Walking with Terrain Reconstruction:
Learning to Traverse Risky Sparse Footholds
Abstract
Traversing risky terrains with sparse footholds presents significant challenges for legged robots, requiring precise foot placement in safe areas. Current learning-based methods often rely on implicit feature representations without supervising physically significant estimation targets. This limits the policy’s ability to fully understand complex terrain structures, which is critical for generating accurate actions. In this paper, we utilize end-to-end reinforcement learning to traverse risky terrains with high sparsity and randomness. Our approach integrates proprioception with single-view depth images to reconstruct robot’s local terrain, enabling a more comprehensive representation of terrain information. Meanwhile, by incorporating implicit and explicit estimations of the robot’s state and its surroundings, we improve policy’s environmental understanding, leading to more precise actions. We deploy the proposed framework on a low-cost quadrupedal robot, achieving agile and adaptive locomotion across various challenging terrains and demonstrating outstanding performance in real-world scenarios. Video at: youtu.be/ReQAR4D6tuc.
I INTRODUCTION
Quadrupedal robots are confronted with the challenge of operating on risky and complex terrains with sparse footholds, such as stepping stones, balance beams and gaps. To traverse these terrains stably and swiftly, robots need to perceive their environment accurately and adjust their gait flexibly while maintaining balance and stability. They must plan and execute each step with precision to ensure that each foot lands securely within the safe area.
Existing research often employs model-based hierarchical controllers [1, 2, 3, 4, 5], which depend on manual model design tailored to specific scenarios. The trade-off between model accuracy and computational cost constrains their scalability to more complex terrains [6]. Recently, model-free reinforcement learning (RL) have been employed to learn direct mappings from vision and proprioception to actions [7, 8, 9, 10, 11, 12]. By leveraging robust proprioceptive sensors along with forward-looking exteroceptive sensors, the robots can implicitly extract environmental features to infer and represent its surrounding terrains, demonstrating successful sim-to-real transfer in various unstructured environments.

However, several challenges limit the application of these end-to-end RL methods on risky terrains with sparse footholds. First, the success of the policy hinges on its ability to fully capture and understand complex environmental features from limited observations while planing precise actions to avoid failure. The absence of explicit supervision targets for feature extraction, coupled with sparse rewards, exacerbate the difficulty of exploration and end-to-end learning in sufficiently representing intricate terrain structures. Second, the policy relies on visual inputs to gather terrain information, including unseen areas beneath and behind the robot, to plan foot placement in safe regions. Limitations in the current viewpoint and potential occlusions introduce partially observable challenges, placing greater demands for the policy to memorize past observations and integrate them into a cohesive terrain representation. Furthermore, the common practice of using a two-phase paradigm or training specialized policies for different terrains [11, 13] complicates the training process while the former also potentially leads to information loss during behavior cloning [14]. Integrating diverse locomotion behaviors into a single policy through a simple process without compromising performance remains a hurdle.
In this paper, we propose an end-to-end RL-based framework for traversing risky terrains with sparse footholds. To tackle the challenges of extracting, memorizing and understanding terrain features, our framework is divided into two key components: a locomotion policy and a terrain reconstructor. The locomotion policy takes robot’s local heightmap and proprioception as inputs, requiring only one-stage training. It utilizes implicit-explicit estimation to infer robot’s state and surroundings, enabling thorough extraction and accurate understanding of environmental features. Correspondingly, the memory-based terrain reconstructor uses proprioception and egocentric single-view depth images to precisely reconstruct local heightmap, including unseen areas beneath and behind the body. This local terrain reconstruction provides the policy with explicit, physically significant supervision targets, ensuring a more comprehensive representation of terrain information crucial for safe navigation (e.g., positions of stones and terrain edges). Additionally, it avoids using global mapping and localization to generate heightmap, which often leads to perceptual noise and drift issues [15]. We deploy our framework on a low-cost quadrupedal robot and demonstrate agile locomotion on challenging terrains such as stepping stones and balance beams.
In summary, our main contributions include:
-
•
A one-stage locomotion policy based on implicit-explicit estimation is proposed to comprehensively extract environmental features and generate precise actions using proprioception and local heightmap.
-
•
A terrain reconstructor is proposed to accurately reconstruct the local heightmap using only proprioception and egocentric depth images, providing the policy with explicit supervision targets thus significantly enhancing its understanding and representation of terrain features.
-
•
Successful sim-to-real transfer of agile locomotion on risky terrains with sparse footholds such as stepping stones, balance beams, stepping beams and gaps, demostrating exceptional adaptability and robustness.
II RELATED WORK
II-A Locomotion on Sparse Footholds and Risky Terrain
Legged locomotion on risky terrains with sparse footholds relies on tight integration of perception and control. Traditional model-based approaches often decompose the problem into multiple stages of perception, planning, and control [16]. Robots use SLAM to produce heightmap and employ nonlinear optimization [17] or graph search [3] to solve motion trajectories, which are then tracked by low-level controllers [6, 16, 18, 19]. Some studies also integrate RL into planning or control, such as using it to generate robot’s base trajectories [20] or foot placements [16, 19]. Recent work [21] utilizes a model-based trajectory optimization (TO) method to generate foot placements followed by RL-based tracking, demonstrating remarkable performance in complex environments. However, this decoupled architecture may lead to information loss and limit the behavior of each module.
