Unveiling Class-Labeling Structure for Universal Domain Adaptation
Abstract
As a more practical setting for unsupervised domain adaptation, Universal Domain Adaptation (UDA) is recently introduced, where the target label set is unknown. One of the big challenges in UDA is how to determine the common label set shared by source and target domains, as there is simply no labeling available in the target domain. In this paper, we employ a probabilistic approach for locating the common label set, where each source class may come from the common label set with a probability. In particular, we propose a novel approach for evaluating the probability of each source class from the common label set, where this probability is computed by the prediction margin accumulated over the whole target domain. Then, we propose a simple universal adaptation network (S-UAN) by incorporating the probabilistic structure for the common label set. Finally, we analyse the generalization bound focusing on the common label set and explore the properties on the target risk for UDA. Extensive experiments indicate that S-UAN works well in different UDA settings and outperforms the state-of-the-art methods by large margins.
Index Terms:
Universal domain adaptation, prediction margin, simple universal adaptation network, probabilistic structure.I Introduction
Domain adaptation (DA) is a technology that allows learning models trained on available source domain (or domains) generalize to unseen target domain. To verify the performance of domain adaptation, supervised information of the target domain is required in the test stage. For training, only the target data is available if we implement domain adaptation on a new target task without any annotation. However, for classification applications, previous works supposed that the relationship between source and target label sets is known, i.e. the target label set is the same label set as source domain [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18], a subset of source label set [19, 20, 21, 22] or a set partly intersecting with source label set [23, 24]. Recently, a new domain adaptation scenario has been established in [25], called Universal Domain Adaptation. Different from previous settings, UDA is a general scenario of domain adaptation, where new, unknown classes can be present and some known classes can not be found in the target domain. To solve UDA problems, a universal adaptation network (UAN) [25] was proposed as shown in Fig. 1. In UAN, a novel weighting mechanism is proposed to weight samples when implementing domain adversarial training as shown in Eq. 1, where or is defined as the probability that a source (or target) sample belongs to the common label set. This method aims to pick up samples in the common label set for alignment, because only these samples can be transferred positively. When the label in the target domain is available for verification, the ideal distribution of or is shown as Fig. 2(a). In this case, or is always equal to 1 if belongs to the common label set, while or is always equal to 0 if belongs to private label sets. Then, the universal domain adaptation degenerates to close-set domain adaptation.
| (1) | ||||
| (2) |
| (3) |
In the weighting mechanism of UAN, a non-adversarial domain classifier is designed specifically for calculating (Eq. 2) and (Eq. 3), where is the probability that belongs to the source domain estimated by the independent binary classifier . However, the use of is still not sufficient to distinguish between the common and private label sets in the source domain considerably as shown in Fig. 2(b). In our weighting mechanism, the class-labeling structure is fully utilized to capture discriminative information, which shows a conspicuous difference between common and private label sets as shown in Fig. 2(c).

By empirically computing the distribution of or in UAN, we find that source label set cannot be well separated by its weighting mechanism as shown in Fig. 2(b). There is a confusing hypothesis in their transferability criterion [25]: in the common label set, the prediction entropy of samples from source domain becomes larger because they are influenced by the high entropy samples from target domain. Based on this hypothesis, the entropy of source prediction is used to weight samples in Eq. 2. Actually, during the training process, it is ensured that each source sample is confident in its prediction. Even if the domain adversarial training encourages features to become similar between two domains, feature extractor prefers to move the target distribution to the source ones, since this is the most effective way to minimize classification loss and maximize the domain loss simultaneously. The behavior shown in Fig. 3 is the basic assumption of domain adaptation [26]. This results in a smaller prediction entropy of target samples, rather than a larger prediction entropy of source samples [25].





According to both theoretical analysis and experimental results, the prediction entropy of samples from the source domain is not discriminative enough to find out the common label set. Essentially, it is the target data that determines the common and private classes in the source domain. In this paper, we propose a novel approach without use of the additional non-adversarial domain classifier. Instead, we exploit the class-labeling structure between source and target domains, and we propose a simple but effective way to distinguish between common and private classes in the source domain: the prediction margin of target samples as illustrated in Fig. 4. The prediction margin is defined as the largest prediction probability minus the second largest prediction probability as shown in Fig. 4. This margin measures the confidence in assigning a target sample to its pseudo-label, which has the largest prediction probability. From another perspective, when one class is predicted as the pseudo-label often with a large margin, this class is considered common in two domains. On the contrary, when one class is predicted with a small margin, this class is considered private to the target domain.

Based on this hypothesis, we propose a margin vector to average the empirical margin along each pseudo-class. Each dimension of the margin vector is the empirical margin averaged over the target samples with the same pseudo-label. Through margin vector, one can easily evaluate the reliability of a known class appearing in the current data distribution. Specifically, in UDA setting, margin vector integrates the reliability of each known class belonging to the common label set. These reliabilities can be used to weight source classes when implementing domain adversarial training. Experimental results show that this class-wise weighting mechanism is more practical and effective than the sample-wise weighting mechanism in [25]. Actually, samples in the same class should share a common weight, since the probability of a class belonging to the common label set can be estimated.
The empirical margin can only be calculated after all the target data have been predicted. To this end, we propose a target margin register (TMR) that allows the margin vector to be updated during batch iteration. After an epoch of training, the margin vector stored in the TMR is equal to the empirical margin vector of all the target data. Due to lack of labeling for target samples, we use the highest probability of prediction to weight target samples. The distribution of our weighting mechanism is shown in Fig. 2(c), where samples in the common and private label set are separated considerably.
