Unleash Graph Neural Networks from Heavy Tuning
Abstract
Graph Neural Networks (GNNs) are deep-learning architectures designed for graph-type data, where understanding relationships among individual observations is crucial. However, achieving promising GNN performance, especially on unseen data, requires comprehensive hyperparameter tuning and meticulous training. Unfortunately, these processes come with high computational costs and significant human effort. Additionally, conventional searching algorithms such as grid search may result in overfitting on validation data, diminishing generalization accuracy. To tackle these challenges, we propose a graph conditional latent diffusion framework (GNN-Diff) to generate high-performing GNNs directly by learning from checkpoints saved during a light-tuning coarse search. Our method: (1) unleashes GNN training from heavy tuning and complex search space design; (2) produces GNN parameters that outperform those obtained through comprehensive grid search; and (3) establishes higher-quality generation for GNNs compared to diffusion frameworks designed for general neural networks.
1 Introduction
Graph Neural Networks (GNNs) are deep-learning architectures tailored for analyzing graph-structured data, where capturing the relationships among observations is essential wu2020comprehensive ; zhou2020graph . Akin to the training of most deep learning architectures, GNN training requires iterative optimization algorithms such as stochastic gradient descent (SGD) and hyperparameter tuning. Except for the model-related hyperparameters such as the teleport probability in APPNP gasteiger2019predict , the optimizer alone requires heavy tuning on learning rate, weight decay, etc. Besides, we notice that the choice of hyperparameters indeed has a nontrivial impact on the final prediction outcome, especially for unseen data. While automated search algorithms like grid search are commonly used to reduce manual effort, they still necessitate careful design of the search space. A limited search space cannot guarantee promising configurations, whereas an overly broad search space incurs high computational and time costs. This motivates us to develop an alternative method to replace heavy tuning while preserving the model accuracy.
Previous works on GNN training generally focus on two topics: GNN pre-training and GNN architecture search. GNN pre-training involves using node, edge, or graph level tasks to find appropriate initialization of GNN parameters before fine-tuning with ground truth labels hu2019strategies ; hu2020gpt ; lu2021learning . This approach still inevitably relies on hyperparameter tuning to boost model performance. GNN architecture search aims to find appropriate GNN architectures given data and tasks gao2019graphnas ; you2020design . However, it was explored in shchur2018pitfalls that under comprehensive hyperparameter tuning and proper training process, simple GNN architectures such as GCN may even outperform sophisticated ones. Unfortunately, this also comes with high computational costs and significant human effort.
Novelty and Contributions To alleviate the burden of heavy hyperparameter tuning, we propose a graph conditional latent diffusion framework (GNN-Diff) to directly generate high-performing GNN parameters by learning from checkpoints saved during a coarse search within a much smaller search space. While parameter and network generation have been extensively studied in previous research erkocc2023hyperdiffusion ; peebles2022learning ; schurholt2022hyper ; soro2024diffusion ; wang2024neural , the intrinsic relationship between data characteristics and network parameters remains underexplored. Our approach uses a task-oriented graph autoencoder to integrate data and graph structural information as a condition for GNN parameter generation. We validate through empirical experiments on node classification that GNN-Diff: (1) reduces the need of extensive tuning and complex search space design by providing an alternative method to sample reliable parameters directly; (2) produces GNN parameters that outperform those obtained through comprehensive grid search by fully exploring the underlying population of "good parameters"; and (3) incorporates graph guidance to establish superior GNN parameter generation compared to diffusion frameworks designed for general neural networks. The implementation code of GNN-Diff will be released after the review process.
2 Preliminary
2.1 Graph Neural Networks
We denote an undirected graph with nodes as , where and are sets of nodes and edges and is the adjacency matrix containing information of relationships. can be either weighted or unweighted, normalized or unnormalized. The graph signals are stored in a matrix , where is the number of features. Traditional Multi-Layer Perceptrons (MLPs) integrate data information solely from the feature direction for representation learning, overlooking potential connections between nodes. This limitation is addressed by Graph Neural Networks (GNNs), a deep-learning architecture that incorporates additional relationship information through graph convolutions. Typically, there are two types of GNNs: spatial GNNs that aggregate neighboring nodes with message passing hamilton2017inductive ; kipf2017semisupervised ; gasteiger2019predict and spectral GNNs developed from the graph spectral theory defferrard2016convolutional ; lin2023magnetic ; zou2023simple . With both types, the most important component of their architecture is the convolutional layer, which usually consists of graph convolution, linear transformation, and non-linear activation functions. For example, the very classic convolutional layer in GCN kipf2017semisupervised is formulated as , where graph convolution involves node aggregation with graph adjacency , linear transformation is conducted with linear operator , and is the activation function. The GNN training process often involves learning parameters in the linear transformation and for some architectures such as ChebNetdefferrard2016convolutional and the graph convolution.
2.2 Latent Diffusion Models
Diffusion models generate a step-by-step denoising process that recovers data in the target distribution from random white noises. A typical diffusion model adopts a pair of forward-backward Markov chains, where the forward chain perturbs the observed samples eventually to white noises, and then the backward chain learns how to remove the noises and recover the original data. Assume that is the original data (e.g., vectorized network parameters) from the target distribution . Then, the forward-backward chains are formulated as follows.
Forward Chain For diffusion steps , Gaussian noises are injected to until . By the Markov property, one may jump to any diffusion steps via , where with is a pre-defined noise schedule.
Backward Chain The backward chain removes noises from gradually via a backward transition kernel , which is usually approximated by a neural network with learnable parameters . Here we use the framework of denoising diffusion probabilistic models (DDPMs). Thus, we alternatively find a denoising network to predict noise injected at each diffusion step with the loss function
| (1) |
Latent Diffusion Classic two-layer GNNs such as GCN and ChebNet usually contain 10k to 500k parameters for benchmark graph datasets with 1k to 4k features. So generating GNN parameters directly with diffusion models may lead to slow training and long inference time. As a common solution to such problems, latent diffusion models (LDM) rombach2022high ; soro2024diffusion ; wang2024neural first learn a parameter autoencoder (PAE) to convert the target parameters to a low-dimensional latent space with , then generate in the latent space before reconstructing the original target with a sufficiently precise decoder. The loss function is usually formulated as the mean squared error (MSE) between original data and reconstructed data .
3 Related Works
Hypernetworks Network generation usually refers to the generation of neural network parameters. Hypernetwork ha2016hypernetworks ; stanley2009hypercube is an early concept of deep learning technique for network generation and now serves as a general framework that encompasses many existing methods. A hypernetwork is a neural network that learns how to predict the parameters of another neural network (target network). The input of a hypernetwork may be as simple as parameter positioning embeddings stanley2009hypercube , or more informative, such as encodings of data, labels, and tasks deutsch2018generating ; ha2016hypernetworks ; ratzlaff2019hypergan ; zhang2018graph ; zhmoginov2022hypertransformer .
