\ul
Unrolling Plug-and-Play Network for Hyperspectral Unmixing
Abstract
Deep learning based unmixing methods have received great attention in recent years and achieve remarkable performance. These methods employ a data-driven approach to extract structure features from hyperspectral image, however, they tend to be less physical interpretable. Conventional unmixing methods are with much more interpretability, whereas they require manually designing regularization and choosing penalty parameters. To overcome these limitations, we propose a novel unmixing method by unrolling the plug-and-play unmixing algorithm to conduct the deep architecture. Our method integrates both inner and outer priors. The carefully designed unfolding deep architecture is used to learn the spectral and spatial information from the hyperspectral image, which we refer to as inner priors. Additionally, our approach incorporates deep denoisers that have been pretrained on a large volume of image data to leverage the outer priors. Secondly, we design a dynamic convolution to model the multiscale information. Different scales are fused using an attention module. Experimental results of both synthetic and real datasets demonstrate that our method outperforms compared methods.
Index Terms:
Hyperspectral unmixing, unrolling, plug-and-play, ADMM, inner priors, outer priors.I Introduction
Hyperspectral imaging stands as a pivotal domain in remote sensing, capturing data that incorporates both spatial and spectral characteristics of the target. The dense spectral information with hundreds of spectral bands allows it to be widely applied in many fields, such as environmental monitoring and agriculture [1, 2, 3]. However, due to the high work distance and low spatial resolution of hyperspectral sensors, a pixel may contain several materials, which degrades the performance of subsequent high-level data processing. Spectral unmixing is one of the most prominent tools to cope with this issue, aiming to decompose the mixed pixels into pure components, termed as endmembers, and their corresponding fraction abundances.
From the standpoint of physical interpretability and simplicity, the most commonly used mixing model is the linear mixing model (LMM), presuming that an observed pixel is a linear combination of endmembers weighted by abundances, i.e.:
| (1) |
where is a vector containing spectral bands associated with the obtained pixel, is the endmember matrix with spectral signatures of pure constituents, is the corresponding abundance, denotes the additive noise. Due to the physical interpretation of hyperspectal image and mixing model, the endmembers and abundances are considered to satisfy the nonnegativity constraint (ENC and ANC), and the abundances are also assumed to satisfy sum-to-one for each pixel (ASC). It is important to highlight that the ASC can be ignored for some physically motivated reasons. This may occur, for instance, when there are local variations in the topography of the scene [4]. In our work, we take into account all these constraints, i.e.,
| (2) | ||||
| (3) |
in which and are the feasible regions of endmembers and abundances, respectively.
For a hyperspectral image with pixels, the hyperspectral unmixing task is formulated by the following optimization problem:
| (4) |
where the first term is the data fitting term, the second term serves as regularization aiming to enforce certain desirable properties of endmembers and abundances, and is the trade-off parameter. Different regularization techniques have been devised. Conventional methods typically design regularization according to the spatial and spectral characteristics in hyperspectral images. For instance, in most scenes, the pixel values of an image are piece wise continuous in the spatial dimension. The works [5, 6, 7] introduce total variation (TV) to achieve this purpose. As a pixel usually contains much fewer materials than the number of pure materials contained in the endmember matrix, sparse constraints are introduced to the abundance matrix to obtain sparse results [5, 7]. Minimum-volume simplex regularization is incorporated in the objective function to constrain the volume of the simplex formed by endmembers [8].
Typically, the alternative direction method of multipliers (ADMM) is a powerful tool to solve problem (4), which decomposes a complicated optimization problem into several easier subproblems. The work [5] utilises this strategy to address the objective function with two regularizations on abundance, namely -norm and TV. A nonstandard application of ADMM with a block coordinate descent scheme is designed to address a 3D TV constrained problem, which can model the spatial and spectral correlations and gain sharper edges [9]. In [10], an ADMM based blind hyperspetral unmixing method is proposed, which can simultaneously estimate abundances and endmembers. A graph TV regularization is considered to capture the spatial correlation information. The work [11] uses this tool to solve a graph regularized nonlinear unmixing method with the multilinear mixing model to indicate the nonlinearity between endmembers. Many other ADMM-based unmixing methods have also been proposed, including those for nonlinear unmixing using kernel methods [12] and those addressing unmixing problems that consider spectral variability [13]. While ADMM is a versatile and powerful tool for solving the unmixing optimization problems, the choice of penalty parameters inherently limits the performance.
Compared to traditional methods that rely on manually designed regularization terms, deep neural networks (DNNs) can automatically extract and model complex patterns and nonlinear relationships in data. DNNs have achieved breakthrough results in hyperspectral image processing tasks such as object recognition [14], band selection [15], and image super-resolution [16]. The encoding and decoding processes of autoencoder perfectly fits the formulation of the unmixing problems, and this kind of methods have achieved great advances [17]. Thus many unmixing methods have been proposed based on deep autoencoders [18]. To effectively leverage the spatial structure information of hyperspectral image, deep convolutional neural network (CNN) based autoencoders are conducted [19, 20]. Some unmixing networks with modified autoencoder architectures have also been proposed. For instance, MSSS-Net [21] builds a two-stream unmixing framework, which adopts an end-to-end manner to simultaneously learn spatial stream and multi-view spectral stream networks, and fuses information of different scales to achieve more effective unmixing. In work [22], an endmember-guided subnetwork is introduced alongside the basic autoencoder framework to extract features from pure or near-pure spectra. Meanwhile, a weight sharing strategy is used to guide the learning of the basic network. However, DNNs are often regarded as “black boxes” and lack of physical interpretability.
