UVCPNet: A UAV-Vehicle Collaborative Perception Network for 3D Object Detection
Abstract
With the advancement of collaborative perception, the role of aerial-ground collaborative perception, a crucial component, is becoming increasingly important. The demand for collaborative perception across different perspectives to construct more comprehensive perceptual information is growing. However, challenges arise due to the disparities in the field of view between cross-domain agents and their varying sensitivity to information in images. Additionally, when we transform image features into Bird’s Eye View (BEV) features for collaboration, we need accurate depth information. To address these issues, we propose a framework specifically designed for aerial-ground collaboration. First, to mitigate the lack of datasets for aerial-ground collaboration, we develop a virtual dataset named V2U-COO for our research. Second, we design a Cross-Domain Cross-Adaptation (CDCA) module to align the target information obtained from different domains, thereby achieving more accurate perception results. Finally, we introduce a Collaborative Depth Optimization (CDO) module to obtain more precise depth estimation results, leading to more accurate perception outcomes. We conduct extensive experiments on both our virtual dataset and a public dataset to validate the effectiveness of our framework. Our experiments on the V2U-COO dataset and the DAIR-V2X dataset demonstrate that our method improves detection accuracy by 6.1% and 2.7%, respectively.
Index Terms:
Collaborative Perception, Unmanned Aerial Vehicle (UAV), Object Detection, Remote Sensing.I Introduction
Collaborative perception [1, 2, 3] achieves efficient and comprehensive research methods for environmental monitoring and data collection by integrating the advantages of multiple sensor networks. This technology enables the coverage of a broad geographic area while providing detailed ground-level information to address the issues of occlusion and small object detection from high altitudes, thereby significantly enhancing the accuracy and efficiency of monitoring efforts. The technology supports a variety of application scenarios, including agricultural precision management, urban planning, and disaster response. This is of great significance for intelligent and automated decision support systems [4].
In the task of collaborative perception between intelligent agents, BEV feature maps can unify different field of view information into feature maps at the same level, which has been widely used and has important significance in collaborative perception. By converting the feature information of optical images into the BEV feature space, information from various perspectives can be uniformly presented on the same feature level. However, the majority of research [5, 6, 7, 8] on collaborative perception utilizing BEV feature maps operates under an overly simplistic assumption: that all intelligent agents are homogenous or have a small height gap. Specifically, this entails that all agents are equipped with identical sensor models and share the same detection model. However, with the advancement of computer vision and collaborative perception technology, the role of aerial-ground collaboration has become increasingly significant. As drones are integrated into collaborative networks for joint tasks, the participating intelligent agents become heterogeneous. Exploring aerial-ground collaboration based on the foundation of homogenous agent collaborative perception research presents us with two primary challenges.
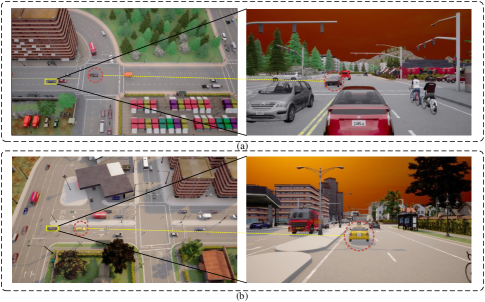
The first challenge pertains to the issue of cross-domain collaborative perception among heterogeneous agents. In the study of heterogeneous agents, there are considerable disparities in the visual information among agents, as well as varying degrees of sensitivity to information in images, as depicted in Fig. 1. This results in the generation of BEV feature maps for each domain being more inclined to include information from areas sensitive to that particular domain, while neglecting important information from other domains. This inevitably leads to the creation of a domain gap. Such a gap hinders the effective fusion of perceptual information by the agents and reduces their capabilities for collaborative detection. The second challenge pertains to the inaccuracy of depth estimation encountered when generating BEV feature maps from optical images across different domains. The generation of BEV feature maps relies on the accurate estimation of depth and scene information within optical images. However, the depth range of targets relative to agents varies across different domains, indicating that the estimated depth values differ when applied within two distinct networks. This leads to inconsistencies in depth estimation for optical images under different agents. When utilizing these inconsistent depth information for BEV perspective transformation, the scene presented in the BEV feature space will exhibit errors in the relative positions of targets observed by agents across different domains.
To address the challenges mentioned above, we propose a collaborative task network architecture named UVCPNet, a framework specifically designed for aerial-ground collaboration. To tackle the first challenge, we introduce a Cross-Domain Cross-Adaptation (CDCA) module aimed at aligning the BEV feature maps generated from different domains. After generating BEV feature maps on cross-domain agents, this module facilitates the cross-adaptation of BEV features’ relevance among agents, thereby enhancing the features obtained by each agent. By aligning the features acquired by each agent in the BEV feature map space, we ultimately achieve the effective integration of information from both aerial and ground perspectives. To response the second challenge, given that accurate depth estimation is essential for collaborative perception of BEV feature maps at each agent, we introduce a Collaborative Depth Optimization (CDO) module. This module optimizes depth estimation using Conditional Random Fields (CRF) [9, 10, 11, 12]. By transforming the optical image information of each agent to a unified scale through a camera parameter network, it integrates the depth estimation information obtained from cross-domain agents with the contextual pixel information of optical images. Utilizing the pixel information of optical images to optimize the depth estimation results, this approach enhances the accuracy of depth estimation. To assess the effectiveness of our network architecture and further advance research in aerial-ground collaboration, we introduce a large-scale aerial-ground collaborative dataset named V2U-COO. The dataset contains a large number of optical images of UAV and vehicle cooperation, which will be described in detail later.
In summary, our contributions can be summarized as follows:
1. We introduce the pioneering UVCPNet framework, a multi-view aerial-ground collaborative framework based on BEV. Notably, this framework represents the first task framework custom-designed specifically for aerial-ground collaboration.
2. To address the challenge of cross-domain information fusion during the collaborative process, we designed a module named CDCA. This module cleverly overcomes the barriers to effective collaboration by promoting seamless integration of information across different domains.
3. To enhance the precision of depth estimation in collaborative perception scenarios, we introduce the CDO module. Utilizing CRF, this module autonomously monitors and refines depth estimation information, ensuring an improvement in accuracy throughout the collaborative process.
4. In a groundbreaking initiative, we meticulously curated the V2U-COO dataset, custom-tailored for aerial-ground collaboration. This dataset represents a pioneering contribution and stands as the most significant dataset specifically designed for collaborative perception between vehicles and drones.
II RELATED WORK
In this section, we provide an overview of related work, focusing primarily on advancements in aerial-ground collaboration, cross-domain perception, and depth estimation.
