capbtabboxtable[][\FBwidth]
22institutetext: Lenovo Research
22email: {rosaurav,maithal,amnikhil,jnichol}@lenovo.com
Unified-EGformer: Exposure Guided Lightweight Transformer for Mixed-Exposure Image Enhancement
Abstract
Despite recent strides made by AI in image processing, the issue of mixed exposure, pivotal in many real-world scenarios like surveillance and photography, remains inadequately addressed. Traditional image enhancement techniques and current transformer models are limited with primary focus on either overexposure or underexposure. To bridge this gap, we introduce the Unified-Exposure Guided Transformer (Unified-EGformer). Our proposed solution is built upon advanced transformer architectures, equipped with local pixel-level refinement and global refinement blocks for color correction and image-wide adjustments. We employ a guided attention mechanism to precisely identify exposure-compromised regions, ensuring its adaptability across various real-world conditions. U-EGformer, with a lightweight design featuring a memory footprint (peak memory) of only 1134 MB (0.1 Million parameters) and an inference time of 95 ms (9.61x faster than the average111Average inference time is calculated among representative models in Table 2. in Ye et al., [67]), is a viable choice for real-time applications such as surveillance and autonomous navigation. Additionally, our model is highly generalizable, requiring minimal fine-tuning to handle multiple tasks and datasets with a single architecture.
Keywords:
Computer Vision Image Processing Image Restoration Low-Light Image Enhancement Unified Learning1 Introduction

AI-driven image processing have significantly broadened the scope for enhancing visual media quality. A critical challenge within the low-light image enhancement (LLIE) domain is addressing mixed exposure in images [Fig. 1 g.], where a single frame contains both underlit (below 5 lux, including underexposed)222insufficient brightness in an image where details are lost due to lack of signal. and overlit (overexposed)333excessive brightness in an image where details are lost due to signal clipping or saturation. regions. This issue extends beyond academic interest and has significant real-world implications. For instance, in video calls (e.g., in cafeterias; [Fig. 1 e.]) and live streaming, low-light enhancement is pivotal for clear visual communication. Other areas of application include autonomous driving, surveillance and security, photography, etc. Professional photographers often use high-end DSLR cameras and meticulously adjust settings such as aperture, ISO, and utilize specialized filters to mitigate exposure issues. However, such pre- and post-processing techniques are often not practical.
Existing methods for correcting mixed exposure images have typically treated underexposure ([15, 47, 55]) and overexposure as separate challenges within the low-light image enhancement task. Although these methods (such as FECNet [19], ELCNet+ERL [20], IAT [11]) have made progress, they commonly assume uniform scene illumination, leading to global adjustments that either brighten or darken the entire image. Such approaches falls short when dealing with images that have both overexposed and underexposed regions due to non-uniform lighting, resulting in suboptimal performance. For example, ZeroDCE [15] and RUAS [37] can worsen overexposure in background regions while trying to enhance underexposed foreground subjects [Fig. 1 k.].
We see this as a gap in the literature that hasn’t been fully addressed, despite some efforts such as LCDNet [54] and night enhancement approaches [28, 4, 2]. The motivation for our work arises from the need to address these limitations by developing a solution that can handle mixed exposure scenarios effectively and is suitable for deployment on edge devices. A predominant challenge when applying a low-light enhancement approach to a multi-exposed image is when a model trained solely on underexposed paired images inadvertently exacerbates overexposed regions [Fig. 1 k.], and vice versa. Consequently, the issue of mixed exposure emerges as a pivotal yet largely unexplored frontier. Notably, mobile phone cameras face this issue acutely, requiring lightweight, low-latency models that can operate within the device’s resource constraints while delivering high-quality image enhancement. Our goal is to develop a solution that not only addresses these issues but also offers faster inference and a lower memory footprint, making it ideal for practical applications on edge devices.
This paper aims to develop an effective and computing-efficient approach to tackle mixed exposure in low-light image enhancement. Our major contributions are described as follows:
-
1.
We introduce a unified novel framework within the transformer architecture that leverages attention- and illuminance-maps to enhance precision in processing affected regions on a pixel-level, addressing the challenges of underexposure, overexposure, and mixed exposure in images as a single task.
-
2.
Our method achieves remarkable efficiency, with an average inference speed of 0.095 seconds per image444computed over LOL-v2 test dataset following previous benchmarks [11, 15, 8, 26]., significantly faster with lesser memory consumption than many existing frameworks. Coupled with a compact architecture of only 101 thousand parameters, the model is ideal for deployment on resource-constrained edge devices.
-
3.
We present a novel “Multiplicative-Additive” loss function that intelligently combines contrast scaling and brightness shifting to adaptively enhance images, improving dynamic range and preventing over-smoothing.
-
4.
We develop an Exposure-Aware Fusion (EAF) Block, designed for the efficient fusion of local and global features. This block refines image exposure corrections with heightened precision, enabling context-aware enhancements tailored to the specific exposure needs of each image region.
2 Related Work
Traditional to Advanced Deep Learning Techniques. In the realm of image enhancement and exposure corrections, significant strides have been made to address the challenges posed by exposure scenarios. Early techniques [5, 23, 33] leveraged contrast-based histogram equalization (HE), laying the groundwork for more advanced methods. These initial approaches were followed by studies in Retinex theory, which focused on decomposing images into reflection and illumination maps [32, 31]. The advent of deep learning transformed exposure correction, with a shift from enhancing low-light images to addressing both underexposure and overexposure [1, 2, 9, 15, 55, 63, 69, 73]. The notable work of Afifi et al. [1] stands out, employing deep learning to simultaneously address underexposure and overexposure, a task not adequately tackled by previous methodologies. There was a momentous shift towards convolutional neural network (CNN)-based methods, achieving state-of-the-art results and improving the accuracy and efficiency of exposure correction algorithms [15, 29, 47, 51, 55, 64].
Addressing the Challenges of Mixed Exposure. Despite these advancements, the challenges of mixed exposure have remained relatively unaddressed in high-contrast scenarios. Benchmark datasets such as LOL [60], LOL-[4K;8K] [57], SID [7], SICE [4], and ELD [61] offer limited mixed exposure instances, highlighting a gap in both data and models. Synthetic datasets like SICE-Grad and SICE-Mix are enabling the development of methods tailored to mixed exposure scenarios [38, 75, 12, 50]. Some representative methods of deep learning like RetinexNet [60] and KIND [73], focusing on illumination and reflectance component restoration in images, achieved good performance, most methods focus on either underexposure or overexposure correction, failed to correct various exposures. More recent studies have focused on addressing the challenges of correcting both underexposed and overexposed images [54, 66], a task complicated by the differing optimization processes required for each type of exposure. MSEC [2], a revolutionary work in this area, utilizes a Laplacian pyramid structure to incrementally restore brightness and details, dealing with a range of exposure levels.
