What Makes a Star Teacher? A Hierarchical BERT Model for Evaluating Teacher’s Performance in Online Education
Abstract
Education has a significant impact on both society and personal life. With the development of technology, online education has been growing rapidly over the past decade. While there are several online education studies on student behavior analysis, course concept mining, and course recommendation (Feng, Tang, and Liu 2019; Pan et al. 2017), there is little research on evaluating teachers’ performance in online education. In this paper, we conduct a systematic study to understand and effectively predict teachers’ performance using the subtitles of 1,085 online courses. Our model-free analysis shows that teachers’ verbal cues (e.g., question strategy, emotional appealing, and hedging) and their course structure design are both significantly correlated with teachers’ performance evaluation. Based on these insights, we then propose a hierarchical course BERT model to predict teachers’ performance in online education. Our proposed model can capture the hierarchical structure within each course as well as the deep semantic features extracted from the course content. Experiment results show that our proposed method achieves a significant gain over several state-of-the-art methods. Our study provides a significant social impact in helping teachers improve their teaching style and enhance their instructional material design for more effective online teaching in the future.
Introduction
Education is one of the most important industries for the global economy. The market size of the educational services industry in the United States (US) is $1.6 trillion in 2020 (IBISworld 2020). Education is not only essential at a global level but also significant at a personal level because it plays a crucial role in everyone’s life. With the development of technologies, the online education market has been growing rapidly over the past decade. It is predicted that the global online education market will reach a total market size of $319 billion by 2025 (ResearchAndMarkets 2020).
The impact of online education services has become even more important during the ongoing COVID-19 pandemic, which created an unprecedented disruption of education systems and affected nearly 1.6 billion learners in more than 190 countries(UnitedNations 2020). Most schools turned to online education and required teachers to move to online delivery of lessons due to school closures during this difficult time. However, a recent survey indicated that 70% of the 1.5 million faculty members in the US had never taught an online course before the COVID-19 pandemic (AmericanMarketingAssociation 2020). Therefore, providing practical guidance for teachers to assist them better prepare for online teaching during this challenging time has a significant social impact.

Although there have been several related studies on student behavior analysis (Feng, Tang, and Liu 2019; Trakunphutthirak, Cheung, and Lee 2019), course concept mining (Pan et al. 2017; Yu et al. 2019), and course recommendation (Zhang et al. 2019), few of them have focused on evaluating teachers’ performance based on course content analysis.
Students’ ratings of online courses are direct feedback from their experiences. Understanding what elements of online courses may affect students’ evaluations and developing an automatic rating prediction system for teachers are of great significance, considering that it can provide practical guidance for teachers to enhance their instructional material design and teaching styles for more effective online teaching in the future.
In our study, we aim to investigate this novel problem of predicting teachers’ ratings in online education platforms based on online educational materials. The conceptual illustration of our proposed model is shown in Figure 1. In particular, the input of the system is the raw content of the course materials, consisting of the textual subtitles of the lecture videos organized in multiple sections. The output of the system is the predicted student rating of the teacher or the course. We note that there are several non-trivial research challenges in developing such a system due to the special characteristics of course data:
-
•
First, teachers’ verbal cues may have an important impact on students’ evaluation according to traditional education theories. For example, some studies suggest that a teacher who is proficient at asking the question can help students’ thinking and interaction (Olsher and Kantor 2012; Clough 2007). Another research indicates that a speaker who tends to use more hedging words (e.g., a little, kind of, more or less) implies a lack of commitment to the speech content (Prince et al. 1982), which could be a negative signal of teaching quality. Thus, how to better extract teachers’ verbal cues from courses’ subtitles using state-of-the-art NLP models entails significant challenges.
-
•
Second, every course has a natural hierarchical structure. A course usually consists of multiple sections, and each section has multiple lectures. For example, a course named “Machine Learning With Python” has three sections: Regression, Classification, and Clustering. The Classification section has several different lectures such as K-Nearest Neighbours, Decision Trees, etc. Moreover, the course structure is also an important determinant of the course’s success according to traditional education theory (Bohlin and Hunt 1995). Thus, how to leverage course structure information to assist the design of the system for predicting teachers’ performance is also challenging.
Our Contribution. In our paper, we first conduct a systematic analysis of what elements of online courses may affect students’ evaluations. Moreover, we propose a hierarchical course BERT model to accurately predict teachers’ performance in online education using both linguistic features and course structure information. Specifically, we make the following three contributions to this study.
-
•
First, to the best of our knowledge, we are the first to study the teachers’ performance evaluation in online education. Moreover, traditional education studies mainly rely on the self-reported survey and qualitative analysis limited to small-scale analysis. Our study thus contributes to the education literature by conducting a quantitative analysis leveraging machine learning tools using a large-scale dataset.
-
•
Second, based on traditional education theories, we extract course features including linguistic and course structure characteristics. A model-free analysis shows that question strategy, emotion appealing, hedging, and course structure are significantly correlated with teachers’ ratings. These insights can potentially assist teachers to better prepare for online teaching to enhance students’ evaluations in the future.
-
•
Third, from the methodological perspective, we propose a novel hierarchical course BERT model that can capture courses’ natural hierarchical structure information and the deep semantic features from course subtitles. We demonstrate the superior prediction performance of our approach over several state-of-the-art methods. The proposed approach could be a powerful tool for evaluating and improving teachers’ performance in the future, which can benefit millions of students’ online learning in our society.
