\ul
V-FUSE: Volumetric Depth Map Fusion with Long-Range Constraints
Abstract
We introduce a learning-based depth map fusion framework that accepts a set of depth and confidence maps generated by a Multi-View Stereo (MVS) algorithm as input and improves them. This is accomplished by integrating volumetric visibility constraints that encode long-range surface relationships across different views into an end-to-end trainable architecture. We also introduce a depth search window estimation sub-network trained jointly with the larger fusion sub-network to reduce the depth hypothesis search space along each ray. Our method learns to model depth consensus and violations of visibility constraints directly from the data; effectively removing the necessity of fine-tuning fusion parameters. Extensive experiments on MVS datasets show substantial improvements in the accuracy of the output fused depth and confidence maps. Our code is available at https://github.com/nburgdorfer/V-FUSE
1 Introduction
Much like other areas of computer vision, Multi-View Stereo (MVS) has benefited from the advent of deep learning. Progress has been driven by the creation of end-to-end systems, unifying all aspects of the MVS pipeline, and by replacing heuristics in the components of the pipeline with optimized network modules. An aspect of MVS that requires further investigation is depth map fusion, which is still implemented as a sequence of heuristic operations.
Considering that the top performing MVS systems in terms of geometric accuracy111NeRF [27] has inspired a vastly expanding class of algorithms that produce superior results in view synthesis, but not in 3D reconstruction. We consider NeRF a separate line of work from MVS. use depth map collections as the representation, depth map fusion can be a crucial step for obtaining the final 3D reconstruction of the scene. As has been shown by conventional fusion research [24], fusing depth maps, guided by geometric constraints, improves the precision of correct depth estimates by blending them with supporting estimates for the same part of the surface, detects and removes outliers, and reduces redundancy in the final 3D model. Current deep MVS approaches [3, 11, 22, 26, 43, 41, 42], however, bypass depth map fusion and proceed directly to filtering fusion, which includes various heuristic post-processing steps to obtain a global point cloud by filtering the point cloud reconstructed from the set of depth maps. This approach has been successful; however, without depth map fusion, not all geometric information from the scene is utilized. Our motivation in this work is to build an end-to-end fusion network that can generate much more accurate depth and confidence maps.
 |
 |
 |
 |
Filtering fusion that operates on local 3D neighborhoods is unable to leverage relationships among distant surface primitives, such as a surface being occluded from a faraway object. Similarly, convolution networks have a limited receptive fields and can only reason about local interactions. We present V-FUSE, an approach that allows a 3D convolutional network to benefit from such geometric information, in a differentiable manner, controlled by learnable hyper-parameters.
V-FUSE considers three types of constraints, inspired by the work of Merrell et al. [24]: support among consistent depth estimates across multiple views, occlusions and free-space violations that provide evidence against depth estimates contradicting surfaces estimated in different depth maps. Free-space violations provide the added benefit of encoding conflicts with respect to surfaces that may be invisible in the frame of the reference camera. There are three substantial differences between our approach and that of Merrell et al.: (i) theirs operates in D while ours operates in a 3D volume, (ii) their algorithms make decisions per pixel without considering context, and (iii) all parameters in our approach are learned end-to-end. Specifying visibility constraints in the fusion volume allows V-FUSE to reason based on interactions among depth estimates along the rays, as well as spatially among neighboring voxels. In the absence of these constraints, only the latter would have been possible via 3D convolutions, which cannot reason about long-range conflicts.
Reducing the storage and computational requirements of deep MVS networks is a necessity for increasing the resolution and quality of 3D reconstruction. 3D convolutional networks operating on cost volumes are forced to downsample high resolution inputs. Since our framework is also volumetric, we propose a technique for achieving high resolution near the surfaces while keeping memory requirements manageable. Specifically, we learn to generate a per-pixel, narrow depth search window by examining the input depth and confidence estimates. Unlike previous networks that iteratively refine the depth search space, our framework leverages the availability of input depth and confidence estimates to determine a reduced search space in a single pass.
Our main contributions are:
-
•
An end-to-end learning-based method for the fusion of depth and confidence maps, leveraging long-range, volumetric visibility constraints encoded into a visibility constraint volume (VCV).
-
•
A pixel-wise search window estimation sub-network to refine the depth search space.
We provide extensive evaluation of V-FUSE on MVS benchmarks [1, 20, 44], using 2D and 3D error metrics.
 |
2 Related Work
In this section, we review related work on learning-based MVS, as well as conventional and learning-based depth map fusion.(Unfortunately, no recent surveys on these topics are available, to the best of our knowledge.)
The combination of deep learning and plane-sweeping stereo has inspired a new generation of MVS algorithms. The plane-sweeping volume (PSV) [10] allows the use of cost aggregation and disparity estimation techniques developed for binocular stereo [19] in multi-view settings. The first deep learning-based plane-sweeping algorithm was DeepStereo [8] that addresses view synthesis in a self-supervised manner. Supervised formulations targeting depth map estimation are largely influenced by MVSNet [43] and concurrent work [15, 16]. We also adopt the PSV structure in this work for our fusion volume.
Several methods [3, 11, 22, 26, 36, 41, 42, 45] aim to improve memory efficiency in deep MVS through multi-resolution, iterative schemes that refine the depth search space with each increase in resolution. This is achieved via regular incremental reductions in search range [11, 42], or with a range set using only confidence estimates [3]. We have developed a non-iterative method for estimating per-pixel depth search windows based on information extracted from the distribution of input depth and confidence maps.
