V-MAO: Generative Modeling for Multi-Arm Manipulation of Articulated Objects
Abstract
Manipulating articulated objects requires multiple robot arms in general. It is challenging to enable multiple robot arms to collaboratively complete manipulation tasks on articulated objects. In this paper, we present V-MAO, a framework for learning multi-arm manipulation of articulated objects. Our framework includes a variational generative model that learns contact point distribution over object rigid parts for each robot arm. The training signal is obtained from interaction with the simulation environment which is enabled by planning and a novel formulation of object-centric control for articulated objects. We deploy our framework in a customized MuJoCo simulation environment and demonstrate that our framework achieves a high success rate on six different objects and two different robots. We also show that generative modeling can effectively learn the contact point distribution on articulated objects.
Keywords: Articulated object, generative model, variational inference
1 Introduction
In robotics, one of the core research problems is how to endow robots with the ability to manipulate objects of various geometry and kinematics. Compared to rigid objects, articulated objects contain multiple rigid parts that are kinematically linked via mechanical joints. Because of the rich functionality due to joint kinematics, articulated objects are used in many applications. Examples include opening doors, picking up objects with pliers, and cutting with scissors, etc.
While the manipulation of a known rigid object has been well studied in the literature, the manipulation of articulated objects still remains a challenging problem. Suppose an articulated object has rigid parts. In the most general case, it requires robot grippers to manipulate the object parts where each gripper grasps one rigid part to fully control all configurations of the articulated object, including position and joint angles 111Though in certain scenarios, it is still possible that an articulated object be manipulated by a single gripper, e.g. dexterous manipulation of a pair of scissors with one human hand. However, such manipulation is extremely complex and is not scalable for other arbitrary articulated objects.. How to teach the robot arms to collaborate safely without collision is still a research problem [1, 2]. Our intuition is that, instead of a deterministic model, sampling from a distribution of grasping actions can provide more options and can increase the chance of finding feasible collaborative manipulation after motion planning. Therefore, the generative modeling of grasping can be a solution to the problem.
We hypothesize that an object-centric representation of contact point distribution contains full information about possible grasps and can generalize better across different objects. Therefore it is preferred over robot-centric representation such as low-level torque actions, due to the uncertainty of robot configurations. Specifically for articulated objects, we further hypothesize that the grasping distribution on one rigid part is conditioned on the geometric and kinematics feature as well as grasping actions on other parts, and can be learned from interacting with the environment.
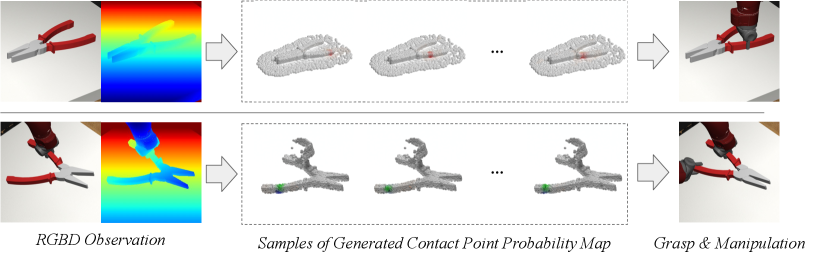
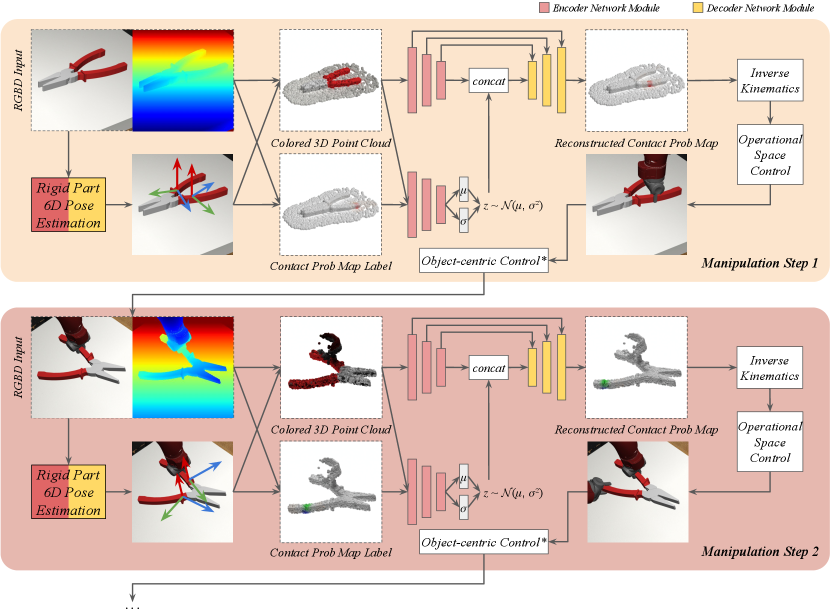
In this paper, we propose a framework named V-MAO for learning manipulation of articulated objects with multiple robot arms based on an object-centric latent generative model for learning grasping distribution. The latent generative model is formulated as a conditional variational encoder (CVAE), where the distribution of contact probability on the 3D point clouds of one object rigid part is modeled by variational inference. Note that the contact probability distribution on one object part is conditioned on the grasping actions already executed on other object parts which can be observed from the current state of 3D geometric and kinematics features. To obtain enough data for training, our framework enables automatic collection of training data using the exploration of contact points and interaction with the environment. To enable interaction, we propose a formulation of Object-centric Control for Articuated Objects (OCAO) to move the articulated parts to desired poses and joint angles after successful grasp. The framework is illustrated in Figure 1.
We demonstrate our V-MAO framework in a simulation environment constructed with MuJoCo physics engine [3]. We evaluate V-MAO on six articulated objects from PartNet dataset [4] and two different robots. V-MAO achieves over 80% success rate with Sawyer robot and over 70% success rate with Panda robot. Experiment results also show that the proposed variational generative model can effectively learn the distribution of successful contacts. The proposed model also shows advantage over the deterministic model baseline in terms of success rate and the ability to deal with variations of environments.
