WaBERT: A Low-resource End-to-end Model for Spoken Language Understanding and Speech-to-BERT Alignment
Abstract
Historically lower-level tasks such as automatic speech recognition (ASR) and speaker identification are the main focus in the speech field. Interest has been growing in higher-level spoken language understanding (SLU) tasks recently, like sentiment analysis (SA). However, improving performances on SLU tasks remains a big challenge. Basically, there are two main methods for SLU tasks: (1) Two-stage method, which uses a speech model to transfer speech to text, then uses a language model to get the results of downstream tasks; (2) One-stage method, which just fine-tunes a pre-trained speech model to fit in the downstream tasks. The first method loses emotional cues such as intonation, and causes recognition errors during ASR process, and the second one lacks necessary language knowledge. In this paper, we propose the Wave BERT (WaBERT), a novel end-to-end model combining the speech model and the language model for SLU tasks. WaBERT is based on the pre-trained speech and language model, hence training from scratch is not needed. We also set most parameters of WaBERT frozen during training. By introducing WaBERT, audio-specific information and language knowledge are integrated in the short-time and low-resource training process to improve results on the dev dataset of SLUE SA tasks by 1.15% of recall score and 0.82% of F1 score. Additionally, we modify the serial Continuous Integrate-and-Fire (CIF) mechanism to achieve the monotonic alignment between the speech and text modalities.
1 Introduction
Speeches contain the complete information of texts, and even contain more information than texts. Deep learning models have potential and are expected to understand spoken language directly, without ASR or other transcription processes, meanwhile achieving better results than methods using transcription processes.
Basically, two classic methods are proposed for SLU tasks, the two-stage method and the one-stage method [16]. For the two-stage method, a speech model is utilized to transfer speeches to texts, then a language model is applied to extract the results of downstream tasks from the text inputs. Significantly, the accuracy of ASR influences the performance of SLU, and the powerful pre-trained language model takes responsibility for the whole understanding process, while the audio-specific information is thrown thoroughly. For the one-stage method, a pre-trained speech model is fine-tuned to fit the downstream tasks. Comparing to linguistic corpora, corpora are at lower abundance and more difficult to obtain in the speech training field. [1, 10]. And they do not even contain all the vocabulary and lack the variety of phrase combinations. Besides the shortage of corpora, compared to language models, some researches [16, 14] demonstrate that the pre-trained speech models do not learn significant semantic information, as speech models are designed for lower-level tasks, like ASR. These two methods are proved effective, but still, have technical bottlenecks to break. Using two models in the two-stage method, and combining them appropriately into an end-to-end model like a one-stage strategy, might be a solution that makes the model own audio-specific information and significant semantic information.
Speech and language are regarded as two different modalities, and the combination of speech and language models can be considered as a kind of multi-modal fusion, which is a common challenge in the cross-modal deep learning field. Different modalities have different feature distributions. For example, in acoustic modal, tokens of the same sounds tend to have similar features, and for linguistic modal, tokens of the same semantics share similarities accordingly. Besides, different modalities have different spatial distributions for the same expression. Though acoustic and linguistic modals have consistent in the time dimension, the paired representations are different in length and duration. These two contradictions should be resolved to make different modalities combined.
In this paper, we propose to employ a CIF aligner with an aligned token similarity loss to solve the problems of multi-modal fusion caused by feature distribution and spatial distributions.
Based on the aligner, the output of the acoustic model is aligned to the same shape as the output of the linguistic model. Instead of using ASR, we replace the word embedding layer and even more transformer layers of the linguistic model, with the aligned acoustic output. In this way, the combination of two modalities is achieved for SLU tasks.
Our contributions can be summarized as follows: (1) We employ the Wave BERT (WaBERT), a novel end-to-end model combining the speech model and the language model to improve the performance of SA tasks. (2) We modify the CIF mechanism to achieve the monotonic alignment between two different modalities, more specifically, speech and text modalities. (3) Instead of training from scratch, by employing a pre-trained speech and language model and setting most parameters of WaBERT frozen during training, we achieve short-time and low-resource training.
