4921
\vgtccategoryResearch
\teaser
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/08b8bd22-5c9e-409d-8932-99eed003fc77/overview2_cut.png) VRDoc provides users a set of three gaze-based interactions that improve users’ reading experience in a virtual environment; Gaze Select-and-Snap, Gaze MagGlass, and Gaze Scroll. We evaluate the results and observe considerable improvement over existing interaction methods.
VRDoc provides users a set of three gaze-based interactions that improve users’ reading experience in a virtual environment; Gaze Select-and-Snap, Gaze MagGlass, and Gaze Scroll. We evaluate the results and observe considerable improvement over existing interaction methods.
VRDoc: Gaze-based Interactions for VR Reading Experience
Abstract
Virtual reality (VR) offers the promise of an infinite office and remote collaboration, however, existing interactions in VR do not strongly support one of the most essential tasks for most knowledge workers, reading. This paper presents VRDoc, a set of gaze-based interaction methods designed to improve the reading experience in VR. We introduce three key components: Gaze Select-and-Snap for document selection, Gaze MagGlass for enhanced text legibility, and Gaze Scroll for ease of document traversal. We implemented each of these tools using a commodity VR headset with eye-tracking. In a series of user studies with 13 participants, we show that VRDoc makes VR reading both more efficient () and less demanding (), and when given a choice, users preferred to use our tools over the current VR reading methods.
Human-centered computingHuman computer interaction (HCI)Interaction paradigmsVirtual reality; \CCScatTwelveHuman-centered computingHuman computer interaction (HCIInteraction techniques;
1 Introduction
Virtual Reality is increasingly being used for both entertainment and collaboration. Increasingly, there is a demand for tools that can support virtual office environments 111https://www.roadtovr.com/vr-apps-work-from-home-remote-office-design-review-training-education-cad-telepresence-wfh/, including Connec2, Glue, Immersed, MeetinVR, MeetingRoom, Rumii, Spatial, vSpatial, etc. Many of these technologies focus on the importance of remote collaboration, but overlook one of the most essential tasks of office work, reading. Reading is essential for knowledge workers and will continue to be crucial even when co-workers want to share documents in a virtual office.
As we look forward to a future of an immersive infinitely collaborative virtual office space, we cannot ignore the importance of a seamless reading experience being part of this virtual environment. Currently, reading in VR is considered difficult if not impossible in a sustainable way [29, 31, 34, 36, 42]. Users typically refer to many hardware-related issues with respect to the current displays which are unable to satisfy the fastidious requirements of the human visual system, including high pixel density, a large number of pixels, wide field-of-view (FOV), and a high refresh rate. At the same time, recent developments including near-eye display optics, accommodation-supporting near-eye displays, foveated displays, and vision-correcting near-eye displays [24] can alleviate some of these problems. It is expected that VR headsets will continue to improve in terms of display technologies and pixel resolution. It is also notable that, in addition to displays, other technologies such as eye tracking are being integrated as a standard feature in forthcoming HMDs [19]. Even with expected improvements in headset hardware, software tools for facilitating tasks will be equally important to promote seamless and sustainable productivity. From our observational study, we have identified two major areas of improvement for VR reading tools: space aware features that facilitate selecting a document from the immersive environment and positioning it for the best reading experience and document interactions that allow users to read documents without physically leaning toward the document or manually grabbing and zooming in order to read.
Our main contributions are a set of three gaze-based interaction methods that can improve the reading experiences in VR: Gaze Select-and-Snap, Gaze MagGlass, and Gaze Scroll. Our tools are general and do not make any assumptions about the underlying task. We use standard interfaces for object manipulation along with eye tracking capabilities available in current HMDs [40]. We first conducted a formative study to evaluate current user pain points that might impact document manipulation and reading in VR using object manipulation and canvas interaction tasks (Section 3.1). Based on this study, we identified three main challenges: difficulty positioning document objects, poor readability in current headsets, and arm fatigue (“gorilla arm” [20]). To overcome these issues, we use three interaction methods: Gaze Select-and-Snap, Gaze MagGlass, and Gaze Scroll (Section 3.2). All these interaction methods are based on eye tracking and eliminate the need to hold controllers or perform repetitive arm gestures, both of which can be tiring in long-term interactions. With Gaze Select-and-Snap, a user can simply gaze at a virtual object tagged as a document to select it and uses a single button confirmation to bring that object into a reading view. In the reading view, Gaze MagGlass tracks the user’s eye movement and locally magnifies the text the user is reading. Finally, when the user reaches the end of a section or page, Gaze Scroll enables the document to scroll automatically enabling seamless continued reading.
We performed user studies to evaluate our interaction tools on two tasks: reading multiple short documents and reading a long document (Section 4). We measured tool usage, reading task completion time, and reading comprehension for both scenarios. We then performed subjective evaluations to measure usability, effectiveness, workload, and preference using SUS and Raw TLX questionnaires. We confirmed that our tools did not increase motion sickness using the SSQ instrument for VR sickness. We observed statistically significant results that indicate that VRDoc is a more usable, less demanding, and preferred interaction method for reading in VR (Section 5). In summary, our contributions include:
-
•
Identifying current user pain points for VR reading experiences.
-
•
Developing three gaze-based user interactions to improve the VR reading experience: Gaze Select-and-Snap, Gaze MagGlass, and Gaze Scroll.
-
•
Evaluating these VRDoc tools on two VR document reading tasks and observing statistically significant results for reading comprehension, task completion, usability and workload, as well as readability, efficiency, and preference.
2 Related Work
In this section, we briefly survey prior work in gaze-based interaction, text presentations in VR systems, and reading experiences in VR, AR, and MR systems.
2.1 Text Presentations in VR
Investigating text presentation on electronic devices to facilitate legibility has been an important issue for decades [13]. Text presentations in virtual environments present different issues than 2D monitor displays due to resolution limits and the presence of a third dimension in which to place documents. Dittrich et al. proposed a set of rules for text visualizations in 3D virtual environments [15]. Their suggestions include having texts enlarged more than those on a 2D display. Jankowski et al. integrated text with video and 3D graphics to investigate the effects of text drawing style, image polarity, and background style (whether the background is a video or 3D) [22]. The results indicated that negative presentation of texts, such as white texts on a black background, performed better in terms of accuracy than positive presentation. Also, the billboard drawing styles, and the semitransparent white and black panels, led to a faster reading time and higher accuracy.
