ViT-1.58b: Mobile Vision Transformers in the 1-bit Era
Abstract
Vision Transformers (ViTs) have achieved remarkable performance in various image classification tasks by leveraging the attention mechanism to process image patches as tokens. However, the high computational and memory demands of ViTs pose significant challenges for deployment in resource-constrained environments. This paper introduces ViT-1.58b, a novel 1.58-bit quantized ViT model designed to drastically reduce memory and computational overhead while preserving competitive performance. ViT-1.58b employs ternary quantization, which refines the balance between efficiency and accuracy by constraining weights to {-1, 0, 1} and quantizing activations to 8-bit precision. Our approach ensures efficient scaling in terms of both memory and computation. Experiments on CIFAR-10 and ImageNet-1k demonstrate that ViT-1.58b maintains comparable accuracy to full-precision Vit, with significant reductions in memory usage and computational costs. This paper highlights the potential of extreme quantization techniques in developing sustainable AI solutions and contributes to the broader discourse on efficient model deployment in practical applications. Our code and weights are available at https://github.com/DLYuanGod/ViT-1.58b.
✓\ding51 \newunicodechar✗\ding55
ViT-1.58b: Mobile Vision Transformers in the 1-bit Era
Zhengqing Yuan1111These authors contributed equally to this work., Rong Zhou2111These authors contributed equally to this work., Hongyi Wang3,4, Lifang He2, Yanfang Ye1, Lichao Sun2222Corresponding author. 1University of Notre Dame, 2Lehigh University, 3Carnegie Mellon University, 4Rutgers University
1 Introduction
The rapid advancement of Transformer Vaswani et al. (2017) architectures has significantly impacted the field of computer vision, particularly with the introduction of Vision Transformers (ViTs) Dosovitskiy et al. (2020). By treating image patches as tokens and leveraging the attention mechanism to process image patches, ViTs effectively capture complex dependencies across entire images, achieving remarkable performance in various image classification tasks Graham et al. (2021); Liu et al. (2021); Yuan et al. (2021). However, the computational and memory demands of ViTs are substantial, stemming primarily from their attention mechanisms, which scale quadratically with the number of tokens Dosovitskiy et al. (2020). This inherent complexity poses significant challenges for deploying ViTs in resource-constrained environments such as mobile devices and embedded systems, where energy efficiency and low latency are critical

Recently, research in neural network efficiency to mitigate these demands has explored various strategies including model pruning Pan et al. (2023); Yu and Wu (2023); Song et al. (2022), knowledge distillation Yang et al. (2022); Touvron et al. (2021); Hao et al. (2022), and quantization Li and Gu (2023); Sun et al. (2022); Lin et al. (2021). Among these, quantization techniques are particularly effective as they directly reduce the precision of weights and activations, thereby significantly lowering the memory and computational requirements of deep learning models. Traditionally, post-training quantization has been favored for its simplicity as it does not necessitate changes to the training pipeline or retraining of the model. However, this method often results in significant accuracy loss at lower precision levels because the model isn’t optimized for the quantized representation during training Frantar et al. (2022); Chee et al. (2024), limiting its utility for high-performance applications. In contrast, Quantization-Aware Training (QAT) Park et al. (2018) integrates the effects of quantization into the training process itself, simulating quantization effects to typically achieve better accuracy than post-training methods. For example, extreme quantization, like 1-bit models used in Binarized neural networks (BNNs) Courbariaux et al. (2016), which utilize binary weights and activations, significantly decreasing computational and memory demands. Recent adaptations of 1-bit quantization techniques to Transformer models, such as BitNet Wang et al. (2023), and BiVit He et al. (2023) have shown that even severe quantization can maintain performance while substantially cutting resource consumption.
However, these 1-bit models using binary quantization often face challenges in preserving model accuracy due to the extreme reduction in weight precision. To address this limitation, research has ventured into ternary quantization, which offers a more balanced approach. A notable example is "The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits" Ma et al. (2024), which explores 1.58-bit quantization where weights can assume values of -1, 0, or 1. This approach refines the balance between performance and computational demands by introducing a zero value, which significantly reduces computational overhead. The inclusion of a non-polar weight (zero) not only allows for sparsity, thereby reducing the number of active computations but also maintains a richer representation than binary weights, potentially leading to less information loss. The success of this quantization strategy in large language models suggests its promising applicability to Vision Transformers, enabling more efficient processing of visual data while preserving model accuracy.
