Using Random Walks for Iterative Phase Estimation
Abstract
In recent years there has been substantial development in algorithms for quantum phase estimation. In this work we provide a new approach to online Bayesian phase estimation that achieves Heisenberg limited scaling that requires exponentially less classical processing time with the desired error tolerance than existing Bayesian methods. This practically means that we can perform an update in microseconds on a CPU as opposed to milliseconds for existing particle filter methods. Our approach assumes that the prior distribution is Gaussian and exploits the fact, when optimal experiments are chosen, the mean of the prior distribution is given by the position of a random walker whose moves are dictated by the measurement outcomes. We then argue from arguments based on the Fisher information that our algorithm provides a near-optimal analysis of the data. This work shows that online Bayesian inference is practical, efficient and ready for deployment in modern FPGA driven adaptive experiments.
1 Introduction
Phase estimation is widely used throughout quantum information to learn the eigenvalues of unitary operators. This is a critical step in realizing computational speedups from algorithms such as Shor’s algorithm [1], versions of the linear systems algorithm [2] and quantum simulation [3, 4, 5, 6]. Moreover, the eigenvalues of unitary operators can carry information about physical parameters, such that phase estimation is critical in quantum metrology applications as well [7, 8] and similar ideas can be used in Hamiltonian learning protocols as well [9, 10, 11].
One very popular approach to minimizing the quantum resources required for phase estimation is iterative phase estimation [12, 13, 14], in which one repeatedly uses the unitary of interest to write a phase onto a single-qubit register, and then processes the data collected from these measurements using classical resources. The data obtained from each iteration can then be used to determine the next measurement to perform, such that classically adaptive protocols are naturally expressed in the iterative phase estimation framework. Across applications for phase estimation, there is a significant benefit to formulating approaches to iterative phase estimation that allow for adaptivity and data processing with very modest classical resources. For instance, Wiebe and Granade [15] have introduced rejection filtering, an iterative phase estimation algorithm that is modest enough to be compatible with modern experimental control hardware such as field-programmable gate arrays (FPGAs). Recent experimental demonstrations have shown the effectiveness of rejection filtering in modern applications [16].
In this work, we simplify the classical processing requirements still further, providing a new algorithm that uses approximately 250 bits of classical memory between iterations and that is entirely deterministic conditioned on the experimental data record. Our new algorithm is thus uniquely well-suited not only for implementation on FPGAs, but as an application-specific integrated circuit (ASIC) or on tightly memory-bound microcontroller platforms, which are common in certain cryogenic applications where it is desirable to have a small low-power controller located as close as possible to the base plate of the dilution refrigerator for latency purposes despite the limited cooling power available at such stages. The ability to use such simple control hardware in turn significantly reduces the cost required for implementing quantum algorithms and new metrology protocols such as distributed sensors [17] in near term quantum hardware.
2 Review of Bayesian Phase Estimation
Concretely, consider a family of unitary operators for a real parameter and a quantum state such that for all for an unknown real number . We are then interested in performing controlled applications of on a copy of the state in order to learn .
There are many ways that the learning problem for phase estimation can be formalized. While the most commonly used methods have historically estimated the phase in a bit-by-bit fashion [18], Bayesian approaches to learning have recently gained in popularity because of their robustness and their statistical efficiency [15]. The idea behind such methods is to quantify the uncertainty in via a prior probability distribution, . Then conditioned on measuring an outcome , the probability distribution describing the uncertainty in conditioned on the measurement is
| (1) |
where is a normalization factor and is the likelihood of the experiment reproducing the observation given that the phase was the true eigenphase of .
The art of Bayesian phase estimation is then to choose experiments in such a way to minimize the resources needed to reduce the uncertainty in an estimate of , given by the estimator [13, 15]. Adaptive versions of Bayesian phase estimation are known to achieve Heisenberg limited scaling and come close to saturating lower bounds on the uncertainty in as a function of experimental time or number of measurements [7, 15]. A complication that arises in choosing a Bayesian method is that each such method requires different amounts of experimental time, total number of measurements, classical memory and processing time and robustness to experimental imperfections. The latter two are especially important for present-day experiments where any form of Bayesian inference that requires classical processing time that is comparable to the coherence time (which is often on the order of microseconds). To this end, finding simple phase estimation methods that are robust, efficient and can be executed within a timescale of hundreds of nanoseconds remains an important problem.