Recent works have explored end-to-end RL approaches to address sparse footholds. For example, [8, 9] utilize a teacher-student training paradigm, where the student policy learns to directly generate joint actions from stacked depth images and proprioception under the guidance of a teacher trained with privileged information. In [10], an implicit 3D voxel feature with SE(3) equivariance is employed to represent surrounding environment. Although these methods have shown excellent results in specific tasks, relying solely on implicit features hinders these policies’ ability to adequately learn representations of more complex terrain structures. Consequently, they tend to learn a single gait pattern averaged across the terrain, limiting adaptability to varying sparsity and randomness. We propose explicit terrain reconstruction to provide clear supervision targets for feature extraction, thereby enhancing policy’s representation and understanding of complex terrain features.
II-B Terrain Reconstruction
Legged robots commonly rely on terrain reconstruction to provide perceptual input for locomotion. Common representations include 2.5D heightmap [15, 22, 23, 24], point cloud [25], or voxel grid [12, 26, 27], with heightmap being widely used due to its simplicity. Model-based approaches [15, 28] construct heightmap by fusing data from odometry and cameras or LiDAR. However, its reconstruction is susceptible to estimation errors or localization drift and often requires a complicated hardware pipeline [10]. Some learning-based approaches [12, 26] have achieved promising results by reconstructing local terrain from noisy multi-view observations, but they still rely on robot’s global pose to provide transformations between consecutive frames. Inspired by [23], our terrain reconstructor is designed to autonomously learn the relationships between visual inputs and provide the policy with accurate local terrain reconstructions.
III METHOD
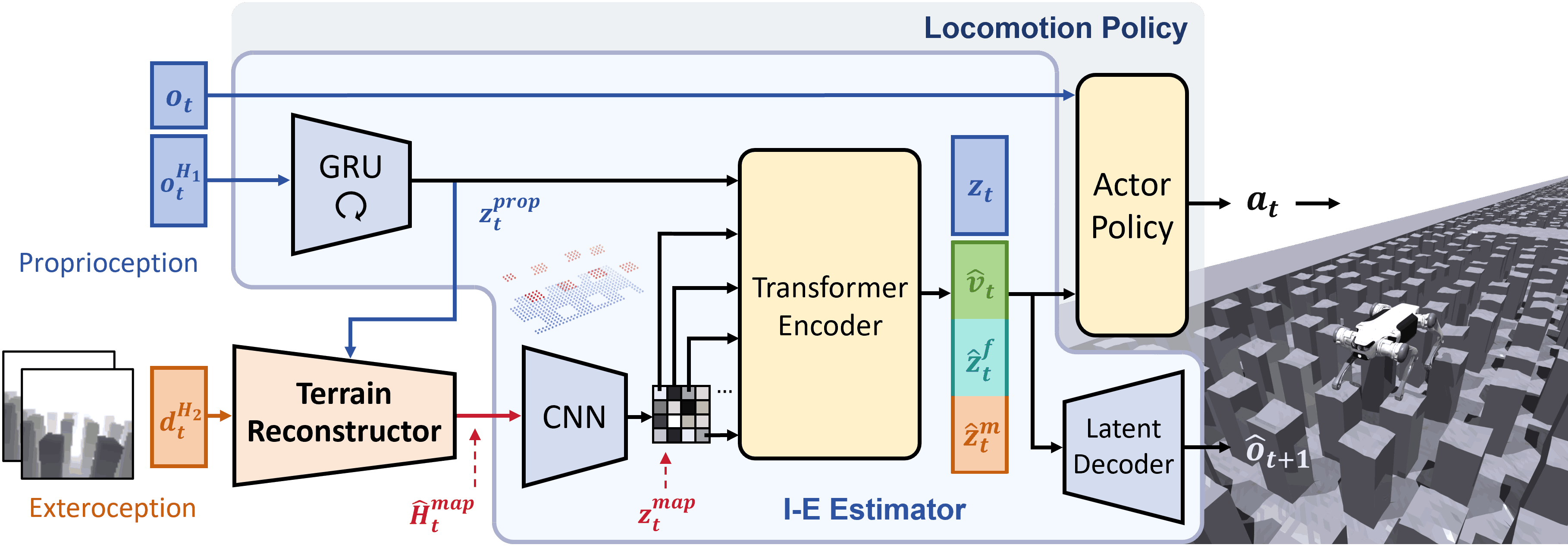
The proposed framework is based on end-to-end RL and utilizes a set of neural network models to generate desired joint angle targets from proprioception and raw depth images. As shown in Fig. 2, the framework mainly consists of a locomotion policy and a terrain reconstructor. All components are jointly optimized in a one-stage training process and could be subsequently deployed to a real robot via zero-shot transfer.
III-A Terrain-Aware Locomotion Policy
The locomotion policy consists of an I-E Estimator and an actor policy. Inspired by [29, 30], I-E Estimator is designed to estimate robot’s state and privileged environmental information implicitly and explicitly, while also reconstructing future proprioception. This enhances the policy’s understanding and adaptability to the environment. The actor policy receives the latest proprioception and estimated vectors to generate joint position targets for PD controllers to track. To avoid data inefficiency and information loss caused by the two-stage training paradigm, we adopt an asymmetric actor-critic structure, simplifying the training into a single stage [31]. The training process for the locomotion policy components involves optimizating the actor-critic architecture and I-E Estimator, with the actor-critic being optimized using the proximal policy optimization (PPO) algorithm [32].
Observations
The actor policy receives as input the latest proprioception , the base velocity , the encodings of the heightmap around the four feet and the body , and the latent vector . The proprioception is directly measured from the joint encoders and IMU, while , , and are estimated by I-E Estimator.