Generative Modelling for Network Generation With the emergence of generative modelling, studies on distributions of network parameters have gained their popularity in relevant research. A pioneering work of unterthiner2020predicting showed that simply knowing the statistics of parameter distributions enabled us to predict model accuracy without accessing the data. Enlightened by this finding, two following works schurholt2022hyper ; schurholt2021self studied the reconstruction and sampling of network parameters from their population distribution. The similar idea was also investigated by peebles2022learning , who proposed that network parameters corresponding to a specific metric value of some specific data and tasks could be generated with a transformer-diffusion model trained on tremendous amount of model checkpoints collected from past training on a group of data and tasks. This method, however, relies highly on the amount and quality of model checkpoints fed to the generative model. A more network- and data-specific approach, p-diff wang2024neural , alternatively collects checkpoints from the training process of the target network and uses an unconditional latent diffusion model to generate better-performing parameters. Another recent work, D2NWG soro2024diffusion , adopts dataset-conditioned latent diffusion to generate parameters for target networks on unseen datasets. Diffusion-based network generation has also been widely applied to other applications, such as meta learning nava2022meta ; zhang2024metadiff and producing implicit neural-filed for 3D and 4D synthesis erkocc2023hyperdiffusion .
Parameter-free Optimization, Bayesian Optimization and Meta Learning. There emerge many recent works on parameter-free optimization, such as defazio2023learning ; ivgi2023dog ; mishchenko2023prodigy that automatically set step-size based on problem characteristics. However, most if not all methods require non-trivial adaptation of existing optimizers and show theoretical guarantees only for convex functions. Bayesian optimization snoek2012practical and meta learning franceschi2018bilevel on the other hand, are more advanced approaches for tuning hyperparameters in a more informed way than grid and random search.
4 Graph Neural Network Diffusion (GNN-Diff)
GNN-Diff takes 4 steps before final prediction on unseen data: (1) inputting graph data, (2) collecting parameters with coarse search, (3) training, and (4) sampling and reconstructing parameters. Training involves the training of three modules: parameter autoencoder (PAE), graph autoencoder (GAE), and graph conditional latent diffusion (G-LDM). We provide a visualized overview of GNN-Diff in Figure 1. Since input data and PAE have been previously discussed with preliminaries, we predominantly focus on the remaining components in this section. The pseudo codes of training and inference algorithms are provided in Appendix A.

4.1 Parameter Collection with Coarse Search
To produce high-performing GNN parameters, we need a set of high-quality parameter samples such that the diffusion module can generate from their underlying population distribution. It is quite intuitive that good model performance is associated with appropriate selection of hyperparameters. So, we start with a coarse search with a relevantly small search space to determine a suitable configuration (details on the search space are discussed in Section 5). This includes the selection of hyperparameters in the optimizer such as learning rate, model architecture such as hidden size, and other model-specific factors such as the teleport probability in APPNP gasteiger2019predict . Since parameter initialization may also influence the training outcome, we provide 10 random initializations for training with each configuration. A good configuration from coarse search is defined as the one leading to the best validation accuracy. After the coarse search, we save model checkpoints from the training process with the selected configuration as parameter samples. We discard the parameters from some start-up epochs where convergence has not been achieved. Parameters are reorganized and vectorized before they are further processed by PAE.
4.2 Graph Autoencoder (GAE)
GAE is designed to encode graph information from graph signals and structure , which will be employed as a condition for GNN generation. In this paper, we mainly focus on the node classification task to evaluate our method, so the GAE structure is oriented by the specific task, which means GAE encoder aims to produce a graph representation that works well on node classification. Straightforwardly, a GNN architecture should be considered. The general principle of GNN propagation is to update the node feature by aggregating its neighboring information. Thus, GNN graph representation has similar features for connected nodes, which will eventually lead to similar label prediction. This is well-suited for homophilic graphs, where connected nodes are normally from the same classes. However, for heterophilic graphs, where nodes with different labels are prone to be linked, such representation leads to an even worse classification outcome than MLP han2024from ; zheng2022graph . Hence, enlightened by some previous works shao2023unifying ; thorpe2022grand ; zhu2020beyond , we introduce the following GAE encoder, which is capable of handling both homophilic and heterophilic graphs:
| (2) |
which is composed of the concatenation of a two-layer GCN, a one-layer GCN, and an MLP, followed by a linear transformation , where and are the dimensions of the concatenation and the latent parameter representation, respectively. is a single layer MLP with being the number of node classes. Thus graph information is fully encapsulated in the output of the encoder. Finally, GAE is trained with cross entropy loss on node labels. The graph condition is then given by mean-pooling the node features
| (3) |
where is the i-th row of graph representation. The purpose of applying mean pooling on nodes is to construct an overall graph condition regardless of the graph size, which will later be combined with latent representation as input of diffusion denoising network. We highlight that our method can be naturally extended to other graph tasks by altering the design and loss function of GAE.