Recently, Dingler et al. investigated user interface designs for displaying texts for VR reading [14]. They were able to identify a set of parameters such as text size, convergence, and color for an optimal text presentation. The findings indicated that users preferred texts presented with a sans-serif font and a negative presentation, that is, either having white text on a black background or having black text on a white background. There have also been efforts to investigate text presentations on 3D objects with various surfaces [42]. It was found that a text is easier to read when it is warped around a 3D object with a single axis instead of two axes. Detailed design recommendations on the field of view and text boxes were presented. While text representation is a fundamental issue for reading in VR, it should be noted that users are given the freedom to interact with texts in an infinite margin space, not a restricted 2D display. Our paper focuses on the interaction aspect to improve users’ reading performance.

.
2.2 Reading in VR/MR systems
Reading performance depends on the devices used to display reading materials. People read slower and less accurately from computer screens than from paper [12, 16], although recently the difference has been diminishing [11]. Reading performances on tablets and paper have also been extensively compared [8, 9]. Rau et al. [34] compared the speed and accuracy of reading in VR and AR environments with reading on an LCD monitor. The authors also compared the reading performance on two VR HMDs that differed in display quality but were otherwise similar in every way. The results indicated that users read at a slower speed with VR and AR compared with a computer screen and had a tendency to respond more accurately and faster when wearing a VR HMD of a higher pixel density.
When reading in immersive reality systems such as VR or MR, users are given more methods to interact with documents. Here, various aspects of the hardware are considered, including the presentation of the document in the VR/MR headset and the type of user input (e.g., gestures, controllers). Rzayeve et al. studied the problem of optimal text presentation type and location [35]. They tested the difference in user reading experience between using the Rapid Serial Visual Presentation (RSVP) method and presenting in a paragraph. In terms of location, the study tested world-fixed, head-fixed, and edge-fixed 2D windows. They found that RSVP is effective for reading short texts when paired with edge-fixed or head-fixed locations, and a full-paragraph presentation works well with world-fixed or edge-fixed locations when minimal movement is required for the user.
For reading with MR systems, Li et al. evaluated a mixed reality experience where users read physical paper documents while seeing related artifacts such as sticky notes, figures, and videos in MR through HoloLens [26]. While the study identified that readers preferred this experience to that of reading on paper, laptop, or mobile devices, this did not test or improve reading in the immersive system but showed that users enjoyed seeing ancillary material in the infinite margins surrounding documents. Pianzola et al. investigated whether reading fiction in VR, having an immersive background, and having the ability to move your head to view texts with different orientations, affect users’ absorption in the story [31]. The results show that VR enhanced users’ intention to read and their affective empathy. These findings indicate that VR can be effectively exploited to promote reading in VR.
2.3 Gaze-based Interactions
In recent years, the interest in gaze-based interactions has surged as consumer-level eye tracking sensors have been introduced to the general public [5]. Eye tracking technology is especially well-utilized for interactions in immersive technologies such as VR and AR [17, 28, 3]. Tanriverdi and Jacob found that in a VR setting, selection with eyes showed a similar speed advantage when compared to 3D motion-tracked pointers [38]. Piumsomboon et al. developed a set of selection methods using natural eye movements and found that such eye gaze-based interactions could improve users’ experience while maintaining performance comparable to standard interaction techniques [32]. While gaze offers fast pointing, its lack of precision and difficulty of selection confirmation has been challenging. To overcome this issue, researchers combined gaze input for selection and hands for manipulation [7, 30, 37, 39]. In this context, Pfeuffer et al. proposed a novel method, Gaze-touch, in which users use multi-touch gestures on interactive surfaces to control gaze-selected targets [30]. Yu et al. further incorporated gaze and hand inputs for a full 3D object manipulation in VR [44]. Biener et al. combined touch-based interactions with gaze for editing presentation slides in VR [4]. With a wide variety of options for utilizing gaze for interactions, it is important to select operations for which eye-tracking can play a big role so that it efficiently supplements conventional hand- or controller-based interaction methods.
In this study, we investigate how existing conventional methods are used when reading documents, identify the drawbacks and needs of the user, and build an enhanced interaction method designed for reading documents in a virtual environment.
3 Reading in VR
Reading documents in a virtual reality typically involves reading a 2D document placed in a window in a 3D virtual world. This is different from users’ experience of reading in 2D displays, as document windows can be positioned at various depths and orientations. This gap might cause discomfort and inconvenience in terms of VR reading, resulting in users being reluctant to attempt this activity on a VR platform. Since prior work has found that users did not prefer head-fixed presentation when reading a paragraph of texts in VR [35] our goal was to study and develop tools that allow the reader to move freely in VR, select and attach/detach documents to a reading frame easily and enhance readability. We envisioned a scenario where readers might encounter multiple documents, both long and short, in VR and that users would need to select and deselect these documents to read them. Whereas previous works have mostly focused on short paragraphs (approximately 100 words) with a uniform font size [36] we instead chose to observe users’ reading behavior with longer documents with different font sizes for structure. Based on observations from our formative study, we identified user pain points for this task using current interaction techniques.
3.1 Formative Study
The goal of our formative study was to identify user pain points for reading in VR from selection to reading completion with currently available tools. We observed eight users interacting with six documents of varying lengths using available VR interaction techniques.
3.1.1 Selected Manipulation Method
Users wore a state-of-the-art VR Headset and were provided with a set of interaction tools that are commonly used across VR platforms for object manipulation and 2D canvas interaction (as surveyed in Section 2). Manipulation was done using the HTC Vive controller. We first asked users to select document windows and make translation movements at distance using a ”laser-pointer” raycasting method [10, 2]. When a VR controller button is pressed by the user, a laser, or a ray cast, is projected in the direction to which the user is pointing, and the first colliding object in the virtual world is selected. Users can also make translation movements by moving the controller while pressing the dedicated button. For 6DOF manipulation, we use a method where users can “grab” and move or rotate 2D windows, which is also a common object manipulation method [41]. Here, when a direct collision is detected between the VR controller and a 2D document window while the assigned button is pressed, the object follows the motion of the controller. An example is depicted in Figure. 1. Based on these interactions, users can manipulate the 2D document windows that are at various orientations.

3.1.2 Participants and Procedure
We recruited eight participants (three females, five males). Three had previous experience in VR but not in reading texts in VR. Participants wore an HTC Vive Pro Eye [40] for the VR HMD, which has pixels per eye ( pixels combined), a Hz refresh rate, and a for the field of view. It also provides eye tracking capabilities.
