Weighted Distillation with Unlabeled Examples
Abstract
Distillation with unlabeled examples is a popular and powerful method for training deep neural networks in settings where the amount of labeled data is limited: A large “teacher” neural network is trained on the labeled data available, and then it is used to generate labels on an unlabeled dataset (typically much larger in size). These labels are then utilized to train the smaller “student” model which will actually be deployed. Naturally, the success of the approach depends on the quality of the teacher’s labels, since the student could be confused if trained on inaccurate data. This paper proposes a principled approach for addressing this issue based on a “debiasing" reweighting of the student’s loss function tailored to the distillation training paradigm. Our method is hyper-parameter free, data-agnostic, and simple to implement. We demonstrate significant improvements on popular academic datasets and we accompany our results with a theoretical analysis which rigorously justifies the performance of our method in certain settings.
1 Introduction
In many modern applications of deep neural networks, where the amount of labeled examples for training is limited, distillation with unlabeled examples [8, 20] has been enormously successful. In this two-stage training paradigm a larger and more sophisticated “teacher model” — typically non-deployable for the purposes of the application — is trained to learn from the limited amount of available training data in the first stage. In the second stage, the teacher model is used to generate labels on an unlabeled dataset, which is usually much larger in size than the original dataset the teacher itself was trained on. These labels are then utilized to train the “student model”, namely the model which will actually be deployed. Notably, distillation with unlabeled examples is the most commonly used training-paradigm in applications where one finetunes and distills from very large-scale foundational models such as BERT [13] and GPT-3 [5] and, additionally, it can be used to significantly improve distillation on supervised examples only (see e.g. [47]).
While this has proven to be a very powerful approach in practice, its success depends on the quality of labels provided by the teacher model. Indeed, often times the teacher model generates inaccurate labels on a non-negligible portion of the unlabeled dataset, confusing the student. As deep neural networks are susceptible to overfitting to corrupted labels [50], training the student on the teacher’s noisy labels can lead to degradation in its generalization performance. As an example, Figure 1 depicts an instance based on CIFAR-10 where filtering out the teacher’s noisy labels is quite beneficial for the student’s performance.
We address this shortcoming by introducing a natural “noise model” for the teacher which allows us to modify the student’s loss function in a principled way in order to produce an unbiased estimate of the student’s clean objective. From a practical standpoint, this produces a fully “plug-and-play” method which adds minimal implementation overhead, and which is composable with essentially every other known distillation technique.
The idea of compressing a teacher model into a smaller student model by matching the predictions of the teacher was initially introduced by Buciluǎ, Caruana and Niculescu-Mizil [6] and, since then, variations of this method [20, 26, 31, 35, 39, 42, 49] have been applied in a wide variety of contexts [37, 48, 51]. (Notably, some of these applications go beyond compression — see e.g. [8, 47, 48, 52] for reference.) In the simplest form of the method [26], and using classification as a canonical example, the labels produced by the teacher are one-hot vectors that represent the class which has the maximum predicted probability — this method is often referred to as “hard”-distillation. More generally, Hinton et. al. [8, 20] have shown that it is often beneficial to train the student so that it minimizes the cross-entropy (or KL-divergence) with the probability distribution produced by the teacher while also potentially using a temperature higher than in the softmax of both models (“soft”-distillation). (Temperatures higher than are used in order to emphasize the difference between the probabilities of the classes with lower likelihood of corresponding to the correct label according to the teacher model.)
The main contribution of this work is a principled method for improving distillation with unlabeled examples by reweighting the loss function of the student. That is, we assign importance weights to the examples labeled by the teacher so that each weight reflects (i) how likely it is that the teacher has made an inaccurate prediction regarding the label of the example and (ii) how “distorted” the unweighted loss function we use to train the student is (measured with respect to using the ground-truth label for the example instead of the teacher’s label). More concretely, our reweighting strategy is based on introducing and analyzing a certain noise model designed to capture the behavior of the teacher in distillation. In this setting, we are able to come up with a closed-form solution for weights that “de-noise” the objective in the sense that (on expectation) they simulate having access to clean labels. Crucially, we empirically observe that the key characteristics of our noise model for the teacher can be effectively estimated through a small validation dataset, since in practice the teacher’s noise is neither random nor adversarial, and it typically correlates well with its “confidence” — see e.g. Figure 1. In particular, we use the validation dataset to learn a map that takes as input the teacher’s and student’s confidence for the label of a certain example and outputs estimates for the quantities mentioned in items (i) and (ii) above. Finally, we plug in these estimates to our closed-form solution for the weights so that, overall, we obtain an automated way of computing the student’s reweighted objective in practice. A detailed description of our method can be found in Section 2.3.
Our main findings and contributions can be summarized as follows:
-
•
We propose a principled and hyperparameter-free reweighting method for knowledge distillation with unlabeled examples. The method is efficient, data-agnostic and simple to implement.
-
•
We present extensive experimental results which show that our method provides significant improvements when evaluated in standard benchmarks.
-
•
Our reweighting technique comes with provable guarantees: (i) it is information-theoretically optimal; and (ii) under standard assumptions SGD optimization of the reweighted objective learns a solution with nearly optimal generalization.


1.1 Related work
Fidelity vs Generalization in knowledge distillation. Conceptually, our work is related to the paper of Stanton et al. [43] where the main message is that “good student accuracy does not imply good distillation fidelity”, i.e., that more closely matching the teacher does not necessarily lead to better student generalization. In particular, [43] demonstrates that when it comes to enlarging the distillation dataset beyond the teacher training data, there is a trade-off between optimization complexity and distillation data quality. Our work can be seen as a principled way of improving this trade-off.
Advanced distillation techniques. Since the original paper of Hinton et. al. [20], there have been several follow-up works [2, 7, 31, 45] which develop advanced distillation techniques which aim to enforce greater consistency between the teacher and the student (typically in the context of distillation on labeled examples). These methods enforce consistency not only between the teacher’s predictions and student’s predictions, but also between the representations learned by the two models. However, in the context of distillation with unlabeled examples, forcing the student to match the teacher’s inaccurate predictions is still harmful, and therefore weighting the corresponding loss functions via our method is still applicable and beneficial. We demonstrate this fact by considering instances of the Variational Information Distillation for Knowledge Transfer (VID) [2] framework, and showing how it is indeed beneficial to combine it with our method in Section 3.1.3. We also show that our approach provides benefits on top of any improvement obtained via temperature-scaling in Appendix B.2.
Learning with noisy data techniques. As we have already discussed, the main conceptual contribution of our work is viewing the teacher model in distillation with unlabeled examples as the source of stochastic noise with certain characteristics. Naturally, one may wonder what is the relationship between our method and works from the vast literature of learning with noisy data (e.g. [4, 14, 16, 23, 25, 27, 29, 33, 36, 38]). The answer is that our method does not attempt to solve the generic “learning with noisy data” problem, which is a highly non-trivial task in the absence of assumptions (both in theory and in practice). Instead, our contribution is to observe and exploit the fact that the noise introduced by the teacher in distillation has structure, as it correlates with several metrics of confidence such as the margin-score, the entropy of the predictions etc. We use and quantify this empirical observation to our advantage in order to formulate a principled method for developing a debiasing reweighting scheme (an approach inspired by the “learning with noisy data"-literature) which comes with theoretical guarantees. An additional difference is that works from the learning with noisy data literature typically assume that the training dataset consists of corrupted hard labels, and often times their proposed method is not compatible with soft-distillation (in the sense that they degrade its performance, making it much less effective) — see e.g. [32] for a study of this phenomenon in the case of label smoothing [28, 44].
Uncertainty-based weighting schemes. Related to our method are approaches for semi-supervised learning where examples are downweighted or filtered out when the teacher is “uncertain.” (A plethora of ways for defining and measuring “uncertainty” have been proposed in the literature, e.g. entropy, margin-score, dropout variance etc.) These methods are independent of the student model (they only depend on the teacher model), and so they cannot hope to remove the bias from the student’s loss function. In fact, these methods can be viewed as preprocessing steps that can be combined with the student-training process we propose. To demonstrate this we both combine and compare our method to the fidelity-based weighting scheme of [12] in Section 3.3.
