Vehicle Tracking in Wireless Sensor Networks via Deep Reinforcement Learning
Abstract
Vehicle tracking has become one of the key applications of wireless sensor networks (WSNs) in the fields of rescue, surveillance, traffic monitoring, etc. However, the increased tracking accuracy requires more energy consumption. In this letter, a decentralized vehicle tracking strategy is conceived for improving both tracking accuracy and energy saving, which is based on adjusting the intersection area between the fixed sensing area and the dynamic activation area. Then, two deep reinforcement learning (DRL) aided solutions are proposed relying on the dynamic selection of the activation area radius. Finally, simulation results show the superiority of our DRL aided design.
Index Terms:
Wireless Sensor Networks, Vehicle Tracking, Deep Reinforcement Learning.I Introduction
With the advances in the fabrication technologies that integrate the sensing and the wireless communication, a large-scale wireless sensor networks (WSNs) is formed in the desired fields by deploying dense tiny sensor nodes. Vehicle tracking in WSNs has several prominent merits: firstly, the sensing unit is close to the vehicle, thus the sensed data will be of a qualitatively good geometric fidelity via vehicle-to-infrastructure (V2I) technology [1]; secondly, the information about the target is simultaneously generated by multiple sensors and thus contains redundancy [2]. However, there still exist some unsolved problems as far as vehicle tracking in WSNs concerned. The first issue is how to guarantee the vehicle to be tracked by sensor nodes. Second is how to maximize the tracking accuracy with the limited resources of WSNs, such as the energy restriction of each node [3].
There are two strategies based on the data processing mechanism, namely centralized strategy and decentralized strategy. Specifically, in centralized strategy, a sensor is artificially selected as a cluster head, and the tracking estimation is performed at this node with all received data [4].
However, the tasks at the cluster head may be overloaded in this strategy. In each iteration of the decentralized strategy, each cluster uses the data from their neighbours to refine its local estimate [5]. Therefore, although the head is closer to the data source than the fixed head in centralized strategy, it has higher energy efficiency. Meanwhile, the works in [6] point out that deep reinforcement learning (DRL) is a problem-solving tool and suitable for decentralized systems in WSNs.
The existing decentralized tracking strategies in WSNs are based on the prediction position to activate a fixed number of nodes, which will result in unnecessary energy consumption. Thus, we propose a dynamic activation area adjustment scheme based on DRL, to save energy consumption while ensuring tracking accuracy. Based on this, we first formulate the problem as a Markov decision process (MDP). Then, we construct the optimization problem as maximizing average rewards of MDP, where the reward consists of both tracking accuracy and energy consumption. Furthermore, we propose a pair of schemes based on deep Q network (DQN) and on deep determined policy gradient (DDPG), to maximize average rewards of MDP. In simulation, our proposed DQN and DDPG based algorithms outperform the conventional Q-learning based method in terms of tracking accuracy and energy consumption.
II System Model
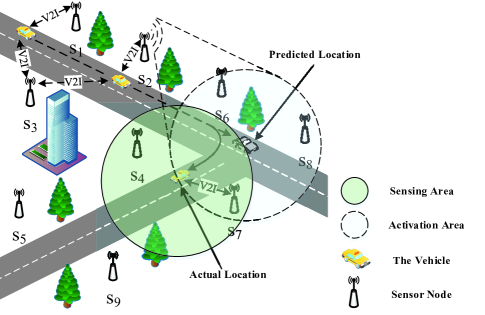
Fig. 1 illustrates an vehicle tracking scenario in a WSNs, which consists of a single vehicle and multiple sensor nodes. The WSNs starts tracking and broadcasting when the object vehicle appears in its monitoring area. Consider that the time slots are denoted by , with unequally duration seconds. The vehicle derives into the monitoring area of the WSNs at time slot , and leaves the WSNs or the WSNs loss vehicle at . Let the vehicle’s vector denote as , where is the 2-D position of the vehicle, and is the velocity of the vehicle at time slot on the plane. As shown in Fig. 1, the connection between the sensor nodes and the vehicle can be established by V2I within a certain range, thus the radius of sensing area is fixed. Moreover, the WSNs activates the sensors in activation area with radius in advance, for tracking with dynamic energy consumption. Additionally, let the sensors in set of intersection area denote as , where is the collection of sensors in , and represents the amount of elements in set .