Participants start from a fixed position with six documents placed in front of them as seen in Fig. 1. The documents were placed such that they formed a semicircle around the user’s starting position. Four of the documents were short passages with about words, while the other two were long passages with about words in length. Following Dingler et al [14], the VR text presentation guideline by having a black background color and white text color for all documents. All six documents had the same canvas size, requiring the long documents to have scroll-able windows. The participants were able to scroll by selecting a document and moving their fingers vertically on the VR controller trackpad.
Each participant was given minutes to freely read all six documents without any specific order. We followed the experience with a semi-constructed interview. The questions focused on the general experience of reading in VR, satisfaction with current interaction techniques, and desired user features.
3.1.3 Observations and Feedback
Through observing users’ behavior and collecting feedback through an interview, we were able to identify the following user pain points.
1. Positioning:
When selecting a document, it took participants multiple attempts to re-orient the document window into the desired position. Unlike general object manipulation, participants tended to have a preferred distance and orientation (upright) for reading. Six participants noted that positioning the document to this preferred location and orientation took more time than expected. P1 commented, “It took me a while to figure out what position worked for me the best to fully view the document.” All eight participants mentioned that switching their attention between multiple documents made them more aware of this inconvenience. P3 commented, “During the trial there was a moment when the document windows start to overlap as I select and position them. The pile definitely made it difficult to identify and select the documents. I wish there could be an easy way where I can quickly pick up a document that I want to read.”. Five participants brought up the need to automate the positioning procedure as they already knew how they wanted the document of interest to be oriented: up right in front of their head position.
2. Readability:
All eight participants reported that document readability was poor due to its resolution and distortion. P2 and P5 commonly mentioned that when reading on a 2D display, they were even able to read texts sideways, but with the VR headset the text appeared blurry and this was not possible. Five participants noted that unless the document was perfectly upright, the slant created a distortion that decreased readability. We observed that participants positioned the documents with smaller font sizes closer, effectively magnifying the font, to enhance readability.
3. Arm Fatigue:
During the minute trial, participants tended to hold the VR controller up constantly to interact with the documents. This behavior was consistently observed even when users were using the controller’s trackpad for scrolling since the rest of the interactions, such as selecting and moving the document, required the user to hold up the physical device. Four of the participants reported arm fatigue which is a known issue (”Gorilla Arm”) for gesture-based interactions [21] which are prevalent in VR. This is exacerbated by the additional weight of the controller when compared to watch-based gesture interactions. Such issues of fatigue would likely increase in longer VR experiences. Based on this formative study, we developed tools specifically to address positioning, readability, and arm fatigue.
3.2 Our Approach: VRDoc
To address user pain points we developed three new tools: Gaze Select-and-Snap, Gaze MagGlass, and Gaze Scroll, which we collectively refer to as VRDoc, tools for better document reading in VR. This section describes our design process from user needs to potential solutions.
Focused on the pain points of positioning, readability, and arm fatigue, our design thinking progressed as follows:
-
1.
Users do not seem to require or desire as much object manipulation freedom when reading documents. Given the user tendency for a specific positioning with respect to documents, we should automate and simplify moving the document to a near-optimal position once selected. Automatically positioning the document in an upright non-skewed position will enhance readability.
-
2.
Users manipulated documents to effectively magnify text, but this often led to documents being positioned too close for the reader to easily contextualize their place in the document. A better solution would be to selectively magnify the current text the user is reading.
-
3.
VR controller use and arm gestures should be minimized. While some VR controller use may still be required, in a virtual office, for longer reading tasks the user should not need to use their arms at all, enabling them to set the controller down. We believe this will reduce fatigue and improve the overall experience.
We believed that the novel eye tracking capability of the Vive headset could be leveraged to develop solutions for some of these issues. Eye-tracking is becoming increasingly available in commodity HMDs [40] and since reading naturally evokes specific eye movements, document interactions with gaze are natural and intuitive. In our approach, we use the SDK provided by HTC Vive222https://developer.vive.com/documents/718/VIVE_Pro_Eye_user_guide.pdf for eye tracking calibration and data with the Unity game engine. The headset provides eye tracking with an accuracy of to at 120 Hz.
3.2.1 Positioning: Gaze Select-and-Snap
The infinite freedom of object manipulation in 3D was actually a negative factor in document positioning. Documents were only readable in the upright position near the users’ direct line of sight. We developed Gaze Select-and-Snap to automate the action of selecting and positioning through the user’s gaze. Prior work has established that users value the ability to select 3D objects with gaze and bring these closer to the user’s hand [23], but this is the first method designed for document objects (a virtual object that is tagged as “document”) that both rotates the 3D object into a specific position and snaps it into a fixed effective 2D perspective specifically for reading.
To engage Gaze Select-and-Snap, the user first directs their gaze toward the 3D document object, the gaze focus is detected and the document object is highlighted with a green stroke to visualize its selection for the user. With a single click of the trigger button, the 3D document object is brought forward towards the head position and snapped into an effective 2D position in front of the user. The window is snapped parallel to the user’s head position, ensuring the window stays upright. An example of this interaction is shown in Figure. 2 (a).
When multiple documents overlap, Gaze Select-and-Snap first highlights the top document, then if the top document is not selected, Gaze Select-and-Snap sequentially brings hidden documents to the forefront until the desired document is identified and selected.
3.2.2 Readability: Gaze MagGlass
To improve text readability once the document was in position, we incorporated a magnifying glass effect that is activated by users’ eye movements: Gaze MagGlass. For low-vision computer users, video-based eye trackers have been used effectively to increase the on-screen magnification in traditional computing settings [43, 27], however, to the best of our knowledge, this is the first implementation of interactive selective text magnification in VR. To enhance usability, Gaze MagGlass is only activated when (1) the user gazes at a document, (2) the document is within a certain distance (), and (3) when the user gazes at the document window for more than seconds. These robust heuristics were designed to ensure that the document in view is the specific document that the user wants to read.
When the activation conditions are met, a second virtual camera is created on the collision point of the user’s gaze and the document object. The virtual camera is perpendicular to the document while following the user’s gaze. The captured scene is rendered at a texture of a 2d plane that is rendered in front of the main camera. The field of view of the virtual camera and the distance from the document object are heuristically determined so that it magnifies the document by 150% with a size that covers approximately to words of three consecutive sentences.
Directly applying raw gaze position data to the virtual camera causes great jittering as eye tracker data are inherently noisy and include tracking errors. This worsens the user experience as the jittering is visualized in a magnified way. To address this issue, we generally follow the saccade detection and smoothing algorithm from [25] so that the position of Gaze MagGlass is calculated as a weighted mean of the set of points within a fixation window.
Gaze MagGlass is automatically initiated when the activation conditions are met but can be manually turned on or off by the user if necessary. Note that activation conditions and the degree of magnification were heuristically determined for the study. An example of the activation is depicted in Figure. 2 (b).