1.2 Organization of the paper.
In Section 2, we present our method in detail, while in Section 3 we present our key experimental results. In Section 4, we discuss the theoretical aspects of our work. In Section 5, we summarize our results, we discuss the benefits and limitations of our method, and future work. Finally, we present extended experimental and theoretical results in the Appendix.
2 Weighted distillation with unlabeled examples
In this section we present our method. In Section 2.1, we review multiclass classification. In Section 2.2, we introduce the noise model for the teacher in distillation, which motivates our approach. And finally, in Section 2.3, we describe our method in detail.
2.1 Multiclass classification
In multiclass classification, we are given a training sample drawn from , where is an unknown distribution over instances and labels . Our goal is to learn a predictor , namely to minimize the risk of . The latter is defined as the expected loss of :
| (1) |
where is drawn from , and is a loss function such that, for a label and prediction vector , is the loss incurred for predicting when the true label is . The most common way to approximate the risk of a predictor is via the so-called empirical risk:
| (2) |
That is, given a hypothesis class of predictors , our goal is typically to find as a way to estimate .
2.2 Debiasing weights
As we have already discussed, the main drawback of distillation with unlabeled examples is essentially that the empirical risk minimizer corresponding to the dataset labeled by the teacher cannot be trusted, since the teacher may generate inaccurate labels. To quantify this phenomenon and guide our algorithmic design, we consider the following simple but natural noise model for the teacher.
Let be an unknown distribution over instances . We assume the existence of a ground-truth classifier so that each is associated with a ground-truth label . In other words, a clean labeled example is of the form (and ). Additionally, we consider a stochastic adversary that given an instance , outputs a “corrupted” label with probability , and the ground-truth label with probability . Let denote the induced adversarial distribution over instances and labels.
It is not hard to see that the empirical risk with respect to a predictor and sample from is not an unbiased estimator of the risk
| (3) |
— see Proposition 2.1. On the other hand, the following weighted empirical risk (5) is indeed an unbiased estimator of . For each let
| (4) |
and define
| (5) |
where . Observe that the weight for each instance depends on (i) how likely it is the adversary corrupts its label; and on (ii) how this corrupted label “distorts” the loss we observe at instance . In the following proposition we establish that the standard (unweighted) empirical risk with respect to distribution and a predictor is a biased estimator of the risk of under the clean distribution , while the weighted empirical risk (5) is an unbiased one.
Proposition 2.1 (Debiasing Weights).
Let be a sample from the adversarial distribution. Defining we have:
Notice that, as expected, the bias of the unweighted predictor is a function of the “power” of the adversary, i.e., a function of how often they can corrupt the label of an instance, and the “distortion” this corruption causes to the loss we observe. The proof of Proposition 2.1 follows from simple, direct calculations and it can be found in Appendix D.3.
2.3 Our method
We consider the standard setting for distillation with unlabeled examples where we are given a dataset of labeled examples from an unknown distribution , and a dataset of unlabeled examples — typically, . We also assume the existence of a (small) clean validation dataset of size . Finally, let be a loss function that takes as input two vectors over the set of labels . We describe our method below and more formally in Algorithm 1 in Appendix A.
Remark 2.1.
The only assumption we need to make about the validation set is that it is not in the train set of the teacher model. That is, set can be used in the train set of the student model if needed — we chose to present as a completely independent hold out set to make our presentation as conceptually clear as possible.
Training the teacher. The teacher model is trained on dataset , and then it is used to generate labels for the instances in . The labels can be one-hot vectors or probability distributions on , depending on whether we apply “hard” or “soft” distillation, respectively.
Training the student. We start by pretraining the student model on dataset . Then, the idea is to think of the teacher model as the source of noise in the setting of Section 2.2, compute a weight for each example based on (4), and finally train the student on the union of labeled and teacher-labeled examples by minimizing the weighted empirical risk (examples from are assigned unit weight).
We point out two remarks. First, in order to apply (4) to compute the weight of an example , we need to have estimates of and . To obtain these estimates we use the validation dataset as we describe in the next paragraph. Second, observe that, according to (4), the weight of an example is a function of the predictor, namely the parameters of the model in the case of neural networks. This means that ideally we should be updating our weights assignment every time the parameters of the student model get updated during training. However, we empirically observe that even estimating the weight assignment only once during the whole training process (right after training the student model on ) suffices for our purposes, and so our method adds minimal overhead to the standard training process. More generally, the fact that our process of computing the weights is simple and inexpensive allows us to recompute them during training (say every few epochs) to improve our approximation of the theoretically optimal weights. We explore the effect of updating the weights during training in Section 3.2.
Estimating the weights. We estimate the weights using the Nearest Neighbors method on to learn a map that takes as input the teacher’s and student’s “confidence” for the label of a certain example , and outputs estimates for and so we can apply (4). In our experiments we measure the confidence of a model either via the margin-score, i.e., the difference between the largest two predicted classes for the label of a given example (see e.g. the so-called “margin” uncertainty sampling variant [40]), or via the entropy of its prediction. However, one could use any metric (not necessarily confidence) that correlates well with the accuracy of the corresponding models.
More concretely, we reduce the task of estimating the weights to a two-dimensional (i.e., two inputs and two outputs) regression task over the validation set which we solve using the Nearest Neighbors method. In particular, our Nearest Neighbor data structure is constructed as follows. Each example of the validation set is assigned the two following pairs of points: (i) (teacher confidence at , student confidence at ) — this is the covariate of the regression task; (ii) (, distortion at ()) if the teacher correctly predicts the label of , or (, distortion at ), if the teacher does not correctly predict the label of — this is the response of the regression task. The query corresponding to an unlabeled example is of the form (teacher confidence at , student confidence at ). The Nearest Neighbors data structure returns the average response over the closest in euclidean distance pairs (teacher confidence at , student confidence at ) in the validation set. The value of is specified in the next paragraph. The pseudocode for our method can be found in Algorithm 2 in Appendix A.
We point out two remarks. First, the number of neighbors we use for our weights-estimation is always . This is because choosing , where is the size of the validation dataset and is the dimension of the underlying metric space ( in our case), is asymptotically optimal, and is a popular choice for the hidden constant used in practice, see e.g. [9, 18]. Second, notice that (4) implies that the weight of an example could be larger than if (and only if) the corresponding distortion value (4) at that example is less than . This could happen for example if both the student and teacher have the same (or very similar) inaccurate prediction for a certain example. In such a case, the value of the weight in (4) informs us that the loss at this example should be larger than the (low) value the unweighted loss function suggests. However, since we do not have the ground-truth label for a point during training — but only the inaccurate prediction of the teacher — having a weight larger than in this case would most likely guide our student model to fit an inaccurate label. To avoid this phenomenon, we always project our weights onto the interval (Line 16 of Algorithm 2). In Appendix D.2 we discuss an additional reason why it is beneficial to project the weights of examples of low distortion onto based on a MSE analysis.
3 Experimental results
In this section we present our experimental results. In Section 3.1 we consider an experimental setup according to which the weights are estimated only once during the whole training process. In Section 3.2 we study the effect of updating the weights during training. Finally, in Section 3.3 we demonstrate that our method can be combined with uncertainty-based weighting techniques by both combining and comparing our method to the fidelity-based weighting scheme of [12].