The main contributions of this paper can be summarized as:
-
1.
We propose a novel approach for evaluating the probability of each source class as from the common label set, where this probability is computed by the prediction margin accumulated over the whole target domain. This weighting mechanism requires no additional non-adversarial domain classifier, but estimates common label set efficiently.
-
2.
We propose a simple universal adaptation network (S-UAN) containing only a feature extractor, a classifier, a domain classifier and two losses, but achieves a widely improvement on four benchmarks compared with the state-of-the-art domain adaptation methods.
-
3.
We derive the generalization bound for UDA focusing on the common label set, and verify the properties of the generalization bound by analyzing experimental target risk.
II Our Approach
The main contribution of our work is a simple but effective solution of universal domain adaptation, where new, unknown classes can be present and some known classes may not exist in the target domain. We propose a simple universal adaptation network to solve this problem. Meanwhile, we analyse the generalization bound for UDA focusing on the common label set.
II-A Symbolization
In typical domain adaptation scenario, one source domain consists of labeled samples and one target domain consists of unlabeled samples are available. The source samples are drawn from the source distribution and the target samples from the target distribution . Let denotes the source label set and denotes the target label set. is the common label set of two domains. and is the label set private to the source and target domain respectively. , and denote the source distribution in , and respectively. Similarly, , , denote the target distributions in , , respectively. Actually, the target domain is unlabeled, and target labels are unavailable during training. The Jaccard distance [25] is used to define a specific UDA scenario, where can be any rational number between 0 and 1. When , UDA degenerates to closed set domain adaptation. A learning model should be designed to work stably with different even if is unknown. Both domain gap and category gap exists in UDA scenario, i.e. and . The main task for UDA is to eliminate the impact of . Meanwhile, the learning model should distinguish between target samples coming from known classes in and unknown classes in . Finally, the model should be learned to minimize the target risk in . Additionally, we derive the theoretical generalization bound of the target risk in in Section II-E.

II-B Margin Vector
We first introduce a class-wise weighting mechanism guaranteed by margin theory to UDA. The margin between features and the classification surface makes an important impact on achieving generalizable classifier. Therefore a margin theory for classification was explored by [27, 28], where the 0-1 loss for classification is replaced by the marginal loss. Here, in an unsupervised manner, we define the margin of a hypothesis predictor (a classifier) at a pseudo-labeled example as
| (4) |
| (5) |
where is the classification probability that belongs to the -th class. This margin measures the confidence in assigning an example to its pseudo-label. In particular, wrong classified samples and samples of unknown classes often have a small margin, where the classification surface intersects here.
Then, the empirical margin vector over a data distribution is defined as
| (6) |
where is the number of classes defined by . In this definition, the -th dimension of the margin vector is the empirical margin of samples with the -th pseudo-label.
Firstly, margin vector can be used to find common label set for partial domain adaptation, where some of source classes do not exist in the target domain. More generally, in UDA, margin vector can be used to extract from by weighting source classes.
II-C Target Margin Register
We first introduce a target margin register (TMR) to UDA. The TMR is formulated as a -dimensional vector , which is updated in each training step. The updated rule is defined as
| (7) |
| (8) |
where is the margin function defined in Eq. 6, which outputs a -dimensional margin vector. Note that is the accumulated margin vector over previous steps. denotes a batch of data sampled from , denotes the prediction function of the classifier, is the updating step and , where is the maximum step set before training. denotes the stored TMR-vector at step . In Eq. 7, the first term is equal to the accumulated prediction over the previous steps, the second term is the margin vector of and in the current training step, and the whole definition is equal to calculate the empirical margin vector of all the trained batches of target samples. In S-UAN algorithn, we update only when the source error lower than as shown in Algorithm 1.
Each dimension of represents the empirical margin of the target samples predicted as corresponding source class. This margin can be directly used to weight a source sample with its label :
| (9) |
where indicates the probability that a source sample belongs to , and is the -th dimension of . Unlike [25], we define the weighting mechanism in terms of class rather than individual sample. Essentially, samples in the same class should share a common weight, when the probability of a class belonging to can be estimated.
Note that or should be further normalized as [25]. In this paper, we use a modified normalization approach as
| (10) | |||
where is the normalized , is the batch size, and is the activation threshold, which is the only hyperparameter in our approach. Here, we suggest setting if is relatively large. And we analyze the hyperparameter in Section III-E.
II-D Simple Universal Adaptation Network
The main challenge of UDA is to reduce the impact of , which called domain shift in . To this end, let be the feature extractor, and be the classifier. Here, and denote the dimension of input images and extracted features respectively. Input from both domains are forwarded into to obtain extracted feature , then, is L2-normalized and fed into to estimate the classification probability of over the -th class in . The probabilities of source input are corrected by cross-entropy loss with source labels, whereas the highest probability of target input can be used to calculate [29], which are defined as
| (11) |
| (12) |
where is cross-entropy loss. Let be the binary classifier discriminating input feature from or . Inspired by [25], the domain classifier can be trained by weighting and as
| (13) | ||||
note that and are normalized as defined in Eq. 10. With such definition, the domain alignment can be implemented in as precisely as possible.
Optimization. The training of the whole model can be summarized as
| (14) |
This optimization objective is extremely simple but particularly effective. We use the gradient reversal layer [18] to reverse the gradient between and , this allows the optimization of all modules in an end-to-end way.
Inference. Finally, a target test sample is assigned to either corresponding known class or the unknown class as
| (15) |
II-E Generalization Bound Analysis for Universal Domain Adaptation
Let and be the proportion of common classes in and respectively, the Jaccard distance can be computed as
| (16) |
Suppose that is class-balanced and the sample size of each class in does not vary widely, with a large probability, the number of samples in the common label set is for randomly-picked samples from .
