UVL2: A Unified Framework for Video Tampering Localization
Abstract
With the advancement of deep learning-driven video editing technology, security risks have emerged. Malicious video tampering can lead to public misunderstanding, property losses, and legal disputes. Currently, detection methods are mostly limited to specific datasets, with limited detection performance for unknown forgeries, and lack of robustness for processed data. This paper proposes an effective video tampering localization network that significantly improves the detection performance of video inpainting and splicing by extracting more generalized features of forgery traces. Considering the inherent differences between tampered videos and original videos, such as edge artifacts, pixel distribution, texture features, and compress information, we have specifically designed four modules to independently extract these features. Furthermore, to seamlessly integrate these features, we employ a two-stage approach utilizing both a Convolutional Neural Network and a Vision Transformer, enabling us to learn these features in a local-to-global manner. Experimental results demonstrate that the method significantly outperforms the existing state-of-the-art methods and exhibits robustness.
Index Terms:
Video manipulation detection, video splicing detection, video inpainting detection, video tampering localization, robustness detection.I Introduction
With the development of deep learning, it has become increasingly easy to produce realistic synthetic videos, making it difficult for people to visually detect the traces of video tampering [1, 2, 3]. In this paper, we investigate video tampering localization, including the detection of video inpainting and video splicing. Video inpainting typically eliminates objects that originally existed in the video, leading people to believe that the objects never existed [1, 4, 2, 3]. On the other hand, video splicing adds an additional object to the original video, leading people to believe that the object originally existed [2, 5, 6]. When these technologies are maliciously used, they may lead to misunderstandings and cause serious consequences, especially in the political and military arenas.
In the pursuit of detecting tampered regions within videos, researchers have introduced a range of efficient detection algorithms. These algorithms aim to enhance detection accuracy by capturing nuanced feature discrepancies between tampered and authentic regions [7, 2, 1, 8, 4, 9]. These methodologies encompass approaches such as error-level analysis [4], tracking spatial and temporal trajectories [10], and the design of specialized feature enhancement networks [11, 12]. For the detection of object splicing, researchers have further leveraged techniques such as JPEG compression artifacts, optical flow inconsistencies, high-pass filtering, boundary artifacts, and pixel noise estimation [13, 14, 8, 2, 15].
However, these methods are often tailored to specific forgery types or datasets, resulting in inefficiencies and limited generalization when faced with the diverse tampering methods and emerging synthesis techniques in the real world. To address these challenges, we propose a generalized video object tampering localization algorithm. Given that video splicing and inpainting essentially involve the synthesis of two non-homologous video segments, either genuine or AI-generated, the tampered regions inherently exhibit inconsistencies with the original regions. This inconsistency provides a theoretical basis for our algorithmic approach.
In practice, videos undergo various post-processing techniques when distributed online, such as resolution adjustment, compression, blurring, image enhancement, and cropping[2, 1, 3, 16]. Existing methods that rely solely on a single feature tend to suffer a significant reduction in performance when detecting unknown types of tampered data, especially when such data has undergone these post-processing steps. As a result, they often fail to generalize effectively and robustly.
Therefore, to improve the generalization performance and robustness of our algorithm for unknown data, it is crucial to conduct thorough research on the forgery traces left by splicing or inpainting tampering. This involves devising a generalizable feature that is resilient to various video tampering methods and post-processing techniques. The proposed algorithm in this paper aims to achieve this by leveraging the inherent inconsistencies between tampered and original regions in videos.
To learn features that are independent of video synthesis methods, we investigate common inherent traces of various types of tampered videos. Since tampered videos are essentially composed of two non-homogeneous videos, the original and tampered regions come from different sources, leading to various inconsistencies. These inconsistencies include: (1) Texture features: It is difficult for two videos from different sources to be completely consistent in natural conditions. Texture information can help analyze the natural environment at the time of filming in different regions. (2) Edge features: Splicing videos or tampering areas often leave uneven boundaries at the edges. Analyzing edge features can effectively improve the detection accuracy. (3) Pixel and noise distribution: Due to the physical imaging principles of camera capture, the noise distribution of each device or AI-generated image is different. Analyzing these pixel or physical noise differences can improve pixel-level detection accuracy. (4) Other tampering traces: Some other traces are not easily detected through various spatial changes, such as compression information. These not easily detected tampering features can be effectively solved by frequency domain characteristics. To extract these features, we designed four corresponding modules.
