Varying Coefficient Model via Adaptive Spline Fitting
Abstract
The varying coefficient model has received broad attention from researchers as it is a powerful dimension reduction tool for non-parametric modeling. Most existing varying coefficient models fitted with polynomial spline assume equidistant knots and take the number of knots as the hyperparameter. However, imposing equidistant knots appears to be too rigid, and determining the optimal number of knots systematically is also a challenge. In this article, we deal with this challenge by utilizing polynomial splines with adaptively selected and predictor-specific knots to fit the coefficients in varying coefficient models. An efficient dynamic programming algorithm is proposed to find the optimal solution. Numerical results show that the new method can achieve significantly smaller mean squared errors for coefficients compared with the equidistant spline fitting method.
Keywords: Mean squared error; Splines and knots; Varying coefficient model.
1 Introduction
The problem of accurately estimating the relationship between a response variable and multiple predictor variables is fundamental to statistics and machine learning, and many other scientific applications. Among parametric models, the linear regression model is a simple and powerful approach, yet it is somewhat limited by its linearity assumption, which is often violated in real applications. In contrast, non-parametric models do not assume any specific type of relationship between the response variable and the predictors, which offer some flexibility in modeling nonlinear relationships, and are powerful alternatives to linear models. However, non-parametric models often need to impose certain local smoothness assumptions which are mostly achieved by employing a certain class of kernels or spline basis functions, to overcome the over-fitting issue. This is known to be plagued by the curse of dimensionality in that these methods are both ineffective in capturing the true relationship and computationally very expensive for high dimensional data sets.
Serving as a bridge between linear and non-parametric models, the varying coefficient model (Hastie & Tibshirani,, 1993) provides an attractive compromise between simplicity and flexibility. In this class of models, the regression coefficients are not set constants and are allowed to depend on other conditioners. As a result, the varying coefficient model is more flexible because of the infinite dimensionality of the corresponding parameter spaces. Compared to standard non-parametric approaches, this method rises as a powerful strategy to cope with the curse of dimensionality. This method also inherits all advantages from linear models of being simple and interpretable. A typical setup for the varying coefficient model is as follows. Given response and predictors , the model assumes that
where is the conditional random variable, which is usually a scalar. The varying coefficient model has a broad range of applications, including longitudinal data (Huang et al.,, 2004; Tang & Cheng,, 2012), functional data (Zhang & Wang,, 2014; Hu et al.,, 2019), and spatial data (Wang & Sun,, 2019; Finley & Banerjee,, 2020). Moreover, varying coefficient models could naturally be extended to time series contexts (Huang & Shen,, 2004; Lin et al.,, 2019).
There are three major approaches to estimate the coefficients . One widely acknowledged approach is the smoothing spline method proposed by Hastie & Tibshirani, (1993), with a recent follow-up work using P-spline (Astrid et al.,, 2009). Fan & Zhang, (1999) and Fan & Zhang, (2000) proposed a predictor-specific kernel approach for estimating the coefficients. The first step is to use local cubic smoothing to model function , and the second step re-applies local cubic smoothing on the residuals. A recent follow-up of their work is an adaptive estimator by Chen et al., (2015). Approximation of the coefficient functions using a basis expansion, e.g. polynomial B-splines, is always popular as it leads to a simple solution to estimation and inference with good theoretical properties. Compared with smoothing spline and kernel methods, the polynomial spline method with a finite number of knots strikes a balance between model flexibility and interpretability of the estimated coefficients. Huang et al., (2002), Huang & Shen, (2004), and Huang et al., (2004) utilized a set of polynomial estimators. The assumptions made in these works are that the knots are equidistant and the number of knots is chosen such that the bias terms become asymptotically negligible to guarantee the local asymptotic normality.
Most polynomial spline approaches run optimization based on a set of finite-dimensional classes of functions, such as a space of polynomial B-splines with equally spaced knots. If the real turning points of the coefficients are not equidistant yet we still use the method assuming equally spaced knots, then should be large enough to make sure the distances between knots in the model are small enough to capture the resolution for the coefficients. In practice, is always chosen by a parameter searching process accompanied with other parameters, as people need to compare a set of parameters before determining the optimal fixed number of knots. Too few knots might ignore the high-frequency information of , while too many knots might over-fit the area where the coefficients barely change. Variable selection for varying coefficient models, especially when the number of predictors is larger than the sample size, is also an interesting direction to study.
