Unsupervised quantum machine learning for fraud detection
Abstract
We develop quantum protocols for anomaly detection and apply them to the task of credit card fraud detection (FD). First, we establish classical benchmarks based on supervised and unsupervised machine learning methods, where average precision is chosen as a robust metric for detecting anomalous data. We focus on kernel-based approaches for ease of direct comparison, basing our unsupervised modelling on one-class support vector machines (OC-SVM). Next, we employ quantum kernels of different type for performing anomaly detection, and observe that quantum FD can challenge equivalent classical protocols at increasing number of features (equal to the number of qubits for data embedding). Performing simulations with registers up to 20 qubits, we find that quantum kernels with re-uploading demonstrate better average precision, with the advantage increasing with system size. Specifically, at 20 qubits we reach the quantum-classical separation of average precision being equal to 15%. We discuss the prospects of fraud detection with near- and mid-term quantum hardware, and describe possible future improvements.
I Introduction
Quantum computing (QC) can potentially offer advantage in solving large-scale computational problems [1]. Most likely beneficiaries of QC include chemistry [2], material science [3, 4], cryptography and secure computing [5, 6], high energy physics [7], multisimulation [8, 9], as well as data [10, 11, 12] and financial [13, 14] analysis. Specifically, financial applications of quantum computing include optimization [13], speeding-up Monte-Carlo for derivative pricing [14, 15], and numerous tasks targeted by quantum machine learning [12, 16].
Quantum machine learning (QML) has attracted attention due to the possibility of speeding up various data-driven tasks. Quantum linear algebra subroutines can offer ways of advancing QML in the long run [11], but are too costly for near-term operation. The rise of variational quantum protocols has brought another wave of ideas in QML [17], with the goal shifted towards constructing expressive models as parametrized quantum circuits [12]. Here, the major ingredient corresponds to feature map-based encoding of data, which favors near-term operation [18, 19, 20]. To date, the most widespread tasks for QML correspond to supervised learning, and in particular classification [21, 22]. Examples include variational quantum classifiers [23, 18, 24, 25, 26], quantum convolutional neural networks [27, 28, 29], and quantum kernel-based classification [23, 19, 30]. Other supervised QML tasks correspond to regression [18, 31], solving linear [32, 33] and differential equations [8, 9, 31], and quantum model discovery [34].
Going beyond supervised methods, generative modelling and specifically generative adversarial networks (GANs) attracted a significant attention [35, 36, 37, 38, 39]. However, other subjects of unsupervised learning, specifically corresponding to clustering, remain under-explored. Among the few advances are quantum principal component analysis (PCA) [10], quantum kernel PCA [40] and q-means (quantum version of k-means clustering) [41]. These however target fault-tolerant operation in the long term and primarily assume a purely quantum dataset. From the near-term perspective, the prediction of financial crashes was analyzed using quantum annealer architecture [42] and recently a variational quantum clustering was proposed for the digital operation mode [43].
In this work, we target an important QML-for-finance application corresponding to the task of fraud detection (FD). This can be seen as detection of anomalies (outliers) in datasets with dominant number of nominal (genuine) samples [44]. One example relevant from the business perspective corresponds to credit card fraud detection [45]. Essentially, the task corresponds to clustering nominal data in an unsupervised fashion, such that potential fraud events can be labeled as anomalous. The problem becomes challenging when datasets are described by samples with many features, which additionally are strongly correlated. Classical machine learning methods approach anomaly detection in several ways. Distance-based anomaly detection is performed by measuring distances between samples and assigning corresponding clusters [46]. Density-based approaches such as local outlier factor (LOF) algorithm [47] use estimates of local density, and predict outliers from low-density regions. Isolation Forest [48] was proposed as a way of isolating anomalies on binary trees. However, the aforementioned methods do not have direct quantum analogs. Deep anomaly detection was recently approached by utilizing deep neural networks, with a notable example of AnoGAN [49, 50], and its quantum version was considered recently in Ref. [51]. Finally, kernel-based methods are regularly used for anomaly detection as performed by one-class support vector machines (OC-SVM) [52] and support vector data description [53], which use high-dimensional support vectors for drawing decision boundaries between nominal and anomalous samples. Recently, kernel-based methods were used as an integral part of state-of-the-art anomaly detection [54, 55].
Here, we develop a connection between quantum kernel methods and unsupervised anomaly detection. Specifically, we use quantum kernels as a basis for one-class SVM and apply the approach to detect fraud in a credit card transaction dataset. Using pre-processing of the dataset, we test the approach at increasing number of qubits (features), and compare to classical results obtained from optimized radial basis function kernels. We observe that at 20 qubits the separation between quantum and classical detection precision reaches 15%, highlighting high expressivity of quantum kernels and potential advantage in boosting FD performance. We also discuss potential prospects and open challenges for the area.
II Fraud detection: classical benchmarks
We aim to develop strategies for detecting anomalies, specifically considering financial applications in fraud detection. For this, we use a credit card fraud dataset from Kaggle [56], where anonymized data is collected into nominal (genuine) and anomalous (fraudulent) transactions as described by 28 anonymized features. These are nameless variables represented by float numbers. Additionally, two features being “time” and “amount” of transaction are supplied. For simplicity, we only consider the 28 anonymized features. The dataset contains 492 fraud cases from the total of 284,807 transactions, and is highly imbalanced. In this situation, the accuracy metric (ratio of the number of correct predictions to total number of predictions) should be avoided as it is not sufficiently informative. The F1 score (harmonic mean of recall and precision with respect to the anomaly class) is often used in imbalanced classification problems. However, as this requires setting a classification score threshold, we prefer using a threshold-free metric called average precision (AP). This corresponds to the precision at each threshold, weighted by the increase in recall from previous threshold and averaged over the full grid.
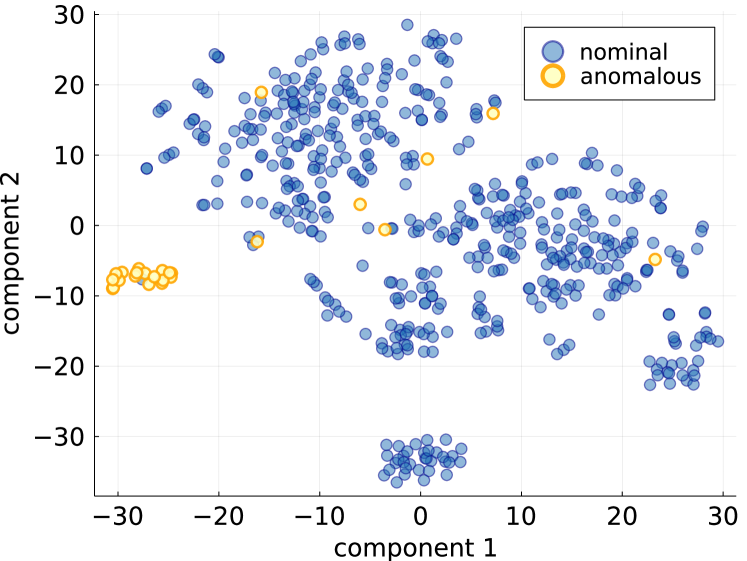
To proceed with the analysis, we sub-sample the dataset to make it manageable for near-term quantum simulations. We furthermore sample selectively to increase the share of anomalies and balance the dataset. We select 500 samples including 25 fraud examples and visualize the high dimensional dataset via t-SNE. The result is shown in Fig. 1. We observe that visually t-SNE shows a separation between nominal and anomalous samples, but sole visualization map does not allow to track all fraudulent transactions, and additional clusters of nominal transactions are also present. This demonstrates the challenge of high-quality fraud detection.
