Video2StyleGAN: Encoding Video in Latent Space for Manipulation
Abstract
Many recent works have been proposed for face image editing by leveraging the latent space of pretrained GANs. However, few attempts have been made to directly apply them to videos, because 1) they do not guarantee temporal consistency, 2) their application is limited by their processing speed on videos, and 3) they cannot accurately encode details of face motion and expression. To this end, we propose a novel network to encode face videos into the latent space of StyleGAN for semantic face video manipulation. Based on the vision transformer, our network reuses the high-resolution portion of the latent vector to enforce temporal consistency. To capture subtle face motions and expressions, we design novel losses that involve sparse facial landmarks and dense 3D face mesh. We have thoroughly evaluated our approach and successfully demonstrated its application to various face video manipulations. Particularly, we propose a novel network for pose/expression control in a 3D coordinate system. Both qualitative and quantitative results have shown that our approach can significantly outperform existing single image methods, while achieving real-time (66 fps) speed.
1 Introduction
Generative Adverserial Networks (GANs) has been actively studied and adapted in many computer vision tasks like image/video generation [23, 35, 46], editing[56, 21, 3] and restoration[15, 20]. Recent works, including BigGAN [12], ProGAN [28] and StyleGAN [31, 32, 29, 30], focus on high-fidelity image synthesis. Among these works, StyleGAN is widely used in image editing, since its disentangled latent space is suitable for manipulating image attributes. Its latent space is often extended to by varying the input to the hierarchical structure of StyleGAN (ranging from lower to higher resolution layers), providing more flexibility in controlling the output image. To edit an existing image in , its equivalent latent vector must be found so that the pretrained StyleGAN can reconstruct the input image. This process is called GAN inversion in the literature. GAN inversion and latent editing for single image have been explored in many works, including optimization [1, 2] and deep-learning [39, 44, 5, 50].

On the other hand, although many sophisticated video editing algorithms are developed [42, 43, 49, 55] due to the demand in many real-world applications, few have discussed the possibility of video editing in latent space. One important advantage of latent space video editing is that, leveraging the prior knowledge from pretrained StyleGAN, complex facial structures do not need to be specifically considered, e.g. generating teeth for the edited lips. In this paper, we aim at solving the video-based GAN inversion problem for face video manipulation in the StyleGAN latent space. To solve this problem, there are three challenges that need to be handled.
First, video encoding and editing require temporal consistency. Any previous image-based GAN inversion method inevitably suffers from inaccuracy in the encoding. Without considering temporal information, these inaccuracies can lead to visual jitters in facial appearance, lighting and background in videos. Figure 1(b) shows the accumulated RMSE magnitude map among 6 spatially aligned neighbor frames in the video. It can be observed that image GAN inversion methods like pSp [39] yield temporally inconsistent results (2nd row). The temporal inconsistencies are usually difficult to model, because the difference caused by jitters is often much smaller than that caused by the video content changes. Inspired by the observation that the majority of the visual jitters reside in the higher resolution layers of StyleGAN, we design a novel video encoding network that reuses the higher resolution portion of the latent vector from the previous frames to reduce visual jitters. Specifically, our encoding network adapts the vision transformer (ViT) [19] structure, which enables easy incorporation of previous frame information. Basically, the network takes the current frame and the latent vector of the previous frame as inputs. It then infers the low resolution layers of latent vector, while the high resolution layers remain the same as the previous frame. Our approach successfully avoids visual jitters and achieves good visual temporal consistency in the resulting video (see 3rd row in Fig. 1(b) and supplementary video #2 ).
Second, the speed of video-based GAN inversion should be fast enough for real applications. Optimization based methods [1, 2, 56] usually require hundreds of iterations to encode a single image, which is prohibitive to live stream video and long videos. Although learning based methods [39, 44, 5] are faster thanks to the adaptation of hierarchical deep convolutional structures, they are still far from real-time. In contrast, our proposed transformer-based framework has an average 15ms/frame (66 fps, see Table. 1) speed in the GAN inversion, which is the first method that achieves real-time performance to our best knowledge.
Last, but most important, subtle expressions and motions like eye blinking and dynamic wrinkles, are critical for reconstructing a high-fidelity face video. However, the accuracy of poses and expressions has not been discussed and evaluated in existing GAN inversion works. These works usually have a strict requirement that the input must reside in the same domain of StyleGAN generated images, with faces aligned to the center. One may argue that face alignment can be done as a pre-processing. Nevertheless, various facial expressions that are not the training set of StyleGAN are still challenging for these works. As a result, these methods usually fail catastrophically in videos because video faces are not aligned properly. As examples shown in Figure 1(a), the image method pSp [39] is less accurate in identity (left and right example) and expression (closed eyes in the middle example). It also produces ambiguous results, like partial glasses in the right example. To solve the alignment problem, in our work, we introduce a novel sparse face landmark loss and a novel dense 3D face mesh loss (Sec. 3.3). Note that although explicit 2D facial landmarks are often used in face manipulation works [36, 57], our approach differs from other methods by leveraging raw feature maps of a landmark detector to implicitly guide the video encoding network with high-level face pose and expression information, yielding significantly more accurate GAN inversion than existing methods (See Fig. 1 and Sec. 4.2).
