Universal Approximation Properties for an ODENet and a ResNet: Mathematical Analysis and Numerical Experiments
Abstract
We prove a universal approximation property (UAP) for a class of ODENet and a class of ResNet, which are simplified mathematical models for deep learning systems with skip connections. The UAP can be stated as follows. Let and be the dimension of input and output data, and assume . Then we show that ODENet of width with any non-polynomial continuous activation function can approximate any continuous function on a compact subset on . We also show that ResNet has the same property as the depth tends to infinity. Furthermore, we derive the gradient of a loss function explicitly with respect to a certain tuning variable. We use this to construct a learning algorithm for ODENet. To demonstrate the usefulness of this algorithm, we apply it to a regression problem, a binary classification, and a multinomial classification in MNIST.
Keywords: Deep neural network, ODENet, ResNet, Universal approximation property
1 Introduction
Recent advances in neural networks have proven immensely successful for regression analysis, image classification, time series modeling, and so on [20]. Neural Networks are models of the human brain and vision [18, 8]. A neural network performs regression analysis, image classification, and time series modeling by performing a series of sequential operations, known as layers. Each of these layers is composed of neurons that are connected to neurons of other (typically, adjacent) layers. We consider a neural network with layers, where the input layer is layer , the output layer is layer , and the number of nodes in layer is . Let be the function of each layer. The output of each layer is, therefore, a vector in . If the input data is , then, at each layer, we have
The final output of the network then becomes , and the network is represented by .
A neural network approaches the regression and classification problem in two steps. Firstly, a priori observed and classified data is used to train the network. Then, the trained network is used to predict the rest of the data. Let be the set of input data, and be the target function. In the training step, the training data are available, where are the inputs, and are the outputs. The goal is to learn the neural network so that approximates . This is achieved by minimizing a loss function that represents a similarity distance measure between the two quantities. In this paper, we consider the loss function with the mean square error
Finding the optimal functions out of all possible such functions is challenging. In addition, this includes a risk of overfitting because of the high number of available degrees of freedom. We restrict the functions to the following form:
| (1.1) |
where is a weight matrix, is a bias vector, and is weight vector of the output of each layer. The operator denotes the Hadamard product (element-wise product) of two vectors defined by (2.2). The function is defined by , where is called an activation function. For a scalar , the sigmoid function , the hyperbolic tangent function , the rectified linear unit (ReLU) function , and the linear function , and so on, are used as activation functions.
If we restrict the functions of the form (1.1), the goal is to learn that approximates in the training step. The gradient method is used for training. Let and be the gradient of the loss function with respect to and , respectively, and let be the learning rate. Using the gradient method, the weights and biases are updated as follows:
Note that the stochastic gradient method [4] has been widely used recently. Then, error backpropagation [19] was used to find the gradient.
It is known that deep (convolutional) neural networks are of great importance in image recognition [21, 23]. In [12], it was found through controlled experiments that the increase of depth in networks actually improves its performance and accuracy, in exchange, of course, for additional time complexity. However, in the case that the depth is overly increased, the accuracy might get stagnant or even degraded [12]. In addition, considering deeper networks may impede the learning process, which is due to the vanishing or exploding of the gradient [3, 10]. Apparently, deeper neural networks are more difficult to train. To address such an issue, the authors in [13] recommended the use of residual learning to facilitate the training of networks that are considerably deeper than those used previously. Such a network is referred to as residual network or ResNet. Let and be the dimensions of the input and output data. Let be the number of nodes in each layer. A ResNet can be represented as
| (1.2) |
The final output of the network then becomes , where and . Moreover, the function is learned from training data.
Transforming (1.2) into
| (1.3) |
where is the step size of the layer, leads to the same equation for the Euler method, which is a method for finding numerical solution to initial value problem for ordinary differential equation. Indeed, putting and , where , and , then the limit of (1.3) as approaches zero yields the following initial value problem of ordinary differential equation
| (1.4) |
We call the function an ODENet [6] associated with the system of ordinary differential equations (1.4).
