Urban mapping in Dar es Salaam using AJIVE
Abstract
Mapping deprivation in urban areas is important, for example for identifying areas of greatest need and planning interventions. Traditional ways of obtaining deprivation estimates are based on either census or household survey data, which in many areas is unavailable or difficult to collect. However, there has been a huge rise in the amount of new, non-traditional forms of data, such as satellite imagery and cell-phone call-record data, which may contain information useful for identifying deprivation. We use Angle-Based Joint and Individual Variation Explained (AJIVE) to jointly model satellite imagery data, cell-phone data, and survey data for the city of Dar es Salaam, Tanzania. We first identify interpretable low-dimensional structure from the imagery and cell-phone data, and find that we can use these to identify deprivation. We then consider what is gained from further incorporating the more traditional and costly survey data. We also introduce a scalar measure of deprivation as a response variable to be predicted, and consider various approaches to multiview regression, including using AJIVE scores as predictors.
Keywords: Dimension reduction; Multiview data; Urban mapping
1 Introduction
Mapping levels of deprivation in urban areas is important, for example for identifying areas with greatest need, in order to plan intervention work and decide where to allocate resources (Smith et al.,, 2013; Blumenstock et al.,, 2015; Steele et al.,, 2017). However, estimates are traditionally based on census data, which for many countries is unavailable or outdated, or household surveys, which are expensive and time-consuming to collect (Smith-Clarke et al.,, 2014). In addition, for cities that are growing rapidly in population, the urban landscape can change rapidly, so results drawn from these sorts of data may be quickly out of date. There is a need therefore to exploit sources of data that are readily available and current.
The goal of this paper is to map poverty in the city of Dar es Salaam in Tanzania by exploiting non-traditional types of data including satellite imagery and phone call detail record (CDR) data. Using Angle-Based Joint and Individual Variance Explained (Feng et al.,, 2018), we detect sources of joint and individual variation within the data, which allows us to understand what information is contained in both data sets, and what is unique to each. Later, we incorporate data from a survey conducted in Dar es Salaam to investigate what additional information, if any, we can gain from this.
Previous studies have shown the potential for using these sorts of data to map poverty in different locations. For example, Xie et al., (2016), Engstrom et al., (2017), and Babenko et al., (2017) use satellite imagery to map poverty. Several studies have used CDR data to derive socioeconomic information: for example, Blumenstock et al., (2015) uses the call histories of individuals to predict their socioeconomic status in Rwanda; Smith-Clarke et al., (2014) uses features derived from CDR data to map deprivation in different regions of Cote d’Ivoire.
Steele et al., (2017) combines remote sensing and CDR data to map poverty in Bangladesh, by using features derived from both these types of data to fit a model to predict poverty. Our approach differs from theirs in the way we use the image data (using a convolutional neural network to generate feature vectors, rather than using hand-crafted features such as roads and vegetation). We also aim to get more insight into the data by finding both joint and individual sources of variation, which their approach does not.
The data that we consider are: (i) cell-phone call detail record (CDR) data; (ii) high-resolution satellite imagery (image data) covering most of the city; and (iii) survey data (see Section 2.3 for details). We focus mainly on the first two, which are easily available and entail little time or expense to collect. However, later on we also incorporate the survey data, to investigate what information contained within the survey data is common to or distinct from the other two data types, and reflect on how much benefit comes from collecting and incorporating it. Our aim is to understand the relationships amongst these different data types, and to exploit them to predict deprivation for different administrative divisions of Dar es Salaam.
The data are high-dimensional and of different types, and so to identify useful low-dimensional structure amongst the data — and ultimately to map deprivation — we use the approach of Angle-Based Joint and Individual Variation Explained (AJIVE) (Feng et al.,, 2018). The goal of AJIVE is to identify a small number of components that explain a large proportion of variation within the data, and for these components to be interpretable as reflecting individual variation (unique to each data type) and joint variation (belonging to both data types). The idea is that there is value in incorporating multiple data types into a joint “multiview” analysis, rather than performing separate individual analyses, both in identifying a stronger signal of poverty and in understanding the information contributed by the different data types.
In Section 2, we explain some further context about Dar es Salaam and describe the available data, plus other derived measures of poverty in Dar es Salaam that we later use for comparison. In Section 3, we summarise the AJIVE algorithm and explain how we estimate the number of components. Section 4 contains results of applying AJIVE and its extensions to the Dar es Salaam data. We investigate using AJIVE with CDR and image data, and also with the survey data in addition to these. We give an interpretation of what each of the joint and individual components shows, and what this tells us about the data sources, comparing AJIVE to results from applying simpler Principal Component Analysis (PCA) to the two data sets independently, emphasising the additional insights that AJIVE provides. We also compare the resulting deprivation estimates to estimates computed using a completely different data set and method (Seymour et al.,, 2022), and investigate how well we can predict deprivation from the AJIVE output using regression modelling.
2 Background & Data
Dar es Salaam is located on the eastern coast of Tanzania. According to World Bank data, the population of Dar es Salaam in 2020 was 6.7 million, having almost tripled from just under 2.3 million in 2000. It is the largest city in Tanzania and the fastest growing city in Africa, with some projections suggesting it could reach a population of over 60 million by 2050 (Locke and Henley,, 2016). Figure 1 (a) and (b) show the locations of Tanzania and Dar es Salaam.
