Variable-Frequency Model Learning and Predictive Control for Jumping Maneuvers on Legged Robots
Abstract
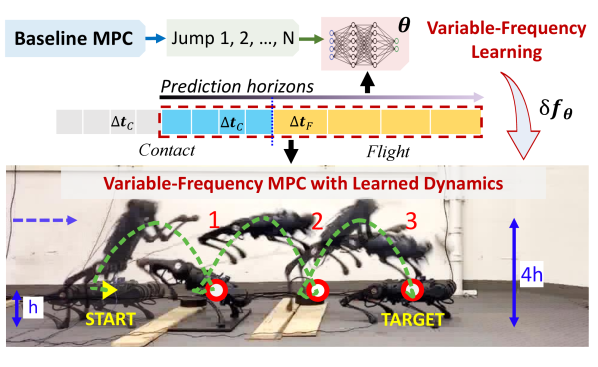
Achieving both target accuracy and robustness in dynamic maneuvers with long flight phases, such as high or long jumps, has been a significant challenge for legged robots. To address this challenge, we propose a novel learning-based control approach consisting of model learning and model predictive control (MPC) utilizing a variable-frequency scheme. Compared to existing MPC techniques, we learn a model directly from experiments, accounting not only for leg dynamics but also for modeling errors and unknown dynamics mismatch in hardware and during contact. Additionally, learning the model with variable-frequency allows us to cover the entire flight phase and final jumping target, enhancing the prediction accuracy of the jumping trajectory. Using the learned model, we also design variable-frequency to effectively leverage different jumping phases and track the target accurately. In a total of jumps on Unitree A1 robot hardware, we verify that our approach outperforms other MPCs using fixed-frequency or nominal model, reducing the jumping distance error times. We also achieve jumping distance errors of less than during continuous jumping on uneven terrain with randomly-placed perturbations of random heights (up to cm or the robot’s standing height). Our approach obtains distance errors of cm on single and continuous jumps with different jumping targets and model uncertainties. Code is available at https://github.com/DRCL-USC/Learning_MPC_Jumping.
Index Terms:
Model Learning for Control, Legged Robots, Whole-Body Motion Planning and ControlI Introduction
Aggressive jumping maneuvers with legged robots have received significant attention recently, and have been successfully demonstrated using trajectory optimization [QuannICRA19, chuongjump3D, matthew_mit2021_1, ChignoliICRA2021], model-based control [YanranDingTRO, continuous_jump_bipedal, GabrielICRA2021, park2017high, ZhitaoIROS22, fullbody_MPC], and learning-based control [zhuang2023robot, RL_jump_bipedal, yang2023cajun, vassil_drl, jumpingrl, lokesh_ogmp]. Unlike walking or running, aggressive motions are particularly challenging due to (1) the extreme underactuation in the mid-air phase (the robot mainly relies on the force control during contact to regulate its global position and orientation), (2) significant dynamics model error and uncertainty that are inherently hard to model accurately, especially with contact and hardware load during extreme motions, and (3) the trade-off between model accuracy and efficient computation for real-time execution. Achieving both target accuracy and robustness for long-flight maneuvers, such as high or long jumps, therefore still presents an open challenge. In this work, we address this challenge by developing a real-time MPC for quadruped jumping using a robot dynamics model learned from experiments.
Many control and optimization techniques have been developed for jumping motions. Trajectory optimization (TO) with full-body nonlinear dynamics is normally utilized to generate long-flight trajectories in an offline fashion (e.g., [QuannICRA19, chuongjump3D]). Many MPC approaches sacrifice model accuracy to achieve robust maneuvers by using simplified models that treat the trunk and legs as a unified body [NMPC_3D_hopping, ZhitaoIROS22, GabrielICRA2021, park2017high, YanranDingTRO]. Our recent iterative learning control (ILC) work [chuong_ilc_jump] handles model uncertainty to realize long-flight jumps via multi-stage optimization that optimizes the control policy after each jump offline until reaching a target accurately. It also relies on a simplified model for computational efficiency. However, this work focuses on target jumping rather than robustness, e.g. requiring the same initial condition for all trials. Different from existing works, we learn a robot dynamics model from experiments and develop real-time MPC using the learned dynamics to achieve both target accuracy and robustness in continuous quadruped jumping.