SVHN

CIFAR-10

CelebA

CelebA

CIFAR-10
3.1 Improvements via one-shot estimation of the weights
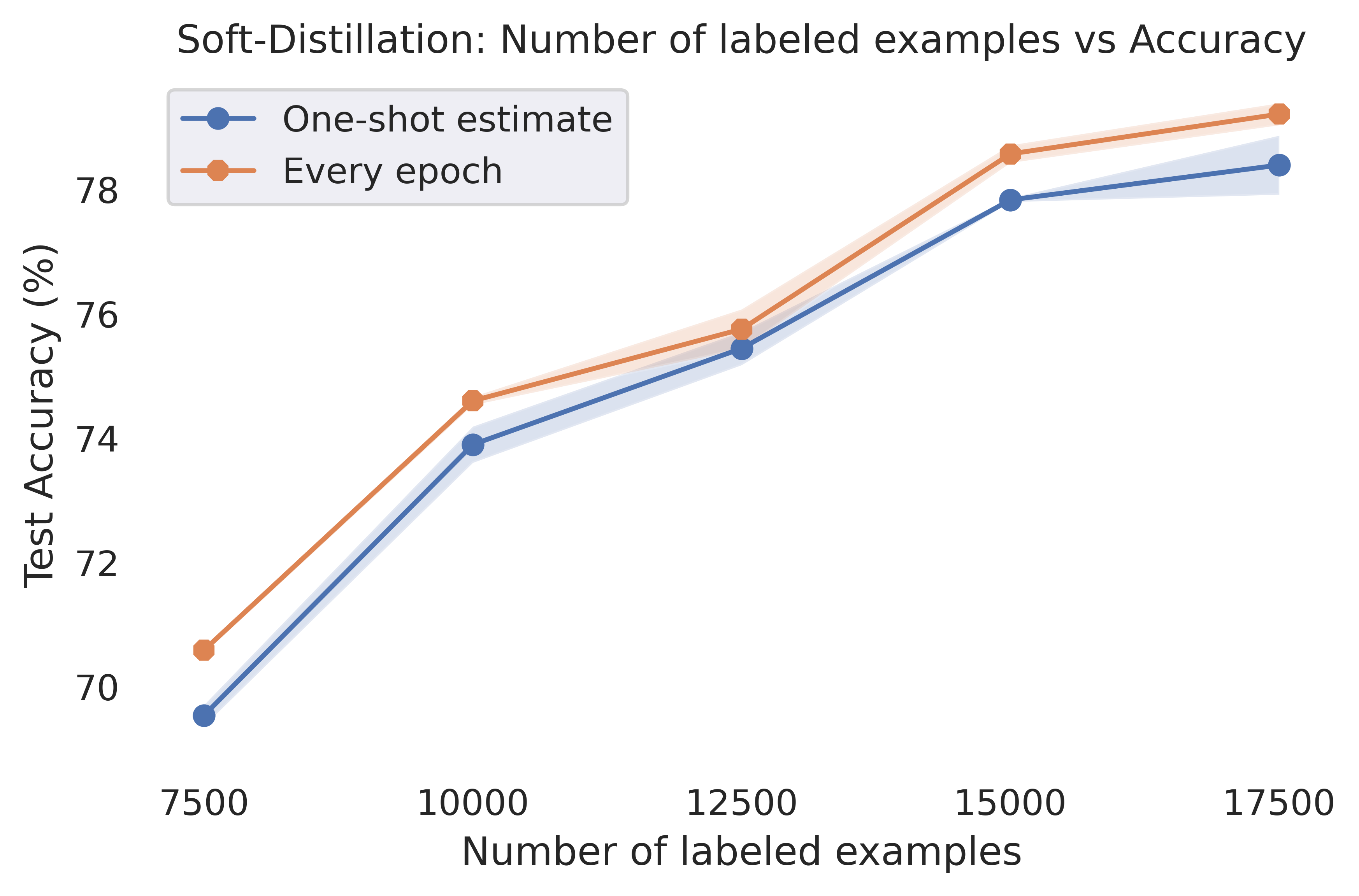
Here we show how applying our reweighting scheme provides consistent improvements on several popular benchmarks even when the weights are estimated only once during the whole training process. We compare our method against conventional distillation with unlabeled examples, but we also show that our method can provide benefits when combined with more advanced distillation techniques such as the framework of [2] (see Figure 9).
More concretely, we evaluate our method on benchmark vision datasets. We compare our method to conventional distillation with unlabeled examples both in terms of the best test accuracy achieved by the student, and in terms of convergence speed (see Figure 2). We also evaluate the comparative advantage of our method as a function of the number of labeled examples available (size of dataset ). We always choose the temperature in the softmax of the models to be for simplicity and consistency, and our metric for confidence is always the margin-score. Implementation details for our experiments and additional results can be found in Appendices B and C. We implemented all algorithms in Python making use of the TensorFlow deep learning library [1]. We use 64 Cloud TPU v4s each with two cores.
3.1.1 Experimental setup
Our experiments are of the following form. The academic dataset we use each time is first split into two parts and . Part , which is typically smaller, is used as the labeled dataset where the teacher model is trained on (recall the setting we described in Section 2.3). Part is randomly split again into two parts which represent the unlabeled dataset and validation dataset , respectively. Then, (i) the teacher and student models are trained once on the labeled dataset ; (ii) the teacher model is used to generate soft-labels for the unlabeled dataset ; (iii) we train the student model on the union of and using our method and conventional distillation with unlabeled examples. We repeat step (iii) a number of times: in each trial we partition part randomly and independently, and then the student model is trained using the (student-)weights reached after completing the training on dataset in step (i) as initialization, both for our method and the competing approaches.
3.1.2 CIFAR-{10, 100} and SVHN experiments
SVHN [34] is an image classification dataset where the task is to classify street view numbers ( classes). The train set of SVHN contains labeled images and its test set contains images. We use a MobileNet [21] with depth multiplier as the teacher, and a MobileNet with depth multiplier as the student111Note that we see the student outperform the teacher here and in other experiments, as can often happen with distillation with unlabeled examples, particularly when the teacher is trained on limited data.. The tables in Figure 4 contain the results of our experiments (averages over trials). In each experiment we use the first examples as the labeled dataset , and then the rest images are randomly split to a labeled validation dataset of size , and an unlabeled dataset of size .
CIFAR-10 and CIFAR-100 [24] are image classification datasets with and classes respectively. Each of them consists of labeled images, which we split to a training set of images, and a test set of images. For CIFAR-10, we use a Mobilenet with depth multiplier as the teacher, and a Mobilenet with depth multiplier as the student. For CIFAR-100, we use a ResNet-110 as a teacher, and a ResNet-56 as the student. We use a validation set of examples. The results of our experiments (averages over trials) can be found in the tables of Figures 5, 6.
| Labeled Examples | |||||
|---|---|---|---|---|---|
| Teacher | |||||
| Weighted (Ours) | |||||
| Unweighted |
| Labeled Examples | |||||
|---|---|---|---|---|---|
| Teacher | |||||
| Weighted (Ours) | |||||
| Unweighted |
| Labeled Examples | |||||
|---|---|---|---|---|---|
| Teacher | |||||
| Weighted (Ours) | |||||
| Unweighted |
3.1.3 CelebA experiments: considering more advanced distillation techniques
As we have already discussed in Section 1.1, our method can be combined with more advanced distillation techniques which aim to enforce greater consistency between the teacher and the student. We demonstrate this fact by implementing the method of Variational Information Distillation for Knowledge Transfer (VID) [2] and showing how it is indeed beneficial to combine it with our method. We chose the gender binary classification task of CelebA [15] as our benchmark (see details in the next paragraph), because it is known (see e.g. [31]) that the more advanced distillation techniques tend to be more effective when applied to classification tasks with few classes. In the table below, “Unweighted VID” corresponds to the implementation of loss described in equations (2), (4) and (6) of [2], and “Weighted VID” corresponds to the reweighting of the latter loss using our method.
CelebA [15] is a large-scale face attributes dataset with more than celebrity images, each with forty attribute annotations. Here we consider the binary male/female classification task. The train set of CelebA contains images and its test set contains images. We use a MobileNet with depth multiplier as the teacher, and a ResNet-11 [19] as the student. The tables in Figure 7 contain the results of our experiments (averages over trials). In each experiment we use the first examples as the labeled dataset , and then the rest images are randomly split to a labeled validation dataset of size , and an unlabeled dataset of size .