2 Related works
2.1 Pre-trained speech models
Recently, self-supervised learning (SSL) has achieved great success in the fields of speech processing. There are multiple approaches for SSL of speech processing, including wav2vec [15], wav2vec 2.0 [2], HuBERT [9], WavLMs [3], and data2vec [1].
wav2vec [15] pre-trains a network optimized via a noise contrastive binary classification task.
wav2vec 2.0 [2], HuBERT [9], WavLMs [3], and data2vec [1] all employ BERT-like Masked Acoustic Model(MAM) task for model pre-training, but utilize different features as aligned target labels for prediction.
These methods have shown impressive results for speech processing, especially in phoneme classification and automatic speech recognition (ASR). It leverages large amounts of speech data to learn universal speech representations, which can benefit almost all speech downstream tasks by fine-tuning.
However, pre-trained speech models still present some challenges. On the one hand, in higher-level SLU tasks, satisfying performance is still hard to reach. Some researches demonstrate that the pre-trained speech models do not learn significant semantic information [16, 14]. On the other hand, speech data is at a lower abundance and more difficult to obtain compared to text data. For example, the text file size of LibriSpeech ASR corpus is 297MB, and wave2vec employs this dataset to achieve SOTA results on ASR tasks. Meanwhile, for natural language processing (NLP) models, Bert [5] uses BooksCorpus and English Wikipedia as datasets, which are summed up to 16GB, and Roberta [10] is trained with datasets Books Corpus, English Wikipedia, CC-News, OpenWebText and Storie, in 161GB, 542 times bigger than LibriSpeech ASR corpus. The lack of data limits the performance of Speech models.
We propose to overcome these challenges by combining a pre-trained speech model with a pre-trained NLP model.
2.2 Pre-trained neural language models
The rapid development in pre-trained neural language models has significantly improved the performance of many NLP tasks. Models like BERT [5], RoBERTa [10] and DeBERTa [8] all get acceptable results on NLP tasks.
NLP tasks are similar to SLU tasks but different in data format. The input data of NLP tasks are texts, while the input data of SLU tasks are audios. Texts and audios are similar and inter-convertible, and they have enormous common knowledge naturally. Therefore, NLP models have the potential to be applied in SLU tasks. However, the different distribution and different lengths between audios and texts prevent NLP models from participating in SLU tasks directly. Instead, NLP models are applied in SLU in a more indirect and auxiliary way, the spoken language is recognized as texts by ASR, and then NLP models is fine-tuned for downstream SLU tasks [16]. Obviously, this method suffers from errors that occur in the ASR process and loses emotion information by dropping the feature of speech models.
We propose to overcome these challenges by forming an end-to-end model, which combines the pre-trained speech model and the pre-trained NLP model by aligning the outputs of speech and NLP models at word-token level.
2.3 Forced alignment strategies
Forced alignment (FA), a strategy to produce the bidirectional mapping between the given text and speech sequences, has been widely used in speech processing tasks for decades. Conventionally, FA models are based on hidden Markov model (HMM) [13], such as Prosodylab-Aligner [7] and Montreal forced aligner (MFA) [11]. Also, neural network based FA strategy like NeuFA [https://arxiv.org/abs/2203.16838] and CIF [6, 4] is proposed. Even Connectionist Temporal Classification (CTC) can be generally regarded as an FA strategy.
Nevertheless, when applying these methods to align text and speech modalities instead of text and speech sequences, most of the methods become ineffective. For HMM methods, the hidden states should be discrete, and the number of hidden states should be limited. Due to words or phonemes being discrete, and the number of words or phonemes being limited, text can play a role as hidden states in HMM methods. For aligning text and speech modals, the tensors that needed to be paired are continuous, and the tensors are unlimited in the account. Therefore, HMM models can not apply in modalities alignments. CTC faces the same problem as HMM models.
NeuFA needs ASR and Text-to-Speech (TTS) tasks for joint training, thus, it is not a lightweight construction and not easy for transfer, which makes it not a good solution for modalities alignment
CIF does not require the paired tensor to be discrete or limited in the account, so CIF shows the potential to work in text and speech modals.
We propose to make CIF a better aligner by modifying the aligned token similarity loss.