To summarize, our contribution includes:
• We design a novel video-based GAN inversion network that leverages the continuity of video frames (Sec. 3.2). To the best of our knowledge, our work is the first GAN inversion model that considers temporal consistency and is specifically designed for videos.
• Our efficient network design makes inversion fast enough for video applications. Our approach achieves real-time performance (66 FPS) and is significantly faster than existing GAN inversion methods (Table. 1).
• We introduce a novel sparse face landmark loss and a dense 3D face mesh loss, which enables accurate inversion of faces with arbitrary pose and expression.
• We successfully exhibit various video manipulations and propose a novel network for pose/expression control in 3D coordinates for face videos.
2 Related Work
GAN Inversion is a relatively new concept in vision tasks. Early ideas use it to quantify model collapse in GAN [10] or edit general image to obey high-level semantics [9]. StyleGAN and its subsequent works [31, 32, 29, 30] enables high fidelity image generation. Motivated by StyleGAN, many works utilize its disentangled latent space for image manipulation. There are two typical approaches: optimization based and learning based. Image2StyleGAN [1, 2] optimize the input latent vector so that the input image can be reconstructed by a pretrained StyleGAN. Learning based approach pSp [39] and its subsequent work e4e [44] train a pyramid network structure to infer the latent vectors at different spatial resolutions. ReStyle [5] introduces an iterative refinement mechanism to pSp and e4e, leading to improved results. Beyond image domain accuracy, many works also argue that GAN inversion results must remain editable in the latent space. Following this line, works like IDInvert [56] and Editing in Style [16] focus on discovering semantics in the StyleGAN latent space.

Semantic Manipulation in Latent Space. The success of GANs on producing photo-realistic images has brought increasing attention to understanding the latent space of pretrained GANs, which is usually considered as Riemannian manifold [33, 6]. Some early works [37, 47, 38] have tried simple arithmetic operations or interpolation of synthesis images in latent space to generate new images. To semantically control the image generation, one solution is to identify the interpretable direction of image transformation and then navigate along this direction in the latent space for a given attribute, such as age, expression, and lighting [40, 4, 17, 22, 27]. As a result, the control is to characterize more or less of an image attribute. Another interesting work by Jahanian et al. [27] is to explore the “steerability” of GANs in latent space to conduct simple transformations such as camera movements and image color changes. On the other hand, some recent works [48, 25, 41] try to identify the manipulation directions in an unsupervised way by leveraging eigenvector decomposition. But, they need to manually select meaningful directions.
One application of latent space manipulation is semantic face editing, which aims at manipulating a target facial attribute while keeping other information unchanged. To this end, some works [14, 45, 8, 34, 52, 53, 18] propose various strategies to train new disentangled GAN models for semantic editing. Recently, more attentions have been shifted to conduct face editing inside the latent space of learned GAN models [39, 44, 56, 16, 40, 1]. Different from face image editing, we aim at learning a disentangled space for face video manipulation, which was rarely explored. As discussed in Sec. 1, our proposal can solve all three challenges in face video manipulation.
3 Embedding Video in Latent Space
3.1 Background
The StyleGAN [31, 32, 29, 30] generator consists of a 9-level pyramid structure operating on spatial resolution from to . Using adaptive instance normalization (AdaIN) [26], the 18 512-dimension vectors, often called styles, are injected into different resolution levels to control the appearance of the output image. The lower-resolution layers control the high-level layout/shape of the face, while the higher-resolution layers control the face details. The space of these vectors is denoted as . In our work, a pretrained StyleGANv2 [32] generator is treated as a black-box renderer. Our goal is to project each frame of the video into a latent vector in , so that the pretrained StyleGAN reconstructs the exact input frame.
As discussed in Sec. 1, video GAN inversion has three challenges: I. Keeping the temporal consistency between consecutive output frames; II. Running at real-time; III. Retaining subtle motion and expression. We will try to solve these challenges in this work.
3.2 Our Framework
Inspired by the structure of StyleGAN, many single image GAN inversion works [39, 44, 50] use a hierarchical structure, which encodes the input image into the latent vectors. For the video GAN inversion, however, in order to follow the same structure, we need to adapt some recurrent structures like convolutional LSTM to incorporate temporal information. But, such designs not only make the network difficult to train due to the high GPU memory demand, but also is inefficient. Unlike existing GAN inversion works, we adapt a vision transformer (ViT) [19] in our framework. It unwraps the input image into patches and embeds them into a low dimensional space. Its benefit is twofold: 1) It embeds neighbor frames into the same space, which enables involving temporal information at minimum cost; 2) It is efficient in speed. So, it can solve Challenge I and II simultaneously.
For simplicity, we use “encoding” to represent GAN inversion in the rest of our discussion. Fig. 2 depicts the overview structure of our framework, which consists of the Single Frame Encoding Network (FrEN) and Video Encoding Network (ViEN). The FrEN is trained to encode each frame separately. It directly regresses the vector from the class token of ViT as shown in Fig. 2(a). As aforementioned, encoding a video frame-by-frame will cause visual jitters in videos. To remove jitters, the ViEN also takes the latent vector of the previous frame as input, other than the current frame. The first frame of a video is encoded by the FrEN.
