Unsupervised Multi-view Clustering by Squeezing Hybrid Knowledge from Cross View and Each View
Abstract
Multi-view clustering methods have been a focus in recent years because of their superiority in clustering performance. However, typical traditional multi-view clustering algorithms still have shortcomings in some aspects, such as removal of redundant information, utilization of various views and fusion of multi-view features. In view of these problems, this paper proposes a new multi-view clustering method, low-rank subspace multi-view clustering based on adaptive graph regularization. We construct two new data matrix decomposition models into a unified optimization model. In this framework, we address the significance of the common knowledge shared by the cross view and the unique knowledge of each view by presenting new low-rank and sparse constraints on the sparse subspace matrix. To ensure that we achieve effective sparse representation and clustering performance on the original data matrix, adaptive graph regularization and unsupervised clustering constraints are also incorporated in the proposed model to preserve the internal structural features of the data. Finally, the proposed method is compared with several state-of-the-art algorithms. Experimental results for five widely used multi-view benchmarks show that our proposed algorithm surpasses other state-of-the-art methods by a clear margin.
Index Terms:
Multi-view Clustering (MVC), Low-rank, Sparse Subspace Clustering (SSC), Adaptive Graph Regularization (AGR)
I Introduction
Multi-view clustering methods are a research subject that has received much attention in recent years. The definition of multi-view clustering is potential to have very broad in the field of pattern recognition [1, 2], computer vision [3, 4, 5] and machine intelligence [6, 7]. Some researchers define it as an object to extract its information from different angles and then combine related information from each angle. In addition, some researchers define multi-view as multi-modal [8], which improves the performance of clusters based on different modal information, such as images, text and speech. Furthermore, multi-view can also be understood as a combination of multiple features [9]. We can use a classic method to represent the characteristics of an image or text, such as SIFT [10], LBP [11], and GABOR [12]. In this paper, multi-view is regarded as combining multiple features to improve the performance of clusters. With the development of multi-view clustering, relevant researchers have proposed many clustering algorithms for multi-view feature combination. We can divide multi-view clustering algorithms according to different levels. For the hierarchical level of clustering, we can classify multi-view clustering algorithms according to the use of training and the number of samples as supervised multi-view clustering [13], semi-supervised multi-view clustering [14] and unsupervised multi-view clustering [15]. The earliest algorithm was the subspace-based supervised clustering algorithms [16, 17], which require the label data of all samples to be known and need to manually select the training samples. Although this method can promise state-of-the-art clustering performance, it consumes large amounts of manual effort and time to a certain extent. In addition, semi-supervised multi-view algorithms based on low-rank sparse total spatial clustering have also appeared [18, 19, 20] in recent years. Although these methods reduce the sample labels and training samples that need to be labelled compared to the method of supervised learning, some defects still exist. For example, if we do not completely know the sample clustering labels, we cannot use this method to effectively cluster the data. Given this drawback, an unsupervised clustering method is needed.
Since it does not require training samples in advance for single-view [21, 22, 23] or multi-view tasks [25, 26, 27, 24], unsupervised clustering has been the focus of research in recent years and the difficulty of research. Especially in the field of multi-view clustering algorithms, through the continuous efforts of relevant scientific researchers, many unsupervised clustering algorithms have been proposed. Xu et al. [28] proposed an unsupervised multi-view intact spatial learning (MISL) algorithm that integrated encoded supplementary information into multiple views to discover a potential complete representation of the data. From the perspective of multi-view feature combination, we can use roughly three categories of multi-view methods: subspace clustering [29], low-rank sparse representation [30] and adaptive graph learning [31]. These works showed that complementary information between views is beneficial for the classification performance. To make full use of the diversity of views, Cao et al. [32] proposed diversity-induced multi-view subspace clustering (DiMSC) using the Hilbert-Schmidt independence criterion (HSIC) to obtain the complementary information of each view. In addition, Wang et al. [33] used a low-rank strategy to extract the complementary information from each view by the -norm, called exclusivity-consistency regularization. These methods considered the use of the complementary information between views but did not consider the common information sharing by each view. In view of this, Ding et al. [34] proposed robust multi-view data analysis through a collective low-rank subspace (CLRS). This method used view information to extract the common information existing in each view. With the development of algorithms in recent years, some ways to extract common information between views have been proposed [35, 36, 37]. The simplest method is to perform a weighted fusion among multiple views. Zhao et al. [38] proposed an adaptive weighted fusion algorithm for each view. Another kind of methods extracts common information between views not only through the constraints of the model but also using data decomposition of sparse representation for the original data. This idea can better reflect the correlation between the feature information of each view. Recently, Wang et al. [39] proposed a new multi-view fusion subspace clustering algorithm (MSC-IAS) that combined the information of each view by adaptively decomposing the original data and used an adaptive manifold to preserve the data structure. The common information and complementary information between views are both important for the representation of an object. Recently, relevant researchers have proposed a new idea for multi-view information utilization that decomposes the original data into the common information and complementary information of each view. This approach can extract the multi-view features to a certain extent and preserve the structural features of the original data when it is decomposed. Luo et al. [40] proposed a novel subspace multi-view clustering algorithm called consistent and specific multi-view subspace clustering (CSMSC). The main idea of this method was to deal with a sparse representation matrix after the decomposition of a multi-view original matrix. The sparse representation matrix for each view was represented by a common feature matrix and each view-specific feature matrix. However, there are still some drawbacks in practice. When dealing with a sparse representation matrix, this method will cause information loss for each view and structural connection between views. To solve this problem, Tang et al. [41] proposed cross-view local structure preserved diversity and consensus learning for multi-view unsupervised feature selection (CPV-DCL). In CPV-DCL, the original multi-view data matrix was adaptively weighted, and then the selected multi-views were directly decomposed into a common feature part and distinctive feature part unique to each view. Finally, these two feature parts were subjected to low-rank sparse constraints, and manifold learning was used to preserve local structural features. Although the above-mentioned algorithms can achieve good results when solving a single problem to a certain extent, there are still some shortcomings in dealing with some comprehensive problems. We need to consider the adaptability of the algorithm in many aspects, such as the application scenarios of low-rank sparse constraints, the extraction of common features, the identification of the unique information of each view, and the similarity measure between samples.
In summary, several issues with clustering multi-view data capture our attention: (1) Remove redundant information from the original matrix, and extract useful information from the error matrix. (2) Make full use of the common information between views and the complementary information of each view. (3) Sparse representation will destroy the feature association between the original samples. Adaptive factor learning is used to maintain the local structural features. (4) Use novel low-rank sparse constraints to solve the existing drawbacks of the nuclear norm and -norm.
