Understanding of Emotion Perception from Art
Abstract
Computational modeling of the emotions evoked by art in humans is a challenging problem because of the subjective and nuanced nature of art and affective signals. In this paper, we consider the above-mentioned problem of understanding emotions evoked in viewers by artwork using both text and visual modalities. Specifically, we analyze images and the accompanying text captions from the viewers expressing emotions as a multimodal classification task. Our results show that single-stream multimodal transformer-based models like MMBT and VisualBERT perform better compared to both image-only models and dual-stream multimodal models having separate pathways for text and image modalities. We also observe improvements in performance for extreme positive and negative emotion classes, when a single-stream model like MMBT is compared with a text-only transformer model like BERT.
1 Introduction
Visual art is a rich medium for expressing human thoughts and emotions. This can manifest in multiple diverse forms; for example, consider the well-known works such as the dreamy starry night canvas created by Van Gogh, the mythical figurines of Boticelli’s Primavera or the mystical characters like Da Vinci’s Mona Lisa. A common unifying factor of an artwork is its ability to convey and evoke emotional reaction in a viewer. In the affective computing realm, prior works like [6], [11], have explored computational models for understanding emotion elicited by art works. However, modeling emotional responses evoked by art works is especially challenged by the uncertainty associated with the subjectivity across individual viewers’ felt experiences. Based on familiarity with art styles, formative experiences and their present mental state and mood, different persons might interpret the same artwork from multiple diverse perspectives. Since language is a powerful tool for explaining subjective emotional responses [13], one approach is to have natural language explanations of why people felt a certain emotion upon looking at a piece of art.

In this work, we investigate the problem of modeling emotion perception from artwork both through the lens of text-only classification from the associated explanations and by considering multimodal interactions of image regions and the associated textual explanations. The experiments of this work are based on the recently released Artemis dataset [1] that has 80K artwork images from WikiArt111https://www.wikiart.org/ along with 9 emotion class annotations. Artemis was considered because it includes around 400K subjective explanations regarding emotion labels associated with artwork. A sample artwork with associated emotional labels and explanations is shown in Fig 1.
2 Related work
Image and video based emotion classification. In the domain of modeling (categorical) affect evoked from art images, a system trained on the widely used stimuli set from the international affective picture system (IAPS) was evaluated on art masterpieces in [21]. 4000 artwork from the Wikiart repository were leveraged in [11] and annotated for a range of emotions along with title and other aspects.
Text based emotion classification. Linguistic descriptions can be used in affective analysis such as reasoning about an expressed felt experience. A variety of computational text analysis methods and tools are available in the literature, building on a variety of word dictionary based resources such as LIWC[19]. With the advent of transformer based methods [20] in various natural language processing tasks, BERT [4] based models have been explored for classifying emotion labels e.g., from Reddit comments [3].
Multimodal vision-language modeling. Recently transformer based models that use vision-language pretraining on large-scale vision datasets have been fine tuned for variety of downstream tasks. Examples of vision-language based models employing transformers for individual streams followed by fusion include LXMERT [18], VILBERT [10]. Examples of single stream models based on concatenation of textual and visual inputs include MMBT [7], VisualBERT [8].
3 Multimodal adaptation for evoked emotion understanding
Textual and visual information pertaining to evoked emotions associated with artwork contain complementary information: perceptually relevant affective cues in images, direct information in text descriptions about felt emotion. A trained text classifier model like BERT[4] predicts sadness if only the caption \qqit makes me think of how things used to be and how simple life once was is used. When the visual artwork image (Fig 2) is shown, then the associated caption along with the artwork evokes a feeling of contentment. Hence we explore a series of multimodal model adaptations for evoked emotion prediction.

3.1 Dual-stream models
For the dual-stream model baseline, we pool the embeddings of text tokens associated with the captions and the region wise embeddings (avg-pooled) from image as shown in Fig. 3(A). The pooled embeddings are then concatenated followed by FC layers for emotion classification.
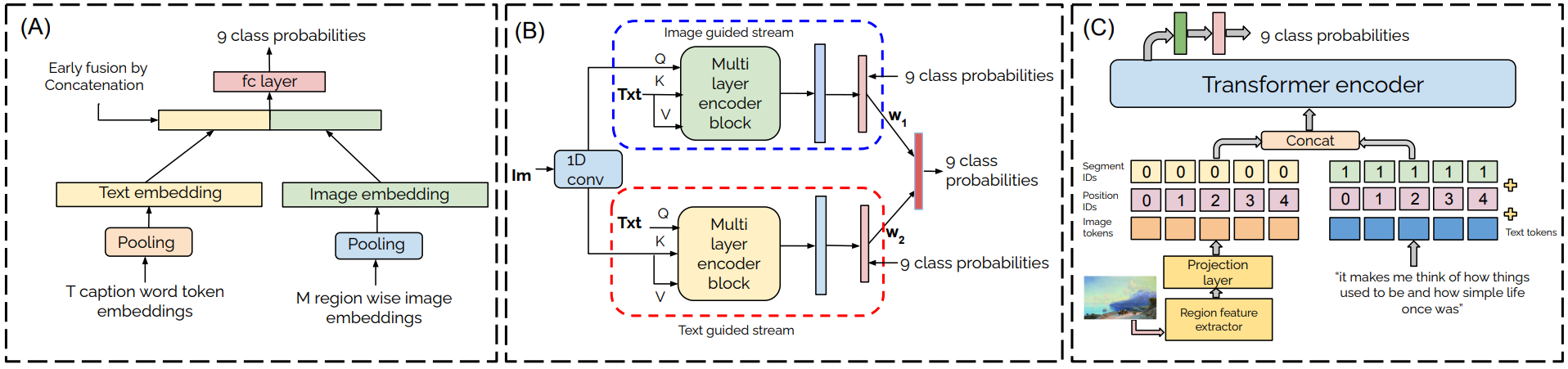
We further explore modeling of explicit interactions between captions and image region features by using image-guided and text-guided streams followed by a weighted late fusion scheme of predicted class probabilities from individual streams. As shown in Fig. 3(B),we use multi-layer self-attention based encoder block. The output embeddings from the encoder blocks of the respective streams are further average pooled and passed through fully connected (FC) layers for classification followed by fusion using weights and .