Dataset
We collect a large-scale dataset consisting of 1,085 free online courses on Coursera. Coursera is the largest global platform of MOOCs (Massive Open Online Courses) with more than 40 million learners worldwide and more than 150 partner universities (Edukatico 2020). The free courses on Coursera are available for learners to download. Each course has multiple sections, and each section has multiple lectures. Besides, each course has two ratings displayed on the platform, the course rating and the instructor rating, given by students who have completed the course. The descriptive statistics for these courses are shown in Table 1. On average, each course has 4.95 sections and 40.09 lectures in our data; each section has 8.13 lectures; each lecture has 1158.87 tokens, and most of the lectures are less than 10 minutes.
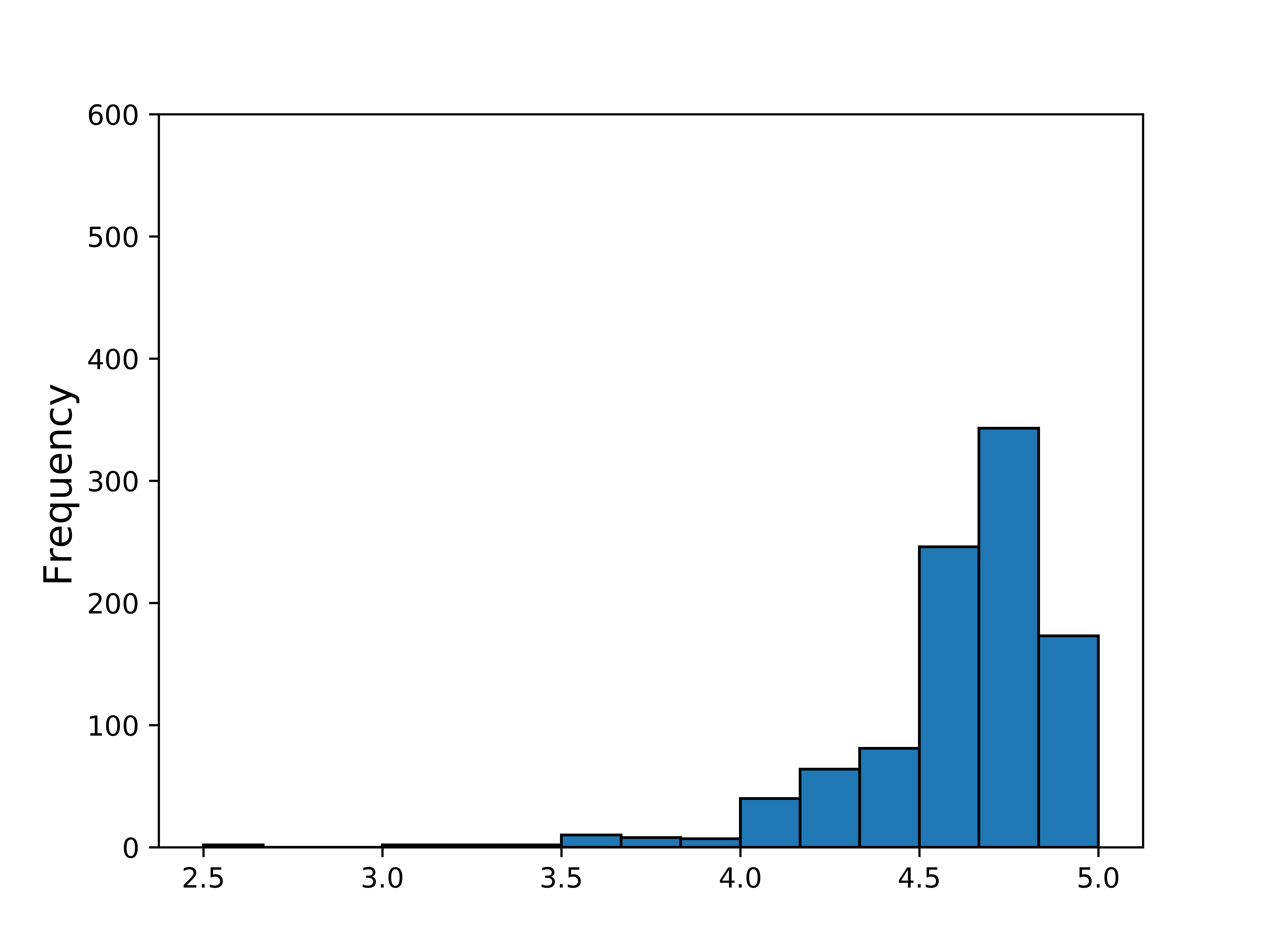
The course rating is aggregated from students’ feedback collected when they complete the course. For the instructor rating, the platform asks all learners to provide feedback for instructors based on the quality of their teaching style. It should be noted that the instructor with multiple courses has multiple ratings rated by the students who have taken that specific course. The distribution of the two ratings is provided in Figure 2. Both ratings range from 0.0 to 5.0.
| Mean | SD | Median | |
|---|---|---|---|
| # Sections | 4.95 | 1.81 | 4.00 |
| # Lectures/course | 40.09 | 25.01 | 35.00 |
| # Lectures/section | 8.13 | 5.24 | 7.00 |
| # Tokens/lecture | 1158.87 | 855.50 | 969.00 |

Exploration of Rating-Correlated Signals
We have conducted a series of exploratory studies to find out potential strong indicators for higher or lower ratings.