Recently, integration model- and deep learning- based methods is a new trend to design unmixing frameworks with both interpretability and data driven advantages. On one hand, the plug-and-play unmixing approaches use a pretrained denoiser to provide priors [23, 24]. However, these methods still require setting the value of penalty parameters. On the other hand, unrolling/unfolding the optimization algorithm to design the unmixing network structure receives great performance [25, 26, 27, 28], which breaks through the drawbacks of iterative algorithms and plugs interpretability to the deep architecture. The work [27] unrolls the constrained sparse regrassion (CSR) problem to construct the abundance estimation network, which has shown better performance with lighter structures and faster convergence speed. The work [27] employs a fully CNN to unroll the variable splitting and augmented Lagrangian algorithm. However, the spatial information learned by this model is still unsatisfactory, and its performance is limited in high-noise scenes.
In our work, to overcome the poor interpretability of deep learning based unmixing architecture, we propose a novel unmixing network, named PnP-Net. Our method unrolls the plug-and-play framework and uses pretrained state-of-the-art denoisers to add information learnt from large scale of image datasets. The main merits of this work are threefold:
-
•
Our proposed method can take advantages of both the optimization- and learning-based methods. We unroll the plug-and-play unmixing framework into a novel neural network scheme, which can be trained in an end-to-end manner. Our approach relies on the ADMM algorithm, and the layers mimic the iterative process.
-
•
By using the denoiser pretrained with external datasets, our proposed framework effectively leverages the information from additional data and combines the priors with internal learning from the hyperspectral data. This strategy bypasses the difficulty of limited hyperspectral data and the training of a large number of network parameters.
-
•
In this work, we design a dynamic convolution using kernels of various sizes to capture multiscale features for spectral unmixing. It increases the model complexity with multiple parallel convolution kernels fused by an attention module.
The remainder of this paper is organized as follows. We describe the background and related works of our method in Section II. In Section III, we present our proposed PnP-Net method in detail and give the main flowchart and training details. Section IV shows the experiment results to validate the effectiveness of our method. Section V concludes this work.
II Related Works
In this section, we briefly review the basic concepts of the plug-and-play unmixing framework and deep unrolling network.
II-A Plug-and-Play Unmixing Methods
The plug-and-play framework benefits from variable splitting technique, allowing the utilization of denoising priors to effectively tackle a range of image restoration problems. It has been used for hyperspectral unmixing [29]. Typically, the denoising regularization is plugged for the abundances with (4) rewritten as:
| (5) |
We use ADMM to resolve the optimization problem described in (5). By introducing an auxiliary variable to replace in the regularization term of (5) and adding constraint , the original problem is decomposed into easier and more manageable subproblems. The iterative optimization process of (5) is as follows:
| (6) | ||||
| (7) | ||||
| (8) |
in which is the dual variable, and is the penalty parameter. The process involves two essential operators. The first is a blind unmixing operator to estimate endmembers and abundances. The second step can be viewed as a denoising of . The regularization term can be implicitly coped by incorporating a denoising operator (), i.e.,
| (9) |
In general, the denoiser can be any readily available denoising operator. For example, the well-known nonlocal means denoising (NLM) [30] and block-matching and 3D filtering (BM3D) [31] have been plugged to capture image priors and get high-quality unmixing results. This provides the possibility of integrating CNN-based denoisers with robust prior learning from mass image data and addressing the drawback of insufficient volume of hyperspectral data.
II-B Deep Unrolling Network
The deep unrolling paradigm involves unfolding iterative optimization algorithms into trainable deep architectures. One popular deep unrolling unmixing method is unfolding the CSR for sparse unmixing [27]. With known and , it introduces an auxiliary variable . The ADMM iteratively addresses the optimization problem through the following steps:
| (10) | ||||
| (11) | ||||
| (12) |
in which and . is the soft-threshold operator to resolve the -norm. The iterative steps from (10) to (12) can be unfolded into network layers, denoted as , and with learnable parameters , where replaces the role of . Thus (10) to (12) can be reexpressed as follows:
| (13) |
| (14) |
| (15) |
Each iteration is decomposed into a single network layer, and combining these layers many times is analogous to performing multiple iterations of CSR. The unrolling deep network can be trained by an end-to-end manner. By this way, the knowledge of classical iterative algorithms are infused in the design of deep network for hyperspectral unmixing. However, the networks obtained by unrolling iterative algorithms are restricted to one pixel only and not take into account of spatial structure information. By some modifications of networks, we can employ the well-designed layers such as convolutional networks to add more spatial priors.
III Proposed Method
III-A Problem Formulation
In (4), handcrafting an effective regularizer and devising an efficient algorithm to solve the objective function are challenging tasks. Rather than using this intricate path, we propose to derive priors from various image data and integrate them into the optimization process by a plug-and-play strategy, where the regularization is implicitly designed by the utilization of a denoising algorithm. In hyperspectral unmixing task, the spatial information is embedded in the abundance, and the spectral information are contained in the endmember. Thus we plug regularization on abundance to fully exploit the spatial information. We introduce regularization by denoising (RED) as the regularizer to add denoising priors, and the corresponding hyperspectral unmixing optimization problem can be reformulated as:
| (16) |
where is an indicator function of a set and is defined as:
| (17) |
is defined as:
| (18) |
where is an off-the-shelf denoiser. RED depends on the inner product between the solution and its residual after denoising . Under mild assumptions, it demonstrates advantageous derivative properties with . This formulation also provides flexibility in accommodating any denoising engines like original plug-and-play denoising framework.
