Using POMDP-based Approach to Address Uncertainty-Aware Adaptation for Self-Protecting Software
Abstract
The threats posed by evolving cyberattacks have led to increased research related to software systems that can self-protect. One topic in this domain is Moving Target Defense (MTD), which changes software characteristics in the protected system to make it harder for attackers to exploit vulnerabilities. However, MTD implementation and deployment are often impacted by run-time uncertainties, and existing MTD decision-making solutions have neglected uncertainty in model parameters and lack self-adaptation. This paper aims to address this gap by proposing an approach for an uncertainty-aware and self-adaptive MTD decision engine based on Partially Observable Markov Decision Process and Bayesian Learning techniques. The proposed approach considers uncertainty in both state and model parameters; thus, it has the potential to better capture environmental variability and improve defense strategies. A preliminary study is presented to highlight the potential effectiveness and challenges of the proposed approach.
Index Terms:
self-protection, moving target defense, uncertainty-aware, runtime modeling, decision-makingI Introduction
As cyberattacks become more sophisticated and widespread, the need for effective security measures to defend against these attacks becomes increasingly important. Self-Protecting Software (SPS) [1] is an important topic of research in the field of cybersecurity and software engineering, as it has the potential to significantly enhance the security and resilience of software systems against a wide range of threats and vulnerabilities. One approach to realizing SPS is Moving Target Defense (MTD) [1, 2], which involves continuously altering the characteristics of a system in order to make it more difficult for an attacker to exploit vulnerabilities or predict the system’s behaviour. However, implementing MTDs can be challenging, as it requires the ability to continuously adapt the defense to the changing circumstances of the attack, and do so in a cost-effective manner that does not disrupt normal system operation. Moreover, the deployment of MTD techniques is often subject to run-time uncertainties that can affect their effectiveness. These uncertainties may include (i) incomplete knowledge of the true state of the environment, (ii) changes in the effectiveness of security countermeasures in the environment (e.g. zero-day attacks), and (iii) variations in the number of distinct attacker groups targeting a given system.
Existing model-based solutions for MTD decision-making have often overlooked the impact of model parameter uncertainty and lack self-adaptation in the face of these run-time uncertainties. Therefore, the main goal of the proposed research is to address this deficiency and to improve the uncertainty-awareness and self-adaptation of MTD decision-making. To achieve this goal, we propose solutions based on Partially Observable Markov Decision Process (POMDP) [3, 4, 5, 6] to quantify decision-making uncertainties and to develop an uncertainty-aware MTD decision engine. The resulting decision engine will be able to adapt to dynamic environments with various unknowns. By taking into account the uncertainty in the model parameters, the proposed approach aims to better (i) capture the inherent variability and complexity of the operating environment, and (ii) better coordinate reliable and effective defense strategies.
II Research Motivation
II-A Moving Target Defense
The basic axiom of MTD techniques is that it is impossible for defenders to provide complete and perfect security for a given software system [2, 7]. Therefore, MTD techniques can be defined as cybersecurity techniques that continuously alter the protected system’s attack surfaces and configurations in order to increase the effort required to exploit the system’s vulnerabilities [2, 8]. Here, the term attack surface is defined as the set of ways in which an attacker can enter the system and potentially cause damage. A graphical example of this idea is shown in Figure 1. Altering the attack surface of the protected system can be achieved by introducing heterogeneity, dynamicity, and non-deterministic behaviour [1]. Some examples of this include shuffling network addresses, rotating encryption keys, or randomly modifying system configurations.

MTD can be used in a variety of contexts, such as individual devices and networked systems. However, there are also some challenges to using MTD. One of the main challenges is that implementing and incorporating MTD can be complex and time-consuming, as it requires careful planning to ensure that the protected system remains functional and secure while it is continuously being altered. It is important to carefully consider the potential benefits and drawbacks of MTD before deploying it in the operating environment. An example of a potential drawback in MTDs is the addition of new threats when the attack surface is changed (as shown in Fig 1.) Examples of other overheads when deploying MTDs include increased memory usage, decreased throughput, operational costs, etc. [2, 8].
