Uniform Interpolation Constrained Geodesic Learning on Data Manifold
Abstract
In this paper, we propose a method to learn a minimizing geodesic within a data manifold. Along the learned geodesic, our method is able to generate high-quality interpolations between two given data samples. Specifically, we use an autoencoder network to map data samples into the latent space and perform interpolation via an interpolation network. We add prior geometric information to regularize our autoencoder for the convexity of representations so that for any given interpolation approach, the generated interpolations remain within the distribution of the data manifold. The Riemannian metric on data manifold is induced by the canonical metric in the Euclidean space in which the data manifold is isometrically immersed. Based on this defined Riemannian metric, we introduce a constant-speed loss and a minimizing geodesic loss to regularize the interpolation network to generate uniform interpolations along the learned geodesic on the manifold. We provide a theoretical analysis of our model and use image interpolation as an example to demonstrate the effectiveness of our method.
1 Introduction
With the success of deep learning on approximating complex non-linear functions, representing data manifolds using neural networks has received considerable interest and been studied from multiple perspectives. Autoencoders (AE) [14], generative adversarial network (GAN) [13] and their combinations [16, 22] are notable generative models for learning the geometry structure or the distribution of data on the manifold. However, they usually fail to generate a convex latent representation when confronting with even simple curved manifolds such as swiss-roll and S-curve. For geodesic learning, Arvanitidis et al. [3, 24] and Chen et al. [10, 9] both present a magnification factor [7] to help find the shortest path that follows the regions of high data density in the latent space as the learned geodesic. But these methods explore geodesics on latent space rather than on data space and lack strict guarantees for geodesics in mathematics.
In this paper, we propose a method to capture the geometric structure of a data manifold and to find smooth geodesics between data samples on the manifold. First, motivated by DIMAL [17], we introduce a framework combining an autoencoder with traditional manifold learning methods to explore the geometric structure of a data manifold. In contrast to existing combinations of autoencoders and GANs, we resort to the classical manifold learning algorithms to obtain an approximation of geodesic distance. Then the encoder and decoder are optimized with this approximation being the constraint. Using this method, we alleviate the problem that the latent distribution is non-convex on curved manifolds, which means our encoder can unfold the data manifold to flattened latent representations.
Second, we propose a geodesic learning method to establish smooth geodesics between data samples on a data manifold. The Riemannian metric on the data manifold can be induced by the canonical metric in the Euclidean space in which the manifold is isometrically immersed. Existing methods cannot guarantee a uniform interpolation along the geodesic. We parameterize the generated curve by a parameter and propose a constant-speed loss to achieve a uniform interpolation by making be an arc-length parameter of the interpolation curve. According to Riemannian geometry [8], we propose a geodesic loss to force the interpolation network to generate points along a geodesic. Another key factor is a minimizing loss to make the geodesic be the minimizing one. Our contributions are summarized as follows:
-
•
We propose a framework in which an autoencoder and an interpolation network are introduced to explore the manifold structure. The autoencoder network promotes convex latent representations achieved by adding some prior geometric information to it, so that the generated samples are able to remain within the distribution of the data manifold.
-
•
We propose a constant-speed loss and a minimizing geodesic loss for the interpolation network to generate the minimizing geodesic on the manifold given two endpoints. We parameterize each geodesic by an arc-length parameter , such that we can generate points moving along the minimizing geodesic with constant speed and thus fulfill a uniform interpolation.
2 Related Work
Traditionally, manifold learning methods aim to infer latent representations that can capture the intrinsic geometric structure of data. They are generally applied in dimensionality reduction and data visualization. Classical nonlinear manifold learning algorithms such as Isomap [21], locally linear embedding [18] and local tangent space alignment (LTSA) [25] preserve local structures in small neighborhoods and derive the intrinsic features of data manifolds.