After extracting the tampering video traces in different aspects such as texture, edge, noise, and frequency domain, in order to comprehensively learn and utilize these features, we need to introduce an efficient network structure. Convolutional Neural Network (CNN) has excellent performance in extracting local features of images, which can better capture local information and details in images[17, 1]. In contrast, Vision Transformer (ViT) is more suitable for sequence data learning and can better adapt to the temporal structure of videos. ViT can extract the global contextual correlation of features. Based on these characteristics, we adopt a two-stage feature extraction method that combines the advantages of CNN and ViT. First, we use a CNN-based model to extract local features of the video, making the feature scale smaller. Then, we use a ViT-based structure to capture the contextual relationship between these local features. Finally, we output the localization results of the tampered area in the video.

Figure 1 demonstrates the video tampering localization results achieved by the proposed method, validating its excellent performance in overall detection and intricate detail handling. In summary, the key contributions of this paper are as follows:
-
•
We introduce a general and efficient video tampering localization network that significantly enhances video detection efficiency and effectively applies to the detection of video inpainting and splicing.
-
•
We design a multi-view feature extraction module, enabling the proposed method to capture more generalized features, thus enhancing the network’s ability to generalize for unknown non-homologous data.
-
•
Extensive experiments across diverse datasets for video inpainting and video splicing tampering localization, have demonstrated that the proposed method exhibits superior generalization and robustness, outperforming current comparative methods.
II Related Works

II-A Video Inpainting Localization
Recent research has witnessed remarkable progress in video inpainting localization techniques. Zhang et al.[11] advanced the field by enhancing artifact modules through the concatenation of a feature extractor and forgery output module, enabling a deeper learning of inpainting features and resulting in more precise localization of inpainting regions. Zhou et al.[4] pioneered a dual-stream encoder-decoder architecture, incorporating attention modules and LSTM, to detect restored video regions. Their approach leverages error level analysis and temporal structure information to accurately identify inpainted areas.
Wei et al.[10] took a different approach, focusing on analyzing spatial-temporal traces left by inpainting operations. They enhanced these traces using intra-frame and inter-frame residuals, guided by optical flow, and then utilized a dual-stream encoder and bidirectional LSTM decoder to predict inpainted regions.
Lou et al. [18] introduced a 3D Uniformer encoder to learn video noise residuals, effectively capturing spatio-temporal forensic features. They further employed supervised contrastive learning to highlight local inconsistencies in repaired videos, improving localization performance. In a follow-up work [19], Lou et al. explored a multi-scale noise extraction module based on 3D high-pass layers to create noise modalities. A cross-modal attention fusion module was utilized to explore the correlation between these modalities, and an attentive noise decoding module selectively enhanced spatial details, further enhancing the network’s localization capabilities.
Given the diversity of object inpainting methods, enhancing the generalization capability of detecting various object-restored videos in a computer vision context is imperative. This capability is crucial for addressing the variations introduced by different inpainting techniques and ensuring accurate detection across various scenarios, thereby providing a more reliable safeguard for the authenticity and integrity of video content.
II-B Video Splicing Localization
The field of video splicing detection, particularly at the object level, has witnessed significant advancements in recent years. Techniques such as PQMECNet[20] have emerged, leveraging local estimation of JPEG primary quantization matrices to distinguish spliced regions originating from different sources. MVSS-Net[2], on the other hand, learns semantically irrelevant yet generalizable features by analyzing noise distributions and boundary artifacts surrounding tampered regions. ComNet[13] customizes approximate JPEG compression operations to enhance detection performance against JPEG compression artifacts.
DCU-Net[21] further advances this field by effectively extracting tampered regions through dual-channel encoding fusion of deep features, the utilization of dilated convolutions, and the integration of decoders. Additionally, TransU2-Net[22] proposes a novel hybrid transformer architecture specifically designed to improve object-level forgery detection in images. MSA-Net[23], in particular, introduces a multi-scale attention network that integrates a multi-scale self-attention mechanism, enabling it to capture global dependencies and fine-grained details, resulting in precise localization of various types and sizes of spliced forged objects.
Yadav et al.[24] also contribute to this field with a visually attentive image splicing localization network that comprises a Multi-Domain Feature Extractor (VA-MDFE) and a Multi-Receptive Field Upsampler (VA-MRFU). The VA-MDFE extracts features from RGB, edge, and depth modalities, while the VA-MRFU upsamples these features using multi-receptive field convolutions. Several researchers have successfully applied semantic segmentation techniques to the task of splicing localization, achieving notable results[25, 26, 2].
