[table]capposition=top \newfloatcommandcapbtabboxtable[][\FBwidth]
Where am I looking at? Joint Location and Orientation Estimation by Cross-View Matching
Abstract
Cross-view geo-localization is the problem of estimating the position and orientation (latitude, longitude and azimuth angle) of a camera at ground level given a large-scale database of geo-tagged aerial (e.g., satellite) images. Existing approaches treat the task as a pure location estimation problem by learning discriminative feature descriptors, but neglect orientation alignment. It is well-recognized that knowing the orientation between ground and aerial images can significantly reduce matching ambiguity between these two views, especially when the ground-level images have a limited Field of View (FoV) instead of a full field-of-view panorama. Therefore, we design a Dynamic Similarity Matching network to estimate cross-view orientation alignment during localization. In particular, we address the cross-view domain gap by applying a polar transform to the aerial images to approximately align the images up to an unknown azimuth angle. Then, a two-stream convolutional network is used to learn deep features from the ground and polar-transformed aerial images. Finally, we obtain the orientation by computing the correlation between cross-view features, which also provides a more accurate measure of feature similarity, improving location recall. Experiments on standard datasets demonstrate that our method significantly improves state-of-the-art performance. Remarkably, we improve the top-1 location recall rate on the CVUSA dataset by a factor of for panoramas with known orientation, by a factor of for panoramas with unknown orientation, and by a factor of for -FoV images with unknown orientation.
1 Introduction

Given an image captured by a camera at ground level, it is reasonable to ask: where is the camera and which direction is it facing? Cross-view image geo-localization aims to determine the geographical location and azimuth angle of a query image by matching it against a large geo-tagged satellite map covering the region. Due to the accessibility and extensive coverage of satellite imagery, ground-to-aerial image alignment is becoming an attractive proposition for solving the image-based geo-localization problem.
However, cross-view alignment remains very difficult due to the extreme viewpoint change between ground and aerial images. The challenges are summarized as follows.
-
(1)
Significant visual differences between the views, including the appearance and projected location of objects in the scene, result in a large domain gap.
-
(2)
The unknown relative orientation between the images, when the northward direction is not known in both, leads to localization ambiguities and increases the search space.
-
(3)
Standard cameras have a limited Field of View (FoV), which reduces the discriminativeness of the ground-view features for cross-view localization, since the image region only covers local information and may match multiple aerial database images.
Existing methods cast this task as a pure location estimation problem and use deep metric learning techniques to learn viewpoint invariant features for matching ground and aerial images. Many approaches require the orientation to be provided, avoiding the ambiguities caused by orientation misalignments [15, 12, 10]. However, the orientation is not always available for ground images in practice. To handle this, some methods directly learn orientation invariant features [18, 5, 2], however they fail to address the large domain gap between ground and aerial images, limiting their localization performance.
To reduce the cross-view domain gap, we explore the geometric correspondence between ground and aerial images. We observe that there are two geometric cues that are statistically significant in real ground images under an equirectangular projection: (i) horizontal lines in the image (parallel to the azimuth axis) have approximately constant depth and so correspond to concentric circles in the aerial image; and (ii) vertical lines in the image have depth that increases with the coordinate and so correspond to radial lines in the aerial image. To be more specific, if the scene was flat, then a horizontal line in the ground image maps to a circle in the aerial image. We make use of these geometric cues by applying a polar coordinate transform to the aerial images, mapping concentric circles to horizontal lines. This reduces the differences in the projected geometry and hence the domain gap, as shown in Figure 2.
We then employ a two-stream CNN to learn feature correspondences between ground and aerial images. We extract feature volumes that preserve the spatial relationships between features, which is a critical cue for geo-localization. However, orientation misalignments lead to inferior results when using spatially-aware image features. Moreover, it is difficult to match features when a limited FoV is imaged, since the ground image contains only a small sector of the aerial image. Therefore, our intuition is to find the orientation alignment and thus facilitate accurate similarity matching.





