m[TODO] #1
VSAG: An Optimized Search Framework for Graph-based Approximate Nearest Neighbor Search
Abstract.
Approximate nearest neighbor search (ANNS) is a fundamental problem in vector databases and AI infrastructures. Recent graph-based ANNS algorithms have achieved high search accuracy with practical efficiency. Despite the advancements, these algorithms still face performance bottlenecks in production, due to the random memory access patterns of graph-based search and the high computational overheads of vector distance. In addition, the performance of a graph-based ANNS algorithm is highly sensitive to parameters, while selecting the optimal parameters is cost-prohibitive, e.g., manual tuning requires repeatedly re-building the index.
This paper introduces VSAG, an open-source framework that aims to enhance the in production performance of graph-based ANNS algorithms. VSAG has been deployed at scale in the services of Ant Group, and it incorporates three key optimizations: (i) efficient memory access: it reduces L3 cache misses with pre-fetching and cache-friendly vector organization; (ii) automated parameter tuning: it automatically selects performance-optimal parameters without requiring index rebuilding; (iii) efficient distance computation: it leverages modern hardware, scalar quantization, and smartly switches to low-precision representation to dramatically reduce the distance computation costs. We evaluate VSAG on real-world datasets. The experimental results show that VSAG achieves the state-of-the-art performance and provides up to speedup over HNSWlib (an industry-standard library) while ensuring the same accuracy.
PVLDB Reference Format:
Xiaoyao Zhong,
Haotian Li,
Jiabao Jin,
Mingyu Yang,
Deming Chu,
Xiangyu Wang,
Zhitao Shen,
Wei Jia,
George Gu,
Yi Xie,
Xuemin Lin,
Heng Tao Shen,
Jingkuan Song, Peng Cheng. PVLDB, 14(1): XXX-XXX, 2020.
doi:XX.XX/XXX.XX
††This work is licensed under the Creative Commons BY-NC-ND 4.0 International License. Visit https://creativecommons.org/licenses/by-nc-nd/4.0/ to view a copy of this license. For any use beyond those covered by this license, obtain permission by emailing [email protected]. Copyright is held by the owner/author(s). Publication rights licensed to the VLDB Endowment.
Proceedings of the VLDB Endowment, Vol. 14, No. 1 ISSN 2150-8097.
doi:XX.XX/XXX.XX
PVLDB Artifact Availability:
The source code, data, and/or other artifacts have been made available at https://github.com/antgroup/vsag.
1. Introduction
At Ant Group (Alipay, 2025a), we have observed an increasing demand to manage large-scale high-dimensional vectors across different departments. This demand is fueled by two factors. First, the advent of Retrieval-Augmented Generation (RAG) for large language models (LLMs) (Lewis et al., 2020; Gao et al., 2024b) requires vector search to address issues such as hallucinations and outdated information. Second, the explosive growth of unstructured data (e.g., documents, images, and videos), requires efficient analysis and storage methods. Many systems transform these unstructured data into embedding vectors for efficient retrieval, e.g., Alipay’s facial-recognition payment (Alipay, 2025b), Google’s image search (Google, 2025), and YouTube’s video search (YouTube, 2025).
Approximate nearest neighbor search (ANNS) is the foundation for these AI and LLM applications. Due to the curse of dimensionality (Indyk and Motwani, 1998), exact nearest neighbor search becomes prohibitively expensive as dimensionality grows. ANNS, however, trades off a small degree of accuracy for a substantial boost in efficiency, establishing itself as the gold standard for large-scale vector retrieval.
Recently, graph-based ANNS algorithms (e.g., HNSW (Malkov and Yashunin, 2020a) and VAMANA (Jayaram Subramanya et al., 2019a)) successfully balance high recall with practical runtime performance. These methods typically construct a graph, where each node is a vector and each edge connects nearby vector pairs. During a query, an approximate -nearest neighbor search starts from a random node and greedily moves closer to the query vector , thereby retrieving its nearest neighbors.
Despite their success, existing graph-based ANNS solutions still face considerable performance challenges. First, they incur random memory-access overhead, since graph traversals with arbitrary jumps often lead to frequent cache misses and elevated costs. Second, repeated distance computations across candidate vectors can dominate total runtime, especially when vectors are high-dimensional. Finally, performance is highly sensitive to parameter settings (e.g., maximum node degree and candidate pool size), yet adjusting these parameters generally requires rebuilding the index, which can take hours or even days. We use a small example from our experiments to illustrate these issues:
Modern production systems (Wang et al., 2021; Johnson et al., 2019a) typically employ vector quantization to reduce the distance computation cost. Therefore, we set our baseline as HNSW with SQ4 quantization (Zhou et al., 2012). We conduct 1,000 vector queries on the GIST1M111http://corpus-texmex.irisa.fr/. In what follows, we report the performance limitations of graph-based ANNS algorithms, using the experimental evidence of the baseline: (i) high memory access cost: each query needs over 2,959 random vector accesses (total 1.4 MB), causing a 67.42% L3 cache miss rate. The memory-access operations consume 63.02% of the search time. (ii) high parameter tuning cost: if we use the optimal parameters instead of the manually selected values, the QPS can increase from 1,530 to 2,182, by 42.6%. However, brute-force tuning of parameters takes more than 60 hours, which is prohibitively expensive. (iii) high distance computation cost: distance computations still take 26.12% of the search time despite using SQ4 quantization.
Contributions. This paper presents VSAG, an open-source framework for enhancing the in-production efficiency of graph-based ANNS algorithms. The optimizations of VSAG are in three-fold. (i) Efficient Memory Access: during graph-based search, it pre-fetches the neighbor vectors, and creates a continuous copy of the neighbor vectors for some vertices. This cache-friendly design can reduce L3 cache misses. (ii) Automated Parameter Tuning: VSAG can automatically tune parameters for environment (e.g., prefetch depth), index (e.g., max degree of graph), and query (e.g., candidate size). Suppose there are 3 index parameters and 5 choices for each parameter. The tuned index parameters of VSAG offer similar performance to that of brute-force tuning, which needs to enumerate all combinations of parameters leading to a total tuning time of times of index construction time. On the contrast, the tuning cost of VSAG is only 2-3 times of index construction time. (iii) Efficient Distance Computation: VSAG provides various approximate distance techniques, such as scalar quantization. All distance computation is well optimized with modern hardware, and a selective re-ranking strategy is used to ensure retrieval accuracy.
Table 1 compares the performance of VSAG with existing works on GIST1M. The results show that VSAG alleviates the performance challenges in memory access, parameter tuning, and distance computation, thus providing higher QPS with the same recall rate.
| Metric | IVFPQFS (André et al., 2015) | HNSW (Malkov and Yashunin, 2020a) | VSAG (this work) |
|---|---|---|---|
| Memory Footprint | 3.8G | 4.0G | 4.5G |
| Recall@10 (QPS=2000) | 84.57% | 59.46% | 89.80% |
| QPS (Recall@10=90%) | 1195 | 511.9 | 2167.3 |
| Distance Computation Cost | 0.71ms | 1.62ms | 0.1ms |
| L3 Cache Miss Rate | 13.98% | 94.46% | 39.23% |
| Parameter Tuning Cost | ¿20h | ¿60h | 2.92h |
| Parameter Tuning | manual | manual | auto |
In summary, we make the following contributions:
-
1.
We enhance the memory access of VSAG in §3. The L3 cache miss rate of VSAG is much less than that of other graph-based ANNS works.
-
2.
We propose automatic parameter tuning for VSAG in §4. It automatically selects performance-optimal parameters that are comparable to grid search without requiring index rebuilding.
-
3.
We accelerate VSAG in distance computation in §5. Compared with other graph-based ANNS works, VSAG requires much less time for distance computation.
-
4.
We evaluate algorithms on real datasets in §6. The results show that VSAG can achieve the SOTA performance and outperform HNSWlib by up to 4 in QPS under the same recall guarantee.
2. Overview of VSAG Framework
| Symbol | Description |
|---|---|
| the base dataset | |
| the graph index | |
| the labels of edges | |
| the distance function with low precision and high precision | |
| a normal, base, query, and neighbor vector | |
| the nearest and approximate nearest neighbors of | |
| the candidate pool size in search and construction phase | |
| the pruning rate used in search and construction phase | |
| the maximum degree of graph used in search and construction phase | |
| prefetch stride | |
| prefetch depth | |
| redundancy ratio |

This section provides an overview of our VSAG framework, which includes memory access optimization, automatic parameter tuning, and distance computation optimization. As shown in Figure 1, VSAG integrates these optimizations into different phases of the search process. First, the PRS manages the storage of vector data and graph indices. It stores low-precision quantized codes of vectors alongside high-precision original vectors to support distance computation optimization. This redundant storage is also utilized to balance resource usage and reduce memory access costs. Second, during each hop of the search process when exploring a vector, we employ Deterministic Access Greedy Search to accelerate memory access by minimizing cache misses. Finally, the visited results are pushed into a heap. We apply Selective Re-rank to combine low- and high-precision distances, ensuring effective search performance. The search process then pops the nearest unfinished point from the heap and proceeds to the next hop. Throughout the entire life-cycle of the index, VSAG uses a smart auto-tuner to select parameters that deliver the best search performance across varying environments and retrieval requirements. We will now detail the three main optimizations used in VSAG. The symbols used in this paper are listed in Table 2.
2.1. Memory Access Optimization
Deterministic Access. Distance computations for neighboring vectors often incur random memory access patterns in graph-based algorithms, leading to significant cache misses. VSAG addresses this by integrating software prefetching (Ayers et al., 2020) (i.e., _mm_prefetch) through a Deterministic Access strategy (see §3.2.1). VSAG strategically inserts prefetch instructions during and before critical computations, proactively loading target data into L3/higher-level caches. This prefetch-pipeline overlap ensures data availability before subsequent computation phases begin, effectively mitigating cache miss penalties. Furthermore, the VSAG framework effectively mitigates suboptimal prefetch operations through batch processing and reordering of the access sequence.