The interpolation between data samples has attracted wide attention because it can achieve a smooth transition from one sample to another, such as intermediate face generation and path planning. There are several works of literature focusing on the interpolation of data manifold. Agustsson et al. [2] propose to use distribution matching transport maps to obtain analogous latent space interpolation which preserves the prior distribution of the latent space, while minimally changing the original operation. It can generate interpolated samples with higher quality but it does not have an encoder to map the given data samples to the latent space. Several other works [5, 19, 12] that combine autoencoders with GANs are proposed to generate interpolated points on data manifold. But limited by the ability of GAN, they usually fail to generate a convex latent representation when confronting with curved manifolds such as swiss-roll and S-curve. To avoid this problem, Arvanitidis et al. [3, 24] and Chen et al. [10] both present that the magnification factor [7] can be seen as a measure of the local distortion of the latent space. This helps the generated geodesics to follow the regions of high data density in the latent space. Chen et al. [9] also find the shortest path in a finite graph of samples as the geodesics on the data manifold. This finite graph is built in the latent space using a binary tree data structure with edge weights based on Riemannian distances.
3 Preliminaries
We briefly present the essentials of Riemannian geometry. For a thorough presentation, see [8]. Suppose is a Riemannian differentiable manifold. is a differentiable curve in . Suppose that , the tangent vector to the curve at is a function defined on the arbitrary function on given by . The set of all tangent vectors to at will be indicated by tangent space . Let be a parametrization of at and for , suppose is the local coordinate of . Then the tangent vector at of the coordinate curve is defined as. spans a tangent space at . If the tangent vector is orthonormal with each other, is the orthonormal basis of tangent space.
Let and be two differentiable manifolds. Given a differentiable mapping , we can define a differential of at as linear mapping given by , for . If is injective for all , then the mapping is said to be an immersion.
A Riemannian manifold is a differentiable manifold equipped with a given Riemannian metric which assigns on each point of an inner product (i.e. a symmetric, bilinear and positive-definite form) on the tangent space . Furthermore, an isometric immersion is an immersion satisfying for and .
A geodesic is a parametrized curve satisfying for all . is the covariant derivative of a vector field along [8]. is the tangent vector at .
4 Manifold Reconstruction
Original AE and some combinations between AE and GANs can generate high-quality samples from specific latent distributions on high-dimensional data manifold. But they fail to get convex embeddings on some curved surfaces with changing curvature such as swiss-roll or S-curve. Some other works [5, 19, 12] were proposed to generate interpolations within the distribution of real data by distinguishing interpolations from real samples. But they generate unsatisfying samples on the above-mentioned low-dimensional manifolds. The encoding results can be seen in Fig. 1. The reason for this problem may be the insufficient ability of GANs and the decoder of AE. The discriminator of GANs can only distinguish the similarities of distributions between generated samples and real ones and the autoencoders are prone to put the curvature information of data manifold in latent representations to make the network simple as possible. So the latent embeddings also have a changing curvature to save the curvature information. It may result in the non-convex representations.
In our method, we add some prior geometric information obtained by traditional manifold learning approaches to encoding a convex latent representation. Traditional nonlinear manifold learning approaches such as Isomap [21], LLE [18] and LTSA [25] are classical algorithms to get a convex embedding by unfolding some curved surfaces. We apply them to our method by adding regularization to the autoencoder. The loss function of the autoencoder can be written as:
| (1) |
where is the input sampled on the data manifold. denotes the number of input . represents the approximated geodesic distance between and . Encoder and Decoder of an autoencoder are trained to minimize the above loss . can be obtained by building a graph from the data with k-nearest neighbors for each node and computing the corresponding pairwise geodesic distances using traditional manifold learning algorithms. For more details we refer the interested reader to [21, 18, 25]. With as an expected approximation, the encoder is forced to train towards obtaining a convex latent representation while the decoder is forced to learn the lost curvature information on latent embeddings. Behaviors induced by the loss can be observed in Fig. 1: the swiss-roll can be flattened on 2-dimensional latent space. For our experiments, we choose LTSA to compute the approximated geodesic distance for regularizing the autoencoder because of its learned local geometry which views the neighborhood of a data point as a tangent space to flat the manifold.