II-B Partially Observable Markov Decision Process
POMDP is a mathematical framework used to model sequential decision-making problems in which an agent must make decisions based on incomplete information about the state of the environment [3, 4]. A POMDP problem is defined by a set of states, actions, observations, a transition function, an observation function, and a reward function [3, 4]. In solving a POMDP problem, the objective is to learn an optimal policy, which is a mapping from states to actions, that will maximize the expected cumulative reward over time.
A key challenge in solving POMDPs is dealing with state uncertainty due to incomplete knowledge of the true state of the system. To address this challenge, a belief state, which is a probability distribution over states of the environment, is used to summarize the agent’s previous experience [3, 4]. Techniques such as filtering and prediction allow the agent to use its belief state to infer the true state of the environment. Overall, there are numerous algorithms that can be used to solve POMDPs, such as exact value iteration, point-based value iteration, and Monte-Carlo (MC) methods [3, 4, 10, 5, 21, 11, 12]. These algorithms use different approaches to compute the values (i.e. expected cumulative rewards) of states and actions to find the optimal policy.
Another challenge related to solving POMDP problems is the issue of model parameter uncertainty (i.e., uncertainty in the model of the system itself). This issue mainly affects model-based POMDP approaches, which rely on a model of the environment to find an optimal policy. Possessing full knowledge about the POMDP model is usually a strong assumption in practice [6]. If decisions are made based on a model that does not perfectly fit with the real problem, the agent may risk executing low return actions [6]. In the context of Reinforcement Learning (RL), this challenge is summarized as the problem of exploration-exploitation (i.e. whether to explore the environment and learn more about it or to exploit the current knowledge about the environment to maximize the objective).
II-C Research Gaps
While there have been many approaches proposed for improving MTD deployment, most have focused on addressing state uncertainty [13, 14, 15] and have overlooked the impact of model parameter uncertainty. The main research gaps in the existing literature are:
-
•
Lack of consideration of model parameter uncertainty during decision-making process
-
•
More self-adaptive MTD mechanisms can be developed to adapt to changing attacker behaviour and defense efficiency
-
•
Lack of scalability in modelling multiple attackers and simultaneous attacks across various system components
The proposed approach is presented in the next section based on these motivations.
III Proposed Approach
The main novelty of the proposed approach is the consideration of model parameter uncertainty and enhanced self-adaptation during the planning process. By taking into account both types of uncertainties, this approach will be able to better respond to the complexity and unpredictability of real-world scenarios. Figure 2 presents an overview of the proposed decision engine.

III-A Assumptions
In designing the proposed approach, the following general assumptions are made regarding the capabilities of the defender and attacker(s).
-
•
The protected system is initially under defender control.
-
•
The true security status of the protected system is not known by the defender at all times.
-
•
The effectiveness of MTDs and intrusion detection systems (IDSs) may vary over time.
-
•
The attacks follow a sequential series of phases, which ultimately lead to compromising the protected system.
-
•
The attack progression is at least partially observable to the defender.
-
•
The number of attackers and attacker activities in the operating environment may vary over time.
III-B Modelling
In order to decide on an appropriate series of actions for self-protection, a comprehensive model of the system is required. The model will capture both domain and uncertainty-related knowledge in a compact manner that can be utilized for MTD decision-making.

III-B1 Capturing the Domain
Fundamentally, all MTD techniques are focused on disrupting attack progression [8]. Disruption of an attack is accomplished by introducing dynamicity to make the protected system less deterministic and homogeneous [8]. In this regard, all MTD techniques can be categorized based on the phase of attack they intend to disrupt along an attack kill chain. Various versions of the attack kill chain exist in literature and may be applied based on specific MTD domain requirements [8]. The proposed approach will rely on a kill chain similar to Figure 3 as the basis for domain modelling during MTD decision-making.