However, the challenge in splicing localization lies in the common video manipulations often found on social media platforms, such as compression, cropping, detail enhancement, and blurring. These manipulations can disrupt the tampering traces of the original forged videos, significantly reducing the robustness of existing detection methods. Therefore, further research is needed to develop splicing detection techniques that are more resilient to such manipulations.
III Method
As shown in Figure 2, our method mainly consists of two core components: multi-view tampering trace extraction and tampering trace fusion learning. We have designed a series of modules to extract features from different perspectives, including texture, edge, pixel and frequency domain. These features are used to analyze the differences between the spliced or inpainted objects and the original video regions. In the tampering trace fusion learning component, we adopt CNN-based and ViT-based modules to process these features, thus achieving relevant learning from local to global. The CNN module focuses on extracting local features, especially good at dealing with edges, textures and other details. In contrast, the ViT module excels at extracting global features, which helps to understand the semantic information of the entire video. Through the joint learning of these two components, we are able to effectively solve the task of video tampering localization, improving detection accuracy and robustness. Finally, we generate a grayscale video of pixel-level localization results of tampering areas, where white represents tampering areas and gray represents original areas.
III-A Texture Feature Extraction Module
When two video segments are spliced together, they often exhibit distinct textural characteristics due to their potentially differing capture locations or physical environments. Detecting these textural features in spliced videos is paramount for analyzing video authenticity. By comparing and analyzing the textural differences between video segments, we can assist in determining whether a video has undergone splicing or tampering. To extract textural features, this section utilizes CNN convolution kernels to implement Gabor filters. Gabor filters, through multi-scale and multi-directional analysis, can efficiently capture various textural information in images. They exhibit excellent sensitivity to textural features of different frequencies, directions, and polarities, making them suitable for a wide range of textural analysis tasks. The mathematical expressions of Gabor filters are given as follows:
Here, and represent the spatial coordinates of the image, while and represent the coordinates after rotation and scaling transformations. controls the bandwidth of the filter, determines the central frequency of the filter, is the decay factor, and represents the phase offset. By applying Gabor filters to input video frames, we can obtain textural responses at different scales and directions. These textural responses can be utilized to construct representations of textural features, which aid in detecting inconsistencies between objects and backgrounds at splicing junctions.
III-B Edge Feature Extraction Module



In order to gain profound insight and comprehension of edge detection characteristics, we have deliberately employed two classical edge detection operators: the Sobel operator and the Laplacian operator. Sobel and Laplacian operators are commonly used for first-order and second-order edge detection, respectively. Sobel filters seek brightness changes in the image by calculating the first-order discrete derivative values of the grayscale function, particularly at edges. This helps highlight areas of brightness and lighting variations. Laplacian filters more precisely locate brightness changes and edges by calculating the second-order gradient of the image, while also enhancing details, including textures and small brightness variations.
As demonstrated in Figure 3a and 3b, we utilize the x and y components of these operators as convolutional kernels within a Convolutional Neural Network (CNN) during implementation. Specifically, these kernels are independently applied to the red (R), green (G), and blue (B) channels of the original video frames to extract edge features. To facilitate the training of the neural network, we further normalize these features to a range of 0-1. The Sobel operator achieves edge detection by computing the image intensity gradient for each pixel, while the Laplacian operator, based on the divergence of the scalar function gradient, exhibits rotational invariance, thus enabling more robust edge detection. The unique advantages of these two operators, when used in tandem, allow for the extraction of more robust and accurate edge features.
III-C Pixel Feature Extraction Module
Due to imaging principles, pixel and noise distribution from different regions can vary. Therefore, analyzing these distributions is crucial. Noise info in videos is stored in pixels, and the Spatial Rich Model (SRM) operator can analyze pixel features. This algorithm relies on pixel statistical features like inter-pixel correlation, skewness, and kurtosis, which reflect the relationships between pixels. Manipulated regions using deep learning often disrupt natural pixel correlations. The SRM operator uses neighboring pixels’ statistical features to represent local image structure.
By analyzing these statistical features, the SRM operator can better represent the destruction of multiple correlations between neighboring pixels in manipulated regions of the image, thereby improving the accuracy and generalization of image tampering detection. We apply the SRM operator to RGB frames, treating pixels in the red, green, and blue channels as three separate images. Each channel will yield a set of SRM features.
III-D Frequency Feature Extraction Module
The extraction of frequency domain information is crucial for video quality analysis. The Discrete Cosine Transform (DCT) is a common method to convert video signals from the spatial domain to the frequency domain. It decomposes videos into different frequency components, and the amplitude and phase information of these components can be used to assess video quality. High amplitudes suggest strong signals, while low ones may indicate signal loss or noise. By analyzing this info, we can evaluate metrics like clarity and distortion levels, enhancing splicing tampering detection accuracy and robustness. This ensures video content’s credibility and integrity.