We use ADMM algorithm to solve (16). Two auxiliary variables and are introduced, and the objective function is rewritten as:
| (19) |
The associated augmented Lagrangian is expressed as:
| (20) |
where and are dual variables, and and are nonnegative parameters. Then the ADMM algorithm involves solving four subproblems at each iteration. In our work, we unroll the ADMM algorithm into a deep network by associating each iteration with a single network layer and then stacking a finite number of layers together. Through unrolling, we can use back-propagation to learn regularization parameters that are difficult to handcraft. This approach allows us to capture image priors through a well-designed network structure and add physical interpretability to the deep network. The proposed unrolling layers (PnP-Net) are presented in detail as follows.
III-B Unrolling Plug-and-play Framework for A Layer
III-B1 Update


The can be satisfied with a Softmax operator. The remained part of -subproblem is a least-square problem defined as
| (21) |
It can be solved with a closed-form as follws:
| (22) |
The -update layer is designed by unfolding (22) and rewrites as
| (23) |
where
| (24) |
As for a closed-form solution, conventional unrolling methods only learn the regularization parameters. In [27] and [28], and are considered as the learnable parameters to enhance the flexibility of network and improve the performance. Following this strategy, we also replace the fixed and as parameters to estimate.
In [27], two fully connected layers with bias set to adding together are used to formulate . In [28], 2D convolutional layers are used to generate this layer, which can capture spatial information. In our work, inspired by the dynamic convolution work [32], we design a novel dynamic convolution with multiscale convolution kernels to formulate this layer, which can capture abundant spatial information from different scales. This layer consolidates multiple parallel convolution kernels dynamically, adjusting their contributions based on input-dependent attentions. Instead of enhancing either the depth or the width of the network, this layer possesses increased representational capability due to the nonlinear aggregation of these kernels through attention. Convolutional kernels with different sizes are able to capture multiscale information. We denote the traditional 2D convolution layer as:
| (25) |
where is the convolutional kernel, denotes the input, and is the output. Our dynamic convolution layer (DCL) with parallel multiscale convolution kernels is defined as:
| (26) |
where is the attention weight of the convolution layer, the size of is the same as the maximum size of convolutional kernels. The size of available weights of is the same as the kernel’s, and they are designed on the centre of . Other positions are padded with zeros. The summation of each position of is one, i.e. (the th position). The size of is inconsistent with . We use to extract the available weights from to make and the same size. is an element-by-element multiplication. An illustration of matrix is shown in Fig. 1. Then the output represents the optimal combination of multiscale features. The weight is associated with the input and learnt by an attention module, and the squeeze-and-excitation module [33] is introduced to calculate it. The global average pooling is firstly applied to squeeze the global spatial information of an input data cube. Then two fully connected layers with an ReLU between them as the activated function are exploited to extract features. A specially designed layer, named Softmaxpro, is used to obtain sum-to-one attention weights with the characteristics described above. To be specific, for the , a fully connected layer is used to map the size of features the same as the th convolutional kernel. Then a zero-padding operator makes it the same as the maximum size of convolutional kernels. Finally, we apply the Softmax to the available weights of each position of to accomplish this goal:
| (27) |
The scheme of our proposed DCL is shown in Fig. 2.
With this useful and efficient network component, (23) is equivalently reformulated as:
| (28) |
where and are the number of kernels, and represent the weights of the th convolution kernel, and and are the attention weight matrices of dynamic convolution.
Then we apply a Softmax operator to constrain the output of within , i.e.,
| (29) |
The neural network structure is illustrated in Fig. 3.

III-B2 Update
The -subproblem is a standard RED objective function:
| (30) |
It also can be solved in a closed-form. We use the fixed-point strategy to solve this problem. By setting the gradient of the objective function to , we have the following equation:
| (31) |
The solution of -subproblem is an iterative scheme as follows:
| (32) |
The -update layer is derived by unrolling (32). The update of the th iteration of is expressed as
| (33) |
where and are learnable parameters and play the role of and . In this manner, we can use a data-driven strategy to learn the regularization parameters, rather than handcraft them. The neural network layer is shown in Fig. 3.
III-B3 Update
As for the update of -subproblem, it aims to solve the following optimization problem:
| (34) |
which can be efficiently solved through a closed-form solution. Then we obtain the following update iteration:
| (35) |
The -update layer is designed by unfolding (35). With the , and given , it is written as follows:
| (36) |
where
| (37) |
We replace and with learnable parameters to enhance flexibility. The neural network layer is presented in Fig. 3 and defined as
| (38) |

III-B4 Update
The -subproblem is a least-square problem with the nonnegative constraint, which is formulated as:
| (39) |
We use a hard threshold operator to solve this problem by mapping to a set of all nonnegative elements. This operation is written as:
| (40) |
In the design of , we use the ReLU to generate this layer:
| (41) |
The neural network layer is shown in Fig. 3.
III-B5 Update and
The is designed to unfold the following iteration:
| (42) |
With and , the th neural network layer to update is designed as
| (43) |
where is a learnable parameter to replace the role of .
is derived from
| (44) |
The same as the design of , this layer uses to replace the role of :
| (45) |
The and neural network layers are also shown in Fig. 3.
III-C Network Architecture
Each unrolling block represents a single iteration of the ADMM based plug-and-play unmixing method and consists of 6 parts: , , , , and . As shown in Fig. 4, we use iteration blocks to conduct the architecture of our proposed method, which can mimic the ADMM based unmixing algorithm with iterations. For the th block, the learnable parameters are . Each block in the network has its own set of learnable parameters that are not shared across blocks, which has demonstrated flexibility and strong learning capability for unmixing task.
