Ivar Ekeland, Roger Temam, Jeffrey Dean, David Grove,
Craig Chambers, Kim B. Bruce, and Elisa Bertino
11institutetext: Arizona State University, Tempe AZ 85281, USA,
11email: [email protected], [email protected],
22institutetext: University of California, Los Angeles CA 90095, USA,
22email: [email protected]
Using Reinforcement Learning to Herd a Robotic Swarm to a Target Distribution
Abstract
In this paper, we present a reinforcement learning approach to designing a control policy for a “leader” agent that herds a swarm of “follower” agents, via repulsive interactions, as quickly as possible to a target probability distribution over a strongly connected graph. The leader control policy is a function of the swarm distribution, which evolves over time according to a mean-field model in the form of an ordinary difference equation. The dependence of the policy on agent populations at each graph vertex, rather than on individual agent activity, simplifies the observations required by the leader and enables the control strategy to scale with the number of agents. Two Temporal-Difference learning algorithms, SARSA and Q-Learning, are used to generate the leader control policy based on the follower agent distribution and the leader’s location on the graph. A simulation environment corresponding to a grid graph with 4 vertices was used to train and validate the control policies for follower agent populations ranging from 10 to 1000. Finally, the control policies trained on 100 simulated agents were used to successfully redistribute a physical swarm of 10 small robots to a target distribution among 4 spatial regions.
keywords:
swarm robotics, graph theory, mean-field model, reinforcement learning1 Introduction
We present two Temporal-Difference learning algorithms [1] for generating a control policy that guides a mobile agent, referred to as a leader, to herd a swarm of autonomous follower agents to a target distribution among a small set of states. This leader-follower control approach can be used to redistribute a swarm of low-cost robots with limited capabilities and information using a single robot with sophisticated sensing, localization, computation, and planning capabilities, in scenarios where the leader lacks a model of the swarm dynamics. Such a control strategy is useful for many applications in swarm robotics, including exploration, environmental monitoring, inspection tasks, disaster response, and targeted drug delivery at the micro-nanoscale.
There has been a considerable amount of work on leader-follower multi-agent control schemes in which the leader has an attractive effect on the followers [2, 3]. Several recent works have presented models for herding robotic swarms using leaders that have a repulsive effect on the swarm [4, 5, 6]. Using such models, analytical controllers for herding a swarm have been constructed for the case when there is a single leader [5, 6] and multiple leaders [4]. The controllers designed in these works are not necessarily optimal for a given performance metric. To design optimal control policies for a herding model, the authors in [7] consider a reinforcement learning (RL) approach. While existing herding models are suitable for the objective of confining a swarm to a small region in space, many applications require a swarm to cover an area according to some target probability density. If the robots do not have spatial localization capabilities, then the controllers developed in [2, 3, 4, 5, 6, 7] cannot be applied for such coverage problems. Moreover, these models are not suitable for herding large swarms using RL-based control approaches, since such approaches would not scale well with the number of robots. This loss of scalability is due to the fact that the models describe individual agents, which may not be necessary since robot identities are not important for many swarm applications.
In this paper, we consider a mean-field or macroscopic model that describes the swarm of follower agents as a probability distribution over a graph, which represents the configuration space of each agent. Previous work has utilized similar mean-field models to design a set of control policies that is implemented on each robot in a swarm in order to drive the entire swarm to a target distribution, e.g. for problems in spatial coverage and task allocation [8]. In this prior work, all the robots must be reprogrammed with a new set of control policies if the target distribution is changed. In contrast, our approach can achieve new target swarm distributions via redesign of the control policy of a single leader agent, while the control policies of the swarm agents remain fixed. The follower agents switch stochastically out of their current location on the graph whenever the leader is at their location; in this way, the leader has a “repulsive” effect on the followers. The transition rates out of each location are common to all the followers, and are therefore independent of the agents’ identities. Using the mean-field model, herding objectives for the swarm are framed in terms of the distribution of the followers over the graph. The objective is to compute leader control policies that are functions of the agent distribution, rather than the individual agents’ states, which makes the control policies scalable with the number of agents.