Recent work has addressed MVS by: combined classification and regression for depth estimation [30, 35], sequential depth interval selection [33], an adaptation of RAFT (Recurrent All-Pairs Field Transforms) [23], operating over adaptive intervals along epipolar lines instead of discrete depths [22], and the use of a non-parametric depth distribution model to mitigate shortcomings of unimodal depth models [41]. Transformers for MVS [6, 12, 34, 37] leverage the intra- and inter-attention mechanisms to achieve more accurate feature matching than previous architectures.
Conventional Depth Map Fusion Conventional fusion methods reduce errors and inconsistencies in MVS pipelines. Merrell et al. [24] propose two algorithms for fusing depth maps by selecting depth estimates with large degrees of support from the input depth maps that outweigh violations of visibility constraints. We employ similar constraints, but in a volumetric formulation while the conventional approach [24] reasons on D depth maps. Hu and Mordohai [14] extend the aforementioned method [24] by modeling geometric uncertainty, in addition to confidence, and by considering multiple depth candidates per pixel.
A popular choice for fusing depth maps among deep MVS pipelines is the work of Galliani et al. [9]. It is based on the projection of depth estimates onto several supporting depth maps to accumulate consensus subject to criteria on reprojection error and surface normal inconsistency. The dense COLMAP pipeline [32] also includes a fusion module that rejects outliers based on lack of photometric and geometric support and clusters inliers. Both techniques require setting several thresholds and parameters, and are limited to filtering depth maps into a final 3D model without improving the underlying depth maps.
Some deep MVS systems introduce custom fusion and filtering steps which are not included in the end-to-end trainable pipeline. These include P-MVSNet [21] that considers pixel and depth reprojection errors, and D2HC-RMVSNet [40] that includes geometric consistency scores. Instead of relying on filtering and averaging depth estimates, our work aims to refine and fuse depth maps before they are filtered and projected into a point cloud.
Learning-Based Depth Map Fusion Most learning-based fusion methods follow the seminal work of Curless and Levoy [5] and adopt a volumetric representation of the truncated signed distance function (TSDF). Learning-based approaches relying on implicit representations [2, 25, 28, 31] model surfaces as continuous decision boundaries of a deep classifier, and are thus ill-suited for open scenes like the ones we reconstruct.
Recent methods [4, 38, 39] propose fusing streams of input depth maps by learning TSDF volume updates [38], by fusing in the latent space and learning a translator to produce a final TSDF volume [39], or by learning pose invariant scene volumes jointly with a MVS sub-network [4]. Volumetric methods suffer from large storage requirements. Our method is volumetric but allows for a very thin volume in the direction of the optical axis.
Donné and Geiger [7] developed a non-volumetric data-driven approach for fusing depth maps, estimated conventionally or by a learning-based technique. DeFuSR filters out wrong depth estimates, but also improves correct ones via refinement and inpainting sub-networks. It operates on re-projected depth estimates and image features at high resolution, depending entirely on 3D convolutions to reason about consensus.
3 Method
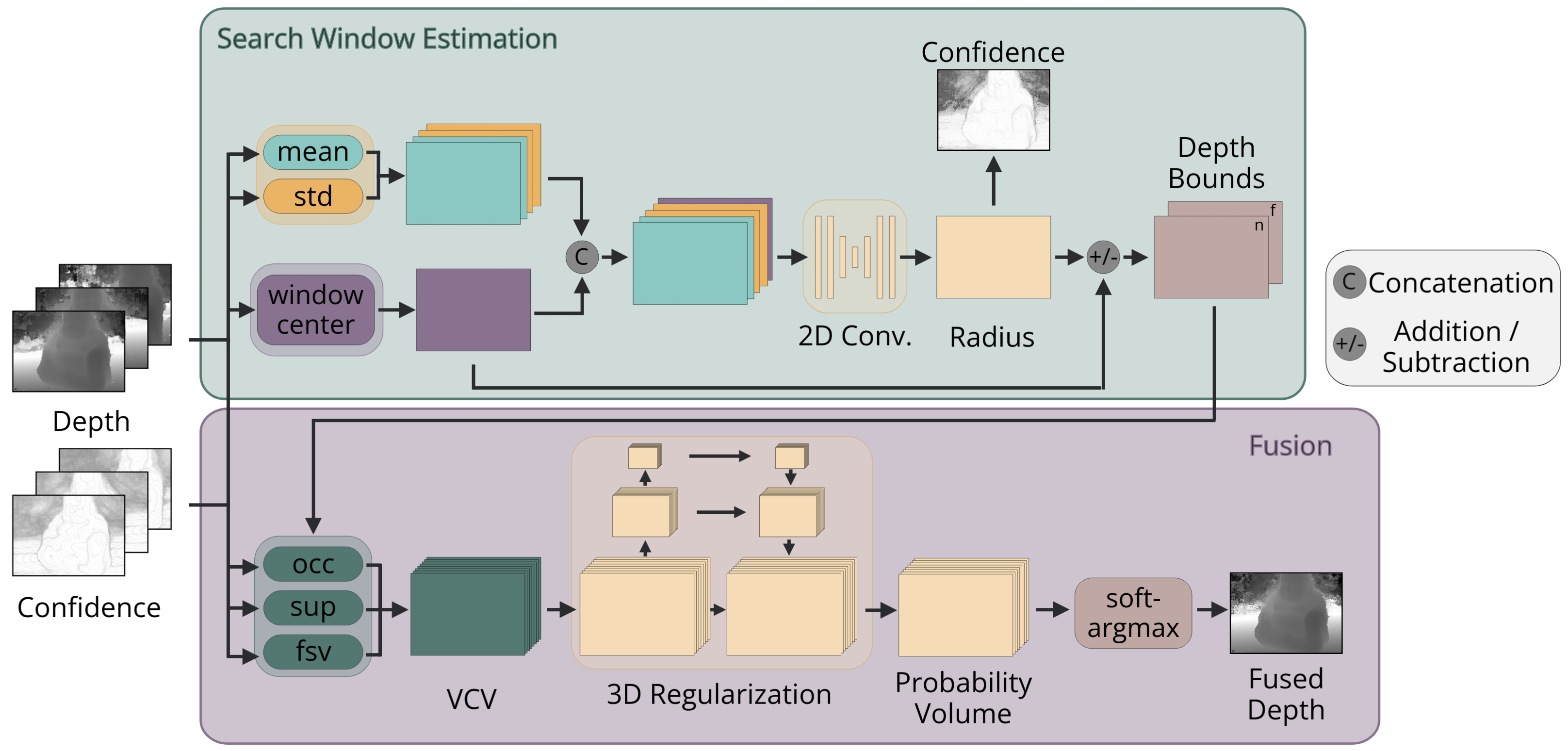
In this section, we introduce the architecture of V-FUSE (an overview can be found in Figure 2). Our network takes as input a reference depth map and the corresponding confidence map , and source depth and confidence maps and respectively. We begin by rendering the input source maps into the reference view to obtain and . With this set of rendered maps, we build a visibility constraint volume (VCV), whose structure follows that of the plane-sweeping volume. The VCV encodes long-range, volumetric, constraints at each voxel. We use a 3D convolutional network to regularize the VCV and regress the final fused depth map. As output, our network produces fused depth and confidence maps for the reference view, and . The construction of the VCV and the 3D convolutional network are supervised using an loss between the estimated and ground truth depth maps. For memory and run-time efficiency, we introduce a novel search window estimation (SWE) sub-network in order to restrict the depth search space used as input in the construction of the VCV. This sub-network is supervised through a novel loss that we discuss in Section 4.2.
3.1 Visibility Constraint Volume
Similar to most deep MVS frameworks, a core component of our network is the construction of a cost volume along the reference camera frustum. However, instead of encoding warped image features, our volume encodes visibility constraints for the purpose of measuring multi-view depth estimate consensus and inconsistency. Specifically, we compute three separate metrics measuring support, occlusions, and free-space violations, and aggregate each metric into separate channels in the VCV. Essentially, each voxel is a collection of the response values for all three constraints from each input view. The constraints are aggregated over all views, each view contributing equally (without favoring the reference view) up to a confidence weighting. We discuss each constraint in detail below. Figure 3 shows a visualization of the three constraints.
The network takes as input a set of initial depth hypotheses . This is the set of depth values measured along the ray of the reference camera. We define to be a given pixel index and to be the corresponding voxel index at the hypothesis. Using the set , we build a hypothesis volume by tiling at every pixel, meaning that each ray uses the same set of depth hypotheses. Using , we can compute a 3-channel VCV, .
| (a) Support |
| (b) Occlusions |
| (c) Free-Space |
Support We first compute the support response for each voxel in the VCV. Intuitively, support is an encoding of the multi-view depth consensus for the rendered depth maps. For a given voxel, the higher the support response, the more probable the true depth value exists at that voxel. For support, we employ a Gaussian distribution centered at each depth estimate in the rendered depth map for each view, encoded along the ray of the reference view.
| (1) |
Here, is the support response for the depth hypothesis at voxel . The subscript is used to indicate that the support response is encoded in the first channel of . The confidence rendered into the reference view for view and pixel is used to weigh the support response. The standard deviation for the Gaussian distribution is a function of the per-pixel window radius (discussed in Section 3.3), which allows the level of support to vary depending on the size of the search window. The formulation of (see supplement) includes a learned hyper-parameter in order for the support window to be learned from the data. Lower values of correspond to a sharper response boundary.
