Unity is Strength: Unifying Convolutional and Transformeral Features for Better Person Re-Identification
Abstract
Person Re-identification (ReID) aims to retrieve the specific person across non-overlapping cameras, which greatly helps intelligent transportation systems. As we all know, Convolutional Neural Networks (CNNs) and Transformers have the unique strengths to extract local and global features, respectively. Considering this fact, we focus on the mutual fusion between them to learn more comprehensive representations for persons. In particular, we utilize the complementary integration of deep features from different model structures. We propose a novel fusion framework called FusionReID to unify the strengths of CNNs and Transformers for image-based person ReID. More specifically, we first deploy a Dual-branch Feature Extraction (DFE) to extract features through CNNs and Transformers from a single image. Moreover, we design a novel Dual-attention Mutual Fusion (DMF) to achieve sufficient feature fusions. The DMF comprises Local Refinement Units (LRU) and Heterogenous Transmission Modules (HTM). LRU utilizes depth-separable convolutions to align deep features in channel dimensions and spatial sizes. HTM consists of a Shared Encoding Unit (SEU) and two Mutual Fusion Units (MFU). Through the continuous stacking of HTM, deep features after LRU are repeatedly utilized to generate more discriminative features. Extensive experiments on three public ReID benchmarks demonstrate that our method can attain superior performances than most state-of-the-arts. The source code is available at https://github.com/924973292/FusionReID.
Index Terms:
Image-based Person Re-identification, Convolutional Neural Network, Vision Transformer, Complementary Integration, Deep Feature FusionI Introduction
Person Re-identification (ReID) aims to retrieve the same person across different scenes and camera views.
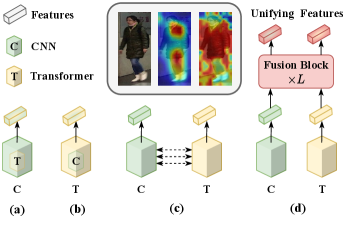
With the advancements in autonomous driving and intelligent surveillance systems, person ReID gains significant attention [1]. Due to variations in viewpoints, lighting conditions and postures, the appearance of the same person can be significantly different [2]. Therefore, most existing methods focus on learning robust and discriminative features to improve the performance. Currently, there are two kinds of outstanding methods for extracting person features, of which one based on Convolutional Neural Networks (CNNs) and the other based on Transformers [3]. In fact, each kind of methods offers its own strengths and limitations. As shown in the middle of Fig. 1, the three images from left to right are the original image, the feature map from ResNet50 [4], and the feature map from Vision Transformer (ViT) [5]. One can observe that CNN-based methods [6, 7, 8, 9, 10, 11, 12, 13, 14, 15] tend to extract local representations of person appearances, while lacking a comprehensive perspective. In contrast, Transformer-based methods [16, 17, 18, 19, 20, 21, 22, 23, 25] concentrate on establishing dependencies between image patches and capture global representations in terms of structural information, such as poses, body shapes and contours. Nevertheless, they may struggle to extract fine-grained features. Given the aforementioned facts, it is imperative to leverage the strengths of both CNNs and Transformers to enhance the ability of feature representations. As shown in Fig. 1(a), some methods [13] enhance CNNs by exploiting non-local blocks and self-attention mechanisms [3]. As shown in Fig. 1(b), some methods [26] leverage convolutional layers to improve the local capacity of Transformers. As shown in Fig. 1(c), some methods[27] build the interaction between CNNs and Transformers with intermediate features. Different from previous methods, as shown in Fig. 1(d), we directly fuse deep features from CNNs and Transformers. Thus, in this paper, we propose a novel fusion framework called FusionReID, which unifies the strengths of CNNs and Transformers for effective person ReID. Our framework comprises of two main components: a Dual-branch Feature Extraction (DFE) and a Dual-attention Mutual Fusion (DMF). More specifically, our DFE includes a CNN branch and a Transformer branch, and enables to independently extract two types of feature maps from a single image. Then, we pass the features into our DMF. The DMF comprises Local Refinement Units (LRU) and Heterogenous Transmission Modules (HTM). In fact, each HTM is composed of a Shared Encoding Unit (SEU) and two Mutual Fusion Units (MFU). At the beginning, we utilize LRU to align the channel dimensions and spatial sizes between two types of deep features. Then, SEU and MFU are deployed to achieve shared feature encoding and mutual feature fusion, respectively. Within the SEU, self-attention is utilized to capture the dependencies between local features. In contrast, MFU employs a cross-attention to explore the associations between local and global features across two branches. Through the stacking of HTM, it continuously fuses deep features from different branches, leading to the effective unity of CNNs and Transformers. We conduct comprehensive experiments on three large-scale person ReID benchmarks. Experimental results demonstrate that our method could attain superior performance than most state-of-the-arts. In short, our contributions can be summarized as follows:
-
•
We propose a new fusion framework called FusionReID to unify the strengths of CNNs and Transformers for image-based person ReID.
-
•
We design a novel Dual-attention Mutual Fusion (DMF), which can generate more discriminative features with stacking Heterogenous Transmission Modules (HTM).
-
•
Our proposed framework achieves superior performances than most state-of-the-art methods on three public person ReID benchmarks.
The rest of this work is organized as follows: Sec. II describes the related works. Sec. III presents our approach, including the introduction of DFE, DMF and the objective function. Sec. IV elaborates the datasets, experimental settings, experimental results and visualization analysis. Sec. V presents the conclusion and future work.
II Related Work
II-A CNN-based Person Re-identification
In recent years, person ReID has achieved impressive performances with deep learning. Typically, image-based person ReID approaches focus on extracting discriminative features [13]. Prior to Transformers, CNN-based methods have dominated person ReID. The importance of local features is first suggested in [28]. Typical methods (e.g., PCB [29], MGN [30]) divide person images into several stripes to obtain multi-grained representations. Besides, Yao et al. [31] introduce a part-based loss to extract fine-grained features from different local parts. Auxiliary information such as human pose [32, 33], parsing [34, 35] is also used for discriminative feature extraction. Other than focusing on the local parts of persons, other researchers try to utilize CNNs to extract more contextual features [36, 37]. However, limited by the local receptive field of CNNs, the contextual relationship between the human parts is not fully extracted. Inherently, the attention mechanism in Transformers adaptively models the relationship between all the human parts. Thus, the superiority of Transformers can help us alleviate this problem.
