Variational Leakage: The Role of
Information Complexity in Privacy Leakage
Abstract.
We study the role of information complexity in privacy leakage about an attribute of an adversary’s interest, which is not known a priori to the system designer. Considering the supervised representation learning setup and using neural networks to parameterize the variational bounds of information quantities, we study the impact of the following factors on the amount of information leakage: information complexity regularizer weight, latent space dimension, the cardinalities of the known utility and unknown sensitive attribute sets, the correlation between utility and sensitive attributes, and a potential bias in a sensitive attribute of adversary’s interest. We conduct extensive experiments on Colored-MNIST and CelebA datasets to evaluate the effect of information complexity on the amount of intrinsic leakage.
A repository of the proposed method implementation, Colored-MNIST dataset generator and the corresponding analysis is publicly available at:
1. Introduction
Sensitive information sharing is a challenging problem in information systems. It is often handled by obfuscating the available information before sharing it with other parties. In (Makhdoumi et al., 2014), this problem has been formalized as the privacy funnel (PF) in an information theoretic framework. Given two correlated random variables and with a joint distribution , where represents the available information and the private latent variable, the goal of the PF model is to find a representation of using a stochastic mapping such that: (i) form a Markov chain; and (ii) representation is maximally informative about the useful data (maximizing Shannon’s mutual information (MI) ) while being minimally informative about the sensitive data (minimizing ). There have been many extensions of this model in the recent literature, e.g., (Makhdoumi et al., 2014; P. Calmon et al., 2015; Basciftci et al., 2016; Sreekumar and Gündüz, 2019; Hsu et al., 2019; Rassouli et al., 2019; Rassouli and Gündüz, 2019; Razeghi et al., 2020; Rassouli and Gündüz, 2021).

In this paper, we will consider a delicate generalization of the PF model considered in (Basciftci et al., 2016; Rassouli and Gündüz, 2021), where the goal of the system designer is not to reveal the data that has available but another correlated utility variable. In particular, we assume that the data owner/user acquires some utility from the service provider based on the amount of information disclosed about a utility random variable correlated with , measured by . Therefore, considering Markov chain , the data owner’s aim is to share a representation of observed data , through a stochastic mapping , while preserving information about utility attribute and obfuscate information about sensitive attribute (see Fig. 1).
The implicit assumption in the PF model presented above and the related generative adversarial privacy framework (Huang et al., 2017; Tripathy et al., 2019) is to have pre-defined interests in the game between the ‘defender’ (data owner/user) and the ‘adversary’; that is, the data owner knows in advance what feature/ variable of the underlying data the adversary is interested in. Accordingly, the data release mechanism can be optimized/ tuned to minimize any inference the adversary can make about this specific random variable. However, this assumption is violated in most real-world scenarios. The attribute that the defender may assume as sensitive may not be the attribute of interest for the inferential adversary. As an example, for a given utility task at hand, the defender may try to restrict inference on gender recognition while the adversary is interested in inferring an individual’s identity or facial emotion. Inspired by (Issa et al., 2019), and in contrast to the above setups, we consider the scenario in which the adversary is curious about an attribute that is unknown to the system designer.
In particular, we argue that the information complexity of the representation measured by MI can also limit the information leakage about the unknown sensitive variable. In this paper, obtaining the parameterized variational approximation of information quantities, we investigate the core idea of (Issa et al., 2019) in the supervised representation learning setup.
Notation: Throughout this paper, random vectors are denoted by capital bold letters (e.g., ), deterministic vectors are denoted by small bold letters (e.g., ), and alphabets (sets) are denoted by calligraphic fonts (e.g., ). We use the shorthand to denote the set . denotes the Shannon’s entropy, while denotes the cross-entropy of the distribution relative to a distribution . The relative entropy is defined as . The conditional relative entropy is defined by:
And the MI is defined by:
We abuse notation to write and for random vectors and .
