Weakly Supervised Patch Label Inference Networks for Efficient Pavement Distress Detection and Recognition in the Wild
Abstract
Automatic image-based pavement distress detection and recognition are vital for pavement maintenance and management. However, existing deep learning-based methods largely omit the specific characteristics of pavement images, such as high image resolution and low distress area ratio, and are not end-to-end trainable. In this paper, we present a series of simple yet effective end-to-end deep learning approaches named Weakly Supervised Patch Label Inference Networks (WSPLIN) for efficiently addressing these tasks under various application settings. WSPLIN transforms the fully supervised pavement image classification problem into a weakly supervised pavement patch classification problem for solutions. Specifically, WSPLIN first divides the pavement image under different scales into patches with different collection strategies and then employs a Patch Label Inference Network (PLIN) to infer the labels of these patches to fully exploit the resolution and scale information. Notably, we design a patch label sparsity constraint based on the prior knowledge of distress distribution and leverage the Comprehensive Decision Network (CDN) to guide the training of PLIN in a weakly supervised way. Therefore, the patch labels produced by PLIN provide interpretable intermediate information, such as the rough location and the type of distress. We evaluate our method on a large-scale bituminous pavement distress dataset named CQU-BPDD and the augmented Crack500 (Crack500-PDD) dataset, which is a newly constructed pavement distress detection dataset augmented from the Crack500. Extensive results demonstrate the superiority of our method over baselines in both performance and efficiency. The source codes of WSPLIN are released on https://github.com/DearCaat/wsplin.
Index Terms:
Pavement Image Analysis, Deep Learning, Image Classification, Image Pyramid, Weakly Supervised LearningI Introduction
With the rapid growth of society and the modern logistics industry, road infrastructure has been greatly increased in today’s world. There are a total of more than 64,000,000 kilometers of roads in the world [1], which leads to massive operational requirements for pavement maintenance. The pavement inspection is one of the key steps [2]. Generally speaking, the cameras are often utilized as pavement inspection equipment due to their low cost and the powerful data representational ability of images. Therefore, the pavement inspection task is often translated into a pavement distress analysis task based on the acquired pavement images, and then this task is accomplished manually by proficient workers. Clearly, such an operation consumes plenty of time and labor resources due to an enormous amount of pavement images produced daily [3]. Therefore, automating the pavement distress analysis is critical in improving efficiency, reducing cost, and avoiding labeling errors in manual pavement inspection.

Pavement distress detection and recognition are two fundamental tasks for pavement distress analysis, which aim at filtering out the distressed pavements and classifying the distressed pavements into specific categories, respectively. This task is distinct from crack detection, which focuses on locating and segmenting cracks on various surfaces. Pavement distress classification (PDC)aims at distinguishing various types of pavement distress, which may or may not be cracks. Both of these two tasks present their own challenges. It is particularly difficult challenging to accurately segment the complex cracks in crack detection due to the irregular structures of these complex cracks. In real-world scenarios, most of the collected pavement images often either do not contain any distress or only have very small, subtle distress areas, as shown in Figure 1. This situation makes the PDC model more difficult to distinguish the distressed pavements from the normal ones, and the complex cracks are the key features for benefiting the classification. Clearly, small cracks or diseased areas are more likely to be challenging factors in PDC. In recent decades, many classical approaches have been applied to PDC.
The first group is to utilize image processing, hand-craft features, and conventional classifiers to recognize pavement distress [4, 5, 6, 7, 8]. For example, Zhou et al. [7] developed a two-step method that conducts the wavelet transform followed by a random transform to classify pavement distress. Sun et al. [4] proposed a crack classification method based on topological properties and chain code. The main drawback of these methods is that they often optimize the feature extraction and classification step separately or even do not involve any learning process, which leads to poor performance. Moreover, it usually needs plenty of sophisticated image pre-processing.
Inspired by the advance of deep learning approaches, it is more and more popular to apply different deep learning-based visual learning models for pavement distress detection and recognition [9, 10, 11, 12, 13]. For example, Laha et al. [14] detected road damage with RetinaNet [15]. Compared to conventional approaches, deep learning-based approaches often achieve better performance. However, most of these approaches only regard the pavement distress detection or recognition problem as common object detection or image classification problem and directly apply the classical deep learning approaches. They seldomly paid attention to the specific characteristics of pavement images, such as the high image resolution, the low distress area ratio.
In order to address the aforementioned issue, IOPLIN [13] employs a Patch Label Inference Network (PLIN) to infer the labels of patches from pavement images, taking advantage of the high-resolution image information. It elaborates an Expectation-Maximization-based strategy and a Patch Label Distillation strategy to iteratively train the network with only image labels, and has achieved remarkable detection performances. This approach represents a brand-new and innovative solution that emphasizes local information extraction and transforms the problem into a weakly supervised patch classification problem for classifying pavement images. However, its model optimization procedure is complex and time-consuming. Moreover, this model is also not end-to-end trainable and cannot be further extended to address the pavement distress recognition issue.
To address the aforementioned issues, we present a novel pavement image classification framework named Weakly Supervised Patch Label Inference Network (WSPLIN) [16] for both pavement distress detection and recognition. Similar to the IOPLIN, WSPLIN also accomplishes the pavement image classification via inferring the labels of patches from the pavement images with Patch Label Inference Networks (PLIN). Thus, WSPLIN inherits the merits of IOPLIN, such as the better image resolution information exploitation and result interpretability, but also suffers from the obstacle of training PLIN only with image labels. Compared to IOPLIN, WSPLIN solves this issue via introducing a more concise end-to-end patch-level weakly supervised learning framework. Such a framework endows WSPLIN with better efficiency and greater flexibility, enabling the pavement distress recognition application.
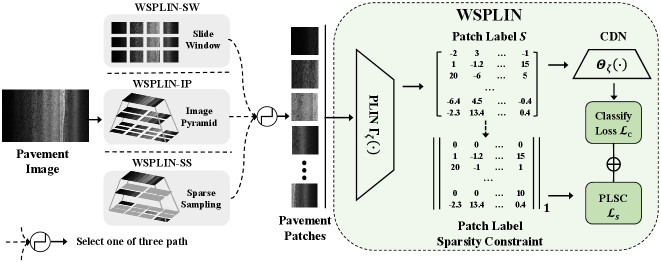
In WSPLIN, the pavement image is divided into patches with different patch collection strategies under different scales for exploiting both global and local information. Then, a CNN is implemented as PLIN for inferring the labels of patches with a sparsity constraint. Finally, the patch label inference results are fed into a Comprehensive Decision Network (CDN) for completing the classification. We integrate PLIN and CDN as an end-to-end deep learning model. In such a manner, the PLIN can be optimized by the guidance of CDN and the patch label sparsity constraint in a cleaner and more efficient fashion. Moreover, three different strategies, namely Sliding Window (SW), Image Pyramid (IP), and Sparse Sampling (SS), are adopted for collecting patches from images. We name these corresponding WSPLIN versions, WSPLIN-SW, WSPLIN-IP, and WSPLIN-SS, respectively. As same as IOPLIN, WSPLIN-SW has not considered any scale information during patch collection. It can be deemed as a naive version of WSPLIN. Different from WSPLIN-SW, WSPLIN-IP incorporates the scale information via dividing images into patches from coarse to fine based on an image pyramid. It is the default version of WSPLIN. WSPLIN-SS conducts a sparse patch sampling to collect only a few patches from the image pyramid to improve the efficiency of WSPLIN. It can be seen as the lightweight version of WSPLIN. We evaluate WSPLIN on a large-scale pavement image dataset named CQU-BPDD [13] and a new pavement image classification dataset constructed from Crack500 under different settings, including distress detection, one-stage recognition, and two-stage recognition. The experimental results show that WSPLIN outperforms extensive baselines and demonstrates prominent advantages over IOPLIN in both efficiency and performance.
