Unleashing the Power of Generic Segmentation Models: A Simple Baseline for Infrared Small Target Detection
Abstract.
Recent advancements in deep learning have greatly advanced the field of infrared small object detection (IRSTD). Despite their remarkable success, a notable gap persists between these IRSTD methods and generic segmentation approaches in natural image domains. This gap primarily arises from the significant modality differences and the limited availability of infrared data. In this study, we aim to bridge this divergence by investigating the adaptation of generic segmentation models, such as the Segment Anything Model (SAM), to IRSTD tasks. Our investigation reveals that many generic segmentation models can achieve comparable performance to state-of-the-art IRSTD methods. However, their full potential in IRSTD remains untapped. To address this, we propose a simple, lightweight, yet effective baseline model for segmenting small infrared objects. Through appropriate distillation strategies, we empower smaller student models to outperform state-of-the-art methods, even surpassing fine-tuned teacher results. Furthermore, we enhance the model’s performance by introducing a novel query design comprising dense and sparse queries to effectively encode multi-scale features. Through extensive experimentation across four popular IRSTD datasets, our model demonstrates significantly improved performance in both accuracy and throughput compared to existing approaches, surpassing SAM and Semantic-SAM by over 14 IoU on NUDT and 4 IoU on IRSTD1k. The source code and models will be released at SimIRSTD.

1. Introduction
Infrared imaging technology offers several advantages over visible light imaging, including robust anti-interference capabilities, adaptability to various environments (Zhao et al., 2022; Shao et al., 2012; Thanh et al., 2008). As a result, it enjoys widespread adoption across various domains such as video surveillance (Teutsch and Krüger, 2010; Yuan et al., 2017), medical and healthcare (Jiang et al., 2005; Jones, 1998; Diakides and Bronzino, 2007) and remote sensing (Weng, 2009; Nilsson, 1995; Lo et al., 1997). In critical scenarios like ocean rescue or remote sensing, it is crucial to identify small targets within infrared images. Traditional infrared small target detection (IRSTD) methods fall within the broader spectrum of three specific categories: filter-based (Jia-xiong and Wen-lin, 1999; Deshpande et al., 1999; Tom et al., 1993; Tomasi and Manduchi, 1998; Hadhoud and Thomas, 1988), local information-based (Kim et al., 2009; Guan et al., 2019; Wang et al., 2012; Chen et al., 2013), and data structure-based (Deng et al., 2016; Zhang et al., 2018, 2019).
Recently, deep learning approaches for IRSTD (Wu et al., 2022; Li et al., 2022; Dai et al., 2021a, b; Zhang et al., 2022b, c) have gained significant attention for their capacity to function without handcrafted priors. However, these data-centric methods pose unique challenges. Constructing a large-scale dataset demands expensive pixel-level annotations while publicly available datasets are often limited in size. Consequently, researchers often resort to data-efficient strategies, such as weakly supervised training (Li et al., 2023a; Ying et al., 2023) or U-shaped models (Ronneberger et al., 2015) tailored specifically for IRSTD (Wu et al., 2022; Li et al., 2022; Dai et al., 2021a, b; Zhang et al., 2022b, c, 2024b), departing from architectures (Dosovitskiy et al., 2020; Liu et al., 2021; Lin et al., 2017) commonly used in generic detection and segmentation tasks. Although prior studies have shown that specially designed networks outperform the common architectures in generic tasks, these conclusions often rely solely on training these models from scratch on the small-scale IRSTD dataset, lacking thorough exploration and neglecting resources from visible light images. Notably, the Segment Anything Model (SAM) (Kirillov et al., 2023) and its derivatives (Xiong et al., 2023; Ke et al., 2024; Zhang et al., 2023a; Zhao et al., 2023; Li et al., 2023b) offer strong backbones trained on extensive datasets and demonstrate effectiveness across various tasks. Thus, it is curious to investigate whether these models offer benefits for IRSTD.
In this study, we aim to build a pioneer model for IRSTD by pre-training on vast visible light data using robust generic segmentation models. This endeavor raises two key questions: 1) How do generic segmentation models like SAM and its derivatives perform in the field of IRSTD? 2) What architectural design effectively facilitates the transferability from these segmentation models to IRSTD? To address the questions, we undertake comprehensive experimentation across various models, including SAM (Kirillov et al., 2023), Semantic-SAM (Li et al., 2023b), SAM-HQ (Ke et al., 2024), as well as SAM’s efficient variants like MobileSAM (Zhang et al., 2023a), and EfficientSAM (Xiong et al., 2023). We compare their performance to established state-of-the-art (SOTA) methods in IRSTD. Despite encountering significant overfitting (Check details in the Appendix) after finetuning, certain SAM-based methods achieve comparable performance to leading IRSTD approaches, as shown in Table 1. Notably, Semantic-SAM consistently outperforms other models. We hypothesize that Semantic-SAM’s hierarchical structure enhances its capability to exploit multi-scale features compared to plain transformer architecture. Additionally, its training strategy facilitates the generation of masks with varying granularity, potentially benefiting transferability to the IRSTD task.
Motivated by these findings, we propose to distill the original Swin-based Semantic-SAM encoder into a lightweight backbone to enhance efficiency and transferability while mitigating performance drops from overfitting. Our approach adopts the many-to-many training strategy from Semantic-SAM (Li et al., 2023b), sharing the decoder and learning objectives. After pre-training, we replace the decoder with a feature pyramid network (FPN) (Lin et al., 2017), coupled with a modified SAM decoder to produce high-resolution masks. This refined pipeline yields a simple and lightweight model that surpasses previous IRSTD methods and SAM’s efficient variants in performance. Additionally, we introduce a novel query design comprising dense and sparse queries, enhancing model performance through multi-level information fusion. These queries interact with each stage from the encoder to the decoder, ultimately aiding in target prediction. Extensive experiments demonstrate that our model achieves state-of-the-art performance across four public datasets. Remarkably, it achieves a mIoU of 97.0 on the NUDT dataset, underscoring its exceptional capabilities. In summary, the contributions of this study are as follows:
-
•
We investigate the SAM and its variants in the context of IRSTD through extensive experiments. Our findings reveal their comparable performance with state-of-the-art methods, offering valuable insights into adapting generic segmentation models for IRSTD
-
•
We propose a simple baseline model leveraging generic segmentation models via knowledge distillation. It incorporates novel query designs to effectively encode multi-scale features through interaction with both the encoder and decoder.
2. Related Work
2.1. IRSTD Methods
IRSTD differs in objective from generic detection tasks. Previous works have often approached IRSTD as a segmentation task, prioritizing this perspective for improved optimization. Dai et al. introduce the first public dataset for IRSTD (Dai et al., 2021a), shifting the task from model-driven to data-driven. They proposed a U-shaped network featuring a bottom-up multi-level information aggregation module, enhancing the model’s detection capabilities. Some other works introduce model-based IRSTD techniques into the network (Zhang et al., 2022c, b, a). Recently, Li et al. propose a densely connected U-net (Li et al., 2022) and Wu et al. propose a U-net in U-net architecture to improve the detection performance further (Wu et al., 2022).
Although U-shaped networks are highly favored for scenarios with limited data and requiring high-resolution output, such as IRSTD, the size of infrared small target data is often inadequate to meet the increasing demands for model performance. One approach to address this issue is leveraging weak supervision to alleviate annotation burdens (Li et al., 2023a; Ying et al., 2023). However, a more natural avenue for exploration is bridging the connection between IRSTD and generic segmentation tasks, given the abundance of data available for the latter, which can be orders of magnitude larger than IRSTD datasets. In such a setting, U-shaped networks encounter challenges in handling large volumes of data and knowledge transfer due to their high computational complexity along with network depth and substantial differences with plain or hierarchical networks, which are more commonly applied in general segmentation tasks.