To illustrate the importance of temporal consistency, we visualize the jitters in Fig. 3. We align 6 reconstructed neighbor frames to their center frame and compute the accumulated root mean square error (RMSE) between the aligned neighbor frame and the center one. The total RMSE is shown at the bottom of each error map. A larger value (red color) indicates the reconstructed video has more visual jitters. In the 2nd column, although the individual frames are reasonably reconstructed from the latent vectors, single frame encoding results in large visual jitters (e.g. lighting and facial appearance). Such jitters are obvious in human eyes, please watch our supplementary video #2 for better effects. In our experiment, we observe that these appearance jitters originate from the higher resolution layers in StyleGAN. So we try to use a Gaussian filter to smooth the 9-18 layers of along the time dimension. The results in the 3rd column of Fig. 3 indicate the Gaussian smoothing can alleviate the jitters to some extend. However, the naive smoothing in the latent space can also average out the motion of the face as shown in the supplementary video #2. This may due to that the face pose is not completely disentangled in the space. To remove jitters, we need to fix the high resolution layers in , and also appropriately compensate the face motion caused by directly using high resolution layers from the previous frame.

Let us denote the high and low resolution layers of the latent vector as and , respectively. As shown in Fig. 2(b), the input of the ViEN is the current frame and the latent vector from the previous frame. Using an MLP projector, we encode the latent vector from the previous frame as an extra embedding input for the “video transformer”. The output of the ViEN is the lower resolution layers . We obtain the encoded latent vector as , where represents concatenation. Please note that at inference time, is the output of ViEN of the previous frame. The first frame of a video is actually encoded by the FrEN. The final reconstructed frame can be rendered by a pretrained StyleGAN as: , where denotes the video encoding network.

3.3 Loss Functions
Having guaranteed temporal consistency by reusing the high resolution portion of the latent vector (Sec. 3.2), we design losses solely focusing on high fidelity reconstruction of the face for an individual frame. Image GAN inversion works have proved the effectiveness of and perceptual loss, which directly evaluate the similarity between the input and reconstructed image. Let the current frame be and the latent vector of last frame as . The loss in our training is then defined as:
| (1) |
LPIPS [54] loss compares extracted intermediate features via a pretrained backbone network to evaluate the perceptual similarity between two images. We apply LPIPS loss to further enhance the image quality:
| (2) |
where both VGG and AlexNet are used as the backbone.
Most importantly, as discussed in Challenge III, being able to accurately encode the facial expression and motion is critical for video encoding. This did not gain attention in previous works, since human vision is not sensitive to the subtle discrepancy in still comparisons. However, in videos, people tend to easily observe inaccurate face motions (e.g. eye blink). To tackle this challenge, we seek to leverage high-level face information, i.e. sparse facial landmarks and dense 3D face mesh, to guide the network to implicitly capture the face motion. As a result, we propose a sparse facial landmark loss, which enforces the reconstructed face to have the same detected landmarks as the input face. This loss is defined based on the 2D FAN [13] landmark detector:
| (3) |
FAN estimates the position of 68 facial landmarks using on the 68 channel heatmaps inferred by the network, which is not differentiable. Therefore, in Eqn. 3, we define the landmark loss over the intermediate heatmaps ( and are the frame height and width) to evaluate the landmark similarity between the input frame and the reconstructed one. It is worth noting that, our way to define the loss differs from most previous face landmark losses [36, 57] which utilize L2 loss on explicit 2D facial landmarks. The continuous feature maps can preserve the original response from a face landmark detector, which provides more implicit guidance for the training of the video encoding network.
In addition, some face motions (e.g., lifting eyebrows) cannot be accurately described by sparse facial landmarks. Hence, we further use 3DDFAv2 [24] to model these face geometry details. Based on the dense 3DMM [11] mean face mesh, 3DDFAv2 [24] estimates the shape and expression parameters so that the geometry of the face mesh matches the input image. Let and denote the mean and result 3D face vertices. The relation between the input frame and the result 3D mesh can be written as:
| (4) |
where and are the principal components of identity and expression provided by 3DMM; , , and are the identity, expression and rigid transformation parameters inferred by 3DDFAv2. We then define the dense 3D loss as:
| (5) |
As discussed in Sec. 4.2, our sparse facial landmark loss and dense 3D loss enable to handle arbitrary face pose and expression without explicitly face alignment as a pre-processing. The final loss function of our network can be written as:
| (6) |
where , and are regularization values for the corresponding losses.
3.4 Training
To train the video encoding network, we collected a face video dataset ( see Sec. 4.1). The training procedure consists of two stages: First, we set , and and train the network for 90,000 iterations. In our experiment, we observed that the result is initially of poor quality, and 3DDFAv2 [24] mostly returns abnormal face geometries. Therefore, we only apply the soft constraint provided by 2D FAN [13] in this stage.
Second, from the 90,000th iteration, we set , and and train until converge. In this stage, the quality of the encoded frames becomes more suitable for 3DDFAv2. We apply a relatively small weight on the dense 3D loss, so that the training is robust to failure cases in 3DDFAv2.