To manage the correction of a wide range of exposures, several recent works were proposed, such as Huang et al. [17] using exposure normalization, CMEC [48] using exposure-invariant spaces to represent exposures, and ECLNet [17] using bilateral activation for exposure consistency. Moreover, Wang et al. [54] tackle the issue of uneven illumination, while FECNet [18] uses a Fourier-based approach for lightness and structure. Still challenges remain unsolved: (1) Handling nonuniform illumination, (2) Simultaneously addressing both overexposure and underexposure within the same frame, and (3) Ensuring that global adjustments do not adversely affect local regions. Our work addresses these challenges by introducing a unified framework that uses attention and illuminance maps to process mixed exposure regions more precisely.
Emerging Trends with Computational Challenges. Recent studies have begun addressing the dual challenge of correcting under and overexposed images through innovative architectures, including transformers [13], despite their computational intensity as noted in works like Vaswani et al. [53]. The realm of image enhancement has seen remarkable models with human-level enhancement capabilities, such as ExposureDiffusion [59], Diff-retinex [68], wavelet-based diffusion [25], PyDiff (Pyramid Diffusion) [76], Global structure aware diffusion [16], LLDiffusion [56], and Maximal diffusion values [30], demonstrating significant advancements. However, these resource-intensive models, alongside the emerging vision-language models (VLMs) in image restoration, present deployment challenges on edge devices, often exceeding an average of 15-30 seconds for processing a single HD & FHD images [58, 42]. In contrast, Unfied-EGformer achieves an average inference speed of 200 milliseconds on HD images.
Despite these obstacles, the transformer based development for image enhancement has propelled forward progress in the field. Methods like ViT [13] MobileViT [46], CVNet [45], IAT [11], LLformer [57], [21] have shown substantial promise. It also applied to other sub-fields of image enhancements like image dehazing [52, 35], super-resolution [41, 10], image-denoising [65].
3 Methodology: Unified-EGformer


Unifed-EGformer achieves image enhancement through an Attention Map Generation mechanism that identifies exposure adjustment regions, a Local Enhancement Block for pixel-wise refinement, a Global Enhancement Block for color and contrast adjustment, and an Exposure Aware Fusion (EAF) block that fuses features from both enhancements for balanced exposure correction Fig. 2.
3.1 Guided Map Generation
Unified-EGformer introduces significant advancements in the attention mechanism and feed-forward network within its architecture to adeptly handle mixed exposure scenarios. These enhancements are encapsulated as follows:



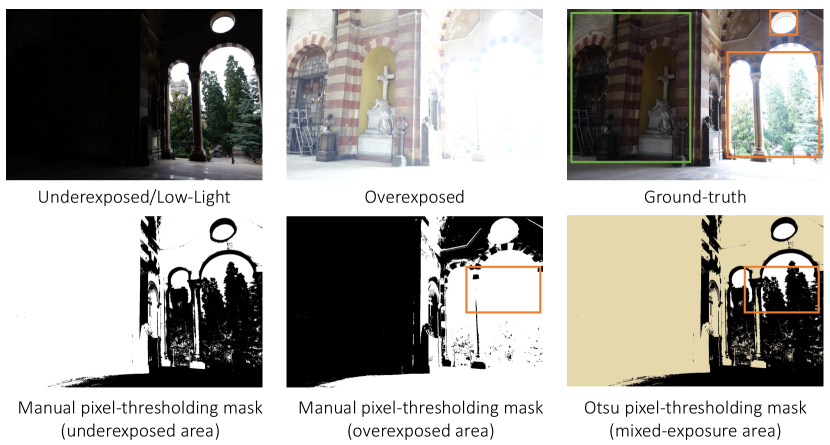
Thresholding. To highlight the sub-regions of the images with impacted exposure problems, we need a way to point out those impacted set of pixels within the input. We use Otsu thresholding, a traditional yet effective technique. It is a global thresholding technique for automatic thresholding that works by selecting the threshold to minimize intra-class variance (variance within a class) or maximize inter-class variance (variance between classes). However, this method induces granular noise in the image [49] due to the non-uniform pixels in low lux regions. The noise is highlighted by the resultant masks as shown in Fig. 3, and will influence the subsequent exposure correction.
To mitigate noise, we implemented adaptive thresholding using pixel blocks and downsampled images. We further reduced noise creep with nearest neighbor downsampling and Gaussian blur. Integrating Charbonnier loss [6] into our attention map mechanism encouraged smoother transitions in areas of high gradient variance, specifically targeting denoising. This component, combined with the SSIM loss that is applied directly on the input, synergistically contributes to noise reduction.

Our implementation of threshold selection is as follows. First, we calculate the Otsu average across the training set to establish a baseline for automatic thresholding. We then apply this average threshold to each image in the dataset. Using a data set-specific threshold, this method ensures a more uniform application555reducing noise propensity in low-light conditions and enhancing exposure correction consistency of the Otsu method.
Attention Map Generator.
The Unified-EGformer begins with a guided attention map generator, designed to identify regions within an image affected by mixed exposure. This process involves generating a map , where , , and represent the height, width, and channel dimensions of the input image . This map, , is used in an element-wise dot product with the image, resulting in a guided input image that undergoes underexposed, overexposed, or mixed exposure enhancement, as depicted in Fig. 4, demonstrating how we apply Otsu thresholding to get attention masks labels.
The architecture incorporates improved Swin transformer [39] blocks, leveraging Axis-based Multi-head Self-Attention (A-MSA) and Dual Gated Feed-Forward Network (DGFN) [57, 53, 13] for efficient, fast and focused feature processing. The A-MSA reduces computational load by applying self-attention across height and width axes sequentially, optimizing for local contexts within high-resolution images, as illustrated in Fig. 5 (see details in Supplement Section 7.2). The DGFN introduces a dual gating mechanism to the feedforward network, allowing selective emphasis on critical features necessary to distinguish and correct underexposed and overexposed areas effectively (see Supplement Section 7.3).
Illumination Map Generator.