4.3 Graph Conditional Latent DDPM (G-LDM)
G-LDM is developed from LDM with additional graph conditions from GAE to provide consolidated guidance on GNN generation. The generative target of G-LDM is latent GNN parameters . The forward pass of G-LDM is the same as traditional DDPM, while the backward pass uses a graph conditional backward kernel for data recovering from white noises. The corresponding G-LDM loss function is given by
| (4) |
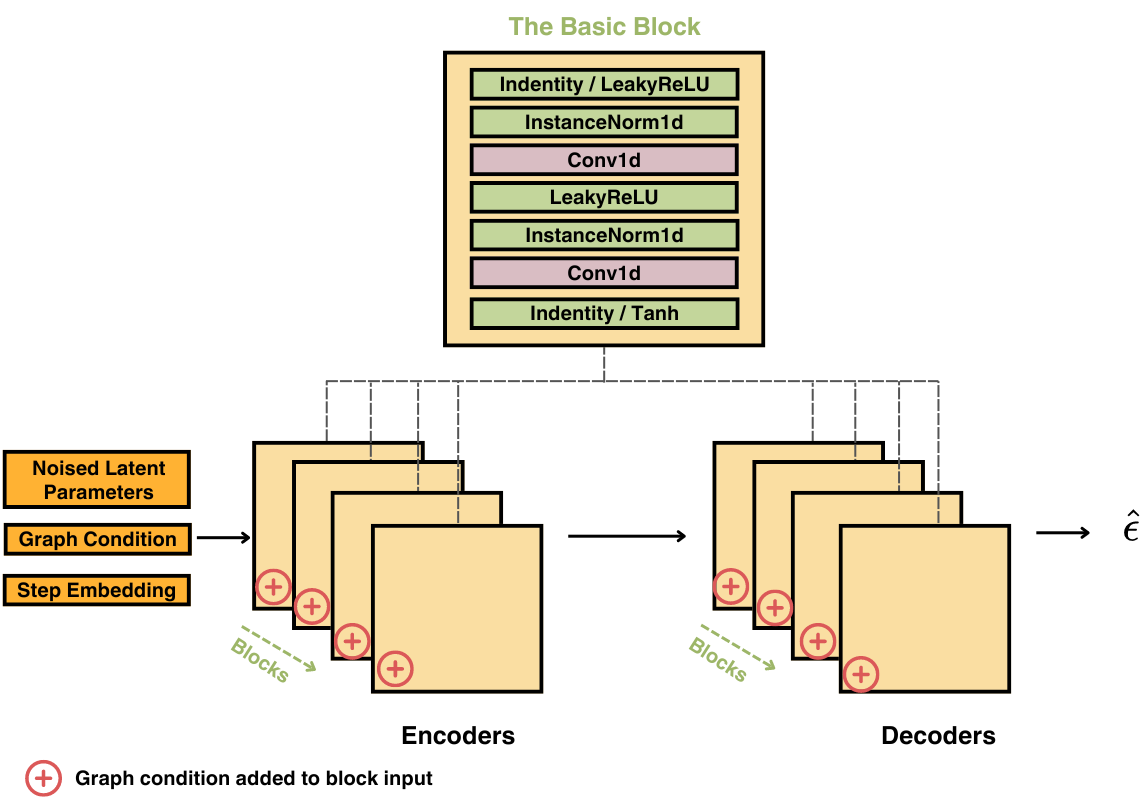
For both PAE and denoising network , we adopt the Conv1d-based architecture in wang2024neural . We include the graph condition by using the sum of , , and as input to . Our method is flexible with PAE and architectures. So, we choose an architecture that has been empirically validated by previous research. We observe in experiments that the most important factor in high-quality generation is to reduce parameter dimension sufficiently while ensuring reconstruction tightness. This can be done by setting the appropriate kernel size and stride for Conv1d layers in PAE. We discuss more details about PAE and architecture and how to ensure high-quality generation in Appendix B and Appendix F, respectively.
4.4 Sampling, Reconstruction, and Prediction
The last step before the final prediction is to obtain parameters and reconstruct the target GNN. G-LDM generates samples of latent parameters from white noises with the learned denoising network. Next, the learned PAE decoder is applied to reconstruct parameters back to the original dimension. These parameters are returned to the target GNN thus we have a group of GNNs with generated parameters. Lastly, we determine the optimal GNN depending on validation performance, which will be used for future predictions.
5 Experiments and Discussions
5.1 Experimental Setup
Dataset and Target GNNs We evaluate our method with 4 benchmark graph datasets, Cora yang2016revisiting , Citeseer yang2016revisiting , Actor Pei2020Geom-GCN , and Chameleon rozemberczki2021multi . Cora and Citeseer are homophilic graphs, while Actor and Chameleon are heterophilic graphs. Data split follows the original works. We use only the first train/val/test mask for Actor and Chameleon. 7 most representative GNNs are selected as target models, including GCNkipf2017semisupervised , APPNP gasteiger2019predict , SAGE hamilton2017inductive , ChebNet defferrard2016convolutional , GIN xu2019how , GAT velivckovic2017graph , and H2GCN zhu2020beyond . In particular, we evaluate GCN with a single layer (GCN1) and two layers (GCN2) to explore the ability of GNN-Diff to generate parameters for models with different depths. H2GCN is H2GCN1 from its original paper. All other architectures are two-layer GNNs. We include more details of datasets in Appendix C and target GNNs and why they are selected in Appendix D.
Experiment Details All experiments are run on a single NVIDIA 4090 GPU with 64GB memory. For each target GNN, we conduct coarse search with a search space of 20-80 hyperparameter configurations, whereas the grid search takes a more comprehensive search space of 144-1269 configurations. A list of search spaces can be found in Appendix E. For each configuration, we train the target GNN with 200 epochs to ensure convergence and 10 parameter initializations to minimize the influence of randomness. GNN-Diff training is designed as a training flow on 3 respective modules: GAE, PAE, and G-LDM. To alleviate hyperparameter tuning, we designed GNN-Diff modules to require minimal tuning. In fact, the only hyperparameters to consider are the PAE kernel size, fold rate, and the number of training epochs. These are determined by the target GNN parameter size with fairly simple rules. We provide relevant training details in Appendix F. For evaluation on the test set, we generate 100 latent parameter representations with G-LDM, which are then reconstructed by the learned P-Decoder and recovered to the target GNN. The generated model with the best validation accuracy will be tested.
Reproducibility and Comparability Random seeds of all packages in the implementation code are set as 42 to mitigate randomness. The same hyperparameter setting and training process are applied to generative models for fair comparison in Subsection 5.4.
5.2 Results on Node Classification
| Model | Cora | Citeseer | Actor | Chameleon | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| G.S. | C.S | G-D | G.S. | C.S | G-D | G.S. | C.S | G-D | G.S. | C.S | G-D | |
| GCN1 | 78.70 | 78.10 | 79.00 | 70.30 | 69.50 | 70.60 | 29.67 | 29.74 | 29.80 | 57.24 | 55.26 | 57.24 |
| GCN2 | 80.90 | 81.80 | 82.10 | 72.50 | 70.20 | 72.70 | 31.38 | 30.13 | 31.84 | 65.57 | 65.35 | 66.01 |
| APPNP | 82.20 | 82.70 | 83.00 | 72.40 | 72.00 | 73.40 | 35.20 | 35.00 | 36.32 | 58.77 | 58.11 | 60.09 |
| SAGE | 80.70 | 80.90 | 81.90 | 70.90 | 67.10 | 71.20 | 36.71 | 35.66 | 37.63 | 61.99 | 60.09 | 61.84 |
| ChebNet | 79.50 | 79.90 | 80.80 | 70.60 | 68.80 | 70.69 | 36.58 | 36.12 | 36.90 | 58.99 | 57.46 | 59.86 |
| GIN | 75.80 | 76.30 | 76.70 | 68.40 | 68.10 | 63.90 | 26.25 | 25.92 | 26.97 | 38.82 | 33.99 | 33.33 |
| GAT | 82.20 | 81.40 | 83.50 | 73.00 | 71.50 | 71.00 | 30.53 | 29.80 | 30.72 | 63.82 | 64.47 | 64.47 |
| H2GCN | 80.90 | 80.20 | 81.40 | 70.40 | 71.20 | 72.00 | 33.49 | 33.49 | 35.26 | 53.29 | 51.75 | 53.95 |
In Table 1, we present the results of GNN-Diff on generating GNNs for node classification. We compare the test accuracy of three models selected respectively from grid search, coarse search, and GNN-Diff generation based on validation accuracy. For simplicity, we will refer them as grid model, coarse model, and GNN-Diff model. Overall, GNN-Diff models outperform grid and coarse models on most GNN architectures and datasets. On Cora and Actor, GNN-Diff models successfully achieve the best test accuracy for all target GNNs. GNN-Diff models improve the test accuracy from 0.20% to 1.30% on Cora and from 0.06% to 1.77% on Actor. On Citeseer and Chameleon, GNN-Diff models also produce good test results for most GNN architectures. Notably, GNN-Diff boosts the test performance for H2GCN on Citeseer by 1.60% and for APPNP on Chameleon by 1.32%. However, GNN-Diff fails to outperform grid results for GIN and GAT on Citeseer and for GIN and SAGE on Chameleon. We have tracked the validation and test accuracy of GIN during the training for grid search, and noticed that good accuracy in grid search could be considered as outliers in overall GIN performance. They appeared abruptly in the training history and had much higher value than neighboring epochs. Thus, it is hard to capture the corresponding parameters based on coarse search samples. We suppose it is reasonable to treat this as special situation. For GAT on Citeseer and SAGE on Chameleon, heavy parameterization of their architectures lays the burden on PAE reconstruction. We suggest that a more sophisticated architecture of PAE may be helpful, though the current architecture still works well on these two GNNs for other datasets.