II-A Aerial-Ground Coordination
Research on aerial-ground collaboration is still in its preliminary stages, with most studies concentrating on exploring multi-stage perspectives. For instance, AGCG [13] proposed a visual servoing approach based on a binocular localization model, adjusting the alignment between the unmanned aerial vehicle (UAV) and the target in the image to determine the target’s position. Utilizing multi-feature fusion recognition and projection imaging techniques, this method enhances the positioning accuracy of UAVs and unmanned ground vehicles (UGVs) in outdoor environments concerning moving targets. However, these methods have not yet proposed a specific aerial-ground collaboration research framework and have only undergone simulated testing, lacking support from actual datasets to validate the accuracy of the methods.
In recent years, with the development of drone technology, many high-quality datasets (such as VisDrone [14, 15, 16], HIT-UAV [17], DroneVehicle [18], etc.) have emerged, containing only images from the UAV perspective. The recently released MAVREC [19] dataset provides images from both ground and aerial perspectives, but lacks three-dimensional annotations and coordinate transformations between UAVs and UGVs, thus only usable as an object detection dataset, incapable of achieving target-level aerial-ground collaborative perception. In summary, current aerial-ground collaboration research mainly focuses on object detection from a single perspective, followed by its extension to other perspectives to supplement information. However, we aspire to integrate information from both ”aerial” and ”ground” domains to obtain more comprehensive collaborative perception results. This will aid in more accurately understanding and addressing targets in complex environments.
II-B Cross-Domain Perception
As collaborative perception tasks mature in the field of autonomous driving, significant progress has been made in collaborative work among homogeneous agents. For example, HM-ViT [20] demonstrates efficient collaborative capabilities by fusing point cloud and optical image data. Additionally, in the context of drone swarm collaboration, When2com [21] proposed a grouping-based cooperative method that successfully reduces the bandwidth requirements. These studies mainly focus on collaborative perception tasks within the domain and do not address challenges in cross-domain scenarios.
To address challenges in cross-domain collaborative perception, some high-quality datasets such as DAIR-V2X [22] and V2X-Sim [23] have emerged, along with proposed collaborative methods. However, most cross-domain collaborative methods [24, 25, 26, 27, 28] still rely on Lidar data. For instance, FFNet [29] solves the problem of asynchronous timing between vehicles and infrastructure using point cloud data, while TransIFF [30] utilizes instance-level features to enhance the robustness of feature fusion. However, due to the large storage space occupied by Lidar data, there is a desire to directly use optical images for cross-domain collaborative perception to reduce storage space usage.
In summary, existing research has made significant progress in collaborative perception tasks within the field and partially addressed challenges in cross domain scenarios. Afterwards, we need to further explore and develop methods that directly utilize optical images for cross domain collaborative perception.
II-C Depth Estimation
Depth estimation tasks [31, 32, 33], as essential auxiliary tasks in 3D visual detection [34, 35, 36, 37], play a crucial role in the modeling process, where accurate depth values help avoid distortions. With the continuous maturity of depth estimation algorithms, some new methods have made remarkable progress. For example, News-CRF treats depth estimation tasks as pixel-level classification problems, making them applicable to CRF applications and achieving advanced depth estimation results.
However, most depth estimation in the collaborative perception domain still relies on Lidar data. For depth estimation from optical images, it primarily relies on the depth estimation scheme proposed in LSS [38]. In collaborative perception, CoCa3D [39] fully utilizes the depth collaboration probability of each intelligent agent to modulate depth values. Although these methods have improved the accuracy of depth estimation to some extent, there is still room for optimization, especially in fully utilizing collaborative information. We hope to fully utilize collaborative information by employing CRF to optimize depth estimation schemes for more accurate feature information. This may include interacting information among multiple intelligent agents and jointly optimizing depth estimation tasks with other relevant tasks to obtain more comprehensive and accurate depth estimation results.
III METHOD
III-A Overview
In our current framework, we employ the BEVDET4D [40] network as the baseline model, which is an enhanced BEV feature extraction framework. The framework consists of two main components: the backbone (including the neck) and the head. The backbone network employs ResNet [41] to extract both low-level geometric features and high-level semantic information. Subsequently, it utilizes the BEV generation method proposed in LSS to translate these features and semantic information into the BEV feature space, thereby obtaining BEV features. The head uses the CenterPoint [42] detector head for 3D target detection. However, this method is traditionally applied to generating BEV from look-around images. By modifying the BEV generation process and introducing timestamp concepts, we establish a collaborative task framework named UVCPNet capable of time synchronization through timestamps. UVCPNet is an aerial-ground collaborative framework for enhanced BEV features that combines multi-domain information. The overall framework of the method is illustrated in Fig. 2.
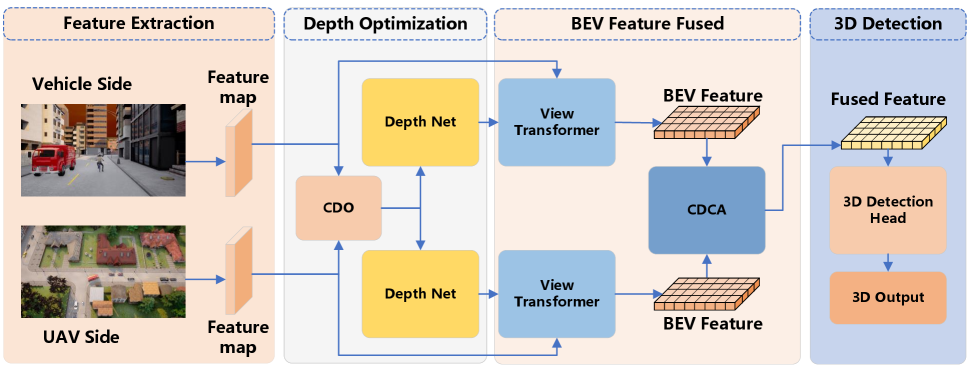
First, we input a set of RGB images of vehicles and UAVs. Second, by combining the features extracted from these RGB images with the estimated depth information, we produce the corresponding BEV feature map for each end. It should be emphasized that the required depth information is obtained through the CDO module. The module optimizes the depth estimation network by using CRF combined with the context semantic information of two perspectives, so as to obtain accurate depth estimation results.
Third, we obtain cross-domain BEV features from multiple ends and achieve alignment and enhancement of these features by the CDCA module. This module combines feature information from the ”Aerial” and ”Ground” domains, facilitating effective cross-domain alignment and feature enhancement. By adjusting the weight of BEV features in each domain, we fuse the enhanced BEV feature map. Finally, we use 3D target detection method to process the fused BEV feature results, and then decode the BEV representation into 3D targets for target detection.
III-B CDO module
Currently, to generate a BEV from optical images, we need to perform a 2D to 3D transformation [43], represented by the following equation:
| (1) |
In this context, represents the depth value of the image, which is the distance of each pixel point from the camera’s focal point. is the intrinsic matrix, is the rotation matrix of the camera, and is its translation matrix. Therefore, to obtain accurate 3D information, it is crucial to acquire precise depth estimation data.