To address the unique demands of large-scale ViT models, we introduce ViT-1.58b, a 1.58-bit quantized ViT model. ViT-1.58b utilizes ternary quantization to optimize both memory and computational efficiency while maintaining competitive performance. This approach leverages the benefits of extreme quantization demonstrated in language models, adapting them to the context of computer vision. Our contributions are summarized as follows:
-
•
We propose ViT-1.58b, the first 1.58-bit quantized ViT model, optimized for efficient scaling in terms of both memory and computation.
-
•
We demonstrate the effectiveness of ViT-1.58b on the CIFAR-10 and ImageNet-1k datasets, showing competitive accuracy with significant reductions in memory and computational costs.
-
•
We provide a comprehensive evaluation, comparing ViT-1.58b with state-of-the-art quantization methods and full-precision ViT models, highlighting its advantages in resource-constrained environments.
2 Methods
As shown in Figure 1, our ViT-1.58b architecture is primarily based on ViT for image classification. The process begins by dividing the input image into patches, followed by applying a linear projection to the flattened patches. These patches then undergo patch and position embedding, as well as class embedding, before being fed into the transformer encoder. The output from the transformer encoder is processed through an MLP to produce the final classification prediction. We employ BitLinear layers from BitNet b1.58 Ma et al. (2024) to replace the conventional nn.Linear layers in the transformer encoder. Different quantization functions are employed to quantize the weights to 1.58-bit precision and the activations to 8-bit precision, ensuring both efficiency and performance. Next, we will introduce how we implement BitLinear layers to achieve 1.58-bit weights and 8-bit activations.
Weights Quantization In the ViT-1.58b, the 1.58-bit weights are achieved using the absmean quantization function that constrains the weights to {-1, 0, 1}. Specifically, we first scale the weight matrix by its average absolute value, thus obtaining , where is a small floating-point number to avoid division by zero and ensure numerical stability, and is the average absolute value of the weight matrix, calculated as:
| (1) |
Then, we round each value in the scaled matrix to the nearest integer among -1, 0, +1:
| (2) |
| (3) |
This RoundClip function rounds the input value to the nearest integer and clips it within the specified range .
Using this method, we can convert the weight matrix into a ternary matrix , where each weight value is constrained to {-1, 0, 1}.
Activations Quantization. Following Dettmers et al. (2022), activations are quantized with b-bit precision by absmax quantization function that scales the activations to the range , where . In the proposed ViT-1.58b, we set , meaning that the activations are quantized to 8-bit precision, providing a balance between computational efficiency and maintaining sufficient precision for effective performance as described in Ma et al. (2024). The activations quantization process is described as follows:
| (4) |
where , representing the maximum absolute value of the activations, and the Clip function ensures that the scaled values are confined within the specified range , defined as:
| (5) |
The core component of ViT-1.58b is the BitLinear layer, which replaces the traditional nn.Linear layer in the Transformer. Initially, the activations undergo a normalization layer Ba et al. (2016) to ensure that the activation values have a variance of 1 and a mean of 0, mathematically represented as . Following this, normalized activations are quantized using the absmax quantization function, resulting in . With weights quantized to 1.58-bit precision, matrix multiplication results in the output , and the output is subsequently dequantized to rescaled with and to the original precision, expressed as , where
These steps collectively enable the BitLinear layer to maintain the performance of the Transformer model while significantly reducing computational cost and storage requirements.
Training Strategy During training, we employ the Straight-Through Estimator (STE) Bengio et al. (2013) to handle non-differentiable functions such as the sign and clip functions in the backward pass. The STE allows gradients to flow through these non-differentiable functions, enabling effective training of the quantized model.