To solve the above-mentioned problems, we propose a new multi-view unsupervised clustering method called unsupervised low-rank clustering. The proposed method is a unified framework for unsupervised multi-view clustering that incorporates the common information of the cross-view and the unique information of each view (UMC-CEV). We combine low-rank sparse decomposition with geometric structure retention to extract the common matrix and complementary information of each view. The main idea is to perform two sparse subspace decompositions on the original multi-view data matrix, one of which decomposes the original multi-view data matrix into a common sparse subspace matrix and the error of each view. The other decomposes the original multi-view data matrix into multiple sparse subspace matrices that represent the complementary information between various views, also called diversity. Insufficient data constraints based on the nuclear norm and -norm will lead to over-penalized and only approximate original problems. We use a low-rank sparse constraint similar to the nuclear norm and -norm to address this problem. In addition, we can use the sparse subspace obtained by decomposing the original data as the similarity measure matrix between different samples and use the sparse matrices for adaptive factor learning. To a certain extent, this approach ensures that the original data are not corrupted when performing sparse representation. Additionally, the discriminant information of intra-classes and inter-classes can be reflected. The specific flow of the proposed algorithm is shown in Fig. 1. The main contributions of this paper can be summarized as follows:
(1) Two kinds of sparse subspace decomposition models are used to process the original multi-view data to extract the common information of cross-view features and the unique information of each view feature.
(2) A new threshold function and singular value decomposition (SVD) are used to replace the low-rank sparse effect of the nuclear norm and -norm to solve the over-penalized problem of the nuclear norm and -norm. Moreover, the error matrix of each view feature and the common features is subject to the nuclear norm to minimize the error matrix of each view.
(3) Using the idea of adaptive factor learning, a common dilution subspace matrix is taken as the similarity measure matrix between samples, and the local geometric features are preserved when the original data are decomposed by sparse representation. In addition, the optimal similarity matrix is used for clustering discrimination.
(4) We use a common view feature extraction model, i.e., the sparse representation of each view feature model, the novel low-rank and sparse representation constraints, and adaptive manifold learning as a unified objective function. Finally, we achieve good results for several public datasets by using spectral clustering.
The rest of this paper is organized as follows. Section II briefly introduces the related works. The proposed algorithm is explained in detail in Section III. Section IV presents the optimization part of our proposed algorithm. The experimental results and analysis are given in Section V. Section VI summarizes the conclusions of this paper.
II Related Work
In this section, we briefly introduce the related technologies involved in our algorithm, including sparse subspace clustering (SSC) [42] and adaptive graph regularization (AGR) [43], which are widely used in machine learning and pattern recognition fields. Our proposed multi-view clustering algorithm is based on the improvement of these two algorithms, which will be described in detail in Section III.
II-A Sparse Subspace Clustering (SSC)
SSC has been developed for many years and has received extensive attention in the field of feature extraction and clustering. Recently, some improved methods of SSC have been presented, such as sparse low-rank and sparse constraints, to make SSC more robust. In general, the nuclear norm and -norm are used to control the rank and sparsity of a sparse subspace matrix. However, Brbic et al. [44] found that the nuclear norm and -norm over-penalize and just approximate the original problem. Therefore, Brbic et al. [44] proposed a novel low-rank SSC algorithm called -motivated low-rank sparse subspace clustering (L0-LSSC). This algorithm uses a multivariate generalization of minimize-concave penalty (GMC-LRSSC) as a regularization constraint. Its expression is as follows:
| (1) | ||||
where denotes the vector containing the singular values of the sparse subspace matrix and : is the GMC-LRSSC penalty, which can be defined as:
| (2a) | |||
| (2b) | |||
| Lemma 1 ([45]): Let,, and . We can define the function as: | |||
| (2c) | |||
where : denotes the generalized Huber function. According to Ref. [45], the variable satisfies in Eq. (2b), if satisfies positive semi-definite matrix and is convex function. We can see that the second term of the penalty constraint in Eq. (1) is very similar to the previous nuclear norm, and the third term of the penalty constraint in Eq. (1) is very similar to the previous -norm. These novel penalty items can be solved by the corresponding relaxation function. Details of GMC-LRSSC can be found in Refs. [44, 45].
II-B Adaptive Graph Regularization (AGR)
Graph regularization is a useful tool for matrix factorization. Its main function is to preserve the local geometry. However, most similarity graph matrix methods are not adaptive [46]. AGR has made a large breakthrough in recent years. In AGR, the similarity matrix continually optimizes the internal geometry of the data during iterations. This guarantees an optimal measure of the similarity between different samples to a certain extent. Zhan et al. [47] proposed a graph learning-based method that improved the quality of the graph. This method used the eigenvalue decomposition method to preserve the local geometry of the similarity matrix. In addition, Wen et al. [48] proposed a novel AGR method that focused on learning a more general graph. This method used two parts of local geometry, including the original data and the clustering. Furthermore, the method used a low-rank constraint on the similarity matrix and the error matrix. The loss function of this algorithm is as follows:
| (3) |
where is the nuclear constraint on the similarity matrix and can be denoted as , where is the singular value of the similarity matrix and can reflect the low-rank constraint effect of the matrix. The error matrix constraint can be calculated as , which is the sparsity selection constraint. In this loss function, the first term preserves the local geometry of the original data, and variable Z is the similarity matrix. The second and third terms are the similarity matrix low-rank constraint and the error matrix sparsity constraint, respectively. The last term preserves the geometry characteristics of the Laplacian matrix by the eigenvalue decomposition. The parameters , and are used to trade off the importance of each constraint. More details of low-rank representation based on adaptive graph regularization (LRR-AGR) can be found in Ref. [48].
As we know, optimization algorithms have always been the focus of machine learning and pattern recognition. Many advanced optimization algorithms have been proposed. For example, Yuan et al. [49] proposed a new conjugate gradient algorithm (PRP-WWP). Li et al. [50] proposed a block-based multi-objective algorithm for the optimization of large-scale feature selection (DMEA-FS).Yong et al. [51] proposed a new bat optimization algorithm (BABLUE) based on cross boundary learning (CBL) and uniform exploitation strategy (UES). These three optimization algorithms take the advantages of fast convergence speed, relatively low computational complexity and global optimization. But they are still inadequate for dealing with non-convex and non-smooth models. Besides, these three optimization algorithms will introduce more optimization variables during the optimization. According to the research of relevant researchers, the alternating direction method of multipliers (ADMM) is an effective optimization method to solve non-convex, non-smooth and non-Lipschitzand models. It can not only process a large amount of data and introduce a small number of optimization variables, but also adapt the Lagrange multiplier introduced by optimization according to the characteristics of the model. In view of the model features and advantages of ADMM, we use it to solve the proposed model.