Lemma 1.
Suppose that both and are class-balanced. By randomly selecting the same number of samples from class-balanced and , theorem 3.4 in [30] can be modified in the common label set:
| (17) |
where is the power of , and it is the probability that induces over the choice of samples. is a collection of subsets of some domain measure space , i.e. , and assume that the VC dimension of is some finite . and are samples drawn i.i.d. from class-balanced and .
Eq.17 bounds the maximum probability that, the error of measuring domain discrepancy over sampled data and or true distribution and , is more than .
Lemma 2.
Proof.
We assume is the true labeling function. For a hypothesis , the expected risk of source and target domains in are
| (23) | ||||
and based on the definition of in [31], for any hypothesis , we have
| (24) |
which has been proved in Lemma 3 in [33]. Following the Definition 2 in [33], let the ideal joint hypothesis be the hypothesis which minimizes the combined risk
| (25) |
and the combined risk of the ideal hypothesis is
| (26) |
Theorem 1.
Let be a hypothesis space of VC dimension d. and are samples drawn i.i.d. from class-balanced and respectively. Then for any , with probability at least (over the choice of the samples), for every :
| (27) | ||||
Proof.
Here, we only bound the expected target risk in . The target risk in is much more hard to be bounded, because the distribution of unknown classes in could be completely different, i.e. . From Theorem 27, we can find that the bound of expected target risk in changes with and . Generally, is known in domain adaptation, we have the following observations:
-
1.
With fixed , if , i.e. , the upper bound of expected target risk in does not depend on the value of . If , i.e. , with the increase of , the upper bound of expected target risk in also increases when the VC dimension of the hypothesis greater than 2.
-
2.
With the increase of , the upper bound of expected target risk in decreases when , note that , i.e. .
| Method | Office-31 | ImageNet-Calech | VisDA | |||||||
| Avg | ||||||||||
| ResNet | 75.94 | 89.60 | 90.91 | 80.45 | 78.83 | 81.42 | 82.86 | 70.28 | 65.14 | 52.80 |
| DANN | 80.65 | 80.94 | 88.07 | 82.67 | 74.82 | 83.54 | 81.78 | 71.37 | 66.54 | 52.94 |
| RTN | 85.70 | 87.80 | 88.91 | 82.69 | 74.64 | 83.26 | 84.18 | 71.94 | 66.15 | 53.92 |
| IWAN | 85.25 | 90.09 | 90.00 | 84.27 | 84.22 | 86.25 | 86.68 | 72.19 | 66.48 | 58.72 |
| PADA | 85.37 | 79.26 | 90.91 | 81.68 | 55.32 | 82.61 | 79.19 | 65.47 | 58.73 | 44.98 |
| ATI | 79.38 | 92.60 | 90.08 | 88.40 | 78.85 | 81.57 | 84.48 | 71.59 | 67.36 | 54.81 |
| OSBP | 66.13 | 73.57 | 85.62 | 72.92 | 47.35 | 60.48 | 67.68 | 62.08 | 55.48 | 30.26 |
| UAN | 85.62 | 94.77 | 97.99 | 86.50 | 85.45 | 85.12 | 89.24 | 75.28 | 70.17 | 60.83 |
| S-UAN | 86.64 | 95.47 | 97.08 | 85.35 | 90.27 | 90.20 | 90.84 | 65.05 | ||
| S-UAN | 93.16 | 97.04 | 98.08 | 93.39 | 91.23 | 91.27 | 94.03 | 78.63 | 72.06 | 65.20 |
| Method | Office-Home | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Avg | |||||||||||||
| ResNet | 59.37 | 76.58 | 87.48 | 69.86 | 71.11 | 81.66 | 73.72 | 56.30 | 86.07 | 78.68 | 59.22 | 78.59 | 73.22 |
| DANN | 56.17 | 81.72 | 86.87 | 68.67 | 73.38 | 83.76 | 69.92 | 56.84 | 85.80 | 79.41 | 57.26 | 78.26 | 73.17 |
| RTN | 50.46 | 77.80 | 86.90 | 65.12 | 73.40 | 85.07 | 67.86 | 45.23 | 85.50 | 77.20 | 55.55 | 78.79 | 70.91 |
| IWAN | 52.55 | 81.40 | 86.51 | 70.58 | 70.99 | 85.29 | 74.88 | 57.33 | 85.07 | 7.48 | 59.65 | 78.91 | 73.39 |
| PADA | 39.58 | 69.37 | 76.26 | 62.57 | 66.39 | 77.47 | 48.39 | 35.79 | 79.60 | 75.94 | 44.50 | 78.10 | 62.91 |
| ATI | 52.90 | 80.37 | 85.91 | 71.08 | 72.41 | 84.39 | 74.28 | 57.84 | 85.61 | 76.06 | 60.17 | 78.42 | 73.29 |
| OSBP | 47.75 | 60.90 | 76.78 | 59.23 | 61.58 | 74.33 | 61.67 | 44.50 | 79.31 | 70.59 | 54.95 | 75.18 | 63.90 |
| UAN | 63.00 | 82.83 | 87.85 | 76.88 | 78.70 | 85.36 | 78.22 | 58.59 | 86.80 | 83.37 | 63.17 | 79.43 | 77.02 |
| S-UAN | 61.91 | 82.85 | 91.73 | 83.41 | 81.78 | 89.32 | 81.86 | 59.83 | 90.51 | 83.42 | 61.84 | 83.45 | 79.33 |
III Experiments
III-A Experimental Setup
III-A1 Datasets
Office-31 [36] dataset contains 31 classes and 3 different domains. They are photos from amazon (A), dslr (D) and webcam (W). The 10 classes shared by Office-31 and Caltech-256 [37] are used as , then in alphabetical order, the next 10 classes as and the reset 11 classes as . In these tasks .