Next, we perform dimensionality reduction to match the number of features with the number of qubits used in simulation. For this, we use principal component analysis and keep only the first principal components. Before applying PCA, we use feature-wise standard scaling, i.e. we subtract the mean and scale by the standard deviation for each feature. We also vary the number of features to see how the classical detection changes with the number of features. Later, we use quantum data loading techniques where corresponds to the number of qubits, thus facilitating the comparison between classical and quantum methods at increasing system size. We note that in the quantum case it is also important to scale features such that each component can be loaded by using quantum circuits.
For the classical fraud detection we choose several protocols, which are separated into supervised and unsupervised approaches. The supervised methods include logistic regression and support vector classification (SVC), although the former is simply for added context rather than comparison to a quantum analogue. For the unsupervised method we use one-class support vector machine (OC-SVM). For both SVC and OC-SVM we use radial basis functions (RBF) as the kernel mapping.
For hyperparameter tuning we choose to tune the regularisation parameter for all models as well as in the case of RBF SVM. Hyperparameter tuning is performed by random search and choosing the parameter values that yield the highest cross-validation AP score. Conceptually, this can be troublesome in the unsupervised setting, as target labels are not supposed to be available. However, it is common practice in research on unsupervised methods to consider labels to be present in the validation set, and we adopt the same approach to establish the optimized classical benchmarks. In the numerical implementations, we use the scikit-learn library for the logistic regression, building SVC models, and performing the hyperparameter search.
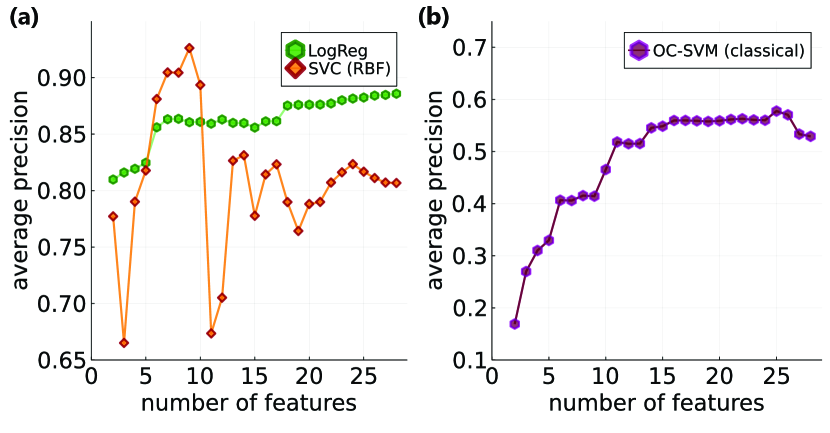
Supervised detection (classification). First, we apply logistic regression (LogReg) with L2 regularization. The results are shown in Fig. 2(a) with green hexagons. With tuning of by cross-validation, the performance improves gradually. At the same time, we note that without tuning the performance peaks at five to ten features, and at increased number of features we observed a deterioration of average precision. This shows that models are prone to overfitting at large number of features.
Second, we use a supervised method based on support vector classification [57]. For this, the pre-processed dataset of credit card transactions is used for building support vectors and drawing a decision boundary via minimizing the hinge loss [22]. The key quantity for building SVC models is a kernel function that quantifies a distance between samples and as their inner product. Typically, kernels are designed such that data points are compared in a high-dimensional space. One of the most successful kernels corresponds to a radial basis function (RBF), which is defined as , where is a hyperparameter that controls kernel bandwidth, and denotes squared Euclidean distance between points. The optimal prediction model can be written as , where are coefficients coming from the hinge loss minimization. As the model is linear, the optimization is convex, and only requires performing matrix-vector multiplications for the vector of labels and a Gram matrix for data points. The Gram matrix is a matrix formed by kernels evaluated for all possible pairs of data points. The evaluation of the Gram matrix is the most computationally expensive part of SVC, as the number of evaluations scales as with the dataset sample size , while other post-processing steps are straightforward (implemented in scikit-learn).
The results of the supervised support vector classification are shown in Fig. 2(a) by red diamonds. We observe a level of performance slightly higher than the logistic regression for five-to-ten feature region, but note that the performance at larger number of features drops slightly in AP, likely due to overfitting. These results set the bar from classical benchmarking of supervised classification, which we later compare to quantum kernel approach. We can conclude that supervised methods overall show high performance, but require prior knowledge of fraud cases and do not generalize to new type of fraud. We proceed to show how to detect previously unseen fraud types with unsupervised methods.
Unsupervised anomaly detection. Once the supervised benchmarks are established, we build a classical workflow for unsupervised anomaly detection. Here, we concentrate on kernel-based methods and specifically the one-class support vector machine approach. The idea is to separate a class of nominal points by a hyperplane such that they are distinct from anomalous samples. This is also sometimes referred as novelty detection [52]. Similarly to SVC, OC-SVM relies on calculating Gram matrices for datasets with confirmed (nominal) transactions. Additionally to kernel-related hyperparameters, OC-SVM relies on another hyperparameter being an estimated fraction of anomalies. We stress that the knowledge about classes of transactions is only used when plotting the average precision, but not used when building models.
The results for OC-SVM anomaly detection with RBF kernels are shown in Fig. 2(b), as a function of increased feature space (number of principal components). Here, we used the default values suggested for OC-SVM taken as and small maximum anomaly fraction . We observe a gradual increase of average precision for anomaly detection at growing number of features, that starts to saturate around 15 features at an AP of 0.55. Hyperparameter tuning of and does not yield significantly different results. A small decrease of AP for large can be seen as an inability to use correlations from remaining principal components. As quantum kernels offer expressivity advantage and believed to be suitable for highly-correlate datasets, we test the unsupervised OC-SVM below using quantum data encoding.