The grid search accuracy we report here for some GNNs may be lower than other relevant works. This is majorly caused by different experiment setting. The grid model evaluated by test set is the model with highest validation accuracy among all others from the entire comprehensive grid search process. Some relevant works run GNNs with each individual hyperparameter configuration, and report the best test accuracy among configurations. Validation data is only used for model selection during the training process with each configuration.
5.3 Visualizations

We further investigate the experiment results by visualization. With coarse search, we only visualize the saved checkpoints for GNN-Diff training to be directly compared with models generated by GNN-Diff. We use GCN2 on Cora as an example and try to answer three questions:
Q1. Why are some coarse search outcomes better than grid search in Table 1?
A1. Comprehensive grid search may overfit validation set.
In Figure 2 (a), we present a scatter plot between validation and test accuracy for partial grid (green), coarse (orange), and GNN-Diff (red) models that achieve at least 70% prediction accuracy on both validation and test set. In our experiments, the models from three methods with the highest validation accuracy are selected for evaluation on test data. We use three black circles to indicate the position of the final models. Clearly, the grid model with the highest validation accuracy has the lowest test accuracy compared to the other two methods. This is a sign of overfitting on validation data, which eventually results in poor generalizability.
Although grid search generally guarantees to find a promising hyperparameter configuration, its reliance on validation may be counterproductive sometimes. Having a smaller search space or using other search algorithms, such as random search, may solve the problem. But how do we know the appropriate search space size? In addition, nearly 80% of our experiment results show that grid search can find better generalized model than coarse search, hence reducing search space or random search may not be good options in most cases. This shows the superiority of our method, which only requires samples from a good configuration and then further optimizes the model performance by exploring the underlying population distribution. This avoids finding a configuration that is optimal for validation but not for unseen data.
Q2. What is the relationship between coarse models and GNN-Diff models?
A2. GNN-Diff parameters follow the coarse distribution and explore into the population.
As we know, the parameters of coarse models are the training data of GNN-Diff. So, the parameters generated by GNN-Diff are expected to follow a similar distribution as coarse model parameters. In Figure 2 (b), we use a bubble isometric mapping plot to visualize coarse (orange) and GNN-Diff (red) parameter distributions via dimensionality reduction. Isometric mapping (Isomap) seeks to preserve the geodesic distances between all pairs of data points in the 2D embedding. It is particularly helpful for visualizing high-dimensional parameters by projecting them onto a low-dimensional space while maintaining the underlying geometry. Additionally, we plot each model point as bubbles with bubble size representing the corresponding test accuracy.
We observe that GNN-Diff parameters follow the pattern of the coarse distribution (a firework-like expanding spread with three directions). Besides, the generation further explores the potential population distribution by extending in two of the three directions. Notably, the generated models close to the center of coarse distribution are associated with lower accuracy, whereas the extended ones have better prediction outcomes. This may validate our conjecture that GNN-Diff has the ability to approximate population parameter distribution with a good hyperparameter configuration and generate better-performing samples from it.
Q3. How can GNN-Diff models produce better prediction result than coarse and grid models?
A3. GNN-Diff leads to more centered accuracy distribution around a high accuracy region.
In Figure 2 (c), we provide the Kernel Density Estimation (KDE) plot of test accuracy distributions for grid models (green), coarse models (orange), and GNN-Diff models (red). The test accuracy of grid models shows a broader distribution with two peaks, one around 20% and the other one around 80%. Grid search, while thorough, spends much unnecessary time and computation on training with sub-optimal or even unsatisfactory configurations. Coarse models present a test accuracy distribution with a peak around 80% but with some variability. Two factors have contributed to this distribution. Firstly, coarse models are collected from a good hyperparameter configuration of coarse search. Secondly, we discard some models from start-up epochs that are generally associated with low test accuracy. The test accuracy distribution of GNN-Diff models has a sharp peak at a comparably higher level, implying high-performing outcomes with less variability than the other two methods. This means GNN-Diff consistently finds models with comparably better generalizability, outperforming both grid search and coarse search in terms of finding high-quality parameters.
5.4 Is Graph Condition Useful for GNN Generation?
Here we focus on whether incorporating graph condition is useful for GNN generation. Previous works have discussed using data and tasks as conditions, but only for the purpose of tailoring their methods for future unseen data or similar tasks nava2022meta ; soro2024diffusion ; zhang2024metadiff . The role of intrinsic data characteristics in network generation is still unexploited. Nevertheless, with graph neural networks, the graph structure is very essential in the network architecture and has a consequential impact on graph signal processing. So, only considering data (graph signals) as the generative condition is insufficient. Previous study nava2022meta includes predictive tasks as the condition by encoding their language descriptions, which requires additional effort to form appropriate descriptions and embedding. Alternatively, we propose a more straightforward way via specific task supervision on condition construction. Therefore, we design the GAE discussed in Subsection 4.2, which incorporates both graph data and structural information in the generative condition and is trained with the task loss function. We conduct two experiments: (1) a comparison experiment between GNN-Diff and p-diff wang2024neural to show how graph condition improves GNN generation quality; (2) an ablation study on GNN-Diff generative condition to validate the current GAE architecture on homophilic and heterophilic graphs. In the first experiment, we chose p-diff because it has the same PAE and as GNN-Diff and no generative condition. Hence, we do not need to consider different performances caused by different generative model architectures. Both methods are trained with the same hyperparameters and experiment settings. For both experiments, we conduct sampling and prediction 5 times and report the best results for all methods/conditions to offset the influence of randomness in diffusion generation and ensure fair comparison.