The main contributions of our work are summarized as follows:
-
•
We propose a novel end-to-end patch-level weakly supervised deep learning model named WSPLIN for addressing both pavement distress detection and recognition issues. WSPLIN transforms the fully supervised pavement image classification task into a weakly supervised patch-level label inference issue for the solution. It not only inherits the merits of IOPLIN, but also enjoys faster training speed, better classification performance, and wider application scenarios over IOPLIN.
-
•
Different from IOPLIN and the conventional CNN-based image classification methods, we introduce image pyramid to WSPLIN-IP for exploiting scale information. Moreover, we design a sparse patch sampling strategy in the image pyramid for further speeding up WSPLIN. The model training time of this faster WSPLIN version (WSPLIN-SS) is only one-fourth of the training time of IOPLIN, while they share similar performance in pavement distress detection.
-
•
We introduce a simple constraint named patch-label sparsity constraint (PLSC) to incorporate the prior knowledge of the pavement distresses together with the Comprehensive Decision Network (CDN) for further boosting the patch-label inference process. The patch labels produced by PLIN enable providing some interpretable intermediate information, such as the rough location and the type of distress.
-
•
We empirically evaluate our model compared with some tailored methods and several state-of-the-art deep learning-based image classification approaches as baselines in pavement distress detection and recognition. Extensive results demonstrate that our proposed method outperforms them in all tasks under different settings on a large-scale bituminous pavement distress dataset named CQU-BPDD and a newly augmented pavement distress detection dataset constructed from Crack500.
II Related Work
II-A Image-based Pavement Distress Analysis
The traditional pavement distress analysis approaches mainly include filter-based methods and hand-crafted feature-based classical classifiers. For example, in [17], wavelet transform is used to decompose a pavement image into different-frequency subbands. Hu et al. [18] propose a novel Local Binary Pattern (LBP) based operator for pavement crack detection. In [19], a random structured forest named CrackForest, which is combined with the integral channel features, is proposed for automatic road crack detection. Kapela et al. [20] propose a crack recognition system based on the Histograms of Oriented Gradients (HOG). Pan et al. [21] use the four popular supervised learning algorithms (KNN, SVM, ANN, RF) to discern pavement damages. However, the traditional methods usually have weak performance owing to numerous artificial design factors, and separate optimization procedures, and they cannot be adapted to a large number of data currently.
Inspired by the recent remarkable successes of deep learning in extensive applications, simple and efficient convolutional neural networks (CNN) based pavement distress analysis methods have gradually become mainstream in recent years. In general, these methods can be divided into three parts according to the task objective: pavement distress segmentation [12, 22, 23, 24], pavement distress location [25, 26], and pavement distress classification [13, 27, 28]. Among them, pixel-based pavement distress segmentation is a hot research field. Zhang et al. [22] leverage CNN to classify the image patch for segmenting pavement distress. In [12], a CNN is used to learn the structure of the cracks from raw images, then the segmentation result is generated by the obtained structure information. Based on the fully conventional network (FCN), Yang et al. [23] fuse multiscale features from top-to-down for pavement crack segmentation. In DeepCrack [24], multiscale deep convolutional features learned at hierarchical convolutional stages are fused together to capture the line structures. For distress localization, Ibragimov et al. [25] propose a method for localizing signs of pavement distress based on a faster region-based conventional neural network. Zhu et al. [26] compare the performance of three state-of-the-art object-detection algorithms on an Unmanned aerial vehicles(UAV) pavement image dataset, which includes six types of distress. Because pavement distress annotation requires professional knowledge and a large amount of time, the datasets used in the above methods are low-resolution and small-scale. However, it remains to be determined whether models derived from small-scale datasets can be applied to real-world practice.
For pavement distress classification, Dong et al. [27] propose a metric-learning based method for multi-target few-shot pavement distress classification on the dataset, which includes ten different kinds of distress. In [28], discriminative super-features constructed by the multi-level context information from the CNN are used to determine whether there is distress in the pavement image and recognize the type of distress. All of these methods do a good job of classification on the dataset they use, which is small and only contains distressed images, and on which the test accuracy even achieves 100% [28]. There have been few works to systematically evaluate the model’s performance on a difficult large-scale multi-type dataset. Moreover, these approaches only regard the pavement distress detection or recognition problem as a common image classification problem and directly apply the classical deep learning approaches. In [13], patch-based weakly learning model IOPLIN and large-scale distress datasets CQU-BPDD are proposed to solve these problems. However, the main drawback of IOPLIN is that the patch label inference strategy based on the pseudo label makes IOPLIN incompatible with pavement recognition, and its optimization process is quite complex and time-consuming. Our approach takes inspiration from IOPLIN but operates with different patch inference strategy and uses more effective and hierarchical patch collection strategies. Besides, Li et al. [29] leverage Spatial Transformer Network [30] to automatically recognize different types of defects and measure the coverage percentage on the ship surface, which introduces a possible solution for pavement image classification.
II-B Deep Learning-based Image Classification
In recent years, due to the popularity of the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) [31], many computer vision algorithms based on deep learning have emerged. Among them, a series of convolutional neural networks (CNNs) play a leading role in the field of image classification. For example, AlexNet [32] first applies the structure of convolutional neural networks to large-scale image classification datasets. Simonyan et al. first propose the deep and large-scale convolutional neural network VGGNet [33] (i.e., the VGG19 model has 19 layers and more than 130 million parameters, while the previous convolutional neural network has less than 10 layers and millions to tens of millions of parameters). In InceptionNet [34], convolution kernel application is proposed for the first time. He et al. [35] propose a residual structure and network extension strategy to construct a network family for the first time. Zoph et al. [36] bring CNN into the embedded mobile terminal and propose MobileNet, specially designed for low computing power and low memory computing platform. Then based on MobileNet and Neural architecture search (NAS) [37], Tan et al. propose an efficient CNN, dubbed EfficientNet [38]. In the past year, inspired by the field of Natural Language Processing (NLP), Dosovitskiya et al. [39] propose a visual classification model based on Transformer [40], named as ViT.
However, it is very challenging to employ the general classification models based on CNN and Transformer for addressing pavement distress analysis issues directly. This is mainly because pavement images have many specific characteristics, such as high image resolution, low distress area ratio, and uneven illumination, compared with object-centric natural images. Our approach intends to employ a patch collection strategy in an image pyramid to incorporate both local and multi-scale information for pavement distress analysis.
III Methodology
The network architecture of the Weakly Supervised Patch Label Inference Network (WSPLIN) is shown in Figure 2. In this section, we first introduce the problem formulation and overview of WSPLIN in section III-A. Then, we introduce the involved patch collection strategies in section III-B. After that, the core modules of WSPLIN, Patch Label Inference Network (PLIN), and Comprehensive Decision Network (CDN) are detailed in section III-C and section III-D respectively. Finally, we will show how to apply WSPLIN to detect and recognize the pavement distress in section III-E.
III-A Problem Formulation and Overview
Both pavement distress detection and recognition can be deemed as image classification tasks from the perspective of computer vision. Let and be the collection of pavement images and their pavement labels, respectively. is a -dimensional one-hot vector where is the number of categories and indicates the -th element of . In the detection case, such a classification task is a binary image classification issue (distressed or normal) where . In the recognition case, this classification task is a multi-class image classification problem where . In a pavement label , if the -th element is the only nonzero element, it indicates that the corresponding pavement image belongs to the -th category. The pavement distress detection or recognition is to learn a classifier or can label the pavement image correctly, .