The city of Dar es Salaam is divided into 452 administrative regions called subwards. In this paper, we treat the subward as the observational unit; in each data set each subward is represented by its own feature vector. Figure 1 (c) displays a map of the city, with subward boundaries shown. The image data only covers 383 subwards, so we include only these subwards in the study; these are shown in blue in Figure 1 (c). Throughout, we use and to refer to the CDR and image data respectively. Each of these matrices has rows representing the subwards; the number of columns, representing feature dimensions, is (CDR) and (image).
The survey data is denoted by . There are two subwards missing from this data set, so we leave these out when we incorporate the survey data into the analysis, giving . The survey data has column dimension .

2.1 CDR data

The phone call detail record (CDR) data were collected from base transceiver station (BTS) towers located over Dar es Salaam (shown in Figure 2), during 122 days in 2014111For more details, see Engelmann et al., (2018).. For each tower, information was collected about all call and SMS interactions recorded, including the time of the interaction, and the user IDs of both sender and receiver. This information was used to calculate a set of features for each user, such as the number of calls and SMS sent and received, the number of BTS towers visited, and the mean time between interactions; Table 2 in the supplementary material gives the full list of features. There are also 5 features calculated at tower level (such as the total number of interactions recorded by each tower). To convert user-level features to tower features, each user ID was assigned a “home” tower based on where the majority of their night-time interactions (between 10pm and 6am) took place; the tower features were calculated as the mean values across individuals who were assigned to that tower.
To calculate feature vectors for each subward, it was first necessary to determine the areas of overlap between the subwards and the regions served by each tower. The tower regions were calculated by constructing a Voronoi diagram, in which a polygon is placed around each tower in such a way that any point contained within it is closer to that tower than to any other. We refer to these polygons as the tower regions. The subward feature vectors were then calculated as weighted averages over the tower feature vectors, with weights proportional to the areas of overlap between the tower regions and subwards.
To describe this mathematically, we label the subwards , and the tower regions . Let denote an matrix with entries , where
Then the feature vector corresponding to subward is given by
where are the row vectors of , and is an vector with all elements equal to 1. After calculating the matrix of subward CDR features , each column is winsorized (i.e. the largest and smallest 1% are replaced with the values of the 99th and 1st percentiles) to remove the effect of large outliers, and then standardized so that each feature has mean 0 and variance 1 across subwards.
2.2 Image data
The image data consists of high-resolution, georeferenced satellite imagery of Dar es Salaam, which is made available by MAXAR (at https://www.maxar.com/open-data/covid19). We divided the images into subwards to create an image for each subward, discarding any sections that were covered by cloud. As a result, we have full or partial images for 383 subwards; the remaining 69 had to be excluded from the analysis, due to either being outside the area covered by the satellite imagery, or to the corresponding section of the image being entirely obscured by cloud. Figure 3 shows an example of the image data for a particular subward.

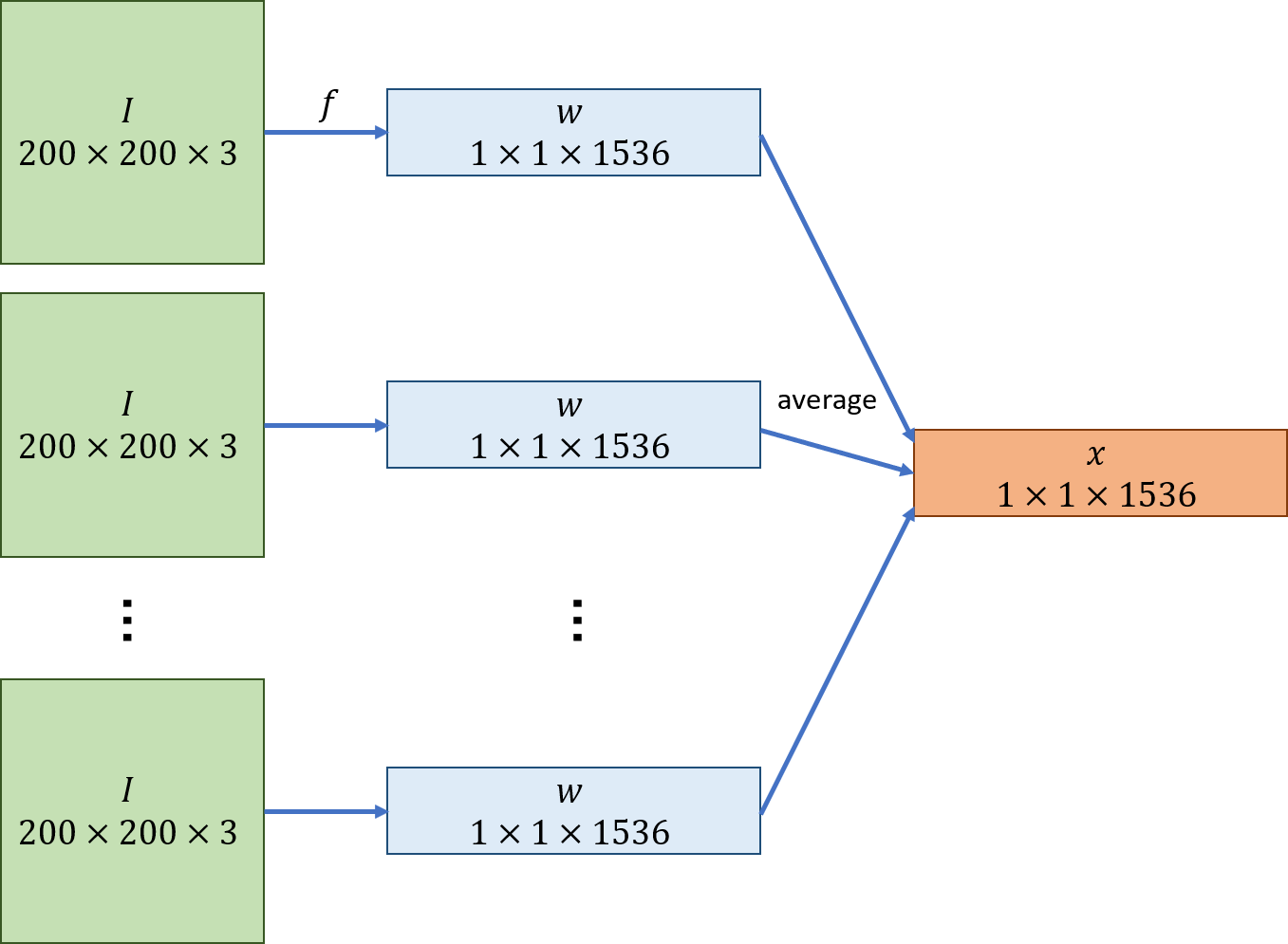
The subward images are high-dimensional and are of different sizes and shapes. To apply AJIVE or PCA, we need to construct a matrix representation of the data, where a row vector corresponds to each subward. To do this, we follow Carmichael et al., (2021) by randomly sampling a set of uniformly-sized patches from each subward image, and applying a pre-trained convolutional neural network (CNN) to map each patch to a lower-dimensional vector. We then take the mean feature vector across the patches for each subward. Figure 4 illustrates this process.