Comparison between GNN-Diff and p-diff

In Figure 3, we compare the generated parameter and test accuracy distributions with and without graph conditions. This experiment is conducted with GCN2 on Cora. Based on the implementation of PyTorch Geometric, GCN2 has 4 learnable components, including biases and weights in two graph convolutional layers. For visualization purposes, we pick one parameter from each component and plot its distributions with sample models from coarse search (orange), GNN-Diff generation (blue, top row), and p-diff generation (blue, bottom row). It is clear that GNN-Diff generation captures the sample distribution and extends the sample distribution range to explore potential population distribution. By contrast, p-diff generation produces much centered distribution but fails to cover the sample distribution. This indicates that graph condition provides a useful guidance on GNN generation, and helps the generative model to better learn the target distribution. We also provide histograms of test accuracy distribution for both methods. p-diff models obtain around 20% to 80% accuracy when being applied to test data. GNN-Diff models, on the other hand, have accuracy more centered around 80%. Also, the worst-performing model generated by GNN-Diff still outperforms many p-diff models. Although high accuracy can be achieved by p-diff, the generation quality is unstable without the guidance of graph conditions.
Ablation Study on Generative Condition

In Figure 4, we present the test accuracy of GNN generation with different conditions. GAE refers to the architecture discussed in Subsection 4.2, which is adopted by GNN-Diff. According to Equation (2), GAE encoder combines GCN and MLP to handle both homophilic and heterophilic graphs. In this experiment, we apply ablation on graph conditions. GCN1 and GCN2 represent graph conditions with only graph convolution-based representation. MLP2 and MLP1 represent conditions with only data information. Lastly, we include no condition (p-diff) as the baseline. Different target GNNs are considered to show the generalizability of the conclusion. On the homophilic graph, Cora, GAE leads to the best test result, while conditions without graph structural information (MLP2 and MLP1) and no condition fail to outperform grid search results. On heterophilic graphs, Actor, MLP2, MLP1, and no condition produced better results than graph convolution-based conditions (GCN2 and GCN1). However, in GAE, the combination of graph convolution and MLP still generates the best prediction outcome. Therefore, we conclude that the current GAE architecture consistently leads to high-performing parameters regardless of the graph type.
5.5 Time Efficiency

Last but not least, we would like to discuss the time efficiency of GNN-Diff. In Figure 5, we use a bar chart to show the time of grid search (green), coarse search (orange), and GNN-Diff training (red) for different target GNNs and datasets. We stack bars of coarse search and GNN-Diff training as the time cost of the entire GNN-Diff process. Inference time is not shown as it is negligible (usually less than 10 seconds). The time is estimated based on the average search iteration time and average epoch time for three GNN-Diff modules. Implementation time may vary due to factors such as data pre-processing and validation. According to the plots, it is very clear that the GNN-Diff method is more efficient than a comprehensive grid search. The advantage is less obvious for simple GNN architectures such as GCN1, for which only a small search space is needed for grid search. However, it is very valuable for architectures with large hyperparameter space such as GAT and GNNs with cumbersome graph convolution such as APPNP.
6 Conclusion
In this paper, we proposed a graph conditional latent diffusion framework, GNN-Diff, to generate high-performing GNN parameters by learning from checkpoints saved with a light-tuning coarse search. We validate with empirical experiments that our method is an efficient alternative to costly search algorithms and generates better prediction outcomes than a comprehensive grid search on unseen data. We have also shown that, by incorporating a carefully designed task-orientated graph condition in the generation process, our method establishes higher-quality generation for GNNs than diffusion methods designed for general network generation. We majorly focus on the node classification task to validate our method, though it can be naturally extended to other graph tasks. Future works may involve the implementation of other tasks and solutions to reconstructing heavy parameterized GNNs.
References
- [1] Aaron Defazio and Konstantin Mishchenko. Learning-rate-free learning by d-adaptation. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors, International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 7449–7479. PMLR, 23–29 Jul 2023.
- [2] Michaël Defferrard, Xavier Bresson, and Pierre Vandergheynst. Convolutional neural networks on graphs with fast localized spectral filtering. In Advances in Neural Information Processing Systems, 2016.
- [3] Lior Deutsch. Generating neural networks with neural networks. arXiv:1801.01952, 2018.
- [4] Ziya Erkoç, Fangchang Ma, Qi Shan, Matthias Nießner, and Angela Dai. Hyperdiffusion: Generating implicit neural fields with weight-space diffusion. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 14300–14310, 2023.
- [5] Luca Franceschi, Paolo Frasconi, Saverio Salzo, Riccardo Grazzi, and Massimiliano Pontil. Bilevel programming for hyperparameter optimization and meta-learning. In International Conference on Machine Learning, pages 1568–1577. PMLR, 2018.
- [6] Yang Gao, Hong Yang, Peng Zhang, Chuan Zhou, and Yue Hu. Graph neural architecture search. In Christian Bessiere, editor, Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI-20, pages 1403–1409. International Joint Conferences on Artificial Intelligence Organization, 7 2020. Main track.
- [7] Johannes Gasteiger, Aleksandar Bojchevski, and Stephan Günnemann. Predict then propagate: Graph neural networks meet personalized pagerank. In International Conference on Learning Representations, 2019.
- [8] David Ha, Andrew Dai, and Quoc V Le. Hypernetworks. arXiv:1609.09106, 2016.
- [9] Will Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation learning on large graphs. In Advances in Neural Information Processing Systems, 2019.
- [10] Andi Han, Dai Shi, Lequan Lin, and Junbin Gao. From continuous dynamics to graph neural networks: Neural diffusion and beyond. Transactions on Machine Learning Research, 2024. Survey Certification.
- [11] Weihua Hu, Bowen Liu, Joseph Gomes, Marinka Zitnik, Percy Liang, Vijay Pande, and Jure Leskovec. Strategies for pre-training graph neural networks. In International Conference on Learning Representations, 2020.
- [12] Ziniu Hu, Yuxiao Dong, Kuansan Wang, Kai-Wei Chang, and Yizhou Sun. Gpt-gnn: Generative pre-training of graph neural networks. In Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, pages 1857–1867, 2020.
- [13] Maor Ivgi, Oliver Hinder, and Yair Carmon. Dog is sgd’s best friend: A parameter-free dynamic step size schedule. In International Conference on Machine Learning, pages 14465–14499. PMLR, 2023.