5 Geodesic Learning
In our model, we denote as a data manifold. The Riemannian metric on can be induced from the canonical metric on the Euclidean space to guarantee the immersion is an isometric immersion. Thus to obtain a geodesic on manifold , we can use the Riemannian geometry on and the characteristics of isometric immersion.
5.1 Interpolation Network
We produce geodesics on manifold by interpolating in the latent space and decoding them into data space. The method of interpolating in the latent space can be varied in different situations. The simplest interpolation is linear interpolation as . For geodesic learning, linear interpolation is not applicable in most situations. Yang et al. [24] propose to use the restricted class of quadratic functions and Chen et al. [10] apply a neural network to parameterize the geodesic curves. For our interpolation network, we employ polynomial functions similar to Yang’s approach. The difference is that we employ cubic functions to parameterize interpolants considering the diversity of latent representations, i.e., . Therefore, a curve generated by our interpolation network has four -dimensional free parametric vectors and , where is the dimension of latent coordinates. In practice, we train a geodesic curve that connects two pre-specified points and , so the function should be constrained to satisfy and . We initialize our interpolation network by setting and to make the initial interpolation be a linear interpolation and perform the optimization using gradient descent. More details can be referred to in Yang’s paper [24].
5.2 Constant-Speed Loss
We can produce interpolations along a curve on manifold by decoding the output of the interpolation network as from 0 to 1. We expect the parameter to be an arc-length parameter which means that the parameter is proportional to the arc length of the curve . To realize this, the following theorem can provide theoretical support.
Theorem 5.2.1.
Suppose is a Riemannian differentiable manifold. The Riemannain metric on is induced from the canonical metric on . If is a geodesic on , is the Cartesian coordinate of in , then is a constant, for.
As stated in Theorem 5.2.1, the length of the tangent vector along a geodesic is constant. Let denote the output of the decoder taking the interpolation curve as input, we design the following constant-speed loss as:
| (2) |
where denotes the number of sampling points and . denotes the derivative of the output with respect to . It can be viewed as the velocity at along and represents the magnitude of this velocity corresponding to in Theorem 5.2.1. Therefore, from a certain angle, constant-speed loss makes have a constant speed with moving from 0 to 1.
5.3 Minimizing Geodesic Loss
After guaranteeing the output curve of our decoder has a constant speed, we need to let the curve be a geodesic. We have the following theorem to ensure a curve is a geodesic.
Theorem 5.3.1.
Suppose is a Riemannian differentiable manifold. The Riemannain metric on is induced from the canonical metric on . is a curve on , is a system of coordinates of with . is the local coordinate of , is the Cartesian coordinate of in , then is a geodesic on , if and only if:
| (3) |
Theorem 5.3.1 demonstrates a curve is a geodesic if and only if its second derivative with respect to parameter is orthogonal to the tangent space. In practice, we can assume our encoder maps a point on the manifold to its local coordinates. So based on Theorem 5.3.1, we are able to optimize the following problem as the geodesic loss:
| (4) |
where is the function of decoder and denotes the derivative of at . is a -dimensional vector corresponding to and is an matrix corresponding to in Theorem 5.3.1. Geodesic loss and constant-speed loss jointly force curve to have zero acceleration. That is, is a geodesic on data manifold. But geodesic connecting two points may not be unique, such as the geodesic on a sphere. According to Theorem 1 in supplementary materials, the minimizing geodesic is the curve with minimal length connecting two points. Thus our model takes advantage of the minimal length to ensure is a minimizing geodesic. We approximate the curve length using the summation of velocity at . The minimizing loss is proposed to minimize curve length as:
| (5) |
For implementation, we use the following difference approximation to reduce the computational burden:
| (6) |
For , we can use the Jacobian of the decoder as implemented by Pytorch or difference approximation that is similar to . To summarize this part, the overall loss function of our interpolation network is:
| (7) |
where , and are the weights to balance these three losses. They have a default setting as , and to ensure a robust performance. Under this loss constraint, we can generate interpolations moving along the minimizing geodesic with constant speed and thus fulfill a uniform interpolation. The overall geodesic learning algorithm is given in Algorithm 1.