For each subward, we took 10 patches of dimension pixels, sampling the top-left pixel uniformly from all possible locations (i.e. the image with the 199 right-most and bottom-most pixels excluded). Patches could overlap. Any patches containing more than black background pixels were replaced, to ensure that the image backgrounds were not a prominent feature in the patches.
For the CNN, we used InceptionResNet-V2 Szegedy et al., (2016) trained on ImageNet; this is one of the best-performing models on ImageNet. The schema is given in Figure 15 of Szegedy et al., (2016). A CNN takes as its input a dimensional array of pixel values (where are the dimensions of the image, and is the number of colour channels, in our case 3), where each element has an integer value between 0 and 255, and outputs a dimensional feature array, where . If we let denote the space of possible images, the CNN can be defined as a mapping
The values of , , and are determined by the model architecture. This array is then usually fed into a final classification layer, which converts it into a vector; however, as the classification task the model was trained on is not directly relevant to our situation, we did not use this. Given the input patch dimensions and choice of model architecture, the output we obtain for each patch is a dimensional array. To reduce the dimension of this further, we used maxpooling, taking the maximum value in each dimensional sub-array to produce a 1536-dimensional vector. We then took the mean across patches to generate a feature vector for each subward. As with the CDR features, the image features are then winsorized and standardized to have mean 0 and variance 1.
2.3 Survey data
The survey data were collected in two phases in May and August 2019. In each subward, data were collected from approximately 8 respondents who were asked to answer questions on that subward. Most subwards had 8 respondents, although some had more or fewer; all had between 2 and 17.
The questions cover various aspects such as poverty and unemployment, education, and medical facilities. The data were originally collected (Ellis,, 2021) to create a set of fine-grained, socio-demographic data about Dar es Salaam, which could be used to inform research on topics such as deprivation and forced labour risk, and to provide a ground truth against which models could be compared. Not all of the questions and responses could be used in our analysis, as some questions had categorical or write-in answers: we only included questions which had numerical or ordinal responses. Tables 3 and 4 in the supplementary material give the full list of survey questions in the data set used for this paper, and possible responses. For each subward we take the median responses for the respondents. The variables are then centred and scaled so that each response variable has mean 0 and variance 1.



2.4 Deprivation estimates based on comparative judgments
Our aim is to explore how we can use the CDR and image data to map deprivation. To provide a comparison, we use deprivation estimates for Dar es Salaam calculated from comparative judgment data, using the Bayesian Spatial Bradley-Terry model (Seymour et al.,, 2022). These are available in the R package BSBT and consist of a score between -1.2 and 2.2 for each subward in Dar es Salaam, where higher scores indicate less deprived subwards. Figure 7 shows a plot of these deprivation scores for the subwards that are included in our analysis.

3 Methodology
In this section we give an overview of the Angle-Based Joint and Individual Variation Explained (AJIVE) algorithm (Feng et al.,, 2018), which we use to obtain the main part of our results. We also use Principal Component Analysis (PCA) for comparison; as AJIVE can be viewed as an extension of PCA to multiple data sets, we outline this first in Section 3.1, followed by AJIVE in Section 3.2. We then, in Section 3.3, discuss how to choose the ranks for low-rank approximation to our data, on which both PCA and AJIVE depend.