2.2. Segment Anything Model
The Segment Anything Model (SAM) (Kirillov et al., 2023) stands as a pivotal achievement in the fundamental image segmentation field, having received extensive attention over the past year. SAM has showcased remarkable capabilities in zero-shot transfer learning and boasts versatility across a diverse array of vision tasks. These tasks span a broad spectrum, encompassing medical image analysis (Ma et al., 2024; Yue et al., 2024; Wu et al., 2023), detection of camouflaged objects (Tang et al., 2023; Chen, 2023; He et al., 2024), object tracking (Yang et al., 2023; Cheng et al., 2023), analysis of AI-Generated Content (AIGC) (Sun et al., 2023; Zhang et al., 2023b), and various segmentation tasks (Wang et al., 2024; Ye et al., 2024). Furthermore, subsequent research efforts have delved into addressing specific needs such as high-resolution output (Ke et al., 2024), semantic understanding (Li et al., 2023b), and real-time application (Xiong et al., 2023; Zhang et al., 2024a; Zhao et al., 2023; Zhang et al., 2023a). An intuitive idea is to investigate the performance of these models, known for their strong generalization capabilities, in the context of IRSTD. This exploration could shed light on the potential applicability of SAM and other generic segmentation models in addressing the unique challenges posed by IRSTD.
2.3. Knowledge Distillation in Segmentation
The majority of research in the realm of segmentation emphasizes semantic awareness, aiming to capture inter and intra-class relations by transferring knowledge from teacher models to student models. In class-agnostic segmentation, distillation techniques typically fall into three categories: direct mimic (Romero et al., 2015), relation-based (Liu et al., 2019; Zagoruyko and Komodakis, 2016; Tung and Mori, 2019), and generation-based (Yang et al., 2022; Bai et al., 2023; Peng et al., 2019) approaches. With the release of SAM and its widespread real-world applications, there has been a growing interest in the practical deployment of SAM, prompting several works to explore distillation techniques to reduce its computational cost. Recognizing the challenge of coupled training between the image encoder and mask decoder, MobileSAM (Zhang et al., 2023a) proposes to decouple their optimization processes, employing simple Mean Squared Error (MSE) loss to mimic the behavior of teacher models directly. EfficientSAM (Xiong et al., 2023), on the other hand, adopts masked image modeling, a generation-based method, to distill SAM into a lightweight Vision Transformer (ViT) model. While our work does not primarily focus on the real-time application of large vision models to the IRSTD task, we employ distillation techniques to achieve more efficient training and establish a simple yet strong baseline for IRSTD.
2.4. Query Design
Drawing inspiration from the Global Workspace Theory in cognitive science, Goyal et al. (Goyal et al., 2021) proposed the concept of a shared global workspace (learned arrays) for coordinating multiple specialists. Additionally, the PERCEIVER network family (Jaegle et al., 2021b, a) employs a latent array to encode implicit information from the input array. Expanding the scope further, similar approaches have been observed in designs such as Involution (Li et al., 2021), and VOLO (Yuan et al., 2022). In these designs, learnable tokens replace original keys, resulting in dynamic affinity matrices. Subsequently, models like QnA (Arar et al., 2022) and TransNeXt (Shi, 2023) adopt learnable queries for attention calculation within their backbones, demonstrating effectiveness. Moreover, the two-way transformer design utilized by the SAM decoder can also be interpreted as a project and broadcast workspace encoded by learnable tokens, drawing inspiration from models such as DETR (Carion et al., 2020), and Maskformer (Cheng et al., 2021).
Our proposed query design draws inspiration from models like QnA and TransNeXt. It utilizes learnable queries instead of original features for cross-attention knowledge transfer. Similar to DETR and Maskformer, we also leverage sparse queries to generate the final output. However, what sets our design apart is its operation not only within a single mixer layer, as observed in QnA and TransNeXt, but also across multiple levels. Moreover, we integrate both dense and sparse queries to encode multi-scale information, further enhancing detection accuracy.
3. Methodology
3.1. Preliminaries
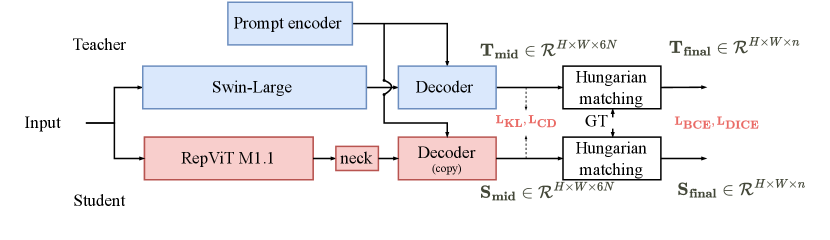
We first review the training strategies employed by variants of SAM (Kirillov et al., 2023). SAM is designed to accommodate flexible segmentation prompts, allowing for various training approaches. Generally, random sampling from labeled training data can be used to generate prompts, driving the end-to-end training of prompt-based mask prediction networks like SAM. SAM-HQ (Ke et al., 2024) and Efficient-SAM (Xiong et al., 2023) adopt this strategy by sampling mixed types of prompts, including bounding boxes, randomly sampled points, and coarse masks as input. In contrast, by employing Hungarian Matching, Semantic-SAM adopts a multi-choice learning strategy (Li et al., 2018; Guzman-Rivera et al., 2012), enabling the network to output six different granularity masks for a single prompt. After finetuning these generic segmentation models on IRSTD datasets, as shown in Table 1 and Appendix, we find: 1) the large generic segmentation models such as SAM, Semantic-SAM, and SAM-HQ encounter significant overfitting issues (see Appendix for details); 2) Despite overfitting, Semantic-SAM consistently outperforms SAM and its variants and achieves comparable performance to state-of-the-art IRSTD approaches. According to the experimental results, we conjecture that Semantic-SAM’s superior performance in IRSTD transferability stems from its unique training strategy and hierarchical network architecture compared to other SAM variants. We therefore use powerful Semantic-SAM as the teacher model to empower our proposed small models in IRSTD. The image encoder in the student model is RepViT M1.1 (Wang et al., 2023) during the pre-training distillation stage and extended to our proposed simple baseline during the fine-tuning stage to align with the different learning objectives. The decoder in the student model is determined by different training stages, which will be illustrated in detail in the following section.
Semantic-SAM comprises three fundamental modules: an image encoder, a prompt encoder, and a mask decoder, akin to SAM and other interactive segmentation models. During training, data is restructured by clustering multiple ground truth (GT) masks of varying levels that share the same click. For each image, prompts (points or boxes) are sampled. Subsequently, each prompt is linked to six queries through a query-based mask decoder, representing six distinct granularities, resulting in output masks. To facilitate multiple predictions matching with GT masks for the same click, Semantic-SAM uses the Hungarian algorithm, enabling many-to-many matching and yielding final output-GT pairs.
3.2. Knowledge Distillation in Pre-training
The backbone in Semantic-SAM, Swin-Large (Liu et al., 2021), consumes approximately 197 million parameters and 200 GFLOPs when processing 512512 images. This poses a great challenge for the model’s deployment in the real world, especially in edge devices. Besides, such a large model’s fine-tuning in infrared target detection (IRSTD) usually encounters overfitting issues because of the small scale of labeled samples, i.e., several hundred to a thousand samples in IRSTD datasets. To this end, we resort to knowledge distillation to help the proposed lightweight backbone efficiently learn knowledge from the powerful teacher, i.e., Semantic-SAM, while mitigating performance drops from overfitting.
