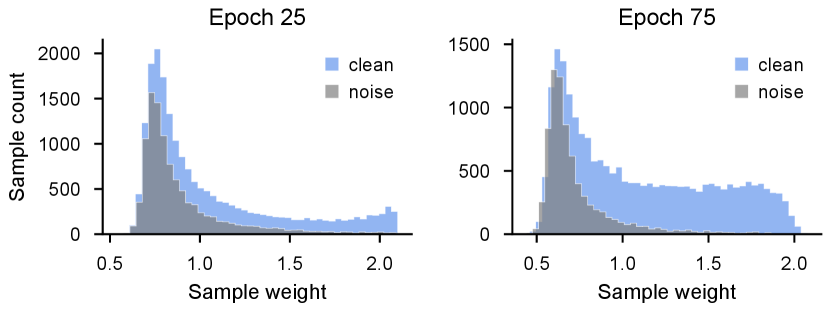
To comprehensively understand loss and uncertainty in our method, we conducted experiments on CIFAR-100 with 40% asymmetric noise. Figure 6 displays how sample weights of FOCI change from soon after the warm-up stage (epoch 25) to convergence (epoch 75). We can observe that clean samples are allocated with larger weights, while noisy samples are allocated with smaller weights as training progresses. Moreover, the number of clean samples with non-zero weights increases, and the number of noisy samples, on the contrary, decreases (see also Figure 5). These results demonstrate our approach’s effectiveness towards minimizing the impact of label noise and boosting the benefits of informative clean samples.
We also evaluated the weighting module for three approaches: placing larger weights on low loss, on high uncertainty, and treating every sample equally. As shown in Table 3, our weighting method outperforms other cases. Interestingly, giving equal weights achieved the best accuracy out of the three alternatives, while emphasizing samples with low loss led to the lowest accuracy. These results are parallel to Figure 4 in that Coteaching, which focuses on low loss samples, performs worse than Active Bias, which emphasizes high uncertainty samples. The detailed results of the ablation study is in Appendix D.
4 .3 Experiments on Clothing1M
To further demonstrate our method’s effectiveness to realistic noise, we test on Clothing1M [29], which comprises clothing data crawled from online shopping websites. Clothing1M consists of 1M images with real-world noisy labels and additional 50K, 14K, 10K verified clean data for training, validation and testing respectively. We retrain ResNet50 pretrained on ImageNet for 20 epochs using the 1M noisy dataset without any clean data in the training process. We use SGD with momentum of 0.9, , , , and because the estimated noise rate is 38% [14, 25]. The initial learning rate is 0.002 and is decreased by 10 every 5 epochs. For preprocessing, we resize images to 256x256 and randomly crop 224x224 from the resized images. This dataset is greatly imbalanced so we randomly select a relatively balanced subset of up to 35,000 samples for each class.
As shown in Table 3, our method achieves 73.8% accuracy, which is higher than recent state-of-the-art methods. For fair comparison, we do not include methods using different backbone models or any clean data during training.
5 Conclusion
In this paper, we have investigated the behavior of loss and uncertainty of samples for various noise. We have shown that for symmetric noise, noisy samples can be clearly identified with respect to either loss or uncertainty. For asymmetric noise—a more complex noisy label scenario that commonly occurs in real-world datasets—it is observed that considering both loss and uncertainty is necessary. Inspired by the findings, we have designed a novel method that aims at downplaying noisy samples while emphasizing clean and informative samples. Through series of experiments, we have demonstrated the effectiveness of FOCI when training with realistic synthetic label noise and real-world datasets as well as its generalizability in that it can be applied to any model architecture.
References
- [1] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009.
- [2] Benoît Frénay and Michel Verleysen. Classification in the presence of label noise: a survey. IEEE Transactions on Neural Networks and Learning Systems, 25(5):845–869, 2013.
- [3] Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol Vinyals. Understanding deep learning requires rethinking generalization. In International Conference on Learning Representations, 2017.
- [4] Haw-Shiuan Chang, Erik Learned-Miller, and Andrew McCallum. Active bias: Training more accurate neural networks by emphasizing high variance samples. In Advances in Neural Information Processing Systems, pages 1002–1012, 2017.
- [5] Eran Malach and Shai Shalev-Shwartz. Decoupling “when to update" from “how to update". In Advances in Neural Information Processing Systems, pages 960–970, 2017.
