Understanding Data Reconstruction Leakage in Federated Learning from a Theoretical Perspective
Abstract
Federated learning (FL) is an emerging collaborative learning paradigm that aims to protect data privacy. Unfortunately, recent works show FL algorithms are vulnerable to the serious data reconstruction attacks. However, existing works lack a theoretical foundation on to what extent the devices’ data can be reconstructed and the effectiveness of these attacks cannot be compared fairly due to their unstable performance. To address this deficiency, we propose a theoretical framework to understand data reconstruction attacks to FL. Our framework involves bounding the data reconstruction error and an attack’s error bound reflects its inherent attack effectiveness. Under the framework, we can theoretically compare the effectiveness of existing attacks. For instance, our results on multiple datasets validate that the iDLG attack inherently outperforms the DLG attack.
1 Introduction
The emerging federated learning (FL) [31] has been a great potential to protect data privacy. In FL, the participating devices keep and train their data locally, and only share the trained models (e.g., gradients or parameters), instead of the raw data, with a center server (e.g., cloud). The server updates its global model by aggregating the received device models, and broadcasts the updated global model to all participating devices such that all devices indirectly use all data from other devices. FL has been deployed by many companies such as Google [15], Microsoft [32], IBM [21], Alibaba [2], and applied in various privacy-sensitive applications, including on-device item ranking [31], content suggestions for on-device keyboards [6], next word prediction [27], health monitoring [38], and medical imaging [23].

Unfortunately, recent works show that, though only sharing device models, it is still possible for an adversary (e.g., malicious server) to perform the severe data reconstruction attack (DRA) to FL [57], where an adversary could directly reconstruct the device’s training data via the shared device models. Later, a bunch of follow-up enhanced attacks [20, 45, 55, 51, 47, 53, 22, 56, 9, 3, 30, 11, 43, 48, 18, 49, 35]) are proposed by either incorporating (known or unrealistic) prior knowledge or requiring an auxiliary dataset to simulate the training data distribution.
However, we note that existing DRA methods have several limitations: First, they are sensitive to the initialization (which is also observed in [47]). For instance, we show in Figure 1 that the attack performance of iDLG [55] and DLG [57] are significantly influenced by initial parameters (i.e., the mean and standard deviation) of a Gaussian distribution, where the initial data is sampled from. Second, existing DRAs mainly show comparison results on a FL model at a snapshot, which cannot reflect attacks’ true effectiveness. As FL training is dynamic, an adversary can perform attacks in any stage of the training. Hence, Attack A shows better performance than Attack B at a snapshot does not imply A is truly more effective than B. Third, worse still, they lack a theoretical understanding on to what extent the training data can be reconstructed. These limitations make existing DRAs cannot be easily and fairly compared and hence it is unknown which attacks are inherently more effective.
In this paper, we aim to bridge the gap and propose a theoretical framework to understand DRAs to FL. Specifically, our framework aims to bounds the error between the private data and the reconstructed counterpart in the whole FL training, where an attack’s (smaller) error bound reflects its inherent (better) attack effectiveness. Our theoretical results show that when an attacker’s reconstruction function has a smaller Lipschitz constant, then this attack intrinsically performs better. Under the framework, we can theoretically compare the existing DRAs by directly comparing their bounded errors. We test our framework on multiple state-of-the-art attacks and benchmark datasets. For example, our results show that InvGrad [13] performs better than DLG [57] and iDLG [55] on complex datasets, while iDLG is comparable or performs slightly better than DLG.
2 Related Work
Existing DRAs to FL are roughly classified as optimization based and close-form based.
Optimization-based DRAs to FL: A series of works [20, 57, 45, 55, 47, 53, 22, 9, 3, 11, 48, 30] formulate DRAs as the gradient matching problem, i.e., an optimization problem that minimizes the difference between gradient from the raw data and that from the reconstructed counterpart. Some works found the gradient itself includes insufficient information to well recover the data [22, 56]. For example, [56] show there exist pairs of data (called twin data) that visualize different, but have the same gradient. To mitigate this issue, a few works propose to incorporate prior knowledge (e.g., total variation (TV) regularization [13, 53], batch normalization (BN) statistics [53]) into the training data, or introduce an auxiliary dataset to simulate the training data distribution [20, 45, 22] (e.g., via generative adversarial networks (GANs) [14]). Though empirically effective, these methods are less practical or data inefficient, e.g., TV is limited to natural images, BN statistics are often unavailable, and training an extra model (e.g., GAN [14]) requires a large amount of data samples.
Closed-form DRAs to FL: A few recent works [13, 56, 11] derive closed-form solutions to reconstruct data, but they require the neural network used in the FL algorithm be fully connected [13], linear/ReLU [11], or convolutional [56].
We will design a framework to theoretically understand the DRA to FL in a general setting, and provide a way to compare the effectiveness of existing DRAs.
3 Preliminaries and Problem Setup
3.1 Federated Learning (FL)
The FL paradigm enables a server to coordinate the training of multiple local devices through multiple rounds of global communications, without sharing the local data. Suppose there are devices and a central server participating in FL. Each -th device owns a training dataset with samples, and each sample has a label . FL considers the following distributed optimization problem:
| (1) |
where is the weight of the -th device and ; the -th device’s local objective is defined by , with an algorithm-dependent loss function.
FedAvg [31]: It is the de factor FL algorithm to solve Equation (1) in an iterative way. In each communication round, each -th device only shares the gradients instead of the raw data to the server. Specifically, in the current round , each -th device first downloads the latest global model (denoted as ) from the server and initializes its local model as ; then it performs (e.g., ) local SGD updates as below:
| (2) |
where is the learning rate and is sampled from the local data uniformly at random.