There are two strategies for accomplishing the pavement distress recognition task. One is the two-stage recognition flow path, and the other is the one-stage recognition flow path. The two-stage recognition is to identify distressed images first via pavement distress detection and then apply the pavement distress recognition to further classify each distressed image into a specific type of pavement distress. The one-stage recognition directly considers the normal case as an additional category in the recognition procedure. Therefore, the pavement distress detection and recognition tasks are jointly tackled with one image classification model.
Similar to Iteratively Optimized Patch Label Inference Network (IOPLIN), WSPLIN is a patch-based pavement image classification method whose main obstacle is to train Patch Label Inference Network (PLIN) only with the image label. WSPLIN introduces an additional module named Comprehensive Decision Network (CDN) to guide the optimization of PLINs in an end-to-end weakly supervised learning manner. The flow path of WSPLIN is very concise. In WSPLIN, the pavement image is divided into several patches first, and then PLIN is used to infer the labels of these patches. Finally, the inferred labels are fed into CDN to yield the final pavement label. WSPLIN has two core modules, namely PLIN and CDN, whose corresponding mapping functions are and , respectively.
III-B Patches Collection
We adopt three different patch collection strategies for producing patches. They are Slide Window (SW), Image Pyramid (IP), and Sparse Sampling (SS). The first strategy is also adopted by IOPLIN. WSPLIN uses the second strategy to exploit image information from different scales fully. The third strategy is newly designed by us based on the IP strategy for speeding up WSPLIN via reducing the patch amount for training.
Slide Window: The pavement image is simply divided into a series of uniform scale patches following a non-overlapping strategy. We adopt as the sliding window size with 300 sliding stride. The patch collection can be denoted as where is our patch extraction operation.
Image Pyramid: The slide window strategy does not consider the scale information. So we resize the pavement image into three resolutions, , and (the original size), to construct a three-layer image pyramid from top to down, and then employ sliding window method for dividing the image into patches. The patch collection can be denoted as where and indicates the layer ID. Similar to the slide window strategy, we also apply as the sliding window size with 300 sliding strides in the image pyramid. Therefore, , , and .
Sparse Sampling: The patch number determines the scale of training data, and the patches in the same image pyramid also contain some redundant information in the scale space. Therefore, we can sample some patches for each image to reduce the training burden and speed up the model. More specifically, let be the sparse sample ratio to control the number of sampled patches for each layer, where returns the smallest integer that is greater than or equal to the input. We design a simple strategy for sampling patches in each layer. In this strategy, the sampled patches of all three layers should cover all scales while maximizing spatial coverage. The optimal patch sparse sampling strategy is mathematically denoted as follows,
| (1) |
where returns the volume of the given set and denotes an index subset to patches in -th layer. Since the solutions to the above problem are limited, we can use the enumeration method to address this issue efficiently when is fixed. In this paper, we empirically set . In such a manner, , and .
For distinguishing different versions of WSPLIN, WSPLIN-SW, WSPLIN-IP, and WSPLIN-SS indicate the versions that use sliding window, image pyramid, and sparse sampling patch collection strategies, respectively. The default version of WSPLIN is WSPLIN-IP, since WSPLIN-IP is the best-performing version. WSPLIN-SS is the lightweight version of WSPLIN, which takes a good trade-off between performance and efficiency due to its special design. WSPLIN-SW is an ideal choice in the case that the distresses have not suffered from the high diversity in scale.
III-C Patch Label Inference Network
Similar to IOPLIN [13], we adopt EfficientNet-B3 [38] as our Patch Label Inference Network (PLIN) due to its good trade-off between performance and efficiency. We denote as the mapping function of PLIN. The patch label inference procedure is denoted as,
| (2) |
where is an -dimensional matrix in which every column encodes the label inference confidences of patches. Such confidences are expected to be zero if the patch does not contain the distress and reflect the possibility of the certain distress that the corresponding patch has. Please note, there is no supervised information on patches, so all these labels are randomly produced just via forward propagation. We need to leverage the follow-up comprehensive decision network to guide the PLIN to generate reasonable patch labels with image-level labels in a weakly supervised manner. We will introduce such a procedure later.
Patch Label Sparsity Constraint (PLSC): Since most pavement distress areas are actually only a tiny fraction of images, most patches in a pavement image should not have any distress, and the model should output low responses to these. In such a manner, the label confidence matrix should only have very limited nonzero elements, which indicates that should be sparse. Thus, we introduce an -norm constraint to the label confidence matrices of the distressed training samples,
| (3) |
where is the label of the normal pavement image. We introduce this constraint only to the distressed samples, since there should be no nonzero element in the label confidence matrices of the normal samples,
III-D Comprehensive Decision Network
We establish a Comprehensive Decision Network (CDN) for accomplishing the final pavement image classification based on the aforementioned patch label results. CDN consists of four layers where the first two layers are all the fully connection layers followed by a ReLU, and Dropout layer, the third layer is also an fully connection layer, and the size of output fully connection layer is . Here, is the number of categories. Let be the mapping function of CDN, then the predicted pavement distress label can be obtained by,
| (4) |
We use the cross-entropy to measure the discrepancy between the predicted label and ground-truth and denote it as the classification loss ,
| (5) |
Finally, the optimal WSPLIN model is learned by minimizing the following loss,
| (6) |
where is a positive parameter for reconciling the classification loss and the sparsity constraint.
WSPLIN is an end-to-end deep learning framework that uses back-propagation to compute the loss deviation and update the parameters layer by layer. In WSPLIN, CDN requires the patch label results produced by PLIN that should be useful for the final classification. The patch label sparsity constraint forces WSPLIN to highlight only a few of the most crucial patches for participating in the final decision. Clearly, these highlighted patches should be distressed ones, and their inferred patch label results should be nonzero since only the distressed patches can provide helpful information for the final detection and recognition. In such a manner, CDN essentially guides the training of PLIN in a weakly supervised manner.
III-E Pavement Distress Detection and Recognition
Detection and One-Stage Recognition: The pavement detection and one-stage pavement distress detection can be deemed as a one-stage pavement image classification problem. To tackle these tasks, we can train our model as a pavement image classifier. Once the model is trained, the pavement image can be divided into patches with different patch collection strategies, which are fed into WSPLIN for yielding the final classification,
| (7) |
where and the predicted category should be corresponding to the maximum element of .
Two-Stage Recognition: The two-stage recognition has two stages to accomplish pavement distress recognition. The first stage is to train our model as a pavement distress detector for filtering out the normal samples and finding the distressed samples. The second stage is to train our model as a multi-class pavement image classifier for completing the final distress recognition,
| (8) |
where and the maximum element of reflects the specific pavement distress category of the distressed pavement image .
IV Experiments and Results
IV-A Dataset and Setup
IV-A1 Pavement Image Classification Tasks
We test our method on pavement distress detection and recognition tasks under four application settings. The first one is the one-stage recognition (I-REC), which tackles the pavement distress detection and recognition tasks jointly. In this setting, all samples (including both the distressed and normal ones) and their fine-grained category label are available for training and testing the model. Moreover, both the detection and recognition performances can be evaluated under this setting. The second one is the one-stage detection (I-DET), which is the conventional detection fashion. In this setting, all samples (including both the distressed and normal ones) are involved, but only the binary coarse-grained category label (distressed or normal) is available. The other two settings are all from the two-stage recognition scenario. One is the ideal second-stage recognition II-REC(i), which assumes all distressed samples are ideally detected via the first-stage detection. In this setting, the recognition models are only evaluated with distressed pavement images. The last setting is the normal second-stage recognition II-REC(n). The training stage of II-REC(i) and II-REC(n) are identical. But their testing stages are different. In II-REC(n), the recognition models are only evaluated on the images detected by the detection model trained in I-DET. In such a manner, the recognition error under this setting is the errors accumulated by both the first-stage detection and the second-stage recognition, since some distressed images may be incorrectly filtered out while some normal images may be incorrectly classified as distressed ones by the detector in the recognition testing stage under II-REC(n). The results in II-REC(n) can reflect the comprehensive performances of two-stage recognition.