As the polar transform projects the aerial image into the ground-view camera coordinate frame, it allows to estimate the orientation of each ground image with respect to its aerial counterpart by feature correlation. In this paper, we propose a Dynamic Similarity Matching (DSM) module to achieve that goal. To be specific, we compute the correlation between the ground and aerial features in order to generate a similarity score at each angle, marked by the red curve in Figure 1. The position of the similarity score maximum corresponds to the latent orientation of the ground image with respect to the aerial image. If the ground image has a limited FoV, we extract the appropriate local region from the aerial feature representation for localization. By using our DSM module, the feature similarity between the ground and aerial images is measured more accurately. Therefore, our method outperforms the state-of-the-art by a large margin.
The contributions of our work are:
-
•
the first image-based geo-localization method to jointly estimate the position and orientation111Throughout this paper, orientation refers to the 1-DoF azimuth angle. of a query ground image regardless of its Field of View;
-
•
a Dynamic Similarity Matching (DSM) module to measure the feature similarity of the image pair while accounting for the orientation of the ground image, facilitating accurate localization; and
-
•
extensive experimental results demonstrating that our method achieves significant performance improvements over the state-of-the-art in various geo-localization scenarios.
2 Related Work

Existing cross-view image-based geo-localization aims to estimate the location (latitude and longitude) of a ground image by matching it against a large database of aerial images. Due to the significant viewpoint changes between ground and aerial images, hand-crafted feature matching [3, 9, 11] becomes the bottleneck of the performance of cross-view geo-localization. Deep convolutional neural networks (CNNs) have proven their powerful capability on image representations [13]. This motivates recent geo-localization works to extract features from ground and aerial images with CNNs.
Workman and Jacobs [19] first introduced deep features to the cross-view matching task. They used an AlexNet [7] network fine-tuned on Imagenet [13] and Places [22] to extract deep features for cross-view image matching. They demonstrated that further tuning of the aerial branch by minimizing the distance between matching ground and aerial pairs led to better localization performance [20]. Vo and Hays [18] investigated a set of CNN architectures (classification, hybrid, Siamese and triplet CNNs) for matching cross-view images. Considering the orientation misalignments between ground and aerial images, they proposed an auxiliary orientation regression block to let the network learn orientation-aware feature representations, and used multiple aerial images with different orientations during testing phase. To learn orientation invariant features, Hu et al. [5] embedded a NetVlad layer [1] on top of a two-branch CNN for cross-view image matching. Cai et al. [2] introduced a lightweight attention module to reweight spatial and channel features to obtain more representative descriptors, and then proposed a hard exemplar reweighting triplet loss to improve the quality of network training. They also employed an orientation regression block to force the network to learn orientation-aware features. Sun et al. [17] employed capsule networks to encode spatial feature hierarchies for feature representations. Although these methods learned orientation-aware descriptors for localization, they overlooked the domain difference between ground and aerial images.
To bridge the large domain gap between ground and aerial images, Zhai et al. [21] learned a transformation matrix between aerial and ground features for predicting ground semantic information from aerial images. Regmi and Shah [12] synthesized an aerial image from a ground one using a generative model, and then fused features of the ground image and the synthesized aerial image as the descriptor for retrieval. Shi et al. [15] proposed a feature transport module to map ground features into the aerial domain and then conducted similarity matching. Shi et al. [14] also used polar transform to first bridge the geometric domain difference and then a spatial-aware feature aggregation module to select salient features for global feature descriptor representation. However, all those methods require ground images to be panoramas or orientation-aligned. Finally, Liu & Li [10] found that the orientation provided important clues for determining the location of a ground image, and thus explicitly encoded the ground-truth orientation as an additional network input.
In contrast to existing works, we aim to estimate the location and orientation of ground images jointly, since exploring orientation information can facilitate cross-view matching for both panoramas and images with limited FoV.
3 Location and Orientation Estimation by Cross-view Image Matching
