Unifying Cosine and PLDA Back-ends for Speaker Verification
Abstract
State-of-art speaker verification (SV) systems use a back-end model to score the similarity of speaker embeddings extracted from a neural network model. The commonly used back-end models are the cosine scoring and the probabilistic linear discriminant analysis (PLDA) scoring. With the recently developed neural embeddings, the theoretically more appealing PLDA approach is found to have no advantage against or even be inferior the simple cosine scoring in terms of SV system performance. This paper presents an investigation on the relation between the two scoring approaches, aiming to explain the above counter-intuitive observation. It is shown that the cosine scoring is essentially a special case of PLDA scoring. In other words, by properly setting the parameters of PLDA, the two back-ends become equivalent. As a consequence, the cosine scoring not only inherits the basic assumptions for the PLDA but also introduces additional assumptions on the properties of input embeddings. Experiments show that the dimensional independence assumption required by the cosine scoring contributes most to the performance gap between the two methods under the domain-matched condition. When there is severe domain mismatch and the dimensional independence assumption does not hold, the PLDA would perform better than the cosine for domain adaptation.
Index Terms: speaker verification, cosine, PLDA, dimensional independence
1 Introduction
Speaker verification (SV) is the task of verifying the identity of a person from the characteristics of his or her voice. It has been widely studied for decades with significant performance advancement. State-of-the-art SV systems are predominantly embedding based, comprising a front-end embedding extractor and a back-end scoring model. The front-end module transforms input speech into a compact embedding representation of speaker-related acoustic characteristics. The back-end model computes the similarity of two input speaker embeddings and determines whether they are from the same person.
There are two commonly used back-end scoring methods. One is the cosine scoring, which assumes the input embeddings are angularly discriminative. The SV score is defined as the cosine similarity of two embeddings and , which are mean-subtracted and length-normalized [1], i.e.,
| (1) | |||
| (2) |
The other method of back-end scoring is based on probabilistic linear discriminant analysis (PLDA) [2]. It takes the assumption that the embeddings (also mean-subtracted and length-normalized) are in general Gaussian distributed.
It has been noted that the standard PLDA back-end performs significantly better than the cosine back-end on conventional i-vector embeddings [3]. Unfortunately, with the powerful neural speaker embeddings that are widely used nowadays [4], the superiority of PLDA vanishes and even turns into inferiority. This phenomenon has been evident in our experimental studies, especially when the front-end is trained with the additive angular margin softmax loss[5, 6].
The observation of PLDA being not as good as the cosine similarity is against the common sense of the back-end model design. Compared to the cosine, PLDA has more learnable parameters and incorporates additional speaker labels for training. Consequently, PLDA is generally considered to be more effective in discriminating speaker representations. This contradiction between experimental observations and theoretical expectation deserves thoughtful investigations on PLDA. In [7, 8, 9], Cai et al argued that the problem should have arise from the neural speaker embeddings. It is noted that embeddings extracted from neural networks tend to be non-Gaussian for individual speakers and the distributions across different speakers are non-homogeneous. These irregular distributions cause the performance degradation of verification systems with the PLDA back-end. In relation to this perspective, a series of regularization approaches have been proposed to force the neural embeddings to be homogeneously Gaussian distributed, e.g., Gaussian-constrained loss [7], variational auto-encoder[8] and discriminative normalization flow[9, 10].
In this paper, we try to present and substantiate a very different point of view from that in previous research. We argue that the suspected irregular distribution of speaker embeddings does not necessarily contribute to the inferiority of PLDA versus the cosine. Our view is based on the evidence that the cosine can be regarded as a special case of PLDA. This is indeed true but we have not yet found any work mentioning it. Existing studies have been treating the PLDA and the cosine scoring methods separately. We provide a short proof to unify them. It is noted that the cosine scoring, as a special case of PLDA, also assumes speaker embeddings to be homogeneous Gaussian distributed. Therefore, if the neural speaker embeddings are distributed irregularly as previously hypothesized, both back-ends should exhibit performance degradation.