Extracted Course Features
Based on traditional education literature, we extract two sets of course features in our data – teachers’ verbal cues and meta-information features.
Part 1. Teachers’ Verbal Cues.
Six linguistic features are extracted by gathering existing hand-crafted, linguistic lexicons for relevant concepts.
-
•
Concreteness Ratio. Concreteness of the course content may have an important impact on students’ comprehension, interest, and learning outcomes (Sadoski, Goetz, and Rodriguez 2000). A larger concreteness ratio represents very concentrated teaching content and less unrelated materials. To quantify the concreteness ratio, we first count the total number of named entities for each course in our data. It has five coarse-grained groups: (1) events, (2) numbers, (3) organizations/locations, (4) persons, and (5) products. Then, a concreteness ratio, namely, the number of named entities in the course divided by the total number of tokens in that course, is calculated.
-
•
Questions Ratio. Asking questions in class can help students’ thinking and interaction (Olsher and Kantor 2012; Clough 2007). To quantify teachers’ question-asking behavior in our data, we use a question detection method – Basic Parse Tree created by Stanford’s CORE NLP111https://stanfordnlp.github.io/CoreNLP/ for each sentence to detect if the sentence is a question. We then calculate the question ratio, defined as the number of question divided by the number of sentences in each course. We use the Penn Treebank’s Clause level tags for question detection. We specifically check for the occurrence of two tags: (1) SBARQ – direct question introduced by a wh-word or a wh-phrase and (2) SQ – inverted yes/no questions.
-
•
Emotion Appealing. This refers to teachers’ elicitation of emotions which may attract students’ attention while learning (Wang et al. 2019). NRC Sentiment Lexicons (Mohammad, Kiritchenko, and Zhu 2013) is used to extract each teacher’s emotions along eight dimensions: anticipation, joy, surprise, trust, anger, disgust, fear, and sadness. Then, the emotion entropy is calculated to measure the emotion diversity of a teacher, which is defined as where denotes the ratio of emotion tokens to total tokens for each specific emotion dimension .
-
•
Hedging. Hedges are lexical choices made by a speaker, which may indicate a lack of commitment to the content of their speech (Prince et al. 1982). We use the single- and multi-word hedge lexicons from (Prokofieva and Hirschberg 2014) to calculate the ratio of hedges to tokens in each course. For example, teachers who tend to use “basically, generally, sometimes (unigrams)”, “a little, kind of, more or less (multi-word)” may imply that they are not quite confident about their teaching materials, which might be a signal of poor teaching quality.
-
•
Other Lexicon-Based Features. We also compute several other lexicon-based features, including ratios of (1) strong modal such as ”always”, ”clearly”, ”undoubtedly” and (2) weak modal such as ”appears”, ”could”, ”possibly” using the respective lexicons from (Loughran and McDonald 2011). In each case, the ratio of terms in the respective category to the number of tokens in each course is computed.
Part 2. Meta-Information Features.
In the second set of our features, we compute several measurements on course-level meta-information.
-
•
Course Length. The total number of tokens in each course is calculated to represent the course length. A longer course could be an indicator of more elaborate teaching which may have an impact on students (Ladson-Billings 1992).
-
•
Course Structure Quality. The structure of the course is also a crucial factor for online education (Bohlin and Hunt 1995). Each course has a default structure, namely, from course to sections, and from sections to lectures. For a well-structured course, every lecture within the same sections should be highly connected but less similar to the lecture from other sections. We use modularity – the measure of the structure of networks or graphs – to measure the quality of the course structure in our data. In our study, a lecture network, where each course has a network and nodes are individual lectures, is established. The edge is calculated by the pair-wise cosine similarity of Word2Vec embedding of each lecture. Given the lecture network and the current default structure , the modularity is calculated to measure the quality of the current default structure as follows:
(1) where is the number of edges, is the adjacency matrix of , is the degree of and is 1 if and are in the same community and 0 otherwise. The graph building and modularity calculation are implemented using NetworkX222https://networkx.github.io/documentation/stable/tutorial.html. Particularly, the higher the modularity, the better the course structure quality.
Interpretation of Correlation Results
We present the results for the correlation analysis in Table 2. In particular, we find some interesting patterns that may guide teachers in an online education setting to enhance students’ evaluations in the future. We expand the statistically significant results for negative () and positive () correlations with the instructor rating.
-
•
() Question ratio. This suggests that the question-asking strategy may enhance students’ learning experience, regardless of the lack of direct interaction with students in the online education setting. Because it can potentially arouse students’ thinking and attract students’ attention.
-
•
() Emotion appealing. This indicates that the entertainment value of a course is also crucial, and it is consistent with online consumer experience theory in the marketing literature (Woltman Elpers, Wedel, and Pieters 2003). In a traditional course in the physical classroom, the teacher and students can have direct interactions and eye-contact, and students are required to sit in the classroom until the class ends. However, in the online education setting, students can leave the course whenever they want and it becomes even more challenging for the teacher to engage students in a class. Teachers who tend to use an emotion appealing strategy could potentially enhance students’ experience and better engage students in the online class.
