Understanding Adversarial Robustness Against On-manifold Adversarial Examples
Abstract
Deep neural networks (DNNs) are shown to be vulnerable to adversarial examples. A well-trained model can be easily attacked by adding small perturbations to the original data. One of the hypotheses of the existence of the adversarial examples is the off-manifold assumption: adversarial examples lie off the data manifold. However, recent research showed that on-manifold adversarial examples also exist. In this paper, we revisit the off-manifold assumption and want to study a question: at what level is the poor performance of neural networks against adversarial attacks due to on-manifold adversarial examples? Since the true data manifold is unknown in practice, we consider two approximated on-manifold adversarial examples on both real and synthesis datasets. On real datasets, we show that on-manifold adversarial examples have greater attack rates than off-manifold adversarial examples on both standard-trained and adversarially-trained models. On synthetic datasets, theoretically, We prove that on-manifold adversarial examples are powerful, yet adversarial training focuses on off-manifold directions and ignores the on-manifold adversarial examples. Furthermore, we provide analysis to show that the properties derived theoretically can also be observed in practice. Our analysis suggests that on-manifold adversarial examples are important, and we should pay more attention to on-manifold adversarial examples for training robust models.
1 Introduction
In recent years, deep neural networks (DNNs) (Krizhevsky et al.,, 2012; Hochreiter and Schmidhuber,, 1997) have become popular and successful in many machine learning tasks. They have been used in different problems with great success. But DNNs are shown to be vulnerable to adversarial examples (Szegedy et al.,, 2013; Goodfellow et al., 2014b, ). A well-trained model can be easily attacked by adding small perturbations to the images. One of the hypotheses of the existence of adversarial examples is the off-manifold assumption (Szegedy et al.,, 2013):
Clean data lies in a low-dimensional manifold. Even though the adversarial examples are close to the clean data, they lie off the underlying data manifold.
DNNs only fit the data in the manifold and perform badly on adversarial examples out of the manifold. Many research support this point of view. Pixeldefends (Song et al.,, 2017) leveraged a generative model to show that adversarial examples lie in a low probability region of the data distribution. The work of (Gilmer et al.,, 2018; Khoury and Hadfield-Menell,, 2018) studied the geometry of adversarial examples. It shows that adversarial examples are related to the high dimension of the data manifold and they are conducted in the directions off the data manifold. The work of (Ma et al.,, 2018) useed Local Intrinsic Dimensionality (LID) to characterize the adversarial region and argues that the adversarial subspaces are of low probability, and lie off (but are close to) the data submanifold.
One of the most effective approaches to improve the adversarial robustness of DNNs is to augment adversarial examples to the training set, i.e., adversarial training. However, the performance of adversarially-trained models are still far from satisfactory. Based on the off-manifold assumption, previous studies provided an explanation on the poor performance of adversarial training that the adversarial data lies in a higher-dimensional manifold. DNNs can work well on a low dimensional manifold but not on a high dimensional manifold. This is discussed in the paper we mentioned above (Gilmer et al.,, 2018; Khoury and Hadfield-Menell,, 2018). There are also other interpretations of the existence of adversarial examples, see Sec. 2.
In recent years, researchers found that on-manifold adversarial examples also exist. They can fool the target models (Lin et al.,, 2020), boost clean generalization (Stutz et al.,, 2019), improve uncertainty calibration (Patel et al.,, 2021), and improve model compression (Kwon and Lee,, 2021). Therefore, the off-manifold assumption may not be a perfect hypothesis explaining the existence of adversarial examples. It motivates us to revisit the off-manifold assumption. Specifically, we study the following question:
At what level is the poor performance of neural networks against adversarial attacks due to on-manifold adversarial examples?
The main difficulty in studying this question is that the true data manifold is unknown in practice. It is hard to obtain the true on-manifold adversarial examples. To have a closer look at on-manifold adversarial examples, we consider two approximated on-manifold adversarial examples, and we consider both real and synthetic datasets.
Approximate on-manifold adversarial examples
We use two approaches to approximate the on-manifold adversarial examples. The first one is generative adversarial examples (Gen-AE). Generative models, such as generative adversarial networks (GAN) (Goodfellow et al., 2014a, ) and variational autoencoder (VAE) (Kingma and Welling,, 2013), are used to craft adversarial examples. Since the generative model is an approximation of the data manifold, the crafted data lies in the data manifold. We perform perturbation in the latent space of the generative model. Since the first approach relies on the quality of the generative models, we consider the second approach: using the eigenspace of the training dataset to approximate the data manifold, which we call eigenspace adversarial examples (Eigen-AE). In this method, the crafted adversarial examples are closer to the original samples. For more details, see Section 4.
To start, we provide experiments of on-manifold attacks on both standard-trained and adversarially-trained models on MNIST, CIFAR-10, CIFAR-100, and ImageNet. The experiments show that on-manifold attacks are powerful, with higher attack rates than off-manifold adversarial examples. It help justifies that the off-manifold assumption might not be a perfect hypothesis of the existence of adversarial examples.
The experiments motivate us to study on-manifold adversarial examples from a theoretical perspective. Since the true data manifold is unknown in practice, we provide a theoretical study on synthetic datasets using Gaussian mixture models (GMMs). In this case, the true data manifold is given. We study the excess risk (Thm. 5.1 and Thm. 5.2) and adversarial distribution shift (Thm. 5.3 and Thm. 5.4) of these two types of on-manifold adversarial examples. Our main technical contribution is providing closed-form solutions to the min-max problems of on-manifold adversarial training. Our theoretical results show that on-manifold adversarial examples incur a large excess risk and foul the target models. Compared to regular adversarial attacks, we show how adversarial training focuses on off-manifold directions and ignores the on-manifold adversarial examples.
Finally, we provide a comprehensive analysis to connect the four settings (two approximate on-manifold attacks on both real and synthetic datasets). We show the similarity of these four cases: 1) the attacks directions of Gen-AE and Eigen-AE are similar on common datasets, and 2) the theoretical properties derived using GMMs (Thm. 5.1 to Thm. 5.4) can also be observed in practice.
Based on our study, we find that on-manifold adversarial examples are important for adversarial robustness. We emphasize that we should pay more attention to on-manifold adversarial examples for training robust models. Our contributions are listed as follows:
-
•
We develop two approximate on-manifold adversarial attacks to take a closer look at on-manifold adversarial examples.
-
•
We provide comprehensive analyses of on-manifold adversarial examples empirically and theoretically. We summarize our main results in Table 1. Our results suggest the importance of on-manifold adversarial examples, and we should pay more attention to on-manifold adversarial examples to train robust models.
- •
2 Related Work
Attack
Adversarial examples for deep neural networks were first intruduced in (Szegedy et al.,, 2013). However, adversarial machine learning or robust machine learning has been studied for a long time (Biggio and Roli,, 2018). In the setting of white box attack (Kurakin et al.,, 2016; Papernot et al.,, 2016; Moosavi-Dezfooli et al.,, 2016; Carlini and Wagner,, 2017), the attackers have fully access to the model (weights, gradients, etc.). In black box attack (Chen et al.,, 2017; Su et al.,, 2019; Ilyas et al.,, 2018), the attackers have limited access to the model. First order optimization methods, which use the gradient information to craft adversarial examples, such as PGD (Madry et al.,, 2017), are widely used for white box attack. Zeroth-order optimization methods (Chen et al.,, 2017) are used in black box setting. (Li et al.,, 2019) improved the query efficiency in black-box attack. Generative adversarial examples: Generative models have been used to craft adversarial examples (Xiao et al.,, 2018; Song et al.,, 2018; Kos et al.,, 2018). The adversarial examples are more natural (Zhao et al.,, 2017).