Additionally, the PnP-Net architecture can be divided into two parts: the endmember estimation network and the abundance estimation network. Each block of the endmember estimation network contains the , and components, there are blocks to estimate the endmember. The abundance estimation network comprises three parts, namely , and . layers are applied to estimate the abundance.
III-D Training Details and Network Initialization
Our PnP-Net is trained by a blind manner with the input hyperspectral image . We use the mean square error (MSE) to compute the differences between the input and its reconstruction. Compared to calculating the MSE loss directly using the reconstruction of the final th block output, calculating it for each block can better constrain the training process of the network. Thus, we use the weighted sum of the reconstructions from each block to compute the loss function, which is defined as:
| (46) |
where denotes the importance of each term, is the corresponding reconstructed image of the th block.
Parameter initialization plays an important role in our PnP-Net, which can accelerate the convergence speed and enhance the endmember and abundance estimation accuracy. The endmember matrix and abundance matrix are calculated by VCA [34] and FCLS [35]. Specially, we obtain the initialization of and according to and , and other values are initialized with zeros.
Our PnP-Net method is flexible to plug various deep denoisers. In this work, we choose 3 novel denoisers, i.e. DnCNN [36], IRCNN [37] and SCUNet [38], as examples. We pretrain these models using images of Waterloo Exploration Database [39], DIV2K [40], and Flick2K [41] datasets with different noise settings. It is worth noting that the parameters of denoiser are fixed during training which can reduce computational stress and take advantage of outer priors. Our PnP-Net with these denoisers are named as PnP-Net-1, PnP-Net-2 and PnP-Net-3. During training, we set the learning rate to . The number of iteration blocks () is set to 5. and are set to 3 with the kernel size setting to , and . We set to .
IV Experiment Results
In this section, we firstly introduce the evaluation indicators used to analyse the effectiveness of the proposed methods. The considered conventional and state-of-the-art compared methods are also briefly presented. Then, the datasets used in the experiments and results are illustrated and discussed.
| Noise level | 5dB | 10dB | 20dB | 30dB | |||||
| Method | Denoiser | aRMSE | PSNR | aRMSE | PSNR | aRMSE | PSNR | aRMSE | PSNR |
| SUnSAL-TV | / | 0.0991 | 27.8650 | 0.0658 | 30.5224 | 0.0225 | 44.0060 | 0.0081 | 50.5379 |
| gtvMBO | / | 0.1149 | 29.6094 | 0.0699 | 34.3044 | 0.0272 | 43.9903 | \ul0.0080 | 53.8601 |
| U-ADMM-BUNet | / | 0.0939 | 30.6719 | 0.0647 | 35.1446 | 0.0256 | 44.0009 | 0.0086 | 53.3713 |
| DIFCNN | / | 0.1044 | 30.4841 | 0.0651 | 34.8753 | 0.0242 | 44.0677 | 0.0081 | 53.1629 |
| AERED | NLM | 0.0907 | 32.2215 | 0.0604 | 35.6194 | 0.0246 | 44.1319 | 0.0081 | 54.4845 |
| BM3D | 0.0927 | 32.4679 | 0.0597 | 36.3611 | 0.0217 | 44.1408 | \ul0.0080 | 54.6312 | |
| PnP-Net | DnCNN | \ul0.0856 | 33.5082 | 0.0572 | 37.6063 | 0.0197 | 44.3506 | 0.0079 | 55.5990 |
| IRCNN | 0.0850 | \ul33.4259 | \ul0.0566 | 37.7314 | 0.0203 | 44.1599 | \ul0.0080 | 55.4729 | |
| SCUNet | 0.0859 | 33.3130 | 0.0535 | \ul37.7282 | \ul0.0199 | \ul44.2947 | \ul0.0080 | \ul55.4810 | |
| Noise level | 5dB | 10dB | 20dB | 30dB | |||||
| Method | Denoiser | mRMSE | mSAD | mRMSE | mSAD | mRMSE | mSAD | mRMSE | mSAD |
| SUnSAL-TV | / | 0.0402 | 6.3464 | 0.0228 | 3.6377 | 0.0052 | 0.9584 | 0.0023 | 0.2176 |
| gtvMBO | / | 0.0502 | 6.4056 | 0.0205 | 2.7845 | 0.0100 | 1.1000 | \ul0.0014 | 0.1913 |
| U-ADMM-BUNet | / | 0.0400 | 6.3073 | 0.0200 | 3.2512 | 0.0050 | 0.9482 | 0.0015 | 0.2003 |
| DIFCNN | / | 0.0423 | 6.4225 | 0.0199 | 3.0286 | 0.0067 | 1.1064 | 0.0017 | 0.2001 |
| AERED | NLM | 0.0415 | 6.2650 | 0.0204 | 2.9087 | 0.0051 | 1.0135 | 0.0015 | 0.2088 |
| BM3D | 0.0401 | 6.2937 | 0.0206 | 2.7587 | 0.0049 | 0.9676 | 0.0014 | 0.2069 | |
| PnP-Net | DnCNN | \ul0.0394 | \ul6.2195 | \ul0.0194 | \ul2.7191 | \ul0.0046 | 0.8658 | 0.0013 | 0.1928 |
| IRCNN | 0.0399 | 6.2858 | 0.0202 | 2.7848 | 0.0049 | 0.9291 | \ul0.0014 | 0.1943 | |
| SCUNet | 0.0390 | 6.1300 | 0.0192 | 2.6464 | 0.0042 | \ul0.8734 | \ul0.0014 | \ul0.1941 | |
IV-A Evaluation Indicators
We use several indicators to evaluate the unmixing results quantitatively in terms of estimated abundances, extracted endmembers and reconstructed images. In addition, we have no available ground truth for the real datasets, we only evaluate the reconstructed image quantitatively and subjectively evaluate the visual effect.