In existing BEV-based methods aimed at addressing depth estimation inaccuracies, such as BEVdepth [44] and Solofusion [45], additional supervision signals in the form of depth information are necessitated. This requirement imposes additional computational burdens on the agent and increases the volume of information that the agent must process. Our method leverages the contextual semantic information inherent in RGB images as implicit supervision signals to optimize the depth estimation network. This approach eliminates the need for additional supervision signals, thereby reducing the burden on agents while simultaneously enhancing depth estimation accuracy. We hope to conduct depth estimation without adding any supervisory information.
The accuracy of depth estimation plays a pivotal role in determining the precision of spatial information for targets within the BEV space [38]. Nevertheless, the majority of cooperative algorithms still rely on basic convolutional neural networks (CNNs) for depth estimation. If we consider depth estimation as a segmentation task and represent each class as a specific depth range, CRF can be utilized to enhance the quality of depth estimation. Since each domain observes the same region, the depth information for the same target should theoretically be consistent after transformation.
However, in current supervised methods, the sampling of feature maps is relatively large, causing the feature maps to lose a significant amount of adversarial information, thereby compromising the effectiveness of CRF optimization for depth. To address this issue, CRF can be employed to refine the semantic information inherent in the optical image context of both the ”Aerial” and ”Ground” domains. Furthermore, leveraging semantic information priors within the depth estimation network can mitigate the challenge of limited depth supervision. This approach significantly improves depth consistency at the pixel level.
We aim to use semantic information from multiple domains for comprehensive optimization. Given that each domain observes the same target, the semantic information within each domain exhibits high similarity. On the feature map of RGB image feature extraction in each domain, we let represent the pixels in the feature graph of the subsampled field, and denote discrete depth values. The responsibility of the depth network is to assign each pixel to various depth values, expressed as . For depth information within each feature map, our objective is to minimize its energy cost [46]:
| (2) |
Among these, represents a unary potential, serving to gauge the cost associated with the initial network output:
| (3) |
is the probability that the depth information of pixel is d. Building upon prior research [47, 48], we define the binary potential as follows:
| (4) |
Here, and represent the semantic information of each image block with the same subsampling step in different domains, denoted by and respectively. Additionally, signifies the compatibility between depth information, quantifying the distance between their centers in the real world. Utilizing CRF as an optimization layer acting upon the depth estimation network, we ultimately obtain the optimized depth information .
In essence, by employing the CDO module, we achieve more precise depth estimates for pixels without the need for additional supervision signals. Consequently, this leads to an enhanced accuracy in generating the BEV feature map for each domain.
III-C CDCA Module
In our collaborative framework, the input consists of a set of RGB images containing vehicles and UAVs of varying heights. After these input optical image features are converted to BEV space, because there are significant differences between different domains in the field of view information and noticed information, it is necessary to align the information obtained across domains. To address this misalignment issue, we introduce a cross-domain cross-adaptation (CDCA) module. As shown in Fig.3, in our module, we perform collaborative cross-adaptation on the obtained BEV images to achieve a well-fused BEV feature map.
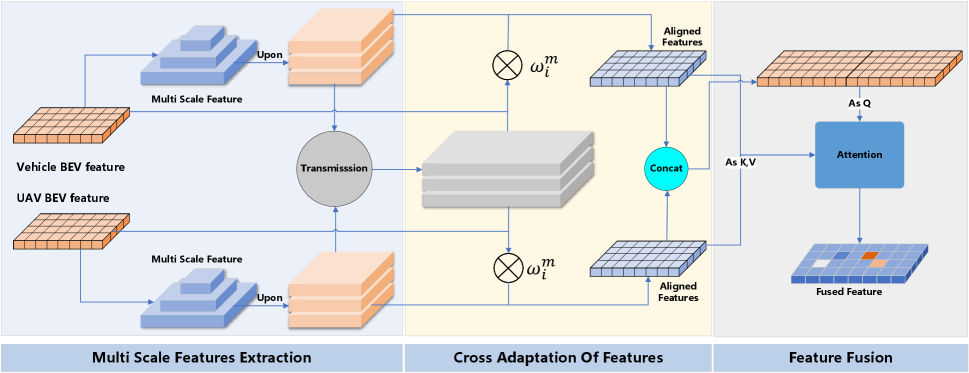
The module exploits feature correlation across domains to facilitate cross-domain adaptation, thereby enhancing feature information and minimizing positional errors. Upon acquiring the BEV feature map of each domain, it is necessary to apply consistent adaptation operations to the information from different domains in order to obtain aligned BEV feature maps. We extract multi-scale feature information from the BEV feature map of each domain, and use these multi-scale information to adapt to the feature information of other domains. After conducting correlation analysis between the information from other domains and the information from the current domain, we align and enhance the feature maps accordingly. After obtaining the enhanced feature information, we perform feature fusion to obtain the final BEV feature map.
CDCA initially requires extracting multi-scale network features. We employ a FPN [49] structure to sample the BEV feature map across four layers, resulting in the feature map after sampling. To ensure consistency in network feature size across each scale, we utilize a Multi-Scale (MS) module to scale the feature map to the same size. After receiving the sampled feature map information transmitted from other domains, we cascade the BEV feature map information at the same level to obtain the cascaded feature map information at this level:
| (5) |
i represents the domain of the BEV feature map, and m represents the level of the cascading feature map.
Then, we analyze the correlation of these cascaded feature maps :
| (6) |
| (7) |
| (8) |
Within this process, represents the autocorrelation analysis results of the features within the domain and the sampled feature maps within the same domain, as well as the cross-correlation analysis results between this domain and other domains. represents the weight information calculated through correlation analysis for each cascaded feature map, denoted as , represents the enhanced and aligned BEV feature map generated by fusion. By performing this operation, we can ascertain the adaptability outcomes for each scale and derive adaptability weights for each scale. Subsequently, we compute the enhanced feature graph information within each domain.
After transforming the information from multiple domains into the BEV space, aligning and enhancing the BEV feature maps, we proceed with the fusion of BEV features. However, due to variations in the observation capabilities of each domain towards the target, ground perspectives typically capture more feature information, while aerial perspectives tend to gather relatively less target information. This leads to inconsistencies in the amount of information contained within the BEV feature maps. To address this issue, we utilize BEV space attention to fuse the BEV feature maps from both aerial and ground domains. This means that the final fused feature map will pay more attention to the BEV feature maps with higher information content, enabling them to play a more crucial role in the final fusion result, thereby enhancing the effectiveness of feature fusion.
This module enhances the model’s attention to different domains by adjusting the weights of the BEV feature maps between the input domains. Firstly, the module connects the cascaded BEV feature maps of the two domains to obtain the concatenated feature map information , of the aerial-ground domains. Subsequently, we utilize the input feature information as and on both sides. Finally, the weights of different domains are computed to guide the fusion process:
| (9) |
Since the output of cross-domain attention in the module is the weighted sum of , which contains all information from the two domains, the essence of the module is to bring the two domains closer to a common center point. Specifically, by leveraging the shared in the cross-domain attention mechanism, this module encourages convergence between the two domains towards a central representation. Finally, a learnable parameter is set to balance the BEV feature maps from the two domains after the attention mechanism:
| (10) |
The module adjusts the ratio of the two parts of the feature maps by learning the weights in different domains. Through this operation, we can obtain a BEV fusion feature map with more accurate information.