II-B Transformer-based Person Re-identification
Transformers have also been introduced to person ReID. As a primary work, He et al. [16] present a pure Transformer-based method named TransReID for object re-identification. Zhu et al. [17] adopt an automatic alignment to extract local features for accurate person ReID. Li et al. [38] propose a harmonious attention network to learn robust feature representations. Li et al. [39] introduce an encoder-decoder Transformer architecture for person ReID. Li et al. [40] leverage frequency-aware information for more robust feature extraction. Although these methods show better results, Transformers lack the inductive bias of CNNs. It has a weak perception of details such as textures, which leads to the ambiguity in persons and backgrounds. Fortunately, CNNs are sensitive to low-level information, so it is necessary to introduce the desired properties for person ReID.

II-C Combination of CNNs and Transformers
Some researchers are focusing on how to effectively fuse the features of CNNs and Transformers. For example, Conformer [41] and Mobile-Former [27] are designed with a parallel structure that allows continuous interaction of deep features. Dai et al. [42] unify depthwise convolutions and self-attentions for visual recognition. Zhang et al. [13] insert Transformer layers into different levels of features in CNNs. Chen et al. [10] enhance the features through channel and spatial attention modules for CNN backbones. For robust person ReID, Wang et al. [15] utilize a CNN backbone and the neighbor cluster method for Transformers. These previous methods [43, 44, 45] typically insert one structure into another or interactively stack two structures. In the case of two-branch structures, the continuous interaction starts at low-level feature extraction, potentially leading to the destruction of deep features. In this work, we abandon the complex structures and use a parallel feature fusion, preserving the inherent properties of CNNs and Transformers. Besides, our method is general and the used backbone can be easily replaced.
III Proposed Method
As shown in Fig. 2, we propose a novel framework named FusionReID to unify convolutional and transformeral features for person ReID. It consists a Dual-branch Feature Extraction (DFE) and a Dual-attention Mutual Fusion (DMF). In DFE, we first utilize the ResNet50 [4] and ViT-B/16 [5] as our backbones to extract convolutional features and transformeral features, respectively. Afterwards, these features are passed into DMF to achieve the deep fusion. The DMF consists of Local Refinement Units (LRU) and Heterogenous Transmission Modules (HTM). LRU is used for feature dimension alignment. Meanwhile, HTM includes a Shared Encoding Unit (SEU) and two Mutual Fusion Units (MFU), which achieve feature shared encoding and deep mutual fusion. To enhance the heterogenous features, HTM is continuously stacked. During training, we deploy the cross-entropy loss [46] and the triplet loss [47] to supervise the whole framework.
III-A Dual-branch Feature Extraction
To jointly extract deep features, previous works mainly modify the basic structures of CNNs and Transformers. Different from them, we directly utilize the CNNs and Transformers as our backbone networks. As shown in the left part of Fig. 2, the ResNet50 [4] is deployed to extract the convolutional features . Here , and present the channel number, height and weight, respectively. Meanwhile, the ViT-B/16 [5] is used to extract transformeral features . Here, denotes the embedding dimensions and represents the number of image patches. Additional learnable class token is also utilized to aggregate the patch features. We also add the camera embedding [16] to all the tokens to enhance the feature discrimination. In the CNN branch, is followed by a Generalized Mean Pooling (GeMP) [48] to obtain the final feature vector . In the Transformer branch, Z is divided into and . Furthermore, and are utilized for loss supervision. and are passed into DMF for the subsequent feature fusion.

III-B Dual-attention Mutual Fusion
After extracting features by DFE, we propose a novel DMF for deep feature fusion, as depicted in Fig. 2. Although feature concatenation can be utilized, this simple fusion strategy fails to fully exploit local features from CNNs and global features from Transformers. Therefore, our approach adopts the attention mechanism, including self-attention and cross-attention, to achieve a deep mutual fusion between the convolutional and transformeral features. More specifically, our proposed DMF consists of Local Refinement Units (LRU) and Heterogenous Transmission Modules (HTM). LRU is used to achieve feature alignment. HTM includes a Shared Encoding Unit (SEU) and two Mutual Fusion Units (MFU). The stacked HTM enables the reuse of deep features from CNNs and Transformers.
Local Refinement Unit. When adopting different backbones, the dimensions of output features may not be consistent. Thus, we first utilize the LRU to adjust the spatial sizes and channel dimensions of convolutional and transformeral features. Besides, LRU is useful for reducing the computational burden and increasing the efficiency. Meanwhile, for the transformeral features, LRU employs local interactions between addjacent patches, which is beneficial for introducing the spatial information. Specifically, taking the transformeral features as an example, is firstly reshaped to . Then, the depth-wise convolution and point-wise convolution are utilized by:
| (1) |
| (2) |
where presents the PReLU [49]. and present the depth-wise convolution and point-wise convolution with a Batch Normalization (BN) layer [50], respectively. The depth-wise convolution is applied to change the spatial size of features, then the point-wise convolution to reduce the channel number. Similarly, the convolutional features directly copied from is also passed into another LRU. Finally, we obtain the refined features and . After applying the Generalized-Mean (GeM) pooling [48] on and , and are utilized to supervise the CNN and Transformer backbones, respectively.
Shared Encoding Unit. In this work, SEU is designed to enable deep feature enhancement. We employ a self-attention mechanism to explore the dependencies among features, highlighting informative regions and suppressing irrelevant noises. As shown in Fig. 3(b), the transformeral features obtained from LRU are first flattened. Then it is concatenated with the global token to form . After that, is passed into SEU. In SEU, the Layer Normalization (LN)[51], Multi-Head Self-Attention (MHSA)[5] and Feed-Forward Network (FFN)[5] with residual connection [52] are utilized to yield transformeral features:
| (3) |
| (4) |
| (5) |
Similarly, the convoluational features is also passed into another SEU to obtain for deep feature enhancement. The SEU is shared in each HTM and encodes the convolutional and transformeral features for MFU.
