Universal sieve-based strategies for efficient estimation
using machine learning tools
Abstract
Suppose that we wish to estimate a finite-dimensional summary of one or more function-valued features of an underlying data-generating mechanism under a nonparametric model. One approach to estimation is by plugging in flexible estimates of these features. Unfortunately, in general, such estimators may not be asymptotically efficient, which often makes these estimators difficult to use as a basis for inference. Though there are several existing methods to construct asymptotically efficient plug-in estimators, each such method either can only be derived using knowledge of efficiency theory or is only valid under stringent smoothness assumptions. Among existing methods, sieve estimators stand out as particularly convenient because efficiency theory is not required in their construction, their tuning parameters can be selected data adaptively, and they are universal in the sense that the same fits lead to efficient plug-in estimators for a rich class of estimands. Inspired by these desirable properties, we propose two novel universal approaches for estimating function-valued features that can be analyzed using sieve estimation theory. Compared to traditional sieve estimators, these approaches are valid under more general conditions on the smoothness of the function-valued features by utilizing flexible estimates that can be obtained, for example, using machine learning.
1 Introduction
1.1 Motivation
A common statistical problem consists of using available data in order to learn about a summary of the underlying data-generating mechanism. In many cases, this summary involves function-valued features of the distribution that cannot be estimated at a parametric rate under a nonparametric model — for example, a regression function or the density function of the distribution. Examples of useful summaries involving such features include average treatment effects [26], average derivatives [13], moments of the conditional mean function [28], variable importance measures [35] and treatment effect heterogeneity measures [14]. For ease of implementation and interpretation, in traditional approaches to estimation, these features have typically been restricted to have simple forms encoded by parametric or restrictive semiparametric models. However, when these models are misspecified, both the interpretation and validity of subsequent inferences can be compromised. To circumvent this difficulty, investigators have increasingly relied on machine learning (ML) methods to flexibly estimate these function-valued features.
Once estimates of the function-valued features are obtained, it is natural to consider plug-in estimators of the summary of interest. However, in general, such estimators are not root--consistent and asymptotically normal, and hence not asymptotically efficient (referred to as efficient henceforth). Lacking this property is problematic since it often forms the basis for constructing valid confidence intervals and hypothesis tests [3, 23]. When the function-valued features are estimated by ML methods, in order for the plug-in estimator to be CAN, the ML methods must not only estimate the involved function-valued features well, but must also satisfy a small-bias property with respect to the summary of interest [23, 33]. Unfortunately, because ML methods generally seek to optimize out-of-sample performance, they seldom satisfy the latter property.
1.2 Existing methodological frameworks
The targeted minimum loss-based estimation (TMLE) framework provides a means of constructing efficient plug-in estimators [30, 33]. Given an (almost arbitrary) initial ML fit that provides a good estimate of the function-valued features involved, TMLE produces an adjusted fit such that the resulting plug-in estimator has reduced bias and is efficient. This adjustment process is referred to as targeting since a generic estimate of the function-valued features is modified to better suit the goal of estimating the summary of interest. Though TMLE provides a general template for constructing efficient estimators, its implementation requires specialized expertise, namely knowledge of the analytic expression for an influence function of the summary of interest. Influence functions arise in semiparametric efficiency theory and are key to establishing efficiency, but can be difficult to derive. Furthermore, even when an influence function is known analytically, additional expertise is needed to construct a TMLE for a given problem.
Alternative approaches for constructing efficient plug-in estimators have been proposed in the literature, including the use of undersmoothing [21], twicing kernels [23], and sieves [4, 22, 28]. These methods neither require knowing an influence function nor performing any targeting of the function-valued feature estimates. Hence, the same fits can be used to simultaneously estimate different summaries of the data-generating distribution, even if these summaries were not pre-specified when obtaining the fit. These approaches also circumvent the difficulties in obtaining an influence function. However, these methods all rely on smoothness conditions on derivatives of the functional features that may be overly stringent. In addition, undersmoothing provides limited guidance on the choice of the tuning parameter; the twicing kernel method requires the use of a higher-order kernel, which may lead to poor performance in small to moderate samples [17].
In contrast, under some conditions, sieve estimation can produce a flexible fit with the optimal out-of-sample performance while also yielding an efficient — and therefore root--consistent and asymptotically normal — plug-in estimator [28]. In this paper, we focus on extensions of this approach. In sieve estimation, we first assume that the unknown function falls in a rich function space, and construct a sequence of approximating subspaces indexed by sample size that increase in complexity as sample size grows. We require that, in the limit, the functions in the subspaces can approximate any function in the rich function space arbitrarily well. These approximating subspaces are referred to as sieves. By using an ordinary fitting procedure that optimizes the estimation of the function-valued feature within the sieve, the bias of the plug-in estimator can decrease sufficiently fast as the sieve grows in order for that estimator to be efficient. Thus sieve estimation requires no explicit targeting for the summary of interest.
The series estimator is one of the best known and most widely used sieve techniques. These sieves are taken as the span of the first finitely many terms in a basis that is chosen by the user to approximate the true function well. Common choices of the basis include polynomials, splines, trigonometric series and wavelets, among others. However, series estimators usually require strong smoothness assumptions on derivative of the unknown function in order for the flexible fit to converge at a sufficient rate to ensure the resulting plug-in estimator is efficient. As the dimension of the problem increases, the smoothness requirement may become prohibitive. Moreover, even if the smoothness assumption is satisfied, a prohibitively large sample size may be needed for some series estimators to produce a good fit. For example, if the unknown function is smooth but is a constant over a region, estimation based on a polynomial series can perform poorly in small to moderate samples.
Series estimators may also require the user to choose the number of terms in the series in such a way that results in a sufficient convergence rate. The rates at which the number of terms should grow with sample size have been thoroughly studied (e.g. [4, 22, 28]). However, these results only provide minimal guidance for applications because there is no indication on how to select the actual number of terms for a given sample size. In practice, the number of terms is the series is often chosen by CV. Upper bounds on the convergence rate of the series estimator as a function of sample size and the number of terms have been derived, and it has been shown that the optimal number of terms that minimizes the bound can also lead to an efficient plug-in estimator [28]. However, CV tends to select the number of terms that optimizes the actual convergence rate [31], which may differ from the number of terms minimizing the derived bound on the convergence rate. Even though the use of CV-tuned sieve estimators has achieved good numerical performance, to the best of our knowledge, there is no theoretical guarantee that they lead to an efficient plug-in estimator.
Two variants of traditional series estimators were proposed in [3]. These methods can use two bases to approximate the unknown function-valued features and the corresponding gradient separately, whereas in traditional series estimators, only one basis is used for both approximations. Consequently, these variants may be applied to more general cases than traditional series estimators. However, like traditional series estimators, they also suffer from the inflexibility of the pre-specified bases.
1.3 Contributions and organization of this article
In this paper we present two approaches that can partially overcome these shortcomings.
-
1.
Estimating the unknown function with Highly Adaptive Lasso (HAL) [1, 29].
If we are willing to assume the unknown functions have a finite variation norm, then they may be estimated via HAL. If the tuning parameter is chosen carefully, then we may obtain an efficient plug-in estimator. This method can help overcome the stringent smoothness assumptions on derivatives that are required by existing series estimators, as we discussed earlier. -
2.
Using data-adaptive series based on an initial ML fit.
As long as the initial ML algorithm converges to the unknown function at a sufficient rate, we show that, for certain types of summaries, it is possible to obtain an efficient plug-in estimator with a particular data-adaptive series. The smoothness assumption on the unknown function can be greatly relaxed due to the introduction of the ML algorithm into the procedure. Moreover, for summaries that are highly smooth, we show that the number of terms in the series can be selected by CV.
Although the first approach is not an example of sieve estimation, both approaches are motivated by the sieve literature and can be shown to lead to asymptotically efficient plug-in estimators using the sieve estimation theory derived in [28]. The flexible fits of the functional features from both approaches can be plugged in for a rich class of estimands.
