11institutetext: Institute for Information and Transmission Problems, Moscow
22institutetext: Skolkovo Institute of Science and Technology, Moscow
33institutetext: Moscow Institute of Physics and Technology, Moscow 44institutetext: Institution of Russian Academy of Sciences Dorodnicyn Computing Centre, Moscow
Using special attention improves change point detection
The change point is a moment of an abrupt alteration in the data distribution. Current methods for change point detection are based on recurrent neural methods suitable for sequential data. However, recent works show that transformers based on attention mechanisms perform better than standard recurrent models for many tasks. The most benefit is noticeable in the case of longer sequences. In this paper, we investigate different attentions for the change point detection task and proposed specific form of attention related to the task at hand. We show that using a special form of attention outperforms state-of-the-art results.
Keywords:
change point detection, transformer, attention, sequential data
1 Introduction
The goal of Change Point Detection (CPD) is to find the moment of data distribution shift. Such tasks appear in different areas, from monitoring systems to video analysis [1] to oilgas [11].
One of the recent methods for CPD [10] proves that a recurrent neural network model constructs meaningful representations and solve a problem better than non-principled approaches.
The state-of-the-art model for sequential data is Transformer [17].
The main benefit of Transformer’s is their ability to
work with long-range dependencies via attention mechanism. Attention matrix specifies at what exact points we should look [17].
A modification of attention matrix allows faster and more efficient processing of longer sequences [16, 15].
We propose specific attention mechanisms that allow efficient work for the change point detection problem.
By considering different autoregression and non-autoregressive attention matrices, we highlight important properties of both the problem and the model based on transformers.
The proposed models work faster and directly incorporate the peculiarities of the problem at hand.
They outperform existing results for the considered change point detection problem in semi-structured sequences of sequential data.
2 Related work
Attention mechanism is an important idea in deep learning for sequential data [17]. It allows usage of the whole sequence and doesn’t a model to have a long memory. Instead, at each layer, the model looks at the whole sequence.
The transformer architecture based on attention shows impressive results in many problems related to the processing of sequential data and in particular NLP [5], [9] and computer vision [8].
However, direct application of this mechanism can be prohibitively expensive:
the computational complexity of the vanilla attention is , where is the sequence length.
A quest for more computationally effective attention leaded to numerous ideas explored in reviews [16, 15].
One of the key ideas in this area is to use so-called sparse attention: instead of the whole attention matrix, we drop parts of it.
This mechanism also allows highlighting a specific part of sequences.
One of the problem statements for sequential data is the change point: we want to detect a change of a distribution in a sequence as fast as possible [12].
Accurate solutions for such problems are vital in different areas, including software maintenance [3] and oilgas industry [11].
Simple statistics-based approaches are sufficient in many cases [4].
However, semi-structured data require deep model to provide reasonable quality of solutions ranging from rather simple neural network [6] to more complex workflows [10, 7] and problem statements [14].
For complex multi-step processing of sequences of videos, we still need efficient models that capture the essential properties of data and can detect the change point detection: both in terms of model training and evaluation time and in detection delay in a sequence.
It seems natural to apply the efficient transformers paradigm to such data:
the attention that pays attention to the recent past is expected to meet these efficiency and quality requirements.
3 Problem statement
The solution of this problem with the neural network was investigated in [10]. Its working principle is as follows.
Let a dataset be a set of sequences , where each sequence has the length and corresponding change point is in , if we have a change point in a sequence and otherwise.
Let the random process of length be given, where is an observation at time . The problem is the quickest detection of the true change moment as possible.
Let be predicted probabilities of the change point at a specified time moment for the -th sequence.
Let and be defined as follows:
(1)
(2)
where is a hyperparameter that restricts the length of the
considered part of the sequence for delay loss and .
According to [10] the equation (3) is the lower bound for the expected value of detection delay and
the equation (2) is lower bound for the expected time to false alarm.
As it was shown in paper above, there is a principled differentiable loss function for solving the CPD problem via neural network :
(3)
4 Methods
As there is a principled differentiable loss function for solving the CPD problem, we can teach any model with this loss function.