3.1.4 ImageNet experiments
ImageNet [41] is a large-scale image classification dataset with classes consisting of approximately M images. For our experiments, we use a ResNet-50 as the teacher, and a ResNet-18 as the student. In each experiment we use the first labeled examples ( and of , respectively) as the labeled dataset , and the rest examples are randomly split to a labeled validation dataset of size , and an unlabeled dataset of size . The results of our experiments (averages over 10 trials) can be found in Figure 8.
| Labeled Examples | of ImageNet | of ImageNet |
|---|---|---|
| Teacher (soft) | ||
| Weighted (Ours) | ||
| Unweighted |
| Labeled Examples | of ImageNet | of ImageNet |
|---|---|---|
| Teacher (hard) | ||
| Weighted (Ours) | ||
| Unweighted |
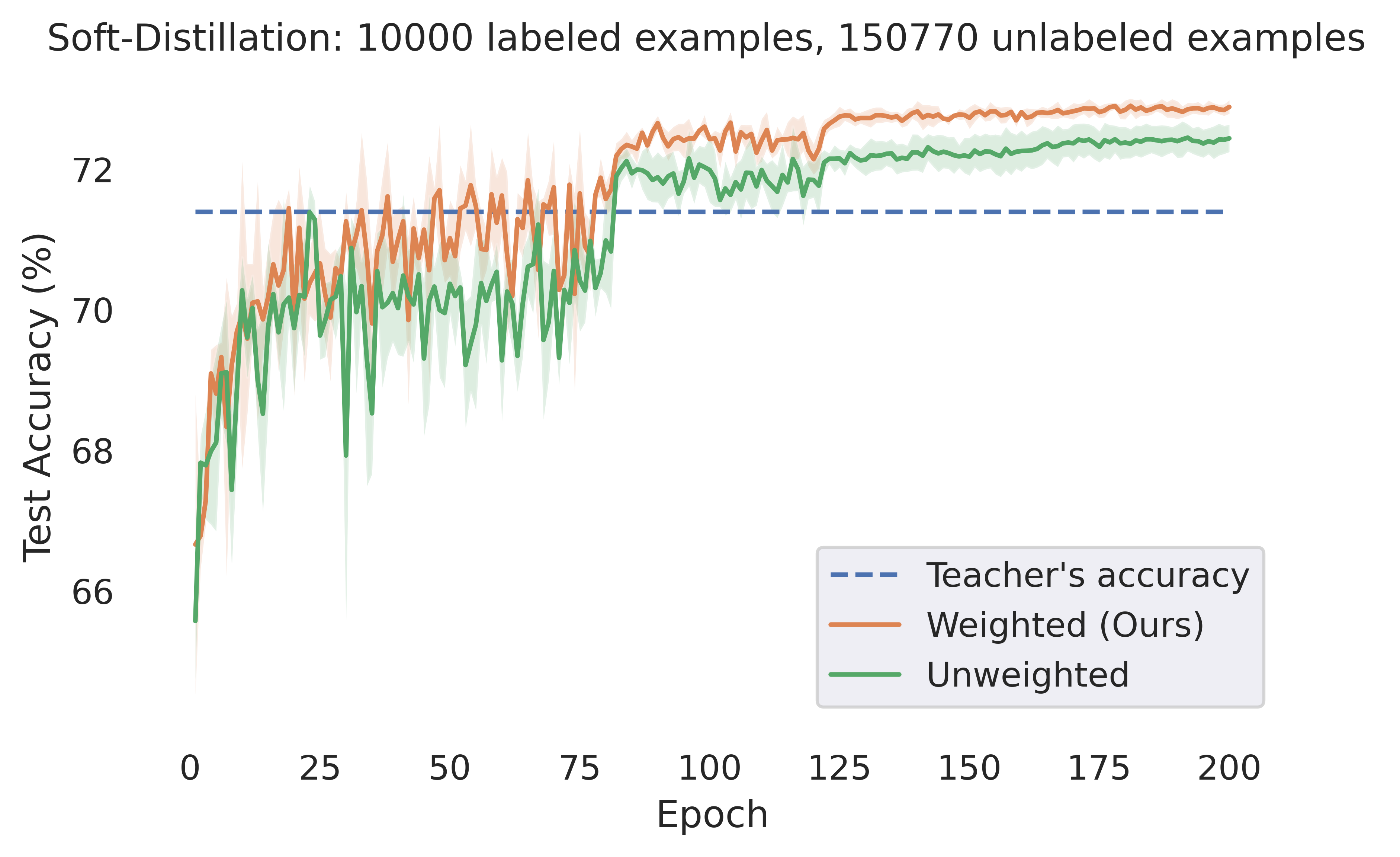
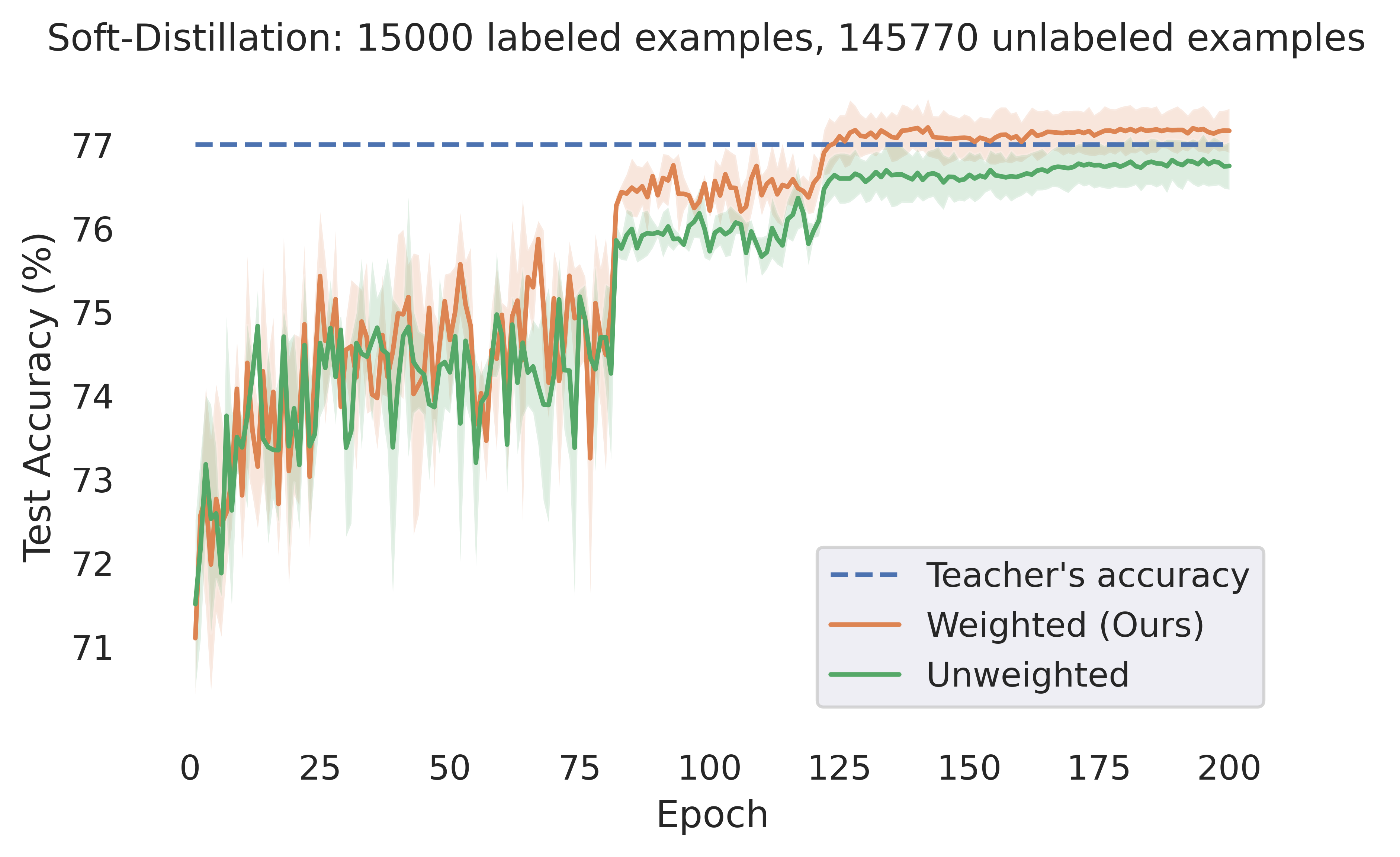
3.2 Updating the weights during training
In this section we consider the effect of updating our estimation of the optimal weights during training. For each dataset we consider, the experimental setup is identical to the corresponding setting in Section 3.1, except for that we always use a validation set of size and the entropy of a model’s prediction as the metric for its confidence. We note that the time required for computing the weight for each example is insignificant compared to total training time (less than 1% of the total training time in all of our experiments), which allows us to conduct experiments in which we update our estimation at the end of every epoch. We see that doing this typically significantly improves the resulting student’s performance (however, in CIFAR-100 we do not observe substantial benefits).