By unifying the cosine and the PLDA back-ends, it can be shown that the cosine scoring puts stricter assumptions on the embeddings than PLDA. Details of these assumptions are explained in Section 3. Among them, the dimensional independence assumption is found to play a key role in explaining the performance gap between the two back-ends. It is evidenced by incorporating the dimensional independence assumption into the training of PLDA, leading to the diagonal PLDA (DPLDA). This variation of PLDA shows a significant performance improvement under the domain-matched condition. However, when severe domain mismatch exists and back-end adaptation is needed, PLDA performs better than both the cosine and DPLDA. This is because the dimension independence assumption does not hold. Analysis on the between-/within-class covariance of speaker embeddings supports these statements.
2 Review of PLDA
Theoretically PLDA is a probabilistic extension to the classical linear discriminant analysis (LDA)[11]. It incorporates a Gaussian prior on the class centroids in LDA. Among the variants of PLDA, the two-covariance PLDA[12] has been commonly used in speaker verification systems. A straightforward way to explain two-covariance PLDA is by using probabilistic graphical model[13].
2.1 Modeling
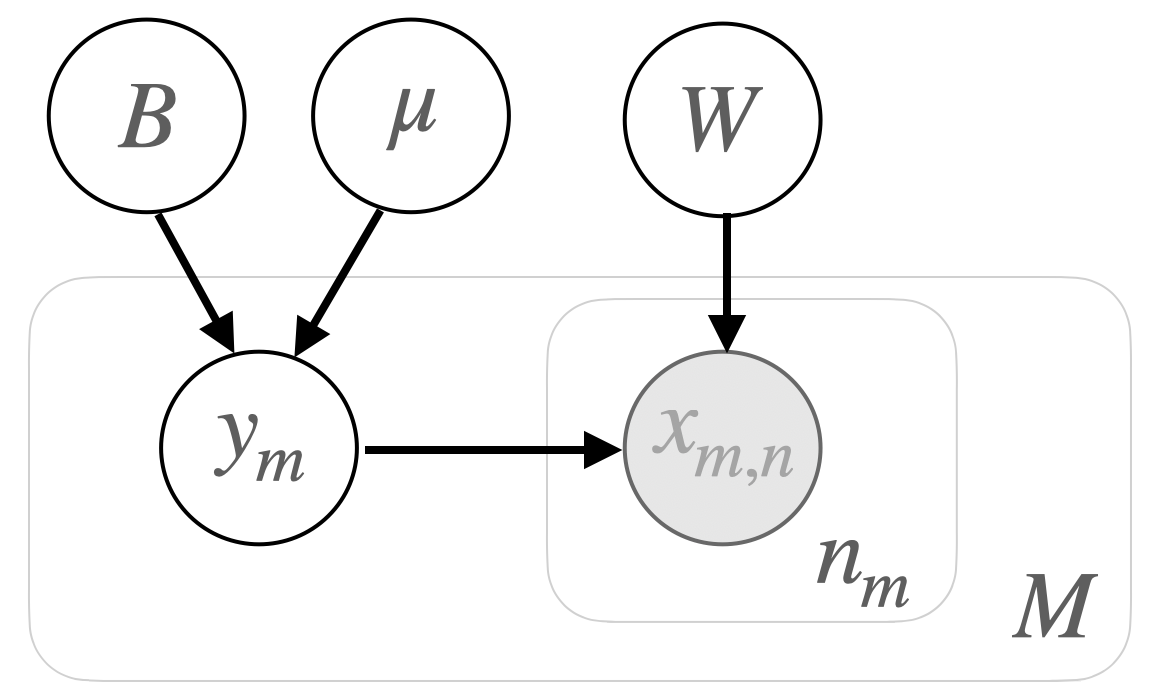
Consider speech utterances coming from speakers, where the -th speaker is associated with utterances. With a front-end embedding extractor, each utterance can be represented by an embedding of dimensions. The embedding of the -th utterance from the -th speaker is denoted as . Let represent these per-utterance embeddings. Additionally, PLDA supposes the existence of per-speaker embeddings . They are referred to as latent speaker identity variables in [14].
