Unsupervised learning of observation functions in
state-space models by nonparametric moment methods
Abstract
We investigate the unsupervised learning of non-invertible observation functions in nonlinear state-space models. Assuming abundant data of the observation process along with the distribution of the state process, we introduce a nonparametric generalized moment method to estimate the observation function via constrained regression. The major challenge comes from the non-invertibility of the observation function and the lack of data pairs between the state and observation. We address the fundamental issue of identifiability from quadratic loss functionals and show that the function space of identifiability is the closure of a RKHS that is intrinsic to the state process. Numerical results show that the first two moments and temporal correlations, along with upper and lower bounds, can identify functions ranging from piecewise polynomials to smooth functions, leading to convergent estimators. The limitations of this method, such as non-identifiability due to symmetry and stationarity, are also discussed.
Key words unsupervised learning, state-space models, nonparametric regression, generalized moment method, RKHS
1 Introduction
We consider the following state-space model for processes in :
| State model: | with | (1.1) | ||||||
| Observation model: | with | (1.2) |
Here is the standard Brownian motion, the drift function and the diffusion coefficient are given, satisfying the linear growth and global Lipschitz conditions. We assume that the initial distribution of is given. Thus, the state model is known, in other words, the distribution of the process is known.
Our goal is to estimate the unknown observation function from data consisting of an ensemble of trajectories of the process , denoted by , where indexes trajectories, are the times at which the observations are made. In particular, there are no pairs being observed, so in the language of machine learning this may be considered an unsupervised learning problem. A case of particular interest in the present work is when the observation function is nonlinear and non-invertible, and it is within a large class of functions, including smooth functions but also, for example, piecewise continuous functions.
We estimate the observation function by matching generalized moments, while constraining the estimator to a suitably chosen finite-dimensional hypothesis (function) space, whose dimension depends on the number of observations, in the spirit of nonparametric statistics. We consider both first- and second-order moments, as well as temporal correlations, of the observation process. The estimator minimizes the discrepancy between the moments over hypothesis spaces spanned by B-spline functions, with upper and lower pointwise constraints estimated from data. The method we propose has several significant strengths:
-
•
the generalized moments do not require the invertibility of the observation function ;
-
•
low-order generalized moments tend to be robust to additive observation noise;
-
•
generalize moments avoid the need of local constructions, since they depend on the entire distribution of the latent and observed processes;
-
•
our nonparametric approach does not require a priori information about the observation function, and, for example, it can deal with both continuous and discontinuous functions;
-
•
the method is computationally efficient because the moments need to be estimated only once, and their computation is easily performed in parallel.
We note that the method we propose readily extends to multivariate state models, with the main statistical and computational bottlenecks coming from the curse-of-dimensionality in the representation and estimation of a higher-dimensional in terms the basis functions.
The problem we are considering has been studied in the contexts of nonlinear system identification [2, 23], filtering and data assimilation [4, 21], albeit typically when observations are in the form of one, or a small number of, long trajectories, and in the case of an invertible or smooth observations function . The estimation of the unknown observation function and of the latent dynamics from unlabeled data has been considered in [14, 17, 10, 27] and references therein. Inference for state-space models (SSMs) has been widely studied; most classical approaches focus on estimating the parameters in the SSM from a single trajectory of the observation process, by expectation-maximization methods maximizing the likelihood, or Bayesian approaches [2, 23, 4, 18, 11], with the recent studies estimating the coefficients in a kernel representation [36] or the coefficients of a pre-specified set of basis functions [35].
Our framework combines nonparametric learning [13, 7] with the generalized moments method, that is mainly studied in the setting of parametric inference [33, 31, 30]. We study the identifiability of the observation function from first-order moments, and show that the first-order generalized moments can identify the function in the closure a reproducing kernel Hilbert space (RKHS) that is intrinsic to the state model. As far as we know, this is the first result on the function space of identifiability for nonparametric learning of observation functions in SSMs.
When the observation function is invertible, its unsupervised regression is investigated [32] by maximizing the likelihood for high-dimensional data. However, in many applications, particularly those involving complex dynamics, the observation functions are non-invertible, for example they are projections or nonlinear non-invertible transformations (e.g., with ). As a consequence, the resulting observed process may have discontinuous or singular probability densities [16, 12]. In [27], it has been shown empirically that delayed coordinates with principal component analysis may be used to estimate the dimension of the hidden process, and diffusion maps [6] may yield a diffeomorphic copy of the observation function.
The remainder of the paper is organized as follows. We present the nonparametric generalized moments method in Section 2. In Section 3 we study the identifiability of the observation function from first-order moments, and show that the function spaces of identifiability are RKHSs intrinsic to the state model. We present numerical examples to demonstrate the effectiveness, and limitations, of the proposed method in Section 4. Section 5 summarizes this study and discusses directions of future research; we review the basic elements about RKHSs in Appendix A.
2 Non-parametric regression based on generalized moments
Throughout this work, we focus on discrete-time observations of the state-space model (1.1)–(1.2), because data in practice are discrete in time, and the extension to continuous time trajectories is straightforward. We thereby suppose that the data is in the form , with indexing multiple independent trajectories, observed at the vector of discrete times .
2.1 Generalized moments method
We estimate the observation function by the generalized moment method (GMM) [33, 31, 30], searching for an observation function , in a suitable finite-dimensional hypothesis (function) space, such that the moments of functionals of the process are close to the empirical ones (computed from data) of .
We consider “generalized moments” in the form , where is a functional of the trajectory . For example, the functional can be , in which case is the vector of the first moments and of temporal correlations at consecutive observation times. The empirical generalized moments are computed from data by Monte Carlo approximation:
| (2.1) |
which converges at the rate by the Central Limit Theorem, since the trajectories are independent. Meanwhile, since the state model (hence the distribution of the state process) is known, for any putative observation function , we approximate the moments of the process by simulating independent trajectories of the state process :
| (2.2) |
Here, with some abuse of notation, . The number can be as large as we can afford from a computational perspective. In what follows, since can be chosen large – only subject to computational constraints – we consider the error in this empirical approximation negligible and work with directly.