Office-Home [38] consists of 65 categories and 4 domains: Artistic (Ar), Clip-Art (Cl), Product (Pr) and Real-World (Rw) images. Similarly, in alphabet order, the first 10 classes are used as and the next 5 classes as . According to the first property of Theorem 27, we use the rest 50 classes as . In these tasks .
VisDA2017 [39] dataset consists of 2 very different domains: synthetic images (Syn) generated by game engines and real images (Real). Both of them contain 12 classes, and we only consider the practical SynReal task. The first 6 classes are used as , the next 3 classes as and the rest as . In these tasks .
ImageNet-Caltech is established from ImageNet-1K () [40] and Caltech-256 () with 1000 and 256 classes respectively. The 84 classes shared by both domains are used as and their private classes as and . This task naturally belongs to the universal domain adaptation scenario due to the category gap between two datasets. There are two UDA tasks can be formed: and Note that the validation sets are used as target domain to eliminate the effects of pre-training. In these tasks .
Some examples in each dataset are shown in Fig. 6.

III-A2 Evaluation Details
Compared Methods. The proposed S-UAN is compared with methods in (1) Source-only without domain adaptation (DA): ResNet [41], (2) close-set DA: Domain-Adversarial Neural Networks (DANN) [18], Residual Transfer Networks (RTN) [8], (3) partial DA: Importance Weighted Adversarial Nets (IWAN) [42], Partial Adversarial DA (PADA) [21], (4) open set DA: Assign-and-Transform-Iteratively (ATI) [24], Open Set Back-Propagation (OSBP) [23], (5) UDA: Universal Adaptation Network (UAN) [25]. These methods are the state of the art in their respective scenarios. In the following experiments, we evaluation all these methods in the UDA scenario.
Evaluation Protocols. All the samples with their labels in are viewed as one unified ”unknown” class and the final accuracy is averaged by per-class accuracy for classes. We extend non-universal methods by threshold mechanism as used in [25]. Only if the prediction confidence is higher than the threshold, the input image is considered as the most likely class, otherwise the image is viewed as the ”unknown” class.
Implementation Details. We implement all the methods in PyTorch and use ResNet-50 [41] as fine-tuned model, which is pre-trained on ImageNet. The hyperparameter is set to 1 in Office-31 and VisDA, where are relatively large. While is set to 0 in Office-Home and ImageNet-Caltech, where are relatively small. Particularly, in ImageNet-Caltech task, a gradually increasing threshold are used in Eq. 15, which reaches 0.5 at the end of training.


III-B Classification Results
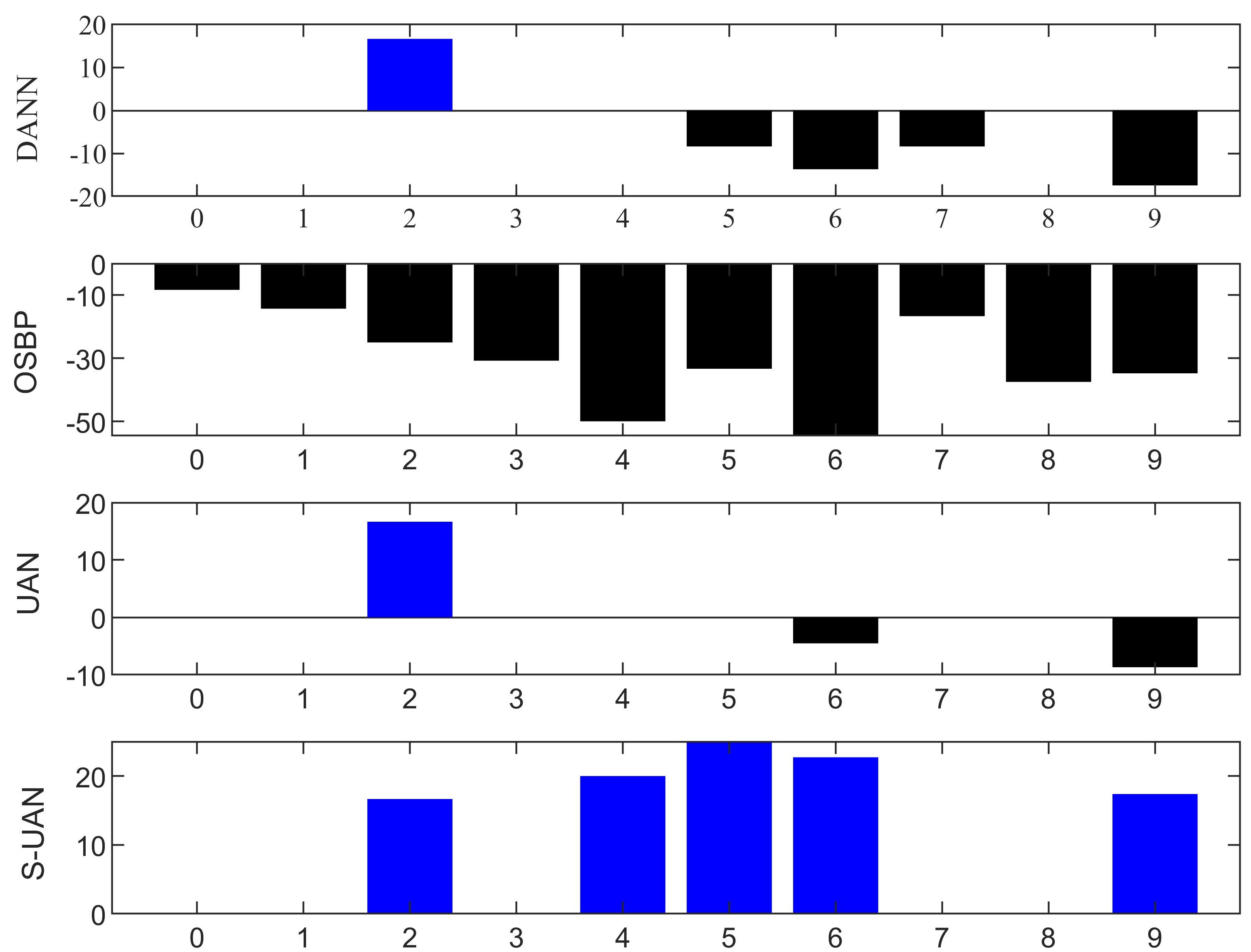
From Tables LABEL:Office-31 and LABEL:Office-Home, we can find that S-UAN outperforms all the compared methods. Particularly, we focus on the comparison with UAN [25]. Although UAN avoids negative transfer in most tasks, it still has negative transfer in some tasks. For example, Fig. 7 indicates the accuracy gain of each class compared to ResNet (no adaptation) on task . We can see that DANN, OSBP and UAN still suffer from negative transfer. Note that the accuracy of the label set arrives in ResNet. Except these classes, S-UAN avoids negative transfer and achieve widely positive transfer in all the classes. This is because S-UAN makes full use of the prediction information of the target data and employs class-wise weighting mechanism in the source domain.
Another perspective to analyze the classification results is the dimension-reduction of features. In general, low-dimensional distinguishable features are easier to distinguish in higher dimensions. To this end, we visualize features extracted from trained models by t-SNE tool. In Fig. 8, we compare S-UAN and UAN on task ImageNet-Caltech, which contains 84 common classes and 1173 total classes. Overall, the distinguishability of UAN features is not as good as S-UAN, so the classification accuracy of S-UAN is higher than UDA’s.
III-C Analysis on UDA Settings