We remark that, although we do not have to restrict ourselves to the plug-in approach in order to construct an asymptotically efficient estimator, other estimators do not overcome the shortcomings described in Section 1.2 and can have other undesirable properties. For example, the popular one-step correction approach (also called debiasing in the recent literature on high-dimensional statistics) [25] constructs efficient estimators by adding a bias reduction term to the plug-in estimator. Thus, it is not a plug-in estimator itself, and as a consequence, one-step estimators may not respect known constraints on the estimand — for example, bounds on a scalar-valued estimand (e.g., the estimand is a probability and must lie in ) or shape constraints on a vector-valued estimand (e.g., monotonicity constraints). This drawback is also typical for other non-plug-in estimators, such as those derived via estimating equations [32] and double machine learning [5, 6]. Additionally, as with the other procedures described above, the one-step correction approach requires the analytic expression of an influence function.
Our paper is organized as follows. We introduce the problem setup and notation in Section 2. We consider plug-in estimators based on HAL in Section 3, data-adaptive series in Section 4, and its generalized version that is applicable to more general summaries in Section 5. Section 6 concludes with a discussion. Technical proofs of lemmas and theorems (Appendix D), simulation details (Appendix E) and other additional details are provided in the Appendix.
2 Problem setup and traditional sieve estimation review
Suppose we have independent and identically distributed observations drawn from . Let be a class of functions, and denote by a (possibly vector-valued) functional feature of — for example, may be a regression function. Throughout this paper we assume that the generic data unit is , where is a (possibly vector-valued) random variable corresponding to the argument of , and may also be a vector-valued random variable. In some cases and is trivial. We use to denote the support of . The estimand of interest is a finite-dimensional summary of . We consider a plug-in estimator , where is an estimator of , and aim for this plug-in estimator to be asymptotically linear, in the sense that with IF an influence function satisfying and . This estimator is efficient under a nonparametric model if the estimator is also regular. By the central limit theorem and Slutsky’s theorem, it follows that is a CAN estimator of , and therefore, . This provides a basis for constructing valid confidence intervals for .
We now list some examples of such problems.
Example 1.
Moments of the conditional mean function [28]: Let be the conditional mean function. The -th moment of , , namely , can be a summary of interest. The values of and are useful for defining the proportion of that is explained by , which may be written as . This proportion is a measure of variable importance [35]. Generally, we may consider for a fixed function .
Example 2.
Average derivative [13]: Let follow a continuous distribution on and be the conditional mean function. Let denote the vector of partial derivatives of . Then summarizes the overall (adjusted) effect of each component of on . Under certain conditions, we can rewrite , where is the Lebesgue density of and is the vector of partial derivatives of . This expression clearly shows the important role of the Lebesgue density of in this summary.
Example 3.
Mean counterfactual outcome [26]: Suppose that where is a binary treatment indicator and is the outcome of interest. Let be the outcome regression function under treatment value 1. Under causal assumptions, the mean counterfactual outcome corresponding to the intervention that assigns treatment 1 to the entire population can be nonparametrically identified by the G-computation formula .
Example 4.
To obtain an asymptotically linear plug-in estimator, must converge to at a sufficiently fast rate and approximately solve an estimating equation to achieve the small bias property with respect to the summary of interest [23, 29, 33]. For simplicity, we assume the estimand to be scalar-valued — when the estimand is vector-valued, we can treat each entry as a separate estimand, and the plug-in estimators of all entries are jointly asymptotically linear if each estimator is asymptotically linear. Therefore, this leads to no loss in generality if the same fits are used for all entries in the summary of interest.
Sieve estimation allows us to obtain an estimator with the small bias property with respect to while maintaining the optimal convergence rate of [4, 28]. The construction of sieve estimators is based on a sequence of approximating spaces to . These approximating spaces are referred to as sieves. Usually is much simpler than to avoid over-fitting but complex enough to avoid under-fitting. For example, can be the space of all polynomials with degree or splines with knots with as . In this paper, with a loss function such that , we consider estimating by minimizing an empirical risk based on , i.e., . Under some conditions, the growth rate of can be carefully chosen so that is an asymptotically linear estimator of while converges to at the optimal rate.
Throughout this paper, for a probability distribution and an integrable function with respect to , we define . We use to denote the empirical distribution. We take to be the -inner product, i.e., , where is the set of real-valued -squared-integrable functions defined on the support of . When the functions are vector-valued, we take . We use to denote the induced norm of . We assume that . We remark that we have committed to a specific choice of inner product and norm to fix ideas; other inner products can also be adopted, and our results will remain valid upon adaptation of our upcoming conditions. We discuss this explicitly via a case study in Appendix A.
For the methods we propose in this article, we assume that is convex. Throughout this paper, we will further require a set of conditions similar to those in [28]. For any , let be the Gâteaux derivative of at in the direction and be the corresponding remainder.
Condition A1 (Linearity and boundedness of Gâteaux derivative operator of loss function).
For all , exists and is linear and bounded in .
Condition A2 (Local quadratic behavior of loss function).
There exists a constant such that, for all such that or is sufficiently small, it holds that .
Remark 1.
A large class of loss functions satisfy Conditions A1 and A2. For example, in the regression setting where is the outcome, the squared-error loss and the logistic loss both satisfy these conditions; a negative working log-likelihood usually also satisfies these conditions. In Examples 1–4, the unknown functions are all conditional mean functions, which can be estimated with the above loss functions. Thus, Conditions A1 and A2 hold. Examples 3 and 4 require a slight modification discussed in more details in Appendix A. We also note that Condition A2 is sufficient for Condition B in [28].
Condition A3 (Differentiability of summary of interest).
exists for all and is a linear bounded operator.
If Condition A3 holds, then, by the Riesz representation theorem, for a gradient function in the completion of the space spanned by .
Condition A4 (Locally quadratic remainder).
There exists a constant so that, for all with sufficiently small , it holds that
The above condition states that the remainder of the linear approximation to is locally bounded by a quadratic function.
Conditions A3 and A4 hold for Examples 1–4. For the generalized moment of the conditional mean function in Example 1, it holds that . For the average derivative of the conditional mean function in Example 2, it holds that . For the average treatment effect and the treatment effect heterogeneity measure in Examples 3 and 4, as we show in Appendix A, also exists and depends on the propensity score function .
3 Estimation with Highly Adaptive Lasso
3.1 Brief review of Highly Adaptive Lasso
Recently, the Highly Adaptive Lasso (HAL) was proposed as a flexible ML algorithm that only requires a mild smoothness condition on the unknown function and has a well-described implementation [1, 29]. In this subsection, we briefly review HAL. We first heuristically introduce its definition and desirable properties, and then introduce the definition and implementation more formally. For ease of presentation, for the moment, we assume that is real-valued.
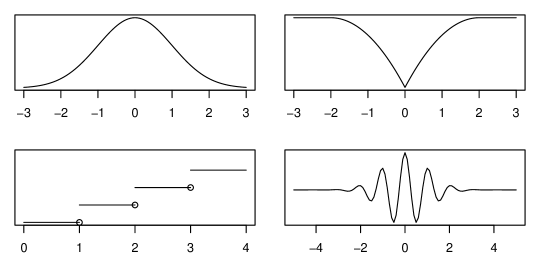
In HAL, is assumed to fall in the class of càdlàg functions (right-continuous with left limits) defined on with variation norm bounded by a finite constant . In this section, we denote this function class by . The variation norm of a càdlàg function , denoted by , characterizes the total variability of as its argument ranges over the domain, so is a global smoothness measure and is a large function class that even contains functions with discontinuities. Fig. 1 presents some examples of univariate càdlàg functions with finite variation norms for illustration. Because is a rich class, it can be plausible that for some . The HAL estimator of is then . Under this assumption, it has been shown that regardless of the dimension of under additional mild conditions [29]. Thus, estimation with HAL replaces the usual smoothness requirement on derivatives of traditional series estimators by a requirement on global smoothness, namely for some .
We next formally present the definition of variation norm of a càdlàg function . Here, and are vectors in ; with being entrywise, .
For any nonempty index set and any , we define and to be entries of with indices in and not in respectively. We defined the -section of as . We can subsequently obtain the following representation of at any in terms of sums and integrals of the variation of -sections of [10]:
The variation norm is then subsequently defined as
We refer to [1] and [29] for more details on variation norm. Notably, this notion of variation norm coincides with that of Hardy and Krause [24].