In our implemented frequency filter model, we utilize four distinct block sizes to process video information across various frequency ranges. These filters process: (1) low-frequency features, encompassing overall structure and larger features. (2) mid-frequency features, between low and high. (3) high-frequency features, capturing details and texture. (4) the entire spectrum, covering low, mid, and high frequencies, for transformations on the entire image. Finally, the outputs from these filters are concatenated to form the final output.
III-E Tampering Traces Fusion Learning
The objective of multi-view fusion learning of tampering traces is to generate pixel-level prediction results that align with ground truth. To achieve this, we leverage the strengths of CNN and ViT models. We use the ResNet[2] module for local feature extraction and the InterlacedFormer[17] module for global feature extraction. By combining CNN and ViT, we gain a deeper understanding of image details and content. CNN excels at extracting local features, focusing on edges and textures, aiding in more precise tampering region localization. Meanwhile, ViT’s strength lies in global feature extraction, enhancing overall video semantic understanding. By integrating global features, the model better understands the relationship between tampered objects and their environments, further improving localization accuracy. Ultimately, we produce pixel-level localization results for tampered regions in videos.
IV Experiments
| Methods |
|
|
|
|
|
|
|
|
|
||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NOI | 0.08/0.14 | 0.09/0.14 | 0.07/ 0.13 | 0.08/0.14 | 0.09/0.14 | 0.07/0.13 | 0.08/0.14 | 0.09/0.14 | 0.07/0.13 | ||||||||||||||||||
| CFA | 0.10/0.14 | 0.08/0.14 | 0.08/0.12 | 0.10/0.14 | 0.08/0.14 | 0.08/0.12 | 0.10/0.14 | 0.08/0.14 | 0.08/0.12 | ||||||||||||||||||
| COSNet | 0.40/0.48 | 0.31/0.38 | 0.36/0.45 | 0.28/0.37 | 0.27/0.35 | 0.38/0.46 | 0.46/0.55 | 0.14/0.26 | 0.44/0.53 | ||||||||||||||||||
| HPF | 0.46/0.57 | 0.49/0.62 | 0.46/0.58 | 0.34/0.44 | 0.41/0.51 | 0.68/0.77 | 0.55/0.67 | 0.19/0.29 | 0.69/0.80 | ||||||||||||||||||
| HPF+LSTM | 0.50/0.61 | 0.39/0.51 | 0.52/0.63 | 0.26/0.36 | 0.38/0.44 | 0.68/0.78 | 0.53/0.64 | 0.20/0.30 | 0.70/0.81 | ||||||||||||||||||
| GSR-Net | 0.57/0.68 | 0.50/0.63 | 0.51/0.63 | 0.30/0.43 | 0.74/0.80 | 0.80/0.85 | 0.59/0.70 | 0.22/0.33 | 0.70/0.77 | ||||||||||||||||||
| GSR-Net+LSTM | 0.55/0.67 | 0.51/0.64 | 0.53/0.64 | 0.33/0.45 | 0.60/0.72 | 0.74/0.83 | 0.58/0.70 | 0.21/0.32 | 0.71/0.81 | ||||||||||||||||||
| VIDNet | 0.55/0.67 | 0.46/0.58 | 0.49/0.63 | 0.31/0.42 | 0.71/0.77 | 0.78/0.86 | 0.58/0.69 | 0.20/0.31 | 0.70/0.82 | ||||||||||||||||||
| VIDNet-BN | 0.62/0.73 | 0.75/0.83 | 0.67/0.78 | 0.30/0.42 | 0.80/0.86 | 0.84/0.92 | 0.58/0.70 | 0.23/0.32 | 0.75/0.85 | ||||||||||||||||||
| VIDNet-IN | 0.59/0.70 | 0.59/0.71 | 0.57/0.69 | 0.39/0.49 | 0.74/0.82 | 0.81/0.87 | 0.59/0.71 | 0.25/0.34 | 0.76/0.85 | ||||||||||||||||||
| FAST | 0.61/0.73 | 0.65/0.78 | 0.63/0.76 | 0.32/0.49 | 0.78/0.87 | 0.82/0.90 | 0.57/ 0.68 | 0.22/0.34 | 0.76/0.83 | ||||||||||||||||||
| TruVIL | 0.61/0.72 | 0.82/0.89 | 0.70/0.81 | 0.42/0.54 | 0.84/0.91 | 0.82/0.89 | 0.63/0.74 | 0.53/0.67 | 0.81/0.88 | ||||||||||||||||||
| ViLocal | 0.66/0.77 | 0.82/0.89 | 0.76/0.85 | 0.61/0.73 | 0.85/0.91 | 0.83/0.90 | 0.69/0.79 | 0.63/0.75 | 0.82/0.89 | ||||||||||||||||||
| VIFST | 0.73/0.84 | 0.81/0.89 | 0.72/0.82 | 0.75/0.85 | 0.72/0.83 | 0.82/0.89 | 0.85/0.91 | 0.79/0.87 | 0.84/0.90 | ||||||||||||||||||
| Ours | 0.78/0.87 | 0.78/0.87 | 0.76/0.85 | 0.76/0.85 | 0.82/0.89 | 0.83/0.89 | 0.85/0.91 | 0.80/0.88 | 0.85/0.91 |
IV-A Experimental Setup
IV-A1 Dataset