2. Problem Formulation
Given the observed data , the data owner wishes to release a representation for a utility task . Our aim is to investigate the potential statistical inference about a sensitive random attribute from the released representation . The sensitive attribute is possibly also correlated with and .
The objective is to obtain a stochastic map such that . This means that the posterior distribution of the utility attribute is similar when conditioned on the released representation or on the original data . Under logarithmic loss, one can measure the utility by Shannon’s MI (Makhdoumi et al., 2014; Tishby et al., 2000; Razeghi et al., 2020). The logarithmic loss function has been widely used in learning theory (Cesa-Bianchi and Lugosi, 2006), image processing (Andre et al., 2006), information bottleneck (Harremoës and Tishby, 2007), multi-terminal source coding (Courtade and Wesel, 2011), and PF (Makhdoumi et al., 2014).
Threat Model: We make minimal assumptions about the adversary’s goal, which can model a large family of potential adversaries. In particular, we have the following assumptions:
-
•
The distribution is unknown to the data user/owner. We only restrict attribute to be discrete, which captures most scenarios of interest, e.g., a facial attribute, an identity, a political preference.
-
•
The adversary observes released representation and the Markov chain holds.
-
•
We assume the adversary knows the mapping designed by the data owner, i.e., the data release mechanism is public. Furthermore, the adversary may have access to a collection of the original dataset with the corresponding labels .
Suppose that the sensitive attribute has a uniform distribution over a discrete set , where . If , then equivalently . Also note that due to the Markov chain , we have . When is not known a priori, the data owner has no control over . On the other hand, can be interpreted as the information complexity of the released representation, which plays a critical role in controlling the information leakage . Note also that a statistic induces a partition on the sample space , where is sufficient statistic for if and only if the assigned samples in each partition do not depend on . Hence, intuitively, a larger induces finer partitions on , which could potentially lead to more leakage about the unknown random function of . This is the core concept of the notion of variational leakage, which we shortly address in our experiments.
Since the data owner does not know the particular sensitive variable of interest to the adversary, we argue that it instead aims to design with the minimum (information) complexity and minimum utility loss. With the introduction of a Lagrange multiplier , we can formulate the objective of the data owner by maximizing the associated Lagrangian functional:
| (1) |
This is the well-known information bottleneck (IB) principle (Tishby et al., 2000), which formulates the problem of extracting, in the most succinct way, the relevant information from random variable about the random variable of interest . Given two correlated random variables and with joint distribution , the goal is to find a representation of using a stochastic mapping such that: (i) , and (ii) is maximally informative about (maximizing ) and minimally informative about (minimizing ).
Note that in the PF model, measures the useful information, which is of the designer’s interest, while in the IB model, measures the useful information. Hence, in PF quantifies the residual information, while in IB quantifies the redundant information.
In the sequel, we provide the parameterized variational approximation of information quantities, and then study the impact of the information complexity on the information leakage for an unknown sensitive variable.
2.1. Variational Approximation of Information Measures
Let , , be variational approximations of the optimal utility decoder distribution , adversary decoder distribution , and latent space distribution , respectively. The common approach is to use deep neural networks (DNNs) to model/parameterized these distributions. Let denote the family of encoding probability distributions over for each element of space , parameterized by the output of a DNN with parameters . Analogously, let and denote the corresponding family of decoding probability distributions and , respectively, parameterized by the output of DNNs and . Let , denote the empirical data distribution. In this case, denotes our joint inference data distribution, and denotes the learned aggregated posterior distribution over latent space .
Information Complexity: The information complexity can be decomposed as:
| (2) | |||||
Where is the latent space’s prior.
Therefore, the parameterized variational approximation of information complexity (2) can be recast as:
| (3) |
The optimal prior minimizing the information complexity is ; however, it may potentially lead to over-fitting. A critical challenge is to guarantee that the learned aggregated posterior distribution conforms well to thd prior (Kingma et al., 2016; Rezende and Mohamed, 2015; Rosca et al., 2018; Tomczak and Welling, 2018; Bauer and Mnih, 2019). We can cope with this issue by employing a more expressive form for , which would allow us to provide a good fit of an arbitrary space for , at the expense of additional computational complexity.
