Understanding the Ability of Deep Neural Networks to Count Connected Components in Images
Abstract
Humans can count very fast by subitizing, but slow substantially as the number of objects increases. Previous studies have shown a trained deep neural network (DNN) detector can count the number of objects in an amount of time that increases slowly with the number of objects. Such a phenomenon suggests the subitizing ability of DNNs, and unlike humans, it works equally well for large numbers. Many existing studies have successfully applied DNNs to object counting, but few studies have studied the subitizing ability of DNNs and its interpretation. In this paper, we found DNNs do not have the ability to generally count connected components. We provided experiments to support our conclusions and explanations to understand the results and phenomena of these experiments. We proposed three ML-learnable characteristics to verify learnable problems for ML models, such as DNNs, and explain why DNNs work for specific counting problems but cannot generally count connected components.
Index Terms:
object counting, subitizing, deep neural networks, connected components, deep learning, learnability, explainable artificial intelligenceI Introduction
Humans detect the number of objects by a spontaneous “number sense” (called “subitizing”) if the number is small, and by deliberately counting and memorizing for a large number. Humans can count very fast by subitizing, but slow substantially as the number of objects increases. In deep learning, previous studies have successfully applied deep neural networks (DNN) to object counting. A trained DNN detector can count the number of objects in an amount of time that increases slowly with the number of objects. Such a phenomenon suggests the subitizing ability of DNNs, and unlike humans, it works equally well for large numbers. Many existing studies have examined the applications of DNNs to object counting, but few studies have studied the subitizing ability of a DNN and its interpretation. In a DNN, subitizing does not first detect and then count objects (as in traditional image processing), but it recognizes the number of objects in an image directly. The DNN’s ability to transform images to binary images through segmentation has been verified by numerous studies. For a DNN’s subitizing, however, its essential ability is to detect connected components in binary images because object counting depends on their connectedness. In this study, we have created binary images containing various numbers of connected components and tested the ability of DNNs to count the number of pixels and connected components in the images. Each component has its size, shape, or/and location selected at random.
I-A Our works
A deep-neural network pixel-wise counter was trained on binary images containing numbers of individual object pixels (i.e., pixel with value 1 is the object and 0 is background) spanning the entire range from 1000 to 3000 and tested on images that included the range from 3 to 10000 pixels. The experiment was repeated 10 times, yielding an overall error rate of (0.094 0.002)%. In addition, we interpreted this pixel-wise counting ability by comparing different structures and analyzing weights and data flow within neural networks. Understanding this ability is an important step toward explaining and trusting object counting with deep learning.
Unfortunately, our experiments show that DNNs cannot generally count connected components in the image. Then, we tentatively provided three explanations based on learnability to understand why DNNs cannot generally count objects but successfully work for many specific counting tasks. We consider that, for machine learning (ML) models (like DNNs), a learnable problem should have the three characteristics (ML-learnable characteristics):
-
1.
It has a finite domain.
-
2.
It has enough number of data to show its pattern (enough data).
-
3.
Its subsets have the similar pattern as the whole set (pattern consistency).
The first two characteristics are simple and well-known but the third one is profound and needs further studies and discussions.
In summary, around using DNNs to count connected components in image, we have done several experiments and tried to provide some insights into the DNN and data for machine learning. This study may raise other questions and discover the starting points of ways for future researchers to make progress in the understanding of deep learning.
I-B Related works
In deep learning, previous studies have successfully applied DNNs to object counting [1, 2, 3, 4, 5]. For the leaf counting challenge [6], leaves are firstly segmented by the SegNet [7] to obtain a binary leaf image and then the number of leaves is counted by using the breadth first search (BFS) or regression. It is counting by segmentation. Object counting is also done by recognition and classification. Object counting tasks can be considered as recognition problems. Oñoro-Rubio & López-Sastre (2016) [8] applied the CNN model to transform an image with vehicles to a density map. Then, the number of vehicles is predicted by a regression model from the density (heat) map. The work of Zhang et al. (2015) [9] seems similar to ours but this work only classifies images with objects into 5 categories: 0 (no clear object), 1, 2, 3, and 4+ (four and more objects). The main drawback of counting through classification is that the countable number of objects is known and limited.
In general, the goal of automated object counting is to count any number of objects (more than the numbers for training) directly from images. The direction means the input of model is an image and its output is the object number. In this study, we examine a simplified situation; the questions are: can DNNs count the general connected components in images? Why or why not? The generalization means the connected components could be in any shapes, sizes, and positions. Nasr et al. (2019) [10] shows that in the final layer of a trained (on ImageNet) CNN model, 9.6% (3,601/37,632) units can react to the number of objects (called numerosity-selective units). By using the responses of these units can build tuning curves to estimate the number of connected components (range from 1 to 30) in images. The problem of this paper is that the numerosity-selective units are selected and tuned by other methods and experiments; the processes are manually interfered and thus the counting is neither direct nor automatic.
II Count pixels
The first part of experiments is to examine whether DNNs can count the number of pixels:
-
•
Dataset: 256x256 binary images that the label of background is “0” and objects is “1” (see Fig. 3, Random pixels). The training set contains 10,000 images with 1000-3000 “1” pixels (20% for Validation) and test set contains 1,000 images with 1-10000 “1” pixels. All “1” pixels are randomly located.
-
•
Models: a fully-connected neural network (FCNN) without hidden layers (Perceptron, ) and a FCNN with only one (128 neurons) hidden layer ().