- [14] Thomas N Kipf and Max Welling. Variational graph auto-encoders. arXiv:1611.07308, 2016.
- [15] Thomas N. Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. In International Conference on Learning Representations, 2017.
- [16] Soo Yong Lee, Fanchen Bu, Jaemin Yoo, and Kijung Shin. Towards deep attention in graph neural networks: Problems and remedies. In International Conference on Machine Learning, pages 18774–18795. PMLR, 2023.
- [17] Lequan Lin and Junbin Gao. A magnetic framelet-based convolutional neural network for directed graphs. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023.
- [18] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In International Conference on Learning Representations, 2019.
- [19] Yuanfu Lu, Xunqiang Jiang, Yuan Fang, and Chuan Shi. Learning to pre-train graph neural networks. In Proceedings of the AAAI conference on artificial intelligence, volume 35, pages 4276–4284, 2021.
- [20] Konstantin Mishchenko and Aaron Defazio. Prodigy: An expeditiously adaptive parameter-free learner. arXiv:2306.06101, 2023.
- [21] Elvis Nava, Seijin Kobayashi, Yifei Yin, Robert K. Katzschmann, and Benjamin F Grewe. Meta-learning via classifier(-free) guidance. In Sixth Workshop on Meta-Learning at the Advances in Neural Information Processing Systems, 2022.
- [22] William Peebles, Ilija Radosavovic, Tim Brooks, Alexei A Efros, and Jitendra Malik. Learning to learn with generative models of neural network checkpoints. arXiv:2209.12892, 2022.
- [23] Hongbin Pei, Bingzhe Wei, Kevin Chen-Chuan Chang, Yu Lei, and Bo Yang. Geom-gcn: Geometric graph convolutional networks. In International Conference on Learning Representations, 2020.
- [24] Neale Ratzlaff and Li Fuxin. Hypergan: A generative model for diverse, performant neural networks. In International Conference on Machine Learning, pages 5361–5369. PMLR, 2019.
- [25] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022.
- [26] Benedek Rozemberczki, Carl Allen, and Rik Sarkar. Multi-scale attributed node embedding. Journal of Complex Networks, 9(2):cnab014, 2021.
- [27] T Konstantin Rusch, Michael M Bronstein, and Siddhartha Mishra. A survey on oversmoothing in graph neural networks. arXiv:2303.10993, 2023.
- [28] Konstantin Schürholt, Boris Knyazev, Xavier Giró-i Nieto, and Damian Borth. Hyper-representations as generative models: Sampling unseen neural network weights. Advances in Neural Information Processing Systems, 35:27906–27920, 2022.
- [29] Konstantin Schürholt, Dimche Kostadinov, and Damian Borth. Self-supervised representation learning on neural network weights for model characteristic prediction. Advances in Neural Information Processing Systems, 34:16481–16493, 2021.
- [30] Zhiqi Shao, Dai Shi, Andi Han, Yi Guo, Qibin Zhao, and Junbin Gao. Unifying over-smoothing and over-squashing in graph neural networks: A physics informed approach and beyond. arXiv:2309.02769, 2023.
- [31] Oleksandr Shchur, Maximilian Mumme, Aleksandar Bojchevski, and Stephan Günnemann. Pitfalls of graph neural network evaluation. arXiv:1811.05868, 2018.
- [32] Dai Shi, Yi Guo, Zhiqi Shao, and Junbin Gao. How curvature enhance the adaptation power of framelet gcns. arXiv:2307.09768, 2023.
- [33] Dai Shi, Andi Han, Lequan Lin, Yi Guo, Zhiyong Wang, and Junbin Gao. Design your own universe: A physics-informed agnostic method for enhancing graph neural networks. arXiv:2401.14580, 2024.
- [34] Dai Shi, Zhiqi Shao, Yi Guo, Qibin Zhao, and Junbin Gao. Revisiting generalized p-laplacian regularized framelet GCNs: Convergence, energy dynamic and as non-linear diffusion. Transactions on Machine Learning Research, 2024.
- [35] Jasper Snoek, Hugo Larochelle, and Ryan P Adams. Practical bayesian optimization of machine learning algorithms. Advances in neural information processing systems, 25, 2012.
- [36] Bedionita Soro, Bruno Andreis, Hayeon Lee, Song Chong, Frank Hutter, and Sung Ju Hwang. Diffusion-based neural network weights generation. arXiv:2402.18153, 2024.
- [37] Kenneth O Stanley, David B D’Ambrosio, and Jason Gauci. A hypercube-based encoding for evolving large-scale neural networks. Artificial life, 15(2):185–212, 2009.
- [38] Matthew Thorpe, Tan Minh Nguyen, Hedi Xia, Thomas Strohmer, Andrea Bertozzi, Stanley Osher, and Bao Wang. GRAND++: Graph neural diffusion with a source term. In International Conference on Learning Representations, 2022.
- [39] Thomas Unterthiner, Daniel Keysers, Sylvain Gelly, Olivier Bousquet, and Ilya Tolstikhin. Predicting neural network accuracy from weights. arXiv:2002.11448, 2020.
- [40] Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. Graph attention networks. In International Conference on Learning Representations, 2018.
- [41] Kai Wang, Zhaopan Xu, Yukun Zhou, Zelin Zang, Trevor Darrell, Zhuang Liu, and Yang You. Neural network diffusion. arXiv:2402.13144, 2024.
- [42] Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang, and S Yu Philip. A comprehensive survey on graph neural networks. IEEE Transactions on Neural Networks and Learning Systems, 32(1):4–24, 2020.
- [43] Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks? In Internation Conference on Learning Representations, 2019.
- [44] Zhilin Yang, William Cohen, and Ruslan Salakhudinov. Revisiting semi-supervised learning with graph embeddings. In International Conference on Machine Learning, pages 40–48. PMLR, 2016.
- [45] Jiaxuan You, Zhitao Ying, and Jure Leskovec. Design space for graph neural networks. Advances in Neural Information Processing Systems, 33:17009–17021, 2020.
- [46] Jiayu Zhai, Lequan Lin, Dai Shi, and Junbin Gao. Bregman graph neural network. In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6250–6254. IEEE, 2024.
- [47] Baoquan Zhang, Chuyao Luo, Demin Yu, Xutao Li, Huiwei Lin, Yunming Ye, and Bowen Zhang. Metadiff: Meta-learning with conditional diffusion for few-shot learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 16687–16695, 2024.
- [48] Chris Zhang, Mengye Ren, and Raquel Urtasun. Graph hypernetworks for neural architecture search. In International Conference on Learning Representations, 2019.