Learning robot models from experiments to capture complex dynamics effects and account for model errors with real hardware has become a popular approach [bauersfeld2021neurobem, hewing2019cautious, saviolo2022physics, duong23porthamiltonian]. Many frameworks learn residual dynamics using neural networks [bauersfeld2021neurobem, salzmann2023real] or Gaussian processes [hewing2019cautious, cao2017gaussian] and use MPC to control the learned systems [salzmann2023real, pohlodek2022hilompc] to improve tracking errors. Most existing works, however, primarily investigate dynamical systems without contact. Recently, Sun et al. [sun2021online] proposed a notable method to learn a linear residual model, addressing unknown dynamics during walking stabilization. Pandala et al. [Pandala_robustMPC] propose to close the gap between reduced- and full-order models by using deep reinforcement learning to learn unmodeled dynamics, which are used in MPC to realize robust walking on various terrains. Meanwhile, we use supervised learning to learn unmodelled dynamics with real data from hardware. Also, we learn dynamics for maneuvers with long-flight periods to tackle (1) the switching between multiple dynamic models due to contact, including flight phase where control action has very little effect on the body dynamics, (2) disturbances and uncertainty in dynamic modeling due to hard impact in jumping, and (3) the effect of intermittent control at contact transitions on state predictions.
In this letter, we propose a residual learning model that uses a variable-frequency scheme, i.e., varying the coarseness of integration time step, to address the aforementioned challenges and enhance long-term trajectory predictions over different jumping phases. MPC has been commonly used for jumping by optimizing the control inputs during the contact phase based on future state prediction during the flight phase (e.g.,[GabrielICRA2021, fullbody_MPC, park2017high, YanranDingTRO, continuous_jump]). A major challenge in MPC for long flight maneuvers is to utilize a limited number of prediction steps yet still effectively cover the entire flight phase and especially the final jumping target. Another challenge is to obtain an accurate model for complex dynamic maneuvers, unknown dynamics, and model mismatch with the real hardware to improve the jumping accuracy, while still ensuring real-time performance. Some recent works have addressed these challenges partially. Many methods use conventional single-rigid-body dynamic (SRBD) models, ignoring the leg dynamics, to achieve real-time execution [GabrielICRA2021, continuous_jump_bipedal, YanranDingTRO]. Using the SRBD model in the contact phase can lead to inaccurate predictions of the robot’s state at take-off, which is the initial condition of the projectile motion in the flight phase. Thus, the trajectory prediction error can accumulate significantly over long flight periods. Some methods account for leg inertia [ZiyiZhouRAL, He2024, fullbody_MPC], however, disturbance and uncertainty in dynamic modeling have not been considered. Recently, planning with multi-fidelity models and multi-resolution time steps has emerged as an effective strategy to enhance target accuracy and robustness [heli_cafempc, Norby_adaptivempc, Heli_hierarchympc]. Li et al. [Heli_hierarchympc] adopt a less accurate model in the far horizon and a more accurate but expensive model in the near future. Norby et al. [Norby_adaptivempc] adapt model complexity based on the task complexity along the prediction horizon. Li et al. [Heli_hierarchympc] also design multi-resolution time steps to cover the whole flight phase. While we vary the coarseness of the time step as [Heli_hierarchympc], we design a novel residual model learning approach combined with variable-frequency MPC to address the aforementioned challenges.
Contributions: The contributions of this letter are summarized as follows.
-
•
We learn a residual dynamics model directly from a small real experiment dataset. The model accounts for nonlinear leg dynamics, modeling errors, and unknown dynamics mismatch in hardware and during contact.