We incorporate the generation of illumination map into the global enhancement block providing a foundational layer for exposure correction. Unlike the complex attention mechanisms required for local block, generating an illuminance map leverages a direct conversion from RGB to luminance (), offering a simpler and faster solution (), where corresponds to the luminosity method666RGB to Y-channel: https://www.itu.int/dms˙pubrec/itu-r/rec/bt/R-REC-BT.601-7-201103-I!!PDF-E.pdf. The block can utilize the illuminance information to dynamically adjust global parameters such as color balance and exposure levels, ensuring the enhancements are computationally efficient. Our ablation studies Tab .8 confirms that these enhancements are perceptually meaningful compared to the baseline without the illumination map.
3.2 Unified-Enhancement
Local Enhancement Block (LEB).
The LEB takes a dot product of attention map and the sRGB image, that uniquely forms a objective mapping from input to output. LEB applies a lightweight convolutional block inspired from DETR, PE-Yolo, UWFormer localized pixel-wise refinement. We utilize a adaptive instance based color normalization for capturing a wider range of colors based on individual inputs. Unlike traditional methods, our approach maintains the integrity of features without down-sampling and up-sampling. The output of this block calculates multiplicative () and additive () correction factors through a feed-forward network, enabling precise pixel-wise enhancement. The local enhancement is formulated as:
| (1) |
where is the locally enhanced image, the original image, and denotes element-wise multiplication.
Global Enhancement Block (GEB).
Complementary to the LEB, the global enhancement block adjusts the image’s overall exposure through adaptive gamma correction and color balance. Unlike static bias adjustments [11], this block dynamically calculates the gamma correction factor and color transformation parameters based on the image’s content. We implement a convolutional subnetwork with GELU activations and adaptive average pooling, followed by a sigmoid to automatically compute global parameters, denoted by . This adaptive approach to global enhancement allows for a more nuanced and content-aware balance of contrast and color. The global correction function is described as:
| (2) |
where is the globally enhanced image, and represents the function for global adjustments, influenced by the calculated parameters .
3.3 Exposure-Aware Fusion (EAF) Block
Our novel exposure aware fusion block is architecturally designed to integrate both local and global enhancement features, enabling comprehensive and cohesive image enhancement. The fusion process begins with two convolutional layers that apply spatial filtering to extract the salient features necessary for exposure correction. We also use global average pooling, mapping the feature maps to the global context vector. These fusion weights serve as a gating mechanism to regulate the contribution of local and global features. They are adaptively learned, encapsulating both detailed texture information and broad illumination context.
| Method | ME-v2 | SICE-v2 | #params | ||||||||||
| Underexposure | Overexposure | Average | Underexposure | Overexposure | Average | ||||||||
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | ||
| RetinexNet [60] | 12.13 | 0.6209 | 10.47 | 0.5953 | 11.14 | 0.6048 | 12.94 | 0.5171 | 12.87 | 0.5252 | 12.90 | 0.5212 | 0.840M |
| URetinexNet [62] | 13.85 | 0.7371 | 9.81 | 0.6733 | 11.42 | 0.6988 | 12.39 | 0.5444 | 7.40 | 0.4543 | 12.40 | 0.5496 | 1.320M |
| Zero-DCE [15] | 14.55 | 0.5887 | 10.40 | 0.5142 | 12.06 | 0.5441 | 16.92 | 0.6330 | 7.11 | 0.4292 | 12.02 | 0.5211 | 0.079M |
| Zero-DCE++ [34] | 13.82 | 0.5887 | 9.74 | 0.5142 | 11.37 | 0.5583 | 11.93 | 0.4755 | 6.88 | 0.4088 | 9.41 | 0.4422 | 0.010M |
| DPED [24] | 20.06 | 0.6826 | 13.14 | 0.5812 | 15.91 | 0.6219 | 16.83 | 0.6133 | 7.99 | 0.4300 | 12.41 | 0.5217 | 0.390M |
| KIND [73] | 15.51 | 0.7115 | 11.66 | 0.7300 | 13.20 | 0.7200 | 15.03 | 0.6700 | 12.67 | 0.6700 | 13.85 | 0.6700 | 0.590M |
| DeepUPE [55] | 19.10 | 0.7321 | 14.69 | 0.7011 | 16.25 | 0.7158 | 16.21 | 0.6807 | 11.98 | 0.5967 | 14.10 | 0.6387 | 7.790M |
| SID [7] | 19.37 | 0.8103 | 18.83 | 0.8055 | 19.04 | 0.8074 | 19.51 | 0.6635 | 16.79 | 0.6444 | 18.15 | 0.6540 | 7.760M |
| SID-ENC [17] | 22.59 | 0.8423 | 22.36 | 0.8519 | 22.45 | 0.8481 | 21.36 | 0.6652 | 19.38 | 0.6843 | 20.37 | 0.6748 | >7.760M |
| RUAS [37] | 13.43 | 0.6807 | 6.39 | 0.4655 | 9.20 | 0.5515 | 16.63 | 0.5589 | 4.54 | 0.3196 | 10.59 | 0.4394 | 0.002M |
| SCI [44] | 9.96 | 0.6681 | 5.83 | 0.5190 | 7.49 | 0.5786 | 17.86 | 0.6401 | 4.45 | 0.3629 | 12.49 | 0.5051 | 0.001M |
| MSEC [2] | 20.52 | 0.8129 | 19.79 | 0.8156 | 20.08 | 0.8210 | 19.62 | 0.6512 | 17.59 | 0.6560 | 18.58 | 0.6536 | 7.040M |
| CMEC [48] | 22.23 | 0.8140 | 22.75 | 0.8336 | 22.54 | 0.8257 | 17.68 | 0.6592 | 18.17 | 0.6811 | 17.93 | 0.6702 | 5.400M |
| LCDPNet [54] | 22.35 | 0.8650 | 22.17 | 0.8476 | 22.30 | 0.8552 | 17.45 | 0.5622 | 17.04 | 0.6463 | 17.25 | 0.6043 | 0.960M |