Rewards
The reward function follows the configurations in [31, 33, 34] to emphasize the performance of our framework. While these rewards are sufficient to generate agile locomotion, inaccurate robot actions can lead to stepping too close to the edges of sparse terrains. This behavior could result in falls in real-world scenarios. To address this issue, we introduce an additional reward term to penalize foot placement near terrain edges, encouraging the robot to select actions that ensure each footstep lands in the safe area:
where indicates the foot-ground contact state. The function calculates the distance between foot’s position and edge of the terrain. When the foot is within 5 cm of the edge, the closer it is, the larger becomes.
I-E Estimator
Recent studies [31, 35] have shown that robots have the ability to infer their state and surroundings from proprioception or exteroception either implicitly or explicitly. This is critical for making full use of observational information and improving adaptability. Therefore, the proposed framework employs I-E Estimator based on multi-head autoencoder structure to estimate the robot’s state and privileged environmental information. The estimator takes temporal proprioception observations (with ) and local terrain reconstruction as inputs. and are processed by a GRU and a CNN encoder respectively to extract proprioception features and terrain features . A set of transformer encoders is employed to fuse multimodal features and generate cross-modal estimated vectors [36], which are then fed into the actor policy. Since each terrain feature token corresponds to an actual local zone, self-attention enables the policy to perform spatial reasoning and focus attention on relevant areas.
Among the estimated vectors, robot’s body velocity , which has physical significance, is explicitly estimated to provide a clear understanding of its motion state. Encodings and are reconstructed by an MLP decoder into heightmaps surrounding robot’s feet and body . This ensures that the encodings contain sufficient terrain features, enhancing environmental understanding and guiding the policy to select appropriate footholds consciously. Additionally, a variational autoencoder (VAE) structure is adopted to extract implicit estimated vector representing other important information [31]. We also promote understanding of environmental state transitions and incorporation of more privileged information by predicting future proprioception from estimated vectors. While uses KL divergence as the VAE loss, remaining estimated vectors are optimized using mean-squared-error (MSE) for estimation loss.
III-B Terrain Reconstructor
Terrain reconstructor receives proprioception features and temporal depth images (with ) as inputs and reconstructs a precise terrain heightmap surrounding the robot in its local frame, as shown in Fig. 1. The heightmap covers an area extending from 0.5m behind the robot to 1.1m in front, with a width of 0.8m and a resolution of 5cm.