We estimate the observation function by minimizing a notion of discrepancy between these two empirical generalized moments:
| (2.3) |
where is restricted to some suitable hypothesis space , and is a proper distance between the moments to be specified later. We choose to be a subset of an -dimensional function space, spanned by basis functions , within which we can write . By the law of large numbers, tends almost surely to .
It is desirable to choose the generalized moment functional and the hypothesis space so that the minimization in (2.3) can be performed efficiently. We select the functional so that the moments , for , can be efficiently evaluated for all . To this end, we choose linear functionals or low-degree polynomials, so that we only need to compute the moments of the basis functions once, and use these moments repeatedly during the optimization process, as discussed in Section 2.2. The selection of the hypothesis space is detailed in Section 2.3.
2.2 Loss functional and estimator
The generalized moments we consider include the first and the second moments, as well as the one-step temporal correlation: we let . The loss functional in (2.3) is then chosen in the following form: for weights ,
| (2.4) | ||||
Let the hypothesis space be a subset of the span of a linearly independent set , which we specify in the next section. For , we can write the loss functionals in (2.4) as
| (2.5) |
where , and the matrix and the vector are given by
| (2.6) |
Similarly, we can write and in (2.4) as
| (2.7) | ||||
Thus, with the above notations in (2.6)-(2.7), the minimizer of the loss functional over is
| (2.8) | ||||
Here, with an abuse of notation, we denote by .
In practice, with data , we approximate the expectations involving the observation process by the corresponding empirical means as in (2.1). Meanwhile, we approximate the expectations involving the state process by Monte Carlo as in (2.2), using trajectories. We assume that the sampling errors in the expectations of , i.e. in the terms , are negligible, since the basis can be chosen to be bounded functions (such as B-spline polynomials) and can be as large as we can afford. We approximate by their empirical means :
| (2.9) | ||||||
| (2.10) | ||||||
| (2.11) |
Then, with and , the estimator from data is
| (2.12) | ||||
The minimization of can be performed with iterative algorithms, with each optimization iteration, with respect to , performed efficiently since the data-based matrices and vectors, and , only need to be computed once. The main source of sampling error is the empirical approximation of the moments of the process . We specify the hypothesis space in the next section and provide a detailed algorithm for the computation of the estimator in Section 2.4.
Remark 2.1 (Moments involving Itô’s formula)
When the data trajectories are continuous in time (or when they are sampled with a high frequency in time), we can utilize additional moments from Itô’s formula. Recall that for , applying Itô formula for the diffusion process in (1.1), we have
where the operator is
| (2.13) |
Hence, , where . Thus, when is small, we can consider matching the generalized moments
| (2.14) |
Similarly, we can further consider the generalized moments and and the corresponding quartic loss functionals. Since they require the moments of the first- and second-order derivatives of the observation function, they are helpful when the observation function is smooth with bounded derivatives.
2.3 Hypothesis space and optimal dimension
We let the hypothesis space be a class of bounded functions in ,
| (2.15) |
where the basis functions are to be specified below, and the empirical bounds
aim to approximate the upper and lower bounds for . Note that the hypothesis space is a bounded convex subset of the linear space . While the pointwise bound constraints are for all , in practice, for efficient computation, we apply these constraints at representative points, for example at the mesh-grid points used when the basis functions are piecewise polynomials. One may apply stronger constraints, such as requiring time-dependent bounds to hold at all times: for each time , where and are the minimum and maximum of the data set .
Basis functions.
As basis functions for the subspace containing we choose B-spline basis consisting of piecewise polynomials (see Appendix B.1 for details). To specify the knots of B-spline functions, we introduce a density function , which is the average of the probability densities of :
| (2.16) |
when and . Here (and its continuous time limit ) describes the intensity of visits to the regions explored by the process . The knots of the B-spline function are from a uniform partition of , the smallest interval enclosing the support of . Thus, the basis functions are piecewise polynomials with knots adaptive to the state model which determines .
Dimension of the hypothesis space.
It is important to select a suitable dimension of the hypothesis space to avoid under- or over-fitting. We select the dimension in two steps. First, we introduce an algorithm, namely Cross-validating Estimation of Dimension Range (CEDR), to estimate the range of the dimension from the quadratic loss functional . Its main idea is to avoid the sampling error amplification due to an unsuitably large dimension. The sampling error is estimated from data by splitting the data into two sets. Then, we select the optimal dimension that minimizes the 2-Wasserstein distance between the measures of data and prediction. See Appendix B.1 for details.
2.4 Algorithm
We summarize the above method of nonparametric regression with generalized moments in Algorithm 1. It minimizes a quartic loss function with the upper and lower bound constraints, and we perform the optimization with multiple initial conditions (see Appendix B.2 for the details).
Computational complexity
The computational complexity is driven by the construction of the normal matrix and vectors and the evaluation of the 2-Wasserstein distances, which require computations of order and , respectively. Thus, the total computational complexity is of order .
2.5 Tolerance to noise in the observations
The (generalized) moment method can tolerate large additive observation noise if the distribution of the noise is known. The estimation error caused by the noise is at the scale of the sampling error, which is negligible when the sample size is large.
More specifically, suppose that we observe from the observation model
| (2.17) |
where is sampled from a process that is independent of and has moments
| (2.18) |
A typical example is when being identically distributed independent Gaussian noise , which gives .
The algorithm in Section 2 applies the noisy data with only a few changes. First, note that the loss functional in (2.4) involves only the moments , and , which are moments of . When in (2.17) has observation noise specified above, we have
for all . Thus, we only need to change the loss functional to be
| (2.19) | ||||
Similar to (2.12), the minimizer of the loss functional can be then computed as
| (2.20) | ||||
where all the -matrices and -vectors are the same as before (e.g., in (2.6)–(2.7) and (2.11)).