CelebA
CIFAR-10

CIFAR-100
3.3 Combining and comparing with uncertainty-based weighting schemes
As we have already discussed in Section 1.1, our method can be combined with uncertainty-based weighting schemes as these are independent of the student model and, therefore, they can be seen as a preprocessing step (modifying the loss function) before applying our method. We demonstrate this by combining and comparing our method with the filelity-based weighting scheme of [12] on CIFAR-10 and CIFAR-100. Details about our experimental setup can be found in Appendix C.3.
| Labeled Examples | |||||
|---|---|---|---|---|---|
| Teacher (soft) | |||||
| Our Method | |||||
| Fidelity-based weighting [12] | |||||
| Composition |
| Labeled Examples | |||||
|---|---|---|---|---|---|
| Teacher (soft) | |||||
| Our Method | |||||
| Fidelity-based weighting [12] | |||||
| Composition |
4 Theoretical motivation
In this section we show that our debiasing reweighting method described in Section 2.2 comes with provable statistical and optimization guarantees. We first show that the method is statistically consistent in the sense that, with a sufficiently large dataset, the reweighted risk converges to the true or “clean” risk. We show (see Appendix D) the following convergence guarantee.
Theorem 4.1 (Uniform Convergence of Reweighted Risk).
Assume that is a dataset of i.i.d. “noisy” samples from . Under standard capacity assumptions for the class of models and regularity assumptions for the loss , for every it holds that
To prove our optimization guarantees we analyze the reweighted objective in the fundamental case where the model is linear, i.e., , and the loss is convex in for every . In this case, the composition of the loss and the model is convex as a function of the parameter . Recall that we denote by the ground truth classifier and by the “clean” distribution, i.e., a sample from has the form where is drawn from a distribution supported on (a subset of) . Finally, we denote by the “noisy” labeled distribution on and assume that the -marginal of is also .
We next give a general definition of debiasing weight functions, i.e., weighting mechanisms that make the corresponding objective function an unbiased estimator of the clean objective for every parameter vector . Recall that the weight function defined in Section 2.2 is debiasing.
Definition 4.2 (Debiasing Weights).
We say that a weight function is a debiasing weight function if it holds that
Since the loss is convex in , one could try to optimize the naive objective that does not reweight and simply minimizes over the noisy examples, . We show (unsurprisingly) that doing this is a bad idea: there are instances where optimizing the naive objective produces classifiers with bad generalization error over clean examples. For the formal statement and proof we refer the reader to Appendix E.
SGD on the naive objective learns parameters with arbitrarily
bad generalization error over the “clean” data.
Our main theoretical insight is that optimizing linear models with the reweighted loss leads to parameters with almost optimal generalization.
Given a debiasing weight function , SGD on the reweighted objective learns a parameter with almost optimal generalization error over the “clean” data.
The main issue with optimizing the reweighted objective is that, in general, we have no guarantees that the weight function preserves its convexity (recall that it depends on the parameter ). However, we know that its population version corresponds to the clean objective which is a convex objective. We show that we can use the convexity of the underlying clean objective to show results for stochastic gradient descent, by proving the following key structural property.
Proposition 4.3 (Stationary Points of the Reweighted Objective Suffice (Informal)).
Let be a dataset of i.i.d. samples from the noisy distribution . Let be any stationary point of the weighted objective constrained on the unit ball (with respect to the Frobenious norm ). Then, with probability at least , it holds that
5 Conclusion
We propose a principled reweighting scheme for distillation with unlabeled examples. Our method is hyper-parameter free, adds minimal implementation overhead, and comes with theoretical guarantees. We evaluated our method on standard benchmarks and we showed that it consistently provides significant improvements. We note that investigating improved data-driven ways of estimating the weights (4) could be of interest, since potential inaccurate estimation of the weights is the main limitation of our work. We leave this question open for future work.
6 Acknowledgements
We are grateful to anonymous reviewers for detailed comments and feedback.
References
- [1] Martín Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv preprint arXiv:1603.04467, 2016.
- [2] Sungsoo Ahn, Shell Xu Hu, Andreas Damianou, Neil D Lawrence, and Zhenwen Dai. Variational information distillation for knowledge transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9163–9171, 2019.
- [3] Martin Anthony and Peter Bartlett. Neural network learning: Theoretical foundations. cambridge university press, 1999.
- [4] Noga Bar, Tomer Koren, and Raja Giryes. Multiplicative reweighting for robust neural network optimization. arXiv preprint arXiv:2102.12192, 2021.
- [5] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- [6] Cristian Buciluǎ, Rich Caruana, and Alexandru Niculescu-Mizil. Model compression. In Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 535–541, 2006.
- [7] Liqun Chen, Dong Wang, Zhe Gan, Jingjing Liu, Ricardo Henao, and Lawrence Carin. Wasserstein contrastive representation distillation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16296–16305, 2021.
- [8] Ting Chen, Simon Kornblith, Kevin Swersky, Mohammad Norouzi, and Geoffrey E Hinton. Big self-supervised models are strong semi-supervised learners. Advances in neural information processing systems, 33:22243–22255, 2020.
- [9] Thomas Cover and Peter Hart. Nearest neighbor pattern classification. IEEE transactions on information theory, 13(1):21–27, 1967.
- [10] Sanjoy Dasgupta, Adam Tauman Kalai, and Claire Monteleoni. Analysis of perceptron-based active learning. COLT’05, page 249–263, Berlin, Heidelberg, 2005. Springer-Verlag.
- [11] Damek Davis and Dmitriy Drusvyatskiy. Stochastic subgradient method converges at the rate on weakly convex functions. arXiv preprint arXiv:1802.02988, 2018.
- [12] Mostafa Dehghani, Arash Mehrjou, Stephan Gouws, Jaap Kamps, and Bernhard Schölkopf. Fidelity-weighted learning. arXiv preprint arXiv:1711.02799, 2017.
- [13] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- [14] Benoît Frénay and Michel Verleysen. Classification in the presence of label noise: a survey. IEEE transactions on neural networks and learning systems, 25(5):845–869, 2013.
- [15] Tommaso Furlanello, Zachary Lipton, Michael Tschannen, Laurent Itti, and Anima Anandkumar. Born again neural networks. In International Conference on Machine Learning, pages 1607–1616. PMLR, 2018.
- [16] Dragan Gamberger, Nada Lavrac, and Ciril Groselj. Experiments with noise filtering in a medical domain. In ICML, volume 99, pages 143–151, 1999.
- [17] Ying Guo, Peter L Bartlett, John Shawe-Taylor, and Robert C Williamson. Covering numbers for support vector machines. In Proceedings of the twelfth annual conference on Computational learning theory, pages 267–277, 1999.
- [18] Trevor Hastie, Robert Tibshirani, Jerome H Friedman, and Jerome H Friedman. The elements of statistical learning: data mining, inference, and prediction, volume 2. Springer, 2009.
- [19] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- [20] Geoffrey E. Hinton, Oriol Vinyals, and Jeffrey Dean. Distilling the knowledge in a neural network. CoRR, abs/1503.02531, 2015.
- [21] Andrew G Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, and Hartwig Adam. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861, 2017.
- [22] Prateek Jain, Dheeraj M. Nagaraj, and Praneeth Netrapalli. Making the last iterate of sgd information theoretically optimal. SIAM Journal on Optimization, 31(2):1108–1130, 2021.
- [23] Lu Jiang, Zhengyuan Zhou, Thomas Leung, Li-Jia Li, and Li Fei-Fei. Mentornet: Learning data-driven curriculum for very deep neural networks on corrupted labels. In International Conference on Machine Learning, pages 2304–2313. PMLR, 2018.
- [24] Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009.
- [25] Abhishek Kumar and Ehsan Amid. Constrained instance and class reweighting for robust learning under label noise. arXiv preprint arXiv:2111.05428, 2021.
- [26] Dong-Hyun Lee et al. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In Workshop on challenges in representation learning, ICML, volume 3, page 896, 2013.
- [27] Tongliang Liu and Dacheng Tao. Classification with noisy labels by importance reweighting. IEEE Transactions on pattern analysis and machine intelligence, 38(3):447–461, 2015.
- [28] Michal Lukasik, Srinadh Bhojanapalli, Aditya Menon, and Sanjiv Kumar. Does label smoothing mitigate label noise? In International Conference on Machine Learning, pages 6448–6458. PMLR, 2020.
- [29] Negin Majidi, Ehsan Amid, Hossein Talebi, and Manfred K Warmuth. Exponentiated gradient reweighting for robust training under label noise and beyond. arXiv preprint arXiv:2104.01493, 2021.