III The Proposed Model
We make full use of the superiority of L0-LSSC and LRR-AGR and then extend them to multi-view clustering. Therefore, this section is divided into three sub-sections, including multi-view generalization and improvement of L0-LSSC, multi-view generalization and improvement of LRR-AGR, and the novel framework (UMC-CEV) based on low-rank SSC and cooperative learning with AGR. The relationship among these three sub-sections is shown in Fig. 2, and details are given in the following section.
III-A Multi-view -Motivated Low-rank Sparse Subspace Clustering (ML0-LSSC)
In an SSC algorithm, we argue that the two constraints of the model (i.e., low rank and sparsity) are critical. These two parts can directly determine the feature extraction of the original data, remove redundant information and reduce the data dimension. L0-LSSC can achieve perfect clustering results when dealing with low-rank and sparse problems. We should make full use of the superiority of the algorithm in low rank and sparseness and generalize them to the multi-view clustering algorithm. Due to the diversity of multi-view data, the diverse information of each view attracts considerable attention. Therefore, we can use the L0-LSSC algorithm to effectively extract the view information by sparse subspace decomposition. In addition, we can effectively integrate various information of each view by cooperative learning. The proposed loss function, which is a modification of L0-LSSC, is as follows:
| (4) | ||||
where the variable denotes the global sparse subspace matrix and the parameter trades off the importance of the global sparse subspace matrix. The second and third terms denote low-rank and sparsity constraints, respectively. For simplicity, we use a uniform variable instead of these two terms as follows:
| (5) |
The fourth term fuses the diversity of each view. Therefore, we can simplify Eq. (4) as:
| (6) | ||||

III-B Multi-view Low-rank Representation with Adaptive Graph Regularization (MLRR-AGR)
Adaptive graph learning also plays an indispensable role in the field of multi-view clustering. The preservation of the local geometry of each view in sparse subspace decomposition and the retention diversity of each view in fusion are two hot research issues. Hence, adaptive graph learning is able to handle these problems well. In this section, our main objective is to improve low-rank representation with AGR in the multi-view field. First, to remove the redundancy and noise information of the original data, we perform a common sparse subspace decomposition of the original data. The raw data are decomposed into a global sparse subspace and the noise space of each view. Then, we use this decomposed global sparse subspace matrix as the global similarity matrix for AGR and discriminant clustering information. The final optimization model can be given as follows:
| (7) | ||||
where , and are the numbers of samples and clusters of the original data, respectively, and denotes the trace operator. By Eq. (7), the original data matrix can be decomposed into a global sparse subspace matrix and the noise matrix of each view. In this way, this approach is able to effectively integrate the diversity between views. The first term is AGR to preserve the local geometry. The second term is used to constrain the error between individual views and the common view, where the nuclear norm is mainly used to minimize the error matrix. The third term is adaptive clustering discrimination learning between samples. It can measure the inter-class and intra-class discrimination information between samples to a certain extent.
III-C The Unified Framework of UMC-CEV
In the above two sub-sections, we have proposed the improvement of SSC and AGR from single feature space to multi-view feature space. In this section, we effectively combine these two parts to generate an optimal model for comprehensive consideration. First, according to the data matrix decomposition methods of ML0-LSSC and MLRR-AGR, each view has its own unique features and some common features between various views. If the common features are not extracted well, they may become redundant information in the final clustering and depress the final classification performance. Therefore, we need to simultaneously extract the effective common features between views and decompose the optimal diversity of each view. We can learn using Eq. (6) by training the views collaboratively to solve the common information between views and the unique information of each view. Second, we should make full use of the low-rank and sparsity constraints to make our model more robust. Finally, the similarity matrix of the entire model should maintain its AGR characteristics. For a loss function that satisfies the above three conditions, we can define the final model as follows:
| (8) | |||
| s.t. | |||
where parameters , , and denote penalty factors that trade off the low-rank sparse subspace matrix, the clustering similarity matrix, the error matrix of each view, the discrimination of the global similarity matrix and the similarity of each view, respectively. is the Laplacian matrix, expressed as , where D is the diagonal matrix, which can be expressed as . The first term primarily preserves the local geometric structure of the original data. The second term is the penalty for the decomposition error matrix of each view by using the nuclear norm. Since the nuclear norm is a low-rank constraint on the error matrix, it can be further retained as much as possible by this way. The third term is included to trade off the clustering similarity. We can obtain a very intuitive understanding of the transformation of the following equation:
| (9) |
where is the clustering index vector, which is an unsupervised learning vector. Eq. (9) uses the similarity matrix as the weight of each sample clustering label to minimize the intra-class error and maximize the inter-class error. The fourth term in Eq. (8) denotes the low-rank and sparsity constraints on the similarity of each view and can effectively extract the complementary information unique to each view. The fifth term in Eq. (8) minimizes the error of the global similarity matrix and view diversity. This allows the global similarity matrix to have more common features for each view.
To sum up, we propose a unified efficiently unsupervised multi-view clustering framework (i.e., UMC-CEV), that contains two specific multi-view clustering sub-modules (ML0-LSSC and MLRR-AGR). ML0-LSSC algorithm focuses on extracting the unique information of each view and the common view information, while MLRR-AGR algorithm focuses on extracting the cross-view common information between views. To fully combine the advantages of ML0-LSSC and MLRR-AGR, UMC-CEV is proposed by considering frame structure context. This paper focuses on introducing the model structure and optimization process of the algorithm UMC-CEV. UMC-CEV is a new unsupervised multi-view clustering framework with sparse and low-rank structure. A common matrix containing all the common information and multiple pure specific view characteristics with each view characteristic are constructed to squeeze context knowledge. This framework utilizes two different novel sparse matrix decomposition methods to extract the features of the common view and specific views. Furthermore, novel adaptive graph learning, and relevant sparse and low-rank constraints are used to maintain the structural features of the original data.
