Uncertainty-Aware (UNA) Bases for Deep Bayesian Regression using Multi-Headed Auxiliary Networks
Abstract
Neural Linear Models (NLM) are deep Bayesian models that produce predictive uncertainties by learning features from the data and then performing Bayesian linear regression over these features. Despite their popularity, few works have focused on methodically evaluating the predictive uncertainties of these models. In this work, we demonstrate that traditional training procedures for NLMs drastically underestimate uncertainty on out-of-distribution inputs, and that they therefore cannot be naively deployed in risk-sensitive applications. We identify the underlying reasons for this behavior and propose a novel training framework that captures useful predictive uncertainties for downstream tasks.
Keywords: Uncertainty Quantification, Deep Bayesian Models, Approximate Inference
1 Introduction
In high-stakes, safety-critical applications of machine learning, reliable measurements of model predictive uncertainty matter just as much as predictive accuracy. Traditionally, applications requiring predictive uncertainty relied on Gaussian Processes (GPs) (Rasmussen and Williams, 2006) for two reasons: (1) with an appropriately chosen kernel, they produce high predictive uncertainty on out-of-distribution inputs and low uncertainty on within-distribution inputs, and (2) their predictive uncertainty can be easily and meaningfully tuned via a small set of hyper-parameters of the kernel function (for example, the smoothness of GPs with an RBF kernel can be tuned via the length-scale and amplitude), allowing domain experts to encode task-relevant knowledge. However, the computational complexity of GP inference has motivated research on fast and scalable alternatives – specifically, deep Bayesian models with approximate inference (e.g. Springenberg et al. (2016); Snoek et al. (2015)).
Bayesian Neural Networks (BNNs) (Neal, 2012b), for example, provide a way of explicitly capturing model uncertainty – uncertainty arising from having insufficient observations to determine the “true” predictor – by placing a prior distribution over network weights. Just like GP inference (rather than point estimates), Bayesian inference for BNNs produces a distribution over possible predictions, whose variance can be used as an indicator of model uncertainty during test time. While promising, these alternatives unfortunately do not retain the two desired properties of GPs. That is, approximate inference methods yield models that are overly certain on test points coming from data-poor regions of the input space (Yao et al., 2019; Foong et al., 2019b), and require an unintuitive hyper-parameter tuning process in order to achieve task-appropriate behavior (Sun et al., 2019). Furthermore, unlike in the case of GP models, it is much more difficult to encode domain knowledge or functional knowledge (prior knowledge about the true predictor) in deep Bayesian models (Sun et al., 2019), and hence the predictive uncertainties of these models are often difficult to tailor to specific downstream tasks.
For this reason, the Neural Linear Model (NLM), a model with BNN-like properties but highly tractable inference, is gaining popularity (Snoek et al., 2015; Riquelme et al., 2018; Pinsler et al., 2019; Zhou and Precioso, 2019). An NLM places a prior only on the last layer of network weights and learns point estimates for the remaining weights; inference for the last weight-layer can then be performed analytically. One can interpret the deterministic network layers as a finite-dimensional feature-space embedding of the data, and the last layer of NLMs as performing Bayesian linear regression on the feature basis, that is, the basis defined by the feature embedding of the data.
Although NLMs are easy to implement and scale to large data-sets, in order to safely deploy them in risk-averse applications, we nonetheless need to verify that these models retain desirable properties of GPs. But despite their increasing popularity, little work has been done to methodically evaluate the quality of uncertainty estimates produced by NLMs. In the first paper to do so (Ober and Rasmussen, 2019), the authors show that NLMs can achieve high log-likelihood on test data sampled from training-data-scarce regions; they treat this as evidence that NLM uncertainties can distinguish data-scarce and data-rich regions. However, as noted by Yao et al. (2019), log-likelihood measures only how well predictive uncertainty aligns with the variation in the observed data and not how well these uncertainties predict data scarcity. In fact, in this work, we will show that the predictive uncertainties of NLMs resulting from traditional inference are overly confident on training-data-poor regions.
In this paper, we describe a novel NLM training framework, UNcertainty-Aware (UNA) training, for producing predictive uncertainties that can distinguish data-rich from data-poor regions. UNA training retains the speed and scalability of traditional NLM inference while explicitly encouraging desirable GP-like properties in the learned model. Our contributions are both theoretical and methodological:
1. We demonstrate that all three traditional training objectives for NLMs – MLE, MAP, and maximum marginal likelihood – all yield predictive uncertainty that cannot distinguish data-scarce from data-rich regions. Furthermore, we identify the precise cause of the problem – traditional NLM training procedures learn feature bases incapable of expressing uncertainty in data-scarce regions (also known as “in-between" uncertainties (Foong et al., 2019b)).
2. We propose a new framework, UNA training, for learning uncertainty-aware and task-aware feature bases for NLMs. Our framework trains a set of auxiliary regressors on a shared feature basis. By specifying the properties needed of these auxiliary regressors for good downstream performance into a training objective, we explicitly encourage the learned feature basis to satisfy task-specific desiderata. Our framework is both scalable and easy to implement.
3. We propose an instantiation of this framework, LUNA, for tasks requiring models that express in-between uncertainty. That is, LUNA is designed for any task that requires models to be more uncertain where there is little data relative to where there is data. We do this by training an auxiliary set of linear predictors on top of the NLM’s feature basis to extrapolate differently outside the data-rich regions (thus producing larger predictive variance in these regions).
4. We empirically demonstrate the utility of LUNA training on a wide range of downstream tasks. (a) On a number of synthetic and real datasets, models trained with LUNA reliably identify data-scarce regions where baselines, including NLM with traditional training, struggle; (b) on transfer learning tasks, we are able to learn bases that outperform bases from traditional NLM training; (c) on Bayesian Optimization benchmarks, models learned with LUNA are comparable to baselines.
2 Related Works
Gaussian Processes.
While expressive and intuitive to tune, inference for Gaussian Processes (GPs) is computationally challenging for large datasets, scaling cubically with respect to the total number of observations. A large body of the literature about increasing the computational efficiency of GP inference focuses on approximate methods like inducing points (e.g. Snelson and Ghahramani (2006)), random feature expansions (e.g. Wilson et al. (2016)) or stochastic variational optimization (e.g. Cheng and Boots (2017)). However, it is not known how well these methods approximate the performance of GP models with exact inference. On the other hand, the recent breakthrough in fast exact GP inference leverages multi-GPU parallelization and may be inappropriate when computational resources are limited (Wang et al., 2019). In this work, we focus on training NLMs with modest-sized neural network architectures that nonetheless retain desired properties of GPs. Lastly, because GPs are non-parametric, it is non-trivial for them to incorporate recent advances in deep learning architectures (like convolutional, recurrent, or graph structures) without significant computational overhead, requiring novel inference methods (e.g. van der Wilk et al. (2017); Mattos and Barreto (2019); Walker and Glocker (2019)). In contrast, in this work we focus on NLMs, which can trivially be adapted to incorporate new innovations in neural network architectures.
Bayesian Neural Networks.
Early work on Bayesian Neural Networks (BNN) inference focuses on Hamiltonian Monte Carlo (HMC) (Neal, 2012a) and Laplace approximations of the posterior (MacKay, 1992; Buntine and Weigend, 1991). While HMC remains the “gold standard” for BNN inference, it does not scale well to large architectures or datasets; classical Laplace approximation, like Linearised Laplace (Foong et al., 2019b), has similar difficulties scaling to modern architectures with large parameter sets. Although variational inference methods can be easily applied to BNN models with larger architectures, a number of these methods, like mean-field variational inference (VI) (Anderson and Peterson, 1987; Hinton and Van Camp, 1993; Blundell et al., 2015) and Monte Carlo Dropout (MCD) (Gal and Ghahramani, 2016) (which can be recast as a form of approximate variational inference with a spike and slab variational distribution), have recently been shown to underestimate predictive uncertainty, especially in data-scarce regions (Foong et al., 2019b; Yao et al., 2019; Foong et al., 2019a).
Bayesian Models with Deterministic Neural Network Feature Extractors.
In order to bypass the difficulties of Bayesian inference for complex models, a number of works divide the models into two parts – a neural network, trained deterministically, and a simple Bayesian model, for which inference can be performed exactly and/or scalably. These works can broadly be divided into two categories: ones for which the simple Bayesian model is a GP, and ones for which it is a Bayesian linear (or logistic) regression. Manifold Gaussian Processes (MGPs), for example, jointly train a GP on top of a neural network feature extractor (Calandra et al., 2016). They are made scalable by Liu et al. (2020), who use a Random Fourier Feature (RFF) expansion GP approximation and isometry-enforcing regularization on the neural network feature map (SNGP). However, since high-quality inference requires a large number of features in the RFF expansion (Alber et al., 2017), inference for these models is still computationally expensive. In contrast to MGPs, the Neural Linear Model (NLM) (Snoek et al., 2015) jointly trains a Bayesian linear regression (instead of a GP) on top of a deterministic neural network feature extractor. Inference for NLMs therefore does not scale cubically with the number of observations (as in GP inference), and does not scale cubically with the number of features in the RFF expansion (as in SNGP); instead, it scales cubically with the number of features extracted by the deterministic neural network. So long as the number of features extracted by the deterministic neural network remains relatively small NLMs are cheap to train. While NLMs have been successfully applied in a number of applications requiring predictive uncertainty like Bayesian Optimization (BayesOpt) (Snoek et al., 2015), in this paper, we show that traditional inference for NLMs will, in most cases, underestimate uncertainty in data-scarce regions. Specifically, we show that the (relatively small number of) features extracted by the neural network hinder the Bayesian model from capturing in-between uncertainty. We then propose a novel training method that alleviates this issue.
Ensemble Methods.