In this paper, we propose two adaptive algorithms that are enabled by first fitting piece-wise linear functions with automatically selected turning points for univariate conditioner variable . Compared with traditional methods above, these algorithms can automatically determine optimal positions of knots modeled as the turning points of the true coefficients. We prove that, if the coefficients are piece-wise linear in , the selected knots by our methods are almost surely the true change points. We further combine the knots selection algorithms with the adaptive group LASSO method for variable selection in high-dimensional problems, following a similar idea as Wei et al., (2011) who applies the adaptive group LASSO to basis expansions of predictors. Our simulation studies demonstrate that the new adaptive method achieves smaller mean squared errors for estimating the coefficients compared to available methods, and improves the variable selection performance. We finally apply the method to study the association between environmental factors and COVID-19 infected cases and observe time-varying effects of the environmental factors, as well as the Boston Housing data (Harrison & Rubinfeld,, 1978).
2 Adaptive spline fitting methods
2.1 Knots selection for polynomial spline
In varying coefficient models, each coefficient is a function of the conditional variable , which can be estimated by fitting a polynomial spline on . In this paper we assume that is a univariate variable. Let , , and denote the th observations of the predictor vector, the conditional variable, and the response variable, respectively, for . Suppose the knots are common to all coefficients located at , and the corresponding B-splines of degree are . Each varying coefficient can be represented as , where the coefficients are estimated by minimizing the following sum of squared errors:
| (1) |
In previous work, the knots for polynomial spline were always chosen as equidistant quantiles of and are the same for all predictors. The approach is computationally straightforward, but the knots chosen cannot properly reflect the varying smoothness between and within the coefficients. We propose an adaptive knot selection approach in which the knots can be interpreted as turning points of the coefficients.
For knots , we define the segmentation scheme for the observed samples ordered by , where , with and . If the true coefficients is a linear function of within each segment, i.e., for , then the observed response satisfies
| (2) |
Thus, the coefficients can be estimated by maximizing the log-likelihood function, which is equivalent to minimizing the loss function:
| (3) |
where is the residual variance by regressing over for .
Because any almost-everywhere continuous function can be approximated by piece-wise linear functions, we can employ the estimating framework in (2) and derive (3). To avoid over-fitting when maximizing the log-likelihood over the parameters and segmentation schemes, we constrain that is greater than a lower bound , and penalize the loss function with the number of segments
| (4) |
where is the penalty strength. The resulting knots correspond to the segmentation scheme that minimizes the penalized loss function (4). When is very large, this strategy tends to select no knots, whereas when gets close to 0 it can select as many knots as . We find the optimal by minimizing the Bayesian information criterion (Schwarz et al.,, 1978) of the fitted model. For a given , suppose knots are finally proposed, and the fitted model is . Then, we have
| (5) |
The optimal is selected by searching over a grid to minimize bic. We call this procedure the global adaptive knots selection strategy as it assumes that all the predictors have the same set of knots. We will discuss in Section 2.4 how to allow each predictor to have its own set of knots.
Here we only use the piece-wise linear model (2) and loss function (4) for knots selection, but will fit the varying coefficients with B-splines derived from the resulting knots via minimizing (1). In this way, the fitted varying coefficients are smooth functions and the smoothness is determined by the degree of the splines. This method is referred to as the global adaptive spline fitting throughout the paper.
2.2 Theoretical property of the selected knots
The proposed method is invariant to marginal distribution of . Without loss of generality, we assume that follows the uniform distribution in . According to Definition 1 below, a turning point of , denoted as , is defined as a local maximum or minimum of any coefficient . In Theorem 1, we show that the adaptive knots selection approach can almost surely detect all the turning points of .
Definition 1
We call the turning points of if for any ,
for some index with .
Theorem 1
Suppose where is bounded and is a bounded continuous function. Moreover, assume are independent. Let be the turning points in Definition 1 and be the selected knots with , then for and large enough,
Although the adaptive spline fitting method is motivated by a piece-wise linear model, Theorem 1 shows that with probability approaching 1, we can detect all the turning points accurately under general varying coefficient functions. The selected knots could be a superset of the real turning points especially when is small, so we tune with bic (5) which penalizes the number of selected knots, to find the optimal set.