3.2.3 Gaze Scroll
Since longer documents are rarely considered in VR reading studies, Gaze Scroll is the first tool designed specifically to help alleviate fatigue when reading longer documents. The objective of gaze scroll is to avoid the necessity of users having to re-engage with the controller after they have begun reading. At this point, the document should be snapped into the 2D reading position and the user should be able to put the controller down. To facilitate document navigation without a controller, two buttons were placed within a document each on the top and the bottom of the window, as seen in Figure 2 (c). When the user’s gaze reaches the button for seconds, the document scrolls up or down by a full sentence. Fixating the gaze on the button can increase the number of sentences. For example, if a user stares at the lower button for 2 seconds, the document scrolls down by four sentences. This activation condition creates a controlled advancement and minimizes focal changes, which can be frequent when scrolling is rapid or uncontrolled.
VRDoc tools are designed to facilitate a better reading experience in VR, from automating the selection and positioning of document windows to magnifying text for readability to allowing gaze-based navigation of longer documents.
4 Evaluation
After implementing our tools we conducted a series of user studies to investigate how users’ reading experiences changed with VRDoc tools. We aimed to answer the following research questions through our evaluation:
-
•
Does Gaze Select-and-Snap improve document handling (positioning)?
-
•
Does Gaze MagGlass improve readability?
-
•
Do VRDoc tools including Gaze Scroll for navigation lessen feelings of fatigue?
-
•
Overall do VRDoc tools work together to improve efficiency and usability?
-
•
Do readers prefer having access to VRDoc tools when reading in VR?
We first evaluated each tool of VRDoc by comparing it to the basic object manipulation defined in Section 3.1 (henceforth, baseline). Then, we conducted a study where users were given access to all VRDoc tools versus a baseline.

4.1 Participants
Thirteen participants (eight male, five female) were recruited from a convenience sample of university students for the evaluation experiment (age range -, , ). Eight participants wore glasses, three wore contact lenses, and the rest did not require vision correction. All of our participants were proficient in English. Eight of the participants had previously experienced VR systems. Participants were compensated USD after the experiment.
4.2 Settings
The experiments were set in a virtual office environment for immersion. The tracking area was set to as our task did not require much movement from the participants. We followed the guidelines suggested from previous work [14] for our experiment setup. The document window contained a view box that displays a total of lines with each line comprising around characters. A white sans-serif Arial font (size ) was used for text and the background was set to black. The texts were left-aligned and the line spacing was set to . The text materials were selected from the “Asian and Pacific Speed Reading for ESL Learners” [33] to guarantee a similar difficulty level. Note that the length of the text materials was slightly edited for the experiments: around 100 words for Short passages so that they do not require scrolling and around 500 words for Long passages.
4.3 Experiment Procedure
We employed within subject experiments in the order of (1) individual tool evaluation and (2) combined evaluation. Each of the tools of VRDoc (Gaze Select-and-Snap, Gaze MagGlass, and Gaze Scroll) was compared to baseline with separate tasks. The order of tasks for individual tool evaluation and tool presentation (VRDoc, baseline) for all experiments was counterbalanced using Latin-square.
Individual Evaluation
-
•
Task 1 (Gaze Select-and-Snap): Five Short passages are placed in front of the starting position in a semicircle, as seen in Fig. 3 (a). The order of the Short passages is random. Readers are required to select each of the five documents to read them. When the reader finishes the fifth document, a five-question reading comprehension test appears. While taking the test, readers can choose to review any of the documents by re-selecting them to help answer the questions.
-
•
Task 2 (Gaze MagGlass): One Short passage is placed in front of the reader in the starting position as seen in Fig. 3. Gaze MagGlass tracks the reader’s gaze and magnifies the font 150%. When the reader reaches the end of the text, a two-question reading comprehension test appears.
-
•
Task 3 (Gaze Scroll): One Long passage is placed in front of the starting position as seen in Fig. 3 with no magnification. When the reader reaches the end of the text, a three-question reading comprehension test appears.
Combined Evaluation
-
•
Task 4 (VRDoc): Two Short passages and one Long passage are placed in front of the starting position in a semicircle, as seen in Fig. 3 (a). The order of the passages is random. The reading comprehension test consists of five questions. Readers are required to select each of the three documents to read them. During the test, readers can choose to review any of the documents (by reselecting) them to help them answer the questions.
Users are asked to solve a reading comprehension test after reading the given documents. The reading comprehension test consists of fact-check, multiple-choice questions based on the given passage. Once the participant verbally determined that they were ready to take the quiz, a 2D plane containing the questions is displayed in front of the user in the VR environment. The task completion time (TCT) was measured separately by reading time and solving time. The reading time is defined as the time from the start of the trial until before reading the questions, and the solving time is the time from after reading the questions until the participant verbally determines the final answer.
The user study was conducted in the following order: A participant was first introduced to the overview and goal of the experiment and filled out a demographic survey. Then, the participant performs each of the individual evaluation tasks in a given order, and finally the combined evaluation task. Each task consists of two trials, one performed using our proposed method and the other using baseline. The order of individual evaluation tasks and the order trials for all tasks were counterbalanced among the participants using Latin-square. Prior to each trial, participants filled out a pre-SSQ [23] survey and were given a tutorial including a five-minute training session. After each trial, participants filled out a SUS questionnaire [6] for system usability, Raw-TLX [18] for workload, post-SSQ for VR sickness, and a subjective evaluation questionnaire on a 5-point Likert scale for readability, effectiveness, and preference (See appendix A). The experimenter reminded participants to consider the interaction aspect when answering the questions. They were given an additional 5-minute break in between trials. Note that, before each trial, we ran HTC Vive Pro Eye’s eye calibration software to ensure proper gaze tracking.
After each task was performed, we conducted a semi-structured interview to collect participants’ comments and feedback. The entire experiment lasted around 90 minutes per participant. All trials performed by the participants were recorded in video files for accurate observation and evaluation. In addition to TCT for all tasks, we measured the time Gaze MagGlass was activated for Task 2 and Task 4.