- [6] Andrew I Schein and Lyle H Ungar. Active learning for logistic regression: an evaluation. Machine Learning, 68(3):235–265, 2007.
- [7] Ajay J Joshi, Fatih Porikli, and Nikolaos Papanikolopoulos. Multi-class active learning for image classification. In IEEE Conference on Computer Vision and Pattern Recognition, pages 2372–2379, 2009.
- [8] Hwanjun Song, Minseok Kim, and Jae-Gil Lee. Selfie: Refurbishing unclean samples for robust deep learning. In International Conference on Machine Learning, pages 5907–5915, 2019.
- [9] Geoffrey E Hinton. To recognize shapes, first learn to generate images. Progress in Brain Research, 165:535–547, 2007.
- [10] Ilya Loshchilov and Frank Hutter. Online batch selection for faster training of neural networks. In International Conference on Learning Representations, 2016.
- [11] Tomasz Malisiewicz, Abhinav Gupta, and Alexei Efros. Ensemble of exemplar-svms for object detection and beyond. In IEEE International Conference on Computer Vision, pages 89–96, 2011.
- [12] Abhinav Shrivastava, Abhinav Gupta, and Ross Girshick. Training region-based object detectors with online hard example mining. In IEEE Conference on Computer Vision and Pattern Recognition, pages 761–769, 2016.
- [13] Bo Han, Quanming Yao, Xingrui Yu, Gang Niu, Miao Xu, Weihua Hu, Ivor Tsang, and Masashi Sugiyama. Co-teaching: Robust training of deep neural networks with extremely noisy labels. In Advances in Neural Information Processing Systems, pages 8527–8537, 2018.
- [14] Jinchi Huang, Lie Qu, Rongfei Jia, and Binqiang Zhao. O2u-net: A simple noisy label detection approach for deep neural networks. In IEEE International Conference on Computer Vision, pages 3326–3334, 2019.
- [15] Pengfei Chen, Ben Ben Liao, Guangyong Chen, and Shengyu Zhang. Understanding and utilizing deep neural networks trained with noisy labels. In International Conference on Machine Learning, pages 1062–1070, 2019.
- [16] Jacob Goldberger and Ehud Ben-Reuven. Training deep neural-networks using a noise adaptation layer. In International Conference on Learning Representations, 2017.
- [17] Scott Reed, Honglak Lee, Dragomir Anguelov, Christian Szegedy, Dumitru Erhan, and Andrew Rabinovich. Training deep neural networks on noisy labels with bootstrapping. In International Conference on Learning Representations, 2015.
- [18] Brendan van Rooyen, Aditya Menon, and Robert C Williamson. Learning with symmetric label noise: The importance of being unhinged. In Advances in Neural Information Processing Systems, pages 10–18, 2015.
- [19] Lu Jiang, Zhengyuan Zhou, Thomas Leung, Li-Jia Li, and Li Fei-Fei. Mentornet: Learning data-driven curriculum for very deep neural networks on corrupted labels. In International Conference on Machine Learning, pages 2309–2318, 2018.
- [20] Yisen Wang, Weiyang Liu, Xingjun Ma, James Bailey, Hongyuan Zha, Le Song, and Shu-Tao Xia. Iterative learning with open-set noisy labels. In IEEE Conference on Computer Vision and Pattern Recognition, pages 8688–8696, 2018.
- [21] Ksenia Konyushkova, Raphael Sznitman, and Pascal Fua. Learning active learning from data. In Advances in Neural Information Processing Systems, pages 4225–4235, 2017.
- [22] Yazhou Yang and Marco Loog. A variance maximization criterion for active learning. Pattern Recognition, 78:358–370, 2018.
- [23] David Rolnick, Andreas Veit, Serge Belongie, and Nir Shavit. Deep learning is robust to massive label noise. arXiv preprint arXiv:1705.10694, 2017.
- [24] Mengye Ren, Wenyuan Zeng, Bin Yang, and Raquel Urtasun. Learning to reweight examples for robust deep learning. In International Conference on Machine Learning, pages 4334–4343, 2018.
- [25] Kun Yi and Jianxin Wu. Probabilistic end-to-end noise correction for learning with noisy labels. In IEEE Conference on Computer Vision and Pattern Recognition, pages 7017–7025, 2019.