IV-A2 Pavement Image Datasets
We employed two pavement image datasets for evaluation. One is the CQU-BPDD dataset, and the other is the augmented Crack500 (Crack500 for Pavement Distress Detection, Crack500-PDD) dataset, which is a newly constructed pavement image classification dataset augmented from the well-known crack detection dataset–Crack500. The examples of these datasets are shown in Figure 3.
The CQU-BPDD is a large-scale bituminous pavement distress dataset, which is specially designed for pavement image classification and enables evaluating the approaches under all four application settings [13]. This dataset involves seven different types of distress: alligator crack, crack pouring, longitudinal crack, massive crack, transverse crack, raveling, and mending. For settings of I-DET, I-REC, and II-REC(n). We simply follow the data split strategy in [13]. With regard to the setting of II-REC(i), 5140 distressed pavement images are randomly selected as the training set, while the rest 11,589 distressed pavement images are for testing. The detailed data split information of different settings is tabulated in Table I.
In order to better assess our methods, we also have constructed a new pavement image dataset named Crack500-PDD via augmenting the Crack500 dataset [41] for Pavement Distress Detection, which is a well-known crack detection dataset. Since the Crack500 dataset only has distress pavement images, we produce some normal pavement images via erasing the crack areas of some carefully selected crack images with their corresponding crack segmentation annotations. Specifically, the normal ones are recovered from their distressed version via replacing the diseased pixels with their neighbor pixels based on the pixel-level labels provided by the dataset. The Crack500-PDD dataset is a small-scale pavement image dataset, which only contains 494 crack images and 286 normal pavement images. The Crack500-PDD dataset can only be leveraged for evaluating the pavement distress detection performances, since it only has normal and crack samples. In an experiment, we randomly select half of the samples for training, while the rest for validation. Because of the small scale of the dataset, we repeated this experiment five times and report the average performance to reduce the impacts of data partitioning.
IV-A3 Implement Details
Similar to IOPLIN, we adopt EfficientNet-B3 as the Patch Label Inference Network (PLIN). Since the comprehensive decision network (CDN) adopts a fully connected layer with fixed dimensions, WSPLIN requires the input size to be fixed at , and the optimizer uses RangerLars, which is just a combination of RAdam[42], LookAhead[43] and LARS[44]. With regard to the Crack500-PDD, we first resized input images to 1200900, and converted them into gray images for a fair comparison. The learning rate is , and the cosine annealing strategy is adopted to adjust the learning rate: the learning rate remained unchanged in the first 25% of the training process, and gradually decreased with the cosine function in the subsequent training process. Data augments such as rotation, flipping, and brightness balance are carried out for the raw images. The dropout rate of the classification layer is 0.5.
| Setting | Classifier | Train | Test | ||
| #Sample | #Class | #Sample | #Class | ||
| I-DET | Detector | 10137 | 2 | 49919 | 2 |
| \hdashline[1.5pt/1.5pt] I-REC | I-Recognizer | 10137 | 8 | 49919 | 8 |
| \hdashline[1.5pt/1.5pt] II-REC(i) | II-Recognizer | 5140 | 7 | 11589 | 7 |
| \hdashline[1.5pt/1.5pt] II-REC(n) | Detector | 10137 | 2 | 49919 | 8 |
| II-Recognizer | 5140 | 7 | |||
IV-B Evaluation Metrics
IV-B1 Evaluation Metrics of Detection
For pavement distress detection task, we adopt Area Under Curve (AUC) of Receiver Operating Characteristic (ROC) [45], which is common in binary classification tasks (this metric is not affected by classification threshold). It is mathematically defined as follows,
| (9) |
where is the sum of all positive samples ranked, while and denote the number of positive and negative samples. Additionally, Binary score, which is the harmonic mean of precision and recall, is used to measure the models more comprehensively. The binary score is defined as:
| (10) |
where P is the precision while R is the recall. , , and are the numbers of true positives, false positives and false negatives respectively. The precision measures how many true positive samples are among the samples that are predicted as positive samples. Similarly, recall measures how many true positive samples are correctly detected among all positive samples. Moreover, in the medical or pavement image analysis tasks, it is more meaningful to discuss the precision under the high recall, since the miss of the positive samples (the distressed sample) may lead to a more serious impact than the miss of the negative ones.
IV-B2 Evaluation Metrics of Recognition
For pavement distress recognition task, we mainly use the Top-1 accuracy and Marco score to evaluate the performance of models. Top-1 accuracy mainly measures the overall accuracy of the models, while Marco score evaluates the accuracy of the model across different categories. The Macro score can be mathematically represented as follows,
| (11) |
where indicates the binary score of the -th category, and is the total number of categories.
Note: The represents and in pavement distress detection and recognition tasks respectively.
IV-C Baselines
Histogram of Oriented Gradient (HOG) [5], Local Binary Pattern (LBP) [46], Fisher Vector(FV) [47], Support Vector Machine (SVM) [48], ResNet-50 [35], Inception-v3 [49], VGG-19 [33], ViT-S/16 [39], ViT-B/16 [39], EfficientNet-B3 [38], Spatial Transformer Networks (STN) [30, 29], and Iterative Optimized Patch Label Inference Network (IOPLIN) [13] are selected as baselines. The first four approaches are the shallow learning-based approaches. ResNet-50, Inception-v3, VGG-19, and EfficientNet-B3 are the classical Convolutional Neural Network (CNN) models. ViT-S/16 and ViT-B/16 are the recently popular transformer models. IOPLIN is a well elaborated pavement distress detection approach. The architectural design of STN is derived from [29].
| Detectors(I-DET) | AUC | P@R=95% |
| EfficientNet-B3 [38] | 99.4% ( 0.25%) | 99.1% ( 0.7%) |
| ViT-B (21k) [39] | 98.9% ( 2.2%) | 96.3% ( 7.3%) |
| ResNet-50 [35] | 99.9% ( 0.2%) | 100.0% ( 0.0%) |
| VGG-19 [33] | 99.9% ( 0.1%) | 99.8% ( 0.2%) |
| Inception-v3 [49] | 99.8% ( 0.1%) | 100.0% ( 0.0%) |
| STN [29] | 95.6% ( 2.7%) | 85.2% ( 7.4%) |
| IOPLIN [13] | 99.4% ( 0.4%) | 98.6% ( 1.0%) |
| WSPLIN-IP | 100.0% ( 0.0%) | 100.0% ( 0.0%) |
| Detectors(I-DET) | AUC | P@R=90% | P@R=95% | |
| HOG+PCA+SVM [5] | 77.7% | 31.2% | 28.4% | - |
| LBP+PCA+SVM [46] | 82.4% | 34.9% | 30.3% | - |
| HOG+FV+SVM [47] | 88.8% | 43.9% | 35.4% | - |
| ResNet-50 [35] | 90.5% | 45.0% | 35.3% | - |
| Inception-v3 [49] | 93.3% | 56.0% | 42.3% | - |
| VGG-19 [33] | 94.2% | 60.0% | 45.0% | - |
| ViT-S/16 [39] | 95.4% | 67.7% | 51.0% | 81.1% |
| ViT-B/16 [39] | 96.1% | 71.2% | 56.1% | 80.6% |
| EfficientNet-B3 [38] | 95.4% | 68.9% | 51.1% | 81.3% |
| STN [29] | 94.9% | 65.0% | 48.8% | 78.0% |
| IOPLIN [13] | 97.4% | 81.7% | 67.0% | 85.3% |
| WSPLIN-IP | 97.5% | 83.2% | 69.5% | 86.4% |
| Recognizers(I-REC) | AUC | P@R=90% | P@R=95% | |
| EfficientNet-B3 [38] | 96.0% | 77.3% | 59.9% | 83.2% |
| WSPLIN-IP | 97.6% | 85.3% | 72.6% | 87.4% |
IV-D Pavement Distress Detection
IV-D1 Crack500-PDD
Table II tabulates the pavement distress detection performances of different approaches on augmented Crack500 (Crack500-PDD). We only conduct evaluation under I-DET, since this dataset only contains two categories, namely crack and normal. From the observations, our method performs the best. However, we also observe that all methods actually achieve nearly perfect performances. For example, WSPLIN-IP, Inception-V3 and ResNet-50 all get 100% accuracies in P@R=95%, and the AUC of all methods are higher than 98%. These phenomena imply that the pavement distress detection issue on this dataset is already well addressed, and this dataset is too simple to assess the performances of different pavement distress detection methods. We attribute this to three facts. The first one is the small scale of this dataset. The Crack500-PDD dataset only contains hundreds of samples. The second one is that the distress features of crack images are very salient, which is much easier to be distinguished from the normal ones, since this dataset is originally designed for crack detection, which focuses more on the extraction of complex crack structures. The third one is that this dataset lacks diversity in distress type. This dataset only contains crack images. However, the distress type is not limited to the cracks, which can be extended to even cracks that have different finer-grained types. In summary, it may not be unsuitable to employ the crack detection dataset for evaluating pavement image classification. Therefore, we further conducted a more systematic study on the CQU-BPDD dataset, which is a much larger dataset and specially designed for validating pavement distress detection and recognition performances.