IV Optimization
In this section, we introduce the optimization process of the proposed model. Due to the complexity of the model, to more easily calculate the solutions of variables, we introduce the auxiliary variables , and and then adopt ADMM to solve the optimization problems. The optimization model in Eq. (8) can be converted to:
| (10) | ||||
To understand the optimization process of the model more intuitively, we rewrite the model as the following augmented Lagrangian formulation:
| (11) | ||||
where and are the coefficient matrices, and are Lagrange multipliers, and and are positive penalty factors. We can optimize one variable by fixing the other variables in Eq. (11). Therefore, we can obtain the optimal values of all variables , , , , , , and . The optimization process for these variables is given as follows:
1) Update : When variables , , , , , and are fixed, the objective function in Eq. (11) for gives the following minimization problem:
| (12) |
Eq. (12) can be solved by the singular value threshold method. can be decomposed by SVD as . The optimal solution to Eq. (12) is as follows:
| (13) |
2) Update : Variables , , , , and should be fixed, and the objective function for can be rewritten as follows:
| (14) | |||
By local derivation of Eq. (14) for , we can obtain the optimal variable as follows:
| (15a) | |||
| (15b) | |||
| (15c) | |||
| (15d) |
3) Update : Variables , , , , and should be fixed, and the objective function for can be rewritten as follows:
| (16) | ||||
In Eq. (16), it is difficult to solve for the variable . However, Eq. (16) is equivalent to solving the following minimization problem by adding Eq. (9):
| (17) | ||||
We further simplify Eq. (17) as:
| (18) |
where , and are the -th rows of , and respectively. Eq. (18) can be effectively solved according to Ref. [47].
4) Update : Fix , , , , , and ; then, the objective function for solving can be rewritten as follows:
| (19) | |||
where is the Laplacian matrix of the similarity matrix . This is a classic spectral clustering model. In general, we perform eigenvalue decomposition on the model and then take the feature vector corresponding to its top smallest eigenvalues as column vectors of the solution .
5) Update : When variables , , , , and are fixed, the objective function for is the following minimization problem:
| (20) | ||||
By local derivation of Eq. (20) for , the solution of can be obtained by:
| (21a) | |||
| (21b) |
| (22) |
6) Update : To solve for this variable, we should fix the other variables , , , , and . Then, the optimal can be obtained by solving the following minimization problem:
| (23) | ||||
Eq. (23) is equivalent to:
| (24) | ||||
According to Eq. (19), can be decomposed by SVD as . Therefore, the closed-form solution of Eq. (24) can be obtained by:
| (25) |
where is the firm threshold function as follows:
| (26) |
7) Update : We should fix the other variables , , , , and . Then, the optimal can be obtained by solving the following minimization problem:
| (27) |
by subtracting the diagonal elements of as follows:
| (28) |
Through the above analysis, we can finally obtain the solution of as follows:
| (29a) | |||
| (29b) |
8) Update other variables: Now, we will update the Lagrange multipliers , , and . These variables can be updated as follows:
| (30) |
| (31) |
| (32) |
where the parameters , and are constants.
When we obtain the global similarity matrix and the individual view similarity matrices through the above optimization method, we use the following formula to combine the two parts:
| (33) |
Then, the optimal global similarity matrix is obtained. After obtaining the optimal similarity matrix, we apply spectral clustering to . The optimization process of the entire model is summarized in Algorithm 1.
In the overall algorithm optimization process, we firstly analyze the main three optimization sub-modules with relatively high algorithm complexity compared with other variable optimization modules. Such as singular value thresholding (in step 3), the inverse operation (in step 4), and eigen-decomposition (in step 6). These are all classical optimization methods, and we can easily get their algorithm complexity of , and , respectively, where is the number of the samples and is the number of the clustering. Besides, the computational complexity of is , where is the number of iterations and is the size of the each sample in step 7. Due to , we can get the computational complexity of the proposed method as , where and are the number of iterations and samples views, respectively. Meanwhile, we can easily get the complexity analysis of several comparison methods of MLSSC, MVGL, LRPP-GRR, L0-LSSC. By comparing the algorithm complexity with these methods, we can see that the proposed algorithm is feasible in theory.
Input:
input parameters Dataset ; parameters , , and ; number of clusters ; number of views
Output:
output The similarity matrix .
Initialization:
Using the k-nearest neighbour graph to initialize the similarity matrix ; ; using the eigenvalue decomposition of Laplacian matrix to initialize matrix . Calculating the initial matrix by Eq. (21); , , ; ; ; ; ; .
V Experiments
This section is divided into several sub-sections: experimental settings, comparison algorithms, evaluation metrics, parameter analysis, clustering results, similarity matrix analysis and convergence analysis. Details are given as follows.
V-A Experimental Settings
To fully consider the superiority of our proposed algorithm, we test our algorithm for four kinds of datasets: face dataset, news article dataset, handwritten digital dataset and textual dataset. The face dataset includes the dataset and the Extended YaleB () dataset. The news article dataset is the 3- dataset. The handwritten digital dataset is the dataset, and the textual dataset is . The statistics of the five real-world datasets are summarized in Table I.
ORL mtv dataset
There are 10 different grey-scale images for 40 different themes. Images are taken under different conditions, such as different lighting, different facial expressions, and different facial details. In this experiment, we used three views to evaluate the algorithm.
Extended YaleB dataset
There are 38 individuals and approximately 64 near-frontal images in this face dataset. These images are under different illuminations. In general, other experiments have used the first 10 classes and 64 near-frontal images, for a total of 640 samples. However, we used 38 individuals and 29 near-frontal images in our experiment, for a total of 1102 samples.
3-sources dataset
This is a collection of news stories collected from three online news sources (BBC, Reuters and The Guardian). All articles are indicated by the "word bag". For 948 articles, we used 169 topic classes with a placeholder for each article in all three datasets.
uci digit dataset
This dataset contains 2000 handwritten digit (0-9) examples extracted from the Dutch utility map. There are 200 examples in each class, and each example has six feature sets. Following the experiment in [52], we used three feature sets: Fourier coefficients of 76 character shapes, 216 profile correlations, and 64 Karhunen-Love coefficients.
BBCSport dataset
This dataset contains the latest articles in the five subject areas of the 2004-2005 BBC Sport website. This textual dataset has 544 documents. In our experiment, we used 116 samples and 5 classes.
| Dataset | Sample | Views | Clusters |
|---|---|---|---|
| ORL mtv | 400 | 3 | 40 |
| EYaleB | 1102 | 2 | 38 |
| 3-sources | 169 | 3 | 6 |
| uci digit | 2000 | 3 | 10 |
| BBCSport | 116 | 3 | 5 |
V-B Comparison Algorithms
In this sub-section, we compare our proposed algorithm with several related state-of-the-art algorithms, including DiMSC [32], latent multi-view subspace clustering (LMSC) [53], exclusivity-consistency regularized multi-view subspace clustering (ECRMSC) [33], multi-view low-rank sparse subspace clustering (MLSSC) [52], graph learning for multi-view clustering (MVGL) [37], low-rank representation with adaptive graph regularization (LRPP-AGR) [48], and L0-LSSC [44]. Detailed descriptions of these state-of-the-art algorithms are given as follows:
DiMSC
This approach mostly concentrates on enhancing the performance of multi-view clustering by exploring additional information between multi-view features. The HSIC is used to explore the diversity information between multi-view features.