Next, the server updates the global model by aggregating full or partial device models. The final global model, i.e., , is downloaded by all devices for their learning tasks.
-
•
Full device participation. It requires all device models for aggregation, and the server performs with and . This means the server must wait for the slowest devices, which is often unrealistic in practice.
-
•
Partial device participation. This is a more realistic setting as it does not require the server to know all device models. Suppose the server only needs () device models for aggregation and discards the remaining ones. Let be the set of chosen devices in the -th iteration. Then, the server’s aggregation step performs with .
Quantifying the degree of non-IID (heterogeneity): Real-world FL applications often do not satisfy the IID assumption for data among local devices. [28] proposed a way to quantify the degree of non-IID. Specifically, let and be the minimum values of and , respectively. Then, the term is used for quantifying the non-IID. If the data are IID, then goes to zero as the number of samples grows. If the data are non-IID, then is nonzero, and its magnitude reflects the heterogeneity of the data distribution.
3.2 Optimization-based DRAs to FL
Existing DRAs assume an honest-but-curious server, i.e., the server has access to all device models in all communication rounds, follows the FL protocol, and aims to infers devices’ private data. Given the private data with private label 111This can be a single data sample or a batch of data samples., we denote the reconstructed data by a malicious server as , where indicates a data reconstruction function, and can be any intermediate global model.
Modern optimization-based DRAs use different , but majorly base on gradient matching. Specifically, they solve the optimization problem:
| (3) |
where we denote the gradient of loss w.r.t. be for notation simplicity. means the gradient matching loss (i.e., the distance between the real gradients and estimated gradients) and is an auxiliary regularizer for the reconstruction. Here, we list and for three representative DRAs, and more attacks are shown in Appendix D.2.
-
•
DLG [57] uses mean squared error as the gradient matching loss, i.e., and uses no regularizer.
- •
-
•
InvGrad [13] improves upon DLG and iDLG. It first estimates the private label as in advance. Then it uses a negative cosine similarity as and a total variation regularizer as an image prior. Specifically, InvGrad solves for .
Algorithm 1 shows the pseudo-code of iterative solvers for DRAs and Algorithm 4 in Appendix shows more details for each attack. As the label can be often accurately inferred, we now only consider reconstructing the data for notation simplicity. Then, the attack performance is measured by the similarity between and . The larger similarity, the better attack performance. In the paper, we use the common similarity metric, i.e., the negative mean-square-error , where the expectation considers the randomness during reconstruction.
4 A Theoretical Framework to Understand DRAs to FL
Though many DRAs to FL have been proposed, it is still unknown how to theoretically compare the effectiveness of existing attacks, as stated in Introduction. In this section, we understand DRAs to FL from a theoretical perspective. We first derive a reconstruction error bound for convex objective losses. The error bound involves knowing the Lipschitz constant of the data reconstruction function. Directly calculating the exact Lipschitz constant is computationally challenging. We then adapt existing methods to calculate its upper bound. We argue that an attack with a smaller upper bound is intrinsically more effective. We also emphasize our theoretical framework is applicable to any adversary who knows the global model during FL training (see below Theorem 1 and Theorem 2).
4.1 Bounding the Data Reconstruction Error
Give random data from a device, our goal is to bound the common norm-based reconstruction error222The norm-based mean-square-error (MSE) bound can be easily generalized to the respective PSNR bound. This is because PSNR = -10 log (MSE). However, it is unable to generalize to SSIM or LPIPS since these metrics do not have an analytic form., i.e., at any round , where can be any DRA and the expectation considers the randomness in , e.g., due to different initializations. Directly bounding this error is challenging because the global model dynamically aggregates local device models, which are trained by a (stochastic) learning algorithm and whose learning procedure is hard to characterize during training. To alleviate this issue, we introduce the optimal global model that can be learnt by the FL algorithm. Then, we can bound the error as follows:
| (4) |
Note that the first term in Equation (4) is a constant and can be directly computed under a given reconstruction function and a convex loss used in FL. Specifically, if the loss in each device is convex, the global model can converge to the optimal based on theoretical results in [28]. Then we can obtain per attack and compute the first term. In our experiments, we run the FL algorithm until the loss difference between two consecutive iterations is less than , and treat the final global model as .
Now our goal reduces to bounding the second term. However, it is still challenging without knowing any property of the reconstruction function . In practice, we note is often Lipschitz continuous, which can be verified later.
Proposition 1.
is -Lipschitz continuous: there exists a constant such that . The smallest is called the Lipschitz constant.
Next, we present our theoretical results and their proofs are seen in Appendix B and Appendix C, respectively. Note that our error bounds consider all randomness in FL training and data reconstruction.
Theoretical results with full device participation:
Theoretical results with partial device participation:
As discussed in Section 3, partial device participation is more practical. Recall that contains the active devices in the -th iteration. To show our theoretical results, we require the devices in are selected from a distribution (e.g., ) independently and with replacement, following [39, 28]. Then FedAvg performs aggregation as .
4.2 Computing the Lipschitz Constant for Data Reconstruction Functions
We show how to calculate the Lipschitz constant for data reconstruction function. Our idea is built upon the strong connection between optimizing DRAs and the corresponding unrolled deep networks; and then adapt existing methods to approximate the Lipschitz upper bound.