Defense
Training algorithms against adversarial attacks can be subdivided into the following categories. Adversarial training: The training data is augmented with adversarial examples to make the models more robust (Madry et al.,, 2017; Szegedy et al.,, 2013; Tramèr et al.,, 2017). Preprocessing: Inputs or hidden layers are quantized, projected onto different sets or other preprocessing methods (Buckman et al.,, 2018; Guo et al.,, 2017; Kabilan et al.,, 2018). Stochasticity: Inputs or hidden activations are randomized (Prakash et al.,, 2018; Dhillon et al.,, 2018; Xie et al.,, 2017). However, some of them are shown to be useless defenses given by obfuscated gradients (Athalye et al.,, 2018). Adaptive attack (Tramer et al.,, 2020) is used for evaluating defenses to adversarial examples. (Xiao et al.,, 2022) consider the Rademacher complexity in adversarial training case.
3 On-manifold Adversarial Attacks
Adversarial Attacks
Given a classifier and a sample data . The goal of regular adversarial attacks is to find an adversarial example to foul the classifier . A widely studied norm-based adversarial attack is to solve the optimization problem where is the loss function and is the perturbation intensity. In this paper, we focus on on-manifold adversarial attacks. We must introduce additional constraints to restrict in the data manifold and preserve the label . In practice, the true data manifold is unknown. Assuming that the true data manifold is a push-forward function , where is a low dimensional Euclidean space and is the support of the data distribution. One way to approximate is to use a generative model such that . The second way is to consider the Taylor expansion of and use the first-order term to approximate . They correspond to the following two approximated on-manifold adversarial examples.
Generative Adversarial Examples
One method to approximate the data manifold is to use generative models, such as GAN and VAE. Let be a generative model and be the inverse mapping of . Generative adversarial attack can be formulated as the following problem
| (3.1) |
Then, is an (approximate) on-manifold adversarial example. In this method, can be large. To preserve the label , we use the conditional generative models (e.g. C-GAN (Mirza and Osindero,, 2014) and C-VAE (Sohn et al.,, 2015), i.e. the generator and inverse mapping are conditioned on the label . In the experiments, we use two widely used gradient-based attack algorithms, fast gradient sign method (FGSM) (Goodfellow et al., 2014b, ) and projected gradient descend (PGD) (Madry et al.,, 2017) in the latent space , which we call GFGSM and GPGD, respectively.
Eigenspace Adversarial Examples
The on-manifold adversarial examples found by the above method are not norm-bounded. To study norm-based on-manifold adversarial examples, we use the eigenspace to approximate the data manifold. Consider the following problem
| (3.2) | ||||
where the rows of is the eigenvectors corresponds to the top eigenvalues of the co-variance matrix of the training data with label . Then, is restricted in the eigenspace. A baseline algorithm for standard adversarial attack is PGD attack (Madry et al.,, 2017). To make a fair comparison, we should use the same algorithm to solve the attack problem. Notice that the inner maximization problem in Eq. (3.2) cannot be solved by PGD in general. Because the projection step is an optimization problem. We consider adversarial attacks in this case. Then, Eq. (3.2) is equivalent to
| (3.3) |
We can use PGD to find eigenspace adversarial examples. In this case, the perturbation constraint is a subset of the constraint of regular adversarial attacks. For comparison, we consider the case that the rows of is the eigenvectors corresponds to the bottom eigenvalues. We call this type of on-manifold and off-manifold adversarial examples as top eigenvectors and bottom eigenvectors subspace adversarial examples.
Target Models
In this paper, we aim to study the performance of on-manifold adversarial attacks on both standard-trained model and adversarially-trained model. For standard training, only the original data is used in training. For adversarial training, adversarial examples are augmented to the training dataset. For ablation studies, we also consider on-manifold adversarial training, i.e., on-manifold adversarial examples crafted by the above mentioned algorithms are augmented to the training dataset.
4 Warm-up: Performance of On-manifold Adversarial Attacks
In this section, we provide experiments in different settings to study the performance of on-manifold adversarial attacks.
| MNIST | clean data | FGSM-Attack | PGD-Attack | GFGSM-Attack | GPGD-Attack |
|---|---|---|---|---|---|
| Std training | 98.82% | 47.38% | 3.92% | 42.37% | 10.74% |
| PGD-AT | 98.73% | 96.50% | 95.51% | 52.17% | 15.53% |
| GPGD-AT | 98.63% | 20.63% | 2.11% | 99.66% | 96.78% |
| joint-PGD-AT | 98.45% | 97.31% | 95.70% | 99.27% | 96.03% |
| CIFAR-10 | clean data | FGSM-Attack | PGD-Attack | GFGSM-Attack | GPGD-Attack |
| Std training | 91.80% | 15.08% | 5.39% | 7.07% | 3.41% |
| PGD-AT | 80.72% | 56.42% | 50.18% | 14.27% | 8.51% |
| GPGD-AT | 78.93% | 10.64% | 3.21% | 40.18% | 26.66% |
| joint-PGD-AT | 79.21% | 50.19% | 49.77% | 42.87% | 28.54% |
| ImageNet | clean data | FGSM-Attack | PGD-Attack | GFGSM-Attack | GPGD-Attack |
| Std training | 74.72% | 2.59% | 0.00% | / | 0.26% |
| PGD-AT | 73.31% | 48.02% | 38.88% | / | 7.23% |
| GPGD-AT | 78.10% | 21.68% | 0.03% | / | 27.53% |
| joint-PGD-AT | 77.96% | 49.12% | 37.86% | / | 20.53% |
4.1 Experiments of Generative Adversarial Attacks
To study the performance of generative adversarial attacks, we compare the performance of different attacks (FGSM, PGD, GFGSM, and GPGD) versus different models (standard training, PGD-adversarial training, and GPGD-adversarial training).
Experiments setup
In this section we report our experimental results on training LeNet on MNIST (LeCun et al.,, 1998), ResNet18 (He et al.,, 2016) on CIFAR-10 (Krizhevsky et al.,, 2009), and ResNet50 on ImageNet (Deng et al.,, 2009). The experiments on CIFAR-100 are discussed in Appendix B.3. On MNIST, we use and 40 steps PGD for adversarial training and use and 40 steps PGD for generative adversarial training. On CIFAR-10 and CIFAR-100, we use , PGD-10 for adversarial training, and , PGD-10 for generative adversarial training. On ImageNet, we adopt the settings in (Lin et al.,, 2020) and use , PGD-5 for adversarial training, and , PGD-5 for generative adversarial training. The choice of in the latent space is based on the quality of the generative examples. In the outer minimization, we use the SGD optimizer with momentum 0.9 and weight decay . For reference Details of the hyperparameters setting are in Appendix B.1.
Generative AT cannot defend regular attack, and vice versa
In Table 2, the test accuracy of GPGD-AT vs PGD-attack is 3.21%, which means that on-manifold adversarial training cannot defend a regular norm-based attack. Similarly, the test accuracy of PGD-AT vs GPGD-Attack is 15.53%, a adversarially-trained model preforms badly on on-manifold attacks. The results on the experiments on CIFAR-10 and ImageNet are similar. PGD-AT is not able to defend GPGD-Attack, and vice versa. In the experiments on CIFAR-10 and ImageNet, we can see that generative attacks have greater attack rates than regular PGD-attacks.
Joint-PGD Adversarial Training
Based on the previous discussion, we may wonder whether we can improve the model robustness by augmenting both on-manifold and regular PGD-adversarial examples to the training set. On MNIST, the jointly-trained model achieves 96.03% and 95.70% test accuracy against GPGD-Attack and PGD-Attack, which are similar to the test accuracy of the single-trained models. We can see similar results on CIFAR-10 and ImageNet. Since generative adversarial examples are not closed to the clean data because of the large Lipschitz of the generative models. We study the performance of norm-bounded on-manifold adversarial examples in the next subsection.
4.2 Eigenspace Adversarial Examples