In the cross-view image-based geo-localization task, ground images are captured by a camera whose image plane is perpendicular to the ground plane and axis is parallel to the gravity direction, and aerial images are captured from a camera whose image plane is parallel to the ground plane. Since there are large appearance variations between these two image domains, our strategy is to first reduce the projection differences between the viewpoints and then to extract discriminative features from the two domains. Furthermore, inspired by how humans localize themselves, we use the spatial relationships between objects as a critical cue for inferring location and orientation. Therefore, we enable our descriptors to encode the spatial relationship among the features, as indicated by and in Figure 3.
Despite the discriminativeness of the spatially-aware features, they are very sensitive to orientation changes. For instance, when the azimuth angle of a ground camera changes, the scene contents will be offset in the ground panorama, and the image content may be entirely different if the camera has a limited FoV, as illustrated in Figure 2. Therefore, finding the orientation of the ground images is crucial to make the spatially-aware features usable. To this end, we propose a dynamic similarity matching (DSM) module, as illustrated in Figure 3. With this module, we not only estimate the orientation of the ground images but also achieve more accurate feature similarity scores, regardless of orientation misalignments and limited FoVs, thus enhancing geo-localization performance.
3.1 A Polar Transform to Bridge the Domain Gap
Since ground panoramas222Although we use panoramic images as an example, the correspondence relationships between ground and aerial images also apply to images with limited FoV. project 360-degree rays onto an image plane using an equirectangular projection, and are orthogonal to the satellite-view images, vertical lines in the ground image correspond to radial lines in the aerial image, and horizontal lines correspond approximately to circles in the aerial image, assuming that the pixels along the line have similar depths, which occurs frequently in practice. This layout correspondence motivates us to apply a polar transform to the aerial images. In this way, the spatial layouts of these two domains can be roughly aligned, as illustrated in Figure 2(b) and Figure 2(c).
To be specific, the polar origin is set to the center of each aerial image, corresponding to the geo-tag location, and the angle is chosen as the northward direction, corresponding to the upwards direction of an aligned aerial image. In addition, we constrain the height of the polar-transformed aerial images to be the same as the ground images, and ensure that the angle subtended by each column of the polar transformed aerial images is the same as in the ground images. We apply a uniform sampling strategy along radial lines in the aerial image, such that the innermost and outermost circles of the aerial image are mapped to the bottom and top line of the transformed image respectively.
Formally, let represent the size of an aerial image and denote the target size of polar transform. The polar transform between the original aerial image points and the target polar transformed ones is
| (1) |
By applying a polar transform, we coarsely bridge the projective geometry domain gap between ground and aerial images. This allows the CNNs to focus on learning the feature correspondences between the ground and polar-transformed aerial images without consuming network capacity on learning the geometric relationship between these two domains.
3.2 A Spatially-Aware Feature Representation
Applying a translation offset along the axis of a polar-transformed image is equivalent to rotating the aerial image. Hence, the task of learning rotational equivariant features for aerial images becomes learning translational equivariant features, which significantly reduces the learning difficulty for our network since CNNs inherently have the property of translational equivariance [8]. However, since the horizontal direction represents a rotation, we have to ensure that the CNN treats the leftmost and rightmost columns of the transformed image as adjacent. Hence, we propose to use circular convolutions with wrap-around padding along the horizontal direction.
We adopt VGG16 [16] as our backbone network. In particular, the first ten layers of VGG16 are used to extract features from the ground and polar-transformed aerial images. Since the polar transform might introduce distortions along the vertical direction, due to the assumption that horizontal lines have similar finite depths, we modify the subsequent three layers which decrease the height of the feature maps but maintain their width. In this manner, our extracted features are more tolerant to distortions along the vertical direction while retaining information along the horizontal direction. We also decrease the feature channel number to by using these three convolutional layers, and obtain a feature volume of size . Our feature volume representation is a global descriptor designed to preserve the spatial layout information of the scene, thus increasing the discriminativeness of the descriptors for image matching.
3.3 Dynamic Similarity Matching (DSM)