-
•
We propose learning the model in an variable-frequency scheme that leverages different time resolutions to capture the entire flight phase, the jumping target, and the contact transitions over a few-step horizon, thereby significantly improving the accuracy of long-term trajectory prediction.
-
•
We develop variable-frequency MPC using the learned model to synthesize controls that improve both target accuracy and robustness in dynamic robot maneuvers.
-
•
Extensive hardware experiments validate the effectiveness and robustness of our approach with single and consecutive jumps on uneven terrains. Comparisons with other MPC techniques using a nominal model or fixed-frequency are also provided.
II Problem Statement
Consider a legged robot modelled by state , consisting of the pose and velocity of the body’s center of mass (CoM), foot positions relative to the body’s CoM, and ground force control input at the legs, sampled at time . We augment the nominal SRBD model (e.g., [GabrielICRA2021, park2017high, YanranDingTRO]) with a learned residual term to account for leg dynamics, model mismatch with the real robot hardware, as well as capture complex dynamic effects in contact and hardware:
| (1) |
where represents the nominal SRBD model, with parameters approximates the residual dynamics, and is the sampling interval. Our first objective is to learn the residual dynamics using a dataset of jumping trajectories.
Problem 1
Given a set of sequences of states, foot positions, and control inputs, find the parameters of the residual dynamics in (1) by rolling out the dynamics model and minimizing the discrepancy between the predicted state sequence and the true state sequence in :
| s.t. | ||||
| (2) |
where is an error function in the state space, and is a regularization term to avoid overfitting. Note that it is not necessary for to be fixed.
After learning to improve the accuracy of model prediction, our second objective is to use the learned model (1) for MPC to track a desired state trajectory .
Problem 2
Given the dynamics model (1), a current robot state and foot positions , a desired trajectory of states , foot positions , and control , design a control law to achieve accurate and robust tracking of the desired state trajectory via shifting-horizon optimization:
| s.t. | ||||
| (3) |
where and are positive definite weight matrices, and represents an input constraint set.
Achieving accurate target jumping with MPC requires not only an accurate model but also the coverage of the final state upon landing, which represents the accuracy of the jumping target. Using a fixed-frequency has shown to be efficient for locomotion tasks with limited aerial phases; however, this can face two challenges in long-flight maneuvers. On the one hand, using a fine time-step dirscretization enhances the model prediction accuracy but requires a large number of steps to capture the entire flight phase, thereby increasing the optimization size and computational cost. On the other hand, using a coarse time-step discretization allows capturing the entire flight phase efficiently but can sacrifice model prediction accuracy. For jumping tasks, different phases may require different model resolutions, e.g., fine time resolution during the contact phase but coarser time resolution during the flight phase as the model complexity is reduced due to unavailable force control and contact. Therefore, we propose to learn a model for dynamic maneuvers (Problem 1) with an variable-frequency scheme that uses a coarse time discretization in the flight phase and a fine time discretization in the contact phase. Importantly, this variable-frequency scheme is also synchronized with the MPC control of the learned model (Problem 2) by utilizing the same time steps for both fitting the learned model and performing the MPC optimization. This synchronization ensures that the same discretization errors are leveraged when using the model for MPC predictions. Thus, in our formulation does not have equal time steps and is a mixture of fine and coarse discretization capturing the contact and flight phases. Note that we use a constant time step during the different jumping phases. It is possible to use as input to the residual model neural networks. However, we need to collect a substantial amount of data for a wide range of to avoid overfitting, which would also increase the size of the neural network and computational cost.
III System Overview
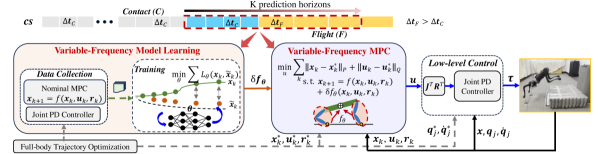
Fig. 2 presents an overview of our system architecture. Our approach consists of two stages: variable-frequency model learning (Sec. IV) and variable-frequency MPC (Sec. V), which solve Problem 1 and Problem 2, respectively.