Experiment Setups
In Fig. 1, we show the results of the experiments of standard training and -adversarial training against -eigenspace adversarial attacks on CIFAR-10 (Krizhevsky et al.,, 2009) and CIFAR-100. For adversarial training, we use 20 steps PGD-attack with for the inner maximization problem. For the eigenspace attack, we restrict the subspace in different dimensions. The results of top eigenvectors subspace attacks restricted in the subspace spanned by the first 500, 1000, 1500, 2500, and 3000 eigenvectors are shown in the blue lines. Correspondingly, the results of bottom eigenvectors subspace attacks restricted in the subspace spanned by the last eigenvectors are shown in the red lines.
Target Model
The target model in Fig. 1 is Wide-ResNet-28. In the experiments on CIFAR-10, for the standard-trained model, the clean accuracy is 92.14%. For the adversarial training model, the clean accuracy is 95.71%, and the robust accuracy against -PGD-20 is 73.22%. On CIFAR-100. for standard training, the clean accuracy is 80.34%. For adversarial training, the clean accuracy is 67.18%, and the robust accuracy against PGD-10 is 43.92%.
On-manifold Adversarial Examples Have Greater Attack Rates on Standard-Trained models
In Fig. 1 (a), if we restrict the attack directions in the subspace spanned by the first or last 500 eigenvectors, the robust accuracies are 12% and 22%. As we increase the dimension of the subspace, the test accuracy will converge to the robust accuracy of standard PGD-attack, 5.27%. If the dimension of subspace increases to 3072, the subspace attacks are equivalent to standard PGD-attacks since the dimension of is on CIFAR-10. On-manifold adversarial examples have greater attack rates than off-manifold adversarial examples against the standard training model. The results in Fig. 1 (c) are similar.
On-manifold Adversarial Examples Have Greater Attack Rates on Adversarially-Trained model
Now, we turn to Fig. 1 (b). If we restrict the attack directions in the first or last 1000 eigenvectors subspace, the robust accuracy is 58.74% and 66.43% against bottom and top eigenvectors subspace attacks, respectively. Similar for other numbers of dimensions. Similarly for the experiments on CIFAR-100 in Fig. 1 (d). We can see that adversarial training can work well on off-manifold attacks, but the performance on on-manifold attacks is not good enough.
Eigenspace Adversarial Training
In this setting, the perturbation constraint is a subset of the constraint of regular adversarial training. The performance of this algorithm is worse than that of regular adversarial training. We provide the experiments in Appendix B.2.
Adversarial Training Ignores On-manifold Adversarial Examples
In these experiments, all the on-manifold adversarial examples are norm-bounded. Adversarial training still performs badly on this kind of attack. In Theorem 5.2 in the next section, we will show that it is because off-manifold adversarial examples have larger losses than on-manifold adversarial examples in the norm constraint. Then, norm-based adversarial training algorithms are not able to find the on-manifold adversarial examples in the small norm ball. Therefore, adversarial training cannot fit the on-manifold adversarial examples well.
Take-away Message
In short, Sec. 4 shows that (approximate) on-manifold adversarial examples are powerful. It has higher attack rates than off-manifold adversarial examples on both standard-trained and adversarially-trained models. Widely use adversarially-trained models performs badly against (approximate) on-manifold attacks.
5 Theoretical Analysis: On-manifold Attacks on Gaussian Mixture Model
In this section, we study the excess risk and the adversarial distribution shift of on-manifold adversarial training. We study the binary classification setting proposed by (Ilyas et al.,, 2019). In this setting, the true data manifold is known. We can derive the optimal closed-form solution of on-manifold adversarial attacks and adversarial training and provide insights to understand on-manifold adversarial examples.
5.1 Theoretical Model Setup
Gaussian mixture model
Assume that data points are sampled according to uniformly and , where and denote the true mean and covariance matrix of the data distribution. For the data in the class , we replace by , then we can view the whole dataset as sampled from .
Classifier
The goal of standard training is to learn the parameters such that
| (5.1) |
where represents the negative log-likelihood function. The goal of adversarial training is to find
| (5.2) |
We use and to denote the standard loss and adversarial loss. After training, we classify a new data point to the class .
Generative Model
In our theoretical study, we use a linear generative model, that is, probabilistic principle components analysis (P-PCA) (Tipping and Bishop,, 1999). P-PCA can be viewed as linear VAE (Dai et al.,, 2017).
Given dataset , let and be the sample mean and sample covariance matrix. The eigenvalue decomposition of is , then using the first eigenvactors, we can project the data to a low dimensional space. P-PCA is to assume that the data are generated by
and . Then we have , and where . The maximum likelihood estimator of and are
where is the matrix of the first columns of , is the matrix of the first eigenvalues of . In the following study, we assume that is large enough such that we can learn the true and . Thus we have , , for the generative model.
Generative Adversarial Examples
To perturb the data in the latent space, data will go through the encode-decode process . Specifically, we sample , then we encode , add a perturbation , and finally, we decode . The following lemma shows that the generative adversarial examples can be rewritten as a new form.
Lemma 5.1 (Generative Adversarial Examples).
Using generative model P-PCA, the adversarial examples can be rewritten as
If the data lie in a dimensional subspace, i.e. the covariance matrix is rank , we have . Then .
Remark
We consider other sampling strategies using generative models in A. We show that the adversarial examples have the same form as in Lemma 5.1 with different .
The adversarial expected risk of generative adversarial training can be rewritten as the following minimax problem
| (5.3) |
Eigenspace Adversarial Examples
If the perturbation is restricted in the eigenspace spanned by . the adversarial examples can be weritten as .
The adversarial expected risk of eigenspace adversarial training can be rewritten as the following minimax problem
| (5.4) |
When , span the whole space. Eq. (5.4) reduce to the regular adversarial training.
5.2 Excess Risk Analysis
We consider the excess risk incurred by the optimal perturbation of on-manifold adversarial examples, i.e. and given the true .
We consider the Lagrange penalty form of the inner maximization problem in Eq. (5.3), i.e. , where is the Lagrange multiplier. Similarly, we consider the Lagrange penalty form of the inner maximization problem in Eq. (5.4).
Theorem 5.1 (Excess risk of generative adversarial examples).
The optimal perturbation in the latent space will incur an excess risk in . The adversarial vulnerability depends on the dimension and the Lagrange multiplier . is negatively related to the perturbation intensity . Then, we analyze the excess risk of eigenspace adversarial examples. Since the perturbation thresholds, , are on different scales, the corresponding Lagrange multipliers are different. We use in the following Theorem.
Theorem 5.2 (Excess risk of eigenspace adversarial examples).
Similar to the case of generative attacks, the adversarial vulnerability depends on the dimension and the Lagrange multiplier .
Excess risk of (regular) adversarial examples
When and the data lie in a low dimensional manifold, i.e. , the excess risk of regular adversarial examples equals to . Regular adversarial attacks focus on the directions corresponding to zero eigenvalues, i.e. the off-manifold directions. However, on-manifold adversarial examples will also incur large excess risks in and . On-manifold adversarial examples are also powerful but regular adversarial attacks tend to ignore the on-manifold adversarial examples.