The contributions of this work are three-fold:
1. A latent generative model for learning manipulation contact. The model extracts articulated object geometric and kinematic representations based on 3D features. The model is implemented based on a conditional variational model.
2. A mechanism for automatic contact label generation from robot interaction with the environment. We also propose a formulation of Object-centric Control for Articuated Objects (OCAO) that enables the interaction by the controllable moving of articulated object parts.
3. We construct a customized MuJoCo simulation environment and demonstrate our framework on six articulated objects from PartNet and two different robots. The proposed model shows advantage over deterministic model baseline in terms of success rate and dealing with environment variations.
2 Related Works
Generative Modeling of Robotic Manipulation. Previous work has proposed to leverage latent generative models such as variational auto-encoder (VAE) [5] and generative adversarial network (GAN) [6] in various aspects of robotic manipulation. Wang et al. [7] proposed to use Causal InfoGAN [8] to learn to generate goal-directed object manipulation plan directly from raw images. Morrison et al. [9] proposed a generative convolutional neural net (CNN) for synthesizing grasp from depth images. Mousavian et al. [10] use VAE to model the distribution of pose of 6D robot grasp pose. Other works have proposed to use generative model to learn more complex grasping tasks such as multi-finger grasping [11] and dexterous grasping [12, 13]. Generative modeling can also be seen in other aspects of robotic manipulation such as for object pose estimation [14] and robot gripper design [15]. Our approach focuses on using variational latent generative model on 3D point clouds for learning object contact point distributions on articulated objects.
Articulated Object Manipulation. The task of manipulating articulated object has been studied on both perception and action perspective in the literature. For example, Katz et al. [16] proposed a relational state representation of object articulation for learning manipulation skill. From interactive perception, Katz et al. [17] learns kinematic model of an unknown articulated object through interaction with the object. Kumar et al. [18] propose to estimate mass distribution of an articulated objects through manipulation. Narayanan et al. [19] introduced kinematic graph representation and an efficient planning algorithm for object articulation manipulation. More recently, Mittal et al. [20] constructed a mobile manipulation platform that integrates articulation perception and planning. Our work models contact point distributions from object geometry using a generative model and propose an object-centric control formulation for manipulating articulated objects.
Multi-Arm in Robotic Manipulation. Using multiple robot arms in manipulation tasks without collision is a challenging problem. Previous works have investigated using decentralized motion planner to avoid collision in multi-arm robot system [1]. Previous works have also investigated using multiple robots in the application of construction assembly [2], pick-and-place [21], and table-top rearrangement [22]. Our work is an application of using multiple robot arms to manipulate articulated objects where we focus on learning the contact point distribution on object parts.
3 Method
Our V-MAO framework consists of: 1) a variational generative model for learning contact distribution on each object rigd part (Section 3.2); and 2) inverse kinematics, planning, and control algorithms for interacting with the articulated object (Section 3.3). In Section 3.1, we first formally define the problem of using the generative model for articulated object manipulation. In Section 3.4, we provide additional details to our framework. The framework is illustrated in Figure 2.
3.1 Problem Definition
We consider the problem of multi-arm manipulation of articulated objects. The object has rigid parts and the system contains robot arms where . Robot arm executes high-level grasping action and moving actions on the objects. Grasping action is represented by the contact points on object part . Moving actions send torque signals to robot to move object part to desired 6D pose . The whole manipulation is a sequence of and .
Given colored 3D point clouds from RGBD sensors, suppose is the 3D point cloud of the -th rigid part of the object, where is the number of points and is the number of feature channels, e.g. color values and motion vectors. Suppose is the 3D point cloud of the non-object scene and is the 6D pose of -th rigid object part after executing grasping actions . Note that the complete 3D point cloud of the scene is a function of grasp actions and object part poses , where is the observation of the environment and depends on robot forward kinematics. We assume there is no cycle in object joint connections so that there is no cyclic dependency among object parts. We formulate the manipulation problem as learning the following joint distribution of given initial scene point cloud :
| (1) |
is the contact point distribution model of -th rigid part. In Equation (1), we use conditional probability to decompose and assume previous point clouds have no effect on the current grasping distribution. Our goal is to learn distribution for each object part that covers the feasible grasping as widely as possible so that sampled grasping actions and subsequent moving actions can successfully take all object parts to desired poses .
3.2 Generative Modeling of Contact Probability
Our generative model is based on variational inference [5]. Different from 2D images where the positions of the pixels are fixed and only the pixel value distribution needs to be modeled, in 3D point clouds, both geometry and point feature distribution need to be modeled. Therefore, instead of directly using multi-layer perceptions (MLPs) on pixel values similar to vanilla VAE, our model needs to learn both local and global point features in hierarchical fashion [23]. Moreover, in our model, the reconstructed feature map should not only be conditioned on latent code, but hierarchical geometric features as well.
Encoder and Decoder for One Single Step. Given a colored 3D point cloud appended with successful grasping probability maps where four feature channels are RGB and probability values, our model split the feature channels to construct two point clouds appended with different features: a 3D color map as the input to geometric learning, and as the 3D contact probability map to reconstruct using generative model.
An encoder network is used to approximate the posterior distribution of the latent code . Another encoder network learns the hierarchical geometric representation and outputs features at different levels:
| (2) |
where and are the predicted mean and standard deviation of the multivariate Gaussian distribution respectively. The latent code is then sampled from the distribution and is used to reconstruct the contact probability map on point clouds with a decoder network :
| (3) |
Note that both and are conditioned on . Therefore, our generative model can be viewed as a conditional variational encoder (CVAE) [24] that learns the latent distribution of the 3D contact probability map conditioned on the deep features of 3D color map . The conditional variational formulation takes observation into account and can improve the generalization.
The encoders and share the same architecture and are instantiated with set abstraction layers from PointNet++ [23]. The Decoder is instantiated with set upconv layers proposed in [25] to propagate features to existing up-sampled point locations in a learnable fashion.
Loss Function. Our generative model is trained to maximize the log-likelihood of the generated contact probability map to be successful contact labels. Due to Jensen’s inequality, the evidence lower bound objective (ELBO) in variational inference can be derived as
| (4) |
The total loss consists of two parts. Reconstruction loss is the cross entropy between and . Latent loss is the KL Divergence of two normal distributions. The goal of the training is to minimize the total loss . The parameters in the three networks, , and , are trained end-to-end to minimize .