-
•
() Hedging. This refers to those teachers who tend to use more hedging words such as “a little”, “kind of”, and “more or less” might be less committed to the content of their speech. Therefore, a higher percentage of hedging words might be a negative signal of teaching quality.
-
•
() Course structure quality. This indicates that the structure quality of the online course might be an essential factor in students’ online learning. A well-structured course is an indicator of a teacher’s effort in preparing the course and its potential high quality.
-
•
() Course length. The length of a course is an indicator of the amount of content contained in the course. A longer course may enable the students to acquire more knowledge from the course and thus result in more positive evaluations.
It is worth noting that our study only reveals the correlations between these signals and the ratings, and this study aims to build a better rating prediction system. However, we caution that strong correlations do not necessarily imply causality.
| Features | Instructor rating | Course rating | ||
|---|---|---|---|---|
| -value | -value | |||
| Concreteness | 0.02 | 0.48 | 0.01 | 0.70 |
| Questions | 0.48* | < | 0.04* | 0.03 |
| Emotion appealing | 0.16* | < | 0.17* | < |
| Hedging | -0.06* | 0.03 | -0.06* | 0.03 |
| Strong modal | -0.12* | < | -0.11* | < |
| Weak modal | 0.08* | < | 0.04 | 0.14 |
| Course length | 0.18* | < | 0.26* | < |
| Course structure | 0.06* | 0.04 | 0.10* | < |
Hierarchical Course BERT Model for Teachers’ Performance Prediction
As demonstrated in the previous section, teachers’ verbal cues and course structure quality are significantly correlated with the ratings. This motivates us to build a more advanced model to better capture teachers’ verbal cues and course structure quality in each course. Pretrained language models (e.g., BERT (Devlin et al. 2018; Beltagy, Peters, and Cohan 2020)) have achieved state-of-the-art performance on a wide range of downstream natural language understanding (NLU) tasks, such as the GLUE benchmark (Wang et al. 2018) and SQuAD (Rajpurkar et al. 2016).
In our study, we propose a hierarchical course BERT model to better capture the course structure quality and linguistic features in each course. The overall structure is shown in Figure 3. Assuming that represent courses, where is course subtitles with lectures . Each lecture is a subtitle, represented by a sequence of tokens. contains integers denoting the section index of each lecture to indicate which section the lecture belongs to; contains integers denoting the relative lecture position within each section; is an additional feature vector for course containing numerical features extracted in the section above. is the corresponding ground-truth label (i.e., ratings).
Local lecture semantic features. For course with lectures, we cannot combine all the lectures’ tokens and feed them through a BERT model due to its 512-token length limit. Since each lecture has 1158.87 tokens on average, we take each individual lecture subtitle as a unit. For lecture where the subtitle sequence is denoted as , we add a special token at the beginning of each lecture, and do a forward pass in a pretrained BERT model. Then we take the output embedding for lecture to represent the lecture, where is hidden size (e.g., 768 hidden units).
Incorporating course structure. (Bai et al. 2020) proposed a segment-aware BERT by adding additional paragraph index, sentence index, and token index embeddings to encode the natural document’s hierarchical structure. Compared to the original BERT model on various NLP tasks, it exhibits a significant gain on predictive performance. Motivated by their findings, in our model additional section embedding is added to encode the lecture’s section position information (i.e., which section does each lecture belong to), and lecture position embedding to encode the order of lectures within each section on top of the lectures token sequence extracted from lecture subtitles. More specifically, for each course, all the lecture tokens in the same section (e.g., section ) are assigned the same section embedding . Within each section, we use the lecture position to encode the order of lectures in each section. For example the first lecture in every section would be assigned the same lecture position embedding . Besides, the maximum section number is set to 8 since 95% of the courses in our data have less than 8 sections. Similarly, the maximum lecture positions within each section are set to 10, since 90% of the courses in our data have less than 10 sections.
We add three embedding together: (1) the lecture embedding which captures the semantic features of each lecture, (2) section embedding, and (3) lecture position embedding to obtain the lecture representation :
| (2) |
Global transformers to exchange the lectures information. We take the sequence of all lectures’ representation and add a new special token – course at the beginning to represent the whole course, denoted as .
We use the global transformers to exchange the lectures tokens information within same course. Here we use vanilla transformer layer (Vaswani et al. 2017) and composed of two sub-layers.
| (3) | ||||
| (4) |
where LayerNorm is a layer normalization proposed in (Ba, Kiros, and Hinton 2016); MHAtt is the multihead attention mechanism introduced in (Vaswani et al. 2017) which allows each token to attend to other tokens with different attention distributions; and FFN is a two-layer feed-forward network with ReLU as the activation function.
We take the course token representation output by the last layer of the global transformers to represent the course semantic and structural features, denoted as .
Extracted course features. In addition to the course tokens, extracted course features shown in the previous correlation sections are also concatenated. These features are different from the semantic features extracted from BERT, since they are extracted using human knowledge, such as the emotion appealing and questions detection.
Linear layer. We concatenate course token and extracted course features together as . Then, the concatenated features are put on a linear layer to conduct the final rating prediction .
| (5) |
where denotes weight matrix and denotes bias.