LMSC
This method consists of finding a potential sparse representation subspace and then reconstructing the data simultaneously based on the learned potential subspace. The method uses the complementarity of multiple view feature spaces to obtain the best view features. This algorithm imposes low-rank constraints on the noise matrix and the sparse subspace matrix.
ECRMSC
This algorithm is mainly divided into two steps: subspace learning and spectral clustering. It uses the -norm as a constraint to extract the complementary information between different sparse subspace matrices.
MLSSC
Multi-view low-rank sparse subspace clustering is a classic low-rank sparse subspace method that uses the nuclear norm and -norm to constrain the low rank and sparsity of the sparse subspace matrix. In addition, this method obtains complementary information between views by means of the mutual derivation of views.
MVGL
This is an adaptive graph learning method. By optimizing the similarity graph matrix, the optimal similarity factor matrix of each view is obtained. Finally, these similarity factor matrices are weighted and fused by the idea of cooperative representation, thus obtaining the most excellent global similarity graph matrix.
LRPP-GRR
This is a novel method based on AGR. It introduces the original data matrix local geometric structure and the cluster label matrix to discriminate between these two manifold learning constraints. In addition, this method uses the nuclear norm and -norm to constrain the sparse subspace matrix and the noisy matrix, respectively.
L0-LSSC
This is a novel method of low-rank sparse subspace clustering. Considering the deficiencies of the nuclear norm and -norm, this method uses a new low-rank and sparse method.
V-C Evaluation Metrics
There are seven evaluation metrics in our paper: clustering accuracy(ACC), normalized information(NMI), purity, precision(P), recall(R), F-score(F) and adjusted rand index(AR).














V-D Parameter Analysis
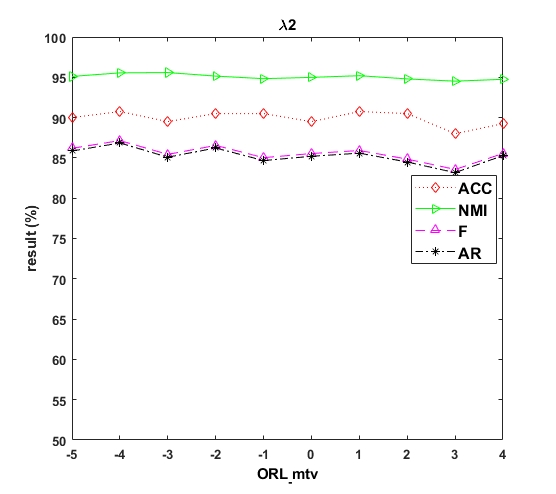
According to Algorithm 1, there are three parameters in our algorithm that need to be determined, i.e., the trade off parameters , and . These trade off parameters denote the low-rank constraint on the noisy matrix of each view, the discrimination constraint on the global matrix cluster, and the low-rank and sparsity constraints on each view, respectively. In this sub-section, we analyse the sensitivity of these three sensitive parameters in different datasets. In our experiments, the three parameters are defined within a uniform scope. We choose ten digits for the three parameter values in the range of . Figs.3,4,5 show the clustering results according to different values of these three parameters , and , respectively. The results for the ORL mtv and uci digit datasets are relatively stable for different values of , and . The maximum and minimum accuracies are 92.75% and 88.75% for the ORL mtv dataset, respectively, and the error between the maximum and minimum accuracies for the uci digit dataset is very small, i.e., 1.15%. Especially for parameter in Fig. 4, the curves of ACC, NMI and AR in the uci digit dataset are basically unchanged. This is because the uci digit dataset has a large number of samples for each class, and the pictures are handwritten numbers that are easy to distinguish. Therefore, the role of discriminative constraints between different classes is not very large. However, the 3-sources, BBCSport and EYaleB datasets are sensitive to the parameters , and . When parameter , the experimental results for the datasets (3-sources, BBCSport and EYaleB) exhibit particularly obvious fluctuations and are very poor. Thus, it is very important to apply low-rank and sparse constraints in each view. Although the best results can be obtained by constantly adjusting the values of the parameters for different datasets, to guarantee the generality of the proposed algorithm, we use uniform settings for the three parameters in all datasets. We set these three parameters as , and for all datasets. Using these values for the parameters, the experimental results are still very good in all datasets.