With the graphical model shown in Fig.1, these embeddings are generated as follows,
-
•
Randomly draw the per-speaker embedding , for ;
-
•
Randomly draw the per-utterance embedding , for .
where denotes the model parameters of PLDA. Note that and are precision matrices. The joint distribution can be derived as,
| (3) |
2.2 Training
Estimation of PLDA model parameters can be done with the iterative E-M algorithm, as described in Algorithm 1. The algorithm requires initialization of model parameters. In kaldi[15], the initialization strategy is to set and .
2.3 Scoring
Assuming the embeddings are mean-subtracted and length-normalized, we let to simplify the scoring function. Given two per-utterance embeddings , the PLDA generates a log-likelihood ratio (LLR) that measures the relative likelihood of the two embeddings coming from the same speaker. The LLR is defined as,
| (4) |
where and represent the same-speaker and different-speaker hypotheses. To derive the score function, without loss of generality, consider a set of embeddings that come from the same speaker. It can be proved that
3 Cosine as a typical PLDA
Relating Eq.6 to Eq.2 for the cosine similarity measure, it is noted that when , the LLR of PLDA degrades into the cosine similarity, as . It is also noted that the condition of is not required. PLDA is equivalent to the cosine if and only if and , where .
Given , we have
| (9) | ||||
| (10) |
Without loss of generality, we let . In other words, the cosine is a typical PLDA with both within-class covariance and between-class covariance fixed as an identity matrix.
So far we consider only the simplest pairwise scoring. In the general case of many-vs-many scoring, the PLDA and cosine are also closely related. For example, let us consider two sets of embeddings and of size and , respectively. Their centroids are denoted by and . It can be shown,
| (11) | ||||
| (12) |
under the condition of . The term depends only on and .
This has shown that the cosine puts more stringent assumptions than PLDA on the input embeddings. These assumptions are:
-
1.
(dim-indep) Dimensions of speaker embeddings are mutually uncorrelated or independent;
-
2.
Based on 1), all dimensions share the same variance value.
As the embeddings are assumed to be Gaussian, dimensional uncorrelatedness is equivalent to dimensional independence.
3.1 Diagonal PLDA
With Gaussian distributed embeddings, the dim-indep assumption implies that speaker embeddings have diagonal covariance. To analyse the significance of this assumption to the performance of SV backend, a diagonal constraint is applied to updating and in Algorithm 1, i.e.,
| (13) | ||||
| (14) |
where denotes the Hadamard square. The PLDA trained in this way is named as the diagonal PLDA (DPLDA). The relationship between DPLDA and PLDA is similar to that between the diagonal GMM and the full-covariance GMM.
4 Experimental setup
Experiments are carried out with the Voxceleb1+2 [16] and the CNCeleb1 databases[17]. A vanilla ResNet34[18] model is trained with 1029K utterances from 5994 speakers in the training set of Voxceleb2. Following the state-of-the-art training configuration111https://github.com/TaoRuijie/ECAPA-TDNN, data augmentation with speed perturbation, reverberation and spectrum augmentation[19] is applied. The AAM-softmax loss[5] is adopted to produce angular-discriminative speaker embeddings.
The input features to ResNet34 are 80-dimension filterbank coefficients with mean normalization over a sliding window of up to 3 seconds long. Voice activity detection is carried out with the default configuration in kaldi222https://github.com/kaldi-asr/kaldi/blob/master/egs/voxceleb/v2/conf. The front-end module is trained to generate 256-dimension speaker embeddings, which are subsequently mean-subtracted and length-normalized. The PLDA backend is implemented in kaldi and modified to the DPLDA according to Eq. 13-14.
Performance evaluation is carried out on the test set in VoxCeleb1 and CNCeleb1. The evaluation metrics are equal error rate (EER) and decision cost function (DCF) with or .
4.1 Performance comparison between backends
As shown in Table 1, the performance gap between cosine and PLDA backends can be observed from the experiment on VoxCeleb. Cosine outperforms PLDA by relatively improvements of in terms of equal error rate (EER) and in terms of minimum Decision Cost Function with (DCF). The performance difference becomes much more significant with DCF, e.g., by PLDA versus by the cosine. Similar results are noted on other test sets of VoxCeleb1 ((not listed here for page limit)).