We apply RL-based approaches to the mean-field model to construct leader control policies that minimize the time required for the swarm of follower agents to converge to a user-defined target distribution. The RL-based control policies are not hindered by curse-of-dimensionality issues that arise in classical optimal control approaches. Additionally, RL-based approaches can more easily accommodate the stochastic nature of the follower agent transitions on the graph. There is prior work on RL-based control approaches for mean-field models of swarms in which each agent can localize itself in space and a state-dependent control policy can be assigned to each agent directly [9, 10, 11]. However, to our knowledge, there is no existing work on RL-based approaches applied to mean-field models for herding a swarm using a leader agent. Our approach provides an RL-based framework for designing scalable strategies to control swarms of resource-constrained robots using a single leader robot, and it can be extended to other types of swarm control objectives.
2 Methodology
2.1 Problem Statement
We first define some notation from graph theory and matrix analysis that we use to formally state our problem. We denote by a directed graph with a set of vertices, , and a set of edges, , where if there is an edge from vertex to vertex . We define a source map and a target map for which and whenever . Given a vector , refers to the coordinate value of . For a matrix , refers to the element in the row and column of .
We consider a finite swarm of follower agents and a single leader agent. The locations of the leader and followers evolve on a graph, , where is a finite set of vertices and is a set of edges that define the pairs of vertices between which agents can transition. The vertices in represent a set of spatial locations obtained by partitioning the agents’ environment. We will assume that the graph is strongly connected and that there is a self-edge at every vertex . We assume that the leader agent can count the number of follower agents at each vertex in the graph. The follower agents at a location only decide to move to an adjacent location if the leader agent is currently at location and is in a particular behavioral state. In other words, the presence of the leader repels the followers at the leader’s location. The leader agent does not have a model of the follower agents’ behavior.
The leader agent performs a sequence of transitions from one location (vertex) to another. The leader’s location at time is denoted by . In addition to the spatial state , the leader has a behavioral state at each time , defined as . The location of each follower agent is defined by a discrete-time Markov chain (DTMC) that evolves on the state space according to the conditional probabilities
| (1) |
For each and each such that , is given by
| (2) |
where are positive parameters such that . Additionally, for each , is given by
| (3) |
For each vertex , we define a set of possible actions taken by the leader when it is located at :
| (4) |
The leader transitions between states in according to the conditional probabilities
| (5) |
if , the action taken by the leader at time when it is at vertex , is given by .
The fraction, or empirical distribution, of follower agents that are at location at time is given by , where if and otherwise. Our goal is to learn a policy that navigates the leader between vertices using the actions such that the follower agents are redistributed (“herded”) from their initial empirical distribution among the vertices to a desired empirical distribution at some final time , where is as small as possible. Since the identities of the follower agents are not important, we aim to construct a control policy for the leader that is a function of the current empirical distribution , rather than the individual agent states . However, is not a state variable of the DTMC. In order to treat as the state, we consider the mean-field limit of this quantity as . Let be the simplex of probability densities on . When , the empirical distribution converges to a deterministic quantity , which evolves according to the following mean-field model, a system of difference equations that define the discrete-time Kolmogorov Forward Equation:
| (6) |
where are matrices whose entries are given by
The random variable is related to the solution of the difference equation (6) by the relation .
We formulate an optimization problem that minimizes the number of time steps required for the follower agents to converge to , the target distribution. In this optimization problem, the reward function is defined as
| (7) |
Problem 2.1.
Given a target follower agent distribution , devise a leader control policy that drives the follower agent distribution to , where the final time is as small as possible, by minimizing the total reward . The leader action at time when it is at vertex is defined as for all , where .