Mutual Fusion Unit. MFU allows for global and local interactions between features of different attributes, forming a unified fusion framework through symmetric operations on tokenlized features. Specifically, MFU utilizes the cross-attention mechanism to achieve the deep feature fusion between the convolutional and transformeral features. As shown in Fig. 3(c), we first feed the global convolutional feature and local transformeral features into MFU. In MFU, we employ a Multi-Head Cross-Attention (MHCA), which consists of heads. More specifically, in the -th head of the CNN branch, the global token is passed into a linear transformation to generate , which is seen as the Query. The local features from the Transformer branch are passed into two linear transformations to generate and , which are seen as the Key and Value, respectively. Here, , , , . By utilizing them, the cross-attention is defined as:
| (6) |
where is the softmax activation function and means the transposition operation. The outputs of multiple heads () are concatenated to be . In the -th head of MHCA, the global feature from the Transformer branch is passed into a linear transformation to generate , which is seen as the Query. The local features from the CNN branch are passed into two linear transformations to generate and , which are seen as the Key and Value, respectively. Similarly, , , . The interaction is formulated as:
| (7) |
Here, () are concatenated to be . Then, by utilizing different FFNs, the features and are further encoded to obtain and :
| (8) |
| (9) |
Here, each FFN has two linear projections with the Gaussian Error Linear Unit (GELU) [53]. Finally, by utilizing the cross-attention mechanism, our proposed MFU could fuse two types of deep features to generate the unified representations.
Stacking of HTM. In this work, we combine a SEU and two MFUs as the Heterogenous Transmission Module (HTM). As shown in Fig. 2, we continuously stack HTM to fuse the deep features from the two-branch framework. Noted that, will be concatenated with the patch tokens in again, As shown in Fig. 3 (a), in the -1 step, has fused the information from the Transformer branch. Then, it is concatenated with initial deep features from , following self-attention to model their internal relationships again. By interacting with the local features, the transmission of heterogeneous information is achieved. The symmetry operation will be applied to . Through this continuously stacking, we unify two types of deep features. Thus, the mutual guidance and heterogenous transmission are achieved. In this way, it enables DMF to use different information at multiple levels. Then, the output and of the last layer are obtained for loss supervision. Finally, as shown in Fig. 2, six features are supervised during training. During testing, we concatenate these six features to form for the final retrieval.
III-C Objective Function
As shown in Fig. 2, six output features from DFE and DMF are supervised by the label smoothing cross-entropy loss [46] and triplet loss [47]. More specifically, the features and from the CNN branch and Transformer branch in DFE are first supervised for dual-branch learning. Taking as an example, the label smoothing cross-entropy loss can be defined by:
| (10) |
where is the corresponding ground-truth label. denotes the total number of classes. In a mini-batch, we build a feature triplet set . Here, presents the anchor features. and present its positive features and negative features, respectively. Thus, the triplet loss can be defined by:
| (11) |
where refers to the L2 norm. Afterwards, to improve the discriminative ability [54], we also employ the supervision after aligned features ( and ) and fused features ( and ) in DMF. Finally, we optimize the whole framework with six features simultaneously by a total loss:
| (12) |
IV Experiments
IV-A Datasets and Evaluation Metrics
We conduct experiments on three large-scale ReID datasets, i.e., Market1501 [55], DukeMTMC [5] and MSMT17 [56]. Market1501 consists of 32,668 images of 1,501 identities. DukeMTMC consists of 16,522 training images of 1,404 identities. It has 2,228 queries images and 17,661 gallery images. MSMT17 is the most challenging dataset. There are 126,441 images of 4,101 identities observed under 15 different cameras. All images provide their camera IDs in three datasets, which can be used as additional information when training and testing. Following previous works, we adopt the mean Average Precision (mAP) and Cumulative Matching Characteristics (CMC) at Rank-1 as our evaluation metrics.
IV-B Implementation Details
In this work, we realize our model with the Pytorch toolbox, and conduct experiments on two NVIDIA A800 GPUs. In DFE, we employ the pre-trained CNNs and Transformers on the ImageNet dataset [57] as our backbones. All person images are resized to 256128. When training, these images are augmented by random horizontal flipping, random cropping and random erasing [58]. The min-batch size is set to 128, containing 8 identities and 16 images per identity. During training, we adopt the Stochastic Gradient Descent (SGD) optimizer with a momentum of 0.9 and the weight decay of 1e-4. Besides, the learning rate is initialized as 5e-4. In the first 10 epoch, we adopt a warmup strategy with a linearly growing learning rate to 5e-3. Then, it decreases with a cosine decay for the next 170 epochs.
| Method | Backbone | Pattern | Market1501 | DukeMTMC | MSMT17 | |||
| mAP | Rank-1 | mAP | Rank-1 | mAP | Rank-1 | |||
| MGN [30] | ResNet50 | Conv | 86.9 | 95.7 | 78.4 | 88.7 | - | - |
| BFE [11] | ResNet50 | Conv | 86.2 | 95.3 | 75.9 | 88.9 | 51.5 | 78.8 |
| OSNet[59] | OSNet | Conv | 84.9 | 94.8 | 73.5 | 88.6 | 52.9 | 78.7 |
| HOReID[12] | ResNet50 | Conv | 84.9 | 94.2 | 75.6 | 86.9 | - | - |
| CDNet[60] | CDNet | Conv | 86.0 | 95.1 | 76.8 | 88.6 | 54.7 | 78.9 |
| TransReID[16] | ViT-B/16∗ | Trans | 88.9 | 95.2 | 82.0 | 90.7 | 67.4 | 85.3 |
| PFD[61] | ViT-B/16∗ | Trans | 89.7 | 95.5 | - | - | 64.4 | 83.8 |
| AAformer[17] | ViT-B/16∗ | Trans | 87.7 | 95.4 | 80.0 | 90.1 | 62.6 | 83.1 |
| GLTrans[20] | ViT-B/16 | Trans | 90.0 | 95.6 | 82.4 | 90.7 | 69.0 | 85.8 |
| ALDER [62] | ResNet50 | Conv + Trans | 88.9 | 95.6 | 78.9 | 89.9 | 59.1 | 82.5 |
| IGOAS [63] | ResNet50 | Conv + Trans | 84.1 | 93.4 | 75.1 | 86.9 | - | - |
| HAT[13] | ResNet50 | Conv + Trans | 89.5 | 95.6 | 81.4 | 90.4 | 61.2 | 82.3 |
| RGA-SC[14] | ResNet50 | Conv + Trans | 88.4 | 96.1 | - | - | 57.5 | 80.3 |
| ABDNet [10] | ResNet50 | Conv + Trans | 88.3 | 95.6 | 78.6 | 89.0 | 60.8 | 82.3 |
| FED[64] | ViT-B/16 | Conv + Trans | 86.3 | 95.0 | - | - | - | - |
| NFormer[15] | ResNet50 | Conv + Trans | 91.1 | 94.7 | 83.5 | 89.4 | 59.8 | 77.3 |
| FusionReID | ResNet50 + ViT-B/16* | Conv + Trans | 91.7 | 96.3 | 83.5 | 91.0 | 69.5 | 86.7 |
| FusionReID | ResNet50 + ViT-B/16 | Conv + Trans | 90.9 | 95.9 | 82.9 | 90.3 | 68.3 | 86.1 |
| FusionReID | ResNet50 + ViT-B/16* | Conv + Trans | 91.6 | 96.2 | 83.7 | 91.0 | 70.5 | 87.3 |
| FusionReID | ResNet50 + ViT-B/16 | Conv + Trans | 91.1 | 96.0 | 83.5 | 90.8 | 69.5 | 86.6 |
IV-C Comparison with State-of-the-arts
Tab. I shows the evaluation on three public ReID benchmarks, i.e., Market1501, DukeMTMC and MSMT17.