At time slot , WSNs enables an activation area in advance, which is an area based on the predicted vector and . When the vehicle moves from to , sensors in track the vehicle cooperatively, and then only one sensor node is selected for transmitting data to the sensors in .
II-A Motion Model
In our model, the vehicle’s vector is 4-dimensional. For simplicity, we model the vehicle’s motion vector as a linear moving model [7] as , where A represents the vector transition matrix, D is the transition duration matrix, and denotes the noise adding on the vehicle, which is a zero-mean white Gaussian noise with covariance matrix Q.
II-B Measurement Model
The vehicle’s measurement model can be given by , where represents the measurement of the -th sensor at time , and the measurement matrix H is assumed to be same for each sensor node. is the measurement noise of the -th sensor, which is assumed to be a zero-mean white Gaussian with covariance matrix . Additionally, the observation noises that are added on different sensor nodes are independent.
II-C Filtering Model
In this paper, we employ the Kalman filtering approach for WSNs to track the vehicle. To be specific, the iterative process with motion and measurement model can be given by [5] as
| (1a) | |||
| (1b) |
where the priori estimated vector and its covariance is obtained from the data in time slot . Then, the priori data is modified by and :
| (2a) | |||
| (2b) |
Herein, denotes the optimal measurement by broadcasting the data of selected sensor nodes in , where . The goal of this selection strategy can help improve tracking accuracy, namely the smaller is, the better estimation quality becomes[8]. Next, we select a sensor with best measuring performance according to , where is the data that the fusion center needs to transmit to .
II-D Time Model
In this paper, for obtaining the time interval of tracking vehicle in WSNs, we quantify the time based on the formula as [9]:
| (3a) | |||
| (3b) |
where in (3b) denotes the path loss per meter, thus is the channel gain between position and . In , denotes the bits of each task, is the communication bandwidth, is transmission power, and is power of Gaussian white noise in WSNs. Therefore the data transmission duration is calculated as . Furthermore, the processing time consists of three parts:
-
1.
Data Gathering Time Model: Based on the estimated vector , activation radius , and the sensing area , the sensors in will detect the vehicle. Let , , thus , where the estimated position is . In addition, let be the the longest duration, which based on the channel gain with the distance between the vehicle and the furthest node .
-
2.
Data Fusion Time Model: After data gathering, the senors in should establish a communication mechanism to find the optimal tracking data. Thus, the system randomly selects a node as a virtual data fusion center which is responsible for receiving data from other sensor node , . Let , , thus . Let represent the duration of total data fusion process, which based on the channel gain with distance between and furthest node .
-
3.
Data Broadcast Time Model: After data fusion in , the center transfers the optimal data to the sensors in . Let , , thus . Similarly, denote the amount of sensors of , and denote the total data broadcast duration based on the minimum channel gain with the longest distance between and the sensor .
In summary, the time duration in each round includes these three parts .
III Problem Formulation
This paper solves the problem of improving tracking accuracy and energy saving when tracking vehicle in WSNs. Explicitly, the number of the sensor nodes for tracking contributes to the tracking accuracy [5]. Nevertheless, with the increase of the sensor nodes, the energy consumption for communication and data processing becomes higher. To efficiently track the vehicle, we propose a dynamic activation area adjustment scheme to balance the trade-off between tracking accuracy and energy consumption. In this section, we model this scheme as an MDP based on the nature of the dynamic decision-making problem.
-
•
State Space: Let denote the state space of the WSNs, where includes the estimated vector of the vehicle in time slot , the estimated vector of vehicle based on and the measurement , and the radius of the activation area . The elements in except are described in the Kalman filtering model.
-
•
Action Space: Let denote the action space of the WSNs, where is the radius of .
-
•
Reward: Assuming that and are circles with radius of and , the prediction error in time slot is denoted as , where the predicted position is . In the process of the tracking, we consider the reward consisting of both the tracking accuracy and the energy consumption in each time slot:
-
1.
Tracking Accuracy: For quantifying the tracking accuracy to measure the tracking effect of WSNs, classical measurement (such as estimation error covariance) represents the error between and , but we would like to measure the error between and , which depends on and . By adopting as the metric, we can can measure the effect of on energy consumption and track accuracy. As such, satisfies when and , thus as increases, the predicted position becomes more accurate. We define the . Herein, and are the angles of intersection area, which are obtained by and , respectively.