Iterative solvers for optimization-based DRAs as unrolled deep feed-forward networks: Recent works [7, 29, 34] show a strong connection between iterative algorithms and deep network architectures. The general idea of algorithm unrolling is: starting with an abstract iterative algorithm, we map one iteration into a single network layer, and stack a finite number of (e.g., ) layers to form a deep network, which is also called unrolled deep network. Feeding the data through an -layer network is hence equivalent to executing the iterative algorithm iterations. The parameters of the unrolled networks are learnt from data by training the network in an end-to-end fashion. From Algorithm 1, we can see the trajectory of an iterative solver for an optimization-based DRA corresponds to a customized unrolled deep feed-forward network. Specifically, we treat the initial (and ) as the input, the intermediate reconstructed as the -th hidden layer, followed by a clip nonlinear activation function, and the final reconstructed data as the output of the network. Given intermediate with a set of data samples, we can train parameterized deep feed-forward networks (universal approximation) to fit them, e.g., via the greedy layer-wise training strategy [5], where each means the model parameter connecting the -th layer and -th layer. Figure 2 visualizes the unrolled deep feed-forward network for the optimization-based DRA.
Definition 1 (Deep Feed-Forward Network).
An -layer feed-forward network is an function , where , the -th hidden layer is an affine function and is a non-linear activation function.
Upper bound Lipschitz computation: [44] showed that computing the exact Lipschitz constant for deep (even 2-layer) feed-forward networks is NP-hard. Hence, they resort to an approximate computation and propose a method called AutoLip to obtain an upper bound of the Lipschitz constant. AutoLip relies on the concept of automatic differentiation [16], a principled approach that computes differential operators of functions from consecutive operations through a computation graph. When the operations are all locally Lipschitz-continuous and their partial derivatives can be computed and maximized, AutoLip can compute the Lipschitz upper bound efficiently. Algorithm 2 shows the details of AutoLip.
With Autolip, [44] showed that a feed-forward network with 1-Lipschitz activation functions has an upper bounded Lipschitz constant below.
Lemma 1.
For any -layer feed-forward network with -Lipschitz activation functions, the AutoLip upper bound becomes , where is defined in Definition 1.
Note that a matrix -norm equals to its largest singular value, which could be computed efficiently via the power method [33]. More details are shown in Algorithm 3 (A better estimation algorithm can lead to a tighter upper bounded Lipschitz constant). Obviously, the used Clip activation function is 1-Lipschitz. Hence, by applying Lemma 1 to the optimization-based DRAs, we can derive an upper bounded Lipschitz .
5 Evaluation
| Data/Algorithm | Fed. -LogReg: single | Fed. 2-LinConvNet: single | Fed. -LogReg: batch | |||||||||
| DLG | iDGL | InvGrad | GGL | DLG | iDGL | InvGrad | GGL | DLG | iDGL | InvGrad | GGL | |
| MNIST | 3.48 | 3.38 | 3.09 | 3.14 | 3.69 | 3.50 | 3.42 | 3.29 | 6.38 | 6.28 | 6.08 | 4.94 |
| FMNIST | 3.54 | 3.42 | 3.35 | 3.25 | 3.84 | 3.58 | 3.52 | 3.13 | 6.44 | 6.35 | 6.29 | 4.98 |
| CIFAR10 | 4.32 | 4.13 | 4.13 | 3.92 | 4.52 | 3.37 | 4.33 | 3.70 | 6.46 | 6.45 | 6.63 | 5.31 |
5.1 Experimental Setup
Datasets and models: We conduct experiments on three benchmark image datasets, i.e., MNIST [25], Fashion-MNIST (FMNIST) [50], and CIFAR10 [24]. We examine our theoretical results on the FL algorithm that uses the -regularized logistic regression (-LogReg) and the convex 2-layer linear convolutional network (2-LinConvNet) [37], since their loss functions satisfy Assumptions 1-4. In the experiments, we evenly distribute the training data among the devices. Based on this setting, we can calculate , and used in our theorems, respectively. In addition, we can compute the Lipschitz constant via the unrolled feed-forward network. These values together are used to compute the upper bound of our Theorems 1 and 2. More details about the two algorithms, the unrolled feed-forward network, and the calculation of these parameter values are shown in Appendix D.
Attack baselines: We test our theoretical results on four optimization-based data reconstruction attacks, i.e., DLG [57], iDLG [55], InvGrad [13], and GGL [30]. The algorithms and descriptions of these attacks are deferred to Appendix D. We test these attacks on recovering both the single image and a batch of images in each device.
Parameter setting: Several important hyperparameters in the FL training (i.e., federated -LogReg or federated 2-LinConvNet) that would affect our theoretical results: the total number of devices , the total number of global rounds , and the number of local SGD updates . By default, we set and . We set on the three datasets for the single image recovery, while set on the three datasets for the batch images recovery, considering their different difficulty levels. we consider full device participation. When studying the impact of these hyperparameters, we fix others as the default value.
















5.2 Experimental Results
In this section, we test the upper bound reconstruction error by our theoretical results for single image and batch images recovery. We also show the average (across 10 iterations) reconstruction errors that are empirically obtained by the baseline DRAs with different initializations. The best possible (one-snapshot) empirical results of baseline attacks are reported in Table 1.
