Video-CCAM: Enhancing Video-Language Understanding with Causal Cross-Attention Masks for Short and Long Videos
Abstract
Multi-modal large language models (MLLMs) have demonstrated considerable potential across various downstream tasks that require cross-domain knowledge. MLLMs capable of processing videos, known as Video-MLLMs, have attracted broad interest in video-language understanding. However, videos, especially long videos, contain more visual tokens than images, making them difficult for LLMs to process. Existing works either downsample visual features or extend the LLM context size, risking the loss of high-resolution information or slowing down inference speed. To address these limitations, we apply cross-attention layers in the intermediate projector between the visual encoder and the large language model (LLM). As the naive cross-attention mechanism is insensitive to temporal order, we further introduce causal cross-attention masks (CCAMs) within the cross-attention layers. This Video-MLLM, named Video-CCAM, is trained in a straightforward two-stage fashion: feature alignment and visual instruction tuning. We develop several Video-CCAM models based on LLMs of different sizes (4B, 9B, and 14B). Video-CCAM proves to be a robust Video-MLLM and shows outstanding performance from short videos to long ones. Among standard video benchmarks like MVBench and VideoChatGPT-QA, Video-CCAM shows outstanding performances (1st/2nd/3rd in MVBench and TGIF-QA, 2nd/3rd/4th in MSVD-QA, MSRVTT-QA, and ActivityNet-QA). In benchmarks encompassing long videos, Video-CCAM models can be directly adapted to long video understanding and still achieve exceptional scores despite being trained solely with images and 16-frame videos. Using 96 frames (6 the training number of frames), Video-CCAM models rank 1st/2nd/3rd in VideoVista and 1st/2nd/4th in MLVU among all open-source Video-MLLMs, respectively. We provide a theoretical analysis of its temporal consistency and emphasize several key factors in its architecture through experiments. We hope that Video-CCAM can serve as a straightforward yet robust baseline for future Video-MLLM development. The code is publicly available in https://github.com/QQ-MM/Video-CCAM.
1 Introduction
Large language models (LLMs) such as GPT-4 [33], Gemini [44], and LLaMA3 [32], have significantly reshaped the landscape of artificial intelligence, profoundly impacting our daily lives. These LLMs can engage in text-based conversations with users, meeting their needs and completing specific tasks [61]. Despite their potential as a step towards artificial general intelligence (AGI) assistants, their capabilities are confined to processing natural language. However, human interaction with the world is not limited to language alone; it also encompasses a variety of multi-modal information, such as vision, speech, audio, etc.
To address the language-only limitation, the research community has recently proposed various multi-modal large language models (MLLMs) that integrate additional modalities. Visual modality, especially image, has garnered considerable interest among all modalities. Notable developments include Flamingo [3], which combines pre-trained vision and language models, exhibiting impressive multi-modal few-shot learning capabilities. MiniGPT-4 [64] aligns the visual encoder and Q-Former from BLIP-2 [15] with Vicuna [7] through a single trainable projection layer, achieving advanced vision-language performance. LLaVA [26] further introduces the concept of visual instruction tuning and showcases superior multi-modal abilities across various benchmarks. These pioneering approaches have collectively established a standard pipeline for MLLMs, typically including pre-trained large language models, modality-specific pre-trained encoders, trainable projectors, and datasets for feature alignment and instruction tuning. This framework has proven effective for integrating and leveraging image-text data.
The research field of MLLMs has recently seen a surge in Video-MLLMs [16, 31, 29, 14, 63, 21, 17]. Compared to images with two spatial dimensions, videos have an additional temporal dimension. Therefore, the number of visual tokens is not only related to the spatial resolution but also proportional to the number of video frames, which is difficult to accommodate within the limited context size of LLM. Existing works address this issue from modifying three components of Video-MLLMs, i.e., the LLM, the visual encoder, and the intermediate projector. Some works directly extend the context size of LLMs to hold more visual tokens. LWM [23] gradually increase the number of frames and the context size through multi-stage vision-language training. LongVA [57] first trains long-context LLM and then aligns it with images. However, the computational burden of long-context LLMs is significantly larger than normal ones. Other works adopt pooling [31], downsampling [19, 29, 60], or clustering [14] to directly reduce the number of visual tokens. These approaches are effective but come at the expense of fine-grained information loss. Unlike MLP projectors that do not alter the number of output tokens, cross-attention based projectors (Perceiver [3] and Q-Former [15]) adopt a fixed number of queries to extract relevant information from visual inputs. For example, VideoChat2 [17] uses 96 queries to process video inputs. However, cross-attention mechanism is insensitive to temporal order, which is crucial for accurate video understanding. Besides, these projectors generally have more parameters than MLP projectors.
In this work, we concentrate on the projector to address the abundant visual tokens. Our projector is centered around cross-attention layers, where a fixed number of queries is employed to process videos with different number of frames. This architecture makes it possible to handle extremely large number of video frames at no risk of exceeding the context length. Besides, we make several modifications to better process videos and simplify the training process. First, we propose causal cross-attention masks (CCAMs) within the cross-attention layer, making learnable queries temporally ordered and enhancing the model’s video understanding ability. Second, we simplify the projector structure through reducing the number of layers and increasing the number of queries. We encapsulate our contributions as follows:
-
•
We propose Video-CCAM, an innovative Video-MLLM designed for advanced video-language understanding. Video-CCAM is a flexible model composed of a visual encoder, an LLM, and a projector, which employs cross-attention mechanism to process videos of variable frames and CCAMs to capture the temporal relationship within videos.
-
•
We provide a theoretical analysis on the temporal consistency of CCAM. By treating videos as continuous signals, we demonstrate that the CCAM projector remains consistent for videos with different numbers of frames, making Video-CCAM a reliable Video-MLLM.