We finally briefly introduce the algorithm to compute a HAL estimator. It can be shown that an empirical risk minimizer in is a step function that only jumps at sample points, namely
Here, and all are real numbers. To find an empirical risk minimizer in in the above form, we may solve the following optimization problem:
| subject to | |||
The constraint imposes an upper bound on the norm of a vector. Therefore, for common loss functions, we may use software for LASSO regression [Tibshirani1996]. For example, if the loss function is the squared-error loss, then we may run a LASSO linear regression to obtain a HAL estimate.
3.2 Estimation with an oracle tuning parameter
In this section, we consider plug-in estimators based on HAL. For ease of illustration, for the rest of this section, we consider scalar-valued , and will discuss vector-valued only at the end of this subsection. We further introduce the following conditions needed to establish that the HAL-based plug-in estimator is efficient.
Condition B1 (Càdlàg functions).
and are càdlàg.
Condition B2 (Bound on variation norm).
For some , .
Condition B2 ensures that certain perturbations of still lie in , a crucial requirement for proving the asymptotic linearity of our proposed plug-in estimator. In addition, since may depend on components of other than as in Examples 2–4, Conditions B1–B2 may also impose conditions on these components.
In this section, we fix an that satisfies Condition B2. Additional technical conditions can be found in Appendix B.1. Let denote the HAL fit obtained using the bound in Condition B2.
We note that is not a typical sieve estimator because is fixed and there is no explicit sequence of growing approximating spaces . Nevertheless, we may view this method as a special case of sieve estimation with degenerate sieves for all . This allows us to utilize existing results [28] to show the asymptotic linearity and efficiency of the plug-in estimator based on . We next formally present this result.
Theorem 1 (Efficincy of plug-in estimator).
We note that, for HAL to achieve the optimal convergence rate, we only need that [1, 29]. The requirement of a larger imposed by Condition B2 resembles undersmoothing [21], as using a larger would result in a fit that is less smooth than that based on the CV-selected bound. The -convergence rate of the flexible fit using the larger bound remains the same, but the leading constant may be larger. This is in contrast to traditional undersmoothing, which leads to a fit with a suboptimal rate of convergence.
Under some conditions, the following lemma provides a loose bound on in the case that has a particular structure. Such a bound can be used to select an appropriate bound on variation norm that satisfies Condition B2.
Lemma 1.
Suppose that , where is differentiable. Let where and are entrywise. Assume that is differentiable. If each of , and is finite, then . Hence, .
As we discussed at the end of Section 2, such structures as are common, especially if we augment to include other implicitly relevant components of . For example, in Example 2, we may augment with and ; in Examples 3 and 4, we may augment with the propensity score function.
When is -valued, can often be viewed as a collection of real-valued variation-independent functions . In this case, we can define for a positive vector . The subsequent arguments follow analogously, where now each is treated as a separate function.
We remark that an undersmoothing condition such as B2 appears to be necessary for a HAL-based plug-in estimator to be efficient. We illustrate this numerically in Section 3.3. The choice of a sufficiently large bound required by Theorem 1 is by no means trivial, since this choice requires knowledge that the user may not have. Nevertheless, this result forms the basis of the data-driven method that we propose in Section 3.3 for choosing . We also remark that, if we wish to plug in the same based on HAL for a rich estimands, the chosen bound needs to be sufficiently large for all estimands of interest.
Another method to construct efficient plug-in estimators based on HAL has been independently developed [VanderLaan2019]. Unlike our approach based on sieve theory, in this work, the authors directly analyzed the first-order bias of the plug-in estimator using influence functions. In terms of ease of implementation, their method requires specifying a constant involved in a threshold of the empirical mean of the basis functions, which may be difficult to specify in applications. Our approach in Section 3.3 may also require specifying an unknown constant to obtain a valid upper bound on , but in some cases the constant may be set to zero, and our simulation suggests that the performance is not sensitive to the choice of the constant.
3.3 Data-adaptive selection of the tuning parameter
Since it is hard to prespecify a bound on the variation norm that is sufficiently large to satisfy Condition B2 but also sufficiently small to avoid overfitting for a given data set, it is desirable to select in a data-adaptive manner. A seemingly natural approach makes use of -fold CV. In particular, for each candidate bound , partition the data into folds of approximately equal size ( is fixed and does not depend on ), in each fold evaluate the performance of the HAL estimator fitted on all other folds based on this candidate , and use the candidate bound with the best average performance across all folds to obtain the final fit. It has been shown that can achieve the optimal convergence rate under mild conditions [31], but appears not to satisfy Condition B2 in general. In particular, the derived bound on relies on an empirical process term, namely , and a larger implies a larger space . Therefore, the bound on grows with . Because -fold CV seeks to optimize out-of-sample performance, generally appears to be close to and not sufficiently large to obtain an efficient plug-in estimator.
To avoid this issue with the CV-selected bound, we propose a method that takes inspiration from -fold CV, but modifies the bound so that it is guaranteed to yield an efficient plug-in estimator for . This method may require the analytic expression for . In Sections 4 and 5, we present methods that do not require this knowledge.
-
1.
Derive an upper bound on . This bound is a non-decreasing function of the variation norms of functions that can be learned from data (e.g., using Lemma 1). In other words, find a non-decreasing function such that for unknown functions that can be assumed to be càdlàg with finite variation norm and can be estimated with HAL.
-
2.
Estimate by HAL with -fold CV, and denote the CV-selected bounds for these functions by .
-
3.
For a small , use the bound to estimate with HAL and plug in the fit. We refer to this step of slightly increasing the bounds as -relaxation.
It follows from Lemma 2 in the Appendix that this method would yield a sufficiently large bound with probability tending to one. In practice, it is desirable for the bound derived on to be relatively tight to avoid choosing an overly large bound that leads to overfitting in small to moderate samples. We remark that multiplying by rater than adding to each argument also leads to a valid choice for the bound; that is, the bound is also sufficiently large with probability tending to one. In practice, the user may increase each CV-selected bound by, for example, 5% or 10%. Although it is more natural and convenient to directly use as the bound, we have only been able to prove the result with a small -relaxation. However, if the bound is loose and is continuous, we can show that -relaxation is unnecessary. The formal argument can be found after Lemma 2 in the Appendix.
As for methods based on knowledge of an influence function, deriving and a bound for its variation norm requires some expertise, but in some cases this task can be straightforward. The derivation of an influence function is typically based on a fluctuation in the space of distributions, but in many cases, the relation between such fluctuations and the summary of interest is implicit and difficult to handle. In contrast, the derivation of is based on a fluctuation of , and the summary of interest explicitly depends on . As a consequence, it can be simpler to derive than to derive an influence function. For example, for the summary in Example 1, we find that by straightforward calculation, whereas the influence function given in Theorem 1 is more difficult to directly derive analytically.
We illustrate the fact that may not be sufficiently large and show that our proposed method resolves this issue via a simulation study in which and . We compare the performance of the plug-in estimators based on the 10-fold CV-selected bound on variation norm (M.cv), the bound derived from the analytic expression of with and without -relaxation (M.gcv+ and M.gcv respectively), and a sufficiently large oracle choice satisfying Condition B2 (M.oracle). We According to Lemma 1, M.oracle is and M.gcv is 3M.cv. We also investigate the performance of 95% Wald CIs based on the influence function. For each resulting plug-in estimator, we investigate the following quantities: , and CI coverage. More details of this simulation are provided in Appendix E. In theory, for an efficient estimator, we should find that tends to a constant (the variance of the influence function ), tends to , and 95% Wald CIs have approximately 95% coverage.
We report performance summaries in Fig 2 and Table 1 with this criterion, from which it appears that the plug-in estimators with M.oracle and M.gcv+ achieve efficiency, while the plug-in estimator based on M.cv does not. The desirable performance of M.oracle and M.gcv+ agrees with the available theory, whereas the poor performance of M.cv suggests that cross-validation may not yield a valid choice of variation norm in general. Interestingly, M.gcv performs similarly to M.oracle and M.gcv+. We conjecture that using an -relaxation is unnecessary in this setting. In Fig 3, we can also see that M.cv tends to and has a high probability of being less than M.oracle. Therefore, this simulation suggests that using a sufficiently large bound — in particular, a bound larger than the CV-selected bound — may be necessary and sufficient for the plug-in estimator to achieve efficiency.