3.3 Planning and Control Actions
Given the predicted contact points on object part , the 6D pose of the end-effector of robot can be obtained by solving an inverse kinematics problem. Path planning algorithm such as RRT [26] is used to find an operational space trajectory from initial pose to desired grasping pose. If a path is not found, the framework will iteratively sample contact point distributions from the generative model multiple times. Then we use Operational Space Controller [27] to move the gripper along the trajectory and finally complete the grasping action.
After a successful grasp, the next goal is to apply torques on robot arms and gripper to move the object part to the desired pose. To keep the grasping always valid, there should be no relative motion between the gripper and the object part. We propose Object-centric Control for Articuated Objects (OCAO) formulation. It computes the desired change of the 6D poses of robot end effectors given the desired change of the 6D pose of one of the object rigid parts and the changes of all joint angles. Operational Space Control (OSC) [27] will then be used to execute the desired pose change of the robot end effectors. For more technical details on the mathematical formulation of OCAO, please refer to the supplementary material.
3.4 Additional Implementation Details
Part-level Pose Estimation. To ensure the object contact point is present in the 3D point cloud, we merge the colored object mesh point clouds and the scene point cloud as a combined point cloud. The 6D pose of each object part is estimated using DenseFusion [28], an RGBD-based method for 6D object pose estimation. DenseFusion is trained separately using the simulation synthetic data. Since adding object mesh point cloud to the scene point cloud causes unnatural point density, we use farthest point sampling (FPS) on the merged scene point cloud to ensure uniform point density.
Automatic Label Generation from Exploration. Training the variational generative model requires a large amount of data. To collect sufficient data for training, we propose to automatically generate labels of contact point combinations using random exploration and interaction with the simulation environment. Expert-defined affordance areas of grasping, for example the handle of the plier, are provided to ensure realistic grasping and narrow down the exploration range. We provide initial human-labeled demonstrations of possibly feasible contact point combinations, for example a pair of points at the opposite sides of the plier handle, to speed up exploration efficiency. We then use random exploration on the contact points within the affordance region and verify the contact point combinations through interaction in the simulation environment. Successful contact point combinations are saved in a pool used in training. For more details on the algorithm of random exploration, please refer to the supplementary material.






4 Experiments
We design our experiments to investigate the following hypotheses: 1) given training samples of enough variability, the contact point generative model can effectively learn the underlying distribution; 2) contact point labels can be automatically generated through interaction with the environment; 3) given sampled and generated contact points, after path planning and control, the robot is able to complete the manipulation task.
In this section, we present the experiments on manipulating two-part articulated objects from PartNet [4] with two robot arms. To show that our framework can be applied to arbitrary number of articulated object parts and robot arms, we further conduct experiments on manipulating a three-part articulated object with three robot arms. Please refer to the supplementary material for the details on the three-arm experiments.
4.1 Experiment Setup
Task and Environment. We conduct the experiments in an environment constructed with MuJoCo [3] simulation engine. The environment consists of two robots facing a table in parallel. The articulated object is placed on the table surface with random initial positions and joint angles. The goal of the manipulation is to grasp the object parts and move them to reach the desired pose and joint angle configuration within a certain error threshold.
Objects and Robots. We evaluate our approach on six daily articulated objects from PartNet [4] in the experiments. The objects include three pliers and three laptops illustrated in Figure 3. For the robots in the experiment, we use Sawyer and Panda which are equipped with two-finger parallel-jaw Rethink and Panda grippers. Both robots and grippers are instantiated by high-fidelity models provided in robosuite [29]. For the friction between robot gripper and the object, we assume a friction coefficient of 0.65 and assume pyramidal friction cone.
Baseline. There is no related previous work on multi-arm articulated objects that we can compare our V-MAO with. So we developed a baseline approach denoted as “Top-1 Point” that predicts a deterministic per-point contact probability map on the point cloud using an encoder-decoder architecture and selects the best contact point for each gripper finger within the affordance region. To fairly compare, the baseline uses the same encoder and decoder architectures and is trained on the same interaction data as V-MAO. After contact point selection, the subsequent planning and control steps are also the same for the baseline.
4.2 Quantitative Evaluation
We explore two types of grasping strategy, sequential grasp and parallel grasp. In sequential grasp, object parts are grasped and moved in an sequential fashion. In -th step, robot gripper grasps the -th object part while leaving parts through uncontrolled. We iterate the above step until all parts are grasped. In parallel grasp all object parts are grasped simultaneously. Then the robots move the object parts to the goal locations together.
We report the success rate of manipulation in Table 1. Our V-MAO can achieve more than 80% success rate with Sawyer robot and more than 70% success rate with Panda robot on all objects, which shows V-MAO can effectively learn the contact distribution and complete the task. Besides, on the Panda robot, sequential grasping generally achieves a much better success rate than parallel grasping. This means determining grasping for other robots later may be a better option than determining both robots’ grasping at the beginning in certain cases.
We notice that when using the Panda robot, the performance of both V-MAO and the baseline decrease significantly. The reason is that the Panda robot has a large end effector size. Therefore when manipulating small objects like pliers, in many cases the space is not enough to contain both grippers due to robot collision, while Sawyer robot’s end effector is much smaller. The deterministic prediction baseline achieves a larger success rate on laptops. A possible explanation is that there are less variation in grasping laptops compared to pliers, for example the first grasp of the laptop is almost always grasping the base horizontally. Thus a deterministic model can be more stable in simpler tasks. On the other hand, in environments with larger variability, a generative model can have advantage.