We want to expand the range of these models, and we start with a model such as a transformer. Also, we apply different masks for the source sequence.
To compare with [10] we use the RNN model as a
baseline.
Intuitively, it seems that if we have only one point of change, we do not need to look at the entire sequence of data, but we can only consider some part of it. For this, we will use different masks for the input sequence.
The mask is a boolean matrix of elements equal to the number of elements in the input sequence. In the place where True or 1 stands, the value is not considered, i.e. the mask covers it.
We have chosen several types of masks:
1.
lower triangular mask — consider only past points, that implies an online working mode. The mask has the following form:
(4)
2.
-diagonal mask — n elements on the diagonal, so we consider right and left neighboring elements. It is some implementation of the ”window” method, see more [18]. The matrix for this mask is
(5)
3.
-diagonal mask plus lower triangular with a side of elements — points from the beginning of the dataset are added to the previous point. It seems that the model based on the initial elements will give the best result, the matrix for this mask is
(6)
4.
1-diagonal mask plus lower triangular with side of n elements — this is almost the same as the previous point, but now we do not want to look at the adjacent points to the current one
We investigate how the attention mechanisms can improve change point detection problems compared to an RNN model.
5 Results
5.1 Data
As the dataset to evaluate our approach, we use sequences of handwritten digits based on generative models trained on MNIST similar to [10].
To generate this dataset, we use sequences from embedding space from one digit to another obtained via Conditional Variational Autoencoder [13] (CVAE). Then we take two points corresponding to a certain pair of digits and also add the points from the line connecting two initial points.
For each sequence, we apply a decoder to get sequence images that closely reflect a corresponding digit.
In the dataset, we put sequences with and without a change point.
Our data consist of 1000 sequences with a length 64.
The dataset is balanced: the number of sequences with and without changes is equal.
5.2 Metrics
We use metrics commonly used for the evaluation of change point detection algorithms [4]: score, Covering and Area under the detection curve (Area) [10].
Some of them are inspired by Image segmentation, as these two problem statements share a lot in common [2].
Better methods have bigger scores and Covering, but smaller Area. We refer an interested reader to the review [4] for a more detailed discussion of the metrics.
score
Covering
Area
RNN-based, CPD loss
RNN-based, BCE loss
Transformer without mask, CPD loss
Transformer without mask, BCE loss
Low-triangular mask, CPD loss
Low-triangular mask, BCE loss
2-diagonal mask, CPD loss
2-diagonal mask, BCE loss
8-diagonal mask, CPD loss
1-diag. + 8-lower-triang., BCE loss
1-diag. + 8-lower-triang., CPD loss
3-diag. + 32-lower-triang., BCE loss
Table 1: Comparison of the performance of different approaches, mean std. The best value for each type of loss are in bold. The second-best value for each type of loss are underlined.
5.3 Main results
We compare methods based on the attention mechanism and transformers with more common approaches for sequential data processing.
Among different attention mechanisms, we consider sequential attention with low triangular attention matrix, diagonal and tri-diagonal attention along.
We present our main results in Table 1. As we see from the results, usage of specific loss with attention improves our results compared to Recurrent Neural Network and Binary Cross-Entropy loss.