Information Utility: The parameterized variational approximation of MI between the released representation and the utility attribute can be recast as:
where represents the parameterized decoder uncertainty, and in the last line we use the positivity of the cross-entropy .
3. Learning Model
System Designer. Given independent and identically distributed (i.i.d.) training samples , and using stochastic gradient descent (SGD)-type approach, DNNs , , , and are trained together to maximize a Monte-Carlo approximation of the deep variational IB functional over parameters , , , and (Fig. 2). Backpropagation through random samples from the posterior distribution is required in our framework, which is a challenge since backpropagation cannot flow via random nodes; to overcome this hurdle, we apply the reparameterization approach (Kingma and Welling, 2014)).
The inferred posterior distribution is typically assumed to be a multi-variate Gaussian with a diagonal co-variance, i.e., . Suppose . We first sample a random variable i.i.d. from , then given data sample , we generate the sample , where is the element-wise (Hadamard) product. The latent space prior distribution is typically considered as a fixed -dimensional standard isotropic multi-variate Gaussian, i.e., . For this simple choice, the information complexity upper bound
has a closed-form expression, which reads as:
The -divergences in (3) and (2.1) can be estimated using the density-ratio trick (Nguyen et al., 2010; Sugiyama et al., 2012), utilized in the GAN framework to directly match the data and generated model distributions. The trick is to express two distributions as conditional distributions, conditioned on a label , and reduce the task to binary classification. The key point is that we can estimate the KL-divergence by estimating the ratio of two distributions without modeling each distribution explicitly.
Consider . We now define as , . Suppose that a perfect binary classifier (discriminator) , with parameters , is trained to associate the label to samples from distribution and the label to samples from . Using the Bayes’ rule and assuming that the marginal class probabilities are equal, i.e., , the density ratio can be expressed as:
Therefore, given a trained discriminator and i.i.d. samples from , we estimate as:
| (4) |
Our model is trained using alternating block coordinate descend across five steps (See Algorithm 1).
Inferential Adversary: Given the publicly-known encoder and i.i.d. samples , the adversary trains an inference network to minimize .

4. Experiments
In this section, we show the impact of the following factors on the amount of leakage: (i) information complexity regularizer weight , (ii) released representation dimension , (iii) cardinalities of the known utility and unknown sensitive attribute sets, (iv) correlation between the utility and sensitive attributes, and (v) potential bias in a sensitive attribute of adversary’s interest. We conduct experiments on the Colored-MNIST and large-scale CelebA datasets. The Colored-MNIST111Several papers have employed Colored-MNIST dataset; However, they are not unique, and researchers synthesized different versions based on their application. The innovative concept behind our version was influenced from the one used in (Rodríguez-Gálvez et al., 2020). is our modified version of MNIST (LeCun and Cortes, 2010), which is a collection of colored digits of size . The digits are randomly colored with red, green, or blue based on two distributions, as explained in the caption of Fig. 4. The CelebA (Liu et al., 2015) dataset contains images of size . We used TensorFlow (Abadi et al., 2016) with Integrated Keras API. The method details and network architectures are provided in Appendix. A and Appendix B.







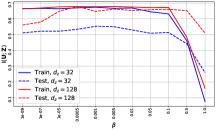
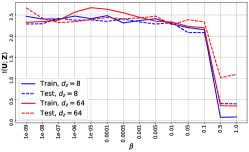
The first and second rows of Fig. 3 and Fig. 4 depict the trade-off among (i) information complexity, (ii) service provider’s accuracy on utility attribute , and (iii) adversary’s accuracy on attribute . The third row depicts the amount of information revealed about , i.e., , for the scenarios considered in the first and second rows, which are estimated using MINE (Belghazi et al., 2018). The fourth row depicts the amount of released information about the utility attribute , i.e., , corresponding to the considered scenarios in the first and second rows, also estimated using MINE. We consider different portions of the datasets available for training adversary’s network, denoted by the ‘data ratio’.