- [30] Andreas Maurer and Massimiliano Pontil. Empirical bernstein bounds and sample variance penalization. arXiv preprint arXiv:0907.3740, 2009.
- [31] Rafael Müller, Simon Kornblith, and Geoffrey Hinton. Subclass distillation. arXiv preprint arXiv:2002.03936, 2020.
- [32] Rafael Müller, Simon Kornblith, and Geoffrey E Hinton. When does label smoothing help? Advances in neural information processing systems, 32, 2019.
- [33] Nagarajan Natarajan, Inderjit S Dhillon, Pradeep K Ravikumar, and Ambuj Tewari. Learning with noisy labels. Advances in neural information processing systems, 26, 2013.
- [34] Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Bo Wu, and Andrew Y Ng. Reading digits in natural images with unsupervised feature learning. 2011.
- [35] Hieu Pham, Zihang Dai, Qizhe Xie, and Quoc V Le. Meta pseudo labels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11557–11568, 2021.
- [36] Geoff Pleiss, Tianyi Zhang, Ethan Elenberg, and Kilian Q Weinberger. Identifying mislabeled data using the area under the margin ranking. Advances in Neural Information Processing Systems, 33:17044–17056, 2020.
- [37] Ilija Radosavovic, Piotr Dollár, Ross Girshick, Georgia Gkioxari, and Kaiming He. Data distillation: Towards omni-supervised learning. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4119–4128, 2018.
- [38] Mengye Ren, Wenyuan Zeng, Bin Yang, and Raquel Urtasun. Learning to reweight examples for robust deep learning. In International conference on machine learning, pages 4334–4343. PMLR, 2018.
- [39] Ellen Riloff. Automatically generating extraction patterns from untagged text. In Proceedings of the national conference on artificial intelligence, pages 1044–1049, 1996.
- [40] Dan Roth and Kevin Small. Margin-based active learning for structured output spaces. In European Conference on Machine Learning, pages 413–424. Springer, 2006.
- [41] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge. International journal of computer vision, 115(3):211–252, 2015.
- [42] Henry Scudder. Probability of error of some adaptive pattern-recognition machines. IEEE Transactions on Information Theory, 11(3):363–371, 1965.
- [43] Samuel Stanton, Pavel Izmailov, Polina Kirichenko, Alexander A Alemi, and Andrew G Wilson. Does knowledge distillation really work? Advances in Neural Information Processing Systems, 34:6906–6919, 2021.
- [44] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2818–2826, 2016.
- [45] Yonglong Tian, Dilip Krishnan, and Phillip Isola. Contrastive representation distillation. arXiv preprint arXiv:1910.10699, 2019.
- [46] Roman Vershynin. High-dimensional probability: An introduction with applications in data science, volume 47. Cambridge university press, 2018.
- [47] Qizhe Xie, Minh-Thang Luong, Eduard Hovy, and Quoc V Le. Self-training with noisy student improves imagenet classification. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10687–10698, 2020.
- [48] I Zeki Yalniz, Hervé Jégou, Kan Chen, Manohar Paluri, and Dhruv Mahajan. Billion-scale semi-supervised learning for image classification. arXiv preprint arXiv:1905.00546, 2019.
- [49] David Yarowsky. Unsupervised word sense disambiguation rivaling supervised methods. In 33rd annual meeting of the association for computational linguistics, pages 189–196, 1995.
- [50] Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol Vinyals. Understanding deep learning (still) requires rethinking generalization. Communications of the ACM, 64(3):107–115, 2021.
- [51] Barret Zoph, Golnaz Ghiasi, Tsung-Yi Lin, Yin Cui, Hanxiao Liu, Ekin Dogus Cubuk, and Quoc Le. Rethinking pre-training and self-training. Advances in neural information processing systems, 33:3833–3845, 2020.
- [52] Yang Zou, Zhiding Yu, Xiaofeng Liu, BVK Kumar, and Jinsong Wang. Confidence regularized self-training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 5982–5991, 2019.
Appendix A Formal description of our method
In this section we present pseudocode for our method.
Appendix B Extended experiments
B.1 The student’s test-accuracy-trajectory
In this section we provide extended experimental results that show the student’s test accuracy over the training trajectory corresponding to experiments we mentioned in Section 3.1. Notice that in the vast majority of cases our method significantly outperforms the conventional approach almost throughout the training process.


















B.2 Considering the effect of temperature
Temperature-scaling, a technique introduced in the original paper of Hinton et. al. [20], is one the most common ways for improving student’s performance in distillation. Indeed, it is known (see e.g. [43]) that choosing the right value for the temperature can be quite beneficial, to the point it can outperform other more advanced techniques for improving distillation. Here we demonstrate that our approach provides benefits on top of any improvement on can get via temperature-scaling by conducting an ablation study on the effect of temperature on CIFAR-100. In our experiment, the teacher model is a Resnet-110 achieving accuracy , the student model is a Resnet-56, the number of labeled examples is , the validation set consists of examples, and we use the entropy of a prediction as a metric of confidence. We apply our method using one-shot estimation of the weights. We compare training the student model using conventional distillation to using our method for different values of temperature. The results can be found in the table below. We see that in almost all cases the student-model trained using our method outperforms the student-model trained using conventional distillation and, in particular, the best student overall is the result of choosing for the value of temperature and applying our method.
| Temperature | Unweighted | Weighted (ours) |
|---|---|---|
Appendix C Implementation details
In this section we describe the implementation details of our experiments. Recall the description of our method in Section 2.3.
C.1 Experiments on CelebA, CIFAR-10, CIFAR-100, SVHN
All of our experiments are performed according to the following recipe. In all cases, the loss function we use is the cross-entropy loss. We train the teacher model for epochs on dataset . We pretrain the student model for epochs on dataset and save its parameters. Then, using the latter saved parameters for initialization each time, we train the student model for epochs optimizing either the weighted or conventional (unweighted) empirical risk, and report its average performance over three trials.
We use the Adam optimizer. The initial learning rate is . We proceed according to the following learning rate schedule (see e.g., [19]):
Finally, we use data-augmentation. In particular, we use random horizontal flipping and random width and height translations with width and height factor, respectively, equal to .
C.2 Experiments on ImageNet
For the ImageNet experiments we follow a similar although not identical recipe to the one described in Appendix C.1. In each training stage above, we train the model (teacher or student) for epochs instead of . We also use SGD with momentum instead of Adam as the optimizer. For data-augmentation we use only random horizontal flipping. Finally, the learning rate schedule is as follows. For the first epochs the learning rate is increased from to linearly. After that, the learning rate changes as follows:
C.3 Details on the experimental setup of Section 3.3
In the CIFAR-10 experiments of Section C.3 the teacher model is a MobileNet with depth multiplier 2, and the student model is a MobileNet with depth multiplier 1. In the CIFAR-100 experiments of the same section, the teacher model is a ResNet-110, and the student model is a ResNet-56. We use a validation set consisting of examples (randomly chosen as always). The student of each method has access to the same number of labeled examples, i.e., the validation set is used for training the student model as we describe in Remark 2.1. We compare the following three methods:
-
•
Fidelity weighting scheme [12]. For every example we use the entropy of the teacher’s prediction as an uncertainty/confidence measure, which we denote by . We then compute the exponential weights described in [12] as , where is the average entropy of the teacher’s predictions over all training examples.
-
•
Our method. We use the entropy as the metric for confidence. In the case of CIFAR-10 we re-estimate the weights at the end of every epoch. In the case of CIFAR-100 the weights are estimated only once in the beginning of the process.
-
•
Composition. We reweight each example in the loss function by multiplying the weights resulting from the two methods above.
Appendix D Extended theoretical motivation: statistical aspects
In this section we study the statistical aspects of our approach. In Section D.1 we revisit and formally state Theorem 4.1 — see Corollary D.2 and Remark D.1. In Section D.2 we perform a Mean-Squared-Error analysis that provides additional justification of our choice to always project the weights on the interval (recall Line 16 of Algorithm 2). Finally, in Section D.3 we provide the proof of Proposition 2.1 which was omitted from the main body of the paper.
D.1 Statistical motivation
Recall the background on multiclass classification in Section 2.1. In this section we study hypothesis classes and loss functions that are “well-behaved” with respect to a certain (standard in the machine learning literature) complexity measure we describe below.