5.3 Adversarial Distribution Shifts
In this subsection we study the optimal solution of optimization problem in Eq. (5.3) and (5.4). Since they are not standard minimax problems, we consider a modified problem of (5.3):
| (5.5) |
Similarly, we switch the order of expectation and maximization in problem (5.4). The following two Theorems are our main results. They give the optimal solution of generative adversarial training and eigenspace adversarial training.
Theorem 5.3 (Optimal solution of generative adversarial training).
We assume that the data lie in a -dimensional manifold again. Then we have for and for . Generative adversarial training amplifies the largest eigenvalues of the covariance matrix of the (adversarial) data distribution.
Theorem 5.4 (Optimal solution of eigenspace adversarial training).
Considering the ratio
the ratio is larger for smaller true eigenvalue . Therefore, eigenspace adversarial training amplifies the small eigenvalues of the eigenspace.
Optimal solution of (regular adversarial training)
When , regular adversarial training amplifies the small eigenvalues of the whole space.
Demonstration of the case
We give a numerical simulation in Fig. 2. The black blocks are the perturbation constraint with the original example in the center. Given the original Gaussian data (plots in (a)), we iteratively solve the max and min problem in Eq. (5.4), the resulting data distribution is plotted in (b). We can see that the radius of the short axis of the ellipse is amplified. In Fig. 2 (d), we iteratively solve the max and min problem in Eq. (5.3), we can see that the radius of the two axes of the ellipse is amplified.
Take-away Message
In the analysis of GMMs, we prove that regular adversarial attacks and defense only focus on off-manifold directions due to the magnitude of eigenvalues. However, on-manifold adversarial examples also incur large excess risk and lead to different adversarial distribution shift. This is why (regular) adversarial training performs badly against on-manifold attacks.
6 Further Analysis of On-manifold Attacks