III Fraud detection: quantum approach
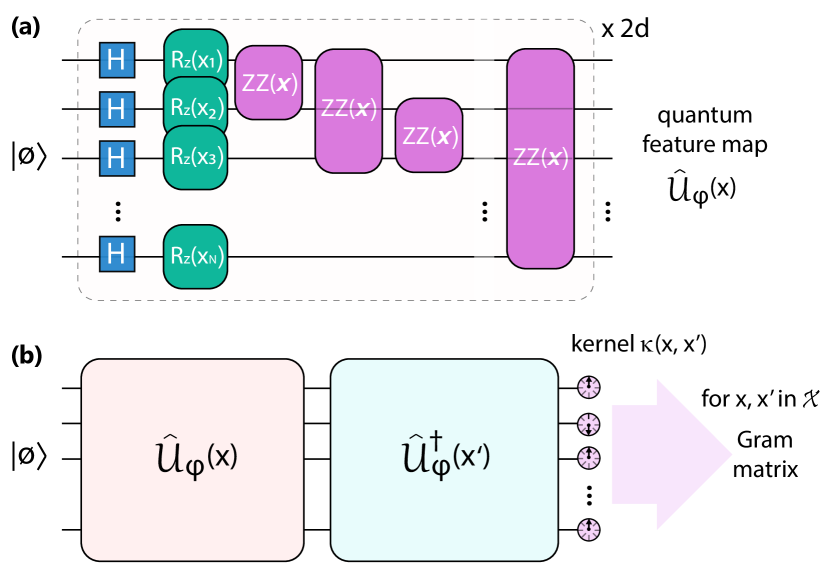
We proceed to develop the protocols for quantum anomaly detection. Given the connection between classical and quantum kernels [30], we propose to use unsupervised learning approaches with the kernel structure, and employ quantum kernels. We start with a dataset of points in the input space . First, we need to embed the data into a quantum state of an -qubit register. We approach this by performing a feature map as a quantum circuit applied to the trivial product state, . One example, corresponding to the instantaneous quantum polynomial (IQP) circuit is shown in Fig. 3(a). This maps a datum into a high dimensional space, facilitating the use of kernel trick as employed in support vector machines, where the (generally nonlinear) map modifies and often increases the space dimension of data (leading to so-called latent space representation). The quantum feature map is defined by the circuit structure , where the function determines gate properties. Additionally, we may use a variational circuit (defined by its structure and a vector of variational parameters ). This adapts the measurement basis for the readout, and can be used later for the quantum kernel alignment [58, 59]. Otherwise, fixed circuit parameters are used. The sequence of circuits is often called a quantum neural network (QNN). It generates a high-dimensional latent space representation of the data point . The choice of a feature map defines the success of learning procedure, determined by its expressivity [19, 60, 20, 61].
For running a quantum protocol we use a quantum kernel trick for support vector machines (SVM). Quantum SVM operation relies on the comparison of data points in the Hilbert space. This can be measured as an inner product . The overlap can be measured in a simple form by evaluating return probabilities [Fig. 3(b)], albeit requiring an increased number of measurement shots. Other options for overlap-based kernel evaluation include SWAP and Hadamard tests [62], that use ancillary qubits and controlled gates. Alternatively, one may substitute state overlap by an effective distance measurement , where expectations of local Pauli operators are compared instead. This is referred as the projective kernel method [63], which led to classification with up to thirty qubits when using high-performance computing. Recently, it was shown that under conditions of controlled kernel bandwidth overlap-based and projected quantum kernels lead to similar performance [64], and it is possible to choose one that is more suitable to particular system. Finally, once the Gram matrix is evaluated on a quantum computer (or its simulator), the model is formed using the same steps as in the classical workflow.
We proceed to choose possible quantum feature maps. Concentrating on the near-term operation, these typically correspond to either products of data-dependent rotations with variational circuits in between [18, 8], evolution circuits with Heisenberg or spin-glass Hamiltonian [63, 65], or IQP circuits that lead to computationally-hard kernels [23, 66]. Other options with proven exponential advantage come from circuits used for solving discrete logarithm problems [67]. Each feature map can be applied several times following the same circuit structure (so-called data re-uploading technique [25, 60]), increasing the expressivity of circuits. Unless some nonlinear map is applied to , the associated quantum kernels can be seen as Fourier series , where a set frequencies is defined by generators of data encoding, and may contain up to exponentially many frequencies [68]. The coefficients of Fourier series are defined by data-independent circuits. We note that given the periodic nature of quantum encoding, it is important to normalize features such that data samples are distinguished without ambiguity.
We perform numerical test for quantum kernels at small system sizes, and observe that overall IQP circuits with re-uploading offer highest performance for classification. We keep the number of qubits being equal to the number of features, where one qubit is responsible for uploading one feature, and the information is spread by quantum circuits that scramble the state. Specifically, we concentrate on IQP circuits re-uploaded times, such that mappings are expressive, yet do not lead to overfitted models. The structure of circuits is described in Refs. [23, 63, 64], and is shown in Fig. 3(a). IQP mapping consists of a layer of Hadamards, followed of -dependent rotations around axis of each qubit (one feature per qubit). Then, we evolve states under pairwise two-qubit interactions of feature type, with phases being dependent on products of two features. The sequence is repeated twice to form the IQP layer (per convention), and re-uploaded times with shallow random quantum circuits in between to avoid coherent gate cancellation. We do not include any trainable parameters in the quantum circuit. The kernels are evaluated using return probabilities, and we use state vector simulation.
We proceed to run quantum kernel classification and anomaly detection. The same credit card dataset is used, with each feature being scaled by a prefactor . This allows to make sure that phases of embedding are all smaller than , and naturally lowers the bandwidth of quantum kernels. We also confirmed that fine-tuning is not necessary and modification of does not lead major performance changes. For defining and simulating the quantum circuits, we used Pennylane library for Python, with the JAX interface that allows for compiling the circuits with XLA. This results in fast, parallelized operation across CPU and GPU resources. Additionally, we implement batched Gram matrix evaluation with kernel evaluations streamlined over different values. For computing we used an NVIDIA A100 GPU with 40 GB memory (peak memory bandwidth up to 1555 GB/s).
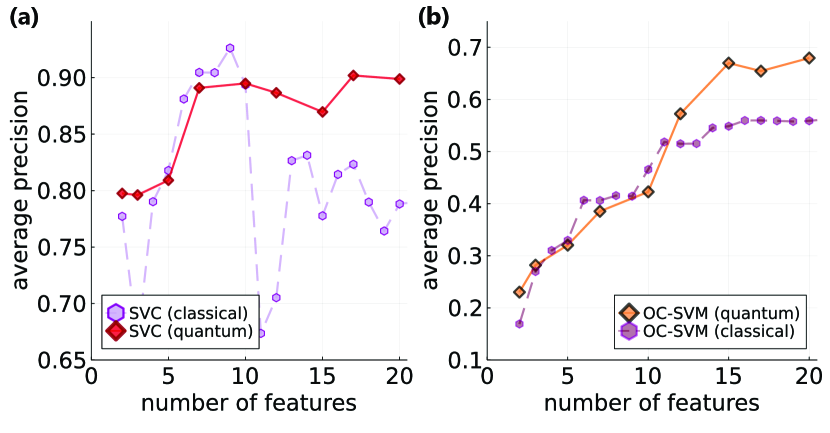
The results of supervised quantum classification are shown in Fig. 4(a), where IQP kernel performance is shown in red diamonds (solid curve). At small number of features we observe increase of average precision up to 0.9 values for five-to-ten features. Notably, the classical kernel model performance deteriorates as we go beyond 10 features, while the quantum kernel model performance does not, and even reaches new highs around 17 features/qubits. At we see a clear separation of performance between quantum and classical (RBF) kernels. This suggests that quantum kernels avoid overfitting, a feature previously studied in other works [69, 70]. It can be also interpreted as quantum mappings being less sensitive to noise added with the higher order principal components. This is a positive sign showing expressivity/learning advantage for certain tasks performed on classical datasets.