The root mean square error (RMSE) is applied to assess the differences between the ground truth and estimated abundances and endmembers. We respectively name them as aRMSE and mRMSE, which are defined as follows:
| (47) |
and
| (48) |
where and represent the estimated and real abundances of the th pixel, and and denote the th extracted and corresponding real endmembers.
We apply the mean spectral angle distance (SAD) to evaluate the degree of distortion between the real and reconstructed spectral signatures, and mSAD denotes the SAD between the estimated and real endmembers. They are calculated by:
| (49) |
and
| (50) |
where and represent the real and reconstructed spectra.
We also use the peak signal-to-noise ratio (PSNR) to evaluate the differences between the real and reconstructed images, calculated by:
| (51) |
where represents the highest pixel value in the reconstructed image.



IV-B Compared Methods
We compare the proposed PnP-Net method with several conventional and state-of-the-art unmixing methods, i.e. SUnSAL-TV [5], gtvMBO [10], U-ADMM-BUNet [27], DIFCNN [28] and AERED [42]. To make a fair comparison, all methods are initialized by the endmembers extracted by VCA [34] and abundances estimated by FCLS [35]. All parameters of these methods are carefully chosen to achieve the best experimental results.
The first two compared methods are conventional methods. The SUnSAL-TV method uses the VCA to extract the endmembers, and a total variation spatial regularization is applied to constraint the estimated abundances. The gtvMBO method is a blind unmixing method with a data-driven graph total variation regularization, and its objective function is solved by ADMM. The U-ADMM-BUNet and DIFCNN are novel unrolling based unmixing methods. AERED integrates the autoencoder based unmixing network with RED, which combines the explicit and implicit priors. We name the AERED with NLM denoiser and block-matching and 4-D ffltering (BM4D) [43] deoiser as AERED-1 and AERED-2, respectively.

IV-C Experiments on Synthetic Datasets
In order to quantitatively verify the unmixing results, we generate a set of synthetic data with the spatial size of . We adapt the method described in [44] to produce these data. The ground-truth of abundance maps are shown in Fig. 5, and they are constrained to satisfy ASC and ANC. The abundance obtained by this strategy shows spatial correlation that similar to the real data. Four spectral signatures selected from the USGS spectral library with 224 bands are applied to generate the endmember matrix. The reference endmember spectra are shown in Fig. 6. Zero mean Gaussian with four levels of signal-to-noise-ratio (SNR), i.e. 5dB, 10dB, 20dB and 30dB, are added to the data.
Table I shows the aRMSE and PSNR results of the synthetic data, and Table II lists the mRMSE and mSAD results. The bold numbers in Tables I and II denote the best results, and the underlined numbers indicate the second best results. From the results of these two tables, it can be observed that the proposed PnP-Net unmixing framework achieves the best unmixing results compared to the benchmark methods. Compared to traditional unmixing methods such as SUnSAL-TV and gtvMBO, the proposed method eliminates the need for penalty parameter selection, instead utilizing a data-driven learning approach. In comparison to unrolling unmixing method, i.e. U-ADMM-BUNet and DIFCNN, this proposed PnP-Net method employs dynamic convolution to achieve multiscale information learning and fusion and gets better results. Our PnP-Net method leverages an externally pretrained denoiser on large datasets to provide outer priors, and also integrate a hyperspectral data-driven and physically interpretable neural network to learn internal priors. This combination results in superior unmixing performance. We can also observe that, due to the use of deep denoisers and deep neural networks, our proposed unmixing method is robust to noise.
Fig. 5 shows the abundance maps of the proposed method and the comparison methods for the synthetic data at 10dB. We observe that all these estimates are very close to the ground-truth. Moreover, it can be seen that the noise in the abundance maps of PnP-Net and AERED is obviously smaller than that of other comparison methods, which indicates the superiority of using denoiser to bring prior information. Furthermore, Fig. 6 illustrates the extracted endmembers of the proposed method. We observe that the result of our method is close to the ground-truth. Fig. 7 illustrates how the number of blocks affect the unmixing performance and also shows that how the number of kernels and impact the unmixing results.
IV-D Experiments on Real Datasets
We also evaluate our proposed method on real datasets. We conduct experiments on two widely used hyperspectral images obtained by airborne sensors, namely Jasper Ridge dataset and Muufl Gulfport dataset. The descriptions and experimental results about these two datasets are presented below.
The Jasper Ridge dataset is captured by Analytical Imaging and Geophysics (AIG) in 1999. It contains 224 bands covering the spectral range from 380nm to 2500nm. After removing the bands affected by water vapor and atmospheric (1-3, 108-112, 154-166, and 220-224), 198 bands are remained. The original size of this data is , a popular region of interest with pixels are cropped. The four endmembers in this data are “water”, “soil”, “tree” and “road”.
The Muufl Gulfport dataset was captured by the CASI-1500 hyperspectral sensor over the University of Southern Mississippi Gulf Park Campus. The original image contains 72 bands with pixels. We remove the first four and the last four bands of the image, which contain a lot of noise. A subimage with the size of pixels is applied in our experiments. We reference the scene label ground-truth map from manually labeling in [45]. There are 5 pure materials in this subimage, namely “roof”, “grass”, “tree”, “shadow” and “asphalt”.