The likelihood function used in iterative phase estimation is given by the quantum circuit provided in Section 2. Computing the probability of observing as an outcome in the circuit shown in Section 2 gives us the likelihood function for phase estimation,
| (2) |
Equipped with a likelihood function, we can thus reason about the posterior probability for a datum by using Bayesian inference.
In this setting we assume that we are able to apply the unitary for any real-valued . This assumption is eminently reasonable in quantum simulation wherein, up to small errors on the order of the simulation error incurred in implementing , such unitaries can be constructed within sufficiently small error. In settings where can only can only be implemented directly for integer valued , an evolution can be closely approximated using a quantum singular value transformation that is an -approximation to using applications of [19] provided that , which is typical for applications in quantum simulation. These observations motivate our assumption that is a continuous function of .
A major challenge that we face when trying to numerically implement Bayesian phase estimation arises from the fact that we need to discretize the posterior distribution to ensure that an update to the distribution can be made in finite time. Fortunately, unlike many other problems in Bayesian inference, the curse of dimensionality does not usually appear because the prior distribution maps to . Three natural approaches emerge when trying to model the posterior distribution are Sequential Monte-Carlo, Grids and Gaussian processes.
Sequential Monte-Carlo is a general approach to Bayesian inference that approximates the posterior distribution as a sum of Dirac-delta functions: for a set of phases . As the posterior distribution is updated the are moved through a resampler to allow the distribution to continue to capture the low-order moments of the distribution even as the learning process excludes an exponentially growing fraction of the original prior distribution. These Sequential-Monte-Carlo approaches been a workhorse for both phase estimation and also Hamiltonian learning: [16, 20]. However, for multimodal distributions these methods can fail and since for most applications, this means that the classical memory requirements of storing the posterior distribution can be exponentially worse than one may expect from its contemporaries. This makes such approaches less well suited for memory limited environments and motivated the development of rejection sampling [15] PE.
3 Random Walk Phase Estimation
The central difference between our approach and most other Bayesian methods that have been proposed is that our method is entirely deterministic. Specifically, the posterior mean (which we use as our estimate of the true eigenphase) shifts left or right upon collection of each datum by a fixed amount that depends only on the experimental outcome. Thus the trajectory that our estimate of the eigenphase takes as the experiment proceeds follows a random walk with exponentially shrinking stepsize. This simplicity allows us to not only store an approximation to the posterior distribution using shockingly little memory; it also only uses basic arithmetic that can be performed within the coherence times of modern quantum devices.
Rather than performing exact Bayesian inference, which is not efficient because the memory required grows exponentially with the number of bits of precision needed, we use a form of approximate Bayesian inference. In particular, we assume that the prior distribution is Gaussian at each step:
| (3) |
Such priors can be efficiently represented because they are only a function of and . Unfortunately, the conjugate priors for (missing) 2 are not Gaussian which means that the posterior distribution is not Gaussian:
| (4) |
However, for most experiments that we consider the posterior distribution will be unimodal and thus the majority of the probability mass will be given by the first two moments of the distribution. This justifies the following approximation,
| (5) |
where and are chosen to match the posterior mean and posterior standard deviation. Specifically,
and similarly
Here, we will take as an approximation that the prior distribution is a Gaussian distribution at each step, and thus the prior can be characterized by its mean and variance . The Bayes update then consists of finding the updated mean and updated variance , which we can then use as the prior distribution at the next step. For the phase estimation likelihood and under the assumption of prior Gaussianity, we can do this explicitly. In calculating the update, we assume without loss of generality that under the prior, and ; the general case is obtained from this case by the standard location–scale transformation. We will express our update rule explicitly without the use of rescaling at the end of our derivation. Without further ado, then, the rescaled update rule is given by
| (6a) | ||||
| (6b) | ||||
where .
Since the posterior variance describes the error that we should expect we will incur in estimating with the currently available observations, we can then choose and to minimize the posterior variance and hence minimize the errors that we will incur. The posterior variance is minimized for both at and , such that we can specialize (missing) 6 at these values to obtain a simpler update rule,
| (7a) | ||||
| (7b) | ||||
In this way, we can derive the particle guess heuristic (PGH) of Wiebe et al. [9] and Wiebe et al. [20] for the special case of phase estimation with a Gaussian conjugate prior. In particular, the PGH selects each new experiment by drawing two samples and from the current posterior, then choosing and , such that minimizing (missing) 6 agrees with the PGH in expectation over and .