| robot | method | grasp order | 100144 | 100182 | 102285 | 10213 | 10356 | 11778 |
|---|---|---|---|---|---|---|---|---|
| Sawyer | Top-1 Point | parallel | 90.0 | 92.0 | 86.0 | 96.0 | 88.0 | 90.0 |
| sequential | 82.0 | 78.0 | 88.0 | 92.0 | 84.0 | 86.0 | ||
| V-MAO (Ours) | parallel | 94.0 | 90.0 | 90.0 | 96.0 | 90.0 | 94.0 | |
| sequential | 92.0 | 86.0 | 92.0 | 96.0 | 88.0 | 90.0 | ||
| Panda | Top-1 Point | parallel | 50.0 | 20.0 | 48.0 | 90.0 | 92.0 | 88.0 |
| sequential | 62.0 | 42.0 | 70.0 | 78.0 | 82.0 | 70.0 | ||
| V-MAO (Ours) | parallel | 52.0 | 36.0 | 64.0 | 90.0 | 84.0 | 88.0 | |
| sequential | 72.0 | 76.0 | 78.0 | 88.0 | 86.0 | 86.0 |






















4.3 Qualitative Results
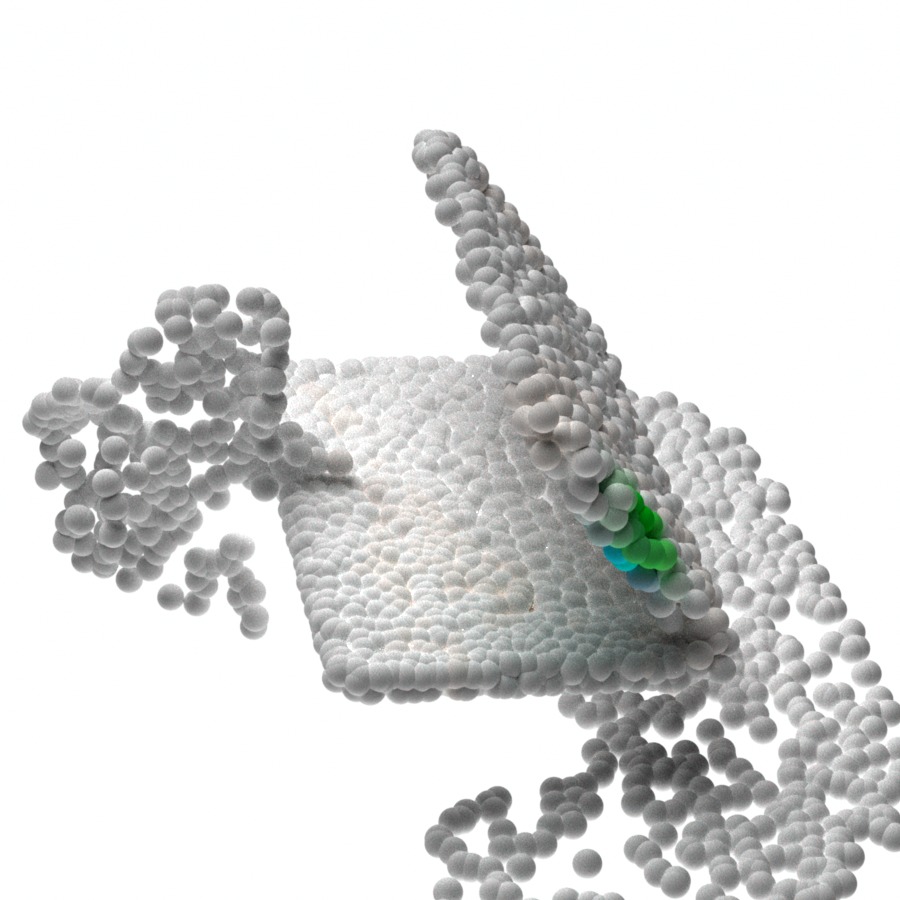
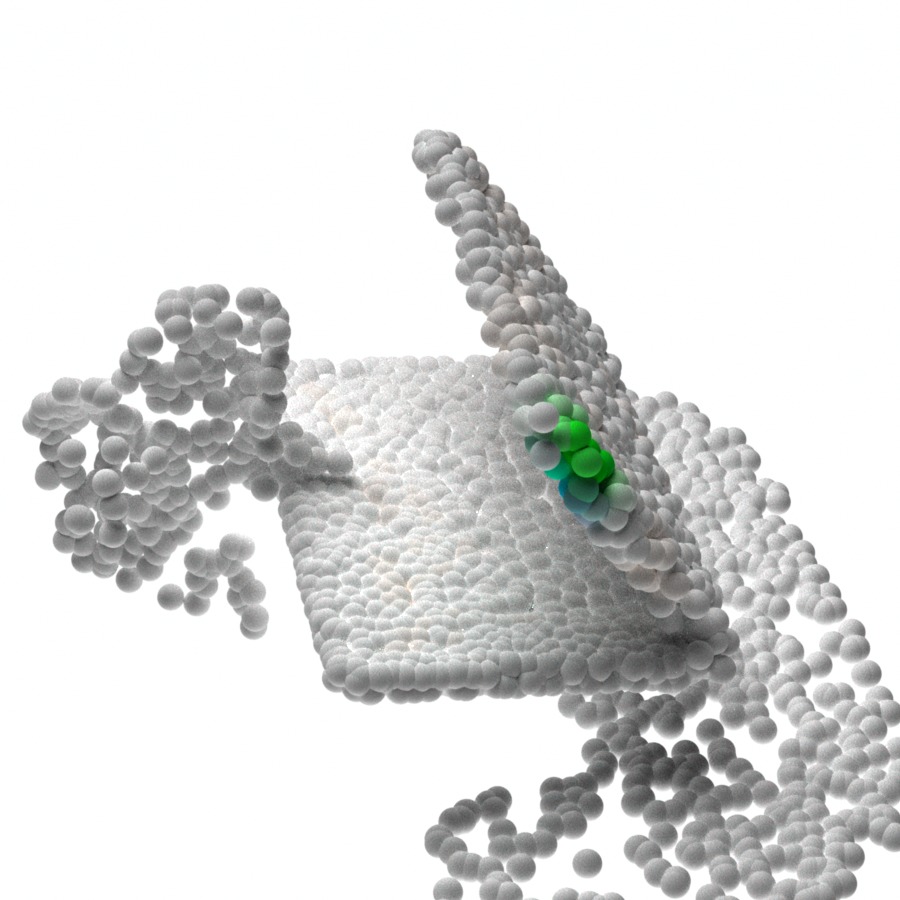