Building on the kill chain as the backbone, analyzing the high-level relationships between domain concepts can serve as a starting point for further domain modelling in the POMDP. The important relationships considered here are:
-
•
Quality Goals and Attacker Goals: For instance, Quality Goals for the protected system could include maintaining availability, throughput, or control-flow integrity, while Attacker Goals could include denial-of-service, data leakage, and identity theft. Quality Goals and Attacker Goals can be used here to derive the reward function in the POMDP. These goals can also assist with the selection of metrics that should be monitored, how the monitored metrics should map to the phases of the attack kill chain, and which MTD techniques should be incorporated as actions available to the agent at run-time.
-
•
MTDs, IDSs, and Attacks: The set of applicable MTDs, IDSs, and potential attacks will vary based on the design and development of the protected system. For example, the choice of the programming language used to develop the protected system has a significant impact on the set of MTDs, IDSs, and attacks that should be considered. The relationship between these components in the model also determines the various probabilistic dynamics of the POMDP model. Domain knowledge regarding these concepts based on historical data can serve to configure the initial model parameters in the POMDP. The set of MTDs also dictates the size of the action space in the POMDP model.
-
•
Security Goals and Non-Security Goals: Quality goals can be further divided into security and non-security goals, which may often be in conflict with one another. For example, an N-variant system can be deployed to run multiple variants of the same application simultaneously and monitor the variants for divergence. The security goal motivating this MTD technique is to mitigate code injection and control injection attacks [8]. However, deploying N-variant systems requires a trade-off between system throughput and resource utilization overhead. In this case, throughput decreases and resource utilization overhead increases linearly as the number of variants goes up.
III-B2 Capturing Uncertainty
Uncertainties in the decision-making process for MTD techniques can be grouped into two categories: uncertainty regarding the true state of the environment (i.e. state uncertainty) and uncertainty regarding the true dynamics of the environment (i.e. model parameter uncertainty). For both categories, a common source of uncertainty in the context of MTD decision-making is the fact that the defender cannot always discern malicious activities from benign activities in the environment. In consequence, the defender is unable to track the progress of attacker activities with full confidence, which leads to state uncertainty. The defender also cannot know the effectiveness of IDS mechanisms and deployed MTD techniques against all attacks (e.g. zero-day attacks) with complete certainty; hence, leading to model parameter uncertainty. Figure 3 also illustrates the consequence of state uncertainty with respect to the transitions in attack progression along the attack kill chain.
In the proposed approach, state uncertainty is addressed by introducing partial observability to a discrete MDP to derive a discrete POMDP. As states cannot be derived from observations and direct mappings from observation to actions are insufficient for optimal decision-making, an alternative Markovian signal for choosing actions is needed [3, 4]. To overcome this issue, belief states can be used. A belief state is a probability distribution over the state space of the POMDP. It provides a sufficient basis for acting optimally under state uncertainty [3, 4].
To address model parameter uncertainty, the proposed approach intends on exploring the application of Bayesian Learning methods. In particular, concepts from Bayes-Adaptive POMDP (BA-POMDP) [6] can be applied to address model parameter uncertainty. The BA-POMDP framework introduces Dirichlet distribution experience counts into the POMDP state space in order to represent uncertainty regarding the transition function and observation function . Hence, the BA-POMDP model tracks the experience counts , which denotes the number of times transition to state after performing action in state , and , which denotes the number of times observation was made in state after performing action [6].
If we let and be the vector of all transition counts and all observation counts respectively, it can be shown that the expected transition probability for and the expected probability for observation are:
| (1) |
| (2) |
Building from this, the BA-POMDP framework incorporates the and vectors into the state space to derive a new model. The new set of states (hyperstates in the format ) is defined as where and . The action space remains the same as in the POMDP. The state transition and observation functions become functions of the hyperstate, while the reward function remains a function of state-action pairs.
III-C Planning
When planning under uncertainty, utilizing belief states allows the agent (i.e. decision engine) to take into account its own degree of uncertainty about state identity. For example, the belief state of an agent that is very confident about the current state of the environment will have few states with high probability and many states with low or zero probability.