We provide further analysis of the theoretical properties on real dataset. We will see that the properties derived in Sec. 5 can also be observed in practice.
On-manifold Attack Directions
Given the training dataset , we conduct SVD on this dataset and let the eigenvectors span a basis of the original space. In Fig. 3 (a) and (b), we plot the absolute value of the average of all the generative adversarial examples in this space. We can see that generative attack focuses on the directions of top eigenvectors. Gen-AE and Eigen-AE have similar attack directions on real datasets.
Adversarial Distribution Shifts
Let and be the adversarially trained and generative adversarially trained neural networks respectively. Given the clean dataset , let the robust dataset be
and . We perform SVD on , , and . We plot the eigenvalues in Fig. 4. The first row is the experiments on MNIST, and the second row is the experiments on CIFAR-10. On MNIST, the number of dimensions is . On CIFAR-10, the numbers of dimension is .
MNIST




CIFAR-10




Generative adversarial training amplifies the top eigenvalues
In Fig. 4 (b) and (f), we plot the top 10 eigenvalues. we can see that the eigenvalues of (blue line) is larger than that of (red line). It means that generative adversarial training will amplify the large eigenvalues, which is consistent with Theorem 5.3. Regular adversarial training does not amplify the top eigenvalues.
Adversarial training amplifies the bottom eigenvalues
Discussion on Adversarial distribution shifts
In general, it is hard to characterize the adversarial distribution shifts in detail since analyzing the minimax problem of adversarial training is challenging. In these experiments, we show that the eigenvalues, which are second-order statistics of the dataset or the variance of the data distribution in the corresponding directions, are good indicators of the adversarial distribution shifts. Adversarial training tries to fit the adversarial examples in directions of small variance, while generative adversarial training tries to fit the adversarial examples in directions of large variance. Therefore, adversarial training ignores on-manifold adversarial examples, which are also important for adversarial robustness.
7 Conclusion
In this paper, We show that on-manifold adversarial examples are also powerful, but adversarial training focuses on off-manifold directions and ignores the on-manifold adversarial examples. On-manifold adversarial examples are also important for adversarial training. We think that our analysis can inspire more theoretical research on adversarial robustness. For example, A well-designed norm-bounded on-manifold adversarial attacks algorithm may improve the performance of adversarial training.
References
- Athalye et al., (2018) Athalye, A., Carlini, N., and Wagner, D. (2018). Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples. arXiv preprint arXiv:1802.00420.
- Biggio and Roli, (2018) Biggio, B. and Roli, F. (2018). Wild patterns: Ten years after the rise of adversarial machine learning. Pattern Recognition, 84:317–331.
- Buckman et al., (2018) Buckman, J., Roy, A., Raffel, C., and Goodfellow, I. (2018). Thermometer encoding: One hot way to resist adversarial examples. In International Conference on Learning Representations.
- Carlini and Wagner, (2017) Carlini, N. and Wagner, D. (2017). Towards evaluating the robustness of neural networks. In 2017 ieee symposium on security and privacy (sp), pages 39–57. IEEE.
- Chen et al., (2017) Chen, P.-Y., Zhang, H., Sharma, Y., Yi, J., and Hsieh, C.-J. (2017). Zoo: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, pages 15–26.
- Dai et al., (2017) Dai, B., Wang, Y., Aston, J., Hua, G., and Wipf, D. (2017). Hidden talents of the variational autoencoder. arXiv preprint arXiv:1706.05148.
- Daskalakis et al., (2018) Daskalakis, C., Gouleakis, T., Tzamos, C., and Zampetakis, M. (2018). Efficient statistics, in high dimensions, from truncated samples. In 2018 IEEE 59th Annual Symposium on Foundations of Computer Science (FOCS), pages 639–649. IEEE.
- Deng et al., (2009) Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., and Fei-Fei, L. (2009). Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee.
- Dhillon et al., (2018) Dhillon, G. S., Azizzadenesheli, K., Lipton, Z. C., Bernstein, J., Kossaifi, J., Khanna, A., and Anandkumar, A. (2018). Stochastic activation pruning for robust adversarial defense. arXiv preprint arXiv:1803.01442.
- Gilmer et al., (2018) Gilmer, J., Metz, L., Faghri, F., Schoenholz, S. S., Raghu, M., Wattenberg, M., and Goodfellow, I. (2018). Adversarial spheres. arXiv preprint arXiv:1801.02774.
- (11) Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., and Bengio, Y. (2014a). Generative adversarial nets. In Advances in neural information processing systems, pages 2672–2680.
- (12) Goodfellow, I. J., Shlens, J., and Szegedy, C. (2014b). Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572.
- Guo et al., (2017) Guo, C., Rana, M., Cisse, M., and Van Der Maaten, L. (2017). Countering adversarial images using input transformations. arXiv preprint arXiv:1711.00117.
- He et al., (2016) He, K., Zhang, X., Ren, S., and Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778.
- Hochreiter and Schmidhuber, (1997) Hochreiter, S. and Schmidhuber, J. (1997). Long short-term memory. Neural computation, 9(8):1735–1780.
- Ilyas et al., (2018) Ilyas, A., Engstrom, L., and Madry, A. (2018). Prior convictions: Black-box adversarial attacks with bandits and priors. arXiv preprint arXiv:1807.07978.
- Ilyas et al., (2019) Ilyas, A., Santurkar, S., Tsipras, D., Engstrom, L., Tran, B., and Madry, A. (2019). Adversarial examples are not bugs, they are features. In Advances in Neural Information Processing Systems, pages 125–136.
- Kabilan et al., (2018) Kabilan, V. M., Morris, B., Nguyen, H.-P., and Nguyen, A. (2018). Vectordefense: Vectorization as a defense to adversarial examples. In Soft Computing for Biomedical Applications and Related Topics, pages 19–35. Springer.
- Karras et al., (2019) Karras, T., Laine, S., and Aila, T. (2019). A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4401–4410.
- Khoury and Hadfield-Menell, (2018) Khoury, M. and Hadfield-Menell, D. (2018). On the geometry of adversarial examples. arXiv preprint arXiv:1811.00525.
- Kingma and Welling, (2013) Kingma, D. P. and Welling, M. (2013). Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114.
- Kos et al., (2018) Kos, J., Fischer, I., and Song, D. (2018). Adversarial examples for generative models. In 2018 IEEE Security and Privacy Workshops (SPW), pages 36–42. IEEE.
- Krizhevsky et al., (2009) Krizhevsky, A., Hinton, G., et al. (2009). Learning multiple layers of features from tiny images.
- Krizhevsky et al., (2012) Krizhevsky, A., Sutskever, I., and Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, pages 1097–1105.
- Kurakin et al., (2016) Kurakin, A., Goodfellow, I., and Bengio, S. (2016). Adversarial examples in the physical world. arXiv preprint arXiv:1607.02533.
- Kwon and Lee, (2021) Kwon, J. and Lee, S. (2021). Improving the robustness of model compression by on-manifold adversarial training. Future Internet, 13(12):300.
- LeCun et al., (1998) LeCun, Y., Bottou, L., Bengio, Y., and Haffner, P. (1998). Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324.
- Li et al., (2019) Li, Y., Li, L., Wang, L., Zhang, T., and Gong, B. (2019). Nattack: Learning the distributions of adversarial examples for an improved black-box attack on deep neural networks. arXiv preprint arXiv:1905.00441.
- Lin et al., (2020) Lin, W.-A., Lau, C. P., Levine, A., Chellappa, R., and Feizi, S. (2020). Dual manifold adversarial robustness: Defense against lp and non-lp adversarial attacks. arXiv preprint arXiv:2009.02470.
- Ma et al., (2018) Ma, X., Li, B., Wang, Y., Erfani, S. M., Wijewickrema, S., Schoenebeck, G., Song, D., Houle, M. E., and Bailey, J. (2018). Characterizing adversarial subspaces using local intrinsic dimensionality. arXiv preprint arXiv:1801.02613.
- Madry et al., (2017) Madry, A., Makelov, A., Schmidt, L., Tsipras, D., and Vladu, A. (2017). Towards deep learning models resistant to adversarial attacks. arXiv preprint arXiv:1706.06083.
- Mirza and Osindero, (2014) Mirza, M. and Osindero, S. (2014). Conditional generative adversarial nets. arXiv preprint arXiv:1411.1784.
- Moosavi-Dezfooli et al., (2016) Moosavi-Dezfooli, S.-M., Fawzi, A., and Frossard, P. (2016). Deepfool: a simple and accurate method to fool deep neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2574–2582.
- Papernot et al., (2016) Papernot, N., McDaniel, P., Jha, S., Fredrikson, M., Celik, Z. B., and Swami, A. (2016). The limitations of deep learning in adversarial settings. In 2016 IEEE European symposium on security and privacy (EuroS&P), pages 372–387. IEEE.
- Patel et al., (2021) Patel, K., Beluch, W., Zhang, D., Pfeiffer, M., and Yang, B. (2021). On-manifold adversarial data augmentation improves uncertainty calibration. In 2020 25th International Conference on Pattern Recognition (ICPR), pages 8029–8036. IEEE.
- Prakash et al., (2018) Prakash, A., Moran, N., Garber, S., DiLillo, A., and Storer, J. (2018). Deflecting adversarial attacks with pixel deflection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 8571–8580.
- Sohn et al., (2015) Sohn, K., Lee, H., and Yan, X. (2015). Learning structured output representation using deep conditional generative models. In Advances in neural information processing systems, pages 3483–3491.
- Song et al., (2017) Song, Y., Kim, T., Nowozin, S., Ermon, S., and Kushman, N. (2017). Pixeldefend: Leveraging generative models to understand and defend against adversarial examples. arXiv preprint arXiv:1710.10766.
- Song et al., (2018) Song, Y., Shu, R., Kushman, N., and Ermon, S. (2018). Constructing unrestricted adversarial examples with generative models. In Advances in Neural Information Processing Systems, pages 8312–8323.
- Stutz et al., (2019) Stutz, D., Hein, M., and Schiele, B. (2019). Disentangling adversarial robustness and generalization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6976–6987.