| DRBN [66] | 19.74 | 0.8290 | 19.37 | 0.8321 | 19.52 | 0.8309 | 17.96 | 0.6767 | 17.33 | 0.6828 | 17.65 | 0.6798 | 0.530M |
| DRBN+ERL [20] | 19.91 | 0.8305 | 19.60 | 0.8384 | 19.73 | 0.8355 | 18.09 | 0.6735 | 17.93 | 0.6866 | 18.01 | 0.6796 | 0.530M |
| DRBN-ERL+ENC [20] | 22.61 | 0.8578 | 22.45 | 0.8724 | 22.53 | 0.8651 | 22.06 | 0.7053 | 19.50 | 0.7205 | 20.78 | 0.7129 | 0.580M |
| ELCNet [22] | 22.37 | 0.8566 | 22.70 | 0.8673 | 22.57 | 0.8619 | 22.05 | 0.6893 | 19.25 | 0.6872 | 20.65 | 0.6861 | 0.018M |
| IAT [11] | 20.34 | 0.8440 | 21.47 | 0.8518 | 20.91 | 0.8479 | 21.41 | 0.6601 | 22.29 | 0.6813 | 21.85 | 0.6707 | 0.090M |
| ELCNet+ERL [20] | 22.48 | 0.8424 | 22.58 | 0.8667 | 22.53 | 0.8545 | 22.14 | 0.6908 | 19.47 | 0.6982 | 20.81 | 0.6945 | 0.018M |
| FECNet [19] | 22.19 | 0.8562 | 23.22 | 0.8748 | 22.70 | 0.8655 | 22.01 | 0.6737 | 19.91 | 0.6961 | 20.96 | 0.6849 | 0.150M |
| FECNet+ERL [20] | 23.10 | 0.8639 | 23.18 | 0.8759 | 23.15 | 0.8711 | 22.35 | 0.6671 | 20.10 | 0.6891 | 21.22 | 0.6781 | >0.150M |
| U-EGformer | 22.50 | 0.8469 | 22.70 | 0.8510 | 22.60 | 0.8490 | 21.63 | 0.7112 | 19.74 | 0.7046 | 20.69 | 0.7079 | 0.099M |
| 22.82 | 0.8578 | 22.90 | 0.8558 | 22.86 | 0.8568 | 22.98 | 0.7192 | 21.84 | 0.7102 | 22.41 | 0.7179 | 0.102M | |
3.4 Loss Functions
To enhance multiple aspects of image quality, our training uses a detailed loss function setup in RGB color space. It includes and losses for handling outliers and detail, SSIM for structural integrity, and VGG for semantic consistency. We also incorporate a novel MUL-ADD (MA) loss to adjust the image’s contrast and brightness accurately, ensuring that the dynamic range is well represented without blurring details. The VGG loss helps match the output to high-level visual quality standards. Our combined loss function , considering both local and global outputs, is detailed below:
| (3) | |||
| (4) |
where and are hyperparameters balancing the influence of each loss term, is the ground truth, is the predicted image, and are the multiplicative and additive components of the local block, is the low-light input, and is the target high-quality image. Our fine-tuning stage’s loss equation can be presented with the physics based KL-divergence loss:
| (5) |
| Methods | LOL-v1 | LOL-v2 | MIT-Fivek | Average |
| DRBN [66] | 19.55/0.746 | 20.13/0.820 | -/- | 19.84/0.783 |
| DPE | -/- | -/- | 23.80/0.880 | - |
| Deep-UPE [55] | -/- | 13.27/0.452 | 23.04/0.893 | 18.15/0.672 |
| 3D-LUT [71] | 16.35/0.585 | 17.59/0.721 | 25.21/0.922 | 19.71/0.742 |
| DRBN+ERL [20] | 19.84/0.824 | -/- | 22.14/0.873 | 20.99/0.848 |
| ECLNet+ERL [20] | 22.01/0.827 | -/- | 23.71/0.853 | 22.39/0.840 |
| FECNet+ERL [20] | 21.08/0.829 | -/- | 24.18/0.864 | 22.63/0.846 |
| RetinexNet [60] | 16.77/0.462 | 18.37/0.723 | -/- | 17.57/0.592 |
| KinD++ [72] | 21.30/0.823 | 19.08/0.817 | -/- | 20.19/0.820 |
| EnlightenGAN [27] | 17.483/0.652 | 18.64/0.677 | -/- | 18.06/0.664 |
| IAT [11] | 23.38/0.809 | 23.50/0.824 | 25.32/0.920 | 24.07/0.851 |
| LLFormer [57] | 25.75/0.823 | 26.19/0.819 | -/- | 25.97/0.816 |
| MIRNet [70] | 24.10/0.832 | 20.35/0.782 | -/- | 22.22/0.807 |
| U-EGformer | 23.56/0.836 | 22.05/0.841 | 24.89/0.928 | 23.5/0.869 |
Adobe FiveK [3], and average.
| Methods | SICE Grad | SICE Mix | ||||
|---|---|---|---|---|---|---|
| PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | |
| RetinexNet | 12.397 | 0.606 | 0.407 | 12.450 | 0.619 | 0.364 |
| ZeroDCE | 12.428 | 0.633 | 0.362 | 12.475 | 0.644 | 0.314 |
| RAUS | 0.864 | 0.493 | 0.525 | 0.8628 | 0.494 | 0.499 |
| SGZ | 10.866 | 0.607 | 0.415 | 10.987 | 0.621 | 0.364 |
| LLFlow | 12.737 | 0.617 | 0.388 | 12.737 | 0.617 | 0.388 |
| URetinexNet | 10.903 | 0.600 | 0.402 | 10.894 | 0.610 | 0.356 |
| SCI | 8.644 | 0.529 | 0.511 | 8.559 | 0.532 | 0.484 |
| KinD | 12.986 | 0.656 | 0.346 | 13.144 | 0.668 | 0.302 |
| KinD++ | 13.196 | 0.657 | 0.334 | 13.235 | 0.666 | 0.295 |
| U-EGformer | 13.272 | 0.643 | 0.273 | 14.235 | 0.652 | 0.281 |
| U-EGformer† | 14.724 | 0.665 | 0.269 | 15.101 | 0.670 | 0.260 |
[74]. indicates the model was finetuned.
4 Experiments
4.1 Framework Setting
Datasets. In our study, we employ eight diverse datasets to rigorously train and evaluate our proposed model: LOL-v1 and LOL-v2 for foundational training and testing with real-world and synthetic images; Multiple-Exposure ME-v2 tailored for diverse exposure scenarios; SICE, including the SICE-Grad and SICE-Mix subsets for gradient and mixed-exposure challenges, respectively; and MIT-FiveK for benchmarking against professionally retouched images. LOL-v1 [60] contains 500 image pairs with 485 and 15 for training and testing datasets, where each image has a resolution of (). LOL-v2 is divided into real and synthetic subsets with detailed configurations for training/testing (with 689 and 100 images for real-world); in the BAcklit Image Dataset (BAID) dataset [43], we only use 380 randomly selected training images from Liang et al. [36] and utilize the complete 368 2K resolution images from the test set.