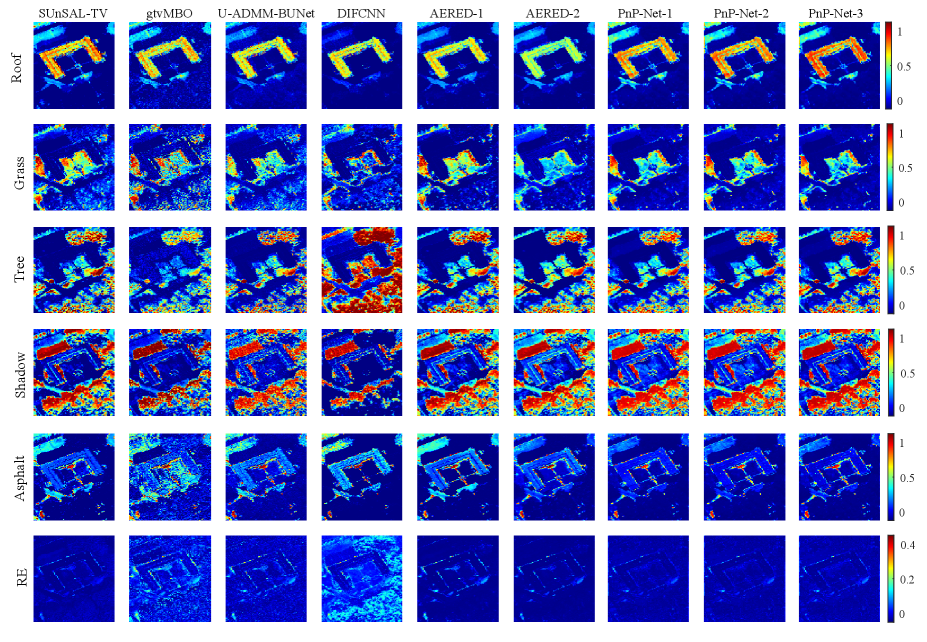
The visual results of the estimated abundance maps of these two datasets are shown in Fig. 8 and Fig. 9. The first four rows of Fig. 8 report the comparisons of our method and compared methods with respect to the Jasper Ridge dataset. All these methods decompose this data with four clear abundance maps. But we observe that the abundance maps of “road” material of SUnSAL-TV and gtvMBO is lighter than other methods. The reason may be that the data contains spectral variability, which makes these two conventional methods hard to extract representative endmember. Our PnP-Net gets clearer abundance results. The last line of Fig. 8 illustrates the reconstructed error between the reconstructed image and real image of these methods. We observe that our method gets good reconstruct results which are also consistent with the results in Table III. To some extent, it proves the advantages of our method to unmix the real data. The abundance maps of Muufl Gulfport dataset are illustrated in Fig. 9. It can be seen that the results of gtvMBO are noisy than other methods, especially for the “asphalt” endmember. The proposed PnP-Net method can estimate the abundance maps much clearer than the compared method. Our results also have more detailed spatial information and sharper edges. The last row of Fig. 9 presents the reconstructed error maps of all methods. DIFCNN shows higher results. It may cause by the loss function selected to train the model. It use the cross entropy-loss to train the network, while other compared deep methods apply the MSE-like loss to train the model. The latter is more conductive to reduce the Euclidean distance between the reconstructed and original image. Table IV lists quantitative results of the Muufl Gulfport data. We get that our method can obtain good reconstructions.
| Method | SUnSAL-TV | gtvMBO | U-ADMM-BUNet | DIFCNN | AERED | PnP-Net | |||
| Denoiser | / | / | / | / | NLM | BM3D | DnCNN | IRCNN | SCUNet |
| PSNR | 28.5721 | 29.5939 | 30.0075 | 29.7343 | 31.3895 | 30.0416 | 29.9136 | \ul30.1203 | 30.0763 |
| SAD | 9.2143 | 6.3181 | 5.6415 | 8.7582 | 5.5519 | \ul5.4386 | 5.5369 | 5.4210 | 5.6177 |
| Method | SUnSAL-TV | gtvMBO | U-ADMM-BUNet | DIFCNN | AERED | PnP-Net | |||
| Denoiser | / | / | / | / | NLM | BM3D | DnCNN | IRCNN | SCUNet |
| PSNR | 31.5959 | 30.1698 | 31.1459 | 25.652 | 32.3154 | 33.4423 | 32.4775 | \ul32.5454 | 32.3401 |
| SAD | 5.2867 | 7.5754 | 6.8583 | 8.3911 | 5.1006 | 4.4823 | 4.9912 | \ul4.9505 | 5.1039 |
V Conclusion
In this paper, we propose a novel PnP-Net method for hyperspectral unmixing. We unroll the plug-and-play unmixing method into trainable deep model. We apply the RED to add denoising priors, and a various of denoisers can be plugged. The ADMM is used to solve the optimization function. We unfold the ADMM based iterative steps to design the layer, and one layer represents one iteration. layers are stacked to conduct the deep architecture. Through unrolling, we can use the end-to-end manner to train the network. To fully exploit the spatial information, we use the dynamic convolution with different sizes of convolution kernels to capture multiscale information. The denoisers are pretrained with a variety of images which make our method leverage the power of external information to enhance the modeling ability. This strategy bypasses the issue of limited hyperspectral data, and provides a way to integrate the inner and outer priors. Extensive experiment results show the superior performance of our method.
References
- [1] S. Li, W. Song, L. Fang, Y. Chen, P. Ghamisi, and J. A. Benediktsson, “Deep learning for hyperspectral image classification: An overview,” IEEE Trans. Image Process., vol. 57, no. 9, pp. 6690–6709, 2019.