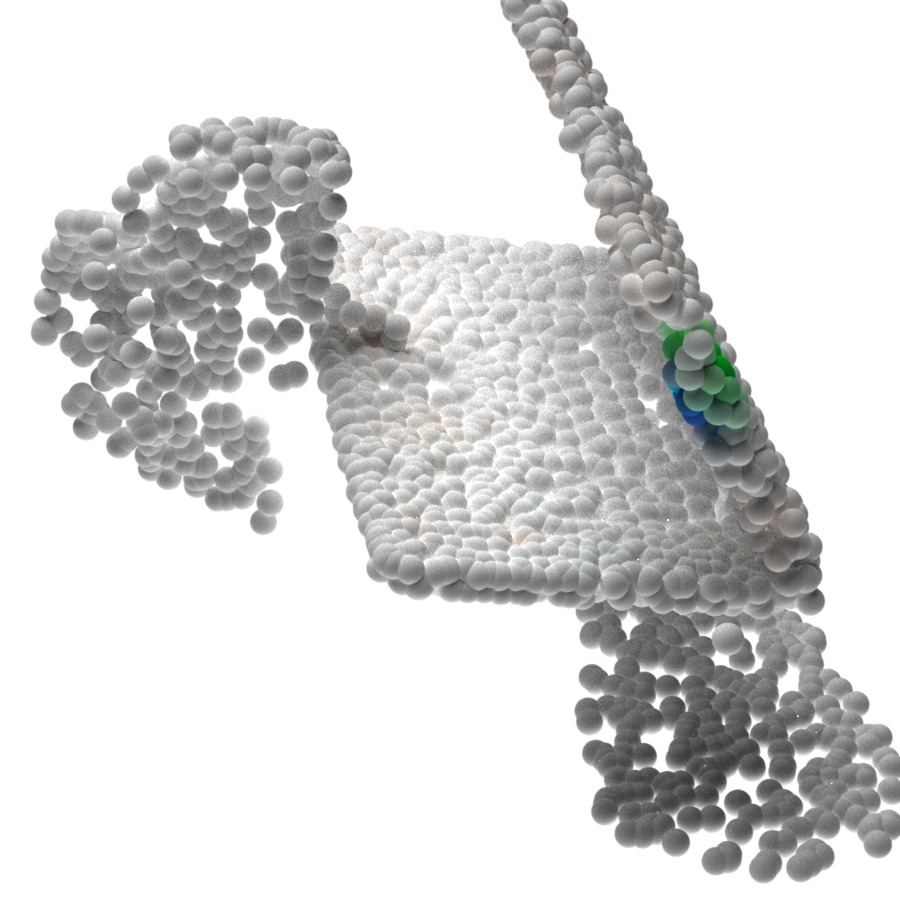
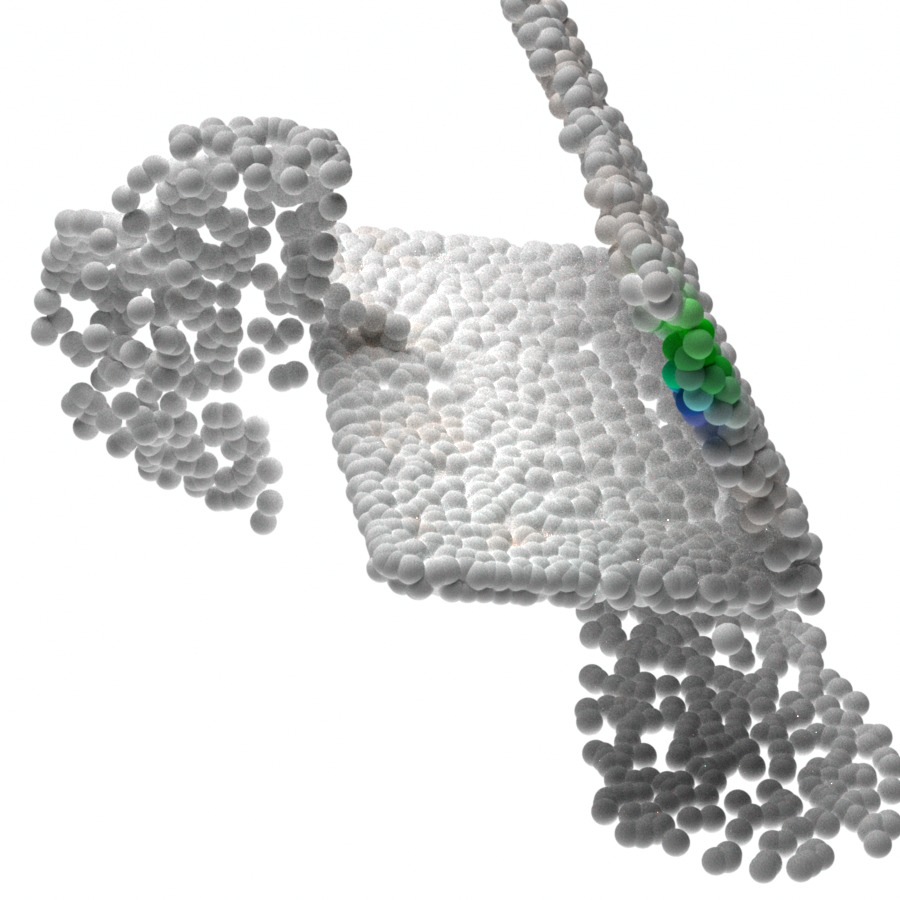
In Figure 4, we visualize the probability map on the 3D point clouds sampled from the generative model given different latent codes . As expected, the maximum value probability value falls on the object points. The points that have the highest probability for the respective gripper also form valid grasps. Given different latent codes , the generated contact points can cover a wide range of feasible contact point combinations. We also notice that there are some object regions that are less covered by the generative model during sampling. One possible reason is that grasping in these regions can introduce collisions in the current or the next steps and have a lower probability of being sampled.