Naturally, the results agree with our expectations. The experiment was repeated 10 times, yielding an overall error rate of (0.094 0.002)%. As Fig. 1 shown, a simple deep learning model can learn the counting of pixels. And we found that the training process of was much faster than that of . As shown in Fig. 2, for , to reach 1.0 train loss needs more than 500 epochs but needs less than 50 epochs. This phenomenon is anti-intuitive and interesting because is a more complex model than and is expected to spend more times to train. In summary, two questions derive from this experiment: 1) how does the DNN count the number of pixels? 2) why is the model with more hidden layers trained faster?

II-A Explanation
We suppose that is the vector of a flattened binary image whose labels for background pixels are “0” and objects are “1”:
The simplest way to obtain the number of objects is to multiply a one vector by the :
Hence, if the model has learned to count, we have:
Where A is the weights matrix and B is the bias of model. Obviously, one correct solution is and . If all weights in are equal to , the loss of training is . Therefore, the destination of training is:
| (1) |
For learning to count:
Where is ReLU activation function: . We suppose that and all weights in and are equal to , then:
If contains objects, then :
The loss of training is . Therefore, the destination of training is :
| (2) |
Since the total number of pixels is a very large value, the destination of training is . From Eq. 1, the destination of training is . Whereas the fact that all weights are initialized near 0, the destinations of for training are much closer to their initialization than that of for training . Thus, the training process of is much faster then that of (see the phenomenon in Fig. 2). Eq. 1 and 2 provide answers to the two questions stated before.
III Count connected components
These experiments used three types of datasets and four models:
-
•
Dataset: 256x256 binary images with “0” and “1” pixels. These images contain various numbers of objects, which are defined by 4-neighbors connected components. The training set has 10,000 images (20% for Validation) and test set has 1,000 images. Their labels are the numbers of objects (connected components). The types of these objects are (Fig. 3):
-
1.
Random pixels (same as previous experiments)
-
2.
Triangles (with different sizes)
-
3.
Circles (with different sizes)
For random pixels sets, the only one parameter is the number of pixels; more pixels may form more connected components. For triangle and circle sets, there are two parameters: object size (diameter) range and object number. Objects will be generated in that size range and located randomly.
-
1.
- •

By combination, there are 12 experiments. None of them, however, shows that DNNs have the ability to learn counting of connected components in the image. No matter how to design the training and test sets, once the sizes or types of objects in test sets differ from training sets, the predictions on test sets become incorrect. For example, Fig. 4 shows the predictions of . Details are in the caption. Only the test set T-15 is well predicted because its average size is very close to that of the training set (T-16).