- [2] B. Lu, P. D. Dao, J. Liu, Y. He, and J. Shang, “Recent advances of hyperspectral imaging technology and applications in agriculture,” Remote Sensing, vol. 12, no. 16, p. 2659, 2020.
- [3] X. Briottet, Y. Boucher, A. Dimmeler, A. Malaplate, A. Cini, M. Diani, H. Bekman, P. Schwering, T. Skauli, I. Kasen et al., “Military applications of hyperspectral imagery,” in Targets and backgrounds XII: Characterization and representation, vol. 6239. SPIE, 2006, pp. 82–89.
- [4] L. Drumetz, M.-A. Veganzones, S. Henrot, R. Phlypo, J. Chanussot, and C. Jutten, “Blind hyperspectral unmixing using an extended linear mixing model to address spectral variability,” IEEE Trans. Image Process., vol. 25, no. 8, pp. 3890–3905, 2016.
- [5] M.-D. Iordache, J. M. Bioucas-Dias, and A. Plaza, “Total variation spatial regularization for sparse hyperspectral unmixing,” IEEE Trans. Geosci. Remote Sens., vol. 50, no. 11, pp. 4484–4502, 2012.
- [6] F. Xiong, Y. Qian, J. Zhou, and Y. Y. Tang, “Hyperspectral unmixing via total variation regularized nonnegative tensor factorization,” IEEE Trans. Geosci. Remote Sens., vol. 57, no. 4, pp. 2341–2357, 2018.
- [7] H. Li, R. Feng, L. Wang, Y. Zhong, and L. Zhang, “Superpixel-based reweighted low-rank and total variation sparse unmixing for hyperspectral remote sensing imagery,” IEEE Trans. Geosci. Remote Sens., vol. 59, no. 1, pp. 629–647, 2020.
- [8] J. Li, A. Agathos, D. Zaharie, J. M. Bioucas-Dias, A. Plaza, and X. Li, “Minimum volume simplex analysis: A fast algorithm for linear hyperspectral unmixing,” IEEE Trans. Geosci. Remote Sens., vol. 53, no. 9, pp. 5067–5082, 2015.
- [9] X. Wang, Y. Zhong, L. Zhang, and Y. Xu, “Blind hyperspectral unmixing considering the adjacency effect,” IEEE Trans. Geosci. Remote Sens., vol. 57, no. 9, pp. 6633–6649, 2019.
- [10] J. Qin, H. Lee, J. T. Chi, L. Drumetz, J. Chanussot, Y. Lou, and A. L. Bertozzi, “Blind hyperspectral unmixing based on graph total variation regularization,” IEEE Trans. Geosci. Remote Sens., vol. 59, no. 4, pp. 3338–3351, 2020.
- [11] M. Li, F. Zhu, A. J. Guo, and J. Chen, “A graph regularized multilinear mixing model for nonlinear hyperspectral unmixing,” Remote Sensing, vol. 11, no. 19, p. 2188, 2019.
- [12] J. Gu, B. Yang, and B. Wang, “Nonlinear unmixing for hyperspectral images via kernel-transformed bilinear mixing models,” IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–13, 2021.
- [13] P.-A. Thouvenin, N. Dobigeon, and J.-Y. Tourneret, “Hyperspectral unmixing with spectral variability using a perturbed linear mixing model,” IEEE Trans. on Signal Process., vol. 64, no. 2, pp. 525–538, 2015.
- [14] X. Yang, M. Zhao, S. Shi, and J. Chen, “Deep constrained energy minimization for hyperspectral target detection,” IEEE J. Sel. Topics Appl. EarthObservations Remote Sensing, vol. 15, pp. 8049–8063, 2022.
- [15] Y. Cai, X. Liu, and Z. Cai, “BS-Nets: An end-to-end framework for band selection of hyperspectral image,” IEEE Trans. Geosci. Remote Sens., vol. 58, no. 3, pp. 1969–1984, 2019.
- [16] Y. Cheng, X. Wang, Y. Ma, X. Mei, M. Wu, and J. Ma, “General hyperspectral image super-resolution via meta-transfer learning,” IEEE Trans. Neur. Net. Lear. Sys., 2024.
- [17] J. Chen, M. Zhao, X. Wang, C. Richard, and S. Rahardja, “Integration of physics-based and data-driven models for hyperspectral image unmixing: A summary of current methods,” IEEE Signal Process. Mag., vol. 40, no. 2, pp. 61–74, 2023.
- [18] B. Palsson, J. R. Sveinsson, and M. O. Ulfarsson, “Blind hyperspectral unmixing using autoencoders: A critical comparison,” IEEE J. Sel. Topics Appl. EarthObservations Remote Sensing, vol. 15, pp. 1340–1372, 2022.
- [19] B. Palsson, M. O. Ulfarsson, and J. R. Sveinsson, “Convolutional autoencoder for spectral–spatial hyperspectral unmixing,” IEEE Trans. Geosci. Remote Sens., vol. 59, no. 1, pp. 535–549, 2020.
- [20] F. Khajehrayeni and H. Ghassemian, “Hyperspectral unmixing using deep convolutional autoencoders in a supervised scenario,” IEEE J. Sel. Topics Appl. EarthObservations Remote Sensing, vol. 13, pp. 567–576, 2020.
- [21] L. Qi, Z. Chen, F. Gao, J. Dong, X. Gao, and Q. Du, “Multiview spatial–spectral two-stream network for hyperspectral image unmixing,” IEEE Trans. Geosci. Remote Sens., vol. 61, pp. 1–16, 2023.