2.2 Design of Leader Control Policies using Temporal-Difference Methods
Two Temporal-Difference (TD) learning methods [1], SARSA and Q-Learning, were adapted to generate an optimal leader control policy. These methods’ use of bootstrapping provides the flexibility needed to accommodate the stochastic nature of the follower agents’ transitions between vertices. Additionally, TD methods are model-free approaches, which are suitable for our control objective since the leader does not have a model of the followers’ behavior. We compare the two methods to identify their advantages and disadvantages when applied to our swarm herding problem. Our approach is based on the mean-field model (6) in the sense that the leader learns a control policy using its observations of the population fractions of followers at all vertices in the graph.
Sutton and Barto [1] provide a formulation of the two TD algorithms that we utilize. Let denote the state of the environment, defined later in this section; denote the action set of the leader, defined as the set in Equation (4); and denote the state-action value function. We define and as the learning rate and the discount factor, respectively. The policy used by the leader is determined by a state-action pair . denotes the reward for the implemented policy’s transition from the current to the next state-action pair and is defined in Equation (7). In the SARSA algorithm, an on-policy method, the state-action value function is defined as:
| (8) |
where the update is dependent on the current state-action pair and the next state-action pair determined by enacting the policy. In the Q-Learning algorithm, an off-policy method, the state-action value function is:
| (9) |
Whereas the SARSA algorithm update (8) requires knowing the next action taken by the policy, the Q-learning update (9) does not require this information.
Both algorithms use a discretization of the observed state and represent the state-action value function in tabular form as a multi-dimensional matrix, indexed by the leader actions and states. The state is defined as a vector that contains a discretized form of the population fraction of follower agents at each location and the location of the leader agent. The leader’s spatial state must be taken into account because the leader’s possible actions depend on its current location on the graph. Since the population fractions of follower agents are continuous values, we convert them into discrete integer quantities serving as a discrete function approximation of the continuous fraction populations. Instead of defining as the integer count of followers at location , which could be very large, we reduce the dimensionality of the state space by discretizing the follower population fractions into intervals and scaling them up to integers between 1 and :
| (10) |
For example, suppose . Then a follower population fraction of 0.24 at location would have a corresponding state value . Using a larger value of provides a finer classification of agent populations, but at the cost of increasing the size of the state . Given these definitions, the state vector is defined as:
| (11) |
The state vector contains many states that are inapplicable to the learning process. For example, the state vector for a grid graph with has possible variations, but only are applicable since they satisfy the constraint that the follower population fractions at all vertices must sum up to (note that the sum may differ slightly from due to the rounding used in Equation (10).) The new state is used as the state in the state-action value functions (8) and (9).
3 Simulation Results
An OpenAI Gym environment [12] was created in order to design, simulate, and visualize our leader-based herding control policies [13]. This open source virtual environment can be easily modified to simulate swarm controllers for different numbers of agents and graph vertices, making it a suitable environment for training leader control policies using our model-free approaches. The simulated controllers can then be implemented in physical robot experiments. Figure 1 shows the simulated environment for a scenario with follower agents, represented by the blue symbols, that are herded by a leader, shown as a red circle, over a grid. The OpenAI environment does not store the individual positions of each follower agent within a grid cell; instead, each cell is associated with an agent count. The renderer disperses agents randomly within a cell based on the cell’s current agent count. The agent count for a grid cell is updated whenever an agent enters or leaves the cell according to the DTMC (1), and the environment is re-rendered. Recording the agent counts in each cell rather than their individual positions significantly reduces memory allocation and computational time when training the leader control policy on scenarios with large numbers of agents.