PRS. To better optimize memory access, VSAG introduces a Partial Redundant Storage (PRS) design (see §3.3), which provides a flexible and high-performance storage foundation to optimize both distance computations and memory access while balancing storage and computational resource usage. In production environments constrained by fixed hardware configurations, such as 4C16G (i.e., equipped with 4 CPU cores and 16GB of memory) and 2C8G (i.e., equipped with 2 CPU cores and 8GB of memory), most algorithms frequently exhibit resource utilization imbalances between computational and memory subsystems. During computational processes, CPUs frequently encounter idle cycles caused by cache misses, which hinders their ability to achieve optimal utilization, and thereby limits the system’s QPS.
To address this challenge, the PRS framework Redundantly Storing Vectors (see §3.3.2) that embeds compressed neighbor vectors at each graph node. This architectural design enables batched distance computations while leveraging more efficient Hardware-based Prefetch (Chen and Baer, 1995) (see §3.3.1) to maintain high cache hit rates. By incorporating advanced quantization methods (Jégou et al., 2011a; Gao and Long, 2024), PRS achieves high vector storage compression ratios, thereby maintaining acceptable storage overhead despite data redundancy.
Balance of Resources. In particular, the system has a parameter called the redundancy ratio , providing flexible control over the Balance of Computational Efficiency and Memory Utilization (see §3.3.3). In compute-bound scenarios with high-throughput demands, VSAG adaptively increases the redundancy ratio to mitigate cache contention, thus minimizing CPU idle cycles during memory access while preserving storage efficiency. In contrast, in memory-constrained low-throughput scenarios, the framework strategically reduces redundancy ratio to optimize the index-memory footprint. Under memory-constrained conditions, this optimization enables deployment on reduced instance tiers, thereby curtailing compute wastage.
2.2. Automatic Parameter Tuning
VSAG addresses parameter selection complexity through a tripartite classification system with specialized optimization strategies: environment-level, query-level, and index-level parameters. Environment-level parameters (e.g., prefetch stride ) exclusively influence query-per-second (QPS) performance without recall rate impacts, thus incurring the lowest tuning overhead. Query-level parameters (e.g., candidate set size (Malkov and Yashunin, 2020b)) exhibit moderate tuning costs by jointly affecting QPS and recall, requiring adjustment based on query vector distributions. Index-level parameters (e.g., maximum degree (Malkov and Yashunin, 2020b)) demand the highest tuning investment due to their tripartite impact on QPS, recall, and index construction time – parameter validation necessitates multiple index rebuilds.
-
•
Environment-level Parameters (see §4.2): VSAG employs a grid search to identify optimal configurations for peak QPS performance through systematic parameter space exploration.
-
•
Query-level Parameters (see §4.3): VSAG implements multi-granular tuning strategies, including fine-grained adaptive optimization that dynamically adjusts parameters based on real-time query difficulty assessments.
-
•
Index-level Parameters (see §4.4): VSAG introduces a novel mask-based index compression technique that encodes multiple parameter configurations into an unified index structure. During searches, edge-label filtering dynamically emulates various construction parameters, thereby reducing index-level parameters to query-level equivalents while keeping a single physical index.
2.3. Distance Computation Optimization
Distance computation is a main overhead in vector retrieval, and its cost increases significantly with the growth of vector dimensions. Quantization methods (see §5.2) can effectively accelerate distance computation. For example, under identical instruction set architectures, AVX512 (Intel, 2025) can process as many INT8 data per instruction compared to FLOAT32 values. However, naive quantization approaches often result in significant accuracy degradation. VSAG uses Selective Re-rank (see §5.4) to improve efficiency without sacrificing the search accuracy. Furthermore, specific distance metrics (i.e., euclidean distance) can be strategically decomposed and precomputed, effectively reducing the number of required instructions during actual search operations.
3. Memory Access Optimization
Graph-based algorithms suffer from random memory access patterns that incur frequent cache misses. The fundamental strategy for mitigating cache-related latency lies in effectively utilizing vector computation intervals to prefetch upcoming memory requests into cache. In VSAG, three primary optimization strategies emerge for maximizing cache utilization efficiency:
-
•
Leveraging software prefetching to improve cache hit rates.
-
•
Optimizing search patterns to enhance the effectiveness of software prefetching.
-
•
Optimizing the memory layout of indexes to efficiently utilize hardware prefetching.
3.1. Software-based Prefetch: Making Random Memory Accesses Logically Continuous
As shown in Figure 2, when computing vector distances, the vector is loaded sequentially from a segment of memory. The CPU fetches data from memory in units of cache lines (Veidenbaum et al., 1999). Consequently, multiple consecutive cache fetch operations are triggered for a single distance computation.
Example 0.
Take standard 64-byte cache line architectures as an example. The 960-dimensional vector of GIST1M stored as float32 format necessitates cache line memory transactions, demonstrating significant pressure on memory subsystems.
This passive caching mechanism creates operational inefficiencies by extensively fetching data only upon cache misses, resulting in synchronous execution bottlenecks. As illustrated in Figure 2, the orange timeline shows how the regular ANNS algorithm serializes the computation and memory access phases: Each cache line fill (analogous to blocking I/O) stalls computation until completion. The accumulated latency from successive cache line transfers introduces a significant constant factor in complexity analysis, particularly in memory-bound scenarios with poor data locality.

Software-based Prefetch. Modern CPUs support software prefetch instructions, which can asynchronously load data into different levels of the cache (Ayers et al., 2020). By leveraging the prefetch instruction to preload data, we can achieve a near-sequential memory access pattern from the CPU level. This indicates that data is preloaded into the cache before the CPU requires it, thereby preventing disruptions in the computational flow caused by random memory address loads. More specifically, prior to computing the distance for the current neighbor, the vector for the next neighbor can be prefetched. As detailed in Figure 2, the green flow represents the use of prefetching. From the perspective of the CPU, the majority of distance computations make use of data that has already been cached. Furthermore, because prefetching operates asynchronously, it does not obstruct ongoing computations. The synergy of asynchronous prefetching and immediate data access optimizes the utilization of CPU computational resources, thereby substantially enhancing search performance.
3.2. Deterministic Access Greedy Search: Advanced Prefetch Validity
In §3.1, the software-based prefetch mechanism initiates the fetching of next-neighbor vector upon completion of each neighbor computation. However, this method results in redundant operations because previously visited neighbors that do not require distance computations still generate prefetch time cost. Example 3.2 illustrates the inherent limitations of previous prefetch schemes:
Example 0.
In Figure 3(a), and have already been visited, and the distances do not need to be recomputed. This renders the previous prefetching of these vectors ineffective. Additionally, when computing , the prefetch may also fail due to the prefetching gap being too short.
In this section, we present two dedicated strategies to address the aforementioned prefetching challenges.

3.2.1. Deterministic Access
In contrast to prefetching during edge access checks, VSAG exclusively prefetches only those edges that have not been accessed. The mechanism begins by batch-processing all neighbor nodes to determine their access status. Following this, unvisited neighbors are logically grouped, and prefetching is performed collectively. This strategic approach ensures that each prefetched memory address corresponds exclusively to computation-essential data, thereby enhancing prefetching efficiency and minimizing redundant memory operations.
3.2.2. Stride Prefetch
Batch processing ensures that each prefetch retrieves data intended for future use. However, prefetch effectiveness varies due to the asynchronous nature of prefetching and the absence of a callback mechanism to confirm prefetch completion. Optimal performance occurs when the required data reside in the cache precisely when the computation flow demands it. Premature prefetching risks cache eviction, while delayed prefetching negates performance gains. This necessitates balancing prefetch timing with computation duration. To address this, stride prefetching dynamically aligns hardware computation throughput with software prefetching rates, maximizing prefetch utility. The key parameter, the prefetch stride (Vanderwiel and Lilja, 2000), determines how many computation steps occur before each prefetch. Adjusting is crucial, and in §4.2, we propose an automated strategy to select its optimal value.
Example 0.
As detailed in Figure 3(b), the adjusted pattern demonstrates that during batch processing, the Deterministic Access strategy eliminates the need to access and . Consequently, the search logic progresses from directly to . This sequence modification enables the prefetch mechanism to target while computing . Figure 3(c) further reveals the temporal characteristics of asynchronous prefetching: The data loading process requires two vector computation cycles to populate the cache line. When computation for initiates, only the vector can be prefetched. After the computations of and , the Stride Prefetch strategy ensures timely cache population of data, which is immediately available for subsequent computation.
Deterministic Access Greedy Search. The cache-optimized search algorithm is formalized in Algorithm 1. The graph index constitutes an oriented graph that maintains base vectors along with their neighbors. The labels of edges in are used for automatic index-level parameters tuning (see §4). We use and to indicate the out-edges and labels of . The low- and high-precision distance functions and are used to accelerate distance computation while maintaining search accuracy, and they are employed in the selective re-ranking process (see §5). The complete algorithm explanation is provided in Appendix A.
3.3. PRS: Flexible Storage Layout Boosting Search Performance
While incorporating well-designed prefetch patterns into search processes can theoretically improve performance, the inherent limitations of Software-based Prefetch prevent guaranteed memory availability for all required vectors. This phenomenon can be attributed to multiple fundamental constraints: (a) Prefetch instructions remain advisory operations rather than mandatory commands. Even when optimal prefetch patterns are implemented, their actual execution cannot be assured. (b) Cache line contention represents another critical challenge. In multi-process environments, aggressive prefetch strategies may induce L3 cache pollution through premature data loading. (c) The intrinsic cost disparity between prefetch mechanisms further compounds these issues. Software-based prefetching intrinsically carries higher operational costs and demonstrates inferior efficiency compared to hardware-implemented alternatives.
3.3.1. Hardware-based Prefetch
Hardware-based prefetching relies on hardware mechanisms that adaptively learn from cache miss events to predict memory access patterns. The system employs a training buffer that dynamically identifies recurring data access sequences to automatically prefetch anticipated data into the cache hierarchy. Compared to software-controlled prefetching, this hardware approach demonstrates better runtime efficiency while functioning transparently at the architectural level. The training mechanism shows particular effectiveness for Sequential Memory Access patterns (Braun and Litz, 2019), where it can rapidly detect and exploit sequential memory access characteristics. This optimization proves particularly beneficial for space-partitioned index structures like inverted file-based index (Jégou et al., 2011b), where vectors belonging to the same partition maintain contiguous storage allocation. Conversely, graph-based indexing architectures exhibit irregular access patterns with poor spatial locality, resulting in inefficient Random Memory Access (Braun and Litz, 2019). The inherent randomness of access sequences prevents the training buffer from establishing effective pattern recognition models.