III-D Loss
The loss of the experiment is mainly composed of two parts, including smooth L1 Loss for bounding box and gaussian focal loss for classification and cross-entropy loss for direction . The final loss function is as follows:
| (11) |
where , and represent the weights of , and respectively.
IV EXPERIMENT
In this section, we evaluate the performance of our designed aerial-ground collaborative perception network using both a custom dataset and a publicly available dataset focused on vehicle-road collaboration. Our evaluation is structured into three parts: First, we introduce the datasets utilized in our experiments. Next, we conduct ablation studies to assess the performance of individual components of our method. Finally, we demonstrate the superiority of our proposed framework through intuitive results visualization.
IV-A Datasets and Experimental Settings
Currently, publicly available collaborative 3D target detection datasets are limited to low-altitude cooperative sensing tasks between vehicles and infrastructure. This gap highlights the absence of datasets for high-altitude collaborative perception involving both vehicles and UAVs. In this study, we utilize the Carla simulation software to construct the V2U-COO dataset, designed specifically for air-to-ground cooperative sensing tasks. This dataset serves as a basis for our investigation into 3D target detection within cooperative sensing tasks.
Given the limitations of existing publicly accessible collaborative 3D target detection datasets, which are confined to low-altitude vehicle and infrastructure cooperative sensing tasks, there is a notable gap in datasets for high-altitude collaborative perception involving both vehicles and UAVs. To address this, we utilized the Carla simulation software to develop the V2U-COO dataset, specifically tailored for air-to-ground cooperative sensing tasks. This dataset facilitates our investigation into 3D target detection within these cooperative sensing scenarios. Furthermore, to validate the effectiveness of our method with real-world data, we conducted experimental tests on the DAIR-V2X, an open vehicle-road collaboration dataset.
IV-A1 DATASETS
a) V2U-COO: In this study, we utilized the NVIDIA RTX-3090 graphics card to construct a virtual dataset for aerial-ground cooperative sensing using the CARLA simulation software. This dataset facilitates multi-agent collaboration by using the same timestamp and identical annotation information for the same target by both vehicles and UAVs. The setup includes one vehicle and two UAVs collaborating in perception tasks. The UAVs are positioned on both the left and right sides of the vehicle to simulate accompanying flight scenarios and also to emulate different oblique viewing angles.
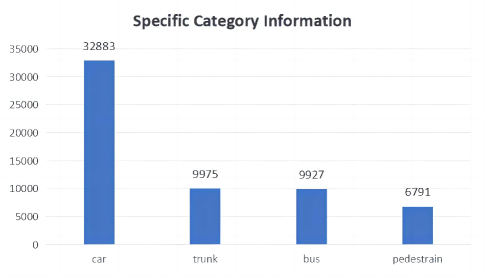

The dataset is configured with scenarios where two UAVS are positioned at the front-left and front-right of an unmanned vehicle, with both UAVs and the vehicle observing the same area. The perception range is set at 160 meters by 110 meters. All images in the dataset are annotated with 3D objects. The dataset categorizes the objects into four classes: car, truck, bus, and pedestrian. Additionally, each agent is equipped with an optical imaging camera, enabling tasks such as target detection and tracking under cooperative optical image perception. We provide a detailed description of the specific configurations of the V2U-COO dataset in Table 1. The specific category information contained in V2U-COO dataset is shown in Fig. 4. Examples from the experimental dataset are illustrated in Fig. 5.
| VEHICLE | UAV-R | UAV-L | |
|---|---|---|---|
| FOV | 70 | 70 | 70 |
| Image Size | |||
| Image Count | 6400 | 6400 | 6400 |
| Agent Height(m) | 2 | 80 | -70 |
| Pitch | 0 | -90 | 90 |
| Yaw | 0 | -60 | -60 |
| Roll | 0 | 0 | 0 |
| Sampling frequency(HZ) | 20 | 20 | 20 |
| Scene count | 7 | 7 | 7 |
b) DAIR-V2X: DAIR-V2X is the world’s first and only publicly available real dataset applied to vehicle-road cooperative perception, featuring an exceptionally large volume of data. It includes images captured by optical cameras at two different heights, from both vehicles and infrastructure. All images in this dataset are annotated with ten 3D object classes. The dataset comprises 9,311 pairs of optical images captured simultaneously from infrastructure and vehicle frames. Annotations for each pair of cooperative optical images are provided in world coordinates, which need to be transformed into vehicle coordinates for training and evaluation. These labels serve as the benchmark for our experiments. Images captured by RGB cameras have a resolution of 1920 × 1080, with a perception range of 100m × 79m.
IV-A2 Experimental Settings
When observations are conducted using a single agent, occlusions can occur, negatively impacting our detection and recognition capabilities. In contrast, cooperative perception allows for a more complete acquisition of sensory information, significantly reducing the effects of occlusions. Our experiments begin by confirming the effectiveness of this cooperative approach. The experimental setup integrates observational data from multiple agents to demonstrate the efficiency of the collaborative framework.
In autonomous scenarios devoid of collaborative mechanisms, observations conducted by individual agents are constrained by their inherent viewing perspectives. This limitation is particularly pronounced in observations from standalone intelligent vehicles, where conventional viewing angles frequently lead to occlusions. These occlusions present a formidable challenge in vehicle perspective observations and are identified as a critical barrier in current ground target detection methodologies. To augment the observational capabilities of vehicles, it is essential to achieve a more exhaustive acquisition of scene information. However, the restricted viewing angles often result in incomplete or non-existent data capture, especially when the intended targets are obscured by other objects. To mitigate the deficiencies caused by such occlusions, this study leverages UAV perspectives as an auxiliary observational resource. By integrating data from UAVs, the framework addresses the incomplete data issues and substantially enhances the accuracy of the perceptual information. Fig. 6 demonstrates a scenario where the vehicle’s view is obstructed; nevertheless, the integration of UAV-derived data facilitates a comprehensive scene understanding through collaborative perception.

When observations are conducted solely using UAVs, the significant observation distance often results in a lack of detail in the visual data captured, particularly for smaller objects. Consequently, the detection accuracy for smaller targets presents a substantial challenge in UAV-based monitoring systems. To enhance the detail and accuracy of the data collected during UAV operations, it is advantageous to integrate these observations with data obtained from ground-based vehicle sensors. Such collaborative sensing can significantly improve the fidelity of the detail captured, leading to more accurate scene perception. An illustrative example is provided in the Fig. 7, which depicts a scenario where a vehicle captures detailed information about a small target initially observed by a UAV.

Therefore, by synergizing the observational data from both vehicles and UAVs, a more comprehensive understanding of the target can be achieved, enhancing the overall accuracy of the information gathered.