Next, we proceed to describe findings from unsupervised quantum anomaly detection. The results are shown in Fig. 4(b). Similarly to classical RBF kernels, quantum kernels based on IQP circuits show improved average precision, with a separation developing past features (qubits). Importantly, AP for quantum kernels continue to grow, and show maximal AP of up to 0.7 at qubits. This shows that quantum kernels outperform classical kernels with additional 15% of precision, showing a favourable operation of quantum kernels. This suggests a potential use of quantum kernels when working with datasets that require learning for correlated multi-feature data in the unsupervised fashion. This represents one of the main messages of the study.
IV Discussion and perspectives
We see that quantum kernels can outperform classical kernels at increasing size of feature space, and show their excellent suitability for unsupervised anomaly detection. Does it make QC a viable choice for industrially-relevant fraud detection? Let us critically analyse potential benefits and drawbacks for future applications of quantum computers in the sector.
As an obvious benefit we consider an increased quality of detecting fraud — even a few-percent increase of average precision can lead to multi-million savings (with a billion pounds of fraud prevented yearly in the UK, changes in detection mechanism of 15% bring £150 million back into economy). Another important feature of developing unsupervised methods is in detecting potentially new types of fraud (unlike simple classification), working towards preventing cases that are not tracked with current methods. To drive the change of detection mechanisms and adopt QC-based (or generally ML-driven) strategies we need to assess the required resources. Specifically, to understand future steps in QC for fraud detection we need to: 1) define relevant timescales and precision targets for training and inference of fraudulent transactions; 2) match these timescales with resources available currently and foreseen in the near- and mid-term future.
Training of FD models based on quantum kernels crucially depends on the ability to evaluate the Gram matrix of distances between samples (e.g. transactions). Typical sizes of credit card datasets count over 100,000 representative samples (further subsampled for scalable training). Given the scaling of the full Gram matrix estimation in terms of kernel evaluations, the computational cost can be large. This shall be ideally parallelized (using different QC nodes) and in principle can take significantly long time for building models. In the case of constantly appearing new transactions needs to be updated on-the-fly. The corresponding cost is in terms of kernel evaluations for adding a sample, which is substantial when working with large datasets. Important training time scales in this case can be at the scale of weeks (or months) during which the fraud landscape evolves, giving enough time for adjusting the fraud detection models. We note that this part is similar to large-scale training of deep neural networks, that despite large computational cost for training (several weeks and more on multi-GPU clusters), offers an excellent way for improving performance. We expect that relevant tasks in fraud detection with quantum computers will require similar training times, matching the pace at which new types of frauds emerge. However, a crucial point is not just in building models, but the time needed for inference. Namely, to assign a label (fraud or not) for detecting new-coming samples we require kernel evaluations. This requires significant resources if all incoming transactions are tested, and can be hindered by relatively slow absolute processing rates of quantum hardware (see the discussion below). If a single entry can be tested with sub-millisecond operational time one can consider it for real-time use. However, if the test requires an hour, this automatically precludes QC runs for real-time detection, and can only be used during additional checks. Thus, QC-based fraud detection may be not well-suited for en masse testing of transactions, but rather checks of highly prioritised cases. We believe that the question of prioritisation and reduction of kernel evaluations (choosing those points that lead to non-negligible overlaps) is one of fundamental questions of quantum fraud detection.
Now, let us match the required timescales to currently available quantum resources (we set them as weeks for training and as short as possible for inference). To do the analysis, we choose three different platforms: 1) superconducting circuits (SCs); 2) trapped ions; 3) optical systems. Importantly, in each case we do not stick to concrete realisations, but rather analyse possible best and median performance as derived from physical limits of each system. For the reduced size dataset (as considered in numerical statevector calculations) we use 500 samples, with the size of Gram matrix being . The quantum cost of kernel evaluation is then defined as circuit runtime times the number of measurement shots needed to collect the statistics. We also consider training and inference times for large datasets that arise in industrially-relevant use-cases, setting the number of samples to .
Superconducting circuits. First, we consider SC chips, which are developed by various companies and academic groups worldwide [71, 72, 73, 74, 75, 76, 77]. This powerful quantum platform has shown tremendous growth due to the mixture of good scalability and microwave-frequency operation. With typical quantum gate times ranging in 10-100 ns [72, 73, 74], and T1 times of s, single circuit evaluation may be performed within a microsecond, leading to MHz repetition. More conservative estimates correspond to 1 kHZ repetition, where a passive reset is used [78]. Reproducible kernel measurements require at least measurement shots, and for high-quality estimates at increased register size this may grow to (e.g. typical budget for near-term quantum chemistry protocols [79]). As we require kernel evaluations, this brings us to s training time at optimistic MHz rates for reduced-size datasets and minimal number of shots. If number of shots grows to , the training time grows to 28 hours with a single QC. For the pessimistic KHz gate rates, the minimal budget of matches the same cost of 28 hours. The inference time is significantly smaller in the case of reduced dataset, as it takes s for minimal shots (can enable close to real time detection), and increases into minuted for shots. This poses an important question of required for stable estimation of Gram matrices and high-quality inference.
For large datesets of samples forming full Gram matrices is an extremely costly procedure. With MHz absolute rates and shots the full calculation can require 16 weeks. However, one may potentially use randomized protocols for a partial inference of Gram matrices, and adaptive detection [80]. In this case the asymptotic scaling of training becomes linear with the number of samples, , reducing its time to min, with potentially much smaller inference times. We note that the task of fraud detection with small training and inference times is a priority for future work and implementation.
Trapped ions. Next, we consider trapped ions platform with high fidelity gates but slower absolute clock rates of quantum processors. With s execution time for a single gate [81, 82], as well as long T1 (up to second), the runtime for a sequence of gates optimistically reaches s (including costly readout), and absolute rates per shot of 10 kHz. Taking the 500-sample dataset with kernel evaluations and assuming measurement shots, we require around 3 hours for training. For full training requires 17 weeks, calling for shot-frugal kernel evaluation and parallel kernel evaluation.
For large datasets of samples forming full Gram matrices at 10 kHz rates may become infeasible with a single processor, as a brute force evaluation even at may require 30 years, with 3 hours of inference time. This suggests that a drastic reduction of the number of kernel evaluations (lowering down scaling to linear) and number of shots is required for working with big data.