- Su et al., (2019) Su, J., Vargas, D. V., and Sakurai, K. (2019). One pixel attack for fooling deep neural networks. IEEE Transactions on Evolutionary Computation, 23(5):828–841.
- Szegedy et al., (2013) Szegedy, C., Zaremba, W., Sutskever, I., Bruna, J., Erhan, D., Goodfellow, I., and Fergus, R. (2013). Intriguing properties of neural networks. arXiv preprint arXiv:1312.6199.
- Tipping and Bishop, (1999) Tipping, M. E. and Bishop, C. M. (1999). Probabilistic principal component analysis. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 61(3):611–622.
- Tramer et al., (2020) Tramer, F., Carlini, N., Brendel, W., and Madry, A. (2020). On adaptive attacks to adversarial example defenses. arXiv preprint arXiv:2002.08347.
- Tramèr et al., (2017) Tramèr, F., Kurakin, A., Papernot, N., Goodfellow, I., Boneh, D., and McDaniel, P. (2017). Ensemble adversarial training: Attacks and defenses. arXiv preprint arXiv:1705.07204.
- Xiao et al., (2018) Xiao, C., Li, B., Zhu, J.-Y., He, W., Liu, M., and Song, D. (2018). Generating adversarial examples with adversarial networks. arXiv preprint arXiv:1801.02610.
- Xiao et al., (2022) Xiao, J., Fan, Y., Sun, R., and Luo, Z.-Q. (2022). Adversarial rademacher complexity of deep neural networks.
- Xie et al., (2017) Xie, C., Wang, J., Zhang, Z., Ren, Z., and Yuille, A. (2017). Mitigating adversarial effects through randomization. arXiv preprint arXiv:1711.01991.
- Zhao et al., (2017) Zhao, Z., Dua, D., and Singh, S. (2017). Generating natural adversarial examples. arXiv preprint arXiv:1710.11342.
Appendix A Proof of the Theorems
A.1 Proof of Lemma 5.1
We first introduce the general form of Lemma 5.1. To perturb the data in the latent space, data will go through the encode-decode process . Based on the probabilistic model, we may choose with the highest probability or just sample it from the distribution we learned. Hence, we could have different strategies.
Strategy 1: Sample , encode , add a perturbation , and finally, decode .
Strategy 2: Sample , then sample , add a perturbation , and finally, sample .
Strategy 3: Sample , add a perturbation , and then sample . In this strategy, can be viewed as the adversarial example of .
Lemma A.1 below is a general form of the Lemma 5.1, where we only consider strategy 1 (). Similar to the proof of Thm. 5.1 to 5.4.
Lemma A.1 (generative adversarial examples).
Using the 3 strategies defined above, the generative adversarial examples can be unified as
where
If the data lie in a dimensional subspace, i.e. the covariance matrix is rank , we have . Then .
Proof:
Using P-PCA generative model, , and where . The maximum likelihood estimator of and are
Strategy 1
Sample , encode , add a perturbation , and finally, decode . Then
Since , we have , Then
With
Strategy 2
Sample , then sample , add a perturbation , and finally, sample . Then
and
With
Strategy 3
Sample , add a perturbation , and then sample . In this strategy, can be viewed as the adversarial example of .
With
In these 3 strageties, the adversarial examples can be summerized as
where corresponding to strategy 1,2 and 3.
If the data lie in a low dimensional space, i.e. the covariance matrix is rank . Then the maximum likelihood of . Then
∎
A.2 Proof of Thm. 5.1
Before we prove Thm. 5.1. We need to prove the following lemma first.
Lemma A.2 (optimal perturbation).
Given , the optimal solution of the inner max problem in equation 5.3 is
where is the lagrange multiplier satisfying .
Proof: Consider problem
The Lagrangian function is
Notice that this quadratic objective function is concave when is larger than the largest eigenvalue of . Calculate the partial derivative with respect to and set it to be zero, we have
The last equation comes from the Woodbury matrix inversion Lemma. We can obtain by solving the equation .∎
Now we move to the proof of Thm. 5.1. To derive the expression of excess risk, we decompose it into two parts
| (A.1) | ||||
Since
We denote as
Besides, we have
Then, the excess risk caused by perturbation is
The excess risk caused by changed of distribution is
If we further assume that the data lie in a dimension manifold, by Lemma A.1, we have . and . Hence the excess risk caused by changed of distribution
The excess risk caused by perturbation is
∎
A.3 Proof of Thm. 5.2
Proof: When , the inner maximization problem is
The Lagrangian function is
Notice that this quadratic objective function is concave when is larger than the largest eigenvalue of . Calculate the partial derivative with respect to and set it to be zero, we have
The excess risk is
On the one hand,
| (A.2) | ||||
A.4 Proof of Thm. 5.3 and Thm. 5.4
We first state the general form of Thm. 5.3.
Theorem A.1 (Optimal solution of generative adversarial training).
The optimal solution of the modified problem in Eq. (5.5) is
where
corresponding to strategies 1,2 and 3.
By Lemma A.2, the optimal perturbation is a matrix times . Consider the problem
| (A.4) |
Lemma A.3 (optimal perturbation of ).
Given the optimal solution of the inner max problem of A.4 is
Proof: Consider the problem
The lagrangian function is
Let , Take the gradient with respect to and set it to be zero, we have
Then we have
The last equality is due to the Woodbury matrix inversion Lemma. ∎
To solve the problem A.4, we need to introduce Danskin’s Theorem.
Theorem A.2 (Danskin’s Theorem).
Suppose is a continuous function of two arguments, where is compact. Define . Then, if for every , is convex and
differentiable in , and is continuous:
The subdifferential of is given by
where is the convex hull, and is
If the outer minimization problem is convex and differentiable, we can use any maximizer for the inner maximization problem to find the saddle point. Now we move to the proof of Theorem 5.3. By Lemma A.3, we have
Which is a diagonal matrix times . Let , and . The optimization problem becomes
| (A.5) | ||||
| s.t. |
Obviously, the inner constraint is compact (by Heine-Borel theorem), we only need to prove the convexity of the outer problem to use Danskin’s Theorem. For any and ,
Let , and , consider the third term, we have
By (Daskalakis et al.,, 2018), The hessian matrix is
Therefore, the outer problem of Eq. (A.5) is a convex problem. By Lemma A.3, a maximizer of the inner problem is
Then
Then the first order derivative (by (Daskalakis et al.,, 2018)) is
From the second equation, we directly have . From the first equation, for , we have
For , we have
It equivalents to a second order equation of
Solving this equation, we obtained
Thm. 5.4 is obtained by replacing with .∎
Appendix B Addtional Experiments
B.1 Training Settings
On MNIST, we use LeNet5 for the classifier and 2 layers MLP (with hidden size 256 and 784) for the encoder and decoder of conditional VAE. For standard training of the classifier, we use 30 epochs, batch size 128, learning rate , and weight decay . For the CVAE, we use 20 epochs, learning rate , batch size 64, and latent size 10. For standard adversarial training and, we use for FGSM and PGD. in PGD, we use 40 steps for the inner part. Adversarial training start after 10 epochs standard training. For generative adversarial training, we use in the latent space with FGSM and PGD. We use 40 steps PGD for latent space adversarial training. Adversarial training start after 10 epoches standard training. In the attack part, we use the same as the adversarial training part.
On CIFAR-10, we use ResNet32 for the classifier and 4 layers CNN for the encoder and decoder of conditional VAE. For standard training of the classifier, we use 200 epochs, batch size 128. The learning rate schedule is 0.1 for the first 100 epochs, 0.01 for the following 50 epochs, and 0.001 for the last 50 epochs. The weight decay is . For the CVAE, we use 200 epochs, learning rate , batch size 64, and latent size 128.
For standard adversarial training, we use for FGSM and PGD. in PGD, we use 10 steps for the inner part. For generative adversarial training, we use in the latent space with FGSM and PGD. Since we see that the modeling power of VAE in CIFAR10 is not good enough. For each of the image, the encode variance is very small. When we add a small perturbation to the encode mean value, the output image are blured. Hence we only use a small . In the attack part, we use for norm-based attacks and for generative attack on the test set.
CIFAR-100
The training hyperparameters are the same as that on CIFAR-10. In Table 3, we provide the experiments results on CIFAR-100. We ca get the same conclusion as in the MNIST and CIFAR-10. Standard adversarial training cannot defense generative attack, and vice versa. Notice that the modeling power of condition-VAE is not good enough for CIFAR-100. Therefore, we use a more powerful StyleGAN for ImageNet.
| CIFAR-100 | clean data | FGSM-Attack | PGD-Attack | VAE-FGSM-Attack | VAE-PGD-Attack |
|---|---|---|---|---|---|
| Std training | 67.26% | 9.13% | 7.31% | 1.67% | 0.34% |
| PGD-AT | 50.85% | 31.49% | 27.27% | 6.41% | 4.18% |
| VAE-PGD-AT | 45.21% | 3.45% | 1.21% | 12.45% | 10.75% |
| joint-PGD-AT | 48.34% | 30.81% | 25.55% | 12.01% | 10.12% |
ImageNet
We adopt the setting of dual manifold adversarial training (DMAT) (Lin et al.,, 2020) in our experiments. DMAT is an algorithm using both on-manifold and off-manifold adversarial examples to train a neural network. The off-manifold adversarial examples are PGD adversarial examples. The on-manifold adversarial examples are crafted by a StyleGAN (Karras et al.,, 2019) trained on ImageNet. The difference between the algorithms we used and DMAT is the generative model, CVAE, and StyleGAN. StyleGAN is better on ImageNet because of the modeling power. In Table 2, we show the results of DMAT on ImageNet. We can see that, on-manifold adversarial training (GPGD-AT) is not able to defend PGD-Attack, with 0.03% robust test accuracy, and vice versa. Joint-AT can achieve comparable robust test accuracy to the single-trained models. Therefore, the results of DMAT support our analysis. Conversely, our theory gives an analysis of the performance of DMAT.
B.2 Eigenspace Adversarial Training