- [26] Devansh Arpit, Stanisław Jastrzębski, Nicolas Ballas, David Krueger, Emmanuel Bengio, Maxinder S Kanwal, Tegan Maharaj, Asja Fischer, Aaron Courville, Yoshua Bengio, and Simon Lacoste-Julien. A closer look at memorization in deep networks. In International Conference on Machine Learning, pages 233–242, 2017.
- [27] Yuncheng Li, Jianchao Yang, Yale Song, Liangliang Cao, Jiebo Luo, and Li-Jia Li. Learning from noisy labels with distillation. In IEEE International Conference on Computer Vision, pages 1910–1918, 2017.
- [28] Tongliang Liu and Dacheng Tao. Classification with noisy labels by importance reweighting. IEEE Transactions on Pattern Analysis and Machine Intelligence, 38(3):447–461, 2015.
- [29] Tong Xiao, Tian Xia, Yi Yang, Chang Huang, and Xiaogang Wang. Learning from massive noisy labeled data for image classification. In IEEE Conference on Computer Vision and Pattern Recognition, pages 2691–2699, 2015.
- [30] Paul Hongsuck Seo, Geeho Kim, and Bohyung Han. Combinatorial inference against label noise. In Advances in Neural Information Processing Systems, pages 1171–1181, 2019.
- [31] Eric Arazo, Diego Ortego, Paul Albert, Noel E O’Connor, and Kevin McGuinness. Unsupervised label noise modeling and loss correction. In International Conference on Machine Learning, June 2019.
- [32] Hongyi Zhang, Moustapha Cisse, Yann N Dauphin, and David Lopez-Paz. mixup: Beyond empirical risk minimization. In International Conference on Learning Representations, 2018.
- [33] Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q Weinberger. Densely connected convolutional networks. In IEEE Conference on Computer Vision and Pattern Recognition, pages 4700–4708, 2017.
- [34] Hanjoo Kim, Minkyu Kim, Dongjoo Seo, Jinwoong Kim, Heungseok Park, Soeun Park, Hyunwoo Jo, KyungHyun Kim, Youngil Yang, Youngkwan Kim, et al. Nsml: Meet the mlaas platform with a real-world case study. arXiv preprint arXiv:1810.09957, 2018.
- [35] Nako Sung, Minkyu Kim, Hyunwoo Jo, Youngil Yang, Jingwoong Kim, Leonard Lausen, Youngkwan Kim, Gayoung Lee, Donghyun Kwak, Jung-Woo Ha, et al. Nsml: A machine learning platform that enables you to focus on your models. arXiv preprint arXiv:1712.05902, 2017.
- [36] Jun Shu, Qi Xie, Lixuan Yi, Qian Zhao, Sanping Zhou, Zongben Xu, and Deyu Meng. Meta-weight-net: Learning an explicit mapping for sample weighting. In Advances in Neural Information Processing Systems, pages 1917–1928, 2019.
- [37] Giorgio Patrini, Alessandro Rozza, Aditya Krishna Menon, Richard Nock, and Lizhen Qu. Making deep neural networks robust to label noise: A loss correction approach. In IEEE Conference on Computer Vision and Pattern Recognition, pages 2233–2241, 2017.
- [38] Jiangchao Yao, Hao Wu, Ya Zhang, Ivor W Tsang, and Jun Sun. Safeguarded dynamic label regression for noisy supervision. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 9103–9110, 2019.
- [39] Daiki Tanaka, Daiki Ikami, Toshihiko Yamasaki, and Kiyoharu Aizawa. Joint optimization framework for learning with noisy labels. In IEEE Conference on Computer Vision and Pattern Recognition, pages 5552–5560, 2018.
- [40] Yilun Xu, Peng Cao, Yuqing Kong, and Yizhou Wang. : A novel information-theoretic loss function for training deep nets robust to label noise. In Advances in Neural Information Processing Systems, pages 6222–6233, 2019.
- [41] Junnan Li, Yongkang Wong, Qi Zhao, and Mohan S Kankanhalli. Learning to learn from noisy labeled data. In IEEE Conference on Computer Vision and Pattern Recognition, pages 5051–5059, 2019.
- [42] Xingjun Ma, Yisen Wang, Michael E Houle, Shuo Zhou, Sarah M Erfani, Shu-Tao Xia, Sudanthi Wijewickrema, and James Bailey. Dimensionality-driven learning with noisy labels. In International Conference on Machine Learning, 2018.