IV-B Evaluation Metrics
We evaluate the performance of the network using the evaluation metrics provided by Nuscenes [50]. These metrics include the mean average precision (mAP), mean translation error (mATE), mean scale error (mASE), mean orientation error (mAOE), mean velocity error (mAVE), mean attribute error (mAAE), and the NuScenes detection score (NDS), which considers both comprehensive accuracy and true positives (TP).
The average precision of object detection is a crucial metric for assessing detection accuracy. However, in NuScenes, the calculation of mAP integrates threshold matching of average precision (AP) without employing Intersection over Union (IoU). Instead, it uses the 2D center distance (d) on the ground plane to compute AP, thereby decoupling the impact of object size and orientation on AP calculation. Here, d is set to meters. The formula for mAP calculation is as follows:
| (12) |
For each TP index, we calculate as follows:
| (13) |
NDS is computed using the TP metric, where half is based on mAP, and the other half is based on the quality of detection performance in terms of position, size, orientation, attributes, and velocity (ATE, ASE, AOE, AVE, AAE). As mAVE, mAOE, and mATE can exceed 1, we constrain each metric between 0 and 1 in the following formula:
| (14) |
IV-C Implementation Details
The framework proposed in this study is experimented with using PyTorch on an RTX-4090 GPU to evaluate its efficacy. To assess the effectiveness of the proposed collaborative framework, we ensure uniformity by employing the same training detection model architecture across all agent nodes. We opt for ResNet-50 as the pre-trained model and subsequently train it on respective datasets.
During the training phase, parameters remain static at each agent, ensuring that updates occur solely within the collaborative module. This guarantees that all improvements stem from the collaborative framework, facilitating a comprehensive evaluation of the network’s capabilities. In the training detection phase, input images are standardized to 704x256 dimensions, with training extending over 40 epochs. We employ a standard gradient optimizer with a weight decay of 0.0005. Additionally, the learning rate is initialized at 0.001.
IV-D Ablation Study
In this section, we conduct experiments based on the proposed V2U-COO dataset. Firstly, to assess the effectiveness of the collaborative network, we compare the results obtained from using only vehicle observations or only UAV observations with those obtained from collaborative network observations under the same network architecture. The specific mAP improvement curve is illustrated in the figure, demonstrating that the collaborative platform outperforms both the vehicle-only and UAV-only approaches. Additionally, to evaluate the effectiveness of each module within UVCP, we conduct extensive experiments on the dataset. To ensure fairness, experiments are conducted in the same environment. The overall experimental results are summarized in the Table II. It can be observed that compared to the baseline model, UVCP achieves an average precision improvement of approximately 6.1%.
| mAP | mATE | mASE | mAOE | mAVE | mAAE | NDS | mAP | |
|---|---|---|---|---|---|---|---|---|
| Baseline- | 0.546 | 0.380 | 0.167 | 0.564 | 1.157 | 0.387 | 0.523 | |
| Baseline+ | 0.607 | 0.355 | 0.145 | 0.544 | 1.082 | 0.315 | 0.568 | 6.1% |
IV-D1 Effectiveness analysis of collaborative perception framework
Table III presents the experimental results conducted on the V2U-COO dataset, comparing the outcomes of utilizing a single agent versus collaborative observation between agents and reverse observation.,The specific accuracy improvement curves are depicted in the Figure 3. When employing single-agent observation, the average precision achieved solely through vehicle observation is merely 12.1%, whereas the average precision attained solely through UAV observation stands at 44.7%. However, upon integrating the collaborative perception framework, the average precision of collaborative detection significantly improves to 60.7%. This improvement is substantial compared to single-agent observations, with a remarkable 48.6% enhancement over vehicle observation and a notable 16.0% improvement over UAV observation.
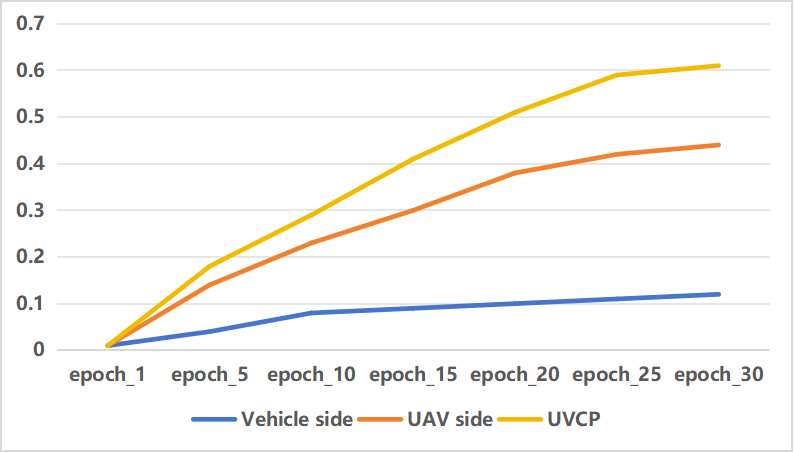
| mAP | mATE | mASE | mAOE | mAVE | mAAE | NDS | mAP | |
|---|---|---|---|---|---|---|---|---|
| Vehicle side | 0.121 | 0.855 | 0.366 | 0.677 | 1.358 | 0.467 | 0.224 | 48.6% |
| UAV side | 0.447 | 0.562 | 0.187 | 1.375 | 2.108 | 0.511 | 0.397 | 16.0% |
| UVCP | 0.607 | 0.355 | 0.145 | 0.544 | 1.082 | 0.315 | 0.568 |
In the aforementioned experiments, we observed that due to occlusion and limited field of view, the results of single-agent vehicle observation were unsatisfactory. Similarly, the effectiveness of UAV observation was compromised due to the scarcity of target information. However, when we integrated these two platforms into a collaborative perception system, a significant improvement in accuracy was observed. This validates the effectiveness of collaborative perception and demonstrates that UAVs can provide a broader field of view for vehicles, while vehicles can offer more precise target information for UAVs.
IV-D2 Effectiveness analysis of each module in collaborative perception framework
As described in Section III, our proposed framework comprises two main modules: the cross-domain adaptation module and the depth estimation optimization module. We conducted a series of ablation experiments on the V2U-COO dataset to analyze the importance of each module.