Market1501: On Market1501, we can see that our method achieves the best mAP and Rank-1. Noted that, RGA-SC [14] gains a comparable Rank-1 on Market1501, which learns a global attention to refine the features. Different from RGA-SC, we utilize HTM to encode and fuse two types of deep features. Thus, our method has a higher mAP than RGA-SC. The best performances show that our proposed framework is able to unify the strengths of CNNs and Transformers to get more discriminative representations.
DukeMTMC: Our method achieves the best Rank-1 and mAP on DukeMTMC. Noted that, NFormer [15] utilizes Transformers to model the relationships between all images, obtaining robust representations. Different from NFormer, we intergrate the heterogeneous information from CNNs and Transformers, resulting in a higher Rank-1 and mAP.
MSMT17: As shown in Tab. I, our method achieves the best mAP and Rank-1 on MSMT17. It is noteworthy that although NFormer performs well on small datasets, it performs poorly on the most challenging large-scale dataset, MSMT17. Although it has a lower number of parameters and FLOPs, our method outperforms it by about 10% on mAP and Rank-1. The results also demonstrate the stronger generalization performance of our method on different scale datasets. Overall, our method attains better performances on three public ReID benchmarks than most state-of-the-art methods. The best mAP and Rank-1 demonstrate the superiors of our method even with low image resolutions, especially on the large-scale dataset.
Performances with Different Configurations: In the last four rows of Tab. I, we compare the performance of FusionReID with different configurations, including the input image resolution and the overlapping of ViT. Generally, using high-resolution images and patch overlapping in ViT can improve the performance of FusioReID on all three datasets. High-resolution images contain more visual information, and the patch overlapping enhances correlations between neighboring areas. These superior performances demonstrate the generalization ability of our proposed FusionReID.
IV-D Ablation Study
Effectiveness of Key Components. We conduct experiments to verify the effectiveness of proposed key components. The ablation results are shown in Tab. II. Comparing the results of the first three rows, one can see that although DFE only concatenates two types of backbone features, higher ReID accuracies are achieved. Furthermore, we employ our DMF after DFE. The results are reported in the last four rows of Tab. I. When utilizing LRU, the performance has been slightly improved. After feature alignment in LRU, we further utilize SEU or MFU to encode and fuse deep features. Therefore, compared with DFE, the utilization of SEU gains 1.0% mAP and 0.7% Rank-1 improvements, and the utilization of MFU gains 1.2% mAP and 0.6% Rank-1 improvements. Furthermore, our method combines all proposed key components and achieves the best performance, i.e., 69.5% mAP and 86.7% Rank-1. Overall, the gradual increase in performances validates the effectiveness of our proposed key components.
| Method | DFE | DMF | MSMT17 | Params | FLOPs | |||
| LRU | SEU | MFU | mAP | Rank-1 | (M) | (G) | ||
| ResNet | ✕ | ✕ | ✕ | ✕ | 54.3 | 78.1 | 23.5 | 4.1 |
| ViT-B | ✕ | ✕ | ✕ | ✕ | 64.6 | 83.2 | 85.7 | 18.1 |
| Method1 | ✓ | ✕ | ✕ | ✕ | 67.5 | 85.1 | 109.1 | 22.1 |
| Method2 | ✓ | ✓ | ✕ | ✕ | 67.7 | 85.4 | 111.3 | 22.4 |
| Method3 | ✓ | ✓ | ✓ | ✕ | 68.7 | 86.1 | 125.5 | 27.3 |
| Method4 | ✓ | ✓ | ✕ | ✓ | 68.9 | 86.0 | 139.7 | 23.3 |
| Method5 | ✓ | ✓ | ✓ | ✓ | 69.5 | 86.7 | 153.8 | 28.1 |

| Method | MSMT17 | Params | FLOPs | ||
| SEU | MFU | mAP | Rank-1 | (M) | (G) |
| Front | Back | 69.5 | 86.7 | 21.3 | 2.9 |
| Only | - | 68.7 | 86.1 | 7.1 | 2.5 |
| Back | Front | 68.5 | 86.2 | 21.3 | 2.9 |
| - | Only | 68.9 | 86.0 | 14.2 | 0.5 |
| Method | MSMT17 | Params | FLOPs | ||
| SEU | MFU | mAP | Rank-1 | (M) | (G) |
| Shared | Shared | 69.1 | 86.6 | 14.2 | 2.9 |
| Shared | Unshared | 69.5 | 86.7 | 21.3 | 2.9 |
| Unshared | Shared | 68.7 | 86.0 | 21.3 | 2.9 |
| Unshared | Unshared | 69.2 | 86.3 | 28.4 | 2.9 |
| Method | MSMT17 | Params | FLOPs | |
| mAP | Rank-1 | (M) | (G) | |
| With GeMP | 69.5 | 86.7 | 153.8 | 28.1 |
| With GAP | 68.6 | 86.2 | 153.8 | 28.1 |
| Method | MSMT17 | Params | FLOPs | |||
| CNN | Transformer | Feature | mAP | Rank-1 | (M) | (G) |
| ResNet50 | - | 54.3 | 78.1 | 23.5 | 4.1 | |
| ResNet101 | - | 58.8 | 81.4 | 42.5 | 6.5 | |
| ResNet152 | - | 61.0 | 82.7 | 58.1 | 8.9 | |
| - | T2T-ViT-14 | 50.9 | 73.7 | 21.0 | 2.8 | |
| - | ViT-B/16∗ | 64.6 | 83.2 | 85.7 | 18.1 | |
| - | DeiT-B/16∗ | 63.3 | 83.1 | 85.7 | 18.1 | |
| ResNet50 | T2T-ViT-14 | 60.8 | 80.2 | 89.0 | 11.4 | |
| 56.7 | 78.3 | |||||
| 61.9 | 81.6 | |||||
| ViT-B/16∗ | 66.0 | 85.4 | 153.8 | 28.1 | ||