- •
2 Related Work
2.1 Image-MLLMs
Images serve as a vital complement to the visual details that text alone cannot convey, thus playing a crucial role in multi-modal learning. Flamingo [3] leverages a pre-trained, frozen vision encoder to process input images and introduces the GATED XATTN-DENSE layer to integrate visual information into language models. However, the high training costs limit its accessibility. With the advancement of LLMs and the emergence of open-source projects [47, 32, 46, 4], there has been a proliferation of studies utilizing these powerful LLMs to create Image-MLLMs. BLIP-2 [15] introduces the Q-Former that connects frozen visual encoders with LLMs, facilitating various image-to-text tasks, including visual knowledge reasoning and conversation. MiniGPT-4 [64] further refines this approach by aligning the visual encoder and Q-Former in BLIP-2 with Vicuna [7] through a single trainable projection layer, resulting in enhanced downstream performance. LLaVA [26] expands the concept of instruction tuning to the visual domain, proposing visual instruction tuning as a follow-up to feature alignment pre-training. LLaVA and its successors [28, 24, 25] demonstrate significant promise in addressing a variety of vision-language tasks. Recent works [52, 5, 48] enhance the capabilities of MLLMs by innovating model architectures, introducing additional training stages, and curating high-quality training datasets, among other strategies.

2.2 Video-MLLMs
As Image-MLLMs continue to mature, researchers are increasingly focusing on videos. Compared to images, videos have an additional temporal dimension, posing additional difficulties and challenges to Video-MLLMs. Similar to their image counterparts, Video-MLLMs primarily utilize two types of projectors: MLPs and Q-Formers [15]. MLP projectors directly convert visual features from the encoder into embeddings. For instance, Video-ChatGPT [31] employs a linear layer to align spatially and temporally pooled video features with the LLM. PLLaVA [51] proposes an pooling strategy to reduce the domain differences between pre-trained image features and video ones. However, MLPs struggle to handle many frames, often forcing a trade-off between spatial resolution and temporal sampling density. Q-Formers output the same number of tokens as the number of learnable queries, independent of the input size. For example, VideoChat [16] employs additional learnable queries to produce aligned visual embeddings. To address the Q-Former’s limited frame differentiation, Vista-LLaMA [30] recursively applies the Q-Former to model the temporal relationships. ST-LLM [27] also applies pre-trained Q-Formers on video frames to obtain compact visual representations. Beyond projectors, Video-MLLMs also face other challenges, particularly regarding the choice of video and image encoders. Since videos are often treated as sequences of images, most studies utilize image encoders to extract frame features, which are subsequently aggregated to represent video features. A majority of works, including VideoChat [16], Video-ChatGPT [31], Valley [29], and Chat-UniVi [14], employ CLIP ViT [40] for processing both video frames and images. Others, such as LLaMA-VID [19], TimeChat [41], and Emu2 [42], opt for EVA CLIP ViT [43] as the visual encoder. Some researchers advocate that pre-trained video encoders are more suitable to capture temporal features. Video-LLaVA [21] underscores the significance of feature alignment across visual modalities and utilizes the visual encoders from LanguageBind [63] for processing visual inputs. UMT-L [18], a pre-trained video foundation model, is employed by VideoChat2 [17] and has shown impressive performance across a range of downstream video-language tasks.
3 Method
As illustrated in Fig. 1, Video-CCAM consists of three principal components: the visual encoder that processes images and videos, the LLM that handles visual and textual embeddings, and the CCAM projector that connects them.
3.1 Visual Encoder
Existing Video-MLLMs generally employ three visual encoding strategies: using an image encoder, a video encoder, or both. In this work, we adopt image encoders for three reasons. Firstly, the generalization capabilities of pre-trained image encoders [40, 43, 54] have been extensively validated, whereas the generalization capabilities of their video counterparts remain underexplored. Secondly, some video encoders have constraints on the number of input frames, whereas image encoders can be applied to arbitrary frames. Video-MLLMs built with these video encoders may give inaccurate responses if the input number of frames is different from that used during training. Lastly, Video-MLLMs with both image and video encoders require additional feature alignment efforts, which are not needed by those with a single encoder. Although most image encoders are not optimized for video processing, we argue that the autoregressive nature of LLMs can compensate for this limitation and enable them to interpret temporal visual tokens effectively.
3.2 Projector
The projector is a crucial intermediary that connects the visual and textual embedding spaces in MLLMs. In this work, we focus on the projector, specifically the cross-attention based projector, to hold the large number of visual tokens in videos. However, naive cross-attention mechanism is insensitive to the temporal order within the video frames, since all queries can attend to all spatial and temporal visual tokens indiscriminately. For simplicity, we focus on one query embedding and one attention head. We denote the key and value functions as , respectively. For image embeddings with length as , the output of the cross-attention layer is computed as follows:
| (1) |
where represents the image embeddings, and is a vector of ones. Subsequently, each query can integrate visual features from all positions. However, when it comes to video embeddings, each query considers visual features from not only all positions but also all moments:
| (2) |
where represents the video embeddings. Under these circumstances, it is possible that the initial queries may focus on the later visual embeddings while the last queries may concentrate on the earlier visual embeddings, which contradicts the LLM’s autoregressive nature and may lead to incorrect responses with respect to the video inputs.
To mitigate this issue, we propose a simple approach by applying causal cross-attention masks (CCAMs), where the cross-attention output for video embeddings is computed as follows:
| (3) |
where if the -th query is accessible to the -th frame . As is generally smaller than , if else , and is the floor function. We visualize the conventional cross-attention mask and our CCAM in Fig. 2. As depicted in Fig. 2, conventional cross-attention masks allow queries to attend to all visual tokens indiscriminately, which hinders the model’s ability to discern temporal order across frames. In contrast, our CCAM, as illustrated in Fig. 2, ensures the initial queries focus on the early visual embeddings while allowing the last queries to access visual embeddings across different moments.


3.3 Temporal consistency
In this work, we use temporal consistency to refer to the ability of the Video-MLLM to 1) effectively process videos with varying, often significantly larger, numbers of frames compared to those encountered during training; and 2) produce consistent outputs for the same video regardless of the number of sampled frames. Owing to the model structure and the training data distribution, some Video-MLLMs may encounter severe performance drops with different sampling strategies. However, a large number of frames is essential for long video understanding, which is significantly different from the training number of frames ( for most Video-MLLMs). Therefore, existing works mostly employ an additional training stage to bridge this gap. Unlike these Video-MLLMs, Video-CCAM, despite being trained with images and 16-frame videos, can directly handle a large number of frames (e.g., 96 in VideoVista [20], MLVU [62], and Video-MME [10]) and shows outstanding performance without additional tuning. We attribute such experimental results to the temporal consistency of the CCAM projector, as illustrated below from the perspective of continuous signals.