| n | M.cv | M.gcv | M.gcv+ | M.oracle |
|---|---|---|---|---|
| 500 | 0.87 | 0.96 | 0.96 | 0.97 |
| 1000 | 0.87 | 0.97 | 0.97 | 0.97 |
| 2000 | 0.90 | 0.95 | 0.95 | 0.96 |
| 5000 | 0.93 | 0.95 | 0.95 | 0.95 |
| 10000 | 0.89 | 0.95 | 0.95 | 0.95 |

4 Data-adaptive series
4.1 Proposed method
For ease of illustration, we consider the case that is scalar-valued in this section. As we will describe next, our proposed estimation procedure for function-valued features does not rely on and hence can be used for a class of summaries.
Suppose that is a vector space of -valued functions equipped with the -inner product. Further, suppose that for some function . This holds, for example, when for a fixed differentiable function in Example 1. In this case, and hence . Particularly useful examples include Examples 1 and 4. For now we assume that the marginal distribution of is known so that we only need to estimate for this summary. We will address the more difficult case in which the marginal distribution of is unknown in Section 4.3.
Let be a given initial flexible ML fit of and consider the data-adaptive sieve-like subspaces based on , , where are -valued basis functions in a series defined on and is a deterministic number of terms in the series — we will consider selecting via CV in Section 4.4. Let denote the series estimator within this data-adaptive sieve-like subspace that minimizes the empirical risk. We propose to use to estimate .
4.2 Results for a deterministic number of terms
Following [4, 28], our proofs of the validity of our data-adaptive series approach make heavy use of projection operators. We use to denote the projection operator for functions in onto with respect to . For any function , let denote the operator that takes as input a function for which and outputs a function such that . In other words, letting be the quantity that depends on and such that , we define . The operator may also be interpreted as follows: letting be the distribution of with , then is the projection operator of functions with respect to the -inner product. We use to denote the identity function in .
We now present additional conditions we will require to ensure that is an efficient estimator of .
Condition C1 (Sufficient convergence rate of initial ML fit).
.
Condition C2 (Sufficiently small estimation error).
.
Condition C3 (Sufficiently small approximation error to for ).
.
Condition C4 (Sufficiently small approximation error to for and convergence rate of ).
.
Appendix B.2 contains further technical conditions and Appendix C discusses their plausibility. As discussed in Appendix C, Conditions C2–C4 typically imply restrictions on the growth rate of : if grows too fast with , then Condition C2 may be violated; if instead grows too slow, then Conditions C3 and C4 may be violated. For the generalized moment with a fixed known function in Example 1, Condition C4 typically also imposes a smoothness condition so that can be approximated by the series well. Our conditions are closely related to the conditions in Theorem 1 of [28]. Conditions C1–C3 and C6 serve as sufficient conditions for the condition on the smoothness of and the convergence rate of in Theorem 1 of [28]. Together with Conditions C4 and C7, we can derive Lemma 4, which is similar to the first part of Condition C of [28]. The empirical process condition C8 is sufficient for Conditions A, D and the second part of C in Theorem 1 in [28].
We now present a theorem ensuring the asymptotic linearity and efficiency of the plug-in estimator based on .
Theorem 2 (Efficiency of plug-in estimator).
Remark 2.
Consider the general case in which it may not be true that can be represented as for some . If the analytic expression of can be derived and can be estimated by such that , then our data-adaptive series can take a special form that is targeted towards . Specifically, letting and , it is straightforward to show that the gradient of is with and , which is a function composed with . We can set and in our data-adaptive series. This approach does not have a growing number of terms in and is not similar to sieve estimation, but can be treated as a special case of data-adaptive series. It can be shown that Conditions C1–C4 are still satisfied for and with this choice of , and hence our data-adaptive series estimator leads to an efficient plug-in estimator. We remark that the introduction of and is a purely theoretical device, and this targeted approach to estimation is quite similar to that used in the context of TMLE [30, 33].
4.3 Summaries involving the marginal distribution of
We now generalize the setting considered thus far by allowing the parameter to depend both on and on , i.e., estimating . The example given at the beginning of Section 4.1, namely that of estimating , is a special case of this more general setting. In what follows, we will make use of the following conditions:
Condition D1 (Conditions with fixed).
Condition D2 (Hadamard differentiability with fixed).
The mapping is Hadamard differentiable at .
By the functional delta method, it follows that for a function satisfying and .
Condition D3 (Negligible second-order difference).
This condition usually holds, for example, when , as in this case the left-hand side is equal to , which is under empirical process conditions.
Theorem 3 (Asymptotic linearity of plug-in estimator).
4.4 CV selection of the number of terms in data-adaptive series
In the preceding subsections, we established the efficiency of the plug-in estimator based on suitable rates of growth for relative to the sample size . In this subsection, we show that, under some conditions, such a can be selected by -fold CV: after obtaining , for each in a range of candidates, we can calculate the cross-validated risk from folds and choose the value of with the smallest CV risk. We denote the number of terms in the series that CV selects by . In this section, we use in the subscripts for notation related to data-adaptive sieves-like spaces and projections; this represents a slight abuse of notation because, in Sections 4.1 and 4.2, these subscripts were instead used for sample size . That is, we use to denote , to denote the projection onto , to denote the operator such that for all with , and to be the data-adaptive series estimator based on and .
Condition C5 (Bounded approximation error of relative to ).
There exists a constant such that, with probability tending to one, for all .
This condition is equivalent to
for all with probability tending to one, which may be interpreted in terms of two simultaneous requirements. The first requirement is that the identity function is not exactly contained in the span of for any , since otherwise, the right-hand side would be zero for all sufficiently large . Therefore, common series such as polynomial and spline series are not permitted for general summaries. In contrast, other series such as trigonometric series and wavelets satisfy this requirement. The second requirement is that the approximation error of the chosen series for the identity function is not much larger than . If a trigonometric or wavelet series is used, then this condition imposes a strong smoothness condition on derivatives of . Nonetheless, this may not be stringent in some interesting examples. For example, if for a fixed function in Example 1, then equals and hence can be expected to satisfy this strong smoothness condition provided that is infinitely differentiable with bounded derivatives. The estimands encountered in many applications involve satisfying this smoothness condition.
The following theorem justifies the use of -fold CV to select under appropriate conditions.
Theorem 4 (Efficiency of CV-based plug-in estimator).
Assume that Conditions A1–A4, C1–C3, C5, C8 and C9 hold for a deterministic . Suppose part (a) of Condition C7 holds, then, with , is an asymptotically linear estimator of with influence function , that is,
As a consequence, with . In addition, under Conditions E1 and E2 in Appendix B.4, is efficient under a nonparametric model.
4.5 Simulation
4.5.1 Demonstration of Theorem 4
We illustrate our method in a simulation in which we take and . This is a special case of Example 1. The true function is chosen to be discontinuous, which violates the smoothness assumptions commonly required in traditional series estimation. In this case, and so the constant in Condition C5 is 2. We compare the performance of plug-in estimators based on three different nonparametric regressions: (i) polynomial regression with degree selected by 10-fold CV (poly), which results in a traditional sieve estimator, (ii) gradient boosting (xgb) [8, 9, 18, 19], and (iii) data-adaptive trigonometric series estimation with gradient boosting as the initial ML fit and 10-fold CV to select the number of terms in the series (xgb.trig). We also compare these plug-in estimators with the one-step correction estimator [25] based on gradient boosting (xgb.1step). Further details of this simulation can be found in Appendix E.