3.3.2. Redundantly Storing Vectors
VSAG integrates the benefits of space-partitioned indexes into graph-based indexing algorithms through redundant vector storage. By co-locating neighbor lists with their corresponding vectors within each node’s data structure, it achieves Sequential Memory Access. This design ensures that neighbor retrieval operations only require sequential access within contiguous memory regions, thereby fully leveraging hardware prefetching (Chen and Baer, 1995) capabilities.
Example 0.
As illustrated in Figure 1, consider 10 vectors stored contiguously in memory. Even when accessing through where and are not immediately required, hardware prefetchers can still proactively load into cache. This behavior stems from the memory locality created by storing adjacent vectors ( to ) in consecutive memory addresses. The consistent memory layout and predictable access patterns effectively compensate for software-based prefetching inefficiencies through hardware optimizations.
3.3.3. Balance of Computational Efficiency and Memory Utilization.
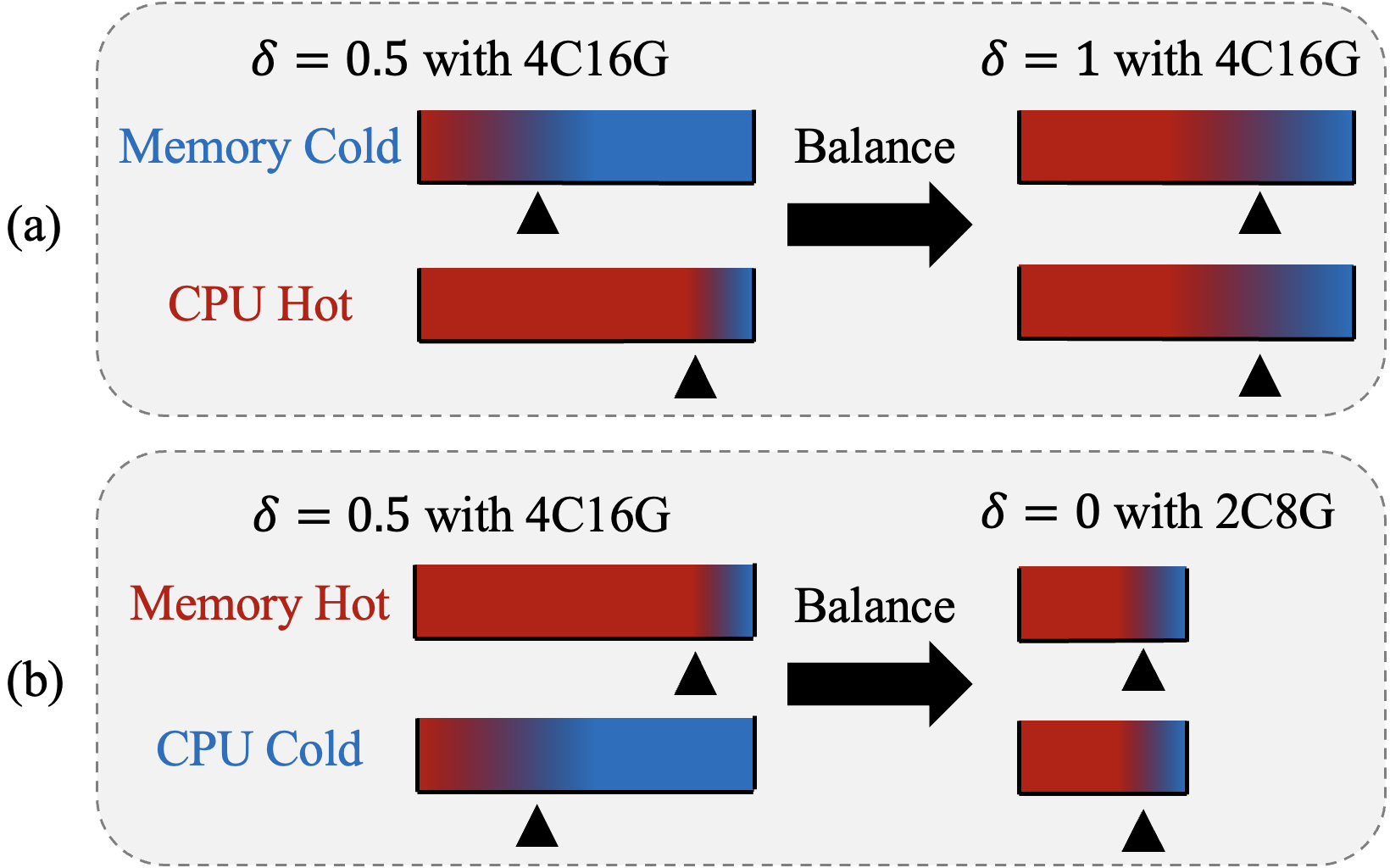
To address the computational-memory resource imbalance caused by fixed instance specifications (e.g., 4C16G, 2C8G) in industrial applications, we propose PRS to take advantage of hardware prefetching to reduce CPU idle time. A dynamically tunable redundancy ratio controls the proportion of redundantly stored neighbor vectors in graph indices, balancing prefetch efficiency and CPU utilization. When , full redundancy maximizes hardware prefetch benefits, achieving peak CPU utilization at the cost of higher memory consumption. In contrast, eliminates redundancy to minimize memory usage but sacrifices prefetch efficiency. This flexibility enables workload-aware resource optimization as shown in Example 3.5.
Example 0.
For high-throughput/high-recall scenarios (Fig. 4 (a)), increasing prioritizes CPU efficiency to meet demanding targets with fewer compute resources. In memory-constrained environments with moderate throughput requirements (Fig. 4 (b)), reducing alleviates memory pressure while allowing instance downsizing (e.g., 4C16G to 2C8G), which maintains service quality through controlled compute scaling and reduces infrastructure costs.
4. Automatic Parameter Tuning
4.1. Parameter Classification
We observe that specific parameters in the retrieval process exert a significant influence (Yang et al., 2024a) on the search performance (e.g., prefetch depth , construction ef , search ef , and candidate pool size ). These parameters can be systematically categorized into three distinct types for discussion: Environment-Level Parameters (ELPs), Query-Level Parameters (QLPs), and Index-Level Parameters (ILPs).
ELPs primarily affect the efficiency (QPS) of the retrieval process and are directly related to the retrieval environment (e.g., prefetch stride , prefetch depth ). Most of these parameters are associated with the execution speed of system instructions rather than the operational flow of the algorithm itself. For instance, prefetch-related parameters mainly influence the timing of asynchronous operations.
QLPs inherently influence both retrieval efficiency (QPS) and effectiveness (Recall) simultaneously. These parameters operate on prebuilt indexes and can be dynamically configured during the retrieval phase (e.g., search parameter , selective reranking strategies). In particular, efficiency and effectiveness exhibit an inherent trade-off: For a static index configuration, achieving higher QPS inevitably reduces Recall performance.
ILPs define an index’s core structure and performance. Tuning the construction-related parameters (e.g., , ) requires rebuilding indices. It is a process far more costly than adjusting QLPs or EIPs. Crucially, ILPs impact both efficiency and effectiveness simultaneously.
Hardness. The complexity of tuning these three parameter categories shows a progressive increase. ELPs focus solely on algorithmic efficiency, resulting in a straightforward single-objective optimization problem. In contrast, QLPs require balancing both efficiency and effectiveness criteria, thereby forming a multi-objective optimization challenge. The most demanding category, ILPs, necessitates substantial index construction time in addition to the aforementioned factors, leading to exponentially higher tuning expenditures. In subsequent sections, we present customized optimization strategies for each parameter category.
4.2. Search-based Automatic ELPs Tuner
The proposed algorithm utilizes multiple ELPs that exhibit substantial variance in optimal configurations in different testing environments and methodologies, as demonstrated by our comprehensive experimental analysis (see §6). As elaborated in §3.2.2, the stride prefetch mechanism operates through two crucial parameters: the prefetch stride and the prefetch depth . The parameter governs the prefetch timing based on the dynamic relationship between the CPU computational speed and the prefetch latency within specific deployment environments. In particular, smaller values are required to initiate earlier prefetching when faced with faster computation speeds or slower prefetch latencies. Meanwhile, the parameter is primarily determined by the CPU’s native prefetch patterns combined with vector dimensionality characteristics.
These environment-sensitive parameters exclusively influence algorithmic efficiency metrics (e.g., QPS) while maintaining consistent effectiveness outcomes (e.g., Recall Rate), thereby enabling independent optimization distinct from core algorithmic logic. The VSAG tuning framework implements an optimized three-step procedure:
-
1.
Conduct an exhaustive grid search for all combinations of environment-dependent parameter.
-
2.
Evaluate performance metrics using statistically sampled base vectors.
-
3.
Select parameter configurations that maximize retrieval speed while maintaining operational stability.
4.3. Fine-Grained Automatic QLPs Tuner
Observation. There are significant differences in the parameters required for different queries to achieve the target recall rate, with a highly skewed distribution. Specifically, 99% of queries can achieve the target recall rate with small query parameters, while 1% of queries require much larger parameters. Experimental results show that assigning personalized optimal retrieval parameters to each query can improve retrieval performance by 3–5 times.
To address the observation of QLPs, we propose a Decision Model for query difficulty classification, enabling personalized parameter tuning while maintaining computational efficiency. We introduce a learning-based adaptive parameter selection framework through a GBDT classifier (Chen and Guestrin, 2016) with early termination capabilities, demonstrating superior performance in fixed-recall scenarios. The model architecture addresses two critical constraints: discriminative power and computational efficiency. Our feature engineering process yields the following optimal feature set:
-
•
Cardinality of scanned points
-
•
Distribution of distances among current top-5 candidates
-
•
Temporal distance progression in recent top-5 results
-
•
Relative distance differentials between top-K candidates and optimal solution
To facilitate efficient feature computation, we implement an optimized sorted array structure that replaces conventional heap-based candidate management.
4.4. Labeling-based Automatic ILPs Tuner
Impact of ILPs. The retrieval efficiency and effectiveness of graph-based indices are fundamentally determined by their structural properties. Modifications to ILPs (e.g., maximum degree (Jayaram Subramanya et al., 2019b; Malkov and Yashunin, 2020b), pruning rate (Jayaram Subramanya et al., 2019b)) induce concurrent alterations in both graph topology and search dynamics, creating non-linear interactions between retrieval speed and accuracy. The following example demonstrates these interdependent effects:
Example 0.