During knowledge distillation, the encoder of the student model is RepViT M1.1 (Wang et al., 2023), the decoder is copied from the pre-trained Semantic-SAM decoder as shown in Figure 2. Besides, we add a lightweight neck module following the student backbone to align the channel dimension between the image encoder and decoder. The distillation is conducted on the part of the SA-1B dataset (Kirillov et al., 2023). The model is optimized by minimizing the disparity between the outputs of the student model and those of Semantic-SAM.
Current work for efficient SAM variants only trains the image encoder part during their distillation stages (Zhang et al., 2023a), using MSE loss to mimic the teacher encoder’s output directly. Despite their success, we find its inadequacy in fully exploiting the rich granularity representation of Semantic-SAM’s decoder output, as features from the image encoder do not directly correspond to the final output mask while the decoder’s outputs encapsulate much richer task-related information. Hence, as shown in Figure 2, we adopt a combination of binary cross-entropy (BCE) loss and DICE loss (Milletari et al., 2016) in the pre-training stage to align the student’s outputs with teacher’s final outputs . Technically, we propose to employ KL-divergence loss along both the channel (Shu et al., 2021) and spatial (Hinton et al., 2015) dimensions between the intermediate teacher and student outputs , i.e., the outputs before Hungarian Matching, to help the student recognize the significance of Semantic-SAM’s outputs. This combination aims to maintain the shapes of masks and simultaneously highlight the relationships among different granularities, thereby enhancing the distillation performance. The final distillation loss can be formulated as follows:
| (1) |
where and represent the BCE loss, DICE loss, vanilla KL loss, and channel-wise KL loss, respectively. is a hyper-parameter to balance the losses, following (Shu et al., 2021; Cheng et al., 2021; Zou et al., 2024; Li et al., 2023b).
3.3. Model Design
After pre-training, we take the pre-trained student backbone as the image encoder in our proposed baseline model for IRSTD. We follow EdgeSAM (Zhou et al., 2023) to integrate a tiny FPN behind the image encoder to enhance multi-scale feature representation. Besides, we modify the SAM decoder to handle high-resolution inputs from the FPN. FPN and the new decoder are both re-initialized, which helps the model avoid overfitting issues. Apart from the above design, we introduce a novel query design comprising dense and sparse queries that interact with the image encoder, FPN, and mask decoder, to further enhance the propagation of semantic information and integrate features across various scales.
The popular multi-scale module FPN progressively upsamples the features from the bottom and performs spatial element-wise addition. However, we observe from experiments that the resulting model tends to rely more heavily on the features from the top layers rather than the image encoder’s deep layers, which contain rich and high-level semantic information.
This phenomenon leads to a critical scenario where the clearly discriminative targets depending on the deeper layer features are not recognized as predictions by the decoder, resulting in low detection accuracy. Therefore, we aim to build a more effective multi-level aggregation module that can encode critical information from layer to layer. This module should seamlessly integrate into various architectures and be applicable throughout the network, offering versatility and adaptability. Inspired by (Goyal et al., 2021; Shi, 2023; Arar et al., 2022), we propose a novel design based on query learning to enhance information aggregation and better semantic information propagation.

Query design: As illustrated in the top left part in Figure 1, the proposed design consists of two types of queries: sparse queries and dense queries. For dense queries, we initialize them as by a duplication of the image encoder’s first stage output. Recognizing the significant computational complexity of cross-attention mechanisms, we opt for multi-scale deformable attention (Zhu et al., 2020) between dense queries and the image features of the image encoder’s next three stages. The deformable attention has linear complexity with the spatial size and thus will not introduce much computation burden. For sparse queries, we categorize them into three groups based on their initial interaction points with the model, i.e., sparse encoder queries , sparse FPN queries , and sparse decoder query , where is the number of queries (4 by default) and is the dimension size. All the sparse queries are learnable and initialized from scratch and have the same channel dimension size. Note that only has one query corresponding to the final output mask. As illustrated in the top right part of Figure 1, within the image encoder, the sparse encoder queries interact with the features of the image encoder’s four stages in a bottom-up fashion, and each interaction is achieved by bi-direction attention follows by four steps: (1) cross-attention from queries to features, (2) a point-wise MLP to encode the queries, (3) self-attention on queries, (4) cross-attention from features to queries. The output of steps 3 and 4 are the updated sparse queries and image features for the following modules. Then, the obtained sparse encoder queries concatenate with the next sparse tokens, i.e., FPN queries, and then interact with each granularity level of features within FPN through several bi-direction attention operations in a top-down manner. Note that all levels of FPN features have the same channel dimension size, guaranteeing dimension consistency between sparse queries and FPN features. Finally, all sparse queries are concatenated together, and useful information from features within the decoder is obtained through bidirectional attention between queries and features. We summarize the pipeline of our query design in the image encoder as pseudocode in Algorithm 1.
Decoding process: As illustrated in Figure 3, the model involves three decoding processes throughout the entire pipeline, i.e., two early decoding processes and one final decoding process. First, after the image encoder, we apply a convolutional layer to the dense queries as the mask feature and feed the first sparse encoder query to a 2-layer MLP simultaneously, resulting in a mask prediction by spatially point-wise product between the mask feature and the MLP’s output. The process after FPN is similar. We use FPN output as mask features and the first sparse FPN query as the other multiplier. The early mask prediction after FPN is encoded by a lightweight convolutional block and then added back to FPN feature maps as clues, following the procedure of dense prompt in SAM. We observe from experiments the early decoding processes facilitate effective information propagation between different modules, further enhancing the mask quality predicted by the final decoder. For the final decoding process, we modified the SAM’s decoder by replacing the 2-layer deconvolutional layer with a two-layer convolutional block, since we already have high-resolution features from the hierarchical architecture. Several stacked two-way transformer blocks process the sparse queries and the image feature maps. Then the dot product between the sparse decoder query and feature maps constructs the final mask prediction. The overall process can be formulated as:
| (2) | |||
| (3) | |||
| (4) |
where I, Z, and M denote the input images, feature maps after encoder, and mask prediction, respectively.