Unfortunately, solving POMDP planning problems exactly with belief states is usually intractable outside of very small domains. However, various approximate algorithms have been proposed to tackle problems with large domains. In particular, online planning via MC tree search is a proven approach that the proposed approach intends to incorporate. The main advantage of MC-based planning compared to other online planning approaches lies in its method for policy evaluation (i.e. value function updating) [16, 5]. MC-based planning uses MC sampling to update the value function by sampling start states from the belief state and sampling histories (i.e. observation-action sequences) from a black box simulator (instead of relying on explicit probability distributions) [5]. By doing so, MC planning can avoid full-width computation in the search tree that non-MC planning algorithms must carry out. The amount of MC simulations can also be reduced by incorporating domain knowledge into the search algorithm as a set of preferred actions. In the context of MTD decision-making under run-time uncertainty, using the augmented hyperstates in BA-POMDP provides further motivation for applying MC planning techniques to improve planning scalability.
Another computationally expensive task during POMDP planning is the belief state update procedure based on the observation received after performing an action. This update can be achieved by Bayes’ theorem, which requires iteration over the state space. As the state space of the POMDP increases, even a single belief state update may become computationally infeasible. To overcome this issue, MC sampling can also be applied to the belief state update procedure. MC belief state update utilizes a particle filter with particles to approximate the belief state. Each particle represents a sample state . The approximated belief state is defined as the sum of all particles.
| (3) |
Here, is the Kronecker delta function. particles are initially sampled from the initial state distribution. Given a real action and observation , MC belief update works by sampling a state from the current belief state (i.e. random selection of a particle from ). The particle is then passed into the black box simulator to generate a successor state and observation . If the sample observation and real observations match (i.e. ), the successor state is added as a new particle to . This overall procedure is repeated until particles have been added.
IV Research Questions
The main research questions we intend to explore in this preliminary study are:
RQ1 How effective is decision-making using MC-based POMDP planning? — The effectiveness of MTD decision-making can be judged from various aspects. We aim to measure the effectiveness of MC-based POMDP planning with respect to the satisfaction of security and non-security goals in the context of the problem domain.
RQ2 What is the impact of neglecting model parameter uncertainty on MTD decision-making? — For this study, we only captured state uncertainty and did not incorporate model parameter uncertainty concepts explicitly. However, the focus here is to lay out the foundations for the proposed approach by evaluating decision-making when model parameter uncertainty is neglected.
V Experimental Evaluation
V-A Experiment Setup
As a proof of concept, a precursor to the proposed approach, utilizing Partially Observable Monte-Carlo Planning (POMCP) [5], was developed and evaluated. The experiments simulate cryptojacking attacks, which involve attackers using compromised machines to mine cryptocurrency without the victim’s consent. With the popularization of cloud computing and containerization, recent cryptojacking attacks, such as Hildegard [17], have started to focus on cloud computing resources. Therefore, the experiments mimic protecting nodes in a Kubernetes-based cluster from cryptojacking. Here, we make the following assumptions regarding the capabilities of the attacker and defender:
-
•
The attacker can simultaneously attack multiple nodes in cluster
-
•
The attack progress only moves in the forward direction along the attack kill chain
-
•
The defender can counter attacks by reimaging nodes (restore to pristine state after being offline for a certain amount of time)
-
•
The defender can fully observe the availability of each node (i.e. online or offline)
-
•
The defender can partially observe the progress of attacks (at a constant observation rates)
-
•
The defender can choose to not reimage any nodes
-
•
The reimaging process is deterministic (always follows Up → Shutdown → Bootup → Up)
-
•
The nodes take constant time to reimage
-
•
Observing attack progress is only possible when attacks advance to the next phase of the attack kill chain
Table I presents the information related to the evaluation domain. In all experiments, the number of nodes in the cluster was limited to 3 (i.e. ). Based on this information, a POMDP problem was formulated and used during the experiments. In order to provide a basis for comparison, a naive rule-based planner was also implemented. Using the definitions in Table I, the rule-based planner follows a simple configurable rule specified by a parameter , which indicates when the defender should act to reimage a node given the observed progress on that node is greater than or equal to (e.g. when , the rule-based defender will always reimage a node whenever (TargetScan)).