First, we treat the video as a continuous signal instead of sampled frames, and then apply the visual encoder on the signal to get the visual embedding as . Next, we replace the summation with the integral in eq. 2 and gradually increase the upper limit of the integral to make the output sensitive to the temporal order:
| (4) |
where and is the duration. Suppose that we sample one frame every , then the discrete version of eq. 4 becomes:
| (5) |
which is equivalent to eq. 3 for . It is straightforward to prove that if are bounded (they are linear modules with bounded inputs in the implementation, so they are bounded). Given two differently sampled visual embeddings of the same video, their corresponding CCAM outputs are just approximations of eq. 4 with different precision. In a word, the CCAM projector is able to not only handle videos of different length but also give consistent outputs for the same video with different numbers of sampled frames.
3.4 Training Pipeline
Video-CCAM is trained using a standard autoregressive loss, where the objective is to maximize the likelihood of the target textual outputs given the visual inputs and textual inputs. We take a simple two-stage training strategy. In the first pre-training stage, We randomly initialize the CCAM projector and leverage it to bridge the pre-trained visual encoder and LLM, both of which remain frozen. Only image-text data is utilized in this stage. In the second visual instruction tuning stage, more parameters in the visual encoder and LLM become tunable in addition to the projector. The instruction tuning dataset is composed of image-text and video-text pairs, thereby providing the model with richer context and more challenging tasks.
4 Experiments
4.1 Setup
Model. We use SigLIP-SO400M [54] as the visual encoder and conduct experiments on three LLMs, i.e., Phi-3-mini-4k-instruct [1] (4B), Yi-1.5-9B-Chat [2], and Phi-3-medium-4k-instruct [1] (14B). The resulting models are denoted as Video-CCAM-4B, Video-CCAM-9B, and Video-CCAM-14B. Our implementation is based on the xtuner [8] repository. In the first stage, only the projector is tuned. In the second stage, we incorporate LoRA [11] on the visual encoder and the LLM. All CCAMs are composed of one causal cross-attention layer and one feed-forward layer with 1,024 learnable queries.
Dataset. In the first stage, we use the LCS-558K [26] for alignment. In the second stage, we combine the instruction tuning datasets of VideoChat2 [17] and LLaVA-Hound [59]. To enrich the data diversity, we further add several question answering and caption datasets (the training split), including EgoTaskQA [13], PerceptionTestQA [39], ActivityNetQA [53], STAR [49], etc. For short or incomplete responses, some are abandoned while the others are rephrased into long and complete sentences by GPT-4o-mini [35] and Gemini 1.5 Flash [45]. Finally, we get 4.4M samples in total. Video-CCAM is trained for 1 epoch with images and 16-frame videos. All experiments are done with NVIDIA H800 GPUs. The total training duration of Video-CCAM-4B and Video-CCAM-14B are 2.5 days and 6 days, respectively.
Evaluation. We evaluate our Video-CCAMs with several benchmarks, i.e., MVBench [17], VideoVista [20], MLVU [62], VideoChatGPT-QA [31], and Video-MME [10]. As shown in Table 1, the videos in all benchmarks except MVBench [17] are significantly longer than those in the training data on average, posing great challenges on our Video-CCAM models.
| Name | Mean | Min | Max | Median | 95 Percentile |
|---|---|---|---|---|---|
| Train | 22.8 | 0.4 | 755.0 | 10.9 | 86.2 |
| MVBench [17] | 26.7 | 1.0 | 527.0 | 14.2 | 117.2 |
| VideoVista [20] | 152.1 | 0.8 | 918.5 | 96.9 | 594.1 |
| MLVU [62] | 704.6 | 180.0 | 32550.1 | 480.0 | 1222.8 |
| Video-MME [10] | 1020.5 | 11.0 | 3579.4 | 487.9 | 3039.0 |
| Model | LLM | Mean | AA | AC | AL | AP | AS | CO | CI | EN | ER | FA |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Size | FP | MA | MC | MD | OE | OI | OS | ST | SC | UA | ||
| Random | - | 28.00 | 33.3 | 33.3 | 25.0 | 25.0 | 25.0 | 33.3 | 30.9 | 25.0 | 20.0 | 25.0 |
| 25.0 | 33.3 | 25.0 | 25.0 | 33.3 | 25.0 | 33.3 | 25.0 | 33.3 | 25.0 | |||
| LLaMA-Adapter | 7B | 31.70 | 51.0 | 29.0 | 21.5 | 28.0 | 23.0 | 31.5 | 32.0 | 22.5 | 28.0 | 30.0 |
| [58] | 25.0 | 41.5 | 22.5 | 25.5 | 53.5 | 32.5 | 33.5 | 30.5 | 39.5 | 33.0 | ||
| VideoChatGPT | 7B | 32.70 | 62.0 | 30.5 | 20.0 | 26.0 | 23.5 | 33.0 | 35.5 | 29.5 | 26.0 | 22.5 |