We synchronize the variable-frequency scheme for both model learning and MPC execution with the same (1) variable prediction timesteps and for contact and flight phase, respectively, (2) the same horizon length for all data collection, training, and MPC, and (3) the same contact schedule. Full-body trajectory optimization (TO) [QuannICRA19] is utilized to generate jumping references for various targets, including body states , joint states , ground contact force , and foot positions . For data collection, we combine a baseline MPC using a nominal SRBD model and joint PD controller, generating diverse motions under disturbances. For training, we design a neural network to learn the discretized residual model with variable sampling time via supervised learning. For control, we design an variable-frequency MPC using the learned dynamics to track a desired reference trajectory obtained from full-body TO. The feedback states from the robot include global body’s CoM , and joint states , and foot positions .
IV Variable-Frequency Model Learning
In this section, we describe how to learn the residual dynamics from data with a variable-frequency scheme that can cover the entire flight phase, the final state upon landing, and the contact transitions between jumping phases.
IV-A Learning Dynamics with Variable-Frequency
We consider a 2D jumping motion on a legged robot with point foot contact, e.g., quadruped robot, with generalized coordinates , where is the CoM’s position, and is the body pitch angle. We define the generalized robot’s velocity as , where and are the linear and angular velocity. Both and are expressed in world-frame coordinates. The robot state is , where the (constant) gravity acceleration is added to obtain a convenient state-space form [Carlo2018]. We define as a rotation matrix of the main body, which converts (a relative foot position relative to the body’s CoM in the body frame) to the world frame . We denote . With the force control input for the front and rear legs as , the nominal discrete-time SRBD model can be written as:
| (4) |
where , , is the time step (e.g., or for the contact or flight phase, respectively), and and are obtained from the continuous-time robot dynamics:
where , , , and are mass and moment inertial of the body, . The residual term in (1) is
| (5) |
where and are represented by neural networks with learning parameters . Since during the flight phase, . We have two separate models for the contact () and flight phase ():
| (6a) | |||
| (6b) | |||
where , , and . We roll out the dynamics based on (6), starting from initial state with given control input sequence to obtain a predicted state sequence . Using the variable-frequency scheme, the state prediction accounts for contact transitions (feet taking off the ground), a long flight phase, and the final robot state upon landing. We define the loss functions in Problem 1 as follows:
| (7) | ||||
The parameters for each phase are updated by gradient descent to minimize the total loss.
IV-B Data Collection
For model learning, we directly collect state-control trajectories from hardware experiments by implementing an MPC controller with the nominal dynamics model (4) and a reference body trajectory obtained from full-body TO. The TO assumes jumping from flat and hard ground with point foot contact. We generated various jumps to different targets under different disturbances (e.g., blocks under the robot feet with random height) to obtain a diverse dataset.
While the MPC aims to track the body reference trajectory , a joint PD controller is used to track the joint reference trajectory from the full-body TO via . Thus, the evolution of the robot states is governed by the combination of MPC and the joint PD controller. We collected the trajectory dataset with inputs where , is the foot Jacobian..
The dataset is collected at the different time steps for the contact and flight phases, i.e., and , respectively. The data for each jump is then chunked by shifting a sliding window, size of by 1 timesteps. Let be the number of collected state-control data points for each jump and be the number of jumps. We then obtain state-control trajectories in total.
V Variable-Frequency MPC with Learned Dynamics
In this section, we design a variable-frequency MPC controller for the learned dynamics (6) to track a desired jumping reference trajectory obtained from full-body TO. For a given robot state , we formulate MPC as:
| (8a) | ||||
| s.t. | ||||
| (8b) | ||||
| (8c) | ||||
| (8d) | ||||
| (8e) | ||||
where (8d) represents input constraints related to friction cone and force limits and (8e) aims to nullify the force on the swing legs based on the contact schedule.