Yu et al. [3] and VIFST [1] introduced the DAVIS-VI dataset, a video inpainting dataset based on the DAVIS dataset. To generate tampered videos, they utilized six video inpainting methods: OPN [27], CPNET [28], DVI [29], FGVC [14], DFGVI [30], and STTN [31]. The DAVIS-VI dataset comprises 50 original videos and 300 tampered videos, totaling 33,550 frames. The Video Splicing (VS) dataset[16] was designed specifically for video splicing detection and consists of a training set with 795 forged videos and a test set with 30 carefully crafted forged videos and 30 real videos.
IV-A2 Evaluation Metrics and Baselines
To evaluate pixel-level manipulation localization, we employ two commonly used metrics: mean Intersection over Union (mIoU), and F1-score (F1). For video inpainting, the methods we compare include: NOI [4], CFA [4], CosNet [3], HPF [8], GSR-Net [15], VIDNet [4], FAST [3], TruVIL [19], ViLocal [18] and VIFST [1]. The results of all these comparative methods are referenced from VIFST [1]. For video splicing, the methods we compare are: PoolFormer [32], MetaFormer [32], HRFormer [17], UVL-Net [5], UVL-Net-S [5], and UVL-Net-F [5]. We have retrained these methods on the VS dataset and validated their performance.
IV-B Results of Video Inpainting Localization
Table I shows the pixel-level detection performance of various models. Compared to the baseline method, our method achieves superior performance in most cases, but it is only slightly inferior to VIDNet-BN and VIFST on one sub-dataset. At the same time, our method performs well in detecting all unknown forged data, which is mainly due to the ability of multi-view features to enhance the generalized feature extraction ability of our method. The experimental results demonstrate that our method is not only efficient, but also has good generalization ability.
IV-C Results of Video Splicing Localization
| Methods |
|
|
|
|
|
|
|
||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PoolFormer | 0.789/0.873 | 0.765/0.852 | 0.786/0.871 | 0.736/0.824 | 0.760/0.847 | 0.787/0.872 | 0.777/0.864 | ||||||||||||||
| MetaFormer | 0.726/0.822 | 0.685/0.779 | 0.727/0.823 | 0.645/0.736 | 0.667/0.761 | 0.720/0.815 | 0.711/0.809 | ||||||||||||||
| HRFormer | 0.788/0.868 | 0.769/0.851 | 0.786/0.867 | 0.748/0.833 | 0.765/0.848 | 0.787/0.869 | 0.775/0.860 | ||||||||||||||
| UVL-Net | 0.783/0.867 | 0.757/0.843 | 0.779/0.863 | 0.750/0.831 | 0.757/0.839 | 0.780/0.863 | 0.781/0.866 | ||||||||||||||
| UVL-Net-S | 0.797/0.877 | 0.770/0.854 | 0.792/0.873 | 0.744/0.823 | 0.765/0.848 | 0.796/0.876 | 0.793/0.875 | ||||||||||||||
| UVL-Net-F | 0.796/0.877 | 0.779/0.863 | 0.794/0.875 | 0.764/0.848 | 0.783/0.865 | 0.798/0.878 | 0.786/0.868 | ||||||||||||||
| Ours | 0.804/0.883 | 0.786/0.865 | 0.798/0.878 | 0.772/0.849 | 0.781/0.860 | 0.802/0.881 | 0.795/0.874 |
Table II presents comparative experiments with the latest methods and robustness testing results. Although related methods perform well, our method demonstrates superior performance in fine-grained pixel-level detection. This advantage may stem from our targeted analysis of video splicing forgery. Additionally, compared to other semantic segmentation methods such as HRFormer, PoolFormer, and MetaFormer, known video splicing detection methods exhibit significant advantages. This indicates that the analysis of forgery traces in these methods is effective. Meanwhile, the detection results for various processed videos, such as those that have undergone compression, blurring, cropping, etc., show that our method exhibits smaller variations in outcome ( 0.03). Experimental results indicate that multi-view forgery trace features contribute to improving the performance and robustness of video splicing detection.