Reducing to 1 causes irreparably damaged graph connectivity. Despite asymptotically increasing the search frontier parameter , this configuration achieves near-zero recall accuracy due to path discontinuity. In contrast, when elevating both and to extreme values, the graph degenerates into brute-force search patterns, with each traversal step requiring a full dataset scan, thereby minimizing retrieval throughput.
The necessity for index reconstruction during parameter space exploration creates prohibitive computational costs (typically 2-3 hours per rebuild for million-scale datasets), particularly when optimizing multiple ILPs simultaneously.
4.4.1. Compression-Based Construction Framework
We empirically observe that indices constructed with varying ILPs exhibit substantial edge overlap. As formalized in Theorem 4.2, when maintaining a fixed pruning rate , a graph built with lower maximum degree constitutes a strict subgraph of its higher-degree counterpart.
Theorem 4.2.
(Maximum Degree-Induced Subgraph Hierarchy) Let and denote indices constructed with maximum degrees and respectively, under identical initialization conditions and fixed . Given equivalent greedy search outcomes for all points under both configurations, then where .
Proof.
Please refer to Appendix B. ∎
VSAG employs an index compression strategy that constructs the index once using relaxed ILPs while labeling edges with specific ILPs. During the search process, the algorithm dynamically selects edges by leveraging labels, shifting the edge selection process from the index construction phase to the search phase. It enables adaptive edge selection without requiring index reconstruction. Thus, it achieves equivalent search performance to maintaining multiple indices with different parameter configurations, while incurring only the overhead of constructing a single index. The parameter labeling mechanism maintains topological flexibility while enhancing storage efficiency through a compressed index representation. Due to space limitations, please refer to Appendix B for the detailed construction algorithm of VSAG. Then, we illustrate the labeling algorithm, which assigns label to each edge.
Prune-based Labeling Algorithm. The pruning strategy of VSAG is shown in Algorithm 2. First, and their distances are sorted in ascending order of distance, and the pruning rates are also sorted in ascending order. The reverse insertion position indicates whether this pruning process occurs during the insertion of a reverse edge. We initialize the out-edges of by (Line 1). Each edge is then assigned a label of (Line 2). Note that when , it indicates that the current pruning occurs during the reverse edge addition phase, and only the labels of edges within the interval need to be updated. Otherwise, all labels should be updated. We use to record the number of neighbors that have non-zero labels (Line 3). When , it means we have already collected all the neighbors we need. At this point, the algorithm should terminate (Lines 4-5).
Next, each is examined in ascending order (Line 4). For each unlabeled neighbor (Lines 5-7), neighbor with smaller distance is used to make pruning decision (Lines 8-9). The pruning decision requires satisfying two conditions (Lines 10-12): (a) The neighbor exists in the graph constructed with the (i.e., ). (b) The pruning condition is satisfied (i.e., ). Here, we accelerate the computation of by using the cached result . If no neighbor can prune with , it is assigned the label (Lines 13-15). Finally, the algorithm returns the neighbor set and labels set of (Lines 16-17).
Building upon the parameter analysis of , we formally establish the subgraph inclusion property for graphs constructed with varying pruning rates in Algorithm 2 through Theorem 4.3.
Theorem 4.3.
(Subgraph Inclusion Property with Varying Pruning Rate ) Fix all ILPs except , and let and be indices constructed by Algorithm 3 in Appendix using pruning rates and respectively, where . Suppose that for every data point , the finite-sized approximate nearest neighbor (ANN) sets retrieved during construction remain identical under both values. Then forms a subgraph of , i.e., all edges in satisfy .
Proof.
Please refer to Appendix C.2. ∎
This theorem reveals a monotonic relationship between pruning rates and graph connectivity. When reducing , any edge pruned under this stricter parameter setting would necessarily be eliminated under larger values. This observation enables us to characterize each edge by its preservation threshold : the minimal pruning rate required to retain the edge during construction. Consequently, all graph indices constructed with pruning rates will contain this edge. This threshold-based perspective permits efficient compression of multiple parameterized graph structures into a unified index, where edges are annotated with their respective values.

Example 0.
As shown in Figure 5, we illustrate the state of the labeled graph generated by Algorithm 2 and the runtime edge selection process. Suppose that during the greedy search in the graph using Algorithm 1, we need to explore the in-hop base point (Line 5 of Algorithm 1). The node has 5 neighbors sorted by distance in ascending order (i.e., ). The distances are , and the corresponding labels are .
Given a relaxed ILP with and , we visit the neighbors of in ascending order of distance. We then filter out neighbors that do not satisfy the pruning condition (Line 8 of Algorithm 1):
-
•
is filtered out because .
-
•
is filtered out because we have found valid neighbors.
Thus, in this search hop, we will visit , , and . As proven in Theorem 4.3 and Theorem 4.2, the search process is equivalent to searching in a graph constructed with and . In other words, we can dynamically adjust the ILPs (i.e., ) by tuning the relaxed QLPs (i.e., ). This approach saves significant costs associated with rebuilding the graph.
Please refer to Appendix D
for details of tuning ILPs after VSAG is constructed with labels.
5. Distance Computation Acceleration
Recent studies (Yang et al., 2024b; Gao and Long, 2023; Yang et al., 2024c) illustrate that the exact distance computation takes the majority of the time cost of graph-based ANNS. Approximate distance techniques, such as scalar quantization, can accelerate this process at the cost of reduced search accuracy. VSAG adopt a two-stage approach that first performs an approximate distance search followed by exact distance re-ranking. §5.1 analyzes the distance computation scheme, with subsequent sections detailing optimization strategies for VSAG component.
5.1. Distance Computation Cost Analysis
VSAG employs low-precision vectors during graph traversal operations while reserving precise distance computations exclusively for final result reranking. The dual-precision architecture effectively minimizes distance computation operations (DCO) (Yang et al., 2024c) overhead while preserving search accuracy through precision-aware hierarchical processing.
If we only consider the cost incurred by distance computation, the total distance computation cost can be expressed as follows:
| (1) |
Here, distance computation cost consists of two components: the computation cost for low-precision vectors and the computation cost for high-precision vectors . Each component is determined by the number of distance computations ( or ) and the cost of a single distance computation ( or ).
The optimization of is closely related to the specific algorithm workflow, while is primarily determined by the computational cost of FLOAT32 vector operations - both of which remain relatively constant. Consequently, the VSAG framework focuses primarily on optimizing the parameters and .
VSAG optimizes the overall cost in three ways:
-
•
The combination of quantization techniques, hardware instruction set SIMD, and memory-efficient storage (§5.2) achieves exponential reduction in low-precision distance computation ().
-
•
Enhanced quantization precision by parameter optimization (§5.3) mitigates candidate inflation from precision loss, achieving sublinear growth in required low-precision computations ().
-
•
Selective re-ranking with dynamic thresholding (§5.4) establishes an accuracy-efficiency equilibrium, restricting high-precision validation () to a logarithmically scaled candidate subset.
5.2. Minimizing Low-Precision Computation Overhead
SIMD and Quantization Methods. Modern CPUs employ SIMD instruction sets (SSE/AVX/AVX512) to accelerate distance computations through vectorized operations. These instructions process 128-bit, 256-bit, or 512-bit data chunks in parallel, with vector compression techniques enabling simultaneous processing of multiple vectors. For example, AVX512 can compute one distance for 16-dimensional FLOAT32 vectors per instruction, but when compressing vectors to 128 bits, it achieves 4x acceleration by processing four vector pairs concurrently. Product Quantization (PQ) (Jégou et al., 2011a) enables high compression ratios for batch processing through SIMD-loaded lookup tables. While PQ-Fast Scan (André et al., 2015) excels in partition-based searches through block-wise computation, its effectiveness diminishes in graph-based searches due to random vector storage patterns and inability to filter visited nodes, resulting in wasted SIMD bandwidth. In contrast, Scalar Quantization (SQ) (Zhou et al., 2012) proves more suitable for graph algorithms by directly compressing vector dimensions (e.g., FLOAT32 INT8/INT4) without requiring lookup tables. As demonstrated in VSAG, SQ achieves the optimal balance between compression ratio and precision preservation while fully utilizing SIMD acceleration capabilities, making it particularly effective for memory-bound graph traversals.
Distance Decomposition. VSAG optimizes Euclidean distance computations by decoupling static and dynamic components. The system precomputes and caches invariant vector norms during database indexing, then combines them with real-time dot product computations during queries. This decomposition reduces operational complexity while preserving mathematical equivalence, as shown by the reformulated Euclidean distance:
The computational optimization strategy can be summarized as follows: Only the Inner Product term requires real-time computation during search operations, while the squared query norm can be pre-computed offline before initiating the search process. By storing just one additional FLOAT32 value per database vector (specifically the precomputed ), we can effectively transform the computationally expensive Euclidean distance computation into an equivalent inner product operation. This space-time tradeoff reduces the subtraction CPU instruction in distance computation, which saves one CPU clock cycle.
5.3. Improving Quantization Precision
Scalar quantization (SQ) compresses floating-point vectors by mapping 32-bit float values to lower-bit integer representations in each dimension. In SQ-b (where b denotes bit-width), the dynamic range is uniformly partitioned into intervals. For SQ4 (4-bit), this creates 16 intervals over , where the k-th interval corresponds to . Values within each interval are encoded as their corresponding integer index. However, practical implementations face critical range estimation challenges: direct use of observed min/max values proves suboptimal when data outliers existing.
Example 0.
Analysis of the GIST1M dataset reveals this limitation – while 99% of dimensions exhibit values below 0.3, using the absolute maximum (1.0) would leave 70% of the quantization intervals (0.3-1.0) underutilized. This interval under-utilization severely degrades quantization precision.
To enhance robustness, we propose Truncated Scalar Quantization using the 99th percentile statistics rather than absolute extremes. This approach discards outlier-induced distortions while preserving quantization resolution over the primary data distribution, achieving superior balance between compression efficiency and numerical precision as shown in Figure 6.