Since the training of our video encoding network requires knowing the previous frame latent vector, we train the FrEN first using the above procedure. After the FrEN converges, we train the ViEN using two consecutive video frames drawn from our face video dataset. The latent vector of the first frame is inferred by the pretrained single frame encoding network, and the ViEN is trained using the second frame and the latent vector of the first frame. For all training steps, we use the Ranger optimizer following pSp [39]. The learning rate is set to 0.0001.

4 Experiments
4.1 Dataset
To train the video GAN inversion network, we collected a dataset containing 16300 face videos from the Internet. The number of frames in each video is between 50 and 100. For each frame, we crop the face region with 256x256 resolution. The total number of individual frames is 1,648,849. The sources are TV News and interviews, which cover a wide range of gender, ethnicity, appearance and expression. These variations play an important role in training the pose-aware video GAN inversion and the pose editing network.
4.2 Video StyleGAN Inversion
For the GAN inversion task, we seek to obtain a sequence of latent vectors so that the pretrained StyleGAN can reconstruct the input video using the latent vectors. We compare our method with learning-based image GAN inversion methods pSp [39], e4e [44], Re-Style [5] and optimization based method Image2StyleGAN [1] and IDInvert [56]. Fig. 4 shows the qualitative comparison.
Example (1) is a relatively neutral expression similar to the images in the StyleGAN training set FFHQ [31]. Example (2) and (3) are typical frames in a talking face video with different expressions compared to FFHQ. Example (4) contains significant expressions, i.e., eye blinking, which is very challenging for existing GAN inversion methods. In general, existing GAN inversion methods fail to properly reconstruct the face in the video due to the variety of facial expressions and head poses. Even if they are able to generate reasonable-looking faces, the result typically contains wrong identity (pSp, e4e and IDInvert in example (1), (3) and (4)) and inaccurate expression (example (4)). Optimization based approach Image2StyleGAN is able to reconstruct identity and expression to some extent, but it may take a significantly longer time to converge to a better result (See Table. 1), and also could not guarantee the visual quality and temporal consistency. Since we introduce losses (Eqn. 3 and Eqn. 5) to implicitly guide the video encoding network, our model automatically perceives the location of the face and is able to handle arbitrary pose and expression. We recommend readers to watch our supplementary video #3 for better comparison, since some attributes of the videos (for example, face motion and temporal consistency) can only be observed in dynamics.
To quantitatively evaluate the performance, we collect a 38 face video test set. In the upper part of Table 1, we evaluate the accuracy of video GAN inversion using a variety of metrics. The PSNR and SSIM measure the image domain similarity. We also include Fréchet inception distance (FID) for the perceptual similarity, since PSNR and SSIM do not evaluate the general fidelity of the reconstructed image. The facial landmark error (LM) is the mean squared error (MSE) between the facial landmarks of the input video and the result, measuring the accuracy of the face pose and expression. To evaluate the temporal consistency of the resulting video, we use the accumulated RMSE of 6 aligned neighbor frames defined in Sec. 3.2, denoted as TC in Table 1.
| PSNR | SSIM | FID | LM | TC | t/frame | |
| pSp [39] | 21.64 | 0.6636 | 93.57 | 110.8 | 0.1967 | 84ms |
| e4e [44] | 20.22 | 0.6247 | 100.5 | 118.6 | 0.2066 | 49ms |
| ReStyle [5] | 23.11 | 0.6973 | 91.59 | 84.05 | 0.2125 | 354ms |
| IDInvert [56] | 18.92 | 0.5696 | 121.9 | 205.6 | 0.2462 | 8s |
| Im2Style [1] | 21.13 | 0.7470 | 100.1 | 4.563 | 0.6871 | 5min |
| Ours | 25.96 | 0.7872 | 39.56 | 2.704 | 0.1483 | 15ms |
| (b) | 25.77 | 0.7655 | 137.2 | 141.4 | 0.1215 | |
| (c) | 23.66 | 0.7363 | 53.14 | 4.325 | 0.1537 | |
| (d) | 23.25 | 0.7314 | 52.75 | 3.830 | 0.1552 | |
| (e) Our Single | 25.52 | 0.7773 | 38.36 | 2.846 | 0.2562 |
In general, existing learning-based single image GAN inversion methods pSp, e4e, ReStyle and IDInvert fail to reconstruct a satisfactory appearance (low PSNR and SSIM, high FID) and expression (high LM) of face videos. Optimization based method Image2StyleGAN [1] is able to reconstruct facial expression details (high SSIM and low LM), but the overall appearance performance (PSNR and FID) remains similar to the learning-based methods. Note that the temporal consistency (TC) of the comparison single image methods are all large, especially Image2StyleGAN [1]. This indicates that existing methods cannot be generalized to videos directly. Our method is significantly better in all the metrics, since our GAN inversion network structure guarantees temporal consistency (Sec. 3.2) and is trained with face-aware losses like sparse face landmark loss (Eqn. 3) and dense 3D face mesh loss (Eqn. 5). Also note the per-frame runtime on the right column, our method is the only real-time method that is realistic for video processing, compared to the prohibitive processing time of IDInvert and Image2StyleGAN.
4.3 Effectiveness of Losses
To demonstrate the effectiveness of the loss design discussed in Sec. 3, we show the comparison of our models trained with different loss setups in Fig. 5. In column (b), the results produced by the network trained only with loss (Eqn. 1) are blurry. Adding the perceptual loss (Eqn. 2) promotes the overall quality of the image in column (c).