| Datasets | ||||||||||||||
| Method | Publication | Type | NUDT | IRSTD1k | SIRST | MDFA | ||||||||
| IoU | IoU | IoU | IoU | |||||||||||
| ACM (Dai et al., 2021a) | WACV’21 | 68.90 | 97.05 | 11.29 | 62.41 | 91.44 | 35.58 | 70.77 | 93.08 | 3.7 | 40.83 | 83.08 | 90.33 | |
| FC3-Net (Zhang et al., 2022b) | ACM MM’22 | 78.56 | 93.86 | 23.922 | 65.07 | 91.54 | 15.55 | 72.44 | 98.14 | 10.85 | 45.62 | 85.29 | 56.76 | |
| ISNet (Zhang et al., 2022c) | CVPR’22 | Specific | 81.77 | 96.3 | 44.47 | 69.93 | 92.6 | 9.21 | 79.83 | 99.02 | 4.61 | 43.44 | 76.42 | 238.15 |
| DNA-net (Li et al., 2022) | TIP’23 | 88.99 | 98.62 | 4.7798 | 69.38 | 93.3 | 11.66 | 79.26 | 98.48 | 2.3 | 41.44 | 75.73 | 180.66 | |
| UIU-net (Wu et al., 2022) | TIP’23 | 92.19 | 97.77 | 15.44 | 69.96 | 91.54 | 65.93 | 70.13 | 95.37 | 35.36 | 41.28 | 75.73 | 86.66 | |
| SAM (Kirillov et al., 2023) | ICCV’23 | 74.10 | 98.3 | 13.32 | 69.12 | 92.61 | 5.88 | 75.21 | 99.07 | 6.82 | 45.27 | 83.08 | 14.64 | |
| SAM-HQ (Ke et al., 2024) | NIPS’23 | 74.02 | 98.31 | 14.48 | 68.85 | 91.54 | 9.56 | 75.27 | 97.22 | 2.87 | 44.99 | 81.61 | 24.41 | |
| Efficient-SAM (Xiong et al., 2023) | CVPR’24 | Generic | 63.20 | 93.75 | 19.51 | 68.29 | 91.24 | 11.58 | 71.57 | 98.14 | 5.744 | 41.9 | 76.47 | 77.51 |
| MobileSAM (Zhang et al., 2023a) | Arxiv’23 | 59.91 | 96.61 | 19.39 | 65.37 | 88.73 | 10.28 | 64.96 | 97.22 | 12.74 | 33.84 | 67.64 | 150.14 | |
| Semantic-SAM (Li et al., 2023b) | Arxiv’23 | 83.18 | 97.14 | 12.36 | 70.27 | 92.25 | 20.16 | 78.67 | 99.07 | 5.48 | 45.53 | 0.8 | 273.85 | |
| Ours w/o query design | 95.53 | 99.15 | 9.07 | 71.28 | 92.25 | 11.89 | 74.49 | 96.29 | 29.97 | 43.74 | 78.67 | 23.19 | ||
| Ours | 97.04 | 99.55 | 0.6897 | 74.21 | 94.36 | 6.47 | 79.83 | 100 | 2.05 | 46.86 | 83.08 | 24.41 | ||
4. Experiments
4.1. Experimental Settings
Datasets
During the distillation process, we conduct training on of the SA-1B dataset. We monitor the distillation pre-training progress using the evaluation set of COCO2017 (Lin et al., 2014) with panoptic segmentation annotations.
To evaluate our methods in the context of IRSTD, we consider four publicly available datasets: SIRST (Dai et al., 2021a), NUDT (Li et al., 2022), IRSTD1k (Zhang et al., 2022c), and MDFA (Wang et al., 2019). The SIRST dataset contains 420 infrared images with resolution varying from to . We follow (Dai et al., 2021a) to split 256 images as training set, and the rest are for evaluation set. The NUDT dataset proposed in (Li et al., 2022) contains 1,327 images and we adhere to their approach by assigning 663 images to the training set and the remaining images to the evaluation set. IRSTD-1k dataset provides 1,001 images at the resolution of . Following (Zhang et al., 2022c), we select 800 images as the training set. Notably, we exclude six images from the remaining set due to inaccurate annotations. To ensure fairness, we test all methods under the same settings and provide details of these excluded images in the appendix. Additionally, the MDFA dataset comprises 10,000 images for the training set and 100 images for the evaluation set.
| Datasets | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| step | Method | NUDT | IRSTD1k | SIRST | MDFA | ||||||||
| IoU | IoU | IoU | IoU | ||||||||||
| 0 | Baseline model | 89.59 | 98.62 | 35.27 | 66.41 | 90.49 | 17.74 | 60.77 | 95.37 | 107.35 | 41.9 | 89.7 | 115.35 |
| 1 | +Distillation | 95.53 (+5.94) | 99.15 (+0.53) | 9.07 (+26.2) | 71.28 (+4.87) | 92.25 (+1.76) | 11.89 (+5.85) | 74.49 (+13.72) | 96.29 (+0.92) | 29.97 (+77.38) | 43.74 (+1.84) | 78.67 (-11.03) | 23.19 (+92.16) |
| 2 | +Query design in FPN | 95.22 (-0.31) | 99.36 (+0.21) | 8.8 (-0.27) | 71.28 (+0.0) | 92.95 (+0.70) | 11.58 (+0.31) | 74.5 (+0.01) | 97.22 (+0.93) | 17.95 (+12.02) | 43.38 (-0.36) | 84.55 (+5.88) | 32.34 (-9.15) |
| 3 | +Early decoding after FPN | 96.14 (+0.92) | 99.36 (+0.00) | 4.13 (+4.67) | 71.69 (+0.41) | 93.3 (+0.05) | 10.93 (+0.65) | 75.58 (+1.08) | 99.07 (+1.85) | 24.23 (-6.28) | 45.04 (+1.66) | 81.61 (-2.94) | 18.54 (+13.80) |
| 4 | + Extending query design to image encoder | 92.57 (-3.57) | 98.94 (-0.42) | 5.58 (-1.45) | 72.23 (+0.54) | 93.36 (+0.06) | 9.91 (+1.02) | 76.43 (+0.85) | 100 (+0.93) | 15.98 (+8.25) | 45.26 (+0.22) | 83.28 (+1.67) | 24.41 (-5.87) |
| 6 | +Early decoding after image encoder | 96.46 (+3.89) | 99.36 (+0.42) | 1.81 (+3.77) | 73.68 (+1.45) | 93.66 (+0.30) | 7.43 (+2.48) | 77.99 (+1.56) | 100 (+0.00) | 7.97 (+8.01) | 46.09 (+0.83) | 86.76 (+3.48) | 39.06 (-14.65) |
| 7 | +Queries and early prediction as prompt | 97.04 (+0.58) | 99.55 (+0.19) | 0.69 (+1.12) | 74.21(+0.53) | 94.36 (+0.70) | 6.47 (+0.96) | 79.83 (+1.84) | 100(+0.00) | 2.05 (+5.92) | 46.86 (+0.77) | 83.08 (-3.68) | 24.41 (+14.65) |



Network details
The RepViT (Wang et al., 2023) is a hierarchical model that outputs latent features of four different sizes: {}. In the context of the IRSTD task, we observe that the large downsampling rate in the original backbone is too aggressive for detecting tiny targets. Therefore, we adjust the initial embedding of RepViT from downsampling to downsampling for IRSTD1k and for the other three datasets. For the tiny FPN employed after the image encoder, it first applies 4 convolutional layers with kernel size to map the output from the image encoder uniformly to 256 channels. Then, the smaller-size feature maps are upsampled through nearest interpolation and added to larger feature maps for multi-level information aggregation. Finally, a convolutional layer is employed to process the output. For the proposed query design, we set the number of queries 4 for , 4 for and 1 for . The are duplicated from the image encoder’s first stage output. The architecture design and hyper-parameters of the decoder are consistent with SAM’s decoder except for replacing the upsample block with a two-layer convolutional block.
Pre-training details
During pertaining on SA-1B, we adopt distillation loss mentioned in section 3.2, and the hyper-parameter is set to 5. Then, we train the model for 20 epochs using the PyTorch framework with a batch size of 16. Following (Li et al., 2023b), we use AdamW optimizer(Loshchilov and Hutter, 2017) with a multi-step learning rate. Initially, the learning rate is set to 1e-4 and reduced by 10 at 90% and 95% of the total number of steps. The training process is conducted on 8 Nvidia GeForce 4090 GPUs.
Tuning details on IRSTD datasets
We use a combination of binary cross entropy loss and DICE loss (Milletari et al., 2016) for the fine-tuning stage: , where is set to 5. Additionally, we follow PointRend (Kirillov et al., 2020) and Implicit PointRend (Cheng et al., 2022), which demonstrate that segmentation models can effectively train with their mask loss calculated using a subset of randomly sampled points instead of the entire mask. After resizing images from the SIRST dataset to , we acquire four datasets with three different sizes: IRSTD1k with sizes of , SIRST and NUDT with , and MDFA with . Then, we train our model for 150 epochs with a cosine learning rate schedule from to with 10 warm-up iterations. For data augmentation, we use a random resize (uniformly from 0.5 to 2.0) and fixed-size crop from Detectron 2 (Wu et al., 2019). Notably, we do not apply data augmentation on the NUDT dataset, as we have observed a degradation in performance.