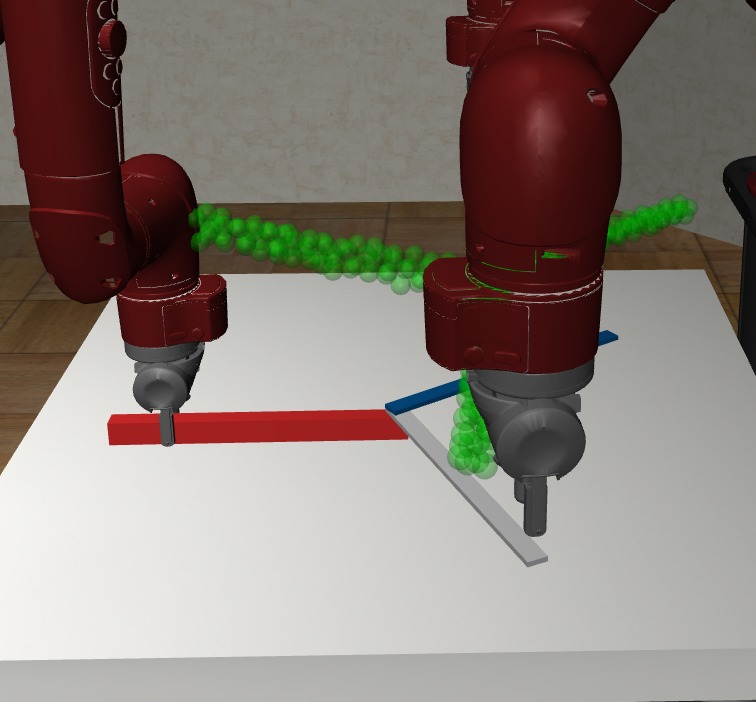
In Figure 5, we visualize the executed sequential manipulation using the contact points sampled from the generative model. As we can see, the robot gripper can successfully reach the contact points after inverse kinematics and path planning. When both grippers are grasping the object, the sampled and generated contact points combination for both robots can also avoid collision between robots. After grasping, both robots can reliably control the object to reach the goal configurations marked by green point cloud.
5 Conclusion
In this paper, we propose V-MAO, a framework for learning multi-arm manipulation of articulated objects. Our framework includes a variational generative model that learns contact point distribution over object rigid parts for each robot arm. We developed a mechanism for automatic contact label generation from robot interaction with the environment. We deploy our framework in a customized MuJoCo simulation environment and demonstrate that our framework achieves high success rate on six different objects and two different robots. V-MAO achieves over 80% success rate with Sawyer robot and over 70% success rate with Panda robot. Experiment results also show that the proposed variational generative model can effectively learn the distribution of successful contacts. As future work, we will investigate articulated object manipulation modeling using other sensor modalities such as stereo RGB images [30, 31] and dynamic point clouds [25, 32], or other pose estimation methods such as [33, 34].
Acknowledgments
This work is funded in part by JST AIP Acceleration, Grant Number JPMJCR20U1, Japan.
References
- Ha et al. [2020] H. Ha, J. Xu, and S. Song. Learning a decentralized multi-arm motion planner. In CoRL, 2020.
- Hartmann et al. [2021] V. N. Hartmann, A. Orthey, D. Driess, O. S. Oguz, and M. Toussaint. Long-horizon multi-robot rearrangement planning for construction assembly. arXiv preprint arXiv:2106.02489, 2021.
- Todorov et al. [2012] E. Todorov, T. Erez, and Y. Tassa. Mujoco: A physics engine for model-based control. In IROS, 2012.
- Mo et al. [2019] K. Mo, S. Zhu, A. X. Chang, L. Yi, S. Tripathi, L. J. Guibas, and H. Su. Partnet: A large-scale benchmark for fine-grained and hierarchical part-level 3d object understanding. In CVPR, 2019.
- Kingma and Welling [2013] D. P. Kingma and M. Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013.
- Goodfellow et al. [2014] I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial networks. In NIPS, 2014.
- Wang et al. [2019] A. Wang, T. Kurutach, K. Liu, P. Abbeel, and A. Tamar. Learning robotic manipulation through visual planning and acting. In RSS, 2019.
- Kurutach et al. [2018] T. Kurutach, A. Tamar, G. Yang, S. Russell, and P. Abbeel. Learning plannable representations with causal infogan. arXiv preprint arXiv:1807.09341, 2018.
- Morrison et al. [2018] D. Morrison, P. Corke, and J. Leitner. Closing the loop for robotic grasping: A real-time, generative grasp synthesis approach. In RSS, 2018.
- Mousavian et al. [2019] A. Mousavian, C. Eppner, and D. Fox. 6-dof graspnet: Variational grasp generation for object manipulation. In ICCV, 2019.
- Lundell et al. [2021] J. Lundell, E. Corona, T. N. Le, F. Verdoja, P. Weinzaepfel, G. Rogez, F. Moreno-Noguer, and V. Kyrki. Multi-fingan: Generative coarse-to-fine sampling of multi-finger grasps. In ICRA, 2021.
- Kopicki et al. [2019] M. S. Kopicki, D. Belter, and J. L. Wyatt. Learning better generative models for dexterous, single-view grasping of novel objects. IJRR, 2019.
- Lundell et al. [2021] J. Lundell, F. Verdoja, and V. Kyrki. Ddgc: Generative deep dexterous grasping in clutter. arXiv preprint arXiv:2103.04783, 2021.
- Chen et al. [2019] X. Chen, R. Chen, Z. Sui, Z. Ye, Y. Liu, R. I. Bahar, and O. C. Jenkins. Grip: Generative robust inference and perception for semantic robot manipulation in adversarial environments. In IROS, 2019.
- Ha et al. [2020] H. Ha, S. Agrawal, and S. Song. Fit2form: 3d generative model for robot gripper form design. CoRL, 2020.
- Katz et al. [2008] D. Katz, Y. Pyuro, and O. Brock. Learning to manipulate articulated objects in unstructured environments using a grounded relational representation. In RSS, 2008.
- Katz and Brock [2008] D. Katz and O. Brock. Manipulating articulated objects with interactive perception. In ICRA, 2008.