Note that due to perspective distortion and due to some 3D points projected from the source depth maps falling out of bounds, a pixel of the reference view may receive fewer than rendered depths and confidences. Therefore, we define to be the number of views that provide a response for the depth hypothesis at voxel .
Occlusions To identify conflicting depth estimates, we include occlusion and free-space violation responses as separate channels in our VCV. Occlusions are events in which the reference depth hypothesis at voxel is farther away from the reference camera than the rendered supporting depth estimate . To encode occlusions, we use a sigmoid computed along the ray of the reference view. The sigmoid is centered at each depth estimate in the rendered depth map for each view and activates behind the estimate. In this way, the response for occlusions contributes a sigmoid response to with magnitude depending on the difference in depth. The response is high for depth hypotheses that are beyond each estimate and low for hypotheses that are in front of each estimates.
| (2) |
Here, is the occlusion response for the depth hypothesis at voxel encoded into the second channel of . The input confidence values are used to weigh the occlusion responses. The multiplier is a function of the per-pixel window radius and is used to adjust the slope of the sigmoid function. The definition for (see supplement) also includes a learned hyper-parameter so that the slope of the sigmoid is learned from the data.
Free-Space Violations In contrast to support and occlusion, free-space violations are measured with respect to the source views. They occur when a depth hypothesis (rendered into the source view ) is closer to the source camera than the depth estimate from the original, non-rendered source depth map . In this context, we state that the depth hypothesis violates the free-space of depth estimate . Much like occlusions, we use a sigmoid to encode free-space violations. The sigmoid function is defined along the ray of projection of the original depth map for each view and activates in front of the depth estimates, contributing a sigmoid response to with magnitude depending on the difference in depth.
| (3) |
Here, is the free-space violation response for the depth hypothesis at voxel encoded into the third channel of . The response values are weighted by the original confidence values for view and pixel . The multiplier is the same parameter used in the encoding of occlusions.
3.2 Evidence Aggregation and Depth Estimation
In order to aggregate neighboring information, we regularize the VCV using a 3D UNet similar to MVSNet [43]. This includes several layers of 3D convolutions with down-sampling and skip-connections to incorporate global context in the latent space, producing a probability volume . We then apply a soft-argmax operator along the depth dimension. The final fused depth map is generated using the depth-wise expectation of probabilities for each depth hypothesis,
| (4) |
Here, we write and using explicit index notation instead of and to clearly indicate the reduction over the depth dimension.
3.3 Dynamic Depth Search Windows
As input, our VCV construction process takes a set of depth hypotheses per ray. Instead of a single constant set of hypotheses for all rays, we aim to formulate a hypothesis set per ray that is learned from the data. For the sake of run-time and memory efficiency, it is important to limit the number of depth hypotheses. Therefore, we look to reduce the search space while maintaining a high probability that it encompasses the true depth.
Our Search Window Estimation (SWE) sub-network takes as input the rendered depth and confidence maps. We compute the mean and standard deviation of both the depth and confidence maps per-pixel. Similar to the formulations of the constraints, we average these metrics over the set of valid inputs . In order to center the search windows around an initial value , we use the input confidence values to select the most confident depth estimate from the input views. See the supplement for the motivation behind this choice.
The input to our search window estimation sub-network is the concatenation of the pixel-wise depth and confidence statistics with . We run this 5-channel feature map through several 2D convolutional layers, followed by a sigmoid activation function. The output is used for estimating the search window radius,
| (5) |
where is the window radius at pixel , and are the minimum and maximum allowable bound for the window radius respectively, and is the output of the 2D convolutional network at pixel . The scalars and are used to select a percentage of the full input hypothesis range as the minimum and maximum allowable search window radii. These parameters are in place to prevent the network from estimating extreme radius values.
Using this estimated window radius, we can define the depth hypothesis bounds centered around the initial window center estimates.
| (6) | ||||
| (7) |
Here, and are the minimum and maximum depth bounds defining the search window at pixel . We then interpolate between these new bounds to obtain depth hypotheses, . The new hypothesis volume , with per-pixel hypotheses sets, is then used to build the VCV as described in Section 3.1.
4 Loss Function
We train our network in a supervised manner on the output depth and confidence maps of MVS frameworks. We formulate two loss functions, one for each sub-network.
4.1 Depth Regression Loss
We specify the depth regression loss as the loss between the estimated fused depth maps and the ground truth depth maps .
| (8) |
Here, is the set of all valid pixels where ground truth depths are available. This loss is mainly used to supervise the construction of the VCV and the regularization network; however, there are no barriers in place to prevent back-propagation through the SWE sub-network. That being said, it is not sufficient to rely on the regression loss to supervise our SWE sub-network.
4.2 Depth Search Window Loss
In order to supervise the SWE network module, we formulate two objective functions. The first term, named the coverage loss, penalizes estimated search windows that do not encompass the ground truth depth.
| (9) |
Using the coverage loss in isolation would not prevent the network from learning to simply maximize the window radius. Therefore, as a regularizing term, we add the magnitude of the window radius to the joint loss function.
| (10) |
This term directly penalizes large window radii, guiding the SWE sub-network to produce tight search windows that include the ground truth depth. The formulation of the loss in this manner bears some similarity to the work of Kendall and Gal [18], with the window radii used as a proxy for uncertainty.
Our total loss is the weighted sum of these three objective functions.
| (11) |
 |