Another example in Fig. 5 shows the predictions of on random pixels sets. If and only if the object numbers in images have been included in training set, the trained model can perform well for such numbers in test set.
For all datasets above, an image with more components may has more pixels because the average size of objects in each dataset is fixed. Although sizes are random in a range, the average size is stable when the number of objects increases. Thus, models could learn the regression of the number of objects on the number of total pixels. To exclude this situation, we built additional datasets that pixels number of all objects in every image is about 5000. Fig. 6 shows some images of these datasets. Since pixels number of objects is fixed, the images with more objects have smaller object sizes.
Even for such fix-object-pixel-number datasets, the predictions on test sets are still incorrect. For example, Fig. 7 shows the predictions of . Details are in the caption.

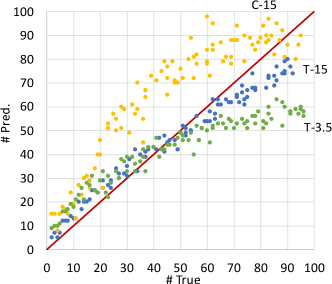
In summary, these results imply that DNNs cannot count the general connected components in images. The generalization is for components in any shapes, sizes and positions. And an ideal DNN counter is like a magic box, whose inputs are raw images and outputs are the numbers of objects to be counted. Hence, there are two questions need to answer: 1) why cannot DNNs achieve general counting? 2) how do DNNs successfully work for many specific counting applications in recent studies? Next, we will provide answers based on three aspects of ML models’ learnability to the two questions.
IV ML-learnable characteristics
-
•
It has a finite domain.
-
•
It has enough number of data to show its pattern.
-
•
Its subsets have the similar pattern as the whole set (pattern consistency).
IV-A Finite domain
We think all patterns of problems could be categorized in two types: generatable and checkable. The generatable patterns mean data with that patterns could be generated by certain rules, such as even numbers are generated by multiplying 2 and integers. And the checkable patterns mean data could be checked/verified having that patterns, but we cannot find specific rules to create such data such as the prime numbers.
For data with generatable patterns, if the generative rules have been learned (like the rule-based machine learning [13, 14]), we consider that the patterns have been learned, even if the domain is infinite. Otherwise, for the problem has infinite domain, if the ML model cannot learn its generative rules or its patterns are not generatable, this problem is not ML-learnable.
Finite/infinite domain of the problem and finite/infinite amount of data in the problem are two different things. If a problem has finite number of data, its domain must be finite; thus, it is ML-learnable because a ML model can memorize all its data, like the k-nearest neighbors (KNN) or DNNs. On the other hand, if a problem has infinite number of data, its domain could be either finite or infinite. The problem having finite domain is ML-learnable because a non-parametric ML model (e.g., Gaussian mixtures) can learn to cover its domain. Hence, ML-learnability is related to the domain of the problem instead of the amount of data.
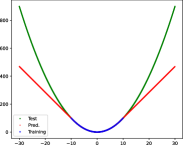

In summary, having finite domain is necessary to a ML-learnable problem. Although infinite domain with generatable patterns is also ML-learnable in theory, it is difficult to train a rule-based ML model to learn these patterns, and many ML models cannot learn generative rules. For example, we fitted by a FCNN. The set of has infinite domain and its pattern is generatable. As shown in Fig. 8, the FCNN model does not learn the pattern because the model only predicts correctly in the same range of training.
The general tasks of counting connected components have infinite domain problems because the image sizes (inputs) and the number of components (outputs) could be arbitrary. And the pattern of such problems is not generatable; there are no specific rules to generate components because their shapes, sizes and positions are arbitrary too. Therefore, general counting connected components is not ML-learnable.
IV-B Enough data
Even a problem has finite domain, we need to have enough data to present its patterns. If the patterns cannot be well presented by a dataset, the ML model cannot learn the correct patterns from the dataset either. Fig. 9 shows an example that the shortage of data could fail to present the patterns.