Note that the observation noise introduces sampling errors through , and , which are at the scale . Also, note the -matrices are independent of the observation noise. Thus, the observation noise affects the estimator only through the sampling error at the scale , the same as the sampling error in the estimator from noiseless data.
3 Identifiability
We discuss in this section the identifiability of the observation function by those loss functionals in the previous section. We show that , the quadratic loss functional based on the 1st-order moments in (2.5), can identify the observation function in the -closure of a reproducing kernel Hilbert space (RKHS) that is intrinsic to the state model. In addition, the loss functional in (2.14) based on the Itô formula, enlarges the function space of identifiability. We also discuss, in Section 3.2, some limitations of the loss functional in (2.19), that combines the quadratic and quartic loss functionals; in particular, symmetry and stationarity may prevent us from identifying the observation function when using only generalized moments.
The starting point is a definition of identifiability, which is a generalization of the uniqueness of minimizer of a loss function in parametric inference (see e.g., [3, page 431] and [8]).
Definition 3.1 (Identifiability)
We say that the observation function is identifiable by a data-based loss functional on a function space if is the unique minimizer of in .
The identifiability consists of three elements: a loss functional , a function space , and a unique minimizer for the loss functional in . When the loss functional is quadratic (such as or ), it has a unique minimizer in a Hilbert space iff its Frechét derivative is invertible in the Hilbert space; thus, the main task is to find such function spaces [22, 20, 24]. We will specify such function spaces for and/or in Section 3.1. We note that these function spaces do not take into account the constraints of upper and lower bounds, which generically lead to minimizers near or at the boundary of the constrained set. This consideration applies also to the piecewise quadratic functionals and , which can be viewed as providing additional constraints (see Section 3.2).
3.1 Identifiability by quadratic loss functionals
We consider the quadratic loss functionals and , and show that they can identify the observation function in the -closure of reproducing kernel Hilbert spaces (RKHSs) that are intrinsic to the state model.
Assumption 3.2
We make the following assumptions on the state-space model.
-
•
The coefficients in the state model (1.1) satisfy a global Lipschitz condition, and therefore also a linear growth condition: there exists a constant such that for all , and . Furthermore, we assume that for all .
-
•
The observation function satisfies .
Theorem 3.3
Given discrete-time data from the state-space model (1.1) satisfying Assumption 3.2, let and be the loss functionals defined in (2.4) and (2.14). Denote the density of the state process at time t, and recall that in (2.16) is the average, in time, of these densities. Let be the adjoint of the 2nd-order elliptic operator in (2.13). Then,
-
(a)
has a unique minimizer in , the closure of the RKHS with reproducing kernel
(3.1) for such that , and otherwise. When the data is continuous (), we have .
-
(b)
has a unique minimizer in , the closure of the RKHS with reproducing kernel
(3.2) for such that , and otherwise. When the data is continuous, we have .
-
(c)
has a unique minimizer in , the closure of the RKHS with reproducing kernel
(3.3) for such that , and otherwise. Similarly, we have for continuous data.
In particular, is the unique minimizer of these loss functionals if is in , or .
To prove this theorem, we first introduce an operator characterization of the RKHS in the next lemma. Similar characterizations hold for the RKHSs and .
Lemma 3.4
The function in (3.1) is a Mercer kernel, that is, it is continuous, symmetric and positive semi-definite. Furthermore, is square integrable in , and it defines a compact positive integral operator :
| (3.4) |
Also, the RKHS has the operator characterization: and is an orthonormal basis of the RKHS , where are the pairs of positive eigenvalues and corresponding eigenfunctions of .
Proof. Since the densities of diffusion process are smooth, the kernel is continuous on the support of and it is symmetric. It is positive semi-definite (see Appendix A for a definition) because for any and , we have
Thus, is a Mercer kernel.
To show that is square integrable, note first that for any . Thus for each , we have
and . It follows that is in .
Since is positive definite and square integrable, the integral operator is compact and positive. The operator characterization follows from Theorem A.3.
Remark 3.5
The above lemma is only applicable to discrete-time observations because it uses the bounds . When the data is continuous in time on , we have if the support of is compact. In fact, to show that is square integrable when is compact, we note that the probability densities are uniformly bounded above, that is, . Thus for each , we have
by Cauchy-Schwartz for the first inequality. Then,
It follows that is in :
When has non-compact support, it remains to be proved that .
Proof of Theorem 3.3. The proof for (a)–(c) are similar, so we focus on (a) and only sketch the proof for (b)–(c).
To prove (a), we only need to show the uniqueness of the minimizer, because Lemma 3.4 has shown that is a Mercer kernel. Furthermore, note that by Lemma 3.4, the closure of the RKHS is , the closure in of the eigenspace of with non-zero eigenvalues, where is the operator defined in (3.4).
For any , with the notation , we have for each (recall that ). Hence, we can write the loss functional as
| (3.5) | ||||
Thus, attains its unique minimizer in at iff with implies that . Note that the second equality in (3.5) implies that iff , i.e. , for all . Then, for each and . Thus, the sum of them is also zero:
for each . By the definition of the operator , this implies that . Thus, because .
The above arguments hold true when the kernel is from continuous-time data: one only has to replace by the averaged integral in time. This completes the proof for (a).
The proof of (b) and (c) are the same as above except the appearance of the operator . Note that in (2.14) reads , thus, it differs from only at the expectation . By integration by parts, we have
for any . Then, the rest of the proof for Part (b) follows exactly as above with and replaced by and .
The following remarks highlight the implications of the above theorem. We consider only , but all the remarks apply also to and .