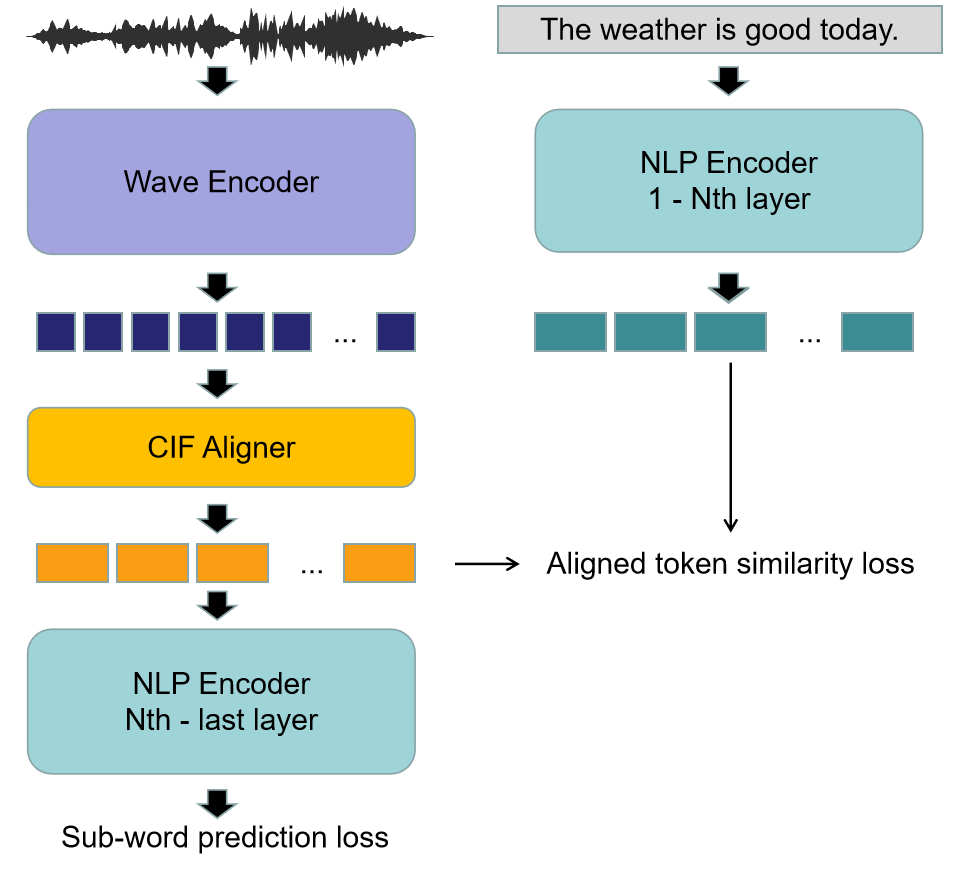
3 Approach
Our model is based on a pre-trained wave encoder and NLP encoder, while any wave and NLP model can be chosen as the component. Concretely, the recently proposed data2vec and classical BERT are utilized. We combine data2vec and BERT to form a new end-to-end model by introducing a CIF aligner. Figure 1 shows an overview of our proposed WaBERT model. We also further improve the alignment between two modals by modifying the align loss. More details of this model are provided in the next subsections.
3.1 Alignment between two modals
Data2vec extracts acoustic representation vectors from raw audio, and corresponding linguistic representation vectors can be obtained from BERT. Suppose the acoustic representation vectors as , and the corresponding linguistic representation vectors from NLP model layer as , where .
Due to the acoustic and linguistic representations being consistent in the time dimension, the outputs of the two modalities should be able to be aligned no matter which model layer’s output is.
To avoid collapse, one modality should be frozen during alignment. For the concern of reducing the information loss of BERT, which contains more information than wave models, the parameters of BERT are fixed. Inspired by the work[4], we use the serial CIF [6] mechanism to achieve the monotonic alignment between the speech and text modalities.
CIF [6] mechanism is a strategy that by acquiring the length the inputs should be resized to, outputs a latent representation that is consistent with the length, also, a predicted length is provided as another output. After applying CIF to the output of wav2vec, acoustic representation vectors as are obtained. Regarding as the learning target of the , We calculate the loss between and . The work[4] uses the equation below to calculate the loss between two modals for alignment:
| (1) |
| (2) |
The similarity between corresponding representations is the only consideration in this loss equation design, and differences between different tokens are ignored. Emphasizing the difference between different representations would make the adjacent tokens easier to distinguish, and make alignment more precise. Therefore, we introduce Info Noise Contrastive Estimation (InfoNCE) to calculate the loss between two modalities for alignment. InfoNCE is defined as below:
| (3) |
And our aligned token similarity loss for calculating the loss between two modalities for alignment is defined as below:
| (4) |
The distance between the speech representation lengths that should be aligned to and the predicted length is measured by:
| (5) |
3.2 Grafting between two modals
After aligning the outputs of data2vec with BERT layer, the outputs of data2vec after the CIF aligner, share similar values with the outputs of NLP model. Grafting between models means replacing a part of the model with another model. Data2vec can be grafted on BERT by replacing the first to BERT layers with the whole data2vec model, and the new grafted model is supposed to get the same result at the top of the BERT as the input is paired texts. Therefore, the original vocabulary ID can be predicted directly with BERT fixed, through this frame, and the BERT-like vocabulary id prediction loss is defined as .