5.4. Selective Re-rank
Quantization methods can significantly enhance retrieval efficiency, but quantization errors may lead to substantial recall rate degradation. While re-ranking with full-precision vectors can mitigate this performance loss. However, applying exhaustive re-ranking to all candidates is inefficient. The VSAG framework addresses this challenge through selective re-ranking, effectively compensating for approximation errors in distance computation without compromising system performance. A straightforward approach is to select only the candidates with small low-precision distances for re-ranking. The optimal number of candidates requiring re-ranking varies significantly depending on query characteristics, quantization error distribution, and search requirement . To address this dynamic requirement, VSAG implements DDC (Yang et al., 2024c) scheme that can automatically adapt re-ranking scope based on error-distance correlation analysis.
6. Experimental Study
6.1. Experimental Setting
Datasets. Table 3 presents the datasets used in our experiments, and they are widely adopted in existing works (Aumüller et al., 2020) and benchmarks (Gao et al., 2024a). For each dataset, we report the vector dimensions (Dim), the number of base vectors (#Base), the number of query vectors (#Query), and the dataset type (Type). All vectors are stored in float32 format.
| Dataset | Dim | #Base | #Query | Type |
|---|---|---|---|---|
| GIST1M | 960 | 1,000,000 | 1,000 | Image |
| SIFT1M | 128 | 1,000,000 | 10,000 | Image |
| TINY | 384 | 5,000,000 | 1,000 | Image |
| GLOVE-100 | 100 | 1,183,514 | 10,000 | Text |
| WORD2VEC | 300 | 1,000,000 | 1,000 | Text |
| OPENAI | 1536 | 999,000 | 1,000 | Text |












Algorithms. We compare VSAG with three graph-based methods (hnswlib, hnsw(faiss), nndescent) and three partition-based methods (faiss-ivf, faiss-ivfpqfs, scann). All methods are widely adopted in industry, and Faiss is the most popular vector search library.
-
•
hnswlib (Malkov and Yashunin, [n.d.]): the most popular graph-based index.
-
•
hnsw(faiss) (Johnson et al., 2019a): the HNSW implementation in Faiss.
-
•
nndescent (Dong et al., 2011): a graph-based index that achieves efficient index construction by iteratively merging the neighbors of base vectors.
-
•
faiss-ivf (Johnson et al., 2019a): the most popular partition-based method.
- •
-
•
scann. (Guo et al., 2020): The partition-based method developed by Google, which is highly optimized for Maximum Inner Product Search (MIPS) through anisotropic vector quantization.
| Algorithm | Construction Parameter Settings |
|---|---|
| VSAG | maximum_degree |
| pruning_rate | |
| hnswlib, hnsw(faiss) | maximum_degree |
| candidate_pool_size | |
| nndescent | pruning_prob |
| leaf_size | |
| n_neighbors | |
| pruning_degree_multiplier | |
| faiss-ivf, faiss-ivfpqfs | n_clusters |
| scann | n_leaves |
| avq_threshold | |
| dims_per_block |
Performance Metrics. We evaluate algorithms with Recall Rate and Queries Per Second (QPS) (Malkov and Yashunin, 2020b; Jayaram Subramanya et al., 2019b). The recall rate is defined as the percentage of actual KNNs among the vectors retrieved by the algorithm, i.e., . If not specified, the QPS is the queries per second when . Each algorithm is evaluated on a dedicated single core.
Parameters. Table 4 reports the parameter configurations of algorithms. Unless otherwise specified, we report the best performance of an algorithm among all combinations of parameter settings.
Environment. The experiments are conducted on a server with an Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz and 512GB memory, except that Section 6.2 is evaluated on an AWS r6i.16xlarge machine with hyperthreading disabled. We implement VSAG in C++, and compile it with g++ 10.2.1, -Ofast flag, and AVX-512 instructions enabled. For other baselines, we use the implementations from the official Docker images.
6.2. Overall Performance
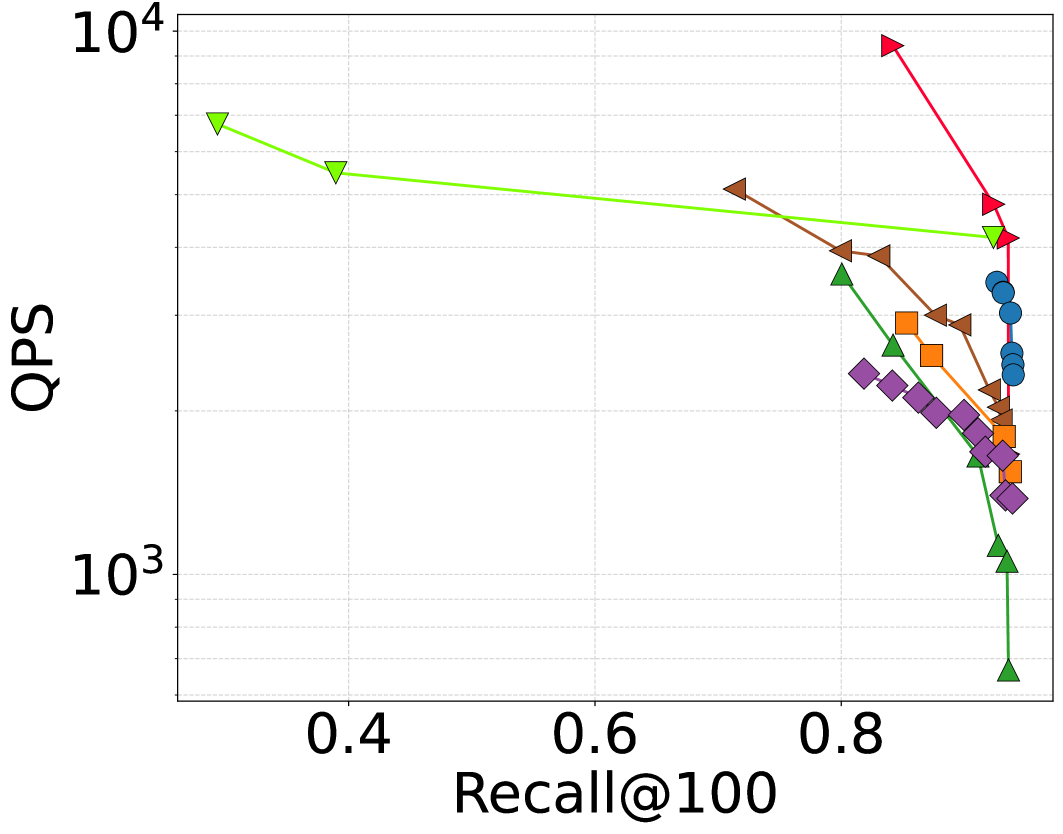
Figure 7 evaluates the recall (Recall@10 and Recall@100) vs. QPS performance of algorithms. We report the best performance of an algorithm under all possible parameter settings. Across all datasets, VSAG can achieve higher QPS with the same recall rate. In addition, VSAG can provide a higher QPS increase on high-dimensional vector datasets, such as GIST1M and OPENAI. In particular, VSAG outperforms hnswlib by 226% in QPS on GIST1M when we ensure , it also provides 400% higher QPS than hnswlib on OPENAI when ensuring . The reason is that VSAG adopts quantization methods, which can provide significant QPS increase without sacrificing the search accuracy, and they are especially effective for high-dimensional data (Gao and Long, 2024).
6.3. Ablation Study
6.3.1. Cache Miss Analysis
| Strategy | Recall@10 | QPS | L3 Cache Load | L3 Cache Miss Rate | L1 Cache Miss Rate | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| GIST1M | SIFT1M | GIST1M | SIFT1M | GIST1M | SIFT1M | GIST1M | SIFT1M | GIST1M | SIFT1M | |
| Baseline | 90.7% | 99.7% | 510 | 1695 | 198M | 112M | 93.89% | 77.88% | 39.37% | 17.55% |
| Above + 1.Quantization | 89.8% | 98.4% | 1272 | 2881 | 125M | 79M | 67.42% | 52.09% | 19.44% | 11.56% |
| Above + 2. Software-based Prefetch | 89.8% | 98.4% | 1490 | 3332 | 120M | 53M | 71.71% | 53.86% | 16.98% | 9.58% |
| Above + 3. Stride Prefetch | 89.8% | 98.4% | 1517 | 3565 | 118M | 50M | 64.57% | 19.26% | 17.18% | 9.66% |
| Above + 4. ELPs Auto Tuner | 89.8% | 98.4% | 2052 | 4946 | 43M | 49M | 45.88% | 32.65% | 16.44% | 10.11% |
| Above + 5. Deterministic Access | 89.8% | 98.4% | 2167 | 5027 | 65M | 72M | 39.23% | 20.98% | 15.43% | 9.91% |
| Above + 6. PRS () | 89.8% | 98.4% | 2255 | 4668 | 55M | 63M | 55.75% | 50.74% | 15.20% | 10.17% |
| Above + 7. PRS () | 89.8% | 98.4% | 2377 | 4640 | 46M | 55M | 71.62% | 74.73% | 14.69% | 9.26% |
Table 5 conduct ablation tests to investigate the effectiveness of VSAG’s strategies (see §3,§4 and§5). We use GIST1M and SIFT1M datasets, and set for VSAG. The strategies are incremental, i.e., the strategy row reports the performance of the baseline with strategies .
Strategy 1 uses quantization methods, and it improves QPS while ensuring the same recall rates. Specifically, the QPS on GIST1M increases from 510 to 1272 (149% growth), and the QPS on SIFT1M increases from 1695 to 2881 (69% growth). This is because quantization can significantly reduce the cost of distance computation.
Strategies 2-5 optimize memory access. As a result, the L3 cache miss rate reduces from 93.89% to 39.23% on GIST1M, and from 77.88% to 20.98% on SIFT1M. Such a drop in cache miss rate leads to a 70% QPS increase on GIST1M , and a 74% QPS increase on SIFT1M. This is because L3 cache loads are the dominate cost in the search time after using quantization methods.
Strategies 6-7 use PRS to balance memory and CPU usage. When increase, VSAG would allocates more memory, and the L3 cache load of will decrease. For example, the L3 cache load decrease by 41% on GIST1M, and by 30% on SIFT1M. On GIST1M dataset, VSAG’s QPS increases from 2167 to 2337, as memory pressure is the performance bottleneck. However, on SIFT1M dataset, VSAG’s QPS on GIST1M decreases from 5027 to 4640, because CPU pressure outweighs memory pressure on this dataset. We can decide whether to use PRS based on the workload of memory and CPU.