The experiments on CelebA consider the scenarios in which the attributes and are correlated, while . We provide utility accuracy curves for (i) training set, (ii) validation set, and (iii) test set. As we have argued, there is a direct relationship between information complexity and intrinsic information leakage. Note that, as increases, the information complexity is reduced, and we observe that this also results in a reduction in the information leakage. We also see that the leakage is further reduced when the dimension of the released representation , i.e., , is reduced. This forces the data owner to obtain a more succinct representation of the utility variable, removing any extra information.
In the Colored-MNIST experiments, provided that the model eliminates all the redundant information and leaves only the information about , we expect the adversary’s performance to be close to ‘random guessing’ since the digit color is independent of its value. We investigate the impact of the cardinality of sets and , as well as possible biases in the distribution of . The results show that it is possible to reach the same level of accuracy on the utility attribute , while reducing the intrinsic leakage by increasing the regularizer weight , or equivalently, by reducing the information complexity . An interesting possible scenario is to consider correlated attributes and with different cardinality sets and . For instance, utility task is personal identification, while the adversary’s interest is gender recognition.
5. Conclusion
We studied the variational leakage to address the amount of potential privacy leakage in a supervised representation learning setup. In contrast to the PF and generative adversarial privacy models, we consider the setup in which the adversary’s interest is not known a priori to the data owner. We study the role of information complexity in information leakage about an attribute of an adversary interest. This was addressed by approximating the information quantities using DNNs and experimentally evaluating the model on large-scale image databases. The proposed notion of variational leakage relates the amount of leakage to the minimal sufficient statistics.
References
- (1)
- Abadi et al. (2016) Martín Abadi et al. 2016. Tensorflow: A system for large-scale machine learning. In USENIX Symp. on Operating Sys. Design and Impl. (OSDI). 265–283.
- Andre et al. (2006) Thomas Andre, Marc Antonini, Michel Barlaud, and Robert M Gray. 2006. Entropy-based distortion measure for image coding. In 2006 International Conference on Image Processing. IEEE, 1157–1160.
- Basciftci et al. (2016) Yuksel Ozan Basciftci, Ye Wang, and Prakash Ishwar. 2016. On privacy-utility tradeoffs for constrained data release mechanisms. In 2016 Information Theory and Applications Workshop (ITA). IEEE, 1–6.
- Bauer and Mnih (2019) Matthias Bauer and Andriy Mnih. 2019. Resampled priors for variational autoencoders. In The 22nd International Conference on Artificial Intelligence and Statistics. 66–75.
- Belghazi et al. (2018) Mohamed Ishmael Belghazi, Aristide Baratin, Sai Rajeshwar, Sherjil Ozair, Yoshua Bengio, Aaron Courville, and Devon Hjelm. 2018. Mutual information neural estimation. In International Conference on Machine Learning. 531–540.
- Cesa-Bianchi and Lugosi (2006) Nicolo Cesa-Bianchi and Gábor Lugosi. 2006. Prediction, learning, and games. Cambridge university press.
- Courtade and Wesel (2011) Thomas A Courtade and Richard D Wesel. 2011. Multiterminal source coding with an entropy-based distortion measure. In 2011 IEEE International Symposium on Information Theory Proceedings. IEEE, 2040–2044.
- Harremoës and Tishby (2007) Peter Harremoës and Naftali Tishby. 2007. The information bottleneck revisited or how to choose a good distortion measure. In 2007 IEEE International Symposium on Information Theory. IEEE, 566–570.