Critically, the variance update in (missing) 7 does not depend on which datum we observe; the reduction in variance at each step is wholly deterministic. Similarly, the mean shifts by the same amount at each step, such that the only dependence on the data of the Gaussian approximation to the posterior distribution is through which direction the mean shifts at each observation. We can thus think of the Gaussian approximation as yielding a random walk that is damped towards the true value of . This leads to two observations:
-
1.
The update rule for the position of the posterior Gaussian distribution is translationally invariant and scale invariant.
-
2.
The update rule for the posterior variance is scale invariant.
Following this identification, we obtain Algorithm 1, which exploits these invariances in the approximate posterior density to render the inference step computationally trivial and therefore suitable for rapid execution in both ASICs and FPGAs.





Algorithm 1 can fail to provide an inaccurate estimate of in two different ways. First, that the mean can only shift by fixed amount at each step implies that the walk on can not go further than
| (8) |
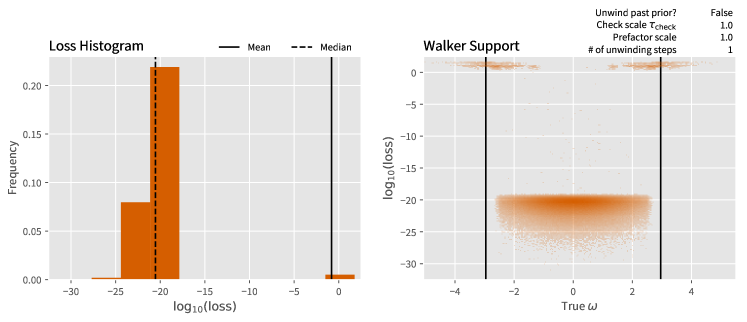
away from its initial position. Assuming and correctly describe the true probability distribution from which are chosen, this corresponds to a failure probability of 0.3%. If we take a prior that is too “tight” by a factor of about 20% (corresponding to a single step of the algorithm), then the failure probability due to finite support of the random walk can be as large as 1.8%. Thankfully, this is an easy failure modality to address, in that we can use an initial prior distribution with an artificially wider variance than our actual prior. We confirm this intuition in Figure 2 wherein we see that these failures tend to lead to rare events where improbable sequences of measurements that causes the mean error to be much larger than the median error due to rare but significant deviations from the true value.
The other failure modality is more severe, in that the Gaussian approximation itself can fail. By contrast to rejection filtering and other such approaches, in random walk phase estimation, we do not choose the variance based on the data itself, but based on an offline analytic computation. Thus, we must have a way to correct for approximation failures. We propose to do this by unwinding data records, returning to an earlier state of the random walk algorithm. In particular, since the data record uniquely describes the entire path of a random walker, we can step backwards along the history of a random walk.
To determine when we should unwind in this fashion, we will perform additional measurements whose outcomes we can accurately predict if the approximation is still accurate. Choosing and for a scale parameter , we obtain that the probability of a 0 outcome is
| (9a) | ||||
| (9b) | ||||
where is assumed to be the normal distribution with mean and variance as per the Gaussianity assumption. For , this corresponds to a false negative rate (that is, inferring the approximation has failed when it has not) of approximately , while gives a false negative rate of . The key idea behind this is to use a low-cost consistency check to determine whether the Gaussian assumptions for the posterior distribution still hold and if they fail then we revert the random walk until the consistency check passes. We list the unwinding together with the original random walk in Algorithm 2.
Notably, both the consistency check data and the unwound data are still useful data. In situations where the data can be efficiently recorded for later use, the entire data record including all unwound data and consistency checks may be used in postprocessing to verify that the estimate derived from the random walk is feasible. In the numerical results presented in Section 4, we use the example of particle filtering to perform postprocessing [23], using the QInfer software library [24].
4 Numerical Results
The data given in Figure 2 provides an indication of the performance of RWPE for typical phase estimation experiments. We find from the data provided that RWPE works extremely well over the trials considered. Specifically, we take our initial value of to be Gaussian distributed according to the initial prior of the distribution. Note that the data as seen from the true distribution is not distributed via a circular distribution but rather a linear Gaussian distribution. While this creates some bias in the output angles in principle, the distribution is broad enough that it approximates a uniform distribution here.