When the orientation of ground and polar-transformed aerial features are aligned, their features can be compared directly. However, the orientation of the ground images is not always available, and orientation misalignments increase the difficulty of geo-localization significantly, especially when the ground image has a limited FoV. When humans are using a map to relocalize themselves, they determine their location and orientation jointly by comparing what they have seen with what they expect to see on the map. In order to let the network mimic this process, we compute the correlation between the ground and aerial features along the azimuth angle axis. Specifically, we use the ground feature as a sliding window and compute the inner product between the ground and aerial features across all possible orientations. Let and denote the aerial and ground features respectively, where and indicate the height and channel number of the features, and represent the width of the aerial and ground features respectively, and . The correlation between and is expressed as
| (2) |
where is the feature response at index (, , ), and denotes the modulo operation. After correlation computation, the position of the maximum value in the similarity scores is the estimated orientation of the ground image with respect to the polar-transformed aerial one.
When a ground image is a panorama, regardless of whether the orientation is known, the maximum value in the correlation results is directly converted to the distance by computing , where and are -normalized. When a ground image has a limited FoV, we crop the aerial features corresponding to the FoV of the ground image at the position of the maximum similarity score. Then we re-normalize the cropped aerial features and calculate the distance between the ground and aerial features as the similarity score for matching. Note that if there are multiple maximum similarity scores, we choose one randomly, since this means that the aerial images has symmetries that cannot be disambiguated.
3.4 Training DSM
During the training process, our DSM module is applied to all ground and aerial pairs, whether they are matching or not. For matching pairs, DSM forces the network to learn similar feature embeddings for ground and polar-transformed aerial images with discriminative feature representations along the horizontal direction (i.e., azimuth). In this way, DSM is able to identify the orientation misalignment as well as find the best feature similarity for matching. For non-matching pairs, as it is the most challenging case when they are aligned (i.e., their similarity is larger), our DSM is also used to find the most feasible orientation for a ground image aligning to a non-matching aerial one, and we minimize the maximum similarity of non-matching pairs to make the features more discriminative. Following traditional cross-view localization methods [5, 10, 15], we employ the weighted soft-margin triplet loss [5] to train our network
| (3) |
where is the query ground feature, and indicate the cropped aerial features from the matching aerial image and a non-matching aerial image respectively, and denotes the Frobenius norm. The parameter controls the convergence speed of training process; following precedents we set it to [5, 10, 15].
3.5 Implementation Details
We use the first ten convolutional layers in VGG16 with pretrained weights on Imagenet [4], and randomly initialize the parameters in the following three layers for global feature descriptor extraction. The first seven layers are kept fixed and the subsequent six layers are learned. The Adam optimizer [6] with a learning rate of is employed for training. Following [18, 5, 10, 15], we adopt an exhaustive mini-batch strategy [18] with a batch size of to create the training triplets. Specifically, for each ground image within a mini-batch, there is one matching aerial image and non-matching ones. Thus we construct triplets. Similarly, for each aerial image, there is one matching ground image and non-matching ones within a mini-batch, and thus we create another triplets. Hence, we have triplets in total.
4 Experiments
4.1 Datasets
We carry out the experiments on two standard cross-view datasets, CVUSA [21] and CVACT [10]. They both contain training ground and aerial pairs and testing pairs. Following an established testing protocol [10, 15], we denote the test sets in CVUSA and CVACT as CVUSA and CVACT_val, respectively. CVACT also provides a larger test set, CVACT_test, which contains cross-view image pairs for fine-grained city-scale geo-localization. Note that the ground images in both of the two datasets are panoramas, and all the ground and aerial images are north aligned. Figure 4 presents samples of cross-view image pairs from the two datasets.
Furthermore, we also conduct experiments on ground images with unknown orientation and limited FoV. We use the image pairs in CVUSA and CVACT_val, and randomly rotate the ground images along the azimuth direction and crop them according to a predetermined FoV. The constructed test set with different FoVs as well as our source code are available via https://github.com/shiyujiao/cross_view_localization_DSM.git.