- Hsu et al. (2019) Hsiang Hsu, Shahab Asoodeh, and Flavio P. Calmon. 2019. Obfuscation via Information Density Estimation. In Proceeding of the International Conference on Artificial Intelligence and Statistics (AISTATS).
- Huang et al. (2017) Chong Huang, Peter Kairouz, Xiao Chen, Lalitha Sankar, and Ram Rajagopal. 2017. Context-aware generative adversarial privacy. Entropy 19, 12 (2017), 656.
- Issa et al. (2019) Ibrahim Issa, Aaron B Wagner, and Sudeep Kamath. 2019. An operational approach to information leakage. IEEE Transactions on Information Theory 66, 3 (2019), 1625–1657.
- Kingma and Ba (2014) D. P Kingma and J. Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014).
- Kingma et al. (2016) Durk P Kingma, Tim Salimans, Rafal Jozefowicz, Xi Chen, Ilya Sutskever, and Max Welling. 2016. Improved variational inference with inverse autoregressive flow. In Advances in neural information processing systems. 4743–4751.
- Kingma and Welling (2014) Diederik P Kingma and Max Welling. 2014. Auto-encoding variational bayes. In International Conference on Learning Representations (ICLR).
- LeCun and Cortes (2010) Yann LeCun and Corinna Cortes. 2010. MNIST handwritten digit database. http://yann.lecun.com/exdb/mnist/. (2010). http://yann.lecun.com/exdb/mnist/
- Liu et al. (2015) Z. Liu, P. Luo, X. Wang, and X. Tang. 2015. Deep Learning Face Attributes in the Wild. In International Conference on Computer Vision (ICCV).
- Makhdoumi et al. (2014) Ali Makhdoumi, Salman Salamatian, Nadia Fawaz, and Muriel Médard. 2014. From the information bottleneck to the privacy funnel. In 2014 IEEE Information Theory Workshop (ITW 2014). IEEE, 501–505.
- Nguyen et al. (2010) XuanLong Nguyen, Martin J Wainwright, and Michael I Jordan. 2010. Estimating divergence functionals and the likelihood ratio by convex risk minimization. IEEE Transactions on Information Theory 56, 11 (2010), 5847–5861.
- P. Calmon et al. (2015) Flavio P. Calmon, Ali Makhdoumi, and Muriel Médard. 2015. Fundamental limits of perfect privacy. In 2015 IEEE International Symposium on Information Theory (ISIT). IEEE, 1796–1800.
- Rassouli and Gündüz (2019) Borzoo Rassouli and Deniz Gündüz. 2019. Optimal utility-privacy trade-off with total variation distance as a privacy measure. IEEE Transactions on Information Forensics and Security 15 (2019), 594–603.
- Rassouli and Gündüz (2021) Borzoo Rassouli and Deniz Gündüz. 2021. On perfect privacy. In to appear in IEEE Journal on Selected Areas in Information Theory (JSAIT). IEEE.
- Rassouli et al. (2019) Borzoo Rassouli, Fernando E Rosas, and Deniz Gündüz. 2019. Data Disclosure under Perfect Sample Privacy. IEEE Trans. on Inform. Forensics and Security (2019).
- Razeghi et al. (2020) Behrooz Razeghi, Flavio P. Calmon, Deniz Gündüz, and Slava Voloshynovskiy. 2020. On Perfect Obfuscation: Local Information Geometry Analysis. In 2020 IEEE International Workshop on Information Forensics and Security (WIFS). 1–6.
- Rezende and Mohamed (2015) Danilo Jimenez Rezende and Shakir Mohamed. 2015. Variational inference with normalizing flows. In Proceedings of the 32nd International Conference on Machine Learning. 1530–1538.
- Rodríguez-Gálvez et al. (2020) Borja Rodríguez-Gálvez, Ragnar Thobaben, and Mikael Skoglund. 2020. A Variational Approach to Privacy and Fairness. arXiv preprint arXiv:2006.06332 (2020).