By the well-known Curse of Dimensionality, the required amount of data to present patterns will increase exponentially in higher dimension space. For 256x256 images, its dimensionality is 65,536. Hence, the training set may not have enough data to train an effective ML model for general counting connected components.
IV-C Pattern consistency
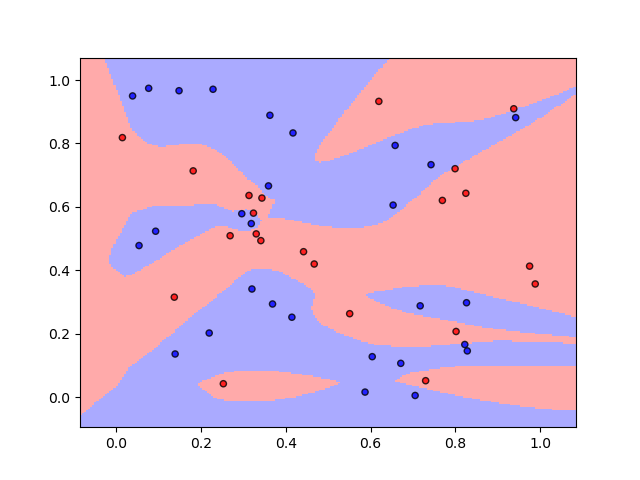
For problems having finite domain, there is another condition that we can never obtain enough data to present its patterns; that is the problem includes infinite number of data and any finite subset does not have the similar pattern as the whole set. In other words, we obviously cannot train ML models on infinite number of data (the whole set) but any finite subset cannot grasp the real pattern of the problem. For example, the infinite random two-class data in . This dataset can have infinite number of data and the decision boundaries of any two subsets of it are different (Fig. 10). Hence, the infinite random two-class data set is not ML-learnable. Some problems have finite domain and infinite number of data are ML-learnable, such as the Gaussian mixtures models because we could find a subset to present their Gaussian distributions.

For some problems, even they have finite number of data, no subset can describe their patterns unless to use the whole set. For example, the -XOR problems, which to fit . It has finite () data and to train models should use all of them.
We trained a FCNN to fit the 6-XOR problem. The training process in Fig. 11 show that if the training batch is the whole set (batch size ), the FCNN model could learn the pattern fast and reach at 100% training accuracy. But if the training batch is a subset (batch size ), the training accuracy increases slowly, oscillates frequently, and seems hard to reach at 100%. Thus, -XOR problems are very difficult to train FCNN models by subsets.

In summary, whatever problems have infinite or finite number of data, if any finite subset does not have the similar pattern as the whole set (no pattern consistency), the problems are not ML-learnable.
By examining the cases with no pattern consistency, we could find two key features: 1) the data in dataset are distributed in high density; 2) the mixture of different-class data is complex, which means different-class data are very close to each other and each datum is surrounded by many different-class data. We suppose that the two features are evidence of problems having no pattern consistency.
Finally, we consider the problems of counting connected components have no pattern consistency because 1) the components could be any number, shapes, sizes, and positions in an image; thus, the dataset is high dense; 2) images with different numbers of connected components can be very similar to each other (close to each other in data space). Fig. 12 shows that one-pixel difference can change the number of connected components. Thus, the mixture of data is complex. Therefore, general counting connected components is not ML-learnable because of no pattern consistency.