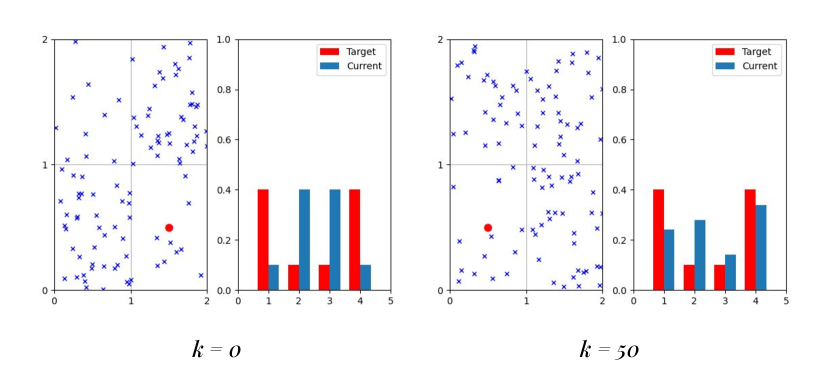
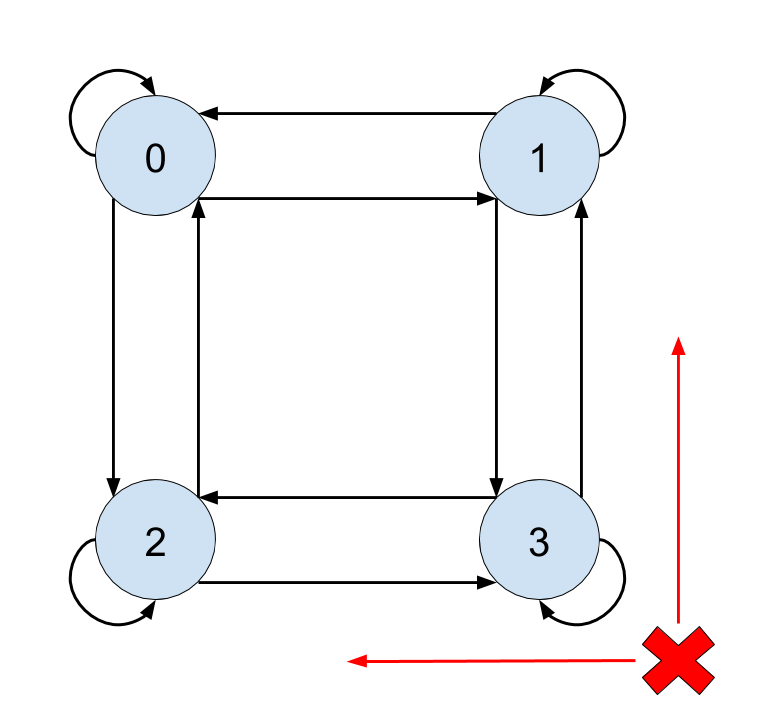
The graph that models the environment in Figure 1, with each vertex of corresponding to a grid cell, was defined as the graph in Figure 2. In the graph, agents transition along edges in either a horizontal or vertical direction, or they can stay at the current vertex. The action set is thus defined as:
| (13) |
Using the graph in Figure 2, we trained and tested a leader control policy for follower agent populations of – at -agent increments. Both the SARSA and Q-Learning paradigms were applied and trained on episodes with iterations each. In every episode, the initial distribution and target distribution of the follower agents were defined as:
| (14) |
| (15) |
The initial leader location, , was randomized to allow many possible permutations of states for training. During training, an episode completes once the distribution of follower agents reaches a specified terminal state. Instead of defining the terminal state as the exact target distribution , which becomes more difficult to reach as increases due to the stochastic nature of the followers’ transitions, we define this state as a distribution that is sufficiently close to . The learning rate and discount factor were set to and , respectively. The follower agent transition rate was defined as the same value for all edges in the graph and was set to , , or . We use the mean squared error (MSE) to measure the difference between the current follower distribution and . The terminal state is reached when the MSE decreases below a threshold value . We trained our algorithms on threshold values of , , , and .