Experiments
Experiment Setup
We experiment with two prediction tasks – instructor rating and course rating prediction. We split 70%, 10%, and 20% of courses as training, validation, and test set. We minimize the MSE loss for training. We take pretrained BERTbase with 12 layers to encode local semantic features from each lecture. Pretrained model weights are obtained from Pytorch transformer repository333https://github.com/huggingface/PyTorch-transformers. We also update the BERTbase parameters during training. The global transformer layers are trained from scratch. Besides, we set the number of global transformer layers as 2 based on the preliminary experiments. We find the 2 layer global transformer layers work much better than 1 layer. Due to the resource limitation, we did not try three layers, and we leave this to future work. We set the number of the final linear layer as 1. All transformer-based models/layers have 768 hidden units. The model is trained on Nvidia V100 GPU. The optimizer is Adam (Kingma and Ba 2014) with learning rate of 3e-5, = 0.9, and = 0.998; we also applied learning rate warmup over the first 500 steps, and decay as in (Vaswani et al. 2017). We set the epochs as 50, batch size as 16. We apply dropout (with a probability of 0.1) before all linear layers.
Baselines
Our proposed hierarchical course BERT model is compared with various baselines.
(1) Extracted course features only. Since extracted course features are part of our proposed hierarchical course BERT model. If the extracted course features have excellent prediction performance, there is no need to build an advanced model. The regression with extracted course features is conducted using seven machine learning algorithms to control for the variability, including linear regression, support vector machines with the radial based kernel (SVM), Multi-layer Perceptron (MLP), Random Forest, AdaBoost, GradientBoosting, and Bagging. For the ensemble method like AdaBoost and Bagging, we use a decision tree as a base component in the ensemble. We perform a grid search in to find the optimal number of components for ensemble methods on the validation set. For MLP, we perform a grid search to find the optimal number of hidden layers () and hidden size () (, ). Adam optimizer is used to optimize the parameters.
(2) Word2Vec + extracted course features. The pre-trained word2vec model on the entire Google News dataset is adopted to obtain 300-dimensional word embedding. Besides, all words in the same course are added to represent the course. These semantic features are similar to BERT features without considering structure information. Moreover, the extracted course features are concatenated to the course word2vec embedding. We repeat the same machine learning algorithms and the hyperparameter tuning process as (1).
(3) Doc2Vec + extracted course features. The paragraph vector algorithm proposed by (Le and Mikolov 2014) is used to obtain 300-dimensional lecture embeddings. Using the Gensim implementation (Rehurek and Sojka 2010), doc2vec models for 50 epochs are trained while words occurring less than 10 times in the respective training corpus are ignored. Doc2vec embeddings are trained over individuals lectures. Besides, we add the doc2vec embedding for lectures in the same course together as the course embedding features. Then, the extracted course features are concatenated to the course doc2vec embedding. We repeat the same machine learning algorithms and the hyperparameter tuning process as (1).
(4) Lecture BERT (LecBERT). In this baseline model, each lecture is regarded as a unit. This baseline does not have access to the course structure information. We assume lectures in the same course share the same rating. We assign the same rating score to the lectures in the same course for training. For each lecture, the lecture is obtained after the BERT model, and the linear layer directly is added after the BERT model to make lecture rating prediction. In the test stage, prediction for each lecture is first conducted; then, we take the average over all lectures in the same course to obtain the course rating. The pretrained BERTbase with 12 layers to encode semantic features from each lecture. We set the epochs as 5, batch size as 64. Other hyperparameters are same as proposed model.
Performance Metrics
We use the following two metrics to measure the prediction performance:
-
•
Root mean squared error (RMSE):
(6) -
•
Mean Absolute Error (MAE):
(7)
Results
Overall comparison. The results are presented in Table 3. Our proposed model performs the best among all the baselines for both the instructor rating prediction task and the course rating prediction task. GradientBoosting in the group of Dov2vec + course is the best baseline model among the course features alone group, word2vec+course group, and doc2vec+course group. Compared to the best baseline model, our proposed model reduces RMSE by 49.6% ( <0.01) and MAE by 63.8% (<0.01) for the instructor rating task. Regarding the course rating task, our proposed model reduces the RMSE by 45.7% (<0.01) and MAE by 62.0% (<0.01) compared to the best baseline model.
Besides, compared to course features only, adding additional semantic features (e.g., Word2vec or Doc2vec) can largely increase the performance for both instructor rating prediction task and course rating prediction task. For example, with Bagging, the group of Doc2vec + course reduces RMSE by 12.4% and MAE by 16.2% compared to the course features alone for instructor rating tasks. Also, adding Doc2vec embedding performs better than Word2Vec. This indicates (1) better semantic features and (2) combination of deep semantic features and extracted course features are two ways to get better performance. Our proposed model builds on these findings.