4.2 Evaluation Metrics
Location estimation: Following the standard evaluation procedure for cross-view image localization [18, 5, 10, 15, 2, 17, 12], we use the top recall as the location evaluation metric to examine the performance of our method and compare it with the state-of-the-art. Specifically, given a ground image, we retrieve the top aerial images in terms of distance between their global descriptors. The ground image is regarded as successfully localized if its corresponding aerial image is retrieved within the top list. The percentage of correctly localized ground images is recorded as recall at top (r@).
Orientation estimation: The predicted orientation of a query ground image is meaningful only when the ground image is localized correctly. Hence, we evaluate the orientation estimation accuracy of our DSM only on ground images that have been correctly localized by the top-1 recall. In this experiment, when the differences between the predicted orientation of a ground image and its ground-truth orientation is within of its FoV, the orientation estimation of this ground image is deemed as a success. We record the percentage of ground images for which the orientation is correctly predicted as the orientation estimation accuracy (orien_acc). Since aerial images are often rotationally symmetric, orientation estimation can yield large errors, such as 180∘ for scenes that look similar in opposite directions. Hence we report the robust median orientation error, denoted as median_error, instead of the mean.
| Methods | CVUSA | |||
|---|---|---|---|---|
| r@1 | r@5 | r@10 | r@1% | |
| Workman et al. [20] | – | – | – | 34.3 |
| Zhai et al. [21] | – | – | – | 43.2 |
| Vo and Hays [18] | – | – | – | 63.7 |
| CVM-NET [5] | 22.47 | 49.98 | 63.18 | 93.62 |
| Liu & Li [10] | 40.79 | 66.82 | 76.36 | 96.12 |
| Regmi and Shah [12] | 48.75 | – | 81.27 | 95.98 |
| Siam-FCANet34 [2] | – | – | – | 98.3 |
| CVFT [15] | 61.43 | 84.69 | 90.49 | 99.02 |
| Ours | 91.96 | 97.50 | 98.54 | 99.67 |
4.3 Localizing Orientation-Aligned Panoramas
| Methods | CVACT_val | |||
|---|---|---|---|---|
| r@1 | r@5 | r@10 | r@1% | |
| CVM-NET [5] | 20.15 | 45.00 | 56.87 | 87.57 |
| Liu & Li [10] | 46.96 | 68.28 | 75.48 | 92.01 |
| CVFT [15] | 61.05 | 81.33 | 86.52 | 95.93 |
| Ours | 82.49 | 92.44 | 93.99 | 97.32 |
We first investigate the location estimation performance of our method and compare it with the state-of-the-art on the standard CVUSA and CVACT datasets, where ground images are orientation-aligned panoramas. In Table 1, we present our results on the CVUSA dataset with the recall rates reported in other works [10, 15, 5, 12, 2]. We also retrain existing networks [5, 10, 15] on the CVACT dataset using source code provided by the authors. The recall results at top-1, top-5, top-10 and top-1% on CVACT_val are presented in Table 2, and the complete r@ performance curves on CVUSA and CVACT_val are illustrated in Figure 5(a) and Figure 5(b), respectively.