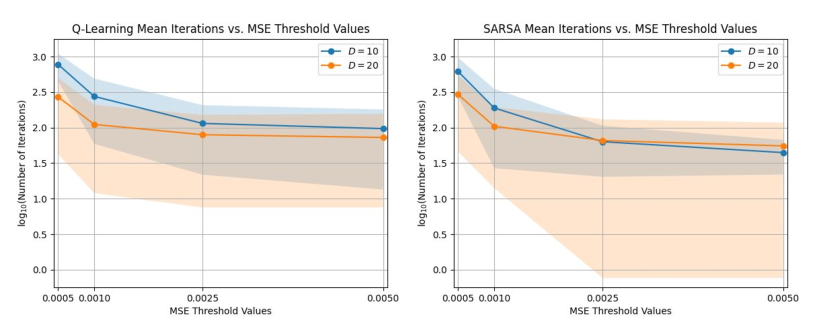
After training the leader control policies on each follower agent population size , the policies were tested on scenarios with the same environment and value of . The policy for each scenario was run times to evaluate its performance. The policies were compared for terminal states that corresponded to the four different MSE threshold values , and were given iterations to converge within the prescribed MSE threshold of the target distribution (15) from the initial distribution (14).
Figure 3 compares the performance of leader control policies that were designed using each TD algorithm as a function of the tested values of . The leader control policies were trained on follower agents, using the parameters and or , and tested in simulations with . The plots show that for both policies, the mean number of iterations required to converge to decreases as the threshold increases for constant , and at low values of , the mean number of iterations decreases when is increased. In addition, as increases, the variance in the number of iterations decreases (note the log scale of the -axis in the plots) or remains approximately constant, except for the case of SARSA.
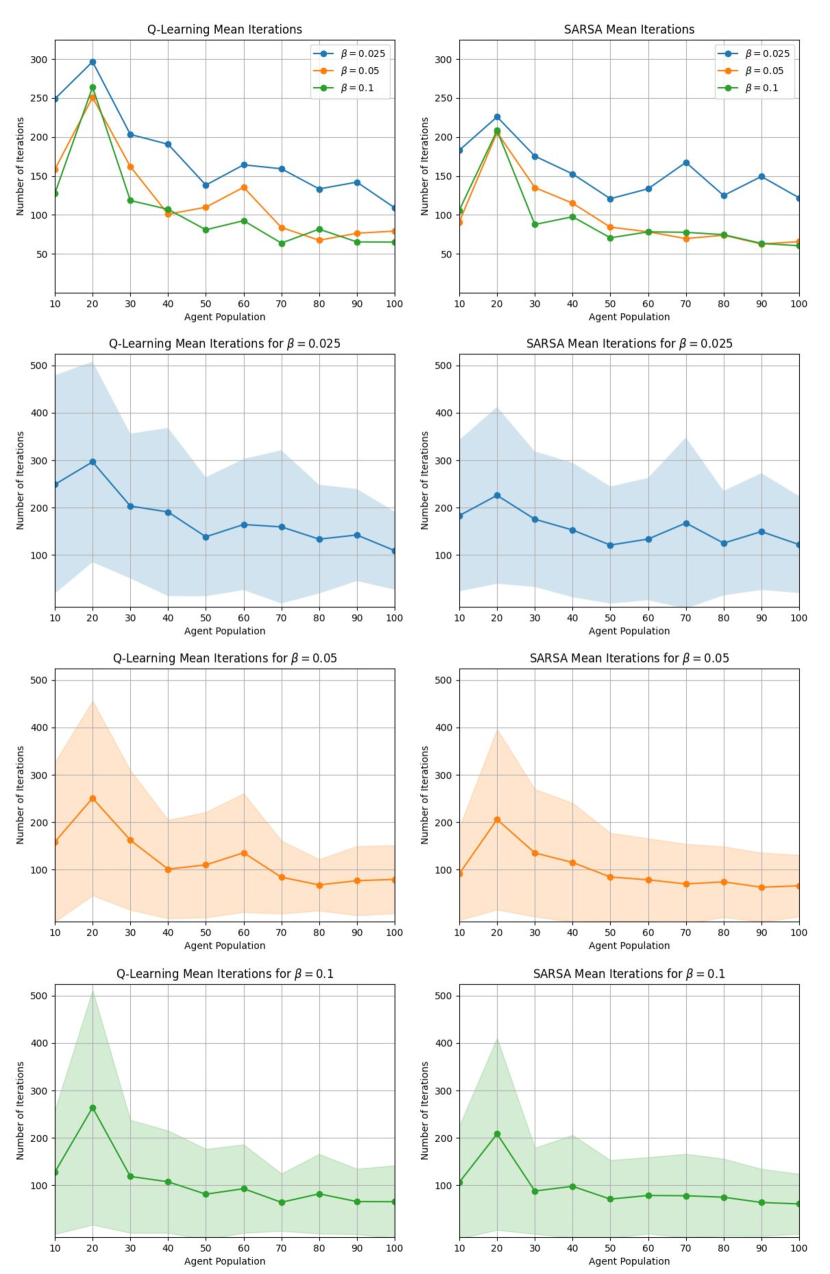
Figure 4 compares the performance of leader control policies that were designed using each algorithm as a function of , where the leader policies were tested in simulations with the same value of that they were trained on. The other parameters used for training were , , and , or . The figures show that raising from to does not significantly affect the mean number of iterations until convergence, while decreasing from to results in a higher mean number of iterations. This effect is evident for both Q-Learning and SARSA trained leader control policies for . Both leader control policies result in similar numbers of iterations for convergence at each agent population size. Therefore, both the Q-Learning and SARSA training algorithms yield comparable performance for these scenarios.