| Class | Model | Instructor rating | Course rating | ||
|---|---|---|---|---|---|
| RMSE | MAE | RMSE | MAE | ||
| Extracted course features only | LR | 0.8725 | 0.6901 | 0.4075 | 0.3571 |
| SVM | 0.3001 | 0.2149 | 0.1809 | 0.1324 | |
| MLP | 0.3079 | 0.2202 | 0.1834 | 0.1427 | |
| RF | 0.3206 | 0.2351 | 0.1886 | 0.1402 | |
| AdaBoost | 0.3812 | 0.3302 | 0.2093 | 0.1750 | |
| GB | 0.3017 | 0.2161 | 0.1823 | 0.1325 | |
| Bagging | 0.3159 | 0.2348 | 0.1847 | 0.1392 | |
| Word2vec + course | LR | 0.3859 | 0.2790 | 0.2475 | 0.1994 |
| SVM | 0.2840 | 0.2063 | 0.1803 | 0.1323 | |
| MLP | 0.2966 | 0.2189 | 0.1786 | 0.1368 | |
| RF | 0.2881 | 0.2095 | 0.1773 | 0.1351 | |
| AdaBoost | 0.2774 | 0.2130 | 0.1766 | 0.1393 | |
| GB | 0.2873 | 0.2077 | 0.1773 | 0.1313 | |
| Bagging | 0.2963 | 0.2157 | 0.1788 | 0.1349 | |
| Doc2vec + course | LR | 0.3149 | 0.2223 | 0.2082 | 0.1604 |
| SVM | 0.2809 | 0.2018 | 0.1727 | 0.1319 | |
| MLP | 0.2920 | 0.2170 | 0.1776 | 0.1380 | |
| RF | 0.2756 | 0.1959 | 0.1744 | 0.1265 | |
| AdaBoost | 0.2739 | 0.2107 | 0.1710 | 0.1319 | |
| GB | 0.2739 | 0.1939 | 0.1680 | 0.1238 | |
| Bagging | 0.2767 | 0.1966 | 0.1709 | 0.1244 | |
| BERT Variant | LecBERT | 0.2432 | 0.1615 | 0.1453 | 0.1153 |
| Our model | 0.1378 | 0.0701 | 0.0913 | 0.0471 | |
Ablation study. The importance of each element in our proposed model is investigated. Then, the following three models are further conducted by removing items step by step.
(1) StrucCourse BERT. The concatenated course features to the model are removed, and other specification from our proposed model is maintained, to study the importance of the sparse feature in addition to the dense features.
(2) Course BERT. For this model, the structure information is further removed from StrucCourse BERT (i.e., section embedding and lecture position embedding). However, we keep the global transformers to exchange the lecture information, suggesting that we drop the structure information while keeping the lectures information exchange. For this model, each lecture is first fed into the BERT model; then, the lecture tokens are directly put into transformers without adding the section embedding and lecture position embedding to explore the importance of course structure information.
(3) Lecture BERT. The lecture exchange information is further removed from Course BERT. Specifically, we remove the global transformer layers and treat each lecture as an independent.
The results are summarized in Figure 4. We find the course structure information is the most important element in our model. The course sparse features and global transformers provide additional gains. Some interesting findings are highlighted as follows.

-
•
Extracted course features can further improve the performance. Adding the extracted course features can further improve the performance. Compared to StrucCourse BERT, the model with additional extracted course features can provide additional gains. Regarding the instructor rating prediction task, our proposed model reduces RMSE by 7.1% and MAE by 19.7% compared to StrucCourse BERT. Regarding the course rating prediction task, our proposed model reduces RMSE by 12.5% and MAE by 17.9% compared to StrucCourse BERT.
-
•
Course structure information provides a significant gain. Adding section embedding and lecture position embedding to represent the natural course structure can significantly improve the performance. Compared to the Course BERT, StrucCourse BERT with additional section embedding and lecture position embedding reduces RMSE by 33.9% and MAE by 39.5% for the instructor rating prediction task. For the course rating prediction task, StrucCourse BERT reduces RMSE by 28.0% and MAE by 43.1% compared to the Course BERT.
-
•
Global transformers to exchanging the lecture information are important. Compared to Lecture BERT treating lectures as independent, the Course BERT using global transformers to exchange the lectures information within the same course exhibits better prediction performance. For example, regarding the instructor rating prediction task, the Course BERT reduces RMSE by 7.7% and MAE by 10.7% compared to Lecture BERT; regarding the course rating prediction task, the Course BERT reduces MAE by 12.5% compared to Lecture BERT.
Related Work
Online education mining. Our work focuses on education mining broadly. There are some MOOC-related studies on student behavior analysis (Feng, Tang, and Liu 2019; Trakunphutthirak, Cheung, and Lee 2019), course concept mining (Pan et al. 2017; Yu et al. 2019), and course recommendation (Zhang et al. 2019). In our paper, we have addressed an important research gap in the existing literature on what makes a star teacher in online education by analyzing teachers’ verbal cues and course structure. Based on our exploratory insights, we further propose a novel hierarchical BERT model to evaluate teachers’ performance in online education. Our study contributes to the literature by providing a practical tool that can be used by teachers to enhance their instructional materials for more effective online teaching in the future.
Traditional education theory. Our work is also closely related to traditional education studies (e.g., teacher’s performance evaluation (Gordon, Kane, and Staiger 2006; Deci et al. 1982; Rowan, Chiang, and Miller 1997) and teaching skills (Shavelson 1973; van de Grift, Helms-Lorenz, and Maulana 2014)). However, these studies mainly depend on the survey or qualitative methods limited to small-scale data. We contribute to the literature by quantifying teachers’ verbal cues and teaching strategy from detailed teaching subtitles and course structure using scalable and automatic methods. Moreover, our proposed model can be used to accurately predict teachers’ performance to help teachers better prepare for online teaching in the future.