|

|
 |

|

|
| (c) Image | (b) Input Error | (b) Fused Error |
5 Experiments
 |

|

|
 |

|

|
| (a) Image | (b) Input Depth | (c) Fused Depth |
| Method | DTU | ||||
|---|---|---|---|---|---|
| MAE | |||||
| MVSNet [43] | 9.200 | 9.55 | 18.67 | 34.55 | 55.35 |
| + Conventional [24] | 9.050 | 13.19 | 25.57 | 45.34 | 65.16 |
| + V-FUSE | 6.838 | 15.00 | 28.57 | 48.45 | 66.51 |
| UCSNet [3] | 12.071 | 9.99 | 19.52 | 35.90 | 56.24 |
| + Conventional [24] | 13.633 | 12.45 | 24.06 | 42.59 | 61.15 |
| + V-FUSE | 9.667 | 12.85 | 24.85 | 43.96 | 62.69 |
| NP-CVP-MVSNet [41] | 12.897 | 11.76 | 23.16 | 42.92 | 64.27 |
| + Conventional [24] | 11.933 | 12.79 | 25.35 | 47.42 | 68.94 |
| + V-FUSE | 8.566 | 16.47 | 31.49 | 53.06 | 70.58 |
| GBi-Net [26] | 5.845 | 12.77 | 24.89 | 45.10 | 65.94 |
| + Conventional [24] | 5.009 | 17.30 | 32.93 | 55.52 | 73.66 |
| + V-FUSE | 4.196 | 18.41 | 34.79 | 57.50 | 74.66 |
5.1 Datasets
DTU The DTU dataset [1] is an indoor dataset that contains images of 124 scenes taken from a camera mounted on an industrial robot arm. All scenes share the same camera trajectories, with ground-truth point clouds captured via a structured light scanner. We follow the training, validation, and evaluation split used by Yao et al. [43].
Tanks & Temples The Tanks & Temples dataset [20] is a large-scale, mostly outdoor dataset containing video sequences of challenging scenes. The dataset is divided into a training set and two evaluations sets; intermediate and advanced.
BlendedMVS The BlendedMVS [44] dataset is a large-scale, synthetic dataset containing images processed by blending original images with rendered images from each scene mesh. The dataset is split into training and validation sets, containing 106 and 7 scenes respectively.
5.2 Implementation Details
Training Details We implement the model with PyTorch [29] and train on the output depth and confidence maps of the DTU [1] dataset from several deep MVS methods, separately. For improved generalization, we follow the robust training strategy used by PatchmatchNet [36], in which we randomly choose of the best source views to use as training for a given reference view. We train on an NVIDIA RTX A6000 GPU for 30 epochs. The model has approximately 300,000 parameters and training takes 1 hour per epoch for the high resolution data. We use the Adam optimizer with a learning rate of using an exponential decay of every epochs. For additional model parameters, please see the supplement.
5.3 Evaluation
Metrics As our method is focused on generating depth and confidence maps, we mainly focus our evaluation on 2D metrics. For depth map evaluation, we report the mean absolute error (MAE) between the estimated and ground truth depth maps. We also report the percentage of pixels with depth estimates within several error thresholds. We also present 3D metrics on output point clouds generated from the fused depth maps. We evaluate our point clouds on the DTU benchmark [1], measuring accuracy, completeness, and overall scores. Accuracy is the mean distance between every point in the estimated point cloud to the closest point in the ground truth model and completeness is the mean distance between every point in the ground truth point cloud to the closest point in the estimated model. The overall score is the average of these metrics. We show a variation of these metrics when comparing to DeFuSR [7] following the evaluations performed in their work. Donné and Geiger [7] report the Chamfer distances as the percentage of points within a threshold of . We also evaluate our point clouds on the Tanks & Temples benchmark. We report the f-score for each scene, as well as the mean f-score for all scenes.
| Method | DTU [Sparse] (mm) | DTU [Dense] (mm) | ||||
|---|---|---|---|---|---|---|
| Acc. | Comp. | Overall | Acc. | Comp. | Overall | |
| \ulMVSNet [43] | ||||||
| + Gipuma [9] | 0.396 | 0.527 | 0.462 | 0.419 | 0.383 | 0.401 |
| + V-FUSE | 0.432 | 0.390 | 0.411 | 0.388 | 0.349 | 0.368 |
| \ulUCSNet [3] | ||||||
| + Gipuma [9] | 0.338 | 0.349 | 0.344 | 0.320 | 0.261 | 0.290 |
| + V-FUSE | 0.354 | 0.329 | 0.342 | 0.265 | 0.276 | 0.270 |
| \ulNP-CVP-MVSNet [41] | ||||||
| + Gipuma [9] | 0.356 | 0.275 | 0.316 | 0.288 | 0.194 | 0.241 |
| + V-FUSE | 0.337 | 0.277 | 0.307 | 0.256 | 0.181 | 0.219 |
| \ulGBi-Net [26] | ||||||
| + COLMAP [32] | 0.315 | 0.262 | 0.289 | 0.254 | 0.173 | 0.214 |
| + V-FUSE | 0.310 | 0.274 | 0.292 | 0.227 | 0.180 | 0.204 |
MVS Baselines We compare the results of applying V-FUSE on the outputs of MVSNet [43], UCSNet [3] as a representative multi-resolution algorithm and two state-of-the-art methods, NP-CVP-MVSNet [41] and GBi-Net [26].
Fusion Baselines We compare the results of V-FUSE with the conventional fusion approach of Merrell et al. [24] for 2D evaluations, and Gipuma [9] for 3D evaluations, since Gipuma is the method of choice by state-of-the-art MVS frameworks to produce final 3D models. We also provide comparisons to the learning-based fusion method, DeFuSR [7]. Methods operating on implicit TSDF volumes, such as VolumeFusion [4], RoutedFusion [38], and NeuralFusion [39] are not included in our evaluations, since they are better suited for reconstructing closed, watertight objects. These papers do not provide any quantitative evaluations on DTU or Tanks & Temples, with NeuralFusion presenting qualitative-only results on select scenes from Tanks & Temples.
| Method | DTU (full) | ||
|---|---|---|---|
| Acc. (%) | Comp. (%) | Mean (%) | |
| MVSNet [43] | 88 | 66 | 77 |
| + DeFuSR [7] | 86 | 65 | 76 |
| + V-FUSE | 98 | 98 | 98 |
 |