The results in Figure 4 show that as increases above agents, the mean number of iterations until convergence decreases slightly or remains approximately constant for all values and for . Moreover, from Figure 3, we see that MSE threshold values for result in a higher number of iterations than the case in Figure 4. This trend may be due to differences in the magnitude of the smallest possible change in MSE over an iteration relative to the MSE threshold for different values of . For example, for , a similarity in iteration counts for all four MSE thresholds can be attributed to the fact that the change in the MSE due to a transition of one agent, corresponding to a change in population fraction of , is much higher than the four MSE thresholds (i.e., , , , and ). Compare this to the iteration count for , which would have a corresponding change in MSE of ; this quantity is much smaller than and , but not much smaller than and . The iteration counts for are much lower, since is much smaller than all four MSE thresholds.
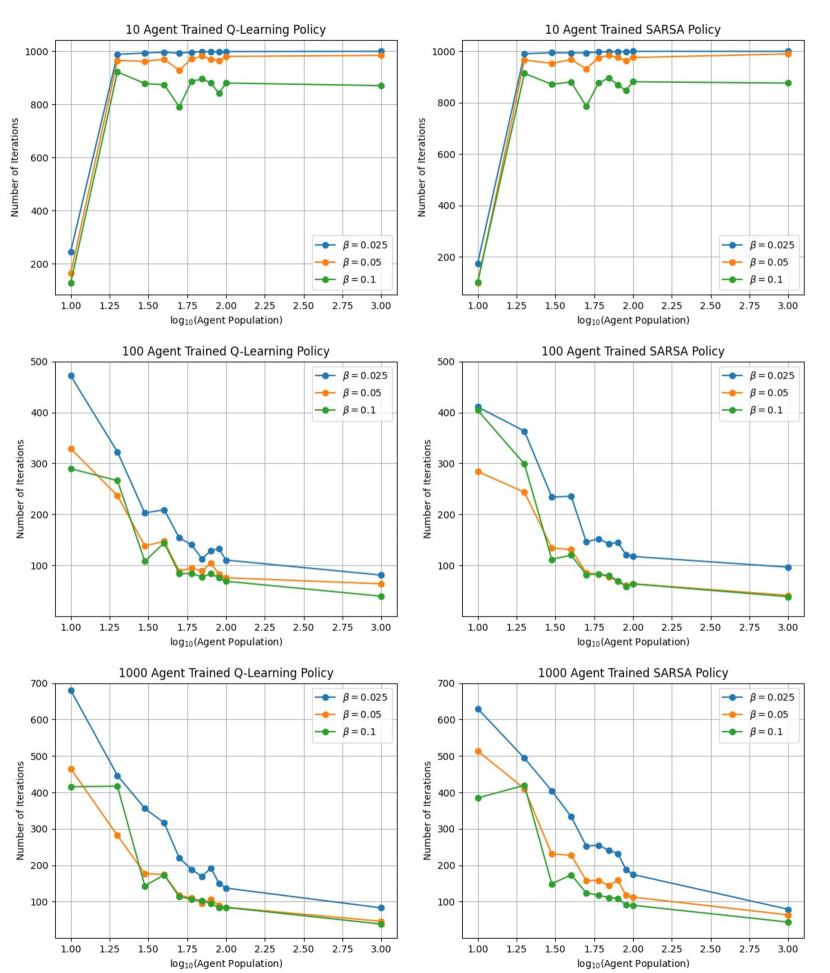
Finally, Figure 5 compares the performance of leader control policies that were designed using each algorithm as a function of , where the leader policies were trained with , , or follower agents and tested in simulations with – (at -agent increments) and agents. This was done to evaluate the robustness of the policies trained on the three agents populations to changes in . The other parameters used for training were , , and , or . As the plots in Figure 5 show, policies trained on the smallest population, , yield an increased mean number of iterations until convergence when applied to populations . The reverse effect is observed, in general, for policies that are trained on higher values of than they are tested on. An exception is the case where the policies are trained on and and tested on , which produce much higher numbers of iterations than the policies that are both trained and tested on . This is likely a result of the large variance, and hence greater uncertainty, in the time evolution of such a small agent population. The lower amount of uncertainty in the time evolution of large swarms may make it easier for leader policies that are trained on large values of to control the distribution of a given follower agent population than policies that are trained on smaller values of . We thus hypothesize that training a leader agent with the mean-field model (6) instead of the DTMC model would lead to improved performance in terms of a lower training time, since the policy would only need to be trained on one value of , and fewer iterations until convergence to the target distribution.
4 Experimental Results