Remark 3.6 (An operator view of identifiability)
The unique minimizer of in defined in Theorem 3.3 is the zero of its Frechét derivative: , which is if . In fact, note that with the integral operator , we can write the loss functional as
Thus, the Frechét derivative of over is and we obtain the unique minimizer. Furthermore, this operator representation of the minimizer conveys two important messages about the inverse problem of finding the minimizer of : (1) it is ill-defined beyond . In particularly, it is ill-defined on when is not strictly positive; (2) the inverse problem is ill-posed on , because the operator is compact and its inverse is unbounded.
Remark 3.7 (Identifiability and normal matrix in regression)
Suppose and denote with being basis functions such as B-splines. As shown in (2.5)-(2.6), the loss functional becomes a quadratic function with normal matrix with , where . Thus, the rank of the matrix is no larger than . Note that is the matrix approximation of on the basis in the sense that
for each . Thus, the minimum eigenvalue of approximates the minimal eigenvalue of restricted in . In particular, if contains a nonzero element in the null space of , then the normal matrix will be singular; if is a subspace of the closure of , then the normal matrix is invertible and we can find a unique minimizer.
Remark 3.8 (Convergence of estimator)
For a fixed hypothesis space, the estimator converges to the projection of in as the data size increases, at the order , with the error coming from the Monte Carlo estimation of the moments of observations. With data adaptive hypothesis spaces, we are short of proving the minimax rate of convergence as in classical nonparametric regression. This is because of the lack of a coercivity condition [25, 22], since the compact operator ’s eigenvalue converges to zero. A minimax rate would require an estimate on the spectrum decay of , and we leave this for future research.
Remark 3.9 (Regularization using the RKHS)
The RKHS can be further utilized to provide a regularization norm in the Tikhonov regularization (see [24]). It has the advantage of being data adaptive and constrains the learning to take place in the function space of learning.
Examples of the RKHS.
We emphasize that the reproducing kernel and the RKHS are intrinsic to the state model (including the initial distribution). We demonstrate the kernels by analytically computing them when the process is either the Brownian motion or the Ornstein-Uhlenbeck (OU) process. For simplicity, we consider continuous-time data. Recall that when the diffusion coefficient in the state-model (1.1) is a constant, the second-order elliptic operators is and its joint operator is
where denotes the probability density of .
Example 3.10 (1D Brownian motion)
Example 3.11 (Ornstein-Uhlenbeck process)
3.2 Non-identifiability due to stationarity and symmetry
When the hypothesis space has a dimension larger than the RKHS’s, the quadratic loss functional may have multiple minimizers. The constraints of upper and lower bounds, as well as the loss functionals and , can help to identify the observation function. However, as we show next, identifiability may still not hold due to symmetry and/or stationarity.
Stationary processes
When the process is stationary, we have limited information from the moments in our loss functionals. We have with , so can only identify a constant function. Also, the loss functional because
In other words, the function space of identifiability by is the space of constant functions. Meanwhile, the quartic loss functionals and also provide limited information: they become and , the second-order moment and the temporal correlation at one-time instance.
To see the limitations, consider the finite-dimensional hypothesis space in (2.15). As in (2.12), with , the loss functional becomes
where is a rank-one matrix, and only bring in two additional constraints. Thus, has multiple minimizers in a linear space with dimension greater than 3. One has to resort to the upper and lower bounds in (2.15) for additional constraints, which lead to minimizers on the boundary of the resulted convex sets.
Symmetry
When the distribution of the state process is symmetric, a moment-based loss functional does not distinguish the true observation function from its symmetric counterpart. More specifically, if a transformation preserves the distribution, i.e., and have the same distribution, then and . Thus, our loss functional will not distinguish from . However, this is totally reasonable: the two functions yield the same observation process (in terms of the distribution), thus the observation data does not provide the necessary information for identifying from .
Example 3.12 (Brownian motion)
Consider the standard Brownian motion , whose distribution is symmetric about (because the two processes and have the same distribution). Let the transformation be . Then, the two functions and lead to the same observation process, thus they cannot be distinguished from the observations.
4 Numerical Examples
We demonstrate the effectiveness and limitations of our algorithm using synthetic data in representative examples. The algorithm works well when the state-model’s densities vary appreciably in time to yield a function space of identifiability whose distance to the true observation function is small. In this case, our algorithm leads to a convergent estimator as the sample size increases. We also demonstrate that when the state process (i.e., the Ornstein-Uhlenbeck process) is stationary or symmetric in distribution (i.e., the Brownian motion), the loss functional can have multiple minimizers in the hypothesis space, preventing us from identifying the observation functions (see Section 4.3).
4.1 Numerical settings
We first introduce the numerical settings used in the tests.
Data generation.
The synthetic data with are generated from the state model, which is solved by the Euler-Maruyama scheme with a time-step for steps. We will consider sample sizes to test the convergence of the estimator.
Inference algorithm.
We follow Algorithm 1 to search for the global minimum of the loss functionals in (2.12). The weights for the ’s are , where is the Euclidean norm on and
for .
For each example, we test B-spline hypothesis spaces with dimension in the range , which is selected by Algorithm 2 with degrees in . We select the optimal dimension and degree with the minimal 2-Wasserstein distance between the predicted and true distribution of . The details are presented in Section C.
Results assessment and presentation.
We present three aspects of the estimator :
-
•
Estimated and true functions. We compare the estimator with the true function , along with the projection of to the linear space expanded by the elements of .
-
•
2-Wasserstein distance. We present the 2-Wasserstein distance (see (B.5)) between the distributions of and for each time with training data and a new set of randomly generated data.
-
•
Convergence of error. We test the convergence of the estimator in as the sample size increases. The error is computed by the Riemann sum approximation. We present the mean and standard deviation of errors from 20 independent simulations. The convergence rate is also highlighted, and we compare it with the minimax convergence rate in classical nonparametric regression (see e.g., [13, 25]), which is with being the degree of the B-spline basis. This minimax rate is not available yet for our method, see Remark 3.8.