However, due to the lack of high-level understanding of face semantics, the accuracy of the face pose(3rd row) and expression (1st and 2nd rows) are not satisfactory. By applying the sparse facial landmark loss (Eqn. 3, our network is able to perceive the facial expression in the video, as shown in column (d). The dense 3D loss (Eqn. 5) further guides our network to capture subtle expression, making the final GAN inversion result accurately reconstructs the input (columns (e) and (f)). Similar to Fig. 3, we include the accumulated RMSE for the result of single frame encoding and video encoding networks. By reusing the high resolution part of the latent vector, our video encoding network is able to reduce the appearance jitters compared to single frame encoding. In the bottom part of Table 1, we also show the quantitative comparisons of these loss setups. Note that although setup (b) and (c) is temporally consistent (low TC) and achieve better PSNR and SSIM, they produce undesired blurry and inaccurate facial expression (high FID and LM) since they are trained solely on image domain losses.
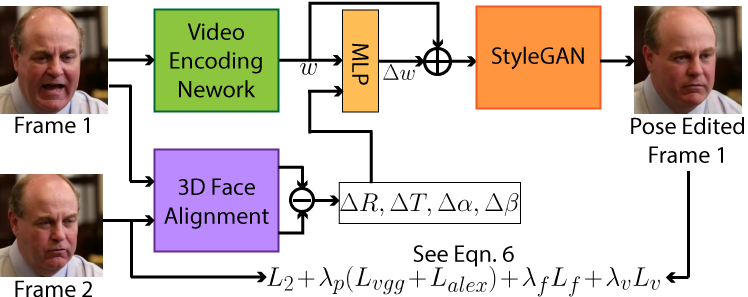
4.4 Pose/Expression Editing
Due to the complexity of the human face, physically modeling and editing the face appearance [42, 43, 49, 55] is difficult in general. One benefit of encoding a video into the latent space is to control the face pose and expression editing, which is important for video generation. Face pose editing is a challenging task, especially for videos. Due to occlusion, part of the face is often invisible in certain frames, e.g. ears and teeth. Adapting the edited face with other regions in the video, e.g. neck and hair, is also difficult. Traditional methods build sophisticated algorithms for face editing, i.e. learning a warp field to transform high dimensional features [49]. However, these methods could be subject to robustness issues due to the complexity of real-world cases.

On the other hand, since StyleGAN latent space encodes the general face semantics, the rendered face is guaranteed to lie in this space, making the pose/expression editing much easier. We are able to focus on changing the face pose/expression, but do not need to put extra effort into maintaining the fidelity of the rendering. Moreover, since temporal consistency is guaranteed by our video encoding network and the same edits are performed on the latent codes, the editing does not need to consider temporal consistency. Our approach of the network is shown in Fig. 6. Thanks to our face video dataset, we are able to train the pose editing network using the complementary face pose variations in the dataset. For each iteration, we select 2 frames ( and ) from the same video clip. To incorporate enough pose and expression difference, and are 10 frames apart. We use 3DDFAv2 [24] to estimate shape , expression , rotation and translation on and . We concatenate the shape difference , expression difference , rotation difference and translation difference as the input of a simple 3-layer MLP, which is responsible for inferring the latent vector displacement . Using our single frame encoding network, we obtain the latent vector for the first frame . Finally, we use the same training losses (Eqn. 6) to enforce the frame reconstructed from to be similar as .

Fig. 7 demonstrates examples on pose and expression editing. Since we define the input based on the 3DMM [11] face model parameters, we are able to edit both pose and expression in a flexible way. Following the coordinate system shown in the upper left image, the face can be rotated in the 3D coordinates. The other parts of the frame, e.g. connection with neck, hair and clothes, are automatically handled. The occlusion relation between face and ears is also handled without any artifacts. In the expression editing (last two columns), although the teeth are not visible in the input frame, our method is able to generate them without any human intervention. Since we have shown that existing single image GAN inversion methods cannot handle videos (Sec. 4.2), they could not produce satisfactory video editing results. Therefore, due to limited space, we only compare with IDInvert [56] and pSp [39] if a pre-trained single image editing model is provided for a task discussed in our paper. Note that they only support binary editing with a specific attribute, and generate artifacts (first two examples) and change identity (third example). Please watch our supplementary video #5 for a better view of the temporal consistency of our results.
4.5 Appearance Editing

Another benefit of our work is the convenient face appearance manipulation. Similar to pose editing, temporal consistency does not need to be considered thanks to our video encoding network. In the first row of Fig. 9, we add a random vector to the latent vectors of a face video, resulting in random faces performing the same face motion. A typical use case of this is protecting the identity in the video by perturbing the look of the person. Following the previous discussion in StyleSpace [51], we can also manipulate individual attributes of the video by adjusting specific dimensions in the StyleSpace. In the second row of Fig. 9, we demonstrate the results of editing individual attributes in the video including lip color, smile, hair color, hairstyle and eye shape.