We also conducted experiments to verify that our herding approach is effective in a real-world environment with physical constraints on robot dynamics and inter-robot spacing. Two of the leader control policies that were generated in the simulated environment were tested on a swarm of small differential-drive robots in the Robotarium [14], a remotely accessible swarm robotics testbed that provides an experimental platform for users to validate swarm algorithms and controllers. Experiments are set up in the Robotarium with MATLAB or Python scripts. The robots move to target locations on the testbed surface using a position controller and avoid collisions with one another through the use of barrier certificates [15], a modification to the robots’ controllers that satisfy particular safety constraints. To implement this collision-avoidance strategy, the robots’ positions and orientations in a global coordinate frame are measured from images taken from multiple VICON motion capture cameras.
A video recording of our experiments is shown in [16]. The environment was represented as a grid, as in the simulations, and 10 robots were used as follower agents. The leader agent, shown as the blue circle, and the boundaries of the four grid cells were projected onto the surface of the testbed using an overhead projector. As in the simulations, at each iteration , the leader moves from one grid cell to another depending on the action prescribed by its control policy. Both the SARSA and Q-Learning leader control policies trained with follower agents, , , and a were implemented, and [16] shows the performance of both control policies. In the video, the leader is red if it is executing the Stay action and blue if it is executing any of the other actions in the set (i.e., a movement action). The current iteration and leader action are displayed at the top of the video frames. Actions that display next to them signify a random action as specified in (12). Each control policy was able to achieve the exact target distribution (15). The SARSA method took iterations to reach this distribution, while the Q-Learning method took iterations.
5 Conclusion and Future Work
We have presented two Temporal-Difference learning approaches to designing a leader-follower control policy for herding a swarm of agents as quickly as possible to a target distribution over a graph. We demonstrated the effectiveness of the leader control policy in simulations and physical robot experiments for a range of swarm sizes , illustrating the scalability of the control policy with , and investigated the effect of on the convergence time to the target distribution. However, these approaches do not scale well with the graph size due to the computational limitations of tabular TD approaches and, in particular, our discretization of the system state into population fraction intervals. Our implementation requires a matrix with state-action values to train the leader control policy. For our grid graph with possible leader actions and intervals, this is about values.