3.3 Training and inference
The loss for training is defined as:
| (6) |
We employ LibriSpeech ASR corpus for training, and it contains 960 hours of training data. We train with the adamw optimizer and a batch size of 128, distributed over 8 GPUs. The learning rate is linearly ramped up during the first 4000 iterations to its base value of 0.0005. After this warmup, we decay the learning rate with a linear schedule. The model is trained for 26 epochs because the loss value is stable enough after 26 epochs.
When coming to inference, the first to NLP layer is dropped. For fine-tuning, with the BERT fixed, the performance of downstream tasks is still acceptable.
4 Experimental results
4.1 CIF alignments
BERT last layer as labels, data2vec are trained over LibriSpeech ASR corpus, with removed. After training of 19 epochs, the loss is stable. The TIMIT dataset is selected as the test dataset. The models are evaluated on the MAE and medians of absolute errors of the predicted left and right boundaries at the word level. Then the comparisons are made with CIF with as the baseline. As shown in Table 1, CIF with outperforms CIF with . The MAE is reduced from 426.44 ms to 126.05 ms, and the medians drop from 386 ms to 77 ms, which means that CIF with always predicts more accurate boundaries than CIF with . This can also be demonstrated by the accuracies at different tolerances (percentage below a cutoff) evaluated and shown in Table 2. The accuracies are improved by 0.2825, 0.5532, 0.2893, and 0.0253 at 50, 100 500, and 1000 ms tolerances for word level.
| Approach | mean | median |
|---|---|---|
| CIF with | 426.44 | 386 |
| CIF with | 126.05 | 77 |
| Approach | 50 ms | 100 ms | 500 ms | 1000 ms |
|---|---|---|---|---|
| CIF with | 0.0201 | 0.0559 | 0.6758 | 0.9698 |
| CIF with | 0.3026 | 0.6091 | 0.9651 | 0.9951 |
Figure 3 proves CIF with is better in other aspects. It shows the heat-map of the similarity between the acoustic representations after alignment and the linguistic representations. And after CIF with , the heat-map shows a valid diagonal, and for CIF with , it is still a mess.


Still, an interesting phenomenon is shown is Figure 4, when using , the distribution of acoustic representations is similar to linguistic representations, and drops the initial acoustic distribution. However, acoustic representations with remains more initial acoustic distribution, and still make a good performance on alignment.

4.2 Performances on SLUE SA tasks
SA refers to classifying a given speech segment as having negative, neutral, or positive sentiment. It is a higher-level task since the semantic content is also very important. For example, negative sentiment can be expressed by disparagement, sarcasm, doubt, suspicion, frustration, etc. [12]. We evaluate SA using weighted recall and F1 scores on SLUE benchmark. The results from Table 3 show that, our model outperforms two-stage pipeline approaches and one-stage approaches in dev dataset.
4.2.1 Comparing to two stage method
Using the two-stage method, SLU tasks are changed to NLU tasks successfully. The NLP top-lines and pipeline approaches results in Table 3, show a conclusion: Errors that occur during ASR, influence the downstream task result. The better the ASR result is the better performance in SLU tasks. Therefore, None of the methods that use ASR exceed the methods that directly use the ground truth text.
For our end-to-end model, though the wave encoder of our model is not able to give exact features as the ground truth, it provides enough accurate information. For example, taking our model as the ASR model, a hard example, "never drink any hard liquors such as whisky brandy gin or cocktails with oysters or clams as it is liable to upset you for the rest of the evening" is recognized as "never drink any hard liquors such as whisky brandy or or eels with oysters or clamps as it is liable to upset you for the rest of theran". Admittedly, there are lots of mistakes in the ASR process, but as shown in Table 4, the right answers all occurred in the top 5 candidates. Our model outputs features that contain the right information to the NLP model, and avoids the influence of the ASR errors. Additionally, the joining of the wave encoder enhances the performance of the whole model, making our result better than the pure BERT model. Compared to the results of the NLP toplines, our model improves 4.39% of the recall score and 1.12% of the F1 score.