By learning a fixed direction in the latent space, we can also manipulate the face video with specific semantic meaning. One example is to edit the age of the face in the video. For the implementation details of our age editing network, please refer to the supplementary material. In Fig. 8, we demonstrate the results of our latent space age editing for face videos. Note that wrinkles are learned without explicit efforts to model. On the right part of Fig. 8, we provide age editing results generated by single image method IDInvert [56]. Since the latent codes for video frames have a significantly different distribution from StyleGAN-like images, the pre-trained latent direction of IDInvert produces wrong attributes like glasses (first three examples) and color bias (last example).

4.6 Colorization and Super-Resolution
Apart from face editing in the video, our face video encoder network also enables common image-domain processing as an image-to-image translation task. Colorization is an operation to recover colored video from the grayscale input video. Super-resolution is to increase the resolution of the input video while reconstruct the high frequency visual details. For colorization task, we simply train the video encoding network with grayscale frames. For super-resolution task, we bicubic downsample the input video then upsampling 4x to its original frame size. The training procedure of these tasks are the same as described in Sec. 3.4. With these simple modifications, our model can be adapted to applications like reconstructing color videos (first row) and improve the visual quality of low-resolution videos (second row), as shown in Fig. 10. The pre-trained super-resolution model of pSp [39] yield wrong head pose and identity in videos.
5 Conclusion
We propose a novel network to encode videos into the StyleGAN latent space. By reusing the high resolution part of the latent vector, our network enforces temporal consistency with minimum additional computation compared to single frame encoding. Thanks to our efficient framework, our method achieves real-time performance and is the best compared to existing GAN inversion works. We introduce facial landmark and 3D face mesh to implicitly guide our network to learn high-level face semantics, handling arbitrary face pose and expression and high fidelity reconstruction of the input video. We demonstrate the ability to manipulate face videos in the latent space using our model, including pose/expression editing, appearance editing, colorization and super-resolution. The limitation of our work is that subtle details in the video, like eye gaze and hair dynamics, are not reconstructed well due to the limited expressing power of StyleGAN. We believe that the visual quality can be improved using more powerful GANs and loss functions in future works.
References
- [1] Rameen Abdal, Yipeng Qin, and Peter Wonka. Image2stylegan: How to embed images into the stylegan latent space? In ICCV, 2019.
- [2] Rameen Abdal, Yipeng Qin, and Peter Wonka. Image2stylegan++: How to edit the embedded images? In CVPR, 2020.
- [3] Rameen Abdal, Peihao Zhu, Niloy J. Mitra, and Peter Wonka. Styleflow: Attribute-conditioned exploration of stylegan-generated images using conditional continuous normalizing flows. ACM Trans. Graph., 40(3), May 2021.
- [4] Rameen Abdal, Peihao Zhu, Niloy J Mitra, and Peter Wonka. Styleflow: Attribute-conditioned exploration of stylegan-generated images using conditional continuous normalizing flows. ACM Transactions on Graphics (TOG), 40(3):1–21, 2021.
- [5] Yuval Alaluf, Or Patashnik, and Daniel Cohen-Or. Restyle: A residual-based stylegan encoder via iterative refinement. In ICCV, 2021.
- [6] Georgios Arvanitidis, Lars Kai Hansen, and Søren Hauberg. Latent space oddity: on the curvature of deep generative models. arXiv preprint arXiv:1710.11379, 2017.
- [7] Sajjad Ayoubi. Facelib. https://github.com/sajjjadayobi/FaceLib, 2020.
- [8] Jianmin Bao, Dong Chen, Fang Wen, Houqiang Li, and Gang Hua. Towards open-set identity preserving face synthesis. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 6713–6722, 2018.
- [9] David Bau, Jun-Yan Zhu, Jonas Wulff, William Peebles, Hendrik Strobelt, Bolei Zhou, and Antonio Torralbaiwei. Gan dissection: Visualizing and understanding generative adversarial networks. In ICLR, 2019.
- [10] David Bau, Jun-Yan Zhu, Jonas Wulff, William Peebles, Hendrik Strobelt, Bolei Zhou, and Antonio Torralbaiwei. Seeing what a gan cannot generate. In ICCV, 2019.
- [11] Volker Blanz and Thomas Vetter. A morphable model for the synthesis of 3d faces. In SIGGRAPH, 1999.
- [12] Andrew Brock, Jeff Donahue, and Karen Simonyan. Large scale GAN training for high fidelity natural image synthesis. In ICLR, 2019.
- [13] Adrian Bulat and Georgios Tzimiropoulos. How far are we from solving the 2d & 3d face alignment problem? (and a dataset of 230,000 3d facial landmarks). In ICCV, 2017.
- [14] Xi Chen, Yan Duan, Rein Houthooft, John Schulman, Ilya Sutskever, and Pieter Abbeel. Infogan: Interpretable representation learning by information maximizing generative adversarial nets. In Proceedings of the 30th International Conference on Neural Information Processing Systems, 2016.
- [15] Mengyu Chu, You Xie, Jonas Mayer, Laura Leal-Taixé, and Nils Thuerey. Learning temporal coherence via self-supervision for gan-based video generation. ACM Trans. Graph., 39(4), July 2020.
- [16] Edo Collins, Raja Bala, Bob Price, and Sabine Susstrunk. Editing in style: Uncovering the local semantics of gans. In CVPR, 2020.