|

|

|

|

|
 |

|

|

|

|

|
| (a) Image | (b) Input Depth | (c) Fused Depth | (d) Image | (e) Input Depth | (f) Fused Depth |
| Method | intermediate | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Mean | Fam. | Franc. | Horse | Light. | M60 | Pan. | Play. | Train | |
| \ulUCSNet [3] | |||||||||
| + Gipuma [9] | 54.83 | 76.09 | 53.16 | 43.03 | 54.00 | 55.60 | 51.49 | 57.38 | 47.89 |
| + V-FUSE | 55.03 | 75.64 | 57.60 | 46.03 | 54.35 | 55.78 | 49.42 | 56.02 | 45.37 |
| \ulGBi-Net [26] | |||||||||
| + COLMAP [32] | 61.42 | 79.77 | 67.69 | 51.81 | 61.25 | 60.37 | 55.87 | 60.67 | 53.89 |
| + V-FUSE | 59.08 | 78.92 | 65.23 | 49.96 | 59.16 | 57.08 | 53.13 | 58.58 | 50.61 |
| Method | Tanks & Temples | |||
|---|---|---|---|---|
| MAE | ||||
| UCSNet [3] | 0.175 | 11.83 | 19.69 | 30.17 |
| UCSNet + V-FUSE | 0.167 | 12.18 | 19.75 | 29.84 |
| NP-CVP-MVSNet [41] | 0.177 | 15.49 | 25.16 | 37.38 |
| NP-CVP-MVSNet + V-FUSE | 0.155 | 15.68 | 25.13 | 37.57 |
| GBi-Net [26] | 0.240 | 12.02 | 19.51 | 29.24 |
| GBi-Net + V-FUSE | 0.243 | 12.88 | 20.57 | 30.22 |
Evaluation on DTU Dataset We first compute ground truth depth maps for DTU in the same manner as MVSNet [43]. Specifically, we run screened Poisson surface reconstruction (SPSR) [17] on the provided ground truth point clouds for each scene and produce a watertight mesh. We then render this mesh into all cameras to obtain ground truth depth maps. To produce our final point clouds, we use heuristic filtering, similar to the post-processing presented in GBi-Net. We first filter out depth estimates that have a confidence value below a threshold. We then project each estimate into neighboring views, using the depth estimates in each view to reproject back to the reference view, measuring the pixel reprojection error and filtering out estimates whose error is above a threshold.
Table 1 shows a comparison of the depth map errors between all baseline methods and V-FUSE. Observing the fused depth map errors, we can see that even using the low resolution inputs of MVSNet, V-FUSE can generate depth maps with a lower MAE than UCSNet and NP-CVP-MVSNet. Additionally, V-FUSE produces depth maps with more inliers at all threshold values compared to the input depth maps generated by all baseline methods. A comparison of error maps is shown in Figure 4. Qualitative depth map results can be seen in Figure 5. We can observe that V-FUSE removes much of the noise in the input depth maps, while producing better estimates near depth discontinuities. In Table 2, we evaluate the final 3D models of all MVS baselines and compare the fusion choice from each method to V-FUSE. V-FUSE shows clear improvements in the overall results in both Sparse and Dense evaluation scenarios. In the case of GBi-Net, the improvements realized by V-FUSE are more noticeable without the sampling procedure used in the Sparse evaluation. DeFuSR [7] provides results evaluating fusion of COLMAP [32] and MVSNet [43] inputs on DTU. We provide a comparison according to the evaluation protocol used in [7] in Table 3. The threshold used by DeFuSR is , which is quite large. V-FUSE outperforms DeFuSR by a substantial margin, which is expected as the authors state they are not able to refine the MVSNet inputs much.
Evaluation on Tanks & Temples Dataset We use the model trained on the DTU output depth and confidence maps of each network without any fine-tuning for evaluation. In order to evaluate the depth maps on Tanks & Temples, we use the training set and the provided ground truth point clouds, computing ground truth depth maps the same way they are computed for DTU. Table 5 shows the depth map errors between each baseline and V-FUSE. The fused depth maps are more accurate overall for UCSNet and NP-CVP-MVSNet. For GBi-Net, we show improved accuracy for estimates within the error thresholds. See Figure 6 for a qualitative comparison of depth maps. Table 4 shows the f-scores for the final point clouds on the Tanks & Temples intermediate set. We show comparable results to both input MVS baselines. We provide the precision and recall split for each method in the supplement.
Additional Experiments We provide results on the validation set of the BlendedMVS [44] dataset in the supplement. Using the outputs of GBi-Net trained on the BlendedMVS training set and the V-FUSE model trained on DTU without any fine-tuning, V-FUSE produces higher quality depth maps for all scenes, with a mean MAE of 0.288 compared to 0.319 for GBi-Net. We also provide evaluations of the output confidence maps, reporting the AUC of all methods. Using GBi-Net as input, the AUC of V-FUSE is 2.480 compared to 3.690 for GBi-Net. We show several ablation studies in the supplement, testing the individual contributions of different aspects of the network architecture. Specifically, we evaluate the contributions of the visibility constraints, as well as the efficiency gains of the SWE sub-network. As detailed in the supplement, introducing the SWE sub-network results in memory and run-time efficiency gains, as well as a decrease in MAE.
6 Conclusion