- Rosca et al. (2018) Mihaela Rosca, Balaji Lakshminarayanan, and Shakir Mohamed. 2018. Distribution matching in variational inference. arXiv preprint arXiv:1802.06847 (2018).
- Sreekumar and Gündüz (2019) Sreejith Sreekumar and Deniz Gündüz. 2019. Optimal Privacy-Utility Trade-off under a Rate Constraint. In 2019 IEEE International Symposium on Information Theory (ISIT). IEEE, 2159–2163.
- Sugiyama et al. (2012) Masashi Sugiyama, Taiji Suzuki, and Takafumi Kanamori. 2012. Density-ratio matching under the Bregman divergence: A unified framework of density-ratio estimation. Annals of the Institute of Statistical Mathematics 64, 5 (2012), 1009–1044.
- Tishby et al. (2000) Naftali Tishby, Fernando C Pereira, and William Bialek. 2000. The information bottleneck method. In IEEE Allerton.
- Tomczak and Welling (2018) Jakub Tomczak and Max Welling. 2018. VAE with a VampPrior. In International Conference on Artificial Intelligence and Statistics. 1214–1223.
- Tripathy et al. (2019) Ardhendu Tripathy, Ye Wang, and Prakash Ishwar. 2019. Privacy-preserving adversarial networks. In 57th Annual Allerton Conference on Communication, Control, and Computing (Allerton). IEEE, 495–505.
Appendices
Appendix A Training Details
All the experiments in the paper have been carried out with the following structure:
A.0.1. Pre-Training Phase
We utilize this phase to warm-up our model before running the main training Algorithm 1 for the Variational Leakage framework within all experiments. In the warm-up phase, we pre-trained encoder and utility-decoder together for the few epochs via backpropagation (BP) with the Adam optimizer (Kingma and Ba, 2014). We found out the warm-up stage was helpful for faster convergence. Therefore, we initialize the encoder and the utility-decoder weights with the obtained values rather than random or zero initialization. For each experiment, the hyper-parameters of the learning algorithm in this phase were:
| Experiment Dataset | Learning Rate | Max Iteration | Batch Size |
|---|---|---|---|
| Colored-MNIST | 0.005 | 50 | 1024 |
| (both version) | |||
| CelebA | 0.0005 | 100 | 512 |
A.0.2. Main Block-wise Training Phase
In contrast to the most DNNs training algorithms, each iteration only has one forward step through the network’s weights and then update weights via BP approach. Our training strategy is block-wise and consists of multiple blocks in the main algorithm loop. At each block, forward and backward steps have been done through the specific path in our model, and then corresponding parameters update based on the block’s output loss path.
Since it was not possible for us to use the Keras API’s default model training function, we implement Algorithm 1 from scratch in the Tensorflow. It is important to remember that we initialize all parameters to zero except for the values which acquired in the previous stage. Furthermore, we set the learning rate of the block (1) in the Algorithm 1, five times larger than other blocks. The hyper-parameters of the Algorithm 1 for each experiment shown in the following table:
| Experiment Dataset | Learning Rate | Max Iteration | Batch Size |
|---|---|---|---|
| [blocks (2)-(5)] | |||
| Colored-MNIST | 0.0001 | 500 | 2048 |
| (both version) | |||
| CelebA | 0.00001 | 500 | 1024 |
Appendix B Network Architectures
B.0.1. MI Estimation
For all experiments in this paper, we report estimation of MI between the released representation and sensitive attribute, i.e., , as well as the MI between the released representation and utility attribute, i.e., . To estimate MI, we employed the MINE model (Belghazi et al., 2018). The architecture of the model is depicted in Table. 1.