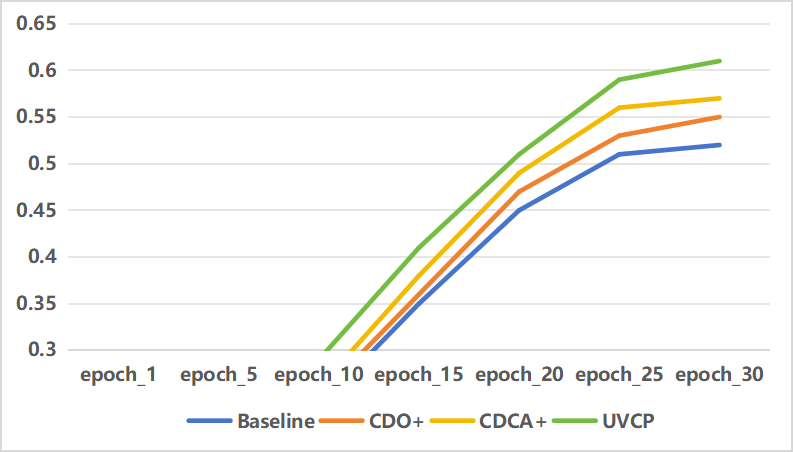

a) Effectiveness analysis of CDO module: The framework relies on accurate depth values during the generation of BEV feature maps. Therefore, achieving precise depth estimation is a crucial aspect of the collaborative perception framework. To address this challenge, we propose the depth estimation optimization module, which leverages contextual semantic information to obtain refined and accurate depth values.
| mAP | mATE | mASE | mAOE | mAVE | mAAE | NDS | mAP | |
|---|---|---|---|---|---|---|---|---|
| CDO- | 0.576 | 0.377 | 0.151 | 0.423 | 0.954 | 0.352 | 0.561 | |
| CDO+ | 0.607 | 0.355 | 0.145 | 0.544 | 1.082 | 0.315 | 0.568 | 3.1% |
The ablation experiments for this module are presented in Table IV, where we compare the changes in various metrics of the model before and after depth optimization, denoted as CDO+ and CDO-, respectively. The results demonstrate that after integrating this module, the model’s accuracy improves from 57.6% to approximately 60.7%, resulting in an enhancement of about 3.1% in accuracy.
Since the depth estimation network performs contextual semantic optimization on images downsampled to a size of 704 × 256, we further validate the effectiveness of the module by reducing the downsampling factor of images to obtain sizes of 1056 × 384 and 1408 × 512 for depth optimization. The experiment results, as shown in Table V, confirm the effectiveness of depth optimization.
| Input size | mAP | mATE | mASE | mAOE | mAVE | mAAE | NDS | mAP |
|---|---|---|---|---|---|---|---|---|
| 704 × 256 | 0.607 | 0.355 | 0.145 | 0.544 | 1.082 | 0.315 | 0.568 | |
| 1056 × 384 | 0.618 | 0.345 | 0.167 | 0.678 | 1.308 | 0.289 | 0.564 | 1.1% |
| 1408 × 512 | 0.631 | 0.334 | 0.139 | 0.593 | 1.493 | 0.343 | 0.575 | 2.4% |
b) Effectiveness analysis of CDCA module: Our primary task in collaborative perception is to integrate information observed by multiple agents into a cohesive representation. However, the challenge lies in aligning the disparate information captured by these agents, leading to inaccurate target localization and redundant detections. To tackle this issue, we introduce a cross-domain cross-adaptation module. This module extracts multi-scale information from each agent and performs cross-adaptation with information obtained by other agents to derive the optimal fused information.
| mAP | mATE | mASE | mAOE | mAVE | mAAE | NDS | mAP | |
|---|---|---|---|---|---|---|---|---|
| CDCA- | 0.559 | 0.329 | 0.169 | 0.409 | 1.026 | 0.372 | 0.551 | |
| CDCA+ | 0.607 | 0.355 | 0.145 | 0.544 | 1.082 | 0.315 | 0.568 | 4.8% |
The results of ablation experiments for this module are summarized in Table VI, where we compare metrics with and without its utilization, denoted as CDCA+ and CDCA-, respectively. It is evident that the integration of this module enhances the average precision from 55.9% to 60.7%, marking an improvement of approximately 4.8%. This underscores the effectiveness of the cross-domain cross-adaptation module in aligning information from diverse domains, thereby mitigating detection errors.
Furthermore, by visually comparing the feature map results of vehicles and UAVs before and after cross-domain fusion, and juxtaposing them with the fused detection BEV results, we can intuitively observe the refinement achieved through fusion.
IV-E Comparison With Other Methods
To rigorously assess the efficacy of our proposed approach, we conducted a series of comparative experiments against both established BEV-based methodologies and select collaborative techniques. Our evaluations included comparisons with BEV-based systems such as BEVDet4D, BEVerse, and BEVFormer, alongside the collaborative approach EMIFF. Detailed outcomes of these comparisons are delineated in Table VII. The results demonstrate a significant enhancement in average precision with our method, exhibiting improvements of approximately 9% over BEVDet4D, 11% over BEVFormer [51], and 8% over BEVerse [52]. Additionally, when compared to the collaborative method EMIFF [53], our approach showed an improvement of about 6%. These findings underscore the superior performance of our proposed method in terms of average precision, highlighting its robustness and effectiveness in the tested scenarios.
| Method | mAP | mATE | mASE | mAOE | mAVE | mAAE | NDS |
|---|---|---|---|---|---|---|---|
| BEVDet4D | 0.515 | 0.421 | 0.157 | 0.430 | 0.913 | 0.376 | 0.528 |
| BEVerse | 0.521 | 0.409 | 0.156 | 0.426 | 0.922 | 0.378 | 0.532 |
| BEVFormer | 0.487 | 0.391 | 0.171 | 0.513 | 1.057 | 0.380 | 0.498 |
| EMIFF | 0.546 | 0.320 | 0.154 | 0.631 | 1.088 | 0.449 | 0.518 |
| Where2com | 0.555 | 0.307 | 0.146 | 0.467 | 1.112 | 0.407 | 0.545 |
| UVCP(ours) | 0.607 | 0.355 | 0.145 | 0.544 | 1.082 | 0.315 | 0.568 |
IV-F Results on the Difficult Dataset DAIR-V2X
To assess the efficacy of our cooperative framework and evaluate its performance within real-world contexts, we conducted validation experiments on the DAIR-V2X dataset. This dataset, comprising a rich array of images from real-world scenarios, presents significant challenges due to various adverse conditions that inherently increase the complexity of detection tasks. The experimental outcomes, as presented in Table VIII, indicate that the application of our proposed method led to an approximate increase of 2.7% in average precision. These results not only confirm the effectiveness of our framework but also demonstrate its robustness and adaptability in realistic settings.
| mAP | mATE | mASE | mAOE | mAVE | mAAE | NDS | ||
|---|---|---|---|---|---|---|---|---|
| Baseline- | 0.336 | 0.681 | 0.185 | 0.645 | 1.095 | 0.334 | 0.368 | |
| Baseline+ | 0.363 | 0.657 | 0.376 | 0.676 | 1.034 | 0.344 | 0.376 | 2.7% |
IV-G Visual Analysis
In this section, we present a comparative analysis of the visualization results obtained from individual observations by vehicles and UAVs, as well as those enhanced through the incorporation of our collaborative framework. The analysis reveals that observations from single agents often suffer from challenges such as missed or duplicate detections. However, by integrating the collaborative framework, the observational outcomes for each agent are significantly improved. This enhancement is evident across multiple scenarios, confirming the effectiveness of the collaborative approach in providing more accurate and reliable detection results.