Remark 1.1.
In the real deep learning system, the vector field should be chosen from a family of the vector fields , where is a parameter that is optimized. In this paper, we consider an ODENet associated with (2.3), which we call an -type ODENet. Instead of the variable in (1.4), we consider in (2.3), where (see Appendix D for the detail). The implementation of ODENet requires (forward) Euler discretization to ResNet. A ResNet with (2.5) corresponds to the discretized version of the -type ODENet, and we call it an -type ResNet.
A neural network of arbitrary width and bounded depth has universal approximation property (UAP). The classical UAP is that continuous functions on a compact subset on can be approximated by a linear combination of activation functions. It has been shown that the UAP for the neural networks holds by choosing a sigmoidal function [7, 14, 5, 9], any bounded function that is not a polynomial function [16, 1], and any function in Lizorkin space including a ReLU function [22] as an activation function. The UAP for neural network and its proof for each activation function is presented in Table 1.
| References | Activation function | How to prove |
|---|---|---|
| Cybenko [7] | Continuous sigmoidal | Hahn-Banach theorem |
| Hornik et al. [14] | Monotonic sigmoidal | Stone-Weierstrass theorem |
| Carroll, Dickinson [5] | Continuous sigmoidal | Radon transform |
| Funahashi [9] | Monotonic sigmoidal | Fourier transform |
| Leshno et al. [16] | Non-polynomial | Weierstrass theorem |
| Attali, Pagès [1] | Non-polynomial | Taylor expansion |
| Sonoda, Murata [22] | Lizorkin distribution | Ridgelet transform |
Recently, some positive results have been established showing the UAP for particular deep narrow networks. Hanin and Sellke [11] have shown that deep narrow networks with ReLU activation function have the UAP, and require only width . Lin and Jegelka [17] have shown that a ResNet with ReLU activation function, arbitrary input dimension, width 1, output dimension 1 have the UAP. For activation functions other than ReLU, Kidger and Lyons [15] have shown that deep narrow networks with any non-polynomial continuous function have the UAP, and require only width . The comparison of the UAPs are shown in Table 2. It is proved in [15, 17] and Theorem 2.7 that the UAP holds as . Theorem 2.3 shows that the UAP holds when the layer is continuous.
| Shallow wide NN | Deep narrow NN | ResNet | |
|---|---|---|---|
| References | [16, 22] | [15] | [17] |
| Input dimension | : any | : any | : any |
| Output dimension | |||
| Activation function | Non-polynomial | Non-polynomial | ReLU |
| Depth | |||
| Width | |||
| -type ResNet | -type ODENet | ||
| References | Theorem 2.7 | Theorem 2.3 | |
| Input dimension | |||
| Output dimension | |||
| Activation function | Non-polynomial | Non-polynomial | |
| Depth | continuous setting | ||
| Width | |||
In this paper, we propose the -type ODENet associated with (2.3) whose width is and show the conditions for the UAP for the -type ODENet and the -type ResNet with (2.5). In Section 2, we show that the UAP holds for the -type ODENet associated with (2.3) and the -type ResNet with (2.5). In Section 3, we derive the gradient of the loss function and a learning algorithm for the -type ODENet in consideration, followed by some numerical experiments in Section 4. Finally, we end the paper with a conclusion in Section 5.
2 Universal Approximation Theorem for -type ODENet and -type ResNet
2.1 Definition of an activation function with universal approximation property
Let and be natural numbers. Our main results, Theorem 2.3 and Theorem 2.7, show that any continuous function on a compact subset on can be approximated using the -type ODENet and the -type ResNet.
In this paper, the following notations are used
for any and . Also, we define
for any . For a function , we define by
| (2.1) |
for . For , their Hadamard product is defined by
| (2.2) |
Definition 2.1 (Universal approximation property for the activation function ).
Let be a real-valued function on and be a compact subset of . Also, consider the set
Suppose that is dense in . In other words, given and , there exists a function such that
for any . Then, we say that has a universal approximation property (UAP) on .