| [31] | 29.0 | 39.5 | 25.5 | 23.0 | 54.0 | 28.0 | 40.0 | 31.0 | 48.5 | 26.5 | ||
| Video-LLaMA | 7B | 34.10 | 51.0 | 34.0 | 22.5 | 25.5 | 27.5 | 40.0 | 37.0 | 30.0 | 21.0 | 29.0 |
| [55] | 32.5 | 32.5 | 22.5 | 22.5 | 48.0 | 40.5 | 38.0 | 43.0 | 45.5 | 39.0 | ||
| VideoChat | 7B | 34.10 | 56.0 | 35.0 | 27.0 | 26.5 | 33.5 | 41.0 | 36.0 | 23.5 | 23.5 | 33.5 |
| [16] | 26.5 | 42.5 | 20.5 | 25.5 | 53.0 | 40.5 | 30.0 | 48.5 | 46.0 | 40.5 | ||
| LLaVA | 7B | 36.00 | 63.0 | 34.0 | 20.5 | 39.5 | 28.0 | 36.0 | 42.0 | 27.0 | 26.5 | 30.5 |
| [26] | 25.0 | 38.5 | 20.5 | 23.0 | 53.0 | 41.0 | 41.5 | 45.0 | 47.0 | 39.0 | ||
| VideoChat2 | 7B | 51.10 | 83.5 | 39.0 | 23.0 | 47.5 | 66.0 | 36.5 | 65.5 | 35.0 | 40.5 | 49.5 |
| [17] | 49.0 | 58.5 | 42.0 | 23.0 | 58.0 | 71.5 | 42.5 | 88.5 | 44.0 | 60.0 | ||
| ST-LLM | 7B | 54.85 | 84.0 | 36.0 | 31.0 | 53.5 | 66.0 | 45.5 | 58.0 | 34.5 | 41.5 | 44.0 |
| [27] | 44.5 | 78.0 | 57.0 | 43.0 | 80.5 | 73.5 | 39.0 | 86.5 | 42.5 | 58.5 | ||
| PLLaVA 34B | 82.0 | 40.5 | 49.5 | 53.0 | 67.5 | 66.5 | 59.0 | 39.5 | 63.5 | 47.0 | ||
| [51] | 34B | 58.13 | 50.0 | 70.0 | 43.0 | 37.5 | 68.5 | 67.5 | 36.5 | 91.0 | 51.5 | 79.0 |
| VideoChat2 HD | 79.5 | 60.0 | 87.5 | 50.0 | 68.5 | 93.5 | 71.5 | 36.5 | 45.0 | 49.5 | ||
| [17] | 7B | 62.30 | 87.0 | 40.0 | 76.0 | 92.0 | 53.0 | 62.0 | 45.5 | 36.0 | 44.0 | 69.5 |
| Video-CCAM-4B | 4B | 62.80 | 85.5 | 56.5 | 32.5 | 61.0 | 81.5 | 75.0 | 58.0 | 30.5 | 67.0 | 52.0 |
| 51.5 | 79.5 | 57.5 | 26.0 | 79.5 | 81.5 | 47.0 | 90.5 | 65.0 | 78.5 | |||
| Video-CCAM-9B | 9B | 64.60 | 89.5 | 59.0 | 29.0 | 67.0 | 83.0 | 77.0 | 59.0 | 34.0 | 73.5 | 49.0 |
| 54.0 | 85.0 | 67.0 | 28.0 | 86.5 | 81.0 | 45.0 | 90.0 | 63.5 | 72.0 | |||
| Video-CCAM-14B | 14B | 63.08 | 88.0 | 59.0 | 38.5 | 66.0 | 84.5 | 76.5 | 52.5 | 29.0 | 79.0 | 47.0 |
| 54.0 | 74.5 | 57.0 | 21.5 | 71.0 | 85.0 | 40.0 | 90.5 | 68.5 | 79.5 |
| Model | LLM Size | Frames | Overall | Understanding | Reasoning |
|---|---|---|---|---|---|
| Open-source MLLMs | |||||
| VideoChatGPT [31] | 7B | 100 | 36.65 | 36.09 | 38.73 |
| Video-LLaVA [21] | 7B | 8 | 56.59 | 53.82 | 66.91 |
| LLaVA-NeXT-Video [60] | 7B | 16 | 56.66 | 54.12 | 66.14 |
| LLaMA-VID [19] | 7B | 1 FPS | 56.87 | 54.00 | 67.61 |
| VideoChat2 HD [17] | 7B | 16 | 61.58 | 59.27 | 70.24 |
| VILA-1.5 [22] | 13B | 8 | 64.18 | 62.27 | 71.34 |
| LongVA [57] | 7B | 128 | 67.36 | 64.67 | 77.39 |
| InternLM-XComposer-2.5 [56] | 7B | 64 | 68.91 | 66.75 | 76.96 |
| Close-source MLLMs | |||||
| GPT-4o-mini [35] | - | 100 | 75.76 | 72.87 | 85.52 |
| Gemini 1.5 Flash [45] | - | 1 FPS | 76.39 | 74.73 | 82.30 |
| GPT-4o [34] | - | 100 | 78.26 | 75.15 | 87.97 |
| Video-CCAM | |||||
| Video-CCAM-4B | 4B | 96 | 70.82 | 67.49 | 82.31 |
| Video-CCAM-9B | 9B | 96 | 69.00 | 65.55 | 80.92 |
| Video-CCAM-14B | 14B | 96 | 76.55 | 73.54 | 86.99 |
4.2 MVBench [17]
MVBench [17] is a comprehensive benchmark that includes 20 distinct video tasks, each with 200 questions designed to probe the model’s understanding of video content. As shown in Table 2, Video-CCAM-4B surpasses all previous MLLMs despite its small size, demonstrating its efficiency and effectiveness in handling video-language understanding tasks. Meanwhile, Video-CCAM-9B sets a new SOTA result, further showcasing its superior performance in this benchmark.
4.3 VideoVista [20]
VideoVista [20] is another comprehensive benchmark tailored for video understanding and reasoning, including 3,400 videos and 25,000 questions across 14 categories. As the experimental results in Table 3 show, Video-CCAM-4B surpasses all previous open-source Video-MLLMs, while Video-CCAM-14B sets a new SOTA result among open-source Video-MLLMs and demonstrates similar performance to GPT-4o-mini [35] and Gemini 1.5 Flash [45].
4.4 MLVU [62]
MLVU [62] is a long video understanding benchmark with 9 distinct tasks divided into Multi-Choice (M) and Generation (G) categories. For the Generation tasks, MLVU utilizes GPT-4-Turbo [36] to assign scores to model responses. While Video-CCAM models do not achieve top results, the performance gaps between them and the best open-source results are small. For the Multi-Choice tasks, Video-CCAM-4B is comparable to previous open-source SOTA Video-MLLMs, while Video-CCAM-14B sets a new SOTA result among open-source Video-MLLMs. Despite the duration differences between training data and MLVU [62] in Table 1, Video-CCAM is still proficient at handling long video understanding.