Alternatively, one can avoid Bayesian inference all together by ensembling (non-Bayesian) neural networks in order to estimate predictive uncertainty using the variance of predictions in the ensemble. For the variance of the predictions in the ensemble to be higher in data-sparse regions of the input space, the ensemble members must be diverse. Some works rely on bootstrapping to achieve this, or on multiple random restarts and adversarial training in ensemble building (e.g. Lakshminarayanan et al. (2017)). Others, like the work of Pearce et al. (2018), relate ensembling to approximate Bayesian inference – i.e. randomized MAP sampling (Lu and Van Roy, 2017; Garipov et al., 2018) – with the introduction of noise in the regularization term of each network (which in turn encourages for functional diversity). Though our focus in this paper is on Bayesian models, we nonetheless compare our methods to ensemble baselines.
3 Background
Let the input space be -dimensional, and suppose we have a dataset of observations, where and . A Neural Linear Model (NLM) consists of: (1) a feature map , parameterized by a neural network with weights , and (2) a Bayesian linear regression model fitted on the data embedded in the feature space:
where the design matrix is called the feature basis and is the feature vector augmented with a 1 (for a bias term). Thus, given the learned feature map, the NLM’s posterior, marginal likelihood, and posterior predictive distributions can all be computed analytically. Intuitively, an NLM represents a neural network with a Gaussian prior over the last-layer weights , and with deterministic weights for the remaining layers.
Inference for NLMs consists of two steps:
-
Step I: Learn (with some objective, described below).
-
Step II: Given , infer analytically.
In Step I, there are three accepted methods of learning : maximum likelihood (MLE), maximum a posteriori (MAP) and Marginal-Likelihood, of which MAP is the most common. In MAP training (Snoek et al., 2015), one maximizes the likelihood of the observed data with respect to and with respect to a point estimate, , of the last layer’s weights (i.e. we train the entire network deterministically, with an -regularization term on the weights of the entire network):
| (1) |
where are weights of the full network. In Step II, we discard and use the learned in Step I to infer analytically. MLE training is the same as MAP training, but with . Lastly, in Marginal-Likelihood training, Step I consists of maximizing the likelihood of the observed data, after having marginalized out the weights :
| (2) | ||||
In this paper, we show that all three inference methods for learning the feature basis (determined by ) in Step I produce models that are unable to distinguish between data-poor and data-rich regions (i.e. these models fail to capture in-between uncertainty). In Section 5 we then propose a novel framework for training NLMs that learns models capable of expressing in-between uncertainty.
4 Analysis of the Expressiveness of Neural Linear Model Uncertainties
In this section, we show that conventional NLM training objectives result in models with predictive uncertainties that fail to distinguish data-rich from data-poor regions. Moreover, we identify the precise cause of the problem: none of the methods encourage diversity in the class of functions that are likely under the prior predictive; in fact, some training objectives explicitly discourage diversity. As a result, the posterior predictive of the learned model will be distributed over a limited function class. The limited functional variation across the input domain under the posterior predictive causes underestimation of in-between uncertainty.
Failure of MAP Training.
When the regularization term in the MAP objective (Equation 1) is non-zero, the feature map is explicitly discouraged from producing bases spanning functions that extrapolate differently away from the observed data. This is because such diversity comes at the cost of larger values in and does not impact the log-likelihood of the observed data.
In Figure 1(a), we show samples from the prior predictive for two NLMs – with a regularized and unregularized feature map, , respectively. With the regularization (), the feature basis spans a limited set of functions – the prior predictive samples show no variation in the data-scarce region. So what kind of posterior predictives does this prior predictive induce? Figure 1(b) shows that when the prior predictive is inexpressive, the posterior predictive shows little in-between uncertainty. In Figure 6 of Appendix D.1, we reproduce the effect of regularization on NLM prior predictives for different values of and over random restarts, and show that (a) regularization consistently leads to inexpressive prior predictives, and (b) that as a result, the posterior predictives are nearly as certain in data-poor regions as they are in data-rich regions.
So what happens when we train the NLM without regularization ()? In this case, the NLM is not explicitly discouraged from expressing diverse functions. As such, for for the particular random restart in Figure 1, the basis for spans a diverse class of functions under the prior distribution; that is, linear combinations of the features under show variation in both the data-rich and data-scarce regions. Correspondingly, Figure 1(b) shows that the posterior predictive is expressive. Based solely on these results, one might suppose that traditional training for NLMs without regularization (i.e. MLE training) does not suffer from the aforementioned issues. However, as we discuss next, MLE training cannot consistently learn models that capture in-between uncertainty.


Failure of MLE Training.
While MAP training explicitly discourages functional diversity under the prior predictive, MLE training does not; however, it also does nothing to encourage it, thereby leaving diversity up to chance. As a result, across random restarts, MLE training () rarely learns models able to distinguish between data-poor and data-rich regions (see Figure 6 of Appendix D.1). As we discuss below, the failure of MLE training to encourage functional diversity actually affects all three training objectives – MLE, MAP, and marginal likelihood training – as well as hyper-parameter selection.
Failure of Marginal Likelihood Training.
When , just like MAP training, Marginal Likelihood training (Equation 2) discourages learning models with expressive prior predictive. Specifically, the feature bases learned by optimizing do not span diverse functions across random restarts; hence the corresponding posterior predictive distributions are inexpressive and are unable to capture in-between uncertainty (Appendix D.1 Figure 10). When is very close to , just like MLE training, the learned feature bases are rarely expressive across random restart (see Appendix D.1 Figure 9).
Most interestingly, however, when is exactly , we show that Marginal Likelihood training suffers from a new failure: the feature map blows up for ReLU networks. Intuitively, increasing the magnitude of by a scalar multiple allows us to decrease the weights of the last layer by the same multiple with no loss to the likelihood, and thus we can trivially increase by scaling the feature basis . We formalize this intuition in the proposition below.
Proposition 1
Suppose ReLU activations and that is invertible. For fixed , and any , we define as but with the last layer of weights scaled by , we also define . For a sufficiently large and any , we have that , where and .
The proof can be found in Appendix A.3. Proposition 1 tells us that that we can continue to increase by scaling any solution by larger and larger ’s – that is, marginal log-likelihood training of is incentivized to trivially increase the magnitude of the feature basis rather than meaningfully change . This blow-up of the learned features necessitates adding a regularization term to the marginal log-likelihood objective, which then limits the expressiveness of the feature bases (and hence the expressiveness of the posterior predictive distribution).
General Failure of Log-Likelihood Based Training.
As observed by Yao et al. (2019), log-likelihood does not measure the quality of a model’s uncertainty in data-poor regions. As such, learning a basis by maximizing the likelihood of the observed data (whether via the MLE, MAP, or marginal likelihood objectives) does not encourage learning a basis spanning a diverse class of functions, and thus does not ensure an expressive prior (and hence posterior) predictive. For example, in Figure 1(b), the test log-likelihood of both models are nearly equivalent, yet one is uncertain in the gap where the other is nearly as confident as on the observed data.
The fact that log-likelihood cannot be used to evaluate the uncertainty of the model in data-poor region additionally presents problems for all three training objectives when selecting hyper-parameters: e.g. (the regularization strength) and (the number of features in the feature map ), or the architecture of (e.g. the depth and width of the neural network). For example, is typically chosen via grid-search or BayesOpt to maximize the log-likelihood on the validation set (sampled from the same distribution as the training data). However, in Figure 1(b), the test log-likelihood of the NLM with the regularized feature map happens to be a hair higher. Thus, by maximizing validation log-likelihood, we may choose a model with a prior predictive that is inexpressive over the data-scarce region and hence unable to capture in-between uncertainty in the posterior predictive.
Similarly, we find that if we use validation log-likelihood to select the architecture of , we are likely to choose models that are unnecessarily large. In Figures 7 and 8 of Appendix D.1, we examine the effect of the depth of the network, as well as the number of features , on the expressiveness of the prior predictives (and hence the posterior predictives) of NLMs. In particular, we show that for shallow and narrow models, even when is unregularized, random restarts consistently result in models with inexpressive prior predictives. On the other hand, for models with more capacity, some random restarts do yield expressive priors predictives. Thus, traditional NLM training and log-likelihood based hyper-parameter selection hinder us from (1) training modest-sized models (i.e. with a small ) that can express in-between uncertainty, and (2) from selecting amongst models with a larger capacity that, by chance, express in-between uncertainty.
This general failure of log-likelihood based objectives motivates our proposed training framework (discussed next), which avoids the failure modes of the three traditional NLM training objectives by explicitly encouraging for functional diversity under the prior predictive. This allows us to learn modest-sized models with expressive posterior predictive distributions that can distinguish between data-poor and data-rich regions.
5 Training Framework: Uncertainty-Aware Bases via Auxiliary Networks

We propose a general training framework, UNcertainty Aware Training (UNA), to learn NLMs that satisfy task-specific desiderata (e.g. to learn an NLM that captures in-between uncertainty). Since it is unintuitive to directly train the feature-basis of an NLM to satisfy task-specific desiderata (i.e. to specify desiderata in “feature-space”), we instead choose to specify our desiderata in “function-space” (i.e. over functions that this basis spans). We do this by training a set of auxiliary regressors on a shared feature basis to satisfy the properties needed for good downstream performance. Like traditional NLM training, UNA training consists of two steps:
Step I: Feature Training with Diverse and Task-Appropriate Auxiliary Regressors. We train auxiliary linear regressors, , on a shared feature basis (see illustration in Figure 2). In this way, we can indirectly specify our desiderata on the feature-basis via an appropriately chosen objective function applied to the regressors. By training the auxiliary regressors to be diverse, for example, the shared feature basis will support a prior predictive distribution over a diverse class of functions. Furthermore, one can impose constraints on the auxiliary regressors expressing domain or functional knowledge.
Step II: Bayesian Linear Regression on Features. After optimizing the feature map, we discard the auxiliary regressors and perform Bayesian linear regression on the expressive feature basis learned in Step I. That is, we infer the posterior . While Step I of UNA is novel, Step II directly follows from traditional NLM training.
Since this framework is quite general, we now propose a concrete instantiation, LUNA, designed to train NLMs that capture in-between uncertainties. Our instantiation is both scalable and easy to implement. In Section 6, we then show that our instantiation produces expressive posterior predictive distributions that capture in-between uncertainties.