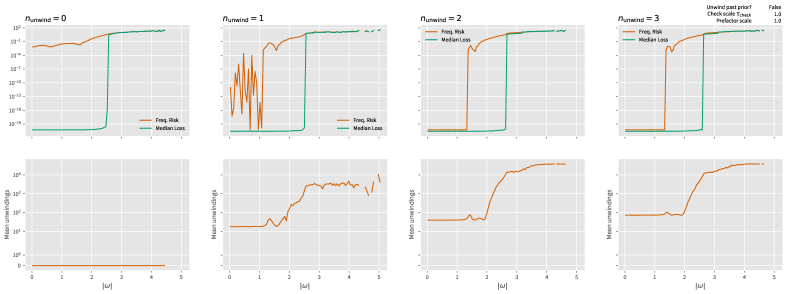
More concretely, we see that for experiments consisting of at most accepted steps for the random walk (and a maximum of total steps) that the median loss for RWPE is low. Specifically, it is on the order of which corresponds to digits of accuracy. Also, as a point of comparison the Heisenberg limit for the phase observed is [7]. We find from RWPE that the median performance is close to the Heisenberg limit, specifically the median is also on the order of ; however, a direct comparison to the Heisenberg limit may not be fully appropriate as the definition is usually formally given in terms of the Holevo variance rather than the median deviation. These differences are apparent in the mean, where we find that the distribution of errors in Figure 2 has losses that are on the order of with non-negligible frequency for the case where no unwinding steps are taken. The impact of this is severely limited by taking one unwinding step; however, we see that for the examples considered a single case of failure (which does not appear in the histogram at the scale presented) causes the mean error to be substantial. Despite the median being small, the large mean errors in both cases suggest that we formally are not Hesienberg limited. In contrast, two unwinding steps were found to completely eliminate these issues and the mean loss was observed to shrink to , which yields a variance that is within less than an order of magnitude of the Heisenberg limit for these experiments.
The cause of many of these failures can be seen in the support of the errors over the true value of . If no unwinding is performed then the mean-square error is on the order unity for true frequencies that are close to or . This is because the update rules for the random walk can only explore according to (8). The ability to unwind our variance past the initial prior allows the unwinding algorithm to deal with this.
We further see from the histogram of the quadratic loss for the reported eigenphase versus the actual eigenphase in Figure 3 that the median performance of RWPE outperforms the results seen by Liu-West when applied to the same dataset. We perform this part in order to ensure that even the data used in the consistency check is provided to both methods. For the case where the check timescale is small, , we see that the median quadratic loss is nearly two orders of magnitude smaller than Liu-West using particles. For the case of the larger time used for the consistency check, , we find that there is a separation between the two on the order of nearly orders of magnitude. The increased separation between the performance is likely because of the larger timesteps used in the consistency check step leading to multi-modal distributions in the particle filter which cannot be well approximated using the Liu-West resampler.
In both cases the mean errors are observed to be large. This is expected as when a failure occurs the error tends to be on the order of unity, which means that when the median is on the order of that rare errors can dominate the mean, however they do not dominate the median. These problems can be mitigated by increasing the number of rewinding steps or increasing the number of particles used in the particle filter approximations.
Here particles are used in the particle filters because previous work [15] found that this tended to yield stable results while also allowing updates to be performed on a scale of tens of milliseconds on a single-core CPU. In contrast, RWPE requires time on the order of a microsecond to perform an update on a single core CPU. The difference between the two processing times means that RWPE is vastly better suited for online setting in superconducting hardware where the coherence times are often on the order of s.




The final question that we wish to probe numerically is whether the algorithm is capable of achieving Heisenberg limited scaling in practice. We defer discussion about the optimal constants for the scaling to the following section. Specifically, for Heisenbert limited scaling we need to have that the Holevo variance scales like the inverse of the square of the total simulation time. The Holevo variance corresponds to the ordinary variance for narrow distributions that have negligible overlap with the branch cut chosen for the eigenphases returned by phase estimation.