- [22] D. Hong, L. Gao, J. Yao, N. Yokoya, J. Chanussot, U. Heiden, and B. Zhang, “Endmember-guided unmixing network (EGU-Net): A general deep learning framework for self-supervised hyperspectral unmixing,” IEEE Trans. Neur. Net. Lear. Sys., vol. 33, no. 11, pp. 6518–6531, 2021.
- [23] Z. Wang, L. Zhuang, L. Gao, A. Marinoni, B. Zhang, and M. K. Ng, “Hyperspectral nonlinear unmixing by using plug-and-play prior for abundance maps,” Remote Sensing, vol. 12, no. 24, p. 4117, 2020.
- [24] X. Wang, J. Chen, and C. Richard, “Tuning-free plug-and-play hyperspectral image deconvolution with deep priors,” IEEE Trans. Geosci. Remote Sens., vol. 61, pp. 1–13, 2023.
- [25] C. Cui, X. Wang, S. Wang, L. Zhang, and Y. Zhong, “Unrolling nonnegative matrix factorization with group sparsity for blind hyperspectral unmixing,” IEEE Trans. Geosci. Remote Sens., 2023.
- [26] Y. Shao, Q. Liu, and L. Xiao, “IVIU-Net: Implicit variable iterative unrolling network for hyperspectral sparse unmixing,” IEEE J. Sel. Topics Appl. EarthObservations Remote Sens., vol. 16, pp. 1756–1770, 2023.
- [27] C. Zhou and M. R. Rodrigues, “ADMM-based hyperspectral unmixing networks for abundance and endmember estimation,” IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–18, 2021.
- [28] F. Kong, M. Chen, Y. Li, D. Li, and Y. Zheng, “Deep interpretable fully CNN structure for sparse hyperspectral unmixing via model-driven and data-driven integration,” IEEE Trans. Geosci. Remote Sens., 2023.
- [29] M. Zhao, X. Wang, J. Chen, and W. Chen, “A plug-and-play priors framework for hyperspectral unmixing,” IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–13, 2021.
- [30] A. Buades, B. Coll, and J.-M. Morel, “Non-local means denoising,” Image Processing On Line, vol. 1, pp. 208–212, 2011.
- [31] K. Dabov, A. Foi, V. Katkovnik, and K. Egiazarian, “Image denoising by sparse 3-D transform-domain collaborative filtering,” IEEE Trans. Image Process., vol. 16, no. 8, pp. 2080–2095, 2007.
- [32] Y. Chen, X. Dai, M. Liu, D. Chen, L. Yuan, and Z. Liu, “Dynamic convolution: Attention over convolution kernels,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), 2020, pp. 11 030–11 039.
- [33] J. Hu, L. Shen, and G. Sun, “Squeeze-and-excitation networks,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), 2018, pp. 7132–7141.
- [34] J. M. Nascimento and J. M. Dias, “Vertex component analysis: A fast algorithm to unmix hyperspectral data,” IEEE Trans. Geosci. Remote Sens., vol. 43, no. 4, pp. 898–910, 2005.
- [35] D. C. Heinz et al., “Fully constrained least squares linear spectral mixture analysis method for material quantification in hyperspectral imagery,” IEEE Trans. Geosci. Remote Sens., vol. 39, no. 3, pp. 529–545, 2001.
- [36] K. Zhang, W. Zuo, Y. Chen, D. Meng, and L. Zhang, “Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising,” IEEE Trans. Image Process., vol. 26, no. 7, pp. 3142–3155, 2017.
- [37] K. Zhang, W. Zuo, S. Gu, and L. Zhang, “Learning deep CNN denoiser prior for image restoration,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), 2017, pp. 3929–3938.
- [38] K. Zhang, Y. Li, J. Liang, J. Cao, Y. Zhang, H. Tang, D.-P. Fan, R. Timofte, and L. V. Gool, “Practical blind image denoising via Swin-Conv-UNet and data synthesis,” Machine Intelligence Research, vol. 20, no. 6, pp. 822–836, 2023.
- [39] K. Ma, Z. Duanmu, Q. Wu, Z. Wang, H. Yong, H. Li, and L. Zhang, “Waterloo exploration database: New challenges for image quality assessment models,” IEEE Trans. Image Process., vol. 26, no. 2, pp. 1004–1016, 2016.
- [40] E. Agustsson and R. Timofte, “Ntire 2017 challenge on single image super-resolution: Dataset and study,” in Proceedings of the IEEE conference on computer vision and pattern recognition workshops, 2017, pp. 126–135.
- [41] D. Liu, B. Wen, Y. Fan, C. C. Loy, and T. S. Huang, “Non-local recurrent network for image restoration,” Advances in neural information processing systems, vol. 31, 2018.
- [42] M. Zhao, J. Chen, and N. Dobigeon, “AE-RED: A hyperspectral unmixing framework powered by deep autoencoder and regularization by denoising,” IEEE Trans. Geosci. Remote Sens., 2024.
- [43] M. Maggioni, V. Katkovnik, K. Egiazarian, and A. Foi, “Nonlocal transform-domain filter for volumetric data denoising and reconstruction,” IEEE Trans. Image Process., vol. 22, no. 1, pp. 119–133, 2012.
- [44] Z. Han, D. Hong, L. Gao, B. Zhang, M. Huang, and J. Chanussot, “AutoNAS: Automatic neural architecture search for hyperspectral unmixing,” IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–14, 2022.
- [45] X. Du and A. Zare, “Technical report: scene label ground truth map for muufl gulfport data set. university of florida, gainesville,” Tech. Rep., vol. 20170417, 2017.