Photonic chips. Finally, we consider potential optical realizations of quantum computers. Hypothetically, these shall be characterized by highest absolute clock rates of quantum processors, defined by photo lifetime in photonic structures reaching 100 ps [83, 84, 85]. With gate sequence times of comparable size, performing makes training of small dataset fast (10 milliseconds) that grows into 10 seconds for training with . The large -sample dataset can take 17 minutes of training at , remaining manageable for more shots if the sparse Gram matrix is used. However, we note that there is no established way to do optical computing with deterministic gates yet, so finding suitable architectures shall be prioritized when measuring large number of shots is required.
V Conclusions
We studied the problem of fraud detection based on unsupervised quantum machine learning. For this we developed protocols that utilize kernel structure (specifically, one-class support vector machines) and tested anomaly detection with different types of quantum kernels. Using the credit card fraud dataset with PCA pre-processing, we tested the approach at increasing number of features (qubits), and compared to fine-tuned classical methods. Our numerical simulations ranged from few to 20 qubits, where we used fast batched simulation run on NVIDIA A100 GPU. For the supervised fraud classification task we observed that quantum kernels offer higher expressivity and generalization, outperforming RBF kernels by over ten percent of average precision (AP). Moreover, for unsupervised fraud detection we observed a clear separation between average precision of quantum kernel methods and classical unsupervised learning, showing 15% increase of AP that grows at larger system size. Given favourable scaling in silico, we analysed possible timescales for future quantum hardware simulations.
We note several directions for future research that may appear crucial for further developing the quantum fraud detection. First, quantum kernels used for fraud detection can be adjusted to optimize the performance, ideally having a structure that represents correlations in each dataset. Here, a possible problem becomes data leakage — once we train model in supervised way, this may hinder unsupervised anomaly detection via additional bias. Second, as size of datasets is typically large, the quadratic scaling for training times shall be lowered. This requires tailored ways of forming a Gram matrix, possibly with randomized or sparse approaches rather than the bruteforce full evaluation. This task is even more crucial for running on quantum hardware with smaller absolute rates of operation. Third, the number of measurement shots needs to be established at the level where kernel measurement is close to deterministic (possibly, controlled by kernel structure), yet is minimized to reduce the runtime.
Let us also comment on the potential for reaching a quantum advantage for considered use-case and approaches. Additionally to the discussion of quantum hardware capabilities, we stress that the timeline for QC-based fraud detection largely depends on insimulability of the proposed approach on classical hardware. Namely, advantageous implementation of quantum FD requires going beyond calculations performed for 20-qubit registers (reaching 50-100 qubits for strong separation), as well as deep quantum kernels. We also note the requirement for fast sampling and low latency operation, which can potentially offer quantum advantage. The exact timeline of implementing quantum FD in industrial pipelines largely depends on the combination of discussed factors and ability to solve open problems.
Disclaimer
This paper was prepared for information purposes, and is not a product of HSBC Bank Plc. or its affiliates. Neither HSBC Bank Plc. nor any of its affiliates make any explicit or implied representation or warranty and none of them accept any liability in connection with this paper, including, but limited to, the completeness, accuracy, reliability of information contained herein and the potential legal, compliance, tax or accounting effects thereof. This document is not intended as investment research or investment advice, or a recommendation, offer or solicitation for the purchase or sale of any security, financial instrument, financial product or service, or to be used in any way for evaluating the merits of participating in any transaction.
Acknowledgements.
We would like to thank Omar Jamil and Felicity Guest for helping with classical benchmarking. The authors acknowledge the support from Innovate UK ISCF Germinator project number 10003408.References
- [1] Michael A. Nielsen and Isaac L. Chuang. Quantum Computation and Quantum Information. Cambridge University Press, 2000.
- [2] Sam McArdle, Suguru Endo, Alán Aspuru-Guzik, Simon C. Benjamin, and Xiao Yuan. Quantum computational chemistry. Rev. Mod. Phys., 92:015003, Mar 2020.
- [3] Qubits meet materials science. Nature Reviews Materials, 6(10):869–869, Oct 2021.
- [4] Chris Cade, Lana Mineh, Ashley Montanaro, and Stasja Stanisic. Strategies for solving the fermi-hubbard model on near-term quantum computers. Phys. Rev. B, 102:235122, Dec 2020.
- [5] Petros Wallden and Elham Kashefi. Cyber security in the quantum era. Commun. ACM, 62(4):120, mar 2019.
- [6] Dominik Leichtle, Luka Music, Elham Kashefi, and Harold Ollivier. Verifying bqp computations on noisy devices with minimal overhead. PRX Quantum, 2:040302, Oct 2021.
- [7] John Preskill. Simulating quantum field theory with a quantum computer, 2018.
- [8] Oleksandr Kyriienko, Annie E. Paine, and Vincent E. Elfving. Solving nonlinear differential equations with differentiable quantum circuits. Phys. Rev. A, 103:052416, May 2021.
- [9] Michael Lubasch, Jaewoo Joo, Pierre Moinier, Martin Kiffner, and Dieter Jaksch. Variational quantum algorithms for nonlinear problems. Phys. Rev. A, 101:010301, Jan 2020.
- [10] Seth Lloyd, Masoud Mohseni, and Patrick Rebentrost. Quantum principal component analysis. Nature Physics, 10(9):631–633, Sep 2014.
- [11] Jacob Biamonte, Peter Wittek, Nicola Pancotti, Patrick Rebentrost, Nathan Wiebe, and Seth Lloyd. Quantum machine learning. Nature, 549(7671):195–202, Sep 2017.
- [12] Marcello Benedetti, Erika Lloyd, Stefan Sack, and Mattia Fiorentini. Parameterized quantum circuits as machine learning models. Quantum Science and Technology, 4(4):043001, nov 2019.
- [13] Román Orús, Samuel Mugel, and Enrique Lizaso. Quantum computing for finance: Overview and prospects. Reviews in Physics, 4:100028, 2019.
- [14] Dylan Herman, Cody Googin, Xiaoyuan Liu, Alexey Galda, Ilya Safro, Yue Sun, Marco Pistoia, and Yuri Alexeev. A survey of quantum computing for finance, 2022.
- [15] Nikitas Stamatopoulos, Guglielmo Mazzola, Stefan Woerner, and William J. Zeng. Towards Quantum Advantage in Financial Market Risk using Quantum Gradient Algorithms. Quantum, 6:770, July 2022.
- [16] Kishor Bharti, Alba Cervera-Lierta, Thi Ha Kyaw, Tobias Haug, Sumner Alperin-Lea, Abhinav Anand, Matthias Degroote, Hermanni Heimonen, Jakob S. Kottmann, Tim Menke, Wai-Keong Mok, Sukin Sim, Leong-Chuan Kwek, and Alán Aspuru-Guzik. Noisy intermediate-scale quantum algorithms. Rev. Mod. Phys., 94:015004, Feb 2022.
- [17] Marco Cerezo, Andrew Arrasmith, Ryan Babbush, Simon C Benjamin, Suguru Endo, Keisuke Fujii, Jarrod R McClean, Kosuke Mitarai, Xiao Yuan, Lukasz Cincio, et al. Variational quantum algorithms. Nature Reviews Physics, 3(9):625–644, 2021.