| 67.8 | 85.6 | |||||
| 69.5 | 86.7 | |||||
| DeiT-B/16∗ | 64.9 | 84.8 | 153.8 | 28.1 | ||
| 67.0 | 85.4 | |||||
| 69.7 | 86.4 | |||||
| ResNet101 | T2T-ViT-14 | 62.7 | 83.0 | 107.0 | 13.9 | |
| 58.4 | 79.9 | |||||
| 63.4 | 82.6 | |||||
| ViT-B/16∗ | 66.9 | 85.8 | 172.8 | 30.5 | ||
| 68.4 | 86.1 | |||||
| 70.5 | 87.3 | |||||
| DeiT-B/16∗ | 66.0 | 85.7 | 172.8 | 30.5 | ||
| 67.5 | 85.8 | |||||
| 70.3 | 87.1 | |||||
| ResNet152 | T2T-ViT-14 | 63.9 | 83.9 | 123.6 | 16.3 | |
| 59.1 | 80.2 | |||||
| 64.5 | 83.4 | |||||
| ViT-B/16∗ | 68.2 | 86.5 | 188.5 | 32.9 | ||
| 69.6 | 87.0 | |||||
| 71.8 | 87.9 | |||||
| DeiT-B/16∗ | 66.6 | 85.7 | 188.5 | 32.9 | ||
| 67.6 | 86.2 | |||||
| 70.9 | 87.5 | |||||
Effects of Various Structures in HTM. As shown in Fig. 4, we design various structures in HTM. The ablation results with various structures are shown in Tab. III. Here, the computation cost only considers the HTM part. One can find that the best performance is achieved by SEU first and then MFUs. The reasons may be twofolds: (1) The shared SEU in front can constrain the distributions of different deep features, which is helpful for the subsequent fusion. (2) The unshared MFU in back can utilize deep mutual fusion to generate better features, which highlights the importance of feature fusion in the last step. Among the four structures, the worst performance is achieved by MFU first and then SEU. There are two reasons for the poor results: (1) For the first HTM layer, the differences of deep features are significant, and it is difficult to fully integrate them through MFU. (2) For the subsequent HTMs, they only change the weighted parameters of global features. When it goes directly to the MFU of next HTM, it is still fusing with each other’s initial deep features. The difference problem in feature distribution still exists. Therefore, the order of SEU and MFU is very important. Thus, we deploy SEU first and then MFU to achieve better deep fusions.
Effects of Weight-Sharing in SEU and MFU. In Tab. IV, we analyze the effect of weight-sharing in SEU and MFU. The weight-sharing in SEU reduces feature differences across branches, improving MFU fusion. Conversely, unshared MFUs allow each branch to focus on distinct fusion patterns, enhancing their effectiveness. The combination of weight-sharing SEU and unshared MFU delivers the best overall performance.
Effects of Different Pooling Structures in DMF. In Tab. V, we compare the performance of different pooling structures in DMF. The GeMP clearly outperforms the Global Average Pooling (GAP), demonstrating its effectiveness to capture the distinctiveness with negligible computational cost.
Complementarity between CNNs and Transformers. We employ different backbone networks in DFE to verify the complementarity between CNNs and Transformers. In the CNN branch, we choose residual networks [4], including ResNet50/101/152. In the Transformer branch, we choose T2T-ViT-14 [65], ViT-B/16 [5] and DeiT-B/16 [66]. As shown in Tab. VI, we find that the performance of ViT-B/16∗ and DeiT-B/16∗ outperforms ResNet50/101/152. And for T2T-ViT-14, its corresponding features are also improved considerably with the help of CNNs. When unifying ResNet50 and ViT-B/16∗, the fused feature attains 66.0% mAP and 85.4% Rank-1, which has 11.7% mAP and 7.3% Rank-1 improvement over ResNet50. Besides, the fused feature attains 3.2% mAP and 1.6% Rank-1 improvement over the results of ViT-B/16∗, respectively. Moreover, the concatenated feature has a better mAP and Rank-1. These improvements suggest that our proposed framework has a significant effectiveness on unifying convolutional and transformeral features. In the same way, when combining ResNet50/101/152 and DeiT-B/16∗, all the metrics are increased significantly. In particular, when unifying ResNet152 and ViT-B/16∗, the overall feature obtains 71.8% mAP and 87.9% Rank-1. The results clearly demonstrate the complementarity between CNNs and Transformers. Meanwhile, they illustrates the generalization of our proposed method with different backbone networks.

Influence of the Stacked HTM. We conduct experiments on MSMT17 to verify the influence of the stacked HTM. The results are shown in Fig. 5. One can see that the accuracy curve changes but not significantly. As the number of stacked layers increases, the model performance gradually improves, especially from 1 to 2 layers. The refined features (middle curves) after LRU are stronger than the original features (lower curves), while the fused features (upper curves) are better than the refined features after LRU. The improvement indicates that the stacked HTM could better extract discriminative features. However, the performance is saturated when stacked layers are more than 2. Thus, we set the layers to 2 by default.