5.2.1 Results on single image recovery
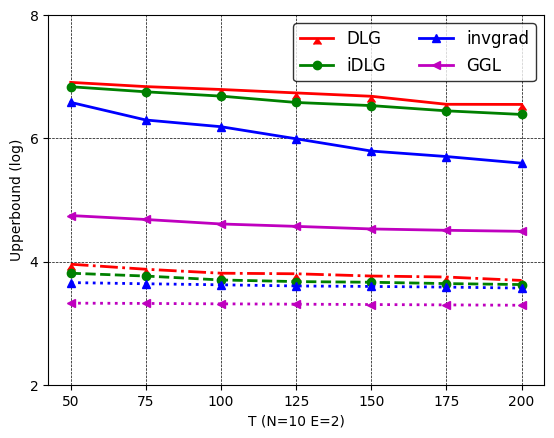
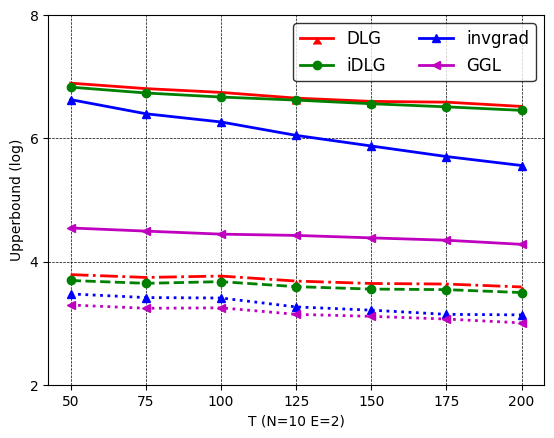
Figure 3-Figure 8 show the single image recovery results on the three datasets and two FL algorithms, respectively. We have several observations. First, iDLG has smaller upper bound errors than DLG, indicating iDLG outperforms DLG intrinsically. One possible reason is that iDLG can accurately estimate the labels, which ensures data reconstruction to be more stable. Such a stable reconstruction yields a smaller Lipschitz , and thus a smaller upper bound in Theorem 1. InvGrad is on top of iDLG and adds a TV regularizer, and obtains smaller error bounds than iDLG. This implies the TV prior can help stabilize the data reconstruction and hence is beneficial for reducing the error bounds. Note that the error bounds of these three attacks are (much) larger than the average empirical errors, indicating there is still a gap between empirical results and theoretical results. Further, GGL has (much) smaller bounded errors than DLG, iDLG, and InvGrad. This is because GGL trains an encoder on the whole dataset to learn the image manifold, and then uses the encoder for data reconstruction, hence producing smaller . In Figure 3(b), we observe its bounded error is close to the empirical error. For instance, we calculate that the estimated for the DLG, iDLG, InvGrad, and GGL attacks in the default setting on MNIST are 22.17, 20.38, 18.43, and 13.36, respectively.
Second, the error bounds are consistent with the average empirical errors, validating they have a strong correlation. Particularly, we calculate the Pearson correlation coefficients between the error bound and the averaged empirical error on these attacks in all settings are .
Third, the error bounds do not consistent correlations with the best empirical errors. For instance, we can see GGL has lower error bounds than InvGrad on -LogReg, but its best empirical error is larger than InvGrad on MNIST (3.14 vs 3.09). Similar observations on CIFAR10 on federated 2-LinConvNet, where InvGrad’s error bound is smaller than iDLG’s, but its best empirical error is larger (4.33 vs 3.37). More details see Table 1. The reason is that the reported empirical errors are the best possible one-snapshot results with a certain initialization, which do not reflect the attacks’ inherent effectiveness. Recall in Figure 1 that empirical errors obtained by these attacks could be sensitive to different initializations. In practice, the attacker may need to try many initializations (which could be time-consuming) to obtain the best empirical error.
Impact of , , and : When the local SGD updates and the number of total clients increase, the upper bound error also increases. This is because a large and will make FL training unstable and hard to converge, as verified in [28]. On the other hand, a larger total number of global rounds tends to produce a smaller upper bounded error. This is because a larger stably makes FL training closer to the global optimal under the convex loss.









5.2.2 Results on batch images recovery
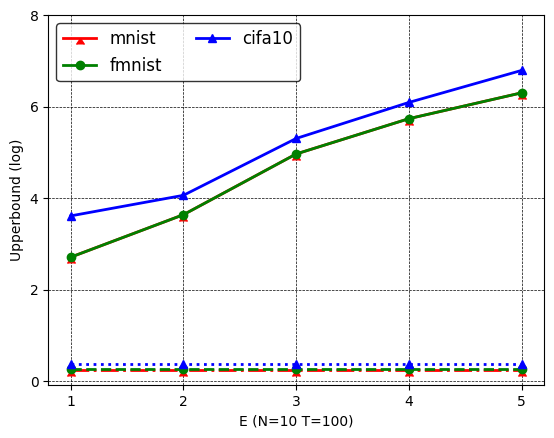
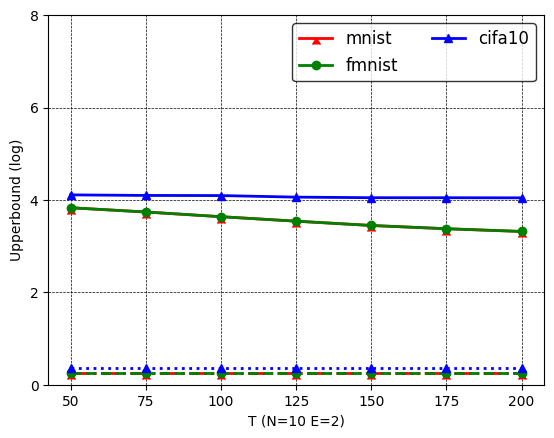
Figures 9-11 show the results of batch images recovery on the three image datasets. As federated 2-LinConvNet has similar trends, we only show federated -LogReg results for simplicity. First, similar to results on single image recovery, GGL performs the best; InvGrad outperforms iDLG, which outperforms DLG both empirically and theoretically. Moreover, a larger and incur larger upper bound error, while a larger generates smaller upper bound error. Second, both empirical errors and upper bound errors for batch images recovery are much larger than those for single image recovery. This indicates that batch images recovery are more difficult than single image recovery, as validated in many existing works such as [13, 53].