4.4 Results
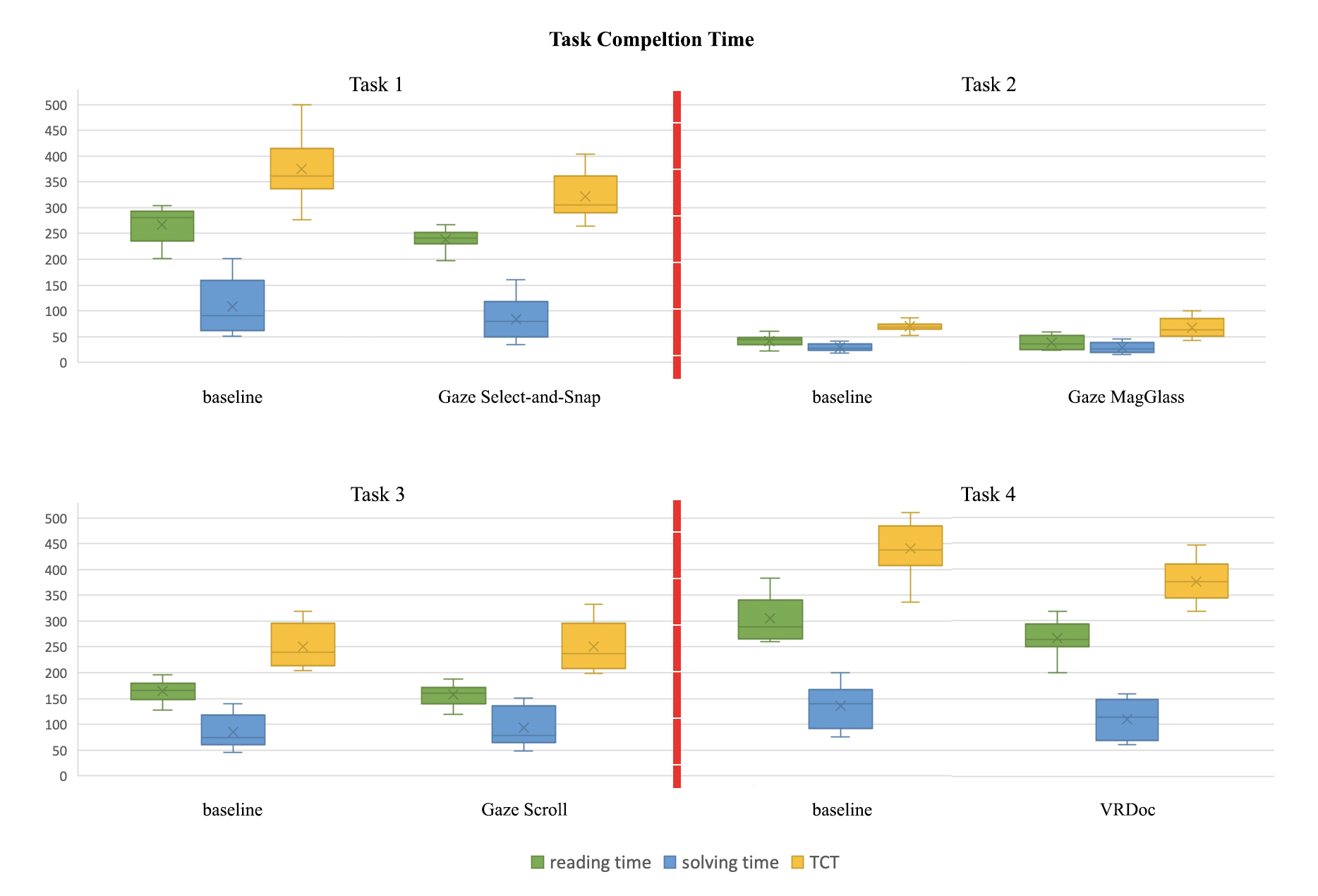
In this section, we divide the evaluation items collected during Task 1 through Task 4 into objective measures and subjective measures. Note that the results are not directly comparable between tasks as the reading conditions vary. The visualized results can be found in appendix B.
4.4.1 Objective Measures
TCT
We measured Task Completion Time (TCT), the sum of reading time and solving time for all four tasks:
-
•
Task 1: Gaze Select-and-Snap allowed readers to complete both the reading task and the comprehension quiz faster than baseline. Reading Time: Gaze Select-and-Snap (, ), baseline (, ); Solving Time: Gaze Select-and-Snap (, ) baseline(, ). Both reading time and solving time revealed a significant difference between the two methods according the the Wilcoxon signed-rank test: reading time (), solving time (), and TCT ().
-
•
Task 2: Readers read slightly faster with Gaze MagGlass (, ) than the baseline (, ) but the difference was not significant (). The solving time and TCT differences were also not significant (solving time: , solving TCT: ). Solving Time: Gaze MagGlass (, ), baseline (, ); TCT: Gaze MagGlass (, ) baseline(, ).
-
•
Task 3: Gaze Scroll allowed readers to read the longer passages slightly faster than baseline, however, Gaze Scroll had a negative impact on test solving time. Reading Time: Gaze Scroll (, ), baseline (, ); Solving Time: Gaze Scroll (, ) baseline(, ). Nevertheless, the differences were not significant which is also reflected in TCT: Gaze Scroll (, ) baseline(, ) (0.235).
-
•
Task 4: With VRDoc, readers have significantly faster reading time and solving time than with baseline. Reading Time: VRDoc (, ), baseline (, ); Solving Time: VRDoc (, ) baseline(, ); TCT: VRDoc (, ) baseline(, ). Both reading time and solving time revealed a significant difference between the two methods according the the Wilcoxon signed-rank test: reading time (), solving time (), and TCT ().
Reading Comprehension Test
There were no significant differences () in comprehension results in any of the four tasks between VRDoc and baseline according to the Wilcoxon signed-rank test. This was expected as (1) VRDoc tools are designed to make the reading task easier and more efficient but do not explicitly aid comprehension, and (2) readers were allowed to review the passages after reading the questions. The results ensure that the participants put the same amount of effort into all tasks.
Gaze MagGlass Activation Time
For Task 2, Gaze MagGlass was activated in an average of 51.72% of the reading time. With Task 4, where all of the tools are integrated, Gaze MagGlass was activated in an average of 67.18% of the reading time.
4.4.2 Subjective Measures
Usability
We measured the usability of the methods by calculating the SUS scores.
-
•
Task 1: Readers found Gaze Select-and-Snap (, ) more usable than baseline (, ) with a significant difference according the the Wilcoxon signed-rank test ().
-
•
Task 2: Readers found Gaze MagGlass (, ) more usable than baseline (, ) with a significant difference ().
-
•
Task 3: The usability of Gaze Scroll (, ) scored and the baseline (, ), trackpad scrolling, were similar in terms of usability, showing no significant differences despite Gaze Scroll having a slightly higher score().
-
•
Task 4: Readers found VRDoc (, ) more usable than baseline (, ) with a significant difference according the the Wilcoxon signed-rank test ().