- [17] Emily Denton, Ben Hutchinson, Margaret Mitchell, and Timnit Gebru. Detecting bias with generative counterfactual face attribute augmentation. arXiv e-prints, pages arXiv–1906, 2019.
- [18] Chris Donahue, Zachary C Lipton, Akshay Balsubramani, and Julian McAuley. Semantically decomposing the latent spaces of generative adversarial networks. arXiv preprint arXiv:1705.07904, 2017.
- [19] Dosovitskiy et al. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR, 2021.
- [20] Ledig et al. Photo-realistic single image super-resolution using a generative adversarial network. In CVPR, 2017.
- [21] Tewari et al. Stylerig: Rigging stylegan for 3d control over portrait images. In CVPR, 2020.
- [22] Lore Goetschalckx, Alex Andonian, Aude Oliva, and Phillip Isola. Ganalyze: Toward visual definitions of cognitive image properties. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 5744–5753, 2019.
- [23] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In NeurIPS, 2014.
- [24] Jianzhu Guo, Xiangyu Zhu, Yang Yang, Fan Yang, Zhen Lei, and Stan Z Li. Towards fast, accurate and stable 3d dense face alignment. In ECCV, 2020.
- [25] Erik Härkönen, Aaron Hertzmann, Jaakko Lehtinen, and Sylvain Paris. Ganspace: Discovering interpretable gan controls. arXiv preprint arXiv:2004.02546, 2020.
- [26] Xun Huang and Serge Belongie. Arbitrary style transfer in real-time with adaptive instance normalization. In ICCV, 2017.
- [27] Ali Jahanian, Lucy Chai, and Phillip Isola. On the” steerability” of generative adversarial networks. arXiv preprint arXiv:1907.07171, 2019.
- [28] Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen. Progressive growing of gans for improved quality, stability, and variation. In ICLR, 2018.
- [29] Tero Karras, Miika Aittala, Janne Hellsten, Samuli Laine, Jaakko Lehtinen, and Timo Aila. Training generative adversarial networks with limited data. In Proc. NeurIPS, 2020.
- [30] Tero Karras, Miika Aittala, Samuli Laine, Erik Härkönen, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. Alias-free generative adversarial networks. In NeurIPS, 2021.
- [31] Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. In CVPR, 2019.
- [32] Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. Analyzing and improving the image quality of stylegan. In CVPR, 2020.
- [33] Line Kuhnel, Tom Fletcher, Sarang Joshi, and Stefan Sommer. Latent space non-linear statistics. arXiv preprint arXiv:1805.07632, 2018.
- [34] Guillaume Lample, Neil Zeghidour, Nicolas Usunier, Antoine Bordes, Ludovic Denoyer, and Marc’Aurelio Ranzato. Fader networks: Manipulating images by sliding attributes. arXiv preprint arXiv:1706.00409, 2017.
- [35] Mehdi Mirza and Simon Osindero. Conditional generative adversarial nets. arXiv preprint arXiv:1411.1784, 2014.
- [36] Yotam Nitzan, Amit Bermano, Yangyan Li, and Daniel Cohen-Or. Face identity disentanglement via latent space mapping. arXiv preprint arXiv:2005.07728, 2020.
- [37] Guim Perarnau, Joost Van De Weijer, Bogdan Raducanu, and Jose M Álvarez. Invertible conditional gans for image editing. arXiv preprint arXiv:1611.06355, 2016.
- [38] Alec Radford, Luke Metz, and Soumith Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434, 2015.
- [39] Elad Richardson, Yuval Alaluf, Or Patashnik, Yotam Nitzan, Yaniv Azar, Stav Shapiro, and Daniel Cohen-Or. Encoding in style: a stylegan encoder for image-to-image translation. In CVPR, 2021.
- [40] Yujun Shen, Jinjin Gu, Xiaoou Tang, and Bolei Zhou. Interpreting the latent space of gans for semantic face editing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9243–9252, 2020.
- [41] Yujun Shen and Bolei Zhou. Closed-form factorization of latent semantics in gans. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1532–1540, 2021.
- [42] Supasorn Suwajanakorn, Steven M. Seitz, and Ira Kemelmacher-Shlizerman. Synthesizing obama: Learning lip sync from audio. ACM Trans. Graph., 36(4), July 2017.
- [43] J. Thies, M. Zollhöfer, M. Stamminger, C. Theobalt, and M. Nießner. Face2face: Real-time face capture and reenactment of rgb videos. In CVPR, 2016.
- [44] Omer Tov, Yuval Alaluf, Yotam Nitzan, Or Patashnik, and Daniel Cohen-Or. Designing an encoder for stylegan image manipulation. ACM Trans. Graph., 40(4):1–14, 2021.
- [45] Luan Tran, Xi Yin, and Xiaoming Liu. Disentangled representation learning gan for pose-invariant face recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2017.
- [46] Sergey Tulyakov, Ming-Yu Liu, Xiaodong Yang, and Jan Kautz. Mocogan: Decomposing motion and content for video generation. In CVPR, 2018.
- [47] Paul Upchurch, Jacob Gardner, Geoff Pleiss, Robert Pless, Noah Snavely, Kavita Bala, and Kilian Weinberger. Deep feature interpolation for image content changes. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2017.