Some activation functions with the universal approximation property are presented in Table 3.
| Activation function | ||
|---|---|---|
| Unbounded functions | ||
| Truncated power function | ||
| ReLU function | ||
| Softplus function | ||
| Bounded but not integrable functions | ||
| Unit step function | ||
| (Standard) Sigmoidal function | ||
| Hyperbolic tangent function | ||
| Bump functions | ||
| (Gaussian) Radial basis function | ||
| Dirac’s function | ||
2.2 Main Theorem for -type ODENet
In this subsection, we show the universal approximation property for the -type ODENet associated with the ODE system (2.3). Since the first (resp. second) equation consists of (resp. ) equations, the width of the -type ODENet is .
Definition 2.2 (-type ODENet).
Suppose that an real matrix and a function are given. We consider a system of ODEs
| (2.3) |
where and are functions from to and , respectively; is an input data and is the final output. Moreover, the functions , , and are design parameters. The function is defined by (2.1) and the operator denotes the Hadamard product defined by (2.2). We call an -type ODENet associated with the ODE system (2.3).
For a compact subset , we define
We will assume that the activation function is locally Lipschitz continuous, in other words,
| (2.4) |
Theorem 2.3 (UAP for -type ODENet).
Suppose that and . If satisfies (2.4) and has UAP on a compact subset , then is dense in . In other words, given and , there exists a function such that
for any .
Corollary 2.4.
Let . Then, is dense in . In other words, given and , there exists a function such that
2.3 Main Theorem for -type ResNet
In this subsection, we show that a universal approximation property also holds for an -type ResNet with the system of difference equations (2.5).
Definition 2.6 (-type ResNet).
Suppose that an real matrix and a function are given. We consider a system of difference equations
| (2.5) |
where and are - and -dimensional real vectors, for all , respectively. Also, denotes the input data while represents the final output. Moreover, the vectors and are design parameters. The functions is defined by (2.1) and the operator denotes the Hadamard product defined by (2.2). We call the function an -type ResNet with a system of difference equations (2.5).
For a compact subset , we define
Theorem 2.7 (UAP for -type ResNet).
Suppose that and . If satisfies (2.4) and has UAP on a compact subset , then is dense in .
2.4 Some lemmas
Lemma 2.9.
Suppose that . Let be a function from to defined by (2.1). For any and which has no zero rows (i.e. for ), there exist , and such that
for any , and , for all . Moreover, if , we can choose such that , for all .
Proof.
Let . For all , there exists such that , . Then, we put
Looking at the -th component, we see that for any , we have
Therefore,
Now, if , then , and so . In particular, we can choose such that . ∎
Lemma 2.10.
Suppose that . Let be a function from to . For any , there exists such that
for any , and , for all . Moreover, if , we can choose such that , for all .
Proof.
This follows from Lemma 2.9. ∎
Lemma 2.11.
Suppose that . Let be an real matrix satisfying . Then, for any satisfying , there exists such that
| (2.6) |
In addition, if and , there exists such that (2.6).
Proof.
-
(i)
Suppose that . From , there exists such that
If we put , we get , .
-
(ii)
Suppose that . We put . Because , we have , and so .
∎
Lemma 2.12.
Let . Suppose that
for , and for all , where and . Then, there exists a real number such that, for any , there exists such that
for any .
Proof.
We define . From [2, Chapter 9, p.239], is path-connected. For all , there exists such that
for any . For , we put
Then, is a continuous function from to . There exists a such that , for any . Let be a sequence of Friedrichs’ mollifiers in . We put
Then, . Since
there exists a number such that, for any ,
for all . Because is bounded, there exists a number such that , for any . Now, we note that
The last summand is calculated as follows
Hence, if , then . Therefore,
for any . ∎
Remark 2.13.
Lemma 2.12 does not hold when (except when is a constant function) because the uniform limit of continuous functions is also continuous.