Evaluation metrics
Following previous works (Li et al., 2023a; Zhang et al., 2022c, b; Dai et al., 2021a; Wu et al., 2022), we adopt the intersection of union (IoU), probability of detection (), and false-alarm rate () as evaluation metrics. Specifically, is an object-level metric that calculates the ratio of correctly predicted targets to total targets , represents the ratio of falsely predicted pixels to all the pixels in an image.
Baselines
To demonstrate the effectiveness of our model, we select five state-of-the-art IRSTD methods for comparison. Since these models are not trained on the SA-1B dataset, we include three large vision models SAM (Kirillov et al., 2023), SAM-HQ (Ke et al., 2024) and Semantic-SAM (Li et al., 2023b), as well as two efficient variants of SAM: MobileSAM (Zhang et al., 2023a) and EfficientSAM (Xiong et al., 2023), for a comprehensive comparison.
Specifically, SAM is trained on the SA-1B dataset for approximately 2 epochs, starting from a pre-trained ViT model. Semantic-SAM is trained using seven datasets, i.e., SA-1B, COCO panoptic (Lin et al., 2014), ADE20k panoptic (Zou et al., 2023), PASCAL part (Chen et al., 2014), PACO (Ramanathan et al., 2023), PartImageNet (He et al., 2022), and Objects365 (Shao et al., 2019). SAM-HQ fine-tunes the pre-trained SAM model on a high-quality dataset, HQSeg-44K (Ke et al., 2024). MobileSAM is trained on of the SA-1B dataset, similar to our approach. EfficientSAM is initially pre-trained on the ImageNet-1K training set (Russakovsky et al., 2015) and then fine-tuned on the entire SA-1B dataset.
4.2. Main Results
We conduct comprehensive experiments involving five state-of-the-art IRSTD approaches and five generalist segmentation models on four datasets, as summarized in Table 1. Our model demonstrates strong performance across different datasets and scales. On the IRSTD1k dataset with an image size of , our model outperforms the second-best model, Semantic-SAM, by approximately 4 IoU, achieving the highest detection probability of 94.36 while maintaining the lowest false-alarm rate . On the NUDT and SIRST datasets with image sizes of , our model achieves an impressive 97.04 IoU, 99.55 detection probability, and 0.6897e-4 false-alarm rate on the NUDT dataset, and 79.83 IoU, 100 detection probability, and 2.05e-4 false-alarm rate on the SIRST dataset. Regarding the MDFA dataset with an image size of , our model still delivers robust performance, reaching 46.86 IoU, 83.08 detection probability, and 24.41e-4 false-alarm rate. The qualitative results are available in Section D of the supplementary materials.
4.3. Ablation Study
4.3.1. The Journey to Our Model
As shown in Table 2, our journey begins with a baseline model consisting of three components: RepViT M1.1 as the image encoder, followed by an FPN and a modified SAM decoder. Without distillation and learned queries, the model demonstrates subpar performance across all four datasets.
Subsequently, we conduct knowledge distillation from Semantic-SAM using of the SA-1B datasets, as outlined in step 1. This process incorporates three essential factors: the multi-granularities awareness from Semantic-SAM and the multi-choice training strategy employed by Semantic-SAM, together with abundant segmentation priors derived from visible images. This effort substantially enhances the model’s performance, resulting in significant improvements of 5.94, 4.87, 13.72, and 1.84 IoU on the NUDT, IRSTD1k, SIRST, and MDFA datasets. This establishes a strong model that outperforms state-of-the-art IRSTD methods and SAM variants.
Then, to address the ineffectiveness of FPN, we introduce a novel query design to levitate multi-scale information, as outlined from step 2 to step 3 in Table 2, and extend it to the image encoder in the stage of step 4 and step 5. Furthermore, we propose to use sparse queries and early predictions to prompt the decoder, as noted in step 7. Our final model significantly outperforms the pre-trained model, achieving a gain of 1.51, 2.93, 5.34, and 3.12 IoU, as well as improvement in detection probability of 0.4, 2.11, 5.34, and 3.12 on the NUDT, IRSTD1k, SIRST, and MDFA datasets, respectively. Furthermore, we observed a reduction in false-alarm rates from 9.07e-4 to 0.69e-4, from 11.89e-4 to 6.47e-4, and from 29.97e-4 to 2.05e-4 on the NUDT, IRSTD1k, and SIRST datasets, respectively. These results validate the effectiveness of the key designs in our model for enhancing detection performance.
4.3.2. Analysis on the Query Design
As illustrated in 4.3 and Table 2, introducing the query design significantly enhances the model’s performance. We further analyze the impact of the queries by visualizing specific layers in Figure 4. In particular, we visualize the output of the P3 and P4 stages before and after the queries are applied, as depicted in Figure 4(c). The heatmaps in Figure 4(a) and 4(b) highlight the differences. Our finding indicates that within the vanilla FPN, the targets identified by higher-level feature maps are diminished after the fusion with low-level features. This issue is largely alleviated by the proposed queries. In Figure 4(b), we observe clearer expression of targets in both stages. The resulting output demonstrates improved visual quality with finer-grained edges.
Computational complexity analysis
Our proposed query design strikes a balance between quality and efficiency. Given an input and sparse queries such as encoder queries where is the batch size, , , and denote the height, width, and dimension of the input, is the number of queries. For a bi-direction attention module depicted in Figure 1, the computational complexity is:
| (5) |
Here, we consider the impact of linear projection and dot product for the complexity above. Since is set to 4 for and , , the complexity is dominated by the second term. The module is of linear complexity with spatial size. The multi-scale deformable attention module involving dense queries is also of linear complexity with and . Details can be checked in (Zhu et al., 2020)

4.3.3. Speed-accuracy tradeoffs
In Figure 5, we investigate the throughput and accuracy of our model against IRSTD SOTA methods, SAM, and SAM variants. Our model achieves a better trade-off between throughput and accuracy. Compared to the latest IRSTD methods, our model surpasses UIU-net, DNA-net, and ISNet by approximately 5 IoU while maintaining a comparable inference speed to UIU-net. In addition, our approach outperforms large vision models such as SAM, SAM-HQ, and the teacher model Semantic-SAM in both performance and throughput, demonstrating that our proposed method fully harnesses the potential of generic segmentation models. Despite the faster throughput of efficient SAM variants like Efficient-SAM and MobileSAM, our method still reaches ‘real-time’ speed and exceeds them by a large margin of 9 IoU.
5. Conclusion
This paper presents a robust segmentation baseline for Infrared Small Target Detection (IRSTD). We begin by investigating the capabilities of the popular vision foundation model SAM and its variants in the context of IRSTD. Subsequently, we propose to use a specific distillation strategy to transfer knowledge from generic models to a more efficient architecture, thus establishing a simple, efficient, yet effective baseline, unleashing the potential of the generic segmentation models. Based on the pre-trained model, we introduce a novel query design to aggregate multi-level features and facilitate effective cross-level semantics propagation. Extensive experiments conducted on four public IRSTD datasets showcase the significantly improved performance of our model compared to SAM, its variants, and previous state-of-the-art methods in IRSTD.
Limitations
Although we demonstrate that a large amount of visible light data can benefit the IRSTD, training on such data requires considerable time and resources. We encourage future research to delve deeper into analyzing the impact of the type and quantity of visible light images on infrared detection ability. By conducting thorough analyses, researchers can identify the most effective strategies for training more efficiently. This could lead to simpler and more effective approaches for IRSTD, ultimately benefiting various applications and domains.