Influence of Fused Dimensions in DMF. Fig. 6 shows the influence of using different fused dimensions. We change the feature dimensions from 384 to 1536. We find that the performance is worst when the dimension is 384, and the performance is best when the dimension is 1152, achieving 70.0% mAP and 86.8% Rank-1. With the dimensions keep rising, the performance of mAP and Rank-1 begins to decrease. The reason may be that the model tends to over-fitting when the dimension is too high. Although the fused dimension of 384 has the smallest number of model parameters and FLOPs, it outperforms most sate-of-the-art methods. To avoid excessive model complexity, we set 768 as the default dimension.
Analysis of Computational Cost. The ablation analysis of computational cost is also presented. In Tab. II, as the accuracy increases, the computational cost increases. In fact, the computational complexity of our proposed method is acceptable. As shown in Fig. 6, when we reduce the fused dimension to 384, the slight increase in model memory and computational complexity results in considerable accuracy gains. For example, in comparison to TransReID, our approach demonstrates superior performance across three datasets, even with a moderate increase in parameters and FLOPs. This also proves that the effectiveness of our method does not come from simple model stacking and parameter increasing.



IV-E Visualization Analysis
In this subsection, we further explain the effectiveness of our approach through visualization analysis. First, we compare feature maps from typical CNNs and Transformers to verify their complementarities. Besides, we visualize attention maps in our DMF to illustrate the effects of deep fusions.
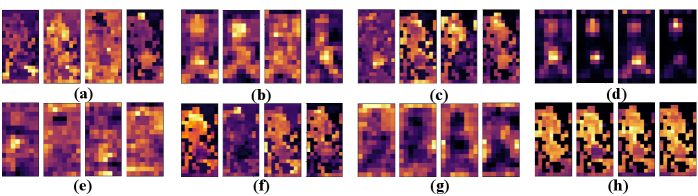
Visualization of Features in LRU and HTM. As shown in Fig. 7, we utilize Grad-CAM [67] to visualize the feature maps in LRU and HTM. Fig. 7(a) shows the original images of six persons. Comparing Fig. 7(b) and Fig. 7(g), one can see that convolutional features generally focus on meaningful local regions of persons, while transformeral features receives the global perception of persons. The differences verify their unique strengthes between CNNs and Transformers. Notably, Fig. 7(g) and Fig. 7(h) demonstrate that Transformers imitate the local perception of CNNs. More edge information is captured by the transformeral features. Comparing Fig. 7(c), Fig. 7(d), Fig. 7(h) and Fig. 7(i), one can see that the convolutional features after LRU appropriately highlight the regions of interest. Different from Fig. 7(d), Fig. 7(e) shows the convolutional features after HTM begin to focus on more regions for comprehensive perceptions. A similar phenomenon occurs in Fig. 7(i) and Fig. 7(j). Noted that, the highlighted regions from CNNs and Transformers are complementary. These visualizations provide a more intuitive understanding of the mutual fusion in our proposed methods.
Visualization of Different Heads in HTM. In Fig. 8, we visualize the attention weights of different heads in HTM, using the same example as in Fig. 9. As shown in Fig. 8(a), different heads focus on different areas. After the first MFU layer (Fig. 8(b)), the Transformer branch shifts to key parts of the body, with a smoother weight distribution, similar to CNN. After SEU (Fig. 8(c)), attention regions change, and the second MFU layer (Fig. 8(d)) narrows the focus to finer details like the head, legs, and briefcase. Meanwhile, after the second MFU layer (Fig. 8(h)), the CNN branch captures the entire human body with discriminative information. These visualizations confirm the effectiveness of the mutual guidance in our proposed methods.
Visualization of Attention Weights in SEU and MFU. As shown in Fig. 9, we visualize the attention weights in SEU and MFU. From the results, one can see that SEU can enhance their unique characteristics in the CNN branch and Transformer branch. For example, in the CNN branch, SEU merely assigns high attention weights to the meaningful local regions. In the Transformer branch, highlighted regions cover the human body and background with a global perception. Meanwhile, Fig. 9(c) and Fig. 9(e) clearly show that the MFU fuses their unique characteristics, which are different with Fig. 9(b) and Fig. 9(d). These visualizations could explain the mechanisms of feature enhancement and mutual fusion in SEU and MFU. Moreover, the changes of attention weights in SEU and MFU validate the effectiveness of our DMF.
V Conclusion and Future Work
In this paper, we propose a flexible fusion framework named FusionReID for image-based person ReID. It comprises a Dual-branch Feature Extraction (DFE) and a Dual-attention Mutual Fusion (DMF). In DFE, we employ CNNs and Transformers to extract deep features from a single image. Besides, DMF consists of the Local Refinement Unit (LRU) and Heterogenous Transmission Module (HTM). Through the continuous stacking of HTM, we unify heterogenous deep features from CNNs and Transformers. Experiments on three large-scale ReID benchmarks demonstrate that our method attains superior performances than most state-of-the-arts. Since the computation is still high, in the future, we will explore more lightweight fusion methods for the framework.
References
- [1] X. Bai, M. Yang, T. Huang, Z. Dou, R. Yu, and Y. Xu, “Deep-person: Learning discriminative deep features for person re-identification,” PR, vol. 98, p. 107036, 2020.
- [2] J. Yang, J. Zhang, F. Yu, X. Jiang, M. Zhang, X. Sun, Y.-C. Chen, and W.-S. Zheng, “Learning to know where to see: A visibility-aware approach for occluded person re-identification,” in ICCV, 2021, pp. 11 885–11 894.
- [3] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” NeurIPS, vol. 30, 2017.
- [4] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in CVPR, 2016, pp. 770–778.
- [5] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” arXiv preprint arXiv:2010.11929, 2020.
- [6] L. Chen, R. Sun, Y. Yu, Y. Du, and X. Zhang, “Visible thermal person re-identification via multi-branch modality residual complementary learning,” IVC, p. 105201, 2024.
- [7] X. Yin, J. Shi, Y. Zhang, Y. Lu, Z. Zhang, Y. Xie, and Y. Qu, “Robust pseudo-label learning with neighbor relation for unsupervised visible-infrared person re-identification,” arXiv preprint arXiv:2405.05613, 2024.