6 Experimental Results
In this section, we present experiments on the geodesic generation and image interpolation to demonstrate the effectiveness of our method.
6.1 Geodesic Generation
First, we do experiments on 3-dimensional datasets since their geodesics can be better visualized. We choose the semi-sphere and swiss-roll as our data manifolds.
 |
 |
 |
 |

|
 |
 |
 |
| (a) AAE [16] | (b) A&H [4] | (c) Chen’s method [10] | (d) ours |
 |
 |
 |
 |
 |
| (a) AAE [16] | (b) ACAI [5] | (c) GAIA [19] | (d) Chen’s method [12] | (e) ours |
Semi-sphere dataset. We randomly sample 4,956 points subjecting to the uniform distribution on semi-sphere. In Fig. 2, we compare our approach with other interpolation methods, i.e., AAE [13], A&H [4] and Chen’s method [10]. From Riemannian geometry, we know the geodesic of a sphere under our defined Riemannian metric is a circular arc or part of it. The center of this circular arc is the center of this sphere. AAE cannot guarantee that the curve connecting two points is a geodesic. A&H can find the shortest path connecting two corresponding reconstructed endpoints. But the endpoints are inconsistent with the original inputs due to the uncertainty of their VAE network and their stochastic Riemannian metric. Chen’s method can generate interpolations along a geodesic, but they cannot fulfill a uniform interpolation. In Fig. 2, we observe that our method can generate uniform interpolation along a fairly accurate geodesic on semi-sphere based on the defined Riemannian metric.
| Loss | Distance |
|---|---|
| Linear | 1.3110 |
| 1.4710 | |
| 1.1571 | |
| 1.1277 | |
| 6.0460 | |
| 1.1028 | |
| real geodesic | 1.0776 |
Swiss-roll dataset. We choose swiss-roll to demonstrate the effectiveness of our method on manifolds that have large curvature variations. We randomly sample 5,000 points subjecting to the uniform distribution on the swiss-roll manifold. We compare our approach with AAE [16], ACAI [5], GAIA [19] and the method that applies GAN on feature space proposed by [12]. Fig. 3 shows the experimental results. We observe that except our approach, other methods fail to generate interpolations within the data manifold because they cannot encode efficient latent embeddings for linear interpolations.
We do ablation studies on the semi-sphere dataset to investigate the effect of different losses proposed in our method, including the constant-speed loss, geodesic loss, and minimizing loss. Fig. 4 presents the results obtained by the combinations of different losses. We observe that the constant-speed loss can promote a uniform interpolation. Compared with linear interpolation, our network can generate a shorter path that is close to real geodesic without the geodesic loss. Although our network can quickly converge to a fairly satisfactory result, the accuracy of the geodesic is not optimal. When incorporated with the geodesic loss, our interpolated points are fine-tuned to move along an accurate geodesic. The estimated curve length shown in Table 1 demonstrates our observation. The generated curve trained with all three losses contributes the best result and the estimated curve length 1.1028 is the closest to the length of real geodesic, namely 1.0776.