As shown in Fig. 3, depth images are processed by a CNN encoder to extract visual features. These are concatenated with proprioception features , which contain robot’s motion state. To memorize information about the currently invisible terrain beneath and behind the robot, the concatenated features are delivered to a GRU encoder, whose output is then processed by an MLP decoder to reconstruct a rough heightmap . The rough heightmap is optimized using MSE with the ground truth for estimation loss. However, recent study [23] has shown that rough heightmap generated through only one-stage reconstruction usually has limited feature representation capabilities, leading to non-flat surfaces around the edges. To address this, we employ a U-Net-based decoder [37] to eliminate the noise and produce a refined heightmap . The refined heightmap is optimized using L1 loss. This refinement process improves the accuracy of edges and flat surfaces difficult to represent during rough reconstruction, reducing the complexity of feature extraction for the subsequent policy. All components of the terrain reconstructor are trained jointly with I-E estimator.
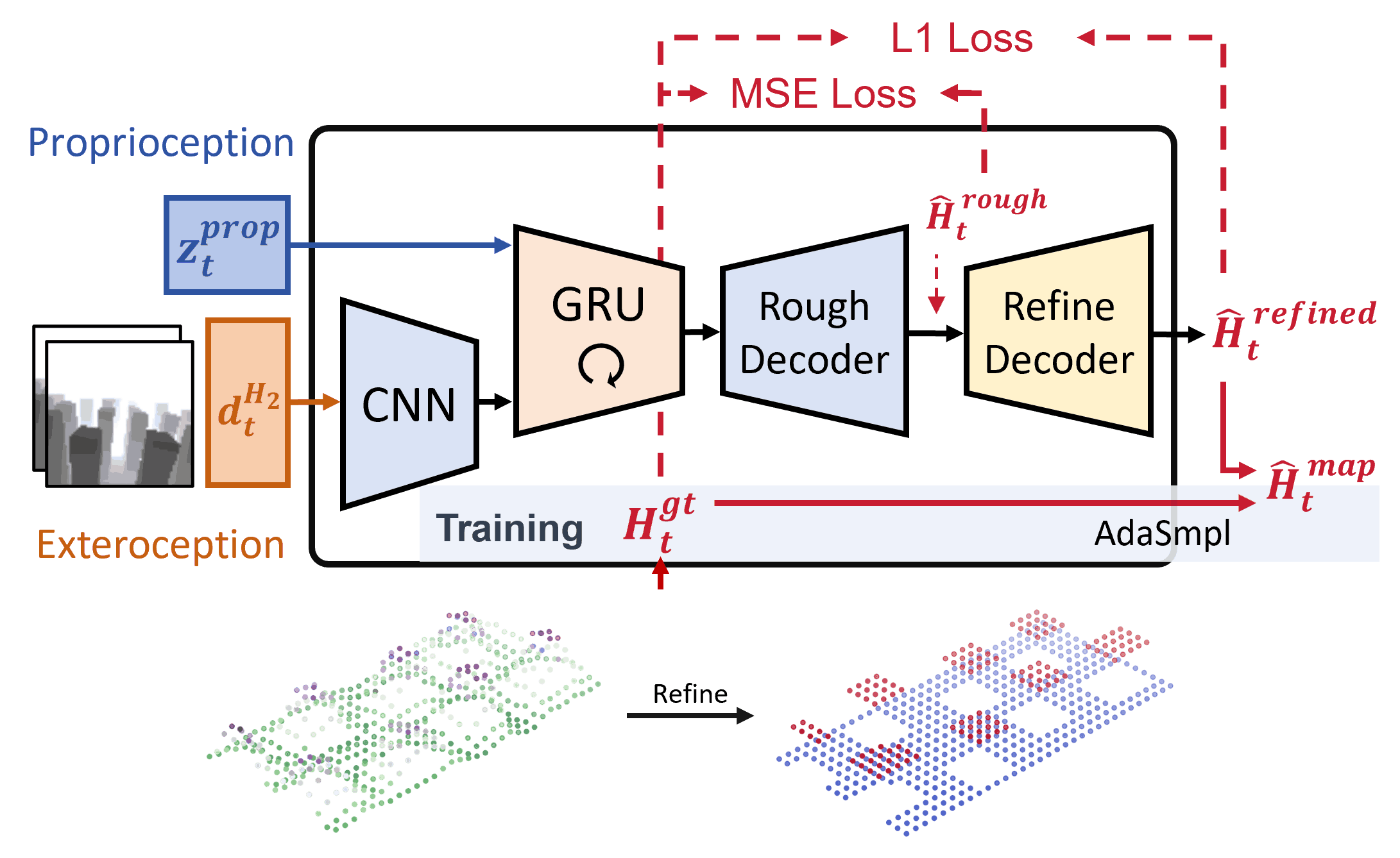
Adaptive Sampling
In the early stages of training, the output from terrain reconstructor often contains significant noise and limited terrain information. This hinders the locomotion policy from developing an accurate environmental understanding. To address this, we propose an adaptive sampling (AdaSmpl) method, where heightmap ground truth is used as policy input with a certain probability during training instead of reconstructed results. This probability is adaptively adjusted based on training performance:
where is the coefficient of variation of episode reward . A larger requires sampling from the ground truth to help the policy accurately understand terrain features. Conversely, a smaller suggests good learning progress, allowing the use of reconstructed results to enhance the policy’s robustness. During deployment, the policy exclusively takes the reconstructed terrain as input.
III-C Terrain Finetuning Strategy
Due to sparse rewards and conflicting optimal gait patterns across various risky terrains with sparse footholds, it is challenging for robots to learn a highly adaptive policy from scratch. Inspired by [13], we first train a generalized base policy on relatively simple and low-randomness terrains. We then finetune this base policy into an advanced policy through a terrain curriculum that progressively transitions from simple terrains to more complex terrains with increased sparsity and randomness, as shown in Fig. 4. The base policy enables the robot to acquire general skills for handling sparse foothold terrains in advance, thereby reducing the exploration difficulty in complex terrains. All locomotion skills are finally integrated into a single advanced policy.

IV EXPIREMENT
IV-A Experimental Setup
Robot and Simulation
The proposed method was deployed on a DEEP Robotics Lite3 robot with 12 joints. The robot uses an Intel RealSense D435i camera on its head to capture raw depth images at 10 Hz. The network inference is executed using TensorRT on an onboard Jetson Orin NX, and actions are output at 50 Hz. The training and simulation environments are implemented in IsaacGym [38].
Terrains
The proposed method was evaluated on four types of typical sparse foothold terrains. At the highest difficulty level, these include: 1) Stepping stones with a sparsity of 76.3%, randomly positioned within a range of 0.48 times the stone spacing; 2) Balance beams with a width of 17.5cm; 3) Stepping beams with a sparsity of 64.7%, randomly positioned within a range of 0.48 times the beam spacing; 4) Gaps with a width of 0.7m (2× the length of the robot).