IV-D Ablation Study
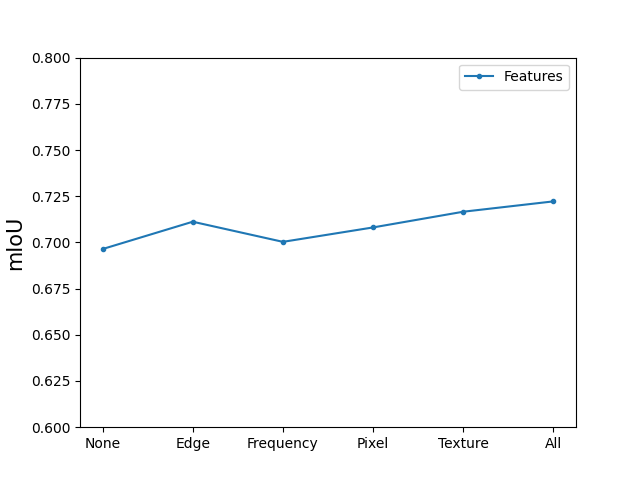

IV-D1 Impact of Various Features
The results in Figure 4a demonstrate the detection outcomes when applying different features. The “All” result, which incorporates the four features mentioned in this paper – edge, pixel, texture, and frequency domain features – achieved the best result. This indicates that combining multiple features can effectively enhance detection accuracy.
The “Edge” module, which utilizes Sobel and Laplacian operators to effectively extract first- and second-order edge features, demonstrates superior performance compared to the “None” baseline. This indicates that edge features are effective in detecting forged regions.
The “Pixel” module, when compared to the “None” baseline, also exhibits superior performance. This suggests that inconsistencies in pixel and noise distribution can aid in detecting differences between original and forged regions.
Similarly, when compared to the “None” baseline, the “Texture” module successfully extracts the different texture between two regions, leading to improved performance.
Lastly, the “Frequency” module, which applies DCT to extract different compression artifacts between two regions, also demonstrates superior performance compared to the “None” baseline. This indicates that the “Frequency” module is effective.
IV-D2 The influence of different components
The figure referred to as Figure 4b validates the effectiveness of our designed network structure for the multi-view forgery trace fusion learning component. Specifically, our CNN+ViT(Ours) outperforms other methods that utilize CNNs and ViTs. When compared to traditional advanced network architectures like MetaFormer and HRFormer, these methods incorporate CNNs into ViTs as a holistic approach to reduce ViT computational overhead for building large-scale models. However, our approach differs in that we utilize CNNs and ViTs in two separate stages. The results demonstrate that this approach is more suitable for video tamper detection and leads to the best performance, albeit with increased memory consumption.
When we only use one of CNN or ViT to learn multi-view features, the performance is lower than CNN+ViT. This is because relying solely on CNN can lead to a lack of global correlation information, which affects pixel-level accuracy. Conversely, using ViT alone can limit sensitivity to local features, resulting in poor detection performance. Experimental results confirm that combining CNN and ViT in this way is effective.
We also evaluated our method by reversing the order of ViT and CNN. Surprisingly, ViT+CNN performed worse than when using either alone. This suggests that first analyzing local tampering traces using CNN and then leveraging ViT to learn global correlations is more beneficial for detecting tampering regions. This aligns with our expectations and common sense.
IV-E Visualization Results Analysis and Discussion


Figure 5 illustrates the localization results of video inpainting and video splicing alterations. Figure 5a present the results of video inpainting detection, including animals, cars, humans, and combined objects. Our detection for single-object alterations is excellent, even for complex objects. Figure 5b demonstrates video object splicing detection with military objects such as aircrafts, tanks, warships, and soldiers. We can easily detect these alterations through analysis of various forgery traces. This indicates that our method is effective for video alteration detection. Through the analysis of multi-view alteration signature characteristics, we have achieved good results in fine-grained detection such as edges, small components, and combined objects. However, there is still room for improvement in the localization of complex alteration objects. In the future, we will strive to enhance our ability to detect alterations of multiple combined objects.