We have presented an end-to-end depth map fusion network that leverages long-range visibility constraints encoded into a learnable pipeline. Our method improves input depth and confidence maps generated by MVS networks, integrating multi-view consensus and inconsistency measures. We also present a novel depth search space refinement sub-network that estimates a narrow search window along each ray to increase memory and run-time efficiency, as well as allow for high resolution depth estimation near surfaces. The combination of these concepts is able to obtain fused depth maps that are quantitatively and qualitatively much better than the inputs. While the depth map fusion in our work is end-to-end, merging the depth estimates into a unified point cloud remains a heuristic-driven process. We aim to incorporate a more principled point cloud reconstruction procedure from a collection of depth maps in future work. We also aim to explore the generalization ability of learning-based fusion.
Acknowledgment This research has been supported in part by the National Science Foundation under award 2024653.
References
- [1] Henrik Aanæs, Rasmus Ramsbøl Jensen, George Vogiatzis, Engin Tola, and Anders Bjorholm Dahl. Large-Scale Data for Multiple-View Stereopsis. IJCV, 2016.
- [2] Zhiqin Chen and Hao Zhang. Learning Implicit Fields for Generative Shape Modeling. In CVPR, 2019.
- [3] Shuo Cheng, Zexiang Xu, Shilin Zhu, Zhuwen Li, Li Erran Li, Ravi Ramamoorthi, and Hao Su. Deep Stereo Using Adaptive Thin Volume Representation With Uncertainty Awareness. In CVPR, 2020.
- [4] Jaesung Choe, Sunghoon Im, Francois Rameau, Minjun Kang, and In So Kweon. VolumeFusion: Deep Depth Fusion for 3D Scene Reconstruction. In ICCV, pages 16086–16095, 2021.
- [5] Brian Curless and Marc Levoy. A Volumetric Method for Building Complex Models from Range Images. In SIGGRAPH, pages 303–312, 1996.
- [6] Yikang Ding, Wentao Yuan, Qingtian Zhu, Haotian Zhang, Xiangyue Liu, Yuanjiang Wang, and Xiao Liu. TransMVSNet: Global Context-Aware Multi-View Stereo Network with Transformers. In CVPR, pages 8585–8594, 2022.
- [7] Simon Donné and Andreas Geiger. Learning Non-Volumetric Depth Fusion Using Successive Reprojections. In CVPR, 2019.
- [8] John Flynn, Ivan Neulander, James Philbin, and Noah Snavely. DeepStereo: Learning to Predict New Views From the World’s Imagery. In CVPR, 2016.
- [9] Silvano Galliani, Katrin Lasinger, and Konrad Schindler. Massively Parallel Multiview Stereopsis by Surface Normal Diffusion. In ICCV, 2015.
- [10] D. Gallup, J.-M. Frahm, P. Mordohai, Q. Yang, and M. Pollefeys. Real-time Plane-sweeping Stereo with Multiple Sweeping Directions. In CVPR, 2007.
- [11] Xiaodong Gu, Zhiwen Fan, Siyu Zhu, Zuozhuo Dai, Feitong Tan, and Ping Tan. Cascade Cost Volume for High-Resolution Multi-View Stereo and Stereo Matching. In CVPR, 2020.
- [12] Vitor Guizilini, Rareș Ambruș, Dian Chen, Sergey Zakharov, and Adrien Gaidon. Multi-Frame Self-Supervised Depth with Transformers. In CVPR, pages 160–170, 2022.
- [13] Xiaoyan Hu and Philippos Mordohai. A Quantitative Evaluation of Confidence Measures for Stereo Vision. IEEE TPAMI, 34(11):2121–2133, 2012.
- [14] Xiaoyan Hu and Philippos Mordohai. Least Commitment, Viewpoint-Based, Multi-view Stereo. In 3DIMPVT, pages 531–538, 2012.
- [15] Po-Han Huang, Kevin Matzen, Johannes Kopf, Narendra Ahuja, and Jia-Bin Huang. DeepMVS: Learning Multi-View Stereopsis. In CVPR, 2018.
- [16] Sunghoon Im, Hae-Gon Jeon, Stephen Lin, and In So Kweon. DPSNet: End-To-End Deep Plane Sweep Stereo. In ICLR, 2019.
- [17] Michael Kazhdan and Hugues Hoppe. Screened Poisson Surface Reconstruction. ACM TOG, 32(3), 2013.
- [18] Alex Kendall and Yarin Gal. What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision? NeurIPS, 30, 2017.
- [19] Alex Kendall, Hayk Martirosyan, Saumitro Dasgupta, Peter Henry, Ryan Kennedy, Abraham Bachrach, and Adam Bry. End-To-End Learning of Geometry and Context For Deep Stereo Regression. In ICCV, pages 66–75, 2017.
- [20] Arno Knapitsch, Jaesik Park, Qian-Yi Zhou, and Vladlen Koltun. Tanks and Temples: Benchmarking Large-Scale Scene Reconstruction. ACM TOG, 36(4), 2017.
- [21] Keyang Luo, Tao Guan, Lili Ju, Haipeng Huang, and Yawei Luo. P-MVSNet: Learning Patch-Wise Matching Confidence Aggregation for Multi-View Stereo. In ICCV, 2019.
- [22] Xinjun Ma, Yue Gong, Qirui Wang, Jingwei Huang, Lei Chen, and Fan Yu. EPP-MVSNet: Epipolar-Assembling Based Depth Prediction for Multi-View Stereo. In ICCV, pages 5732–5740, 2021.
- [23] Zeyu Ma, Zachary Teed, and Jia Deng. Multiview Stereo with Cascaded Epipolar RAFT. In ECCV, 2022.
- [24] Paul Merrell, Amir Akbarzadeh, Liang Wang, Philippos Mordohai, Jan-Michael Frahm, Ruigang Yang, David Nister, and Marc Pollefeys. Real-Time Visibility-Based Fusion of Depth Maps. In ICCV, pages 1–8, 2007.
- [25] Lars Mescheder, Michael Oechsle, Michael Niemeyer, Sebastian Nowozin, and Andreas Geiger. Occupancy Networks: Learning 3D Reconstruction in Function Space. In CVPR, pages 4460–4470, 2019.
- [26] Zhenxing Mi, Chang Di, and Dan Xu. Generalized Binary Search Network for Highly-Efficient Multi-View Stereo. In CVPR, pages 12991–13000, 2022.
- [27] Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. In ECCV, pages 405–421. Springer, 2020.
- [28] Jeong Joon Park, Peter Florence, Julian Straub, Richard Newcombe, and Steven Lovegrove. DeepSDF: Learning Continuous Signed Distance Functions For Shape Representation. In CVPR, pages 165–174, 2019.
- [29] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An Imperative Style, High-Performance Deep Learning Library. NeurIPS, 32, 2019.