When the varying coefficient functions are piece-wise linear, each coefficient can be almost surely defined as
where , and if . When the varying coefficient is a simple linear function of , otherwise we call the change points for coefficients , because the linear relationship varies before and after these points. Then are all the change points of the entire varying coefficient function. In Theorem 2, we show that the adaptive knots selection method can almost surely discover the change points of without false positive selection.
Theorem 2
Suppose follow the same assumption as in Theorem 1, and is a piece-wise linear function of . Let be the change points defined as above and be the selected knots with , then for and large enough,
The theorem shows that if the varying coefficient function is piece-wise linear, the method can discover all the change points with almost 100% accuracy.
2.3 Dynamic programming algorithm for adaptive knots selection
The brute force algorithm to compute the optimal knots has a computation complexity of and is impractical. As summarized by the following algorithm, we propose a dynamic programming approach whose computation complexity is of order . If we further assume that the knots can only be chosen from a predetermined set , e.g. quantiles of ’s, the computation complexity can be further reduced to . Note that the algorithm in Section 2.4 of Wang et al., (2017) is a special case with a constant . The algorithm is summarized in the following three steps:
-
1.
Data preparation: Arrange the data according to order of from small to large. Without lose of generality, we assume that .
-
2.
Obtain the minimum loss by forward recursion: Define as the smallest segment size, and set . Initialize two sequence: with . For , recursively fill in entries of the tables with
Here and where is the residual variance of regressing on .
-
3.
Determine knots by backward tracing: Let . If no knot is needed; otherwise, we recursively add as a new knot with until .
2.4 Predictor specific adaptive knots selection
The global adaptive knots selection method introduced in Section 2.1 assumes that the set of knot locations are the same for all predictors, similar to most of the literature for polynomial spline fitting. However, different coefficients may have a different resolution of smoothness relative to , and a different set of knots for each predictor is preferable. Here we propose a predictor-specific adaptive spline fitting algorithm on top of the global knot selection. Suppose the fitted model for the global adaptive spline fitting is . For predictor , the knots can be updated by performing the same knots selection procedure between it and the residual without it, that is
| (6) |
If bic in (5) is smaller for the corresponding new polynomial spline model with the new knots, the knots and fitted model are update. The steps are repeated until bic cannot be further minimized. The following three steps summarizes the algorithm:
-
1.
global adaptive spline: Run the global adaptive spline fitting algorithm for . Denote as the fitted model and compute model bic with (5).
-
2.
Update knots with bic: For , compute residual variable by (6). Run the global adaptive spline fitting algorithm for the residual and predictor , that is . Denote the new fitted model as and corresponding bic as . Note that when we assume different number of knots for each predictor, the term in (5) should be replaced by , where is the number of knots for predictor .
-
3.
Recursively update model: If and , update the current model by , and repeat Step 3. Otherwise return the fitted model .
An alternative approach to model the heterogeneous relationships between coefficients is to replace the initial model in Step 1 with , and repeat the following two steps. However, starting from the global model is preferred because fitting to residual instead of the original response minimizes the mean squared error more efficiently. Simulation studies in Section 3 show that the predictor-specific knots can further reduce mean squared error for the fitted coefficient, compared with the global knot selection approach.
2.5 Knots selection in sparse high-dimensional problems
When the number of predictors is large and the number of predictors with non-zero varying coefficients is small, we perform a variable selection for all the predictors. For predictor , we run the knots selection procedure between it and the response, and construct B-spline functions as where is the number of knots and is the degree of the B-splines. Then, we perform the variable selection method for varying coefficient model proposed by Wei et al., (2011), which is a generalization of group LASSO (Yuan & Lin,, 2006) and adaptive LASSO (Zou,, 2006). Wei et al., (2011) shows that group LASSO tends to over select variables and suggests adaptive group LASSO for variable selection. In their original algorithm, the knots for each predictor are chosen as equidistant quantiles and not predictor-specific. The following three steps summarize our proposed algorithm:
-
1.
Select knots for each predictor: Run the global adaptive spline fitting algorithm between each predictor and response . Denote the corresponding B-splines as where is the number of knots for predictor and is degree of splines.
-
2.
Group LASSO for first step variable selection: Run group LASSO algorithm for the following loss function
where and is the kernel matrix whose element is . Denote the fitted coefficients as .
-
3.
Adaptive group LASSO for second step variable selection: Run adaptive group LASSO algorithm for the updated loss function
with weight as if , otherwise . Denote the fitted coefficients as and the selected variables are those with .