Fig 4 presents and for each estimator, whereas Table 2 presents the coverage probability of 95% Wald CIs based on these estimators. We find that xgb.trig and xgb.1step estimators perform well, while poly and xgb plug-in estimators do not appear to be efficient. Since polynomial series estimators only work well when estimating smooth functions, in this simulation, we would not expect the fit from the polynomial series estimator to converge sufficiently fast, and consequently, we would not expect the resulting plug-in estimator to be efficient. In contrast, gradient boosting is a flexible ML method that can learn discontinuous functions, so we can expect an efficient plug-in estimator based on this ML method. However, gradient boosting is not designed to approximately solve the estimating equation that achieves the small-bias property for this particular summary, so we would not expect its naïve plug-in estimator to be efficient. Based on gradient boosting, our estimator and the one-step corrected estimator both appear to be efficient, but our method has the advantage of being a plug-in estimator. Moreover, the construction of our estimator does not require knowledge of the analytic expression of an influence function.

| n | poly | xgb | xgb.1step | xgb.trig |
|---|---|---|---|---|
| 500 | 0.90 | 0.90 | 0.95 | 0.95 |
| 1000 | 0.86 | 0.89 | 0.95 | 0.95 |
| 2000 | 0.74 | 0.88 | 0.96 | 0.96 |
| 5000 | 0.47 | 0.88 | 0.94 | 0.94 |
| 10000 | 0.16 | 0.87 | 0.95 | 0.96 |
| 20000 | 0.02 | 0.86 | 0.96 | 0.96 |
We also investigate the effect of the choice of on the performance of our method. Fig 5 presents for the data-adaptive series estimator with different choices of . We can see that our method is insensitive to the choice of in this simulation setting. Although a relatively small performs better, choosing a much larger does not appear to substantially harm the behavior of the estimator. This insensitivity to the selected tuning parameter suggests that in some applications, without using CV, an almost arbitrary choice of that is sufficiently large might perform well.

4.5.2 Violation of Condition C5
For the -fold CV selection of in our method to yield an efficient plug-in estimator, must be highly smooth in the sense that can be approximated by the series about as well as can the identity function (see Condition C5). Although we have argued that this condition is reasonable, in this section, we explore via simulation the behavior of our method based on CV when is rough. We again take and an artificial summary , where is an element of but not of . In this case, is very rough, so we do not expect it to be approximated by a trigonometric series as well as the identity function. However, it is sufficiently smooth to allow for the existence of a deterministic that achieves efficiency. Further simulation details are provided in Appendix E.
Table 3 presents the performance of our estimator based on 10-fold CV. We note that it performs reasonably well in terms of the criterion. However, it is unclear whether its scaled bias converges to zero for large , so our method may be too biased. The coverage of 95% Wald CIs is close to the nominal level, suggesting that the bias is fairly small relative to the standard error of the estimator at the sample sizes considered. One possible explanation for the good performance observed is that the -convergence rate of is much faster than , which allows for a slower convergence rate of the approximation error (see Appendix C). This simulation shows that our proposed method may still perform well even if Condition C5 is violated, especially when the initial ML fit is close to the unknown function.
| n | relative MSE | root- absolute relative bias | 95% Wald CI coverage |
|---|---|---|---|
| 500 | 0.88 | 3.95 | 0.97 |
| 1000 | 0.89 | 3.73 | 0.96 |
| 2000 | 0.79 | 3.15 | 0.97 |
| 5000 | 0.78 | 2.02 | 0.97 |
| 10000 | 0.88 | 2.57 | 0.97 |
| 20000 | 0.88 | 1.75 | 0.96 |
5 Generalized data-adaptive series
5.1 Proposed method
As in Section 4, we consider the case that is scalar-valued in this section. The assumption that may be too restrictive for general summaries as in Examples 2–4, especially if is not derived analytically (see Remark 2). In this section, we generalize the method in Section 4 to deal with these summaries. Letting be the identity function defined on , we can readily generalize the above method to the case where can be represented as for a function ; that is, . This form holds trivially if we set , i.e., is independent of its first argument, but we can utilize flexible ML methods if is nontrivial. Again, we assume is a vector space of -valued function equipped with the -inner product. We assume can be approximated well by a basis , and consider the data-adaptive sieve-like subspace . We propose to use to estimate , where denotes the series estimator within minimizing the empirical risk.
5.2 Results for proposed method
With a slight abuse of notation, in this section we use to denote the function where and . Again, we use to denote the projection operator onto . Let be defined such that, for any function with , it holds that ; that is, letting be the quantity that depends on and such that , we define .
We introduce conditions and derive theoretical results that are parallel to those in Section 4.
Condition C3∗ (Sufficiently small approximation error to for ).
.
Condition C4∗ (Sufficiently small approximation error to for and convergence rate of ).
.
Additional regularity conditions can be found in Appendix B.3. Note that may depend on components of other than , Condition C4∗ may impose smoothness conditions on these components so that can be well approximated by the chosen series. For example, in Example 2, Condition C4∗ requires that and the propensity score can be approximated by the series well; in Examples 3 and 4, Condition C4∗ imposes the same requirement on the propensity score. We now present a theorem that establishes the efficiency of the plug-in estimator based on .
Theorem 5 (Efficiency of plug-in estimator).
Remark 4.
When depends on both and , we can readily adapt this method as in Section 4.3.
We now present a condition for selecting via -fold CV, in parallel with Condition C5 from Section 4.4.
Condition C5∗ (Bounded approximation error of relative to ).
There exists a constant such that, with probability tending to one, for all .
Remark 5.
Similarly to Condition C5, Condition C5∗ requires that the identity function is not contained in the span of finitely many terms of the chosen series and that is sufficiently smooth so that can be approximated well by the chosen series. However, Condition C5∗ may be far more stringent than Condition C5. In fact, it may be overly stringent in practice. Since may depend on components of other than , Condition C5∗ may require these components to be sufficiently smooth. When a common candidate series such as the trigonometric series is used, a sufficient condition for Condition C5∗ is that is infinitely differentiable with bounded derivatives, which further imposes assumptions on the smoothness of other components of . For example, in Example 2, a sufficient condition for Condition C5∗ is that is infinitely differentiable with bounded derivatives; in Examples 3 and 4, a sufficient condition for Condition C5∗ is that Condition C5∗ is that the propensity score function satisfies the same requirement. Due to the stringency of Condition C5∗, we conduct a simulation in Section 5.3.2 to understand the performance of our proposed method when this condition is violated. The simulation appears to indicate that our method may be robust against violation of Condition C5∗.
The following theorem shows that -fold CV can be used to select under certain conditions.
Theorem 6 (Efficiency of CV-based plug-in estimator).
Assume Conditions A1–A4, C1, C2, C3∗, C6∗, C7∗, C8 and C9 hold for a deterministic . Suppose that part (a) of Condition C7∗ holds. With , is an asymptotically linear estimator of with influence function , that is,
Therefore, with . In addition, under Conditions E1 and E2 in Appendix B.4, is efficient under a nonparametric model.
5.3 Simulation
In the following simulations, we consider the problem in Example 4. As we show in Appendix A, letting be the propensity score and setting , with , the generalized data-adaptive series methodology may be used to obtain an efficient estimator. As in Section 4.5, we conduct two simulation studies, the first demonstrating Theorem 6 and the other exploring the robustness of CV against violation of Condition C5∗.
5.3.1 Demonstration of Theorem 6
We choose to be a discontinuous function while is highly smooth. We compare the performance of plug-in estimators based on three different nonparametric regressions: (i) polynomial regression with the degree selected by 5-fold CV (poly), which results in a traditional sieve estimator, (ii) gradient boosting (xgb) [8, 9, 18, 19], and (iii) generalized data-adaptive trigonometric series estimation with gradient boosting as the initial ML fit and 5-fold CV to select the number of terms in the series (xgb.trig). Further details of the simulation setting are provided in Appendix E.
Fig 6 presents and for each estimator, whereas Table 4 presents the coverage probability of 95% Wald CIs based on these estimators. There are a few runs in the simulation with noticeably poor behavior, so we trimmed the most extreme values when computing MSE and bias in Fig 6 (1% of all Monte Carlo runs). The outliers may be caused by the performance of gradient boosting and the instability of 5-fold CV. In practice, the user may ensemble more ML methods and use 10-fold CV to mitigate such behavior. We note that xgb.trig and xgb.1step estimators perform well, while poly and xgb plug-in estimators do not appear to be efficient. Based on gradient boosting, our estimator and the one-step corrected estimator both appear to be efficient, but the construction of our estimator has the advantage of not requiring the analytic expression of an influence function.