We examine this scaling in Figure 4. We find that for zero and one unwinding step, that while the median error is small, the mean error does not shrink as the number of iterations grows. In contrast, we see clear evidence (a line of zero slope) for Heisenberg limited scaling if we use two or three unwinding steps. This suggests that the processing technique that RWPE is capable of achieving Heisenberg limited scaling even in an online setting.
5 Decision Theoretic Bounds
In this work, we have expressed our algorithm as approximating the Bayesian mean estimator (BME) . This choice is motivated by a decision theoretic argument, in which we penalize an estimator by a particular amount for returning a particular estimate when the true value of the parameter of interest is . A function which we use to assign such penalties is called a loss function; as described in the main body, the quadratic loss is a particularly useful and broadly applicable loss function. We will drop the subscript when it is clear from context that we are referring to this choice.
In any case, once we have adopted such a loss function, we can then reason about the average loss incurred by a particular estimator. In particular, the Bayes risk is defined as the expected loss over all hypotheses drawn from a prior and over all data sets . That is,
| (10) |
The celebrated result of Banerjee et al. [25] then provides that the BME minimizes the Bayes risk for any loss function of the form for a convex function . This holds for the quadratic loss, as well as a number of other important examples such as the Kullback–Leibler divergence.
Having thus argued that our approach is approximately optimal for the Bayes risk, we are then interested in how well our algorithm approximately achieves the Bayes risk. To address this, we note that the van Trees inequality [26] lower bounds the Bayes risk achievable by any estimator as
| (11) |
where is the usual Fisher information, and where is a correction for the information provided by the prior distribution . Thus, the van Trees inequality can be thought of as a correction to the traditional Cramér–Rao bound for the effects of prior information [27]. Whereas the Cramér–Rao bound only holds for unbiased estimators, the BME is asymptotically unbiased but may in general be biased for a finite-sized data set.
In the case that is a normal distribution , however, the correction for the bias introduced by the prior distribution is identically zero, such that the van Trees and Cramér–Rao bounds coincide. More generally, the set of true values for which the Cramér–Rao bound can be violated by a biased estimator approaches Lebesgue measure zero asymptotically with the number of observations [28], such that the Cramér–Rao bound is useful for characterizing the performance of biased estimators such as the BME.
Applying this bound to Algorithm 2, we note that the experiments chosen by the algorithm are deterministic unless the unwinding step proceeds backwards from the initial prior. Thus, the Cramér–Rao and hence the van Trees inequalities can be calculated explicitly for the particular experimental choices made by Algorithm 2, yielding that
| (12) |
where we have used that [29]. For , . This corresponds to the mean-square error observed in Figure 2 for the case where unwinding steps is used and thus RWPE performs a nearly optimal analysis of the data using on the order of a millisecond of total processing time.
Critically, the van Trees inequality holds in expectation, such that the loss in any particular experiment can be significantly better than (missing) 12. Moreover, the consistency checks utilized by Algorithm 2 provide additional data not included in the bound given by (missing) 12, such that our algorithm violate the van Trees inequality evaluated only at the accepted measurement results. In that sense, our algorithm can be thought of as a heuristic for importance sampling from amongst the data, such that the usual discussions of optimality and postselection apply [29, 30].
6 Conclusion
To conclude, our work has shown a new approach to adaptive Bayesian phase estimation that uses Gaussian processes coupled with an unwinding rule to improve the stability of the learning process. Our method requires a constant amount of memory to perform the analysis and is further Heisenberg limited. Further, the fact that a constant application needs to be performed at every step in the process means that it is trivial to implement the updates to the prior distribution here using an FPGA without resorting to a lookup table. This makes our approach arguably the best known Heisenberg-limited approach for quantum phase estimation on near-term experiments wherein latency may be a concern and limitations due to heating power proves a bottleneck. Specifically, we find that our approach to phase estimation requires bits of memory to perform phase estimation within error epsilon and requires gate operations to perform the phase estimation assuming a constant number of unwinding steps are needed if single-precision data types are used. In contrast, Bayesian phase estimation using SMC requires arithmetic operations and cosine evaluations to perform phase estimation [31]. This gives our approach a substantial advantage in classical time and space complexity relative to its classical brethren.