 |
 |
 |
| (a) linear interpolation | (b) | (c) |
 |
 |
 |
| (d) | (e) | (f) |








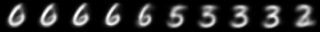













 |
 |
| (a) MNIST | (b) Fashion-MNIST |
6.2 Image interpolation
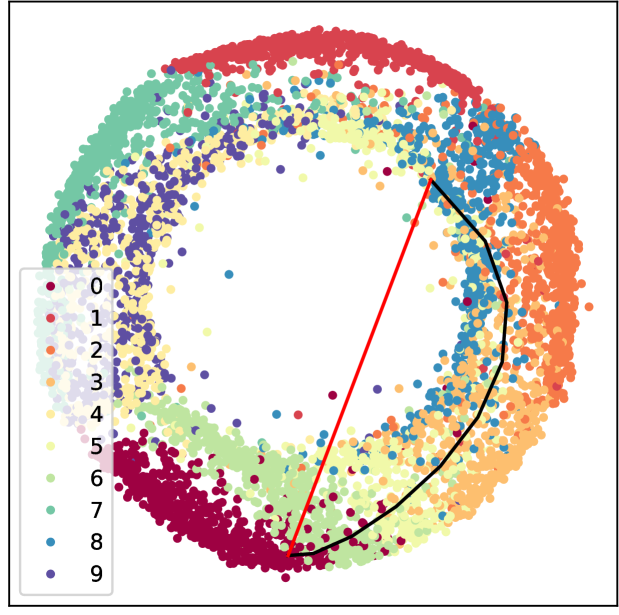
To further demonstrate our model’s effectiveness in image interpolation, we choose MNIST [15] and Fashion-MNIST [23] datasets. They both consist of a training set of 60,000 examples and a test set of 10,000 examples associated with a label from 10 classes. We don’t employ our manifold reconstruction method because the concept of distance-based nearest neighbors is no longer meaningful when the dimension goes sufficiently high [1, 6]. Shao et al. [20] argue that generated high-dimensional manifold has some curvature, but it is close to being zero. Therefore, we can directly employ variational autoencoder (VAE) [14] and adversarial autoencoder (AAE) [16] to obtain latent embeddings. For each dataset, we randomly select two images as the start point and endpoint in the data manifold. We employ different interpolation methods to realize an image interpolation between these two images. For the MNIST dataset, Fig. 5 shows the generated geodesic and linear interpolant trajectories of an AAE where the imposed latent distribution is a 2-D donut. We observe that our approach finds a trajectory in the latent space that is longer than a simple linear interpolation, but the intermediate points look more realistic and provide a semantically meaningful morphing between its endpoints as it does not cross a region without data. Our interpolation method ensures our generated curves to follow the data manifold. From the fourth column in Fig. 5, we can see although the geodesic and linear trajectories are both on the data manifold, the interpolation results can also be very different. We provide more results on MNIST dataset in supplementary materials to verify the invariance of geodesic interpolation with different autoencoders.
For the Fashion-MNIST dataset, we also use the methods above to interpolate images between two selected images and show the results in Fig. 6. We use the velocity defined in Section 5.2 to evaluate the smoothness of different interpolation methods. Our geodesic interpolation can obtain always recognizable images with a smoother speed while linear interpolation may generate some ghosting with two articles when transiting over different classes. This demonstrates our geodesic learning method can fulfill a uniform interpolation along a geodesic.
We further verify the characteristic of the geodesic’s shortest path for our interpolation method. In Fig. 7, we present a comparison of the interpolant trajectory’s length to different interpolation approaches for both VAE and AAE. We randomly choose 250 pairs of endpoints on data manifold for each valuation and approximate the trajectory’s length using the summation of velocity at which is described in Section 5.3. Fig. 7 shows that our geodesic interpolation has smaller average length and variance on both MNIST and Fashion-MNIST datasets. This demonstrates our interpolation method can make the interpolation curve to possess more characteristics of geodesics compared with linear interpolation.