Workload
For all four tasks, our proposed method had significantly lower RTLX scores than the baseline according to Wilcoxon signed-rank test.
-
•
Task 1: Gaze Select-and-Snap (, ) scored lower than baseline (, ) with a significant difference ().
-
•
Task 2: Gaze MagGlass (, ) scored lower than baseline (, ) with a significant difference ().
-
•
Task 3: Gaze Scroll (, ) scored lower than baseline (, ) with a significant difference ().
-
•
Task 4: VRDoc (, ) scored lower than baseline (, ) with a significant difference ().
Readability
For all four tasks, participants reported higher readability with our proposed method than with baseline. All differences were revealed to be significant by the Wilcoxon signed-rank test.
-
•
Task 1: Gaze Select-and-Snap (, ) scored higher than baseline (, ) with a significant difference ().
-
•
Task 2: Gaze MagGlass (, ) scored higher than baseline (, ) with a significant difference ().
-
•
Task 3: Gaze Scroll (, ) scored higher than baseline (, ) with a significant difference ().
-
•
Task 4: VRDoc (, ) scored higher than baseline (, ) with a significant difference ().
Effectiveness
We measured how ‘effective’ readers found the methods to be on a 5-point Likert scale.
-
•
Task 1: Readers found Gaze Select-and-Snap (, ) more effective than baseline (, ) with a significant difference ().
-
•
Task 2: Readers found Gaze MagGlass (, ) more effective than baseline (, ) with a significant difference ().
-
•
Task 3: The perceived effectiveness of Gaze Scroll (, ) was similar to that of baseline (, ) showing no significant statistical difference ().
-
•
Task 4: Readers found VRDoc (, ) more effective than baseline (, ) with a significant difference ().
Preference
Subjects’ preference for each method was measured through a 5-point Likert scale.
-
•
Task 1: Readers preferred Gaze Select-and-Snap (, ) more than baseline (, ) with a significant difference ().
-
•
Task 2: Readers preferred Gaze MagGlass (, ) more than baseline (, ) with a significant difference ().
-
•
Task 3: Gaze Scroll (, ) had a similar preference score with baseline (, ) with no significant difference ().
-
•
Task 4: Readers preferred VRDoc (, ) more than baseline (, ) with a significant difference ().
Sickness
We evaluated the sickness between the pre- and post-SSQs for each task. The results are shown in Table 1. The Wilcoxon signed-rank test revealed that there were no significant differences between the pre- and post-SSQ scores for the two methods in any of the tasks ().
| methods | pre-SSQ | post-SSQ | Z | p | |||
| T1 | baseline | 0.91 | 1.07 | 0.92 | 1.06 | -1.41 | 0.16 |
| Gaze Select-and-Snap | 0.78 | 1.00 | 0.78 | 1.06 | -1.89 | 0.59 | |
| T2 | baseline | 0.76 | 1.01 | 0.78 | 1.03 | -1.73 | 0.83 |
| Gaze MagGlass | 0.75 | 1.08 | 0.73 | 1.05 | -1.55 | 0.61 | |
| T3 | baseline | 0.83 | 1.12 | 0.84 | 1.03 | -1.64 | 0.65 |
| Gaze Scroll | 0.80 | 1.04 | 0.83 | 1.06 | -1.21 | 0.59 | |
| T4 | baseline | 0.86 | 1.06 | 0.97 | 1.05 | -1.50 | 0.42 |
| VRDoc | 0.88 | 1.00 | 0.93 | 1.08 | -1.43 | 0.51 | |
5 Discussion and Analysis
In this section, we analyze and discuss our findings on the quantitative results and post-experiment interviews by revisiting our research questions in Section 4.
5.1 Gaze Select-and-Snap on Positioning
Gaze Select-and-Snap showed the most promising and excellent results among the three VRDoc tools. We were able to observe readers significantly reducing time in selecting and reading document-of-interest out of multiple documents. Three participants commented that they enjoyed using Gaze Select-and-Snap not only for bringing documents up front to read but to move around multiple documents quickly. P4 mentioned, “I found it easier to scatter documents around with my gaze rather than holding up the controller and swaying my arm constantly. I could just look somewhere else to move away documents”. P5 and P11 commonly mentioned how with a larger VR space, they would find Gaze Select-and-Snap even more useful to find and orient document windows.
Although we cannot make direct comparisons between tasks since the conditions differ, when using baseline, the results in workload show that overall users’ perceived workload was higher with multiple short passages (Task 1) than with longer passages (Task 3). Implying that reading multiple documents was more demanding than reading a single long document as it involved frequently re-orienting document windows. This further strengthens the usability of Gaze Select-and-Snap, and how much positioning is important in reading documents in VR settings.
5.2 Gaze MagGlass on Readability
The quantitative results of the ‘readability’ prove that Gaze MagGlass successfully enhances users’ perceived readability when reading in VR. Gaze MagGlass was the only feature that had an on/off option, since, even in a real-world scenario, we do not require magnification glasses at all times. For Task 2 and Task 4, we were able to observe that Gaze MagGlass was activated for more than half of the time. This means that this is a necessary feature for reading in VR that will likely be used. When participants were only provided with the baseline, they often moved their position to better read the passage or reached out to grab the document and manually move the document towards them.
Six participants commented that they anticipate this feature to be utilized when reading documents with a more complex structure such as paragraphs with varying fonts or multi-column documents. Five of the participants mentioned how when used with Gaze Scroll in Task 4, Gaze MagGlass helped in keeping track of where they are in the document.
5.3 Gaze Scroll on Reducing Feelings of Fatigue
Gaze Scroll showed promising results in the measured participants’ subjective perception, yet there were some mixed reviews. Four participants commented that Gaze Scroll was convenient in the initial reading phase since the buttons were naturally placed at the end of the reader’s gaze. However, during the reading comprehension test phase, when the reader had to come back to the passage to look for information, they would prefer to use the controller since it was easier to quickly navigate to the top or bottom of the page. This implies that, for actual implementation, it would be a meaningful approach to integrate the existing trackpad-scrolling with Gaze Scroll to enhance users’ reading experience.
In terms of fatigue, the SSQ results did not reveal a significant difference in fatigue when compared with the baseline. This may be because in the experiment setting, readers were not required to go through documents for hours as much as we do in our daily lives. However, Gaze Scroll is proved to be effective in reducing perceived workload as it showed significantly smaller TLX scores compared to the baseline.