Effect of Varying Size of . We explore the performance of methods mentioned in Section III-B with the different sizes of on in Office31 dataset, note that also changes correspondingly with fixed and . As shown in Fig. 9(a), S-UAN outperforms all the compared methods on all the sizes of . Particularly, when this UDA setting degenerates to the partial domain adaptation, where , and when , this UDA setting degenerates to the open set domain adaptation, where the performance of S-UAN is comparable to UAN’s. When vary between 0 and 21, which are the more general settings, S-UAN performs much better than UAN. When the size of appears in the middle of 0 and 21, S-UAN outperforms other methods with the largest margin. Generally, S-UAN produces better results with all size of .
Effect of Varying Size of . We also explore the performance of these methods with different size of the common label set . The same task is used as before, and we have For simplicity, we let or , and let vary from 0 to 31. Fig. 9(b) shows the performance of these methods with different sizes of . When , there is no known class appearing in target domain, i.e. . We see that the accuracy of S-UAN is similar to UDA’s. When , i.e. , we find that S-UAN outperforms all the compared methods with large margins, revealing that class-wise weighting mechanism of proposed margin vector is more general and effective than sample-wise weighting mechanism in UDA.




III-D Analysis on Target Risk
In this section, we verify the properties of generalization bound by analyzing the target risk for task . We fix . ResNet, DANN, OSBP, UAN and S-UAN are compared in what follows.
Property 1: with fixed and the increase of , the generalization bound increases when . In this experiment, we fix and set =10,13,15,20,25,26, correspondingly, . The experiment results are shown in Fig. 10(a), except DANN and OSBP, other well-behaved methods are all suffered from performance degradation with the increase of when . And when , the performance of three well-behaved methods does not vary obviously. This experimental result verifies the first property of Theorem 27. And we can find that the target risk of the proposed S-UAN is the lowest, which is the best learning algorithm for universal domain adaptation compared with the state-of-the-art domain adaptation methods.
Property 2: with the increase of , the generalization bound decreases. In this experiment, we fix and set , correspondingly, , here . The experiment results are shown in Fig. 10(b), the sampling batch size , we can see that the performance of all the methods is improved with the increase of when . Note that can only be an integer, although the generalization bound becomes higher when varies from 0 to 0.57, we find that the value of generalization bound at is lower than . This experimental result verifies the second property of Theorem 27. And the target risk of the proposed S-UAN is still the lowest of these methods.
III-E Analysis of S-UAN
Weight Analysis. To verify the inference introduced in Section I, we plot the estimated probability density distribution for different components of the and in Fig. 11. Results show that the distributions are well separated between shared and private label sets of both domains, explaining why S-UAN achieves stable performance in different UDA settings. We observe that distributions of source shared and private parts are much more distinguishable compared with UAN’s. And distributions of target shared and private parts are as distinguishable as UAN’s. Note that the definition of the weight of target samples is simple in S-UAN, but is also distinguishable enough for target shared and private parts.



Threshold Sensitivity. Although we have fixed the criterion for distinguishing unknown classes in all experiments, i.e. . We also explore the sensitivity of the threshold for analysis. As shown in Fig. 12, though S-UAN’s accuracies vary by with the change of the threshold, it achieves stable performance and outperforms other methods by large margins with the change of the threshold. Note that in our experiments, UAN’s accuracy on VisDA can’t reach their report in our experiments. However, S-UAN’s accuracies still outperform UAN’s reported accuracy, which is fully tuned and their best accuracy.