The conventional setting of using LDA to preprocess raw speaker embeddings before PLDA is evaluated. It is labelled as LDA+PLDA in Table 1. Using LDA appears to have a negative effect on PLDA. This may be due to the absence of the dim-indep constraint on LDA. We argue that it is unnecessary to apply LDA to regularize the embeddings. The commonly used LDA preprocessing is removed in the following experiments.
| EER% | DCF0.01 | DCF0.001 | |
| cos | 1.06 | 0.1083 | 0.1137 |
| PLDA | 1.86 | 0.2198 | 0.3062 |
| LDA+PLDA | 2.17 | 0.2476 | 0.3715 |
| DPLDA | 1.11 | 0.1200 | 0.1426 |
The DPLDA incorporates the dim-indep constraint into PLDA training. As shown in Table 1, it improves the EER of PLDA from to , which is comparable to cosine. This clearly confirms the importance of dim-indep.
4.2 Performance degradation in Iterative PLDA training
According to the derivation in Section 3, PLDA implemented in Algorithm 1 is initialized as the cosine, e.g., . However, the PLDA has been shown to be inferior to the cosine by the results in Table 1. Logically it would be expected that the performance of PLDA degrades in the iterative EM training. Fig 2 shows the plot of EERs versus number of training iterations. Initially PLDA achieves exactly the same performance as cosine. In the first iteration, the EER seriously increases from 1.06% to 1.707%. For DPLDA, the dim-indep constraint shows an effect of counteracting the degradation.

4.3 When domain mismatch exists
The superiority of cosine over PLDA has been evidenced on the VoxCeleb dataset, of which both training and test data come from the same domain, e.g., interviews collected from YouTube. In many real-world scenarios, domain mismatch between training and test data commonly exists. A practical solution is to acquire certain amount of in-domain data and update the backend accordingly. The following experiment is to analyse the effect of domain mismatch on the performance of backend models.
The CNCeleb1 dataset is adopted as the domain-mismatched data. It is a multi-genre dataset of Chinese speech with very different acoustic conditions from VoxCeleb. The ResNet34 trained on VoxCeleb is deployed to exact embeddings from the utterances in CNCeleb1. The backends are trained and evaluated on the training and test embeddings of CNCeleb1.
As shown in Table2, the performance of both cosine and DPLDA are inferior to PLDA. Due to that the dim-indep assumption no longer holds, the diagonal constraint on covariance does not bring any performance improvement to cosine and DPLDA.
| EER% | DCF0.01 | DCF0.001 | |
| cos | 10.11 | 0.5308 | 0.7175 |
| PLDA | 8.90 | 0.4773 | 0.6331 |
| DPLDA | 10.24 | 0.5491 | 0.8277 |
4.4 Analysis of between-/within-class covariances
To analyze the correlation of individual dimensions of the embeddings, the between-class and within-class covariances, and , are computed as follows,
| (15) | ||||
| (16) |
where and . These are the training equations of LDA and closely related to the M-step of PLDA. Note that for visualization, the elements in and are converted into their absolute value.
In Fig.3, both between-class and within-class covariances show clearly diagonal patterns, in the domain-matched case (plot on the top). This provides additional evidence to support the dim-indep assumption aforementioned. However, this assumption would be broken with strong domain-mismatched data in CNCeleb. As shown by the two sub-plots in the bottom of Fig 3, even though the within-class covariance plot on the right shows a nice diagonal pattern, it tends to vanish for the between-class covariance (plot on the left). Off-diagonal elements have large absolute value and the dimension correlation pattern appears, suggesting the broken of dim-indep. The numerical measure of diagonal index also confirms this observation.

5 Conclusion
The reason why PLDA appears to be inferior to the cosine scoring with neural speaker embeddings has been exposed with both theoretical and experimental evidence. It has been shown that the cosine scoring is essentially a special case of PLDA. Hence, the non-Gaussian distribution of speaker embeddings should not be held responsible for explaining the performance difference between the PLDA and cosine back-ends. Instead, it should be attributed to the dimensional independence assumption made by the cosine, as evidenced in our experimental results and analysis. Nevertheless, this assumption fits well only in the domain-matched condition. When severe domain mismatch exists, the assumption no longer holds and PLDA can work better than the cosine. Further improvements on PLDA need to take this assumption into consideration. It is worth noting that the AAM-softmax loss should have the benefit of regularizing embeddings to be homogeneous Gaussian, considering good performance of the cosine scoring.