Additionally, we use mixed precision training, where weights and activations are quantized to low precision, but gradients and optimizer states are kept in high precision to ensure training stability and accuracy.
3 Experiments and Results
Experimental Setting. We evaluate our ViT-1.58b model on two datasets, CIFAR-10 Krizhevsky et al. (2009) and ImageNet-1k Deng et al. (2009), comparing it with several versions of the Vision Transformer Large (ViT-L): the full-precision ViT-L (i.e. 32-bit precision), and the 16-bit, 8-bit, and 4-bit inference versions in terms of memory cost, training loss, test accuracy for CIFAR-10, and Top-1 and Top-3 accuracy for ImageNet-1k.
The computational framework for this study comprised four NVIDIA TESLA A100 GPUs, each with 80 GB of VRAM. The system’s processing core utilized an AMD EPYC 7552 48-core Processor with 80 GB of system RAM to manage extensive datasets efficiently. We employed PyTorch version 2.0.0 integrated with CUDA 11.8, optimizing tensor operations across GPUs.
| Method | Memory Cost | CIFAR-10 | ImageNet-1k | ||
|---|---|---|---|---|---|
| train loss | test acc. | Top-1 | Top-3 | ||
| ViT-L | 1.14G | 0.024 | 76.28 | 76.54 | 90.23 |
| 16bit Inference ViT-L | 585M | - | 74.61 | 75.29 | 87.44 |
| 8bit Inference ViT-L | 293M | - | 72.20 | 74.11 | 85.26 |
| 4bit Inference ViT-L | 146M | - | 70.69 | 70.88 | 82.50 |
| ViT-1.58b-L (ours) | 57M | 0.026 | 72.27 | 74.25 | 85.78 |
Results. Table 1 shows the performance of the ViT-L model across different bit precisions evaluated on two widely recognized datasets: CIFAR-10 and ImageNet-1k. The results highlight how the reduction in bit precision from full precision (ViT-L) to lower bit configurations (16-bit, 8-bit, 4-bit, and 1.58-bit) affects the model’s effectiveness in terms of training loss, test accuracy, and top-k accuracy metrics.

For CIFAR-10, the full-precision ViT-L model achieved a test accuracy of 76.28%, which serves as a baseline for comparison. When the bit precision was reduced to 16-bit, there was a moderate decline in accuracy to 74.61%. Further reduction to 8-bit and 4-bit resulted in more pronounced declines to 72.20% and 70.69%, respectively. This trend suggests that lower bit precision generally degrades the model’s performance, likely due to the increased quantization error and reduced capacity to capture the variability in the data. The proposed 1.58-ViT-1.58b-L model, which operates at an even lower bit precision than the other quantized variants, recorded a test accuracy of 72.27%. Interestingly, the performance of this model is closer to the 8-bit version than to the 4-bit.
On the more complex and diverse ImageNet-1k dataset, a similar pattern is observed. The full-precision ViT-L model achieved a Top-1 accuracy of 76.54% and a Top-3 accuracy of 90.23%. Reduction to 16-bit precision caused declines to 75.29% and 87.44% in Top-1 and Top-3 accuracies, respectively. These declines became more substantial at 8-bit (Top-1: 74.11%, Top-3: 85.26%) and 4-bit (Top-1: 70.88%, Top-3: 82.50%). The 1.58-bit model managed a Top-1 accuracy of 74.25% and a Top-3 accuracy of 85.78%, showcasing a performance that surpasses the 8-bit version in Top-1 accuracy and nearly matches it in Top-3 accuracy.
As shown in Figure 2, ViT-1.58b-L shows promising results in both training loss and memory consumption compared to the full-precision ViT-L and its quantized versions. The left panel depicts training loss curves, where ViT-1.58b-L’s loss closely follows that of the full-precision ViT-L. This suggests that the 1.58-bit quantization retains the model’s learning capacity effectively. The right panel highlights the memory consumption. The full-precision ViT-L requires 1.14 GB of memory, while ViT-1.58b-L drastically reduces this to just 57 MB. This significant reduction in memory usage makes our model ideal for deployment in resource-constrained environments. Overall, our ViT-1.58b-L model balances competitive performance with substantial memory savings, demonstrating its efficiency and practicality for real-world applications.