- [18] K. Mitarai, M. Negoro, M. Kitagawa, and K. Fujii. Quantum circuit learning. Phys. Rev. A, 98:032309, Sep 2018.
- [19] Maria Schuld and Nathan Killoran. Quantum machine learning in feature hilbert spaces. Phys. Rev. Lett., 122:040504, Feb 2019.
- [20] Amira Abbas, David Sutter, Christa Zoufal, Aurelien Lucchi, Alessio Figalli, and Stefan Woerner. The power of quantum neural networks. Nature Computational Science, 1(6):403–409, Jun 2021.
- [21] N. Schetakis, D. Aghamalyan, P. Griffin, and M. Boguslavsky. Review of some existing qml frameworks and novel hybrid classical–quantum neural networks realising binary classification for the noisy datasets. Scientific Reports, 12(1):11927, Jul 2022.
- [22] Weikang Li and Dong-Ling Deng. Recent advances for quantum classifiers. Science China Physics, Mechanics & Astronomy, 65(2):220301, Dec 2021.
- [23] Vojtěch Havlíček, Antonio D. Córcoles, Kristan Temme, Aram W. Harrow, Abhinav Kandala, Jerry M. Chow, and Jay M. Gambetta. Supervised learning with quantum-enhanced feature spaces. Nature, 567(7747):209–212, Mar 2019.
- [24] Maria Schuld, Alex Bocharov, Krysta M. Svore, and Nathan Wiebe. Circuit-centric quantum classifiers. Phys. Rev. A, 101:032308, Mar 2020.
- [25] Adrián Pérez-Salinas, Alba Cervera-Lierta, Elies Gil-Fuster, and José I. Latorre. Data re-uploading for a universal quantum classifier. Quantum, 4:226, February 2020.
- [26] Nhat A. Nghiem, Samuel Yen-Chi Chen, and Tzu-Chieh Wei. Unified framework for quantum classification. Phys. Rev. Research, 3:033056, Jul 2021.
- [27] Iris Cong, Soonwon Choi, and Mikhail D. Lukin. Quantum convolutional neural networks. Nature Physics, 15(12):1273–1278, Dec 2019.
- [28] Chen Zhao and Xiao-Shan Gao. Analyzing the barren plateau phenomenon in training quantum neural networks with the ZX-calculus. Quantum, 5:466, June 2021.
- [29] Samuel Yen-Chi Chen, Tzu-Chieh Wei, Chao Zhang, Haiwang Yu, and Shinjae Yoo. Quantum convolutional neural networks for high energy physics data analysis. Phys. Rev. Research, 4:013231, Mar 2022.
- [30] Maria Schuld. Supervised quantum machine learning models are kernel methods, 2021.
- [31] Annie E. Paine, Vincent E. Elfving, and Oleksandr Kyriienko. Quantum kernel methods for solving differential equations, 2022.
- [32] Xiaosi Xu, Jinzhao Sun, Suguru Endo, Ying Li, Simon C. Benjamin, and Xiao Yuan. Variational algorithms for linear algebra. Science Bulletin, 66(21):2181–2188, 2021.
- [33] Chih-Chieh Chen, Shiue-Yuan Shiau, Ming-Feng Wu, and Yuh-Renn Wu. Hybrid classical-quantum linear solver using noisy intermediate-scale quantum machines. Scientific Reports, 9(1):16251, Nov 2019.
- [34] Niklas Heim, Atiyo Ghosh, Oleksandr Kyriienko, and Vincent E. Elfving. Quantum model-discovery, 2021.
- [35] Alejandro Perdomo-Ortiz, Marcello Benedetti, John Realpe-Gómez, and Rupak Biswas. Opportunities and challenges for quantum-assisted machine learning in near-term quantum computers. Quantum Science and Technology, 3(3):030502, jun 2018.
- [36] Jinfeng Zeng, Yufeng Wu, Jin-Guo Liu, Lei Wang, and Jiangping Hu. Learning and inference on generative adversarial quantum circuits. Phys. Rev. A, 99:052306, May 2019.
- [37] Christa Zoufal, Aurélien Lucchi, and Stefan Woerner. Quantum generative adversarial networks for learning and loading random distributions. npj Quantum Information, 5(1):103, Nov 2019.
- [38] Jonathan Romero and Alán Aspuru-Guzik. Variational quantum generators: Generative adversarial quantum machine learning for continuous distributions. Advanced Quantum Technologies, 4(1):2000003, 2021.
- [39] Annie E. Paine, Vincent E. Elfving, and Oleksandr Kyriienko. Quantum Quantile Mechanics: Solving Stochastic Differential Equations for Generating Time-Series. aug 2021.
- [40] Jin-Guo Liu and Lei Wang. Differentiable learning of quantum circuit born machines. Phys. Rev. A, 98:062324, Dec 2018.
- [41] Iordanis Kerenidis, Jonas Landman, Alessandro Luongo, and Anupam Prakash. q-means: A quantum algorithm for unsupervised machine learning. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019.
- [42] Román Orús, Samuel Mugel, and Enrique Lizaso. Forecasting financial crashes with quantum computing. Phys. Rev. A, 99:060301, Jun 2019.
- [43] Pablo Bermejo and Roman Orus. Variational quantum and quantum-inspired clustering, 2022.
- [44] Guansong Pang, Chunhua Shen, Longbing Cao, and Anton Van Den Hengel. Deep learning for anomaly detection: A review. ACM Comput. Surv., 54(2), mar 2021.
- [45] Rejwan Bin Sulaiman, Vitaly Schetinin, and Paul Sant. Review of machine learning approach on credit card fraud detection. Human-Centric Intelligent Systems, 2(1):55–68, Jun 2022.
- [46] Sridhar Ramaswamy, Rajeev Rastogi, and Kyuseok Shim. Efficient algorithms for mining outliers from large data sets. SIGMOD Rec., 29(2):427–438, may 2000.
- [47] Markus M. Breunig, Hans-Peter Kriegel, Raymond T. Ng, and Jörg Sander. Lof: Identifying density-based local outliers. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, SIGMOD ’00, page 93–104, New York, NY, USA, 2000. Association for Computing Machinery.
- [48] Fei Tony Liu, Kai Ming Ting, and Zhi-Hua Zhou. Isolation forest. In 2008 Eighth IEEE International Conference on Data Mining, pages 413–422, 2008.
- [49] Thomas Schlegl, Philipp Seeböck, Sebastian M. Waldstein, Ursula Schmidt-Erfurth, and Georg Langs. Unsupervised anomaly detection with generative adversarial networks to guide marker discovery. In Marc Niethammer, Martin Styner, Stephen Aylward, Hongtu Zhu, Ipek Oguz, Pew-Thian Yap, and Dinggang Shen, editors, Information Processing in Medical Imaging, pages 146–157, Cham, 2017. Springer International Publishing.
- [50] Thomas Schlegl, Philipp Seeböck, Sebastian M. Waldstein, Georg Langs, and Ursula Schmidt-Erfurth. f-anogan: Fast unsupervised anomaly detection with generative adversarial networks. Medical Image Analysis, 54:30–44, 2019.