- [49] Xin Zheng, Yi Wang, Yixin Liu, Ming Li, Miao Zhang, Di Jin, Philip S Yu, and Shirui Pan. Graph neural networks for graphs with heterophily: A survey. arXiv:2202.07082, 2022.
- [50] Andrey Zhmoginov, Mark Sandler, and Maksym Vladymyrov. Hypertransformer: Model generation for supervised and semi-supervised few-shot learning. In International Conference on Machine Learning, pages 27075–27098. PMLR, 2022.
- [51] Jie Zhou, Ganqu Cui, Shengding Hu, Zhengyan Zhang, Cheng Yang, Zhiyuan Liu, Lifeng Wang, Changcheng Li, and Maosong Sun. Graph neural networks: A review of methods and applications. AI Open, 1:57–81, 2020.
- [52] Jiong Zhu, Yujun Yan, Lingxiao Zhao, Mark Heimann, Leman Akoglu, and Danai Koutra. Beyond homophily in graph neural networks: Current limitations and effective designs. Advances in Neural Information Processing Systems, 33:7793–7804, 2020.
- [53] Chunya Zou, Andi Han, Lequan Lin, Ming Li, and Junbin Gao. A simple yet effective framelet-based graph neural network for directed graphs. IEEE Transactions on Artificial Intelligence, 2023.
Appendix A Pseudo Code of GNN-Diff
Input: Graph condition from Algorithm 2; the learned P-Decoder from Algorithm 3; the learned denoising network from Algorithm 4.
Output: Generated parameters that can be returned to target GNN for prediction.
Input: Graph signals ; graph structure ; graph label ; graph training mask ; number of training epochs .
Output: Graph condition .
Input: Vectorized parameters collected from coarse search ; number of training epochs .
Output: Latent parameter representation ; the learned decoder .
Input: Latent parameter representation ; graph signals ; graph structure ; number of diffusion steps ; noise schedule ; number of training epochs .
Output: The learned denoising network .
Input: Number of diffusion steps ; noise schedule ; diffusion sampling variance hyperparameter .
Output: Generated latent parameters .
Appendix B Details of PAE and G-LDM Denoising Network Architecture
We provided visualized PAE and G-LDM architectures in Figure 6 and Figure 7, respectively. Taking the idea from [41], both architectures have Conv1d-based layers with LeakyReLU activation and instance normalization. Hyperparameters that need to be tuned during training of GNN-Diff are from Conv1d layers in PAE. More information will be provided in Appendix F. In Figure 7, we mark the positions of graph condition being involved. We include graph condition in each encoder and decoder block by adding it to the input of the block directly. For more details of implementation, please refer to the code attached.

Appendix C Details of Benchmark Datasets
Datasets are retrieved from PyTorch Geometric. Relevant statistics are provided in Table 2.
| Dataset | Type | # Nodes | # Edges | # Features | # Node Classes |
|---|---|---|---|---|---|
| Cora | Homophilic | 2708 | 10556 | 1433 | 7 |
| Citeseer | Homophilic | 3327 | 9104 | 3703 | 6 |
| Actor | Heterophilic | 7600 | 30019 | 932 | 5 |
| Chameleon | Heterophilic | 2277 | 62792 | 2325 | 5 |
Appendix D Details of GNN Models and Why We Choose Them
GCN We start by recalling the popular Graph Convolution Networks (GCN) [14] with the feature propagation rule:
| (5) |
in which we denote as the adjacency matrix of the graph, and as the weight matrix used for channel-mixing. GCN model propagates the graph node signal by spatially aggregating its neighboring information via the graph adjacency matrix, serving as the very first attempt to leverage the deep learning tools for handling the graph-structured data.
GAT Building upon the scheme provided by GCN, the Graph Attention Networks [40] introduces an attention mechanism to enhance the performance of GCN by considering the node feature information. Specifically, we have:
| (6) |
where we denote as the attention score on edge . We note that there are various approaches to generating ; in this paper, we only consider the method proposed in [40], with multi-head attention. Furthermore, compared to GCN (5), which only uses a linear operator () on the graph signals, whereas in GAT, in each layer propagation, the entries of will depend on the current graph features, thus in general, tends to be different between layers, suggesting a non-linear feature propagation.
APPNP Nevertheless, the so-called over-smoothing (OSM) issue is still observed via both models [16]. The OSM problem refers to the observation that node features tend to be identical after a certain propagation of GNN layers, suggesting an exponential decay with respect to a non-similarity measure on the node features [27]. In addition, the OSM problem of GNN is closely related to GNN’s adaption power on the heterophily graph since relatively higher feature variation is required to let GNN produce distinct label predictions. Many attempts have been made to counter the aforementioned problems, and one of the most popular paradigms is to bring back the variation of the features by adding the so-called source term via GNN propagation, resulting a range of GNN models [10, 46, 34]. We start by reviewing the APPNP model [7] which owns the feature propagation as:
| (7) |
where the feature information is bought back by adding additional source term , and which projects the feature from initial feature dimension to the number of classes after times propagation via APPNP.
SAGE Similar to APPNP, the graph sample and aggregate (SAGE) model [9] is with the propagation rule as:
| (8) |
where the source term is generated from the (embedded) feature matrix in addition to the original GCN propagation.
H2GCN Apart from bringing source terms to handle the OSM and heterophily problem, H2GCN [52] propagates the node features by aggregating higher-order neighboring information. Specifically, for any node , its initial feature is firstly embedded by a learnable weight matrix and then after iterations we have:
| (9) | ||||
| (10) |
where we let be the neighboring order (hops) that H2GCN uses to aggregate, and the representation is formed as a combination of all intermediate representations. Lastly, another embedding of is leveraged to make the final prediction of the labels.
ChebNet Along with the development of these classic spatial GNNs, spectral GNNs, which propagate node features via spectral filtering, have also gained popularity. The initial research spectral GNNs can be found in the so-called ChebNet model [2], with the propagation rule as:
| (11) |
where is the Chebyshev polynomial of order evaluated at , where is the largest eigenvalue of the graph Laplacian . We highlight that although many advances [30, 32, 33] have been made to enhance the original ChebNet due to the OSM and heterophily problems, ChebNet still serves as the most fundamental basics of deploying spectral GNNs.
GIN Finally, the last type of GNNs we included in our generative scheme is GNNs that aim to maximize the graph-level expressive power. It has been proved that the standard GCN model (i.e., equation (5))) is with the distinguishing power no higher than the so-called WL test [43]. To address this problem, the Graph Isomorphism Networks (GIN) is defined as:
| (12) |
where is the initial random perturbation on the graph adjacency matrix. We highlight that we use the operator instead of denoting it via a single weight matrix since to maximize the expressive power of GNN, one layer of is not enough according to [43].