4.2 Examples
The state model we consider is a stochastic differential equation with the double-well potential
| (4.1) |
where the density of is the average of and . The distribution of is non-symmetric and far from stationary (see Figure 1(a)). Thus the quadratic loss functional provides a rich RKHS space for learning.
We consider three observation functions representing typical challenges: nearly invertible, non-invertible, and non-invertible discontinuous, in the set :
| Sine function: | (4.2) | |||||
| Sine-Cosine function: | ||||||
| Arch function: |
These functions are shown in 2(a) –4(a). They lead to observation processes with dramatically different distributions, as shown in Fig.1(b-d).



The learning results for these three functions are shown in Figure 2–4. For each of these three observation functions, we present the estimator with the optimal hypothesis space, the 2-Wasserstein distance in prediction and the convergence of the estimator in (see Section 4.1 for details).
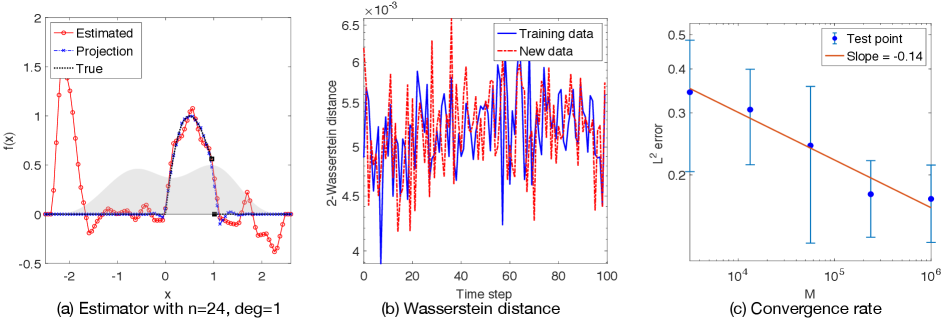
Sine function: Fig. 2(a) shows the estimator with degree-1 B-spline basis with dimension for . The error is and the relative error is 3.47%. Fig. 2(b) shows that the Wasserstein distances are small at the scale . Fig. 2(c) shows that the convergence rate of the error is . This rate is close to the minimax rate .
Sine-Cosine function: Fig. 3(a) shows the estimator with degree-2 B-spline basis with dimension . The error is and the relative error is . Fig. 3(b) shows that the Wasserstein distances are at the scale of . Fig. 3(c) shows that the convergence rate of the error is , less than the classical minimax rate . Note also that the variance of the error does not decrease as increases. In comparison with the results for in Fig.2(a), we attribute this relatively low convergence rate and the large variance to the high-frequency component , which is harder to identify from moments than than the low frequency component .
Arch function: Fig. 4(a) shows the estimator with degree-0 B-spline basis with dimension . The error is and the relative error is . Fig. 4(b) shows that the Wasserstein distances are small at the scale . Fig. 4(c) shows that the convergence rate of the error is , less than the would-be minimax rate .
Arch function with observation noise: To demonstrate that our method can tolerate large observation noise, we present the estimation results from noisy observations of the Arch function, which is the most difficult among the three examples. Suppose that the observation noise in (2.17) is iid . Note that the average of is about , so the signal-to-noise ratio is about . Thus, we have a relatively large noise. However, our method can identify the function using the moments of the noise as discussed in Section 2.5. Fig. 5(a) shows the estimator with degree-1 B-spline basis with dimension . The error is and the relative error is . Fig. 5(b) shows that the Wasserstein distances are small at the scale . The Wasserstein distances is approximated from samples of the noisy data and the noisy prediction . Fig. 5(c) shows that the convergence rate of the error is . The estimation is not as good as the noise-free case because the noisy observation data lead to milder lower and upper bound restrictions in (2.15). We emphasize that the tolerance to noise is exceptional for such an ill-posed inverse problem, and the key is our use of moments, which averages the noise so that the error occurs at the scale .
We have also tested piecewise constant observation functions. Our method has difficulty in identifying such functions, due to two issues: (i) the uniform partition often misses the jump discontinuities (even the projection of has a large error); and (ii) the moments we considered depend on the observation function non-locally, thus, they provide limited information to identify the true function from its local perturbations. We leave it for future research to overcome these difficulties by searching the jump discontinuities and by introducing moments detecting local information.
4.3 Limitations
We demonstrate by examples the non-identifiability due to symmetry and stationarity.
Symmetric distribution
Let the state model be the Brownian motion with initial distribution . The state process has a distribution that is symmetric with respect to the line , i.e., the processes and have the same distribution. Thus, with the reflection function , the processes and have the same distribution, and the observation data does not provide information for distinguishing from . The loss functional (2.4) has at least two minima.
Figure 6 shows that our algorithm finds the reflection of the true function . The hypothesis space has B-spline basis functions with degree 2 and dimension 58. Our estimator is close to . Its error is and its reflection’s error is . Both the estimator and its reflection correctly predict the distribution of the observation process .

Stationary process
When the diffusion process is stationary, the loss functional provides limited information about the observation function. As discussed in Section 3.2, the matrix has rank 1, and and lead to only two more constraints. The constraints from the upper and lower bounds in (2.15) play a major role in leading to a minimizer at the boundary of the convex set .
Figure 7 shows the learning results with the stationary Ornstein-Uhlenbeck process and with the observation function . The stationary density of is . Due the limited information, the estimator has a large error, which is and its prediction has large 2-Wasserstein distances oscillating near .