- [8] J. Shi, Y. Zhang, X. Yin, Y. Xie, Z. Zhang, J. Fan, Z. Shi, and Y. Qu, “Dual pseudo-labels interactive self-training for semi-supervised visible-infrared person re-identification,” in ICCV, 2023, pp. 11 218–11 228.
- [9] J. Shi, X. Yin, Y. Chen, Y. Zhang, Z. Zhang, Y. Xie, and Y. Qu, “Multi-memory matching for unsupervised visible-infrared person re-identification,” arXiv preprint arXiv:2401.06825, 2024.
- [10] T. Chen, S. Ding, J. Xie, Y. Yuan, W. Chen, Y. Yang, Z. Ren, and Z. Wang, “Abd-net: Attentive but diverse person re-identification,” in ICCV, 2019, pp. 8351–8361.
- [11] Z. Dai, M. Chen, X. Gu, S. Zhu, and P. Tan, “Batch dropblock network for person re-identification and beyond,” in ICCV, 2019, pp. 3691–3701.
- [12] G. Wang, S. Yang, H. Liu, Z. Wang, Y. Yang, S. Wang, G. Yu, E. Zhou, and J. Sun, “High-order information matters: Learning relation and topology for occluded person re-identification,” in CVPR, 2020, pp. 6449–6458.
- [13] G. Zhang, P. Zhang, J. Qi, and H. Lu, “Hat: Hierarchical aggregation transformers for person re-identification,” in ACM MM, 2021, pp. 516–525.
- [14] Z. Zhang, C. Lan, W. Zeng, X. Jin, and Z. Chen, “Relation-aware global attention for person re-identification,” in CVPR, 2020, pp. 3186–3195.
- [15] H. Wang, J. Shen, Y. Liu, Y. Gao, and E. Gavves, “Nformer: Robust person re-identification with neighbor transformer,” in CVPR, 2022, pp. 7297–7307.
- [16] S. He, H. Luo, P. Wang, F. Wang, H. Li, and W. Jiang, “Transreid: Transformer-based object re-identification,” in ICCV, 2021, pp. 15 013–15 022.
- [17] K. Zhu, H. Guo, S. Zhang, Y. Wang, G. Huang, H. Qiao, J. Liu, J. Wang, and M. Tang, “Aaformer: Auto-aligned transformer for person re-identification,” arXiv preprint arXiv:2104.00921, 2021.
- [18] P. Zhang, Y. Wang, Y. Liu, Z. Tu, and H. Lu, “Magic tokens: Select diverse tokens for multi-modal object re-identification,” in CVPR, 2024, pp. 17 117–17 126.
- [19] Y. Wang, X. Liu, P. Zhang, H. Lu, Z. Tu, and H. Lu, “Top-reid: Multi-spectral object re-identification with token permutation,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 6, 2024, pp. 5758–5766.
- [20] Y. Wang, P. Zhang, D. Wang, and H. Lu, “Other tokens matter: Exploring global and local features of vision transformers for object re-identification,” CVIU, vol. 244, p. 104030, 2024.
- [21] C. Yu, X. Liu, Y. Wang, P. Zhang, and H. Lu, “Tf-clip: Learning text-free clip for video-based person re-identification,” in AAAI, vol. 38, no. 7, 2024, pp. 6764–6772.
- [22] X. Liu, P. Zhang, C. Yu, X. Qian, X. Yang, and H. Lu, “A video is worth three views: Trigeminal transformers for video-based person re-identification,” TITS, 2024.
- [23] X. Liu, C. Yu, P. Zhang, and H. Lu, “Deeply coupled convolution–transformer with spatial–temporal complementary learning for video-based person re-identification,” TNNLS, 2023.
- [24] X. Liu, P. Zhang, and H. Lu, “Video-based person re-identification with long short-term representation learning,” in ICIG. Springer, 2023, pp. 55–67.
- [25] H. Lu, X. Zou, and P. Zhang, “Learning progressive modality-shared transformers for effective visible-infrared person re-identification,” in AAAI, vol. 37, no. 2, 2023, pp. 1835–1843.
- [26] H. Wu, B. Xiao, N. Codella, M. Liu, X. Dai, L. Yuan, and L. Zhang, “Cvt: Introducing convolutions to vision transformers,” in ICCV, 2021, pp. 22–31.
- [27] Y. Chen, X. Dai, D. Chen, M. Liu, X. Dong, L. Yuan, and Z. Liu, “Mobile-former: Bridging mobilenet and transformer,” in CVPR, 2022, pp. 5270–5279.
- [28] D. Yi, Z. Lei, S. Liao, and S. Z. Li, “Deep metric learning for person re-identification,” in ICPR. IEEE, 2014, pp. 34–39.
- [29] Y. Sun, L. Zheng, Y. Yang, Q. Tian, and S. Wang, “Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline),” in ECCV, 2018, pp. 480–496.
- [30] G. Wang, Y. Yuan, X. Chen, J. Li, and X. Zhou, “Learning discriminative features with multiple granularities for person re-identification,” in ACM MM, 2018, pp. 274–282.
- [31] H. Yao, S. Zhang, R. Hong, Y. Zhang, C. Xu, and Q. Tian, “Deep representation learning with part loss for person re-identification,” TIP, vol. 28, no. 6, pp. 2860–2871, 2019.
- [32] M. S. Sarfraz, A. Schumann, A. Eberle, and R. Stiefelhagen, “A pose-sensitive embedding for person re-identification with expanded cross neighborhood re-ranking,” in CVPR, 2018, pp. 420–429.
- [33] L. Zheng, Y. Huang, H. Lu, and Y. Yang, “Pose-invariant embedding for deep person re-identification,” TIP, vol. 28, no. 9, pp. 4500–4509, 2019.
- [34] L. He, Y. Wang, W. Liu, H. Zhao, Z. Sun, and J. Feng, “Foreground-aware pyramid reconstruction for alignment-free occluded person re-identification,” in ICCV, 2019, pp. 8450–8459.
- [35] Z. Zhang, C. Lan, W. Zeng, and Z. Chen, “Densely semantically aligned person re-identification,” in CVPR, 2019, pp. 667–676.
- [36] H. Luo, Y. Gu, X. Liao, S. Lai, and W. Jiang, “Bag of tricks and a strong baseline for deep person re-identification,” in CVPRW, 2019, pp. 0–0.