For Steps 2 and 3, parameter and are chosen by minimizing bic (5) for the fitted model, where the degree of freedom is computed with only the selected predictors. Simulation studies in Section 3.2 show that, with the knots selection Step 1, the algorithm can always choose the correct predictors with a reasonable number of samples.
3 Empirical studies
3.1 Simulation study for adaptive spline fitting
In this section, we compare the global and predictor-specific adaptive spline fitting approaches we introduced with the equidistant spline fitting approach as well as a commonly used kernel method package tvReg by Casas & Fernandez-Casal, (2019), using the simulation examples from Tang & Cheng, (2012). The model simulates a longitudinal data, which are frequently encountered in biomedical applications. In this example, the conditional random variable represents time and for convenience, we use notation instead of . We simulated individuals, each having a scheduled time set to generate observations. A scheduled time can be skipped with probability 0.6, so no observation will be generated at the skipped time. For each non-skipped scheduled time, the real observed time is the scheduled time plus a random disturbance from . Consider the time-dependent predictors with
The response for individual at observed time is , with
The random error are independent from the predictors, and generated with two components
where , and with correlation structure
Random errors are positively correlated within the same individual and are independent between different individuals. Figure 1 shows the true coefficients and the fitted coefficients by the equidistant and predictor-specific spline fitting methods for an example with , as well as the selected knots. Note that for the equidistant fitting approach, the number of knots is also determined by minimizing the model bic (5). We observe that the fitted coefficients by the predictor-specific method are smoother than those by the equidistant method, especially for the less volatile coefficients and . This is because the predictor-specific method uses only 1 knot for these two coefficient which better reflects the resolution, while the equidistant method uses 7 knots.

We compare the three methods by the mean square errors of their estimated coefficients, i.e.,
| (7) |
where and are the true and estimated coefficients, respectively, is the total number of observations for individual and . We run the simulation with for 1000 repetitions. For adaptive spline methods we only consider knots from quantiles of .
| equidistant | 2.53 (1.14) | 0.26 (0.10) | 0.64 (0.29) | 0.09 (0.04) |
|---|---|---|---|---|
| global | 2.24 (1.12) | 0.32 (0.12) | 0.55 (0.26) | 0.08 (0.04) |
| predictor-specific | 1.30 (0.83) | 0.23 (0.10) | 0.28 (0.21) | 0.04 (0.03) |
| kernel | 2.80 (0.92) | 0.38 (0.11) | 0.81 (0.26) | 0.14 (0.04) |
Table 1 shows the average for the proposed global and predictor-specific methods, in comparison with the equidistant spline fitting and the kernel method. We find that the predictor-specific method has the smallest for all four coefficients, significantly outperforming the other two methods. Interestingly, the equidistant method selects on average 6.9 knots, the global adaptive method selects on average 6.1 global knots for all predictors, whereas the predictor-specific method selects fewer on average: 5.8 knots for , 4.2 for , 1.5 for and 0.8 for . The result is expected since and are less volatile than and . It appears that the predictor-specific procedure can use a smaller number of knots to achieve a better fitting than the other two methods.
3.2 Simulation study for variable selection
We use the simulation example from Wei et al., (2011) to compare the performance of our method with one using adaptive group LASSO and equidistant knots. Similar to the previous subsection, there are individuals, each having a scheduled time set to generate observations and a skipping probability of 0.6. For each non-skipped scheduled time, the real observed time is the scheduled time adding a random disturbance generated from . We construct time-dependent predictors as follows:
The same individual’s predictors are correlated with . The response for individual at observed time is . The time-varying coefficients are
The random error is independent from the predictors and follows the same distribution as that in Section 3. We simulate cases with and replicate each set for 200 times. Three metrics are considered: average number of selected variables, percentage of cases when there is no false negative, and percentage of cases when there is no false positive or negative. A comparison of our method with the variable selection method using equidistant knots (Wei et al.,, 2011) is summarized in Table 2. We find that our method clearly outperforms the method with no predictor-specific knots selection, and can always select the correct predictors when is larger than 100.