For , a class of functions and an integer , the “growth function" is defined as
| (6) |
where and for the number is the smallest cardinality of a set such that is contained in the union of -balls centered at points in , in the metric induced by The growth number is a complexity measure of function classes commonly used in the machine learning literature [3, 17].
The following theorem from [30] provides large deviation bounds for function classes of polynomial growth.
Theorem D.1 (Theorem 6, [30]).
Let be a random variable taking values in distributed according to distribution , and let be a class of functions. Fix and set
Then with probability at least in the random vector , for every we have:
where is the sample variance of the sequence .
A straightforward corollary of Theorem D.1 and Proposition 2.1, and the main motivation for our method, is the following corollary.
Corollary D.2.
Let be a loss function and fix . Consider any hypothesis class of predictors , and the two induced classes , of functions and , respectively. Fix , , and set and . Then, with probability at least over ,
| (7) | |||||
| (8) |
where are the sample variances of the loss values , , respectively.
The following remark formally captures Theorem 4.1.
Remark D.1.
Under the assumptions of Corollary D.2, if we additionally have that and are polynomially bounded in , then, for every it holds that
D.2 Studying the MSE of a fixed prediction
In this section we study the Mean-Squared-Error (MSE) of a fixed prediction for an arbitrary instance , predictor , and loss function , in order to gain some understanding on when the importance weighting scheme could potentially underperform the standard unweighted approach from a bias-variance perspective (i.e., when the training sample is “small enough” so that asymptotic considerations are ill-suited). These considerations lead us to an additional justification for always projecting the weights to the interval (recall Line 16 of Algorithm 2).
Formally, we study the behavior of the quantities:
Recalling the definition of distortion (4) we have the following proposition.
Proposition D.3.
Let be a bounded loss function. Fix and a predictor . We have if and only if:
-
1.
; and
-
2.
.
Proof sketch.
Via direct calculations we obtain:
| (9) | |||||
and
| (10) | |||||
Recalling the definition of weights (4), and combining it with (9) and (10) implies the claim.
∎
In words, Proposition D.3 implies that when the adversary does not have the power to corrupt the label of an instance with high enough probability, i.e., is sufficiently small, and the prediction of the student is “close enough" to the adversarial label (i.e., when is small enough), then it potentially makes sense to use the unweighted estimator instead of the weighted one from a bias-variance trade-off perspective, as the former has smaller MSE in this case. Notice that this observation aligns well with our method as we always project to (observe that iff and ).
D.3 Proof of Proposition 2.1
Appendix E Extended theoretical motivation: optimization aspects
To prove our optimization guarantees, we analyze the reweighted objective in the fundamental case where the model is linear, i.e., , and the loss is convex in for every . In this case, the composition of the loss and the model is convex as a function of the parameter . Recall that we denote by the ground truth classifier and by the “clean” distribution, i.e., a sample from has the form where is drawn from a distribution supported on (a subset of) . Finally, we denote by the “noisy” labeled distribution on and assume that the -marginal of is also .
Notation
In what follows, for any elements of the same dimensions we denote by their inner product. For example for two vectors we have . Similarly, for two matrices we have . We denote by the for vectors and the spectral norm for matrices. We use to denote the standard tensor (Kronecker) product between two vectors or matrices. For example, for two matrices we have and for two vectors we have . We denote by the Frobenious norm for matrices. We remark that we use standard asymptotic notation , etc. and to omit factors that are poly-logarithmic (in the appearing arguments).
For example, training a linear model with the Cross Entropy loss corresponds to using and minimizing the objective
More generally, in what follows we shall refer to the population loss over the clean distribution as , i.e.,
We next give a general definition of debiasing weight functions, i.e., weighting mechanisms that make the corresponding objective function an unbiased estimator of the clean objective for every parameter vector .
Definition E.1 (Debiasing Weights).
We say that a weight function is a debiasing weight function if it holds that
Remark E.1.
We remark that the weight function depends on the current hypothesis, , and also on the noise advice that we are given with every example. In order to keep the notation simple, we do not explicitly track these dependencies and simply write . We also remark that, in general, in order to construct the weight function we may also use “clean” data, which may be available, e.g., as a validation dataset, as we did in Section 2.2.
Our main result is that, given a convex loss and a debiasing weight function that satisfy standard regularity assumptions, stochastic gradient descent on the reweighted objective produces a parameter vector with good generalization error. We first present the assumptions on the example distributions, the loss, and the weight function. In what follows, we view the gradient of a function as an -matrix and the hessian as an -tensor (or equivalently as a -matrix).
Definition E.2 (Regularity Assumptions).
The -marginal of and is supported on (a subset of) the ball of radius , .
The training model is linear and the parameter space is the unit ball, i.e., .
For every label in the support of , the loss is a twice differentiable, convex function in . Moreover is -bounded, -Lipschitz, and -smooth, i.e., , , and , for all with .
For every example in the support of the weight function is twice differentiable, -bounded, -Lipschitz, and -smooth, i.e., , , and for all with 222Recall that, formally, is a -tensor . For this tensor we overload notation and set to be the standard operator norm when we view as an -matrix. .
Remark E.2.
Observe that if a property in the above definition is satisfied by some parameter-value , then it is also satisfied for any other . For example, if the loss function is -Lipschitz it is also -Lipschitz. Therefore, to simplify the expressions, in what follows we shall assume (without loss of generality) that all the regularity parameters, i.e., , are larger than .
Since the loss is convex, it is straightforward to optimize the naive objective that does not reweight the loss and simply minimizes over the noisy examples, . We first show that (unsurprisingly) it is not hard to construct instances (even in binary classification) where optimizing the naive objective produces classifiers with large generalization error over clean examples. For simplicity, since in the following lemma we consider binary classification, we assume that the labels and the parameter of the linear model is a vector .
Proposition E.3 (Naive Objective Fails).
Fix any . Let be the Binary Cross Entropy loss, i.e., . There exists a “clean” distribution and a noisy distribution on so that the following hold.
-
1.
The -marginal of both and is uniform on a sphere.
-
2.
The clean labels of are consistent with a linear classifier .
-
3.
has (total) label noise .
-
4.
The minimizer of the (population) naive objective , constrained on the unit has generalization error
where is the “clean” risk, .
Our positive results show that, having a debiasing weight function that is not very “wild” (see the regularity assumptions of Definition E.2) and optimizing the corresponding weighted objective with SGD, gives models with almost optimal generalization. The main issue with optimizing the reweighted objective is that, in general, we have no guarantees that the weight function preserves its convexity (recall that it depends on the parameter ). However, we know that its population version corresponds to the clean objective which is a convex objective. We show that we can use the convexity of the underlying clean objective to show results for both single- and multi-pass stochastic gradient descent. We first focus on single-pass stochastic gradient descent where at every iteration a fresh noisy sample is drawn from , see Algorithm 3.
Input: Number of iterations , Step size sequence
Output: Parameter vector .
-
Initialize .
-
For :
-
Draw sample .
-
Update using the gradient of the weighted objective:
-
-
Return .
Theorem E.4 (Generalization of Reweighted Single-Pass SGD).
The main observation in the single-pass setting is that, since the weight function is debiasing, we can view the gradients of the reweighted objective as stochastic gradients of the true objective over the clean samples. Therefore, as long as we draw a fresh i.i.d. noisy sample at each round, the corresponding sequence of gradients corresponds to stochastic unbiased estimates of the gradients of the true loss . We next turn our attention to multi-pass SGD (see Algorithm 4), where at each round we pick one of the samples with replacement and update according to its gradient. The key difference between single- and multi-pass SGD is that the expected loss over the stochastic algorithm for single-pass SGD is the population risk, while the expected loss for multi-pass SGD is the empirical risk. In other words, in the multi-pass setting we have a stochastic gradient oracle to the empirical reweighted objective which is not necessarily convex. Our second theorem shows that under the regularity conditions of Definition E.2 multi-pass SGD also achieves good generalization error.
Theorem E.5 (Generalization of Reweighted Multi-Pass SGD).