V Conclusion
In this paper, we have presented an effective video tampering localization strategy that significantly improves the detection performance of video inpainting and splicing. With the advancement of deep learning-driven video editing technology, the emergence of security risks, such as malicious video tampering, has become a pressing concern. We address this issue by extracting more generalized features of forgery traces, considering the inherent differences between tampered videos and original videos. To effectively fuse these features, we adopt a CNN+ViT two-stage method to learn them in a local-to-global manner. Experimental results demonstrate that our method significantly outperforms the existing state-of-the-art methods and exhibits robustness. Our future work will focus on extending this localization strategy to other types of video tampering and exploring more advanced feature extraction methods to further improve detection performance.
Acknowledgments
This should be a simple paragraph before the References to thank those individuals and institutions who have supported your work on this article.
References
- [1] P. Pei, X. Zhao, J. Li, and Y. Cao, “VIFST: video inpainting localization using multi-view spatial-frequency traces,” in PRICAI 2023, vol. 14327. Jakarta, Indonesia: Springer, 2023, pp. 434–446.
- [2] C. Dong, X. Chen, R. Hu, J. Cao, and X. Li, “Mvss-net: Multi-view multi-scale supervised networks for image manipulation detection,” IEEE TPAMI, vol. 45, no. 3, pp. 3539–3553, 2023.
- [3] B. Yu, W. Li, X. Li, J. Lu, and J. Zhou, “Frequency-aware spatiotemporal transformers for video inpainting detection,” in ICCV, October 2021, pp. 8188–8197.
- [4] P. Zhou, N. Yu, Z. Wu, L. Davis, A. Shrivastava, and S. Lim, “Deep video inpainting detection,” in 32nd British Machine Vision Conference 2021, BMVC, Online, 2021, p. 35.
- [5] P. Pei, X. Zhao, J. Li, and Y. Cao, “Uvl: A unified framework for video tampering localization,” 2023.
- [6] X. Jin, Z. He, J. Xu, Y. Wang, and Y. Su, “Video splicing detection and localization based on multi-level deep feature fusion and reinforcement learning,” Multim. Tools Appl., vol. 81, no. 28, pp. 40 993–41 011, 2022.
- [7] P. Pei, L. Guoqing, and L. Tao, “Multi-view inconsistency analysis for video object-level splicing localization,” International Journal of Emerging Technologies and Advanced Applications, vol. 1, no. 3, p. 1–5, Apr. 2024.
- [8] H. Li and J. Huang, “Localization of deep inpainting using high-pass fully convolutional network,” in ICCV, Seoul, Korea (South), 2019, pp. 8300–8309.
- [9] X. Xiang, Y. Zhang, L. Jin, Z. Li, and J. Tang, “Sub-region localized hashing for fine-grained image retrieval,” IEEE TIP, vol. 31, pp. 314–326, 2022.
- [10] S. Wei, H. Li, and J. Huang, “Deep video inpainting localization using spatial and temporal traces,” in ICASSP, 2022, pp. 8957–8961.
- [11] Y. Zhang, Z. Fu, S. Qi, M. Xue, Z. Hua, and Y. Xiang, “Localization of inpainting forgery with feature enhancement network,” IEEE Transactions on Big Data, vol. 9, no. 3, pp. 936–948, 2023.
- [12] J. Li, X. Zhao, and Y. Cao, “Generalizable deep video inpainting detection based on constrained convolutional neural networks,” in Digital Forensics and Watermarking - 22nd International Workshop, IWDW 2023, Jinan, China, November 25-26, 2023, Revised Selected Papers, ser. Lecture Notes in Computer Science, vol. 14511. Springer, 2023, pp. 125–138. [Online]. Available: https://doi.org/10.1007/978-981-97-2585-4\_9
- [13] Y. Rao and J. Ni, “Self-supervised domain adaptation for forgery localization of JPEG compressed images,” in ICCV, Montreal, QC, Canada, 2021, pp. 15 014–15 023.
- [14] C. Gao, A. Saraf, J. Huang, and J. Kopf, “Flow-edge guided video completion,” in ECCV, vol. 12357, Glasgow, UK, 2020, pp. 713–729.
- [15] P. Zhou, B. Chen, X. Han, M. Najibi, A. Shrivastava, S. Lim, and L. Davis, “Generate, segment, and refine: Towards generic manipulation segmentation,” in AAAI, New York, NY, USA, 2020, pp. 13 058–13 065.