5 Discussions and conclusion
We have proposed a nonparametric learning method to estimate the observation functions in nonlinear state-space models. It matches the generalized moments via constrained regression. The algorithm is suitable for large sets of unlabeled data. Moreover, it can deal with challenging cases when the observation function is non-invertible. We address the fundamental issue of identifiability from first-order moments. We show that the function spaces of identifiability are the closure of RKHS spaces intrinsic to the state model. Numerical examples show that the first two moments and temporal correlations, along with upper and lower bounds, can identify functions ranging from piecewise polynomials to smooth functions and tolerate considerable observation noise. The limitations of this method, such as non-identifiability due to symmetry and stationarity, are also discussed.
This study provides a first step in the unsupervised learning of latent dynamics from abundant unlabeled data. There are several directions calling for further exploration: (i) a mixture of unsupervised and supervised learning that combines unlabeled data with limited labeled data, particularly for high-dimensional functions; (ii) enlarging the function space of learning, either by construction of more first-order generalized moments or by designing experiments to collect more informative data; (iii) joint estimation of the observation function and the state model.
Appendix A A review of RKHS
Positive definite functions
We review the definitions and properties of positive definite kernels. The following is a real-variable version of the definition in [1, p.67].
Definition A.1 (Positive definite function)
Let be a nonempty set. A function is positive definite if and only if it is symmetric (i.e. ) and for all , and . The function is strictly positive definite if the equality hold only when .
RKHS and positive integral operators
We review the definitions and properties of the Mercer kernel, the RKHS, and the related integral operator, see e.g., [7] for them on a compact domain [34] for them on a non-compact domain.
Let be a metric space and be continuous and symmetric. We say that is a Mercer kernel if it is positive definite (as in Definition A.1). The reproducing kernel Hilbert space (RKHS) associated with is defined to be closure of with the inner product
for any and . It is the unique Hilbert space such that: (1) the linear space is dense in it; (2) it has the reproducing kernel property in the sense that for all and , (see [7, Theorem 2.9]).
By means of the Mercer Theorem, we can characterize the RKHS through the integral operator associated with the kernel. Let be a nondegenerate Borel measure on (that is, for every open set ). Define the integral operator on by
The RKHS has the operator characterization (see e.g., [7, Section 4.4] and [34]):
Theorem A.3
Assume that the is a Mercer kernel and . Then
-
1.
is a compact positive self-adjoint operator. It has countably many positive eigenvalues and corresponding orthonormal eigenfunctions . Note that when zero is an eigenvalue of , the linear space is a proper subspace of .
-
2.
is an orthonormal basis of the RKHS .
-
3.
The RKHS is the image of the square root of the integral operator, i.e., .
Appendix B Algorithm details
B.1 B-spline basis and dimension of the hypothesis space
The choice of hypothesis space is important for the nonparametric regression. We choose the basis functions to be the B-splines. To select an optimal dimension of the hypothesis space, we introduce a new algorithm to estimate the range for the dimension and then we select the optimal dimension that minimizes the 2-Wasserstein distance between the measures of data and prediction.
B-Spline basis functions
We briefly review the definition of B-spline basis functions and we refer to [29, Chapter 2] and [26] for details. Given a nondecreasing sequence of real numbers, called knots, , the B-spline basis functions of degree , denoted by , are defined recursively as
Each function is a nonnegative local polynomial of degree , supported on . At a knot with multiplicity , it is times continuously differentiable. Hence, the differentiability increases with the degree but decreases when the knot multiplicity increases. The basis satisfies a partition unity property: for each , .
We set the knots of the spline functions to be a uniform partition of (the support of the measure in (2.16)) . For any choice of degree , we set the basis functions of the hypothesis space , contained in a subspace with dimension , to be
Thus, the basis functions are piecewise degree- polynomials with knots adaptive to .
Dimension of the hypothesis space.
The choice of dimension of is important to avoid under- and over-fitting: we choose it by minimizing the 2-Wasserstein distance between the empirical distributions of observed process and that predicted by our estimated observation function. To reduce the computational burden, we proceed in 2 steps: first we determine a rough range for , and then within this range we select the dimension with the minimal Wasserstein distance.
Step 1: we introduce an algorithm, called Cross-validating Estimation of Dimension Range (CEDR), to estimate the range for the dimension of the hypothesis space, based on the quadratic loss functional . Its main idea is to restrict to avoid overly amplifying the estimator’s sampling error, which is estimated by splitting the data into two sets. It incorporates the function space of identifiability in Section 3.1 into the SVD analysis [9, 15] of the normal matrix and vector from .
The CEDR algorithm estimates the sampling error in the minimizer of loss functional through SVD analysis in three steps. First, we compute the normal matrix and vector in (2.6) by Monte Carlo; to estimate the sampling error in , we compute two copies, and , of from two halves of the data:
| (B.1) |
Second, we implement an eigen-decomposition to find an orthonormal basis of , the default function space of learning. We view the matrix as a representation of the integral operator in Lemma 3.4 on . The eigen-decomposition requires the generalized eigenvalue problem
| (B.2) |
(see [20, Theorem 5.1]). Denote the eigen-pairs by , where the eigenvalues are non-increasingly ordered and the eigenvectors are subject to normalization . Thus, we have (assuming that all ’s are positive; otherwise, we drop those zero eigenvalues). The least-squares estimators from and are and , respectively. Third, the difference between their function estimators represents the sampling error (with )
| (B.3) | ||||
where . The ratio is in the same spirit as the Picard projection ratio in [15], which is used to detect overfitting. Note that the eigenvalues will vanish as increases because the operator is compact. Clearly, the sampling error should be less than , which is the average of the second moments. Thus, we set to be
| (B.4) |
We note that this threshold is relatively large, neglecting the rich information in , a subject worthy of further investigation.
Algorithm 2 summarizes the above procedure.