In Figure 5 (a) and (b), we give the experimental results of on-manifold adversarial training, i.e. adversarial training restricted in the subspace spanned by the top eigenvectors. The red lines are the standard test accuracies and the blue lines are the robust test accuracies against PGD-10 attacks. (c) and (d) are the results of off-manifold adversarial training.
Bridging the generalization-robustness trade-off
The range of the x-axis is from 0 to 3072. Notice that if the number of subspace dimension is , no perturbation is allowed. It equivalents to the standard training case. If the number of subspace dimension is , the perturbation can be chosen in the whole norm ball . It equivalents to the regular adversarial training case. Therefore, subspace adversarial training is a middle situation between standard training and adversarial training.
On-manifold adversarial training improves generalization
In Figure 5 (a), the best test accuracy is 96.17%, achieved in subspace adversarial training restricted to the top 100 eigenvectors. In Figure 5 (c), we can see that off-manifold adversarial training cannot obtain a better test accuracy than standard training. It is because on-manifold adversarial examples will cause a small distributional shift, the negative effect of distributional shift is smaller than the positive effect of data augmentation. But for off-manifold adversarial examples, the negative effect of off-manifold adversarial examples is larger.
Eigenspace adversarial training cannot improves robustness
In Figure 5, we show the experiments of Off-manifold adversarial training. We can see that eigenspace adversarial training cannot improves robustness.