3.1 Principal Components Analysis (PCA)
For a centred data matrix, , PCA identifies the subspace of a chosen dimension, , in which the data have greatest variance. It can be computed in terms of the Singular Value Decomposition (SVD):
where, with , is an diagonal matrix containing the singular values of in decreasing order; and and are respectively and matrices with columns corresponding respectively to the left and right singular vectors of , such that (the identity matrix).
Reducing the dimension of the data to the chosen dimension by PCA entails approximating using the rank- truncated SVD, that is
| (1) |
where and are matrices containing the first columns of and respectively, and is the diagonal matrix containing the first singular values of . The PC scores are the rows of the matrix .
3.2 AJIVE
Angle-Based Joint and Individual Variation Explained (AJIVE) (Feng et al.,, 2018) is a dimension reduction algorithm which can be applied to two or more data sets, where the data correspond to the same group of individuals, but are of different types. It is applicable when we believe there is some joint structure common to both data sets, but also some information which is unique to each: in contrast to methods such as Principal Component Analysis, where each data matrix is decomposed separately, or Canonical Correlation Analysis, which finds only joint components, AJIVE allows us to analyse both joint and individual variation within the data. It was developed as a more efficient version of Joint and Individual Variation Explained (JIVE) (Lock et al.,, 2013).
AJIVE (Feng et al.,, 2018) aims to decompose each data matrix as
where is the joint variation matrix (of rank ), are the individual variation matrices (each of which have rank ), and represent noise.
We can decompose as
| (2) |
which we obtain by taking the (exact) rank- SVD of . is the matrix of joint scores (in our case, each row corresponds to a subward), and is the matrix of joint loadings (each row corresponds to a CDR or image feature). contains the singular values of and controls the relative weights of each component. Figure 8 illustrates this decomposition.
Similarly, for the th individual component () we decompose as
where is the score matrix, the loading matrix, and contains the non-zero singular values of .
The AJIVE algorithm is given in detail in (Feng et al.,, 2018); we give an outline here. The algorithm has three main stages:
Stage 1. We choose initial signal ranks (see Section 3.3) and approximate each by its rank- truncated SVD:
Stage 2. To estimate the joint scores , we combine the score matrices into one matrix , from which we will extract the joint signal:
and calculate its SVD:
We then choose the joint rank , based on the singular values of , (again, see Section 3.3), and set the estimate of the joint scores to be , where is a matrix containing the first columns of .
To estimate the joint matrix , we project onto :
and decompose as , by taking its rank- SVD (which gives an exact decomposition since has rank ):
(Note that although generally (unless ), we have : they are both estimates of the score space of .)
Stage 3. To estimate the individual matrices , we note that for each , we require the joint scores to be orthogonal to . Hence, we project each onto the orthogonal complement of :
where is the identity matrix. We then take a final rank- SVD of this matrix :
3.3 Rank estimation
To implement AJIVE we must provide estimates of the initial ranks , joint rank , and individual ranks . We describe here how we do this. For simplicity, we will refer to the case where we have the CDR and image data, so : we later incorporate the survey data as well, but the methods are the same.
Initial ranks. In selecting the initial ranks, we aim to distinguish signal from noise in each data set. We do this by inspecting scree plots of and (Figure 9 (a)–(b)). On both plots there is a sizeable jump after the third singular value, so we take .

Joint rank. After combining the initial score matrices into one matrix (see previous section), we want to find out which components of have sufficiently large singular values to be regarded as part of the joint signal. To do this we use a random direction bound, as in Feng et al., (2018). To recap, we have
where is an dimensional matrix.
We create 1000 random matrices of the same dimensions as , with elements sampled independently from , and calculate the largest singular value in each case. We take the 95th percentile of these values as a lower bound for the singular values of that correspond to joint signal. Figure 9 (c) illustrates this process for the CDR and image data. The red points show the ordered singular values of (excluding those that are equal to 0), whilst the black points correspond to the maximum singular values of each randomly generated matrix, as described above. The horizontal black line corresponds to the threshold for the joint signal. There are two red points above the black line, so we take .
Individual ranks. After calculating the joint components, we subtract from each the corresponding part of the joint signal matrix, and calculate its SVD:
The initial rank was selected by inspecting a scree plot, but we could equivalently have selected a threshold
where and are the th and th largest singular values of , such that we only keep components with singular values greater than or equal to . For the individual components, we use the same threshold, so we keep the individual components which have corresponding singular values greater than or equal to and discard those which are smaller. For the CDR and image data, this gives .
4 Results
We implement the AJIVE algorithm in R. We first inspect scree plots (Figure 9) for and to choose the initial ranks and : we set . To select the joint rank , we use a random direction bound (see Section 3.3), with 1000 random samples, which leads to a value of . The individual ranks for both the CDR and image data ( and ) are estimated to be 1. Throughout, we refer to the joint components as JC1 and JC2, and the individual components as IC1CDR and IC1Image.
We look first at each of the components individually (Figures 10 to 13). For each component, the figure shows the subward scores (columns of or ), patches from the subwards at the extreme positive and negative ends of each component, and, where applicable, the CDR feature loadings (rows of or ). (Although the relative values of scores and loadings are of interest, it is arbitrary which end is negative and which is positive.)