Among those comparison methods, [20, 21, 18] are first explorers to apply deep-based methods to cross-view related tasks. CVM-NET [5] and Siam-FCANet34 [2] focus on designing powerful feature extraction networks. Liu & Li [10] introduce the orientation information to networks so as to facilitate geo-localization. However, all of them ignore the domain difference between ground and aerial images, thus leading to inferior performance. Regmi and Shah [12] adopt a conditional GAN to generate aerial images from ground panoramas. Although it helps to bridge the cross-view domain gap, undesired scene contents are also induced in this process. Shi et al. [15] propose a cross view feature transport module (CVFT) to better align ground and aerial features. However, it is hard for networks to learn geometric and feature response correspondences simultaneously. In contrast, our polar transform explicitly reduces the projected geometry difference between ground and aerial images, and thus eases the burden of networks. As is clear in Table 1 and Table 2, our method significantly outperforms the state-of-the-art methods by a large margin.
Fine-grained localization: We also compare our method with state-of-the-art methods on the CVACT_test dataset. This dataset provides fine-grained geo-tagged aerial images that densely cover a city, and the localization performance is measured in terms of distance (meters). Specifically, a ground image is considered as successfully localized if one of the retrieved top aerial images is within 5 meters of the ground truth location of the query ground image. Following the evaluation protocol in Liu & Li [10], we plot the percentage of correctly localized ground images (recall) at different values of in Figure 5(c). Our method achieves superior results compared to state-of-the-art on this extremely challenging test set.
| Dataset | Comparison Algorithms | FoV= | FoV= | FoV= | FoV= | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| r@1 | r@5 | r@10 | r@1% | r@1 | r@5 | r@10 | r@1% | r@1 | r@5 | r@10 | r@1% | r@1 | r@5 | r@10 | r@1% | ||
| CVUSA | CVM-NET [5] | 16.25 | 38.86 | 49.41 | 88.11 | 7.38 | 22.51 | 32.63 | 75.38 | 2.76 | 10.11 | 16.74 | 55.49 | 2.62 | 9.30 | 15.06 | 21.77 |
| CVFT [15] | 23.38 | 44.42 | 55.20 | 86.64 | 8.10 | 24.25 | 34.47 | 75.15 | 4.80 | 14.84 | 23.18 | 61.23 | 3.79 | 12.44 | 19.33 | 55.56 | |
| Ours | 78.11 | 89.46 | 92.90 | 98.50 | 48.53 | 68.47 | 75.63 | 93.02 | 16.19 | 31.44 | 39.85 | 71.13 | 8.78 | 19.90 | 27.30 | 61.20 | |
| CVACT_val | CVM-NET [5] | 13.09 | 33.85 | 45.69 | 81.80 | 3.94 | 13.69 | 21.23 | 59.22 | 1.47 | 5.70 | 9.64 | 38.05 | 1.24 | 4.98 | 8.42 | 34.74 |
| CVFT [15] | 26.79 | 46.89 | 55.09 | 81.03 | 7.13 | 18.47 | 26.83 | 63.87 | 1.85 | 6.28 | 10.54 | 39.25 | 1.49 | 5.13 | 8.19 | 34.59 | |
| Ours | 72.91 | 85.70 | 88.88 | 95.28 | 49.12 | 67.83 | 74.18 | 89.93 | 18.11 | 33.34 | 40.94 | 68.65 | 8.29 | 20.72 | 27.13 | 57.08 | |
4.4 Localizing With Unknown Orientation and Limited FoV
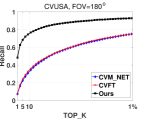
In this section, we test the performance of our algorithm and other methods, including CVM-NET [5] and CVFT [15], on the CVUSA and CVACT_val datasets in a more realistic localization scenario, where the ground images do not have a known orientation and have a limited FoV. Recall that Liu & Li [10] require orientation information as an input, so we cannot compare with this method.
Location estimation: Since existing methods are only designed to estimate the location of ground images, we only evaluate their location recall performance. In order to evaluate the impact of orientation misalignments and limited FoVs on localization performance, we randomly shift and crop the ground panoramas along the azimuth direction for the CVUSA and CVACT_val datasets. In this manner, we mimic the procedure of localizing images with limited FoV and unknown orientation. The first results column in Table 3 demonstrates the performance of localizing panoramas with unknown orientation. It is clear that our method significantly outperforms all the comparison algorithms, obtaining a improvement on CVUSA and a improvement on CVACT in terms of r@1. We also conduct comparisons with the other methods on ground images with FoVs of (fish-eye camera), (wide-angle camera) and (general phone camera) respectively in Table 3. Note that the orientation is also unknown. As illustrated in Figure 11(d), as the FoV of the ground image decreases, the image become less discriminative. This increases the difficulty of geo-localization especially when the orientation is unknown. As indicated in the second, third and fourth results column of Table 3, our method, benefiting from its DSM module, significantly reduces the ambiguity caused by unknown orientations and measures feature similarity more accurately, achieving better performance than the state-of-the-art.
Orientation estimation: As previously mentioned, the experiments of orientation estimation is conducted on ground images which are correctly localized in terms of top-1 retrieved candidates. The first row in Table 4 presents the orientation prediction accuracy of ground images with different FoVs. As indicated in the table, the orientation of almost all ground images with and FoV is predicted correctly, demonstrating the effectiveness of our DSM module for estimating the orientation of ground images. It is also clear that the matching ambiguity increases as the FoV decreases. Considering that scene contents in an aerial image might be very similar in multiple directions, the orientation estimation can be inaccurate while the estimated location is correct. For instance, a person standing on a road is able to localize their position but will find it difficult to determine their orientation if the view is similar along the road in both directions. We provide an example of this in the supplementary material. Therefore, even when our method estimates orientation inaccurately, it is still possible to localize the position correctly using our DSM module. We also report the median value of the errors (in degrees) between the estimated and ground truth orientation in the second row of Table 4. The estimated errors are very small with respect to the FoV of the image, and so will not negatively affect the localization performance. Figure 11 shows the estimated orientation of ground images with and FoVs, and Figure 7 presents some qualitative examples on joint location and orientation estimation. More visualization results on orientation estimation are provided in the supplementary material.