5.1 Learned Uncertainty-Aware (LUNA) Bases
Using the insights from Section 4, we propose an instantiation of UNA. In this instantiation, we explicitly encourage the feature basis to span diverse functions under the prior (i.e. we do not leave diversity up to chance, as with MLE training). To do this, we design a training objective for Step I that maximizes the average log-likelihood of the auxiliary regressors on the training data, measured by , while encouraging for functional diversity amongst them, measured by (defined further below):
| (3) |
where , parameterizes the shared design matrix and are the weights of the auxiliary regressor . The constant controls for the degree to which we prioritize diversity. After optimizing our feature map via:
we discard the auxiliary regressors and perform Bayesian linear regression on the diversified feature basis, the LUNA basis. That is, we analytically infer the posterior over the Bayesian last layer of weights in the NLM (as in Step II of traditional NLM training). In summary, LUNA training results in a basis that supports a diverse set of predictions by varying .
: Fitting the Auxiliary Regressors.
We learn the regressors jointly with , by maximizing the average training log-likelihood of the regressors on the training data, with penalty on as well as on the weights of each regressor:
: Enforcing diversity.
We enforce diversity in the auxiliary regressors as a proxy for the diversity of the functions spanned by the feature basis. We adapt the Local Independence Training (LIT) objective proposed by Ross et al. (2018) to encourage our regressors to extrapolate differently away from the training data,
where CosSim is cosine similarity. Intuitively, iterates over pairs of auxiliary regressors , encouraging the angle between their gradients with respect to the inputs to be large. In doing so, this penalty encourages that different regressors extrapolate differently away from the data. We avoid expensive gradient computations using a finite difference approximation – see Appendix B for a detailed explanation of .
Model Selection.
Since in Section 4, we show that log-likelihood cannot be used to distinguish between models that do and do not capture in-between uncertainty, we cannot use log-likelihood (alone) for hyper-parameter selection. As such, we incorporate the diversity penalty into the model selection process as follows. After training, we scale the diversity penalty by , which is the number of combinations of auxiliary regressors, so that the diversity penalty is comparable across choices of . Then, across all hyper-parameter choices and random restarts, we keep only models that score in the top on validation log-likelihood, out of which we select the hyper-parameters of models that exhibit the most diversity (i.e. the lowest ). In this way, we select models that both have good fit on the observed data, and capture in-between uncertainty.
Demonstration on 1-D synthetic data.
LUNA’s auxiliary regressors and resultant posterior predictive are visualized in Figure 3, on the “Cubic Gap Example” (described in Appendix C.3). The figure shows that the regressors both fit the data and extrapolate differently, and therefore the resultant model expresses in-between uncertainty. In contrast to MLE training, LUNA consistently captures in-between uncertainty across a varying number of auxiliary regressors and across random restarts (see Appendix D.1 Figure 11). That is, unlike traditional NLM training, which struggles to capture in-between uncertainty (especially for smaller architectures), LUNA training better utilizes the available capacity of the NLM to fit the data and express uncertainty.
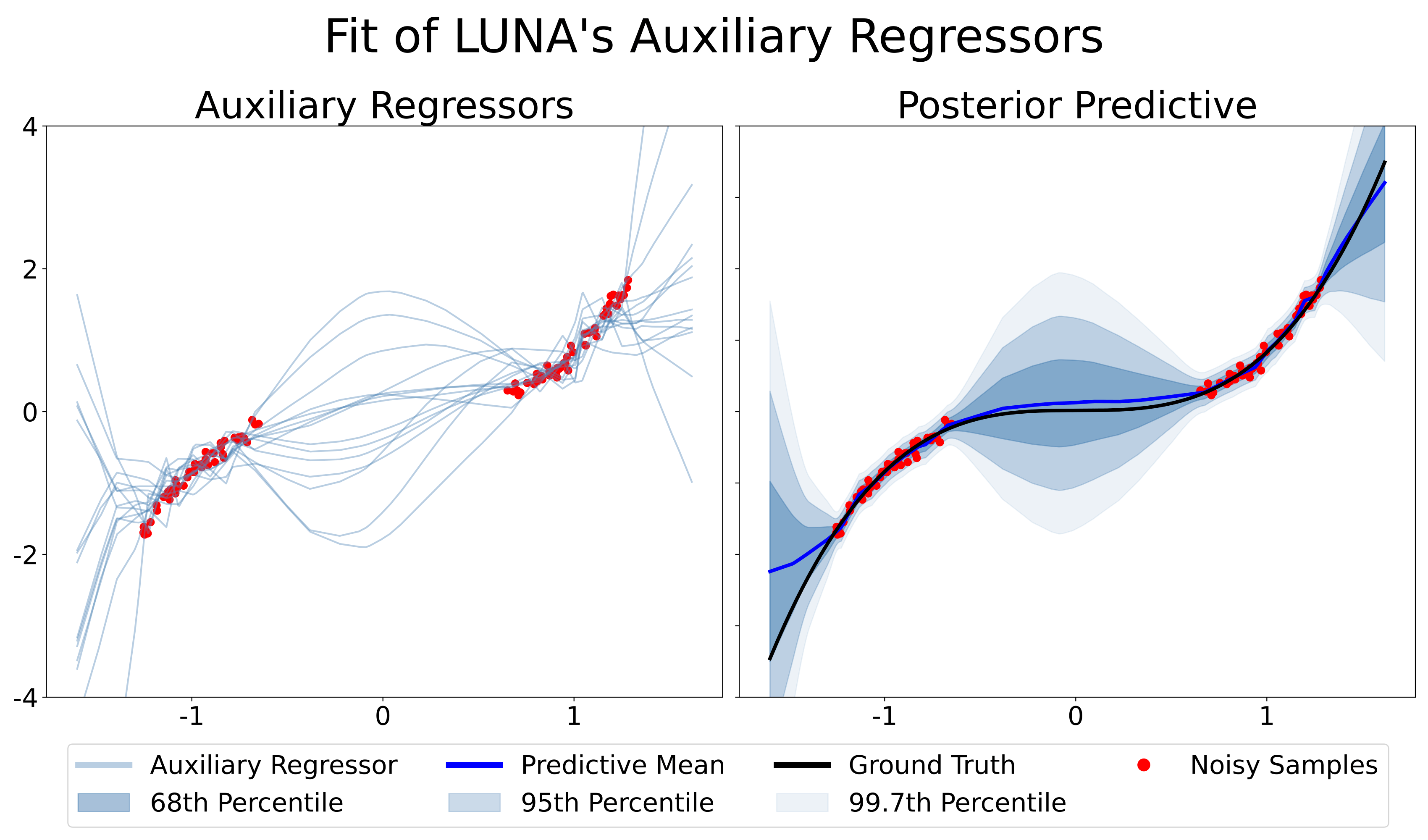
6 Experiments
We compare LUNA to traditional NLM training as well as to a variety of baselines on 3 synthetic and on 6 UCI “gap” datasets (Foong et al., 2019b). We show that LUNA bases can distinguish data-scarce regions from data-rich regions where baseline methods struggle. We then show that as a result, LUNA offers competitive performance relative to baselines on a variety of downstream tasks. On the transfer learning task, we show that with fewer features, LUNA bases achieve lower generalization error and retain their utility under covariate shift. On Bayesian Optimization tasks, we show that LUNA bases are comparable to baselines.
Baselines.
In our experiments, we consider several baselines. First, we compare against NLMs with traditional inference (NLM). Second, when it is not too computationally taxing, we compare LUNA bases against Gaussian Processes (GP) and BNNs with HMC inference (HMC). We regard these as our “gold standard”, since, with appropriately chosen hyper-parameters, both explain the data well and capture in-between uncertainty. When using small architectures, we also compare against BNNs with Linearised Laplace (Lin Lap) inference (Foong et al., 2019b) (which scales poorly to large architectures). Third, we compare against a recently proposed method that, like an NLM, consists of a Bayesian regressor trained on-top of a deterministic feature extractor: Spectral-normalized Neural Gaussian Processes using a GP final layer (SNGP) as well as using a Random Fourier Features regression final layer (RFF SNGP) (Liu et al., 2020). Lastly, we compare against other existing models and inference for capturing uncertainty: MC Dropout (MCD) (Gal and Ghahramani, 2016), BNN with mean-field variational inference (BBVI), Vanilla Ensembles (ENS VAN), Anchored Ensembles (ENS ANC) (Pearce et al., 2020), and Bootstrap Ensembles (ENS BOOT). Experimental setup detailed in Appendix C.
Evaluation Metrics.
In addition to using downstream tasks to compare the quality of LUNA’s predictions and predictive uncertainty against the aforementioned baselines, we also use the following metrics: Average Log-Likelihood (LL) and Root Mean Square Error (RMSE) to assess model fit, and gap to not-gap Epistemic Uncertainty Relative Change (EURC), to assess whether a model’s predictive uncertainty is higher where there is no data (relative to where there is data). All metrics are described in Appendix C.2.