2.5 Proofs
2.5.1 Proof of Theorem 2.3
Proof.
Since is defined by (2.1), where satisfies a UAP, then given and , there exist a positive integer , -valued vectors and , and matrices , for all , such that
| (2.7) |
for any . From Lemma 2.10, we know that , for . In addition, when , we have . In view of Lemma 2.11, there exists a matrix such that and , for each . We put so that . In addition, we let
Then, for any and
Let be a sequence of Friedrichs’ mollifiers. We put and . Then, and . From Lemma 2.12, there exists a real number such that, given , there exists from which we have
for any . If we put
| (2.8) |
| (2.9) |
then
Hence, we have
Because and are piecewise constant functions, then they are bounded. Since , there exists such that , for any . On the other had, we have the estimate
Similarly, because , then is bounded. We assume that , , for any ,
Therefore,
We know that there exists a number such that
| (2.10) |
for any . Thus, from (2.7) and (2.10),
for any . For all , we know that , so is invertible. This allows us to define
This gives us
Hence, . Therefore, given and , there exist some functions , , and such that
for any . ∎
2.5.2 Proof of Theorem 2.7
Proof.
Again, we start with the fact that is defined by (2.1), where satisfies a UAP; that is, given and , there exist a positive integer , -valued vectors and , and matrices , for all , such that
for any . By virtue of Lemma 2.10, we know that , for all . Moreover, if , we have . On the other hand, from Lemma 2.11, there exists such that and , for each . Putting , we get , from which we obtain
Next, we define
for all , and set , . Because and hold true, then
Hence, . Therefore, given and , there exists such that
for any . ∎
3 The gradient and learning algorithm
3.1 The gradient of the loss function with respect to the design parameter
We consider the -type ODENet associated with the ODE system of (2.3). We also consider the approximation of . Let be the number of training data and be the training data. We divide the label of the training data into the following disjoint sets.
Let and be the solution to (2.3) with the initial value . For all , let and . We define the loss function as follows:
| (3.1) |
| (3.2) |
We consider the learning for each label set using the gradient method. We fix . Let be the adjoint and satisfy the following adjoint equation for any .
| (3.3) |
Then, the gradient and of the loss function (3.1) at and with respect to can be represented as
respectively.
3.2 Learning algorithm
In this section, we describe the learning algorithm of the -type ODENet associated with an ODE system (2.3). The initial value problems of ordinary differential equations (2.3) and (3.3) are computed using the explicit Euler method. Let be the size of the time step. We define . By discretizing the ordinary differential equations (2.3), we obtain
for any . Furthermore, by discretizing the adjoint equation (3.3), we obtain
with for any . Here we put
for all .
We perform the optimization of the loss function (3.2) using stochastic gradient descent (SGD). We show the learning algorithm in Algorithm 1.
4 Numerical results
4.1 Sinusoidal Curve
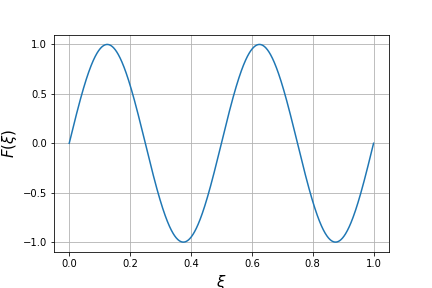
We performed a numerical example of the regression problem of a 1-dimensional signal defined on . Let the number of training data be , and let the training data be
We run Algorithm 1 until . We set the learning rate to , to the matrix with ones on the diagonal and zeros elsewhere, and
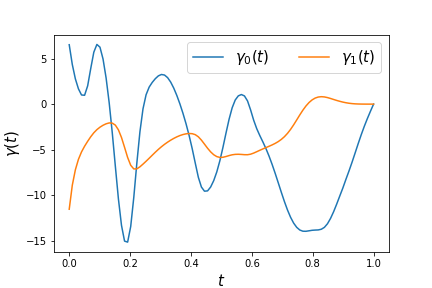
Let the number of validation data be . The signal sampled with was used as the validation data. Let be the set of input data used for the validation data. Fig. 2. shows the training data which is sampled from with . Fig. 2. shows the result predicted using validation data when . The validation data is shown as a blue line, and the result predicted using the validation data is shown as an orange line. Fig. 4. shows the initial values of parameters and . Fig. 4. shows the learning results of each design parameter at . Fig. 5. shows the change in the loss function during learning for each of the training data and validation data.