Eigenspace adversarial training on CIFAR-100
As it is shown in Figure 6, on-manifold adversarial training (top 100 dimensions) get the same test accuracy as standard training. Off-manifold training (bottom 3000 dimensions) get larger robust accuracy (42.89%) than standard adversarial training (24.60%). The results are similar to those in CIFAR-10.
B.3 Ablation study of adversarial distribution shift
We plot the adversarial distribution shift of all the classes in this section, see Figure 7 and 8. For all the 10 classes, We can see that adversarial training will amplify the small eigenvalues and generative adversarial training will amplify the large eigenvalues.
Class 0




Class 1




Class 2




Class 3
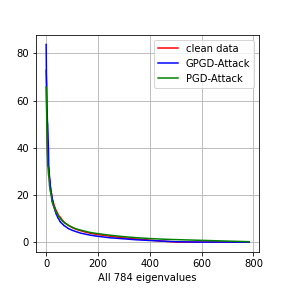
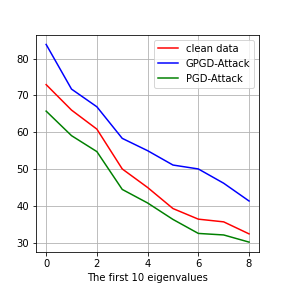


Class 4



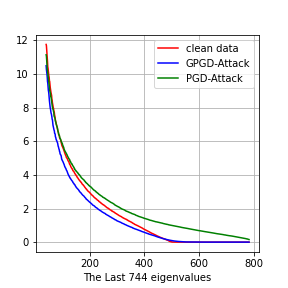
Class 5




Class 6




Class 7



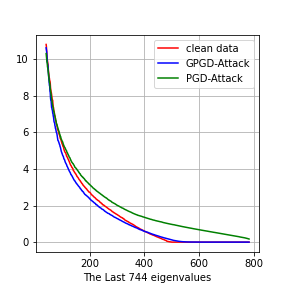
Class 8

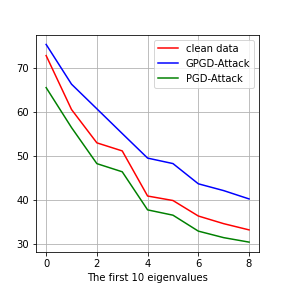


Class 9