6.1 LUNA bases captures in-between uncertainty on synthetic and real data
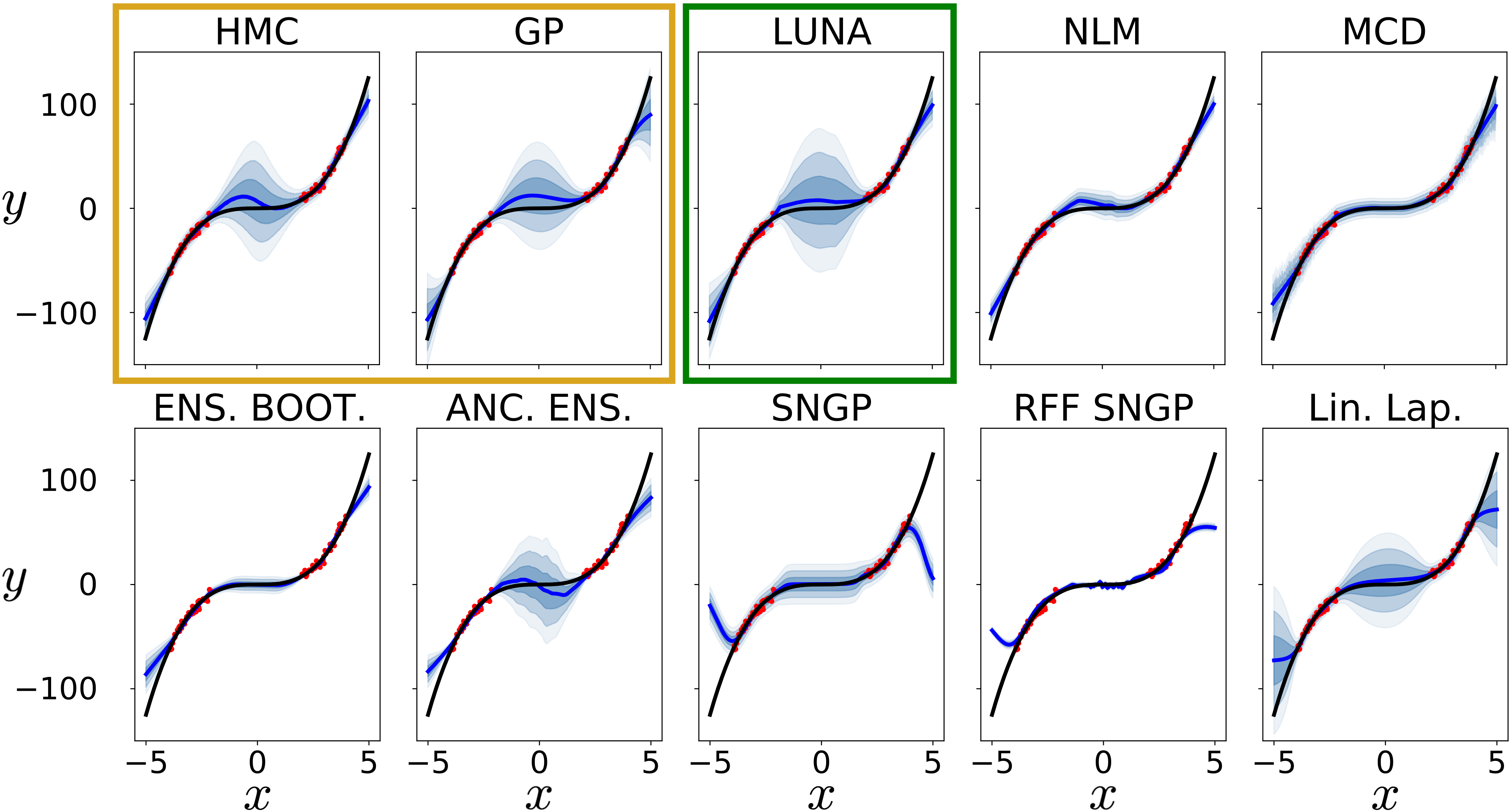

LUNA training captures in-between uncertainty on toy data.
We construct a synthetic 1-D “Cubic Gap” regression data set, sampled from a cubic function with a gap in the training input (detailed in Appendix C.3). Figure 4 shows that LUNA bases, along with Anchored Ensembles and Linearised Laplace, matches the performance of the “gold-standards” – BNN with HMC and GP – while other baselines either drastically underestimate in-between uncertainty or express uncertainties that do not scale with respect to the distance to distance to the training data (e.g. RFF SNGP). While Linearised Laplace performs well on small toy datasets, unlike other baselines, it does not scale to larger networks, and has difficulties with various activation functions (Foong et al., 2019b). As such, we do not include it in the remaining experiments.
Gap to Not-Gap Avg. Epistemic Uncertainty Relative Change Yacht - FROUDE Concrete - CEMENT Concrete - SUPER Boston - RM Boston - LSTAT Boston - PTRATIO ENS BOOT 0.00% 0.00% 40.85% 7.60% 87.64% 15.79% -9.22% 9.57% 6.40% 10.97% -1.33% 8.13% ENS VAN 26.68% 11.75% 120.70% 26.68% 163.28% 26.81% -5.61% 11.41% 18.84% 11.47% 39.83% 16.37% ENS ANC 8.66% 23.98% 93.03% 25.66% 149.31% 31.30% -8.94% 11.15% 10.03% 10.72% 31.12% 22.25% NLM 24.08% 17.23% -5.92% 3.63% 4.50% 5.89% -7.47% 3.57% -5.79% 7.53% -3.81% 6.32% GP 71.73% 19.75% 75.59% 15.12% 119.48% 19.55% -16.34% 6.76% -2.40% 9.20% 17.74% 13.17% MCD -52.43% 10.17% 6.86% 5.92% 11.95% 7.30% -16.09% 9.55% -11.76% 9.48% -5.22% 6.88% SNGP 38.33% 63.97% -6.05% 4.39% -2.93% 4.23% -10.61% 3.88% -6.43% 5.46% -6.92% 5.94% BBVI -10.08% 6.15% -18.15% 5.58% 10.85% 12.68% -13.74% 5.15% -31.91% 3.27% 20.30% 8.54% LUNA 59.17% 36.87% 55.93% 28.83% 416.02% 197.69% -11.09% 5.20% 29.09% 18.15% 60.60% 45.32%
Root Mean Square Error (Test) Yacht - FROUDE Concrete - CEMENT Concrete - SUPER Boston - RM Boston - LSTAT Boston - PTRATIO Not Gap Gap Not Gap Gap Not Gap Gap Not Gap Gap Not Gap Gap Not Gap Gap ENS BOOT 1.21 0.47 0.51 0.08 5.27 0.97 6.04 0.10 4.70 0.93 7.55 0.26 2.81 0.86 3.07 0.10 3.28 1.04 3.47 0.14 3.46 0.87 3.20 0.08 ENS VAE 0.84 0.39 0.40 0.04 5.06 0.90 6.10 0.18 4.44 0.78 7.49 0.18 2.78 0.90 3.04 0.08 3.12 1.12 3.20 0.13 3.41 0.77 3.27 0.08 ENS ANC 0.91 0.33 0.86 0.07 5.54 0.87 6.36 0.22 5.33 0.69 7.77 0.46 2.90 0.74 3.09 0.12 3.30 1.17 3.33 0.15 3.40 0.87 3.16 0.07 NLM 0.65 0.26 0.72 0.14 5.31 0.97 7.01 0.49 4.60 0.94 8.47 0.36 3.02 0.87 3.21 0.11 3.69 1.51 3.93 0.35 3.70 0.67 3.68 0.12 GP 1.89 0.54 1.37 0.21 6.01 0.89 6.21 0.07 5.91 0.78 8.01 0.16 3.10 0.91 3.27 0.19 3.52 1.16 3.32 0.15 3.45 0.78 3.28 0.04 MCD 0.89 0.31 6.78 0.37 5.09 1.07 7.27 0.40 4.80 0.91 7.93 0.34 3.45 1.15 3.17 0.10 3.40 1.09 4.08 0.36 3.69 1.02 3.27 0.18 SNGP 1.04 0.68 1.31 1.11 5.15 0.74 5.93 0.17 5.00 0.69 7.33 0.32 3.07 0.56 3.41 0.18 3.79 1.02 4.18 0.26 3.75 1.00 3.77 0.21 BBVI 17.27 5.87 30.05 2.99 5.68 0.80 6.36 0.07 24.17 7.56 54.56 4.58 3.47 0.87 3.53 0.05 3.76 1.22 3.82 0.12 9.16 3.29 30.52 2.84 LUNA 1.16 0.42 0.57 0.10 5.50 1.32 7.12 0.36 4.92 0.66 10.13 1.05 3.34 1.09 3.17 0.38 3.57 1.44 3.92 0.26 3.58 1.09 3.34 0.14
Avg. Log-Likelihood (Test) Yacht - FROUDE Concrete - CEMENT Concrete - SUPER Boston - RM Boston - LSTAT Boston - PTRATIO Not Gap Gap Not Gap Gap Not Gap Gap Not Gap Gap Not Gap Gap Not Gap Gap ENS BOOT N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A ENS VAN N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A ENS ANC N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A N/A NLM -1.29 0.90 -1.45 0.52 -3.15 0.26 -3.71 0.19 -2.97 0.25 -4.29 0.16 -2.56 0.30 -2.58 0.03 -2.82 0.70 -2.79 0.12 -2.73 0.25 -2.72 0.04 GP -1.76 0.30 -1.56 0.04 -3.18 0.14 -3.17 0.01 -3.19 0.19 -3.40 0.01 -2.53 0.12 -2.60 0.02 -2.62 0.18 -2.61 0.02 -2.63 0.19 -2.63 0.01 MCD -1.13 0.27 -32.49 12.07 -2.94 0.18 -3.54 0.06 -2.96 0.18 -3.71 0.06 -2.59 0.22 -2.52 0.02 -2.59 0.20 -2.69 0.11 -2.59 0.16 -2.58 0.05 SNGP -4.35 5.66 -8.14 13.55 -3.12 0.21 -3.35 0.05 -3.07 0.20 -3.87 0.14 -2.56 0.17 -2.65 0.06 -2.81 0.39 -2.90 0.10 -2.81 0.39 -2.77 0.07 BBVI -68.40 31.42 -207.53 34.99 -3.15 0.17 -3.30 0.02 -6.74 2.24 -27.14 3.45 -2.63 0.09 -2.64 0.01 -2.70 0.21 -2.63 0.02 -3.49 0.35 -8.14 1.22 LUNA -2.82 2.09 -0.96 0.16 -3.14 0.30 -3.55 0.13 -3.00 0.13 -4.28 0.36 -2.56 0.15 -2.54 0.03 -2.72 0.44 -2.75 0.07 -2.69 0.31 -2.65 0.06
Bayesian Optimization Function Steps LUNA GP NLM MCD ENS ANC ENS BOOT ENS VAN SNGP BBVI branin 50 0.01 0.00 0.00 0.00 0.01 0.01 0.01 0.01 0.01 0.01 0.06 0.12 0.01 0.02 0.00 0.00 0.01 0.00 hartmann6 200 0.32 0.02 0.01 0.00 0.57 0.44 0.76 0.25 0.23 0.21 0.65 0.28 0.68 0.28 0.22 0.00 0.71 0.23 svm 30 1.19 0.12 1.20 0.00 1.20 0.06 1.10 0.00 1.18 0.12 1.11 0.18 1.13 0.05 1.19 0.14 1.30 0.35 logistic 30 7.64 0.06 7.40 0.00 7.64 0.10 7.91 0.29 7.66 0.09 7.64 0.08 7.59 0.07 7.64 0.07 7.92 0.33
LUNA training capture in-between uncertainty in UCI gap datasets.