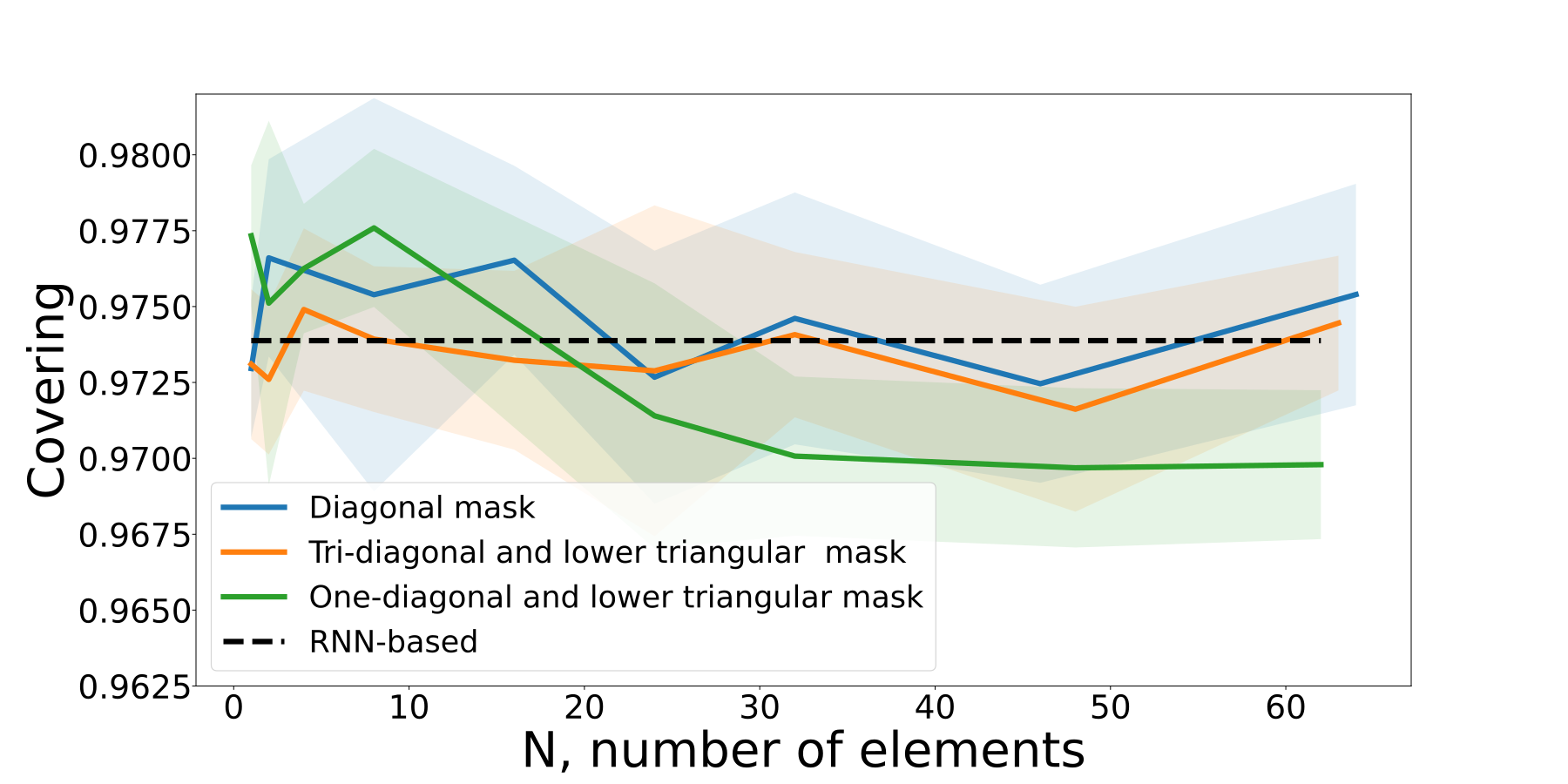
Along with the table, we present figures with a variation of the main hyperparameter of our approach: how many off-diagonal elements we use.
Figures 2 – 6 in Appendix demonstrates the dynamic of the performance of our methods with respect to this hyperparameters.
We consider score, Area under the detection curve and Covering.
All the results for both the table and figures were obtained by averaging over 10 runs. For all metrics, we see an improvement compared to a vanilla RNN approach. We also see that BCE loss is typically less stable than CPD loss. The diagonal mask with lower-triangular seems to perform the best among introduced approaches if the correct window size is used.
6 Acknowledgements
The work of Alexey Zaytsev was supported by the Russian Foundation for Basic Research grant 20-01-00203.
The work of Evgenya Romanenkova was supported by the Russian Science Foundation (project 20-71-10135).
7 Conclusions
We propose a method of change-point detection based on an attention mechanism. We prove that choosing an attention matrix with respect to the nature of the task solve the change point detection problem more efficiently. Choosing any reasonable matrices with a combination of principled loss functions improves results in all metrics. However, the most successful methods are diagonal and diagonal with a small lower-triangular tail. We show that our approach outperforms RNN-based state-of-the-art on up to 15% area under the detection curve, which means faster and accurate predictions.