- [48] Andrey Voynov and Artem Babenko. Unsupervised discovery of interpretable directions in the gan latent space. In International Conference on Machine Learning, pages 9786–9796. PMLR, 2020.
- [49] Ting-Chun Wang, Arun Mallya, and Ming-Yu Liu. One-shot free-view neural talking-head synthesis for video conferencing. In CVPR, 2021.
- [50] Tianyi Wei, Dongdong Chen, Wenbo Zhou, Jing Liao, Weiming Zhang, Lu Yuan, Gang Hua, and Nenghai Yu. A simple baseline for stylegan inversion. arXiv preprint arXiv:2104.07661, 2021.
- [51] Zongze Wu, Dani Lischinski, and Eli Shechtman. Stylespace analysis: Disentangled controls for stylegan image generation. In CVPR, June 2021.
- [52] Taihong Xiao, Jiapeng Hong, and Jinwen Ma. Elegant: Exchanging latent encodings with gan for transferring multiple face attributes. In Proceedings of the European conference on computer vision (ECCV), pages 168–184, 2018.
- [53] Xi Yin, Xiang Yu, Kihyuk Sohn, Xiaoming Liu, and Manmohan Chandraker. Towards large-pose face frontalization in the wild. In Proceedings of the IEEE international conference on computer vision, pages 3990–3999, 2017.
- [54] Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In CVPR, 2018.
- [55] Hang Zhou, Yasheng Sun, Wayne Wu, Chen Change Loy, Xiaogang Wang, and Ziwei Liu. Pose-controllable talking face generation by implicitly modularized audio-visual representation. In CVPR, 2021.
- [56] Jiapeng Zhu, Yujun Shen, Deli Zhao, and Bolei Zhou. In-domain gan inversion for real image editing. In ECCV, 2020.
- [57] Yuhao Zhu, Qi Li, Jian Wang, Cheng-Zhong Xu, and Zhenan Sun. One shot face swapping on megapixels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4834–4844, 2021.
Supplementary Material
A Introduction
This supplementary material is organized as follows. In Sec. B, we discuss the details of our age editing approach mentioned in the Sec. 4.5 of the main paper. In Sec. C, beside Fig. 4 in the main paper, we provide additional qualitative comparison of GAN inversion in videos. All the examples in this supplementary material can be viewed in dynamics in supplementary video #3.
B Age Editing
Our age editing approach is shown in Fig. S1. We seek to learn a fixed direction in the latent space, so that the reconstructed face from is years younger/older than the input face. To learn , we randomly sample a target age and an input frame . Using the pretrained StyleGAN , we obtain the edited frame denoted as :
| (S1) |
We use the pretrained age detector FaceLib [7] to detect the age of the face in the input frame and edited frame. The training loss aims to make the age difference close to :
| (S2) |
where represent the age detected from the frame. In Eqn. S2, to constrain the other attributes of the face, like pose and expression, we also impose the sparse facial landmark loss and dense 3D loss introduced in Sec. 3 in the main paper.
C Additional Comparison
In addition to Fig. 4 in the main paper, we provide more qualitative comparison with pSp [39], e4e [44], ReStyle [5], IDInvert [56] and Image2StyleGAN [1] in Fig. S2. These examples cover various challenging scenarios for high-fidelity GAN inversion: I) Normal head pose: Examples (1), (2), (3), (10), (14), (19), (21), (24) and (26) are talking videos with normal head poses. These type of videos is relatively easy for existing single image GAN inversion methods. II) Large expression: Examples (4), (5), (9), (13), (15), (16), (20), (22), (25) and (27) contains large expression like closed eyes. These videos require high accuracy in GAN inversion since human is sensitive to unnatural face movements in the video. III) Large head pose: Examples (6), (7), (8), (11), (12), (17), (18) and (23) involve with large head pose in the image space. Existing single image GAN inversion methods could not handle this case in general, since they assume center-aligned face in the input image and are not aware of the actual pose and expression of the face.

According to the qualitative results, we have the following observations:
1)It is worth noting that existing GAN inversion methods like pSp, e4e and their subsequent work ReStyle cannot guarantee the accurate identity and expression reconstruction in videos, even for simple cases like examples (1), (2) and (3).
2)IDInvert also fails catastrophically in many videos, e.g., examples (7), (12), (15) and (20). Some of the failure patterns (e.g. (15) and (20) are highly similar, indicating that many input video frames reside outside the domain of FFHQ images and causing the saturation of the pre-trained GAN inversion network. This further support our claim that existing single-image GAN inversion approaches cannot handle videos in a straightforward way.
3)Optimization based method Image2StyleGAN [1] sometimes reconstruct the pose and expression accurately, like examples (2), (5), (7) and (12), but it requires more than 5min (1500 iterations) per frame and the visual quality is still inferior to our method. Although it is possible that their result is able to converge to the input frame exactly, the extremely long processing time is prohibitive to video applications.
4)With high-level facial landmark loss and face mesh loss, our model is able to handle arbitrary pose and expression, even in large pose and expression cases like examples (4), (7), (12) , (17) and (18).
To sum up, our method is the only method that can handle video GAN inversion, and is the only one achieving real-time performance among comparison methods.