References
- [1] D. Garcia-Romero and C. Y. Espy-Wilson, “Analysis of i-vector length normalization in speaker recognition systems,” in Twelfth annual conference of the international speech communication association, 2011.
- [2] S. Ioffe, “Probabilistic linear discriminant analysis,” in European Conference on Computer Vision. Springer, 2006, pp. 531–542.
- [3] N. Dehak, P. J. Kenny, R. Dehak, P. Dumouchel, and P. Ouellet, “Front-end factor analysis for speaker verification,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 19, no. 4, pp. 788–798, 2010.
- [4] H. Zeinali, S. Wang, A. Silnova, P. Matějka, and O. Plchot, “But system description to voxceleb speaker recognition challenge 2019,” arXiv preprint arXiv:1910.12592, 2019.
- [5] J. Deng, J. Guo, N. Xue, and S. Zafeiriou, “Arcface: Additive angular margin loss for deep face recognition,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 4690–4699.
- [6] X. Xiang, S. Wang, H. Huang, Y. Qian, and K. Yu, “Margin matters: Towards more discriminative deep neural network embeddings for speaker recognition,” in 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC). IEEE, 2019, pp. 1652–1656.
- [7] L. Li, Z. Tang, Y. Shi, and D. Wang, “Gaussian-constrained training for speaker verification,” in ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019, pp. 6036–6040.
- [8] Y. Zhang, L. Li, and D. Wang, “Vae-based regularization for deep speaker embedding,” arXiv preprint arXiv:1904.03617, 2019.
- [9] Y. Cai, L. Li, A. Abel, X. Zhu, and D. Wang, “Deep normalization for speaker vectors,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 733–744, 2020.
- [10] L. Li, D. Wang, and T. F. Zheng, “Neural discriminant analysis for deep speaker embedding,” arXiv preprint arXiv:2005.11905, 2020.
- [11] S. Balakrishnama and A. Ganapathiraju, “Linear discriminant analysis-a brief tutorial,” Institute for Signal and information Processing, vol. 18, no. 1998, pp. 1–8, 1998.
- [12] A. Sizov, K. A. Lee, and T. Kinnunen, “Unifying probabilistic linear discriminant analysis variants in biometric authentication,” in Joint IAPR International Workshops on Statistical Techniques in Pattern Recognition (SPR) and Structural and Syntactic Pattern Recognition (SSPR). Springer, 2014, pp. 464–475.
- [13] M. I. Jordan, “An introduction to probabilistic graphical models,” 2003.
- [14] N. Brümmer and E. De Villiers, “The speaker partitioning problem.” in Odyssey, 2010, p. 34.
- [15] D. Povey, A. Ghoshal, G. Boulianne, L. Burget, O. Glembek, N. Goel, M. Hannemann, P. Motlicek, Y. Qian, P. Schwarz et al., “The kaldi speech recognition toolkit,” in Proc. of ASRU, no. EPFL-CONF-192584. IEEE Signal Processing Society, 2011.
- [16] A. Nagrani, J. S. Chung, and A. Zisserman, “Voxceleb: a large-scale speaker identification dataset,” arXiv preprint arXiv:1706.08612, 2017.
- [17] L. Li, R. Liu, J. Kang, Y. Fan, H. Cui, Y. Cai, R. Vipperla, T. F. Zheng, and D. Wang, “Cn-celeb: multi-genre speaker recognition,” Speech Communication, 2022.
- [18] J. S. Chung, J. Huh, S. Mun, M. Lee, H. S. Heo, S. Choe, C. Ham, S. Jung, B.-J. Lee, and I. Han, “In defence of metric learning for speaker recognition,” arXiv preprint arXiv:2003.11982, 2020.
- [19] D. S. Park, W. Chan, Y. Zhang, C.-C. Chiu, B. Zoph, E. D. Cubuk, and Q. V. Le, “Specaugment: A simple data augmentation method for automatic speech recognition,” arXiv preprint arXiv:1904.08779, 2019.