Fig. 5. shows that the loss function can be decreased using Algorithm 1. Fig. 2. suggests that the prediction is good. In addition, the learning results of the parameters and are continuous functions.




4.2 Binary classification
We performed numerical experiments on a binary classification problem for 2-dimensional input. We set and . Let the number of the training data be , and let be the set of randomly generated points. Let
| (4.1) |
be the training data. We run Algorithm 1 until . We set the learning rate to , to the matrix with ones on the diagonal and zeros elsewhere, and
Let the number of validation data be . The set of points randomly generated on and is used as the validation data. Fig. 7. shows the training data in which randomly generated are classified in (4.1). Fig. 7. shows the prediction result using validation data at . The results that were successfully predicted are shown in dark red and dark blue, and the results that were incorrectly predicted are shown in light red and light blue. Fig. 9. shows the result of predicting the validation data using -nearest neighbor algorithm at . Fig. 9. shows the result of predicting the validation data using a multi-layer perceptron with nodes. Fig. 11. shows the initial value of parameters and . Fig. 11., 13. and 13. show the learning results of each parameters at . Fig. 15. shows the change of the loss function during learning for each of the training data and validation data. Fig. 15. shows the change of accuracy during learning. The accuracy is defined as
Table 4 shows the value of the loss function and the accuracy of the prediction of each method.
From Fig. 15. and 15., we observe that the loss function can be decreased and accuracy can be increased using Algorithm 1. Fig. 7. shows that some points in the neighborhood of are wrongly predicted; however, most points are well predicted. The results are similar when compared with Fig. 9. and 9. In addition, the learning results of the parameters , and are continuous functions. From Table 4, the -nearest neighbor algorithm minimizes the value of the loss function among the three methods. We consider that this is because the output of ODENet is , while the output of the -nearest neighbor algorithm is . Compared to K-NN and MLP, the -type ODENet gives a slightly worse result (Table 4). However, the binary classification is not a suitable problem to test the potential of ODENet, because the output values of ODENet are continuous. It should also be noted that the proposed model is not very tuned to increase accuracy. Considering these facts, this result also shows the potential of ODENet.






| Method | Loss | Accuracy |
|---|---|---|
| This paper (-type ODENet) | 0.02629 | 0.9592 |
| -nearest neighbor algorithm (K-NN) | 0.006000 | 0.9879 |
| Multilayer perceptron (MLP) | 0.006273 | 0.9883 |
4.3 Multinomial classification in MNIST
We performed a numerical experiment on a classification problem using MNIST, a dataset of handwritten digits. The input is a image and the output is a one-hot vector of labels attached to the MNIST dataset. We set and . Let the number of training data be and let the batchsize be . We run Algorithm 1 until . However, the momentum SGD was used to update the design parameters. We set the learning rate as , the momentum rate as , to the matrix with ones on the diagonal and zeros elsewhere, and
Let the number of validation data be . Fig. 17. shows the change of the loss function during learning for each of the training data and validation data. Fig. 17. shows the change of accuracy during learning. Using the test data, the values of the loss function and accuracy are
at , respectively.
Fig. 17. and 17. suggest that the loss function can be decreased and accuracy can be increased using Algorithm 1 (using the Momentum SGD).
5 Conclusion
In this paper, we proposed the -type ODENet and the -type ResNet and showed that they uniformly approximate an arbitrary continuous function on a compact set. This result shows that the -type ODENet and the -type ResNet can represent a variety of data. In addition, we showed the existence and continuity of the gradient of the loss function in a general ODENet. We performed numerical experiments on some data and confirmed that the gradient method reduces the loss function and represents the data.