IV-D2 CQU-BPDD
Table III reports pavement distress detection performances of different approaches on CQU-BPDD. We evaluate our methods on all pavement distress detection settings. These approaches include the detectors trained under I-DET and the recognizers trained under I-REC where recognizers address the detection issue along with the recognition task. Based on observations, WSPLIN-IP outperforms all baselines in all evaluation metrics under both I-DET and I-REC. In I-DET, WSPLIN-IP improves the performances of IOPLIN by 0.1%, 1.5%, 2.5%, and 1.1% in AUC, P@R=90%, P@R=95%, and respectively. In I-REC, WSPLIN-IP achieves 1.6%, 8.0%, 12.7%, and 4.2% performance gains over EfficientNet-B3 in AUC, P@R=90%, P@R=95%, and respectively. Moreover, the methods under I-REC consistently perform much better than the ones under I-DET. For example, the WSPLIN-IP trained under I-REC achieves 0.1%, 2.1%, 3.1%, and 1.0% performance gains than the WSPLIN-IP trained under I-DET in AUC, P@R=90%, P@R=95%, and respectively. Similarly, the gains of EfficientNet-B3 are 0.6%, 8.4%, 8.8%, and 1.9%. We attribute this to the fact that recognizers trained under I-REC utilize fine-grained distress labels instead of binary distress labels for training the pavement image classification models. It reflects that the much finer-grained supervised information, such as the specific pavement distress information, can benefit pavement distress detection.
| Recognizers(I-REC) | Para. | Top-1 | |
| ResNet-50 [35] | 23M | 88.3% | 60.2% |
| VGG-16 [33] | 134M | 87.7% | 58.4% |
| ViT-S/16 [39] | 22M | 86.8% | 59.0% |
| ViT-B/16 [39] | 86M | 88.1% | 61.2% |
| Inception-v3 [49] | 22M | 89.3% | 62.9% |
| EfficientNet-B3 [38] | 11M | 88.1% | 63.2% |
| STN [29] | 11M | 79.1% | 21.8% |
| WSPLIN-IP | 11M | 91.1% | 66.3% |
| Recognizers(II-REC(n)) | Para. | Top-1 | |
| ResNet-50 [35] | 23M | 82.8% | 53.6% |
| VGG-16 [33] | 134M | 86.5% | 55.0% |
| ViT-S/16 [39] | 22M | 86.7% | 56.6% |
| ViT-B/16 [39] | 86M | 87.5% | 59.6% |
| Inception-v3 [49] | 22M | 88.3% | 59.8% |
| EfficientNet-B3 [38] | 11M | 88.9% | 61.2% |
| STN [29] | 11M | 76.8% | 18.1% |
| WSPLIN-IP | 11M | 90.0% | 64.5% |
| Recognizers(II-REC(i)) | Para. | Top-1 | |
| ResNet-50 [35] | 23M | 71.2% | 61.5% |
| VGG-16 [33] | 134M | 74.6% | 65.0% |
| ViT-S/16 [39] | 22M | 75.0% | 64.9% |
| ViT-B/16 [39] | 86M | 75.3% | 67.0% |
| Inception-v3 [49] | 22M | 77.6% | 69.8% |
| EfficientNet-B3 [38] | 11M | 78.6% | 70.3% |
| STN [29] | 11M | 65.1% | 54.8% |
| WSPLIN-IP | 11M | 85.0% | 77.2% |
IV-E Pavement Distress Recognition
Table IV records the pavement distress recognition performances and parameter scales of different approaches under different application settings on the CQU-BPDD dataset. Similar to the pavement distress detection performances, WSPLIN-IP achieves better recognition performances than baselines under all settings, while enjoys a smaller parameter scale. In I-REC, the performance gains of WSPLIN-IP over Inception-v3, which is the second-best method, are 1.8% and 3.4% in top-1 accuracy and , respectively. In II-REC(n) and II-REC(i), the EfficientNet-B3 achieves the second-best performance. The performance gains of WSPLIN-IP over it under II-REC(n) are 1.1% and 3.3% in top-1 accuracy and , respectively. Such gains under II-REC(i) are 6.4% and 6.9%. The distribution of different pavement image categories is imbalanced. Top-1 accuracy is sensitive to this data imbalance, while is more stable to this imbalance. Therefore, can better reflect the comprehensive performances of recognizers. According to the observations, WSPLIN-IP shows more advantages compared with baselines in .
The test settings of I-REC and II-REC(n) are identical as seen in Table I. However, the models trained under I-REC outperform the ones of II-REC(n). For example, Inception-v3, ViT-B/16, EfficientNet-B3, and WSPLIN-IP trained under I-REC achieve 3.1%, 1.6%, 2.0%, and 1.8% improvements over the ones under II-REC(n) in . This implies that the end-to-end pavement distress recognition solution, which addresses detection and recognition tasks jointly (I-REC), enjoys more advantages than the conventional two-stage implementation solution, which addresses detection and recognition tasks individually (II-REC(n)), in the real-world application. We attribute this to that the end-to-end solution exploits the complementarity of these two tasks and introduces global optimization.
An interesting phenomenon is observed from Table IV that the top-1 accuracies of II-REC(i) are lower than the ones of the rest two settings while its F1-scores are higher than the F1-scores of the rest settings. This is because the test setting of II-REC(i) is different from the settings of I-REC and II-REC(n), which does not involve any normal pavement sample. Top-1 accuracy is measured in sample-wise but is measured in category-wise. The normal samples comprise a large proportion of the whole data in I-REC and II-REC(n). Therefore, the superabundant normal samples will make the recognizers trained under I-REC bias to the classification of the normal sample, which leads to the high top-1 accuracy but the low . With regard to II-REC(n), the massive normal samples push up the top-1 accuracy. However, the measure of is independent of the sample amount and the classification error of II-REC(n) is accumulated from both the detection and recognition stages. Therefore, it achieves a lower in comparison with II-REC(i).
| Method | I-DET (P@R=90%) | I-REC () |
|
||
| IOPLIN | 81.7% | - | 12.5h | ||
| WSPLIN-SW | 80.9% | 64.4% | 9.6h (-23%) | ||
| WSPLIN-IP w/o PLSC | 81.2% | 64.5% | 11.0h (-12%) | ||
| WSPLIN-IP | 83.2% | 66.3% | 11.1h (-11%) | ||
| WSPLIN-SS () | 81.1% | 64.1% | 3.2h (-74%) | ||
| WSPLIN-SS () | 81.4% | 64.9% | 5.7h (-54%) | ||
| WSPLIN-SS () | 80.0% | 63.7% | 8.4h (-33%) |
IV-F Ablation Study
In this section, we evaluated the impact of various components and hyperparameters on the performance and efficiency of our model, as well as compared to IOPLIN. The results of these experiments are recorded in Table V.