| Model | Frames | M-Avg | G-Avg |
|---|---|---|---|
| VideoChatGPT [31] | 100 | 31.3 | 3.90 |
| LLaMA-VID [19] | 1 FPS | 33.2 | 4.22 |
| LLaVA-NeXT-Video [60] | 16 | 39.3 | 3.23 |
| Qwen-VL-Max [5] | 16 | 42.2 | 3.96 |
| Video-LLaVA [21] | 8 | 47.3 | 3.84 |
| VideoChat2 HD [17] | 16 | 47.9 | 3.99 |
| LongVA [57] | 256 | 56.3 | 4.33 |
| VILA-1.5 [22] | 14 | 56.7 | 4.31 |
| GPT-4o [34] | 0.5 FPS | 64.6 | 5.80 |
| Video-CCAM-4B | 96 | 56.5 | 4.09 |
| Video-CCAM-9B | 86 | 58.5 | 3.98 |
| Video-CCAM-14B | 96 | 63.1 | 4.01 |
4.5 VideoChatGPT-QA [31]
| Method | LLM | MSVD-QA | MSRVTT-QA | ActivityNet-QA | TGIF-QA | ||||
| Size | Acc. | Score | Acc. | Score | Acc. | Score | Acc. | Score | |
| LLaMA-Adapter [58] | 7B | 54.9 | 3.1 | 43.8 | 2.7 | 34.2 | 2.7 | - | - |
| Video-LLaMA [55] | 7B | 51.6 | 2.5 | 29.6 | 1.8 | 12.4 | 1.1 | - | - |
| VideoChatGPT [31] | 7B | 64.9 | 3.3 | 49.3 | 2.8 | 35.2 | 2.7 | 51.4 | 3.0 |
| Video-LLaVA [21] | 7B | 70.7 | 3.9 | 59.2 | 3.5 | 45.3 | 3.3 | 70.0 | 4.0 |
| Chat-UniVi [14] | 7B | 65.0 | 3.6 | 54.6 | 3.1 | 45.8 | 3.2 | 60.3 | 3.4 |
| VideoChat [16] | 7B | 56.3 | 2.8 | 45.0 | 2.5 | 26.5 | 2.2 | 34.4 | 2.3 |
| VideoChat2 [17] | 7B | 70.0 | 3.9 | 54.1 | 3.3 | 49.1 | 3.3 | - | - |
| Vista-LLaMA [30] | 7B | 65.3 | 3.6 | 60.5 | 3.3 | 48.3 | 3.3 | - | - |
| LLaMA-VID [19] | 13B | 70.0 | 3.7 | 58.9 | 3.3 | 47.5 | 3.3 | - | - |
| ST-LLM [27] | 7B | 74.6 | 3.9 | 63.2 | 3.4 | 50.9 | 3.3 | - | - |
| PLLaVA [51] | 34B | 79.9 | 4.2 | 68.7 | 3.8 | 60.9 | 3.7 | 80.6 | 4.3 |
| Video-CCAM-4B | 4B | 76.9 | 4.1 | 64.4 | 3.7 | 58.0 | 3.7 | 83.0 | 4.4 |
| Video-CCAM-9B | 9B | 77.9 | 4.2 | 65.9 | 3.8 | 59.7 | 3.8 | 84.0 | 4.5 |
| Video-CCAM-14B | 14B | 78.6 | 4.2 | 66.3 | 3.8 | 60.4 | 3.8 | 84.4 | 4.5 |
VideoChatGPT-QA [31] encompasses a variety of validation/test datasets from MSRVTT-QA [50], MSVD-QA [50], TGIF-QA [12], and ActivityNet-QA [53]. Following VideoChatGPT [31], we employ GPT-3.5-Turbo [37] to evaluate the predictions. As shown in Table 5, Video-CCAM-4B outperforms all previous works except PLLaVA-34B [51], and Video-CCAM-14B further closes the gap between medium-sized Video-MLLMs and PLLaVA-34B [51]. Notably, both Video-CCAM models have better accuracies and scores in TGIF-QA [12] than all previous models.
4.6 Video-MME [10]
Video-MME [10] is another comprehensive multi-modal evaluation benchmark for Video-MLLMs, offering a highly diverse range of video types and temporal durations and posing significant challenges for Video-MLLMs trained with few frames. As shown in Table 6, Video-CCAM-4B demonstrates competitive performance and is only slightly weaker than the much larger InternVL-Chat-V1.5 [6] and Qwen-VL-Max [5]. Video-CCAM-14B ranks the highest among all open-source MLLMs with fewer than 30B parameters.
| Method | LLM | Frames | Overall (%) | Short (%) | Medium (%) | Long (%) | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| Size | w/o s | w s | w/o s | w s | w/o s | w s | w/o s | w s | ||
| Open-source MLLMs | ||||||||||
| Video-LLaVA [21] | 7B | 8 | 39.9 | 41.6 | 45.3 | 46.1 | 38.0 | 40.7 | 36.2 | 38.1 |
| ST-LLM [27] | 7B | 64 | 37.9 | 42.3 | 45.7 | 48.4 | 36.8 | 41.4 | 31.3 | 36.9 |
| InternVL-Chat-V1.5 [6] | 20B | 10 | 50.7 | 52.4 | 60.2 | 61.7 | 46.4 | 49.1 | 45.6 | 46.6 |
| LongVA [57] | 7B | 128 | 52.6 | 54.3 | 61.1 | 61.6 | 50.4 | 53.6 | 46.2 | 47.6 |
| VILA-1.5 [22] | 34B | 14 | 60.1 | 61.1 | 68.7 | 69.9 | 58.8 | 59.7 | 53.0 | 53.8 |
| LLaVA-NeXT-Video [60] | 32B | 32 | 60.2 | 63.0 | 73.2 | 76.0 | 57.0 | 59.7 | 50.3 | 53.3 |
| Close-source MLLMs | ||||||||||
| Qwen-VL-Max [5] | - | 4 | 51.3 | 51.2 | 55.8 | 57.6 | 49.2 | 48.9 | 48.9 | 47.0 |
| GPT-4V [38] | - | 10 | 59.9 | 63.3 | 70.5 | 73.2 | 55.8 | 59.7 | 53.5 | 56.9 |
| Gemini 1.5 Flash [45] | - | 1/2 FPS | 70.3 | 75.0 | 78.8 | 79.8 | 68.8 | 74.7 | 61.1 | 68.8 |
| GPT-4o [34] | - | 384 | 71.9 | 77.2 | 80.0 | 82.8 | 70.3 | 76.6 | 65.3 | 72.1 |
| Gemini 1.5 Pro [45] | - | 1/2 FPS | 75.0 | 81.3 | 81.7 | 84.5 | 74.3 | 81.0 | 67.4 | 77.4 |
| Video-CCAM | ||||||||||
| Video-CCAM-4B | 4B | 96 | 50.1 | 51.2 | 59.6 | 58.9 | 49.9 | 51.4 | 40.9 | 43.5 |
| Video-CCAM-9B | 9B | 96 | 50.3 | 52.6 | 61.9 | 63.1 | 49.2 | 52.3 | 39.6 | 42.4 |
| Video-CCAM-14B | 14B | 96 | 53.9 | 56.1 | 62.1 | 63.9 | 52.8 | 55.9 | 47.0 | 48.3 |
4.7 Ablation Study
We conduct several ablation studies with Video-CCAM-4B.