Our future work is to show that the design parameters converge to a global minimizer of the loss function using a continuous gradient. We also plan to show that ODENet with other forms, such as convolution, can represent arbitrary data.
6 Acknowledgement
This work is partially supported by JSPSKAKENHI JP20KK0058, and JST CREST Grant Number JPMJCR2014, Japan.
References
- [1] J.-G. Attali and G. Pagès. Approximations of functions by a multilayer perceptron: a new approach. Neural Networks, 10(6):1069–1081, 1997.
- [2] A. Baker. Matrix groups: An Introduction to Lie Group Theory. Springer Science & Business Media, 2003.
- [3] Y. Bengio, P. Simard, and P. Frasconi. Learning long-term dependencies with gradient descent is difficult. IEEE Transactions on Neural Networks, 5(2):157–166, 1994.
- [4] L. Bottou. Online algorithms and stochastic approximations. In Online Learning and Neural Networks. Cambridge University Press, 1998.
- [5] S.M. Carroll and B.W. Dickinson. Construction of neural nets using the radon transform. In International 1989 Joint Conference on Neural Networks, volume 1, pages 607–611. IEEE, 1989.
- [6] R.T.Q. Chen, Y. Rubanova, J. Bettencourt, and D.K. Duvenaud. Neural ordinary differential equations. In Advances in Neural Information Processing Systems, volume 31, pages 6571–6583, 2018.
- [7] G. Cybenko. Approximation by superpositions of a sigmoidal function. Mathematics of Control, Signals and Systems, 2(4):303–314, 1989.
- [8] K. Fukushima and S. Miyake. Neocognitron: A self-organizing neural network model for a mechanism of visual pattern recognition. In Competition and Cooperation in Neural Nets, pages 267–285. Springer, 1982.
- [9] K.-I. Funahashi. On the approximate realization of continuous mappings by neural networks. Neural Networks, 2(3):183–192, 1989.
- [10] X. Glorot and Y. Bengio. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the 13th International Conference on Artificial Intelligence and Statistics, volume 9, pages 249–256. PMLR, 2010.
- [11] B. Hanin and M. Sellke. Approximating continuous functions by ReLU nets of minimal width. arXiv preprint arXiv:1710.11278, 2017.
- [12] K. He and J. Sun. Convolutional neural networks at constrained time cost. In 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 5353–5360. IEEE, 2015.
- [13] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778. IEEE, 2016.
- [14] K. Hornik, M. Stinchcombe, and H. White. Multilayer feedforward networks are universal approximators. Neural Networks, 2(5):359–366, 1989.
- [15] P. Kidger and T. Lyons. Universal Approximation with Deep Narrow Networks. In Proceedings of 33rd Conference on Learning Theory, pages 2306–2327. PMLR, 2020.
- [16] M. Leshno, V.Y. Lin, A. Pinkus, and S. Schocken. Multilayer feedforward networks with a nonpolynomial activation function can approximate any function. Neural Networks, 6(6):861–867, 1993.
- [17] H. Lin and S. Jegelka. ResNet with one-neuron hidden layers is a universal approximator. In Advances in Neural Information Processing Systems, volume 31, pages 6169–6178. Curran Associates, Inc., 2018.
- [18] W.S. McCulloch and W. Pitts. A logical calculus of the ideas immanent in nervous activity. The bulletin of mathematical biophysics, 5:115–133, 1943.
- [19] D.E. Rumelhart, G.E. Hinton, and R.J. Williams. Learning representations by back-propagating errors. Nature, 323(6088):533–536, 1986.
- [20] J. Schmidhuber. Deep learning in neural networks: An overview. Neural Networks, 61:85–117, 2015.
- [21] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In International Conference on Learning Representations, 2015.