| equidistant knots | |||
|---|---|---|---|
| # selected variables | % no false negative | % no false positive or negative | |
| 7.04 | 72 | 68 | |
| 6.21 | 87 | 84 | |
| 6.13 | 99 | 93 | |
| adaptive selected knots | |||
| # selected variables | % no false negative | % no false positive or negative | |
| 5.96 | 96.50 | 96.50 | |
| 6.00 | 100 | 100 | |
| 6.00 | 100 | 100 | |
4 Applications
4.1 Environmental factors and COVID-19
The dataset we investigate contains daily measurements of meteorological data and air quality data in 7 counties of the state of New York between March 1, 2020, and September 30, 2021. The meteorological data were obtained from the National Oceanic and Atmospheric Administration Regional Climate Centers, Northeast Regional Climate Center at Cornell University: http://www.nrcc.cornell.edu. The daily data are based on the average of the hourly measurements of several stations in each county and composed of records of five meteorological components: temperature in Fahrenheit, dew point in Fahrenheit, wind speed in miles per hour, precipitation in inches, and humidity in percentage. The air quality data were from the Environmental Protection Agency: https://www.epa.gov. The data contain daily records of two major air quality components, the fine particles with an aerodynamic diameter of 2.5 or less, i.e., , in and ozone in . The objective of the study is to understand the association between the meteorological measurements, in conjunction with pollutant levels, and the number of infected cases for COVID-19, a contagious disease caused by severe acute respiratory syndrome coronavirus 2, and examine whether the association varies over time. The daily infected records were retrieved from the official website of the Department of Health, New York state: https://data.ny.gov. Figure 2 shows scatter plots of daily infected cases in New York County and the 7 environmental components over time. In order to remove the variation of recorded cases between weekdays and weekends, in the following study, we consider the weekly averaged infected cases which are the average between each day and the following 6 days. We also find that the temperature factor and dew point factor are highly correlated, and we remove the dew point factor when fitting the model.

We first take the logarithmic transformation of the weekly averaged infected cases, denoted as , and then fit a varying coefficient model with the following predictors: as intercept, as temperature, as wind speed, as precipitation, as humidity, as and as ozone. Time is the conditioner for our model. All predictors except the constant are normalized to make varying coefficients comparable. The varying coefficient model has the form:
| (8) |
where is the th record time for the th county, with and being the corresponding records for county at time , and denotes the error term.
We apply the equidistant and the proposed predictor-specific adaptive spline fitting method to fit the data. Figure 3 shows the fitted for each predictor by the two methods. Figures show that there is a strong time effect on each coefficient function. For example, there are several peaks for the intercept, which correspond to the initial outbreak and delta variant outbreak. Moreover, there are rapid changes of coefficients around March 2020. This could be explained by the fact that at the beginning of the outbreak, the test cases were fewer and the number of infected cases was underestimated. Moreover, the coefficient curves show that the most important predictor is temperature. For most of the period, the coefficient is negative, indicating that high temperature is negatively associated with transmission of the virus, which is also observed in the study by Notari, (2021) such that COVID-19 spread is slower at high temperatures. Besides the negatively correlated relationship, our analysis also demonstrates the time-varying property of the coefficient. Moreover, the fitted coefficients by the predictor-specific knots are less volatile than the equidistant knots, especially for temperature, wind speed, precipitation, humidity and .

We evaluate the predictivity of proposed approach by a rolling window approach, with the training size of at least of 1 year, and rolling window of 1 week. That is to say for each date after March 1, 2021, we fit two models with equidistant and predictor-specific knots with , and predicts . The root mean squared error for equidistant knots fitting is 0.932 and for predictor-specific knots fitting is 0.901.
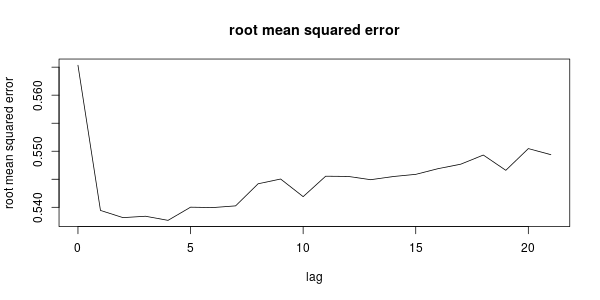
We note that environmental factors may not have an immediate effect on the number of recorded COVID-19 cases since there is 2-14 days of incubation period before the onset of symptoms and it takes another 2-7 days before a test result is available. To study whether there are lagging effects between the predictor and response variables, we fit a varying coefficient model with predictor-specific knots, for each time lag , i.e., using data and , to fit model (8) similarly as in Fan & Zhang, (1999). Figure 4 shows the residual root mean squared error for each time lag. We find that the root mean squared error is the smallest with 4 days lag. Note that represents the logarithm of the weekly average between day and . This means the predictors at day are most predictive for infected numbers between day and , which is consistent with the incubation period and test duration.