IV-F1 Discussion on Patch Collection Strategies
We adopted three strategies named Slide Window (SW), Image Pyramid (IP), and Sparse Sampling (SS) to collect the patches from pavement images. Their corresponding versions are WSPLIN-SW, WSPLIN-IP, and WSPLIN-SS, respectively. In all three versions, WSPLIN-IP, which is the default version of WSPLIN, achieves the best performances under two application settings with different evaluation metrics. WSPLIN-IP achieves 1.5% performance gains in P@R=90% in the pavement distress detection case. However, its training time is only 89% of the training time of IOPLIN. In comparison with WSPLIN-SW, WSPLIN-IP exploits not only the local information but also the scale information of pavement images. The results indicate that such scale information can further improve the performance of WSPLIN. Although WSPLIN-SW has not outperformed IOPLIN with a 0.8% performance decrease in pavement distress detection, WSPLIN-SW is much faster than WSPLIN-IP and its training only takes around 3/4 of the training time of IOPLIN. We attribute this to the efficiency advantage of the end-to-end model optimization strategy. Moreover, compared with other versions, WSPLIN-SW has not suffered from the scale variation, so it can produce better patch label inference visualization results and thereby enjoys better interpretability.
WSPLIN-SS also takes the scale information into consideration, and can be deemed as a lightweight version of WSPLIN-IP. The best-performed WSPLIN-SS () achieves similar performance as IOPLIN where is a hyperparameter to control the number of sampled patches in each layer of an image pyramid. However, WSPLIN-SS saves around half of the training time compared with IOPLIN, and it is only 76% of the training time of WSPLIN-IP. Clearly, WSPLIN-SS highly speeds up WSPLIN only with an acceptable performance decrease. Another interesting phenomenon is observed that WSPLIN-SS with a higher does not always enjoy better performance. Generally, a higher implies collecting more patches which means more information can be preserved for classification. However, the results indicate that not all preserved information is necessary for classification. Moreover, the less amount of patches per image means more images can be taken into one batch for model optimization since the memory size is fixed in our case. The higher diversity of pavement images in each batch benefits model optimization. A good sparse sampling strategy should optimize the trade-off between patch preservation and the diversity of samples in the same batch. We believe this is the reason why WSPLIN-SS () performs well in both tasks.
In summary, all WSPLIN approaches show prominent advantages in training efficiency with similar or even better performances. We recommend using WSPLIN-IP in the application scenarios, which is the best-performing version. And the lightweight WSPLIN-SS introduces a good trade-off between performance and efficiency benefits from its unique design. In particular, WSPLIN-SW should be the ideal choice if the distress does not suffer from the high diversity in scale.
IV-F2 Discussion on Patch Label Sparsity Constraint
The distressed area is often a small proportion of the whole image. Therefore, we introduce the Patch Label Sparsity Constraint (PLSC) to model and leverage this prior property for improving the discriminating power of the model and better addressing the pavement image classification issue. Table V reports the performances of WSPLIN-IP with and without PLSC. WSPLIN-IP with PLSC achieves 2.0% more accuracies in P@R=90% under I-DET and 1.8% greater F1-scores under I-REC over WSPLIN without PLSC. This implies that PLSC can offer a considerable improvement to WSPLIN. We also leverage Grad-CAM [50] to plot the Class Activation Maps (CAM) of the features extracted by the WSPLIN-IP models before and after using PLSC in Figure 4. The CAM visualization results also validate that PLSC benefits the distressed feature extraction.
is a positive hyperparameter for reconciling the classification loss and the PLSC. Figure 5 plots the relationships between the different values of and the performances of WSPLIN-IP under I-DET and I-REC. From observations, we can find that the WSPLIN-IP is insensitive to the setting of . The optimal is .


IV-F3 The Efficiency of WSPLIN
According to observations in Table V, all WSPLIN approaches are more efficient than IOPLIN. Moreover, IOPLIN and WSPLIN have very similar network structure, so they have the same parameter scale.
IV-G Weakly and Self Supervised Analysis
| Method | Settings |
|
|
||||
| Grad-CAM [51] | WSOD | 68.9% | 63.2% | ||||
| C2AM [52] | WSODWSSS | 59.0% | 51.0% | ||||
| DINO [53] | SSIC | 24.8% | 11.0% | ||||
| SimSiam [54] | SSIC | 24.8% | 11.4% | ||||
| IOPLIN [13] | FSIC | 81.7% | - | ||||
| WSPLIN-IP | FSIC | 83.2% | 66.3% |
Our method is a fully supervised learning approach from the perspective of image classification, since the output and input of our model are pavement images and category labels, respectively, and all this information is available for training. Since our method is a fully supervised learning method, why do we call it a Weakly Supervised Patch Label Inference Network (WSPLIN)? This is because we transform this image-level fully supervised learning problem as a patch-level weakly supervised learning issue for a solution. The main idea of our work is to divide images into patches and then use neural networks to infer the patch labels. Finally, the patch labels are aggregated to infer the label of images. The core step of our method is patch label inference. Since this step has no patch-level supervised information, the patch label inference is conducted in a weakly supervised learning manner.
In order to further analyze pavement image classification in different learning manners, we employ some recent advanced weakly and self-supervised learning approaches, namely Grad-CAM [51], C2AM [52], DINO [53], and SimSiam [54], for addressing pavement image classification issue. Grad-CAM and C2AM are the weakly supervised learning approaches, while DINO and SimSiam are the self-supervised learning approaches. The experimental results are reported in Table VI. The results show that the fully supervised learning manner performs much better than the weakly and self-supervised learning manners. For example, the performance gains of WSPLIN-IP over Grad-CAM, C2AM, DINO and SimSiam in F1 are 3.1%, 15.3%, 55.3%, and 54.9%, respectively. Grad-CAM is the best-performed weakly supervised learning approach. It is a post-processing method. Thus, it actually has not introduced any impact on the training process of the original classification model, and the classification performance only depends on its backbone–EfficientNet-B3. C2AM is a SOTA one-stage weakly supervised learning method. However, it performs even worse than its backbone (-9.9% on I-DET, -12.2% on I-REC). We believe this is due to the interference from the pseudo label generation process, since all the processes are optimized together and the model is originally designed for object detection and segmentation instead of classification. The self-supervised learning approaches, such as DINO and SimSiam, almost fails in pavement distress detection and recognition tasks. This reveals the importance of supervised information in the feature learning step. Note, we here only use self-supervised learning methods to train the feature learning part and train the classifiers with supervised information. In summary, directly applying the weakly or self-supervised learning approaches to address pavement distress detection and recognition issues will lead to unsatisfactory performances, and the fully supervised fashion is still the best way for pavement image classification.