V Discussions
Although we have shown that the DNN cannot count the general connected components in images, it can count the objects in images for specific counting problems because they have the three ML-learnable characteristics.
In recent studies that have successfully applied DNNs to object counting, their problems:
-
•
have finite domain because they count specific objects, such as persons, cars, leaves, etc. These specific objects have limited patterns domain for shape, size, color, and/or position.
-
•
are solved by using pre-processing to reduce dimensionality, such as to apply objects matching, recognition, segmentation, etc. before counting because their objects are specified. Thus, the data they have could be enough to train an effective ML model for counting specific objects.
-
•
are not complex and datasets are not high dense because the limitations show before. For example, to count car numbers, images with different numbers of cars are not similar to each other (far from each other in data space).
V-A Future works
To show DNNs cannot generally count connected components in images, more experiments in controlled conditions would strengthen this conclusion. And we could provide explanations to these results, such as to answer what leads the counting to fail.
We will refine the theory about pattern consistency to quantitatively define the similar-pattern subsets and find metrics to examine if a problem has such characteristic or not.
In addition, we will try to find the boundary between countable and non-countable problems for DNNs; that is, the boundary between specific and general counting problems in terms of the three ML-learnable characteristics or other applicable theories.
VI Conclusions
In this paper, we found DNNs do not have the ability of counting general connected components but can count pixels. We provide many experiments to support our conclusions and explanations to understand the results and phenomena of experiments. We consider that learnable problems for ML models, such as DNNs, should have the three ML-learnable characteristics. The theory of learnable patterns for DNNs has explained why DNNs work for specific counting problems but cannot generally count connected components.
References
- [1] N. Ilyas, A. Shahzad, and K. Kim, “Convolutional-Neural Network-Based Image Crowd Counting: Review, Categorization, Analysis, and Performance Evaluation,” Sensors (Basel, Switzerland), vol. 20, no. 1, Dec. 2019.
- [2] S. Aich, “Object Counting with Deep Learning,” Thesis, University of Saskatchewan, Apr. 2019. [Online]. Available: https://harvest.usask.ca/handle/10388/12155
- [3] L. Liu, H. Wang, G. Li, W. Ouyang, and L. Lin, “Crowd Counting using Deep Recurrent Spatial-Aware Network,” in Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence. Stockholm, Sweden: International Joint Conferences on Artificial Intelligence Organization, Jul. 2018, pp. 849–855.
- [4] H. Yao, K. Han, W. Wan, and L. Hou, “Deep Spatial Regression Model for Image Crowd Counting,” arXiv:1710.09757 [cs], Oct. 2017. [Online]. Available: http://arxiv.org/abs/1710.09757
- [5] S. He, J. Jiao, X. Zhang, G. Han, and R. W. Lau, “Delving into Salient Object Subitizing and Detection,” in 2017 IEEE International Conference on Computer Vision (ICCV). Venice: IEEE, Oct. 2017, pp. 1059–1067.
- [6] “Leaf Counting Challenge.” [Online]. Available: https://www.plant-phenotyping.org/CVPPP2017-challenge
- [7] V. Badrinarayanan, A. Kendall, and R. Cipolla, “SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 39, no. 12, pp. 2481–2495, Dec. 2017.
- [8] D. Oñoro-Rubio and R. J. López-Sastre, “Towards Perspective-Free Object Counting with Deep Learning,” in Computer Vision – ECCV 2016, ser. Lecture Notes in Computer Science, B. Leibe, J. Matas, N. Sebe, and M. Welling, Eds. Cham: Springer International Publishing, 2016, pp. 615–629.
- [9] J. Zhang, S. Ma, M. Sameki, S. Sclaroff, M. Betke, Z. Lin, X. Shen, B. Price, and R. Měch, “Salient Object Subitizing,” in 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Jun. 2015, pp. 4045–4054, iSSN: 1063-6919.
- [10] K. Nasr, P. Viswanathan, and A. Nieder, “Number detectors spontaneously emerge in a deep neural network designed for visual object recognition,” Science Advances, vol. 5, no. 5, p. eaav7903, May 2019.
- [11] K. Simonyan and A. Zisserman, “Very Deep Convolutional Networks for Large-Scale Image Recognition,” arXiv:1409.1556 [cs], Sep. 2014, arXiv: 1409.1556. [Online]. Available: http://arxiv.org/abs/1409.1556
- [12] “Convolutional Neural Network for MNIST.” [Online]. Available: https://github.com/hwalsuklee/tensorflow-mnist-cnn
- [13] L. Coulibaly, B. Kamsu-Foguem, and F. Tangara, “Rule-based machine learning for knowledge discovering in weather data,” Future Generation Computer Systems, vol. 108, pp. 861–878, Jul. 2020.
- [14] S. M. Weiss and N. Indurkhya, “Rule-based Machine Learning Methods for Functional Prediction,” arXiv:cs/9512107, Nov. 1995. [Online]. Available: http://arxiv.org/abs/cs/9512107