4.2 The Boston housing data
We consider the Boston housing price data from Harrison & Rubinfeld, (1978) with observations for the census districts of the Boston metropolitan area. The data is available in the R-package lmbench. Following (Wang et al.,, 2009; Hu & Xia,, 2012), we use medv (mediam value of owner-occupied homes in 1,000 USD) as the response, and lstat as the conditioner, which is defined as a linear combination of the proportion of adults with high school education or above and proportion of male workers classified as laborers. The predictors are: int (the intercept), crim (per capita crime rate by town), rm (average number of rooms per dwelling), ptratio (pupil-teacher ratio by town), nox (nitric oxides concentration parts per 10 million), tax (full-value property-tax rate per 10,000 USD), and age (proportion of owner-occupied units built prior to 1940). We transform the conditioner lstat so that its marginal distribution is , and make a logarithm transformation of the response medv. For the predictors (except for intercept), we first transform them to the standard normal. Since some of the predictors are highly correlated with the conditioner, we further regress each predictor against the transformed lstat , and use the normalized residuals in the follow-up analysis.
We fit a predictor-specific varying coefficient linear model to predict the response with the residualized predictors using lstat as the conditioner. Figure 5 shows the fitted coefficients as a function of the conditioner, with the red lines showing the 95% confidence interval and the dashed lines being the x-axis. The confidence interval are computed conditioning on the selected knots for each predictor. The results show clear conditioner-varying effects of most predictors. The intercept appears to vary most significantly along with lstat, demonstrating that the the housing price is negatively and nearly linearly impacted by lstat. The coefficient for rm is in general positive, but trends towards insignificant as lstat increases. An interpretation is that houses with more rooms are generally more expensive, but its impact becomes insignificant in areas where lstat is large. The variable crim is highly correlated with lstat. After regressing out lstat, the residualized crim has an interesting fluctuation: varying from insignificant to positive and then to negative. We suspect that the positive impact of crim for certain areas may be due to a confounding effect with other unused variables such as the location’s convenience and attractiveness for tourists.
We also compare the predictive power of the simple linear model and the varying coefficient model by 10-fold cross validation. For the simple linear model, we include all the predictors used in the varying coefficient model as well as the conditioner lstat . The mean squared error (MSE) for the simple linear model is 23.52 while the MSE for the varying coefficient model is 20.51. When comparing the MSE, the observed and predicted responses are transformed back to the original scale. The results show that the varying coefficient model can better describe the relationship between the housing price and the predictors.

5 Discussion
In this paper, we introduce two algorithms for fitting varying coefficient models with adaptive polynomial splines. The first algorithm selects knots globally using a recursive method, assuming the same set of knots for all the predictors, whereas the second algorithm allows each predictor to have its own set of knots and also uses a recursive method for individualized knots selection.
Coefficients modeled by polynomial splines with a finite number of non-regularly positioned knots are more flexible as well as more interpretable than the standard ones with equidistant knot placements. Simulation studies show that both global and predictor-specific algorithms outperform the commonly used kernel method, as well as equidistant spline fitting method, in terms of mean squared errors, while the predictor-specific algorithm achieves the best performance. A fast dynamic programming algorithm is introduced, with a computation complexity no more than and can be of order if the knots are chosen from quantiles of the conditional variable .
Throughout the paper we assume that the conditioner variable is univariate. The proposed predictor-specific spline approach can be easily generalized to the case when each coefficient has its own univariate conditioner variable . However, it is still a challenging problem to generalize the proposed method to multi-dimensional conditioners and to model correlated errors.
Acknowledgement
We are grateful to the National Oceanic and Atmospheric Administration Regional Climate Centers, Northeast Regional Climate Center at Cornell University for kindly sharing the meteorological data. We are thankful to the Environmental Protection Agency and the Department of Health, New York State for publishing the air quality data and daily infected records online.
References
- Astrid et al., (2009) Astrid, J., Philippe, L., Benoit, B., & F, V. (2009). Pharmacokinetic parameters estimation using adaptive bayesian p-splines models. Pharm Stat, 8.