Summary In this section, we illustrate four types of GNN models: classic spatial GNNs, spectral GNNs, GNNs with source terms, and GNNs with maximized expressive power. Although many other GNN models have been proposed in recent years, these four types of GNNs are typical enough to represent the GNN families, thus sufficient to illustrate the enhancement power of our proposed generative schemes.
Appendix E Search Spaces of Grid Search and Coarse Search
E.1 Coarse search
Optimizer and training hyperparameters:
-
•
Optimizer: [SGD, Adam]
-
•
SGD momentum: [0.9]
-
•
Learning rate: [1, 0.5, 0.1, 0.05, 0.005]
-
•
Weight decay: [5e-3, 5e-4]
-
•
Dropout: [0.5]
Model architecture and other hyperparameters:
-
•
GCN1: None
-
•
GCN2: Hidden size = [16, 64]
-
•
APPNP: Teleport probability = [0.1, 0.5, 0.9]
-
•
SAGE: Hidden size = [16, 64]
-
•
ChebNet: Hidden size = [16, 64], = 2
-
•
GIN: Hidden size = [16, 64]
-
•
GAT: Hidden size = [16, 64], num_heads = [4, 8]
-
•
H2GCN: Hidden size = [16, 64]
E.2 Grid search
Optimizer and training hyperparameters:
-
•
Optimizer: [SGD, Adam]
-
•
SGD momentum: [0.9]
-
•
Learning rate: [1, 0.5, 0.1, 0.05, 0.01, 0.005]
-
•
Weight decay: [1e-3, 5e-3, 1e-4, 5e-4]
-
•
Dropout: [0.1, 0.5, 0.9]
Model architecture and other hyperparameters:
-
•
GCN1: None
-
•
GCN2: Hidden size = [16, 32, 64]
-
•
APPNP: Teleport probability = [0.1, 0.3, 0.5, 0.7, 0.9]
-
•
SAGE: Hidden size = [16, 32, 64]
-
•
ChebNet: Hidden size = [16, 32, 64], = [1, 2, 3]
-
•
GIN: Hidden size = [16, 32, 64]
-
•
GAT: Hidden size = [16, 32, 64], num_heads = [4, 6, 8]
-
•
H2GCN: Hidden size = [16, 32, 64]
E.3 Number of Configurations
We list the number of configurations of coarse search and grid search for target GNNs in Table 3. It is clear that the search spaces of grid search are much broader than coarse search. The number of configurations in grid search space is around 7 to 30 times of that in coarse search space.
| Method | GCN1 | GCN2 | APPNP | SAGE | ChebNet | GIN | GAT | H2GCN |
|---|---|---|---|---|---|---|---|---|
| Coarse search | 20 | 40 | 60 | 40 | 40 | 40 | 80 | 40 |
| Grid search | 144 | 432 | 720 | 432 | 1269 | 432 | 1269 | 432 |
Appendix F Details of GNN-Diff Training
Training The total number of training epochs is , with , between and depending on the parameter size, and . GAE is trained with the same graph data as coarse search. PAE is trained with vectorized parameter samples, while G-LDM learns from their latent representation. Batch size for PAE and G-LDM training is 50. All three modules are trained with the same AdamW optimizer [18] with learning rate 1e-3 and weight decay 2e-3.
GAE The concatenation dimension is set the same as the latent parameter dimension , which is decided by the Conv1d layer in PAE. Dropout is applied before linear operator and with dropout rate .
PAE P-Encoder and P-Decoder are both composed of 4 basic blocks in Figure 6. Since the input is latent representation of vectorized parameters, the number of input channel of the first block in P-Encoder is 1. The number of output channels for Conv1d layers in P-Encoder are . Accordingly, the number of input channels of P-Decoder is also . The number of output channels of P-Decoder are [512,512,8,1]. To ensure high quality generation, we observe in experiments that the latent parameter dimension is best between and . It is worth noting that the latent parameter is actually the concatenation of output channels of P-Encoder, which means the output dimension for each channel is best between and . This is done by appropriately setting the stride value. Besides, kernal size needs to be properly tuned for good performance as well. To minimize the effort caused by hyperparameter tuning in GNN-Diff, we provide a fairly simple rule to decide suitable configurations. We set the same value for stride and kernel rate, and decide this value based on the original parameter size of target GNN. For example, we set both stride and kernel size as for a parameter vector containing 5k to 10k parameters. When multiple values can reduce the parameter dimension to to , usually choosing the one that reduces to lower dimension (i.e., to ) leads to better generation results. In Table 4, we provide the configurations we used for different target GNNs on various datasets.
| Dataset | Cora | Citeseer | ||||
|---|---|---|---|---|---|---|
| Model | Parameter size | Stride | Kernal size | Parameter size | Stride | Kernal size |
| GCN1 | 10038 | 5 | 5 | 22224 | 7 | 7 |
| GCN2 | 23063 | 6 | 6 | 59366 | 9 | 9 |
| APPNP | 10038 | 5 | 5 | 22224 | 7 | 7 |
| SAGE | 46103 | 8 | 8 | 118710 | 9 | 9 |
| ChebNet | 46103 | 8 | 8 | 118710 | 10 | 10 |
| GIN | 96447 | 9 | 9 | 241648 | 12 | 12 |
| GAT | 93780 | 9 | 9 | 238792 | 12 | 12 |
| H2GCN | 23264 | 7 | 7 | 59536 | 9 | 9 |
| Dataset | Actor | Chameleon | ||||
| Model | Parameter size | Stride | Kernal size | Parameter size | Stride | Kernal size |
| GCN1 | 4665 | 5 | 5 | 11630 | 6 | 6 |
| GCN2 | 60037 | 9 | 9 | 37301 | 7 | 7 |
| APPNP | 4665 | 5 | 5 | 11630 | 6 | 6 |
| SAGE | 120005 | 10 | 10 | 74581 | 9 | 9 |
| ChebNet | 30005 | 7 | 7 | 298309 | 13 | 13 |
| GIN | 15315 | 6 | 6 | 37603 | 8 | 8 |
| GAT | 124920 | 11 | 11 | 150332 | 11 | 11 |
| H2GCN | 15152 | 6 | 6 | 37440 | 8 | 8 |
G-LDM We set the number of diffusion steps . We choose the linear beta schedule with and . The denoising network adopts an encoder-decoder structure with 8 basic blocks in Figure 7. The number of input channels and output channels, stride, and kernal rate are the same as in [41]. Since PAE has conducted dimensionality reduction on parameters, and the input of G-LDM, latent parameter representation, has sufficiently low dimension regardless of the target GNN architecture and the dataset, we can use the same hyperparameter configuration in to ensure generation quality.