V-B Obtained Results

V-B1 RQ1 How effective is decision-making using MC-based POMDP planning?
From the perspective of the security goal, we can observe from Figure 4 that the total number of compromise events (i.e. the number of times attacker successfully deployed their cryptomining process) for the POMCP planner is generally lower than the corresponding rule-based planners across the range of observation rates. In addition, Figure 5 also illustrates that the POMCP planner is able to extend the average amount of timesteps (i.e. effort) required by the attacker to successfully compromise a node in the cluster.
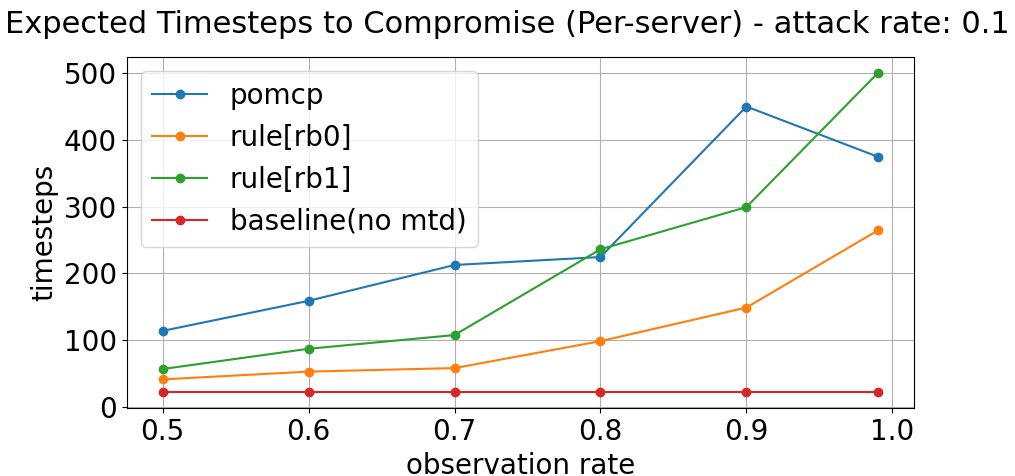
From the perspective of the non-security goal, we can observe the percentage of time there was at least one node available and uncompromised in the cluster in Figure 6. Here, the POMCP planner proved to be sufficient in meeting the objective of maximizing availability for benign users relative to the other planners. The only evaluation dimension in which the POMCP solution consistently trailed the rule-based planners is the percentage of time when all nodes were available and uncompromised during the experiments in Figure 7. Regarding this, one can reasonably argue the sacrifices made here are justified based on the enhanced protection offered by the POMCP planner.
|
Domain
Information |
Description |
|---|---|
| Relevant Attributes | For each node , the attributes and observed attributes are and where, |
| (attack progress) | |
| (compromised) | |
| (availability) | |
| (obs. progress) | |
| MTD Countermeasures () | The only MTD countermeasure considered is to reimage a node (i.e. restore a node to a pristine state by taking it offline for a certain amount of time). |
| IDSs () | Indicators of compromise for the Hildegard attack include the presence of files named ”install_monerod.bash” and ”sGAU.sh” [17]. IDS techniques to detect network scanning [18, 19] are also applicable here. |
| Quality Goals () | The security goal for the defender is to prevent attackers from using nodes for unwarranted cryptocurrency mining. The non-security goal is to maximize the availability of the cluster. |
| Attacker Goals () | The goal of the attacker is to launch mining scripts on cluster nodes while remaining hidden from IDS. |
| Attacks () | The attacks deployed by the attacker include port scanning, defense evasion (e.g. library injection, ELF binary encryption), and cryptojacking. |


V-B2 RQ2 What is the impact of neglecting model parameter uncertainty on MTD decision-making?