| Methods | ACC | NMI | Purity | P | R | F | AR |
|---|---|---|---|---|---|---|---|
| LRPP-GRR bestview | |||||||
| L0-LSSC bestview | |||||||
| Ours bestview | |||||||
| MLSSC | |||||||
| MVGL | |||||||
| LMSC | |||||||
| DiMSC | |||||||
| ECRMSC | |||||||
| MLRPP-GRR | |||||||
| ML0-LSSC | |||||||
| Ours |
| Methods | ACC | NMI | Purity | P | R | F | AR |
|---|---|---|---|---|---|---|---|
| LRPP-GRR bestview | |||||||
| L0-LSSC bestview | |||||||
| Ours bestview | |||||||
| MLSSC | |||||||
| MVGL | |||||||
| LMSC | |||||||
| DiMSC | |||||||
| ECRMSC | |||||||
| MLRPP-GRR | |||||||
| ML0-LSSC | |||||||
| Ours |
| Methods | ACC | NMI | Purity | P | R | F | AR |
|---|---|---|---|---|---|---|---|
| LRPP-GRR bestview | |||||||
| L0-LSSC bestview | |||||||
| Ours bestview | |||||||
| MLSSC | |||||||
| MVGL | |||||||
| LMSC | |||||||
| DiMSC | |||||||
| ECRMSC | |||||||
| MLRPP-GRR | |||||||
| ML0-LSSC | |||||||
| Ours |
| Methods | ACC | NMI | Purity | P | R | F | AR |
|---|---|---|---|---|---|---|---|
| LRPP-GRR bestview | |||||||
| L0-LSSC bestview | |||||||
| Ours bestview | |||||||
| MLSSC | |||||||
| MVGL | |||||||
| LMSC | |||||||
| DiMSC | |||||||
| ECRMSC | |||||||
| MLRPP-GRR | |||||||
| ML0-LSSC | |||||||
| Ours |
| Methods | ACC | NMI | Purity | P | R | F | AR |
|---|---|---|---|---|---|---|---|
| LRPP-GRR bestview | |||||||
| L0-LSSC bestview | |||||||
| Ours bestview | |||||||
| MLSSC | |||||||
| MVGL | |||||||
| LMSC | |||||||
| DiMSC | |||||||
| ECRMSC | |||||||
| MLRPP-GRR | |||||||
| ML0-LSSC | |||||||
| Ours |




V-E Clustering Results
The experimental results of the different algorithms are shown in Tables II-VI for the ORL mtv, 3-sources, BBCSport, EYaleB and uci digit databases, respectively. Tables II-VI clearly show that our proposed algorithm achieves very promising results for these databases. A detailed analysis is conducted as follows:
Table II shows the experimental results for the ORL mtv dataset, which provides perfect clustering performance. Table II shows that our algorithm achieves significant improvements of 6%, 1%, 2%, 7%, 3%, 5% and 6% over the second-best result in the indexes of ACC, NMI, purity, precision, recall, F-score and AR, respectively. In addition, MLSSC has poor performance. This is because MLSSC uses the traditional nuclear norm and -norm to realize low-rank and sparse representation of the similarity matrices. However, we have solved the shortcomings of traditional low-rank and sparse representation to a certain extent by using novel low-rank and sparse representation constraints. Moreover, MLSSC obtains the diversity between different views by means of mutual differences between views. This only guarantees that the obtained view matrix fuses some common information of each view but does not make full use of the specific information contained in each view.
Table III shows the experimental results for the 3-sources dataset, which is a text dataset. The classification results for the text dataset are not as stable as those for the image dataset since the text dataset contains fewer feature points and has a tight context. Strong semantic information is required to perform inter-class and intra-class discrimination. Therefore, the final classification results fluctuate greatly. However, our algorithm again exhibits great improvement, while some comparison algorithms achieve poor performance, such as MVGL and ECRMSC. The main reasons can be summarized as follows: 1) MVGL is adaptive graph learning; it only considers the retention of the local structure of the similarity factor of the original data matrix and the cooperative representation of the similarity matrix of each view but does not fully consider the information redundancy and other information. 2) ECRMSC uses the -norm as a constraint to extract the complementary information between different sparse subspace matrices. However, ECRMSC does not make full use of the common information of each view and the retention of local structural features in the sparse representation process. As a comparison, our proposed algorithm has been improved on this basis, and the results are greatly improved (at least 3%) for some evaluation metrics.
Table IV displays the clustering performance for the BBCSport dataset. This is a test dataset, and the final classification results fluctuate greatly. Table IV shows the effect of LMSC on the synthesis, which is only the last third, when our proposed algorithm achieves the best performance. Although LMSC exhibits a certain gap in performance with that of our proposed algorithm, there are certain similarities in the algorithm models. For example, both algorithms decompose the original matrix into sparse representation and noise error parts. Additionally, low-rank constraints are imposed on the sparse representation matrix and the noise error matrix. From this, we can conclude that the low-rank processing we imposed on the sparse representation matrix and the noise error matrix is very helpful for improving the clustering effect.
Table V shows the experimental results for the EYaleB face dataset. Since this dataset and the ORL mtv dataset are both face datasets, the experimental results for these two datasets are similar. First, their clustering effects are better and shows a greater improvement. Second, the results for the two datasets that have been clustered multiple times are very close for each indicator. The only difference is that the EYaleB dataset and other comparison algorithms exhibit polarization in the clustering results. Some algorithms do not perform very well for this dataset, such as DiMSC and MVGL. Since one sample of each view in the EYaleB dataset has more than 10,000 features, these features may contain some redundant information causing noise, and the clustering performance will be greatly affected. In this way, we need to perform sparse representation and dimensionality reduction on the dataset. However, DiMSC and MVGL do not consider the noise matrix or remove redundant information, which decreases their performance.
The experimental results for the uci digit dataset are shown in Table VI. The performance of the proposed method for this dataset is relatively stable compared to that of the other algorithms. The experimental results of our proposed algorithm show slight improvement compared to the second-best results in some evaluations, such as improvements of 0.13%, 0.45% and 0.47% for NMI, purity, and recall in the evaluation metrics, respectively. However, there is a remarkable improvement over the second-best comparison algorithm for some evaluation metrics, such as ACC, precision, F-score and AR. The improvements of the experimental results for these metrics are approximately 2%, 3%, 3% and 2%, respectively.
V-F Similarity Matrix Analysis
In this sub-section, the global similarity matrix is analysed. The similarity matrix can interpret the clustering performance effect very well. Because of space limitations, the global similarity matrices of only three datasets, the ORL mtv, EYaleB and uci digit datasets, are shown in Fig. 7. The first line in Fig. 7 represents the original generated visual pictures. To show them clearly, we partially zoom in, and the shaded area in the first line in the figure is enlarged. The second line shows the visualization of the shaded area in the first line. From the second line in Fig. 7, we can see that different classes are clearly divided into squares. The more concentrated on the diagonal lines and the smoother it is outside the boxes, the better the clustering effect is. It can be seen that all three results are very good.
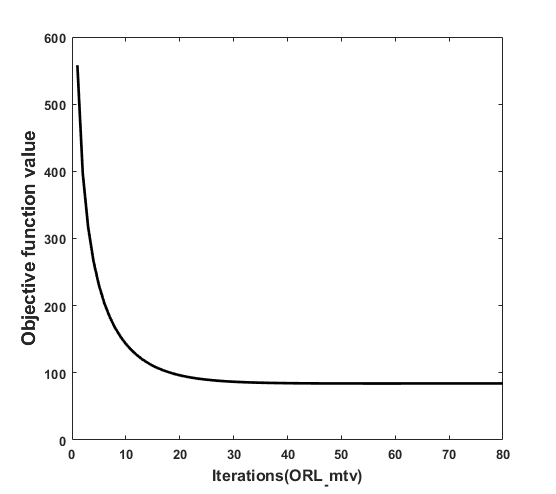
V-G Convergence Analysis
To solve Eq. (10), we update each variable in the form of a locally optimal solution. For an optimization model, the convergence of the objective function is very important. Therefore, to intuitively explain the convergence of the proposed model, we present the analysis in Fig. 6. It shows that the BBCSport and 3-sources datasets converge very quickly and need only 3 iterations to converge, as they are two text datasets. In addition, the EYaleB dataset reports such a large number of iterations. According to the complexity analysis of the algorithm, we propose that the computational effectiveness of the method depends only on the number of clustering categories, the number of samples and the dimension of samples. First of all, the dataset EYaleB is a gray scale face dataset and has 1102 samples, which contains the faces of 38 different individuals. Second, the dimensions of each sample are very large containing 32,256 features. This is very complex. Therefore, when this data set is applied to our proposed algorithm, its iteration times are much more than that of other data sets. By comparison with the algorithm complexity in this paper, such as MLSSC, MVGL, LRPP-GRR, L0-LSSC.The complexity of the proposed algorithm is reasonable in theory.