6 Discussion
First term vs second term in the error bound: We calculate the first term and second term of the error bound in our theorem in the default setting. The two terms in DLG, iDLG, InvGrad, and GGL on MNIST are (30.48, 396.72), (25.25, 341.10), (22.06, 218.28), and (20.21, 29.13) respectively. This implies the second term dominates the error bound.
Error bounds vs. degree of non-IID: The non-IID of data across clients can be controlled by the number of classes per client—small number indicates a larger degree of non-IID. Here, we tested #classes=2, 4, 6, 8 on MNIST and the results are shown in Figure 12a. We can see the bounded errors are relatively stable vs. #classes on DLG, iDLG, and GGL, while InvGrad has a larger error as the #classes increases. The possible reason is that DLG and iDLG are more stable than InvGrad, which involves a more complex optimization.
Error bounds vs. batch size: Our batch results use a batch size 20. Here, we also test batch size=10, 15, 25, 30 and results are in Figure 12b. We see bounded errors become larger with larger batch size. This is consistent with existing observations [13] on empirical evaluations.







Error bounds on closed-form DRAs: Our theoretical results can be also applied in closed-form attacks. Here, we choose the Robbing attack [11] for evaluation and its details are in Appendix D.2. The results for single image and batch images recovery on the three datasets and two FL algorithms are shown in Figures 13, 14, and 15, respectively. We can see Robbing obtains both small empirical errors and bounded errors (which are even smaller than GGL). This is because its equation solving is suitable to linear layers, and hence relatively accurate on the federated -LogReg and federated 2-LinConvNet models.
Practical use of our error bound: Our error bound has several benefits in practice. First, it can provide guidance or insights to attackers, e.g., the attack performance can be estimated with our error bound prior to the attacks. Then, attackers can make better decisions on the attacks, e.g., try to improve the attack beyond the worst-case bound (using different settings), choose to not perform the attack if the estimated error is too high. Second, it can understand the least efforts to guide the defense design, e.g., when we pursue a minimum obfuscation of local data/model (maintain high utility) and minimum defense based on the worst-case attack performance sometimes could be acceptable in practice.
Defending against DRAs: Various defenses have been proposed against DRAs [46, 57, 43, 12, 26, 17, 19]. However, there are two fundamental limitations in existing defenses: First, empirical defenses are soon broken by stronger/adaptive attacks [8, 40, 4]. Second, provable defenses based on differential privacy (DP) [10, 1, 52, 17, 19]) incur significant utility losses to achieve reasonable defense performance since the design of such randomization-based defenses did not consider specific inference attacks. Vert recently, [35] proposed an information-theoretical framework to learn privacy-preserving representations against DRAs, and showed better utility than DP-SGD [1, 17] under close privacy performance. It is interesting future work to incorporate information-theoretical privacy into FL to prevent data reconstruction.
7 Conclusion
Federated learning (FL) is vulnerable to data reconstruction attacks (DRAs). Existing attacks mainly enhance the empirical attack performance, but lack a theoretical understanding. We study DRAs to FL from a theoretical perspective. Our theoretical results provide a unified way to compare existing attacks theoretically. We also validate our theoretical results via evaluations on multiple datasets and baseline attacks. Future works include: 1) designing better or adapting existing Lipschitz estimation algorithms to obtain tighter error bounds; 2) generalizing our theoretical results to non-convex losses; 3) designing theoretically better DRAs (i.e., with smaller Lipschitz) as well as effective defenses against the attacks (i.e., ensuring larger Lipschitz of their reconstruction function), inspired by our framework; and 4) developing effective provable defenses against DRAs.
References
- [1] Martin Abadi, Andy Chu, Ian Goodfellow, H Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang. Deep learning with differential privacy. In CCS, 2016.
- [2] Alibaba Federated Learning. https://federatedscope.io/, 2022.
- [3] Mislav Balunovic, Dimitar Iliev Dimitrov, Robin Staab, and Martin Vechev. Bayesian framework for gradient leakage. In ICLR, 2022.
- [4] Mislav Balunovic, Dimitar Iliev Dimitrov, Robin Staab, and Martin Vechev. Bayesian framework for gradient leakage. In ICLR, 2022.
- [5] Yoshua Bengio, Pascal Lamblin, Dan Popovici, and Hugo Larochelle. Greedy layer-wise training of deep networks. NeurIPS, 2006.
- [6] Keith Bonawitz, Hubert Eichner, Wolfgang Grieskamp, Dzmitry Huba, Alex Ingerman, Vladimir Ivanov, Chloe Kiddon, Jakub Konevcnỳ, Stefano Mazzocchi, H Brendan McMahan, Timon Van Overveldt, David Petrou, Daniel Ramage, and Jason Roselander. Towards federated learning at scale: System design. MLSys, 2019.
- [7] Xiaohan Chen, Jialin Liu, Zhangyang Wang, and Wotao Yin. Theoretical linear convergence of unfolded ista and its practical weights and thresholds. In NeurIPS, 2018.
- [8] Christopher A Choquette-Choo, Florian Tramer, Nicholas Carlini, and Nicolas Papernot. Label-only membership inference attacks. In ICML, 2021.
- [9] Trung Dang, Om Thakkar, Swaroop Ramaswamy, Rajiv Mathews, Peter Chin, and Franccoise Beaufays. Revealing and protecting labels in distributed training. NeurIPS, 2021.
- [10] Cynthia Dwork. Differential privacy. In ICALP, 2006.