Types of Noise
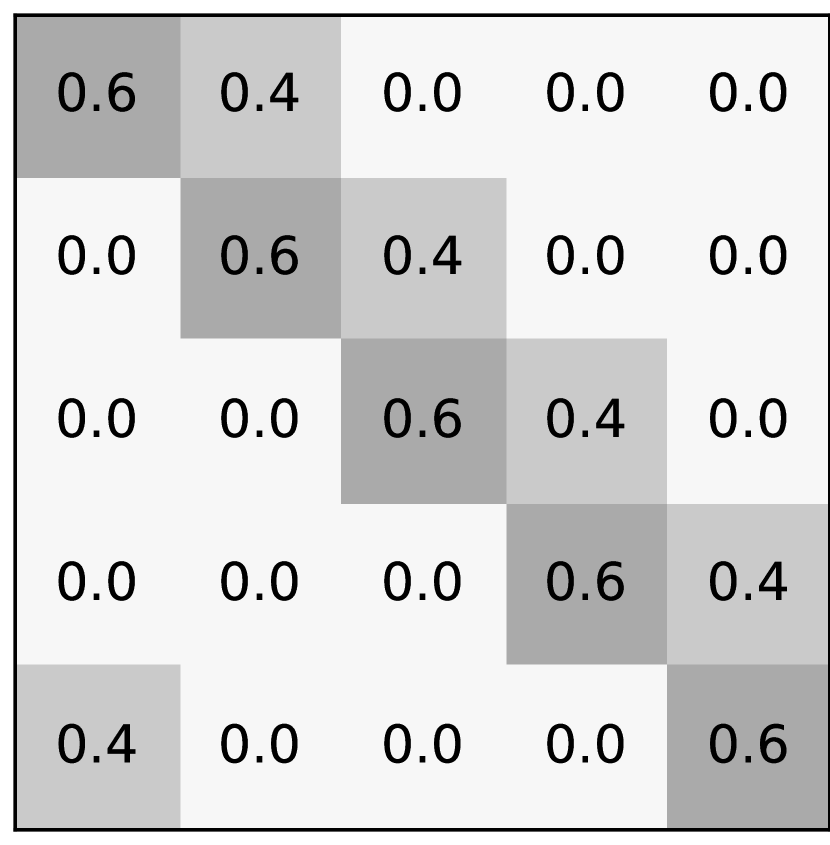
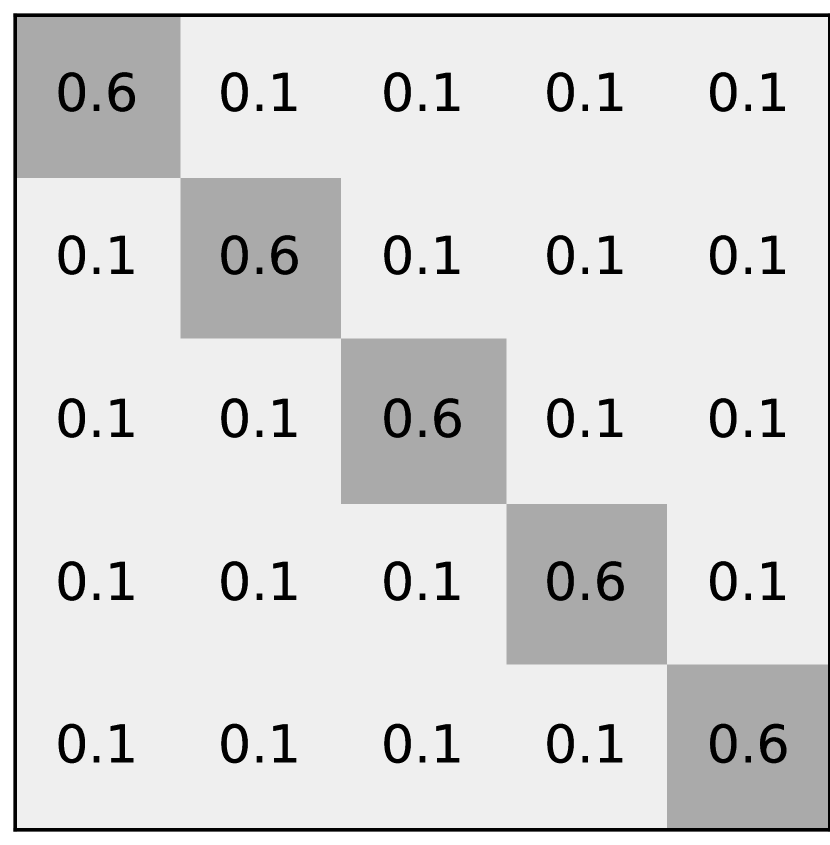
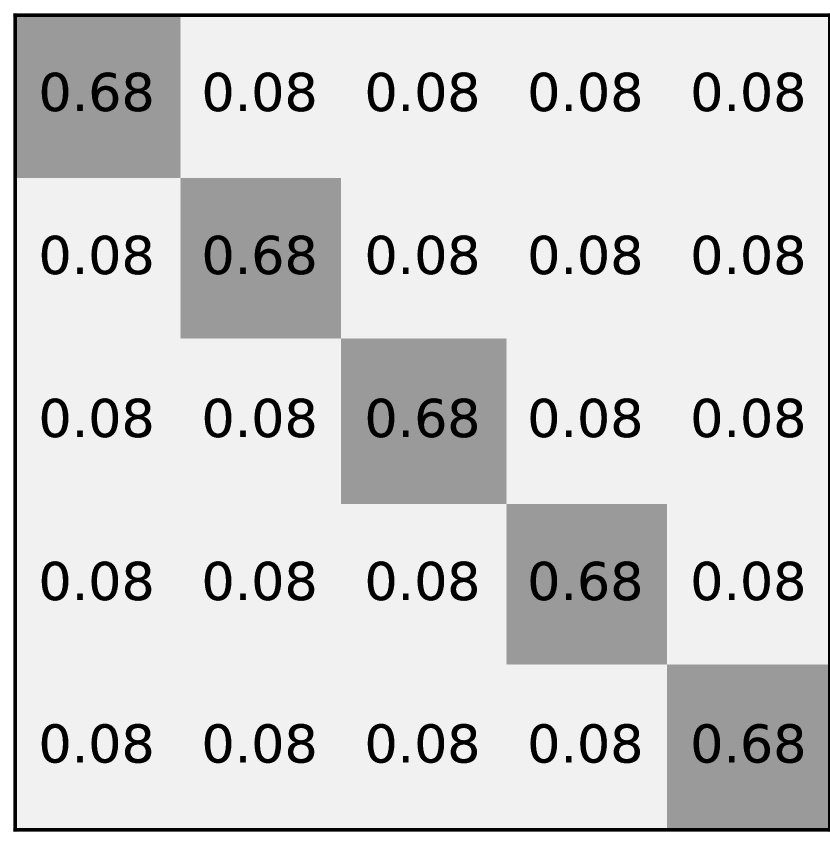
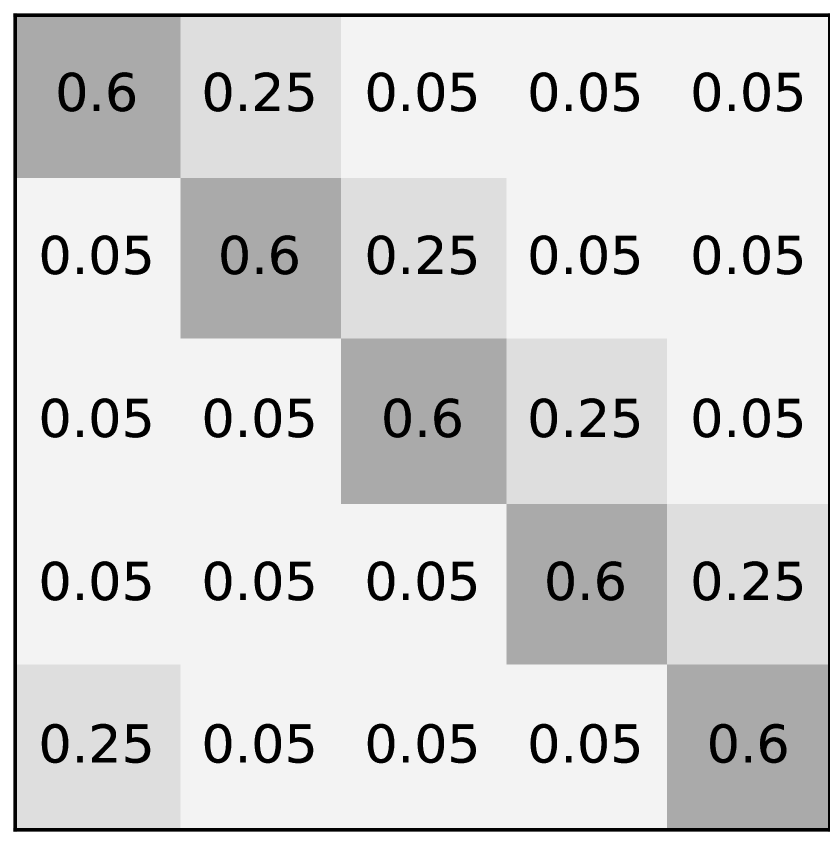
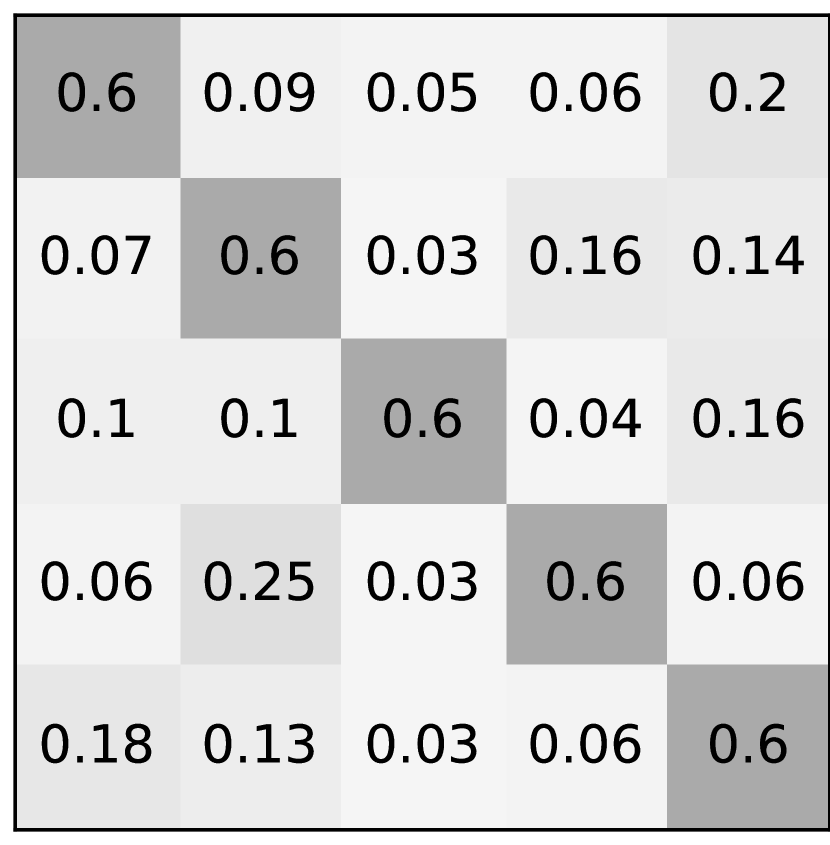
There are four types of noise used in this paper: asymmetric noise, symmetric noise, mixed noise, and nearest noise. The noise rate is denoted by . Figure 7 displays the noise transition matrices of each noise type.
As can be seen from Figure 7, asymmetric noise swaps labels between two classes with a probability of . Asymmetric noise is problematic and similar to real-world noise [24, 25]. We, therefore, place more emphasis on the results of asymmetric noise to provide a promising method for realistic noise.
For symmetric noise, which is less practical than asymmetric noise [13, 24], the true label can be swapped to any other label. There are two definitions of symmetric noise in prior works. As shown in Figure 7, one popular label noise criterion is random labeling while the true label is not selected [19, 20]. In this case, the probability of being swapped to another label is uniformly distributed with value , so the sum of probabilities being swapped becomes the noise rate . As displayed in Figure 7, another criterion for symmetric noise addition consists of randomly selecting labels for a percentage of the training data using all possible labels (i.e. the true label could be randomly maintained) [32, 39]. The probability of being swapped to another label is thus .
Mixed noise is when asymmetric noise and symmetric noise are added together as can be seen in Figure 7. Mixed noise represents the scenario of noise mainly injected from another class along with some random noise. We have experimented with mixed noise to produce more realistic noise.