6.3.2. Performance
Figure 8 illustrates the cumulative performance gaps under varying numbers of optimization strategies. For each strategy, varying from 10 to 100 yields specific Recall@10 and QPS values. For example, the top-left point in the Baseline corresponds to , while the bottom-right point corresponds to . The strategies contributing most to QPS improvements are 1. Quantization and 4. ELPs Auto Tuner. The former drastically reduces distance computation overhead, while the latter significantly enhances the prefetch effectiveness in 3. Stride Prefetch. However, applying only 3. Stride Prefetch shows minimal difference compared to 2. Software-based Prefetch, as prefetch efficiency heavily depends on environment-level parameters and .
6.4. Evaluation of ILPs Auto-Tuner
6.4.1. Tuning Cost
We evaluate the tuning time and memory footprint when varying index-level parameters and . The compared method including FIX (fix parameter and , building with hnswlib) and BF (construct indexes of all combination of index-level parameters, building with hnswlib). Table 6 shows results (Mem for memory footprint in gigabytes; Time for building time in hours).
Among the four datasets, the method with minimal construction time and memory usage is FIX, while BF requires the most. This is because baseline methods can only brute-force traverse each parameter configuration and build indexes separately. Additionally, it can dynamically select edges during search using edge labels acquired during construction, enabling parameter adjustment at search time without repeated index construction. This allows VSAG to achieve a tuning time saving compared to BF on GIST1M. Moreover, the use of to cache distances during construction eliminates redundant computations, further accelerating VSAG’s tuning. In terms of memory usage, graphs built with different and share significant structural overlap. This enables VSAG to compress these graphs via edge labels, resulting in over memory footprint reduction during tuning compared to BF. Compared to FIX, VSAG only introduces minimal additional memory costs for storing extra edges and label sets.



6.4.2. Tuning Performance
Beyond tuning costs, we also demonstrate the performance of the ILPs auto tuned index. As shown in Figure 9, we randomly selected two index-level parameter configurations (A and B) as baselines and plotted the performance of all parameter combinations in running cases. VSAG exhibits significant performance gains over these baselines. For example, on the GIST1M dataset at a fixed QPS of 2500, the worst-case Recall@10 among all running cases is 62%, while the tuned index achieves Recall@10=88%, representing a 26% (absolute) improvement. At a fixed Recall@10=70%, the worst-case QPS is 2000, while VSAG achieves 4000 QPS - an improvement of 100%. Similar trends hold for the GLOVE-100 dataset: maximum Recall@10 improvements exceed 15% at fixed QPS of 500, and QPS improves from around 4000 to 7000 (over 75% gain) at a fixed recall rate of 60%.
6.5. Evaluation of QLPs Auto-Tuner
Table 7 evaluates the QLPs tuning result on GIST1M and SIFT1M, under a recall guarantee of 94% and 97%. The baseline method (i.e., FIX) manually selects the smallest that ensures the target recall. In contrast, VSAG employs a decision tree classification approach to divide queries into two categories: (1) Simple queries, which can converge to the target accuracy with a smaller value and incur lower computational cost. For these queries, an appropriate can help improve retrieval speed. (2) Complex queries, which require larger values to achieve the desired accuracy. For these queries, an appropriate can help improve retrieval precision. For both types of queries, the QLPs Auto-Tuner can intelligently selects the required , leading to over a 5% increase in QPS when recall thresholds equal 94% and 97%, respectively.
| Dataset | FIX | BF | VSAG (Ours) | |||
|---|---|---|---|---|---|---|
| Mem | Time | Mem | Time | Mem | Time | |
| GIST1M | 3.83G | 3.20H | 89.87G | 61.64H | 4.07G | 2.92H |
| SIFT1M | 0.73G | 0.85H | 15.48G | 30.79H | 0.97G | 1.86H |
| GLOVE-100 | 0.74G | 1.22H | 15.36G | 41.94H | 1.03G | 2.13H |
7. Case Studies and Applications
Product Search and Recommendation Systems. Vector retrieval has become a cornerstone in product search and recommendation engines for e-commerce. By converting signals such as user behavior, browsing history, and purchase data into vector representations, similarity-based retrieval can pinpoint products that match user preferences, thereby enabling personalization at scale. E-commerce platforms (Taobao, 2025; Amazon, 2025) typically maintain millions of product and user vectors, which demand high-performance and low-latency retrieval solutions. Leveraging VSAG’s memory access optimization and distance computation optimization, these services can achieve the same target QPS with fewer computational resources. In a product search scenario at Ant Group, which involves 512-dimensional embeddings, VSAG not only lowered overall resource usage by a factor of 4.6 but also cut service latency by 1.2, surpassing contemporary partition-based methods.
In practice, production environments span various resource classes (e.g., 4C16G vs. 2C8G) and platforms (e.g., x86 vs. ARM). Realizing optimal performance across this heterogeneous infrastructure required extensive parameter tuning, with limited transferability once resource classes changed. VSAG ’s automatic parameter tuning feature relieves engineers from repeated manual fine-tuning, drastically reducing the overhead of deploying and maintaining vector retrieval services. This translates into robust performance across diverse platforms and ever-shifting requirements.
Large Language Model. In large language model (LLM) applications (Lewis et al., 2020), high-dimensional text embeddings are essential for reducing hallucinations and delivering real-time interactive responses. Modern embedding models, such as text-embedding-3-small222https://platform.openai.com/docs/guides/embeddings, produce 1,536-dimensional vectors, while text-embedding-3-large outputs up to 3,072 dimensions—significantly more than the typical 256-dimensional image embeddings. Effective retrieval over these large embedding vectors demands both precise distance computation and careful memory management. VSAG ’s dedicated distance computation and memory access optimizations excel at handling these high-dimensional workloads.
Deep Research is quickly emerging as a next-generation standard for LLM-based applications, functioning as a specific form of agentic search that relies on chain-of-thought reasoning (Shen et al., 2025) and multi-step retrieval (Ji et al., 2025; Zhang et al., 2025). In Retrieval-Augmented Generation (RAG) (Gao et al., 2024b), this process repeatedly refines queries and explores multiple reasoning paths while adaptively gathering domain-specific information. Such iterative lookups impose substantial demands on both system throughput and latency, particularly with high-dimensional vectors (e.g., 1,536 dimensions). VSAG delivers up to a 5 improvement in retrieval capacity, critical for maintaining real-time responsiveness in the context-aware exploration that agentic search enables.
| Method | Metric | GIST1M | SIFT1M | ||
|---|---|---|---|---|---|
| 94% | 97% | 94% | 97% | ||
| FIX | Recall@10 | 94.64% | 97.49% | 94.54% | 97.61% |
| QPS | 1469 | 902 | 4027 | 2834 | |
| VSAG (Ours) | Recall@10 | 94.71% | 97.58% | 94.63% | 97.66% |
| QPS | 1534 | 967 | 4050 | 2912 | |
8. Related Work
The mainstream methods for vector retrieval can be divided into two categories: space partitioning-based and graph-based. Graph-based algorithms (Malkov and Yashunin, 2020a; Jayaram Subramanya et al., 2019a; Fu et al., 2019a; Fu et al., 2022; Lu et al., 2021; Peng et al., 2023a; Azizi et al., 2023; Li et al., 2020) can ensure high recall with practical efficiency, e.g., HNSW (Malkov and Yashunin, 2020a), NSG (Fu et al., 2019b), VAMANA (Jayaram Subramanya et al., 2019a), and -MNG (Peng et al., 2023b). These methods build a proximity graph where each node is a base vector and edges connect pairs of nearby vectors. During a vector search, they greedily move towards the query vector to identify its nearest neighbors. Our VSAG framework can adapt to graph-based algorithms mentioned above, to improve the performance in production.
Space partitioning-based methods (e.g., IVFADC (André et al., 2015; Babenko and Lempitsky, 2015; Wang et al., 2017; Dong et al., 2020)) group similar vectors into subspaces with K-means (André et al., 2015; Johnson et al., 2019b) or Locality-Sensitive Hashing (LSH) (Gionis et al., 1999; Datar et al., 2004; Gan et al., 2012; Zheng et al., 2020; Sun et al., 2014; Raginsky and Lazebnik, 2009). During the search process, they traverse some vector subspaces to find the nearest neighbors. These methods can achieve high cache hit rates due to the continuous organization of vectors, but they suffer from a low recall issue. In comparison, graph-based ANNS algorithms (e.g., VSAG and HNSW) usually achieve a higher QPS under the same recall. Note that the technique of VSAG cannot be applied to space partitioning-based algorithms.
9. Conclusion
In this work, we present VSAG, an open-source framework for ANNS that can be applied to most of the graph-based indices. To address the challenge of high memory access costs, we employ software-based prefetch, deterministic access greedy search, and PRS to significantly reduce the cache miss rate. For the challenge of high parameter tuning costs, we propose a three-level parameter tuning mechanism that automatically adjusts different parameters based on their tuning complexity. To tackle the issue of high distance computation costs, we combine quantization and selective re-ranking to integrate low- and high-precision distance computations, thereby enhancing search efficiency without sacrificing effectiveness. Experiments on real-world datasets demonstrate that VSAG outperforms baselines in both retrieval performance and parameter tuning cost.
References
- (1)
- Alipay (2025a) Alipay. 2025a. Ant Group. https://www.antgroup.com.
- Alipay (2025b) Alipay. 2025b. Face Recognition. https://open.alipay.com/api/detail?code=I1080300001000043632.
- Amazon (2025) Amazon. 2025. Product Search. https://www.amazon.com/.
- André et al. (2015) Fabien André, Anne-Marie Kermarrec, and Nicolas Le Scouarnec. 2015. Cache locality is not enough: High-Performance Nearest Neighbor Search with Product Quantization Fast Scan. Proceedings of the VLDB Endowment 9, 4 (2015).
- Aumüller et al. (2020) Martin Aumüller, Erik Bernhardsson, and Alexander Faithfull. 2020. ANN-Benchmarks: A benchmarking tool for approximate nearest neighbor algorithms. Information Systems 87 (2020), 101374.