- [11] Liam H Fowl, Jonas Geiping, Wojciech Czaja, Micah Goldblum, and Tom Goldstein. Robbing the fed: Directly obtaining private data in federated learning with modified models. In ICLR, 2022.
- [12] Wei Gao, Shangwei Guo, Tianwei Zhang, Han Qiu, Yonggang Wen, and Yang Liu. Privacy-preserving collaborative learning with automatic transformation search. In CVPR, 2021.
- [13] Jonas Geiping, Hartmut Bauermeister, Hannah Dröge, and Michael Moeller. Inverting gradients–how easy is it to break privacy in federated learning? In NeurIPS, 2020.
- [14] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In NeurIPS, 2014.
- [15] Google Federated Learning. https://federated.withgoogle.com/, 2022.
- [16] Andreas Griewank and Andrea Walther. Evaluating derivatives: principles and techniques of algorithmic differentiation. SIAM, 2008.
- [17] Chuan Guo, Brian Karrer, Kamalika Chaudhuri, and Laurens van der Maaten. Bounding training data reconstruction in private (deep) learning. In International Conference on Machine Learning, pages 8056–8071. PMLR, 2022.
- [18] Niv Haim, Gal Vardi, Gilad Yehudai, Ohad Shamir, and Michal Irani. Reconstructing training data from trained neural networks. In NeurIPS, 2022.
- [19] Jamie Hayes, Borja Balle, and Saeed Mahloujifar. Bounding training data reconstruction in dp-sgd. Advances in Neural Information Processing Systems, 36, 2023.
- [20] Briland Hitaj, Giuseppe Ateniese, and Fernando Perez-Cruz. Deep models under the gan: information leakage from collaborative deep learning. In CCS, 2017.
- [21] IBM Federated Learning. https://www.ibm.com/docs/en/cloud-paks/cp-data/4.0?topic=models-federated-learning, April 2022.
- [22] Jinwoo Jeon, Jaechang Kim, Kangwook Lee, Sewoong Oh, and Jungseul Ok. Gradient inversion with generative image prior. NeurIPS, 2021.
- [23] Georgios A Kaissis, Marcus R Makowski, Daniel Rückert, and Rickmer F Braren. Secure, privacy-preserving and federated machine learning in medical imaging. Nature Machine Intelligence, 2(6):305–311, 2020.
- [24] Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009.
- [25] Yann LeCun. The mnist database of handwritten digits. http://yann. lecun. com/exdb/mnist/, 1998.
- [26] Hongkyu Lee, Jeehyeong Kim, Seyoung Ahn, Rasheed Hussain, Sunghyun Cho, and Junggab Son. Digestive neural networks: A novel defense strategy against inference attacks in federated learning. computers & security, 2021.
- [27] Tian Li, Anit Kumar Sahu, Ameet Talwalkar, and Virginia Smith. Federated learning: Challenges, methods, and future directions. IEEE Signal Processing Magazine, 37(3):50–60, 2020.
- [28] Xiang Li, Kaixuan Huang, Wenhao Yang, Shusen Wang, and Zhihua Zhang. On the convergence of fedavg on non-iid data. In ICLR, 2020.
- [29] Yuelong Li, Mohammad Tofighi, Vishal Monga, and Yonina C Eldar. An algorithm unrolling approach to deep image deblurring. In ICASSP, 2019.
- [30] Zhuohang Li, Jiaxin Zhang, Luyang Liu, and Jian Liu. Auditing privacy defenses in federated learning via generative gradient leakage. In CVPR, 2022.
- [31] Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. Communication-efficient learning of deep networks from decentralized data. In AISTATS, 2017.
- [32] Microsoft Federated Learning. https://www.microsoft.com/en-us/research/blog/flute-a-scalable-federated-learning -simulation-platform/, May 2022.
- [33] RV Mises and Hilda Pollaczek-Geiringer. Praktische verfahren der gleichungsauflösung. ZAMM-Journal of Applied Mathematics and Mechanics/Zeitschrift für Angewandte Mathematik und Mechanik, 9(1):58–77, 1929.
- [34] Vishal Monga, Yuelong Li, and Yonina C Eldar. Algorithm unrolling: Interpretable, efficient deep learning for signal and image processing. IEEE Signal Processing Magazine, 38(2):18–44, 2021.
- [35] Sayedeh Leila Noorbakhsh, Binghui Zhang, Yuan Hong, and Binghui Wang. Inf2guard: An information-theoretic framework for learning privacy-preserving representations against inference attacks. In USENIX Security, 2024.
- [36] Papailiopoulos. https://papail.io/teaching/901/scribe_05.pdf, 2018.
- [37] Mert Pilanci and Tolga Ergen. Neural networks are convex regularizers: Exact polynomial-time convex optimization formulations for two-layer networks. In ICML, 2020.
- [38] Nicola Rieke, Jonny Hancox, Wenqi Li, Fausto Milletari, and et al. The future of digital health with federated learning. NPJ digital medicine, 2020.
- [39] Anit Kumar Sahu, Tian Li, Maziar Sanjabi, Manzil Zaheer, Ameet Talwalkar, and Virginia Smith. Federated optimization for heterogeneous networks. arXiv, 2018.
- [40] Liwei Song and Prateek Mittal. Systematic evaluation of privacy risks of machine learning models. In USENIX Security, 2021.
- [41] Sebastian U Stich. Local SGD converges fast and communicates little. arXiv, 2018.
- [42] Sebastian U Stich, Jean-Baptiste Cordonnier, and Martin Jaggi. Sparsified SGD with memory. In NIPS, pages 4447–4458, 2018.
- [43] Jingwei Sun, Ang Li, Binghui Wang, Huanrui Yang, Hai Li, and Yiran Chen. Provable defense against privacy leakage in federated learning from representation perspective. In CVPR, 2021.