Acknowledgements.
This work was supported in part by the National Natural Science Foundation of China under Grant 62272363, Grant 62036007, Grant U21A20514, and Grant 62061047; in part by the National Key Research and Development Program of China under Grant 2023YFA100860; in part by the Young Elite Scientists Sponsorship Program by China Association for Science and Technology (CAST) under Grant 2021QNRC001; and in part by the Joint Laboratory for Innovation in Satellite-Borne Computers and Electronics Technology Open Fund 2023 under Grant 2024KFKT001-1.References
- (1)
- Arar et al. (2022) Moab Arar, Ariel Shamir, and Amit H Bermano. 2022. Learned queries for efficient local attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10841–10852.
- Bai et al. (2023) Yutong Bai, Zeyu Wang, Junfei Xiao, Chen Wei, Huiyu Wang, Alan L Yuille, Yuyin Zhou, and Cihang Xie. 2023. Masked autoencoders enable efficient knowledge distillers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 24256–24265.
- Carion et al. (2020) Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. 2020. End-to-end object detection with transformers. In European Conference on Computer Vision. Springer, 213–229.
- Chen et al. (2013) CL Philip Chen, Hong Li, Yantao Wei, Tian Xia, and Yuan Yan Tang. 2013. A local contrast method for small infrared target detection. IEEE Transactions on Geoscience and Remote Sensing 52, 1 (2013), 574–581.
- Chen (2023) Tianrun et al. Chen. 2023. Sam-adapter: Adapting segment anything in underperformed scenes. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 3367–3375.
- Chen et al. (2014) Xianjie Chen, Roozbeh Mottaghi, Xiaobai Liu, Sanja Fidler, Raquel Urtasun, and Alan Yuille. 2014. Detect what you can: Detecting and representing objects using holistic models and body parts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1971–1978.
- Cheng et al. (2022) Bowen Cheng, Omkar Parkhi, and Alexander Kirillov. 2022. Pointly-supervised instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2617–2626.
- Cheng et al. (2021) Bowen Cheng, Alex Schwing, and Alexander Kirillov. 2021. Per-pixel classification is not all you need for semantic segmentation. Advances in Neural Information Processing Systems (2021).
- Cheng et al. (2023) Yangming Cheng, Liulei Li, Yuanyou Xu, Xiaodi Li, Zongxin Yang, Wenguan Wang, and Yi Yang. 2023. Segment and track anything. arXiv preprint arXiv:2305.06558 (2023).
- Dai et al. (2021a) Yimian Dai, Yiquan Wu, Fei Zhou, and Kobus Barnard. 2021a. Asymmetric contextual modulation for infrared small target detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 950–959.
- Dai et al. (2021b) Yimian Dai, Yiquan Wu, Fei Zhou, and Kobus Barnard. 2021b. Attentional local contrast networks for infrared small target detection. IEEE Transactions on Geoscience and Remote Sensing 59, 11 (2021), 9813–9824.
- Deng et al. (2016) He Deng, Xianping Sun, Maili Liu, Chaohui Ye, and Xin Zhou. 2016. Infrared small-target detection using multiscale gray difference weighted image entropy. IEEE Trans. Aerospace Electron. Systems 52, 1 (2016), 60–72.
- Deshpande et al. (1999) Suyog D Deshpande, Meng Hwa Er, Ronda Venkateswarlu, and Philip Chan. 1999. Max-mean and max-median filters for detection of small targets. In Signal and Data Processing of Small Targets, Vol. 3809. SPIE, 74–83.
- Diakides and Bronzino (2007) Nicholas A Diakides and Joseph D Bronzino. 2007. Advances in medical infrared imaging. In Medical infrared imaging. CRC press, 19–32.
- Dosovitskiy et al. (2020) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. 2020. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020).
- Goyal et al. (2021) Anirudh Goyal, Aniket Didolkar, Alex Lamb, Kartikeya Badola, Nan Rosemary Ke, Nasim Rahaman, Jonathan Binas, Charles Blundell, Michael Mozer, and Yoshua Bengio. 2021. Coordination among neural modules through a shared global workspace. arXiv preprint arXiv:2103.01197 (2021).
- Guan et al. (2019) Xuewei Guan, Zhenming Peng, Suqi Huang, and Yingpin Chen. 2019. Gaussian scale-space enhanced local contrast measure for small infrared target detection. IEEE Geoscience and Remote Sensing Letters 17, 2 (2019), 327–331.
- Guzman-Rivera et al. (2012) Abner Guzman-Rivera, Dhruv Batra, and Pushmeet Kohli. 2012. Multiple choice learning: Learning to produce multiple structured outputs. Advances in Neural Information Processing Systems (2012).
- Hadhoud and Thomas (1988) Mohiy M Hadhoud and David W Thomas. 1988. The two-dimensional adaptive LMS (TDLMS) algorithm. IEEE Transactions on Circuits and Systems 35, 5 (1988), 485–494.
- He et al. (2024) Chunming He, Kai Li, Yachao Zhang, Guoxia Xu, Longxiang Tang, Yulun Zhang, Zhenhua Guo, and Xiu Li. 2024. Weakly-supervised concealed object segmentation with sam-based pseudo labeling and multi-scale feature grouping. Advances in Neural Information Processing Systems (2024).
- He et al. (2022) Ju He, Shuo Yang, Shaokang Yang, Adam Kortylewski, Xiaoding Yuan, Jie-Neng Chen, Shuai Liu, Cheng Yang, Qihang Yu, and Alan Yuille. 2022. Partimagenet: A large, high-quality dataset of parts. In European Conference on Computer Vision. Springer, 128–145.
- Hinton et al. (2015) Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531 (2015).
- Jaegle et al. (2021a) Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, et al. 2021a. Perceiver io: A general architecture for structured inputs & outputs. arXiv preprint arXiv:2107.14795 (2021).
- Jaegle et al. (2021b) Andrew Jaegle, Felix Gimeno, Andy Brock, Oriol Vinyals, Andrew Zisserman, and Joao Carreira. 2021b. Perceiver: General perception with iterative attention. In International Conference on Machine Learning. PMLR, 4651–4664.
- Jia-xiong and Wen-lin (1999) Peng Jia-xiong and Zhou Wen-lin. 1999. Infrared background suppression for segmenting and detecting small target. Acta Electronica Sinica 27, 12 (1999), 47–51.
- Jiang et al. (2005) LJ Jiang, EYK Ng, ACB Yeo, S Wu, F Pan, WY Yau, JH Chen, and Y Yang. 2005. A perspective on medical infrared imaging. Journal of medical engineering & technology 29, 6 (2005), 257–267.
- Jones (1998) Bryan F Jones. 1998. A reappraisal of the use of infrared thermal image analysis in medicine. IEEE Transactions on Medical Imaging 17, 6 (1998), 1019–1027.
- Ke et al. (2024) Lei Ke, Mingqiao Ye, Martin Danelljan, Yu-Wing Tai, Chi-Keung Tang, Fisher Yu, et al. 2024. Segment anything in high quality. Advances in Neural Information Processing Systems (2024).
- Kim et al. (2009) Sungho Kim, Yukyung Yang, Joohyoung Lee, and Yongchan Park. 2009. Small target detection utilizing robust methods of the human visual system for IRST. Journal of Infrared, Millimeter, and Terahertz Waves 30 (2009), 994–1011.
- Kirillov et al. (2023) Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. 2023. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 4015–4026.
- Kirillov et al. (2020) Alexander Kirillov, Yuxin Wu, Kaiming He, and Ross Girshick. 2020. Pointrend: Image segmentation as rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 9799–9808.