- [30] Rui Peng, Rongjie Wang, Zhenyu Wang, Yawen Lai, and Ronggang Wang. Rethinking depth estimation for multi-view stereo: A unified representation. In CVPR, pages 8645–8654, 2022.
- [31] Songyou Peng, Michael Niemeyer, Lars Mescheder, Marc Pollefeys, and Andreas Geiger. Convolutional Occupancy Networks. In ECCV, pages 523–540, 2020.
- [32] Johannes L Schönberger, Enliang Zheng, Jan-Michael Frahm, and Marc Pollefeys. Pixelwise view selection for unstructured multi-view stereo. In ECCV, pages 501–518, 2016.
- [33] Christian Sormann, Mattia Rossi, Andreas Kuhn, and Friedrich Fraundorfer. IB-MVS: An Iterative Algorithm for Deep Multi-View Stereo Based on Binary Decisions. In BMVC, 2021.
- [34] Dan Wang, Xinrui Cui, Xun Chen, Zhengxia Zou, Tianyang Shi, Septimiu Salcudean, Z Jane Wang, and Rabab Ward. Multi-view 3d reconstruction with transformers. In ICCV, pages 5722–5731, 2021.
- [35] Fangjinhua Wang, Silvano Galliani, Christoph Vogel, and Marc Pollefeys. IterMVS: Iterative Probability Estimation for Efficient Multi-View Stereo. In CVPR, pages 8606–8615, 2022.
- [36] Fangjinhua Wang, Silvano Galliani, Christoph Vogel, Pablo Speciale, and Marc Pollefeys. PatchmatchNet: Learned Multi-View Patchmatch Stereo. In CVPR, pages 14194–14203, 2021.
- [37] Xiaofeng Wang, Zheng Zhu, Fangbo Qin, Yun Ye, Guan Huang, Xu Chi, Yijia He, and Xingang Wang. MVSTER: Epipolar Transformer for Efficient Multi-View Stereo. In ECCV, 2022.
- [38] Silvan Weder, Johannes Schonberger, Marc Pollefeys, and Martin R. Oswald. RoutedFusion: Learning Real-Time Depth Map Fusion. In CVPR, 2020.
- [39] Silvan Weder, Johannes L. Schonberger, Marc Pollefeys, and Martin R. Oswald. NeuralFusion: Online Depth Fusion in Latent Space. In CVPR, pages 3162–3172, 2021.
- [40] Jianfeng Yan, Zizhuang Wei, Hongwei Yi, Mingyu Ding, Runze Zhang, Yisong Chen, Guoping Wang, and Yu-Wing Tai. Dense Hybrid Recurrent Multi-View Stereo Net With Dynamic Consistency Checking. In ECCV, pages 674–689. Springer, 2020.
- [41] Jiayu Yang, Jose M. Alvarez, and Miaomiao Liu. Non-Parametric Depth Distribution Modelling Based Depth Inference for Multi-View Stereo. In CVPR, pages 8626–8634, 2022.
- [42] Jiayu Yang, Wei Mao, Jose M. Alvarez, and Miaomiao Liu. Cost Volume Pyramid Based Depth Inference for Multi-View Stereo. In CVPR, 2020.
- [43] Yao Yao, Zixin Luo, Shiwei Li, Tian Fang, and Long Quan. MVSNet: Depth Inference for Unstructured Multi-view Stereo. In ECCV, 2018.
- [44] Yao Yao, Zixin Luo, Shiwei Li, Jingyang Zhang, Yufan Ren, Lei Zhou, Tian Fang, and Long Quan. Blendedmvs: A large-scale dataset for generalized multi-view stereo networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1790–1799, 2020.
- [45] Jingyang Zhang, Yao Yao, Shiwei Li, Zixin Luo, and Tian Fang. Visibility-Aware Multi-View Stereo Network. BMVC, 2020.
Supplementary Material
In this document, we provide additional implementation details (Section S.1), formulations for learnable geometric constraints (Section S.2), details on confidence computation and evaluation (Section S.3), ablation studies evaluating architecture contributions (Section S.4), further quantitative evaluations (Section S.5), and additional qualitative comparisons and examples (Section S.6).
S.1 Implementation Details
During training and inference, we set the number of input views for fusion to and the number of depth planes to for input depth maps from all methods. For the DTU [1] dataset, we use the maximum output resolution of each method as the input for V-FUSE. Specifically, we use for MVSNet, for UCSNet, and for NP-CVP-MVSNet and GBi-Net. For training, we scale the input by a factor of , with the exception of MVSNet, for which we train at the full resolution. For Tanks & Temples [20], we use input resolutions of for UCSNet and for both NP-CVP-MVSNet and GBi-Net. As the minimum and maximum allowable search window radii, we use and . The terms of the loss are weighed by , , and .
S.2 Hyper-parameters
We define two parameters used in the formulations of the geometric constraints. For support, we use to determine the sharpness of the support response boundary.
| (12) |
Here, is a learned hyper-parameter, and are the minimum and maximum depth bounds per pixel, is the number of depth hypotheses, and and are the overall minimum and maximum depth bounds that are given as input for the current reference view. Lower values of correspond to a tighter support window. Since this is a function of the per-pixel depth bounds, support adapts to the confidence at each pixel.
For occlusions and free-space violations, we use to determine the sharpness of the sigmoid response boundary.
| (13) |
Here, is a learned hyper-parameter. Lower values of correspond to a softer sigmoid response boundary. Occlusions and free-space violations also adapt to the confidence at each pixel. See Figure S.1 for a visualization of the response boundary.
| (a) Occlusions | (b) Support |
| Method | AUC | |
|---|---|---|
| DTU | Tanks & Temples | |
| MVSNet [43] | 6.12 | - |
| MVSNet + V-FUSE | 4.08 | - |
| UCSNet [3] | 20.29 | 0.394 |
| UCSNet + V-FUSE | 4.96 | 0.208 |
| NP-CVP-MVSNet [41] | 8.28 | 0.212 |
| NP-CVP-MVSNet + V-FUSE | 4.35 | 0.154 |
| GBi-Net [26] | 3.69 | 0.464 |
| GBi-Net + V-FUSE | 2.48 | 0.448 |
 |