To evaluate the impact of neglecting model parameter uncertainty on POMCP, experiments were carried out where noise was applied to the attack rate parameter of the model, which represents the speed of attacker progression in the system.


The three bar charts on the left in Figure 8, show the result of experiments where the true attack rate was 0.1 but the attack rate used during the POMCP simulations was 0.1, 0.5, and 0.9 respectively. The initial observation here suggests that the noisy models were able to outperform the accurate model. However, upon taking into account the 3 pie charts in the left column of Figure 9, we can notice that the decrease in compromise events for the noisy models can be attributed to the fact that nodes were frequently reimaged (offline) in the cluster. Intuitively, this aligns with the fact that positive noise injected in these experiments triggered the planner to overestimated the capabilities (i.e. speed) of the adversary. As a result, while this means the attacker can no longer compromise the node, it also means benign users will suffer a drastically reduced quality of service.
On the other hand, the right three bar charts in Figure 8 are related to the outcome when the defender underestimates the capabilities of its adversaries. In this case, planning based on the model with a noise value of -0.8 consistently resulted in particle deprivation during experiments. Overall, the results in compromise event count and cluster availability trend in the opposite direction of the overestimating scenarios.
V-C Limitations
In terms of limitations, more effort is required to compare the proposed approach with more advanced, state-of-the-art techniques found in the literature to identify areas of strengths and weaknesses. Furthermore, the results presented in this paper are not at the scale of real-world scenarios (only 3 nodes were considered in the experiments). The main challenge here is how to capture relevant information in the environment without state space explosion. For the POMCP-based solution in this preliminary experiment, a consequence of increased state space is the occurrence of particle deprivation during the planning process. The current workaround for this is to increase the number of simulations and particles during experiments. However, this obviously will not scale. A potential direction for future exploration is the integration of Factored POMDPs [11, 20]. In addition, as shown from the experimental results presented for RQ2, neglecting model parameter uncertainty has the potential to be detrimental to the satisfaction of security and non-security goals. The next step here is to incorporate Bayesian Learning techniques [6, 21] into the planning process and analyze the impact of model parameter uncertainty-awareness in the decision-making outcome.
VI Related Works
There exist some interesting approaches for MTD planning in current literature, such as using evolutionary algorithms [22] and renewal reward theory [23]. However, a widely popular method for MTD planning is the application of Game Theory (GT). One study applied GT to optimize MTD platform diversity and showed that deterministic strategies leveraging fewer platforms can increase system security [24]. Research using Empirical GT analysis to model interactions between defender and attacker has also been explored [14]. Furthermore, Empirical GT has also been applied to analyze the effectiveness of MTD in defending against Distributed Denial of Service attacks [25]. Another GT-based approach applies Bayesian Stackelberg games for decision-making that balances between computational performance and data privacy [26]. The authors model the interactions between cloud providers and users in a risk-aware manner by considering each party’s risk preferences. A similar study also utilized Bayesian Stackelberg games to show that MTDs can be improved when combined with information disclosure via a signalling scheme [27]. In addition, a recent study proposed using Dynamic Markov Differential Game Model that considers the interplay between the defender and the attacker in MTD [28]. The model takes into account the dynamics of the system state and the impact of defense decisions on the system’s behaviour. Nonetheless, one limitation to many GT-based approaches is the consideration of only a single attacker or a single protected system in their analysis.
Reinforcement Learning (RL) techniques have also been extensively studied for MTD planning. For example, RL algorithms were used for generating adaptive strategies in real-time to defend against Heartbleed attacks [29]. RL has also been applied to derive dynamic configuration strategies for the live migration of Linux containers based on a predator (attacker) vs prey (containers) game [30]. Another study utilized RL to develop a cost-effective and adaptive defense against multi-stage attacks [31]. Moreover, Multi-objective RL has also been used to optimize the attack surface and configuration diversity of computer systems [32]. Deep RL and multi-agent POMDP modelling has been explored to increase the difficulty of exploiting system vulnerabilities [13]. A POMDP-based approach using attack kill chains has also been explored in a recent study that aims to determine the optimal trade-off between defense effectiveness and costs [15]. With exception to [31], a key aspect missing from the aforementioned RL-based approaches is the consideration of model parameter uncertainty.