IV-H User Scenarios
In highway maintenance, the engineer will use a professional pavement vehicle to capture pavement images of the highway at regular intervals. Once they obtain the pavement images, they will find out the distressed pavements, assess the severity of the distress, and then accomplish the pavement distress statistics for a highway. The pavement distress detection and recognition all have actual application values in this pipeline. For a 120-kilometer length highway with four lanes, each inspection will produce more than 240,000 pavement images. More than 95% are actually normal pavement images that will not be further analyzed in the next step. Conventionally, the engineers must manually filter out these normal pavement images, leading to heavy labor costs. Like IOPLIN, WSPLIN enables engineers to filter out most normal images automatically, thereby significantly reducing manual labor costs. More specifically, WSPLIN often produces a confidence score for each pavement image to measure the probability that the image belongs to the diseased one. Thus, we can filter out most of the normal pavement images by setting a confidence score threshold.
Moreover, WSPLIN has wider application scenarios in comparison to IOPLIN. IOPLIN can only address the pavement distress detection problem, which is a typical binary image classification issue and attempts to find the distressed samples only. WSPLIN can tackle both the pavement distress detection and the recognition tasks under various aforementioned application settings shown in Table I. Roughly distress localization and quality pavement distress recognition can assist engineers in automatically accomplishing detailed pavement distress statistics for roads over a while. This statistics information is crucial to assess the health situations of roads and speculate on the risk elements that cause pavement distress. This information is also vital for designing a suitable pavement maintenance strategy and estimating pavement maintenance expenditure. Moreover, not all pavement distresses are cracks, and some pavement distresses may need some special analysis. The pavement distress recognition system can automatically group the distress pavement images based on their distress types, thereby facilitating the engineers to analyze the different types of pavement distress further. Figure 6 gives some examples of this scenario via visualizing the patch labels produced by the trained WSPLIN.
V Conclusions
In this paper, we present a novel patch-based deep learning model named WSPLIN for automatic pavement distress detection and recognition in the wild. WSPLIN divides the pavement image into patches with different patch collection strategies and then learns the label of patches in a weakly supervised manner. Finally, these inferred patch labels are fed into a comprehensive decision network for yielding the final recognition results. Similar to IOPLIN, WSPLIN can sufficiently utilize the resolution and scale information, and can also provide interpretable information, such as the location of the distressed area. However, WSPLIN is more efficient than IOPLIN with similar or even better performance. The experiments on a large pavement distress dataset validate the effectiveness of our approach. In the future, incorporating Spatial Transformer Networks (STN) [29], which is a popular technique in defect classification, into our method should be an interesting direction. Moreover, employing the self-supervised learning methods to pre-train our models may potentially further boost performances.
References
- [1] CIA, “Roadways - the world factbook,” Jun. 2021. [Online]. Available: https://www.cia.gov/the-world-factbook/field/roadways/country-comparison
- [2] S. M. Piryonesi and T. El-Diraby, “Using data analytics for cost-effective prediction of road conditions: Case of the pavement condition index,” Federal Highway Administration: McLean, VA, USA, 2018.
- [3] A. Benedetto, F. Tosti, L. Pajewski, F. D’Amico, and W. Kusayanagi, “Fdtd simulation of the gpr signal for effective inspection of pavement damages,” in Proceedings of the 15th International Conference on Ground Penetrating Radar. IEEE, 2014, pp. 513–518.
- [4] C. Wang, A. Sha, and Z. Sun, “Pavement crack classification based on chain code,” in 2010 Seventh international conference on fuzzy systems and knowledge discovery, vol. 2. IEEE, 2010, pp. 593–597.
- [5] N. Dalal and B. Triggs, “Histograms of oriented gradients for human detection,” in 2005 IEEE computer society conference on computer vision and pattern recognition (CVPR’05), vol. 1. IEEE, 2005, pp. 886–893.
- [6] J. Chou, W. A. O’Neill, and H. Cheng, “Pavement distress classification using neural networks,” in Proceedings of IEEE International Conference on Systems, Man and Cybernetics, vol. 1. IEEE, 1994, pp. 397–401.
- [7] J. Zhou, P. Huang, and F.-P. Chiang, “Wavelet-based pavement distress classification,” Transportation research record, vol. 1940, no. 1, pp. 89–98, 2005.
- [8] F. M. Nejad and H. Zakeri, “An expert system based on wavelet transform and radon neural network for pavement distress classification,” Expert Systems with Applications, vol. 38, no. 6, pp. 7088–7101, 2011.
- [9] K. Gopalakrishnan, S. K. Khaitan, A. Choudhary, and A. Agrawal, “Deep convolutional neural networks with transfer learning for computer vision-based data-driven pavement distress detection,” Construction and Building Materials, vol. 157, pp. 322–330, 2017.
- [10] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in 2009 IEEE conference on computer vision and pattern recognition. IEEE, 2009, pp. 248–255.
- [11] B. Li, K. C. Wang, A. Zhang, E. Yang, and G. Wang, “Automatic classification of pavement crack using deep convolutional neural network,” International Journal of Pavement Engineering, vol. 21, no. 4, pp. 457–463, 2020.
- [12] Z. Fan, Y. Wu, J. Lu, and W. Li, “Automatic pavement crack detection based on structured prediction with the convolutional neural network,” arXiv preprint arXiv:1802.02208, 2018.
- [13] W. Tang, S. Huang, Q. Zhao, R. Li, and L. Huangfu, “An iteratively optimized patch label inference network for automatic pavement distress detection,” IEEE Transactions on Intelligent Transportation Systems, 2021.
- [14] L. Ale, N. Zhang, and L. Li, “Road damage detection using retinanet,” in IEEE International Conference on Big Data, 2018, pp. 5197–5200.
- [15] T.-Y. Lin, P. Goyal, R. Girshick, K. He, and P. Dollár, “Focal loss for dense object detection,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 2980–2988.
- [16] G. Huang, S. Huang, L. Huangfu, and D. Yang, “Weakly supervised patch label inference network with image pyramid for pavement diseases recognition in the wild,” in ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 7978–7982.
- [17] J. Zhou, P. S. Huang, and F.-P. Chiang, “Wavelet-based pavement distress detection and evaluation,” Optical Engineering, vol. 45, no. 2, p. 027007, 2006.
- [18] Y. Hu and C.-x. Zhao, “A novel lbp based methods for pavement crack detection,” Journal of pattern Recognition research, vol. 5, no. 1, pp. 140–147, 2010.
- [19] Y. Shi, L. Cui, Z. Qi, F. Meng, and Z. Chen, “Automatic road crack detection using random structured forests,” IEEE Transactions on Intelligent Transportation Systems, vol. 17, no. 12, pp. 3434–3445, 2016.
- [20] R. Kapela, P. Śniatała, A. Turkot, A. Rybarczyk, A. Pożarycki, P. Rydzewski, M. Wyczałek, and A. Błoch, “Asphalt surfaced pavement cracks detection based on histograms of oriented gradients,” in 2015 22nd International Conference Mixed Design of Integrated Circuits & Systems (MIXDES). IEEE, 2015, pp. 579–584.
- [21] Y. Pan, X. Zhang, M. Sun, and Q. Zhao, “Object-based and supervised detection of potholes and cracks from the pavement images acquired by uav.” International Archives of the Photogrammetry, Remote Sensing & Spatial Information Sciences, vol. 42, 2017.
- [22] L. Zhang, F. Yang, Y. D. Zhang, and Y. J. Zhu, “Road crack detection using deep convolutional neural network,” in 2016 IEEE international conference on image processing (ICIP). IEEE, 2016, pp. 3708–3712.
- [23] F. Yang, L. Zhang, S. Yu, D. Prokhorov, X. Mei, and H. Ling, “Feature pyramid and hierarchical boosting network for pavement crack detection,” IEEE Transactions on Intelligent Transportation Systems, vol. 21, no. 4, pp. 1525–1535, 2019.
- [24] Q. Zou, Z. Zhang, Q. Li, X. Qi, Q. Wang, and S. Wang, “Deepcrack: Learning hierarchical convolutional features for crack detection,” IEEE Transactions on Image Processing, vol. 28, no. 3, pp. 1498–1512, 2018.