- Kumar et al. [2019] K. N. Kumar, I. Essa, S. Ha, and C. K. Liu. Estimating mass distribution of articulated objects using non-prehensile manipulation. arXiv preprint arXiv:1907.03964, 2019.
- Narayanan and Likhachev [2015] V. Narayanan and M. Likhachev. Task-oriented planning for manipulating articulated mechanisms under model uncertainty. In ICRA, 2015.
- Mittal et al. [2021] M. Mittal, D. Hoeller, F. Farshidian, M. Hutter, and A. Garg. Articulated object interaction in unknown scenes with whole-body mobile manipulation. arXiv preprint arXiv:2103.10534, 2021.
- Shome and Bekris [2019] R. Shome and K. E. Bekris. Anytime multi-arm task and motion planning for pick-and-place of individual objects via handoffs. In International Symposium on Multi-Robot and Multi-Agent Systems (MRS), 2019.
- Shome et al. [2021] R. Shome, K. Solovey, J. Yu, K. Bekris, and D. Halperin. Fast, high-quality two-arm rearrangement in synchronous, monotone tabletop setups. IEEE Transactions on Automation Science and Engineering, 2021.
- Qi et al. [2017] C. R. Qi, L. Yi, H. Su, and L. J. Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In NIPS, 2017.
- Sohn et al. [2015] K. Sohn, H. Lee, and X. Yan. Learning structured output representation using deep conditional generative models. NIPS, 2015.
- Liu et al. [2019] X. Liu, C. R. Qi, and L. J. Guibas. Flownet3d: Learning scene flow in 3d point clouds. In CVPR, 2019.
- LaValle et al. [1998] S. M. LaValle et al. Rapidly-exploring random trees: A new tool for path planning. 1998.
- Khatib [1995] O. Khatib. Inertial properties in robotic manipulation: An object-level framework. IJRR, 1995.
- Wang et al. [2019] C. Wang, D. Xu, Y. Zhu, R. Martín-Martín, C. Lu, L. Fei-Fei, and S. Savarese. Densefusion: 6d object pose estimation by iterative dense fusion. In CVPR, 2019.
- Zhu et al. [2020] Y. Zhu, J. Wong, A. Mandlekar, and R. Martín-Martín. robosuite: A modular simulation framework and benchmark for robot learning. In arXiv preprint arXiv:2009.12293, 2020.
- Liu et al. [2020] X. Liu, R. Jonschkowski, A. Angelova, and K. Konolige. Keypose: Multi-view 3d labeling and keypoint estimation for transparent objects. In CVPR, 2020.
- Liu et al. [2021] X. Liu, S. Iwase, and K. M. Kitani. Stereobj-1m: Large-scale stereo image dataset for 6d object pose estimation. In ICCV, 2021.
- Liu et al. [2019] X. Liu, M. Yan, and J. Bohg. Meteornet: Deep learning on dynamic 3d point cloud sequences. In ICCV, 2019.
- Liu et al. [2021] X. Liu, S. Iwase, and K. M. Kitani. Kdfnet: Learning keypoint distance field for 6d object pose estimation. arXiv preprint arXiv:2109.10127, 2021.
- Iwase et al. [2021] S. Iwase, X. Liu, R. Khirodkar, R. Yokota, and K. M. Kitani. Repose: Real-time iterative rendering and refinement for 6d object pose estimation. arXiv preprint arXiv:2104.00633, 2021.
Appendix A Object-centric Control for Articulated Objects
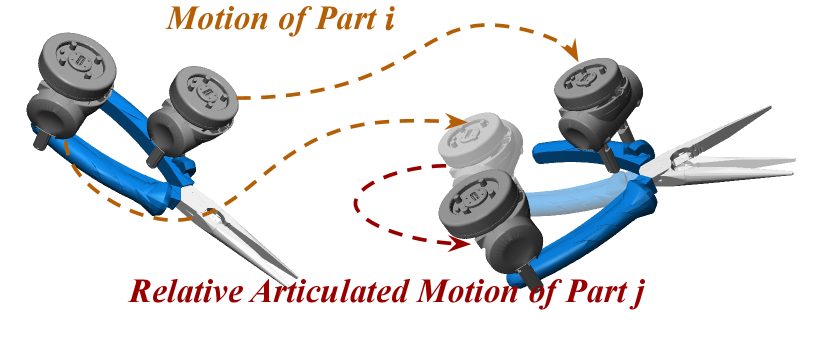
After a successful grasp, the next goal is to apply torques on robot arms and grippers to move the object part to the desired pose. In Section 3.3, we mentioned Object-centric Control for Articuated Objects (OCAO) formulation. In this section, we provide more technical details.
Different from multiple independently moving objects, the articulated object parts are connected with mechanical joints and their motion is under constraints. Our goal is to control the motion of articulated object parts with robot grippers while respecting the mechanical constraints. The core idea is to compute the desired change of the 6D poses of robot grippers given the desired change of the 6D pose of one of the object rigid parts and the changes of all joint angles. As illustrated in Figure 6, to satisfy the mechanical constraints, the rigid motion of one object part has to depend on the rigid motion of another connected object part. We define a dependency graph for the articulated object where each node is an object rigid part and two nodes are connected by an edge if there is a mechanical joint connecting the two object parts. The edge directions in the graph define the dependency of rigid motion decomposition during control. We assume there is no cycle in object joint connections, i.e. the graph is acyclic. Therefore, we can find a dependency in the graph such that each node has exactly one dependency.
Suppose is the set of edges in the graph and for all and , revolute joint connects object parts and , where is represented by its 6D pose including rotation component and translation component , and is represented by joint axis anchor , joint axis direction , and joint angle .
Suppose moves to and joint angle changes to after motion. Suppose the 6D poses of robot gripper before and after motion are and . To ensure that the grasps are always valid for gripper , there should be no relative motion between robot gripper and the object part being grasped . Therefore we have
| (5) |
which represents applying the rigid transformation of object part on gripper .
Supposed , i.e. the motion of depends on . We decompose the rigid motion of into two parts: 1) the rigid motion of and 2) relative articulated motion due to the change of joint angle . Suppose the 6D poses of robot gripper before and after motion are and . Similarly, to ensure that the grasps are always valid for gripper , there should be no relative motion between robot gripper and the object part being grasped . Therefore we have
| (6) |
where is the matrix of rotation of angle with respect to axis .