V CONCLUSION
In this paper, we propose an aerial-ground collaborative perception framework named UVCP. UVCP primarily focuses on the collaborative fusion of information observed by agents at different altitudes. Compared to scenarios where observations are made solely by vehicles or solely by drones, UVCP unifies the observational data from both drones and vehicles, addressing the limitations inherent to each single-agent perspective. This integration compensates for the deficiencies of single-view observations, thereby enhancing the accuracy of 3D object detection.
Additionally, since we convert the original images to BEV images, we designed the CDO module to ensure better depth information values and thereby obtain accurate BEV feature maps. Moreover, considering the challenge of aligning target information obtained by different agents during the fusion process, we devised the CDCA module to enable effective cross-domain information fusion through mutual adaptation of information from different perceptual perspectives.
To facilitate the research on aerial-ground collaboration, we utilized CARLA to create a dataset aimed at aerial-ground collaboration, named V2U-COO. We conducted extensive experiments and analyses on both our dataset and the publicly available DAIR-V2X dataset to verify the accuracy of our method in 3D object detection. Experimental results indicate that the detection accuracy of the collaborative strategy significantly surpasses that of single-agent scenarios. Additionally, the CDCA and CDO modules have also significantly improved the detection accuracy. However, the proposed method still has limitations in scenarios where multi-agent observations are temporally asynchronous. In our future research, we plan to address the temporal asynchrony issues by modeling historical information to reduce information errors. Additionally, we aim to leverage multi-modal data from optical and point cloud sensors in collaborative perception to further enhance the processing capabilities in distributed scenarios, which can be applied to real-world applications demanding quick response and high precision.
References
- [1] Y.-C. Liu, J. Tian, C.-Y. Ma, N. Glaser, C.-W. Kuo, and Z. Kira, “Who2com: Collaborative perception via learnable handshake communication,” in 2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020, pp. 6876–6883.
- [2] Y. Han, H. Zhang, H. Li, Y. Jin, C. Lang, and Y. Li, “Collaborative perception in autonomous driving: Methods, datasets, and challenges,” IEEE Intelligent Transportation Systems Magazine, 2023.
- [3] Y. Hu, S. Fang, Z. Lei, Y. Zhong, and S. Chen, “Where2comm: Communication-efficient collaborative perception via spatial confidence maps,” Advances in neural information processing systems, vol. 35, pp. 4874–4886, 2022.
- [4] C. Chen, Z. Liao, Y. Ju, C. He, K. Yu, and S. Wan, “Hierarchical domain-based multicontroller deployment strategy in sdn-enabled space–air–ground integrated network,” IEEE Transactions on Aerospace and Electronic Systems, vol. 58, no. 6, pp. 4864–4879, 2022.
- [5] R. Xu, J. Li, X. Dong, H. Yu, and J. Ma, “Bridging the domain gap for multi-agent perception,” in 2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 6035–6042.
- [6] J. Cui, H. Qiu, D. Chen, P. Stone, and Y. Zhu, “Coopernaut: End-to-end driving with cooperative perception for networked vehicles,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 17 252–17 262.
- [7] N. Vadivelu, M. Ren, J. Tu, J. Wang, and R. Urtasun, “Learning to communicate and correct pose errors,” in Conference on Robot Learning. PMLR, 2021, pp. 1195–1210.
- [8] T.-H. Wang, S. Manivasagam, M. Liang, B. Yang, W. Zeng, and R. Urtasun, “V2vnet: Vehicle-to-vehicle communication for joint perception and prediction,” in Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part II 16. Springer, 2020, pp. 605–621.
- [9] S. Lan, X. Yang, Z. Yu, Z. Wu, J. M. Alvarez, and A. Anandkumar, “Vision transformers are good mask auto-labelers,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 23 745–23 755.
- [10] S. Lan, Z. Yu, C. Choy, S. Radhakrishnan, G. Liu, Y. Zhu, L. S. Davis, and A. Anandkumar, “Discobox: Weakly supervised instance segmentation and semantic correspondence from box supervision,” in 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Oct 2021. [Online]. Available: http://dx.doi.org/10.1109/iccv48922.2021.00339
- [11] F. Liu, C. Shen, and G. Lin, “Deep convolutional neural fields for depth estimation from a single image,” in 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2015. [Online]. Available: http://dx.doi.org/10.1109/cvpr.2015.7299152
- [12] W. Yuan, X. Gu, Z. Dai, S. Zhu, and P. Tan, “Newcrfs: Neural window fully-connected crfs for monocular depth estimation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2022.
- [13] Z. Sun, Y. Liu, L. Zhang, and F. Deng, “Agcg: Air–ground collaboration geolocation based on visual servo with uncalibrated cameras,” IEEE Transactions on Industrial Electronics, 2024.
- [14] P. Zhu, L. Wen, D. Du, X. Bian, H. Ling, Q. Hu, Q. Nie, H. Cheng, C. Liu, X. Liu, et al., “Visdrone-det2018: The vision meets drone object detection in image challenge results,” in Proceedings of the European Conference on Computer Vision (ECCV) Workshops, 2018, pp. 0–0.
- [15] D. Du, P. Zhu, L. Wen, X. Bian, H. Lin, Q. Hu, T. Peng, J. Zheng, X. Wang, Y. Zhang, et al., “Visdrone-det2019: The vision meets drone object detection in image challenge results,” in Proceedings of the IEEE/CVF international conference on computer vision workshops, 2019, pp. 0–0.
- [16] Y. Cao, Z. He, L. Wang, W. Wang, Y. Yuan, D. Zhang, J. Zhang, P. Zhu, L. Van Gool, J. Han, et al., “Visdrone-det2021: The vision meets drone object detection challenge results,” in Proceedings of the IEEE/CVF International conference on computer vision, 2021, pp. 2847–2854.
- [17] J. Suo, T. Wang, X. Zhang, H. Chen, W. Zhou, and W. Shi, “Hit-uav: A high-altitude infrared thermal dataset for unmanned aerial vehicle-based object detection,” Scientific Data, vol. 10, no. 1, p. 227, 2023.
- [18] Y. Sun, B. Cao, P. Zhu, and Q. Hu, “Drone-based rgb-infrared cross-modality vehicle detection via uncertainty-aware learning,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 10, pp. 6700–6713, 2022.
- [19] A. Dutta, S. Das, J. Nielsen, R. Chakraborty, and M. Shah, “Multiview aerial visual recognition (mavrec): Can multi-view improve aerial visual perception?” 2023.
- [20] H. Xiang, R. Xu, and J. Ma, “Hm-vit: Hetero-modal vehicle-to-vehicle cooperative perception with vision transformer,” in 2023 IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 284–295.
- [21] Y.-C. Liu, J. Tian, N. Glaser, and Z. Kira, “When2com: Multi-agent perception via communication graph grouping,” in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 4105–4114.