With the MPC horizon including steps in the contact phase and steps in the flight phase, we define as a concatenation of the control inputs in the contact phase. With this notation, the predicted trajectory is:
| (9a) | ||||
| (9b) | ||||
where and denote the concatenation of predicted states belonging to the contact and flight phase, respectively. The matrices and are computed as
While we use the current robot state for training the neural networks , as presented in Sec. IV, we utilize the reference trajectory () in future MPC horizons for guiding the MPC since the future robot states are not available at each MPC update ([continuous_jump_bipedal, YanranDingTRO, GabrielICRA2021, ZhitaoIROS22, park2017high]). The reference will be used to compute the output of the neural networks and in future horizons. In particular, we still use the current robot state and foot position to evaluate the residual term for each MPC update, then define , . In (9a), we obtain and its residual
For the sake of notation, we define , as the actual and reference robot state and foot trajectory. The residual matrix in (9) is , where is lower triangular matrix with each entry , . The residual matrix where is lower triangular matrix with each entry defined , . The state prediction at the end of steps can be computed as
| (10) |
where , , and . Substituting (10) into (9) yields the state prediction as
| (11) |
| (12) |
where, , , , , and .
The objective of the MPC in (8) can be rewritten as:
| (13) |
leading to a quadratic program (QP):
| (14) |
where
VI Evaluation
VI-A Experiment Setup
We evaluated our approach using a A1 robot. To get data for real-time control, we utilized a motion capture system for estimating the position and orientation of the robot trunk at kHz with position errors of mm. We obtain velocity data from position data using forward finite-difference method.
We used Pytorch to implement and train the residual dynamics model. The trained Pytorch model was converted to a torch script trace, which in turn, was loaded in our MPC implementation in C++. The MPC is solved by a QP solver (qpOASES). We utilized the optimization toolbox CasADi [casadi] to set up and solve the full-body TO for various jumping targets within m on a flat ground. We considered jumping motions with contact phase (C) consisting of an all-leg contact period (e.g., ms) and a rear-leg contact period (e.g., ms). With the flight phase (F) scheduled for ms, the front legs and rear legs become swing legs (SW) up to and of the entire jumping period, respectively. Jumping maneuvers feature long flight phases, i.e., the robot can jump up to times its normal standing height during the mid-air period. All jumping experiments are executed with sufficient battery level ()
VI-B Data Collection and Training
| Parameter | Symbol | Value |
| Variable time steps | ||
| Prediction steps | ||
| NN architecture | - Tanh - Tanh - | |
| - Tanh - Tanh - | ||
| - Tanh - Tanh - | ||
| Learning rate | ||
| Regulation weights | ||
| Total training steps |
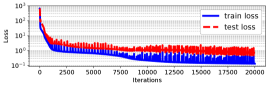
We aim to learn a residual dynamics model that is not trajectory-specific and can generalize to a whole family of forward jumps. To collect a sufficient dataset for training, we utilized a baseline MPC controller with a nominal model (Sec. IV-B) to generate diverse trajectories under a variety of unknown disturbances (box under the front feet with random height within cm) and zero-height jumping targets. We collected data from jumps with for training and for testing. The data points were sampled with variable sampling time ms, ms, and horizon length of .
The training parameters are listed in Table LABEL:tab:training_params. We used fully-connected neural networks with architectures listed in Table LABEL:tab:training_params: the first number is the input dimension, the last number is the output dimension, and the numbers in between are the hidden layers’ dimensions and activation functions. The output of is then converted to a matrix. The training and testing losses are illustrated in Fig. 3.