Hyperparameter Analysis. The only hyperparameter in S-UAN is the activated threshold of the normalized function as shown in Eq.10. The value of can be 0 or 1. When , has no effect on Eq.10, and all the or can be activated. When , only the or greater than the average value can be activated, and the remaining or are set to 0. In the default settings of S-UAN, is set to 1 in Office-31 and VisDA, where . And is set to 0 in Office-Home and ImageNet-Caltech, where . To do ablation study on , we also set in Office-31 and VisDA (S-UAN ) in Table LABEL:Office-31. We can find that S-UAN outperforms all the compared methods, even if in all experiments.
IV Related Work
In this section, we briefly review DA methods and margin theory in classification.
IV-A Universal Domain Adaptation
Universal Domain Adaptation was first proposed in [25], where the target label set is unknown. In traditional domain adaptation settings, the target label set or its relationship with source label set is assumed to be known. These traditional settings can be summarized by three types: closed set, partial and open set DA. Closed set DA assumes that , where the domain shift is eliminated as much as possible [1, 2, 3]. These methods provide insight in developing deep adaptation methods [4, 5, 6, 7, 8, 9, 10, 11, 43, 44, 45, 46, 47]. And some other deep adaptation methods explore architecture designs [12, 13, 14, 15, 16, 17, 48, 49, 50]. Meanwhile, with the proposal of Generative Adversarial Nets (GAN) [51], GAN-based DA methods are proposed [6, 9, 18, 52, 53]. In these methods, a discriminator is designed to distinguish source and target features, meanwhile, the feature extractor is encouraged to generate domain-invariant features which confuse . Overall, the adversarial loss is usually defined as
| (28) | ||||
We can see that the only difference between Eq. 1 and Eq. 28 is the sample-wise weighting mechanism. And the ideal distribution of or mentioned in Section I can degenerate universal domain adaptation problem by
| (29) | ||||
where and is the ideal or . A well-defined weight mechanism ensures further domain adaptation in . This is one of the basic solution for UDA.
Partial DA assumes that the target label set can be contained in the souce label set [19, 20, 21]. Obviously, this setting is not practical in the wild. Open set DA assumes that [23, 24]. And in [24], the classes private to each domain are totally consider as an “unknown” class. This setting is more practical than partial domain adaptation, but still hold that the classes private to each domain exist. Therefore, a general scenario of domain adaptation is established in [25], called universal domain adaptation.
IV-B Margin Theory for Classification
In the early study of classification problems, maximum margin techniques have been used to identify relevant-irrelevant label pairs [54] or output coding margins [55]. And a margin theory for classification was developed by [56], where the 0-1 loss for classification is replaced by developed margin loss. Recently, [57] maximize margins between relevant-relevant label pairs with different importance degrees. In [58], a maximum margin multi-dimensional classification is investigated by leveraging classification margin maximization on individual class variable and modeling relationship regularization across class variables. Based on the margin theory introduced in [56], [28] introduced the margin loss to domain adaptation scenarios, achieving better performance than the use of traditional 0-1 loss.
In our previous work [59], the margin of classification is used to adaptively adjust the margin of triplet loss. In this work, the margin of classification is used to find known classes in the target label set. And a novel margin vector is firstly introduced to universal domain adaptation setting.
V Conclusion
In this paper, we employ a probabilistic method for locating the common label set, where each source class may come from the common label set with a probability. In particular, we propose a novel margin vector for evaluating the probability of each source class from the common label set, which can estimate the probability accurately. We further propose a target margin register to enable margin vector to update continuously during iterative training. This technology can solve UDA problem efficiently. Then we propose a simple universal adaptation network (S-UAN), which is more simple but efficient than existing UDA methods. A comprehensive evaluation shows that S-UAN works well in general UDA setting and outperforms the state-of-the-art methods by large margins.
Acknowledgments
This work was supported in part by the National Natural Science Foundation of China under Grant 61671252, 61571233 and 61901229; the Natural Science Research of Higher Education Institutions of Jiangsu Province under Grant 19KJB510008.
References
- [1] K. Saenko, B. Kulis, M. Fritz, and T. Darrell, “Adapting visual category models to new domains,” in Proceedings of the European Conference on Computer Vision, ECCV, 2010, pp. 213–226.
- [2] L. Duan, I. W. Tsang, and D. Xu, “Domain transfer multiple kernel learning,” IEEE Trans. Pattern Anal. Mach. Intell., pp. 465–479, 2012.
- [3] K. Zhang, B. Schölkopf, K. Muandet, and Z. Wang, “Domain adaptation under target and conditional shift,” in Proceedings of the 30th International Conference on Machine Learning, ICML, 2013, pp. 819–827.
- [4] E. Tzeng, J. Hoffman, N. Zhang, K. Saenko, and T. Darrell, “Deep domain confusion: Maximizing for domain invariance,” CoRR, vol. abs/1412.3474, 2014.
- [5] M. Long, Y. Cao, J. Wang, and M. I. Jordan, “Learning transferable features with deep adaptation networks,” in Proceedings of the 32nd International Conference on Machine Learning, ICML, 2015, pp. 97–105.
- [6] Y. Ganin, E. Ustinova, H. Ajakan, P. Germain, H. Larochelle, F. Laviolette, M. Marchand, and V. S. Lempitsky, “Domain-adversarial training of neural networks,” J. Mach. Learn. Res., pp. 59:1–59:35, 2016.