To address this issue, our future work focuses on designing leader control policies using the mean-field model rather than the DTMC model for training, as suggested at the end of Section 3. In this approach, the leader policies would be trained on follower agent population fractions that are computed from solutions of the discrete-time mean-field model (6), rather than from discrete numbers of agents that transition between locations according to a DTMC. The leader control policies can also be modified to use function approximators such as neural networks for our training algorithm, allowing for utilization of modern deep reinforcement learning techniques. Neural network function approximators provide a more practical approach than tabular methods to improve the scalability of the leader control policy with graph size, in addition to swarm size. In addition, the control policies could be implemented on a swarm robotic testbed in a decentralized manner, in which each follower robot avoids collisions with other robots based on its local sensor information.
Acknowledgment Many thanks to Dr. Sean Wilson at the Georgia Tech Research Institute for running the robot experiments on the Robotarium.
References
- [1] Richard S Sutton and Andrew G Barto. Reinforcement learning: An introduction. MIT Press, 2018.
- [2] Meng Ji, Giancarlo Ferrari-Trecate, Magnus Egerstedt, and Annalisa Buffa. Containment control in mobile networks. IEEE Transactions on Automatic Control, 53(8):1972–1975, 2008.
- [3] Mehran Mesbahi and Magnus Egerstedt. Graph theoretic methods in multiagent networks, volume 33. Princeton University Press, 2010.
- [4] Alyssa Pierson and Mac Schwager. Controlling noncooperative herds with robotic herders. IEEE Transactions on Robotics, 34(2):517–525, 2017.
- [5] Karthik Elamvazhuthi, Sean Wilson, and Spring Berman. Confinement control of double integrators using partially periodic leader trajectories. In American Control Conference, pages 5537–5544, 2016.
- [6] Aditya A Paranjape, Soon-Jo Chung, Kyunam Kim, and David Hyunchul Shim. Robotic herding of a flock of birds using an unmanned aerial vehicle. IEEE Transactions on Robotics, 34(4):901–915, 2018.
- [7] Clark Kendrick Go, Bryan Lao, Junichiro Yoshimoto, and Kazushi Ikeda. A reinforcement learning approach to the shepherding task using SARSA. In International Joint Conference on Neural Networks, pages 3833–3836, 2016.
- [8] Karthik Elamvazhuthi and Spring Berman. Mean-field models in swarm robotics: A survey. Bioinspiration & Biomimetics, 15(1):015001, 2019.
- [9] Adrian Šošić, Abdelhak M Zoubir, and Heinz Koeppl. Reinforcement learning in a continuum of agents. Swarm Intelligence, 12(1):23–51, 2018.
- [10] Maximilian Hüttenrauch, Sosic Adrian, and Gerhard Neumann. Deep reinforcement learning for swarm systems. Journal of Machine Learning Research, 20(54):1–31, 2019.
- [11] Yaodong Yang, Rui Luo, Minne Li, Ming Zhou, Weinan Zhang, and Jun Wang. Mean field multi-agent reinforcement learning. In International Conference on Machine Learning, pages 5567–5576, 2018.
- [12] Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. OpenAI Gym. arXiv preprint arXiv:1606.01540, 2016.
- [13] Zahi Kakish. Herding OpenAI Gym Environment, 2019. https://github.com/acslaboratory/gym-herding.
- [14] S. Wilson, P. Glotfelter, L. Wang, S. Mayya, G. Notomista, M. Mote, and M. Egerstedt. The Robotarium: Globally impactful opportunities, challenges, and lessons learned in remote-access, distributed control of multirobot systems. IEEE Control Systems Magazine, 40(1):26–44, 2020.
- [15] L. Wang, A. D. Ames, and M. Egerstedt. Safety barrier certificates for collisions-free multirobot systems. IEEE Transactions on Robotics, 33(3):661–674, 2017.
- [16] Z. Kakish, K. Elamvazhuthi, and S. Berman. Using reinforcement learning to herd a robotic swarm to a target distribution, 2020. Autonomous Collective Systems Laboratory YouTube channel, https://youtu.be/py3Pe24YDjE.