| n | poly | xgb | xgb.1step | xgb.trig |
|---|---|---|---|---|
| 500 | 0.85 | 0.76 | 0.89 | 0.90 |
| 1000 | 0.68 | 0.78 | 0.93 | 0.93 |
| 2000 | 0.44 | 0.81 | 0.93 | 0.92 |
| 5000 | 0.11 | 0.80 | 0.89 | 0.87 |
| 10000 | 0.00 | 0.79 | 0.92 | 0.90 |
| 20000 | 0.00 | 0.67 | 0.91 | 0.88 |
5.3.2 Violation of Condition C5∗
We also study via simulation the behavior of our estimator when Condition C5∗ is violated. We note that whether Condition C5∗ holds depends on the smoothness of . We choose to be rougher than with being an element of but not of . Consequently, cannot be approximated by our generalized data-adaptive series as well as , but its smoothness is sufficient for the existence of a deterministic to achieve efficiency. Appendix E describes further details of this simulation setting.
Table 5 presents the performance of our estimator based on 5-fold CV. We observe that its scaled MSE appears to converge to one, but it is unclear whether its scaled bias converges to zero for large , and so our method may be overly biased.. The coverage of 95% Wald CIs is close to the nominal level, suggesting that the bias may be fairly small relative to the standard error of the estimator at the sample sizes considered. Therefore, according to this simulation, our generalized data-adaptive series methodology appears to be robust against violation of Condition C5∗.
| n | relative MSE | root- absolute relative bias | 95% Wald CI coverage |
|---|---|---|---|
| 500 | 1.02 | 0.28 | 0.92 |
| 1000 | 1.13 | 0.26 | 0.91 |
| 2000 | 1.10 | 0.19 | 0.94 |
| 5000 | 1.03 | 0.02 | 0.93 |
| 10000 | 0.96 | 0.23 | 0.95 |
| 20000 | 0.99 | 0.24 | 0.94 |
6 Discussion
Numerous methods have been proposed to construct efficient estimators for statistical parameters under a nonparametric model, but each of them has one or more of the following undesirable limitations: (i) their construction may require specialized expertise that is not accessible to most statisticians; (ii) for any given data set, there may be little guidance, if any, on how to select a key tuning parameter; and (iii) they may require stringent smoothness conditions, especially on derivatives. In this paper, we propose two sieve-like methods that can partially overcome these difficulties.
Our first approach, namely that based on HAL, can be further generalized to the case in which the flexible fit is an empirical risk minimizer over a function class assumed to contain the unknown function. The key condition B2 may be modified in that case as long as it ensures that certain perturbations of the unknown function still lie in that function class. We note that our methods may also be applied under semiparametric models.
A major direction for future work is to construct valid CIs without the knowledge of the influence function of the resulting plug-in estimator. The nonparametric bootstrap is in general invalid when the overall summary is not Hadamard differentiable and especially when the method relies on CV [2, 11], but a model-based bootstrap is a possible solution (Chapter 28 of [33]). In many cases only certain components of the true data-generating distribution must be estimated to obtain a plug-in estimator, while its variance may depend on other components that are not explicitly estimated. Therefore, generating valid model-based bootstrap samples is generally difficult.
Our proposed sieve-like methods may be used to construct efficient plug-in estimators for new applications in which the relevant theoretical results are difficult to derive. They may also inspire new methods to construct such estimators under weaker conditions.
Appendix A Modification of chosen norm for evaluating the conditions: case study of mean counterfactual outcome
In this appendix, we consider a parameter that requires a modification in the chosen norm for evaluating the conditions. In particular, we discuss estimating counterfactual mean outcome in Example 3.
Let be the propensity score function. A natural choice of the loss function is . Indeed, learning a function with this loss function is equivalent to fitting a function within the stratum of observations that received treatment 1. Unfortunately, this loss function does not satisfy Condition A2 with -norm, because cannot be well approximated by for any constant unless is a constant. One way to overcome this challenge is to choose the alternative inner product and its induced norm . In this case, Condition A2 is satisfied once is replaced by in the condition statement. Under this choice, . We may redefine the corresponding similarly as the function that satisfies
and it immediately follows that . Moreover, under a strong positivity condition, namely a.s. for some , which is a typical condition in causal inference literature [33, 36], then it is straightforward to show that ; that is, is equivalent to -norm. Using this fact, it can be shown that all other conditions with respect to the -inner product are equivalent to the corresponding conditions with respect to .
Therefore, the data-adaptive series can be applied to estimation of the counterfactual mean outcome under our conditions for -inner product. If we use the targeted form in Remark 2, then we need a flexible estimator of and the procedure is almost identical to a TMLE [33]. If we use the generalized data-adaptive series, we would require sufficient amount of smoothness for . In the latter case, the change in norm when evaluating the conditions is a purely technical device and the estimation procedure is the same as would have been used if we had used the -norm. We also note that the same argument may be used to show that in Example 4, with being the usual squared-error loss, we may choose the alternative inner product and find that , as we did in Section 5.3.
Appendix B Additional conditions
Throughout the rest of this appendix, we use to denote a general absolute positive constant that can vary line by line.
B.1 HAL
Condition B3 (Empirical processes conditions).
For any fixed and some , it holds that , and are càdlàg for all and all . Moreover, the following terms are all finite:
In addition, and converge to 0 in probability.
Condition B4 (Finite variance of influence function).
.
B.2 Data-adaptive series
Condition C6 (Local Lipschitz continuity of ).
For sufficiently large ,
for all with .
Condition C7 (Local Lipschitz continuity of and ).
For sufficiently large , for all with ,
-
(a)
;
-
(b)
.
Condition C8 (Empirical process conditions).
There exists some constant such that
Condition C9 (Finite variance of influence function).
.
B.3 Generalized data-adaptive series
Condition C6∗ (Local Lipschitz continuity of projected for ).
For sufficiently large , for all .
Condition C7∗ (Local Lipschitz continuity of and its projection for ).
For sufficiently large , for all ,
-
(a)
;
-
(b)
.
B.4 Conditions for efficiency of the plug-in estimator
Define a collection of submodels
for which: (i) is a subset of and the -closure of its linear span is ; and (ii) each is a regular univariate parametric submodel that passes through and has score for at . For each and , we define . In this appendix, for all small and big notations, we let with fixed.
Condition E1 (Sufficiently close risk minimizer).
For any given , .
Condition E2 (Quadratic behavior of loss function remainder near 0).
For any given and , there exists positive such that .
Appendix C Discussion of technical conditions for data-adaptive series and its generalization
C.1 Theorem 2
Condition C2 usually imposes an upper bound on the growth rate of . To see this, we show that Condition C2 is equivalent to a term being , and an upper bound of this term is controlled by . Let be the true-risk minimizer in . Under Conditions A2, C1, C3 and C6, by Lemma 5, it follows that Condition C2 is equivalent to requiring that . Note that minimizes the empirical risk in , and M-estimation theory [34] can show that can be upper bounded by an empirical process term, whose upper bound is related to the complexity of , namely how fast grows with sample size. To ensure this bound is , must not grow too quickly.
Condition C3 assumes that the identity function can be well approximated by the series with the specified number of terms in the sense. If does not contain for any , then sufficiently many terms must be included to satisfy this condition; that is, this condition imposes a lower bound on the rate at which should grow with . Even if does contain for some finite , this condition still requires that is not too small.
Condition C4s.
.
This condition is similar to Condition C3. However, in general, we do not expect to be contained in for any , and hence this condition generally imposes a lower bound on the rate of . Note that Condition C4s is stronger than Condition C4, and there are interesting examples where C4 holds but C4s fails to hold. Indeed, if converges to at a rate much faster than , then C4 can be satisfied even if decays to zero in probability relatively slowly — that is, the convergence rate of can compensate for the approximation error of . This is one way in which we can benefit from using flexible ML algorithms to estimate : if converges to at a fast rate, then we can expect to also have a fast convergence rate.