We use 6 UCI “gap” datasets (Foong et al., 2019b) with artificially created gaps in the training set (described in Appendix C.4), and demonstrate that, as desired, LUNA’s epistemic uncertainty distinguishes between the gap region and data-rich regions of the input space without significant decrease in predictive performance. Table 1 shows that across all but one of the data-sets (on which all methods struggle), only LUNA and Vanilla Ensemble consistently learn models that are more uncertain on out-of-distribution (or in-gap) test data, relative to within distribution test data. We evaluate both test log-likelihood (Table 3), and test RMSE (Table 2) on data sampled inside vs. outside the gap to show that LUNA’s fit is comparable to that of the remaining baselines.
6.2 LUNA bases are competitive with baselines on downstream tasks
LUNA bases are better for transfer learning, even with few features.
We assess how useful the learned feature bases are when the Bayesian regression model is retrained given new data – specifically, data under covariate shift. For this task, we compare LUNA against traditional NLM training, as well as against SNGP, since those are the only methods that consist of a Bayesian model trained on a deterministic feature map. We show that across all numbers of features in , LUNA bases outperform both baselines. We construct a synthetic 1-D dataset (the “Squiggle Gap” data in Appendix C.3), visualized in Figure 5(a), which unlike the “Cubic Gap” data, has unexpected variations in the held-out gap region. After training on the non-gap data, we fix the feature map , and we infer the posterior over the last layer using data from the gap. Figure 5(b) shows that LUNA bases can easily be adapted to modeling data from the gap, while feature bases of baseline methods struggle to adapt, even as we increase the number of features.
LUNA training is comparable to baselines on BayesOpt.
We compare LUNA training against baselines on 4 Bayesian optimization benchmark tasks (see BayesOpt in Appendix C.3). In Table 4, we see that LUNA’s performance is comparable to baselines.


6.3 Application: LUNA’s predictive uncertainty detects sampling bias in image data.
We show that LUNA’s predictive uncertainty is sensitive to out-of-distribution points, and is therefore capable of detecting sampling bias in an image data-set. For this task, we use LUNA trained NLMs with a ResNet18 architecture to perform age regression on the Wikipedia faces dataset, containing 62,328 facial images of actors (details in Appendix C.5).
In our first experiment, we trained LUNA on 26,375 faces of only male actors and test on 10,918 male (in-distribution) and 10,918 female (out-of-distribution) faces. We obtain a Mean Absolute Error (MAE) comparable to that of a vanilla ResNet18 ( on training data, and and on in-distribution and out-of-distribution test-data, respectively). At the same time, the epistemic uncertainty is on average higher on the out-of-distribution test data than on training data (in comparison to higher on the in-distribution test data relative to on training data). In our second experiment, we trained LUNA on 28,271 faces of individuals younger than 30 or older than 40, while testing on 9,424 in-distribution faces and 10,376 faces of individuals between the ages of 30 and 40 (out-of-distribution). Here, we again see higher average epistemic uncertainty on out-of-distribution test data (27% increase) than on in-distribution test data (2.02% increase).
In both of these experiments, we show that the predictive uncertainty provided by LUNA trained models can be used to identify test data from underrepresented sub-populations; predictions for such out-of-distribution test data can then be deferred to human experts. This task also shows that LUNA can leverage structured data more easily than GPs by using task-appropriate network architecture.
7 Discussion
Traditional NLM inference hinders learning models that express in-between uncertainty.
Traditional NLM inference methods learn feature bases that span a limited class of functions under the prior predictive distribution, and hence the NLM posterior predictive uncertainty does not distinguish data-poor regions from data rich-ones. We identify the cause of the problem: MLE training does not explicitly encourage the feature bases to span diverse functions away from training data, and MAP training discourages the feature bases from spanning a diverse function class. Moreover, we show that this problem cannot be solved by maximizing the marginal log-likelihood.
UNA is a general NLM training framework for encoding for task-specific desiderata.
We present a novel framework for training feature bases for NLMs. Our framework leverages the insight that it is difficult to train NLMs with task-specific desiderata by directly specifying an appropriate objective on the feature basis; instead, it is easier to work in “function-space”, by designing an objective for functions spanned by the basis. This objective therefore indirectly encourages the feature basis to satisfy our desiderata.
We then propose an instantiation of this framework, LUNA, which provides a general-purpose method to obtain uncertainties that are calibrated in data-rich regions and higher in data-poor ones. On both real and synthetic data, we demonstrate that LUNA training produces models with high-quality predictions on in-distribution inputs, while remaining uncertain on out-of-distribution inputs. In comparison, nearly all baselines fail to consistently remain uncertain on these out-of-distribution inputs. We further show that LUNA outperforms baselines on a number of downstream tasks that require capturing in-between uncertainty. Lastly, we show that LUNA can easily be scaled and adapted to work on architectures (e.g. ResNet), and that LUNA’s predictive uncertainty can detect sampling bias in image data.
Future work.
LUNA bases span functions that both fit the observed data and generalize differently in data-poor regions; these bases are useful for tasks in which it would suffice to use any model with predictive uncertainty that can distinguish between data-sparse and data-rich regions. However, for some tasks, one needs to additionally incorporate domain knowledge, e.g. a length-scale or amplitude for the function likely under the prior. In future work, we hope to develop additional instantiations of UNA that can encode for other types of domain knowledge.
In addition to proposing other instantiations of UNA, in future work we also hope to draw a broader theoretical connection between NLM training and hyper-parameter selection. That is, one can regard the feature map of an NLM as a hyper-parameter of the Bayesian linear regression that is trained on top of it. Thus, our work shows that there is a general need for uncertainty-aware frameworks for hyper-parameter selection as alternatives to likelihood-based selection.
8 Conclusion
In this paper, we show that while NLMs are scalable and easy to implement, when trained with traditional inference, they cannot be naively deployed in risk-sensitive applications, since traditional NLM inference methods yield models that are overly certain on data from data-scarce regions of the input-space. We then propose a novel training framework, UNA, as well as an instantiation of this framework, LUNA, that mitigates this issue. LUNA training explicitly encourages for functional diversity under the NLM’s prior predictive, and as a results learns models that are more uncertain on out-of-distribution inputs than on in-distribution inputs.
Acknowledgments
ST, CL, and WP are supported by the Harvard Institute of Applied Computational Sciences. YY acknowledges support from NIH 5T32LM012411-04 and from IBM Research.
References
- Alber et al. (2017) Maximilian Alber, Pieter-Jan Kindermans, Kristof Schütt, Klaus-Robert Müller, and Fei Sha. An empirical study on the properties of random bases for kernel methods. In Advances in Neural Information Processing Systems 30, pages 2763–2774, 2017.
- Anderson and Peterson (1987) James R Anderson and Carsten Peterson. A mean field theory learning algorithm for neural networks. Complex Systems, 1:995–1019, 1987.
- Blundell et al. (2015) Charles Blundell, Julien Cornebise, Koray Kavukcuoglu, and Daan Wierstra. Weight uncertainty in neural networks. arXiv preprint arXiv:1505.05424, 2015.
- Buntine and Weigend (1991) Wray L Buntine and Andreas S Weigend. Bayesian back-propagation. Complex systems, 5(6):603–643, 1991.
- Calandra et al. (2016) Roberto Calandra, Jan Peters, Carl Edward Rasmussen, and Marc Peter Deisenroth. Manifold gaussian processes for regression. In 2016 International Joint Conference on Neural Networks (IJCNN), pages 3338–3345. IEEE, 2016.
- Cheng and Boots (2017) Ching-An Cheng and Byron Boots. Variational inference for gaussian process models with linear complexity. In Advances in Neural Information Processing Systems, pages 5184–5194, 2017.
- Dua and Graff (2017) Dheeru Dua and Casey Graff. UCI machine learning repository, 2017. URL http://archive.ics.uci.edu/ml.
- Eggensperger et al. (2013) Katharina Eggensperger, Matthias Feurer, Frank Hutter, James Bergstra, Jasper Snoek, Holger H. Hoos, and Kevin Leyton-Brown. Towards an empirical foundation for assessing bayesian optimization of hyperparameters. In Neural Information Processing Systems (NIPS): Workshop on Bayesian Optimization in Theory and Practice, 2013.
- Foong et al. (2019a) Andrew Y. K. Foong, David R. Burt, Yingzhen Li, and Richard E. Turner. Pathologies of factorised gaussian and mc dropout posteriors in bayesian neural networks. In 4th Workshop on Bayesian Deep Learning (NeurIPS), 2019a.
- Foong et al. (2019b) Andrew Y. K. Foong, Yingzhen Li, José Miguel Hernández-Lobato, and Richard E. Turner. ‘in-between’ uncertainty in bayesian neural networks. In International Conference on Machine Learning (ICML): Workshop on Uncertainty & Robustness in Deep Learning, 2019b.
- Gal and Ghahramani (2016) Yarin Gal and Zoubin Ghahramani. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. In Proceedings of the 33rd International Conference on Machine Learning (ICML), page 1050–1059, 2016.