4.2.2 Comparing to one stage method
Compared to the results of the one-stage method (E2E approaches in Table 3), our model improves 1.19% of recall score and 0.72% of F1 score. The performance proves that the join of an NLP encoder enhances the understanding of spoken language.
| Model | Dev | ||
| Speech model | LM | Text model | Weighted |
| NLP Toplines : | |||
| N/A (GT text) | N/A | BERT-B | 77.8 / 78.9 |
| DeBERTa-B | 75.5 / 77.3 | ||
| DeBERTa-L | 77.7 / 79.3 | ||
| Pipeline approaches : | |||
| W2V2-B-LS960 | - | BERT-B | 77.1 / 78.2 |
| W2V2-B-LS960 | - | DeBERTa-B | 74.9 / 76.9 |
| W2V2-B-LS960 | - | DeBERTa-L | 76.6 / 78.1 |
| W2V2-L-LL60K | - | DeBERTa-L | 76.5 / 78.0 |
| W2V2-B-LS960 | BERT-B | 77.5 / 78.2 | |
| W2V2-B-LS960 | DeBERTa-B | 73.9 / 75.9 | |
| W2V2-B-LS960 | DeBERTa-L | 75.9 / 77.7 | |
| W2V2-L-LL60K | DeBERTa-L | 76.4 / 78.2 | |
| E2E approaches : | |||
| W2V2-B-LS960 | N/A | N/A | 81.0 / 79.7 |
| W2V2-B-VP100K | N/A | N/A | 78.8 / 77.0 |
| HuBERT-B-LS960 | N/A | N/A | 80.5 / 79.4 |
| W2V2-L-LL60K | N/A | N/A | 79.2 / 79.6 |
| Ours : | |||
| data2vec-B-LS960 | N/A | N/A | 80.62/80.28 |
| data2vec-B-LS960 | N/A | BERT-B(w/o 1-3 layers) | 82.19/80.42 |
| data2vec-B-LS960 | N/A | BERT-B(w/o 1-6 layers) | 80.42/79.92 |
| data2vec-B-LS960 | N/A | BERT-B(w/o 1-9 layers) | 80.83/80.37 |
| data2vec-B-LS960 | N/A | BERT-B(w/o 1-12 layers) | 80.73/80.40 |
| Labels | gin | or | cocktails | clams | the | evening | |||
|---|---|---|---|---|---|---|---|---|---|
| Top-1 | or | or | eels | cl | -amp | -s | as | the | -ran |
| Top-2 | gin | cock | tails | cr | -am | -ams | it | , | evening |
| Top-3 | gill | char | beans | or | -umb | -mes | -s | . | he |
| Top-4 | chin | a | turtles | the | -ab | as | that | a | ang |
| Top-5 | and | og | ears | br | -lar | -as | in | to | night |
5 Ablation studies
Table 3 shows that, when aligning data2vec’s outputs to the outputs of , , and BERT layer, the result of and layer is better than others. The output of is more near to word embedding layers, and is more close to the classification layer, which are under more strict constraints than other compared layers, thus, the outputs are more independence and easy to separate. align technique is easier to show its effort.
For the comparison of output of and layers, the layer method keeps more BERT structure, and this part gives model the abilities to outperform the layers method.
6 Conclusions
Multi-modal alignment is different, the labels are more flexible and dependent compared to label-fixed FA. This paper showed that CIF can be used as a multi-modal aligner when a proper align loss is chosen. The main reason is that this strategy convergences feature distributions and space distributions.
By using WaBERT, we were able to integrate audio-specific information and language knowledge to improve the performance of SA tasks in a short-time and low-resource training process.
7 Further studies
(1) The loss between sub-word prediction and the label is calculated for all tokens, though some researches show that only calculating the loss between labels and masked tokens leads to better performance. This method would be applied in our further studies.
(2) In this paper, we only adopt BERT as the NLP encoder and data2vec as the wave encoder, the influence of different combinations of models should be another direction of further studies.