- [7] P. Häusser, T. Frerix, A. Mordvintsev, and D. Cremers, “Associative domain adaptation,” in IEEE International Conference on Computer Vision, ICCV, 2017, pp. 2784–2792.
- [8] M. Long, H. Zhu, J. Wang, and M. I. Jordan, “Unsupervised domain adaptation with residual transfer networks,” in Advances in neural information processing systems, 2016, pp. 136–144.
- [9] E. Tzeng, J. Hoffman, K. Saenko, and T. Darrell, “Adversarial discriminative domain adaptation,” in IEEE Conference on Computer Vision and Pattern Recognition, CVPR, 2017, pp. 2962–2971.
- [10] K. Saito, K. Watanabe, Y. Ushiku, and T. Harada, “Maximum classifier discrepancy for unsupervised domain adaptation,” in IEEE Conference on Computer Vision and Pattern Recognition, CVPR, 2018, pp. 3723–3732.
- [11] M. Long, Z. Cao, J. Wang, and M. I. Jordan, “Conditional adversarial domain adaptation,” in Advances in Neural Information Processing Systems, 2018, pp. 1640–1650.
- [12] F. M. Carlucci, L. Porzi, B. Caputo, E. Ricci, and S. R. Bulò, “Autodial: Automatic domain alignment layers,” in IEEE International Conference on Computer Vision, ICCV, 2017, pp. 5077–5085.
- [13] S. Xie, Z. Zheng, L. Chen, and C. Chen, “Learning semantic representations for unsupervised domain adaptation,” in Proceedings of the 35th International Conference on Machine Learning, ICML, 2018, pp. 5419–5428.
- [14] Z. Murez, S. Kolouri, D. J. Kriegman, R. Ramamoorthi, and K. Kim, “Image to image translation for domain adaptation,” in 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR, 2018, pp. 4500–4509.
- [15] R. Volpi, P. Morerio, S. Savarese, and V. Murino, “Adversarial feature augmentation for unsupervised domain adaptation,” in IEEE Conference on Computer Vision and Pattern Recognition, CVPR, 2018, pp. 5495–5504.
- [16] L. Hu, M. Kan, S. Shan, and X. Chen, “Duplex generative adversarial network for unsupervised domain adaptation,” in IEEE Conference on Computer Vision and Pattern Recognition, CVPR, 2018, pp. 1498–1507.
- [17] Q. Chen, Y. Liu, Z. Wang, I. J. Wassell, and K. Chetty, “Re-weighted adversarial adaptation network for unsupervised domain adaptation,” in IEEE Conference on Computer Vision and Pattern Recognition, CVPR, 2018, pp. 7976–7985.
- [18] Y. Ganin, E. Ustinova, H. Ajakan, P. Germain, H. Larochelle, F. Laviolette, M. Marchand, and V. Lempitsky, “Domain-adversarial training of neural networks,” The Journal of Machine Learning Research, vol. 17, no. 1, pp. 2096–2030, 2016.
- [19] Z. Cao, M. Long, J. Wang, and M. I. Jordan, “Partial transfer learning with selective adversarial networks,” in IEEE Conference on Computer Vision and Pattern Recognition, CVPR, 2018, pp. 2724–2732.
- [20] J. Zhang, Z. Ding, W. Li, and P. Ogunbona, “Importance weighted adversarial nets for partial domain adaptation,” in IEEE Conference on Computer Vision and Pattern Recognition, CVPR, 2018, pp. 8156–8164.
- [21] Z. Cao, L. Ma, M. Long, and J. Wang, “Partial adversarial domain adaptation,” in Proceedings of the European Conference on Computer Vision, ECCV, 2018, pp. 135–150.
- [22] C. Ren, P. Ge, P. Yang, and S. Yan, “Learning target-domain-specific classifier for partial domain adaptation,” IEEE Transactions on Neural Networks and Learning Systems, pp. 1–13, 2020.
- [23] K. Saito, S. Yamamoto, Y. Ushiku, and T. Harada, “Open set domain adaptation by backpropagation,” in Proceedings of the European Conference on Computer Vision, ECCV, 2018, pp. 153–168.
- [24] P. Panareda Busto and J. Gall, “Open set domain adaptation,” in Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 754–763.
- [25] K. You, M. Long, Z. Cao, J. Wang, and M. I. Jordan, “Universal domain adaptation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 2720–2729.
- [26] Y. Ganin and V. S. Lempitsky, “Unsupervised domain adaptation by backpropagation,” in Proceedings of the 32nd International Conference on Machine Learning, ICML, vol. 37, 2015, pp. 1180–1189.
- [27] V. Koltchinskii, D. Panchenko et al., “Empirical margin distributions and bounding the generalization error of combined classifiers,” The Annals of Statistics, vol. 30, no. 1, pp. 1–50, 2002.
- [28] Y. Zhang, T. Liu, M. Long, and M. I. Jordan, “Bridging theory and algorithm for domain adaptation,” arXiv preprint arXiv:1904.05801, 2019.
- [29] H. Liu, Z. Cao, M. Long, J. Wang, and Q. Yang, “Separate to adapt: Open set domain adaptation via progressive separation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 2927–2936.
- [30] D. Kifer, S. Ben-David, and J. Gehrke, “Detecting change in data streams,” in Proceedings of the Thirtieth International Conference on Very Large Data Bases, VLDB. Morgan Kaufmann, 2004, pp. 180–191.
- [31] J. Blitzer, K. Crammer, A. Kulesza, F. Pereira, and J. Wortman, “Learning bounds for domain adaptation,” in NeurIPS. Curran Associates, Inc., 2007, pp. 129–136.