Important applications of these ideas include not only quantum phase estimation for algorithmic applications but also metrology applications and further these ideas are sufficiently cost effective that in some platforms with slow quantum operations, they could be used to assist in adaptive measurement of qubits or other quantum systems. Further, while this work focuses on applications within the quantum domain, similar considerations also apply outside of this setting and the ability to do adaptive inference in memory limited environment may have further applications in broader settings such as with autonomous drones or in control engineering. Regardless, the ideas behind this work show that adaptive Bayesian inference need not be expensive and through the use of clever heuristics can be brought within the reach of even the most modest control hardware.
References
- Shor [1994] P. W. Shor, “Algorithms for quantum computation: discrete logarithms and factoring,” in Proceedings 35th annual symposium on foundations of computer science (Ieee, 1994) pp. 124–134.
- Harrow et al. [2009] A. W. Harrow, A. Hassidim, and S. Lloyd, “Quantum algorithm for linear systems of equations,” Physical review letters 103, 150502 (2009).
- Reiher et al. [2017] M. Reiher, N. Wiebe, K. M. Svore, D. Wecker, and M. Troyer, “Elucidating reaction mechanisms on quantum computers,” Proceedings of the national academy of sciences 114, 7555 (2017).
- Abrams and Lloyd [1997] D. S. Abrams and S. Lloyd, “Simulation of many-body fermi systems on a universal quantum computer,” Physical Review Letters 79, 2586 (1997).
- von Burg et al. [2021] V. von Burg, G. H. Low, T. Häner, D. S. Steiger, M. Reiher, M. Roetteler, and M. Troyer, “Quantum computing enhanced computational catalysis,” Physical Review Research 3, 033055 (2021).
- Su et al. [2021] Y. Su, D. W. Berry, N. Wiebe, N. Rubin, and R. Babbush, “Fault-tolerant quantum simulations of chemistry in first quantization,” PRX Quantum 2, 040332 (2021).
- Berry et al. [2001] D. W. Berry, H. M. Wiseman, and J. K. Breslin, “Optimal input states and feedback for interferometric phase estimation,” Physical Review A 63, 053804 (2001).
- Hentschel and Sanders [2010] A. Hentschel and B. C. Sanders, “Machine Learning for Precise Quantum Measurement,” Physical Review Letters 104, 063603 (2010).
- Wiebe et al. [2014] N. Wiebe, C. Granade, C. Ferrie, and D. G. Cory, “Hamiltonian learning and certification using quantum resources,” Physical Review Letters 112, 190501 (2014).
- Zintchenko and Wiebe [2016] I. Zintchenko and N. Wiebe, “Randomized gap and amplitude estimation,” Physical Review A 93, 062306 (2016).
- Wang et al. [2017] J. Wang, S. Paesani, R. Santagati, S. Knauer, A. A. Gentile, N. Wiebe, M. Petruzzella, J. L. O’Brien, J. G. Rarity, A. Laing, et al., “Experimental quantum hamiltonian learning,” Nature Physics 13, 551 (2017).
- Kitaev et al. [2002] A. Y. Kitaev, A. Shen, M. N. Vyalyi, and M. N. Vyalyi, Classical and quantum computation, 47 (American Mathematical Soc., 2002).
- Svore et al. [2013] K. M. Svore, M. B. Hastings, and M. Freedman, “Faster phase estimation,” arXiv:1304.0741 (2013).
- Kimmel et al. [2015] S. Kimmel, G. H. Low, and T. J. Yoder, “Robust calibration of a universal single-qubit gate set via robust phase estimation,” Physical Review A 92, 062315 (2015).
- Wiebe and Granade [2016] N. Wiebe and C. Granade, “Efficient Bayesian phase estimation,” Phys. Rev. Lett. 117, 010503 (2016).
- Paesani et al. [2017] S. Paesani, A. A. Gentile, R. Santagati, J. Wang, N. Wiebe, D. P. Tew, J. L. O’Brien, and M. G. Thompson, “Experimental Bayesian Quantum Phase Estimation on a Silicon Photonic Chip,” Physical Review Letters 118, 100503 (2017).
- Eldredge et al. [2016] Z. Eldredge, M. Foss-Feig, S. L. Rolston, and A. V. Gorshkov, “Optimal and secure measurement protocols for quantum sensor networks,” arXiv:1607.04646 [quant-ph] (2016), arXiv: 1607.04646.