- Ayers et al. (2020) Grant Ayers, Heiner Litz, Christos Kozyrakis, and Parthasarathy Ranganathan. 2020. Classifying Memory Access Patterns for Prefetching. In Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems (Lausanne, Switzerland) (ASPLOS ’20). Association for Computing Machinery, New York, NY, USA, 513–526. https://doi.org/10.1145/3373376.3378498
- Azizi et al. (2023) Ilias Azizi, Karima Echihabi, and Themis Palpanas. 2023. Elpis: Graph-based similarity search for scalable data science. Proceedings of the VLDB Endowment 16, 6 (2023), 1548–1559.
- Babenko and Lempitsky (2015) Artem Babenko and Victor S. Lempitsky. 2015. The Inverted Multi-Index. IEEE Trans. Pattern Anal. Mach. Intell. 37, 6 (2015), 1247–1260.
- Braun and Litz (2019) Peter Braun and Heiner Litz. 2019. Understanding memory access patterns for prefetching. In International Workshop on AI-assisted Design for Architecture (AIDArc), held in conjunction with ISCA.
- Chen and Guestrin (2016) Tianqi Chen and Carlos Guestrin. 2016. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, August 13-17, 2016, Balaji Krishnapuram, Mohak Shah, Alexander J. Smola, Charu C. Aggarwal, Dou Shen, and Rajeev Rastogi (Eds.). ACM, 785–794. https://doi.org/10.1145/2939672.2939785
- Chen and Baer (1995) Tien-Fu Chen and Jean-Loup Baer. 1995. Effective hardware-based data prefetching for high-performance processors. IEEE transactions on computers 44, 5 (1995), 609–623.
- Datar et al. (2004) Mayur Datar, Nicole Immorlica, Piotr Indyk, and Vahab S Mirrokni. 2004. Locality-sensitive hashing scheme based on p-stable distributions. In Proceedings of the twentieth annual symposium on Computational geometry. 253–262.
- Dong et al. (2011) Wei Dong, Charikar Moses, and Kai Li. 2011. Efficient k-nearest neighbor graph construction for generic similarity measures. In Proceedings of the 20th international conference on World wide web. 577–586.
- Dong et al. (2020) Yihe Dong, Piotr Indyk, Ilya P Razenshteyn, and Tal Wagner. 2020. Learning Space Partitions for Nearest Neighbor Search. ICLR (2020).
- Fu et al. (2022) Cong Fu, Changxu Wang, and Deng Cai. 2022. High Dimensional Similarity Search With Satellite System Graph: Efficiency, Scalability, and Unindexed Query Compatibility. IEEE Trans. Pattern Anal. Mach. Intell. 44, 8 (2022), 4139–4150.
- Fu et al. (2019a) Cong Fu, Chao Xiang, Changxu Wang, and Deng Cai. 2019a. Fast Approximate Nearest Neighbor Search With The Navigating Spreading-out Graph. Proc. VLDB Endow. 12, 5 (2019), 461–474.
- Fu et al. (2019b) Cong Fu, Chao Xiang, Changxu Wang, and Deng Cai. 2019b. Fast approximate nearest neighbor search with the navigating spreading-out graph. Proc. VLDB Endow. 12, 5 (Jan. 2019), 461–474. https://doi.org/10.14778/3303753.3303754
- Gan et al. (2012) Junhao Gan, Jianlin Feng, Qiong Fang, and Wilfred Ng. 2012. Locality-sensitive hashing scheme based on dynamic collision counting. In Proceedings of the 2012 ACM SIGMOD international conference on management of data. 541–552.
- Gao et al. (2024a) Jianyang Gao, Yutong Gou, Yuexuan Xu, Yongyi Yang, Cheng Long, and Raymond Chi-Wing Wong. 2024a. Practical and Asymptotically Optimal Quantization of High-Dimensional Vectors in Euclidean Space for Approximate Nearest Neighbor Search. arXiv preprint arXiv:2409.09913 (2024).
- Gao and Long (2023) Jianyang Gao and Cheng Long. 2023. High-Dimensional Approximate Nearest Neighbor Search: with Reliable and Efficient Distance Comparison Operations. Proc. ACM Manag. Data 1, 2 (2023), 137:1–137:27. https://doi.org/10.1145/3589282
- Gao and Long (2024) Jianyang Gao and Cheng Long. 2024. RaBitQ: Quantizing High-Dimensional Vectors with a Theoretical Error Bound for Approximate Nearest Neighbor Search. Proc. ACM Manag. Data 2, 3 (2024), 167. https://doi.org/10.1145/3654970
- Gao et al. (2024b) Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, and Haofen Wang. 2024b. Retrieval-Augmented Generation for Large Language Models: A Survey. arXiv:2312.10997 [cs.CL] https://arxiv.org/abs/2312.10997
- Gionis et al. (1999) Aristides Gionis, Piotr Indyk, Rajeev Motwani, et al. 1999. Similarity search in high dimensions via hashing. In Vldb, Vol. 99. 518–529.
- Google (2025) Google. 2025. Search Engine. https://www.google.com/.
- Guo et al. (2020) Ruiqi Guo, Philip Sun, Erik Lindgren, Quan Geng, David Simcha, Felix Chern, and Sanjiv Kumar. 2020. Accelerating large-scale inference with anisotropic vector quantization. In International Conference on Machine Learning. PMLR, 3887–3896.
- Indyk and Motwani (1998) Piotr Indyk and Rajeev Motwani. 1998. Approximate nearest neighbors: towards removing the curse of dimensionality. In Proceedings of the thirtieth annual ACM symposium on Theory of computing. 604–613.
- Intel (2025) Intel. 2025. AVX512. https://www.intel.com/content/www/us/en/products/docs/accelerator-engines/what-is-intel-avx-512.html.
- Jayaram Subramanya et al. (2019a) Suhas Jayaram Subramanya, Fnu Devvrit, Harsha Vardhan Simhadri, Ravishankar Krishnawamy, and Rohan Kadekodi. 2019a. Diskann: Fast accurate billion-point nearest neighbor search on a single node. Advances in Neural Information Processing Systems 32 (2019).
- Jayaram Subramanya et al. (2019b) Suhas Jayaram Subramanya, Fnu Devvrit, Harsha Vardhan Simhadri, Ravishankar Krishnawamy, and Rohan Kadekodi. 2019b. Diskann: Fast accurate billion-point nearest neighbor search on a single node. Advances in neural information processing Systems 32 (2019).
- Jégou et al. (2011a) Hervé Jégou, Matthijs Douze, and Cordelia Schmid. 2011a. Product Quantization for Nearest Neighbor Search. IEEE Trans. Pattern Anal. Mach. Intell. 33, 1 (2011), 117–128. https://doi.org/10.1109/TPAMI.2010.57
- Jégou et al. (2011b) Hervé Jégou, Matthijs Douze, and Cordelia Schmid. 2011b. Product Quantization for Nearest Neighbor Search. IEEE Trans. Pattern Anal. Mach. Intell. 33, 1 (2011), 117–128.
- Ji et al. (2025) Kaixuan Ji, Guanlin Liu, Ning Dai, Qingping Yang, Renjie Zheng, Zheng Wu, Chen Dun, Quanquan Gu, and Lin Yan. 2025. Enhancing Multi-Step Reasoning Abilities of Language Models through Direct Q-Function Optimization. arXiv:2410.09302 [cs.LG] https://arxiv.org/abs/2410.09302
- Johnson et al. (2019a) Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2019a. Billion-scale similarity search with GPUs. IEEE Transactions on Big Data 7, 3 (2019), 535–547.
- Johnson et al. (2019b) Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2019b. Billion-scale similarity search with GPUs. IEEE Transactions on Big Data 7, 3 (2019), 535–547.
- Lewis et al. (2020) Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems 33 (2020), 9459–9474.
- Li et al. (2020) Wen Li, Ying Zhang, Yifang Sun, Wei Wang, Mingjie Li, Wenjie Zhang, and Xuemin Lin. 2020. Approximate Nearest Neighbor Search on High Dimensional Data - Experiments, Analyses, and Improvement. IEEE Trans. Knowl. Data Eng. 32, 8 (2020), 1475–1488.
- Lu et al. (2021) Kejing Lu, Mineichi Kudo, Chuan Xiao, and Yoshiharu Ishikawa. 2021. HVS: Hierarchical Graph Structure Based on Voronoi Diagrams for Solving Approximate Nearest Neighbor Search. Proc. VLDB Endow. 15, 2 (2021), 246–258.
- Malkov and Yashunin ([n.d.]) Yu A Malkov and Dmitry A Yashunin. [n.d.]. hnswlib. https://github.com/nmslib/hnswlib.
- Malkov and Yashunin (2020a) Yury A. Malkov and Dmitry A. Yashunin. 2020a. Efficient and Robust Approximate Nearest Neighbor Search Using Hierarchical Navigable Small World Graphs. IEEE Trans. Pattern Anal. Mach. Intell. 42, 4 (2020), 824–836.
- Malkov and Yashunin (2020b) Yury A. Malkov and Dmitry A. Yashunin. 2020b. Efficient and Robust Approximate Nearest Neighbor Search Using Hierarchical Navigable Small World Graphs. IEEE Trans. Pattern Anal. Mach. Intell. 42, 4 (2020), 824–836. https://doi.org/10.1109/TPAMI.2018.2889473
- Peng et al. (2023a) Yun Peng, Byron Choi, Tsz Nam Chan, Jianye Yang, and Jianliang Xu. 2023a. Efficient Approximate Nearest Neighbor Search in Multi-dimensional Databases. Proc. ACM Manag. Data 1, 1 (2023), 54:1–54:27. https://doi.org/10.1145/3588908
- Peng et al. (2023b) Yun Peng, Byron Choi, Tsz Nam Chan, Jianye Yang, and Jianliang Xu. 2023b. Efficient Approximate Nearest Neighbor Search in Multi-dimensional Databases. Proc. ACM Manag. Data 1, 1, Article 54 (May 2023), 27 pages. https://doi.org/10.1145/3588908
- Raginsky and Lazebnik (2009) Maxim Raginsky and Svetlana Lazebnik. 2009. Locality-sensitive binary codes from shift-invariant kernels. Advances in neural information processing systems 22 (2009).