- Garipov et al. (2018) Timur Garipov, Pavel Izmailov, Dmitrii Podoprikhin, Dmitry P Vetrov, and Andrew G Wilson. Loss surfaces, mode connectivity, and fast ensembling of dnns. In Advances in Neural Information Processing Systems, pages 8789–8798, 2018.
- Hinton and Van Camp (1993) Geoffrey E Hinton and Drew Van Camp. Keeping the neural networks simple by minimizing the description length of the weights. In Proceedings of the sixth annual conference on Computational learning theory, pages 5–13, 1993.
- Lakshminarayanan et al. (2017) Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and scalable predictive uncertainty estimation using deep ensembles. In Advances in neural information processing systems, pages 6402–6413, 2017.
- Liu et al. (2020) Jeremiah Zhe Liu, Zi Lin, Shreyas Padhy, Dustin Tran, Tania Bedrax-Weiss, and Balaji Lakshminarayanan. Simple and principled uncertainty estimation with deterministic deep learning via distance awareness. arXiv preprint arXiv:2006.10108, 2020.
- Lu and Van Roy (2017) Xiuyuan Lu and Benjamin Van Roy. Ensemble sampling. In Advances in neural information processing systems, pages 3258–3266, 2017.
- MacKay (1992) David JC MacKay. A practical bayesian framework for backpropagation networks. Neural computation, 4(3):448–472, 1992.
- Mattos and Barreto (2019) César Lincoln C. Mattos and Guilherme A. Barreto. A stochastic variational framework for recurrent gaussian processes models. Neural Networks, 112:54–72, 2019. ISSN 0893-6080. doi: https://doi.org/10.1016/j.neunet.2019.01.005. URL https://www.sciencedirect.com/science/article/pii/S0893608019300164.
- Neal (2012a) Radford M Neal. Bayesian learning for neural networks, volume 118. Springer Science & Business Media, 2012a.
- Neal (2012b) Radford M Neal. Bayesian learning for neural networks, volume 118. Springer Science & Business Media, 2012b.
- Ober and Rasmussen (2019) Sebastian W. Ober and Carl Edward Rasmussen. Benchmarking the neural linear model for regression. In Advances in Approximate Bayesian Inference (AABI), 2019.
- Pearce et al. (2018) Tim Pearce, Nicolas Anastassacos, Mohamed Zaki, and Andy Neely. Bayesian inference with anchored ensembles of neural networks, and application to exploration in reinforcement learning. arXiv preprint arXiv:1805.11324, 2018.
- Pearce et al. (2020) Tim Pearce, Felix Leibfried, Alexandra Brintrup, Mohamed Zaki, and Andy Neely. Uncertainty in neural networks: Approximately bayesian ensembling, 2020.
- Pinsler et al. (2019) Robert Pinsler, Jonathan Gordon, Eric Nalisnick, and José Miguel Hernández-Lobato. Bayesian batch active learning as sparse subset approximation. In Advances in Neural Information Processing Systems 32, pages 6359–6370, 2019.
- Rasmussen and Williams (2006) CE. Rasmussen and CKI. Williams. Gaussian Processes for Machine Learning. Adaptive Computation and Machine Learning. MIT Press, Cambridge, MA, USA, January 2006.
- Riquelme et al. (2018) Carlos Riquelme, George Tucker, and Jasper Snoek. Deep bayesian bandits showdown: An empirical comparison of bayesian deep networks for thompson sampling. In International Conference on Learning Representations (ICLR), 2018.
- Ross et al. (2018) Andrew Slavin Ross, Weiwei Pan, and Finale Doshi-Velez. Learning qualitatively diverse and interpretable rules for classification. In International Conference on Machine Learning (ICML): Workshop on Human Interpretability in Machine Learning, 2018.
- Snelson and Ghahramani (2006) Edward Snelson and Zoubin Ghahramani. Sparse gaussian processes using pseudo-inputs. In Advances in neural information processing systems, pages 1257–1264, 2006.
- Snoek et al. (2015) Jasper Snoek, Oren Rippel, Kevin Swersky, Ryan Kiros, Nadathur Satish, Narayanan Sundaram, Md. Mostofa Ali Patwary, Prabhat, and Ryan P. Adams. Scalable bayesian optimization using deep neural networks. In Proceedings of the 32nd International Conference on Machine Learning (ICML), pages 2171–2180, 2015.
- Springenberg et al. (2016) Jost Tobias Springenberg, Aaron Klein, Stefan Falkner, and Frank Hutter. Bayesian optimization with robust bayesian neural networks. In Advances in Neural Information Processing Systems 29, pages 4134–4142, 2016.
- Sun et al. (2019) Shengyang Sun, Guodong Zhang, Jiaxin Shi, and Roger Grosse. Functional variational bayesian neural networks. In International Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=rkxacs0qY7.
- van der Wilk et al. (2017) Mark van der Wilk, Carl Edward Rasmussen, and James Hensman. Convolutional Gaussian Processes. arXiv e-prints, art. arXiv:1709.01894, September 2017.
- Walker and Glocker (2019) Ian Walker and Ben Glocker. Graph convolutional Gaussian processes. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors, Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 6495–6504. PMLR, 09–15 Jun 2019. URL https://proceedings.mlr.press/v97/walker19a.html.
- Wang et al. (2019) Ke Wang, Geoff Pleiss, Jacob Gardner, Stephen Tyree, Kilian Q Weinberger, and Andrew Gordon Wilson. Exact gaussian processes on a million data points. In Advances in Neural Information Processing Systems, pages 14648–14659, 2019.
- Wilson et al. (2016) Andrew Gordon Wilson, Zhiting Hu, Ruslan Salakhutdinov, and Eric P Xing. Deep kernel learning. In Artificial intelligence and statistics, pages 370–378, 2016.
- Yao et al. (2019) J. Yao, W. Pan, S. Ghosh, and F. Doshi-Velez. Quality of uncertainty quantification for bayesian neural network inference. In International Conference on Machine Learning (ICML): Workshop on Uncertainty & Robustness in Deep Learning, 2019.
- Zhou and Precioso (2019) Weilin Zhou and Frederic Precioso. Adaptive bayesian linear regression for automated machine learning. Technical Report arXiv:1904.00577 [cs.LG], ArXiV, 2019.
Appendix
A Neural Linear Model Details
A.1 Posterior Predictive
An NLM uses a neural network to parameterize basis functions for a Bayesian linear regression model by treating the output weights of the network probabilistically, while treating the rest of the network’s parameters as hyper-parameters. Using notation from Section 3 and following standard Bayesian linear regression analysis, we can derive the posterior predictive,
| (4) |
where
| (5) |
A.2 MAP Training
For the MAP-trained NLM, we maximize the following objective:
| (6) |
where represents the parameters of the full network (including the output weights). We would then extract from and perform the Bayesian linear regression as above.
A.3 Marginal Likelihood Training
We optimize to maximize the evidence or log marginal likelihood of the data by integrating out . For training stability and identifiability, we further regularize as done by Ober and Rasmussen (2019). The full objective is hence:
| (7) |
Ober and Rasmussen (2019) note that the addition of a regularization term to is necessary in order to estimate the observation noise variance, which otherwise tends towards zero. In Proposition 1, we also show that without this regularization term, the features experience pathological blow-up for ReLU networks, since large reduce the magnitude of the posterior mean , and hence increase .
See 1
Proof Let us first establish the relationship between and in the asymptotic case . From Equation 5,
Hence,
Note that the loss is equal to , since is scaled by and this scaling is canceled by . Thus, since , we have that .
The above proposition tells us that that we can continue to increase by reducing . Hence, if we do not regularize , the training will continually increase to affect a decrease in .
The addition of the regularization term to , however, biases training towards inexpressive feature bases for the same reason we identified in Section 4. In Figure 10, we show that with regularization, the feature bases learned by optimizing are inexpressive. In Figure 9 we see that even with set close to zero, the learned feature bases are not consistently expressive across random restarts.
B LUNA’s Diversity Penalty
We adopted the diversity penalty in LUNA’s objective from the work of Ross et al. (2018). We use the cosine similarity function on the gradients of the auxiliary regressors:
This acts as a measure of orthogonality, equal to one when the two inputs are parallel, and 0 when they are orthogonal. A higher penalty, , in the training objective penalizes parallel components, hence enforcing diversity.
In practice, these gradients can be computed using a finite differences approximation. That is, we approximate gradients as:
where represents a D-dimensional vector of zeros with a small perturbation in the dimension. We sample these perturbations according to , where can be set using the range of the data.
In our experiments, we anneal the weight of the diversity penalty using a number of different schedules. We also scaled the diversity penalty by a factor , where is batch size, and is the number of auxiliary regressors, so that it carried the same weight across different values of and . The three annealing schedules we tested were , , and , where is the number of epochs. We use the model selection schemed described in Section 5.1 to select an annealing schedule.
C Experimental Setup
C.1 Baseline Methods
Linearised Laplace (Lin Lap) Foong et al. (2019b).
Linearised Laplace is an approximate inference method for BNNs that finds a mode of the BNN posterior, and then fits a Gaussian to that mode. As noted by Foong et al. (2019b), this inference method scales cubically with the number of parameters in the model. Additionally, Foong et al. (2019b) note that Linearised Laplace does not work with all activation functions, e.g. ReLU (which is commonly used in standard architectures for its desirable extrapolation properties).
Monte Carlo Dropout (MCD) (Gal and Ghahramani, 2016).
MCD casts dropout training in neural networks as approximate Bayesian inference in Deep Gaussian Processes. While dropout during training is a common feature of modern neural network architectures, MCD maintains the dropout during testing time too. Using multiple stochastic forward passes through the network and averaging the results, MCD is able to obtain a predictive distribution.
Spectral-normalized Neural Gaussian Process (SNGP) (Liu et al., 2020).
SNGP is a model that was originally designed for classification, but in this work we have adapted it for regression. It uses a distance-aware Recurrent Neural Network (RNN) to learn a feature map for the data. This feature map is then used as input for a GP. In this work, we use a GP with an RBF kernel at the last layer and perform inference either analytically (SNGP) or with a random Fourier feature expansion (RFF SNGP).