Conditions C2, C3 and C4 are not stringent provided sufficient smoothness on derivatives of and a reasonable series. For example, as noted in [4], when has a bounded -th order derivative and the polynomial, trigonometric series or spline with degree at least is used, then if ( for polynomial series), the term in Condition C2 is ; the terms in Condition C3 and the sufficient Condition C4s are . Therefore, we can select to grow at a rate faster than and slower than ( for polynomial series). If is large, then this allows for a wide range of rates for . Typically (and hence ) is only related to the summary of interest but not the true function . For example, for the summary at the beginning of Section 4.1, is variation independent of . It is often the case that is smooth and so is , so is often sufficiently large for this window to be wide.
Condition C6 is usually easy to satisfy. Since is a linear combination of and is an approximation of a highly smooth function , if the series is smooth, then we can expect that will be Lipschitz uniformly over , that is, that Condition C6 holds. For example, using polynomial series, cubic splines or trigonometric series imply that this condition holds.
C.2 Theorem 5
The conditions are similar to those in Theorem 2. However, Condition C4∗ can be more stringent than Condition C4. For generalized data-adaptive series, the dimension of the argument of the series is larger. Hence, as noted in [4], C4∗ may require more smoothness of in order that can be well approximated by . However, in general, we do not expect the smoothness of to depend on alone but no components of , so the amount of smoothness of may be more limited in practice.
It is also worth noting that, similarly to Theorem 2, a sufficient condition for Condition C4∗ is the following:
Condition C4∗s.
.
Appendix D Lemmas and technical proofs
D.1 Highly Adaptive Lasso (HAL)
Proof of Theorem 1.
Proof of Lemma 1.
Recall that . Similar to , let where and are entrywise. To avoid clumsy notations, in this proof we drop the subscript in and use instead. This should not introduce confusion because other functions (e.g., an estimator of ) are not involved in the statement or proof. Using the results reviewed in Section 3.1,
Since
we have for all , so
∎
Lemma 2 (CV-selected bound not much smaller than the bound of the true function’s variation norm).
Suppose that Condition B1 holds, is càdlàg, and for any , . Let be a (possibly random) sequence such that . Then for any , with probability tending to one, . Therefore, for any fixed , with probability tending to one, .
Proof of Lemma 2.
We prove by contradiction. Suppose the claim is not true, i.e. there exists such that for all , where is an infinite set. Let . Then for all , with probability at least ,
which is a positive constant since the function class does not contain and this term is non-negligible bias. This contradicts the assumption that and hence the desired follows. ∎
Therefore, if for a known increasing function , then with probability tending to one, is a valid bound on that can be used to obtain an efficient plug-in estimator. Moreover, if the bound is loose, i.e. , and is continuous, then there exists some such that and hence with probability tending to one.
Note that this lemma only concerns learning a function-valued feature but not estimating . There are examples where depends on components of , say , other than . However, if can be learned via HAL, then Lemma 2 can be applied. Therefore, if it is known that for a known increasing function , then we can use a bound on obtained in a similar fashion as above from the sequence to construct an efficient plug-in estimator .
Now consider obtaining by -fold CV from a set of candidate bounds. Then, under Conditions B1–B3, by (i) Lemma 1 and its corollary of [29], and (ii) the oracle inequality for -fold CV in [31], if (i) one candidate bound is no smaller than , and (ii) the number of candidate bounds is fixed. Therefore, the above results apply to this case.
D.2 Data-adaptive series estimation
Lemma 3 (Convergence rate of the sieve estimator).
Proof of Lemma 3.
By triangle inequality, . We bound these three terms separately.
Term 1: By Condition C1, .
Term 2: By the definition of projection operator,
We bound the right-hand side by showing this term is close to up to an term. By the reverse triangle inequality and the triangle inequality,
| (Condition C6) | |||
which is by Condition C1. Therefore, by Condition C3,
Term 3: By the definition of projection and Condition C1, .
Conclusion from the three bounds: .
If, in addition, Condition C2 also holds, then . ∎
The same result holds for the generalized data-adaptive series under Conditions C1, C6∗, C3∗ and C2 (if relevant). The proof is almost identical and is therefore omitted.
Proof of Lemma 4.
By the definition of the projection operator and triangle inequality,
We bound the two terms on the right-hand side separately.
Term 1: By Condition C7, .
Term 2: This term can be bounded similarly as in Lemma 3. By the reverse triangle inequality and the triangle inequality,
| (Condition C7) | |||
Therefore, by the definition of the projection operator and Condition C7,
Conclusion from the two bounds: .
Note that is a linear operator. Lemma 3 and 4 along with other conditions essentially satisfy the assumptions in Corollary 2 in [28]. We can prove the asymptotic linearity result of Theorem 2 similarly to this result as follows.
Proof of Theorem 2.
We note that
Let be an arbitrary sequence of positive real numbers that is . We may replace with in the above equation. We first consider :
| (1) | ||||
Take the difference between the above two equations. By the linearity of and , we have that
We next analyze the three lines on the right-hand side of the above equation separately.
Line 1: Under Condition A2,
| We subtract and add in the first term. By the fact that is linear and , the display continues as | ||||
| By Cauchy-Schwards inequality, the display continues as | ||||
| By Lemmas 3–4 and the assumption that , the display continues as | ||||
Line 2: We subtract and add . By linearity of , Condition C8, and the fact that , we have that
Line 3: By Condition C8, this term is .
Conclusion of the three lines: It holds that
Since is an empirical risk minimizer, the left-hand side is non-negative. Thus,
The proof of Theorem 5 is almost identical.
Nest we present and prove a lemma allows us to interpret Condition C2 as an upper bound on the rate of .
Proof of Lemma 5.
We finally prove the efficiency of the data-adaptive series estimator with selected by CV.
Proof of Theorem 4.
By Lemma 3 and Condition A2, for that existing deterministic , . By the oracle inequality for CV in [31], . By Condition A2, and hence . So with probability tending to one,
| (Condition C5) | ||||
| (definition of the projection operator) | ||||
| (triangle inequality) | ||||
which is by Condition C1. Hence,
| (Condition C7) | ||||
which is by Condition C1.
This bounds the approximation error for , a result that is similar to Lemma 4 combined with Conditions C1 and C4∗s. Similarly to Theorem 2, along with other conditions, the assumptions in Corollary 2 in [28] are essentially satisfied and hence an almost identical argument shows that is an asymptotically linear estimator of . We prove the efficiency in Appendix D.3. ∎
D.3 Efficiency
Proof of efficiency of the proposed estimators.
It is sufficient to show that the influence function of our proposed estimators is the canonical gradient under a nonparametric model. Let be fixed. In the rest of this proof, for all small and big notations, we let . The proof is similar to the proof of asymptotic linearity in [28] except that the estimator of and the empirical distribution are replaced by and respectively.
Let satisfy Condition E2. We note that
We also note that if is sufficiently small. Then, similarly, by replacing with in the above equation, we have that
| (2) | ||||
Take the difference between the above two equations. By the linearity of , we have that
| (Condition A2) | |||
| (Condition E2) | |||
Since the left-hand side of the above display is nonnegative, by Condition E1, we have that
Similarly, by replacing with in (LABEL:eq:_regularity_key2), we show that . Therefore, and
| (Condition E1) | ||||
Consequently, and hence the canonical gradient of under a nonparametric model is . Since the influence functions of our asymptotically linear estimators are equal to this canonical gradient, our proposed estimators are efficient under a nonparametric model. ∎
Appendix E Simulation setting details
In all simulations, since is the conditional mean function, the loss function was chosen to be the square loss .
E.1 HAL
In the simulation, we generate data from the distribution defined by
The sample sizes being considered are 500, 1000, 2000, 5000 and 10000. For each scenario we run 1000 replicates. We chose M.gcv+ to be 3.1 times M.cv.
E.2 Data-adaptive series
E.2.1 Demonstration of Theorem 4
In the simulation, we generate data from the distribution defined by where
When using the trigonometric series, we first shift and scale the initial function range to be and then use the basis for the interval (i.e. ) in sieve estimation to avoid the poor behavior of trigonometric series near the boundary. We consider sample sizes 500, 1000, 2000, 5000, 10000 and 20000. For each sample size, we run 1000 simulations.