- [22] S. Sonoda and N. Murata. Neural network with unbounded activation functions is universal approximator. Applied and Computational Harmonic Analysis, 43(2):233–268, 2017.
- [23] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V Vanhoucke, and A Rabinovich. Going deeper with convolutions. In 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1–9, 2015.
Appendix A Differentiability with respect to parameters of ODE
We discuss the differentiability with respect to the design parameters of ordinary differential equations.
Theorem A.1.
Let and be natural numbers, and be a positive real number. We define and . We consider the initial value problem for the ordinary differential equation:
| (A.1) |
where is a function from to , and is the initial value; is the design parameter; is a continuously differentiable function from to ; There exists such that
for any , and . Then, the solution to (A.1) satisfies . Furthermore, if we define
for any , the following relations
are satisfied.
Proof.
Let be the set of continuous functions from to . Because is Lipschitz continuous for any and , there exists a unique solution in (A.1). We define the map as
The map satisfies
Since , .
Take an arbitrary . For any , let
We define the map as
The map satisfies
and are bounded because they are continuous functions on a compact interval. Because , there exists such that for any . From
is satisfied. Hence, . Let us fix . We take such that .
Hence, .
Form the Taylor expansion of , we obtain
for any and . We obtain
For any , there exists such that
We obtain
Hence,
From , .
By fixing , there exists a solution of (A.1) such that
That is,
is satisfied. If satisfies for any , then
Because the solution to this ordinary differential equation exists uniquely, there exists an inverse map such that .
From the implicit function theorem, for any , there exists such that . From , we obtain . We put
for any . From ,
Therefore, we obtain
∎
Appendix B General ODENet
In this section, we describe the general ODENet and the existence and continuity of the gradient of a loss function with respect to the design parameter. Let and be natural numbers and be a positive real number. Let the input data be a compact set. We define and . We consider the ODENet with the following system of ordinary differential equations.
| (B.1) |
where is a function from to ; is the input data; is the final output; is the design parameter; and are and real matrices; is a continuously differentiable function from to , and is Lipschitz continuous for any and . For an input data , we denote the output data as . We consider an approximation of using ODENet with a system of ordinary differential equations (B.1). We define the loss function as
We define the gradient of the loss function with respect to the design parameter as follows:
Definition B.1.
Let be a real Banach space. Assume that the inner product is defined on . The functional is a Fréchet differentiable at . The Fréchet derivative is denoted by . If exists such that
for any , we call the gradient of at with respect to the inner product .
Remark.
If there exists a gradient of the functional at with respect to the inner product , the algorithm to find the minimum value of by
is called the steepest descent method.
Theorem B.2.
Given the design parameter , let be the solution to (B.1) with the initial value . Let be the adjoint and satisfy the following adjoint equation:
We define the functional as . Then, there exists a gradient of as with respect to the inner predict such that
for any .
Proof.
is a continuously differentiable function from to , and the solution of (B.1) satisfies from the Theorem A.1. Hence, . For any ,
We put . From Theorem A.1, we obtain
Since the assumption,
is satisfied. We define
Then, is satisfied. We calculate the inner product of and ,
Therefore, there exists a gradient of at with respect to the inner product such that
∎
Appendix C General ResNet
In this section, we describe the general ResNet and error backpropagation. We consider a ResNet with the following system of difference equations
| (C.1) |
where is an -dimensional real vector for all ; is the input data; is the final output; are the design parameters; and are and real matrices; is a continuously differentiable function from to for all . We consider an approximation of using ResNet with a system of difference equations (C.1). Let be the number of training data and be the training data. We divide the label of the training data into the following disjoint sets.
Let denote the final output for a given input data . We set . We define the loss function for all as follows:
| (C.2) |
We consider the learning for each label set using the gradient method. We find the gradient of the loss function (C.2) with respect to the design parameter for all using error backpropagation. Using the chain rule, we obtain
for all . From (C.1),
We define for all and . We obtain
Also,
Therefore, we can find the gradient of the loss function (C.2) with respect to the design parameters by using the following equations