VI Conclusion
In this paper, we propose a new multi-view clustering algorithm for a low-rank sparse subspace. We use two decomposition methods to decompose the original data matrix. One method decomposes the original data into global sparse subspace and multi-view error matrices, and the other method decomposes the original data into some multi-view sparse subspace matrices. The two parts are combined by a regularization norm, resulting in an optimal global matrix and a greater diversity of individual view features. Furthermore, we use a new low-rank and sparse norm constraint for the defects of the nuclear norm and -norm. The similarity matrix of the proposed method is adaptive. Finally, we put these sub-modules in a unified optimization framework and use the ADMM for optimization updates. Experiments are carried out for five well-known public datasets to verify the effectiveness of the proposed algorithm compared with several similar state-of-the-art algorithms. The experimental results show that the proposed method obtained the best results.



References
- [1] R. Zhang, J. Li, H. Sun, Y. Ge, P. Luo, X. Wang, and L. Lin, “Scan: Self-and-collaborative attention network for video person re-identification,” IEEE Transactions on Image Processing, vol. 28, no. 10, pp. 4870–4882, 2019.
- [2] L. Zhao, X. Li, Y. Zhuang, and J. Wang, “Deeply-learned part-aligned representations for person re-identification,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 3219–3228.
- [3] Q. Cao, L. Lin, Y. Shi, X. Liang, and G. Li, “Attention-aware face hallucination via deep reinforcement learning,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 690–698.
- [4] Y. Shi, H. Zhong, Z. Yang, X. Yang, and L. Lin, “Ddet: Dual-path dynamic enhancement network for real-world image super-resolution,” IEEE Signal Processing Letters, vol. 27, pp. 481–485, 2020.
- [5] Y. Shi, K. Wang, C. Chen, L. Xu, and L. Lin, “Structure-preserving image super-resolution via contextualized multitask learning,” IEEE transactions on multimedia, vol. 19, no. 12, pp. 2804–2815, 2017.
- [6] G. Lu, X. Zhang, W. Ouyang, L. Chen, Z. Gao, and D. Xu, “An end-to-end learning framework for video compression,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.
- [7] Y. Shi, L. Guanbin, Q. Cao, K. Wang, and L. Lin, “Face hallucination by attentive sequence optimization with reinforcement learning,” IEEE transactions on pattern analysis and machine intelligence, 2019.
- [8] F. Wu, Z. Yu, Y. Yang, S. Tang, Y. Zhang, and Y. Zhuang, “Sparse multi-modal hashing,” IEEE Transactions on Multimedia, vol. 16, no. 2, pp. 427–439, 2013.
- [9] J. Chen, Z. Chen, Z. Chi, and H. Fu, “Facial expression recognition in video with multiple feature fusion,” IEEE Transactions Affective Computing, vol. 9, no. 1, pp. 38–50, 2018.
- [10] D. G. Lowe, “Distinctive image features from scale-invariant keypoints,” International Journal of Computer Vision, vol. 60, no. 2, pp. 91–110, 2004.
- [11] T. Ahonen, A. Hadid, and M. Pietikäinen, “Face description with local binary patterns: Application to face recognition,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 28, no. 12, pp. 2037–2041, 2006.
- [12] T. S. Lee, “Image representation using 2d gabor wavelets,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 18, no. 10, pp. 959–971, 1996.
- [13] Q. Wang, H. Lv, J. Yue, and E. Mitchell, “Supervised multiview learning based on simultaneous learning of multiview intact and single view classifier,” Neural Computing and Applications, vol. 28, no. 8, pp. 2293–2301, 2017.
- [14] C. Zhang, Y. Liu, Y. Liu, Q. Hu, X. Liu, and P. Zhu, “FISH-MML: fisher-hsic multi-view metric learning,” in Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI 2018, July 13-19, 2018, Stockholm, Sweden, 2018, pp. 3054–3060.
- [15] C. Hou, F. Nie, H. Tao, and D. Yi, “Multi-view unsupervised feature selection with adaptive similarity and view weight,” IEEE Transactions on Knowledge and Data Engineering, vol. 29, no. 9, pp. 1998–2011, 2017.
- [16] S. Tulsiani, T. Zhou, A. A. Efros, and J. Malik, “Multi-view supervision for single-view reconstruction via differentiable ray consistency,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017, 2017, pp. 209–217.
- [17] J. Xu, J. Han, and F. Nie, “Discriminatively embedded k-means for multi-view clustering,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, June 27-30, 2016, 2016, pp. 5356–5364.
- [18] F. Nie, G. Cai, J. Li, and X. Li, “Auto-weighted multi-view learning for image clustering and semi-supervised classification,” IEEE Transactions Image Processing, vol. 27, no. 3, pp. 1501–1511, 2018.
- [19] F. Nie, G. Cai, and X. Li, “Multi-view clustering and semi-supervised classification with adaptive neighbours,” in Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, February 4-9, 2017, San Francisco, California, USA, 2017, pp. 2408–2414.
- [20] Z. Xue, J. Du, D. Du, G. Li, Q. Huang, and S. Lyu, “Deep constrained low-rank subspace learning for multi-view semi-supervised classification,” IEEE Signal Processing Letters, vol. 26, no. 8, pp. 1177–1181, 2019.
- [21] C. Lu, J. Feng, Z. Lin, T. Mei, and S. Yan, “Subspace clustering by block diagonal representation,” IEEE Transactions on Pattern Pnalysis and Machine Intelligence, vol. 41, no. 2, pp. 487–501, 2018.
- [22] C. Li and R. Vidal, “A structured sparse plus structured low-rank framework for subspace clustering and completion,” IEEE Transactions Signal Processing, vol. 64, no. 24, pp. 6557–6570, 2016.