Step 2: We select the dimension and degree for B-spline basis functions to be the one with the smallest 2-Wasserstein distance between the distribution of the data and that of the predictions. More precisely, let and denote the distributions of and , respectively. Let and denote their cumulative distribution functions (CDF), with and being their inversion. We compute from the data and from independent simulation. We approximate their inversions by quantile, and compute the 2-Wasserstein distance
| (B.5) |
This method of computing the Wasserstein distance is based on an observation in [5], and it has been used in [28, 19]. Recall that the 2-Wasserstein distance of two probability density functions and over with finite second order moments is given by , where denotes the set of all measures on with and as marginals. Let and be the CDFs of and respectively, and let and be their quantile functions. Then the distance of the quantile functions is equal to the 2-Wasserstein distance .
B.2 Optimization with multiple initial conditions
With the convex hypothesis space in (2.15), the minimization in (2.12) is a constrained optimization problem and it may have multiple local minima. Note that the loss functional in (2.12) consists of a quadratic term and two quartic terms. The quadratic term, which represents in (2.5), has a Hessian matrix which is often not full rank because it is the average of rank-one matrices by its definition (2.6). Thus, the quadratic term has a valley of minima in the kernel of . The two quartic terms have valleys of minima at the intersections of the ellipse-shaped manifolds for . Also, symmetry in the distribution of the state process will also lead to multiple minima (see Section 3.2 for more discussions).
To reduce the possibility of obtaining a local minimum, we search for a minimizer from multiple initial conditions. We consider the following initial conditions: (1) the least squares estimator for the quadratic term; (2) the minimizer of the quadratic term in the hypothesis space, which is solved by least squares with linear constraints using @MATLAB function lsqlin, starting from the LSE estimator; (3) the minimizers of the quartic terms over the hypothesis space, which is found by constrained optimization through @MATLAB fmincon with the interior-point search. Then, among the minimizers from these initial conditions, we take the one leading to the smallest 2-Wasserstein distance.
Appendix C Selection of dimension and degree of the B-spline basis
We demonstrate the selection of the dimension and degree of the B-spline basis functions of the hypothesis space. As described in Section 2.3, we select the dimension and degree in two steps: we first select a rough range for the dimension by the Cross-validating Estimation of Dimension Range (CEDR) algorithm; then we pick the dimension and degree to be the ones with minimal 2-Wasserstein distance between the true and estimated distribution of the observation processes.
The CEDR algorithm helps to reduce the computational cost by estimating the dimension range for the hypothesis space. It is based on an SVD analysis of the normal matrix and vector from the quadratic loss functional . The key idea is to control the sampling error’s effect on the estimator in the metric of the function space of learning. The sampling error is estimated by computing two copies of the normal vector through splitting the data into two halves. The function space of learning plays an important role here: it directs us to use a generalized eigenvalue problem for the SVD analysis. This is different from the classical SVD analysis in [15], where the information of the function space is neglected.
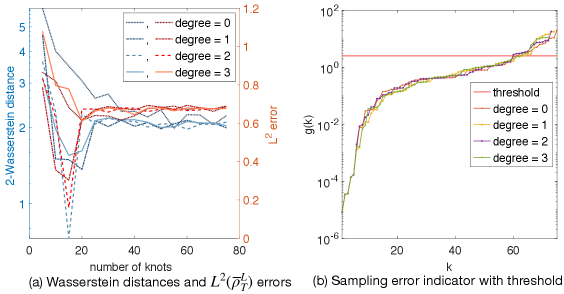
Figure 8 shows the dimension selection by 2-Wasserstein distances and by the CEDR algorithm for the example of sine-cosine function. To confirm the effectiveness of our CEDR algorithm, we compute the 2-Wasserstein distances for all dimensions in (a), side-by-side with the CEDR sampling error indicator in (b) with relatively large dimensions for . First, the left figure suggests that the optimal dimension and degree are and , where the 2-Wasserstein distance reaches minimum among all cases, and at the same time as the error. For the other degrees, the minimum 2-Wasserstein distances are either reached before of after the error. Thus, the 2-Wasserstein distance correctly selects the optimal dimension and degree for the hypothesis space. Second, (a) shows that the CEDR algorithm can effectively select the dimension range. With the threshold in (B.4) being , which is relatively large (representing a tolerance of 100% relative error), the dimension upper bounds are around for all degrees, and the ranges encloses the optimal dimensions selected by the 2-Wasserstein distance in (b).
Here we used a relatively large threshold for a rough estimation of the range of dimension. Clearly, our cross-validating error indicator in (B.3) provides rich information about the increase of sampling error as the dimension increases. A future direction is to extract the information, along with the decay of the integral operator, to find the trade-off between sampling error and approximation error.
Acknowledgments
MM, YGK and FL are partially supported by DE-SC0021361 and FA9550-21-1-0317. FL is partially funded by the NSF Award DMS-1913243.
References
- [1] C. Berg, J. P. R. Christensen, and P. Ressel. Harmonic analysis on semigroups: theory of positive definite and related functions, volume 100. New York: Springer, 1984.
- [2] S. A. Billings. Nonlinear System Identification. John Wiley & Sons, Ltd, Chichester, UK, 2013.
- [3] P. Brockwell and R. Davis. Time series: theory and methods. Springer, New York, 2nd edition, 1991.
- [4] O. Cappé, E. Moulines, and T. Rydén. Inference in Hidden Markov Models. Springer Series in Statistics. Springer, New York ; London, 2005.
- [5] J. A. Carrillo and G. Toscani. Wasserstein metric and large–time asymptotics of nonlinear diffusion equations. In New Trends in Mathematical Physics: In Honour of the Salvatore Rionero 70th Birthday, pages 234–244. World Scientific, 2004.
- [6] R. R. Coifman, S. Lafon, A. B. Lee, M. Maggioni, B. Nadler, F. Warner, and S. W. Zucker. Geometric diffusions as a tool for harmonic analysis and structure definition of data: Diffusion maps. Proceedings of the National Academy of Sciences of the United States of America, 102(21):7426–7431, 2005.