- [51] Daniel Herr, Benjamin Obert, and Matthias Rosenkranz. Anomaly detection with variational quantum generative adversarial networks. Quantum Science and Technology, 6(4):045004, jul 2021.
- [52] Bernhard Schölkopf, Robert C Williamson, Alex Smola, John Shawe-Taylor, and John Platt. Support vector method for novelty detection. In S. Solla, T. Leen, and K. Müller, editors, Advances in Neural Information Processing Systems, volume 12. MIT Press, 1999.
- [53] David M.J. Tax and Robert P.W. Duin. Support vector data description. Machine Learning, 54(1):45–66, Jan 2004.
- [54] Lukas Ruff, Robert Vandermeulen, Nico Goernitz, Lucas Deecke, Shoaib Ahmed Siddiqui, Alexander Binder, Emmanuel Müller, and Marius Kloft. Deep one-class classification. In Jennifer Dy and Andreas Krause, editors, Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pages 4393–4402. PMLR, 10–15 Jul 2018.
- [55] Zheng Zhang and Xiaogang Deng. Anomaly detection using improved deep svdd model with data structure preservation. Pattern Recognition Letters, 148:1–6, 2021.
- [56] Kaggle credit card fraud detection: Anonymized credit card transactions labeled as fraudulent or genuine. https://www.kaggle.com/datasets/mlg-ulb/creditcardfraud. Accessed: 2022-03-31.
- [57] Sun Yuan Kung. Kernel methods and machine learning. Cambridge University Press, 2014.
- [58] Thomas Hubregtsen, David Wierichs, Elies Gil-Fuster, Peter-Jan H. S. Derks, Paul K. Faehrmann, and Johannes Jakob Meyer. Training quantum embedding kernels on near-term quantum computers, 2021.
- [59] Jennifer R. Glick, Tanvi P. Gujarati, Antonio D. Corcoles, Youngseok Kim, Abhinav Kandala, Jay M. Gambetta, and Kristan Temme. Covariant quantum kernels for data with group structure, 2021.
- [60] Maria Schuld, Ryan Sweke, and Johannes Jakob Meyer. Effect of data encoding on the expressive power of variational quantum-machine-learning models. Phys. Rev. A, 103:032430, Mar 2021.
- [61] Oleksandr Kyriienko and Vincent E. Elfving. Generalized quantum circuit differentiation rules. Phys. Rev. A, 104:052417, Nov 2021.
- [62] Maria Schuld, Ville Bergholm, Christian Gogolin, Josh Izaac, and Nathan Killoran. Evaluating analytic gradients on quantum hardware. Phys. Rev. A, 99:032331, Mar 2019.
- [63] Hsin-Yuan Huang, Michael Broughton, Masoud Mohseni, Ryan Babbush, Sergio Boixo, Hartmut Neven, and Jarrod R. McClean. Power of data in quantum machine learning. Nature Communications, 12(1):2631, May 2021.
- [64] Ruslan Shaydulin and Stefan M. Wild. Importance of kernel bandwidth in quantum machine learning, 2021.
- [65] Louis-Paul Henry, Slimane Thabet, Constantin Dalyac, and Loïc Henriet. Quantum evolution kernel: Machine learning on graphs with programmable arrays of qubits. Phys. Rev. A, 104:032416, Sep 2021.
- [66] Brian Coyle, Daniel Mills, Vincent Danos, and Elham Kashefi. The born supremacy: quantum advantage and training of an ising born machine. npj Quantum Information, 6(1):60, Jul 2020.
- [67] Yunchao Liu, Srinivasan Arunachalam, and Kristan Temme. A rigorous and robust quantum speed-up in supervised machine learning. Nature Physics, 17(9):1013–1017, Sep 2021.
- [68] Oleksandr Kyriienko, Annie E. Paine, and Vincent E. Elfving. Protocols for Trainable and Differentiable Quantum Generative Modelling. feb 2022.
- [69] Matthias C. Caro, Elies Gil-Fuster, Johannes Jakob Meyer, Jens Eisert, and Ryan Sweke. Encoding-dependent generalization bounds for parametrized quantum circuits. Quantum, 5:582, November 2021.
- [70] Matthias C. Caro, Hsin-Yuan Huang, M. Cerezo, Kunal Sharma, Andrew Sornborger, Lukasz Cincio, and Patrick J. Coles. Generalization in quantum machine learning from few training data, 2021.
- [71] Abhinav Kandala, Antonio Mezzacapo, Kristan Temme, Maika Takita, Markus Brink, Jerry M. Chow, and Jay M. Gambetta. Hardware-efficient variational quantum eigensolver for small molecules and quantum magnets. Nature, 549(7671):242–246, Sep 2017.
- [72] Petar Jurcevic, Ali Javadi-Abhari, Lev S Bishop, Isaac Lauer, Daniela F Bogorin, Markus Brink, Lauren Capelluto, Oktay Günlük, Toshinari Itoko, Naoki Kanazawa, Abhinav Kandala, George A Keefe, Kevin Krsulich, William Landers, Eric P Lewandowski, Douglas T McClure, Giacomo Nannicini, Adinath Narasgond, Hasan M Nayfeh, Emily Pritchett, Mary Beth Rothwell, Srikanth Srinivasan, Neereja Sundaresan, Cindy Wang, Ken X Wei, Christopher J Wood, Jeng-Bang Yau, Eric J Zhang, Oliver E Dial, Jerry M Chow, and Jay M Gambetta. Demonstration of quantum volume 64 on a superconducting quantum computing system. Quantum Science and Technology, 6(2):025020, mar 2021.
- [73] Frank Arute, Kunal Arya, Ryan Babbush, Dave Bacon, Joseph C. Bardin, Rami Barends, Rupak Biswas, Sergio Boixo, Fernando G. S. L. Brandao, David A. Buell, Brian Burkett, Yu Chen, Zijun Chen, Ben Chiaro, Roberto Collins, William Courtney, Andrew Dunsworth, Edward Farhi, Brooks Foxen, Austin Fowler, Craig Gidney, Marissa Giustina, Rob Graff, Keith Guerin, Steve Habegger, Matthew P. Harrigan, Michael J. Hartmann, Alan Ho, Markus Hoffmann, Trent Huang, Travis S. Humble, Sergei V. Isakov, Evan Jeffrey, Zhang Jiang, Dvir Kafri, Kostyantyn Kechedzhi, Julian Kelly, Paul V. Klimov, Sergey Knysh, Alexander Korotkov, Fedor Kostritsa, David Landhuis, Mike Lindmark, Erik Lucero, Dmitry Lyakh, Salvatore Mandrà, Jarrod R. McClean, Matthew McEwen, Anthony Megrant, Xiao Mi, Kristel Michielsen, Masoud Mohseni, Josh Mutus, Ofer Naaman, Matthew Neeley, Charles Neill, Murphy Yuezhen Niu, Eric Ostby, Andre Petukhov, John C. Platt, Chris Quintana, Eleanor G. Rieffel, Pedram Roushan, Nicholas C. Rubin, Daniel Sank, Kevin J. Satzinger, Vadim Smelyanskiy, Kevin J. Sung, Matthew D. Trevithick, Amit Vainsencher, Benjamin Villalonga, Theodore White, Z. Jamie Yao, Ping Yeh, Adam Zalcman, Hartmut Neven, and John M. Martinis. Quantum supremacy using a programmable superconducting processor. Nature, 574(7779):505–510, Oct 2019.