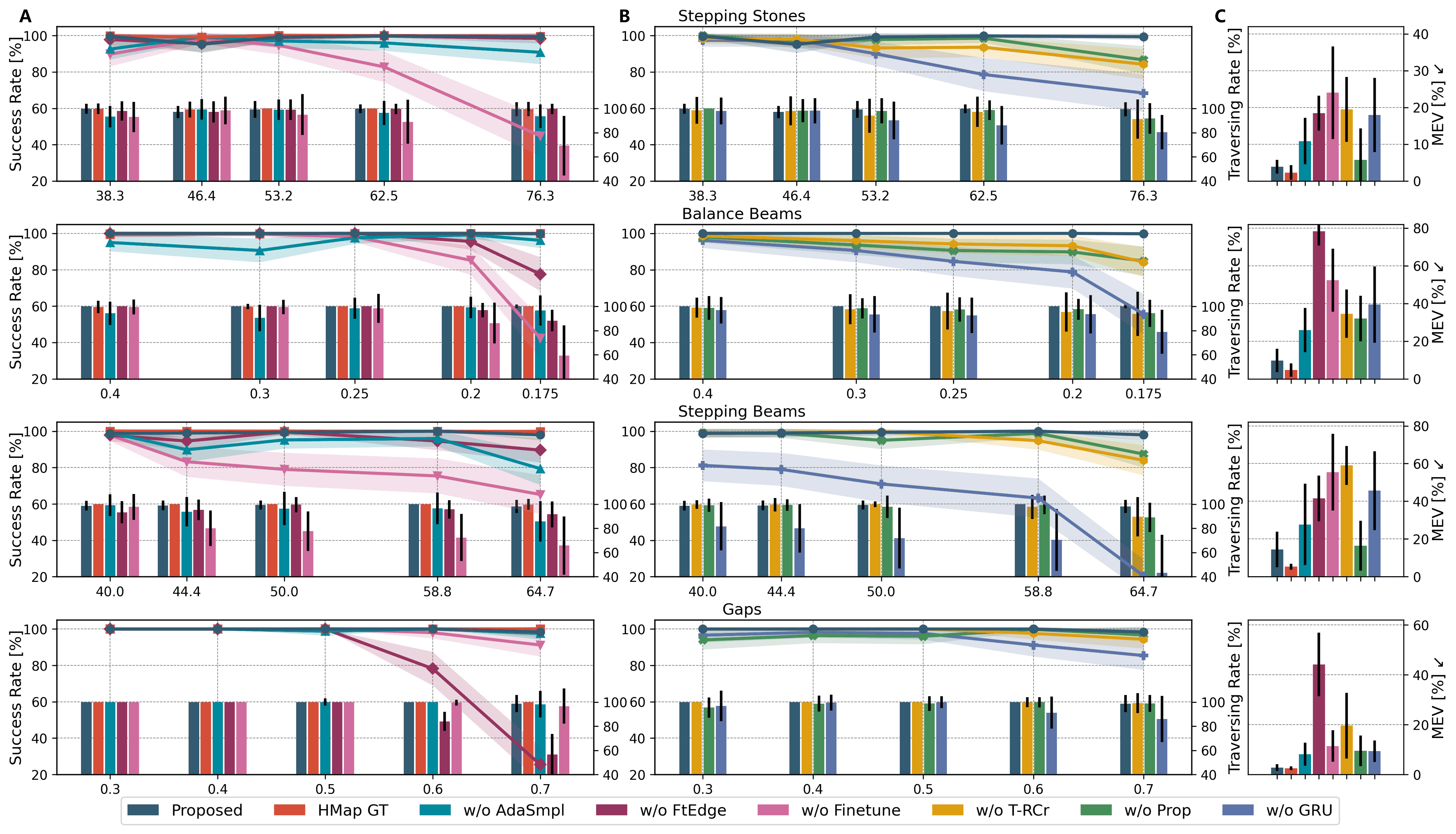
IV-B Ablation Studies
We conducted seven ablation studies and compared them with the proposed method. Since the importance of implicit-explicit estimation for locomotion has been thoroughly evaluated in [29, 30], this component is not included in ablation studies. The first set tests the design of training pipeline:
-
•
HMap GT: Locomotion policy recieves heightmap ground truth as input. An upper bound of performance.
-
•
w/o AdaSmpl: Locomotion policy is trained without AdaSmpl and always uses reconstructed terrain as input.
-
•
w/o FtEdge: Remove term.
-
•
w/o Finetune: The policy is trained directly on all risky sparse terrains without finetuning.
The second set tests the design of model architecture:
-
•
w/o T-RCr: Depth images are processed by a 2D-GRU instead of terrain reconstructor, retaining the policy’s memory without reconstructing the terrain.
-
•
w/o Prop: Terrain reconstructor doesn’t receive proprioception and relies solely on depth images.
-
•
w/o GRU: Replace the GRU in terrain reconstructor with an MLP encoder, removing its ability to memorize terrain features.
| Terrain | Terrain Reconstruction Loss (MAE) [cm] | ||
| Proposed | w/o Prop | w/o GRU | |
| Stepping Stones | 5.21±0.57 | 6.56±0.64 | 9.45±1.47 |
| Balance Beams | 4.09±0.34 | 4.46±1.38 | 6.31±1.33 |
| Stepping Beams | 8.29±1.15 | 9.42±3.83 | 10.76±4.29 |
| Gaps | 2.39±0.75 | 3.28±2.30 | 5.09±0.61 |
IV-C Simulation Experiments
For each terrain, we conducted three sets of experiments to evaluate the performance of the proposed framework and ablation studies: 1) Success rate and traversing rate (the ratio of distance traveled before falling relative to total distance) for crossing 6m at different difficulty levels; 2) Mean edge violation (MEV, the ratio of steps landing on terrain edges to the total number of steps taken) and 3) terrain reconstruction loss while crossing 6m at the highest difficulty level. All experiments were conducted with 500 robots on 10 randomly generated terrains.