Anchored Ensembles (Pearce et al., 2018).
Anchored Ensembles is an alternative training method for neural network ensembles, in which the ensemble members are initialized using an “anchoring” distribution and are then regularized towards their initial parameters:
The regularization matrix is defined as , where is the noise variance of the data, is the anchor variance. That is, the anchoring parameters are sampled according to . In our case, we used one value of and always set . Additionally, we follow the original work and decouple the initial parameters from the anchoring distribution, where initial parameters are sampled according to . These anchoring points ensure that the ensemble fits to the data but also maintains its original diversity from the initialization, thereby allowing it capture uncertainty in data-scarce regions. Moreover, this training method implicitly performs Bayesian inference on a Gaussian Process as the ensemble and network sizes tend towards infinity.
Bootstrap Ensembles.
We construct an ensemble of neural network regressors, each trained on a different sub-sample of the original training set. We then use mean and variance of the outputs across all ensemble members as a predictive distribution.
Vanilla Ensembles.
We construct an ensemble of neural network regressors, each initialized randomly and trained independently via gradient descent. We then use mean and variance of the outputs across all ensemble members as a predictive distribution.
C.2 Evaluation Metrics
We used the following evaluation metrics to compare the performance of UNA against our baselines:
Avg. Test Log-Likelihood (LL).
We compute average the probability of each test point under the model’s posterior predictive:
| LL | (8) |
For NLM (and UNA), this is computed as:
| LL | (9) |
Test Root Mean Square Error (RMSE).
We compute the RMSE between the mean of the posterior predictive, and the corresponding true outcome across the test set.
| RMSE | (10) |
For NLM (and UNA), this is computed as:
| RMSE | (11) |
Epistemic Uncertainty (EU).
Since in this work, we assume homoscedastic noise for all models, we compute epistemic uncertainty as the standard deviation of the posterior predictive, without the added observation noise :
| EU | (12) |
For NLM (and UNA), this is computed as:
| EU | (13) |
In this work, we evaluate epistemic uncertainty both where there is data (i.e. “not in gap”) and where there is no data (i.e. “in the gap”).
Gap to Non-Gap Epistemic Uncertainty Relative Change.
To check whether a model has higher epistemic uncertainty where there is no data, we compute the relative change between the epistemic uncertainty in the gap vs. not-gap regions:
| EURC | (14) |
When EURC positive, it means that the model is more uncertain in data-sparse regions, and when it is negative, it is even more confident where there no data relative to where there is data.
C.3 Synthetic Data
Cubic Gap Example.
Following Ober and Rasmussen (2019), we construct a synthetic 1-D dataset comprising 100 train and 100 test pairs , where is sampled uniformly in the range and is generated as .
Squiggle Gap Example (for the Transfer Learning Task).
We construct a synthetic 1-D dataset in which the training ’s are uniformly sampled in the range and . As shown in Figure 5(a), this function is identical to the function from the Cubic Gap Example, but with unexpected variations in the gap. For the generalization experiment, the test ’s were sampled from the non-gap region , whereas for the transfer learning experiment, test ’s were sampled from the gap region .
BayesOpt Examples.
We used common BayesOpt benchmarks to evaluate the usefulness of our uncertainties. These benchmarks were adapted from HPOLib 1.5 (Eggensperger et al., 2013) and represent a variety of tasks that are difficult or impossible for traditional optimization techniques.
First, we used the Branin function, a 2-dimensional benchmark with multiple global minima and shallow valleys between the minima. The function is defined as:
The input domain used is the square and . In this domain, the global minima occur at , , and , with minimum .
The Hartmann6 function was also used and is a higher dimensional function on a small domain. It is defined as:
where ,
The input domain used is the hypercube for all , with global minimum at
A popular application for BayesOpt is hyper-parameter tuning. In our case, we used each model to optimize classification models for MNIST data. The SVM model was optimized over the regularization parameter and kernel coefficient, where the domain for each parameter is on the log-scale. Due to computational complexity, the first 5,000 data points in the training set were used in this experiment. Similarly, the logistic benchmark is a logistic regression classifier in which the learning rate, -regularization, batch size, and dropout ratio on inputs was tuned. The learning rate domain is on the log-scale, the -regularization domain is , the batch size domain is , and the dropout ratio domain is .
All results for the BayesOpt examples are reported in terms of the error, , where classification global minimum is at 0.
C.4 Real Data
UCI Gap Data.
We used 3 standard UCI (Dua and Graff, 2017) regression data sets and modify them to create 6 “gap data-sets”, wherein we purposefully created a gap in the data where we can test our model’s in-between uncertainty (i.e. we train our model on the non-gap data and test the model’s epistemic uncertainty on the gap data). We adapt the procedure from Foong et al. (2019b) to convert these UCI data sets into UCI gap data sets. For a selected input dimension, we (1) sort the data in increasing order in that dimension, and (2) remove middle to create a gap. We specifically selected input dimensions that have high correlation with the output in order to ensure that the learned model should have epistemic uncertainty in the gap; that is, if we select a dimension that is not useful for prediction, any model need not have increased uncertainty in the gap. The features we selected are:
-
•
Boston Housing: “Rooms per Dwelling” (RM), “Percentage Lower Status of the Population” (LSTAT), and “Parent Teacher Ratio” (PTRATIO)
-
•
Concrete Compressive Strength: “Cement” and “Superplasticizer”
-
•
Yacht Hydrodynamics: “Froude Number”
The not gap region of the data was then split into 10 different 80-10-10 train,test, validation splits. Final results are computed as the mean and standard deviation of the predictions over all of the splits.
Standard UCI Data.
We used 6 UCI regression data sets to benchmark our models. Those are the Boston Housing, Concrete Compressive Strength, Yacht Hydrodynamics, Energy Efficiency, Abalone (Kin8nm), and Red Wine Quality datasets. For each experiment, we split the data into 90% train data and 10% test data. We then used 20% of the training data for the validation set.
C.5 Architecture
Cubic Gap Experiments.
We used 2-layer 50 hidden units ReLU networks for all neural network based architectures (except for the BNN with HMC, in which a 1-layer ReLU network was used to reduce computational cost, and except for the BNN with Linearised Laplace, in which we used Tanh activation since ReLU did not work (Foong et al., 2019b), and except RFF SNGP, in which we again used Tanh activation since ReLU did not work). We used auxiliary regressors in LUNA, and 50 independent networks for the bootstrap ensemble. We used a GP with a kernel that is the sum of a Matern- kernel with length scale and a white kernel with ground truth noise variance . For SNGP, we used an RBF kernel with length scale of , a normalization factor of 20, and dropout rate of 0. We trained it using SGD with 1000 epochs, a step size of , and no mini-batching. For the RFF SNGP, we used a scaling coefficient of , normalizing factor of , GP layer width of , regularization parameter of and dropout rate of 0. We again trained it using SGD with 50 epochs, a step size of , and a mini-batch size of 10. We found that training longer, or with higher scaling coefficient led to instability in the posterior covariance prediction. We trained an Anchored Ensemble consisting of 5 networks, using an anchor mean of 0, anchor variance of 10, data variance of 3, and alpha of 0.5. We trained using SGD with 500 epochs, a step size of , and a mini-batch size of 32.
Squiggle Gap Experiments.
We use 2-layer ReLU networks with 50 units in the first hidden layer and variable units in the second hidden layer, depending on the experiment. LUNA used auxiliary regressors. With the RFF SNGP model, we use a 2-layer 50 unit model with Tanh activation, regularization of , a dropout rate of 0, normalization factor of 10, and a scaling coefficient of .
BayesOpt Experiments.
For the BayesOpt experiments, the neural networks had 3 hidden layers with 50 ReLU units in each layer, following the setup of Snoek et al. (2015). LUNA used auxiliary regressors. RFF SNGP used a GP width of 200 units and and Tanh activation. SNGP used an RBF kernel with length scale of 1.0.
Detecting Sampling Bias Experiments.
For the sampling bias in data detection experiment, the images were first put through a pre-trained ResNet18 to obtain 1000-dimensional features. A single hidden layer neural network with 500 ReLU units was then fit on these features using LUNA training. For the experiment where female faces were held out from the train set, reasonable values of , and were used without any tuning. For the experiment where faces of ages 30-40 were held out from the train set, reasonable values of , and were used without any tuning. Training for both experiments were done for 10 epochs using a mini-batch size of 1024.
C.6 Hyper-parameters
We selected hyper-parameters for all models using of the training data as a held-out validation set. For all baselines (except for LUNA, which has its own model selection criteria), we selected hyper-parameters based on validation log-likelihood.
Synthetic Data
The ground truth noise variance was used in all models.
For NLM, the regularization hyper-parameter was selected by maximizing validation log-likelihood using 50 iterations of Bayesian optimization over the range , initialized with 10 iterations of random search.
For LUNA, the regularization hyper-parameter and the diversity hyper-parameter were selected using using 50 iterations of Bayesian optimization over the range and , initialized with 10 iterations of random search.
For MCD, the dropout rate was selected using 50 iterations of Bayesian optimization over the range , initialized with 10 iterations of random search. The model precision was set to the inverse of the ground truth noise variance . A reasonable forward passes were used to obtain model uncertainty.
For Anchored Ensembles, we hand tuned the hyper-parameters to obtain good in-between uncertainty. We used hyper-parameters an anchor mean of 0, an anchor variance of 10, a data variance of 3, and an initial variance of 0.5.
For bootstrap ensembles, we used 50 neural nets with no regularization.
For SNGP, we hand tuned hyper-parameters to obtain better in-between uncertainty, we used , and no dropout.
For RFF SNGP, we hand tuned hyper-parameters to obtain better in-between uncertainty. We used Tanh activation, a GP layer width of 500, , , .
Real Data
We first fit a maximum a posteriori (MAP) model to the data sets and use the variance of the output errors as the noise variance in all models.
For NLM, the regularization hyper-parameter was selected by maximizing validation log-likelihood using 50 iterations of Bayesian optimization over the range , initialized with 10 iterations of random search.