(3) Most of the WaBERT parameters are frozen during training. However, making all parameters trainable might be a way to improve the performance. We will try to do speech pre-train tasks, NLP pre-train tasks, and our aligned tasks together for joint training in the next step.
(4) The aligner only aligns one layer in our method, in the next step, we will align different layers respectively at the same time, to achieve a more precise alignment.
References
- [1] Baevski, A., Hsu, W., Xu, Q., Babu, A., Gu, J., Auli, M.: data2vec: A general framework for self-supervised learning in speech, vision and language. CoRR abs/2202.03555 (2022), https://arxiv.org/abs/2202.03555
- [2] Baevski, A., Zhou, H., Mohamed, A., Auli, M.: wav2vec 2.0: A framework for self-supervised learning of speech representations. CoRR abs/2006.11477 (2020), https://arxiv.org/abs/2006.11477
- [3] Chen, S., Wang, C., Chen, Z., Wu, Y., Liu, S., Chen, Z., Li, J., Kanda, N., Yoshioka, T., Xiao, X., Wu, J., Zhou, L., Ren, S., Qian, Y., Qian, Y., Wu, J., Zeng, M., Wei, F.: Wavlm: Large-scale self-supervised pre-training for full stack speech processing. CoRR abs/2110.13900 (2021), https://arxiv.org/abs/2110.13900
- [4] Deng, K., Cao, S., Zhang, Y., Ma, L., Cheng, G., Xu, J., Zhang, P.: Improving ctc-based speech recognition via knowledge transferring from pre-trained language models (2022). https://doi.org/10.48550/ARXIV.2203.03582, https://arxiv.org/abs/2203.03582
- [5] Devlin, J., Chang, M., Lee, K., Toutanova, K.: BERT: pre-training of deep bidirectional transformers for language understanding. CoRR abs/1810.04805 (2018), http://arxiv.org/abs/1810.04805
- [6] Dong, L., Xu, B.: CIF: continuous integrate-and-fire for end-to-end speech recognition. CoRR abs/1905.11235 (2019), http://arxiv.org/abs/1905.11235
- [7] Gorman, K., Howell, J., Wagner, M.: Prosodylab-aligner: A tool for forced alignment of laboratory speech. vol. 39 (09 2011)
- [8] He, P., Liu, X., Gao, J., Chen, W.: Deberta: Decoding-enhanced BERT with disentangled attention. CoRR abs/2006.03654 (2020), https://arxiv.org/abs/2006.03654
- [9] Hsu, W., Bolte, B., Tsai, Y.H., Lakhotia, K., Salakhutdinov, R., Mohamed, A.: Hubert: Self-supervised speech representation learning by masked prediction of hidden units. CoRR abs/2106.07447 (2021), https://arxiv.org/abs/2106.07447
- [10] Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., Stoyanov, V.: Roberta: A robustly optimized BERT pretraining approach. CoRR abs/1907.11692 (2019), http://arxiv.org/abs/1907.11692
- [11] McAuliffe, M., Socolof, M., Mihuc, S., Wagner, M., Sonderegger, M.: Montreal forced aligner: Trainable text-speech alignment using kaldi. In: Interspeech. vol. 2017, pp. 498–502 (2017)
- [12] Mohammad, S.: A practical guide to sentiment annotation: Challenges and solutions. In: Proceedings of the 7th workshop on computational approaches to subjectivity, sentiment and social media analysis. pp. 174–179 (2016)
- [13] Rabiner, L., Juang, B.: An introduction to hidden markov models. IEEE ASSP Magazine 3(1), 4–16 (1986). https://doi.org/10.1109/MASSP.1986.1165342
- [14] Sanabria, R., Hsu, W.N., Baevski, A., Auli, M.: Measuring the impact of individual domain factors in self-supervised pre-training (2022). https://doi.org/10.48550/ARXIV.2203.00648, https://arxiv.org/abs/2203.00648
- [15] Schneider, S., Baevski, A., Collobert, R., Auli, M.: wav2vec: Unsupervised pre-training for speech recognition. CoRR abs/1904.05862 (2019), http://arxiv.org/abs/1904.05862
- [16] Shon, S., Pasad, A., Wu, F., Brusco, P., Artzi, Y., Livescu, K., Han, K.J.: SLUE: new benchmark tasks for spoken language understanding evaluation on natural speech. CoRR abs/2111.10367 (2021), https://arxiv.org/abs/2111.10367