- [22] H. Yu, Y. Luo, M. Shu, Y. Huo, Z. Yang, Y. Shi, Z. Guo, H. Li, X. Hu, J. Yuan, and Z. Nie, “Dair-v2x: A large-scale dataset for vehicle-infrastructure cooperative 3d object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2022, pp. 21 361–21 370.
- [23] Y. Li, D. Ma, Z. An, Z. Wang, Y. Zhong, S. Chen, and C. Feng, “V2x-sim: Multi-agent collaborative perception dataset and benchmark for autonomous driving,” IEEE Robotics and Automation Letters, vol. 7, no. 4, pp. 10 914–10 921, 2022.
- [24] J. Tan, F. Lyu, L. Li, F. Hu, T. Feng, F. Xu, and R. Yao, “Dynamic v2x autonomous perception from road-to-vehicle vision,” arXiv preprint arXiv:2310.19113, 2023.
- [25] Z. Wu, Y. Wang, H. Ma, Z. Li, H. Qiu, and J. Li, “Cmp: Cooperative motion prediction with multi-agent communication,” arXiv preprint arXiv:2403.17916, 2024.
- [26] W. Su, L. Chen, Y. Bai, X. Lin, G. Li, Z. Qu, and P. Zhou, “What makes good collaborative views? contrastive mutual information maximization for multi-agent perception,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 16, 2024, pp. 17 550–17 558.
- [27] X. Li, J. Yin, W. Li, C. Xu, R. Yang, and J. Shen, “Di-v2x: Learning domain-invariant representation for vehicle-infrastructure collaborative 3d object detection,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 4, 2024, pp. 3208–3215.
- [28] S. Wei, Y. Wei, Y. Hu, Y. Lu, Y. Zhong, S. Chen, and Y. Zhang, “Asynchrony-robust collaborative perception via bird’s eye view flow,” Advances in Neural Information Processing Systems, vol. 36, 2024.
- [29] H. Yu, Y. Tang, E. Xie, J. Mao, P. Luo, and Z. Nie, “Flow-based feature fusion for vehicle-infrastructure cooperative 3d object detection,” in Advances in Neural Information Processing Systems, 2023.
- [30] Z. Chen, Y. Shi, and J. Jia, “Transiff: An instance-level feature fusion framework for vehicle-infrastructure cooperative 3d detection with transformers,” in 2023 IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 18 159–18 168.
- [31] A. Torralba and A. Oliva, “Depth estimation from image structure,” IEEE Transactions on pattern analysis and machine intelligence, vol. 24, no. 9, pp. 1226–1238, 2002.
- [32] Y. Ming, X. Meng, C. Fan, and H. Yu, “Deep learning for monocular depth estimation: A review,” Neurocomputing, vol. 438, pp. 14–33, 2021.
- [33] A. Mertan, D. J. Duff, and G. Unal, “Single image depth estimation: An overview,” Digital Signal Processing, vol. 123, p. 103441, 2022.
- [34] T. Wang, X. Zhu, J. Pang, and D. Lin, “Fcos3d: Fully convolutional one-stage monocular 3d object detection,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 913–922.
- [35] ——, “Probabilistic and geometric depth: Detecting objects in perspective,” 5th Annual Conference on Robot Learning,5th Annual Conference on Robot Learning, Jun 2021.
- [36] X. Shi, Z. Chen, and T.-K. Kim, “Distance-normalized unified representation for monocular 3d object detection,” in Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXIX 16. Springer, 2020, pp. 91–107.
- [37] C. Reading, A. Harakeh, J. Chae, and S. L. Waslander, “Categorical depth distribution network for monocular 3d object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 8555–8564.
- [38] J. Philion and S. Fidler, “Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d,” in Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XIV 16. Springer, 2020, pp. 194–210.
- [39] Y. Hu, Y. Lu, R. Xu, W. Xie, S. Chen, and Y. Wang, “Collaboration helps camera overtake lidar in 3d detection,” in 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 9243–9252.
- [40] J. Huang and G. Huang, “Bevdet4d: Exploit temporal cues in multi-camera 3d object detection,” arXiv preprint arXiv:2203.17054, 2022.
- [41] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
- [42] T. Yin, X. Zhou, and P. Krahenbuhl, “Center-based 3d object detection and tracking,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 11 784–11 793.
- [43] X. Yang, Z. Ma, Z. Ji, and Z. Ren, “Gedepth: Ground embedding for monocular depth estimation,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 12 719–12 727.
- [44] Y. Li, Z. Ge, G. Yu, J. Yang, Z. Wang, Y. Shi, J. Sun, and Z. Li, “Bevdepth: Acquisition of reliable depth for multi-view 3d object detection,” vol. 37, no. 2, pp. 1477–1485, 2023.
- [45] J. Park, C. Xu, S. Yang, K. Keutzer, K. M. Kitani, M. Tomizuka, and W. Zhan, “Time will tell: New outlooks and a baseline for temporal multi-view 3d object detection,” 2022.
- [46] P. Krähenbühl and V. Koltun, “Efficient inference in fully connected crfs with gaussian edge potentials,” Neural Information Processing Systems,Neural Information Processing Systems, Dec 2011.
- [47] Y. Cao, Z. Wu, and C. Shen, “Estimating depth from monocular images as classification using deep fully convolutional residual networks,” IEEE Transactions on Circuits and Systems for Video Technology, p. 3174–3182, Nov 2018. [Online]. Available: http://dx.doi.org/10.1109/tcsvt.2017.2740321
- [48] S. Zheng, S. Jayasumana, B. Romera-Paredes, V. Vineet, Z. Su, D. Du, C. Huang, and P. H. Torr, “Conditional random fields as recurrent neural networks,” pp. 1529–1537, 2015.
- [49] T.-Y. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature pyramid networks for object detection,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2117–2125.
- [50] H. Caesar, V. Bankiti, A. H. Lang, S. Vora, V. E. Liong, Q. Xu, A. Krishnan, Y. Pan, G. Baldan, and O. Beijbom, “nuscenes: A multimodal dataset for autonomous driving,” arXiv preprint arXiv:1903.11027, 2019.
- [51] Z. Li, W. Wang, H. Li, E. Xie, C. Sima, T. Lu, Y. Qiao, and J. Dai, “Bevformer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers,” in European conference on computer vision. Springer, 2022, pp. 1–18.
- [52] Y. Zhang, Z. Zhu, W. Zheng, J. Huang, G. Huang, J. Zhou, and J. Lu, “Beverse: Unified perception and prediction in birds-eye-view for vision-centric autonomous driving,” arXiv preprint arXiv:2205.09743, 2022.
- [53] Z. Wang, S. Fan, X. Huo, T. Xu, Y. Wang, J. Liu, Y. Chen, and Y.-Q. Zhang, “Emiff: Enhanced multi-scale image feature fusion for vehicle-infrastructure cooperative 3d object detection,” in 2024 IEEE International Conference on Robotics and Automation (ICRA), 2024.