Note that Equation (6) can be iteratively applied to all object parts based on specified dependencies in the object part graph. After all goal poses are computed, we use Operational Space Control (OSC) to move the all grippers to the goal poses, which will also move the articulated objects to the desired configurations.
Since the dependencies between the object parts are usually not unique, the intermediate trajectory of and in Equations (5) and (6) can be different given different object part dependencies. We leave the study of the choice of the object part dependencies and its impact on manipulation as future work.
Appendix B Exploration of Contact Point Combination
In Section 3.4, we mentioned automatic contact label generation from exploration. In this section, we provide more technical details of it. The algorithm of random exploration of contact point combinations is illustrated in Algorithm 1.
To facilitate the collection of successful contact point combinations for grasping, we first a set of human expert demonstrations of feasible contact point combinations . The human demonstrations are selected intuitively, e.g. two points on the opposite sides of the plier handle. The training label set will be initialized with .
We randomly sample a successful contact point tuple from the training label set. Then from the sampled contact points, we randomly sample points within the neighborhood of radius of the successful contact points to form a new contact point tuple. Using the new contact point tuple, manipulation actions including inverse kinematics, planning, and Operational Space Control will be executed. If the manipulation is successful, the new contact point tuple will be considered a success and added to the training label set. The above process is repeated until the size of the training label set is large enough.
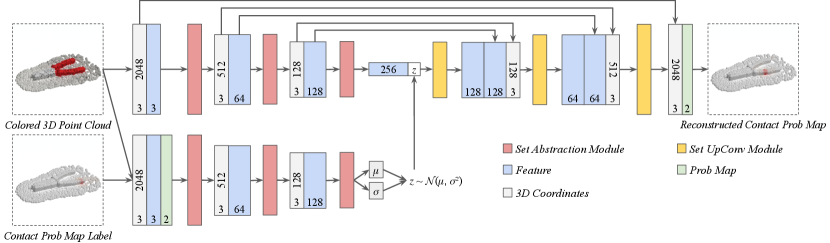

Appendix C Neural Network Architecture
We illustrate the details of the CVAE architecture used in V-MAO in Figure 7. The neural network architecture is instantiated by set abstraction layers from [23] and set upconv layers from [25]. During training, we send both the 3D point cloud appended with RGB values and the same 3D point cloud appended with probability map into the neural network while during inference, only the 3D point cloud appended with RGB values are fed into the network.
During decoding, each layer of set upconv [25] iteratively up-sample the point cloud to recover the resolution before down-sampling and eventually recover the original full 3D point cloud. The cross entropy loss between the two point clouds and is the average/sum of the cross entropy between the contact probability values of each corresponding point pair from the two point clouds.
The architecture of the deterministic baseline “Top-1” is the same as the Figure 7(b), i.e. the architecture of V-MAO used during inference, except for there is no latent code included. This ensures V-MAO is fairly compared against the deterministic baseline.
Appendix D Experiments on Objects with Three Rigid Parts
In the main paper, we conduct experiments on two robots and articulated objects with two rigid parts. In this section, we conduct an additional experiment on three robots and an object with three parts. The object consists of three rectangular sticks in color of red, white and blue respectively that can rotate with respect to the same axis. The articulated object is placed on the table surface with random initial positions and joint angles. We use three Sawyer robots to manipulate the object. Two of the three robots face the table in parallel and the other robot faces the table in opposite direction. Similar to the experiment in the main paper, the goal of the manipulation is to grasp the object parts and move them to reach the desired positions and joint angles within a certain error threshold.
We explore three types of grasping strategy for the three-rigid-part object: sequential grasp, sequential-parallel grasp, and parallel grasp. In sequential grasp, the object parts are grasped and moved in a sequential fashion. In the -th step, robot gripper grasps the -th object part while leaving parts through uncontrolled. We iterate the above step until all parts are grasped and controlled. In sequential-parallel grasp, the object parts 1 through are grasped and moved by robots 1 through respectively in a sequential fashion. Then the rest of the robots through simultaneously grasp and move the rest of the object parts to the goal locations together. In parallel grasp, all object parts are grasped simultaneously. Then the robots move the object parts to the goal locations together.
| robot | method | grasp order | success rate |
|---|---|---|---|
| Sawyer | Top-1 Point | parallel | 80.0 |
| sequential-parallel | 86.0 | ||
| sequential | 90.0 | ||
| V-MAO (Ours) | parallel | 86.0 | |
| sequential-parallel | 86.0 | ||
| sequential | 92.0 |




We report the success rate of manipulation in Table 2. Our V-MAO can achieve more than 80% success rate with Sawyer robot. The performance gap between the V-MAO and the deterministic prediction baseline is small. A possible explanation is that the object parts are long sticks, so it is unlikely for the robots to collide with each other during manipulation. Manipulation fails when some goal locations are not possible for a gripper to reach, in which case both deterministic “Top-1 Point” baseline and our method will fail to reach the goal.
In Figure 8, we visualize the executed sequential manipulation using the contact points sampled from the generative model. The sampled contact points combinations for all robots can avoid collision between robots when all three grippers are grasping the object. After grasping, all three robots can reliably control the object to reach the goal configurations marked by green point cloud.
Appendix E More Visualization of Contact Probability maps
In Section 4.3, we provide visualizations of sampled contact probability map from our generative model. In this section, we provide more visualizations of sampled contact probability map and shows how the geometric features affect the generated maps.
As illustrated in Figure 9, the articulated objects are grasped and lifted by the first gripper. The grasping from the second gripper has not started yet. The sampled contact probability maps of the second gripper not only depend on latent code , but also depend on the geometry of the objects and the scene. For example, after the pliers are lifted from the table, the sampled contact probability map shows that grasping from both horizontal and vertical directions is feasible, while only grasping from the vertical direction is allowed before the pliers are lifted. It further shows that our generative model can effectively incorporate geometric features to learn the contact point distribution on articulated objects.