VII Conclusion
In summary, this paper presents a novel approach to MTD decision-making based on POMDP modelling with additional run-time uncertainty-awareness via Bayesian Learning techniques. The primary novelty presented here lies in the consideration of model parameter uncertainty on top of state uncertainty. The initial outcomes from the preliminary experiments provide encouraging evidence regarding the plausibility of this research. Nevertheless, further in-depth investigations and evaluations regarding the proposed approach are required before its full potential can be realized.
References
- [1] E. Yuan, N. Esfahani, and S. Malek, “A systematic survey of self-protecting software systems,” ACM Transactions on Autonomous and Adaptive Systems, vol. 8, no. 4, pp. 1–41, 2014.
- [2] J.-H. Cho, D. P. Sharma, H. Alavizadeh, S. Yoon, N. Ben-Asher, T. J. Moore, D. S. Kim, H. Lim, and F. F. Nelson, “Toward proactive, adaptive defense: A survey on moving target defense,” IEEE Communications Surveys & Tutorials, vol. 22, no. 1, pp. 709–745, 2020.
- [3] M. T. Spaan, “Partially observable markov decision processes,” Adaptation, Learning, and Optimization, pp. 387–414, 2012.
- [4] L. P. Kaelbling, M. L. Littman, and A. R. Cassandra, “Planning and acting in partially observable stochastic domains,” Artificial Intelligence, vol. 101, no. 1-2, pp. 99–134, 1998.
- [5] D. Silver and J. Veness, “Monte-Carlo planning in large POMDPs,” Proceedings of the 23rd International Conference on Neural Information Processing Systems, vol. 2, pp. 2164–2172, Dec. 2010.
- [6] S. Ross, J. Pineau, and B. Chaib-draa, “A Bayesian Approach for Learning and Planning in Partially Observable Markov Decision Processes,” Journal of Machine Learning Research, vol. 12, pp. 1729–1770, Jul. 2011.
- [7] M. Torquato and M. Vieira, “Moving target defense in cloud computing: systematic mapping study,” Computers & Security, vol. 92, p. 101742, 2020.
- [8] B. Ward, S. Gomez, R. Skowyra, D. Bigelow, J. Martin, J. Landry, and H. Okhravi, “Survey of cyber moving targets,” Massachusetts Inst of Technology Lexington Lincoln Lab, Tech. Rep. 1228, Jan. 2018.
- [9] S. Jajodia, A. K. Ghosh, V. S. Subrahmanian, V. Swarup, C. Wang, and X. S. Wang, Moving target defense II application of game theory and Adversarial Modeling. New York, NY: Springer New York, 2013.
- [10] N. Ye, A. Somani, D. Hsu, and W. S. Lee, “Despot: Online POMDP planning with regularization,” Journal of Artificial Intelligence Research, vol. 58, pp. 231–266, 2017.
- [11] S. Katt, F. A. Oliehoek, and C. Amato, “Bayesian Reinforcement Learning in Factored POMDPs,” Proceedings of the 18th International Conference on Autonomous Agents and Multiagent Systems, pp. 7–15, 2019.
- [12] M. T. J. Spaan and N. Vlassis, “Perseus: Randomized point-based value iteration for POMDPs,” Journal of Artificial Intelligence Research, vol. 24, pp. 195–220, 2005.
- [13] T. Eghtesad, Y. Vorobeychik, and A. Laszka, “Adversarial deep reinforcement learning based adaptive moving Target Defense,” Lecture Notes in Computer Science, pp. 58–79, 2020.
- [14] A. Prakash and M. P. Wellman, “Empirical game-theoretic analysis for Moving Target Defense,” Proceedings of the Second ACM Workshop on Moving Target Defense, 2015.