4.1 Joint components
Figure 10 shows the results for the first joint component (JC1). The positive end of the component shows green, rural areas; at the negative end, the patches show built-up areas with small, residential buildings. We can also see from Figure 10(a) that most subwards with negative scores are small and located close to the city centre. The most positive CDR features are the number of calls initiated by users, the average distance between users and the people they call, and the ratio of calls to SMS. This suggests that residents in these areas are more likely to initiate calls and to make calls rather than sending SMS, compared to those at the negative end of the component. It also seems reasonable that people living in rural areas, with low population density, would tend to communicate with people further away, as there are fewer people living close by. The most negative CDR features are the number of day, evening, and night interactions, and the number of active users; these are likely to be correlated with population.
For the second joint component (JC2) (Figure 11), the subwards with the most positive scores again appear to be more rural areas, but the negative end appears to show mostly commercial and industrial areas. The most negative subwards are located close to the city centre and on the coast, whilst the subwards in the south-west and south-east of the city tend to be those with the most positive scores. The most positive CDR features are the percentage of contacts that account for of a user’s call interactions, entropy of contacts — which are both measures of the diversity of contacts with whom a user interacts — and the number of active users. Looking at the CDR features with the most negative loadings, we infer that at this end of the component, users move around more (to different towers), make more calls, and use their phones on more days.
4.2 Individual components
For the CDR individual component (IC1CDR) (Figure 12), the most positive CDR features are those related to entropy of locations and contacts, and the total number of SMS sent. At the negative end are the ratio of calls to texts, and the standard deviation of interevent times. This end of the component also seems to contain built-up areas with taller buildings, although it is less clear what the patches from the positive end show. (This is perhaps not surprising, as this component does not directly use information from the patches.)
The most positive subward seems to have a particularly extreme value: we can see that it is much brighter than all the other subwards in Figure 12 (a). This subward contains the University of Dar es Salaam, as well as a large shopping centre (part of the roof of this is shown in one of the patches in Figure 12 (c)); it seems reasonable to assume that these would have an impact on patterns of phone usage, as people’s activities in this subward will likely be different to other areas of the city.
For the image individual component (IC1Image) (Figure 13), it looks like the positive end corresponds to industrial and commercial areas, whereas the negative end is mostly rural. There are no CDR feature loadings to display for this component. As for IC1CDR, there appears to be one extreme subward, this time at the negative end of the component: one of the patches from this component (Figure 13 (b)) looks unusual, so this may be responsible. However, when we re-implement AJIVE with this subward removed, there is not a noticeable difference in the results for the other subwards, so it does not seem to be having too much influence on the results. (This is also the case for the outlier subward in IC1CDR.
| Positive | Negative | |
| Joint component 1 | Rural | High-density, slum housing |
| More initiation of calls | Total CDR interactions | |
| Joint component 2 | Rural or semi-rural | Industrial/commercial |
| Diversity of contacts | ||
| CDR individual component | Low-density housing | Industrial/commercial |
| High entropy CDR data | High calls to text ratio | |
| Image individual component | Industrial/commercial | Rural |
IC1CDR and IC1Image have virtually no correlation (), so we can surmise that all joint variation is adequately captured by JC1 and JC2: correlation between the individual components would suggest that the joint rank was too small. We can therefore assume that the information captured in IC1CDR and IC1Image is unique to the CDR and image data sets respectively.
Table 1 briefly summarises our observations in this section.

4.3 Comparison with deprivation estimates
One of the main aims of this paper is to investigate whether AJIVE can be used to predict deprivation. We are interested in whether our methods and data sources can be used to do this in situations where alternative data sources are unavailable; however, to assess how well it works, we here use deprivation estimates created from a completely distinct data set (details were given in Section 2.4).
Figure 15 shows correlations between the deprivation estimates and AJIVE and PC scores. There is a fairly strong positive correlation between deprivation and JC2 (). Hence, this component seems to be picking up joint variation in the data which is relevant for determining deprivation. In particular, this indicates that deprivation information is present in both and . For each of the other AJIVE components there is no or very little correlation with deprivation.
4.4 Comparison with Principal Components Analysis
One question is whether using AJIVE gives a significant advantage over using Principal Components Analysis (PCA). PCA can be used either on and separately, or on the concatenated data matrix . We consider both of these options here, and compare their output to that of AJIVE.
As a reminder, from Section 3.1, using rank- PCA we represent an data matrix as
where and are and matrices containing the first left and right singular vectors of respectively, and is an diagonal matrix containing the first singular values of along its diagonal. As with AJIVE, we can interpret the columns of and as score and loading vectors respectively. The singular values in control the relative importance of each component.
To compare AJIVE with separate PC analyses of and , we computed the first three principal components (referred to as PC1, PC2, and PC3) for each data set. (Each data set has three AJIVE components related to it — two joint and one individual — so this seems a fair comparison.) Figure 15 shows correlations between scores for the AJIVE and PC components. (Note that JC1 and JC2 are forced to be orthogonal to each other, as well as to the individual components, and the PC components for each data matrix are also forced to be orthogonal.)