VI-C Comparative Analysis
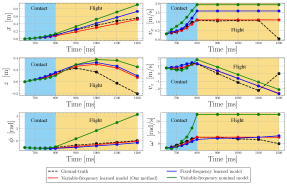
VI-C1 Evaluation on testing dataset
We rolled out the learned dynamics with variable frequency to predict the future state trajectories and compared with (i) those of the variable-frequency nominal model, (ii) those of the fixed-frequency learned model, and (iii) the ground-truth states in Fig. 4. The fixed-frequency learned model is trained with and ms. The figure shows that our proposed learned model (red lines) outperforms variable-frequency nominal model (green lines) and fixed-frequency learned model (blue lines). We highlight a large deviation in trajectory prediction of variable-frequency nominal model with the others. This inaccuracy can be explained by the use of conventional SRBD for the entire prediction horizon and the coarse Euler integration for the flight phase. Our variable-frequency learned model helps address the inaccuracies introduced by the nominal model and keeps sufficient accuracy of trajectory prediction while allowing real-time MPC by keeping a small number of decision variables.
VI-C2 Effect of prediction horizon
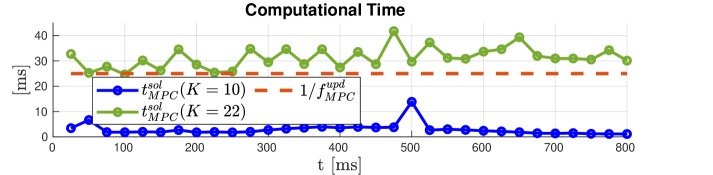
Fig. 5 compares the solving time for MPC with different horizons. With our variable-frequency scheme, we can use a few prediction horizons, e.g., ( for contact and for the flight phase), allowing QP solving time for each MPC update ((14)) to be ms only on average. This efficient computation enables real-time performance for MPC. Using a fixed-frequency scheme with sample time of ms requires MPC to use a large number of steps, e.g. ( for contact and for the whole flight phase). This long horizon yields a large optimization problem, which takes ms for each MPC update and deteriorates the real-time performance.
VI-C3 Execution
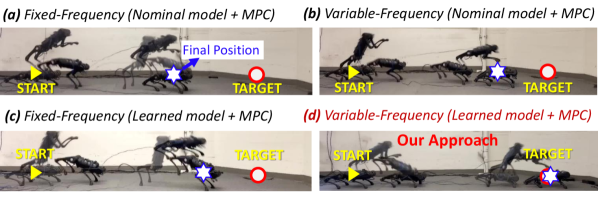
We verified that our proposed approach enables both robust and accurate target jumping to various targets. We compared (a) nominal model fixed-frequency MPC, (b) nominal model variable-frequency MPC, (c) fixed-frequency learned model fixed-frequency MPC, and (d) variable-frequency learned model variable-frequency MPC (our approach). The fixed-frequency scheme uses and variable-frequency one utilizes . All MPCs use the prediction horizon , thus the fixed-frequency MPC does not cover the entire flight phase.
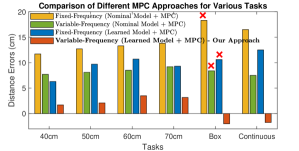
For each combination, we perform jumps consisting of (i) 3 single jumps for each of five targets: cm, cm, cm, cm for jump on box, and cm, and (ii) continuous jumps of cm. This yields a total of jumps for comparison. Fig. 6 shows the average final jump target errors of four different MPC combinations across different jumping tasks. Our approach outperforms the methods that adopt fixed-frequency or nominal models, reducing the jumping distance error up to times. Our method demonstrates successful jumping on a box with landing angle errors , while the fixed-frequency MPC or nominal model MPC fail, as shown in Fig. 7. Note that the box-jumping task is not executed during data collection, verifying the scalability of our method to generalize to unseen reference trajectories and unseen tasks. With our method, the robot also successfully jumps under model uncertainty, e.g, an unknown block ( robot standing height) placed under the front feet (Fig. 7). This task uses a reference trajectory designed for flat ground and demonstrates an example where the robot significantly deviates from the reference trajectory.