Training Strategy. In tackling the mixed exposure challenge in image processing, our approach adopts a pre-training stage and a finetuning stage as shown in Fig. 2. We engage in pre-training using our custom loss function, (Eq. 3.4), which combines several loss components with individually set hyperparameters for input-output pairs. In the finetuning phase, we refine the model with a physics-based pixel-wise reconstruction loss function tailored to camera sensors obeying Poisson distribution [59] (more details are in the supplementary material).
Both stages of training leverage a combination of loss functions, which are detailed in the following subsection. This systematic progression from foundational learning to focused refinement helps to address the complexities inherent in mixed exposure challenges. (More details can be found in the supplementary material.)
4.2 Qualitative Results

| Components | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | ||
| Warmup | ✗ | ✗ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓* | ||
| LEB | Attention map | ✗ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| GEB | Attention map | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | |
|
✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ||
|
✗ | ✗ | ✗ | ✓ | ✓ | ✓ | ✓ | ✗ | ||
| Attention Trans. Block | ✗ | 3 | 8 | 8 | 5 | 5 | 5 | 5 | ||
| EAF Block | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ||
| Mul-Add - SL1 Loss | ✗ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| Adaptive Gamma net. | ✓ | ✗ | ✗ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| PSNR | 21.12 | 18.28 | 18.82 | 20.32 | 20.66 | 21.33 | 21.90 | 22.05 | ||
| SSIM | 81.56 | 72.12 | 74.24 | 81.96 | 81.36 | 79.86 | 83.92 | 84.10 | ||
The LOL dataset is still one of the challenging datasets even for state-of-the-art models due to its extremely low-light scenario. In Fig. 9. top, we compare recent top models, where most of the models fail to match the color of the wood pane in this case with a lower PSNR score. In Fig. 9. bottom, we show visual results for the SICE Grad dataset for the mixed-exposure task. In Fig. 13, we show a few most challenging examples where LEB and GEB alone could not manage certain cases with extreme low and bright pixels, where the EAF block helps in re-highlighting the attended features from GAMG.
Quantitative Comparison. Tab. 1 reports the PSNR and SSIM scores for the U-EGFormer and . U-EGformer demonstrates superior performance in handling both underexposure and overexposure scenarios across ME-v2 and SICE-v2 datasets, outperforming majority existing methods with significantly fewer parameters. Despite SID-L [17] with params we compare very close (with difference of 0.0398/0.05 for SSIM/PSNR), where U-EGformer is 115 times smaller network than SID-L. In Tab. 2(a), we show the remarkable generalization across LOL-v1, LOL-v2, and MIT-FiveK datasets, outperforming many baselines and illustrating its robustness in exposure correction. Moreover, Tab. 2(b) sets new benchmarks on the challenging SICE Grad and SICE Mix datasets, underscoring its superior performance in correcting mixed exposure images. In [Fig. 8], we show a direct comparison of ssim map over the enhanced outputs between IAT and U-EGformer framework. Darker pixels in SSIM maps as seen more in IAT than in U-EGformer, indicate areas where the enhanced outputs from the two frameworks significantly differ with ground-truth. Moreover, in [Fig. 11], we emphasize the noise and the color consistency that visually seems better in U-EGformer’s output.


Adaptable Learning Across Diverse Exposures. Tackling the challenge of dataset diversity, our methodology enhances transferability and adaptability of learned models. Leveraging mechanisms such as attention masks allows us to consider simultaneously varying exposure conditions. Our unified framework demonstrates enhanced generalization capabilities, enabling effective fine-tuning across different datasets. Evidence of this robust adaptability is showcased in Tab. 2(b), illustrating our model’s consistent performance on varied datasets with minimal fine-tuning adjustments.
Ablation Study. Our framework utilizes a data-centric approach with a smaller memory footprint (12.5 Mb777over LOL-v2 input image) and computation alongside other strategies as we have shown through Tab. 1’s ‘#params’ column. Through Tab. 8, we show the effectiveness of each module in our framework over LOL-v2 dataset. We demonstrate that the inverse illuminance map, combined with the attention map and exposure-aware fusion block, achieves the best results when configured with the appropriate combination of loss functions. The first column achieves better performance on LOLv2. Additionally, Tab. 8 highlights a notable improvement in LPIPS score compared to the closest baseline [72].
5 Conclusion
Our work introduces the Unified-EGformer, addressing mixed exposure challenges in images with a novel transformer model. Through specialized local and global refinement alongside guided attention, it demonstrates superior performance across various scenarios. Its lightweight architecture makes it suitable for real-time applications, advancing the field of image enhancement and restoration. Enhancing Unified-EGFormer could involve refining the attention mechanism to become color independent to diminish the influence of color artifacts in the enhanced output. Additionally, exploring the integration of lightweight state space models [14], with bi-exposure guidance offers promising avenues for further optimizing the network for efficiency and performance in image enhancement tasks.