We see that JC1 is strongly correlated with PC2CDR and is also correlated with both PC1Image and PC2Image, whilst JC2 is correlated with PC1CDR and PC3Image. IC1CDR is strongly correlated with PC3CDR, and IC1Image is correlated with PC1Image and PC2Image. IC1CDR appears to be uncorrelated with the image PC scores, and the same applies to IC1Image and the CDR PC scores. AJIVE appears to give similar overall results to doing separate PCAs of the CDR and image data, but the division of components is different. Hence, AJIVE identifies which parts of the components are common to both data sets and which are unique to each data set.
When doing PCA on the concatenated data matrix , we find that the first few PCs of are almost identical to the corresponding PCs of . This is not surprising as has a much higher dimensionality than (). However, this shows that applying PCA to the concatenated data matrix is not useful for our data, as we essentially lose the information from . This would also apply to other situations where the number of dimensions differs greatly between data matrices.
4.4.1 Proportion of variance explained

Figure 16 shows the proportion of variance explained by each of the components for the CDR and image data. For the CDR data, the three AJIVE components together account for around of the variance in the data, with JC1 contributing the most. For the image data, the total variance explained is much smaller, likely due to being much more high-dimensional ( compared to for the CDR data). The individual component contributes more than either JC1 or JC2. In both cases the proportion of variance explained by PCA is slightly greater than that explained by AJIVE. (This is what would be expected, as PCA maximizes the proportion of variance explained.)
4.5 Incorporating the survey data
So far, we have looked at applying AJIVE and PCA to the CDR and image data sets. We now repeat the foregoing analysis but with the addition of the survey data introduced earlier in Section 2.3. Recall that the survey data are slower and more costly to collect than the CDR and image data, so it is natural to ask: what extra information does the survey data provide, and does it warrant the cost of collecting the data in the first place?

The scree plot (Figure 17) suggests an initial rank of 2 for the survey data. Applying the random direction bound to estimate the joint rank (as in Section 3.3, but using all three data matrices) returns a joint rank . We also obtain individual rank estimates of .
Figure 18 shows a plot of the survey individual component (IC1Survey) scores for each subward, and 5 patches from two most positive and most negative subwards. Corresponding plots for the other components (JC1, JC2, IC1CDR, and IC1Image) are shown in the supplementary material (Section C): they are very similar to those we obtained using only the CDR and image data (Figures 10 to 13). Figure 19 shows correlations between AJIVE and PC components for the three data matrices. Comparing with Figure 15, the relations between JC1, JC2, IC1CDR and IC1Image, and the CDR and image PCs are virtually unchanged, so incorporating the survey data does not have much effect on the decomposition. However, looking at the survey individual component allows us to see what information may be present in the survey data that we cannot get from the other data sets. From Figure 18 (b), it appears that IC1Survey highlights a risk of forced labour and exploitation: the variables with the most negative loadings are those relating to forced work and arranged marriage, whilst as the positive end we have higher rates of children and teenagers in education, and more use of technology, which may be associated with lower risks of forced labour.

4.6 Regression modelling to predict deprivation
We have investigated correlation between the dimension-reduced representations of the data (AJIVE and PC scores) and deprivation scores, but the approaches to dimension reduction were “unsupervised” in the sense that they did not involve using the deprivation data. In this section, we consider the “supervised” approach of using deprivation as a response variable in a regression model geared towards prediction of deprivation from the CDR, image and survey data. We particularly investigate whether it aids prediction to use AJIVE and/or PCA as a step of dimension reduction to construct “features” for the regression model.
A recently introduced approach (Ding et al.,, 2022) for incorporating multiple data “views” into a regression model involves minimising the objective
| (3) |
with respect to the regression parameters , in which is vector of parameters corresponding to the th view, , and is a response variable to be predicted. For the special case with parameters and , this is the objective for LASSO regression of on the concatenated data . But when , the final term encourages “cooperation” between the predictions from the different individual views, which in some circumstances leads to better predictive performance for out-of-sample data, i.e. new observations not used in fitting the model (Ding et al.,, 2022).

For a given choice of , the fitted parameters are determined by minimising (3), and prediction of the response variable for a new observation with predictor vector is . One way to select the hyper-parameters is by cross-validation, i.e., repeatedly partitioning the observations into training and “held-out” test sets, finding based on the training data for various different values of the hyper-parameters, then selecting the hyper-parameter values that minimise mean-squared error in predictions for the held-out test data.
To compare the performance of different ’s, we select using cross-validation with 20 folds, and calculate the average Mean Squared Error (MSE) across folds: we choose the value of which minimizes this. A lower MSE means the model is more accurate at predicting deprivation . In various numerical investigations exploring values with different choices of predictor data , we found no circumstances where performed better than — see for example Figure 20 — so we set in all following experiments.

Figure 21 shows the results using and different choices for . Except for PCA on the CDR data (where we have a maximum of 20 components to work with), all AJIVE and PCA regressions are done with 30 total components, which are divided equally between data sets and, for AJIVE, between joint and individual components.
We first consider using each data set individually, setting to be either the entire data set or the matrix of principal components. The CDR data gives the lowest MSE, whilst the survey data does by far the worst. In each case using PCA gives similar results to using the entire data set.