| Terrain | Metrics | Real World Results | ||||||
| Proposed | w/o AdaSmpl | w/o FtEdge | w/o Finetune | w/o T-RCor | w/o Prop | w/o GRU | ||
| Stepping Stones (76.3% sparsity) | Success Rate | 1.0 | 0.8 | 0.6 | 0.2 | 0.2 | 0.4 | 0.2 |
| Traversing Rate | 1.00±0.00 | 0.97±0.06 | 0.75±0.34 | 0.55±0.37 | 0.59±0.25 | 0.89±0.19 | 0.53±0.28 | |
| Balance Beams (0.2m width) | Success Rate | 0.8 | 0.6 | 0.4 | 0.4 | 0.4 | 0.4 | 0.2 |
| Traversing Rate | 0.99±0.03 | 0.89±0.16 | 0.78±0.21 | 0.87±0.14 | 0.74±0.20 | 0.75±0.19 | 0.74±0.25 | |
| Stepping Beams (58.8% sparsity) | Success Rate | 1.0 | 0.8 | 0.4 | 0.6 | 0.4 | 0.6 | 0.2 |
| Traversing Rate | 1.00±0.00 | 0.99±0.03 | 0.78±0.31 | 0.80±0.28 | 0.62±0.39 | 0.85±0.25 | 0.42±0.33 | |
| Gaps (0.7m width) | Success Rate | 1.0 | 0.8 | 0.0 | 0.4 | 0.2 | 0.6 | 0.4 |

Terrain Reconstruction Accuracy
We evaluated the quality of terrain reconstruction as shown in Table I. The proposed terrain reconstructor achieves the best reconstruction performance across all complex terrains. By ignoring important motion states from proprioception features, w/o Prop is hard to learn the relationship between recent observations and previous reconstructions using visual inputs alone. This leads to an inability to accurately update the memory of terrain features. w/o GRU cannot memorize historical terrain features and relies solely on information from the recent two frames. As a result, it struggles to reconstruct the terrain beneath and behind the robot, resulting in the highest reconstruction loss. These indicate that precise terrain reconstruction requires a combination of proprioception, vision and memory.
Policy Performance
As shown in Fig. 5, owing to an efficient training pipeline and a well-structured model architecture, the proposed framework demonstrates outstanding performance across all risky terrains. It achieves results very close to the upper-bound HMap GT, which benefits from privileged heightmap ground truth. Accurate terrain reconstruction and comprehensive environmental understanding allow the proposed policy to anticipate upcoming changes in the terrain and select safe footholds with precision. Although w/o AdaSmpl exhibits only a slight decline in performance, its ability to extract terrain features is hindered by the noisy reconstructions encountered during the early stages of learning. In contrast, w/o FtEdge and w/o Finetune suffer significant drops in effectiveness. The former often places feet on terrain edges, leading to instability or falls, resulting in a high edge violation rate. The latter struggles to learn optimal actions as it trains directly on all challenging terrains from scratch without finetuning. This causes complete failure on risky terrains with sparse footholds.
In terms of model architecture, w/o T-RCr and w/o Prop yield similar results as both essentially use a GRU to process depth images. However, w/o T-RCr only represents visual features implicitly without explicit terrain reconstruction, making it more difficult to extract valuable information from images. This weakens the policy’s understanding of the terrain and leads to a higher edge violation rate. Both w/o Prop and w/o GRU exhibit higher terrain reconstruction loss, resulting in reduced effectiveness compared to the proposed policy. Notably, w/o GRU performs worse across all terrains due to its inability to memorize critical terrain features. This impairs accurate reconstruction of the terrain beneath and behind the robot, increasing the likelihood of selecting unsafe footholds and frequent missteps.
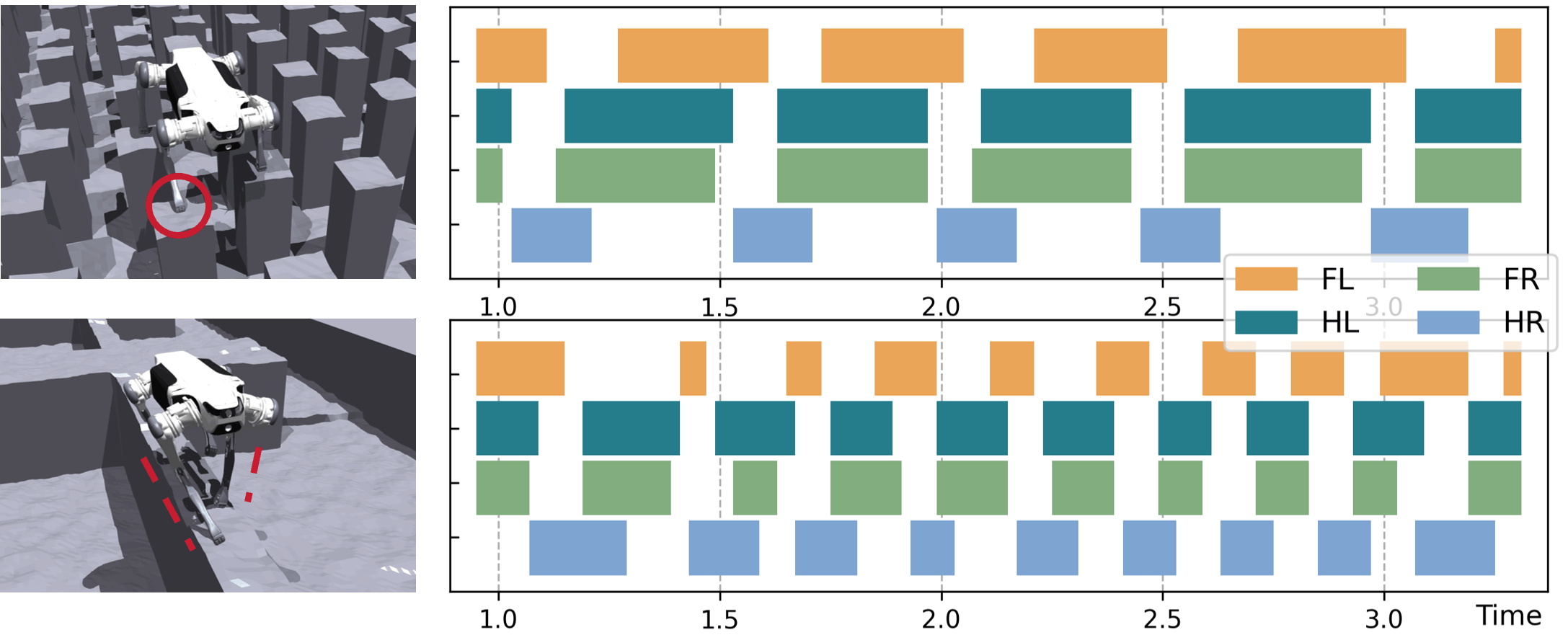
IV-D Real-World Experiments
As shown in Table II and Fig. 7, we build terrains in the real world similar to those in simulation and tested the proposed framework alongside ablation policies (excluding HMap GT). With precise terrain reconstruction and comprehensive environmental understanding, the proposed framework consistently demonstrated robust performance across all terrains, highlighting its strong sim-to-real transferability. w/o FtEdge exhibited a tendency to place feet close to terrain edges, leading to complete failures on gaps due to unstable slips or missing the edges. w/o Finetune, which was trained directly on the most challenging terrains, struggled to discover highly adaptive policies, resulting in unrealistic actions in the real world. Surprisingly, the performance of w/o HMap RC deteriorated significantly in real-world tests, often leading to missteps, edge placements, or directional deviations that caused falls. This suggests that relying solely on implicit visual feature representation is insufficient for extracting effective terrain information and forming an accurate understanding of the environment.