References
- [1] Afifi, M., Brown, M.S.: Deep white-balance editing. In: Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition. pp. 1397–1406 (2020)
- [2] Afifi, M., Derpanis, K.G., Ommer, B., Brown, M.S.: Learning multi-scale photo exposure correction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9157–9167 (2021)
- [3] Bychkovsky, V., Paris, S., Chan, E., Durand, F.: Learning photographic global tonal adjustment with a database of input / output image pairs. In: The Twenty-Fourth IEEE Conference on Computer Vision and Pattern Recognition (2011)
- [4] Cai, J., Gu, S., Zhang, L.: Learning a deep single image contrast enhancer from multi-exposure images. IEEE Transactions on Image Processing 27(4), 2049–2062 (2018)
- [5] Celik, T., Tjahjadi, T.: Contextual and variational contrast enhancement. IEEE Transactions on Image Processing 20(12), 3431–3441 (2011)
- [6] Charbonnier, P., Blanc-Feraud, L., Aubert, G., Barlaud, M.: Two deterministic half-quadratic regularization algorithms for computed imaging. In: International Conference on Image Processing. vol. 2, pp. 168–172 vol.2 (1994)
- [7] Chen, C., Chen, Q., Xu, J., Koltun, V.: Learning to see in the dark. In: 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018. pp. 3291–3300. Computer Vision Foundation / IEEE Computer Society (2018)
- [8] Chen, H., Wang, Y., Guo, T., Xu, C., Deng, Y., Liu, Z., Ma, S., Xu, C., Xu, C., Gao, W.: Pre-trained image processing transformer. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12299–12310 (2021)
- [9] Chen, Y.S., Wang, Y.C., Kao, M.H., Chuang, Y.Y.: Deep photo enhancer: Unpaired learning for image enhancement from photographs with gans. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 6306–6314 (2018)
- [10] Conde, M.V., Choi, U.J., Burchi, M., Timofte, R.: Swin2sr: Swinv2 transformer for compressed image super-resolution and restoration. In: European Conference on Computer Vision. pp. 669–687. Springer (2022)
- [11] Cui, Z., Li, K., Gu, L., Su, S., Gao, P., Jiang, Z., Qiao, Y., Harada, T.: You only need 90k parameters to adapt light: a light weight transformer for image enhancement and exposure correction. In: 33rd British Machine Vision Conference 2022, BMVC 2022, London, UK, November 21-24, 2022. BMVA Press (2022)
- [12] Cui, Z., Qi, G.J., Gu, L., You, S., Zhang, Z., Harada, T.: Multitask aet with orthogonal tangent regularity for dark object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 2553–2562 (2021)
- [13] Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020)
- [14] Gu, A., Dao, T.: Mamba: Linear-time sequence modeling with selective state spaces (2024)
- [15] Guo, C., Li, C., Guo, J., Loy, C.C., Hou, J., Kwong, S., Cong, R.: Zero-reference deep curve estimation for low-light image enhancement. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 1780–1789 (2020)
- [16] Hou, J., Zhu, Z., Hou, J., Liu, H., Zeng, H., Yuan, H.: Global structure-aware diffusion process for low-light image enhancement. Advances in Neural Information Processing Systems 36 (2024)
- [17] Huang, J., Liu, Y., Fu, X., Zhou, M., Wang, Y., Zhao, F., Xiong, Z.: Exposure normalization and compensation for multiple-exposure correction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6043–6052 (2022)
- [18] Huang, J., Liu, Y., Zhao, F., Yan, K., Zhang, J., Huang, Y., Zhou, M., Xiong, Z.: Deep fourier-based exposure correction network with spatial-frequency interaction. In: European Conference on Computer Vision. pp. 163–180. Springer (2022)
- [19] Huang, J., Xiong, Z., Fu, X., Liu, D., Zha, Z.J.: Hybrid image enhancement with progressive laplacian enhancing unit. In: Proceedings of the 27th ACM International Conference on Multimedia. p. 1614–1622. MM ’19, Association for Computing Machinery, New York, NY, USA (2019)
- [20] Huang, J., Zhao, F., Zhou, M., Xiao, J., Zheng, N., Zheng, K., Xiong, Z.: Learning sample relationship for exposure correction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9904–9913 (2023)
- [21] Huang, J., Zhou, M., Liu, Y., Yao, M., Zhao, F., Xiong, Z.: Exposure-consistency representation learning for exposure correction. In: Proceedings of the 30th ACM International Conference on Multimedia. pp. 6309–6317 (2022)
- [22] Huang, X., Belongie, S.: Arbitrary style transfer in real-time with adaptive instance normalization (2017)
- [23] Ibrahim, H., Kong, N.S.P.: Brightness preserving dynamic histogram equalization for image contrast enhancement. IEEE Transactions on Consumer Electronics 53(4), 1752–1758 (2007)
- [24] Ignatov, A., Kobyshev, N., Timofte, R., Vanhoey, K., Van Gool, L.: Dslr-quality photos on mobile devices with deep convolutional networks. In: Proceedings of the IEEE international conference on computer vision (2017)
- [25] Jiang, H., Luo, A., Fan, H., Han, S., Liu, S.: Low-light image enhancement with wavelet-based diffusion models. ACM Transactions on Graphics (TOG) 42(6), 1–14 (2023)
- [26] Jiang, H., Tian, Q., Farrell, J., Wandell, B.A.: Learning the image processing pipeline. IEEE Transactions on Image Processing 26(10), 5032–5042 (2017)
- [27] Jiang, Y., Gong, X., Liu, D., Cheng, Y., Fang, C., Shen, X., Yang, J., Zhou, P., Wang, Z.: EnlightenGAN: Deep light enhancement without paired supervision. IEEE Transactions on Image Processing 30, 2340–2349 (2021)
- [28] Jin, Y., Yang, W., Tan, R.T.: Unsupervised night image enhancement: When layer decomposition meets light-effects suppression. In: European Conference on Computer Vision. pp. 404–421. Springer (2022)
- [29] Kim, H., Choi, S.M., Kim, C.S., Koh, Y.J.: Representative color transform for image enhancement. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 4459–4468 (2021)
- [30] Kim, W., Lee, R., Park, M., Lee, S.H.: Low-light image enhancement based on maximal diffusion values. IEEE Access 7, 129150–129163 (2019)
- [31] Land, E.H.: The retinex theory of color vision. Scientific american 237(6), 108–129 (1977)
- [32] Land, E.H.: An alternative technique for the computation of the designator in the retinex theory of color vision. Proceedings of the national academy of sciences 83(10), 3078–3080 (1986)
- [33] Lee, C., Lee, C., Kim, C.S.: Contrast enhancement based on layered difference representation of 2d histograms. IEEE transactions on image processing 22(12), 5372–5384 (2013)
- [34] Li, C., Guo, C.G., Loy, C.C.: Learning to enhance low-light image via zero-reference deep curve estimation. In: IEEE Transactions on Pattern Analysis and Machine Intelligence (2021)
- [35] Li, H., Zhang, Y., Liu, J., Ma, Y.: Gtmnet: a vision transformer with guided transmission map for single remote sensing image dehazing. Scientific Reports 13(1), 9222 (2023)
- [36] Liang, Z., Li, C., Zhou, S., Feng, R., Loy, C.C.: Iterative prompt learning for unsupervised backlit image enhancement. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 8094–8103 (2023)
- [37] Liu, J., Dejia, X., Yang, W., Fan, M., Huang, H.: Benchmarking low-light image enhancement and beyond. International Journal of Computer Vision 129, 1153–1184 (2021)
- [38] Liu, J., Xu, D., Yang, W., Fan, M., Huang, H.: Benchmarking low-light image enhancement and beyond. International Journal of Computer Vision 129, 1153–1184 (2021)
- [39] Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B.: Swin transformer: Hierarchical vision transformer using shifted windows. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 10012–10022 (October 2021)