We then combine data sets: we consider using the CDR and image data, as we did for our main analysis, and then adding in the survey data. Here, we find that PCA regression does slightly better than using the entire data. The difference between PCA and AJIVE is less clear: when we have just the CDR and image data, AJIVE seems to do slightly better than PCA, but this is not the case once we also add in the survey data, although the differences in MSE are very small, so it is difficult to draw firm conclusions. However, as mentioned above AJIVE with CDR, image and survey data gives the additional useful information about forced labour risk and so this is our preferred approach.

Figure 22 shows a plot of the MSE versus the number of components, when we use several combinations of components for the CDR and image data. The black horizontal line corresponds to the null model. In each case the MSE decreases until we have around 20 components, then levels off. There does not appear to be much difference in performance between the three choices of we use here.
5 Discussion
We have seen that AJIVE allows us to identify common features across the CDR and image data sets, as well as features which are unique to each. The joint components we have found are also useful for predicting deprivation.
Incorporating the survey data, in addition to CDR and image data, does not much affect the joint components, or contribute to our ability to predict deprivation. This is perhaps surprising, but it shows that much of the information contained within the survey data can also be obtained from the other two data types. However, it may also be the case that the methods we have used are less well suited to the survey data, as it consists mostly of categorical and ordinal variables, whereas PCA and AJIVE are designed for continuous data. However, we do find that the survey data provides information about forced labour risk, which we could not detect from the other data sets.
Future research could include conducting similar analyses in different regions, to see whether the results are similar to those we have observed. In addition, since the data are cheap to obtain and the analysis is straightforward to implement, it should be possible to generate updated analyses using data from different time periods (e.g. years), which could also make way for further exploration of how the situation changes over time.
Acknowledgements
This work was supported by the Engineering and Physical Sciences Research Council [grant reference EP/T003928/1].
References
- Babenko et al., (2017) Babenko, B., Hersh, J., Newhouse, D., Ramakrishnan, A., and Swartz, T. (2017). Poverty mapping using convolutional neural networks trained on high and medium resolution satellite images, with an application in Mexico. arXiv preprint arXiv:1711.06323.
- Blumenstock et al., (2015) Blumenstock, J., Cadamuro, G., and On, R. (2015). Predicting poverty and wealth from mobile phone metadata. Science, 350(6264):1073–1076.
- Carmichael et al., (2021) Carmichael, I., Calhoun, B. C., Hoadley, K. A., Troester, M. A., Geradts, J., Couture, H. D., Olsson, L., Perou, C. M., Niethammer, M., Hannig, J., and Marron, J. S. (2021). Joint and individual analysis of breast cancer histologic images and genomic covariates. The Annals of Applied Statistics, 15(4):1697.
- Ding et al., (2022) Ding, D. Y., Li, S., Narasimhan, B., and Tibshirani, R. (2022). Cooperative learning for multiview analysis. Proceedings of the National Academy of Sciences, 119(38):e2202113119.
- Ellis, (2021) Ellis, M. (2021). Detection of vulnerable communities in East Africa via novel data streams and dynamic stochastic block models. PhD thesis, University of Nottingham.
- Engelmann et al., (2018) Engelmann, G., Smith, G., and Goulding, J. (2018). The unbanked and poverty: Predicting area-level socio-economic vulnerability from M-Money transactions. In 2018 IEEE International Conference on Big Data, pages 1357–1366. IEEE.
- Engstrom et al., (2017) Engstrom, R., Hersh, J. S., and Newhouse, D. L. (2017). Poverty from space: Using high-resolution satellite imagery for estimating economic well-being. World Bank Policy Research Working Paper, 8284.
- Feng et al., (2018) Feng, Q., Jiang, M., Hannig, J., and Marron, J. (2018). Angle-based joint and individual variation explained. Journal of multivariate analysis, 166:241–265.
- Lock et al., (2013) Lock, E. F., Hoadley, K. A., Marron, J. S., and Nobel, A. B. (2013). Joint and individual variation explained (JIVE) for integrated analysis of multiple data types. The annals of applied statistics, 7(1):523.
- Locke and Henley, (2016) Locke, A. and Henley, G. (2016). Urbanisation, land and property rights.
- Seymour et al., (2022) Seymour, R. G., Sirl, D., Preston, S. P., Dryden, I. L., Ellis, M. J. A., Perrat, B., and Goulding, J. (2022). The Bayesian Spatial Bradley–Terry model: Urban deprivation modelling in Tanzania. Journal of the Royal Statistical Society: Series C (Applied Statistics), 71(2):288–308.
- Shannon, (1948) Shannon, C. E. (1948). A mathematical theory of communication. The Bell system technical journal, 27(3):379–423.
- Smith et al., (2013) Smith, C., Mashhadi, A., and Capra, L. (2013). Ubiquitous sensing for mapping poverty in developing countries. Paper submitted to the Orange D4D Challenge.
- Smith-Clarke et al., (2014) Smith-Clarke, C., Mashhadi, A., and Capra, L. (2014). Poverty on the cheap: Estimating poverty maps using aggregated mobile communication networks. In Proceedings of the SIGCHI conference on human factors in computing systems, pages 511–520.