-
2.
Energy Consumption: In duration of , the energy consumption generated by data transmission is
(4) where and denotes the power of nodes for transmitting and receiving data, respectively. In addition, the energy consumption of nodes for waking up in and working in is , where denote the amount of sensors of , and the power of the nodes in working mode is denoted as and the power of the nodes in idle mode is denoted as [5]. Thus, the total energy consumption is .
Therefore, as the goal of this system is to improve the tracking accuracy and to minimize the energy consumption, we can define reward by combining normalized and as , where denotes the maximum energy consumption in each time duration.
-
1.
It is noteworthy that, as the number of the training episodes increases, the total rewards in a single episode may exist a certain degree of disturbance, thus the increase of the total rewards in a single episode does not represent an accurate improvement of the system performance. Therefore, our goal is to find an optimal policy with the maximum average total reward, given by:
| (5) |
IV Proposed DRL Based Methods
In this section, to solve the problem (5), we adopt the policy iteration based DDPG method, and the value iteration based DQN method. Additionally, in DQN method, we use the action selection strategy of ’softmax’ to compare with the ’greedy’ strategy.
IV-A Proposed DDPG Based Method
DDPG method is an algorithm which combines the Actor-Critic framework and the neural network[10], where the Actor-Critic learns both the policy and value network. In DDPG, when the state and action value are the input of a Q-function, it estimates a Q-value according to a policy as , where and are the current state and action, and are the next state and action, and is a discount factor to the future reward. The policy network is termed as the actor and the value network is termed as the critic. In DDPG, the critic receives and produces a temporal-difference (TD) error . With TD error, the actor network updates with the direction suggested by the critic network. In DDPG based algorithm, for avoiding the influence of data correlation in training, the actor network is divided into a current actor network and a target actor network , while the critic network is divided into the current critic network and the target critic network . The weights of four NNs will be updated as and , where is the learning decrement.
IV-B Proposed DQN Based Method
This paper considers two action selection methods:
-
•
-Greedy Policy: In each time slot, action selection according to when , and is a random variable. Then, select randomly in . At the end of each episode, the parameter will be updated by , where is the minimum for , and is the decrease speed.
-
•
Softmax Policy: For getting the selection probability of action , the softmax based action selection policy is formulated as , where is the reward based on action , is the reward based on current action .
Additionally, DQN employs the two networks with the same structure but different parameters and respectively. For training the model, we search the weights by minimizing the loss function , where , represents a predicted maximum Q-value with weight , and represents the target Q-value with weight . The details of this process are shown in Algorithm 1.
V Simulations and Results
| parameter | value | parameter | value | parameter | value |
|---|---|---|---|---|---|
| (dBm) | -110 |
Based on the previous research in [7], we consider the field of WSNs is . Besides, the motion model is
| (6) |
where is the vector of the vehicle, is the length of each time interval, and is the vector noise. The initial vector is , which means the initial speed is 40 kmph. The vector noise accounting for the unpredictable modeling error is characterized by .
In the tracking of a single vehicle, there are many sensors that can be used in the scenario, such as cameras [5] and logical combination of ranging sensors [2]. By adopting the strategy of uniform distribution of sensor nodes in [5], we set 375 nodes in the sensing range with the density of 1 sensor/24m, and the linear measurement model of each sensor is , where . Notably, the motion model can also be a non-linear model, which can be estimated by extended Kalman filter, particle filter or other methods. The parameters of the measurement noise covariance are . We randomly initialize , and the parameters used in this model are shown in Table 1.
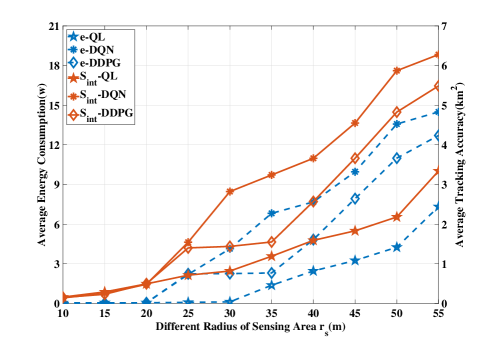
Fig. 2 plots the trends of the average tracking accuracy and the average energy consumption with different , where each value of and is the final convergence value obtained by training 1800 episodes. Clearly, increasing sensing area achieves higher and .