- Li et al. (2023a) Boyang Li, Yingqian Wang, Longguang Wang, Fei Zhang, Ting Liu, Zaiping Lin, Wei An, and Yulan Guo. 2023a. Monte Carlo linear clustering with single-point supervision is enough for infrared small target detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 1009–1019.
- Li et al. (2022) Boyang Li, Chao Xiao, Longguang Wang, Yingqian Wang, Zaiping Lin, Miao Li, Wei An, and Yulan Guo. 2022. Dense nested attention network for infrared small target detection. IEEE Transactions on Image Processing 32 (2022), 1745–1758.
- Li et al. (2021) Duo Li, Jie Hu, Changhu Wang, Xiangtai Li, Qi She, Lei Zhu, Tong Zhang, and Qifeng Chen. 2021. Involution: Inverting the inherence of convolution for visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 12321–12330.
- Li et al. (2023b) Feng Li, Hao Zhang, Peize Sun, Xueyan Zou, Shilong Liu, Jianwei Yang, Chunyuan Li, Lei Zhang, and Jianfeng Gao. 2023b. Semantic-sam: Segment and recognize anything at any granularity. arXiv preprint arXiv:2307.04767 (2023).
- Li et al. (2018) Zhuwen Li, Qifeng Chen, and Vladlen Koltun. 2018. Interactive image segmentation with latent diversity. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 577–585.
- Lin et al. (2017) Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. 2017. Feature pyramid networks for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2117–2125.
- Lin et al. (2014) Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. 2014. Microsoft coco: Common objects in context. In European Conference on Computer Vision. Springer, 740–755.
- Liu et al. (2019) Yifan Liu, Ke Chen, Chris Liu, Zengchang Qin, Zhenbo Luo, and Jingdong Wang. 2019. Structured knowledge distillation for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2604–2613.
- Liu et al. (2021) Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. 2021. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 10012–10022.
- Lo et al. (1997) Chor Pang Lo, Dale A Quattrochi, and Jeffrey C Luvall. 1997. Application of high-resolution thermal infrared remote sensing and GIS to assess the urban heat island effect. International Journal of Remote Sensing 18, 2 (1997), 287–304.
- Loshchilov and Hutter (2017) Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017).
- Ma et al. (2024) Jun Ma, Yuting He, Feifei Li, Lin Han, Chenyu You, and Bo Wang. 2024. Segment anything in medical images. Nature Communications 15, 1 (2024), 654.
- Milletari et al. (2016) Fausto Milletari, Nassir Navab, and Seyed-Ahmad Ahmadi. 2016. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In 2016 Fourth International Conference on 3D Vision. 565–571.
- Nilsson (1995) Hans-Eric Nilsson. 1995. Remote sensing and image analysis in plant pathology. Canadian Journal of Plant Pathology 17, 2 (1995), 154–166.
- Peng et al. (2019) Baoyun Peng, Xiao Jin, Jiaheng Liu, Dongsheng Li, Yichao Wu, Yu Liu, Shunfeng Zhou, and Zhaoning Zhang. 2019. Correlation congruence for knowledge distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 5007–5016.
- Ramanathan et al. (2023) Vignesh Ramanathan, Anmol Kalia, Vladan Petrovic, Yi Wen, Baixue Zheng, Baishan Guo, Rui Wang, Aaron Marquez, Rama Kovvuri, Abhishek Kadian, et al. 2023. Paco: Parts and attributes of common objects. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 7141–7151.
- Romero et al. (2015) Adriana Romero, Nicolas Ballas, Samira Ebrahimi Kahou, Antoine Chassang, Carlo Gatta, and Yoshua Bengio. 2015. FitNets: Hints for Thin Deep Nets. arXiv:1412.6550 [cs.LG]
- Ronneberger et al. (2015) Olaf Ronneberger, Philipp Fischer, and Thomas Brox. 2015. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 234–241.
- Russakovsky et al. (2015) Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. 2015. Imagenet large scale visual recognition challenge. International Journal of Computer Vision 115 (2015), 211–252.
- Shao et al. (2019) Shuai Shao, Zeming Li, Tianyuan Zhang, Chao Peng, Gang Yu, Xiangyu Zhang, Jing Li, and Jian Sun. 2019. Objects365: A large-scale, high-quality dataset for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 8430–8439.
- Shao et al. (2012) Xiaopeng Shao, Hua Fan, Guangxu Lu, and Jun Xu. 2012. An improved infrared dim and small target detection algorithm based on the contrast mechanism of human visual system. Infrared Physics & Technology 55, 5 (2012), 403–408.
- Shi (2023) Dai Shi. 2023. TransNeXt: Robust Foveal Visual Perception for Vision Transformers. arXiv preprint arXiv:2311.17132 (2023).
- Shu et al. (2021) Changyong Shu, Yifan Liu, Jianfei Gao, Zheng Yan, and Chunhua Shen. 2021. Channel-wise knowledge distillation for dense prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 5311–5320.
- Sun et al. (2023) Quan Sun, Yufeng Cui, Xiaosong Zhang, Fan Zhang, Qiying Yu, Zhengxiong Luo, Yueze Wang, Yongming Rao, Jingjing Liu, Tiejun Huang, et al. 2023. Generative multimodal models are in-context learners. arXiv preprint arXiv:2312.13286 (2023).
- Tang et al. (2023) Lv Tang, Haoke Xiao, and Bo Li. 2023. Can sam segment anything? when sam meets camouflaged object detection. arXiv preprint arXiv:2304.04709 (2023).
- Teutsch and Krüger (2010) Michael Teutsch and Wolfgang Krüger. 2010. Classification of small boats in infrared images for maritime surveillance. In 2010 International WaterSide Security Conf. 1–7.
- Thanh et al. (2008) Nguyen Trung Thanh, Hichem Sahli, and Dinh Nho Hao. 2008. Infrared thermography for buried landmine detection: Inverse problem setting. IEEE Transactions on Geoscience and Remote Sensing 46, 12 (2008), 3987–4004.
- Tom et al. (1993) Victor T Tom, Tamar Peli, May Leung, and Joseph E Bondaryk. 1993. Morphology-based algorithm for point target detection in infrared backgrounds. In Signal and Data Processing of Small Targets 1993, Vol. 1954. SPIE, 2–11.
- Tomasi and Manduchi (1998) Carlo Tomasi and Roberto Manduchi. 1998. Bilateral filtering for gray and color images. In Sixth International Conference on Computer Vision. IEEE, 839–846.
- Tung and Mori (2019) Frederick Tung and Greg Mori. 2019. Similarity-preserving knowledge distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 1365–1374.
- Wang et al. (2023) Ao Wang, Hui Chen, Zijia Lin, Hengjun Pu, and Guiguang Ding. 2023. Repvit: Revisiting mobile cnn from vit perspective. arXiv preprint arXiv:2307.09283 (2023).
- Wang et al. (2024) Di Wang, Jing Zhang, Bo Du, Minqiang Xu, Lin Liu, and Dacheng et al. Tao. 2024. Samrs: Scaling-up remote sensing segmentation dataset with segment anything model. Advances in Neural Information Processing Systems (2024).
- Wang et al. (2019) Huan Wang, Luping Zhou, and Lei Wang. 2019. Miss detection vs. false alarm: Adversarial learning for small object segmentation in infrared images. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 8509–8518.
- Wang et al. (2012) Xin Wang, Guofang Lv, and Lizhong Xu. 2012. Infrared dim target detection based on visual attention. Infrared Physics & Technology 55, 6 (2012), 513–521.
- Weng (2009) Qihao Weng. 2009. Thermal infrared remote sensing for urban climate and environmental studies: Methods, applications, and trends. ISPRS Journal of Photogrammetry and Remote Sensing 64, 4 (2009), 335–344.