| MINE |
|---|
| Input Code; |
| x = Concatenate([z, u]) |
| FC(100), ELU |
| FC(100), ELU |
| FC(100), ELU |
| FC(1) |
B.0.2. Colored-MNIST
In the Colored-MNIST experiment, we had two versions for data utility and privacy leakage evaluation. In the first version, we set the utility data to the class’ label of the input image and consider the color of the input image as sensitive data, and for the second one, we did vice versa. It is worth mentioning that both balanced and unbalanced Colored-MNIST datasets are applied with the same architecture given in Table 2.
| Encoder |
| Input Color Image |
| Conv(64,5,2), BN, LeakyReLU |
| Conv(128,5,2), BN, LeakyReLU |
| Flatten |
| FC(), BN, Tanh |
| : FC(), : FC() |
| =SamplingWithReparameterizationTrick[,] |
| Utility Decoder |
| Input Code |
| FC(), BN, LeakyReLU |
| FC(), SOFTMAX |
| Latent Space Discriminator |
| Input Code |
| FC(), BN, LeakyReLU |
| FC(), BN, LeakyReLU |
| FC(), Sigmoid |
| Utility Attribute Class Discriminator |
| Input |
| FC(), BN, LeakyReLU |
| FC(), BN, LeakyReLU |
| FC(), Sigmoid |
B.0.3. CelebA
In this experiment, we considered three scenarios for data utility and privacy leakage evaluation, as shown in Table 3. Note that all of the utility and sensitive attributes are binary. The architecture of the networks are presented in Table 4.
| Scenario Number | Utility Attribute | Sensitive Attribute |
|---|---|---|
| 1 | Gender | Heavy Makeup |
| 2 | Mouth Slightly Open | Smiling |
| 3 | Gender | Blond Hair |
| Encoder |
| Input Color Image |
| Conv(16,3,2), BN, LeakyReLU |
| Conv(32,3,2), BN, LeakyReLU |
| Conv(64,3,2), BN, LeakyReLU |
| Conv(128,3,2), BN, LeakyReLU |
| Conv(256,3,2), BN, LeakyReLU |
| Flatten |
| FC(), BN, Tanh |
| : FC(), : FC() |
| =SamplingWithReparameterizationTrick[,] |
| Utility Decoder |
| Input Code |
| FC(), BN, LeakyReLU |
| FC(), SOFTMAX |
| Latent Space Discriminator |
| Input Code |
| FC(), BN, LeakyReLU |
| FC(), BN, LeakyReLU |
| FC(), Sigmoid |
| Utility Attribute Class Discriminator |
| Input |
| FC(), BN, LeakyReLU |
| FC(), BN, LeakyReLU |
| FC(), Sigmoid |



Appendix C Implementation Overview
Fig. 6 demonstrates all sub networks of the proposed framework that attached together and their parameters learned in the Algorithm 1.

However, we did not define and save our model in this form because of technical reasons to efficiently implement the training algorithm. As shown in Algorithm 1, the main loop consists of five blocks where only some networks are used in the forward phase, and mostly one of them would update their parameters via BP in each block. Therefore, we shattered the model into three sub-modules in the training stage for simplicity and performance. Fig. 5 shows the corresponding sub-modules of Fig. 6, which are used in our implementation. During training, all of the sub-module (a) parameters, call "autoencoder part" would update with BP after each forward step. For the (b) and (c) sub-modules, only the parameters of one network are updated when the corresponding error function values backpropagate, and we freeze the other networks parameters in the sub-module. For example, block (3) of Algorithm 1 is related to the (b) sub-module, but at the BP step, the latent space discriminator is frozen to prevent its parameters from updating. This procedure is vice versa for module (b) at block (2).
It should be mentioned that during our experiments, we found out that before running our main algorithm, it is beneficial to pre-train the autoencoder sub-module since we need to sample from the latent space, which uses in other parts of the main model during training. We justify this by mentioning that sampling meaningful data rather than random ones from latent variables from the beginning of learning helps the model to converge better and faster in comparison with starting Algorithm 1 with a randomly initiated autoencoder.