FoV=, Azimuth=

FoV=, Azimuth=

FoV=, Azimuth=

FoV=, Azimuth=
















| Dataset | CVUSA | CVACT_val | ||||||
|---|---|---|---|---|---|---|---|---|
| FoV | ||||||||
| orien_acc | 99.41 | 98.54 | 76.15 | 61.67 | 99.84 | 99.10 | 74.51 | 55.18 |
| median_error | 2.38 | 2.38 | 4.50 | 4.88 | 1.97 | 2.89 | 5.21 | 6.22 |
5 Conclusion
In this paper we have proposed an effective algorithm for image-based geo-localization, which can handle complex situation when neither location nor orientation is known. Contrast to many existing methods, our algorithm recovers both location and orientation by joint cross-view image matching. Key components of our framework include a polar-transformation to bring different domains closer and a novel Dynamic Similarity Matching module (DSM) to regress on relative orientation. Benefited from the two items, our network is able to extract appropriate aerial features if the ground image is disoriented and has a limited FoV. We obtained higher location recalls for cross-view image matching, significantly improve the state-of-the-art in multitude practical scenarios.
6 Acknowledgments
This research is supported in part by the Australian Research Council (ARC) Centre of Excellence for Robotic Vision (CE140100016), ARC-Discovery (DP 190102261) and ARC-LIEF (190100080), as well as a research grant from Baidu on autonomous driving. The first author is a China Scholarship Council (CSC)-funded PhD student to ANU. We gratefully acknowledge the GPUs donated by the NVIDIA Corporation. We thank all anonymous reviewers and ACs for their constructive comments.
References
- [1] Relja Arandjelovic, Petr Gronat, Akihiko Torii, Tomas Pajdla, and Josef Sivic. Netvlad: Cnn architecture for weakly supervised place recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5297–5307, 2016.
- [2] Sudong Cai, Yulan Guo, Salman Khan, Jiwei Hu, and Gongjian Wen. Ground-to-aerial image geo-localization with a hard exemplar reweighting triplet loss. In The IEEE International Conference on Computer Vision (ICCV), October 2019.
- [3] Francesco Castaldo, Amir Zamir, Roland Angst, Francesco Palmieri, and Silvio Savarese. Semantic cross-view matching. In Proceedings of the IEEE International Conference on Computer Vision Workshops, pages 9–17, 2015.
- [4] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009.
- [5] Sixing Hu, Mengdan Feng, Rang M. H. Nguyen, and Gim Hee Lee. Cvm-net: Cross-view matching network for image-based ground-to-aerial geo-localization. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
- [6] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- [7] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, pages 1097–1105, 2012.
- [8] Karel Lenc and Andrea Vedaldi. Understanding image representations by measuring their equivariance and equivalence. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 991–999, 2015.
- [9] Tsung-Yi Lin, Serge Belongie, and James Hays. Cross-view image geolocalization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 891–898, 2013.
- [10] Liu Liu and Hongdong Li. Lending orientation to neural networks for cross-view geo-localization. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.
- [11] Arsalan Mousavian and Jana Kosecka. Semantic image based geolocation given a map. arXiv preprint arXiv:1609.00278, 2016.
- [12] Krishna Regmi and Mubarak Shah. Bridging the domain gap for ground-to-aerial image matching. In The IEEE International Conference on Computer Vision (ICCV), October 2019.
- [13] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge. International Journal of Computer Vision, 115(3):211–252, 2015.
- [14] Yujiao Shi, Liu Liu, Xin Yu, and Hongdong Li. Spatial-aware feature aggregation for image based cross-view geo-localization. In Advances in Neural Information Processing Systems, pages 10090–10100, 2019.
- [15] Yujiao Shi, Xin Yu, Liu Liu, Tong Zhang, and Hongdong Li. Optimal feature transport for cross-view image geo-localization. arXiv preprint arXiv:1907.05021, 2019.
- [16] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. CoRR, abs/1409.1556, 2014.
- [17] Bin Sun, Chen Chen, Yingying Zhu, and Jianmin Jiang. Geocapsnet: Aerial to ground view image geo-localization using capsule network. arXiv preprint arXiv:1904.06281, 2019.
- [18] Nam N Vo and James Hays. Localizing and orienting street views using overhead imagery. In European Conference on Computer Vision, pages 494–509. Springer, 2016.
- [19] Scott Workman and Nathan Jacobs. On the location dependence of convolutional neural network features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pages 70–78, 2015.
- [20] Scott Workman, Richard Souvenir, and Nathan Jacobs. Wide-area image geolocalization with aerial reference imagery. In Proceedings of the IEEE International Conference on Computer Vision, pages 3961–3969, 2015.
- [21] Menghua Zhai, Zachary Bessinger, Scott Workman, and Nathan Jacobs. Predicting ground-level scene layout from aerial imagery. In IEEE Conference on Computer Vision and Pattern Recognition, volume 3, 2017.
- [22] Bolei Zhou, Agata Lapedriza, Jianxiong Xiao, Antonio Torralba, and Aude Oliva. Learning deep features for scene recognition using places database. In Advances in neural information processing systems, pages 487–495, 2014.
Appendix A Localization with Unknown Orientation and Limited FoV
A.1 Location Estimation
In the main paper, we report the top-1, top-5, top-10 and top-1% recall rates of our algorithm and the state-of-the-art on localizing ground images with unknown orientation and varying FoVs. In this section, we present the complete r@ performance in Figure 8. It can be seen that our method achieves consistently better performance than the state-of-the-art algorithms in all the localization scenarios.







Training and Testing on Different FoVs: In real-world scenarios, a camera’s FoV at inference time may not be the same as that used during training. Therefore, we also investigate the impact of using a model trained on a different FoV. We employ a model trained on ground images with a specific FoV and test its performance on ground images with varying FoVs. Figure 9 illustrates the recall curves at top-1, top-5, top-10 and top-1% with respect to different testing FoVs, and the numerical results are presented in Table 5.
It is apparent in Figure 9 that, as the test FoV increases, all models attain better performance. This implies that having a greater amount of scene contents reduces the matching ambiguity, and our method is able to exploit such information to achieve better localization. Furthermore, using a model trained with a FoV similar to the test image produces better results in general. Therefore, it is advisable to adopt a pretrained model with FoV similar to the test image.
A.2 Orientation Estimation