- [44] Aladin Virmaux and Kevin Scaman. Lipschitz regularity of deep neural networks: analysis and efficient estimation. NeurIPS, 31, 2018.
- [45] Zhibo Wang, Mengkai Song, Zhifei Zhang, Yang Song, Qian Wang, and Hairong Qi. Beyond inferring class representatives: User-level privacy leakage from federated learning. In INFOCOM, 2019.
- [46] Kang Wei, Jun Li, Ming Ding, Chuan Ma, Howard H Yang, Farhad Farokhi, Shi Jin, Tony QS Quek, and H Vincent Poor. Federated learning with differential privacy: Algorithms and performance analysis. IEEE TIFS, 2020.
- [47] Wenqi Wei, Ling Liu, Margaret Loper, Ka-Ho Chow, Mehmet Emre Gursoy, Stacey Truex, and Yanzhao Wu. A framework for evaluating client privacy leakages in federated learning. In European Symposium on Research in Computer Security, pages 545–566. Springer, 2020.
- [48] Yuxin Wen, Jonas A Geiping, Liam Fowl, Micah Goldblum, and Tom Goldstein. Fishing for user data in large-batch federated learning via gradient magnification. In ICML, 2022.
- [49] Ruihan Wu, Xiangyu Chen, Chuan Guo, and Kilian Q Weinberger. Learning to invert: Simple adaptive attacks for gradient inversion in federated learning. In UAI, 2023.
- [50] Han Xiao, Kashif Rasul, and Roland Vollgraf. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms. arXiv preprint arXiv:1708.07747, 2017.
- [51] Shangyu Xie and Yuan Hong. Reconstruction attack on instance encoding for language understanding. In EMNLP, pages 2038–2044, 2021.
- [52] Shangyu Xie and Yuan Hong. Naacl-hlt. 2022.
- [53] Hongxu Yin, Arun Mallya, Arash Vahdat, Jose M Alvarez, Jan Kautz, and Pavlo Molchanov. See through gradients: Image batch recovery via gradinversion. In CVPR, 2021.
- [54] Hao Yu, Sen Yang, and Shenghuo Zhu. Parallel restarted sgd with faster convergence and less communication: Demystifying why model averaging works for deep learning. In AAAI, 2019.
- [55] Bo Zhao, Konda Reddy Mopuri, and Hakan Bilen. idlg: Improved deep leakage from gradients. arXiv, 2020.
- [56] Junyi Zhu and Matthew Blaschko. R-gap: Recursive gradient attack on privacy. ICLR, 2021.
- [57] Ligeng Zhu, Zhijian Liu, and Song Han. Deep leakage from gradients. In NeurIPS, 2019.
Appendix A Assumptions
Assumptions on the devices’ loss function: To ensure FedAvg guarantees to converge to the global optimal, existing works have the following assumptions on the local devices’ loss functions .
Assumption 1.
are -smooth: .
Assumption 2.
are -strongly convex: .
Assumption 3.
Let be sampled from -th device’s data uniformly at random. The variance of stochastic gradients in each device is bounded: .
Assumption 4.
The expected squared norm of stochastic gradients is uniformly bounded, i.e., .
Note that Assumptions 1 and 2 are generic. Typical examples include regularized linear regression, logistic regression, softmax classifier, and recent convex 2-layer ReLU networks [37]. For instance, the original FL [31] uses a 2-layer ReLU networks. Assumptions 3 and 4 are used by the existing works [41, 42, 54, 28] to derive the convergence condition of FedAvg to reach the global optimal. Note that the loss of deep neural networks is often non-convex, i.e., do not satisfy Assumption 2. We acknowledge it is important future work to generalize our theoretical results to more challenging non-convex losses.
Appendix B Proof of Theorem 1 for Full Device Participation
Notations: Let be the total number of user devices and be the maximal number of devices that participate in every communication round. Let be the total number of every device’s SGDs, and be the number of each device’s local updates between two communication rounds. Thus is the number of communications, assuming is dividable by .
Let be the model parameter maintained in the -th device at the -th step. Let be the set of global aggregation steps, i.e., . If , i.e., the devices communicate with the server and the server performs the FedAvg aggregation on device models. Then the update of FedAvg with partial devices active can be described as
| (7) | |||
| (10) |
Motivated by [41, 28], we define two virtual sequences and . results from an single step of SGD from . When , both are inaccessible. When , we can only fetch . For convenience, we define and . Hence, and .
Proof sketch: Lemma 2 is mainly from Lemma 1 in [28]. The proof idea is to bound three terms, i.e., the inner product , the square norm , and the inner product . Then, the left-hand term in Lemma 2 can be rewritten in terms of the three terms and be bounded by the right-hand four terms in Lemma 2. Specifically, 1) It first bounds using the strong convexity of the loss function (Assumption 2); 2) It bounds using the smoothness of the loss function (Assumption 1); and 3) It bounds using the convexity of the loss function (Assumption 2).
Lemma 3 (Bounding the variance).
Assume Assump. 3 holds. Then .
Lemma 4 (Bounding the divergence of ).
Assume Assump. 4 holds, and is non-increasing and for all . It follows that
Now, we complete the proof of Theorem 1.
Proof.
First, we observe that no matter whether or in Equation (10), we have . Denote . From Lemmas 2 to 4, we have
| (11) |
where
For a diminishing stepsize, for some and such that and . We will prove where .