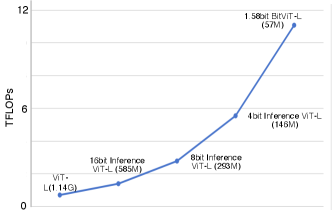
In Figure 3, as bit precision decreases, computational performance (measured in TFLOPs) significantly increases. Full-precision achieves 0.692 TFLOPs, while ours reaches 11.069 TFLOPs. This substantial increase in performance with lower precision highlights the efficiency gains achievable through extreme quantization. Our model offers a dramatic boost in computational throughput, making it highly suitable for high-performance computing environments where both speed and resource efficiency are critical.
4 Conclusion
In this paper, we introduced ViT-1.58b, a 1.58-bit quantized Vision Transformer that efficiently addresses computational and memory challenges in vision model deployment through ternary quantization. Our results show that ViT-1.58b achieves competitive accuracy on benchmarks like CIFAR-10 and ImageNet-1k with significantly lower resource requirements. This model demonstrates the potential of advanced quantization techniques in complex Transformer architectures, highlighting their role in developing sustainable AI solutions. Future work will explore ViT-1.58b’s scalability and integration into larger systems, enhancing its practical utility and environmental benefits.
5 Limitations
While the ViT-1.58b model exhibits promising performance and demonstrates efficient computational usage, it also presents certain limitations that need to be addressed. This section outlines the primary challenges associated with our approach.
Requirement for Pre-Training. One significant limitation of the ViT-1.58b architecture is the necessity for pre-training the ViT model from scratch when applying our ternary quantization techniques. This requirement can significantly raise the barrier to entry for utilizing our proposed model, as pre-training demands extensive computational resources and time. Organizations or individuals with limited access to such resources might find it challenging to adopt this technology without pre-trained models readily available. Moreover, pre-training introduces additional complexity in ensuring the robustness and generalizability of the model before it can be deployed effectively.
Training Difficulty. Another critical challenge is the increased difficulty in training the 1.58-bit ViT model compared to its full-precision counterpart. During our experiments, as shown in Figure 2, we observed that training the 1.58-bit ViT on CIFAR-10 required approximately 250 epochs to achieve a training loss around 0.026, whereas the standard ViT could reach a comparable loss of 0.024 in just 200 epochs. This increased training duration for the 1.58-bit model suggests a lower learning efficiency, likely due to the reduced precision and the consequent limitations in the model’s capacity to capture detailed feature representations.
References
- Ba et al. (2016) Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. 2016. Layer normalization. arXiv preprint arXiv:1607.06450.
- Bengio et al. (2013) Yoshua Bengio, Nicholas Léonard, and Aaron Courville. 2013. Estimating or propagating gradients through stochastic neurons for conditional computation. arXiv preprint arXiv:1308.3432.
- Chee et al. (2024) Jerry Chee, Yaohui Cai, Volodymyr Kuleshov, and Christopher M De Sa. 2024. Quip: 2-bit quantization of large language models with guarantees. Advances in Neural Information Processing Systems, 36.
- Courbariaux et al. (2016) Matthieu Courbariaux, Itay Hubara, Daniel Soudry, Ran El-Yaniv, and Yoshua Bengio. 2016. Binarized neural networks: Training deep neural networks with weights and activations constrained to+ 1 or-1. arXiv preprint arXiv:1602.02830.
- Deng et al. (2009) Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee.
- Dettmers et al. (2022) Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. 2022. Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale. Advances in Neural Information Processing Systems, 35:30318–30332.
- Dosovitskiy et al. (2020) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. 2020. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929.
- Frantar et al. (2022) Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. 2022. Optq: Accurate quantization for generative pre-trained transformers. In The Eleventh International Conference on Learning Representations.
- Graham et al. (2021) Benjamin Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, and Matthijs Douze. 2021. Levit: a vision transformer in convnet’s clothing for faster inference. In Proceedings of the IEEE/CVF international conference on computer vision, pages 12259–12269.