Assume that the example distributions , the loss , and the weight function satisfy the assumptions of Definition E.2. Set and define the empirical reweighted objective with i.i.d. samples from the noisy distribution as
Then, after iterations, multi-pass SGD with constant step size sequence 333 is a constant that depends on the regularity parameters of Definition E.2. (see Algorithm 4) on outputs a list that, with probability at least , contains a vector that satisfies
We remark that our analysis also applies to the multi-pass SGD variant where, at every epoch we pick a random permutation of the samples and update with their gradients sequentially.
Input: Number of Rounds , Number of Samples ,
Step size sequence .
Output: List of weight vectors .
-
Draw i.i.d. samples .
-
Initialize .
-
For :
-
Pick uniformly at random from and update using the gradient of the reweighted objective:
-
-
Return .
E.1 The proof of Proposition E.3
In this subsection we restate and prove Proposition E.3.
Proposition E.6 (Naive Objective Fails (Restate of E.3) ).
Fix any . Let be the Binary Cross Entropy loss, i.e., . There exists a “clean” distribution and a noisy distribution on so that the following hold.
-
1.
The -marginal of both and is uniform on a sphere.
-
2.
The clean labels of are consistent with a linear classifier .
-
3.
has (total) label noise .
-
4.
The minimizer of the (population) naive objective , constrained on the unit has generalization error
where is the “clean” risk, .
Proof.
We set the -marginal to be the uniform distribution on a sphere of radius to be specified later in the proof. We first observe that the unit vector minimizes the (clean) Binary Cross Entropy . We can now pick a different parameter vector with angle with , and construct a noisy instance as follows: we first draw (recall that we want the -marginal of the noisy distribution to be the same as the “clean”) and then set . By the symmetry of the uniform distribution on the sphere we have that
Therefore, by picking the angle to be equal to we obtain that as required by Proposition E.3. Moroever, we have that the minimizer of the “naive” BCE objective (constrained on the unit ball) is and the minimizer of the clean objective is . We have that
Moreover, we have that
We next need to bound from below the “margin” of the optimal weight vector , i.e., provide a lower bound on that holds with high probability. We will use the following anti-concentration inequality on the probability of a origin-centered slice under the uniform distribution on the sphere. For a proof see, e.g., Lemma 4 in [10].
Lemma E.7 (Anti-Concentration of Uniform vectors, [10]).
Let be any unit vector and let be the uniform distribution on the sphere. It holds that
Using Lemma E.7, we obtain that
where, at the last step, we used the elementary inequality . Assuming that is much larger than , we can pick . For this choice of we obtain that . Therefore, for we obtain that
Therefore, combining the above bounds we obtain that . ∎
E.2 The Proof of Theorem E.4
In this section we restate and prove our result on the generalization error of single-pass stochastic gradient descent on the weighted objective.
Theorem E.8 (Generalization of Reweighted Single-Pass SGD (Restate of E.4)).
Proof.
We observe that, since is a debiasing weight function, given a sample it holds that is an unbiased gradient estimate of . We will use the following result on the convergence of the last-iterate of SGD for convex objectives. For simplicity, we state the following theorem for the case where the parameter is a vector in (instead of a matrix).
Lemma E.9 (Last Iterate Stochastic Gradient Descent [22]).
Let be a closed convex set of diameter . Moreover, let be a convex, -Lipschitz function. Define the stochastic gradient descent iteration as
where is an unbiased gradient estimate of . Assume that for all it holds for all . There exists a step size sequence that depends only on such that, with probability at least , it holds
To simplify notation we let and . For a sample , the gradient of the weighted loss is:
Using the triangle inequality for the Frobenious norm and the assumptions of Definition E.2 on the functions and , we obtain that . Using Lemma E.9 we obtain that with , the last iteration of Algorithm 3 satisfies the claimed guarantee. ∎
E.3 The proof of Theorem E.5
In this section we prove our result on multi-pass SGD. For convenience, we first restate it.
Theorem E.10 (Generalization of Multi-Pass SGD (Restate of E.5)).
Set and define the empirical reweighted objective with i.i.d. samples from the noisy distribution as
Then, after iterations, multi-pass SGD (see Algorithm 4) on outputs a list that, with probability at least , contains a vector that satisfies
Proof.
To prove the theorem we shall first show that all stationary points of the empirical objective (which for arbitrary weight functions may be non-convex) will have good generalization guarantees. Before we proceed we formally define approximate stationary points. To simplify notation we shall assume that the parameter is a vector . The definition extends directly to the case where is a function of a parameter matrix by using the corresponding matrix inner product.
Definition E.11 (-approximate Stationary Points).
Let be a differentiable function and be any convex subset of . A vector is an -approximate stationary point of if for every it holds that
Proposition E.12.
Set and define the empirical reweighted objective with i.i.d. samples from the noisy distribution as
Let be any -stationary point of constrained on . Then, with probability at least , it holds that
Proof.
We first show that, as long as the empirical gradients are close to the population gradients, any stationary point of the weighted empirical objective will achieve good generalization error. In what follows we shall denote by the parameter that minimizes the clean objective:
Since the population objective is convex in , we have that for any it holds that
We have that the contstraint set is convex and therefore for a stationary point of we have that . Therefore, satisfies
Since is a debiasing weighting function, we know that, as the number of samples , the empirical gradients of the reweighted objective will converge to the gradients of the population clean objective , i.e., it holds that . Therefore, to finish the proof, we need to provide a uniform convergence bound for the gradient field of the empirical objective. We first consider estimating the gradient of some fixed parameter matrix . We will use McDiarmid’s inequality.
Lemma E.13 (McDiarmid’s Inequality).
Let be i.i.d. random variables taking values in . Let be such that whenever and differ only on the -th coordinate. It holds that
We consider the i.i.d. random variables . We have that the empirical gradient of the weighted loss function is equal to
We have that is -bounded and -Lipschitz, is -bounded and -Lipschitz, and . Therefore, the maximum value of each coordinate of each term in the sum of the empirical gradient is bounded by . Using this fact we obtain that each coordinate of the empirical gradient is a function of the i.i.d. random variables that satisfies the bounded differences assumption with constants that satisfy . From Lemma E.13, we obtain that
We next need to provide a uniform convergence guarantee over the whole parameter space . We will use the following standard lemma bounding the cardinality of an -net of the unit ball in -dimensions. For a proof see, e.g., [46].
Lemma E.14 (Cover of the Unit Ball [46]).
Let be the -dimensional unit ball around the origin. There exists an -net of with cardinality at most .
Since we plan to construct a net for the gradient of we first need to show that the weighted loss is a smooth function of its parameter or, in other words, that its gradients do not change very fast with respect to . The following lemma follows directly from the regularity assumptions of Defintion E.2 and the chain and product rules for the derivatives.
Lemma E.15.
For all , it holds that the function is -smooth for all with , with .
Proof.
For simplicy we shall denote simply by and similarly by . Using the chain rule, we have that the gradient of the weighted loss is equal to
Using again the chain and product rules we find the Hessian of :
where is the tensor with element . Recall that we view as an and to prove that it is smooth we have to find its operator (spectral) norm. Using the assumptions of Definition E.2 we obtain that . For the term we consider any with . We assume that is indexed as for and . We have
Similarly, we bound the spectral norm of the term . Finally for the term we have
where has . Observe that since and we have that . Therefore, from the assumption of Definition E.2, we obtain that .
We conclude that the function is -smooth on the unit ball with . ∎
Let be an -net of the unit ball . Using Lemma E.15 we first observe that the vector maps and are both -Lipschitz, where is the constant defined in Lemma E.15. Using the triangle inequality and the fact that and are -Lipschitz, we have that
Combining the above, and performing a union bound over the -net , we obtain that
We conclude that with samples, it holds that , uniformly for all parameters with , with probability at least . ∎
We now have to show that the multi-pass SGD finds an approximate stationary point of the empirical objective. We will use the following result on non-convex projected SGD. To simplify notation, we state the following optimization lemma assuming that the parameter is a vector .
Lemma E.16 (Non-Convex Projected Stochastic Gradient Descent [11]).
Let be a closed convex set of diameter . Moreover, let be an -Lipschitz and -smooth function. Define the stochastic gradient descent iteration as
where is an unbiased gradient estimate of . Fix a number of iterations and assume that for all it holds for all . Set the step-size . With probability at least , there exists a such that is an -stationary point of constrained on .
Theorem E.5 now follows directly by applying Lemma E.16 on the empirical objective to find an -approximate stationary point and then using Proposition E.12.
∎