- Casas & Fernandez-Casal, (2019) Casas, I. & Fernandez-Casal, R. (2019). tvreg: Time-varying coefficient linear regression for single and multi-equations in r. SSRN.
- Chen et al., (2015) Chen, Y., Wang, Q., & Yao, W. (2015). Adaptive estimation for varying coefficient models. Journal of Multivariate Analysis, 137, 17–31.
- Fan & Zhang, (1999) Fan, J. & Zhang, W. (1999). Statistical estimation in varying coefficient models. The Annals of Statistics, 27(5), 1491 – 1518.
- Fan & Zhang, (2000) Fan, J. & Zhang, W. (2000). Simultaneous confidence bands and hypothesis testing in varying-coefficient models. Scandinavian Journal of Statistics, 27(4), 715–731.
- Finley & Banerjee, (2020) Finley, A. O. & Banerjee, S. (2020). Bayesian spatially varying coefficient models in the spbayes r package. Environmental Modelling & Software, 125, 104608.
- Harrison & Rubinfeld, (1978) Harrison, D. & Rubinfeld, D. L. (1978). Hedonic housing prices and the demand for clean air. Journal of environmental economics and management, 5(1), 81–102.
- Hastie & Tibshirani, (1993) Hastie, T. & Tibshirani, R. (1993). Varying-coefficient models. Journal of the Royal Statistical Society. Series B (Methodological), 55(4), 757–796.
- Hu et al., (2019) Hu, L., Huang, T., & You, J. (2019). Estimation and identification of a varying-coefficient additive model for locally stationary processes. Journal of the American Statistical Association, 114(527), 1191–1204.
- Hu & Xia, (2012) Hu, T. & Xia, Y. (2012). Adaptive semi-varying coefficient model selection. Statistica Sinica, (pp. 575–599).
- Huang & Shen, (2004) Huang, J. Z. & Shen, H. (2004). Functional coefficient regression models for non-linear time series: A polynomial spline approach. Scandinavian Journal of Statistics, 31(4), 515–534.
- Huang et al., (2002) Huang, J. Z., Wu, C. O., & Zhou, L. (2002). Varying-coefficient models and basis function approximations for the analysis of repeated measurements. Bimoetrika, 89(1), 111–128.
- Huang et al., (2004) Huang, J. Z., Wu, C. O., & Zhou, L. (2004). Polynomial spline estimation and inference for varying coefficient models with longitudinal data. Statistica Sinica, (pp. 763–788).
- Lin et al., (2019) Lin, H., Yang, B., Zhou, L., Yip, P. S., Chen, Y.-Y., & Liang, H. (2019). Global kernel estimator and test of varying-coefficient autoregressive model. Canadian Journal of Statistics, 47(3), 487–519.
- Notari, (2021) Notari, A. (2021). Temperature dependence of covid-19 transmission. Science of The Total Environment, 763, 144390.
- Schwarz et al., (1978) Schwarz, G. et al. (1978). Estimating the dimension of a model. The annals of statistics, 6(2), 461–464.
- Tang & Cheng, (2012) Tang, Q. & Cheng, L. (2012). Componentwise b-spline estimation for varying coefficient models with longitudinal data. Statistical Papers, 53, 629–652.
- Wang et al., (2009) Wang, H. J., Zhu, Z., & Zhou, J. (2009). Quantile regression in partially linear varying coefficient models. The Annals of Statistics, 37(6B), 3841–3866.
- Wang & Sun, (2019) Wang, W. & Sun, Y. (2019). Penalized local polynomial regression for spatial data. Biometrics, 75(4), 1179–1190.
- Wang et al., (2017) Wang, X., Jiang, B., & Liu, J. (2017). Generalized r-squared for detecting dependence. Biometrika, 104(1), 129–139.
- Wei et al., (2011) Wei, F., Huang, J., & Li, H. (2011). Variable selection and estimation in high-dimensional varying-coefficient models. Statistica Sinica, 21(4), 1515.
- Yuan & Lin, (2006) Yuan, M. & Lin, Y. (2006). Model selection and estimation in regression with grouped variables. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 68(1), 49–67.
- Zhang & Wang, (2014) Zhang, X. & Wang, J.-L. (2014). Varying-coefficient additive models for functional data. Biometrika, 102(1), 15–32.
- Zou, (2006) Zou, H. (2006). The adaptive lasso and its oracle properties. Journal of the American statistical association, 101(476), 1418–1429.