5.4 Usability, Efficiency, and Preference of VRDoc
Subjective measures proved that individually, readers had a positive experience with each of the tools. When combined, we are able to see that all three subjective measures; effectiveness, readability, and preference were higher than the individual scores of each tool. This implies that with the three tools combined, the tools form a synergy effect.
As shown in the results, with VRDoc, users stated that they perceived improved readability for both long passages and short passages. We observe a similar conclusion with respect to how efficient the methods were in assisting users’ reading experience. All these led to VRDoc having a significantly higher preference. Eight of the participants collectively mentioned how VRDoc presented a new possibility in reading in VR, which is what they have not imagined before. P13 commented, “I used to think reading in virtual reality would be unbearable, but this opened my eyes that with the right tool, it is quite enjoyable.”. Similarly, P11 mentioned “I especially liked how I felt in control of the reading space. With appropriate annotation tools, I can see reading in VR could be more useful in certain cases.” Five participants pointed out that reader-specific interactions are essential in the virtual environment, and the lack of them prevents them from even attempting to read long texts in a VR setup. Hence, for real-world applications, developers should consider providing readers in VR with a set of tools that tackle pain points to maximize users’ performance.
6 Conclusion, Limitations and Future work
We present VRDoc, a set of three gaze-based interactions that improve users’ reading experience in VR. Through a formative study, we identified major issues users face when reading documents with conventional object manipulation methods in a VR setting. We utilize eye-tracking as a solution to streamline basic interactions for users’ convenience while minimizing the need to continuously hold up a VR controller. VRDoc consists of three gaze-based interactions that each addresses the aforementioned problems: Gaze Select-and-Snap for selecting and positioning document windows, Gaze MagGlass for improving readability through magnification, and Gaze Scroll for scrolling long documents with gaze. We evaluated our method through a series of reading tasks and overall results indicated that the combined VRDoc tools significantly improve participants’ performance speed, usability with less workload when compared to using conventional methods.
Our study offers insights on how gaze-based interactions could assist VR reading interfaces. Our current approach assumes that good eye tracking capabilities are available in the VR system. Since participants’ performances are highly governed by the experiment settings, further investigation is needed to evaluate VRDoc in general applications corresponding to virtual offices or remote collaboration. The detailed setting used for VRDoc were all empirically determined for our study. Further research should be conducted to investigate the optimal distance to place document windows for Gaze Select-and-Snap, the degree of magnification and size of canvas for Gaze MagGlass, and the placement of buttons and activation conditions for Gaze Scroll.
The experiment setting used in our approach assumed minimal movement from the participants. It is anticipated that there will be a different set of interactions that users would need assistance with when VR locomotion is considered. Our current study follows the guidelines on how to present texts in VR [14]. However, these guidelines might not always be applicable when we read documents with complex layouts or structures, such as academic papers with two columns or documents with multimedia resources. Similar to recent efforts on identifying the optimal format for reading in mobile phones [1], it would be worth investigating a detailed format of how the structures should be converted for optimal reading experiences in VR.
Going beyond simply consuming documents, it is notable that VR offers a possibility of a collaborative workspace. For our future work, we aim to investigate collaborative interactions when multiple users read, share and discuss documents. The findings can be adapted to various multi-user applications such as virtual classrooms and virtual conferences. As new display technologies and headsets are developed to deal with the challenging issues related to pixel density, pixel resolution, field-of-view, refresh rate and distortion, it would be useful to evaluate their impact on VR reading experiences.
References
- [1] Adobe acrobat liquid mode. https://www.adobe.com/devnet-docs/acrobat/android/en/lmode.html. Accessed: 2021-10-27.
- [2] Virtual reality toolkit. https://vrtoolkit.readme.io. Accessed: 2019-10-31.
- [3] S. Agledahl and A. Steed. Magnification vision–a novel gaze-directed user interface. In 2021 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW), pp. 474–475. IEEE, 2021.
- [4] V. Biener, T. Gesslein, D. Schneider, F. Kawala, A. Otte, P. O. Kristensson, M. Pahud, E. Ofek, C. Campos, M. Kljun, et al. Povrpoint: Authoring presentations in mobile virtual reality. IEEE Transactions on Visualization and Computer Graphics, 28(5):2069–2079, 2022.
- [5] J. Blattgerste, P. Renner, and T. Pfeiffer. Advantages of eye-gaze over head-gaze-based selection in virtual and augmented reality under varying field of views. In Proceedings of the Workshop on Communication by Gaze Interaction, pp. 1–9, 2018.
- [6] J. Brooke et al. Sus-a quick and dirty usability scale. Usability evaluation in industry, 189(194):4–7, 1996.
- [7] I. Chatterjee, R. Xiao, and C. Harrison. Gaze+ gesture: Expressive, precise and targeted free-space interactions. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, pp. 131–138, 2015.
- [8] G. Chen, W. Cheng, T.-W. Chang, X. Zheng, and R. Huang. A comparison of reading comprehension across paper, computer screens, and tablets: Does tablet familiarity matter? Journal of Computers in Education, 1(2):213–225, 2014.
- [9] C. Connell, L. Bayliss, and W. Farmer. Effects of ebook readers and tablet computers on reading comprehension. International Journal of Instructional Media, 39(2), 2012.
- [10] V. Corporation. Steamvr. https://store.steampowered.com/app/250820/SteamVR/. Accessed: 2019-06-01.
- [11] P. Delgado, C. Vargas, R. Ackerman, and L. Salmerón. Don’t throw away your printed books: A meta-analysis on the effects of reading media on reading comprehension. Educational Research Review, 25:23–38, 2018.
- [12] A. Dillon. Reading from paper versus screens: A critical review of the empirical literature. Ergonomics, 35(10):1297–1326, 1992.
- [13] A. Dillon, J. Richardson, and C. McKnight. The effects of display size and text splitting on reading lengthy text from screen. Behaviour & Information Technology, 9(3):215–227, 1990.
- [14] T. Dingler, K. Kunze, and B. Outram. Vr reading uis: Assessing text parameters for reading in vr. In Extended Abstracts of the 2018 CHI Conference on Human Factors in Computing Systems, pp. 1–6, 2018.
- [15] E. Dittrich, S. Brandenburg, and B. Beckmann-Dobrev. Legibility of letters in reality, 2d and 3d projection. In International Conference on Virtual, Augmented and Mixed Reality, pp. 149–158. Springer, 2013.
- [16] J. D. Gould, L. Alfaro, R. Finn, B. Haupt, and A. Minuto. Reading from crt displays can be as fast as reading from paper. Human factors, 29(5):497–517, 1987.