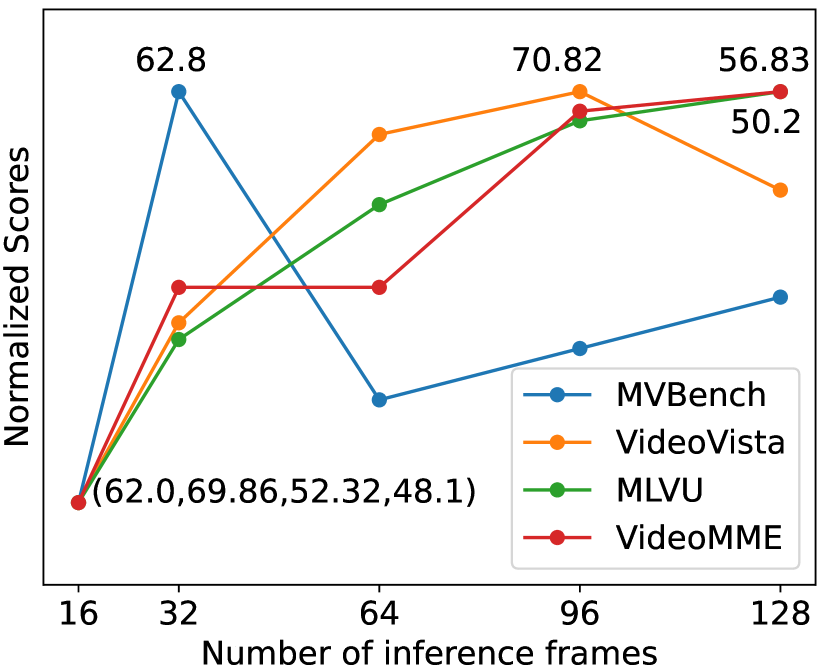
Number of Inference Frames. We validate the temporal consistency of Video-CCAM by varying the number of inference frames in Figure 3. In MVBench [17], mostly composed of short videos, its influence is small. However, the number of inference frames plays a vital role in other benchmarks consisting of many long videos, where the score significantly increases from 16 to 96 frames and plateaus around 96 and 128 frames. Besides, no sudden improvement or degradation is observed for all benchmarks.
CCAM. We replace the CCAM in Video-CCAM-4B with full masks to demonstrate its necessity. We also conduct ablation studies on temporal position embeddings (TPE) as some MLLMs [17] use them for temporal understanding. As shown in Table 7, CCAM outperforms full masks by a large margin, while temporal position embeddings have a negligible impact.
Number of Queries. We conduct experiments by changing the number of queries to 512, 1,024, and 2,048, where Video-CCAM-4B achieves the highest score with 1,024 queries in Table 7. Additionally, the training duration for 2,048 queries increases by around 50% compared to that of 1,024 queries. As a result, we settle on 1,024 learnable queries to balance performance and efficiency.
| Temporal | #Queries | MVBench (%) |
| CCAM | 1,024 | 62.80 |
| CCAM+TPE | 1,024 | 61.93 |
| Full | 1,024 | 59.08 |
| Full+TPE | 1,024 | 59.13 |
| CCAM | 512 | 60.78 |
| CCAM | 2,048 | 62.68 |
5 Conclusion
In this work, we introduce Video-CCAM, a novel Video-MLLM specifically designed to tackle video-language understanding tasks for both short and long videos. We integrate the causal cross-attention mask within the cross-attention layer and develop the CCAM projector to handle a large number of visual tokens and effectively model temporal dynamics. To validate its effectiveness, we conduct experiments with LLMs of different sizes on a diverse range of tasks involving both short and long videos, where Video-CCAM models consistently achieve top ranks. Our theoretical analysis and empirical studies on CCAM elucidate the factors contributing to the model’s exceptional performance. Through this work, we aim to simplify the complexities of Video-MLLM development and encourage continued innovation in video-language understanding.
References
- [1] Marah Abdin, Sam Ade Jacobs, Ammar Ahmad Awan, Jyoti Aneja, Ahmed Awadallah, Hany Awadalla, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Harkirat Behl, Alon Benhaim, Misha Bilenko, Johan Bjorck, Sébastien Bubeck, Martin Cai, Caio César Teodoro Mendes, Weizhu Chen, Vishrav Chaudhary, Parul Chopra, Allie Del Giorno, Gustavo de Rosa, Matthew Dixon, Ronen Eldan, Dan Iter, Amit Garg, Abhishek Goswami, Suriya Gunasekar, Emman Haider, Junheng Hao, Russell J. Hewett, Jamie Huynh, Mojan Javaheripi, Xin Jin, Piero Kauffmann, Nikos Karampatziakis, Dongwoo Kim, Mahoud Khademi, Lev Kurilenko, James R. Lee, Yin Tat Lee, Yuanzhi Li, Chen Liang, Weishung Liu, Eric Lin, Zeqi Lin, Piyush Madan, Arindam Mitra, Hardik Modi, Anh Nguyen, Brandon Norick, Barun Patra, Daniel Perez-Becker, Thomas Portet, Reid Pryzant, Heyang Qin, Marko Radmilac, Corby Rosset, Sambudha Roy, Olatunji Ruwase, Olli Saarikivi, Amin Saied, Adil Salim, Michael Santacroce, Shital Shah, Ning Shang, Hiteshi Sharma, Xia Song, Masahiro Tanaka, Xin Wang, Rachel Ward, Guanhua Wang, Philipp Witte, Michael Wyatt, Can Xu, Jiahang Xu, Sonali Yadav, Fan Yang, Ziyi Yang, Donghan Yu, Chengruidong Zhang, Cyril Zhang, Jianwen Zhang, Li Lyna Zhang, Yi Zhang, Yue Zhang, Yunan Zhang, and Xiren Zhou. Phi-3 technical report: A highly capable language model locally on your phone, 2024.