7 Conclusion
We explore the geometric structure of the data manifold by proposing a uniform interpolation constrained geodesic learning algorithm. We add prior geometric information to regularize our autoencoder to generate interpolants within the data manifold. We also propose a constant-speed loss and a minimizing geodesic loss to generate geodesic on the underlying manifold given two endpoints. Different from existing methods in which geodesic is defined as the shortest path on the graph connecting data points, our model defines geodesic consistent with the definition of a geodesic in Riemannian geometry. Experiments demonstrate our model can fulfill a uniform interpolation along the minimizing geodesics both on 3-D curved manifolds and high-dimensional image space.
References
- [1] Charu C Aggarwal, Alexander Hinneburg, and Daniel A Keim. On the surprising behavior of distance metrics in high dimensional space. In International conference on database theory, pages 420–434. Springer, 2001.
- [2] Eirikur Agustsson, Alexander Sage, Radu Timofte, and Luc Van Gool. Optimal transport maps for distribution preserving operations on latent spaces of Generative Models. In Proceedings of the 7th International Conference on Learning Representations(ICLR), 2019.
- [3] Georgios Arvanitidis, Lars Kai Hansen, and Søren Hauberg. Latent Space Oddity: On the Curvature of Deep Generative Models. In Proceedings of the 6th International Conference on Learning Representations(ICLR), 2018.
- [4] Georgios Arvanitidis, Søren Hauberg, Philipp Hennig, and Michael Schober. Fast and Robust Shortest Paths on Manifolds Learned from Data. In Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics (AISTATS), page 10, 2019.
- [5] David Berthelot, Colin Raffel, Aurko Roy, and Ian Goodfellow. Understanding and improving interpolation in autoencoders via an adversarial regularizer. In Proceedings of the 7th International Conference on Learning Representations(ICLR), 2019.
- [6] Kevin Beyer, Jonathan Goldstein, Raghu Ramakrishnan, and Uri Shaft. When is “nearest neighbor” meaningful? In International conference on database theory, pages 217–235. Springer, 1999.
- [7] Christopher M Bishop, Markus Svens’ en, and Christopher KI Williams. Magnification factors for the som and gtm algorithms. In Proceedings 1997 Workshop on Self-Organizing Maps, 1997.
- [8] Manfredo Perdigao do Carmo. Riemannian geometry. Birkhäuser, 1992.
- [9] Nutan Chen, Francesco Ferroni, Alexej Klushyn, Alexandros Paraschos, Justin Bayer, and Patrick van der Smagt. Fast approximate geodesics for deep generative models. In International Conference on Artificial Neural Networks, 2019.
- [10] Nutan Chen, Alexej Klushyn, Richard Kurle, Xueyan Jiang, Justin Bayer, and Patrick van der Smagt. Metrics for Deep Generative Models. in Proceedings of the 21st International Conference on Artificial Intelligence and Statistics (AISTATS), 2018.
- [11] Weihuan Chen and Xingxiao Li. Introduction to Riemann Geometry: Volume I. Peking University Press, 2004.
- [12] Ying-Cong Chen, Xiaogang Xu, Zhuotao Tian, and Jiaya Jia. Homomorphic latent space interpolation for unpaired image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2408–2416, 2019.
- [13] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Advances in neural information processing systems, pages 2672–2680, 2014.
- [14] Diederik P. Kingma and Max Welling. Auto-Encoding Variational Bayes. In Proceedings of the 2nd International Conference on Learning Representations (ICLR), 2014.
- [15] Yann LeCun. The mnist database of handwritten digits. http://yann. lecun. com/exdb/mnist/, 1998.
- [16] Alireza Makhzani, Jonathon Shlens, Navdeep Jaitly, Ian Goodfellow, and Brendan Frey. Adversarial autoencoders. arXiv preprint arXiv:1511.05644, 2015.
- [17] Gautam Pai, Ronen Talmon, Alex Bronstein, and Ron Kimmel. DIMAL: Deep Isometric Manifold Learning Using Sparse Geodesic Sampling. In 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), 2019.
- [18] Sam T Roweis and Lawrence K Saul. Nonlinear dimensionality reduction by locally linear embedding. science, 290(5500):2323–2326, 2000.