- [40] Liu, Z., Wang, Y., Vaidya, S., Ruehle, F., Halverson, J., Soljačić, M., Hou, T.Y., Tegmark, M.: Kan: Kolmogorov-arnold networks. arXiv preprint arXiv:2404.19756 (2024)
- [41] Lu, Z., Li, J., Liu, H., Huang, C., Zhang, L., Zeng, T.: Transformer for single image super-resolution. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 457–466 (2022)
- [42] Luo, Z., Gustafsson, F.K., Zhao, Z., Sjölund, J., Schön, T.B.: Controlling vision-language models for universal image restoration. arXiv preprint arXiv:2310.01018 (2023)
- [43] Lv, X., Zhang, S., Liu, Q., Xie, H., Zhong, B., Zhou, H.: Backlitnet: A dataset and network for backlit image enhancement. Computer Vision and Image Understanding 218, 103403 (2022)
- [44] Ma, L., Ma, T., Liu, R., Fan, X., Luo, Z.: Toward fast, flexible, and robust low-light image enhancement. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5637–5646 (June 2022)
- [45] Mehta, S., Abdolhosseini, F., Rastegari, M.: Cvnets: High performance library for computer vision. In: Proceedings of the 30th ACM International Conference on Multimedia. MM ’22 (2022)
- [46] Mehta, S., Rastegari, M.: Mobilevit: Light-weight, general-purpose, and mobile-friendly vision transformer. In: International Conference on Learning Representations (2022)
- [47] Moran, S., Marza, P., McDonagh, S., Parisot, S., Slabaugh, G.: Deeplpf: Deep local parametric filters for image enhancement. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12826–12835 (2020)
- [48] Nsampi, N.E., Hu, Z., Wang, Q.: Learning exposure correction via consistency modeling. In: Proc. Brit. Mach. Vision Conf. (2021)
- [49] Otsu, N.: A threshold selection method from gray-level histograms. IEEE Transactions on Systems, Man, and Cybernetics 9(1), 62–66 (1979)
- [50] Sasagawa, Y., Nagahara, H.: Yolo in the dark-domain adaptation method for merging multiple models. In: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXI 16. pp. 345–359. Springer (2020)
- [51] Sharma, A., Tan, R.T.: Nighttime visibility enhancement by increasing the dynamic range and suppression of light effects. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 11977–11986 (2021)
- [52] Song, Y., He, Z., Qian, H., Du, X.: Vision transformers for single image dehazing. IEEE Transactions on Image Processing 32, 1927–1941 (2023)
- [53] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L.u., Polosukhin, I.: Attention is all you need. In: Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R. (eds.) Advances in Neural Information Processing Systems. vol. 30. Curran Associates, Inc. (2017)
- [54] Wang, H., Xu, K., Lau, R.W.: Local color distributions prior for image enhancement. In: European Conference on Computer Vision. pp. 343–359. Springer (2022)
- [55] Wang, R., Zhang, Q., Fu, C.W., Shen, X., Zheng, W.S., Jia, J.: Underexposed photo enhancement using deep illumination estimation. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2019)
- [56] Wang, T., Zhang, K., Shao, Z., Luo, W., Stenger, B., Kim, T.K., Liu, W., Li, H.: Lldiffusion: Learning degradation representations in diffusion models for low-light image enhancement. arXiv preprint arXiv:2307.14659 (2023)
- [57] Wang, T., Zhang, K., Shen, T., Luo, W., Stenger, B., Lu, T.: Ultra-high-definition low-light image enhancement: A benchmark and transformer-based method. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 37, pp. 2654–2662 (2023)
- [58] Wang, X., Wang, W., Cao, Y., Shen, C., Huang, T.: Images speak in images: A generalist painter for in-context visual learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 6830–6839 (June 2023)
- [59] Wang, Y., Yu, Y., Yang, W., Guo, L., Chau, L.P., Kot, A.C., Wen, B.: Exposurediffusion: Learning to expose for low-light image enhancement. arXiv preprint arXiv:2307.07710 (2023)
- [60] Wei, C., Wang, W., Yang, W., Liu, J.: Deep retinex decomposition for low-light enhancement. In: British Machine Vision Conference 2018, BMVC 2018, Newcastle, UK, September 3-6, 2018. p. 155. BMVA Press (2018)
- [61] Wei, K., Fu, Y., Yang, J., Huang, H.: A physics-based noise formation model for extreme low-light raw denoising. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2758–2767 (2020)
- [62] Wu, W., Weng, J., Zhang, P., Wang, X., Yang, W., Jiang, J.: Uretinex-net: Retinex-based deep unfolding network for low-light image enhancement. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5891–5900 (2022)
- [63] Xu, K., Yang, X., Yin, B., Lau, R.W.: Learning to restore low-light images via decomposition-and-enhancement. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 2281–2290 (2020)
- [64] Xu, X., Wang, R., Fu, C.W., Jia, J.: Snr-aware low-light image enhancement. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 17714–17724 (2022)
- [65] Yang, J., Luo, K.Z., Li, J., Weinberger, K.Q., Tian, Y., Wang, Y.: Denoising vision transformers. arXiv preprint arXiv:2401.02957 (2024)
- [66] Yang, W., Wang, S., Fang, Y., Wang, Y., Liu, J.: From fidelity to perceptual quality: A semi-supervised approach for low-light image enhancement. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3063–3072 (2020)
- [67] Ye, L., Wang, D., Yang, D., Ma, Z., Zhang, Q.: Velie: A vehicle-based efficient low-light image enhancement method for intelligent vehicles. Sensors 24(4) (2024)
- [68] Yi, X., Xu, H., Zhang, H., Tang, L., Ma, J.: Diff-retinex: Rethinking low-light image enhancement with a generative diffusion model. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 12302–12311 (2023)
- [69] Yu, R., Liu, W., Zhang, Y., Qu, Z., Zhao, D., Zhang, B.: Deepexposure: Learning to expose photos with asynchronously reinforced adversarial learning. Advances in Neural Information Processing Systems 31 (2018)
- [70] Zamir, S.W., Arora, A., Khan, S., Hayat, M., Khan, F.S., Yang, M.H., Shao, L.: Learning enriched features for real image restoration and enhancement. In: ECCV (2020)
- [71] Zeng, H., Cai, J., Li, L., Cao, Z., Zhang, L.: Learning image-adaptive 3d lookup tables for high performance photo enhancement in real-time. IEEE Transactions on Pattern Analysis and Machine Intelligence 44(04), 2058–2073 (2022)
- [72] Zhang, Y., Guo, X., Ma, J., Liu, W., Zhang, J.: Beyond brightening low-light images. Int. J. Comput. Vision 129(4), 1013–1037 (apr 2021)
- [73] Zhang, Y., Zhang, J., Guo, X.: Kindling the darkness: A practical low-light image enhancer. In: Proceedings of the 27th ACM International Conference on Multimedia. p. 1632–1640. MM ’19, Association for Computing Machinery, New York, NY, USA (2019)
- [74] Zheng, S., Ma, Y., Pan, J., Lu, C., Gupta, G.: Low-light image and video enhancement: A comprehensive survey and beyond. arXiv preprint arXiv:2212.10772 (2022)
- [75] Zheng, Y., Zhang, M., Lu, F.: Optical flow in the dark. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6749–6757 (2020)
- [76] Zhou, D., Yang, Z., Yang, Y.: Pyramid diffusion models for low-light image enhancement. arXiv preprint arXiv:2305.10028 (2023)
Supplementary Material
6 Future Work & Discussion
The challenges presented by mixed exposure in images are not just specific to any single methodology but are a broader issue within the field of image enhancement. As illustrated in [Fig. 4], both overexposure and underexposure present unique challenges. Overexposure often results in the loss of critical details such as edges and contours, while underexposure can hide essential information in darkness. These scenarios make effective image reconstruction a complex task.