- [2] 01. AI, :, Alex Young, Bei Chen, Chao Li, Chengen Huang, Ge Zhang, Guanwei Zhang, Heng Li, Jiangcheng Zhu, Jianqun Chen, Jing Chang, Kaidong Yu, Peng Liu, Qiang Liu, Shawn Yue, Senbin Yang, Shiming Yang, Tao Yu, Wen Xie, Wenhao Huang, Xiaohui Hu, Xiaoyi Ren, Xinyao Niu, Pengcheng Nie, Yuchi Xu, Yudong Liu, Yue Wang, Yuxuan Cai, Zhenyu Gu, Zhiyuan Liu, and Zonghong Dai. Yi: Open foundation models by 01.ai, 2024.
- [3] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob L Menick, Sebastian Borgeaud, Andy Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikoł aj Bińkowski, Ricardo Barreira, Oriol Vinyals, Andrew Zisserman, and Karén Simonyan. Flamingo: a visual language model for few-shot learning. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 23716–23736. Curran Associates, Inc., 2022.
- [4] Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou, and Tianhang Zhu. Qwen technical report, 2023.
- [5] Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond, 2023.
- [6] Zhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, Zhangwei Gao, Erfei Cui, Wenwen Tong, Kongzhi Hu, Jiapeng Luo, Zheng Ma, et al. How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites. arXiv preprint arXiv:2404.16821, 2024.
- [7] Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality, March 2023.
- [8] XTuner Contributors. Xtuner: A toolkit for efficiently fine-tuning llm. https://github.com/InternLM/xtuner, 2023.
- [9] Wenliang Dai, Junnan Li, Dongxu Li, Anthony Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. InstructBLIP: Towards general-purpose vision-language models with instruction tuning. In Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- [10] Chaoyou Fu, Yuhan Dai, Yondong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. arXiv preprint arXiv:2405.21075, 2024.
- [11] Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022.
- [12] Yunseok Jang, Yale Song, Youngjae Yu, Youngjin Kim, and Gunhee Kim. Tgif-qa: Toward spatio-temporal reasoning in visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017.
- [13] Baoxiong Jia, Ting Lei, Song-Chun Zhu, and Siyuan Huang. Egotaskqa: Understanding human tasks in egocentric videos. In The 36th Conference on Neural Information Processing Systems (NeurIPS 2022) Track on Datasets and Benchmarks, 2022.
- [14] Peng Jin, Ryuichi Takanobu, Caiwan Zhang, Xiaochun Cao, and Li Yuan. Chat-univi: Unified visual representation empowers large language models with image and video understanding, 2023.
- [15] Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models, 2023.
- [16] KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. Videochat: Chat-centric video understanding, 2024.
- [17] Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, Limin Wang, and Yu Qiao. Mvbench: A comprehensive multi-modal video understanding benchmark, 2024.
- [18] Kunchang Li, Yali Wang, Yizhuo Li, Yi Wang, Yinan He, Limin Wang, and Yu Qiao. Unmasked teacher: Towards training-efficient video foundation models. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 19948–19960, October 2023.
- [19] Yanwei Li, Chengyao Wang, and Jiaya Jia. Llama-vid: An image is worth 2 tokens in large language models, 2023.
- [20] Yunxin Li, Xinyu Chen, Baotian Hu, Longyue Wang, Haoyuan Shi, and Min Zhang. Videovista: A versatile benchmark for video understanding and reasoning, 2024.
- [21] Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual representation by alignment before projection, 2023.
- [22] Ji Lin, Hongxu Yin, Wei Ping, Yao Lu, Pavlo Molchanov, Andrew Tao, Huizi Mao, Jan Kautz, Mohammad Shoeybi, and Song Han. Vila: On pre-training for visual language models, 2023.
- [23] Hao Liu, Wilson Yan, Matei Zaharia, and Pieter Abbeel. World model on million-length video and language with ringattention, 2024.
- [24] Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning, 2023.
- [25] Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Improved reasoning, ocr, and world knowledge, January 2024.
- [26] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. Advances in neural information processing systems, 36, 2024.
- [27] Ruyang Liu, Chen Li, Haoran Tang, Yixiao Ge, Ying Shan, and Ge Li. St-llm: Large language models are effective temporal learners, 2024.
- [28] Shilong Liu, Hao Cheng, Haotian Liu, Hao Zhang, Feng Li, Tianhe Ren, Xueyan Zou, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang, Jianfeng Gao, and Chunyuan Li. Llava-plus: Learning to use tools for creating multimodal agents, 2023.
- [29] Ruipu Luo, Ziwang Zhao, Min Yang, Junwei Dong, Da Li, Pengcheng Lu, Tao Wang, Linmei Hu, Minghui Qiu, and Zhongyu Wei. Valley: Video assistant with large language model enhanced ability, 2023.
- [30] Fan Ma, Xiaojie Jin, Heng Wang, Yuchen Xian, Jiashi Feng, and Yi Yang. Vista-llama: Reliable video narrator via equal distance to visual tokens, 2023.
- [31] Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Shahbaz Khan. Video-chatgpt: Towards detailed video understanding via large vision and language models, 2023.
- [32] Meta AI. Meta Llama 3, 2024. [Online; accessed 10-May-2024].
- [33] OpenAI. Gpt-4 technical report, 2024.
- [34] OpenAI. GPT-4o, 2024. [Online; accessed 10-July-2024].
- [35] OpenAI. GPT-4o mini, 2024. [Online; accessed 10-July-2024].
- [36] OpenAI. GPT-4V, 2024. [Online; accessed 10-July-2024].
- [37] OpenAI. GPT-4V, 2024. [Online; accessed 10-July-2024].
- [38] OpenAI. GPT-4V, 2024. [Online; accessed 10-July-2024].
- [39] Viorica Pătrăucean, Lucas Smaira, Ankush Gupta, Adrià Recasens Continente, Larisa Markeeva, Dylan Banarse, Skanda Koppula, Joseph Heyward, Mateusz Malinowski, Yi Yang, Carl Doersch, Tatiana Matejovicova, Yury Sulsky, Antoine Miech, Alex Frechette, Hanna Klimczak, Raphael Koster, Junlin Zhang, Stephanie Winkler, Yusuf Aytar, Simon Osindero, Dima Damen, Andrew Zisserman, and João Carreira. Perception test: A diagnostic benchmark for multimodal video models. In Advances in Neural Information Processing Systems, 2023.