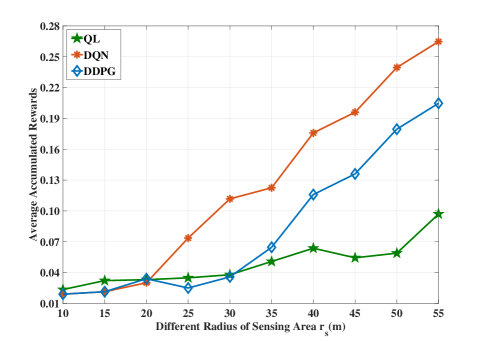
Fig. 3 shows the average accumulated rewards of the proposed algorithms. Firstly, we can observe that although and increase with , their gaps in terms of the average accumulated rewards enlarge gradually. Secondly, as episodes go by, the average accumulated rewards based on DQN is much higher than other methods. The reasons include two aspects: first the QL based method leads to the lowest value because of the Q-table has a limited capacity; second the value iteration of DQN is based on the unbiased estimation of data, while the DDPG is based on the biased estimation.
VI Conclusions
This paper focuses on improving the tracking accuracy and energy saving of target vehicle in WSNs. Thus, we propose a decentralized vehicle tracking strategy, which dynamically adjusts the activation area to improve tracking accuracy and energy saving. Then, we define the problem as a MDP and use DRL method to solve it. Finally, the simulation results show that the DQN-based method has a better performance than other DRL-based methods. In future, we can explore multi-agent DRL algorithms in cooperative tracking scenarios.
References
- [1] O. Popescu, S. Sha-Mohammad, H. Abdel-Wahab, D. C. Popescu, and S. El-Tawab, “Automatic incident detection in intelligent transportation systems using aggregation of traffic parameters collected through v2i communications,” IEEE Intell. Trans. Syst. Mag., vol. 9, pp. 64–75, Summer 2017.
- [2] B. Wu, Y. Feng, H. Zheng, and X. Chen, “Dynamic cluster members scheduling for target tracking in sensor networks,” IEEE Sensors J., vol. 16, pp. 7242–7249, Oct. 2016.
- [3] K. Zheng, H. Wang, H. Li, W. Xiang, L. Lei, J. Qiao, and X. S. Shen, “Energy-efficient localization and tracking of mobile devices in wireless sensor networks,” IEEE Trans. Veh. Technol., vol. 66, pp. 2714–2726, Mar. 2017.
- [4] U. Baroudi, “Robot-assisted maintenance of wireless sensor networks using wireless energy transfer,” IEEE Sensors J., vol. 17, pp. 4661–4671, Jul. 2017.
- [5] J. Li, Q. Jia, X. Guan, and X. Chen, “Tracking a moving object via a sensor network with a partial information broadcasting scheme,” vol. 181, pp. 4733–4753, 2011.
- [6] Y. Su, X. Lu, Y. Zhao, L. Huang, and X. Du, “Cooperative communications with relay selection based on deep reinforcement learning in wireless sensor networks,” IEEE Sensors J., vol. 19, pp. 9561–9569, Oct. 2019.
- [7] Z. Zhao, X. Wang, and T. Wang, “A novel measurement data classification algorithm based on svm for tracking closely spaced targets,” IEEE Trans. Instrum. Meas., vol. 68, pp. 1089–1100, Apr. 2019.
- [8] W. Xiao, C. K. Tham, and S. K. Das, “Collaborative sensing to improve information quality for target tracking in wireless sensor networks,” in IEEE PERCOM Workshops, pp. 99–104, Mar. 2010.
- [9] J. Li, S. Chu, F. Shu, J. Wu, and D. N. K. Jayakody, “Contract-based small-cell caching for data disseminations in ultra-dense cellular networks,” IEEE Trans. Mobile Comput., vol. 18, pp. 1042–1053, May 2019.
- [10] P. Wu, J. Li, L. Shi, M. Ding, K. Cai, and F. Yang, “Dynamic content update for wireless edge caching via deep reinforcement learning,” IEEE Commun. Lett., vol. 23, pp. 1773–1777, Oct. 2019.