V CONCLUSION
Comprehensive perception and precise environmental awareness are crucial for traversing risky terrains with sparse footholds. In this work, we propose a novel one-stage end-to-end RL-based framework that significantly enhances robot’s environmental understanding through high-quality, explicit local terrain reconstructions. Our framework enables highly adaptive, agile and stable locomotion on terrains characterized by high sparsity and randomness, using only onboard sensors for proprioception and single-view depth images. It consistently demonstrates outstanding performance in real-world scenarios. In the future, we aim to further explore voxel grids for terrain reconstruction to improve the robot’s ability to traverse 3D terrains with overhanging structures.
References
- [1] R. Grandia, F. Jenelten, S. Yang, F. Farshidian, and M. Hutter, “Perceptive locomotion through nonlinear model-predictive control,” IEEE Transactions on Robotics, vol. 39, no. 5, pp. 3402–3421, 2023.
- [2] A. Agrawal, S. Chen, A. Rai, and K. Sreenath, “Vision-aided dynamic quadrupedal locomotion on discrete terrain using motion libraries,” in 2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022, pp. 4708–4714.
- [3] R. J. Griffin, G. Wiedebach, S. McCrory, S. Bertrand, I. Lee, and J. Pratt, “Footstep planning for autonomous walking over rough terrain,” in 2019 IEEE-RAS 19th international conference on humanoid robots (humanoids). IEEE, 2019, pp. 9–16.
- [4] C. Mastalli, I. Havoutis, M. Focchi, D. G. Caldwell, and C. Semini, “Motion planning for quadrupedal locomotion: Coupled planning, terrain mapping, and whole-body control,” IEEE Transactions on Robotics, vol. 36, no. 6, pp. 1635–1648, 2020.
- [5] S. Fahmi, V. Barasuol, D. Esteban, O. Villarreal, and C. Semini, “Vital: Vision-based terrain-aware locomotion for legged robots,” IEEE Transactions on Robotics, vol. 39, no. 2, pp. 885–904, 2022.
- [6] G. B. Margolis, T. Chen, K. Paigwar, X. Fu, D. Kim, S. bae Kim, and P. Agrawal, “Learning to jump from pixels,” in Conference on Robot Learning. PMLR, 2022, pp. 1025–1034.
- [7] T. Miki, J. Lee, J. Hwangbo, L. Wellhausen, V. Koltun, and M. Hutter, “Learning robust perceptive locomotion for quadrupedal robots in the wild,” Science robotics, vol. 7, no. 62, p. eabk2822, 2022.
- [8] A. Agarwal, A. Kumar, J. Malik, and D. Pathak, “Legged locomotion in challenging terrains using egocentric vision,” in Conference on robot learning. PMLR, 2023, pp. 403–415.
- [9] X. Cheng, K. Shi, A. Agarwal, and D. Pathak, “Extreme parkour with legged robots,” in 2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 11 443–11 450.
- [10] R. Yang, G. Yang, and X. Wang, “Neural volumetric memory for visual locomotion control,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 1430–1440.
- [11] Z. Zhuang, Z. Fu, J. Wang, C. G. Atkeson, S. Schwertfeger, C. Finn, and H. Zhao, “Robot parkour learning,” in Conference on Robot Learning. PMLR, 2023, pp. 73–92.
- [12] D. Hoeller, N. Rudin, D. Sako, and M. Hutter, “Anymal parkour: Learning agile navigation for quadrupedal robots,” Science Robotics, vol. 9, no. 88, p. eadi7566, 2024.
- [13] C. Zhang, N. Rudin, D. Hoeller, and M. Hutter, “Learning agile locomotion on risky terrains,” arXiv preprint arXiv:2311.10484, 2023.
- [14] Z. Fu, X. Cheng, and D. Pathak, “Deep whole-body control: learning a unified policy for manipulation and locomotion,” in Conference on Robot Learning. PMLR, 2023, pp. 138–149.
- [15] P. Fankhauser, M. Bloesch, and M. Hutter, “Probabilistic terrain mapping for mobile robots with uncertain localization,” IEEE Robotics and Automation Letters, vol. 3, no. 4, pp. 3019–3026, 2018.