References
[1]Samaneh Aminikhanghahi and Diane J Cook
“A survey of methods for time series change point detection”
In Knowledge and information systems51.2Springer, 2017, pp. 339–367
[2]Pablo Arbelaez, Michael Maire, Charless Fowlkes and Jitendra Malik
“Contour detection and hierarchical image segmentation”
In IEEE transactions on pattern analysis and machine intelligence33.5IEEE, 2010, pp. 898–916
[3]Alexey Artemov and Evgeny Burnaev
“Detecting performance degradation of software-intensive systems in the presence of trends and long-range dependence”
In 2016 IEEE 16th International Conference on Data Mining Workshops (ICDMW), 2016, pp. 29–36
IEEE
[4]Gerrit JJ Burg and Christopher KI Williams
“An evaluation of change point detection algorithms”
In arXiv:2003.06222, 2020
[5]Ivan Fursov et al.
“A Differentiable Language Model Adversarial Attack on Text Classifiers”
In arXiv:2107.11275, 2021
[6]Mikhail Hushchyn, Kenenbek Arzymatov and Denis Derkach
“Online Neural Networks for Change-Point Detection”
In CoRRabs/2010.01388, 2020
arXiv: https://arxiv.org/abs/2010.01388
[7]Roman Kail, Evgeny Burnaev and Alexey Zaytsev
“Recurrent convolutional neural networks help to predict location of earthquakes”
In IEEE Geoscience and Remote Sensing LettersIEEE, 2021
[8]Salman Khan et al.
“Transformers in vision: A survey”
In arXiv preprint arXiv:2101.01169, 2021
[9]Eduardo Souza Dos Reis et al.
“Transformers aftermath: current research and rising trends”
In Communications of the ACM64.4ACM New York, NY, USA, 2021, pp. 154–163
[10]Evgenia Romanenkova, Alexey Zaytsev, Ramil Zainulin and Matvey Morozov
“Principled change point detection via representation learning”
In arXiv:2106.02602, 2021
[11]Evgeniya Romanenkova et al.
“Real-Time Data-Driven Detection of the Rock-Type Alteration During a Directional Drilling”
In IEEE Geoscience and Remote Sensing Letters17.11, 2020, pp. 1861–1865
DOI: 10.1109/LGRS.2019.2959845
[12]AN Shiryaev
“Stochastic Change-Point Detection Problems”
In Moscow: MCCME (in Russian), 2017
[13]Kihyuk Sohn, Honglak Lee and Xinchen Yan
“Learning structured output representation using deep conditional generative models”
In Advances in neural information processing systems28, 2015, pp. 3483–3491
[14]Waqas Sultani, Chen Chen and Mubarak Shah
“Real-world anomaly detection in surveillance videos”
In Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 6479–6488
[15]Yi Tay, Mostafa Dehghani, Dara Bahri and Donald Metzler
“Efficient transformers: A survey”
In arXiv:2009.06732, 2020
[16]Yi Tay et al.
“Long range arena: A benchmark for efficient transformers”
In arXiv:2011.04006, 2020
[17]Ashish Vaswani et al.
“Attention is all you need”
In Advances in neural information processing systems, 2017, pp. 5998–6008
[18]Yanguang Wang et al.
“Change Point Detection with Mean Shift Based on AUC from Symmetric Sliding Windows”
In Symmetry12, 2020, pp. 599
DOI: 10.3390/sym12040599
Appendix
There are results from variation of the main hyper-parameter of our approach.
Figure 1: Dynamic of covering for different masks size, BCE loss
Figure 2: Dynamic of covering for different masks size, CPD loss
Figure 3: Dynamic of F1-score for different masks size, BCE loss
Figure 4: Dynamic of F1-score for different masks size, CPD loss
Figure 5: Dynamic of area under the detection curve for different masks, BCE loss
Figure 6: Dynamic of area under the detection curve for different masks, CPD loss