3.2 Single-stream models
For single-stream design of multimodal models, we rely on the multimodal bitransformer model (MMBT) [7] consisting of 12 encoder layers and include a configurable image encoder to extract region wise features, as shown in Fig. 3(C). Since the image and text features are combined together as a single input to the encoder model, separate segment IDs are provided to the image (segment ID = 0) and text (segment ID = 1) modalities. For individual modalities i.e., image and text, the input embeddings are obtained as the sum of token, positional and segment embeddings. The representation associated with [CLS] (classification) token is used for downstream emotion classification.
4 Experiments and Results
We conduct our experiments on the Artemis dataset [1]. Artemis is built on top of 81,446 art work images from the Wikiart dataset, spanning 27 art styles and 1119 artists from the 15th to 21st century. We perform the same train, test, and validation set split as in [1].
4.1 Experimental Setup
We use categorical cross entropy as loss function with label smoothing [12] as a regularization technique while training the multimodal models. We use the AdamW optimizer [9] and linear scheduler with warm-up (warm-up steps varied between 1000 to 10000). The learning rate is tuned in the range {1e-5, 6e-5} in steps of 1e-5. For text-based baselines, we fine-tune BERT [4] to predict emotion classes from the text captions. For the multi-layer encoder design in dual stream weighted later fusion model, we use 5 encoder layers and 8 heads. For the image modality, we extract bottom-up features [2] from the top- salient image regions (sorted by scores) by using a Visual-Genome based pretrained Faster RCNN [14] model with a ResNet-101[5] backbone. We also look at ResNeXt-152 C4 based object detection model [22] to extract enhanced region-wise representations (VinVL). For the image based models, we fine-tune VGG-16[17] and ResNet-50 [5] pretrained on ImageNet [15] by using a KL-divergence loss between the network outputs and per-image distribution of emotions based on responses of annotators.
4.2 Results
We compare performances in terms of 9 class accuracies and macro-F1 for image-only, text-only and multimodal models. After tuning on the validation set, the optimal weights for late fusion in the dual stream multi layer encoder model are obtained as and for the image- and text-guided streams respectively.
| Model | Acc | F1 | Feat |
| \cellcolor[HTML]DAE8FCImage (N = 79327) | |||
| VGG-16 | 47.36 | 27.04 | |
| ResNet-50 | 44.98 | 21.31 | |
| \cellcolor[HTML]00D2CBText (N = 429431) | |||
| BERT | 66.2 | 61.42 | |
| \cellcolor[HTML]CBCEFBMultimodal (N = 429431) | |||
| Early fusion avg pool | 56.35 | 46.72 | BU+Bert |
| Early fusion first token | 56.98 | 48.34 | BU+Bert |
| Weighted late fusion | 65.14 | 60.27 | BU+Bert |
| MMBT | 66.33 | 62.24 | BU+Bert |
| VisualBERT | 66.03 | 61.47 | VinVL+Bert |

4.2.1 Performance variation with image features
We explore different configurations of bottom up and VinVL [22] features by varying the number of detected boxes. From Table 2, it can be seen that there is a slight improvement on usage of bottom up features (), when compared with VinVL [22]. However, the overall impact of varying the configuration of region-wise features does not result in significant improvements in emotion classification performance.
| Img | Acc. | F1 |
|---|---|---|
| BU-10 | 66.03 | 61.69 |
| BU-30 | 66.07 | 61.39 |
| BU-50 | 66.33 | 62.24 |
| VinVL-10 | 66.26 | 61.79 |
| VinVL-20 | 66.05 | 61.76 |
4.3 Discussion

As seen from Table 1, the MMBT model (initialized with pretrained BERT weights) along with bottom up region features ( = 50) performs on par with the text-only finetuned BERT baseline. Further, as seen in Fig. 4, MMBT shows an improvement in performance for extreme positive and negative emotion classes with overt visual features: amusement, awe, anger and disgust. When compared with dual stream models that rely on explicit modeling of relationships between text tokens and region-wise features, single stream models like MMBT, VisualBERT also perform better. For image-only models, accuracies and F1-scores are reported based on the predicted dominant emotion label (in terms of occurrences). Their inferior performance can be attributed to the challenge involved in predicting a single emotion label from an art work due to inherent subjectivity and multiple possible interpretations.