- [15] A. Mcabee, M. Tummala, and J. Mceachen, “The use of partially observable Markov decision processes to optimally implement moving target defense,” Proceedings of the Annual Hawaii International Conference on System Sciences, 2021.
- [16] R. S. Sutton, F. Bach, and A. G. Barto, Reinforcement learning: An introduction. Massachusetts: MIT Press Ltd, 2018.
- [17] A. S. Jay Chen, “Hildegard: New teamtnt cryptojacking malware targeting kubernetes,” Unit 42, 28-Jan-2022. [Online]. Available: https://unit42.paloaltonetworks.com/hildegard-malware-teamtnt/. [Accessed: 30-Jan-2023].
- [18] H. N. Viet, Q. N. Van, L. L. Trang, and S. Nathan, “Using deep learning model for network scanning detection,” Proceedings of the 4th International Conference on Frontiers of Educational Technologies, 2018.
- [19] J. Gadge and A. A. Patil, “Port Scan detection,” 2008 16th IEEE International Conference on Networks, 2008.
- [20] C. Boutilier and D. Poole, “Computing Optimal Policies for Partially Observable Decision Processes Using Compact Representations,” Proceedings of the Thirteenth National Conference on Artificial Intelligence, vol. 2, pp. 1168–1175, 1996.
- [21] S. Katt, F. A. Oliehoek, and C. Amato, “Learning in POMDPs with Monte Carlo Tree Search,” Proceedings of the 34th International Conference on Machine Learning, vol. 70, pp. 1819–1827, 2017.
- [22] D. J. John, R. W. Smith, W. H. Turkett, D. A. Cañas, and E. W. Fulp, “Evolutionary based moving Target Cyber Defense,” Proceedings of the Companion Publication of the 2014 Annual Conference on Genetic and Evolutionary Computation, 2014.
- [23] H. Wang, F. Li, and S. Chen, “Towards cost-effective moving target defense against ddos and covert channel attacks,” Proceedings of the 2016 ACM Workshop on Moving Target Defense, 2016.
- [24] K. M. Carter, J. F. Riordan, and H. Okhravi, “A game theoretic approach to strategy determination for dynamic platform defenses,” Proceedings of the First ACM Workshop on Moving Target Defense, 2014.
- [25] M. Wright, S. Venkatesan, M. Albanese, and M. P. Wellman, “Moving target defense against ddos attacks,” Proceedings of the 2016 ACM Workshop on Moving Target Defense, 2016.
- [26] Y. Bai, L. Chen, L. Song, and J. Xu, “Bayesian Stackelberg game for risk-aware edge computation offloading,” Proceedings of the 6th ACM Workshop on Moving Target Defense, 2019.
- [27] X. Feng, Z. Zheng, D. Cansever, A. Swami, and P. Mohapatra, “A signaling game model for Moving target defense,” IEEE INFOCOM 2017 - IEEE Conference on Computer Communications, 2017.
- [28] H. Zhang, J. Tan, X. Liu, and J. Wang, “Moving target defense decision-making method,” Proceedings of the 7th ACM Workshop on Moving Target Defense, 2020.
- [29] M. Zhu, Z. Hu, and P. Liu, “Reinforcement learning algorithms for adaptive cyber defense against Heartbleed,” Proceedings of the First ACM Workshop on Moving Target Defense, 2014.
- [30] M. Azab, B. M. Mokhtar, A. S. Abed, and M. Eltoweissy, “Smart moving target defense for linux container resiliency,” 2016 IEEE 2nd International Conference on Collaboration and Internet Computing (CIC), 2016.
- [31] Z. Hu, M. Zhu, and P. Liu, “Adaptive Cyber defense against multi-stage attacks using learning-based POMDP,” ACM Transactions on Privacy and Security, vol. 24, no. 1, pp. 1–25, 2020.
- [32] B. Tozer, T. Mazzuchi, and S. Sarkani, “Optimizing attack surface and configuration diversity using multi-objective reinforcement learning,” 2015 IEEE 14th International Conference on Machine Learning and Applications (ICMLA), 2015.