- [23] S. Zhan, J. Wu, N. Han, J. Wen, and X. Fang, “Unsupervised feature extraction by low-rank and sparsity preserving embedding,” Neural Networks, vol. 109, pp. 56–66, 2019.
- [24] X. Li, H. Zhang, R. Wang, and F. Nie, “Multi-view clustering: A scalable and parameter-free bipartite graph fusion method,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.
- [25] S. Yang, L. Li, S. Wang, W. Zhang, Q. Huang, and Q. Tian, “Skeletonnet: A hybrid network with a skeleton-embedding process for multi-view image representation learning,” IEEE Transactions on Multimedia, vol. 21, no. 11, pp. 2916–2929, 2019.
- [26] C. Ma, Y. Guo, J. Yang, and W. An, “Learning multi-view representation with lstm for 3-d shape recognition and retrieval,” IEEE Transactions on Multimedia, vol. 21, no. 5, pp. 1169–1182, 2018.
- [27] S. Zhang, X. Yu, Y. Sui, S. Zhao, and L. Zhang, “Object tracking with multi-view support vector machines,” IEEE Transactions on Multimedia, vol. 17, no. 3, pp. 265–278, 2015.
- [28] C. Xu, D. Tao, and C. Xu, “Multi-view intact space learning,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 37, no. 12, pp. 2531–2544, 2015.
- [29] H. Gao, F. Nie, X. Li, and H. Huang, “Multi-view subspace clustering,” in 2015 IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, December 7-13, 2015, 2015, pp. 4238–4246.
- [30] X. Zhang, H. Sun, Z. Liu, Z. Ren, Q. Cui, and Y. Li, “Robust low-rank kernel multi-view subspace clustering based on the schatten p-norm and correntropy,” Information Science, vol. 477, pp. 430–447, 2019.
- [31] J. Wen, Y. Xu, and H. Liu, “Incomplete multiview spectral clustering with adaptive graph learning,” IEEE Transactions on Cybernetics, 2018.
- [32] X. Cao, C. Zhang, H. Fu, S. Liu, and H. Zhang, “Diversity-induced multi-view subspace clustering,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 586–594.
- [33] X. Wang, X. Guo, Z. Lei, C. Zhang, and S. Z. Li, “Exclusivity-consistency regularized multi-view subspace clustering,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 923–931.
- [34] Z. Ding and Y. Fu, “Robust multiview data analysis through collective low-rank subspace,” IEEE Transactions on Neural Networks and Learning Systems, vol. 29, no. 5, pp. 1986–1997, 2017.
- [35] A. Kumar and H. Daumé, “A co-training approach for multi-view spectral clustering,” in Proceedings of the 28th International Conference on Machine Learning (ICML-11), 2011, pp. 393–400.
- [36] K. Zhan, C. Niu, C. Chen, F. Nie, C. Zhang, and Y. Yang, “Graph structure fusion for multiview clustering,” IEEE Transactions on Knowledge and Data Engineering, vol. 31, no. 10, pp. 1984–1993, 2019.
- [37] K. Zhan, F. Nie, J. Wang, and Y. Yang, “Multiview consensus graph clustering,” IEEE Transactions on Image Processing, vol. 28, no. 3, pp. 1261–1270, 2018.
- [38] H. Zhao, H. Liu, Z. Ding, and Y. Fu, “Consensus regularized multi-view outlier detection,” IEEE Transactions on Image Processing, vol. 27, no. 1, pp. 236–248, 2017.
- [39] X. Wang, Z. Lei, X. Guo, C. Zhang, H. Shi, and S. Z. Li, “Multi-view subspace clustering with intactness-aware similarity,” Pattern Recognition, vol. 88, pp. 50–63, 2019.
- [40] S. Luo, C. Zhang, W. Zhang, and X. Cao, “Consistent and specific multi-view subspace clustering,” in Thirty-Second AAAI Conference on Artificial Intelligence, 2018, pp. 3730–3737.
- [41] C. Tang, X. Zhu, X. Liu, and L. Wang, “Cross-view local structure preserved diversity and consensus learning for multi-view unsupervised feature selection,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, 2019, pp. 5101–5108.
- [42] E. Elhamifar and R. Vidal, “Sparse subspace clustering: Algorithm, theory, and applications,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 35, no. 11, pp. 2765–2781, 2013.
- [43] G.-F. Lu, Y. Wang, and J. Zou, “Low-rank matrix factorization with adaptive graph regularizer,” IEEE Transactions on Image Processing, vol. 25, no. 5, pp. 2196–2205, 2016.
- [44] M. Brbić and I. Kopriva, “L0-motivated low-rank sparse subspace clustering,” IEEE Transactions on Cybernetics, 2018.
- [45] I. Selesnick, “Sparse regularization via convex analysis,” IEEE Transactions on Signal Processing, vol. 65, no. 17, pp. 4481–4494, 2017.
- [46] C. Tang, X. Zhu, X. Liu, M. Li, P. Wang, C. Zhang, and L. Wang, “Learning joint affinity graph for multi-view subspace clustering,” IEEE Transactions on Multimedia, vol. 21, no. 7, pp. 1724–1736, 2019.
- [47] K. Zhan, C. Zhang, J. Guan, and J. Wang, “Graph learning for multiview clustering,” IEEE Transactions on Cybernetics, vol. 48, no. 10, pp. 2887–2895, 2017.
- [48] J. Wen, X. Fang, Y. Xu, C. Tian, and L. Fei, “Low-rank representation with adaptive graph regularization,” Neural Networks, vol. 108, pp. 83–96, 2018.
- [49] G. Yuan, J. Lu, and Z. Wang, “The prp conjugate gradient algorithm with a modified wwp line search and its application in the image restoration problems,” Applied Numerical Mathematics, vol. 152, pp. 1–11, 2020.
- [50] H. Li, F. He, Y. Liang, and Q. Quan, “A dividing-based many-objective evolutionary algorithm for large-scale feature selection,” Soft Computing, pp. 1–20, 2019.
- [51] J.-s. Yong, F.-z. He, H.-r. Li, and W.-q. Zhou, “A novel bat algorithm based on cross boundary learning and uniform explosion strategy,” Applied Mathematics-A Journal of Chinese Universities, vol. 34, no. 4, pp. 480–502, 2019.
- [52] M. Brbić and I. Kopriva, “Multi-view low-rank sparse subspace clustering,” Pattern Recognition, vol. 73.
- [53] C. Zhang, Q. Hu, H. Fu, P. Zhu, and X. Cao, “Latent multi-view subspace clustering,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 4279–4287.