BERT-based real-world applications. Prior research applying BERT to various real-world problems have achieved huge success in many tasks such as humour detection, hate speech detection, fake news detection, and adverse drug reaction detection from tweets (Mao and Liu 2019; Liu et al. 2019; Mozafari, Farahbakhsh, and Crespi 2019; Roitero, Cristian Bozzato, and Serra 2020; Breden and Moore 2020). To the best of our knowledge, our paper is the first study to apply the BERT model to course corpus and achieve a significant performance result.
Conclusion and Future Work
In this paper, we conduct a systematic study to evaluate teachers’ performance in online education using courses’ subtitles. Our results indicate that teachers’ verbal cues and course structure quality have significant correlations with teachers’ performance in online education. Based on the gained insights, we propose a novel hierarchical course BERT model to accurately predict teachers’ performance. Our proposed model can capture the course’s natural hierarchical structure and the deep semantic features from course subtitles. Our experiments demonstrate that our proposed method achieves a significant gain over several state-of-the-art methods. Our study provides immediate and actionable implications for teachers by developing a practical tool for teachers to predict and enhance their teaching performance for more effective online education in the future. For future work, multi-modal features (e.g., audio and visual features) can be extracted to have a more robust model.
References
- AmericanMarketingAssociation (2020) AmericanMarketingAssociation. 2020. Higher education marketing statistics before and during the COVID-19 pandemic. Retrieved on August 24, 2020, from https://www.ama.org/marketing-news/higher-education-marketing-statistics-before-and-during-the-covid-19-pandemic/ .
- Ba, Kiros, and Hinton (2016) Ba, J. L.; Kiros, J. R.; and Hinton, G. E. 2016. Layer normalization. arXiv preprint arXiv:1607.06450 .
- Bai et al. (2020) Bai, H.; Shi, P.; Lin, J.; Tan, L.; Xiong, K.; Gao, W.; and Li, M. 2020. SegaBERT: Pre-training of Segment-aware BERT for Language Understanding. arXiv preprint arXiv:2004.14996 .
- Beltagy, Peters, and Cohan (2020) Beltagy, I.; Peters, M. E.; and Cohan, A. 2020. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150 .
- Bohlin and Hunt (1995) Bohlin, R. M.; and Hunt, N. P. 1995. Course structure effects on students’ computer anxiety, confidence and attitudes. Journal of Educational Computing Research 13(3): 263–270.
- Breden and Moore (2020) Breden, A.; and Moore, L. 2020. Detecting Adverse Drug Reactions from Twitter through Domain-Specific Preprocessing and BERT Ensembling. arXiv preprint arXiv:2005.06634 .
- Clough (2007) Clough, M. P. 2007. What is so important about asking questions? Iowa Science Teachers Journal 34(1): 2–4.
- Deci et al. (1982) Deci, E. L.; Spiegel, N. H.; Ryan, R. M.; Koestner, R.; and Kauffman, M. 1982. Effects of performance standards on teaching styles: Behavior of controlling teachers. Journal of educational psychology 74(6): 852.
- Devlin et al. (2018) Devlin, J.; Chang, M.-W.; Lee, K.; and Toutanova, K. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 .
- Edukatico (2020) Edukatico. 2020. Coursera: Biggest global MOOC platform with millions of learners worldwide. Retrieved on August 24, 2020, from https://www.edukatico.org/en/report/coursera-biggest-global-mooc-platform-with-millions-of-learners-worldwide .
- Feng, Tang, and Liu (2019) Feng, W.; Tang, J.; and Liu, T. X. 2019. Understanding dropouts in MOOCs. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, 517–524.
- Gordon, Kane, and Staiger (2006) Gordon, R. J.; Kane, T. J.; and Staiger, D. 2006. Identifying effective teachers using performance on the job. Brookings Institution Washington, DC.
- IBISworld (2020) IBISworld. 2020. Educational services in the US market size 2005-2026. Retrieved on August 24, 2020 from https://www.ibisworld.com/industry-statistics/market-size/educational-services-united-states/ .
- Kingma and Ba (2014) Kingma, D. P.; and Ba, J. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 .
- Ladson-Billings (1992) Ladson-Billings, G. 1992. Culturally relevant teaching: The key to making multicultural education work. Research and multicultural education: From the margins to the mainstream 106–121.
- Le and Mikolov (2014) Le, Q.; and Mikolov, T. 2014. Distributed representations of sentences and documents. In International conference on machine learning, 1188–1196.
- Liu et al. (2019) Liu, C.; Wu, X.; Yu, M.; Li, G.; Jiang, J.; Huang, W.; and Lu, X. 2019. A Two-Stage Model Based on BERT for Short Fake News Detection. In International Conference on Knowledge Science, Engineering and Management, 172–183. Springer.
- Loughran and McDonald (2011) Loughran, T.; and McDonald, B. 2011. When is a liability not a liability? Textual analysis, dictionaries, and 10-Ks. The Journal of Finance 66(1): 35–65.
- Mao and Liu (2019) Mao, J.; and Liu, W. 2019. A BERT-based Approach for Automatic Humor Detection and Scoring. In IberLEF@ SEPLN, 197–202.
- Mohammad, Kiritchenko, and Zhu (2013) Mohammad, S. M.; Kiritchenko, S.; and Zhu, X. 2013. NRC-Canada: Building the state-of-the-art in sentiment analysis of tweets. arXiv preprint arXiv:1308.6242 .