For LUNA, the regularization hyper-parameter and the diversity hyper-parameter were selected using using 50 iterations of Bayesian optimization over the range and , initialized with 10 iterations of random search.
For MCD, the dropout rate was selected between by maximizing validation log-likelihood, following the specification in (Gal and Ghahramani, 2016). Since the other models used the same learned noise variance , we set the model precision to the inverse of this . A reasonable forward passes were used to obtain model uncertainty.
For Anchored Ensembles, 5 networks with anchor mean 0 were used in each case. Initially, a grid search in log space was used, where anchor variance, data variance, and initial variance were searched in . Training was done with SGD for 50,000 epochs and a learning rate of and no batches. This learning rate was chosen help with numerical stability. This training resulted in poor fit to the data. After hand-tuning, we arrived at an anchor variance of 1.0, data variance of 1.0, and initial variance of 0.5, trained with SGD for 10,000 epochs, a step size of , and no batches.
For Bootstrapped Ensembles, 25 networks were used with no regularization.
For SNGP, we had to hand-tune the parameters. We used the RBF kernel with length scale 1.0, and no dropout. For training, we used SGD with 5000 epochs, a step size of , and no batches.
For RFF SNGP, after searching over , dropout rate of , with ReLU activation, we found the model did not fit the data. We then used Tanh activation and a GP layer width of 200, scaling coefficient of , normalizing factor of 10.0, regularization of , and dropout rate of 0 for all datasets. It was trained using SGD for 100 epochs with step size of and batch size of 10.
BayesOpt
BayesOpt hyper-parameters were generally chosen with a grid search in log-space. Each run was initialized with different randomly selected points. We used 5 points for the Branin function, 10 points for the Hartmann6 function, 3 points for the SVM function, and 3 points for the logistic function. Additionally, early stopping was found to both improve results and significantly reduce training time for many of the models. Note: many of the models achieved near-optimal performance after very little tuning. Because of this, only those values were tested.
For LUNA, on all functions, we searched over , and .
For NLM, on all functions, we searched over and .
For MCD, on all functions, we searched over , , with 50 forward passes.
For anchored ensembles, we searched for anchor variance, data variance, and initial variance. Initially, the anchor variance search domain was , the data variance search domain was , and initial variance search domain was for the Branin and Hartmann6 functions.
For bootstrapped ensembles, we searched the regularization parameter over .
For the GP, we used an RBF kernel and performed grid search for length scale. For all benchmarks the domain used was
For SNGP, we used an RBF kernel with length scale 1, and for all functions, used and dropout rate was
For RFF SNGP, we used , dropout rate was , . We set .
D Experimental Results
D.1 Qualitative Evaluation of NLM Predictive Uncertainty Across Random Restarts
In this section we present a qualitative evaluation of the NLM predictive uncertainty, specifically examining the effect of regularization as well as the depth and width of the feature basis across random restarts. We demonstrate that the NLM training objective, as justified by our theoretical analysis, either explicitly discourages expressing or is not consistently able to express in-between uncertainty.
Effect of Regularization on NLM Posterior Predictive Uncertainty.
In Figure 6, we show NLM prior predictive samples and posterior predictive distributions, with and without regularization, across random restarts. With regularization, NLM is unable to get expressive prior predictive samples and hence increased in-between posterior predictive uncertainty. While this can be achieved with no regularization, since the training objective does not explicitly encourage for diversity in the prior predictive, the posterior predictive does not consistently express in-between uncertainty across random restarts.
While in low dimensional data we can visually select for the random restarts for which the NLM prior predictive is diverse, on a real high-dimensional data, we cannot. Moreover, on such data we do not know where the data-scarce regions are and thus where to expect in-between uncertainty, since we have shown in Section 4 that we cannot use log-likelihood to evaluate uncertainty.
Effect of the NLM Basis Dimensionality on NLM Posterior Predictive Uncertainty.
In Figure 7, we show the NLM posterior predictive distributions across a varying numbers of basis features and across random restarts, and in Figure 8 we show the NLM posterior predictive across a varying numbers of hidden layers and across random restarts. We see that increasing number of features is more important than increasing depth for expressing posterior predictive in-between uncertainty.
Effect of Regularization and Prior Variances on Marginal Likelihood NLM Training on Posterior Predictive Uncertainty.
We show NLM prior predictive samples and posterior predictive distributions for marginal data likelihood training (described in Appendix A.3). This is shown for different regularization and prior variances across random restarts in Figures 9 and 10. We see the same trends here as what was observed above with traditional MAP training: (1) with high regularization (high or low ), the feature bases for the learned do not span diverse functions in the prior predictive and hence cannot capture in-between uncertainty, and (2) with low regularization (low or high ), the model has the potential to capture in-between uncertainty, but it does so inconsistently across random restarts and needs to rely on good initialization.






D.2 Additional Quantitative Results
Tables 5 and Tables 6 compare LUNA’s log-likelihood and RMSE on the standard (non-gap) UCI data. As the tables show, LUNA has comparably good fit on these data-sets relative to baselines.
Avg. Log-Likelihood (Test) Boston Concrete Yacht Kin8nm Energy Wine ENS BOOT N/A N/A N/A N/A N/A N/A ENS VAN N/A N/A N/A N/A N/A N/A ENS ANC N/A N/A N/A N/A N/A N/A NLM -3.67 0.01 -5.33 0.00 -2.32 0.01 1.03 0.03 -2.78 0.00 -1.02 0.03 GP -3.69 0.02 -5.34 0.00 -2.69 0.13 0.91 0.03 -2.86 0.01 -1.03 0.04 MCD -3.67 0.01 -5.32 0.00 -2.31 0.01 0.93 0.04 -2.77 0.00 -1.02 0.04 SNGP -3.66 0.01 -5.33 0.00 -2.34 0.03 0.86 0.15 -2.79 0.02 -1.05 0.05 BBVI -3.77 0.02 -5.37 0.00 -2.61 0.07 0.97 0.02 -2.90 0.01 -1.08 0.04 LUNA -3.67 0.01 -5.33 0.00 -2.31 0.01 1.02 0.03 -2.79 0.00 -1.05 0.06
Root Mean Square Error (Test) Boston Concrete Yacht Kin8nm Energy Wine ENS BOOT 2.86 0.97 4.68 0.50 0.81 0.38 0.08 0.00 0.50 0.07 0.57 0.06 ENS VAN 2.78 0.91 4.48 0.57 0.53 0.24 0.08 0.00 0.42 0.06 0.58 0.07 ENS ANC 2.80 0.80 4.61 0.52 0.67 0.23 0.08 0.00 0.53 0.06 0.58 0.06 NLM 3.11 0.93 4.68 0.65 0.55 0.30 0.08 0.00 0.37 0.06 0.59 0.04 GP 4.21 1.22 11.94 0.40 3.45 0.90 0.09 0.01 2.58 0.23 0.60 0.05 MCD 2.94 0.86 4.36 0.68 0.58 0.22 0.09 0.01 0.40 0.08 0.58 0.05 SNGP 3.06 0.93 5.00 0.50 1.10 0.43 0.10 0.01 0.87 0.50 0.62 0.07 BBVI 5.31 1.29 16.45 0.62 1.91 0.51 0.09 0.00 2.39 0.16 0.64 0.05 LUNA 3.18 1.00 4.70 0.56 0.51 0.20 0.08 0.00 0.40 0.06 0.62 0.08
Avg. Epistemic Uncertainty Yacht - FROUDE Concrete - CEMENT Concrete - SUPER Boston - RM Boston - LSTAT Boston - PTRATIO Not Gap Gap Not Gap Gap Not Gap Gap Not Gap Gap Not Gap Gap Not Gap Gap ENS BOOT 0.73 0.11 0.58 0.03 3.63 0.24 5.10 0.15 4.46 0.39 8.32 0.23 1.54 0.18 1.38 0.04 1.59 0.20 1.67 0.08 1.61 0.17 1.58 0.08 ENS VAN 0.39 0.03 0.49 0.02 2.10 0.23 4.58 0.21 1.92 0.20 5.01 0.15 0.92 0.12 0.85 0.02 0.92 0.10 1.09 0.03 0.90 0.14 1.23 0.04 ENS ANC 0.60 0.23 0.63 0.19 2.76 0.38 5.25 0.29 2.53 0.36 6.23 0.49 1.18 0.16 1.06 0.05 1.10 0.10 1.20 0.08 1.13 0.19 1.44 0.07 NLM 0.12 0.01 0.15 0.02 0.77 0.05 0.73 0.04 0.74 0.05 0.78 0.04 0.37 0.03 0.34 0.03 0.90 0.07 0.85 0.06 0.76 0.07 0.73 0.04 GP 0.94 0.13 1.59 0.10 3.04 0.25 5.31 0.07 2.76 0.27 6.01 0.13 1.88 0.14 1.57 0.02 1.76 0.15 1.71 0.06 1.93 0.25 2.23 0.08 MCD 1.61 0.23 0.75 0.08 1.36 0.07 1.45 0.03 1.29 0.08 1.44 0.03 0.79 0.08 0.65 0.02 0.80 0.07 0.70 0.04 0.81 0.07 0.77 0.03 SNGP 0.07 0.01 0.10 0.05 0.33 0.03 0.31 0.03 0.28 0.04 0.27 0.04 0.29 0.04 0.26 0.04 0.56 0.05 0.52 0.06 0.29 0.03 0.27 0.02 BBVI 1.60 0.11 1.43 0.02 2.79 0.16 2.28 0.09 6.34 0.35 7.00 0.70 2.48 0.20 2.13 0.05 2.50 0.18 1.70 0.08 5.70 0.38 6.84 0.45 LUNA 0.44 0.10 0.68 0.14 1.32 0.15 2.05 0.37 1.45 0.31 7.29 2.61 1.12 0.09 1.00 0.07 1.81 0.25 2.30 0.22 1.14 0.09 1.83 0.52