- [19] Tim Sainburg, Marvin Thielk, Brad Theilman, Benjamin Migliori, and Timothy Gentner. Generative adversarial interpolative autoencoding: adversarial training on latent space interpolations encourage convex latent distributions. arXiv preprint arXiv:1807.06650, 2018.
- [20] H. Shao, A. Kumar, and P. T. Fletcher. The riemannian geometry of deep generative models. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 428–4288, 2018.
- [21] Joshua B Tenenbaum, Vin De Silva, and John C Langford. A global geometric framework for nonlinear dimensionality reduction. science, 290(5500):2319–2323, 2000.
- [22] Ilya Tolstikhin, Olivier Bousquet, Sylvain Gelly, and Bernhard Schoelkopf. Wasserstein Auto-Encoders. In Proceedings of the 6th International Conference on Learning Representations (ICLR), 2018.
- [23] Han Xiao, Kashif Rasul, and Roland Vollgraf. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms. 2017.
- [24] Tao Yang, Georgios Arvanitidis, Dongmei Fu, Xiaogang Li, and Søren Hauberg. Geodesic Clustering in Deep Generative Models. arXiv:1809.04747 [cs, stat], September 2018.
- [25] Zhenyue Zhang and Hongyuan Zha. Nonlinear dimension reduction via local tangent space alignment. In International Conference on Intelligent Data Engineering and Automated Learning, pages 477–481. Springer, 2003.
| Supplementary Materials: Uniform Interpolation Constrained Geodesic Learning on Data Manifold |
Appendix A Theoretical part
Lemma 1.
If is a geodesic on Riemannian manifold , then the length of the tangent vector is constant.
Proof.
Suppose is the Riemannian connection of , then we have
| (8) |
Thus,
| (9) |
Proof of Theorem 5.2.1.
Proof.
Suppose the Riemannian metric on is induced from by identity mapping . is the Cartesian coordinate system of . is the Cartesian coordinate of . Based on the characteristic of , we obtain the corresponding tangent vector of in :
| (10) |
According to the canonical metric on , we have
| (11) |
Because is a geodesic on , from Lemma 1, we know is a constant. Considering identity mapping is a isometric immersion, we have
| (12) |
Thus, is a constant, for.
Proof of Theorem 5.3.1.
Proof.
Suppose the Riemannian metric on is induced from by identity mapping . is the Cartesian coordinate system of . From the definition of , we can get . Suppose is the -th component of , according to the characteristic of di, we can deduce the corresponding tangent vector of on as follows:
| (13) |
spans a tangent space at . Suppose is the Riemannian connection on . According to the definition of (refer to Chapter 2, Eq.(3.1), in [11]), we have
| (14) |
The first equality holds by Remark 3.2 of Chapter 2 in [11]. denotes the orthographic projection from to the tangent space on . Because Riemannian connection is invariant under isometric condition (see Theorem 4.6 of Chapter 2 in [11]), we have
| (15) |
Combined with Eq. (10), we can deduce
| (16) |
Therefore, based on the definition of geodesic, is a geodesic on , if and only if:
| (17) |
It means is orthogonal to tangent space . That is,
| (18) |
Eq. (18) is eqivalent to
| (19) |
We write it in the form of matrix multiplication,
| (20) |
Theorem 1.
If a piece-wise differentiable curve [8], with parameter proportional to arc length, has length less or equal to the length of any other piece-wise differentiable curve joining to then is a geodesic.
Appendix B Experimental part
B.1 Model Architecture
For 3-dimensional datasets, we trained our interpolation network for 3000 iterations. Table 2 describes the autoencoder architecture.