- [7] F. Cucker and D. X. Zhou. Learning theory: an approximation theory viewpoint, volume 24. Cambridge University Press, 2007.
- [8] J. Fan and Q. Yao. Nonlinear Time Series: Nonparametric and Parametric Methods. Springer, New York, NY, 2003.
- [9] R. D. Fierro, G. H. Golub, P. C. Hansen, and D. P. O’Leary. Regularization by Truncated Total Least Squares. SIAM J. Sci. Comput., 18(4):1223–1241, 1997.
- [10] C. Gelada, S. Kumar, J. Buckman, O. Nachum, and M. G. Bellemare. DeepMDP: Learning Continuous Latent Space Models for Representation Learning. ArXiv190602736 Cs Stat, 2019.
- [11] A. Ghosh, S. Mukhopadhyay, S. Roy, and S. Bhattacharya. Bayesian inference in nonparametric dynamic state-space models. Statistical Methodology, 21:35–48, 2014.
- [12] N. Guglielmi and E. Hairer. Classification of Hidden Dynamics in Discontinuous Dynamical Systems. SIAM J. Appl. Dyn. Syst., 14(3):1454–1477, 2015.
- [13] L. Györfi, M. Kohler, A. Krzyzak, and H. Walk. A distribution-free theory of nonparametric regression. Springer Science & Business Media, 2006.
- [14] D. Hafner, T. Lillicrap, I. Fischer, R. Villegas, D. Ha, H. Lee, and J. Davidson. Learning Latent Dynamics for Planning from Pixels. ArXiv181104551 Cs Stat, 2019.
- [15] P. C. Hansen. The L-curve and its use in the numerical treatment of inverse problems. In in Computational Inverse Problems in Electrocardiology, ed. P. Johnston, Advances in Computational Bioengineering, pages 119–142. WIT Press, 2000.
- [16] M. R. Jeffrey. Hidden Dynamics: The Mathematics of Switches, Decisions and Other Discontinuous Behaviour. Springer International Publishing, Cham, 2018.
- [17] L. Kaiser, M. Babaeizadeh, P. Milos, B. Osinski, R. H. Campbell, K. Czechowski, D. Erhan, C. Finn, P. Kozakowski, S. Levine, A. Mohiuddin, R. Sepassi, G. Tucker, and H. Michalewski. Model-Based Reinforcement Learning for Atari. ArXiv190300374 Cs Stat, 2020.
- [18] N. Kantas, A. Doucet, S. Singh, and J. Maciejowski. An Overview of Sequential Monte Carlo Methods for Parameter Estimation in General State-Space Models. IFAC Proc. Vol., 42(10):774–785, 2009.
- [19] N. Kolbe. Wasserstein distance. https://github.com/nklb/wasserstein-distance, 2020.
- [20] Q. Lang and F. Lu. Identifiability of interaction kernels in mean-field equations of interacting particles. arXiv preprint arXiv:2106.05565, 2021.
- [21] K. Law, A. Stuart, and K. Zygalakis. Data Assimilation: A Mathematical Introduction. Springer, 2015.
- [22] Z. Li, F. Lu, M. Maggioni, S. Tang, and C. Zhang. On the identifiability of interaction functions in systems of interacting particles. Stochastic Processes and their Applications, 132:135–163, 2021.
- [23] L. Ljung. System identification. In Signal analysis and prediction, pages 163–173. Springer, 1998.
- [24] F. Lu, Q. Lang, and Q. An. Data adaptive RKHS Tikhonov regularization for learning kernels in operators. arXiv preprint arXiv:2203.03791, 2022.
- [25] F. Lu, M. Zhong, S. Tang, and M. Maggioni. Nonparametric inference of interaction laws in systems of agents from trajectory data. Proc. Natl. Acad. Sci. USA, 116(29):14424–14433, 2019.
- [26] T. Lyche, C. Manni, and H. Speleers. Foundations of Spline Theory: B-Splines, Spline Approximation, and Hierarchical Refinement, volume 2219, pages 1–76. Springer International Publishing, Cham, 2018.
- [27] C. Moosmüller, F. Dietrich, and I. G. Kevrekidis. A geometric approach to the transport of discontinuous densities. ArXiv190708260 Phys. Stat, 2019.
- [28] V. M. Panaretos and Y. Zemel. Statistical aspects of wasserstein distances. Annual review of statistics and its application, 6:405–431, 2019.
- [29] L. Piegl and W. Tiller. The NURBS Book. Monographs in Visual Communication. Springer Berlin Heidelberg, Berlin, Heidelberg, 1997.
- [30] Y. Pokern, A. M. Stuart, and P. Wiberg. Parameter estimation for partially observed hypoelliptic diffusions. J. R. Stat. Soc. Ser. B Stat. Methodol., 71(1):49–73, 2009.
- [31] B. L. S. Prakasa Rao. Statistical inference from sampled data for stochastic processes. In N. U. Prabhu, editor, Contemporary Mathematics, volume 80, pages 249–284. American Mathematical Society, Providence, Rhode Island, 1988.
- [32] A. Rahimi and B. Recht. Unsupervised regression with applications to nonlinear system identification. In Advances in Neural Information Processing Systems, pages 1113–1120, 2007.
- [33] M. Sørensen. Estimating functions for diffusion-type processes. In Statistical Methods for Stochastic Differential Equations, volume 124, pages 1–107. Monogr. Statist. Appl. Probab, 2012.
- [34] H. Sun. Mercer theorem for RKHS on noncompact sets. Journal of Complexity, 21(3):337 – 349, 2005.
- [35] A. Svensson and T. B. Schön. A flexible state–space model for learning nonlinear dynamical systems. Automatica, 80:189–199, 2017.
- [36] F. Tobar, P. M. Djuric, and D. P. Mandic. Unsupervised State-Space Modeling Using Reproducing Kernels. IEEE Trans. Signal Process., 63(19):5210–5221, 2015.