- Hao et al. (2022) Zhiwei Hao, Jianyuan Guo, Ding Jia, Kai Han, Yehui Tang, Chao Zhang, Han Hu, and Yunhe Wang. 2022. Learning efficient vision transformers via fine-grained manifold distillation. Advances in Neural Information Processing Systems, 35:9164–9175.
- He et al. (2023) Yefei He, Zhenyu Lou, Luoming Zhang, Jing Liu, Weijia Wu, Hong Zhou, and Bohan Zhuang. 2023. Bivit: Extremely compressed binary vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 5651–5663.
- Krizhevsky et al. (2009) Alex Krizhevsky, Geoffrey Hinton, et al. 2009. Learning multiple layers of features from tiny images.
- Li and Gu (2023) Zhikai Li and Qingyi Gu. 2023. I-vit: integer-only quantization for efficient vision transformer inference. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 17065–17075.
- Lin et al. (2021) Yang Lin, Tianyu Zhang, Peiqin Sun, Zheng Li, and Shuchang Zhou. 2021. Fq-vit: Post-training quantization for fully quantized vision transformer. arXiv preprint arXiv:2111.13824.
- Liu et al. (2021) Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. 2021. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022.
- Ma et al. (2024) Shuming Ma, Hongyu Wang, Lingxiao Ma, Lei Wang, Wenhui Wang, Shaohan Huang, Li Dong, Ruiping Wang, Jilong Xue, and Furu Wei. 2024. The era of 1-bit llms: All large language models are in 1.58 bits. arXiv preprint arXiv:2402.17764.
- Pan et al. (2023) Bowen Pan, Rameswar Panda, Rogerio Schmidt Feris, and Aude Jeanne Oliva. 2023. Interpretability-aware redundancy reduction for vision transformers. US Patent App. 17/559,053.
- Park et al. (2018) Eunhyeok Park, Sungjoo Yoo, and Peter Vajda. 2018. Value-aware quantization for training and inference of neural networks. In Proceedings of the European Conference on Computer Vision (ECCV), pages 580–595.
- Song et al. (2022) Zhuoran Song, Yihong Xu, Zhezhi He, Li Jiang, Naifeng Jing, and Xiaoyao Liang. 2022. Cp-vit: Cascade vision transformer pruning via progressive sparsity prediction. arXiv preprint arXiv:2203.04570.
- Sun et al. (2022) Mengshu Sun, Haoyu Ma, Guoliang Kang, Yifan Jiang, Tianlong Chen, Xiaolong Ma, Zhangyang Wang, and Yanzhi Wang. 2022. Vaqf: fully automatic software-hardware co-design framework for low-bit vision transformer. arXiv preprint arXiv:2201.06618.
- Touvron et al. (2021) Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Hervé Jégou. 2021. Training data-efficient image transformers & distillation through attention. In International conference on machine learning, pages 10347–10357. PMLR.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems, 30.
- Wang et al. (2023) Hongyu Wang, Shuming Ma, Li Dong, Shaohan Huang, Huaijie Wang, Lingxiao Ma, Fan Yang, Ruiping Wang, Yi Wu, and Furu Wei. 2023. Bitnet: Scaling 1-bit transformers for large language models. arXiv preprint arXiv:2310.11453.
- Yang et al. (2022) Zhendong Yang, Zhe Li, Ailing Zeng, Zexian Li, Chun Yuan, and Yu Li. 2022. Vitkd: Practical guidelines for vit feature knowledge distillation. arXiv preprint arXiv:2209.02432.
- Yu and Wu (2023) Hao Yu and Jianxin Wu. 2023. A unified pruning framework for vision transformers. Science China Information Sciences, 66(7):179101.
- Yuan et al. (2021) Li Yuan, Yunpeng Chen, Tao Wang, Weihao Yu, Yujun Shi, Zi-Hang Jiang, Francis EH Tay, Jiashi Feng, and Shuicheng Yan. 2021. Tokens-to-token vit: Training vision transformers from scratch on imagenet. In Proceedings of the IEEE/CVF international conference on computer vision, pages 558–567.