- [40] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In Marina Meila and Tong Zhang, editors, Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pages 8748–8763. PMLR, 18–24 Jul 2021.
- [41] Shuhuai Ren, Linli Yao, Shicheng Li, Xu Sun, and Lu Hou. Timechat: A time-sensitive multimodal large language model for long video understanding, 2023.
- [42] Quan Sun, Yufeng Cui, Xiaosong Zhang, Fan Zhang, Qiying Yu, Zhengxiong Luo, Yueze Wang, Yongming Rao, Jingjing Liu, Tiejun Huang, and Xinlong Wang. Generative multimodal models are in-context learners, 2023.
- [43] Quan Sun, Yuxin Fang, Ledell Wu, Xinlong Wang, and Yue Cao. Eva-clip: Improved training techniques for clip at scale, 2023.
- [44] Gemini Team. Gemini: A family of highly capable multimodal models, 2023.
- [45] Gemini Team. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context, 2024.
- [46] InternLM Team. Internlm: A multilingual language model with progressively enhanced capabilities. https://github.com/InternLM/InternLM, 2023.
- [47] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. Llama 2: Open foundation and fine-tuned chat models, 2023.
- [48] Weihan Wang, Qingsong Lv, Wenmeng Yu, Wenyi Hong, Ji Qi, Yan Wang, Junhui Ji, Zhuoyi Yang, Lei Zhao, Xixuan Song, Jiazheng Xu, Bin Xu, Juanzi Li, Yuxiao Dong, Ming Ding, and Jie Tang. Cogvlm: Visual expert for pretrained language models, 2024.
- [49] Bo Wu, Shoubin Yu, Zhenfang Chen, Joshua B. Tenenbaum, and Chuang Gan. STAR: A benchmark for situated reasoning in real-world videos. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021.
- [50] Dejing Xu, Zhou Zhao, Jun Xiao, Fei Wu, Hanwang Zhang, Xiangnan He, and Yueting Zhuang. Video question answering via gradually refined attention over appearance and motion. In Proceedings of the 25th ACM International Conference on Multimedia, MM ’17, page 1645–1653, New York, NY, USA, 2017. Association for Computing Machinery.
- [51] Lin Xu, Yilin Zhao, Daquan Zhou, Zhijie Lin, See Kiong Ng, and Jiashi Feng. Pllava : Parameter-free llava extension from images to videos for video dense captioning, 2024.
- [52] Qinghao Ye, Haiyang Xu, Jiabo Ye, Ming Yan, Anwen Hu, Haowei Liu, Qi Qian, Ji Zhang, Fei Huang, and Jingren Zhou. mplug-owl2: Revolutionizing multi-modal large language model with modality collaboration, 2023.
- [53] Zhou Yu, Dejing Xu, Jun Yu, Ting Yu, Zhou Zhao, Yueting Zhuang, and Dacheng Tao. Activitynet-qa: a dataset for understanding complex web videos via question answering. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence and Thirty-First Innovative Applications of Artificial Intelligence Conference and Ninth AAAI Symposium on Educational Advances in Artificial Intelligence, AAAI’19/IAAI’19/EAAI’19. AAAI Press, 2019.
- [54] Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 11975–11986, October 2023.
- [55] Hang Zhang, Xin Li, and Lidong Bing. Video-LLaMA: An instruction-tuned audio-visual language model for video understanding. In Yansong Feng and Els Lefever, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 543–553, Singapore, December 2023. Association for Computational Linguistics.
- [56] Pan Zhang, Xiaoyi Dong, Yuhang Zang, Yuhang Cao, Rui Qian, Lin Chen, Qipeng Guo, Haodong Duan, Bin Wang, Linke Ouyang, Songyang Zhang, Wenwei Zhang, Yining Li, Yang Gao, Peng Sun, Xinyue Zhang, Wei Li, Jingwen Li, Wenhai Wang, Hang Yan, Conghui He, Xingcheng Zhang, Kai Chen, Jifeng Dai, Yu Qiao, Dahua Lin, and Jiaqi Wang. Internlm-xcomposer-2.5: A versatile large vision language model supporting long-contextual input and output, 2024.
- [57] Peiyuan Zhang, Kaichen Zhang, Bo Li, Guangtao Zeng, Jingkang Yang, Yuanhan Zhang, Ziyue Wang, Haoran Tan, Chunyuan Li, and Ziwei Liu. Long context transfer from language to vision. arXiv preprint arXiv:2406.16852, 2024.
- [58] Renrui Zhang, Jiaming Han, Chris Liu, Aojun Zhou, Pan Lu, Hongsheng Li, Peng Gao, and Yu Qiao. LLaMA-adapter: Efficient fine-tuning of large language models with zero-initialized attention. In The Twelfth International Conference on Learning Representations, 2024.
- [59] Ruohong Zhang, Liangke Gui, Zhiqing Sun, Yihao Feng, Keyang Xu, Yuanhan Zhang, Di Fu, Chunyuan Li, Alexander Hauptmann, Yonatan Bisk, and Yiming Yang. Direct preference optimization of video large multimodal models from language model reward, 2024.
- [60] Yuanhan Zhang, Bo Li, haotian Liu, Yong jae Lee, Liangke Gui, Di Fu, Jiashi Feng, Ziwei Liu, and Chunyuan Li. Llava-next: A strong zero-shot video understanding model, April 2024.
- [61] Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, and Ji-Rong Wen. A survey of large language models, 2023.
- [62] Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Shitao Xiao, Xi Yang, Yongping Xiong, Bo Zhang, Tiejun Huang, and Zheng Liu. Mlvu: A comprehensive benchmark for multi-task long video understanding. arXiv preprint arXiv:2406.04264, 2024.
- [63] Bin Zhu, Bin Lin, Munan Ning, Yang Yan, Jiaxi Cui, WANG HongFa, Yatian Pang, Wenhao Jiang, Junwu Zhang, Zongwei Li, Cai Wan Zhang, Zhifeng Li, Wei Liu, and Li Yuan. Languagebind: Extending video-language pretraining to n-modality by language-based semantic alignment. In The Twelfth International Conference on Learning Representations, 2024.
- [64] Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models, 2023.