We also studied the effect of uncertainty in the model by evaluating the jumping performance if we only utilize a joint PD controller to track the joint reference from full-body TO [QuannICRA19], via . The full-order model can be conservative by assuming hard feet, point-to-surface contact, and hard ground. These assumptions, however, are not valid for the Unitree A1 robot equipped with deformable feet [Zachary_RAL_online_calibration_2022]. Uncertainties due to DC motors working at extreme conditions or motor deficiency are difficult to model and are normally ignored in the full-body model. These factors affect the model accuracy and prevent the robot from reaching the jumping target if we solely rely on the joint PD, as can be seen in Fig. 7.
We evaluate the target accuracy and robustness with our method for continuous jumps on flat ground. The results are presented in Fig. 9, showing some selected snapshots of the first and the last jump to the final target m. Our method achieves the highest target accuracy, allowing the robot to traverse m with an average distance error of only cm per jump. During flight periods, the robot can jump up to its standing height.
Note that computing residual matrices can consume significant time if we feed the neural network with sequentially. To improve computational efficiency, we combined the current state and reference as a batch, then feed-forward the entire batch to the learned neural networks all at once, reducing the neural network query time to less than ms.
We further evaluate MPC with different models learned with other timing choices of ms, in addition to the two timesteps we already discussed above.
| Task | ||||
| Box-Jump |
Three jumps are conducted separately for each timing choice of jumping on box task, and the experiments are summarized in Tab. LABEL:tab:vary_timestep. We also achieved successful jumps using the variable-frequency scheme ms. We also observed that using higher timestep in contact to cover the whole flight phase even with fixed-frequency scheme, e.g., ms does not guarantee successful jumps. This confirms our rationale that due to the higher complexity of the robot dynamics during the contact phase, a coarse time step during this phase leads to higher accumulated prediction errors, even in the flight phase, causing task failures.
VI-D Continuous Jumping on Uneven Terrain
We tested the robustness and target accuracy of our learning-based MPC for continuous jumping on uneven terrains with a target of cm for each jump, as illustrated in Fig. 1 and Fig. 9. The terrain consisted of multiple blocks with random heights between cm, randomly placed on the ground. Since the robot legs can impact the ground early or late on the real robot, there is usually a mismatch between scheduled contact and actual contact states. Whenever both contacts happen (i.e., the landing phase starts), we activate a separate landing MPC to make a transition between two jumps in a short period of ms [continuous_jump]. The landing MPC is designed with simplified dynamics, , and ms. This aims to track the body reference trajectory from TO for continuous jumping [continuous_jump] and connects two jumps seamlessly. Figure 1 shows the actual trajectory of three continuous jumps, leaping around cm in total that yields only cm distance error () for each jump on the uneven terrain. Compared to our prior work [continuous_jump], we successfully achieve continuous jumping in hardware in this work. With our framework, we also achieve a target jumping error of less than cm () on single and continuous jumps with different targets and uneven terrain.
VII Discussion and Conclusion
In this letter, we developed a learned-model MPC approach that enables both target accuracy and robustness for aggressive planar jumping motions. We learned a residual model from a limited dataset to account for the effect of leg dynamics and model mismatch with real hardware. Given the learned model, we designed a learning-based variable-frequency MPC that considers the jumping transitions, the entire flight phase, and the jumping target during the optimization process. We demonstrated the scalability of our approach to handle new jumping targets with unseen reference trajectories. While allowing real-time computation, our approach uses the reference trajectory to evaluate the neural network residual model and ensure a linear model for MPC, which sacrifices a certain degree of accuracy if the system does not operate around the reference under substantial disturbances. To overcome this limitation, our future work will explore the use of nonlinear MPC and address its associated higher computational cost. We will also generalize the model learning and control framework with varying contact schedules. Further, we will incorporate line-foot, rolling, and soft contact in learning aggressive legged locomotion maneuvers.