Nearest noise is used to simulate confusions between visually similar classes [30]. As shown in Figure 7, the probabilities of being swapped are different for each class. For the nearest neighbor search, we use a confusion matrix of a pretrained network of the dataset. The validation accuracy of the pretrained network trained on CIFAR-100 was 53.12%.
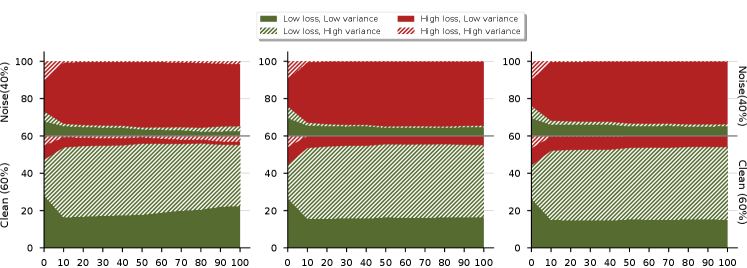
Loss and Uncertainty During Training
Figure 8 and 9 show how loss and uncertainty change throughout the training process. Clean (60%) and noisy (40%) samples are divided vertically. The green and red colors represent low and high loss samples, and the solid and stripe patterns represent low and high uncertainty samples, respectively.
As can be seen from the figures, after 10 epochs, there are subtle changes in proportions concerning loss and uncertainty during training. For symmetric noise, the proportions remain constant throughout the training process (see Figure 8). For asymmetric noise, although there are slight changes throughout training, the changes are negligible (see Figure 9). We can also observe that asymmetric noise is more problematic than symmetric noise, because samples for each combination are distributed fairly evenly for noisy and clean samples.
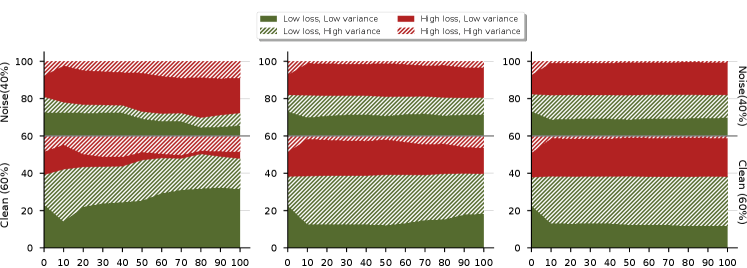
Symmetric Noise Results
More research has focused on symmetric noise or random labeling, so we compare our results with recent state-of-the-art methods: bootstrapping, forward loss, mixup, MentorNet, D2L, and MD-DYR-SH, which uses dynamic mixup, soft to hard dynamic bootstrapping with regularization. As explained in Appendix A, when adding symmetric noise, the true label can be included or excluded from the candidates of labels to be swapped. We have hence evaluated our method for both cases.
Table 4 displays the classification accuracy results of 40% symmetric noise for CIFAR-10 and CIFAR-100. FOCI was trained on datasets using PreAct ResNet-18 following the experimental settings of Arazo et al. [31]. We report the results from the paper and as shown from the table, our method achieves accuracy higher than or equivalent to other state-of-the-art methods for both symmetric noise types. However, the results on symmetric noise excluding true labels should be interpreted with care because some methods employed different architectures and used clean data during training such as in [19].
Ablation Study on Hyperparameters
We present an ablation study on hyperparameters: (queue size), (warm-up), and (threshold). We recorded the classification accuracies (%) over three runs for CIFAR-100 with 40% asymmetric noise (default q=15, g=25, e=0.1). As shown in Table LABEL:tab:hyperparam, the results do not greatly depend on hyperparameters except for the strictest case (e=0). Therefore, it can be concluded that our method is practical due to its insensitivity to hyperparameters.
[
pos=h,
caption = Ablation study on hyperparameters: .,
center,
label = tab:hyperparam,
doinside = ]ccc|c
Accuracy (%)
15 25 0.1 59.5 0.9
5 25 0.1 58.1 0.8
25 25 0.1 57.6 1.2
15 15 0.1 57.9 0.9
15 35 0.1 58.8 0.3
15 45 0.1 58.6 0.2
15 25 0.0 55.9 0.1
15 25 0.2 59.4 0.6
15 25 0.3 59.3 0.3