- [17] J. P. Hansen, V. Rajanna, I. S. MacKenzie, and P. Bækgaard. A fitts’ law study of click and dwell interaction by gaze, head and mouse with a head-mounted display. In Proceedings of the Workshop on Communication by Gaze Interaction, pp. 1–5, 2018.
- [18] S. G. Hart. Nasa-task load index (nasa-tlx); 20 years later. In Proceedings of the human factors and ergonomics society annual meeting, vol. 50, pp. 904–908. Sage publications Sage CA: Los Angeles, CA, 2006.
- [19] N. Hideaki. Playstation vr2 and playstation vr2 sense controller, the next generation of vr gaming on ps5. https://blog.playstation.com/2022/01/04/playstation-vr2-and-playstation-vr2-sense-controller-the-next-generation-of-vr-gaming-on-ps5/, January 2022.
- [20] S. Jang, W. Stuerzlinger, S. Ambike, and K. Ramani. Modeling cumulative arm fatigue in mid-air interaction based on perceived exertion and kinetics of arm motion. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems, CHI ’17, p. 3328–3339. Association for Computing Machinery, New York, NY, USA, 2017. doi: 10 . 1145/3025453 . 3025523
- [21] S. Jang, W. Stuerzlinger, S. Ambike, and K. Ramani. Modeling cumulative arm fatigue in mid-air interaction based on perceived exertion and kinetics of arm motion. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems, pp. 3328–3339, 2017.
- [22] J. Jankowski, K. Samp, I. Irzynska, M. Jozwowicz, and S. Decker. Integrating text with video and 3d graphics: The effects of text drawing styles on text readability. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, pp. 1321–1330, 2010.
- [23] R. S. Kennedy, N. E. Lane, K. S. Berbaum, and M. G. Lilienthal. Simulator sickness questionnaire: An enhanced method for quantifying simulator sickness. The international journal of aviation psychology, 3(3):203–220, 1993.
- [24] G. A. Koulieris, K. Akşit, M. Stengel, R. K. Mantiuk, K. Mania, and C. Richardt. Near-eye display and tracking technologies for virtual and augmented reality. In Computer Graphics Forum, vol. 38, pp. 493–519. Wiley Online Library, 2019.
- [25] M. Kumar. Guide saccade detection and smoothing algorithm. Technical Rep. Stanford CSTR, 3:2007, 2007.
- [26] Z. Li, M. Annett, K. Hinckley, K. Singh, and D. Wigdor. Holodoc: Enabling mixed reality workspaces that harness physical and digital content. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, pp. 1–14, 2019.
- [27] N. Maus, D. Rutledge, S. Al-Khazraji, R. Bailey, C. O. Alm, and K. Shinohara. Gaze-guided magnification for individuals with vision impairments. In Extended Abstracts of the 2020 CHI Conference on Human Factors in Computing Systems, pp. 1–8, 2020.
- [28] D. Miniotas. Application of fitts’ law to eye gaze interaction. In CHI’00 extended abstracts on human factors in computing systems, pp. 339–340, 2000.
- [29] J. Mirault, A. Guerre-Genton, S. Dufau, and J. Grainger. Using virtual reality to study reading: An eye-tracking investigation of transposed-word effects. Methods in Psychology, 3:100029, 2020.
- [30] K. Pfeuffer, J. Alexander, M. K. Chong, and H. Gellersen. Gaze-touch: combining gaze with multi-touch for interaction on the same surface. In Proceedings of the 27th annual ACM symposium on User interface software and technology, pp. 509–518, 2014.
- [31] F. Pianzola, K. Bálint, and J. Weller. Virtual reality as a tool for promoting reading via enhanced narrative absorption and empathy. Scientific Study of Literature, 9(2):163–194, 2019.
- [32] T. Piumsomboon, G. Lee, R. W. Lindeman, and M. Billinghurst. Exploring natural eye-gaze-based interaction for immersive virtual reality. In 2017 IEEE symposium on 3D user interfaces (3DUI), pp. 36–39. IEEE, 2017.
- [33] E. Quinn, I. S. P. Nation, and S. Millett. Asian and pacific speed readings for esl learners. ELI Occasional Publication, 24:74, 2007.
- [34] P.-L. P. Rau, J. Zheng, Z. Guo, and J. Li. Speed reading on virtual reality and augmented reality. Computers & Education, 125:240–245, 2018.
- [35] R. Rzayev, P. Ugnivenko, S. Graf, V. Schwind, and N. Henze. Reading in vr: The effect of text presentation type and location. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, pp. 1–10, 2021.
- [36] R. Rzayev, P. W. Woźniak, T. Dingler, and N. Henze. Reading on smart glasses: The effect of text position, presentation type and walking. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, pp. 1–9, 2018.
- [37] S. Stellmach, S. Stober, A. Nürnberger, and R. Dachselt. Designing gaze-supported multimodal interactions for the exploration of large image collections. In Proceedings of the 1st conference on novel gaze-controlled applications, pp. 1–8, 2011.
- [38] V. Tanriverdi and R. J. Jacob. Interacting with eye movements in virtual environments. In Proceedings of the SIGCHI conference on Human Factors in Computing Systems, pp. 265–272, 2000.
- [39] E. Velloso, J. Turner, J. Alexander, A. Bulling, and H. Gellersen. An empirical investigation of gaze selection in mid-air gestural 3d manipulation. In IFIP Conference on Human-Computer Interaction, pp. 315–330. Springer, 2015.
- [40] VIVE. Pro Eye HMD - Full Kit, 2021. https://www.vive.com/us/product/vive-pro-eye/overview/.
- [41] R. Wang, S. Paris, and J. Popović. 6d hands: markerless hand-tracking for computer aided design. In Proceedings of the 24th annual ACM symposium on User interface software and technology, pp. 549–558, 2011.
- [42] C. Wei, D. Yu, and T. Dingler. Reading on 3d surfaces in virtual environments. In 2020 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), pp. 721–728. IEEE, 2020.
- [43] W. Wittich, J. Jarry, E. Morrice, and A. Johnson. Effectiveness of the apple ipad as a spot-reading magnifier. Optometry and Vision Science, 95(9):704, 2018.
- [44] D. Yu, X. Lu, R. Shi, H.-N. Liang, T. Dingler, E. Velloso, and J. Goncalves. Gaze-supported 3d object manipulation in virtual reality. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, pp. 1–13, 2021.
Appendix A Subjective Questionnaires
| Measure | Questionnaire |
| Readability | How was your perceived readability with the presented method? |
| Effectiveness | How effective did you find the presented method in performing the task? |
| Preference | How preferable was the presented method? |
Appendix B Statistical Results