- [16] W. Yu, D. Jain, A. Escontrela, A. Iscen, P. Xu, E. Coumans, S. Ha, J. Tan, and T. Zhang, “Visual-locomotion: Learning to walk on complex terrains with vision,” in Conference on Robot Learning. PMLR, 2022, pp. 1291–1302.
- [17] A. W. Winkler, C. D. Bellicoso, M. Hutter, and J. Buchli, “Gait and trajectory optimization for legged systems through phase-based end-effector parameterization,” IEEE Robotics and Automation Letters, vol. 3, no. 3, pp. 1560–1567, 2018.
- [18] O. Villarreal, V. Barasuol, P. M. Wensing, D. G. Caldwell, and C. Semini, “Mpc-based controller with terrain insight for dynamic legged locomotion,” in 2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020, pp. 2436–2442.
- [19] S. Gangapurwala, M. Geisert, R. Orsolino, M. Fallon, and I. Havoutis, “Rloc: Terrain-aware legged locomotion using reinforcement learning and optimal control,” IEEE Transactions on Robotics, vol. 38, no. 5, pp. 2908–2927, 2022.
- [20] Z. Xie, X. Da, B. Babich, A. Garg, and M. v. de Panne, “Glide: Generalizable quadrupedal locomotion in diverse environments with a centroidal model,” in International Workshop on the Algorithmic Foundations of Robotics. Springer, 2022, pp. 523–539.
- [21] F. Jenelten, J. He, F. Farshidian, and M. Hutter, “Dtc: Deep tracking control,” Science Robotics, vol. 9, no. 86, p. eadh5401, 2024.
- [22] B. Yang, Q. Zhang, R. Geng, L. Wang, and M. Liu, “Real-time neural dense elevation mapping for urban terrain with uncertainty estimations,” IEEE Robotics and Automation Letters, vol. 8, no. 2, pp. 696–703, 2022.
- [23] H. Duan, B. Pandit, M. S. Gadde, B. Van Marum, J. Dao, C. Kim, and A. Fern, “Learning vision-based bipedal locomotion for challenging terrain,” in 2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 56–62.
- [24] C. Chung, G. Georgakis, P. Spieler, C. Padgett, A. Agha, and S. Khattak, “Pixel to elevation: Learning to predict elevation maps at long range using images for autonomous offroad navigation,” IEEE Robotics and Automation Letters, 2024.
- [25] C. Forster, M. Pizzoli, and D. Scaramuzza, “Svo: Fast semi-direct monocular visual odometry,” in 2014 IEEE international conference on robotics and automation (ICRA). IEEE, 2014, pp. 15–22.
- [26] D. Hoeller, N. Rudin, C. Choy, A. Anandkumar, and M. Hutter, “Neural scene representation for locomotion on structured terrain,” IEEE Robotics and Automation Letters, vol. 7, no. 4, pp. 8667–8674, 2022.
- [27] A. Hornung, K. M. Wurm, M. Bennewitz, C. Stachniss, and W. Burgard, “Octomap: An efficient probabilistic 3d mapping framework based on octrees,” Autonomous robots, vol. 34, pp. 189–206, 2013.
- [28] P. Fankhauser and M. Hutter, “A universal grid map library: Implementation and use case for rough terrain navigation,” Robot Operating System (ROS) The Complete Reference (Volume 1), pp. 99–120, 2016.
- [29] Z. Wang, W. Wei, R. Yu, J. Wu, and Q. Zhu, “Toward understanding key estimation in learning robust humanoid locomotion,” arXiv preprint arXiv:2403.05868, 2024.
- [30] S. Luo, S. Li, R. Yu, Z. Wang, J. Wu, and Q. Zhu, “Pie: Parkour with implicit-explicit learning framework for legged robots,” 2024. [Online]. Available: https://arxiv.org/abs/2408.13740
- [31] I. M. A. Nahrendra, B. Yu, and H. Myung, “Dreamwaq: Learning robust quadrupedal locomotion with implicit terrain imagination via deep reinforcement learning,” in 2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 5078–5084.
- [32] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” arXiv preprint arXiv:1707.06347, 2017.
- [33] N. Rudin, D. Hoeller, P. Reist, and M. Hutter, “Learning to walk in minutes using massively parallel deep reinforcement learning,” in Conference on Robot Learning. PMLR, 2022, pp. 91–100.
- [34] J. Lee, J. Hwangbo, L. Wellhausen, V. Koltun, and M. Hutter, “Learning quadrupedal locomotion over challenging terrain,” Science robotics, vol. 5, no. 47, p. eabc5986, 2020.
- [35] G. Ji, J. Mun, H. Kim, and J. Hwangbo, “Concurrent training of a control policy and a state estimator for dynamic and robust legged locomotion,” IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 4630–4637, 2022.
- [36] R. Yang, M. Zhang, N. Hansen, H. Xu, and X. Wang, “Learning vision-guided quadrupedal locomotion end-to-end with cross-modal transformers,” in Deep RL Workshop NeurIPS 2021, 2021.
- [37] O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” in Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18. Springer, 2015, pp. 234–241.
- [38] V. Makoviychuk, L. Wawrzyniak, Y. Guo, M. Lu, K. Storey, M. Macklin, D. Hoeller, N. Rudin, A. Allshire, A. Handa et al., “Isaac gym: High performance gpu-based physics simulation for robot learning,” arXiv preprint arXiv:2108.10470, 2021.