- [37] T. Xiao, H. Li, W. Ouyang, and X. Wang, “Learning deep feature representations with domain guided dropout for person re-identification,” in CVPR, 2016, pp. 1249–1258.
- [38] W. Li, X. Zhu, and S. Gong, “Harmonious attention network for person re-identification,” in CVPR, 2018, pp. 2285–2294.
- [39] Y. Li, J. He, T. Zhang, X. Liu, Y. Zhang, and F. Wu, “Diverse part discovery: Occluded person re-identification with part-aware transformer,” in CVPR, 2021, pp. 2898–2907.
- [40] C. Li, S. Chen, and M. Ye, “Adaptive high-frequency transformer for diverse wildlife re-identification,” in ECCV. Springer, 2025, pp. 296–313.
- [41] A. Gulati, J. Qin, C.-C. Chiu, N. Parmar, Y. Zhang, J. Yu, W. Han, S. Wang, Z. Zhang, Y. Wu et al., “Conformer: Convolution-augmented transformer for speech recognition,” arXiv preprint arXiv:2005.08100, 2020.
- [42] Z. Dai, H. Liu, Q. V. Le, and M. Tan, “Coatnet: Marrying convolution and attention for all data sizes,” NeurIPS, vol. 34, pp. 3965–3977, 2021.
- [43] Z. Gao, P. Chen, T. Zhuo, M. Liu, L. Zhu, M. Wang, and S. Chen, “A semantic perception and cnn-transformer hybrid network for occluded person re-identification,” TCSVT, vol. 34, no. 4, pp. 2010–2025, 2024.
- [44] Q. Yan, S. Liu, S. Xu, C. Dong, Z. Li, J. Q. Shi, Y. Zhang, and D. Dai, “3d medical image segmentation using parallel transformers,” PR, vol. 138, p. 109432, 2023.
- [45] X. Xie, D. Wu, M. Xie, and Z. Li, “Ghostformer: Efficiently amalgamated cnn-transformer architecture for object detection,” PR, vol. 148, p. 110172, 2024.
- [46] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna, “Rethinking the inception architecture for computer vision,” in CVPR, 2016, pp. 2818–2826.
- [47] A. Hermans, L. Beyer, and B. Leibe, “In defense of the triplet loss for person re-identification,” arXiv preprint arXiv:1703.07737, 2017.
- [48] F. Radenović, G. Tolias, and O. Chum, “Fine-tuning cnn image retrieval with no human annotation,” TPAMI, vol. 41, no. 7, pp. 1655–1668, 2018.
- [49] K. He, X. Zhang, S. Ren, and J. Sun, “Delving deep into rectifiers: Surpassing human-level performance on imagenet classification,” in ICCV, 2015, pp. 1026–1034.
- [50] S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” in ICML. pmlr, 2015, pp. 448–456.
- [51] R. Xiong, Y. Yang, D. He, K. Zheng, S. Zheng, C. Xing, H. Zhang, Y. Lan, L. Wang, and T. Liu, “On layer normalization in the transformer architecture,” in ICML. PMLR, 2020, pp. 10 524–10 533.
- [52] K. He, X. Zhang, S. Ren, and J. Sun, “Identity mappings in deep residual networks,” in ECCV. Springer, 2016, pp. 630–645.
- [53] D. Hendrycks and K. Gimpel, “Gaussian error linear units (gelus),” arXiv preprint arXiv:1606.08415, 2016.
- [54] P. Zhang, D. Wang, H. Lu, H. Wang, and X. Ruan, “Amulet: Aggregating multi-level convolutional features for salient object detection,” in ICCV, 2017, pp. 202–211.
- [55] L. Zheng, L. Shen, L. Tian, S. Wang, J. Wang, and Q. Tian, “Scalable person re-identification: A benchmark,” in ICCV, 2015, pp. 1116–1124.
- [56] L. Wei, S. Zhang, W. Gao, and Q. Tian, “Person transfer gan to bridge domain gap for person re-identification,” in CVPR, 2018, pp. 79–88.
- [57] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in CVPR. IEEE, 2009, pp. 248–255.
- [58] Z. Zhong, L. Zheng, G. Kang, S. Li, and Y. Yang, “Random erasing data augmentation,” in AAAI, vol. 34, no. 07, 2020, pp. 13 001–13 008.
- [59] K. Zhou, Y. Yang, A. Cavallaro, and T. Xiang, “Omni-scale feature learning for person re-identification,” in ICCV, 2019, pp. 3702–3712.
- [60] H. Li, G. Wu, and W.-S. Zheng, “Combined depth space based architecture search for person re-identification,” in CVPR, 2021, pp. 6729–6738.
- [61] T. Wang, H. Liu, P. Song, T. Guo, and W. Shi, “Pose-guided feature disentangling for occluded person re-identification based on transformer,” in AAAI, vol. 36, no. 3, 2022, pp. 2540–2549.
- [62] Q. Zhang, J. Lai, Z. Feng, and X. Xie, “Seeing like a human: Asynchronous learning with dynamic progressive refinement for person re-identification,” TIP, vol. 31, pp. 352–365, 2021.
- [63] C. Zhao, X. Lv, S. Dou, S. Zhang, J. Wu, and L. Wang, “Incremental generative occlusion adversarial suppression network for person reid,” TIP, vol. 30, pp. 4212–4224, 2021.
- [64] Z. Wang, F. Zhu, S. Tang, R. Zhao, L. He, and J. Song, “Feature erasing and diffusion network for occluded person re-identification,” in CVPR, 2022, pp. 4754–4763.
- [65] L. Yuan, Y. Chen, T. Wang, W. Yu, Y. Shi, Z.-H. Jiang, F. E. Tay, J. Feng, and S. Yan, “Tokens-to-token vit: Training vision transformers from scratch on imagenet,” in ICCV, 2021, pp. 558–567.
- [66] H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablayrolles, and H. Jégou, “Training data-efficient image transformers & distillation through attention,” in ICML. PMLR, 2021, pp. 10 347–10 357.
- [67] R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra, “Grad-cam: Visual explanations from deep networks via gradient-based localization,” in ICCV, 2017, pp. 618–626.