- Shen et al. (2025) Zhenyi Shen, Hanqi Yan, Linhai Zhang, Zhanghao Hu, Yali Du, and Yulan He. 2025. CODI: Compressing Chain-of-Thought into Continuous Space via Self-Distillation. arXiv:2502.21074 [cs.CL] https://arxiv.org/abs/2502.21074
- Sun et al. (2014) Yifang Sun, Wei Wang, Jianbin Qin, Ying Zhang, and Xuemin Lin. 2014. SRS: Solving c-Approximate Nearest Neighbor Queries in High Dimensional Euclidean Space with a Tiny Index. Proc. VLDB Endow. 8, 1 (2014), 1–12.
- Taobao (2025) Taobao. 2025. Product Search. https://www.taobao.com/.
- Vanderwiel and Lilja (2000) Steven P Vanderwiel and David J Lilja. 2000. Data prefetch mechanisms. ACM Computing Surveys (CSUR) 32, 2 (2000), 174–199.
- Veidenbaum et al. (1999) Alexander V Veidenbaum, Weiyu Tang, Rajesh Gupta, Alexandru Nicolau, and Xiaomei Ji. 1999. Adapting cache line size to application behavior. In Proceedings of the 13th international conference on Supercomputing. 145–154.
- Wang et al. (2021) Jianguo Wang, Xiaomeng Yi, Rentong Guo, Hai Jin, Peng Xu, Shengjun Li, Xiangyu Wang, Xiangzhou Guo, Chengming Li, Xiaohai Xu, et al. 2021. Milvus: A purpose-built vector data management system. In Proceedings of the 2021 International Conference on Management of Data. 2614–2627.
- Wang et al. (2017) Jingdong Wang, Ting Zhang, Nicu Sebe, Heng Tao Shen, et al. 2017. A survey on learning to hash. IEEE transactions on pattern analysis and machine intelligence 40, 4 (2017), 769–790.
- Yang et al. (2024c) Mingyu Yang, Wentao Li, Jiabao Jin, Xiaoyao Zhong, Xiangyu Wang, Zhitao Shen, Wei Jia, and Wei Wang. 2024c. Effective and General Distance Computation for Approximate Nearest Neighbor Search. arXiv preprint arXiv:2404.16322 (2024).
- Yang et al. (2024b) Mingyu Yang, Wentao Li, and Wei Wang. 2024b. Fast High-dimensional Approximate Nearest Neighbor Search with Efficient Index Time and Space. arXiv preprint arXiv:2411.06158 (2024).
- Yang et al. (2024a) Tiannuo Yang, Wen Hu, Wangqi Peng, Yusen Li, Jianguo Li, Gang Wang, and Xiaoguang Liu. 2024a. VDTuner: Automated Performance Tuning for Vector Data Management Systems. In 2024 IEEE 40th International Conference on Data Engineering (ICDE). 4357–4369. https://doi.org/10.1109/ICDE60146.2024.00332
- YouTube (2025) YouTube. 2025. Video Search. https://www.youtube.com/.
- Zhang et al. (2025) Kongcheng Zhang, Qi Yao, Baisheng Lai, Jiaxing Huang, Wenkai Fang, Dacheng Tao, Mingli Song, and Shunyu Liu. 2025. Reasoning with Reinforced Functional Token Tuning. arXiv:2502.13389 [cs.AI] https://arxiv.org/abs/2502.13389
- Zheng et al. (2020) Bolong Zheng, Xi Zhao, Lianggui Weng, Nguyen Quoc Viet Hung, Hang Liu, and Christian S. Jensen. 2020. PM-LSH: A Fast and Accurate LSH Framework for High-Dimensional Approximate NN Search. Proc. VLDB Endow. 13, 5 (2020), 643–655.
- Zhou et al. (2012) Wengang Zhou, Yijuan Lu, Houqiang Li, and Qi Tian. 2012. Scalar quantization for large scale image search. In Proceedings of the 20th ACM Multimedia Conference, MM ’12, Nara, Japan, October 29 - November 02, 2012, Noboru Babaguchi, Kiyoharu Aizawa, John R. Smith, Shin’ichi Satoh, Thomas Plagemann, Xian-Sheng Hua, and Rong Yan (Eds.). ACM, 169–178. https://doi.org/10.1145/2393347.2393377
- Zitzler and Thiele (1999) E. Zitzler and L. Thiele. 1999. Multiobjective evolutionary algorithms: a comparative case study and the strength Pareto approach. IEEE Transactions on Evolutionary Computation 3, 4 (1999), 257–271. https://doi.org/10.1109/4235.797969
Appendix A Detail Explanation of Deterministic Access Greedy Search
The initialization phase establishes candidate and visited sets (Lines 1-3). The candidate set dynamically maintains the nearest points discovered during traversal, while the visited set tracks explored points. The algorithm iteratively extracts the nearest unvisited point from the candidate set and processes its neighbors through four key phases (Lines 4-17).
At each iteration, the nearest unvisited point is retrieved from the candidate set (Line 5). Batch processing then identifies valid neighbors through three filtering criteria (Lines 6-10): 1) unvisited (), 2) label validity (), and 3) degree constraint (). The latter two conditions implement automatic index-level parameters tuning as detailed in Section 4. It is important to note that we differentiate between the identifier and vector data - a distinction that impacts cache performance as memory access may incur cache misses while identifier operations do not.
The prefetching mechanism operates through two parameters: controls the prefetch stride (Lines 11, 14), while specifies the prefetch depth (Lines 12, 15). The batch distances computation of neighbors follows a three-stage pipeline (Lines 13-17): 1) stride prefetch for subsequent points (Lines 14-15), 2) data access(Line 16), and 3) distance calculation with candidate set maintenance (Line 17). When , we pop farthest-point in to keep (Line 17). When all candidate points are processed, we apply selective re-ranking (see Section 5) to enhance the distances precision (Line 18). is the high precision distances between points in and . Finally, the algorithm returns with related distances (Line 19).
Appendix B VSAG Index Construction Algorithm.
In VSAG, the insertion process for each new point (Lines 3–4) can be divided into three steps. First, a search is conducted on the graph to obtain the approximate nearest neighbors and their corresponding distances (Line 5). Next, pruning is performed on , and the edges along with their labels are added to the graph index (Line 6). The first step, the search process, is similar to that of other graph-based index constructions. However, the second step, the pruning process, differs from other indices. Instead of performing actual pruning, VSAG assigns labels. Specifically, VSAG assigns a label to each edge in graph (see Algorithm 2). Note that the label is used to indicate whether an edge exists under a certain construction parameter. Given , if , it indicates that the edge exists in the graph constructed using or larger value as the pruning rate. During the search and pruning processes, only edges satisfying need to be considered to retrieve the graph corresponding to the given construction parameters, which is proven in Theorem 4.3.
Next, for each new neighbor, reverse edges are added, and pruning is performed (Lines 7–14). If the distance from the current neighbor to is greater than the maximum distance among ’s neighbors and ’s neighbor list is already full (Line 8), no reverse edge is added (Line 9). Otherwise, is inserted into ’s neighbor list at an appropriate position to maintain and in ascending order (Lines 10–13). Subsequently, pruning and labeling are reapplied to the neighbors of located after position . Finally, the algorithm returns the edges and labels of the graph index.
Appendix C Proof of Theorem
C.1. Proof of Theorem 4.2
Proof.
The only difference in construction under varying maximum degrees lies in the termination timing of the loop. Note that during the edge connection process, existing edges are never deleted. Specifically, when inserting , the neighbors edges are continuously added to until or . Since , the condition will be satisfied first during edge addition. In the construction process with maximum degree , the first edges added in the loop are identical to those in . The subsequent edges inserted do not remove the first edges. Thus, . ∎
C.2. Proof of Theorem 4.3
Proof.
We prove this by mathematical induction. Consider the insertion process of and , examining each point sorted by distance in ascending order.
Base Case: When inserting , since both and are initially empty, no edges can trigger pruning, so is guaranteed to be inserted. Thus, , and we have .
First Iteration: Inserting : We analyze the cases:
-
•
1: Both sets remain unchanged. If , will not be added to . Since , it follows that , so will also not be added to . In this case, .
-
•
2: Both sets change. If , since , it follows that . In this case, .
-
•
3: Only changes. If and , then .
-
•
4: Only changes. If and , this situation cannot occur because . Thus, for the second insertion, we still have .
Inductive Step: Inserting : Assume that before the -th insertion, . We analyze the cases:
-
•
1: Both sets remain unchanged. If such that , then must also hold, so remains unchanged. Since , there must exist such that , so also remains unchanged. Thus, .
-
•
2: Both sets change. If , , and , , these conditions are compatible and may occur. In this case, .
-
•
3: Only changes. If , and , , these conditions are compatible and may occur. In this case, .
-
•
4: Only changes. This case does not exist because Lines 5-6 of Algorithm 2 ensure that if a point is not be pruned in , it will not be pruned again in . Therefore, if is added to , its label is set as . During subsequent iterations of , the condition in Lines 5-6 of Algorithm 2 ensures that this point is no longer considered.
∎
Appendix D Selecting Optimal ILP Configurations.
Under specified optimization objectives for the accuracy and efficiency of retrieval, different configurations of parameter at the index level represent candidate solutions in the design space. When environment-level and query-level parameters remain fixed, each configuration induces unique performance characteristics in terms of target metrics. The complete combinatorial space of index-level parameters constitutes the solution domain for multi-objective optimization. VSAG’s automated tuning mechanism aims to identify a solution subset where no configuration in the space is Pareto superior (Zitzler and Thiele, 1999) to any member of this subset. This set of non-dominated solution forms the Pareto Optimal Frontier (Zitzler and Thiele, 1999), representing optimal trade-offs between competing objectives.
Through systematic evaluation of ILP configurations, VSAG generates performance profiles containing retrieval accuracy and latency measurements, enabling Pareto Frontier derivation. When users specify target accuracy thresholds or latency constraints, the system performs optimal configuration selection by identifying the minimal Pareto-optimal solution that satisfies the specified requirements.
Example 0.
Consider a user-defined constraint of with three Pareto Frontier candidates: , , , where tuples denote (configuration, Recall@10, queries per second). Configuration B emerges as the optimal selection, satisfying the recall threshold while maximizing query throughput through its superior QPS performance.