| r@1 | r@5 | r@10 | r@1% | r@1 | r@5 | r@10 | r@1% | r@1 | r@5 | r@10 | r@1% | r@1 | r@5 | r@10 | r@1% | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CVUSA | 78.11 | 89.46 | 92.90 | 98.50 | 48.38 | 66.73 | 73.82 | 90.93 | 16.36 | 30.67 | 37.78 | 63.82 | 9.26 | 19.82 | 26.08 | 52.45 | |
| 74.30 | 87.37 | 91.25 | 98.27 | 48.53 | 68.47 | 75.63 | 93.02 | 17.91 | 33.51 | 41.24 | 67.40 | 10.42 | 22.43 | 29.06 | 55.98 | ||
| 60.13 | 76.23 | 82.40 | 96.21 | 38.98 | 57.94 | 66.38 | 89.39 | 16.19 | 31.44 | 39.85 | 71.13 | 10.15 | 22.02 | 29.50 | 62.78 | ||
| 51.65 | 69.56 | 76.09 | 93.75 | 31.79 | 49.99 | 58.45 | 85.69 | 12.74 | 26.78 | 34.73 | 68.00 | 8.78 | 19.90 | 27.30 | 61.20 | ||
| CVACT_val | 72.91 | 85.70 | 88.88 | 95.28 | 44.43 | 63.23 | 69.73 | 87.09 | 13.26 | 26.62 | 33.14 | 60.33 | 6.70 | 16.18 | 21.77 | 48.05 | |
| 72.87 | 85.68 | 88.97 | 95.67 | 49.12 | 67.83 | 74.18 | 89.93 | 17.13 | 33.68 | 41.55 | 67.99 | 10.00 | 22.10 | 28.97 | 56.26 | ||
| 64.00 | 78.11 | 82.77 | 94.10 | 43.42 | 61.17 | 68.22 | 86.80 | 18.11 | 33.34 | 40.94 | 68.05 | 11.14 | 23.65 | 31.34 | 59.73 | ||
| 55.73 | 71.63 | 77.35 | 92.02 | 34.92 | 52.62 | 60.52 | 83.31 | 13.86 | 27.81 | 35.24 | 64.14 | 9.29 | 20.72 | 27.13 | 57.08 | ||





Aerial


Ground


Similarity Curve


Aerial


Ground


Similarity Curve


Aerial


Ground


Similarity Curve


Aerial


Ground


Similarity Curve


Aerial


Ground


Similarity Curve


Aerial


Ground


Similarity Curve


Aerial


Ground


Similarity Curve


Aerial


Ground


Similarity Curve
We provide additional visualization of estimating orientations for ground images with , , and FoV in Figure 11. As illustrated in Figure 11, our Dynamic Similarity Matching (DSM) module is able to estimate the orientation of ground images with varying FoVs.
When a camera has a small FoV, it suffers high ambiguity to determine the orientation by matching the ground image to its corresponding aerial one. We illustrate an example in Figure 11(c) where the error of orientation estimation for a road can be . As seen in the first instance of Figure 11(c), the road occupies a large portion of the ground image. While in the aerial image, the road is symmetric in respect to the image center (i.e., camera location). Thus there are two peaks in the similarity curve.
If the peak on the left is taller than the peak on the right, the estimated orientation will be wrong. Figure 10 provides another three examples where scene contents are similar in multiple directions. At these locations, it is hard to determine the orientation of a ground camera which has a small FoV while the estimated location is correct.
Appendix B Time Efficiency
In order to improve the time efficiency, we compute the correlation in our DSM module by using Fast Fourier Transform during the inference process. To be specific, we store the Fourier coefficients of aerial features in the database, and calculate the Fourier coefficients of the ground feature in the forward pass. By doing so, the computation flops of the correlation are (including flops for coefficients multiplication in the spectral domain, and flops for the inverse Fast Fourier Transform), where , and is the height, width and channel number of the global feature descriptor of an aerial image, is the number of database aerial images, and in our method. In contrast to conducting correlation in the spatial domain where the computation flops are , the computation time is reduced by a factor of ().
We conduct the retrieval process of a query image on a 3.70 GHz i7 CPU system, and the codes are implemented in Python3.6. For a ground panorama with unknown orientation, it takes an average time of for retrieving its aerial counterpart from a database containing 8884 reference images. This demonstrates the efficiency of the proposed algorithm.
Appendix C Trainable Parameters
Since the authors of CVM-NET [5], Liu & Li [10] and CVFT [15] provide the source code of their works, we compare the trainable parameters and model size of our network with their methods in Table 6. Our network not only outperforms the state-of-the-art but also is more compact, facilitating the deployment of our network.