A further complication arises when considering the standard for evaluation—what exactly constitutes an ideal ground truth in the context of mixed exposure? Often, ground truth images themselves may lack details in over-exposed areas, complicating the assessment of enhancement algorithms as can be seen in [Fig. 4]. This highlights a significant gap in our current understanding and capabilities, emphasizing the need for advancements that can precisely discern and correct varying degrees of exposure while preserving the integrity of the image details.
The field of mixed exposed is not new, however has limited exploration and yet far away to successfully solve the problem. Potential solutions such as Integrating Kolmogorov-Arnold Networks (KANs) [40] in place of MLP blocks in transformers can yield more efficient and explainable models. KANs’ adaptive activation functions can better distinguish and process overexposed and underexposed regions, enhancing image quality.
While current methods address many aspects of image quality, there is still room for improvement in creating color-independent ground truths for guided attention map generators. Color-independent techniques prevent issues such as greens appearing yellow due to color influence, ensuring accurate hue representation and processing. Understanding and correcting these color dynamics involve using attention map generators to identify inconsistencies.
Such methods must not only navigate the complexities introduced by mixed exposure but also contribute to a deeper understanding of what ideal image enhancement should entail in diverse real-world conditions.
7 Model Design Components
This extended material provides with more details in our model design components.
7.1 Algorithm
The details presented in the training are shown in the algorithm below:
7.2 A-MSA
The A-MSA component can be mathematically represented as:
| (6) |
where is the attention map, , , and denote the query, key, and value projections of the input , and is the dimensionality of the key, thereby guiding the model to focus on relevant features, when and how much attention should be paid to each element in the sequence when processing a query.
7.3 Dual Gating Feedforward Network (DGFN).
[Eq. 7.3] The DGFN mechanism involves two parallel pathways that process the input features through distinct gating mechanisms, utilizing GELU activations () and element-wise products. Each path applies a sequence of convolutional transformations to enrich local context, comprising a convolution followed by a depth-wise convolution. Moreover, depth-wise convolutions facilitate spatial information processing while significantly reducing computational costs, making them particularly suitable for developing a light-weight environment without compromising performance. Following Wang et al.’s, [57] approach, the outputs of these parallel pathways are then merged using element-wise summation, allowing for a comprehensive feature refinement that incorporates both detailed and global information.
Mathematically, the operation of DGFN on input features can be formulated as follows:
where and denote the convolutional filters in the two pathways, and represents element-wise multiplication. The final output thus combines the processed features from both pathways, ensuring that the network selectively emphasizes informative regions for enhanced exposure correction in the attention map generation process.
This design allows the network to make more nuanced adjustments to the attention maps, focusing on areas of the image that require exposure correction while maintaining the integrity of well-exposed regions.
7.4 Model Training
For LOL-v1 [60], we adopt the standard split provided, comprising images of dimensions , with 500 images allocated for both training and evaluation. Similarly, for LOL-v2 [60], we utilize the real-world dataset for both training and evaluation, consisting of images of size , with 689 and 100 images in the respective splits. We adopt patch sizes of and for training across both LOL-v1 and LOL-v2 datasets. Additionally, we incorporate the MIT-Adobe FiveK [3] (FiveK) dataset for comparative analysis with other baseline methods. The FiveK dataset comprises 5,000 image pairs, each meticulously retouched by experts (A - E), with the best-performing result reported. To align with established practices [11, 2], we crop the training images to dimensions, subsequently fine-tuning over and patches, while the test images are resized to a maximum dimension of 512 pixels. Additionally, we incorporate the MSEC [2] dataset, which features realistic underexposure and overexposure scenarios derived from the MIT-FiveK dataset. Our experimental setup involves 17,675 training images, 750 for validation, and 5,905 for testing, adhering to the general experimental protocol of our baselines. Furthermore, we utilize the SICE [4] dataset, employing the SICE-v2 variant, a resized version of the original dataset, following the approach outlined in [21, 20]. Lastly, to comprehensively evaluate mixed-exposure scenarios, we assess our model’s performance on two variants of the SICE dataset: SICE-Grad and SICE-Mix [74], which feature mixed under and overexposure regions within single images.
To facilitate network training, we employ the cosine annealing schedule along with the Cosine-Annealing learning rate scheduler, incorporating 15 warm-up epochs and setting eta_min to . Additionally, we utilize the Adam optimizer with and , along with an epsilon value of . Our initial learning rate is set to for pretraining purposes. Furthermore, we adopt a batch size of 4 and a weight decay of to stabilize training and improve model performance.
8 Extended Experimental Results
8.1 Generalization in the Wild
Our model demonstrates impressive visual qualitative results on the BAID dataset. Initially trained on the LOLv2 dataset, the model was finetuned using only 300 randomly selected images from the BAID train dataset, out of the 3000 available backlit images. These BAID images were originally downsampled images and were directly used from Liang et al., [36]. The backlit images in BAID present a challenging scenario due to uneven exposure, typically featuring underexposure in the foreground and overexposure in the background. Traditional approaches often struggle with these conditions, but Unified-EGformer, particularly with our Global Enhancement Block (GEB) combined with the Exposure Aware Fusion Block (EAF), excel by exploiting contextual features. Despite the limited finetuning data, our model significantly enhances backlit images, effectively generalizing to both indoor and outdoor scenes under diverse backlit conditions.