- Wu et al. (2023) Junde Wu, Rao Fu, Huihui Fang, Yuanpei Liu, Zhaowei Wang, Yanwu Xu, Yueming Jin, and Tal Arbel. 2023. Medical sam adapter: Adapting segment anything model for medical image segmentation. arXiv preprint arXiv:2304.12620 (2023).
- Wu et al. (2022) Xin Wu, Danfeng Hong, and Jocelyn Chanussot. 2022. UIU-Net: U-Net in U-Net for infrared small object detection. IEEE Transactions on Image Processing 32 (2022), 364–376.
- Wu et al. (2019) Yuxin Wu, Alexander Kirillov, Francisco Massa, Wan-Yen Lo, and Ross Girshick. 2019. Detectron2. https://github.com/facebookresearch/detectron2.
- Xiong et al. (2023) Yunyang Xiong, Bala Varadarajan, Lemeng Wu, Xiaoyu Xiang, Fanyi Xiao, Chenchen Zhu, Xiaoliang Dai, Dilin Wang, Fei Sun, Forrest Iandola, et al. 2023. Efficientsam: Leveraged masked image pretraining for efficient segment anything. arXiv preprint arXiv:2312.00863 (2023).
- Yang et al. (2023) Jinyu Yang, Mingqi Gao, Zhe Li, Shang Gao, Fangjing Wang, and Feng Zheng. 2023. Track anything: Segment anything meets videos. arXiv preprint arXiv:2304.11968 (2023).
- Yang et al. (2022) Zhendong Yang, Zhe Li, Mingqi Shao, Dachuan Shi, Zehuan Yuan, and Chun Yuan. 2022. Masked generative distillation. In European Conference on Computer Vision. Springer, 53–69.
- Ye et al. (2024) Maoyuan Ye, Jing Zhang, Juhua Liu, Chenyu Liu, Baocai Yin, Cong Liu, Bo Du, and Dacheng Tao. 2024. Hi-SAM: Marrying Segment Anything Model for Hierarchical Text Segmentation. arXiv preprint arXiv:2401.17904 (2024).
- Ying et al. (2023) Xinyi Ying, Li Liu, Yingqian Wang, Ruojing Li, Nuo Chen, Zaiping Lin, Weidong Sheng, and Shilin Zhou. 2023. Mapping degeneration meets label evolution: Learning infrared small target detection with single point supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 15528–15538.
- Yuan et al. (2017) Chi Yuan, Zhixiang Liu, and Youmin Zhang. 2017. Fire detection using infrared images for UAV-based forest fire surveillance. In 2017 International Conference on Unmanned Aircraft Systems. IEEE, 567–572.
- Yuan et al. (2022) Li Yuan, Qibin Hou, Zihang Jiang, Jiashi Feng, and Shuicheng Yan. 2022. Volo: Vision outlooker for visual recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence 45, 5 (2022), 6575–6586.
- Yue et al. (2024) Wenxi Yue, Jing Zhang, Kun Hu, Yong Xia, Jiebo Luo, and Zhiyong Wang. 2024. Surgicalsam: Efficient class promptable surgical instrument segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 6890–6898.
- Zagoruyko and Komodakis (2016) Sergey Zagoruyko and Nikos Komodakis. 2016. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. arXiv preprint arXiv:1612.03928 (2016).
- Zhang et al. (2023a) Chaoning Zhang, Dongshen Han, Yu Qiao, Jung Uk Kim, Sung-Ho Bae, Seungkyu Lee, and Choong Seon Hong. 2023a. Faster segment anything: Towards lightweight sam for mobile applications. arXiv preprint arXiv:2306.14289 (2023).
- Zhang et al. (2018) Landan Zhang, Lingbing Peng, Tianfang Zhang, Siying Cao, and Zhenming Peng. 2018. Infrared small target detection via non-convex rank approximation minimization joint l 2, 1 norm. Remote Sensing 10, 11 (2018), 1821.
- Zhang et al. (2022a) Mingjin Zhang, Haichen Bai, Jing Zhang, Rui Zhang, Chaoyue Wang, Jie Guo, and Xinbo Gao. 2022a. Rkformer: Runge-kutta transformer with random-connection attention for infrared small target detection. In Proceedings of the 30th ACM International Conference on Multimedia. 1730–1738.
- Zhang et al. (2024b) Mingjin Zhang, Handi Yang, Jie Guo, Yunsong Li, Xinbo Gao, and Jing Zhang. 2024b. IRPruneDet: Efficient Infrared Small Target Detection via Wavelet Structure-Regularized Soft Channel Pruning. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 7224–7232.
- Zhang et al. (2022b) Mingjin Zhang, Ke Yue, Jing Zhang, Yunsong Li, and Xinbo Gao. 2022b. Exploring feature compensation and cross-level correlation for infrared small target detection. In Proceedings of the 30th ACM International Conference on Multimedia. 1857–1865.
- Zhang et al. (2022c) Mingjin Zhang, Rui Zhang, Yuxiang Yang, Haichen Bai, Jing Zhang, and Jie Guo. 2022c. ISNet: Shape matters for infrared small target detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 877–886.
- Zhang et al. (2023b) Renrui Zhang, Zhengkai Jiang, Ziyu Guo, Shilin Yan, Junting Pan, Hao Dong, Peng Gao, and Hongsheng Li. 2023b. Personalize segment anything model with one shot. arXiv preprint arXiv:2305.03048 (2023).
- Zhang et al. (2019) Tianfang Zhang, Hao Wu, Yuhan Liu, Lingbing Peng, Chunping Yang, and Zhenming Peng. 2019. Infrared small target detection based on non-convex optimization with Lp-norm constraint. Remote Sensing 11, 5 (2019), 559.
- Zhang et al. (2024a) Zhuoyang Zhang, Han Cai, and Song Han. 2024a. EfficientViT-SAM: Accelerated Segment Anything Model Without Performance Loss. arXiv preprint arXiv:2402.05008 (2024).
- Zhao et al. (2022) Mingjing Zhao, Wei Li, Lu Li, Jin Hu, Pengge Ma, and Ran Tao. 2022. Single-frame infrared small-target detection: A survey. IEEE Geoscience and Remote Sensing Magazine 10, 2 (2022), 87–119.
- Zhao et al. (2023) Xu Zhao, Wenchao Ding, Yongqi An, Yinglong Du, Tao Yu, Min Li, Ming Tang, and Jinqiao Wang. 2023. Fast segment anything. arXiv preprint arXiv:2306.12156 (2023).
- Zhou et al. (2023) Chong Zhou, Xiangtai Li, Chen Change Loy, and Bo Dai. 2023. EdgeSAM: Prompt-In-the-Loop Distillation for On-Device Deployment of SAM. arXiv preprint arXiv:2312.06660 (2023).
- Zhu et al. (2020) Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. 2020. Deformable detr: Deformable transformers for end-to-end object detection. arXiv preprint arXiv:2010.04159 (2020).
- Zou et al. (2023) Xueyan Zou, Zi-Yi Dou, Jianwei Yang, Zhe Gan, Linjie Li, Chunyuan Li, Xiyang Dai, Harkirat Behl, Jianfeng Wang, Lu Yuan, et al. 2023. Generalized decoding for pixel, image, and language. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 15116–15127.
- Zou et al. (2024) Xueyan Zou, Jianwei Yang, Hao Zhang, Feng Li, Linjie Li, Jianfeng Wang, Lijuan Wang, Jianfeng Gao, and Yong Jae Lee. 2024. Segment everything everywhere all at once. Advances in Neural Information Processing Systems (2024).