We prove it by induction. Firstly, the definition of ensures that it holds for . Assume the conclusion holds for some , it follows that
By the -Lipschitz continuous property of ,
Then we have
Specifically, if we choose , then . We also verify that the choice of satisfies for . Then, we have
Hence,
∎
Appendix C Proofs of Theorem 2 for Partial Device Participation
Recall that is -th device’s model at the -th step, is the set of global aggregation steps; and , and and . We denote by the multiset selected which allows any element to appear more than once. Note that is only well defined for . For convenience, we denote by the most recent set of chosen devices where .
In partial device participation, FedAvg first samples a random multiset of devices and then only performs updates on them. Directly analyzing on the is complicated. Motivated by [28], we can use a thought trick to circumvent this difficulty. Specifically, we assume that FedAvg always activates all devices at the beginning of each round and uses the models maintained in only a few sampled devices to produce the next-round model. It is clear that this updating scheme is equivalent to that in the partial device participation. Then the update of FedAvg with partial devices activated can be described as:
| (12) | |||
| (15) |
Note that in this case, there are two sources of randomness: stochastic gradient and random sampling of devices. The analysis for Theorem 1 in Appendix B only involves the former. To distinguish with it, we use an extra notation to consider the latter randomness.
First, based on [28], we have the following two lemmas on unbiasedness and bounded variance. Lemma 5 shows the scheme is unbiased, while Lemma 6 shows the expected difference between and is bounded.
Lemma 5 (Unbiased sampling scheme).
If , we have
Lemma 6 (Bounding the variance of ).
For , assume that is non-increasing and for all . Then the expected difference between and is bounded by
Now, we complete the proof of Theorem 2.
Proof.
Note that
When expectation is taken over , the term vanishes due to the unbiasedness of .
If , vanishes since . We use Lemma 6 to bound . Then,
We observe that the only difference between eqn. (C) and eqn. (11) is the additional . Thus we can use the same argument there to prove the theorems here. Specifically, for a diminishing stepsize, for some and such that and , we can prove where .
Then by the -Lipschitz continuous property of ,
Specifically, if we choose ,
∎
Appendix D More Experimental Setup
D.1 Details about the FL algorithms and unrolled feed-forward network
We first show how to compute , and in Assumptions 1-4 on federated -regularized logistic regression (-LogReg) and federated 2-layer linear convolutional network (2-LinConvNet); Then we show how to compute the Lipschitz on each data reconstruction attack.
Federated -LogReg: Each device ’s local objective is . In our results, we simply set for brevity.
-
•
Compute : first, all ’s are -smooth [36]; then ;
-
•
Compute : all ’s are -strongly convex for the regularized logistic regression [36] and .
-
•
Compute and : we first traverse all training data in the -th device in any -th round and then use them to calculate the maximum square norm differences . Similarly, can be calculated as the maximum value of the expected square norm among all devices and rounds .
Federated 2-LinConvNet [37]. Let a two-layer network with neurons be: , where and are the weights for hidden and output layers, and is an activation function. Two-layer convolutional networks with filters can be described by patch matrices (e.g., images) . For flattened activations, we have .
We consider the 2-layer linear convolutional networks and its non-convex loss is:
| (17) |
[37] show that the above non-convex problem can be transferred to the below convex optimization problem via its duality. and the two problems have the identical optimal values:
| (18) |
We run federated learning with convex 2-layer linear convolutional network, where each device trains the local loss and it can converge to the optimal model .
-
•
Compute : Let . For each client , we require its local loss should satisfy for any ; With Equation 18, we have ; Then we have the smoothness constant to be the maximum eigenvalue of , which is ; Hence, .
-
•
Compute : Similar as computing , is the minimum eigenvalue of for all , that is, .
-
•
Compute and : Similar computation as in -regularized logistic regression.
Unrolled feed-forward network and its training and performance. In our experiments, we set the number of layers to be 20 in the unrolled feed-forward network for the three datasets. We use 1,000 data samples and their intermediate reconstructions to train the network. To reduce overfitting, we use the greedy layer-wise training strategy. For instance, the average MSE (between the input and output of the unrolled network) of DLG, iDLG, InvGrad, and GGL on MNIST is 1.22, 1.01, 0.76, and 0.04, respectively—indicating that the training performance is promising. After training the unrolled network, we use the AutoLip algorithm to calculate the Lipschitz .
D.2 Details about Data Reconstruction Attacks
GGL [30]: GGL considers the scenario where clients realize the server will infer their private data and they hence perturb their local models before sharing them with the server as a defense. To handle noisy models, GGL solves an optimization problem similar to InvGrad, but uses a pretrained generator as a regularization. The generator is trained on the entire MNIST dataset and can calibrate the reconstructed noisy image to be within the image manifold. Specifically, given a well-trained generator on public datasets and assume the label is inferred by iGLD, GGL targets the following optimization problem:
| (19) |
where is the latent space of the generative model, is a lossy transformation (e.g., compression or sparsification) acting as a defense, and is a regularization term that penalizes the latent if it deviates from the prior distribution. Once the optimal is obtained, the image can be reconstructed as and should well align the natural image.
In the experiments, we use a public pretrained GAN generator for MNIST, Fashion-MNIST, and CIFAR. We adopt gradient clipping as the defense strategy performed by the clients. Specifically, . Note that since is trained on the whole image dataset, it produces stable reconstruction during the optimization.
Robbing [11]: Robbing approximately reconstructs the data via solving an equation without any iterative optimization. Assume a batch of data with unique labels in the form of one-hot encoding. Let be element-wise division. Then, Robbing observes that each row in , i.e., , actually recovers
In other others, Robbing directly maps the model to the reconstructed data. Hence, in our experiment, the unrolled feed-forward neural network reduces to 1-layer ReLU network. We then estimate Lipschitz upper bound on this network.