- [32] W. Ochs, “On the strong law of large numbers in quantum probability theory,” J. Philos. Log., vol. 6, no. 1, pp. 473–480, 1977.
- [33] S. Ben-David, J. Blitzer, K. Crammer, A. Kulesza, F. Pereira, and J. W. Vaughan, “A theory of learning from different domains,” Mach. Learn., vol. 79, no. 1-2, pp. 151–175, 2010.
- [34] S. Ben-David, J. Blitzer, K. Crammer, and F. Pereira, “Analysis of representations for domain adaptation,” in NeurIPS. MIT Press, 2006, pp. 137–144.
- [35] K. Crammer, M. J. Kearns, and J. Wortman, “Learning from multiple sources,” J. Mach. Learn. Res., vol. 9, pp. 1757–1774, 2008.
- [36] K. Saenko, B. Kulis, M. Fritz, and T. Darrell, “Adapting visual category models to new domains,” in European conference on computer vision. Springer, 2010, pp. 213–226.
- [37] B. Gong, Y. Shi, F. Sha, and K. Grauman, “Geodesic flow kernel for unsupervised domain adaptation,” in 2012 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2012, pp. 2066–2073.
- [38] H. Venkateswara, J. Eusebio, S. Chakraborty, and S. Panchanathan, “Deep hashing network for unsupervised domain adaptation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 5018–5027.
- [39] X. Peng, B. Usman, N. Kaushik, D. Wang, J. Hoffman, and K. Saenko, “Visda: A synthetic-to-real benchmark for visual domain adaptation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2018, pp. 2021–2026.
- [40] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein et al., “Imagenet large scale visual recognition challenge,” International journal of computer vision, vol. 115, no. 3, pp. 211–252, 2015.
- [41] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
- [42] J. Zhang, Z. Ding, W. Li, and P. Ogunbona, “Importance weighted adversarial nets for partial domain adaptation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 8156–8164.
- [43] L. Zhang, J. Fu, S. Wang, D. Zhang, Z. Dong, and C. L. Philip Chen, “Guide subspace learning for unsupervised domain adaptation,” IEEE Transactions on Neural Networks and Learning Systems, pp. 1–15, 2019.
- [44] Y. Liu, B. Du, W. Tu, M. Gong, Y. Guo, and D. Tao, “Logdet metric-based domain adaptation,” IEEE Transactions on Neural Networks and Learning Systems, pp. 1–15, 2020.
- [45] P. Wei, Y. Ke, and C. K. Goh, “Feature analysis of marginalized stacked denoising autoenconder for unsupervised domain adaptation,” IEEE Transactions on Neural Networks and Learning Systems, vol. 30, no. 5, pp. 1321–1334, 2019.
- [46] W. Deng, A. Lendasse, Y. Ong, I. W. Tsang, L. Chen, and Q. Zheng, “Domain adaption via feature selection on explicit feature map,” IEEE Transactions on Neural Networks and Learning Systems, vol. 30, no. 4, pp. 1180–1190, 2019.
- [47] R. Cai, J. Li, Z. Zhang, X. Yang, and Z. Hao, “Dach: Domain adaptation without domain information,” IEEE Transactions on Neural Networks and Learning Systems, pp. 1–13, 2020.
- [48] X. Shen, Q. Dai, S. Mao, F. Chung, and K. Choi, “Network together: Node classification via cross-network deep network embedding,” IEEE Transactions on Neural Networks and Learning Systems, pp. 1–14, 2020.
- [49] Z. Wang, B. Du, and Y. Guo, “Domain adaptation with neural embedding matching,” IEEE Transactions on Neural Networks and Learning Systems, vol. 31, no. 7, pp. 2387–2397, 2020.
- [50] J. Li, K. Lu, Z. Huang, L. Zhu, and H. T. Shen, “Heterogeneous domain adaptation through progressive alignment,” IEEE Transactions on Neural Networks and Learning Systems, vol. 30, no. 5, pp. 1381–1391, 2019.
- [51] I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. C. Courville, and Y. Bengio, “Generative adversarial nets,” in NeurIPS, 2014, pp. 2672–2680.
- [52] C. Wang, M. Niepert, and H. Li, “Recsys-dan: Discriminative adversarial networks for cross-domain recommender systems,” IEEE Transactions on Neural Networks and Learning Systems, pp. 1–10, 2019.
- [53] G. Cai, Y. Wang, L. He, and M. Zhou, “Unsupervised domain adaptation with adversarial residual transform networks,” IEEE Transactions on Neural Networks and Learning Systems, pp. 1–14, 2019.
- [54] A. Elisseeff and J. Weston, “A kernel method for multi-labelled classification,” in NeurIPS, 2001, pp. 681–687.
- [55] W. Liu and I. W. Tsang, “Large margin metric learning for multi-label prediction,” in Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, 2015, pp. 2800–2806.
- [56] V. Koltchinskii and D. Panchenko, “Empirical margin distributions and bounding the generalization error of combined classifiers,” The Annals of Stats, vol. 30, no. 1, 2000.
- [57] M. Xu, Y. Li, and Z. Zhou, “Robust multi-label learning with pro loss,” IEEE Transactions on Knowledge and Data Engineering, pp. 1–1, 2019.
- [58] B. Jia and M. Zhang, “Maximum margin multi-dimensional classification,” in The Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI, 2020, pp. 4312–4319.
- [59] Y. Yin, Z. Yang, H. Hu, and X. Wu, “Metric-learning-assisted domain adaptation,” CoRR, vol. abs/2004.10963, 2020.