4.4 Visualizations
We provide visualizations for image-only model i.e. VGG16 using Grad-CAM [16]. As shown in Fig 5(A), for ground truth majority class “awe”, the VGG-16 network is focusing on the mountains and the sky region while predicting the correct majority class. In case of “sadness” label shown in Fig 5(B), the network focuses more on the expression shown on the man’s face, while predicting the correct label “sadness”. For the MMBT model, since we rely on region wise embeddings from images, we compute the importance of individual image regions using gradient based attributions. We normalize the importance of the image regions by dividing the individual importance scores by the maximum important score and showcase the top-3 important regions in the image, marked as (1), (2) and (3).
5 Conclusions
In this study, we explore multiple approaches for predicting evoked emotions from art-works through the perspective of different modalities. Based on the results, it can be seen that single-stream multimodal models like MMBT and VisualBERT perform better when compared to dual-stream approaches. In terms of visual information for multimodal analysis, including region-based features results in improvements over the text-only baseline i.e., BERT. Future directions include extraction of holistic image features based on art-styles, color, lighting and modeling their interactions with the textual captions to classify evoked emotions.
References
- [1] Panos Achlioptas, Maks Ovsjanikov, Kilichbek Haydarov, Mohamed Elhoseiny, and Leonidas J. Guibas. Artemis: Affective language for visual art. CoRR, abs/2101.07396, 2021.
- [2] Peter Anderson, Xiaodong He, Chris Buehler, Damien Teney, Mark Johnson, Stephen Gould, and Lei Zhang. Bottom-up and top-down attention for image captioning and visual question answering. In CVPR, 2018.
- [3] Dorottya Demszky, Dana Movshovitz-Attias, Jeongwoo Ko, Alan Cowen, Gaurav Nemade, and Sujith Ravi. GoEmotions: A Dataset of Fine-Grained Emotions. In 58th Annual Meeting of the Association for Computational Linguistics (ACL), 2020.
- [4] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding, 2019.
- [5] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. arXiv preprint arXiv:1512.03385, 2015.
- [6] Jia Jia, Sen Wu, Xiaohui Wang, Peiyun Hu, Lianhong Cai, and Jie Tang. Can we understand van gogh’s mood? learning to infer affects from images in social networks. In Proceedings of the 20th ACM International Conference on Multimedia, MM ’12, page 857–860, New York, NY, USA, 2012. Association for Computing Machinery.
- [7] Douwe Kiela, Suvrat Bhooshan, Hamed Firooz, and Davide Testuggine. Supervised multimodal bitransformers for classifying images and text. arXiv preprint arXiv:1909.02950, 2019.
- [8] Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, and Kai-Wei Chang. Visualbert: A simple and performant baseline for vision and language, 2019.
- [9] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net, 2019.
- [10] Jiasen Lu, Dhruv Batra, Devi Parikh, and Stefan Lee. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. arXiv preprint arXiv:1908.02265, 2019.
- [11] Saif M. Mohammad and Svetlana Kiritchenko. An annotated dataset of emotions evoked by art. In Proceedings of the 11th Edition of the Language Resources and Evaluation Conference (LREC-2018), Miyazaki, Japan, 2018.
- [12] Rafael Müller, Simon Kornblith, and Geoffrey E Hinton. When does label smoothing help? In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019.
- [13] Andrew Ortony, Gerald L Clore, and Allan Collins. The cognitive structure of emotions. Cambridge university press, 1990.
- [14] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In C. Cortes, N. Lawrence, D. Lee, M. Sugiyama, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 28. Curran Associates, Inc., 2015.
- [15] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. ImageNet Large Scale Visual Recognition Challenge. International Journal of Computer Vision (IJCV), 115(3):211--252, 2015.
- [16] Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Oct 2017.
- [17] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. In International Conference on Learning Representations, 2015.
- [18] Hao Tan and Mohit Bansal. Lxmert: Learning cross-modality encoder representations from transformers. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, 2019.
- [19] Yla R. Tausczik and James W. Pennebaker. The psychological meaning of words: Liwc and computerized text analysis methods. Journal of Language and Social Psychology, 29(1):24--54, 2010.
- [20] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. arXiv preprint arXiv:1706.03762, 2017.
- [21] Victoria Yanulevskaya, Jan C van Gemert, Katharina Roth, Ann-Katrin Herbold, Nicu Sebe, and Jan-Mark Geusebroek. Emotional valence categorization using holistic image features. In 2008 15th IEEE international conference on Image Processing, pages 101--104. IEEE, 2008.
- [22] Pengchuan Zhang, Xiujun Li, Xiaowei Hu, Jianwei Yang, Lei Zhang, Lijuan Wang, Yejin Choi, and Jianfeng Gao. Vinvl: Revisiting visual representations in vision-language models. In CVPR 2021, June 2021.