- Steele et al., (2017) Steele, J. E., Sundsøy, P. R., Pezzulo, C., Alegana, V. A., Bird, T. J., Blumenstock, J., Bjelland, J., Engø-Monsen, K., de Montjoye, Y.-A., Iqbal, A. M., Hadiuzzaman, K. N., Lu, X., Wetter, E., Tatem, A. J., and Bengtsson, L. (2017). Mapping poverty using mobile phone and satellite data. Journal of The Royal Society Interface, 14(127):20160690.
- Szegedy et al., (2016) Szegedy, C., Ioffe, S., Vanhoucke, V., and Alemi, A. (2016). Inception-v4, Inception-ResNet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence.
- Xie et al., (2016) Xie, M., Jean, N., Burke, M., Lobell, D., and Ermon, S. (2016). Transfer learning from deep features for remote sensing and poverty mapping. In Proceedings of the Thirtieth AAAI Conference on Artifical Intelligence (AAAI-16), pages 3929–3935.
Supplementary material
Appendix A List of CDR features
Table 2 lists CDR features with definitions.
| Variable | Level | Description |
| ratio_call_text | User | Number of calls made, divided by number of SMS sent |
| initiated_calls | User | Percent of calls which were outgoing |
| percent_initiated | User | Percent of calls and SMS which were outgoing |
| percent_pareto_calls | User | Percentage of contacts that account for of |
| call interactions | ||
| entropy_contacts | User | Entropy of call contacts |
| total_sms | User | Total SMS sent or received |
| norm_entropy | User | Entropy of visited BTS (base transceiver stations) |
| unique_bts | User | Number of unique BTS at which calls/SMS sent or received |
| frequent_bts | User | Number of BTS that account for of locations where |
| the user sent or received calls or SMS | ||
| interevent_time_sd* | User | Standard deviation of time between events (call or SMS) |
| active_days | User | Number of days on which the user sent or received a call |
| or SMS | ||
| interevent_time_call_mean | User | Mean time between call initiations |
| mean_call_interactions | User | Mean number of call interactions with each contact |
| response_delay_mean | User | Mean response delay in seconds, for texts |
| response_delay_sd | User | Standard deviation of response delay in seconds, for texts |
| active_users | Tower | Number of users for whom this tower is their home tower |
| day_interactions_overall | Tower | Total interactions between 8am and 7pm |
| evening_interactions_overall | Tower | Total interactions between 7pm and 12pm |
| night_interactions_overall | Tower | Total interactions between 12pm and 8am |
| distance_overall | Tower | Mean distance to call recipient |
Appendix B List of survey features
| How strongly do you agree with the following statement? (1-5) | |
|---|---|
| overcrowding | Overcrowding is a problem in this subward. |
| litter | The level of litter in this subward is a problem. |
| day.safety | I would feel safe in this subward during the day. |
| night.safety | I would feel safe in this subward during the night. |
| unemployment | The level of unemployment in this subward is a problem. |
| unemployment.compare | The level of unemployment in this subward is high compared |
| to the rest of Dar. | |
| poverty | Poverty is a problem in this subward. |
| medical.care | There is a good availability to medical care in this subward. |
| theft.violence | Theft or violence is a problem in this subward. |
| well.paid | People are paid well in this subward compared to the rest of |
| Dar es Salaam. | |
| Percentage scale (0-20%, 20-40%, 40-60%, 60-80%, 80-100%) | |
| move.work | In your opinion what percentage of people move to this subward |
| for work? | |
| teens.school | In your opinion what percentage of teenagers in this subward |
| aged 13-18 are in school? | |
| children.school | In your opinion what percentage of children in this subward |
| aged 12 and under are in school? | |
| mobile.money | What percentage of people in this subward use mobile money? |
| own.device | What percentage of people in this subward own a mobile device? |
Variable name Question Possible responses street.lighting Is there street lighting in this subward? No / Yes, but it’s limited and/or broken / Yes formal.employment What is the most common type of employment in this subward? Informal / Formal residence.length On average how long do people remain living in this subward? Under a year / 1-5 years / 5-10 years / 10+ years reason.travel.to What is the most common reason people travel to this subward? Social / Mixture or Other / Work reason.travel.from What is the most common reason people travel out from this subward? Social / Mixture or Other / Work time.out.weekends How much of the day do residents spend outside Less than half of the day / of this subward during the weekends? Half of the day / Most of the day time.out.week How much of the day do residents spend outside Less than half of the day / of this subward during week days? Half of the day / Most of the day start.work In your opinion what age do people generally 0-11 years / 12-14 years / start paid work in this subward? 15-17 years / 18-20 years / 21+ years medical.facilities What medical facilities are available in this Hospital / Small medical facility subward? Select all that apply. but not hospital / Doctors are working without a building, no small medical facility or hospital / None age.marriage What age do people tend to get married in this subward? min.age.marriage What is the youngest age people get married in this subward? religion What religion are most people in this subward? Christian / Mixed or Other / Muslim education.level What level of education do most people reach Primary / O-Level / A-Level / in this subward? University id.docs Do most people in this subward have identification documentations (such as passports, driving license)? Yes / No
Appendix C AJIVE with survey data
Figure 23 displays the subward scores for JC1, JC2, IC1CDR, and IC1Image, when the survey data is included in AJIVE. Figure 24 shows plots of the survey feature loadings for the two joint components. Figure 25 shows a plot of the CDR and survey loadings for JC1 and JC2.