- [74] K. J. Satzinger, Y.-J Liu, A. Smith, C. Knapp, M. Newman, C. Jones, Z. Chen, C. Quintana, X. Mi, A. Dunsworth, C. Gidney, I. Aleiner, F. Arute, K. Arya, J. Atalaya, R. Babbush, J. C. Bardin, R. Barends, J. Basso, A. Bengtsson, A. Bilmes, M. Broughton, B. B. Buckley, D. A. Buell, B. Burkett, N. Bushnell, B. Chiaro, R. Collins, W. Courtney, S. Demura, A. R. Derk, D. Eppens, C. Erickson, L. Faoro, E. Farhi, A. G. Fowler, B. Foxen, M. Giustina, A. Greene, J. A. Gross, M. P. Harrigan, S. D. Harrington, J. Hilton, S. Hong, T. Huang, W. J. Huggins, L. B. Ioffe, S. V. Isakov, E. Jeffrey, Z. Jiang, D. Kafri, K. Kechedzhi, T. Khattar, S. Kim, P. V. Klimov, A. N. Korotkov, F. Kostritsa, D. Landhuis, P. Laptev, A. Locharla, E. Lucero, O. Martin, J. R. McClean, M. McEwen, K. C. Miao, M. Mohseni, S. Montazeri, W. Mruczkiewicz, J. Mutus, O. Naaman, M. Neeley, C. Neill, M. Y. Niu, T. E. O’Brien, A. Opremcak, B. Pató, A. Petukhov, N. C. Rubin, D. Sank, V. Shvarts, D. Strain, M. Szalay, B. Villalonga, T. C. White, Z. Yao, P. Yeh, J. Yoo, A. Zalcman, H. Neven, S. Boixo, A. Megrant, Y. Chen, J. Kelly, V. Smelyanskiy, A. Kitaev, M. Knap, F. Pollmann, and P. Roushan. Realizing topologically ordered states on a quantum processor. Science, 374(6572):1237–1241, 2021.
- [75] Yulin Wu, Wan-Su Bao, Sirui Cao, Fusheng Chen, Ming-Cheng Chen, Xiawei Chen, Tung-Hsun Chung, Hui Deng, Yajie Du, Daojin Fan, Ming Gong, Cheng Guo, Chu Guo, Shaojun Guo, Lianchen Han, Linyin Hong, He-Liang Huang, Yong-Heng Huo, Liping Li, Na Li, Shaowei Li, Yuan Li, Futian Liang, Chun Lin, Jin Lin, Haoran Qian, Dan Qiao, Hao Rong, Hong Su, Lihua Sun, Liangyuan Wang, Shiyu Wang, Dachao Wu, Yu Xu, Kai Yan, Weifeng Yang, Yang Yang, Yangsen Ye, Jianghan Yin, Chong Ying, Jiale Yu, Chen Zha, Cha Zhang, Haibin Zhang, Kaili Zhang, Yiming Zhang, Han Zhao, Youwei Zhao, Liang Zhou, Qingling Zhu, Chao-Yang Lu, Cheng-Zhi Peng, Xiaobo Zhu, and Jian-Wei Pan. Strong quantum computational advantage using a superconducting quantum processor. Phys. Rev. Lett., 127:180501, Oct 2021.
- [76] A.D. Patterson, J. Rahamim, T. Tsunoda, P.A. Spring, S. Jebari, K. Ratter, M. Mergenthaler, G. Tancredi, B. Vlastakis, M. Esposito, and P.J. Leek. Calibration of a cross-resonance two-qubit gate between directly coupled transmons. Phys. Rev. Applied, 12:064013, Dec 2019.
- [77] Sebastian Krinner, Nathan Lacroix, Ants Remm, Agustin Di Paolo, Elie Genois, Catherine Leroux, Christoph Hellings, Stefania Lazar, Francois Swiadek, Johannes Herrmann, Graham J. Norris, Christian Kraglund Andersen, Markus Müller, Alexandre Blais, Christopher Eichler, and Andreas Wallraff. Realizing repeated quantum error correction in a distance-three surface code. Nature, 605(7911):669–674, May 2022.
- [78] A. D. Córcoles, Maika Takita, Ken Inoue, Scott Lekuch, Zlatko K. Minev, Jerry M. Chow, and Jay M. Gambetta. Exploiting dynamic quantum circuits in a quantum algorithm with superconducting qubits. Phys. Rev. Lett., 127:100501, Aug 2021.
- [79] Jonas M. Kübler, Andrew Arrasmith, Lukasz Cincio, and Patrick J. Coles. An Adaptive Optimizer for Measurement-Frugal Variational Algorithms. Quantum, 4:263, May 2020.
- [80] Tobias Haug, Chris N. Self, and M. S. Kim. Large-scale quantum machine learning, 2021.
- [81] Laird Egan, Dripto M. Debroy, Crystal Noel, Andrew Risinger, Daiwei Zhu, Debopriyo Biswas, Michael Newman, Muyuan Li, Kenneth R. Brown, Marko Cetina, and Christopher Monroe. Fault-tolerant control of an error-corrected qubit. Nature, 598(7880):281–286, Oct 2021.
- [82] A. C. Hughes, V. M. Schäfer, K. Thirumalai, D. P. Nadlinger, S. R. Woodrow, D. M. Lucas, and C. J. Ballance. Benchmarking a high-fidelity mixed-species entangling gate. Phys. Rev. Lett., 125:080504, Aug 2020.
- [83] Bryan Nelsen, Gangqiang Liu, Mark Steger, David W. Snoke, Ryan Balili, Ken West, and Loren Pfeiffer. Dissipationless flow and sharp threshold of a polariton condensate with long lifetime. Phys. Rev. X, 3:041015, Nov 2013.
- [84] Ke Liu, Shuai Sun, Arka Majumdar, and Volker J. Sorger. Fundamental scaling laws in nanophotonics. Scientific Reports, 6(1):37419, Nov 2016.
- [85] Tintu Kuriakose, Paul M. Walker, Toby Dowling, Oleksandr Kyriienko, Ivan A. Shelykh, Phillipe St-Jean, Nicola Carlon Zambon, Aristide Lemaître, Isabelle Sagnes, Luc Legratiet, Abdelmounaim Harouri, Sylvain Ravets, Maurice S. Skolnick, Alberto Amo, Jacqueline Bloch, and Dmitry N. Krizhanovskii. Few-photon all-optical phase rotation in a quantum-well micropillar cavity. Nature Photonics, 16(8):566–569, Aug 2022.