- [25] E. Ibragimov, H.-J. Lee, J.-J. Lee, and N. Kim, “Automated pavement distress detection using region based convolutional neural networks,” International Journal of Pavement Engineering, pp. 1–12, 2020.
- [26] J. Zhu, J. Zhong, T. Ma, X. Huang, W. Zhang, and Y. Zhou, “Pavement distress detection using convolutional neural networks with images captured via uav,” Automation in Construction, vol. 133, p. 103991, 2022.
- [27] H. Dong, K. Song, Q. Wang, Y. Yan, and P. Jiang, “Deep metric learning-based for multi-target few-shot pavement distress classification,” IEEE Transactions on Industrial Informatics, pp. 1–1, 2021.
- [28] H. Dong, K. Song, Y. Wang, Y. Yan, and P. Jiang, “Automatic inspection and evaluation system for pavement distress,” IEEE Transactions on Intelligent Transportation Systems, 2021.
- [29] L. Yu, K. Metwaly, J. Z. Wang, and V. Monga, “Surface defect detection and evaluation for marine vessels using multi-stage deep learning,” arXiv preprint arXiv:2203.09580, 2022.
- [30] M. Jaderberg, K. Simonyan, A. Zisserman et al., “Spatial transformer networks,” Advances in neural information processing systems, vol. 28, 2015.
- [31] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein et al., “Imagenet large scale visual recognition challenge,” International journal of computer vision, vol. 115, no. 3, pp. 211–252, 2015.
- [32] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” Advances in neural information processing systems, vol. 25, pp. 1097–1105, 2012.
- [33] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
- [34] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich, “Going deeper with convolutions,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 1–9.
- [35] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
- [36] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “Mobilenets: Efficient convolutional neural networks for mobile vision applications,” arXiv preprint arXiv:1704.04861, 2017.
- [37] B. Zoph and Q. V. Le, “Neural architecture search with reinforcement learning,” arXiv preprint arXiv:1611.01578, 2016.
- [38] M. Tan and Q. V. Le, “Efficientnet: Rethinking model scaling for convolutional neural networks,” arXiv preprint arXiv:1905.11946, 2019.
- [39] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” arXiv preprint arXiv:2010.11929, 2020.
- [40] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in neural information processing systems, 2017, pp. 5998–6008.
- [41] F. Yang, L. Zhang, S. Yu, D. Prokhorov, X. Mei, and H. Ling, “Feature pyramid and hierarchical boosting network for pavement crack detection,” IEEE Transactions on Intelligent Transportation Systems, vol. 21, no. 4, pp. 1525–1535, 2019.
- [42] L. Liu, H. Jiang, P. He, W. Chen, X. Liu, J. Gao, and J. Han, “On the variance of the adaptive learning rate and beyond,” arXiv preprint arXiv:1908.03265, 2019.
- [43] M. Zhang, J. Lucas, J. Ba, and G. E. Hinton, “Lookahead optimizer: k steps forward, 1 step back,” in Advances in Neural Information Processing Systems, 2019, pp. 9597–9608.
- [44] Y. You, I. Gitman, and B. Ginsburg, “Large batch training of convolutional networks,” arXiv preprint arXiv:1708.03888, 2017.
- [45] D. J. Hand and R. J. Till, “A simple generalisation of the area under the roc curve for multiple class classification problems,” Machine learning, vol. 45, no. 2, pp. 171–186, 2001.
- [46] T. Ahonen, A. Hadid, and M. Pietikainen, “Face description with local binary patterns: Application to face recognition,” IEEE transactions on pattern analysis and machine intelligence, vol. 28, no. 12, pp. 2037–2041, 2006.
- [47] F. Perronnin, J. Sánchez, and T. Mensink, “Improving the fisher kernel for large-scale image classification,” in European conference on computer vision. Springer, 2010, pp. 143–156.
- [48] L. Breiman, “Random forests,” Machine learning, vol. 45, no. 1, pp. 5–32, 2001.
- [49] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna, “Rethinking the inception architecture for computer vision,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 2818–2826.
- [50] R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra, “Grad-cam: Visual explanations from deep networks via gradient-based localization,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 618–626.
- [51] ——, “Grad-cam: Visual explanations from deep networks via gradient-based localization,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 618–626.
- [52] J. Xie, J. Xiang, J. Chen, X. Hou, X. Zhao, and L. Shen, “C2am: Contrastive learning of class-agnostic activation map for weakly supervised object localization and semantic segmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 989–998.
- [53] M. Caron, H. Touvron, I. Misra, H. Jégou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision transformers,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 9650–9660.
- [54] X. Chen and K. He, “Exploring simple siamese representation learning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 15 750–15 758.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/74bc5468-88b9-473f-a244-9077ebb5a391/Sheng.jpg) |
Sheng Huang (M’15) received his BEng and PhD degrees both from Chongqing University, Chongqing, P.R.China, in 2010 and 2015 respectively. He was a visiting PhD student at the department of computer science, Rutgers University, New Brunswick, NJ, USA, from 2012 to 2014. He is currently an associate professor at the school of big data and software engineering, Chongqing University. He has authored/coauthored more than 30 scientific papers in venues, such as CVPR, AAAI, TIP, TIFS and TCSVT. His research interests include computer vision, machine learning, image processing and artificial intelligent applications. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/74bc5468-88b9-473f-a244-9077ebb5a391/tang.png) |
Wenhao Tang is currently a master student in Big Data & Software Engineering from Chongqing University (CQU), Chongqing, P.R. China. His research interests include computer vision, intelligent transportation systems, and artificial intelligent applications. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/74bc5468-88b9-473f-a244-9077ebb5a391/Huang.jpg) |
Guixin Huang (M’15) is currently working at Global Function and Technology department of Citigroup as a backend developer. He obtained his Master’s degree in software engineering from Chongqing University in 2021. His research fields mainly focus on image recognition and processing. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/74bc5468-88b9-473f-a244-9077ebb5a391/huangfu.jpg) |
Luwen Huangfu received the B.S. degree in software engineering from Chongqing University, Chongqing, China, the M.S. degree in computer science from the Chinese Academy of Sciences, Beijing, China, and the Ph.D. degree in management information systems from University of Arizona, Tucson, AZ, USA. She is currently an Assistant Professor with Fowler College of Business, San Diego State University, San Diego, CA, USA, where she is also with the Center for Human Dynamics in the Mobile Age. She has authored/coauthored more than 30 scientific papers in venues, such as IEEE Transactions on Cybernetics, IJCAI, ACM MM, Journal of Medical Internet Research (JMIR), IEEE Transactions on Intelligent Transportation Systems, Pacific Asia Journal of the Association for Information Systems, IEEE Signal Processing Letters, LREC, ICASSP, and IEEE ISI. Her research interests include business analytics, text mining, data mining, image processing, computer vision, artificial intelligence, and healthcare management. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/74bc5468-88b9-473f-a244-9077ebb5a391/yang.png) |
Dan Yang received the B.Eng. degree in automation, the M.S. degree in applied mathematics, and the Ph.D. degree in machinery manufacturing and automation from Chongqing University, Chongqing. From 1997 to 1999, he held a post-doctoral position with the University of Electro-Communications, Tokyo, Japan. He is currently the President with Southwest Jiaotong University, and still holds the academic position with the School of Big Data and Software Engineering, Chongqing University. He has authored over 150 scientific papers and some of them are published in some authoritative journals and conferences, such as IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, IEEE TRANSACTIONS ON IMAGE PROCESSING, IEEE TRANSACTIONS ON MEDICAL IMAGING, CVPR, and BMVC. His research interests include computer vision, image processing, pattern recognition, software engineering, and scientific computing. |