- [16] P. Pei, X. Zhao, J. Li, Y. Cao, and X. Lai, “Vision transformer based video hashing retrieval for tracing the source of fake videos,” Security and Communication Networks, vol. 2023, 2023.
- [17] Y. Yuan, R. Fu, L. Huang, W. Lin, C. Zhang, X. Chen, and J. Wang, “Hrformer: High-resolution vision transformer for dense predict,” in NeurIPS, Virtual, 2021, pp. 7281–7293.
- [18] Z. Lou, G. Cao, and M. Lin, “Video inpainting localization with contrastive learning,” 2024. [Online]. Available: https://arxiv.org/abs/2406.17628
- [19] M. L. Zijie Lou, Gang Cao, “Trusted video inpainting localization via deep attentive noise learning,” 2024. [Online]. Available: https://arxiv.org/abs/2406.13576
- [20] Y. Niu, B. Tondi, Y. Zhao, R. Ni, and M. Barni, “Image splicing detection, localization and attribution via JPEG primary quantization matrix estimation and clustering,” IEEE Trans. Inf. Forensics Secur., vol. 16, pp. 5397–5412, 2021.
- [21] H. Ding, L. Chen, Q. Tao, Z. Fu, L. Dong, and X. Cui, “Dcu-net: a dual-channel u-shaped network for image splicing forgery detection,” Neural Comput. Appl., vol. 35, no. 7, pp. 5015–5031, 2023.
- [22] C. Yan, S. Li, and H. Li, “Transu2-net: A hybrid transformer architecture for image splicing forgery detection,” IEEE Access, vol. 11, pp. 33 313–33 323, 2023.
- [23] C. Yan, H. Wei, Z. Lan, and H. Li, “Msa-net: Multi-scale attention network for image splicing localization,” Multim. Tools Appl., vol. 83, no. 7, pp. 20 587–20 604, 2024. [Online]. Available: https://doi.org/10.1007/s11042-023-16131-0
- [24] A. Yadav and D. K. Vishwakarma, “A visually attentive splice localization network with multi-domain feature extractor and multi-receptive field upsampler,” 2024. [Online]. Available: https://arxiv.org/abs/2401.06995
- [25] A. Zayed, G. Mordido, S. Shabanian, I. Baldini, and S. Chandar, “Fairness-aware structured pruning in transformers,” in Thirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence, IAAI 2024, Fourteenth Symposium on Educational Advances in Artificial Intelligence, EAAI 2014, February 20-27, 2024, Vancouver, Canada, M. J. Wooldridge, J. G. Dy, and S. Natarajan, Eds. AAAI Press, 2024, pp. 22 484–22 492. [Online]. Available: https://doi.org/10.1609/aaai.v38i20.30256
- [26] D. Dordevic, V. Bozic, J. Thommes, D. Coppola, and S. P. Singh, “Rethinking attention: Exploring shallow feed-forward neural networks as an alternative to attention layers in transformers (student abstract),” in Thirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence, IAAI 2024, Fourteenth Symposium on Educational Advances in Artificial Intelligence, EAAI 2014, February 20-27, 2024, Vancouver, Canada, M. J. Wooldridge, J. G. Dy, and S. Natarajan, Eds. AAAI Press, 2024, pp. 23 477–23 479. [Online]. Available: https://doi.org/10.1609/aaai.v38i21.30436
- [27] S. W. Oh, S. Lee, J. Lee, and S. J. Kim, “Onion-peel networks for deep video completion,” in ICCV, Seoul, Korea (South), 2019, pp. 4402–4411.
- [28] S. Lee, S. W. Oh, D. Won, and S. J. Kim, “Copy-and-paste networks for deep video inpainting,” in ICCV, Seoul, Korea (South), 2019, pp. 4412–4420.
- [29] D. Kim, S. Woo, J. Lee, and I. S. Kweon, “Deep video inpainting,” in CVPR. Long Beach, CA, USA: IEEE, 2019, pp. 5792–5801.
- [30] R. Xu, X. Li, B. Zhou, and C. C. Loy, “Deep flow-guided video inpainting,” in CVPR. Long Beach, CA, USA: IEEE, 2019, pp. 3723–3732.
- [31] Y. Zeng, J. Fu, and H. Chao, “Learning joint spatial-temporal transformations for video inpainting,” in ECCV, vol. 12361, Glasgow, UK, 2020, pp. 528–543.
- [32] Q. Diao, Y. Jiang, B. Wen, J. Sun, and Z. Yuan, “Metaformer: A unified meta framework for fine-grained recognition,” in CVPR. New Orleans, Louisiana, USA: IEEE, 2022.