|

|
 |

|

|
| (c) Image | (d) Input Confidence | (c) Fused Confidence |
| Method | DTU |
|---|---|
| MAE | |
| GBi-Net [26] | 5.845 |
| + V-FUSE [brute-force] | 5.344 |
| + V-FUSE [sup] | 4.813 |
| + V-FUSE [fsv+occ] | 4.477 |
| + V-FUSE | 4.196 |
S.3 Confidence Estimates
To evaluate the quality of confidence estimates, we report the area under the curve (AUC). The AUC is the area under the ROC curve, which maps the error rate for the depth map as a function of density based on the sorted confidence values [13]. We first sort the estimated depths according to confidence, and form the sparsification curve of MAE vs. depth map density by progressively dropping the least confident depths [13] to obtain depth maps of lower density, and presumably lower error. Small area under the sparsification curve indicates that confidence has been estimated well and can be used to rank depth estimates accurately.
The fused confidence maps are directly computed from the estimated search window radius. After we normalize the per-pixel window radii from 0 to 1, the confidence value at each pixel is . Intuitively, a larger estimated radius for a given pixel should indicate lower confidence in the final depth estimate. This relationship is also reflected and enforced in our loss function. To compare the quality of the confidence maps, we report the AUC for all methods in Table S.1. The output confidence values after fusion prove to be more reliable estimates of confidence. Qualitative confidence map results can be seen in Figure S.2.
| Method | V-FUSE [brute-force] | V-FUSE [swe] |
|---|---|---|
| Memory(GB) | 37.734 | 4.439 |
| Parameters | 289,587 | 297,429 |
| Inference Time(s) | 22.95 | 2.51 |
| Method | DTU |
|---|---|
| AUC | |
| V-FUSE [pv] | 7.66 |
| V-FUSE [pv+swe] | 6.06 |
| V-FUSE [swe] | 2.48 |
| Method | Tanks & Temples | ||
|---|---|---|---|
| Precision | Recall | F-Score | |
| \ulUCSNet [3] | |||
| + Gipuma [9] | 46.66 | 70.34 | 54.83 |
| UCSNet + V-FUSE | 47.08 | 68.64 | 55.03 |
| \ulGBi-Net [26] | |||
| + Gipuma [9] | 54.49 | 71.25 | 61.42 |
| + V-FUSE | 50.16 | 73.08 | 59.08 |
| Method | BlendedMVS [MAE] | |||||||
|---|---|---|---|---|---|---|---|---|
| Mean | scan106 | scan107 | scan108 | scan109 | scan110 | scan111 | scan112 | |
| GBi-Net [26] | 0.319 | 1.661 | 0.006 | 0.027 | 0.017 | 0.025 | 0.031 | 0.462 |
| + V-FUSE | 0.288 | 1.539 | 0.001 | 0.015 | 0.011 | 0.010 | 0.024 | 0.417 |
 |

|

|

|

|
 |

|

|

|

|
 |

|

|

|

|
 |

|

|

|

|
| (a) Image | (b) NP-CVP-MVSNet Depth [41] | (c) V-FUSE Depth | (d) NP-CVP-MVSNet Error [41] | (e) V-FUSE Error |










S.4 Ablation Studies
We provide ablation studies evaluating the contributions of several aspects of the network architecture. In Table S.2, we evaluate the MAE isolating the SWE sub-network, as well as the different constraints. We show the contributions of using the brute-force search space approach, as well as the contributions of using only support and only occlusions and free-space violations. In Table S.3, we show the memory, run-time, and parameter difference between the brute-force approach and the SWE sub-network.
Most state-of-the-art Deep MVS architectures directly compute confidence estimates from the output probability volume of the network, using a small window around the estimated depth voxel. We explore using this method, incorporating the radius estimate from the SWE sub-network, as well as using only the radius to compute confidence. Specifically, following previous work in Deep MVS, we compute confidence maps from the output probability volume of the network by summing the probability values for the four surrounding voxels corresponding to the index of the selected depth. We then test adding the inverse of the radius value from the SWE sub-network as a weighting to this confidence. Finally, we test using only the inverse radius value to compute our confidence. We evaluate these different methods of producing confidence maps in Table S.4. In all instances, the confidence maps produced by V-FUSE are better indications of depth estimate quality, and can be used to more effectively rank depth estimates.
S.5 Additional Quantitative Evaluations
We provide additional results on the BlendedMVS [44] dataset. We report the MAE on the validation set between the GBi-Net [26] input depth maps and the V-FUSE output fused depth maps. We used the pre-trained GBi-Net model trained on the BlendedMVS training set and tested V-FUSE using the model trained on DTU without any fine-tuning. The quantitative results are presented in Table S.6. We show significant improvements in all scenes. Qualitative results can be viewed in Figure S.4.
We also provide the Precision and Recall, alongside the F-Score on the Tanks & Temples [20] intermediate test set, retrieved from the benchmark leaderboard. The Precision score is the percentage of points in the reconstructed point cloud that have a Chamfer distance to the closest point in the ground-truth point cloud below some threshold, . The Recall score is the percentage of points in the ground truth-point cloud that have a Chamfer distance to the closest point in the reconstructed point cloud below the same threshold, . The F-Score is then the harmonic mean of these two scores. Quantitative results can be found in Table S.5. We improve the Precision and F-Score using UCSNet as input, and improve the Recall using GBi-Net as input.
S.6 Additional Qualitative Results
We show additional qualitative results for all baselines. Figure S.3 shows a comparison of depth and error maps between NP-CVP-MVSNet [41] and V-FUSE on several scenes from the DTU [1] evaluation set. In Figure S.5, we provide a comparison between the final 3D reconstruction results of NeuralFusion [39] and V-FUSE. We only provide a qualitative comparison, as NeuralFusion does not provide any quantitative results on any of the datasets used in our experiments. Figure S.6 shows a comparison of depth and confidence maps between GBi-Net [26] and V-FUSE on several scenes from the DTU evaluation set. In Figure S.7, we can observe the depth maps comparison of scenes from the Tanks & Temples [20] dataset between GBi-Net [26] and V-FUSE. We provide depth map comparisons from several scenes of the validation set from BlendedMVS [44] using GBi-Net [26] as input in Figure S.8. We also show final reconstructions from the DTU and Tanks & Temples datasets in Figure S.9 and Figure S.10, respectively.
 |

|

|

|

|
 |

|

|

|

|
 |

|

|

|

|
| (a) Image | (b) GBi-Net Depth [26] | (c) V-FUSE Depth | (d) GBi-Net Confidence [26] | (e) V-FUSE Confidence |
 |

|

|
 |

|

|
 |

|

|
| (a) Image | (b) GBi-Net [26] Depth | (c) V-FUSE Depth |
 |

|

|
 |

|

|
 |

|

|
 |

|

|
| (c) Image | (d) GBi-Net [26] Depth | (c) V-FUSE Depth |