- Kitaev [1995] A. Y. Kitaev, “Quantum measurements and the Abelian stabilizer problem,” arXiv:quant-ph/9511026 (1995), quant-ph/9511026 .
- Gilyén et al. [2019] A. Gilyén, Y. Su, G. H. Low, and N. Wiebe, “Quantum singular value transformation and beyond: exponential improvements for quantum matrix arithmetics,” in Proceedings of the 51st Annual ACM SIGACT Symposium on Theory of Computing (2019) pp. 193–204.
- Wiebe et al. [2015] N. Wiebe, C. Granade, and D. G. Cory, “Quantum bootstrapping via compressed quantum Hamiltonian learning,” New Journal of Physics 17, 022005 (2015).
- Tipireddy and Wiebe [2020] R. Tipireddy and N. Wiebe, “Bayesian phase estimation with adaptive grid refinement,” arXiv preprint arXiv:2009.07898 (2020).
- Lumino et al. [2018] A. Lumino, E. Polino, A. S. Rab, G. Milani, N. Spagnolo, N. Wiebe, and F. Sciarrino, “Experimental phase estimation enhanced by machine learning,” Physical Review Applied 10, 044033 (2018).
- Doucet and Johansen [2011] A. Doucet and A. M. Johansen, A Tutorial on Particle Filtering and Smoothing: Fifteen Years Later (2011).
- Granade et al. [2017] C. Granade, C. Ferrie, I. Hincks, S. Casagrande, T. Alexander, J. Gross, M. Kononenko, and Y. Sanders, “QInfer: Statistical inference software for quantum applications,” Quantum 1, 5 (2017).
- Banerjee et al. [2005] A. Banerjee, X. Guo, and H. Wang, “On the optimality of conditional expectation as a Bregman predictor,” IEEE Transactions on Information Theory 51, 2664 (2005).
- Gill and Levit [1995] R. D. Gill and B. Y. Levit, “Applications of the van Trees inequality: A Bayesian Cramér-Rao bound,” Bernoulli 1, 59 (1995).
- Cover and Thomas [1991] T. M. Cover and J. A. Thomas, “Information theory and statistics,” Elements of information theory 1, 279 (1991).
- Opper [1998] M. Opper, “On-line learning in neural networks,” (Cambridge University Press, New York, NY, USA, 1998) pp. 363–378.
- Ferrie et al. [2013] C. Ferrie, C. E. Granade, and D. G. Cory, “How to best sample a periodic probability distribution, or on the accuracy of Hamiltonian finding strategies,” Quantum Information Processing 12, 611 (2013).
- Combes et al. [2014] J. Combes, C. Ferrie, Z. Jiang, and C. M. Caves, “Quantum limits on postselected, probabilistic quantum metrology,” Physical Review A 89, 052117 (2014).
- Granade et al. [2012] C. E. Granade, C. Ferrie, N. Wiebe, and D. G. Cory, “Robust online hamiltonian learning,” New Journal of Physics 14, 103013 (2012).
Appendix A Unwinding Past the Initial Prior
In Figure 2, we presented the results of using Algorithm 2 with unwinding steps that can continue backwards past the initial prior. Effectively, unwinding past the initial prior automates interventions such as those used by rejection filtering PE [15] by allowing RWPE to explore hypothesis that are considered improbable under the initial prior distribution.
In this Appendix, we underscore that this rule is critical to allow the random walk to exceed the finite constraints of the basic walk presented Algorithm 1 by repeating the previous analysis with unwinding on actual data only. That is, in the results presented within Figure 5, if an unwinding step would pop an empty stack , then the unwinding step is aborted instead.


We note that the constrained unwinding, while still an improvement over the initial version of Algorithm 1, does not adequately deal with the effects of the finite support of the basic walk. This observation is underscored by the results presented in Figure 6, where we consider the frequentist risk rather than the traditional Bayes risk. Concretely, the frequentist risk is defined as the average loss that incurred by an estimation when the true value of is fixed, . We then observe that without allowing the unwinding step to proceed backwards from the initial prior, the frequentist risk suddenly worsens by approximately when the finite extent of the random walk begins to dominate.
Constrained Unwinding
Unwinding Past Initial Prior

By contrast, the frequentist risk for RWPE with unwinding of at least two steps past the initial prior is much more flat, representing that the risk remains acceptable across the full range of valid hypotheses.