For MNIST and Fashion-MNIST datasets, we trained our interpolation for 30,000 iterations. Table 3 and Table 4 describe the network architecture of VAE and AAE respectively.
| Encoder | ||
|---|---|---|
| Operation | Input | Output |
| FC | 3 | 64 |
| BN,PReLU,FC | 64 | 64 |
| BN,PReLU,FC | 64 | 64 |
| BN,PReLU,FC | 64 | 64 |
| BN,PReLU,FC | 64 | 3 |
| FC | 3 | 2 |
| Decoder | ||
| BN,FC | 2 | 64 |
| BN,ReLU,FC | 64 | 64 |
| BN,ReLU,FC | 64 | 64 |
| BN,ReLU,FC | 64 | 64 |
| BN,ReLU,FC | 64 | 64 |
| BN,ReLU,FC | 64 | 3 |
| Encoder | ||||
| Operation | Kernel | Strides | Feature maps | |
| Conv2D,LReLU | 4 | 2 | 64 | |
| Conv2D,BN,LReLU | 4 | 2 | 128 | |
| Conv2D,BN,LReLU | 4 | 2 | 256 | |
| Conv2D,BN,LReLU | 4 | 2 | 512 | |
| Reshape,Linear | 64 | |||
| BN,ReLU | 64 | |||
| Reshape,Linear | 2 | |||
| Conv2D,LReLU | 4 | 2 | 64 | |
| Conv2D,BN,LReLU | 4 | 2 | 128 | |
| Conv2D,BN,LReLU | 4 | 2 | 256 | |
| Conv2D,BN,LReLU | 4 | 2 | 512 | |
| Reshape,Linear | 64 | |||
| BN,ReLU | 64 | |||
| Reshape,Linear | 2 | |||
| Decoder | ||||
| LReLU,ConvTranspose2D,BN | 4 | 2 | 512 | |
| ReLU,ConvTranspose2D,BN | 4 | 2 | 256 | |
| ReLU,ConvTranspose2D,BN | 4 | 2 | 128 | |
| ReLU,ConvTranspose2D,BN | 4 | 2 | 64 | |
| ReLU,ConvTranspose2D,Tanh | 4 | 2 | 1 | |
| Encoder | |||
|---|---|---|---|
| Operation | Kernel | Strides | Feature maps |
| Conv2D,LReLU | 4 | 2 | 64 |
| Conv2D,BN,LReLU | 4 | 2 | 128 |
| Conv2D,BN,LReLU | 4 | 2 | 256 |
| Conv2D,BN,LReLU | 4 | 2 | 512 |
| Conv2D,BN | 4 | 2 | 2 |
| Decoder | |||
| LReLU,ConvTranspose2D,BN | 4 | 2 | 512 |
| ReLU,ConvTranspose2D,BN | 4 | 2 | 256 |
| ReLU,ConvTranspose2D,BN | 4 | 2 | 128 |
| ReLU,ConvTranspose2D,BN | 4 | 2 | 64 |
| ReLU,ConvTranspose2D,Tanh | 4 | 2 | 1 |
B.2 More experimental results on MNIST dataset
In this section, we provide more results for image interpolation on the MNIST dataset to verify the invariance of geodesic interpolation. Fig. 8 illustrates the visual interpolation results for both VAE and AAE being the autoencoder respectively. It worth mentioning that geodesics do not depend on the distributions of latent space because they only depend on the geometry structure of data manifold. Thus we should theoretically get the same interpolation results for different autoencoders if the interpolations are along geodesics. From Fig. 8, we can observe for linear interpolation, different autoencoders result in very different results. For geodesic interpolation, although there is a slight difference between results with different autoencoders, the general transition tendency is consistent. Specifically, when we transit digit ’2’ to ’4’ shown in Fig. 8, the linear interpolation with AAE will transit ’2’ to ’1’, then to ’4’, which is different from that with VAE transiting ’2’ to ’4’ directly. But geodesic interpolation with VAE and AAE both transit ’2’ to ’4’ directly and have a semantic transfer at similar sampling time. Other digit transitions have similar situations. These experimental results prove the invariance of geodesic interpolation with different autoencoders.
 |
 |
| (a) VAE | (b) AAE |