- Mozafari, Farahbakhsh, and Crespi (2019) Mozafari, M.; Farahbakhsh, R.; and Crespi, N. 2019. A BERT-based transfer learning approach for hate speech detection in online social media. In International Conference on Complex Networks and Their Applications, 928–940. Springer.
- Olsher and Kantor (2012) Olsher, G.; and Kantor, I.-D. 2012. Asking questions as a key strategy in guiding a novice teacher: A self-study. Studying Teacher Education 8(2): 157–168.
- Pan et al. (2017) Pan, L.; Wang, X.; Li, C.; Li, J.; and Tang, J. 2017. Course concept extraction in moocs via embedding-based graph propagation. In Proceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 875–884.
- Prince et al. (1982) Prince, E. F.; Frader, J.; Bosk, C.; et al. 1982. On hedging in physician-physician discourse. Linguistics and the Professions 8(1): 83–97.
- Prokofieva and Hirschberg (2014) Prokofieva, A.; and Hirschberg, J. 2014. Hedging and speaker commitment. In 5th Intl. Workshop on Emotion, Social Signals, Sentiment & Linked Open Data, Reykjavik, Iceland.
- Rajpurkar et al. (2016) Rajpurkar, P.; Zhang, J.; Lopyrev, K.; and Liang, P. 2016. Squad: 100,000+ questions for machine comprehension of text. arXiv preprint arXiv:1606.05250 .
- Rehurek and Sojka (2010) Rehurek, R.; and Sojka, P. 2010. Software framework for topic modelling with large corpora. In In Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks. Citeseer.
- ResearchAndMarkets (2020) ResearchAndMarkets. 2020. Global online education market worth $319+ billion by 2025 - north America anticipated to provide the highest revenue generating opportunities. Retrieved on August 24, 2020 from https://www.globenewswire.com/news-release/2020/04/16/2017102/0/en/Global-Online-Education-Market-Worth-319-Billion-by-2025-North-America-Anticipated-to-Provide-the-Highest-Revenue-Generating-Opportunities.html .
- Roitero, Cristian Bozzato, and Serra (2020) Roitero, K.; Cristian Bozzato, V.; and Serra, G. 2020. Twitter goes to the Doctor: Detecting Medical Tweets using Machine Learning and BERT. In Proceedings of the International Workshop on Semantic Indexing and Information Retrieval for Health from heterogeneous content types and languages (SIIRH 2020).
- Rowan, Chiang, and Miller (1997) Rowan, B.; Chiang, F.-S.; and Miller, R. J. 1997. Using research on employees’ performance to study the effects of teachers on students’ achievement. Sociology of education 256–284.
- Sadoski, Goetz, and Rodriguez (2000) Sadoski, M.; Goetz, E. T.; and Rodriguez, M. 2000. Engaging texts: Effects of concreteness on comprehensibility, interest, and recall in four text types. Journal of Educational Psychology 92(1): 85.
- Shavelson (1973) Shavelson, R. J. 1973. What is the basic teaching skill? Journal of teacher education 24(2): 144–151.
- Trakunphutthirak, Cheung, and Lee (2019) Trakunphutthirak, R.; Cheung, Y.; and Lee, V. C. 2019. A study of educational data mining: Evidence from a thai university. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, 734–741.
- UnitedNations (2020) UnitedNations. 2020. Policy brief: Education during COVID-19 and beyond. Retrieved on August 24, 2020, from https://www.un.org/development/desa/dspd/wp-content/uploads/sites/22/2020/08/sg˙policy˙brief˙covid-19˙and˙education˙august˙2020.pdf .
- van de Grift, Helms-Lorenz, and Maulana (2014) van de Grift, W.; Helms-Lorenz, M.; and Maulana, R. 2014. Teaching skills of student teachers: Calibration of an evaluation instrument and its value in predicting student academic engagement. Studies in educational evaluation 43: 150–159.
- Vaswani et al. (2017) Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, Ł.; and Polosukhin, I. 2017. Attention is all you need. In Advances in neural information processing systems, 5998–6008.
- Wang et al. (2018) Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; and Bowman, S. R. 2018. Glue: A multi-task benchmark and analysis platform for natural language understanding. arXiv preprint arXiv:1804.07461 .
- Wang et al. (2019) Wang, X.; Shi, W.; Kim, R.; Oh, Y.; Yang, S.; Zhang, J.; and Yu, Z. 2019. Persuasion for good: Towards a personalized persuasive dialogue system for social good. arXiv preprint arXiv:1906.06725 .
- Woltman Elpers, Wedel, and Pieters (2003) Woltman Elpers, J. L.; Wedel, M.; and Pieters, R. G. 2003. Why Do Consumers Stop Viewing Television Commercials? Two Experiments on the Influence of Moment-to-Moment Entertainment and Information Value. Journal of Marketing Research (JMR) 40(4).
- Yu et al. (2019) Yu, J.; Wang, C.; Luo, G.; Hou, L.; Li, J.; Liu, Z.; and Tang, J. 2019. Course Concept Expansion in MOOCs with External Knowledge and Interactive Game. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 4292–4302.
- Zhang et al. (2019) Zhang, J.; Hao, B.; Chen, B.; Li, C.; Chen, H.; and Sun, J. 2019. Hierarchical reinforcement learning for course recommendation in moocs. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, 435–442.