E.2.2 Violation of Condition C5
In the simulation, we generate data from the distribution defined by where . The estimand is where
We consider sample sizes 500, 1000, 2000, 5000, 10000 and 20000; for each sample size, we run 1000 simulations. Our goal is to explore the behavior of the plug-in estimator when , instead of , is rough, so we use kernel regression [20] to estimate for convenience.
E.3 Generalized data-adaptive series
E.3.1 Demonstration of Theorem 6
E.3.2 Violation of Condition C5∗
In the simulation, we generate data from the distribution defined by where () and
We consider sample sizes 500, 1000, 2000, 5000, 10000 and 20000; for each sample size, we run 1000 simulations. Our goal is to explore the behavior of the plug-in estimator when , instead of , is rough, so we use kernel regression [20] to estimate for convenience.
Acknowledgements
This work was partially supported by the National Institutes of Health under award number DP2-LM013340 and R01HL137808. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
References
- Benkeser and van Der Laan [2016] Benkeser, D. and M. van Der Laan (2016). The Highly Adaptive Lasso Estimator. In Data Science and Advanced Analytics (DSAA), 2016 IEEE International Conference on, pp. 689–696. IEEE.
- Bickel et al. [1997] Bickel, P., F. Götze, and W. vanZwet (1997). Resampling fewer than n observations: Gains, losses, and remedies for losses. STATISTICA SINICA 7(1).
- Bickel and Ritov [2003] Bickel, P. J. and Y. Ritov (2003). Nonparametric estimators which can be “plugged-in”. Annals of Statistics 31(4), 1033–1053.
- Chen [2007] Chen, X. (2007). Chapter 76 Large Sample Sieve Estimation of Semi-Nonparametric Models. Handbook of Econometrics 6(SUPPL. PART B), 5549–5632.
- Chernozhukov et al. [2017] Chernozhukov, V., D. Chetverikov, M. Demirer, E. Duflo, C. Hansen, and W. Newey (2017). Double/debiased/Neyman machine learning of treatment effects. American Economic Review 107(5), 261–265.
- Chernozhukov et al. [2018] Chernozhukov, V., D. Chetverikov, M. Demirer, E. Duflo, C. Hansen, W. Newey, and J. Robins (2018). Double/debiased machine learning for treatment and structural parameters. Econometrics Journal 21(1), C1–C68.
- Fan et al. [1998] Fan, J., W. Härdle, and E. Mammen (1998). Direct estimation of low-dimensional components in additive models. The Annals of Statistics 26(3), 943–971.
- Friedman [2001] Friedman, J. H. (2001). Greedy Function Approximation: A Gradient Boosting Machine. Technical Report 5.
- Friedman [2002] Friedman, J. H. (2002). Stochastic gradient boosting. Computational Statistics and Data Analysis 38(4), 367–378.
- Gill et al. [1993] Gill, R. D., M. J. van der Laan, and J. A. Wellner (1993). Inefficient estimators of the bivariate survival function for three models. Rijksuniversiteit Utrecht. Mathematisch Instituut.
- Hall [2013] Hall, P. (2013). The bootstrap and Edgeworth expansion. Springer Science & Business Media.
- Hall et al. [2004] Hall, P., J. Racine, and Q. Li (2004). Cross-validation and the estimation of conditional probability densities. Journal of the American Statistical Association 99(468), 1015–1026.
- Härdle and Stoker [1989] Härdle, W. and T. M. Stoker (1989). Investigating smooth multiple regression by the method of average derivatives. Journal of the American Statistical Association 84(408), 986–995.
- Levy et al. [2018] Levy, J., M. van der Laan, A. Hubbard, and R. Pirracchio (2018). A Fundamental Measure of Treatment Effect Heterogeneity.
- Li and Racine [2004] Li, Q. and J. Racine (2004). Cross-Validated local Linear Nonparametric Regression. Statistica Sinica 14, 485–512.
- Mallat [2009] Mallat, S. (2009). A Wavelet Tour of Signal Processing. Elsevier.
- Marron [1994] Marron, J. S. (1994). Visual understanding of higher-order kernels. Journal of Computational and Graphical Statistics 3(4), 447–458.
- Mason et al. [1999] Mason, L., J. Baxter, P. Bartlett, and M. Frean (1999). Boosting Algorithms as Gradient Descent in Function Space. Technical report.
- Mason et al. [2000] Mason, L., J. Baxter, P. L. Bartlett, and M. Frean (2000). Boosting Algorithms as Gradient Descent. Technical report.
- Nadaraya [1964] Nadaraya, E. A. (1964). On estimating regression. Theory of Probability & Its Applications 9(1), 141–142.
- Newey et al. [1998] Newey, W., F. Hsieh, and J. Robins (1998). Undersmoothing and Bias Corrected Functional Estimation. Working papers.
- Newey [1997] Newey, W. K. (1997). Convergence rates and asymptotic normality for series estimators. Journal of Econometrics 79(1), 147–168.
- Newey et al. [2004] Newey, W. K., F. Hsieh, and J. M. Robins (2004). Twicing Kernels and a Small Bias Property of Semiparametric Estimators. Econometrica 72(3), 947–962.
- Owen [2005] Owen, A. B. (2005). Multidimensional variation for quasi-monte carlo. In Contemporary Multivariate Analysis And Design Of Experiments: In Celebration of Professor Kai-Tai Fang’s 65th Birthday, pp. 49–74. World Scientific.
- Pfanzagl [1982] Pfanzagl, J. (1982). Contributions to a General Asymptotic Statistical Theory, Volume 13 of Lecture Notes in Statistics. New York, NY: Springer New York.
- Rubin [1974] Rubin, D. B. (1974). Estimating causal effects of treatments in randomized and nonrandomized studies. Journal of Educational Psychology 66(5), 688–701.
- Sheather and Jones [1991] Sheather, S. J. and M. C. Jones (1991). A Reliable Data-Based Bandwidth Selection Method for Kernel Density Estimation. Journal of the Royal Statistical Society: Series B (Methodological) 53(3), 683–690.
- Shen [1997] Shen, X. (1997). On methods of sieves and penalization. Annals of Statistics 25(6), 2555–2591.
- van Der Laan [2017] van Der Laan, M. (2017). A Generally Efficient Targeted Minimum Loss Based Estimator based on the Highly Adaptive Lasso. International Journal of Biostatistics 13(2).
- van der Laan and Rubin [2006] van der Laan, M. and D. Rubin (2006). Targeted Maximum Likelihood Learning. U.C. Berkeley Division of Biostatistics Working Paper Series.
- van der laan and Dudoit [2003] van der laan, M. J. and S. Dudoit (2003). Unified cross-validation methodology for selection among estimators and a general cross-validated adaptive epsilon-net estimator: Finite sample oracle inequalities and examples. U.C. Berkeley Division of Biostatistics Working Paper Working Pa.
- van der Laan and Robins [2003] van der Laan, M. J. and J. M. Robins (2003). Unified Methods for Censored Longitudinal Data and Causality. Springer Series in Statistics. New York, NY: Springer New York.
- van der Laan and Rose [2018] van der Laan, M. J. and S. Rose (2018). Targeted Learning in Data Science.
- van der Vaart and Wellner [2000] van der Vaart, A. and J. Wellner (2000). Weak Convergence and Empirical Processes: With Applications to Statistics. Springer Series in Statistics. Springer.
- Williamson et al. [2017] Williamson, B., P. Gilbert, N. Simon, and M. Carone (2017). Nonparametric variable importance assessment using machine learning techniques. UW Biostatistics Working Paper Series.
- Yang and Ding [2018] Yang, S. and P. Ding (2018). Asymptotic inference of causal effects with observational studies trimmed by the estimated propensity scores. Biometrika 105(2), 487–493.
- Zhang [2010] Zhang, C. H. (2010). Nearly unbiased variable selection under minimax concave penalty. Annals of Statistics 38(2), 894–942.